The Well-Grounded Rubyist, Second Edition (2014)
Part 3. Ruby dynamics
Chapter 14. Callable and runnable objects
This chapter covers
· Proc objects as anonymous functions
· The lambda method for generating functions
· Code blocks
· The Symbol#to_proc method
· Method objects
· Bindings
· The eval family of methods
· Threads
· Executing external programs
In addition to the basic, bread-and-butter method calls that account for most of what happens in your program, Ruby provides an extensive toolkit for making things happen in a variety of ways. You need two or more parts of your code to run in parallel? Create some Thread objects and run them as needed. Want to choose from among a set of possible functions to execute, and don’t have enough information in advance to write methods for them? Create an array of Proc objects—anonymous functions—and call the one you need. You can even isolate methods as objects, or execute dynamically created strings as code.
This chapter is about objects that you can call, execute, or run: threads, anonymous functions, strings, and even methods that have been turned into objects. We’ll look at all of these constructs along with some auxiliary tools—keywords, variable bindings, code blocks—that make Ruby’s inclusion of callable, runnable objects possible.
Be warned: runnable objects have been at the forefront of difficult and changeable topics in recent versions of Ruby. There’s no getting around the fact that there’s a lot of disagreement about how they should work, and there’s a lot of complexity involved in how they do work. Callable and runnable objects differ from each other, in both syntax and purpose, and grouping them together in one chapter is a bit of an expedient. But it’s also an instructive way to view these objects.
14.1. Basic anonymous functions: The Proc class
At its most straightforward, the notion of a callable object is embodied in Ruby through objects to which you can send the message call, with the expectation that some code associated with the objects will be executed. The main callable objects in Ruby are Proc objects, lambdas, and method objects. Proc objects are self-contained code sequences that you can create, store, pass around as method arguments, and, when you wish, execute with the call method. Lambdas are similar to Proc objects. Truth be told, a lambda is a Proc object, but one with slightly special internal engineering. The differences will emerge as we examine each in turn. Method objects represent methods extracted into objects that you can, similarly, store, pass around, and execute.
We’ll start our exploration of callable objects with Proc objects.
Note
For the sake of conciseness, the term proc (in regular font) will serve in the text to mean Proc object, much as string refers to an instance of the class String. Lambda will mean an instance of the lambda style of Proc object. (Don’t worry; you’ll see what that means soon!) The term function is a generic term for standalone units of code that take input and return a value. There’s no Function class in Ruby. Here, however, you’ll sometimes see function used to refer to procs and lambdas. It’s just another, slightly more abstract way of identifying those objects.
14.1.1. Proc objects
Understanding Proc objects thoroughly means being familiar with several things: the basics of creating and using procs; the way procs handle arguments and variable bindings; the role of procs as closures; the relationship between procs and code blocks; and the difference between creating procs with Proc.new, the proc method, the lambda method, and the literal lambda constructor ->. There’s a lot going on here, but it all fits together if you take it one layer at a time.
Let’s start with the basic callable object: an instance of Proc, created with Proc.new. You create a Proc object by instantiating the Proc class, including a code block:
pr = Proc.new { puts "Inside a Proc's block" }
The code block becomes the body of the proc; when you call the proc, the block you provided is executed. Thus if you call pr
pr.call
it reports as follows:
Inside a Proc's block
That’s the basic scenario: a code block supplied to a call to Proc.new becomes the body of the Proc object and gets executed when you call that object. Everything else that happens, or that can happen, involves additions to and variations on this theme.
Remember that procs are objects. That means you can assign them to variables, put them inside arrays, send them around as method arguments, and generally treat them as you would any other object. They have knowledge of a chunk of code (the code block they’re created with) and the ability to execute that code when asked to. But they’re still objects.
The proc method
The proc method takes a block and returns a Proc object. Thus you can say proc { puts "Hi!" } instead of Proc.new { puts "Hi!" } and get the same result. Proc.new and proc used to be slightly different from each other, with proc serving as a synonym for lambda (see section 14.2) and theproc/lambda methods producing specialized Proc objects that weren’t quite the same as what Proc.new produced. Yes, it was confusing. But now, although there are still two variants of the Proc object, Proc.new and proc do the same thing, whereas lambda produces the other variant. At least the naming lines up more predictably.
Perhaps the most important aspect of procs to get a handle on is the relation between procs and code blocks. That relation is intimate and turns out to be an important key to further understanding.
14.1.2. Procs and blocks and how they differ
When you create a Proc object, you always supply a code block. But not every code block serves as the basis of a proc. The snippet
[1,2,3].each {|x| puts x * 10 }
involves a code block but does not create a proc. Yet the plot is a little thicker than that. A method can capture a block, objectified into a proc, using the special parameter syntax that you saw briefly in chapter 9:
def call_a_proc(&block)
block.call
end
call_a_proc { puts "I'm the block...or Proc...or something." }
The output isn’t surprising:
I'm the block...or Proc...or something.
But it’s also possible for a proc to serve in place of the code block in a method call, using a similar special syntax:
p = Proc.new {|x| puts x.upcase }
%w{ David Black }.each(&p)
Here’s the output from that call to each:
DAVID
BLACK
But the question remains: exactly what’s going on with regard to procs and blocks? Why and how does the presence of (&p) convince each that it doesn’t need an actual code block?
To a large extent, the relation between blocks and procs comes down to a matter of syntax versus objects.
Syntax (blocks) and objects (procs)
An important and often misunderstood fact is that a Ruby code block is not an object. This familiar trivial example has a receiver, a dot operator, a method name, and a code block:
[1,2,3].each {|x| puts x * 10 }
The receiver is an object, but the code block isn’t. Rather, the code block is part of the syntax of the method call.
You can put code blocks in context by thinking of the analogy with argument lists. In a method call with arguments
puts c2f(100)
the arguments are objects but the argument list itself—the whole (100) thing—isn’t an object. There’s no ArgumentList class, and there’s no CodeBlock class.
Things get a little more complex in the case of block syntax than in the case of argument lists, though, because of the way blocks and procs interoperate. An instance of Proc is an object. A code block contains everything that’s needed to create a proc. That’s why Proc.new takes a code block: that’s how it finds out what the proc is supposed to do when it gets called.
