The Well-Grounded Rubyist, Second Edition (2014)
Part 3. Ruby dynamics
Ruby is dynamic, like human nature.
Matz, at RubyConf 2001
The phrase Ruby dynamics is almost redundant: everything about Ruby is dynamic. Variables don’t care what class of object you bind them to, which means you don’t have to (indeed, you can’t) declare their type in advance. Objects get capabilities from the classes that create them but can also branch away from their classes by having individual methods added to them. Classes and modules can be reopened and modified after their initial definitions. Nothing necessarily stays the same over the life cycle of the running program.
And those examples are just the beginning. In this last part of the book, we’ll look more deeply and widely than we yet have at the ways in which Ruby allows you to alter the execution circumstances of your program in your program.
First, in chapter 13, we’ll look at object individuation, going into the details of how Ruby makes it possible for individual objects to live their own lives and develop their own characteristics and behaviors outside of the class-based characteristics they’re “born” with. We’ll thus circle back to one of the book’s earliest topics: adding methods to individual objects. But here, equipped with the knowledge from the intervening material, we’ll zero in much more closely on the underlying mechanisms of object individuation.
Chapter 14 looks at callable objects: objects you can execute. You’ve seen methods already, of course—but you haven’t seen method objects, which we’ll discuss here, as well as anonymous functions in the form of Proc objects. Strings aren’t callable themselves, but you can evaluate a string at runtime as a piece of Ruby code, and chapter 14 will include that (sometimes questionable) technique. The chapter will also introduce you to Ruby threads, which allow you to run segments of code in parallel.
Finally, chapter 15 looks at the facilities Ruby provides for runtime reflection: examining and manipulating the state of your program and your objects while the program is running and the objects exist. Ruby lets you ask your objects for information about themselves, such as what methods they can execute at runtime; and a number of hooks are available, in the form of methods you can write using special reserved names, to intercept runtime events like class inheritance and module inclusion. Here we’re entering the territory of dynamic reflection and decision making that gives Ruby its characteristic and striking quality of flexibility and power.
Chapter 13 also includes information—and advice—about the process of making changes to the Ruby core language in your own programs. In fact, this entire part of the book includes many best-practices pointers (and pointers away from some not-so-best practices). That’s not surprising, given the kind of ground these chapters cover. This is where your programs can distinguish themselves, for better or worse, as to the nature and quality of their use of Ruby’s liberal dynamic-programming toolset. It definitely pays to think through not only the how and why but also thewhether of some of these powerful techniques in certain circumstances. Used judiciously and advisedly, Ruby’s dynamic capabilities can take you to new and fascinating heights.
Chapter 13. Object individuation
This chapter covers
· Singleton methods and classes
· Class methods
· The extend method
· Overriding Ruby core behavior
· The BasicObject class
One of the cornerstones of Ruby’s design is object individuation—that is, the ability of individual objects to behave differently from other objects of the same class. Every object is a full-fledged citizen of the runtime world of the program and can live the life it needs to.
The freedom of objects to veer away from the conditions of their birth has a kind of philosophical ring to it. On the other hand, it has some important technical implications. A remarkable number of Ruby features and characteristics derive from or converge on the individuality of objects. Much of Ruby is engineered to make object individuation possible. Ultimately, the individuation is more important than the engineering: Matz has said over and over again that the principle of object individuality is what matters, and how Ruby implements it is secondary. Still, the implementation of object individuation has some powerful and useful components.
We’ll look in this chapter at how Ruby goes about allowing objects to acquire methods and behaviors on a per-object basis, and how the parts of Ruby that make per-object behavior possible can be used to greatest advantage. We’ll start by examining in detail singleton methods—methods that belong to individual objects—in the context of singleton classes, which is where singleton-method definitions are stored. We’ll then discuss class methods, which are at heart singleton methods attached to class objects. Another key technique in crafting per-object behavior is the extendmethod, which does something similar to module inclusion but for one object at a time. We’ll look at how you can use extend to individuate your objects.
Perhaps the most crucial topic connected in any way with object individuation is changing the core behavior of Ruby classes. Adding a method to a class that already exists, such as Array or String, is a form of object individuation, because classes are objects. It’s a powerful and risky technique. But there are ways to do it with comparatively little risk—and ways to do it per object (adding a behavior to one string, rather than to the String class)—and we’ll walk through the landscape of runtime core changes with an eye to how per-object techniques can help you get the most out of Ruby’s sometimes surprisingly open class model.
Finally, we’ll renew an earlier acquaintance: the BasicObject class. BasicObject instances provide about the purest laboratory imaginable for creating individual objects, and we’ll consider how that class and object individuation complement each other.
13.1. Where the singleton methods are: The singleton class
Most of what happens in Ruby involves classes and modules, containing definitions of instance methods
class C
def talk
puts "Hi!"
end
end
and, subsequently, the instantiation of classes and the calling of those instance methods:
![]()
But as you saw earlier (even earlier than you saw instance methods inside classes), you can also define singleton methods directly on individual objects:

And you’ve also seen that the most common type of singleton method is the class method—a method added to a Class object on an individual basis:
class Car
def self.makes
%w{ Honda Ford Toyota Chevrolet Volvo }
end
end
But any object can have singleton methods added to it. (Almost any object; see sidebar.) The ability to define behavior on a per-object basis is one of the hallmarks of Ruby’s design.
Some objects are more individualizable than others
Almost every object in Ruby can have methods added to it. The exceptions are instances of certain Numeric subclasses, including integer classes and floats, and symbols. If you try this
def 10.some_method; end
you’ll get a syntax error. If you try this
class << 10; end
you’ll get a type error and a message saying “Can’t define singleton.” The same is true, in both cases, of floating-point numbers and symbols.
Instance methods—those available to any and all instances of a given class—live inside a class or module, where they can be found by the objects that are able to call them. But what about singleton methods? Where does a method live, if that method exists only to be called by a single object?
13.1.1. Dual determination through singleton classes
Ruby, true to character, has a simple answer to this tricky question: an object’s singleton methods live in the object’s singleton class. Every object ultimately has two classes:
· The class of which it’s an instance
· Its singleton class
An object can call instance methods from its original class, and it can also call methods from its singleton class. It has both. The method-calling capabilities of the object amount, all together, to the sum of all the instance methods defined in these two classes, along with methods available through ancestral classes (the superclass of the object’s class, that class’s superclass, and so forth) or through any modules that have been mixed in or prepended to any of these classes. You can think of an object’s singleton class as an exclusive stash of methods, tailor-made for that object and not shared with other objects—not even with other instances of the object’s class.
13.1.2. Examining and modifying a singleton class directly
Singleton classes are anonymous: although they’re class objects (instances of the class Class), they spring up automatically without being given a name. Nonetheless, you can open the class-definition body of a singleton class and add instance methods, class methods, and constants to it, as you would with a regular class.
