How to Use Objects: Code and Concepts (2016)
Part I: Language Usage
Chapter 2. Fundamental Object Structures
In Chapter 1, we analyzed Java’s perception of “objects” and their usage in professional software development. Chapter 3 will add the aspect of abstraction by inheritance and interfaces. After that, we will have discussed the most prominent language features, and by working and experimenting with the guidelines you will have become a sound and reliable developer.
Professional software development is, however, more than just the goal-oriented application of elementary language constructs in code. For one thing, it involves strategic planning and effective communication about goals and software structures. For these purposes, individual objects, with their various methods and fields, are too fine-grained. It would take forever to explain all the method interactions to colleagues one-by-one. One viable![]() 100 tool for thinking in more comprehensive terms is design patterns, many of which have already been presented as a conceptual background for using individual language constructs properly. Nevertheless, the discussion has remained mostly focused on single objects, sometimes with a hypothetical client or service provider to complete the picture.
100 tool for thinking in more comprehensive terms is design patterns, many of which have already been presented as a conceptual background for using individual language constructs properly. Nevertheless, the discussion has remained mostly focused on single objects, sometimes with a hypothetical client or service provider to complete the picture.
This chapter presents frequent constructs involving several objects. First, the OBSERVER pattern explains how objects communicate about state changes. Given that state is a central ingredient to objects, it is necessary![]() 1.1 to handle changes effectively, predictably, and uniformly. Next, we discuss a few fundamental terms and guidelines concerning compound objects in general and move on to recursive or hierarchical structures, which we approach by the COMPOSITE and VISITOR patterns. Finally, it is often the case that an existing object must be wrapped: by an ADAPTERbecause its interface does not suit its clients, by a DECORATOR because the interface is incomplete, or by a PROXY because the real object is hard to work with.
1.1 to handle changes effectively, predictably, and uniformly. Next, we discuss a few fundamental terms and guidelines concerning compound objects in general and move on to recursive or hierarchical structures, which we approach by the COMPOSITE and VISITOR patterns. Finally, it is often the case that an existing object must be wrapped: by an ADAPTERbecause its interface does not suit its clients, by a DECORATOR because the interface is incomplete, or by a PROXY because the real object is hard to work with.
2.1 Propagating State Changes: Observer
An object’s fields, including the contained data structures, are summarily referred to as the object’s state. In object-oriented programming, the usual case is that the state can change by side effects on these fields and data structures. This is in stark contrast to other paradigms, such as functional![]() 1.8.4
1.8.4 ![]() 245,42,196
245,42,196 ![]() 63,164 programming or logic programming, where data structures never change once they have been initialized. An object’s behavior is also in contrast to
63,164 programming or logic programming, where data structures never change once they have been initialized. An object’s behavior is also in contrast to![]() 72
72 ![]() 1.1 imperative data structures, since objects are active: They do not passively suffer modifications, but they react to these changes in a suitable manner. Furthermore, because objects collaborate to perform common tasks, it is very common that their own state reflects that of their collaborators in some way.
1.1 imperative data structures, since objects are active: They do not passively suffer modifications, but they react to these changes in a suitable manner. Furthermore, because objects collaborate to perform common tasks, it is very common that their own state reflects that of their collaborators in some way.
![]() 100The quintessential design pattern, from this perspective, is the OBSERVER pattern, as depicted in Fig. 2.1. In this pattern, a subject sends out notifications about state changes to an arbitrary number and type of observer objects.
100The quintessential design pattern, from this perspective, is the OBSERVER pattern, as depicted in Fig. 2.1. In this pattern, a subject sends out notifications about state changes to an arbitrary number and type of observer objects.
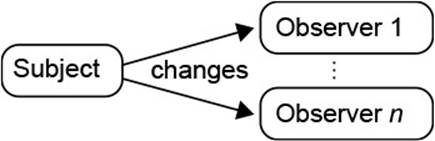
Figure 2.1 Basic Idea of Observer Pattern
Pattern: Observer
One object, the subject, holds some state on which several observers of diverse kinds depend. The subject offers a service to register the observers and to notify them whenever a state change occurs.
1. Think about the possible ways in which the subject’s state may change. Define an interface whose methods represent messages about those possible changes. It is also customary to have a single method taking an event object that describes the change in detail.
2. Add to the subject a field listeners to hold the registered observers. Add also methods addListener() and removeListener() so that observers can register and de-register.
3. Add a private or protected method fire ... () for each possible change that iterates through the observers and invokes the right method. Invoke the fire method whenever a change has taken place.
4. Let all observers implement the defined interface and register them with the subject, so that they receive the change notifications. Make sure to de-register observers that are no longer interested in the subject’s state.
Since the OBSERVER pattern is central to the craft, this section explores its implementation and consequences in some detail. Further details are also![]() 2.2.4 added in connection with compound objects.
2.2.4 added in connection with compound objects.
2.1.1 Example: Observing Background Jobs
Let us start to explore the pattern by examining an extended example. We choose a nontrivial case here, because it also demonstrates the more intricate points and decisions. In addition, it shows to what extent the pattern can be adapted without losing its overall structure. If you would like to see a simpler example, we encourage you to trace the pattern for text changes in JFace class Document, the principal text storage in Eclipse.
We have already looked at Eclipse’s JobManager, which orchestrates![]() 1.3.2 all background jobs in the Eclipse platform. It is clear that several objects will be interested in when a job starts or ends, and whether it has finished successfully. You will be familiar, for example, with the progress information displayed to the far right in the status line and the progress view.
1.3.2 all background jobs in the Eclipse platform. It is clear that several objects will be interested in when a job starts or ends, and whether it has finished successfully. You will be familiar, for example, with the progress information displayed to the far right in the status line and the progress view.
We start with step 1 and consider the possible “state changes.” First, the job manager itself is rather static; observers will be interested in the states of the managed Jobs. So what can happen to a Job? It can be scheduled, eventually started, can finish execution, and some more things. This enumeration is represented in the IJobChangeListener interface, by one method for each change. The IJobChangeEvent then contains the details of the change—for example, the job to which it applies.
org.eclipse.core.runtime.jobs.IJobChangeListener
public interface IJobChangeListener {
public void scheduled(IJobChangeEvent event);
public void aboutToRun(IJobChangeEvent event);
public void running(IJobChangeEvent event);
public void done(IJobChangeEvent event);
...
}
Defining this interface was the main design challenge, because it fixes all![]() 2.1.2 further decisions. The remainder of the implementation is merely technical.
2.1.2 further decisions. The remainder of the implementation is merely technical.
For step 2, the job manager keeps a listener list in a field. It employs a specialized class, because the notification process makes some special provisions (see below):
org.eclipse.core.internal.jobs.JobManager
private final JobListeners jobListeners = new JobListeners();
It provides two methods that enable observers to register and de-register:
org.eclipse.core.internal.jobs.JobManager
public void addJobChangeListener(IJobChangeListener listener) {
jobListeners.add(listener);
}
public void removeJobChangeListener(IJobChangeListener listener) {
jobListeners.remove(listener);
}
The methods according to step 3 are not contained in the JobManager itself, but in the helper object JobListeners. For each kind of change, it offers a corresponding method to send out events, as prescribed by the pattern. The following one, for instance, notifies the listeners that a job has just been started. It creates an event object and delivers it to the observers via an internal helper method, which implements the behavior that “global” listeners interested in jobs in general are notified before “local” listeners interested in a particular job.
org.eclipse.core.internal.jobs.JobListeners
public void running(Job job) {
doNotify(running, newEvent(job));
}
![]() 9.3.2 A more usual pattern of a fire method is found in Viewer, which shows data on the screen and enables the user to select items. It notifies listeners when the selection changes:
9.3.2 A more usual pattern of a fire method is found in Viewer, which shows data on the screen and enables the user to select items. It notifies listeners when the selection changes:
org.eclipse.jface.viewers.Viewer
protected void fireSelectionChanged(final SelectionChangedEvent
event) {
Object[] listeners = selectionChangedListeners.getListeners();
for (int i = 0; i < listeners.length; ++i) {
ISelectionChangedListener l =
(ISelectionChangedListener) listeners[i];
l.selectionChanged(event);
}
}
![]() It is essential to copy the listener list before traversing it, because some listeners might decide to de-register when they receive the notification, or to register new observers. In a direct traversal of the listener list, this would cause havoc.
It is essential to copy the listener list before traversing it, because some listeners might decide to de-register when they receive the notification, or to register new observers. In a direct traversal of the listener list, this would cause havoc.
To finish step 3, the observers must be notified whenever the state has changed. In the example, starting a new job results in that job being run, which is reflected directly in the code (job is started by the omitted code):
org.eclipse.core.internal.jobs.JobManager
protected Job startJob(Worker worker) {
...
jobListeners.running(job);
return job;
}
Finally, we turn to the observers for step 4. For instance, the progress display implements and registers a job tracker changeListener as follows.1 Any subsequent changes to the jobs’ status will be delivered to that object and will cause the progress manager to update its internal data structures.
1. In fact, the story is more involved, due to the strict model-view separation (Section 9.1). If you use call hierarchy on the add-listener methods, you find a cascade of listeners, so that job changes propagate as follows: JobManager → ProgressManager → ProgessViewUpdater → ProgressContentProvider (Section 9.3.2).
org.eclipse.ui.internal.progress.ProgressManager
Job.getJobManager().addJobChangeListener(this.changeListener);
We have now walked through the overall implementation. It is important to note that the sequence of steps is not arbitrary: You should think![]() 2.1.2 about step 1 in some depth, because it contains the crucial design decisions. Then, you can quickly and mechanically implement steps 2 and 3. At this point, the pattern is complete, and arbitrary observers can be added to the system in step 4. That last step is in principle open ended; at any time, new observers can turn up and can register for change notifications.
2.1.2 about step 1 in some depth, because it contains the crucial design decisions. Then, you can quickly and mechanically implement steps 2 and 3. At this point, the pattern is complete, and arbitrary observers can be added to the system in step 4. That last step is in principle open ended; at any time, new observers can turn up and can register for change notifications.
2.1.2 Crucial Design and Implementation Constraints
The implementation guideline gives the salient points for solving the problem of change propagation. However, there are further invisible or implied constraints on the actual solution that professionals follow but learners must first become aware of. This section makes those constraints explicit, because neglecting them means ruining the entire effort of using OBSERVER.
The observer interface does not reflect information about concrete observers.
The implementation guideline states that the observer interface is to reflect the possible state changes of the subject. Implicitly, this means that the interface does not reflect any concrete observer objects that the developer may have in mind. The reason is very simple: OBSERVER adds to the subject a general infrastructure for change propagation. If tomorrow a new kind of observer should turn up in the system, it must fit with that infrastructure.
Unfortunately, honoring this constraint requires some mental effort. Often the pattern is applied when the first object depends on the subject’s state. At this point, it is natural that you should tailor the observer interface to this concrete observer’s needs, because doing so simplifies the implementation of that observer—after all, it gets just the information that it requires.
If you decide to use the pattern, use it properly. Sit back, purge the first observer from your mind, and focus on the subject alone: What are the relevant aspects of its state? In which ways can those aspects change? The answers to those questions will shape the observer interface in such a way that tomorrow’s observer will benefit from the infrastructure. Always keep in mind that the final goal is that any kind of interested object can attach itself to the subject. If you feel that you cannot come up with a good![]() 2.1.4 general interface, maybe it is best to avoid the pattern and to stick with special notifications for now.
2.1.4 general interface, maybe it is best to avoid the pattern and to stick with special notifications for now.
Notifications must not reveal the subject’s internals.
![]() 1.1It is easy to leak internal information accidentally. Suppose your subject has a list of data items that may be modified. In sending the notification, you
1.1It is easy to leak internal information accidentally. Suppose your subject has a list of data items that may be modified. In sending the notification, you![]() 1.3.3 want to be helpful and pass along the current list. Unless you are careful, the observer may now be able to modify the list. When you have finished your observer interface, you should therefore lean back again and compare it to the normal interface of the subject. The notifications must not leak information that is otherwise inaccessible.
1.3.3 want to be helpful and pass along the current list. Unless you are careful, the observer may now be able to modify the list. When you have finished your observer interface, you should therefore lean back again and compare it to the normal interface of the subject. The notifications must not leak information that is otherwise inaccessible.
The subject must be consistent before it sends notifications.
Changes to an object’s state are rarely as elementary as setting a single field. For example, replacing some text in a Document updates not only![]() 1.3.1 the text (line 6 in the following code), but also the ranges of the lines
1.3.1 the text (line 6 in the following code), but also the ranges of the lines![]() 4.4
4.4 ![]() 4.2.3 (line 7). In between the two, the object is inconsistent—you might also say “broken.” If at that point some client were to get the text of a line, it would get the wrong text, because the line positions have not been updated. Unfortunately, sending change notifications transfers the control to other objects, and they may invoke methods on the broken subject. The preceding rule must therefore be followed very strictly.