One important implication of the fact that the code block is a syntactic construct and not an object is that code blocks aren’t method arguments. The matter of providing arguments to a method is independent of whether a code block is present, just as the presence of a block is independent of the presence or absence of an argument list. When you provide a code block, you’re not sending the block to the method as an argument; you’re providing a code block, and that’s a thing unto itself. Let’s take another, closer look now at the conversion mechanisms that allow code blocks to be captured as procs, and procs to be pressed into service in place of code blocks.
14.1.3. Block-proc conversions
Conversion between blocks and procs is easy—which isn’t too surprising, because the purpose of a code block is to be executed, and a proc is an object whose job is to provide execution access to a previously defined code block. We’ll look first at block-to-proc conversions and then at the use of procs in place of blocks.
Capturing a code block as a Proc
Let’s start with another simple method that captures its code block as a Proc object and subsequently calls that object:
def capture_block(&block)
block.call
end
capture_block { puts "Inside the block" }
What happens is a kind of implicit call to Proc.new, using the same block. The proc thus created is bound to the parameter block.
Figure 14.1 provides an artist’s rendering of how a code block becomes a proc. The first event (at the bottom of the figure) is the calling of the method capture_block with a code block. Along the way, a new Proc object is created (step 2) using the same block. It’s this Proc object to which the variable block is bound, inside the method body (step 3).
Figure 14.1. A phantom Proc instantiation intervenes between a method call and a method.
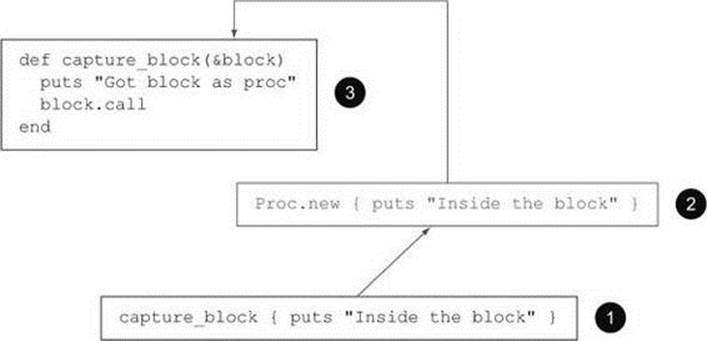
The syntactic element (the code block) thus serves as the basis for the creation of an object. The “phantom” step of creating the proc from the block also explains the need for the special &-based syntax. A method call can include both an argument list and a code block. Without a special flag like &, Ruby has no way of knowing that you want to stop binding parameters to regular arguments and instead perform a block-to-proc conversion and save the results.
The & also makes an appearance when you want to do the conversion the other way: use a Proc object instead of a code block.
Using procs for blocks
Here’s how you might call capture_block using a proc instead of a code block:
p = Proc.new { puts "This proc argument will serve as a code block." }
capture_block(&p)
The output is
This proc argument will serve as a code block.
The key to using a proc as a block is that you actually use it instead of a block: you send the proc as an argument to the method you’re calling. Just as you tag the parameter in the method definition with the & character to indicate that it should convert the block to a proc, so too you use the &on the method-calling side to indicate that the proc should do the job of a code block.
Keep in mind that because the proc tagged with & is serving as the code block, you can’t send a code block in the same method call. If you do, you’ll get an error. The call
capture_block(&p) { puts "This is the explicit block" }
results in the error “both block arg and actual block given.” Ruby can’t decide which entity—the proc or the block—is serving as the block, so you can use only one.
An interesting subplot is going on here. Like many Ruby operators, the & in &p is a wrapper around a method: namely, the method to_proc. Calling to_proc on a Proc object returns the Proc object itself, rather like calling to_s on a string or to_i on an integer.
But note that you still need the &. If you do this
capture_block(p)
or this
capture_block(p.to_proc)
the proc serves as a regular argument to the method. You aren’t triggering the special behavior whereby a proc argument does the job of a code block.
Thus the & in capture_block(&p) does two things: it triggers a call to p’s to_proc method, and it tells Ruby that the resulting Proc object is serving as a code block stand-in. And because to_proc is a method, it’s possible to use it in a more general way.
Generalizing to_proc
In theory, you can define to_proc in any class or for any object, and the & technique will then work for the affected objects. You probably won’t need to do this a lot; the two classes where to_proc is most useful are Proc (discussed earlier) and Symbol (discussed in the next section), andto_proc behavior is already built into those classes. But looking at how to roll to_proc into your own classes can give you a sense of the dynamic power that lies below the surface of the language.
Here is a rather odd but instructive piece of code:
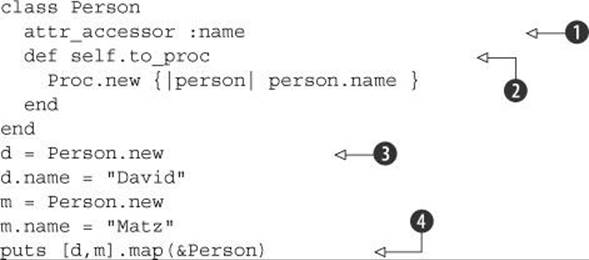
The best starting point, if you want to follow the trail of breadcrumbs through this code, is the last line ![]() . Here, we have an array of two Person objects. We’re doing a map operation on the array. As you know, Array#map takes a code block. In this case, we’re using a Proc object instead. That proc is designated in the argument list as &Person. Of course, Person isn’t a proc; it’s a class. To make sense of what it sees, Ruby asks Person to represent itself as a proc, which means an implicit call to Person’s to_proc method
. Here, we have an array of two Person objects. We’re doing a map operation on the array. As you know, Array#map takes a code block. In this case, we’re using a Proc object instead. That proc is designated in the argument list as &Person. Of course, Person isn’t a proc; it’s a class. To make sense of what it sees, Ruby asks Person to represent itself as a proc, which means an implicit call to Person’s to_proc method ![]() .
.
That method, in turn, produces a simple Proc object that takes one argument and calls the name method on that argument. Person objects have name attributes ![]() . And the Person objects created for purposes of trying out the code, sure enough, have names
. And the Person objects created for purposes of trying out the code, sure enough, have names ![]() . All of this means that the mapping of the array of Person objects ([d,m]) will collect the name attributes of the objects, and the entire resulting array will be printed out (thanks to puts).
. All of this means that the mapping of the array of Person objects ([d,m]) will collect the name attributes of the objects, and the entire resulting array will be printed out (thanks to puts).