You do this with a special form of the class keyword. Usually, a constant follows that keyword:
class C
# method and constant definitions here
end
But to get inside the definition body of a singleton class, you use a special notation:
class << object
# method and constant definitions here
end
The << object notation means the anonymous, singleton class of object. When you’re inside the singleton class–definition body, you can define methods—and these methods will be singleton methods of the object whose singleton class you’re in.
Consider this program, for example:
str = "I am a string"
class << str
def twice
self + " " + self
end
end
puts str.twice
The output is
I am a string I am a string
The method twice is a singleton method of the string str. It’s exactly as if we had done this:
def str.twice
self + " " + self
end
The difference is that we’ve pried open the singleton class of str and defined the method there.
The difference between def obj.meth and class << obj; def meth
This question often arises: Is there any difference between defining a method directly on an object (using the def obj.some_method notation) and adding a method to an object’s singleton class explicitly (by doing class << obj; def some_method)? The answer is that there’s one difference: constants are resolved differently.
If you have a top-level constant N, you can also define an N inside an object’s singleton class:
N = 1
obj = Object.new
class << obj
N = 2
end
Given this sequence of instructions, the two ways of adding a singleton method to obj differ in which N is visible from within the method definition:
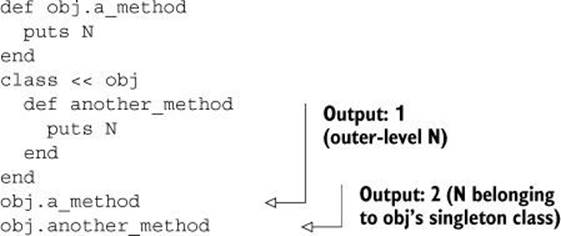
It’s relatively unusual for this difference in the visibility of constants to affect your code; in most circumstances, you can regard the two notations for singleton-method definition as interchangeable. But it’s worth knowing about the difference, because it may matter in some situations and it may also explain unexpected results.
The class << object notation has a bit of a reputation as cryptic or confusing. It needn’t be either. Think of it this way: it’s the class keyword, and it’s willing to accept either a constant or a << object expression. What’s new here is the concept of the singleton class. When you’re comfortable with the idea that objects have singleton classes, it makes sense for you to be able to open those classes with the class keyword. The << object notation is the way the concept “singleton class of object” is expressed when class requires it.
By far the most frequent use of the class << object notation for entering a singleton-method class is in connection with class-method definitions.
Defining class methods with class <<
Here’s an idiom you’ll see often:
class Ticket
class << self
def most_expensive(*tickets)
tickets.max_by(&:price)
end
end
end
This code results in the creation of the class method Ticket.most_expensive—much the same method as the one defined in section 3.6.3, but that time around we did this:
def Ticket.most_expensive(*tickets) # etc.
In the current version, we’re using the class << object idiom, opening the singleton class of the object; and in this particular case, the object involved is the class object Ticket, which is the value of self at the point in the code where class << self is invoked. The result of defining the method most_expensive inside the class-definition block is that it gets defined as a singleton method on Ticket—which is to say, a class method.
The same class method could also be defined like this (assuming this code comes at a point in the program where the Ticket class already exists):
class << Ticket
def most_expensive(tickets)
# etc.
Because self is Ticket inside the class Ticket definition body, class << self inside the body is the same as class << Ticket outside the body. (Technically, you could even do class << Ticket inside the body of class Ticket, but in practice you’ll usually see class << self whenever the object whose singleton class needs opening is self.)
The fact that class << self shows up frequently in connection with the creation of class methods sometimes leads to the false impression that the class << object notation can only be used to create class methods, or that the only expression you can legally put on the right is self. In fact,class << self inside a class-definition block is just one particular use case for class << object. The technique is general: it puts you in a definition block for the singleton class of object, whatever object may be.
In chapter 4, we looked at the steps an object takes as it looks for a method among those defined in its class, its class’s class, and so forth. Now we have a new item on the radar: the singleton class. What’s the effect of this extra class on the method-lookup process?
13.1.3. Singleton classes on the method-lookup path
Recall that method searching goes up the class-inheritance chain, with detours for any modules that have been mixed in or prepended. When we first discussed this process, we hadn’t talked about singleton classes and methods, and they weren’t present in the diagram. Now we can revise the diagram to encompass them, as shown in figure 13.1.
Figure 13.1. Method-search order, revised to include singleton classes
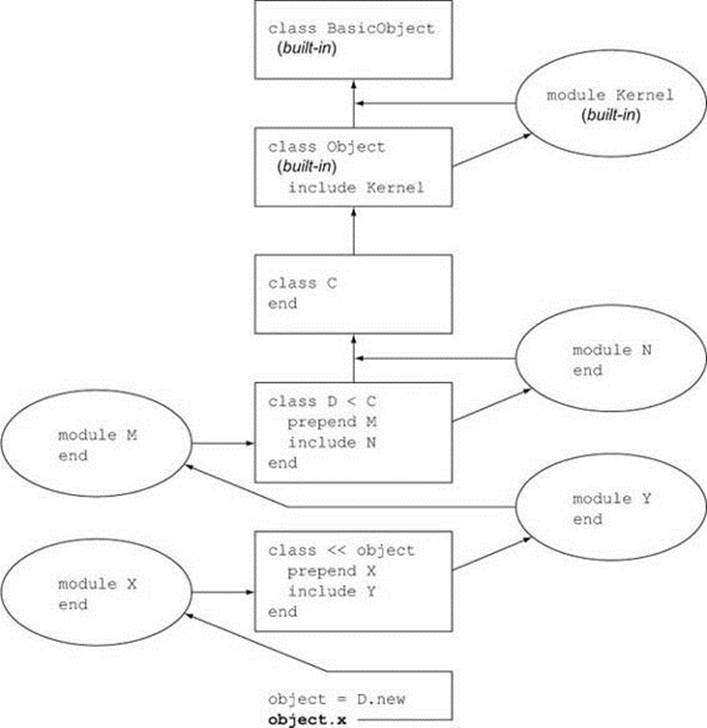
The box containing class << object represents the singleton class of object. In its search for the method x, object looks first for any modules prepended to its singleton class; then it looks in the singleton class itself. It then looks in any modules that the singleton class has included. (In the diagram, there’s one: the module N.) Next, the search proceeds up to the object’s original class (class D), and so forth.
Note in particular that it’s possible for a singleton class to prepend or include a module. After all, it’s a class.