4.2.3 (line 7). In between the two, the object is inconsistent—you might also say “broken.” If at that point some client were to get the text of a line, it would get the wrong text, because the line positions have not been updated. Unfortunately, sending change notifications transfers the control to other objects, and they may invoke methods on the broken subject. The preceding rule must therefore be followed very strictly.
org.eclipse.jface.text.AbstractDocument
1 public void replace(int pos, int length, String text,
2 long modificationStamp)
3 throws BadLocationException {
4 ...
5 DocumentEvent e = new DocumentEvent(this, pos, length, text);
6 getStore().replace(pos, length, text);
7 getTracker().replace(pos, length, text);
8 fireDocumentChanged(e);
9 }
All is well if you can summarize all changes that have occurred in one notification: You can simply send it at the end of the public method that performs the changes. In the document example, the changes to the line information are not observable—only the text is. Otherwise, you might introduce compound notifications that list the individual changes that occurred during the run of a method. These notifications are then, again, sent at the very end, when the subject is consistent. You can find a typical example in Swing’s DefaultStyledDocument, where methodsbeginEdits() and endEdits() bracket and aggregate modifications.
Beware of overriding methods that send notifications.
The previous problem occurs in general when a method that sends a notification gets extended by overriding. Suddenly, the notification is sent in![]() 1.4.11 the middle of the new method, and very probably, the object is “broken” at that point—otherwise, the extension would not be necessary. If you foresee future extensions, you might want to employ TEMPLATE METHOD to inject
1.4.11 the middle of the new method, and very probably, the object is “broken” at that point—otherwise, the extension would not be necessary. If you foresee future extensions, you might want to employ TEMPLATE METHOD to inject![]() 1.4.9 the extensions before the notification.
1.4.9 the extensions before the notification.
Beware of observers that modify the subject.
The previous two points lay out a clear sequence of events: first perform a modification, then send out the notifications once the subject’s state is stable again. This sequence can be broken not only within the subject, but also from without. Suppose a subject has three observers a, b, and c. When b receives a change notification, it calls an operation on the subject, causing yet another state change. As a result, the subsequent notification to c is stale, because the state it reports may no longer be valid. For a concrete example, think of a subject holding some list. When it reports the addition of an element at the end of the list, b decides to remove that element. When c tries to look at the supposedly new element, it gets an index-out-of-bounds exception.
Ensure de-registration of observers.
Observers that are once registered hang around in the subject’s listener list until they are de-registered explicitly. Even if the observer is technically “dead”—for instance, because the window that it represents was closed by the user—it will continue to receive notifications. (Also, it cannot be![]() 1.8.9 garbage collected.) Usually, this will lead to unexpected exceptions, such as null pointer exceptions, because the internal structure of the observer has been destroyed and is no longer in working order when it tries to react to notifications.
1.8.9 garbage collected.) Usually, this will lead to unexpected exceptions, such as null pointer exceptions, because the internal structure of the observer has been destroyed and is no longer in working order when it tries to react to notifications.
The general rule, then, is this: Whenever you register an observer, you must also set up a mechanism by which it will be de-registered when it is no longer interested. For example, suppose you have a window that displays running jobs. When that window is opened, it starts tracking jobs, as shown![]() 2.1.1 previously. At the same time, it sets up a mechanism for de-registering the observer when it is no longer interested in the jobs.
2.1.1 previously. At the same time, it sets up a mechanism for de-registering the observer when it is no longer interested in the jobs.
observer.JobDisplayWindow.open
Job.getJobManager().addJobChangeListener(jobListener);
addDisposeListener(new DisposeListener() {
public void widgetDisposed(DisposeEvent e) {
Job.getJobManager().removeJobChangeListener(jobListener);
}
});
![]() There is one technical approach to working around the requirement of de-registration.
There is one technical approach to working around the requirement of de-registration.![]() 50(§7.2.2.2) Especially in larger applications, where some modules may not be trusted to be conscientious about de-registration, one can keep listeners in weak references: When the listener is not referenced anywhere else in the system, the garbage collector sets the weak reference to null, which the subject recognizes when sending notifications. This solution is, however, only partial, since a notification may still be sent to a broken observer before the garbage collector runs.
50(§7.2.2.2) Especially in larger applications, where some modules may not be trusted to be conscientious about de-registration, one can keep listeners in weak references: When the listener is not referenced anywhere else in the system, the garbage collector sets the weak reference to null, which the subject recognizes when sending notifications. This solution is, however, only partial, since a notification may still be sent to a broken observer before the garbage collector runs.
Always include a subject reference in notifications.
When thinking about the first observer of a subject, you will usually have the feeling that the observer knows which subject it is working with. Since general observers, however, very often register with several subjects, the notifications should always include a reference to their sender.
2.1.3 Implementation Details and Decisions
Implementations of OBSERVER exhibit a rather large degree of flexibility. We now discuss a few decision points to exhibit some of that flexibility.
Management of Registered Listeners
The usage pattern of listener lists differs subtly from that of ordinary data lists in several ways. For instance, additions and deletions are relatively rare, while traversals with copies are very frequent. Furthermore, listener lists are usually very small or even empty, so that space concerns dominate runtime concerns. You should therefore avoid the space-intensive amortized addition strategy of![]() 1.3.1 ArrayList and Vector, as well as the overhead of LinkedList.
1.3.1 ArrayList and Vector, as well as the overhead of LinkedList.
Frameworks usually offer special data structures for listener lists. Eclipse uses ListenerList (in package org.eclipse.core.runtime), which keeps listeners in a plain array with no extra space and optimizes the case of the![]() 1.3.3 empty list by a constant empty array. The generic PropertyChangeSupport goes together well with objects that are primarily information holders, such as JavaBeans. In the context of UIs, there are many types of listeners, but for each widget, only a few types are actually used. Swing’s implementation EventListenerListtherefore keeps different types of listeners together in one array, by tagging each with the type of registered listener. Similarly, SWT’s internal EventTable keeps the listener type for each slot. The Widget base class further optimizes the case of no attached listeners, by
1.3.3 empty list by a constant empty array. The generic PropertyChangeSupport goes together well with objects that are primarily information holders, such as JavaBeans. In the context of UIs, there are many types of listeners, but for each widget, only a few types are actually used. Swing’s implementation EventListenerListtherefore keeps different types of listeners together in one array, by tagging each with the type of registered listener. Similarly, SWT’s internal EventTable keeps the listener type for each slot. The Widget base class further optimizes the case of no attached listeners, by![]() 1.6.1 creating the event table only on demand.
1.6.1 creating the event table only on demand.
Push Versus Pull
The design of the observer interface involves a classic![]() 100 choice: Should the subject send a detailed description of the change, or should it just point out that its state has changed, but not mention any details? The first variant is called the push model, the second the pull model. The general rule followed by subjects throughout the Eclipse platform, and elsewhere, is to provide as much detail as possible about the change. In consequence, the JobManager describes which job has changed to what state,
100 choice: Should the subject send a detailed description of the change, or should it just point out that its state has changed, but not mention any details? The first variant is called the push model, the second the pull model. The general rule followed by subjects throughout the Eclipse platform, and elsewhere, is to provide as much detail as possible about the change. In consequence, the JobManager describes which job has changed to what state,![]() 2.1.1 the resource framework sends tree-structured IResourceDeltas, and so on.
2.1.1 the resource framework sends tree-structured IResourceDeltas, and so on.
The reason to prefer the push variant is that the updates performed by the observers in response to the notification may be expensive. Just consider a text document that merely says “I changed” when the user types a character. Any display for the document would have to repaint the entire text, or else perform an expensive difference computation. Always remember that the infrastructure you create must be good enough for tomorrow’s observers.
Sending Notifications Safely
Sending notifications always incurs the risk that the receiver is buggy and will throw an unexpected exception. Having one such observer ruins the whole scheme, because later observers will not receive the notification at all. It is therefore common practice to wrap the actual sending in atry/catch block, especially when the observers are likely to come from other modules or the subject is central to the entire application. Eclipse provides the SafeRunner class for that purpose. The class also takes care of properly logging any thrown exception, if desired.
Different Methods or Event Types
Subjects usually send different kinds of changes. This can be expressed in the observer interface through different methods, such as in the case of IJobChangeListeners or SWT’s![]() 2.1.1
2.1.1 ![]() 7.8 MouseListeners. Alternatively, you can introduce an enum or int constants that capture the different kinds of changes. The latter option can be seen, for instance, in IResourceDelta or the low-level SWT Event. Both approaches are viable, and you must weigh their relative benefits: With separate methods, the client is spared a switch on the type. At the same time, making the type explicit and packaging it the event makes it easier to forward the change notification, since only one method call is necessary. In the end, it is the client’s perspective and its needs that matter.
7.8 MouseListeners. Alternatively, you can introduce an enum or int constants that capture the different kinds of changes. The latter option can be seen, for instance, in IResourceDelta or the low-level SWT Event. Both approaches are viable, and you must weigh their relative benefits: With separate methods, the client is spared a switch on the type. At the same time, making the type explicit and packaging it the event makes it easier to forward the change notification, since only one method call is necessary. In the end, it is the client’s perspective and its needs that matter.![]() 1.1
1.1
Event Objects
It is a common practice to wrap the information about a change into an event object, rather than having observer methods with different parameters. There are several advantages to this approach. Event objects are extensible if new kinds of changes or new data occur, so that the overall implementation remains more flexible. Also, sending objects is usually more efficient: One must create the object once, but can then pass the reference, which consists of one machine word, to observers, which may again pass it on to helper methods.
Tool: Introduce Parameter Object
To convert an observer method with several parameters to one with an event object, use Refactor/Introduce Parameter Object (Alt-Shift-T). The tool also modifies all call sites. You should, however, go back to the fire methods, because the tool does not move the object creation outside the loop.
Implementing the Observer Interface
Objects that are interested in the changes of the subject must register an observer. However, it may not always be the best choice to register themselves as observers, since they would need to implement the observer interface and the implements clause is public![]() 3.2.1 information: Some client might think that it can actually use the object as an observer. It is usually better to keep the implements hidden from clients.
3.2.1 information: Some client might think that it can actually use the object as an observer. It is usually better to keep the implements hidden from clients.
![]() 2.1.1 For example, we have already mentioned that the ProgressManager observes the background jobs inside Eclipse. It does implement IJobChange Listener, although it has a hidden field containing an observer object. The
2.1.1 For example, we have already mentioned that the ProgressManager observes the background jobs inside Eclipse. It does implement IJobChange Listener, although it has a hidden field containing an observer object. The![]() 1.8.8.3 field is initialized with an anonymous nested class, so that the observer can access the surrounding ProgressManager directly.
1.8.8.3 field is initialized with an anonymous nested class, so that the observer can access the surrounding ProgressManager directly.
org.eclipse.ui.internal.progress.ProgressManager
IJobChangeListener changeListener;
It is common that the nested class merely delegates notifications to the outer class. An example is found in CCombo, SWT’s custom implementation of a combo box. The shown listener is attached to all parts of the widget, so as to get notification of all user interactions.
org.eclipse.swt.custom.CCombo.CCombo
listener = new Listener() {
public void handleEvent(Event event) {
if (popup == event.widget) {
popupEvent(event);
return;
}
...
}
};
![]() 1.8.8.1The benefit of this delegation is that the outer class remains self-contained:
1.8.8.1The benefit of this delegation is that the outer class remains self-contained:![]() 4.1 Its code alone defines its entire behavior and is responsible for keeping the object consistent.
4.1 Its code alone defines its entire behavior and is responsible for keeping the object consistent.
![]()
![]() 1.4.5You can create the methods to delegate to by wishful thinking. Specifically, within a nested class, Create Method lets you choose between creating a private method in the nested class or a protected method in the outer class.
1.4.5You can create the methods to delegate to by wishful thinking. Specifically, within a nested class, Create Method lets you choose between creating a private method in the nested class or a protected method in the outer class.
Sometimes, however, an object so obviously is an observer that it is acceptable![]() 3.1.1 to implement the interface directly. In particular, this is the case for controllers or mediators. Their purpose is precisely to receive notifications
3.1.1 to implement the interface directly. In particular, this is the case for controllers or mediators. Their purpose is precisely to receive notifications![]() 9.2
9.2 ![]() 7.7 and to decide how to process or to delegate them. Their role in the system justifies the declaration that they are observers.
7.7 and to decide how to process or to delegate them. Their role in the system justifies the declaration that they are observers.
Similarly, you may find that an anonymous observer attracts more and more code, and more and more of the actual logic. It is then better to![]() 1.2.3 introduce a named class, so as to capture its intention clearly.
1.2.3 introduce a named class, so as to capture its intention clearly.