It’s a long way around. And the design is a bit loose; after all, any method that takes a block could use &Person, which might get weird if it involved non-person objects that didn’t have a name method. But the example shows you that to_proc can serve as a powerful conversion hook. And that’s what it does in the Symbol class, as you’ll see next.
14.1.4. Using Symbol#to_proc for conciseness
The built-in method Symbol#to_proc comes into play in situations like this:
%w{ david black }.map(&:capitalize)
The result is
["David", "Black"]
The symbol :capitalize is interpreted as a message to be sent to each element of the array in turn. The previous code is thus equivalent to
%w{ david black }.map {|str| str.capitalize }
but, as you can see, more concise.
If you just saw &:capitalize or a similar construct in code, you might think it was cryptic. But knowing how it parses—knowing that :capitalize is a symbol and & is a to_proc trigger—allows you to interpret it correctly and appreciate its expressiveness.
The Symbol#to_proc situation lends itself nicely to the elimination of parentheses:
%w{ david black }.map &:capitalize
By taking off the parentheses, you can make the proc-ified symbol look like it’s in code-block position. There’s no necessity for this, of course, and you should keep in mind that when you use the to_proc & indicator, you’re sending the proc as an argument flagged with & and not providing a literal code block.
Symbol#to_proc is, among other things, a great example of something that Ruby does for you that you could, if you had to, do easily yourself. Here’s how.
Implementing Symbol#to_proc
Here’s the to_proc case study again:
%w{ david black }.map(&:capitalize)
We know it’s equivalent to this:
%w{ david black }.map {|str| str.capitalize }
And the same thing could also be written like this:
%w{ david black }.map {|str| str.send(:capitalize) }
Normally, you wouldn’t write it that way, because there’s no need to go to the trouble of doing a send if you’re able to call the method using regular dot syntax. But the send-based version points the way to an implementation of Symbol#to_proc. The job of the block in this example is to send the symbol :capitalize to each element of the array. That means the Proc produced by :capitalize#to_proc has to send :capitalize to its argument. Generalizing from this, we can come up with this simple (almost anticlimactic, one might say) implementation of Symbol#to_proc:
class Symbol
def to_proc
Proc.new {|obj| obj.send(self) }
end
end
This method returns a Proc object that takes one argument and sends self (which will be whatever symbol we’re using) to that object.
You can try the new implementation in irb. Let’s throw in a greeting from the method so it’s clear that the version being used is the one we’ve just defined:
class Symbol
def to_proc
puts "In the new Symbol#to_proc!"
Proc.new {|obj| obj.send(self) }
end
end
Save this code to a file called sym2proc.rb, and from the directory to which you’ve saved it, pull it into irb using the –I (include path in load path) flag and the -r (require) flag:
irb --simple-prompt –I. -r sym2proc
Now you’ll see the new to_proc in action when you use the &:symbol technique:
>> %w{ david black }.map(&:capitalize)
In the new Symbol#to_proc!
=> ["David", "Black"]
You’re under no obligation to use the Symbol#to_proc shortcut (let alone implement it), but it’s useful to know how it works so you can decide when it’s appropriate to use.
One of the most important aspects of Proc objects is their service as closures: anonymous functions that preserve the local variable bindings that are in effect when the procs are created. We’ll look next at how procs operate as closures.
14.1.5. Procs as closures
You’ve already seen that the local variables you use inside a method body aren’t the same as the local variables you use in the scope of the method call:
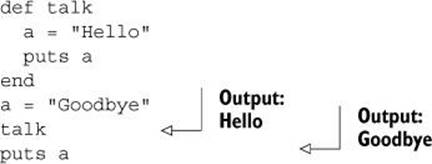
The identifier a has been assigned to twice, but the two assignments (the two a variables) are unrelated to each other.
You’ve also seen that code blocks preserve the variables that were in existence at the time they were created. All code blocks do this:
m = 10
[1,2,3].each {|x| puts x * m }
This behavior becomes significant when the code block serves as the body of a callable object:

In this example, the method multiply_by returns a proc that can be called with any argument but that always multiplies by the number sent as an argument to multiply_by. The variable m, whatever its value, is preserved inside the code block passed to Proc.new and therefore serves as the multiplier every time the Proc object returned from multiply_by is called.
Proc objects put a slightly different spin on scope. When you construct the code block for a call to Proc.new, the local variables you’ve created are still in scope (as with any code block). And those variables remain in scope inside the proc, no matter where or when you call it.
Look at the following listing, and keep your eye on the two variables called a.
Listing 14.1. Proc object preserving local context

As in the previous example, there’s an a in the method definition ![]() and an a in the outer (calling) scope
and an a in the outer (calling) scope ![]() . Inside the method is a call to a proc. The code for that proc, we happen to know, consists of puts a. Notice that when the proc is called from inside the method
. Inside the method is a call to a proc. The code for that proc, we happen to know, consists of puts a. Notice that when the proc is called from inside the method ![]() , the a that’s printed out isn’t the a defined in the method; it’s the a from the scope where the proc was originally created:
, the a that’s printed out isn’t the a defined in the method; it’s the a from the scope where the proc was originally created:
'a' to be used in Proc block
irrelevant 'a' in method scope
'a' to be used in Proc block
The Proc object carries its context around with it. Part of that context is a variable called a to which a particular string is assigned. That variable lives on inside the Proc.
A piece of code that carries its creation context around with it like this is called a closure. Creating a closure is like packing a suitcase: wherever you open the suitcase, it contains what you put in when you packed it. When you open a closure (by calling it), it contains what you put into it when it was created. Closures are important because they preserve the partial running state of a program. A variable that goes out of scope when a method returns may have something interesting to say later on—and with a closure, you can preserve that variable so it can continue to provide information or calculation results.
The classic closure example is a counter. Here’s a method that returns a closure (a proc with the local variable bindings preserved). The proc serves as a counter; it increments its variable every time it’s called:

The output is
1
2
1
3
The logic in the proc involves adding 1 to n ![]() ; so the first time the proc is called, it evaluates to 1; the second time to 2; and so forth. Calling make_counter and then calling the proc it returns confirms this: first 1 is printed, and then 2
; so the first time the proc is called, it evaluates to 1; the second time to 2; and so forth. Calling make_counter and then calling the proc it returns confirms this: first 1 is printed, and then 2 ![]() . But a new counter starts again from 1; the second call to make_counter
. But a new counter starts again from 1; the second call to make_counter ![]() generates a new, local n, which gets preserved in a different proc. The difference between the two counters is made clear by the third call to the first counter, which prints 3
generates a new, local n, which gets preserved in a different proc. The difference between the two counters is made clear by the third call to the first counter, which prints 3 ![]() . It picks up where it left off, using the n variable that was preserved inside it at the time of its creation.