Including a module in a singleton class
Let’s build a little program that illustrates the effect of including a module in a singleton class. We’ll start with a simple Person class and a couple of instances of that class:
class Person
attr_accessor :name
end
david = Person.new
david.name = "David"
matz = Person.new
matz.name = "Matz"
ruby = Person.new
ruby.name = "Ruby"
Now let’s say that some persons—that is, some Person objects—don’t like to reveal their names. A logical way to add this kind of secrecy to individual objects is to add a singleton version of the name method to each of those objects:
def david.name
"[not available]"
end
At this point, Matz and Ruby reveal their names, but David is being secretive. When we do a roll call
puts "We've got one person named #{matz.name}, "
puts "one named #{david.name},"
puts "and one named #{ruby.name}."
we get only two names:
We've got one person named Matz,
one named [not available],
and one named Ruby.
So far, so good. But what if more than one person decides to be secretive? It would be a nuisance to have to write def person.name... for every such person.
The way around this is to use a module. Here’s what the module looks like:
module Secretive
def name
"[not available]"
end
end
Now let’s make Ruby secretive. Instead of using def to define a new version of the name method, we’ll include the module in Ruby’s singleton class:
class << ruby
include Secretive
end
The roll call now shows that Ruby has gone over to the secretive camp; running the previous puts statements again produces the following output:
We've got one person named Matz,
one named [not available],
and one named [not available].
What happened in Ruby’s case? We sent the message “name” to the object ruby. The object set out to find the method. First it looked in its own singleton class, where it didn’t find a name method. Then it looked in the modules mixed into its singleton class. The singleton class of ruby mixed in the Secretive module, and, sure enough, that module contains an instance method called name. At that point, the method gets executed.
Given an understanding of the order in which objects search their lookup paths for methods, you can work out which version of a method (that is, which class or module’s version of the method) an object will find first. Examples help, too, especially to illustrate the difference between including a module in a singleton class and in a regular class.
Singleton module inclusion vs. original-class module inclusion
When you mix a module into an object’s singleton class, you’re dealing with that object specifically; the methods it learns from the module take precedence over any methods of the same name in its original class. The following listing shows the mechanics and outcome of doing this kind ofinclude operation.
Listing 13.1. Including a module in a singleton class

The output from this listing is as follows:
Hi from original class!
Hello from module!
The first call to talk ![]() executes the talk instance method defined in c’s class, C. Then, we mix the module M, which also defines a method called talk, into c’s singleton class
executes the talk instance method defined in c’s class, C. Then, we mix the module M, which also defines a method called talk, into c’s singleton class ![]() . As a result, the next time we call talk on c
. As a result, the next time we call talk on c ![]() , the talk that gets executed (the one that c sees first) is the one defined in M.
, the talk that gets executed (the one that c sees first) is the one defined in M.
It’s all a matter of how the classes and modules on the object’s method lookup path are stacked. Modules included in the singleton class are encountered before the original class and before any modules included in the original class.
You can see this graphically by using the ancestors method, which gives you a list of the classes and modules in the inheritance and inclusion hierarchy of any class or module. Starting from after the class and module definitions in the previous example, try using ancestors to see what the hierarchy looks like:
c = C.new
class << c
include M
p ancestors
end
You get an array of ancestors—essentially, the method-lookup path for instances of this class. Because this is the singleton class of c, looking at its ancestors means looking at the method lookup path for c. Note that c’s singleton class comes first in the ancestor list:
[#<Class:#<C:0x007fbc8b9129f0>>, M, C, Object, Kernel, BasicObject]
Now look what happens when you not only mix M into the singleton class of c but also mix it into c’s class (C). Picking up after the previous example,
class C
include M
end
class << c
p ancestors
end
This time you see the following result:
[#<Class:#<C:0x007fbc8b9129f0>>, M, C, M, Object, Kernel, BasicObject]
The module M appears twice! Two different classes—the singleton class of c and the class C—have mixed it in. Each mix-in is a separate transaction. It’s the private business of each class; the classes don’t consult with each other. (You could even mix M into Object, and you’d get it three times in the ancestors list.)
You’re encouraged to take these examples, modify them, turn them this way and that, and examine the results. Classes are objects, too—so see what happens when you take the singleton class of an object’s singleton class. What about mixing modules into other modules? Try some examples with prepend, too. Many permutations are possible; you can learn a lot through experimentation, using what we’ve covered here as a starting point.
The main lesson is that per-object behavior in Ruby is based on the same principles as regular, class-derived object 'margin-top:12.0pt;margin-right:0cm;margin-bottom: 0cm;margin-left:0cm;margin-bottom:.0001pt;text-align:justify;line-height:normal'>13.1.4. The singleton_class method
To refer directly to the singleton class of an object, use the singleton_class method. This method can save you some class << object roundtrips.
Here’s how you’d use this method to get the ancestors of an object’s singleton class:
string = "a string"
p string.singleton_class.ancestors
Now let’s go back and look at a special case in the world of singleton methods (special, because it’s common and useful): class methods.
13.1.5. Class methods in (even more) depth
Class methods are singleton methods defined on objects of class Class. In many ways, they behave like any other singleton method:

But class methods also exhibit special behavior. Normally, when you define a singleton method on an object, no other object can serve as the receiver in a call to that method. (That’s what makes singleton methods singleton, or per-object.) Class methods are slightly different: a method defined as a singleton method of a class object can also be called on subclasses of that class. Given the previous example, with C, you can do this:
class D < C
end
D.a_class_method
Here’s the rather confusing output (confusing because the class object we sent the message to is D, rather than C):
Singleton method defined on C
You’re allowed to call C’s singleton methods on a subclass of C in addition to C because of a special setup involving the singleton classes of class objects. In our example, the singleton class of C (where the method a_class_method lives) is considered the superclass of the singleton class of D.
When you send a message to the class object D, the usual lookup path is followed—except that after D’s singleton class, the superclass of D’s singleton class is searched. That’s the singleton class of D’s superclass. And there’s the method.
Figure 13.2 shows the relationships among classes in an inheritance relationship and their singleton classes.
Figure 13.2. Relationships among classes in an inheritance relationship and their singleton classes
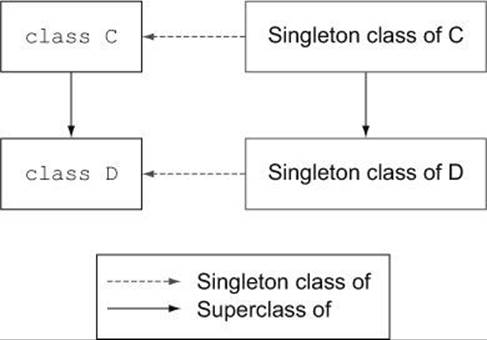
As you can see from figure 13.2, the singleton class of C’s child, D, is considered a child (a subclass) of the singleton class of C.
Singleton classes of class objects are sometimes called meta-classes. You’ll sometimes hear the term meta-class applied to singleton classes in general, although there’s nothing particularly meta about them and singleton class is a more descriptive general term.