Tool: Convert Anonymous to Nested
To introduce a name for an anonymous class, place the cursor after the new, Quick-Fix (Ctrl-1) or Refactor (Alt-Shift-T), and choose Convert anonymous to nested class.
Going one step further, the observer’s logic may become so extensive that its interaction with the surrounding class becomes unclear: After all, the observer may access and modify the outer class’s fields anywhere within its own code. It is then better to move it to a separate, package-visible class,![]() 1.7 so that it can access the surrounding object only through a well-defined method interface.
1.7 so that it can access the surrounding object only through a well-defined method interface.
Tool: Move Type to New File
To extract a nested class that has become dominating from its surrounding class, invoke Refactor (Alt-Shift-T) and choose Move Type to New File.
2.1.4 Judging the Need for Observers
No pattern is compulsory. One can design great object collaborations without![]() 11 using OBSERVER. Indeed, there are strong reasons against using it: When there is only one observer, in the beginning, the pattern introduces a lot of implementation overhead, meaning code that must be written and maintained. Furthermore, the sole observer will not get messages tailored to its needs, but only the changes of the subject, from which it must deduce its own correct reaction. Both of these have a strong smell of “speculative generality”—an infrastructure that you pay for, but that you never exploit.
11 using OBSERVER. Indeed, there are strong reasons against using it: When there is only one observer, in the beginning, the pattern introduces a lot of implementation overhead, meaning code that must be written and maintained. Furthermore, the sole observer will not get messages tailored to its needs, but only the changes of the subject, from which it must deduce its own correct reaction. Both of these have a strong smell of “speculative generality”—an infrastructure that you pay for, but that you never exploit.![]() 92
92
If you suspect that your first observer may remain single for quite some time, and if it bears a strong logical relationship to the alleged subject anyway, for instance because they work on the same task, then it might be better to add to the “subject” a simple reference to the “observer.” Instead of sending general change reports, the subject can directly call some methods in the “observer” wherever that object is interested in the developments. In the end, special-purpose “hooks” are sprinkled throughout the “subject,” but these hooks cost no implementation overhead. There’s nothing wrong![]() 1.1
1.1 ![]() 109
109 ![]() 1.4.1 with such collaborations. Indeed, objects sending messages to each other is at the very core of object-oriented programming.
1.4.1 with such collaborations. Indeed, objects sending messages to each other is at the very core of object-oriented programming.
OBSERVER, however, can help you to create a flexible and extensible system. Since the subject makes only the barely necessary assumptions about its observers, it will collaborate with any part of your system that is interested in its state, including future extensions. Fig. 2.2 gives a graphical intuition: The subject sends its message to some abstract observer, which is specified by an interface. It neither knows nor cares what is beyond that interface. In effect, it does not depend on these details. Software engineers![]() 12.1 summarize this by saying that the subject and observer are loosely coupled.
12.1 summarize this by saying that the subject and observer are loosely coupled.
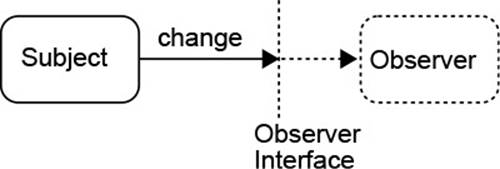
Figure 2.2 Decoupling in the Observer Pattern
A further benefit of the pattern is that observers can also be creative about what they do with the raw change information. Consider, again, the![]() 2.1.1 management of jobs in the Eclipse platform. Job listeners are usually interested about when jobs finish, so that they can show their results to the user. They can, however, do arbitrary things. Suppose you want to implement a scheduler for regular tasks, such as cleanup or summary computations. You want to run such jobs when the platform is “idle”—when no background job has run for, say, half a minute. All your scheduler must do is observe the JobManager to gain that information; it can simply keep a time-stamp whenever a job is scheduled and finishes. The job manager was never written with that purpose in mind, nor would it have been easy to anticipate it. Yet, it fully supports this scenario.
2.1.1 management of jobs in the Eclipse platform. Job listeners are usually interested about when jobs finish, so that they can show their results to the user. They can, however, do arbitrary things. Suppose you want to implement a scheduler for regular tasks, such as cleanup or summary computations. You want to run such jobs when the platform is “idle”—when no background job has run for, say, half a minute. All your scheduler must do is observe the JobManager to gain that information; it can simply keep a time-stamp whenever a job is scheduled and finishes. The job manager was never written with that purpose in mind, nor would it have been easy to anticipate it. Yet, it fully supports this scenario.
In the end, providing OBSERVER is an investment: You believe that the infrastructure will come in useful in the future, so you pay a little more than would be strictly necessary right now. With some experience, you will become a shrewd judge of the expected return on investment. Furthermore,![]() 9.1 some situations do demand OBSERVER. For instance, an object structure
9.1 some situations do demand OBSERVER. For instance, an object structure![]() 2.2.4 that will be displayed on the screen must support observers, although perhaps at some coarser level of granularity.
2.2.4 that will be displayed on the screen must support observers, although perhaps at some coarser level of granularity.
2.2 Compound Objects
![]() 1.1Objects should not be large, monolithic entities that undertake substantial tasks by themselves—objects are small and share tasks among them. In consequence, objects frequently hold references to, or are composed of, several other objects. This section explores this relationship and some of its implications.
1.1Objects should not be large, monolithic entities that undertake substantial tasks by themselves—objects are small and share tasks among them. In consequence, objects frequently hold references to, or are composed of, several other objects. This section explores this relationship and some of its implications.
Before we start, let us summarize briefly where compound objects have occurred previously: Data structures may be constructed from (dumb) objects (Section 1.3.1); some collaborators of an object may actually be private helpers (Section 1.3.2); reusable functionality may be extracted to separate objects (Section 1.4.8.3); lazy initialization keeps object creation cheap (Section 1.6.1). All in all, compound objects can structure the solution, can establish separation of concerns, and can help to avoid duplication and foster reuse.
2.2.1 Ownership
When working with objects that employ other objects to achieve their purpose, it is frequently useful to ask whether those other objects become in some sense a part of their employer. Fig. 2.3 shows the two extreme configurations: In (a), object A contains objects B and C, and they are logically parts of A. One also says that A owns B and C, and that A is the host object of B and C. In (b), in contrast, A merely employs B and C, and even shares C with another object D.
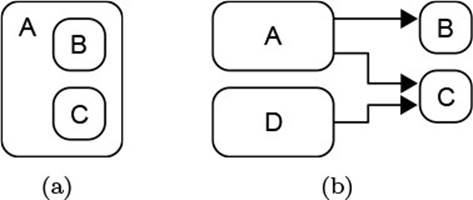
Figure 2.3 Ownership and Sharing
The UML differentiates further and introduces three levels of objects![]() 47
47 ![]() 198(Table 7.3) “belonging to” other objects (Fig. 2.4), by introducing relationships between their classes:
198(Table 7.3) “belonging to” other objects (Fig. 2.4), by introducing relationships between their classes:
• The loosest form, association, merely means that instances of A somehow hold a reference to instances of B so that they can invoke the methods of that class. The fact that this relationship is directional can be made explicit by navigability, which is denoted by open arrow heads at the end of the association.
• Aggregation expresses whole–part relationships, which are associations that do not permit cycles. Another name for aggregation is “has-a” relationship. Unlike ownership, aggregation does not preclude structure sharing.
• Composition is full “ownership”: It is an aggregation where the “whole” object controls the lifetime of the “part” and manages the part completely, and different “wholes” cannot share “parts.”
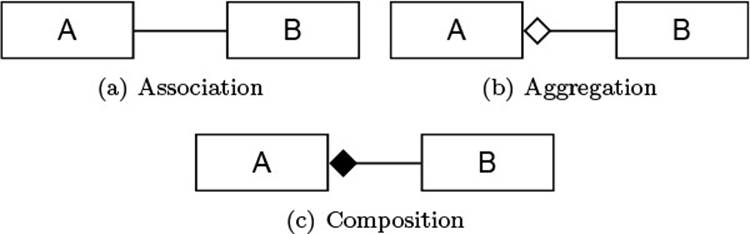
Figure 2.4 Class Relationships in the UML
We will now explore different aspects of aggregation and composition that developers usually connect with these concepts.
The “whole” manages the life cycle of its “parts.”
First, and foremost, ownership implies linked life cycles. The host object, or “whole,” manages the “part.” Very often, it creates the “part.” In the end, when the “whole” becomes invalid, it also destroys the “part.” In many cases, this happens implicitly during garbage collection: Since the “whole” holds the only reference to the “part,” the “part” is reclaimed with the “whole.”
When one of the objects allocates resources, destruction must be arranged explicitly. A typical example can be found in SWT’s CCombo implementation of a combo box. It combines, as usual, a text field and a selection list, which is available through an arrow button. The selection list must be displayed above other elements on the screen, in a separate pop-up window. This is arranged by two objects list and popup:
org.eclipse.swt.custom.CCombo
List list;
Shell popup;
The two elements are created, at the latest, when the list is to be shown. Note that in line 4, the first argument to list is the window popup;![]() 7.1 afterward, popup owns list. Fig. 2.5 shows the resulting nested ownership relations.
7.1 afterward, popup owns list. Fig. 2.5 shows the resulting nested ownership relations.

Figure 2.5 Ownership in the CCombo Example
org.eclipse.swt.custom.CCombo
1 void createPopup(String[] items, int selectionIndex) {
2 popup = new Shell (getShell (), SWT.NO_TRIM | SWT.ON_TOP);
3 ...
4 list = new List (popup, listStyle);
5 ...
6 }
When the life cycle of the combo box ends, for instance because the user closes the containing window, the combo box takes care to end the life cycle of its parts as well. This is accomplished by the following snippet.![]() 7.1 (Technically, it is executed as a part of a callback when the combo box is destroyed.) Line 2 ensures that the object is not informed about the disposal of the list, which it initiates itself in line 3 by disposing its owner popup (Fig. 2.5).
7.1 (Technically, it is executed as a part of a callback when the combo box is destroyed.) Line 2 ensures that the object is not informed about the disposal of the list, which it initiates itself in line 3 by disposing its owner popup (Fig. 2.5).
org.eclipse.swt.custom.CCombo.comboEvent
1 if (popup != null && !popup.isDisposed ()) {
2 list.removeListener (SWT.Dispose, listener);
3 popup.dispose ();
4 }
Ownership can change dynamically.
The CCombo example also shows that the host object does not necessarily create the objects it owns, but can start to manage them when they are passed as arguments to constructors or methods: Starting at the point where it conceptually “owns” the parts, the host object also assumes responsibility for their life cycles. In the example, the popup will destroy the list whenever it is destroyed—regardless of how its destruction was actually triggered.
Ownership can be hierarchical.
If object A owns object B, and B in turn owns object C, then implicitly A owns C (i.e., ownership is a transitive relation). Thus, when A is destroyed, it will destroy B, which will cause C to be destroyed in turn (Fig. 2.5).
Parts often hold references to their owners.
Since a “part” can have only one single owner at a time, it is often useful to be able to navigate to this owner. Specifically, in hierarchical structures![]() 2.3.1 that do not imply encapsulation, clients will often want to navigate freely up and down the tree of objects.
2.3.1 that do not imply encapsulation, clients will often want to navigate freely up and down the tree of objects.
Provide a mechanism to enforce the consistency of parent references.
It is, of course, essential to keep the parent reference consistent with ownership: Whenever the ownership relation is established or changes, the parent reference must change immediately as well. In particular, you should not leave the update to clients, because some of those will not be aware of their duty and will break the link.
![]() 7.1There are two main techniques. First, as in the case of SWT, one can pass the parent to the child and add the child to the parent implicitly. Similarly, a setParent method can be made responsible for adding the part to its owner. Second, the parent can have methods for adding children.
7.1There are two main techniques. First, as in the case of SWT, one can pass the parent to the child and add the child to the parent implicitly. Similarly, a setParent method can be made responsible for adding the part to its owner. Second, the parent can have methods for adding children.![]() 214 Figures in the Graphical Editing Framework use this technique. The add method then also re-parents the new child figure:
214 Figures in the Graphical Editing Framework use this technique. The add method then also re-parents the new child figure:
org.eclipse.draw2d.Figure.add
if (figure.getParent() != null)
figure.getParent().remove(figure);
children.add(index, figure);
figure.setParent(this);
An alternative to re-parenting consists in requiring that the new child does not have a parent so far. This choice is exhibited in the abstract syntax trees used in the Eclipse Java tooling:
org.eclipse.jdt.core.dom.ASTNode
static void checkNewChild(ASTNode node, ASTNode newChild,
boolean cycleCheck, Class nodeType) {
...
if (newChild.getParent() != null)
throw new IllegalArgumentException();
...