. It picks up where it left off, using the n variable that was preserved inside it at the time of its creation.
Like any code block, the block you provide when you create a Proc object can take arguments. Let’s look in detail at how block arguments and parameters work in the course of Proc creation.
14.1.6. Proc parameters and arguments
Here’s an instantiation of Proc, with a block that takes one argument:
pr = Proc.new {|x| puts "Called with argument #{x}" }
pr.call(100)
The output is
Called with argument 100
Procs differ from methods, with respect to argument handling, in that they don’t care whether they get the right number of arguments. A one-argument proc, like this
>> pr = Proc.new {|x| p x }
=> #<Proc:0x000001029a8960@(irb):1>
can be called with any number of arguments, including none. If it’s called with no arguments, its single parameter gets set to nil:
>> pr.call
nil
If it’s called with more than one argument, the single parameter is bound to the first argument, and the remaining arguments are discarded:
>> pr.call(1,2,3)
1
(Remember that the single value printed out is the value of the variable x.)
You can, of course, also use “sponge” arguments and all the rest of the parameter-list paraphernalia you’ve already learned about. But keep in mind the point that procs are a little less fussy than methods about their argument count—their arity. Still, Ruby provides a way to create fussier functions: the lambda method.
14.2. Creating functions with lambda and ->
Like Proc.new, the lambda method returns a Proc object, using the provided code block as the function body:
>> lam = lambda { puts "A lambda!" }
=> #<Proc:0x0000010299a1d0@(irb):2 (lambda)>
>> lam.call
A lambda!
As the inspect string suggests, the object returned from lambda is of class Proc. But note the (lambda) notation. There’s no Lambda class, but there is a distinct lambda flavor of the Proc class. And lambda-flavored procs are a little different from their vanilla cousins, in three ways.
First, lambdas require explicit creation. Wherever Ruby creates Proc objects implicitly, they’re regular procs and not lambdas. That means chiefly that when you grab a code block in a method, like this
def m(&block)
the Proc object you’ve grabbed is a regular proc, not a lambda.
Second, lambdas differ from procs in how they treat the return keyword. return inside a lambda triggers an exit from the body of the lambda to the code context immediately containing the lambda. return inside a proc triggers a return from the method in which the proc is being executed. Here’s an illustration of the difference:

The output of this snippet is "Still here!" You’ll never see the second message ![]() printed out because the call to the Proc object
printed out because the call to the Proc object ![]() triggers a return from the return_test method. But the call to the lambda
triggers a return from the return_test method. But the call to the lambda ![]() triggers a return (an exit) from the body of the lambda, and execution of the method continues where it left off.
triggers a return (an exit) from the body of the lambda, and execution of the method continues where it left off.
Warning
Because return from inside a (non-lambda-flavored) proc triggers a return from the enclosing method, calling a proc that contains return when you’re not inside any method produces a fatal error. To see a demo of this error, try it from the command line: ruby -e 'Proc.new { return }.call'.
Finally, and most important, lambda-flavored procs don’t like being called with the wrong number of arguments. They’re fussy:
>> lam = lambda {|x| p x }
=> #<Proc:0x000001029901f8@(irb):3 (lambda)>
>> lam.call(1)
1
=> 1
>> lam.call
ArgumentError: wrong number of arguments (0 for 1)
>> lam.call(1,2,3)
ArgumentError: wrong number of arguments (3 for 1)
In addition to the lambda method, there’s a lambda literal constructor.
The “stabby lambda” constructor, ->
The lambda constructor (nicknamed the “stabby lambda”) works like this:
>> lam = -> { puts "hi" }
=> #<Proc:0x0000010289f140@(irb):1 (lambda)>
>> lam.call
hi
If you want your lambda to take arguments, you need to put your parameters in parentheses after the ->, not in vertical pipes inside the code block:
>> mult = ->(x,y) { x * y }
=> #<Proc:0x00000101023c38@(irb):7 (lambda)>
>> mult.call(3,4)
=> 12
A bit of history: the stabby lambda exists in the first place because older versions of Ruby had trouble parsing method-style argument syntax inside the vertical pipes. For example, in Ruby 1.8 you couldn’t use default-argument syntax like this:
lambda {|a,b=1| "Doesn't work in Ruby 1.8 -- syntax error!" }
The problem was that Ruby didn’t know whether the second pipe was a second delimiter or a bitwise OR operator. The stabby lambda was introduced to make it possible to use full-blown method-style arguments with lambdas:
->(a, b=1) { "Works in Ruby 1.8!" }
Eventually, the parser limitation was overcome; you can now use method-argument syntax, in all its glory, between the vertical pipes in a code block. Strictly speaking, therefore, the stabby lambda is no longer necessary. But it attracted a bit of a following, and you’ll see it used fairly widely.
In practice, the things you call most often in Ruby aren’t procs or lambdas but methods. So far, we’ve viewed the calling of methods as something we do at one level of remove: we send messages to objects, and the objects execute the appropriately named method. But it’s possible to handle methods as objects, as you’ll see next.
14.3. Methods as objects
Methods don’t present themselves as objects until you tell them to. Treating methods as objects involves objectifying them.
14.3.1. Capturing Method objects
You can get hold of a Method object by using the method method with the name of the method as an argument (in string or symbol form):
class C
def talk
puts "Method-grabbing test! self is #{self}."
end
end
c = C.new
meth = c.method(:talk)
At this point, you have a Method object—specifically, a bound Method object: it isn’t the method talk in the abstract, but rather the method talk specifically bound to the object c. If you send a call message to meth, it knows to call itself with c in the role of self:
meth.call
Here’s the output:
Method-grabbing test! self is #<C:0x00000101201a00>.
You can also unbind the method from its object and then bind it to another object, as long as that other object is of the same class as the original object (or a subclass):
class D < C
end
d = D.new
unbound = meth.unbind
unbound.bind(d).call
Here, the output tells you that the method was, indeed, bound to a D object (d) at the time it was executed:
Method-grabbing test! self is #<D:0x000001011d0220>.