You can treat this explanation as a bonus topic. It’s unlikely that an urgent need to understand it will arise often. Still, it’s a great example of how Ruby’s design is based on a relatively small number of rules (such as every object having a singleton class, and the way methods are looked up). Classes are special-cased objects; after all, they’re object factories as well as objects in their own right. But there’s little in Ruby that doesn’t arise naturally from the basic principles of the language’s design—even the special cases.
Because Ruby’s classes and modules are objects, changes you make to those classes and modules are per-object changes. Thus a discussion of how, when, and whether to make alterations to Ruby’s core classes and modules has a place in this discussion of object individuation. We’ll explore core changes next.
Singleton classes and the singleton pattern
The word “singleton” has a second, different meaning in Ruby (and elsewhere): it refers to the singleton pattern, which describes a class that only has one instance. The Ruby standard library includes an implementation of the singleton pattern (available via the command require 'singleton'). Keep in mind that singleton classes aren’t directly related to the singleton pattern; the word “singleton” is just a bit overloaded. It’s generally clear from the context which meaning is intended.
13.2. Modifying Ruby’s core classes and modules
The openness of Ruby’s classes and modules—the fact that you, the programmer, can get under the hood of the language and change what it does—is one of the most important features of Ruby and also one of the hardest to come to terms with. It’s like being able to eat the dishes along with the food at a restaurant. How do you know where one ends and the other begins? How do you know when to stop? Can you eat the tablecloth too?
Learning how to handle Ruby’s openness is a bit about programming technique and a lot about best practices. It’s not difficult to make modifications to the core language; the hard part is knowing when you should, when you shouldn’t, and how to go about it safely.
In this section, we’ll look at the landscape of core changes: the how, the what, and the why (and the why not). We’ll examine the considerable pitfalls, the possible advantages, and ways to think about objects and their behaviors that allow you to have the best of both worlds: flexibility and safety.
We’ll start with a couple of cautionary tales.
13.2.1. The risks of changing core functionality
The problem with making changes to the Ruby core classes is that those changes are global: as long as your program is running, the changes you’ve made will be in effect. If you change how a method works and that method is used somewhere else (inside Ruby itself or in a library you load), you’ve destabilized the whole interpreter by changing the rules of the game in midstream.
It’s tempting, nonetheless, to customize Ruby to your liking by changing core methods globally. After all, you can. But this is the least safe and least advisable approach to customizing core-object behaviors. We’re only looking at it so you can get a sense of the nature of the problem.
One commonly cited candidate for ad hoc change is the Regexp class.
Changing Regexp#match (and why not to)
As you’ll recall from chapter 11, when a match operation using the match method fails, you get back nil; when it succeeds, you get back a MatchData object. This result is irritating because you can’t do the same things with nil that you can with a MatchData object.
This code, for example, succeeds if a first capture is created by the match:
some_regexp.match(some_string)[1]
But if there’s no match, you get back nil—and because nil has no [] method, you get a fatal NoMethodError exception when you try the [1] operation:
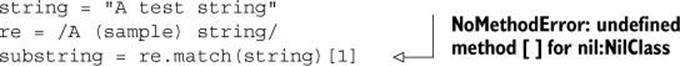
It may be tempting to do something like this to avoid the error:

This code first sets up an alias for match, courtesy of the alias keyword ![]() . Then the code redefines match. The new match hooks into the original version of match (through the alias) and then returns either the result of calling the original version or (if that call returns nil) an empty array.
. Then the code redefines match. The new match hooks into the original version of match (through the alias) and then returns either the result of calling the original version or (if that call returns nil) an empty array.
Note
An alias is a synonym for a method name. Calling a method by an alias doesn’t involve any change of behavior or any alteration of the method-lookup process. The choice of alias name in the previous example is based on a fairly conventional formula: the addition of the word old plus the leading and trailing underscores. (A case could be made that the formula is too conventional and that you should create names that are less likely to be chosen by other overriders who also know the convention!)
You can now do this:
/abc/.match("X")[1]
Even though the match fails, the program won’t blow up, because the failed match now returns an empty array rather than nil. The worst you can do with the new match is try to index an empty array, which is legal. (The result of the index operation will be nil, but at least you’re not trying to index nil.)
The problem is that the person using your code may depend on the match operation to return nil on failure:
if regexp.match(string)
do something
else
do something else
end
Because an array (even an empty one) is true, whereas nil is false, returning an array for a failed match operation means that the true/false test (as embodied in an if/else statement) always returns true.
Maybe changing Regexp#match so as not to return nil on failure is something your instincts would tell you not to do anyway. And no one advocates doing it; it’s more that some new Ruby users don’t connect the dots and therefore don’t see that changing a core method in one place changes it everywhere.
Another common example, and one that’s a little more subtle (both as to what it does and as to why it’s not a good idea), involves the String#gsub! method.
The return value of String#gsub! and why it should stay that way
As you’ll recall, String#gsub! does a global replace operation on its receiver, saving the changes in the original object:

As you can see, the return value of the call to gsub! is the string object with the changes made ![]() . (And examining the object again via the variable string confirms that the changes are indeed permanent
. (And examining the object again via the variable string confirms that the changes are indeed permanent ![]() .)
.)
Interestingly, though, something different happens when the gsub! operation doesn’t result in any changes to the string:
>> string = "Hello there!"
=> "Hello there!"
>> string.gsub!(/zzz/, "xxx")
=> nil
>> string
=> "Hello there!"
There’s no match on /zzz/, so the string isn’t changed—and the return value of the call to gsub! is nil.
Like the nil return from a match operation, the nil return from gsub! has the potential to make things blow up when you’d rather they didn’t. Specifically, it means you can’t use gsub! reliably in a chain of methods:

This example does something similar (but not quite the same) twice. The first time through, the chained calls to gsub! and reverse! ![]() return the newly gsub!’d and reversed string
return the newly gsub!’d and reversed string ![]() . But the second time, the chain of calls results in a fatal error
. But the second time, the chain of calls results in a fatal error ![]() : the gsub! call didn’t change the string, so it returned nil—which means we called reverse! on nil rather than on a string.
: the gsub! call didn’t change the string, so it returned nil—which means we called reverse! on nil rather than on a string.
The tap method
The tap method (callable on any object) performs the somewhat odd but potentially useful task of executing a code block, yielding the receiver to the block, and returning the receiver. It’s easier to show this than to describe it:
>> "Hello".tap {|string| puts string.upcase }.reverse
HELLO
=> "olleH"
Called on the receiver "Hello", the tap method yields that string back to its code block, as confirmed by the printing out of the uppercased version of the string. Then tap returns the entire string—so the reverse operation is performed on the string. If you call gsub! on a string inside a tapblock, it doesn’t matter whether it returns nil, because tap returns the string. Be careful, though. Using tap to circumvent the nil return of gsub! (or of other similarly behaving bang methods) can introduce complexities of its own, especially if you do multiple chaining where some methods perform in-place operations and others return object copies.