}
While parent links may simplify navigation in the data structure, they have the drawback of tying the part to the particular context. In other words, the type of the parent link determines where the part can be employed. Parent links therefore make the parts less reusable, a drawback that must be weighed against the benefit of navigation.
2.2.2 Structure Sharing
Ownership implies that objects are located in a particular place in a hierarchical structure. From the opposite perspective, they cannot occur in two places at once. In case of large and/or nested object structures, this is, however, very desirable: the same object can be shared between different parts of the overall structure to save memory. We have already seen![]() 1.8.4 that immutable objects in a functional programming style can benefit from structure sharing. UML’s notion of aggregation captures just this case: hierarchical organization without ownership.
1.8.4 that immutable objects in a functional programming style can benefit from structure sharing. UML’s notion of aggregation captures just this case: hierarchical organization without ownership.
![]() 2.3.1Suppose, for instance, that we wish to capture mathematical expressions. In this case, each operator or function application is one object, and the arguments become the object’s children. Then sin(e) is an object with a single child, which points to the representation of expression e. When we wish to compute the derivative, here cos(e), we can create a single new object for cos, which happens to share its argument with the original sin(e). No matter how deeply nested e is, derivation costs only a single new object.
2.3.1Suppose, for instance, that we wish to capture mathematical expressions. In this case, each operator or function application is one object, and the arguments become the object’s children. Then sin(e) is an object with a single child, which points to the representation of expression e. When we wish to compute the derivative, here cos(e), we can create a single new object for cos, which happens to share its argument with the original sin(e). No matter how deeply nested e is, derivation costs only a single new object.![]() 17 In general, structure sharing can be useful for symbolic computation.
17 In general, structure sharing can be useful for symbolic computation.
Possible applications of sharing are, in fact, frequent. When representing Java code as abstract syntax trees, such as when generating code, it is useful to link some generated expression into different places, just wherever it happens to occur. In the hierarchical organization of file systems, hard![]() 238 or soft links can be represented by sharing File objects in different places.
238 or soft links can be represented by sharing File objects in different places.
In general, hierarchical object structures with sharing constitute directed![]() 72 acyclic graphs (DAGs). Whenever you recognize such special graphs, you can think about using aggregation with structure sharing. However, it must be clarified that not every DAG is aggregation. For instance, the JDT compiler represents classes and interfaces as SourceTypeBindings. In these, it maintains the extends and implements relationships in the following two fields:
72 acyclic graphs (DAGs). Whenever you recognize such special graphs, you can think about using aggregation with structure sharing. However, it must be clarified that not every DAG is aggregation. For instance, the JDT compiler represents classes and interfaces as SourceTypeBindings. In these, it maintains the extends and implements relationships in the following two fields:
org.eclipse.jdt.internal.compiler.lookup.SourceTypeBinding
public ReferenceBinding superclass;
public ReferenceBinding[] superInterfaces;
While they do establish a graph structure and a hierarchy with sharing, they do not constitute aggregation. The main entry point to accessing reference types is through the compiler’s symbol tables, if there is any form of aggregation at all, it is the symbol table that “owns” the types.
In the other direction, full ownership does not preclude cross-referencing: If the object structure is public, any client can keep references to nested objects. These cross-references do not establish sharing in the sense of aggregation, nor do they destroy the property of unique parents. While each object still has a unique place, there can be more references to it elsewhere.
Similarly, structure sharing can be combined with parent links. In this case, however, each object can have multiple parents, which makes navigation quite awkward and often unusable.
2.2.3 Compound Objects and Encapsulation
When an object creates and manages several helpers, a natural question is whether other parts of the system will be aware of these auxiliary structures. A broad view will be taken in the discussion of design for decoupling. For![]() 12.2.1
12.2.1 ![]() 12.1.4 now, let us stay with analyzing code.
12.1.4 now, let us stay with analyzing code.
Ownership can, but need not, imply encapsulation.
Ownership is a dynamic relationship about linked life cycles. As in the CCombo example of Section 2.2.1, it often implies as well that the parts are hidden from the clients—that their use is private. Fig. 2.3 and Fig. 2.5 indicate this by placing the parts inside their owners. This encapsulation is, however, not mandatory. For instance, the ownership between popup and list in the same example is public under the concept of a widget tree:![]() 7.1 Elements on the screen are nested hierarchically, so using getChildren() on popoup will yield list.
7.1 Elements on the screen are nested hierarchically, so using getChildren() on popoup will yield list.
Ownership is often tied to consistency conditions.
An object creates and manages its parts to solve specific subtasks of its own overall task. Usually, the subtasks are not stand-alone entities, but rather are linked to one another, because only together can they contribute to the![]() 4.1
4.1 ![]() 23,21 overall goal. This implies that there will usually be consistency conditions between parts, and the host object is responsible for maintaining these conditions.
23,21 overall goal. This implies that there will usually be consistency conditions between parts, and the host object is responsible for maintaining these conditions.
In the CCombo example of Section 2.2.1, popup and list show the selection list when prompted by the user. Several consistency conditions apply—for instance, either both are null or both are non-null; if they are non-null, list is owned by popup and the list fills the entirepopup window; the list contains all entries that the CCombo itself contains, and has the same font as CCombo. All of those conditions are enforced by CCombo.
Hide internal object structures, especially those with complex consistency conditions.
Revealing auxiliary object structures has the disadvantage that clients will start to rely on these structures, so that they cannot be modified later on. What is more, clients may invoke methods on the parts that destroy the![]() 1.3.1 overall consistency of the owner object. Especially in the case of objects used as data structures, this can be disastrous. In other cases, it might just
1.3.1 overall consistency of the owner object. Especially in the case of objects used as data structures, this can be disastrous. In other cases, it might just![]() 2.1 mean more effort: The owner might have to observe its parts to maintain consistency despite changes triggered by clients.
2.1 mean more effort: The owner might have to observe its parts to maintain consistency despite changes triggered by clients.
Publish structure that constitutes a valid client interface.
You must have compelling reasons for publishing helper objects. They are![]() 1.1 usually related to defining an interface that suits clients. As with methods, there is always the fundamental dilemma of hiding knowledge to change details later and publishing knowledge to enable effective work with the object. In some cases, the wisest path is to publish selected aspects as
1.1 usually related to defining an interface that suits clients. As with methods, there is always the fundamental dilemma of hiding knowledge to change details later and publishing knowledge to enable effective work with the object. In some cases, the wisest path is to publish selected aspects as![]() 3.2.2 objects. For instance, all editors in Eclipse offer a getAdapter() method to access selected internals through well-defined interfaces. For instance, they offer a helper for performing find/replace operations (and create this
3.2.2 objects. For instance, all editors in Eclipse offer a getAdapter() method to access selected internals through well-defined interfaces. For instance, they offer a helper for performing find/replace operations (and create this![]() 1.6.1 helper lazily):
1.6.1 helper lazily):
org.eclipse.ui.texteditor.AbstractTextEditor.getAdapter
if (IFindReplaceTarget.class.equals(required)) {
if (fFindReplaceTarget == null) {
IFindReplaceTarget target =
fSourceViewer.getFindReplaceTarget();
fFindReplaceTarget = new FindReplaceTarget(this, target);
}
return fFindReplaceTarget;
}
2.2.4 Compound Objects and Observers
The parts of a compound object cling together quite closely: They are![]() 2.2.1 created and destroyed together, and may obey complex relationships during
2.2.1 created and destroyed together, and may obey complex relationships during![]() 2.2.3 their lifetime. It is therefore sensible to assume that:
2.2.3 their lifetime. It is therefore sensible to assume that:
The owner’s state comprises its parts’ state.
In the context of state updates, the OBSERVER pattern technically addresses![]() 2.1 updates to a single object’s state. With the preceding insight, one would therefore channel change notifications on parts to observers of their owner, as shown in Fig. 2.6. In this situation, the parts themselves may not even implement OBSERVER, but rather call hook methods, or even the fire
2.1 updates to a single object’s state. With the preceding insight, one would therefore channel change notifications on parts to observers of their owner, as shown in Fig. 2.6. In this situation, the parts themselves may not even implement OBSERVER, but rather call hook methods, or even the fire![]() 1.4.7 method, on their owner directly.
1.4.7 method, on their owner directly.
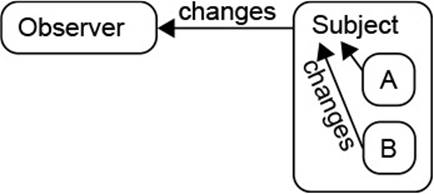
Figure 2.6 Compound Objects in the Observer Pattern
Implement OBSERVER on the owner and forward changes from parts.
The benefits are clear: Observers have to register only once, instead of for all parts separately. Especially when parts are created and destroyed dynamically, this saves a lot of machinery. Similarly, the parts do not have to store essentially the same lists of observers several times. The parts do not even have to implement the observer pattern, but can rely on their owner’s infrastructure.
A typical example is found in the deeply nested XML DOM trees. The![]() 256(§1.6.4) specification says that events generated at some node “bubble” upward and are delivered to any event listener registered on the nodes encountered on the way. Different types of events are available to meet the application’s demands. To receive notifications about any change at all at the granularity of the nodes of the DOM, one registers for DOMSubtreeModified events at the root. Registration is tied to a special interface EventTarget, which is
256(§1.6.4) specification says that events generated at some node “bubble” upward and are delivered to any event listener registered on the nodes encountered on the way. Different types of events are available to meet the application’s demands. To receive notifications about any change at all at the granularity of the nodes of the DOM, one registers for DOMSubtreeModified events at the root. Registration is tied to a special interface EventTarget, which is![]() 3.2.4 implemented by different kinds of nodes.
3.2.4 implemented by different kinds of nodes.
observer.XmlDomObserver.main
((EventTarget) doc).addEventListener("DOMSubtreeModified", listener,
false);
Element subsection1 =
(Element) doc.getElementsByTagName("subsection").item(0);
subsection1.setAttribute("title", "New Title");
The change notifications then include information about which specific node has been modified:
observer.XmlDomObserver.main
public void handleEvent(Event evt) {
MutationEvent mut = (MutationEvent) evt;
Node changedNode = (Node) mut.getTarget();
...
}
![]() 2.1.1A second example has already been seen in observers for background jobs. There, one can register with the system’s (singleton) JobManager to receive status updates on any running job:
2.1.1A second example has already been seen in observers for background jobs. There, one can register with the system’s (singleton) JobManager to receive status updates on any running job:
org.eclipse.ui.internal.progress.ProgressManager
Job.getJobManager().addJobChangeListener(this.changeListener);
In large structures, send out accumulated changes.
Eclipse has several object structures that are both large and widely used. Among them, the resources represent the workspace structure and the Java model keeps track of the current structure of the sources and libraries. Both offer the OBSERVER pattern, where clients register with the container. Because the data structures have a central position, many observers do get registered, so that sending every single change in isolation would involve some overhead. Instead, both accumulate changes through operations and send them in IResourceChangeEvent andElementChangeEvent, respectively.
2.3 Hierarchical Structures
Computer scientists adore trees—at least in the form of file systems, XML data, language syntax, classification hierarchies, a book’s table of contents, and many more. It is therefore a crucial question of how to organize hierarchical data in object-oriented systems. While the data representation using objects as tree nodes is straightforward, the proper treatment of operations, in particular recursive ones, requires some thought and decisions.
2.3.1 The Composite Pattern
Hierarchical data is easily stored as objects: Each object in the tree just owns its immediate child objects. Fig. 2.7 gives the idea. In part (a) of this figure, to represent an arithmetic expression 2 * x + 3 * y, we build a tree according to the expression’s structure (i.e., the nesting of a version with full parentheses added). In part (b), each node in the tree is an instance of Expr, of which there are several kinds: The numbers are Literals, the variables are Vars, and the operators are Plus and Muls, respectively. The latter two share the feature of having left and right operands, so these are extracted into a common superclass Binary.![]() 3.1.4
3.1.4
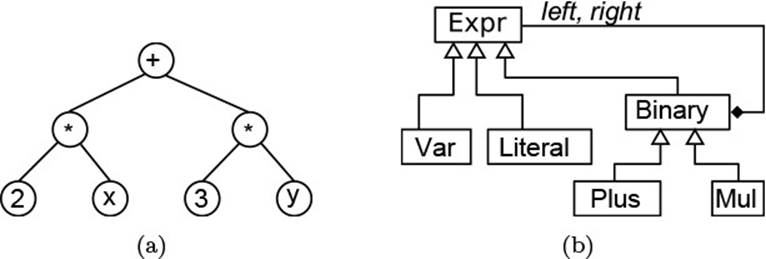
Figure 2.7 Representing Arithmetic Expressions
A crucial question is how operations on the nested compound object can be represented so that the clients do not have to perform case-distinction operations by using instanceof. The COMPOSITE pattern includes this![]() 3.1.9
3.1.9 ![]() 100 aspect. In it, one declares the desired operations in the base class:
100 aspect. In it, one declares the desired operations in the base class:
expr.Expr
public abstract double eval(Valuation v) throws EvalError;
One then implements them in the concrete subclasses, according to the respective case. For variables, for instance, one can just look up their value:
expr.Var.eval
public double eval(Valuation v) throws EvalError {
return v.get(varName);
}
Pattern: Composite
Represent hierarchical data structures and let clients work uniformly with different types of nodes.