To get hold of an unbound method object directly without having to call unbind on a bound method, you can get it from the class rather than from a specific instance of the class using the instance_method method. This single line is equivalent to a method call plus an unbind call:
unbound = C.instance_method(:talk)
After you have the unbound method in captivity, so to speak, you can use bind to bind it to any instance of either C or a C subclass like D.
But why would you?
14.3.2. The rationale for methods as objects
There’s no doubt that unbinding and binding methods is a specialized technique, and you’re not likely to need more than a reading knowledge of it. But aside from the principle that at least a reading knowledge of anything in Ruby can’t be a bad idea, on some occasions the best answer to a “how to” question is, “With unbound methods.”
Here’s an example. The following question comes up periodically in Ruby forums:
Suppose I’ve got a class hierarchy where a method gets redefined:
class A
def a_method
puts "Definition in class A"
end
end
class B < A
def a_method
puts "Definition in class B (subclass of A)"
end
end
class C < B
end
And I’ve got an instance of the subclass:
c = C.new
Is there any way to get that instance of the lowest class to respond to the message (a_method) by executing the version of the method in the class two classes up the chain?
By default, of course, the instance doesn’t do that; it executes the first matching method it finds as it traverses the method search path:
c.a_method
The output is
Definition in class B (subclass of A)
But you can force the issue through an unbind and bind operation:
A.instance_method(:a_method).bind(c).call
Here the output is
Definition in class A
You can even stash this behavior inside a method in class C:\
class C
def call_original
A.instance_method(:a_method).bind(self).call
end
end
and then call call_original directly on c.
This is an example of a Ruby technique with a paradoxical status: it’s within the realm of things you should understand, as someone gaining mastery of Ruby’s dynamics, but it’s outside the realm of anything you should probably do. If you find yourself coercing Ruby objects to respond to methods you’ve already redefined, you should review the design of your program and find a way to get objects to do what you want as a result of and not in spite of the class/module hierarchy you’ve created.
Still, methods are callable objects, and they can be detached (unbound) from their instances. As a Ruby dynamics inductee, you should at least have recognition-level knowledge of this kind of operation.
We’ll linger in the dynamic stratosphere for a while, looking next at the eval family of methods: a small handful of methods with special powers to let you run strings as code and manipulate scope and self in some interesting, use-case-driven ways.
Alternative techniques for calling callable objects
So far we’ve exclusively used the call method to call callable objects. You do, however, have a couple of other options.
One is the square-brackets method/operator, which is a synonym for call. You place any arguments inside the brackets:
mult = lambda {|x,y| x * y }
twelve = mult[3,4]
If there are no arguments, leave the brackets empty.
You can also call callable objects using the () method:
twelve = mult.(3,4)
Note the dot before the opening parenthesis. The () method has to be called using a dot; you can’t just append the parentheses to a Proc or Method object the way you would with a method name. If there are no arguments, leave the parentheses empty.
14.4. The eval family of methods
Like many languages, Ruby has a facility for executing code stored in the form of strings at runtime. In fact, Ruby has a cluster of techniques to do this, each of which serves a particular purpose but all of which operate on a similar principle: that of saying in the middle of a program, “Whatever code strings you might have read from the program file before starting to execute this program, execute this code string right now.”
The most straightforward method for evaluating a string as code, and also the most dangerous, is the method eval. Other eval-family methods are a little softer, not because they don’t also evaluate strings as code but because that’s not all they do. instance_eval brings about a temporary shift in the value of self, and class_eval (also known by the synonym module_eval) takes you on an ad hoc side trip into the context of a class-definition block. These eval-family methods can operate on strings, but they can also be called with a code block; thus they don’t always operate as bluntly as eval, which executes strings.
Let’s unpack this description with a closer look at eval and the other eval methods.
14.4.1. Executing arbitrary strings as code with eval
eval executes the string you give it:
>> eval("2+2")
=> 4
eval is the answer, or at least one answer, to a number of frequently asked questions, such as, “How do I write a method and give it a name someone types in?” You can do so like this:
print "Method name: "
m = gets.chomp
eval("def #{m}; puts 'Hi!'; end")
eval(m)
This code outputs
Hi!
A new method is being written. Let’s say you run the code and type in abc. The string you subsequently use eval on is
def abc; puts 'Hi!'; end
After you apply eval to that string, a method called abc exists. The second eval executes the string abc—which, given the creation of the method in the previous line, constitutes a call to abc. When abc is called, “Inside new method!” is printed out.
The Binding class and eval-ing code with a binding
Ruby has a class called Binding whose instances encapsulate the local variable bindings in effect at a given point in execution. And a top-level method called binding returns whatever the current binding is.
The most common use of Binding objects is in the position of second argument to eval. If you provide a binding in that position, the string being eval-ed is executed in the context of the given binding. Any local variables used inside the eval string are interpreted in the context of that binding.
Here’s an example. The method use_a_binding takes a Binding object as an argument and uses it as the second argument to a call to eval. The eval operation, therefore, uses the local variable bindings represented by the Binding object:
def use_a_binding(b)
eval("puts str", b)
end
str = "I'm a string in top-level binding!"
use_a_binding(binding)
The output of this snippet is "I'm a string in top-level binding!". That string is bound to the top-level variable str. Although str isn’t in scope inside the use_a_ binding method, it’s visible to eval thanks to the fact that eval gets a binding argument of the top-level binding, in which stris defined and bound.
Thus the string "puts str", which otherwise would raise an error (because str isn’t defined), can be eval-ed successfully in the context of the given binding.
eval gives you a lot of power, but it also harbors dangers—in some people’s opinion, enough danger to rule it out as a usable technique.
14.4.2. The dangers of eval
Executing arbitrary strings carries significant danger—especially (though not exclusively) strings that come from users interacting with your program. For example, it would be easy to inject a destructive command, perhaps a system call to rm –rf /*, into the previous example.
eval can be seductive. It’s about as dynamic as a dynamic programming technique can get: you’re evaluating strings of code that probably didn’t even exist when you wrote the program. Anywhere that Ruby puts up a kind of barrier to absolute, easy manipulation of the state of things during the run of a program, eval seems to offer a way to cut through the red tape and do whatever you want.
But as you can see, eval isn’t a panacea. If you’re running eval on a string you’ve written, it’s generally no less secure than running a program file you’ve written. But any time an uncertain, dynamically generated string is involved, the dangers mushroom.