One possible way of handling the inconvenience of having to work around the nil return from gsub! is to take the view that it’s not usually appropriate to chain method calls together too much anyway. And you can always avoid chain-related problems if you don’t chain:
>> string = "Hello there!"
=> "Hello there!"
>> string.gsub!(/zzz/, "xxx")
=> nil
>> string.reverse!
=> "!ereht olleH"
Still, a number of Ruby users have been bitten by the nil return value, either because they expected gsub! to behave like gsub (the non-bang version, which always returns its receiver, whether there’s been a change or not) or because they didn’t anticipate a case where the string wouldn’t change. So gsub! and its nil return value became a popular candidate for change.
The change can be accomplished like this:
class String
alias __old_gsub_bang__ gsub!
def gsub!(*args, &block)
__old_gsub_bang__(*args, &block)
self
end
end
First the original gsub! gets an alias; that will enable us to call the original version from inside the new version. The new gsub! takes any number of arguments (the arguments themselves don’t matter; we’ll pass them along to the old gsub!) and a code block, which will be captured in the variable block. If no block is supplied—and gsub! can be called with or without a block—block is nil.
Now we call the old version of gsub!, passing it the arguments and reusing the code block. Finally, the new gsub! does the thing it’s being written to do: it returns self (the string), regardless of whether the call to __old_gsub_bang__ returned the string or nil.
And now, the reasons not to do this.
Changing gsub! this way is probably less likely, as a matter of statistics, to get you in trouble than changing Regexp#match is. Still, it’s possible that someone might write code that depends on the documented behavior of gsub!, in particular on the returning of nil when the string doesn’t change. Here’s an example—and although it’s contrived (as most examples of this scenario are bound to be), it’s valid Ruby and dependent on the documented behavior of gsub!:

We start with a hash of state abbreviations and full names ![]() . Then comes a string that uses state abbreviations
. Then comes a string that uses state abbreviations ![]() . The goal is to replace the abbreviations with the full names, using a gsub! operation that captures any two consecutive uppercase letters surrounded by word boundaries (\b) and replaces them with the value from the hash corresponding to the two-letter substring
. The goal is to replace the abbreviations with the full names, using a gsub! operation that captures any two consecutive uppercase letters surrounded by word boundaries (\b) and replaces them with the value from the hash corresponding to the two-letter substring ![]() . Along the way, we take note of whether any such replacements are made. If any are, gsub! returns the new version of string. If no substitutions are made, gsub! returns nil. The result of the process is printed out at the end
. Along the way, we take note of whether any such replacements are made. If any are, gsub! returns the new version of string. If no substitutions are made, gsub! returns nil. The result of the process is printed out at the end ![]() .
.
The damage here is relatively light, but the lesson is clear: don’t change the documented behavior of core Ruby methods. Here’s another version of the states-hash example, using sub! rather than gsub!. In this version, failure to return nil when the string doesn’t change triggers an infinite loop. Assuming we have the states hash and the original version of string, we can do a one-at-a-time substitution where each substitution is reported:
>> string = "Eastern states include NY, NJ, and ME."
=> "Eastern states include NY, NJ, and ME."
>> while string.sub!(/\b([A-Z]{2})\b/) { states[$1] }
>> puts "Replacing #{$1} with #{states[$1]}..."
>> end
Replacing NY with New York...
Replacing NJ with New Jersey...
Replacing ME with Maine...
If string.sub! always returns a non-nil value (a string), then the while condition will never fail, and the loop will execute forever.
What you should not do, then, is rewrite core methods so that they don’t do what others expect them to do. There’s no exception to this. It’s something you should never do, even though you can.
That leaves us with the question of how to change Ruby core functionality safely. We’ll look at four techniques that you can consider. The first three are additive change, hook or pass-through change, and per-object change. Only one of them is truly safe, although all three are safe enough to use in many circumstances. The fourth technique is refinements, which are module-scoped changes to classes and which can help you pinpoint your core Ruby changes so that they don’t overflow into surrounding code and into Ruby itself.
Along the way, we’ll look at custom-made examples as well as some examples from the Active Support library, which is typically used as part of the Rails web application development framework. Active Support provides good examples of the first two kinds of core change: additive and pass-through. We’ll start with additive.
13.2.2. Additive changes
The most common category of changes to built-in Ruby classes is the additive change: adding a method that doesn’t exist. The benefit of additive change is that it doesn’t clobber existing Ruby methods. The danger inherent in it is that if two programmers write added methods with the same name, and both get included into the interpreter during execution of a particular library or program, one of the two will clobber the other. There’s no way to reduce that risk to zero.
Added methods often serve the purpose of providing functionality that a large number of people want. In other words, they’re not all written for specialized use in one program. There’s safety in numbers: if people have been discussing a given method for years, and if a de facto implementation of the method is floating around the Ruby world, the chances are good that if you write the method or use an existing implementation, you won’t collide with anything that someone else may have written.
The Active Support library, and specifically its core extension sublibrary, adds lots of methods to core Ruby classes. The additions to the String class provide some good examples. Active Support comes with a set of “inflections” on String, with methods like pluralize and titleize. Here are some examples (you’ll need to run gem install activesupport to run them, if you don’t have the gem installed already):
>> require 'active_support/core_ext'
=> true
>> "person".pluralize
=> "people"
>> "little_dorritt".titleize
=> "Little Dorritt"
Any time you add new methods to Ruby core classes, you run the risk that someone else will add a method with the same name that behaves somewhat differently. A library like Active Support depends on the good faith of its users and on its own reputation: if you’re using Active Support, you presumably know that you’re entering into a kind of unwritten contract not to override its methods or load other libraries that do so. In that sense, Active Support is protected by its own reputation and breadth of usage. You can certainly use Active Support if it gives you something you want or need, but don’t take it as a signal that it’s generally okay to add methods to core classes. You need to be quite circumspect about doing so.
Another way to add functionality to existing Ruby classes and modules is with a passive hooking or pass-through technique.
13.2.3. Pass-through overrides
A pass-through method change involves overriding an existing method in such a way that the original version of the method ends up getting called along with the new version. The new version does whatever it needs to do and then passes its arguments along to the original version of the method. It relies on the original method to provide a return value. (As you know from the match and gsub! override examples, calling the original version of a method isn’t enough if you’re going to change the basic interface of the method by changing its return value.)
You can use pass-through overrides for a number of purposes, including logging and debugging:
class String
alias __old_reverse__ reverse
def reverse
$stderr.puts "Reversing a string!"