1. Define a base class Component for all types of nodes in the tree.
2. Decide which operations clients should be able to use without knowing the concrete node type. Add them to the base class.
3. Derive one concrete class for each type of node.
4. If desired, introduce intermediate classes with supporting infrastructure. For instance, each node type with children can derive from a class Composite that provides management of children.
5. Implement the operations from step 2 for each concrete node. Use recursive calls to the operations on children as necessary.
COMPOSITE occurs throughout the Eclipse code base. Here are a few examples:

None of these has the straightforward—not to say simplistic—structure of arithmetic expressions. Instead, they enable us to study more advanced questions. But let us start with a few implications and guidelines for the pattern.
Composite creates extensibility by new node types.
Clients of composed objects will work with references to the base class![]() 1.4.10 only, and the abstract operations declared there will be delegated to the concrete node types. In the arithmetic example, clients would invoke the eval method and will not care about the concrete node type at the expression’s root. In consequence, it is always possible to add new types of operators, such as function calls.
1.4.10 only, and the abstract operations declared there will be delegated to the concrete node types. In the arithmetic example, clients would invoke the eval method and will not care about the concrete node type at the expression’s root. In consequence, it is always possible to add new types of operators, such as function calls.
This extensibility lies at the core of Figures and Controls: New kinds of visual elements will appear in almost any application, so it is essential that they can be added without changing the existing code. It is worthwhile to examine the hierarchy below Figure from this perspective: It comprises more than 100 cases, which range from simple textual labels, through buttons for GEF’s palette, to layers of drawings and even special cases in![]() 1.8.8.3 anonymous classes.
1.8.8.3 anonymous classes.
Strive to include all necessary operations in the base class.
The above extensibility holds only as long as clients never have to downcast to access type-specific operations. Otherwise, their case distinctions will easily become incomplete if new node types are added. The pattern therefore works at its best if the operations required by clients are foreseen already in the definition of the base class. For example, all Figures can be moved and re-sized and they can have different kinds of observers.
Of course, this guideline does not address operations that are typically performed right after the creation of an object, because clients do know the concrete type at this point. For instance, Clickable figures comprise different kinds of buttons. They do offer specialized action listeners, which are notified when the user clicks the button, because such listeners are usually attached right after creation.
Furthermore, intermediate classifications offer advanced functionality.![]() 3.1.5 The client does not downcast to single types, but to a super-type that captures some abstract concept useful in itself. For instance, generic nodes of type JavaElements from the Java model offer almost no functionality to clients. A Member, in contrast, allows clients to copy, move, and delete the element, regardless of whether the member is a field, method, or class.
3.1.5 The client does not downcast to single types, but to a super-type that captures some abstract concept useful in itself. For instance, generic nodes of type JavaElements from the Java model offer almost no functionality to clients. A Member, in contrast, allows clients to copy, move, and delete the element, regardless of whether the member is a field, method, or class.
Exploit superclasses to extract common infrastructure.
Extensions by new node types must be as simple as possible to create a practical benefit. The rationale is simple: If every concrete type has to implement all offered operations from scratch, nobody will bother to do it. Even in very simple examples, it is therefore worthwhile to look out for common functionality, which can easily be shared in intermediate base![]() 3.1.3
3.1.3 ![]() 3.1.4 classes. Very often, the abstract operations from the base class can then take the form of TEMPLATE METHODs, so that new node types have to
3.1.4 classes. Very often, the abstract operations from the base class can then take the form of TEMPLATE METHODs, so that new node types have to![]() 1.4.9 fill in only the really crucial points. For binary expressions, for instance, evaluation usually computes the results of subexpressions recursively and then applies an operator:
1.4.9 fill in only the really crucial points. For binary expressions, for instance, evaluation usually computes the results of subexpressions recursively and then applies an operator:
expr.Binary.eval
public final double eval(Valuation v) throws EvalError {
return evalOp(left.eval(v), right.eval(v));
}
protected abstract double evalOp(double v1, double v2)
throws EvalError;
New binary operations then need just fill in the operator itself:
expr.Plus.evalOp
protected double evalOp(double v1, double v2) {
return v1 + v2;
}
Other functionality may have a default implementation. For instance, Figures are rendered by their paint method. As a TEMPLATE METHOD, it paints the figure itself, the children, and the border. By default, the first step fills its occupied area:
org.eclipse.draw2d.Figure
protected void paintFigure(Graphics graphics) {
if (isOpaque())
graphics.fillRectangle(getBounds());
...
}
![]() 1.4.11Subclasses can then extend that behavior as they see fit:
1.4.11Subclasses can then extend that behavior as they see fit:
org.eclipse.draw2d.ImageFigure
protected void paintFigure(Graphics graphics) {
super.paintFigure(graphics);
...
graphics.drawImage(getImage(), x, y);
}
Of course, the base class can also gather functionality ready for use: Generic Figures manage children (but optimize by lazy creation of the child list). Resource implements fundamental operations such as copy and delete using the workspace infrastructure.
Build the class hierarchy by commonalities, not case distinctions.
![]() 3.1Even experienced programmers are sometimes led astray by the possibility of expressing detailed conceptual case distinctions in the hierarchy of node types. However, you should be aware that each class must justify its existence by making a contribution to the system’s purpose: Each class creates costs in development, maintenance, and documentation, so it must have corresponding benefits. The best justification here is common behavior and infrastructure that does not have to be reimplemented in different concrete node types. Another one could be that some clients actually work at an intermediate level of abstraction, so that introducing an intermediate class can make these clients uniform over a set of node types. For instance, Eclipse introduces Container as an abstraction over resources that have recursive structure, such as folders or projects. Clients that merely wish to follow some path, for example, can do so independently of the concrete case.
3.1Even experienced programmers are sometimes led astray by the possibility of expressing detailed conceptual case distinctions in the hierarchy of node types. However, you should be aware that each class must justify its existence by making a contribution to the system’s purpose: Each class creates costs in development, maintenance, and documentation, so it must have corresponding benefits. The best justification here is common behavior and infrastructure that does not have to be reimplemented in different concrete node types. Another one could be that some clients actually work at an intermediate level of abstraction, so that introducing an intermediate class can make these clients uniform over a set of node types. For instance, Eclipse introduces Container as an abstraction over resources that have recursive structure, such as folders or projects. Clients that merely wish to follow some path, for example, can do so independently of the concrete case.
Decide whether child management is in the base class.
The hierarchical object structure requires some management of children. In many cases, such as for ASTNodes or JavaElements, only the concrete type determines how many and which children exactly make sense. In other cases, such as for Figures and Controls, arbitrary numbers of children can be attached. Then, one must decide whether their management goes into the base class or a specialized subclass. Both are valid choices: Figure includes children, while Control defers their implementation to the subclass Composite. Here is a typical choice of methods:
org.eclipse.draw2d.Figure
public void add(IFigure figure, int index)
public void remove(IFigure figure)
public List getChildren()
The decision is between a greater uniformity in the first case, where clients can always work with Figures, and a restriction in using objects when many objects cannot have children for logical reasons.
Composite makes it hard to add new operations.
The downside of extensibility by node types is the loss of extensibility by new generic operations: Those would have to be added to the base class, so that any existing concrete node type would have to be adapted. Imagine the outcry if Figure were suddenly to acquire a new abstract operation that does not have a default implementation. In such a scenario, all applications depending on Draw2D would suddenly fail to compile! When defining the base class interface, you should therefore seek to be complete, and you should also write some actual client code to understand the requirements.
Offer a parent pointer if structure sharing is not intended.
Since clients are aware of the tree structure of the composite objects, they![]() 2.2.1 frequently wish to navigate upward in the tree to find surrounding elements. All of the listed examples have parent pointers. The only good reason against having them is the intention of structure sharing.
2.2.1 frequently wish to navigate upward in the tree to find surrounding elements. All of the listed examples have parent pointers. The only good reason against having them is the intention of structure sharing.
If the class hierarchy is closed, offer a type field.
In many cases, the class hierarchy of the pattern is not meant to be extended by applications, or is not likely to change at all. For instance, the various ASTNodes representing Java syntax trees will need to be extended only when the language changes; certainly, applications will never do it. The hierarchy is therefore, in effect, a closed case distinction. Clients can determine the![]() 3.1.6 concrete node type using the following method and can then switch over the result to avoid a linear search by instanceof. The base class ASTNode defines a constant for each node type. By throwing an exception in the
3.1.6 concrete node type using the following method and can then switch over the result to avoid a linear search by instanceof. The base class ASTNode defines a constant for each node type. By throwing an exception in the![]() 1.5.5 default case, clients can guard against later language changes.
1.5.5 default case, clients can guard against later language changes.
org.eclipse.jdt.core.dom.ASTNode
public final int getNodeType()
Wrap COMPOSITEs in top-level containers to simplify their use.
Trees are rather fine-grained objects that must be constructed, can be traversed, can change in nested locations, and so on. When the overall tree has a more comprehensive meaning, it can be a good idea to wrap it with a separate top-level object. For instance, clients of the Java model willtraverse and analyze JavaElements (through the interface IJavaElement and its subtypes), but the tree is really managed by the JavaModel, which in turn is contained in the (singleton) JavaModelManager. Such wrappers![]() 2.2.4 can then take care of observers, and can also organize the creation, update, and disposal of the entire tree.
2.2.4 can then take care of observers, and can also organize the creation, update, and disposal of the entire tree.
2.3.2 The Visitor Pattern
![]() 2.3.1The COMPOSITE pattern, as seen earlier, explains how to represent hierarchical object structures and how to implement (possibly recursive) operations on these structures. This pattern is great because it allows new node types to be added later on, without modifying existing code. Unfortunately, it is rather hard to implement new operations, because this may potentially break existing classes, which are perhaps developed by other teams or even other companies.
2.3.1The COMPOSITE pattern, as seen earlier, explains how to represent hierarchical object structures and how to implement (possibly recursive) operations on these structures. This pattern is great because it allows new node types to be added later on, without modifying existing code. Unfortunately, it is rather hard to implement new operations, because this may potentially break existing classes, which are perhaps developed by other teams or even other companies.
In many cases, however, the ability to add new operations is essential. For instance, there are too many application-specific operations on file systems![]() 2.3.1 to include all of them in the Eclipse’s Resource class. Similarly, one can run so many analyses on Java sources that ASTNode will never provide
2.3.1 to include all of them in the Eclipse’s Resource class. Similarly, one can run so many analyses on Java sources that ASTNode will never provide![]() 100 all of them.
100 all of them.
Pattern: Visitor
Make the set of operations on an object structure extensible by representing each operation by a Visitor object and letting the object structure pass each node in turn to the visitor.
1. Introduce an interface Visitor. Include a visit method for each type of node in the structure, and give it an argument of that node type.
2. Add a method accept(v) to each node type that takes a visitor v and passes this to the corresponding visit method of v and that invokes accept recursively on other nodes to pass the visitor on through the object structure.
3. Provide a base class of Visitor with empty stub implementations of all methods. Clients can then focus on the nodes they are interested in.
![]() 2.3.1For a prototypical implementation, let’s look again at arithmetic expressions. The interface for step 1 is clear; for simplicity, we integrate it with step 3 into an abstract base class:
2.3.1For a prototypical implementation, let’s look again at arithmetic expressions. The interface for step 1 is clear; for simplicity, we integrate it with step 3 into an abstract base class:
expr.ExprVisitor
public abstract class ExprVisitor {
public void visitLiteral(Literal node) {}
public void visitVar(Var var) {}
public void visitPlus(Plus node) {}
}
Step 2 is also straightforward and almost mechanical: The COMPOSITE’s base has a new accept method, the leaf nodes pass themselves, and the inner nodes additionally recurse into subtrees.
expr.Expr
public abstract void accept(ExprVisitor v);
expr.Var.accept
public void accept(ExprVisitor v) {
v.visitVar(this);
}
expr.Plus.accept
public void accept(ExprVisitor v) {
left.accept(v);
right.accept(v);
v.visitPlus(this);
}
When working with predefined composite objects, look out for VISITOR.
VISITOR makes most sense for large, predefined data structures that have![]() 3.1.4 many clients and are general in nature. An example is found in the Eclipse JDT’s syntax trees for Java sources, which are represented by ASTNodes. Any ASTNode can pass around a visitor:
3.1.4 many clients and are general in nature. An example is found in the Eclipse JDT’s syntax trees for Java sources, which are represented by ASTNodes. Any ASTNode can pass around a visitor:
org.eclipse.jdt.core.dom.ASTNode
public final void accept(ASTVisitor visitor) {
...
accept0(visitor);
...