In particular, it’s difficult to clean up user input (including input from web forms and files) to the point that you can feel safe about running eval on it. Ruby maintains a global variable called $SAFE, which you can set to a high number (on a scale of 0 to 4) to gain protection from dangers like rogue file-writing requests. $SAFE makes life with eval a lot safer. Still, the best habit to get into is the habit of not using eval.
It isn’t hard to find experienced and expert Ruby programmers (as well as programmers in other languages) who never use eval and never will. You have to decide how you feel about it, based on your knowledge of the pitfalls.
Let’s move now to the wider eval family of methods. These methods can do the same kind of brute-force string evaluation that eval does, but they also have kinder, gentler behaviors that make them usable and useful.
14.4.3. The instance_eval method
instance_eval is a specialized cousin of eval. It evaluates the string or code block you give it, changing self to be the receiver of the call to instance_eval:
p self
a = []
a.instance_eval { p self }
This snippet outputs two different selfs:
main
[]
instance_eval is mostly useful for breaking into what would normally be another object’s private data—particularly instance variables. Here’s how to see the value of an instance variable belonging to any old object (in this case, the instance variable of @x of a C object):
class C
def initialize
@x = 1
end
end
c = C.new
c.instance_eval { puts @x }
This kind of prying into another object’s state is generally considered impolite; if an object wants you to know something about its state, it provides methods through which you can inquire. Nevertheless, because Ruby dynamics are based on the changing identity of self, it’s not a bad idea for the language to give us a technique for manipulating self directly.
The instance_exec method
instance_eval has a close cousin called instance_exec. The difference between the two is that instance_exec can take arguments. Any arguments you pass it will be passed, in turn, to the code block.
This enables you to do things like this:
![]()
(Not that you’d need to, if you already know the delimiter; but that’s the basic technique.)
Unfortunately, which method is which—which of the two takes arguments and which doesn’t—just has to be memorized. There’s nothing in the terms eval or exec to help you out. Still, it’s useful to have both on hand.
Perhaps the most common use of instance_eval is in the service of allowing simplified assignment code like this:
david = Person.new do
name "David"
age 55
end
This looks a bit like we’re using accessors, except there’s no explicit receiver and no equal signs. How would you make this code work?
Here’s what the Person class might look like:

The key here is the call to instance_eval ![]() , which reuses the code block that has already been passed in to new. Because the code block is being instance_eval’d on the new person object (the implicit self in the definition of initialize), the calls to name and age are resolved within thePerson class. Those methods, in turn, act as hybrid setter/getters
, which reuses the code block that has already been passed in to new. Because the code block is being instance_eval’d on the new person object (the implicit self in the definition of initialize), the calls to name and age are resolved within thePerson class. Those methods, in turn, act as hybrid setter/getters ![]() : they take an optional argument, defaulting to nil, and set the relevant instance variables, conditionally, to the value of that argument. If you call them without an argument, they just return the current value of their instance variables
: they take an optional argument, defaulting to nil, and set the relevant instance variables, conditionally, to the value of that argument. If you call them without an argument, they just return the current value of their instance variables ![]() .
.
The result is that you can say name "David" instead of person.name = "David". Lots of Rubyists find this kind of miniature DSL (domain-specific language) quite pleasingly compact and elegant.
instance_eval (and instance_exec) will also happily take a string and evaluate it in the switched self context. However, this technique has the same pitfalls as evaluating strings with eval, and should be used judiciously if at all.
The last member of the eval family of methods is class_eval (synonym: module_eval).
14.4.4. Using class_eval (a.k.a. module_eval)
In essence, class_eval puts you inside a class-definition body:

But you can do some things with class_eval that you can’t do with the regular class keyword:
· Evaluate a string in a class-definition context
· Open the class definition of an anonymous class
· Use existing local variables inside a class-definition body
The third item on this list is particularly noteworthy.
When you open a class with the class keyword, you start a new local-variable scope. But the block you use with class_eval can see the variables created in the scope surrounding it. Look at the difference between the treatment of var, an outer-scope local variable, in a regular class-definition body and a block given to class_eval:
>> var = "initialized variable"
=> "initialized variable"
>> class C
>> puts var
>> end
NameError: undefined local variable or method `var' for C:Class
from (irb):3
>> C.class_eval { puts var }
initialized variable
The variable var is out of scope inside the standard class-definition block but still in scope in the code block passed to class_eval.
The plot thickens when you define an instance method inside the class_eval block:
>> C.class_eval { def talk; puts var; end }
=> nil
>> C.new.talk
NameError: undefined local variable or method `var' for #<C:0x350ba4>
Like any def, the def inside the block starts a new scope—so the variable var is no longer visible.
If you want to shoehorn an outer-scope variable into an instance method, you have to use a different technique for creating the method: the method define_method. You hand define_method the name of the method you want to create (as a symbol or a string) and provide a code block; the code block serves as the body of the method.
To get the outer variable var into an instance method of class C, you do this:
>> C.class_eval { define_method("talk") { puts var } }
=> :talk
The return value of define_method is a symbol representing the name of the newly defined method.
At this point, the talk instance method of C will have access to the outer-scope variable var:
>> C.new.talk
initialized variable
You won’t see techniques like this used as frequently as the standard class- and method-definition techniques. But when you see them, you’ll know that they imply a flattened scope for local variables rather than the new scope triggered by the more common class and def keywords.
define_method is an instance method of the class Module, so you can call it on any instance of Module or Class. You can thus use it inside a regular class-definition body (where the default receiver self is the class object) if you want to sneak a variable local to the body into an instance method. That’s not a frequently encountered scenario, but it’s not unheard of.
Ruby lets you do lightweight concurrent programming using threads. We’ll look at threads next.
14.5. Parallel execution with threads
Ruby’s threads allow you to do more than one thing at once in your program, through a form of time sharing: one thread executes one or more instructions and then passes control to the next thread, and so forth. Exactly how the simultaneity of threads plays out depends on your system and your Ruby implementation. Ruby will try to use native operating-system threading facilities, but if such facilities aren’t available, it will fall back on green threads (threads implemented completely inside the interpreter). We’ll black-box the green-versus-native thread issue here; our concern will be principally with threading techniques and syntax.
Creating threads in Ruby is easy: you instantiate the Thread class. A new thread starts executing immediately, but the execution of the code around the thread doesn’t stop. If the program ends while one or more threads are running, those threads are killed.