__old_reverse__
end
end
puts "David".reverse
The output of this snippet is as follows:
Reversing a string!
divaD
The first line is printed to STDERR, and the second line is printed to STDOUT. The example depends on creating an alias for the original reverse and then calling that alias at the end of the new reverse.
Aliasing and its aliases
In addition to the alias keyword, Ruby has a method called alias_method, which is a private instance method of Module. The upshot is that you can create an alias for a method either like this
class String
alias __old_reverse__ reverse
end
or like this:
class String
alias_method :__old_reverse__, :reverse
end
Because it’s a method and not a keyword, alias_method needs objects rather than bare method names as its arguments. It can take symbols or strings. Note also that the arguments to alias don’t have a comma between them. Keywords get to do things like that, but methods don’t.
It’s possible to write methods that combine the additive and pass-through philosophies. Some examples from Active Support demonstrate how to do this.
Additive/pass-through hybrids
An additive/pass-through hybrid is a method that has the same name as an existing core method, calls the old version of the method (so it’s not an out-and-out replacement), and adds something to the method’s interface. In other words, it’s an override that offers a superset of the functionality of the original method.
Active Support features a number of additive/pass-through hybrid methods. A good example is the to_s method of the Time class. Unchanged, Time#to_s provides a nice human-readable string representing the time
>> Time.now.to_s
=> "2013-12-31 08:37:32 -0500"
Active Support adds to the method so that it can take an argument indicating a specific kind of formatting. For example (assuming you have required active_support) you can format a Time object in a manner suitable for database insertion like this:
>> Time.now.to_s(:db)
=> "2013-12-31 08:37:40"
If you want the date represented as a number, ask for the :number format:
>> Time.now.to_s(:number)
=> " 20131231083748 "
The :rfc822 argument nets a time formatted in RFC822 style, the standard date format for dates in email headers. It’s similar to the Time#rfc822 method:
>> Time.now.to_s(:rfc822)
=> "Tue, 31 Dec 2013 08:38:00 -0500"
The various formats added to Time#to_s work by using strftime, which wraps the system call of the same name and lets you format times in a large number of ways. So there’s nothing in the modified Time#to_s that you couldn’t do yourself. The optional argument is added for your convenience (and of course the database-friendly :db format is of interest mainly if you’re using Active Support in conjunction with an object-relational library, such as ActiveRecord). The result is a superset of Time#to_s. You can ignore the add-ons, and the method will work like it always did.
As with pure method addition (such as String#pluralize), the kind of superset-driven override of core methods represented by these examples entails some risk: specifically, the risk of collision. Is it likely that you’ll end up loading two libraries that both add an optional :db argument toTime#to_s? No, it’s unlikely—but it’s possible. Once again, a library like Active Support is protected by its high profile: if you load it, you’re probably familiar with what it does and will know not to override the overrides. Still, it’s remotely possible that another library you load might clash with Active-Support. As always, it’s difficult or impossible to reduce the risk of collision to zero. You need to protect yourself by familiarizing yourself with what every library does and by testing your code sufficiently.
The last major approach to overriding core Ruby behavior we’ll look at—and the safest way to do it—is the addition of functionality on a strictly per-object basis, using Object#extend.
13.2.4. Per-object changes with extend
Object#extend is a kind of homecoming in terms of topic flow. We’ve wandered to the outer reaches of modifying core classes—and extend brings us back to the central process at the heart of all such changes: changing the behavior of an individual object. It also brings us back to an earlier topic from this chapter: the mixing of a module into an object’s singleton class. That’s essentially what extend does.
Adding to an object’s functionality with extend
Have another look at section 13.1.3 and in particular the Person example where we mixed the Secretive module into the singleton classes of some Person objects. As a reminder, the technique was this (where ruby is a Person instance):
class << ruby
include Secretive
end
Here’s how the Person example would look, using extend instead of explicitly opening up the singleton class of the ruby object. Let’s also use extend for david (instead of the singleton method definition with def):

Most of this program is the same as the first version, as is the output. The key difference is the use of extend ![]() , which has the effect of adding the Secretive module to the lookup paths of the individual objects david and ruby by mixing it into their respective singleton classes. That inclusion process happens when you extend a class object, too.
, which has the effect of adding the Secretive module to the lookup paths of the individual objects david and ruby by mixing it into their respective singleton classes. That inclusion process happens when you extend a class object, too.
Adding class methods with extend
If you write a singleton method on a class object, like so
class Car
def self.makes
%w{ Honda Ford Toyota Chevrolet Volvo }
end
end
or like so
class Car
class << self
def makes
%w{ Honda Ford Toyota Chevrolet Volvo }
end
end
end
or with any of the other notational variants available, you’re adding an instance method to the singleton class of the class object. It follows that you can achieve this, in addition to the other ways, by using extend:
module Makers
def makes
%w{ Honda Ford Toyota Chevrolet Volvo }
end
end
class Car
extend Makers
end
If it’s more appropriate in a given situation, you can extend the class object after it already exists:
Car.extend(Makers)
Either way, the upshot is that the class object Car now has access to the makes method.
As with non-class objects, extending a class object with a module means mixing the module into the class’s singleton class. You can verify this with the ancestors method:
p Car.singleton_class.ancestors
The output from this snippet is
[#<Class:Car>, Makers, #<Class:Object>, #<Class:BasicObject>, Class, Module,
Object, Kernel, BasicObject]
The odd-looking entries in the list are singleton classes. The singleton class of Car itself is included; so are the singleton class of Object (which is the superclass of the singleton class of Car) and the singleton class of BasicObject (which is the superclass of the singleton class of Object). The main point for our purpose is that Makers is included in the list.
Remember too that subclasses have access to their superclass’s class methods. If you subclass Car and look at the ancestors of the new class’s singleton class, you’ll see Makers in the list.
Our original purpose in looking at extend was to explore a way to add to Ruby’s core functionality. Let’s turn now to that purpose.
Modifying core behavior with extend
You’ve probably put the pieces together by this point. Modules let you define self-contained, reusable collections of methods. Kernel#extend lets you give individual objects access to modules, courtesy of the singleton class and the mix-in mechanism. Put it all together, and you have a compact, safe way of adding functionality to core objects.
Let’s take another look at the String#gsub! conundrum—namely, that it returns nil when the string doesn’t change. By defining a module and using extend, it’s possible to change gsub!’s behavior in a limited way, making only the changes you need and no more. Here’s how:
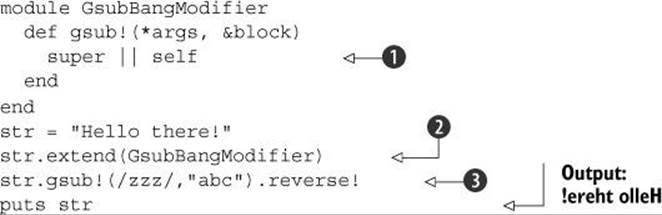
In the module GsubBangModifier, we define gsub!. Instead of the alias-and-call technique, we call super, returning either the value returned by that call or self—the latter if the call to super returns nil ![]() . (You’ll recall that super triggers execution of the next version of the current method up the method-lookup path. Hold that thought....)