}
abstract void accept0(ASTVisitor visitor);
Suppose you wish to find all methods in a given Java source file. You would first parse the source into a syntax tree:
ASTParser parser = ASTParser.newParser(AST.JLS4);
parser.setKind(ASTParser.K_COMPILATION_UNIT);
... provide source as string
CompilationUnit cu = (CompilationUnit) parser.createAST(null);
Then, you can define a visitor that simply keeps all methods it encounters. (The return value false denotes that we do not wish to descend into the method.)
visitor.MethodAccumulator
public class MethodAccumulator extends ASTVisitor {
private List<MethodDeclaration> methods;
...
public boolean visit(MethodDeclaration method) {
methods.add(method);
return false;
}
...
}
Finally, you ask the root node CompilationUnit to pass around your visitor and you extract the result:
MethodAccumulator accu = new MethodAccumulator();
cu.accept(accu);
List<MethodDeclaration> methods = accu.getMethods();
In many cases, the tasks to be performed are so small that the visitor is![]() 1.8.8.3 best implemented as an anonymous class. This choice carries the additional implication for the human reader that the operation is used locally and does not have to be understood outside of the local context.
1.8.8.3 best implemented as an anonymous class. This choice carries the additional implication for the human reader that the operation is used locally and does not have to be understood outside of the local context.
final List<MethodDeclaration> methods =
new ArrayList<MethodDeclaration>();
cu.accept(new ASTVisitor() {
public boolean visit(MethodDeclaration meth) {
methods.add(meth);
return false;
}
});
Similarly, you can easily search for files with a specific extension below an IResource, or all classes defined in a JAR on the class path. Even change notifications for resources, which are very detailed and tree-structured, support visitors:
org.eclipse.core.resources.IResourceDelta
public void accept(IResourceDeltaVisitor visitor)
throws CoreException;
In all cases, the underlying object structure knows best how to reach all entries, so you just have to pass a visitor that is being “shown around.”
![]() Visitors for resources and resource deltas do not adhere to the pattern precisely, as they receive generic IResources in a single method, rather than concrete files, folders, and other items in different methods. The case distinction on the type of resource must
Visitors for resources and resource deltas do not adhere to the pattern precisely, as they receive generic IResources in a single method, rather than concrete files, folders, and other items in different methods. The case distinction on the type of resource must![]() 3.1.9 be implemented by instanceof and subsequent downcasts.
3.1.9 be implemented by instanceof and subsequent downcasts.
VISITOR is an instance of double dispatch.
When you come to think of it, VISITOR achieves something astoundingly general: You can execute an arbitrary operation on many different types of nodes. In other words, what it does is provide a generic binary operation execute(operation, object), where the concrete behavior ofexecute depends on the dynamic types of both the operation and the object. Unfortunately, the dynamic dispatch built into object-oriented languages works only for the this object on which a method is invoked, not for the arguments.![]() 1.4.1
1.4.1
Binary operations depending on the dynamic types of both arguments are usually implemented by double dispatch (Fig. 2.8). That is, you use dynamic dispatch once on the first argument, passing along the second argument. Then, you use dynamic dispatch again on the second argument, this time passing along the first argument. The trick is that in the first dispatch, you gain the information about the dynamic type of this, which you can use to invoke a type-specific method in the second step. Since the dynamic type of this of b becomes available in the second step, the final methods can depend on both arguments, as required.
Figure 2.8 Double Dispatch
VISITOR can then be understood as an instance of double dispatch. Let us look through the case of ASTVisitors. The first dynamic dispatch is triggered by the accept() method in an ASTNode, which invokes accept0() on itself.
org.eclipse.jdt.core.dom.ASTNode
public final void accept(ASTVisitor visitor) {
...
accept0(visitor);
...
}
abstract void accept0(ASTVisitor visitor);
Each type of node overrides accept0() and thereby gains the information about its own dynamic type in the this pointer. The second dispatch then occurs by invoking the corresponding method from the visitor. For instance, in the following implementation fromMethodDeclaration, the call to visit() chooses the overloading for MethodDeclaration. The visitor can act correspondingly, as seen in the preceding example. The recursive traversal of the children follows the introductory expression example.
org.eclipse.jdt.core.dom.MethodDeclaration
void accept0(ASTVisitor visitor) {
boolean visitChildren = visitor.visit(this);
if (visitChildren) {
...
}
...
}
Decide on top-down or bottom-up traversal, or combine both.
In a tree structure, you have several alternatives for the order in which nodes![]() 72 are visited. Top-down (or pre-order) traversal, as we have just seen, gives the visitor the chance to decide whether substructures should be visited at all. Bottom-up (or post-order) traversal, as we shall see inSection 2.3.4, enables the visitor to compute (some) recursive operations more easily. You can also combine both by “bracketing” visits in method calls: one when descending into a subtree in a top-down fashion, and one when leaving the subtree in a bottom-up manner. Here is an example from ASTNode, which does this throughout:
72 are visited. Top-down (or pre-order) traversal, as we have just seen, gives the visitor the chance to decide whether substructures should be visited at all. Bottom-up (or post-order) traversal, as we shall see inSection 2.3.4, enables the visitor to compute (some) recursive operations more easily. You can also combine both by “bracketing” visits in method calls: one when descending into a subtree in a top-down fashion, and one when leaving the subtree in a bottom-up manner. Here is an example from ASTNode, which does this throughout:
org.eclipse.jdt.core.dom.ASTVisitor
public boolean visit(MethodDeclaration node)
public void endVisit(MethodDeclaration node)
![]() XML documents can nowadays be regarded, perhaps, as the recursive data structure per se. A very efficient way of accessing external XML documents without reading them into memory consists of SAX parsers. In the current context, it is interesting to note that SAX parsers implement, in fact, VISITOR: They traverse the tree structure of the XML document and call back a ContentHandler for each node in that tree, once at the beginning and once at the end of the subtree traversal.
XML documents can nowadays be regarded, perhaps, as the recursive data structure per se. A very efficient way of accessing external XML documents without reading them into memory consists of SAX parsers. In the current context, it is interesting to note that SAX parsers implement, in fact, VISITOR: They traverse the tree structure of the XML document and call back a ContentHandler for each node in that tree, once at the beginning and once at the end of the subtree traversal.
org.xml.sax.ContentHandler
public void startElement(String uri, String localName, String qName,
Attributes atts) throws SAXException;
public void endElement(String uri, String localName, String qName)
throws SAXException;
Beware that VISITOR fixes the set of node types.
Implementation step 1 of the pattern fixes the types of nodes that can occur in the object structure. Adding a new node type breaks all existing visitors, since they would be missing the corresponding method. Simply adding a default empty implementation is rather more dangerous, since it may break the visitors’ logic without making the clients aware of it. You should add the Visitor pattern only to structures that are unlikely to change.
It is also instructive to contrast the question of extensibility with that of COMPOSITE: There, it is possible to add new node types, but adding operations can break clients; here, it is possible to add new operations, but adding node types breaks clients. So when you need a new operation on a COMPOSITE, you have to decide whether adding it to the composite or introducing VISITOR is better in the long run. As usual, there is no silver bullet; rather, you will have to think carefully about the clients’ needs before![]() 1.1 deciding on either strategy.
1.1 deciding on either strategy.
Visitors must build results by causing side effects.
VISITOR promises extensibility by all kinds of application-specific operations.![]() 100 In fact, this is only half the truth: While operations in COMPOSITE are usually recursive (i.e., they call themselves on children of a node), visitors cannot obtain any “result” computed on child nodes. We will take a closer look at the resulting stack structures using the concept of stack
100 In fact, this is only half the truth: While operations in COMPOSITE are usually recursive (i.e., they call themselves on children of a node), visitors cannot obtain any “result” computed on child nodes. We will take a closer look at the resulting stack structures using the concept of stack![]() 2.3.4 machines. For now, we observe that a visitor will have to build internal data structures with partial results while it traverses the object structure. In the introductory example presented earlier, this structure merely kept a list of relevant files. For an extended case study, look at the Eclipse Modeling
2.3.4 machines. For now, we observe that a visitor will have to build internal data structures with partial results while it traverses the object structure. In the introductory example presented earlier, this structure merely kept a list of relevant files. For an extended case study, look at the Eclipse Modeling![]() 235 Framework’s persistence mechanism. It reads XML-based formats using XMLHandler (and subclasses), which is used as a visitor on external XML documents. It constructs the target in-memory objects on the fly. The class introduces around 60 fields that keep track of objects already constructed, their types, links that need to be resolved later on, and many other details.
235 Framework’s persistence mechanism. It reads XML-based formats using XMLHandler (and subclasses), which is used as a visitor on external XML documents. It constructs the target in-memory objects on the fly. The class introduces around 60 fields that keep track of objects already constructed, their types, links that need to be resolved later on, and many other details.
![]() Even the entirely different paradigm of functional programming has devised a coding scheme similar to VISITOR, which emphasizes the importance of that pattern. Functional programmers have recognized early on that they tended to repeat themselves.
Even the entirely different paradigm of functional programming has devised a coding scheme similar to VISITOR, which emphasizes the importance of that pattern. Functional programmers have recognized early on that they tended to repeat themselves.![]() 245(Ch.7, 9) That is, whenever they introduced a tree-structured data type, functions on the type
245(Ch.7, 9) That is, whenever they introduced a tree-structured data type, functions on the type![]() 42(§4.5, §4.6) roughly proceeded in three steps: (1) Switch on the type of node; (2) apply the same function recursively to all arguments of the node; and (3) combine the recursively computed results according to the type of node. They recognized that the redundancy could
42(§4.5, §4.6) roughly proceeded in three steps: (1) Switch on the type of node; (2) apply the same function recursively to all arguments of the node; and (3) combine the recursively computed results according to the type of node. They recognized that the redundancy could![]() 178 be avoided by introducing for each data type a catamorphism (with Greek prefix “cata-” for “downward” and “morphism” as a structure-related function, such as in “homomorphism”). Very briefly, a catamorphism is a function that implements steps 1 and 2. For step 3, it takes as arguments one function per node type, and invokes that function with the recursively computed values whenever it encounters that type of node.
178 be avoided by introducing for each data type a catamorphism (with Greek prefix “cata-” for “downward” and “morphism” as a structure-related function, such as in “homomorphism”). Very briefly, a catamorphism is a function that implements steps 1 and 2. For step 3, it takes as arguments one function per node type, and invokes that function with the recursively computed values whenever it encounters that type of node.
2.3.3 Objects as Languages: Interpreter
Developers depend on languages to express the solutions they create for given problems. Mostly, this means programming in some general-purpose language such as Java, C++, C#, or Python. Surprisingly often, however, developers find that their solutions take similar shapes because the problems![]() 35,249,179 they solve stem from a common domain. Then, it may be worthwhile to create a special-purpose domain-specific language (DSL) that enables developers to express solutions for that domain straightforwardly and reliably. For instance, JSF facelets describe web pages, the Unified Expression Language (EL) captures data access in that context, SVG describes vector graphics, and Ant files describe a build process.
35,249,179 they solve stem from a common domain. Then, it may be worthwhile to create a special-purpose domain-specific language (DSL) that enables developers to express solutions for that domain straightforwardly and reliably. For instance, JSF facelets describe web pages, the Unified Expression Language (EL) captures data access in that context, SVG describes vector graphics, and Ant files describe a build process.
In fact, domain-specific languages are not always separate “languages.” Often, they are simply libraries with a specific structure given by the![]() 100 INTERPRETER pattern discussed next. In this form, you will almost certainly create a domain-specific language before long.
100 INTERPRETER pattern discussed next. In this form, you will almost certainly create a domain-specific language before long.
INTERPRETER guides the way to DSLs.
The core of many computer languages consists of a hierarchical, tree-like![]() 2 structure of operations. This is called the abstract syntax of the language, because it suppresses external detail such as whitespace, line breaks, and comments, as well as keywords such as if, else, and while, because they merely serve to mark and separate the language constructs in the source text. The abstract syntax would provide nodes ifthenelse and while, with children for the Boolean tests and the then, else, and body statements.
2 structure of operations. This is called the abstract syntax of the language, because it suppresses external detail such as whitespace, line breaks, and comments, as well as keywords such as if, else, and while, because they merely serve to mark and separate the language constructs in the source text. The abstract syntax would provide nodes ifthenelse and while, with children for the Boolean tests and the then, else, and body statements.![]() 2.3.1 As another example, the Expr nodes introduced earlier represent the abstract syntax of arithmetic expressions.