Here’s a kind of inside-out example that will get you started with threads by showing you how they behave when a program ends:
Thread.new do
puts "Starting the thread"
sleep 1
puts "At the end of the thread"
end
puts "Outside the thread"
Thread.new takes a code block, which constitutes the thread’s executable code. In this example, the thread prints a message, sleeps for one second, and then prints another message. But outside of the thread, time marches on: the main body of the program prints a message immediately (it’s not affected by the sleep command inside the thread), and then the program ends. Unless printing a message takes more than a second—in which case you need to get your hardware checked! The second message from the thread will never be seen. You’ll only see this:
Starting the thread
Outside the thread
Now, what if we want to allow the thread to finish executing? To do this, we have to use the instance method join. The easiest way to use join is to save the thread in a variable and call join on the variable. Here’s how you can modify the previous example along these lines:
t = Thread.new do
puts "Starting the thread"
sleep 1
puts "At the end of the thread"
end
puts "Outside the thread"
t.join
This version of the program produces the following output, with a one-second pause between the printing of the first message from the thread and the printing of the last message:

In addition to joining a thread, you can manipulate it in a variety of other ways, including killing it, putting it to sleep, waking it up, and forcing it to pass control to the next thread scheduled for execution.
14.5.1. Killing, stopping, and starting threads
To kill a thread, you send it the message kill, exit, or terminate; all three are equivalent. Or, if you’re inside the thread, you call kill (or one of its synonyms) in class-method form on Thread itself.
You may want to kill a thread if an exception occurs inside it. Here’s an example, admittedly somewhat contrived but brief enough to illustrate the process efficiently. The idea is to read the contents of three files (part00, part01, and part02) into the string text. If any of the files isn’t found, the thread terminates:
puts "Trying to read in some files..."
t = Thread.new do
(0..2).each do |n|
begin
File.open("part0#{n}") do |f|
text << f.readlines
end
rescue Errno::ENOENT
puts "Message from thread: Failed on n=#{n}"
Thread.exit
end
end
end
t.join
puts "Finished!"
The output, assuming part00 exists but part01 doesn’t, is this:
Trying to read in some files...
Message from thread: Failed on n=1
Finished!
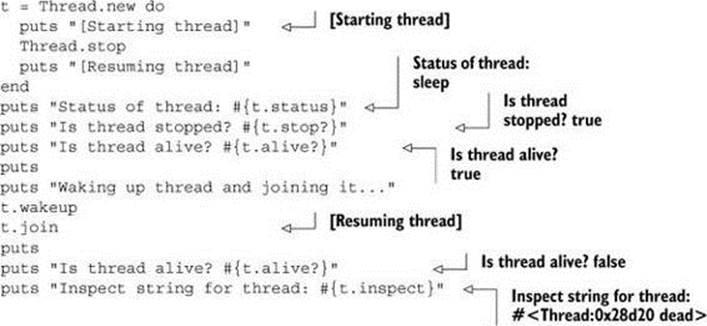
You can also stop and start threads and examine their state. A thread can be asleep or awake, and alive or dead. Here’s an example that puts a thread through a few of its paces and illustrates some of the available techniques for examining and manipulating thread state:
Fibers: A twist on threads
In addition to threads, Ruby has a Fiber class. Fibers are like reentrant code blocks: they can yield back and forth to their calling context multiple times.
A fiber is created with the Fiber.new constructor, which takes a code block. Nothing happens until you tell the fiber to resume, at which point the code block starts to run. From within the block, you can suspend the fiber, returning control to the calling context, with the class methodFiber.yield.
Here’s a simple example involving a talking fiber that alternates control a couple of times with its calling context:
f = Fiber.new do
puts "Hi."
Fiber.yield
puts "Nice day."
Fiber.yield
puts "Bye!"
end
f.resume
puts "Back to the fiber:"
f.resume
puts "One last message from the fiber:"
f.resume
puts "That's all!"
Here’s the output from this snippet:
Hi.
Back to the fiber:
Nice day.
One last message from the fiber:
Bye!
That's all!
Among other things, fibers are the technical basis of enumerators, which use fibers to implement their own stop and start operations.
Let’s continue exploring threads with a couple of networked examples: a date server and, somewhat more ambitiously, a chat server.
14.5.2. A threaded date server
The date server we’ll write depends on a Ruby facility that we haven’t looked at yet: TCPServer. TCPServer is a socket-based class that allows you to start up a server almost unbelievably easily: you instantiate the class and pass in a port number. Here’s a simple example of TCPServer in action, serving the current date to the first person who connects to it:

Put this example in a file called dateserver.rb, and run it from the command line. (If port 3939 isn’t available, change the number to something else.) Now, from a different console, connect to the server:
telnet localhost 3939
You’ll see output similar to the following:
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Hi. Here's the date.
Sat Jan 18 07:29:11 EST 2014
Connection closed by foreign host.
The server has fielded the request and responded.
What if you want the server to field multiple requests? Easy: don’t close the socket, and keep accepting connections.
require 'socket'
s = TCPServer.new(3939)
while true
conn = s.accept
conn.puts "Hi. Here's the date."
conn.puts `date`
conn.close
end
Now you can ask for the date more than once, and you’ll get an answer each time.
Things get trickier when you want to send information to the server. Making it work for one user is straightforward; the server can accept input by calling gets:

But if a second client connects to the server while the server is still waiting for the first client’s input, the second client sees nothing—not even What's your name?—because the server is busy.
That’s where threading comes in. Here’s a threaded date server that accepts input from the client. The threading prevents the entire application from blocking while it waits for a single client to provide input:

In this version, the server listens continuously for connections ![]() . Each time it gets one, it spawns a new thread
. Each time it gets one, it spawns a new thread ![]() . The significance of the argument to Thread.new is that if you provide such an argument, it’s yielded back to you as the block parameter. In this case, that means binding the connection to the parameter c. Although this technique may look odd (sending an argument to a method, only to get it back when the block is called), it ensures that each thread has a reference to its own connection rather than fighting over the variable conn, which lives outside any thread.
. The significance of the argument to Thread.new is that if you provide such an argument, it’s yielded back to you as the block parameter. In this case, that means binding the connection to the parameter c. Although this technique may look odd (sending an argument to a method, only to get it back when the block is called), it ensures that each thread has a reference to its own connection rather than fighting over the variable conn, which lives outside any thread.
Even if a given client waits for several minutes before typing in a name ![]() , the server is still listening for new connections, and new threads are still spawned. The threading approach thus allows a server to scale while incorporating two-way transmission between itself and one or more clients.