. (You’ll recall that super triggers execution of the next version of the current method up the method-lookup path. Hold that thought....)
Next, we create a string str and extend it with GsubBangModifier ![]() . Calling str.gsub!
. Calling str.gsub! ![]() executes the gsub! in GsubBangModifier, because str encounters GsubBangModifier in its method-lookup path before it encounters the class String—which, of course, also contains a gsub! definition. The call to super inside GsubBangModifier#gsub! jumps up the path and executes the original method, String#gsub!, passing it the original arguments and code block, if any. (That’s the effect of calling super with no arguments and no empty argument list.) And the result of the call to super is either the string itself or nil, depending on whether any changes were made to the string.
executes the gsub! in GsubBangModifier, because str encounters GsubBangModifier in its method-lookup path before it encounters the class String—which, of course, also contains a gsub! definition. The call to super inside GsubBangModifier#gsub! jumps up the path and executes the original method, String#gsub!, passing it the original arguments and code block, if any. (That’s the effect of calling super with no arguments and no empty argument list.) And the result of the call to super is either the string itself or nil, depending on whether any changes were made to the string.
Thus you can change the behavior of core objects—strings, arrays, hashes, and so forth—without reopening their classes and without introducing changes on a global level. Having calls to extend in your code helps show what’s going on. Changing a method like gsub! inside the String class itself has the disadvantage not only of being global but also of being likely to be stashed away in a library file somewhere, making bugs hard to track down for people who get bitten by the global change.
There’s one more important piece of the puzzle of how to change core object behaviors: a new feature called refinements.
13.2.5. Using refinements to affect core behavior
Refinements were added to Ruby 2.0, but were considered “experimental” until the 2.1 release. The idea of a refinement is to make a temporary, limited-scope change to a class (which can, though needn’t, be a core class).
Here’s an example, in which a shout method is introduced to the String class but only on a limited basis:

Two different methods appear here, and they work hand in hand: refine ![]() and using
and using ![]() . The refine method takes a class name and a code block. Inside the code block you define the behaviors you want the class you’re refining to adopt. In our example, we’re refining the String class, adding a shout method that returns an upcased version of the string followed by three exclamation points.
. The refine method takes a class name and a code block. Inside the code block you define the behaviors you want the class you’re refining to adopt. In our example, we’re refining the String class, adding a shout method that returns an upcased version of the string followed by three exclamation points.
The using method flips the switch: once you “use” the module in which you’ve defined the refinement you want, the target class adopts the new behaviors. In the example, we use the Shout module inside the Person class. That means that for the duration of that class (from the using statement to the end of the class definition), strings will be “refined” so that they have the shout method.
The effect of “using” a refinement comes to an end with the end of the class (or module) definition in which you declare that you’re using the refinement. You can actually use using outside of a class or module definition, in which case the effect of the refinement persists to the end of the file in which the call to using occurs.
Refinements can help you make temporary changes to core classes in a relatively safe way. Other program files and libraries your program uses at runtime will not be affected by your refinements.
We’ll end this chapter with a look at a slightly oddball topic: the BasicObject class. BasicObject isn’t exclusively an object-individuation topic (as you know from having read the introductory material about it in chapter 3). But it pertains to the ancestry of all objects—including those whose behavior branches away from their original classes—and can play an important role in the kind of dynamism that Ruby makes possible.
13.3. BasicObject as ancestor and class
BasicObject sits at the top of Ruby’s class tree. For any Ruby object obj, the following is true:
obj.class.ancestors.last == BasicObject
In other words, the highest-up ancestor of every class is BasicObject. (Unless you mix a module into BasicObject—but that’s a far-fetched scenario.)
As you’ll recall from chapter 3, instances of BasicObject have few methods—just a survival kit, so to speak, so they can participate in object-related activities. You’ll find it difficult to get a BasicObject instance to tell you what it can do:
>> BasicObject.new.methods.sort
NoMethodError: undefined method `methods' for #<BasicObject:0x007fafa308b0d8>
But BasicObject is a class and behaves like one. You can get information directly from it, using familiar class-level methods:
>> BasicObject.instance_methods(false).sort
=> [:!, :!=, :==, :__id__, :__send__, :equal?, :instance_eval, :instance_exec]
What’s the point of BasicObject?
13.3.1. Using BasicObject
BasicObject enables you to create objects that do nothing, which means you can teach them to do everything—without worrying about clashing with existing methods. Typically, this entails heavy use of method_missing. By defining method_missing for BasicObject or a class that you write that inherits from it, you can engineer objects whose behavior you’re completely in charge of and that have little or no preconceived sense of how they’re supposed to behave.
The best-known example of the use of an object with almost no methods is the Builder library by Jim Weirich. Builder is an XML-writing tool that outputs XML tags corresponding to messages you send to an object that recognizes few messages. The magic happens courtesy ofmethod_missing.
Here’s a simple example of Builder usage (and all Builder usage is simple; that’s the point of the library). This example presupposes that you’ve installed the builder gem.

xml is a Builder::XmlMarkup object ![]() . The object is programmed to send its output to -STDOUT and to indent by two spaces. The instruct! command
. The object is programmed to send its output to -STDOUT and to indent by two spaces. The instruct! command ![]() tells the XML builder to start with an XML declaration. All instance methods of Builder::XmlMarkup end with a bang (!). They don’t have non-bang counterparts—which bang methods should have in most cases—but in this case, the bang serves to distinguish these methods from methods with similar names that you may want to use to generate XML tags via method_missing. The assumption is that you may want an XML element called instruct, but you won’t need one called instruct!. The bang is thus serving a domain-specific purpose, and it makes sense to depart from the usual Ruby convention for its use.
tells the XML builder to start with an XML declaration. All instance methods of Builder::XmlMarkup end with a bang (!). They don’t have non-bang counterparts—which bang methods should have in most cases—but in this case, the bang serves to distinguish these methods from methods with similar names that you may want to use to generate XML tags via method_missing. The assumption is that you may want an XML element called instruct, but you won’t need one called instruct!. The bang is thus serving a domain-specific purpose, and it makes sense to depart from the usual Ruby convention for its use.