2.3.1 As another example, the Expr nodes introduced earlier represent the abstract syntax of arithmetic expressions.
![]() 2.3.1While COMPOSITE is sufficient for creating the tree structure, it says nothing about how to execute the language formed by the objects. INTERPRETER adds precisely this new aspect, in step 2 below. Very often, it is sufficient to interpret the language recursively along its tree structure. In
2.3.1While COMPOSITE is sufficient for creating the tree structure, it says nothing about how to execute the language formed by the objects. INTERPRETER adds precisely this new aspect, in step 2 below. Very often, it is sufficient to interpret the language recursively along its tree structure. In![]() 100 other words, the interpretation or execution can be implemented according to the COMPOSITE pattern.
100 other words, the interpretation or execution can be implemented according to the COMPOSITE pattern.
Pattern: Interpreter
Represent the abstract syntax of a language together with its interpreter.
1. Define the language’s abstract syntax and represent it by COMPOSITE.
2. Add an operation interpret to the COMPOSITE to execute the language.
3. Decide about the concrete syntax.
4. Write a parser that transforms source code to abstract syntax trees.
The original presentation does not include the parsing aspect in steps 3![]() 100 and 4, but it clarifies the relation to the notion of a “language.” We will explore these steps later.
100 and 4, but it clarifies the relation to the notion of a “language.” We will explore these steps later.
But first, let us examine a real-world example for the first two steps—namely, the Unified Expression Language (EL) used in JSP and JSF to access data. We use the implementation from the Jasper JSP engine of Apache Tomcat (jasper-el.jar). Let us first consider step 1, the abstract![]() 11 syntax. It is given by a COMPOSITE with root type SimpleNode. The individual nodes in the abstract syntax reflect the language specification.
11 syntax. It is given by a COMPOSITE with root type SimpleNode. The individual nodes in the abstract syntax reflect the language specification.![]() 200 So there are, for instance, nodes AstIdentifier for identifiers; nodes AstInteger, AstTrue, and AstFalse for literals; and nodes AstPlus and AstMul for arithmetic operators. Their common superclass SimpleNode already provides the child management. The field image holds the text of the operator, identifier, number, and other data that this node represents.
200 So there are, for instance, nodes AstIdentifier for identifiers; nodes AstInteger, AstTrue, and AstFalse for literals; and nodes AstPlus and AstMul for arithmetic operators. Their common superclass SimpleNode already provides the child management. The field image holds the text of the operator, identifier, number, and other data that this node represents.
org.apache.el.parser.SimpleNode
public abstract class SimpleNode extends ELSupport implements Node {
protected Node parent;
protected Node[] children;
protected String image;
...
}
![]() Just in case you are fluent with the EL API and have never seen these classes: The API is given by the facade ValueExpression (package javax.el in el-api.jar of
Just in case you are fluent with the EL API and have never seen these classes: The API is given by the facade ValueExpression (package javax.el in el-api.jar of![]() 11 Tomcat). The Jasper implementation ValueExpressionImpl basically wraps a parser-level
11 Tomcat). The Jasper implementation ValueExpressionImpl basically wraps a parser-level![]() 1.7.2
1.7.2 ![]() 2.4.4 Node, whose implementation is given by SimpleNode and its subclasses.
2.4.4 Node, whose implementation is given by SimpleNode and its subclasses.
But now for the core step 2. There are two basic modes of evaluating an EL expression: read the accessed data and write it. Correspondingly, SimpleNode provides two methods. Subsequently, we will focus on getValue() for simplicity:
org.apache.el.parser.SimpleNode
public Object getValue(EvaluationContext ctx) throws ELException
public void setValue(EvaluationContext ctx, Object value)
throws ELException
Interpretation usually needs a context object.
The execution of nearly all programming languages uses some kind of context: to look up variables, to store data, to access external devices, and so![]() 2.3.1 on. But even the evaluation of simple arithmetic expressions, as we have seen, requires a mapping from variable names to values. In the EL example, the EvaluationContext similarly contains entities accessible from expressions:
2.3.1 on. But even the evaluation of simple arithmetic expressions, as we have seen, requires a mapping from variable names to values. In the EL example, the EvaluationContext similarly contains entities accessible from expressions:
org.apache.el.lang.EvaluationContext
public final class EvaluationContext extends ELContext {
private final ELContext elContext;
private final FunctionMapper fnMapper;
private final VariableMapper varMapper;
...
}
It is good to think beforehand about the necessary information and to put![]() 1.8.3 it in a context object that can be passed around easily.
1.8.3 it in a context object that can be passed around easily.
![]() The first field elContext may look odd, given that EvaluationContext also implements ELContext. In fact, many methods of EvaluationContext just delegate to elContext. Evaluation of EL expressions uses many indirections to enable plugins to
The first field elContext may look odd, given that EvaluationContext also implements ELContext. In fact, many methods of EvaluationContext just delegate to elContext. Evaluation of EL expressions uses many indirections to enable plugins to![]() 12.2change the behavior. From the aspect of designing for flexibility, it is instructive to analyze Jasper’s implementation, starting from ELContextImpl, as well as the substitution of objects from the EL evaluation process in the web application’s deployment descriptor web.xml.
12.2change the behavior. From the aspect of designing for flexibility, it is instructive to analyze Jasper’s implementation, starting from ELContextImpl, as well as the substitution of objects from the EL evaluation process in the web application’s deployment descriptor web.xml.
The interpretation method assigns a meaning to each operator object.
Designing any kind of programming language requires some experience. A![]() 11.5.3 good rule of thumb is compositionality: you define a number of elementary constructs that can be combined in arbitrary manners. The meaning of each construct must furthermore be defined on a stand-alone basis, without reference to the surrounding constructs (except implicitly through the context object). In the end, you will find that you implement in the interpretation method just the meaning of the construct that the operator class represents. You have applied the pattern well and designed the language well if that code is readable and understandable—if you can express clearly in a few lines of code what the construct really means.
11.5.3 good rule of thumb is compositionality: you define a number of elementary constructs that can be combined in arbitrary manners. The meaning of each construct must furthermore be defined on a stand-alone basis, without reference to the surrounding constructs (except implicitly through the context object). In the end, you will find that you implement in the interpretation method just the meaning of the construct that the operator class represents. You have applied the pattern well and designed the language well if that code is readable and understandable—if you can express clearly in a few lines of code what the construct really means.
Here are some concrete cases from the EL example. The binary “+” performs addition, as would be expected (loading off coercions and other tasks to a helper):
org.apache.el.parser.AstPlus
class AstPlus {
...
public Object getValue(EvaluationContext ctx)
throws ELException {
Object obj0 = this.children[0].getValue(ctx);
Object obj1 = this.children[1].getValue(ctx);
return ELArithmetic.add(obj0, obj1);
}
}
A literal integer is returned “as is” (parsing the image field in a helper method getInteger()).
org.apache.el.parser.AstInteger
public final class AstInteger extends SimpleNode {
...
public Object getValue(EvaluationContext ctx)
throws ELException {
return this.getInteger();
}
}
![]() A central operation in the EL is, of course, the access of object fields, array elements, and map entries through dots “.” and brackets “[]”, both termed “suffixes.” Because the exact types of the target and the suffix are not known until runtime, all cases are represented by a common node type AstValue. This makes the class too complex to study here, but we still encourage you to do so.
A central operation in the EL is, of course, the access of object fields, array elements, and map entries through dots “.” and brackets “[]”, both termed “suffixes.” Because the exact types of the target and the suffix are not known until runtime, all cases are represented by a common node type AstValue. This makes the class too complex to study here, but we still encourage you to do so.
![]() Interpreters written with this pattern are not very efficient, because for each operation
Interpreters written with this pattern are not very efficient, because for each operation![]() 100 they must perform a dynamic dispatch and follow several references to different objects. For full languages, it is better to define a virtual machine to minimize the overhead
100 they must perform a dynamic dispatch and follow several references to different objects. For full languages, it is better to define a virtual machine to minimize the overhead![]() 2.3.4 of operations. Nevertheless, you should “do the simplest thing that could possibly work” and try INTERPRETER first—you can always move the code to the stack machine later on.
2.3.4 of operations. Nevertheless, you should “do the simplest thing that could possibly work” and try INTERPRETER first—you can always move the code to the stack machine later on.
![]() A second example, which is more readily available than Tomcat’s Jasper engine, is found in the JDK’s implementation of regular expressions in Pattern. Internally, it represents regular operators as Nodes with an operation to recognize strings:
A second example, which is more readily available than Tomcat’s Jasper engine, is found in the JDK’s implementation of regular expressions in Pattern. Internally, it represents regular operators as Nodes with an operation to recognize strings:![]() 122
122
boolean match(Matcher matcher, int i, CharSequence seq)
Note again the context object Matcher, which receives the start and end of matches and the text matched by groups in the regular expression. It is worthwhile studying the implementations of match() in the different subclasses of Node. Start with the simple case ofCharProperty and work your way to Branch (operator “|”) and Loop (operator “*”). Concatenation is available with any node through its next field.
Parsers transform concrete syntax to abstract syntax.
So steps 1 and 2 of INTERPRETER describe how a language works at its core. After completing these steps, you can already stick together an “expression” in your language by creating and connecting objects. We now show that it is not so hard to create a real language. The remaining steps are similar![]() 9.1 to building applications: After defining their functional core, we create a suitable user interface that accesses this core. We will walk through the steps
9.1 to building applications: After defining their functional core, we create a suitable user interface that accesses this core. We will walk through the steps![]() 2.3.1 using the abstract syntax of simple arithmetic expressions Expr introduced earlier.
2.3.1 using the abstract syntax of simple arithmetic expressions Expr introduced earlier.
![]() 2,206,190The main task is to parse the source text, which is just a sequence of characters, into the structured form of the abstract syntax. There are a number of tools available to assist with this task, since writing parsers by hand is time-consuming and error-prone. For very simple languages, such as arithmetic expressions, you can consider shift-reduce parsers. For example, the online supplement includes such a parser, which we employ like this
2,206,190The main task is to parse the source text, which is just a sequence of characters, into the structured form of the abstract syntax. There are a number of tools available to assist with this task, since writing parsers by hand is time-consuming and error-prone. For very simple languages, such as arithmetic expressions, you can consider shift-reduce parsers. For example, the online supplement includes such a parser, which we employ like this![]() 9.4.2
9.4.2 ![]() 12.4 (the parser is generic over the concrete node type to make it reusable in different contexts):
12.4 (the parser is generic over the concrete node type to make it reusable in different contexts):
interpreter.DSLOverall.evalExpression
Parser<Expr> parser = new Parser<Expr>(new SimpleNodeFactory());
Parsing the concrete syntax of an arithmetic expression then yields its abstract syntax tree as an Expr:
interpreter.DSLOverall.evalExpression
Expr ast = parser.parse(expr);
![]() 2.3.1Finally, we can evaluate the arithmetic expression, using a Valuation as a context object:
2.3.1Finally, we can evaluate the arithmetic expression, using a Valuation as a context object:
interpreter.DSLOverall.evalExpression
double res = ast.eval(v);
![]()
![]() 2.3.2You get the parser, as well as the VISITOR pattern, for free when you base your language on XML and employ a SAX parser. As seen before, the ContentHandler can be understood as a visitor. Whenever an XML element ends, its children have been processed and the results are available. The implementation then leads to a stack machine,
2.3.2You get the parser, as well as the VISITOR pattern, for free when you base your language on XML and employ a SAX parser. As seen before, the ContentHandler can be understood as a visitor. Whenever an XML element ends, its children have been processed and the results are available. The implementation then leads to a stack machine,![]() 2.3.4 as will be seen in the next section.
2.3.4 as will be seen in the next section.
2.3.4 Excursion: Composites and Stack Machines
Our treatment of hierarchical structures has revealed two shortcomings:![]() 2.3.2 VISITORs must build their results by creating side effects on some internal
2.3.2 VISITORs must build their results by creating side effects on some internal![]() 2.3.3 data structures and the INTERPRETER pattern can become too inefficient for implementing programming languages, because the overhead on executing a single operation is too high. In this section, we will highlight the connection of both issues to the concept of stack machines. This connection is, indeed, reflected in many of the more complex visitors occurring in practice. For instance, EMF’s XMLHandler uses three stacks as its central data structure and treats XML elements as “instructions” for building in-memory objects’ structures. Understanding the connection is essential for understanding and developing such complex visitors.
2.3.3 data structures and the INTERPRETER pattern can become too inefficient for implementing programming languages, because the overhead on executing a single operation is too high. In this section, we will highlight the connection of both issues to the concept of stack machines. This connection is, indeed, reflected in many of the more complex visitors occurring in practice. For instance, EMF’s XMLHandler uses three stacks as its central data structure and treats XML elements as “instructions” for building in-memory objects’ structures. Understanding the connection is essential for understanding and developing such complex visitors.
A stack machine is a (virtual) machine that stores temporary values on![]() 231,135 a stack, rather than in named registers or in memory. The idea of stack machines is ubiquitous in language implementations; the Java Virtual Machine
231,135 a stack, rather than in named registers or in memory. The idea of stack machines is ubiquitous in language implementations; the Java Virtual Machine![]() 159 itself is only one example. The appeal of this type of machine is its simplicity: The code can be stored efficiently in an array, one operation after the other, instead of in objects as in INTERPRETER. The operations are stored as numeric op-codes, usually bytes. In each cycle, the machine loads one op-code from the code array, performs aswitch, pops the corresponding number of operands from the stack, performs the operation, and places the result (if any) back on the stack.
159 itself is only one example. The appeal of this type of machine is its simplicity: The code can be stored efficiently in an array, one operation after the other, instead of in objects as in INTERPRETER. The operations are stored as numeric op-codes, usually bytes. In each cycle, the machine loads one op-code from the code array, performs aswitch, pops the corresponding number of operands from the stack, performs the operation, and places the result (if any) back on the stack.
To illustrate the connection to the previous material, let us start with an example from Fig. 2.7(a) (page 117), which shows a tree for the expression 2 * x + 3 * y.
Stack machine code is obtained by a post-order traversal of the syntax tree.
The stack machine code places the operations in the order in which they will be executed. Since syntax trees are executed bottom-up, each node’s operator is placed after the code of all of its children. In other words, a post-order![]() 72 traversal of the syntax tree yields the code. In the example, numbers and variables mean “place that value on the stack,” and operators mean “take two values from the stack and push the result back on.”
72 traversal of the syntax tree yields the code. In the example, numbers and variables mean “place that value on the stack,” and operators mean “take two values from the stack and push the result back on.”
2 x * 3 y * +
The execution of this code yields the sequence of stacks shown in Fig. 2.9.

Figure 2.9 Example Expression on a Stack Machine
Implementing a stack machine ArithVM is straightforward: The class defines numeric constants for the operators and offers an auxiliary class Code as a linear container for an instruction sequence. The example can then be coded up as a test case (code is a Code object; val is a valuation![]() 5 for “x” and “y”).
5 for “x” and “y”).
interpreter.MachineTest.exampleExpr
Code code = new ArithVM.Code();
code.literal(2);
code.var("x");
code.op(ArithVM.MUL);
code.literal(3);
code.var("y");
code.op(ArithVM.MUL);
code.op(ArithVM.PLUS);
ArithVM vm = new ArithVM();
double res = vm.run(code, val);
Below you find the core of the machine, the execution loop. It demonstrates both the efficient storage and the low operation overhead enabled by numeric op-codes. We also introduce a special-purpose stack, whose push and pop operations are hard-coded. Its size is fixed, since the limit could in principle be derived from the code to be run. The two operations shown in the example illustrate the principle. The VAR operation is followed by an index into a pool of variable names, similar to the treatment of strings![]() 159 and identifiers in the JVM. The code then pushes the variable’s current value onto the stack. The PLUS case is optimized even further: After popping the result of the right subexpression, the top pointer stays the same to overwrite the left operand with the result.
159 and identifiers in the JVM. The code then pushes the variable’s current value onto the stack. The PLUS case is optimized even further: After popping the result of the right subexpression, the top pointer stays the same to overwrite the left operand with the result.
interpreter.ArithVM.run
int ip = 0;
VarName var[] = code.varNames;
int instr[] = code.instructions;
double tmp[] = new double[STACK_SIZE];
int top = -1;
while (ip != instr.length) {
switch (instr[ip++]) {
case VAR: tmp[++top] = val.get(var[instr[ip++]]);
break;
case PLUS:
r = tmp[top--];
l = tmp[top];
tmp[top] = l + r;
break;
...
}
}
Let us now examine the connection to the VISITOR pattern somewhat further. If the visitor traverses the object structure bottom-up (i.e., postorder), it is simple to generate stack machine code in a visitor: At each node, just write out the operator corresponding to the node’s type.
interpreter.CodeGenerator
public class CodeGenerator extends ExprVisitor {
private Code code;
...
public void visitLiteral(Literal node) {
code.literal(node.getValue());
}
...
public void visitPlus(Plus node) {
code.op(ArithVM.PLUS);
}
...
}
For efficient execution of languages, introduce a virtual machine.
We can now make explicit an idea given in the original presentation of![]() 100 the pattern: When INTERPRETER becomes too inefficient, use a recursive operation in the COMPOSITE to compile the syntax to some machine code and execute that code. Especially if the code contains loops, this will save a lot of overhead. Building on the concepts discussed so far, we can code the idea for the running arithmetic example: Line 1 parses the expression,
100 the pattern: When INTERPRETER becomes too inefficient, use a recursive operation in the COMPOSITE to compile the syntax to some machine code and execute that code. Especially if the code contains loops, this will save a lot of overhead. Building on the concepts discussed so far, we can code the idea for the running arithmetic example: Line 1 parses the expression,![]() 2.3.3 line 2 generates stack machine code, and lines 3–4 execute this code.
2.3.3 line 2 generates stack machine code, and lines 3–4 execute this code.
interpreter.MachineTest.codeGeneration
1 Expr expr = parser.parse("2*x+3*y");
2 expr.accept(new CodeGenerator(code)); // recursive code generation
3 ArithVM vm = new ArithVM();
4 double res = vm.run(code, val);
Complex visitors often contain conceptual stack machines.
So far, we have seen that visitors and stack machines build on common ground: A post-order traversal of the syntax tree by the visitor creates post-fix code that stack machines can execute directly. This scenario solves the inefficiency of INTERPRETER. Let’s now cut out the middle man, the state machine, to arrive at a very common scheme for implementing visitors for complex operations, such as reading XMI files in EMF and compiling JSF pages.
The strategy is clear: The visitor contains a stack, and instead of emitting an operation to be executed later by the stack machine, we execute the operation within the visitor. Let us apply the strategy to the running example. The stack is simple enough:
visitor.StackEvalVisitor
private Stack<Double> tmp;
Variables are again evaluated by fetching their value:
visitor.StackEvalVisitor.visitVar
public void visitVar(Var var) {
tmp.push(vals.get(var.getVarName()));
}
For binary operators, just pop the results of the subexpressions and push back the operation’s result:
visitor.StackEvalVisitor.visitPlus
public void visitPlus(Plus node) {
double r = tmp.pop();
double l = tmp.pop();
tmp.push(l + r);
}
The content of the stack during the run will be as shown in Fig. 2.9; after all, the very same sequence of computations is carried out. In the end, the result of the overall traversal will be left as the only value on the visitor’s![]() 1.5.4 stack (we check this expectation because of the complex logic):
1.5.4 stack (we check this expectation because of the complex logic):
visitor.StackEvalVisitor
public double value() {
assert(tmp.size() == 1);
return tmp.peek();
}
Stack-based processing is a natural strategy for visitors.
To summarize, the hierarchical structure of COMPOSITEs in combination with the linear traversal of VISITOR require internal data structures to maintain intermediate results. Due to the connection of post-order traversal, post-fix code, and stack machines, the natural choice for data structure in post-order visitors are stacks: At each node, the visitor pops the results of the subtrees and combines them to a new result, which it moves on to the stack.
2.4 Wrappers: Adapters, Proxies, and Decorators
It is surprisingly commonplace to discover that the functionality that you are looking for is actually there in some subsystem or library, and is even![]() 1.8.2 packaged up as a nice, reusable service provider object, yet for some reason you still cannot employ it directly. Perhaps the interface is not quite what you need, it is lacking some functionality, or the object uses resources heavily and you can’t afford to have it around all the time.
1.8.2 packaged up as a nice, reusable service provider object, yet for some reason you still cannot employ it directly. Perhaps the interface is not quite what you need, it is lacking some functionality, or the object uses resources heavily and you can’t afford to have it around all the time.
Fig. 2.10(a) gives the generic solution: You create a wrapper around your real collaboration target, and that wrapper provides just the missing bit of behavior. Specifically, the wrapper might translate the interface, add a bit of functionality, or transparently allocate and deallocate the object. These three purposes of wrappers, and some more, are captured by three![]() 100 patterns: ADAPTER, DECORATOR, and PROXY. Fig. 2.10(b) adds the detail that communication is often two-way: The client invokes services s,
100 patterns: ADAPTER, DECORATOR, and PROXY. Fig. 2.10(b) adds the detail that communication is often two-way: The client invokes services s,![]() 2.1 but expects notifications n through OBSERVER; both directions must be translated.
2.1 but expects notifications n through OBSERVER; both directions must be translated.
Figure 2.10 Wrapper Objects
2.4.1 The Adapter Pattern
Development folklore has it that some parts of the system will just need some glue code to stick together seamlessly. That is, it is imagined that some other team has invented an interface that you are supposed to use, but that does not precisely meet your demands—so you just put in some flexible glue, some adapters, to make it work. However, most adapters do not indicate bad design at all. Rather, it might simply be the case that the expected interface and the actual interface as they are make perfect sense in![]() 1.8.7 their respective subsystems. Then it is a valid—and even recommendable—decision
1.8.7 their respective subsystems. Then it is a valid—and even recommendable—decision![]() 12.1 to keep the subsystems in good shape separately, and to incur the slight overhead of writing adapters.
12.1 to keep the subsystems in good shape separately, and to incur the slight overhead of writing adapters.![]() 100
100
Pattern: Adapter
Some client needs to work with a given object, but the interface does not meet the client’s expectations. Write an adapter object that translates all communication between the client and the target object.
1. Define the interface Target that the Client expects, or would ideally wish to be present. Program the client against that interface.
2. Create an Adapter that implements the Target interface.
3. Translate method calls to the Adapter to the target object, which is also called the Adaptee in this context, as it is the object that has been adapted.
4. Translate any notifications that the Adaptee sends, for instance by the OBSERVER pattern, into notifications for the Client.
Very often, it is not necessary to create a separate interface in step 1. Instead, the interface of the adapter from step 2 is used directly.
A typical example of subsystems with different notions of “good interfaces”![]() 9.1 occurs in UI programming: User interfaces are all about text and images to be shown on the screen. In contrast, the application’s logic is usually complex enough without bothering about those “fancy details.” Suppose then that the UI is to show some data in a tree, so that the user can
9.1 occurs in UI programming: User interfaces are all about text and images to be shown on the screen. In contrast, the application’s logic is usually complex enough without bothering about those “fancy details.” Suppose then that the UI is to show some data in a tree, so that the user can![]() 9.3.2 select some items. For step 1, an ideal interface lets it traverse the data in tree fashion, starting from the root elements, then navigating between nodes and their children. The interface uses generic Objects since it must apply to different data structures.
9.3.2 select some items. For step 1, an ideal interface lets it traverse the data in tree fashion, starting from the root elements, then navigating between nodes and their children. The interface uses generic Objects since it must apply to different data structures.
org.eclipse.jface.viewers.ITreeContentProvider
public interface ITreeContentProvider
extends IStructuredContentProvider {
public Object[] getElements(Object inputElement);
public Object[] getChildren(Object parentElement);
public Object getParent(Object element);
public boolean hasChildren(Object element);
}
For each node in the tree, the UI then retrieves the suitable text and icon.
org.eclipse.jface.viewers.ILabelProvider
public interface ILabelProvider extends IBaseLabelProvider {
public Image getImage(Object element);
public String getText(Object element);
}
One example of such a tree is the Package Explorer you are familiar with; it lets you look at and select parts of the Java code you are editing. Maintaining that information is heavy work, which is performed by the Java Model![]() 2.3.1 component. It keeps essentially a tree structure ofIJavaElements, but does not bother with providing the UI-related methods. Instead, an adapter simulates that tree structure on the fly for steps 2 and 3. For projects, it retrieves the source folders and libraries; for those, it retrieves the packages, and for packages it finds the types and subpackages. A similar adapter exists for the texts and images.
2.3.1 component. It keeps essentially a tree structure ofIJavaElements, but does not bother with providing the UI-related methods. Instead, an adapter simulates that tree structure on the fly for steps 2 and 3. For projects, it retrieves the source folders and libraries; for those, it retrieves the packages, and for packages it finds the types and subpackages. A similar adapter exists for the texts and images.
org.eclipse.jdt.ui.StandardJavaElementContentProvider
public Object[] getChildren(Object element) {
if (element instanceof IJavaProject)
return getPackageFragmentRoots((IJavaProject) element);
if (element instanceof IPackageFragmentRoot)
return getPackageFragmentRootContent
((IPackageFragmentRoot) element);
if (element instanceof IPackageFragment)
return getPackageContent((IPackageFragment) element);
...
}
Finally, the adapter within the package explorer must take care of step 4: Whenever the tree changes, because you edit your code, you expect to see the modification immediately. Toward that end, the adapter registers for