The output from our Builder script is this:
<?xml version="1.0" encoding="UTF-8"?>
<friends>
<friend source="college">
<name>Joe Smith</name>
<address>
<street>123 Main Street</street>
<city>Anywhere, USA 00000</city>
</address>
</friend>
</friends>
The various XML tags take their names from the method calls. Every missing method results in a tag, and code blocks represent XML nesting. If you provide a string argument to a missing method, the string will be used as the text context of the element. Attributes are provided in hash arguments.
Builder uses BasicObject to do its work. Interestingly, Builder existed before BasicObject did. The original versions of Builder used a custom-made class called BlankSlate, which probably served as an inspiration for BasicObject.
How would you implement a simple BasicObject-based class?
13.3.2. Implementing a subclass of BasicObject
Simple, in the question just asked, means simpler than Builder::XmlMarkup (which makes XML writing simple but is itself fairly complex). Let’s write a small library that operates on a similar principle and outputs an indented list of items. We’ll avoid having to provide closing tags, which makes things a lot easier.
The Lister class, shown in the following listing, will inherit from BasicObject. It will define method_missing in such a way that every missing method is taken as a heading for the list it’s generating. Nested code blocks will govern indentation.
Listing 13.2. Lister class: Generates indented lists from a BasicObject subclass
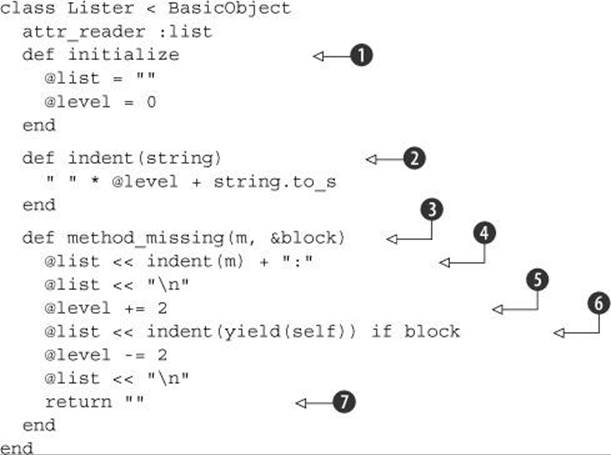
On initialization, two instance variables are set ![]() : @list will serve as the string accumulator for the entire list, and @level will guide indentation. The indent method
: @list will serve as the string accumulator for the entire list, and @level will guide indentation. The indent method ![]() takes a string (or anything that can be converted to a string; it calls to_s on its argument) and returns that string indented to the right by @level spaces.
takes a string (or anything that can be converted to a string; it calls to_s on its argument) and returns that string indented to the right by @level spaces.
Most of the action is in method_missing ![]() . The symbol m represents the missing method name—presumably corresponding to a header or item for the list. Accordingly, the first step is to add m (indented, and followed by a colon) to @list, along with a newline character
. The symbol m represents the missing method name—presumably corresponding to a header or item for the list. Accordingly, the first step is to add m (indented, and followed by a colon) to @list, along with a newline character ![]() . Next we increase the indentation level
. Next we increase the indentation level ![]() and yield
and yield ![]() . (This step happens only if block isn’t nil. Normally, you can test for the presence of a block with block_given?, but BasicObject instances don’t have that method!) Yielding may trigger more missing method calls, in which case they’re processed and their results added to @list at the new indentation level. After getting the results of the yield, we decrement the indentation level and add another newline to @list.
. (This step happens only if block isn’t nil. Normally, you can test for the presence of a block with block_given?, but BasicObject instances don’t have that method!) Yielding may trigger more missing method calls, in which case they’re processed and their results added to @list at the new indentation level. After getting the results of the yield, we decrement the indentation level and add another newline to @list.
At the end, method_missing returns an empty string ![]() . The goal here is to avoid concatenating @list to itself. If method_missing ended with an expression evaluating to @list (like @list << "\n"), then nested calls to method_missing inside yield instructions would return @list and append it to itself. The empty string breaks the cycle.
. The goal here is to avoid concatenating @list to itself. If method_missing ended with an expression evaluating to @list (like @list << "\n"), then nested calls to method_missing inside yield instructions would return @list and append it to itself. The empty string breaks the cycle.
Here’s an example of Lister in use:
lister = Lister.new
lister.groceries do |item|
item.name { "Apples" }
item.quantity { 10 }
item.name { "Sugar" }
item.quantity { "1 lb" }
end
lister.freeze do |f|
f.name { "Ice cream" }
end
lister.inspect do |i|
i.item { "car" }
end
lister.sleep do |s|
s.hours { 8 }
end
lister.print do |document|
document.book { "Chapter 13" }
document.letter { "to editor" }
end
puts lister.list
The output from this run is as follows:
groceries:
name:
Apples
quantity:
10
name:
Sugar
quantity:
1 lb
freeze:
name:
Ice cream
inspect:
item:
car
sleep:
hours:
8
print:
book:
Chapter 13
letter:
to editor
Admittedly not as gratifying as Builder—but you can follow the yields and missing method calls and see how you benefit from a BasicObject instance. And if you look at the method names used in the sample code, you’ll see some that are built-in methods of (nonbasic) objects. If you don’t inherit from BasicObject, you’ll get an error when you try to call freeze or inspect. It’s also interesting to note that sleep and print, which are private methods of Kernel and therefore not normally callable with an explicit receiver, trigger method_missing even though strictly speaking they’re private rather than missing.
Our look at BasicObject brings us to the end of this survey of object individuation. We’ll be moving next to a different topic that’s also deeply involved in Ruby dynamics: callable and runnable objects.
13.4. Summary
In this chapter, you’ve seen
· Singleton classes and how to add methods and constants to them
· Class methods
· The extend method
· Several approaches to changing Ruby’s core behavior
· BasicObject and how to leverage it
We’ve looked at the ways that Ruby objects live up to the philosophy of Ruby, which is that what happens at runtime is all about individual objects and what they can do at any given point. Ruby objects are born into a particular class, but their ability to store individual methods in a dedicated singleton class means that any object can do almost anything.
You’ve seen how to open singleton class definitions and manipulate the innards of individual objects, including class objects that make heavy use of singleton-method techniques in connection with class methods (which are, essentially, singleton methods on class objects). You’ve also seen some of the power, as well as the risks, of the ability Ruby gives you to pry open not only your own classes but also Ruby’s core classes. This is something you should do sparingly, if at all—and it’s also something you should be aware of other people doing, so that you can evaluate the risks of any third-party code you’re using that changes core behaviors.
We ended with an examination of BasicObject, the ultimate ancestor of all classes and a class you can use in cases where even a vanilla Ruby object isn’t vanilla enough.
The next chapter will take us into the area of callable and runnable objects: functions (Proc objects), threads, eval blocks, and more. The fact that you can create objects that embody runnable code and manipulate those objects as you would any object adds yet another major layer to the overall topic of Ruby dynamics.