, the server is still listening for new connections, and new threads are still spawned. The threading approach thus allows a server to scale while incorporating two-way transmission between itself and one or more clients.
The next level of complexity is the chat server.
14.5.3. Writing a chat server using sockets and threads
We’ll start code-first this time. Listing 14.2 shows the chat-server code. A lot of what it does is similar to what the date server does. The main difference is that the chat server keeps a list (an array) of all the incoming connections and uses that list to broadcast the incoming chat messages.
Listing 14.2. Chat server using TCPServer and threads


There’s a lot of code in this listing, so we’ll take it in the order it executes. First comes the mandatory loading of the socket library ![]() . The next several lines define some needed helper methods; we’ll come back to those after we’ve seen what they’re helping with. The real beginning of the action is the instantiation of TCPServer and the initialization of the array of chatters
. The next several lines define some needed helper methods; we’ll come back to those after we’ve seen what they’re helping with. The real beginning of the action is the instantiation of TCPServer and the initialization of the array of chatters ![]() .
.
The server goes into a while loop similar to the loop in the date server ![]() . When a chatter connects, the server welcomes it (him or her, really, but it will do)
. When a chatter connects, the server welcomes it (him or her, really, but it will do) ![]() . The welcome process involves the welcome method
. The welcome process involves the welcome method ![]() , which takes a chatter—a socket object—as its argument, prints a nice welcome message, and returns a line of client input. Now it’s time to notify all the current chatters that a new chatter has arrived. This involves the broadcast method
, which takes a chatter—a socket object—as its argument, prints a nice welcome message, and returns a line of client input. Now it’s time to notify all the current chatters that a new chatter has arrived. This involves the broadcast method ![]() , which is the heart of the chat functionality of the program: it’s responsible for going through the array of chatters and sending a message to each one. In this case, the message states that the new client has joined the chat.
, which is the heart of the chat functionality of the program: it’s responsible for going through the array of chatters and sending a message to each one. In this case, the message states that the new client has joined the chat.
After being announced, the new chatter is added to the chatters array. That means it will be included in future message broadcasts.
Now comes the chatting part. It consists of an infinite loop wrapped in a begin/rescue clause ![]() . The goal is to accept messages from this client forever but to take action if the client socket reports end-of-file. Messages are accepted via readline
. The goal is to accept messages from this client forever but to take action if the client socket reports end-of-file. Messages are accepted via readline ![]() , which has the advantage over gets (in this situation, anyway) that it raises an exception on end-of-file. If the chatter leaves the chat, then the next attempt to read a line from that chatter raises EOFError. When that happens, control goes to the rescue block
, which has the advantage over gets (in this situation, anyway) that it raises an exception on end-of-file. If the chatter leaves the chat, then the next attempt to read a line from that chatter raises EOFError. When that happens, control goes to the rescue block ![]() , where the departed chatter is removed from the chatters array and an announcement is broadcast to the effect that the chatter has left
, where the departed chatter is removed from the chatters array and an announcement is broadcast to the effect that the chatter has left ![]() .
.
If there’s no EOFError, the chatter’s message is broadcast to all chatters ![]() .
.
When using threads, it’s important to know how the rules of variable scoping and visibility play out inside threads—and in looking at this topic, which we’ll do next, you’ll also find out about a special category of thread-specific variables.
14.5.4. Threads and variables
Threads run using code blocks, and code blocks can see the variables already created in their local scope. If you create a local variable and change it inside a thread’s code block, the change will be permanent:
>> a = 1
=> 1
>> Thread.new { a = 2 }
=> #<Thread:0x390d8c run>
>> a
=> 2
You can see an interesting and instructive effect if you stop a thread before it changes a variable, and then run the thread:
>> t = Thread.new { Thread.stop; a = 3 }
=> #<Thread:0x3e443c run>
>> a
=> 2
>> t.run
=> #<Thread:0x3e443c dead>
>> a
=> 3
Global variables remain global, for the most part, in the face of threads. That goes for built-in globals, such as $/ (the input record separator), as well as those you create yourself:
>> $/
=> "\n"
>> $var = 1
=> 1
>> Thread.new { $var = 2; $/ = "\n\n" }
=> #<Thread:0x38dbb4 run>
>> $/
=> "\n\n"
>> $var
=> 2
But some globals are thread-local globals—specifically, the $1, $2, ..., $n that are assigned the parenthetical capture values from the most recent regular expression–matching operation. You get a different dose of those variables in every thread. Here’s a snippet that illustrates the fact that the$n variables in different threads don’t collide:

The rationale for this behavior is clear: you can’t have one thread’s idea of $1 overshadowing the $1 from a different thread, or you’ll get extremely odd results. The $n variables aren’t really globals once you see them in the context of the language having threads.
In addition to having access to the usual suite of Ruby variables, threads also have their own variable stash—or, more accurately, a built-in hash that lets them associate symbols or strings with values. These thread keys can be useful.
14.5.5. Manipulating thread keys
Thread keys are basically a storage hash for thread-specific values. The keys must be symbols or strings. You can get at the keys by indexing the thread object directly with values in square brackets. You can also get a list of all the keys (without their values) using the keys method.
Here’s a simple set-and-get scenario using a thread key:
t = Thread.new do
Thread.current[:message] = "Hello"
end
t.join
p t.keys
puts t[:message]
The output is
[:message]
Hello
Threads seem to loom large in games, so let’s use a game example to explore thread keys further: a threaded, networked rock/paper/scissors (RPS) game. We’ll start with the (threadless) RPS logic in an RPS class and use the resulting RPS library as the basis for the game code.
A basic rock/paper/scissors logic implementation
The next listing shows the RPS class, which is wrapped in a Games module (because RPS sounds like it might collide with another class name). Save this listing to a file called rps.rb.
Listing 14.3. RPS game logic embodied in Games::RPS class

The RPS class includes the Comparable module ![]() ; this serves as the basis for determining, ultimately, who wins a game. The WINS constant contains all possible winning combinations in three arrays; the first element in each array beats the second element
; this serves as the basis for determining, ultimately, who wins a game. The WINS constant contains all possible winning combinations in three arrays; the first element in each array beats the second element ![]() . There’s also a move attribute, which stores the move for this instance of RPS
. There’s also a move attribute, which stores the move for this instance of RPS ![]() . The initialize method
. The initialize method ![]() stores the move as a string (in case it comes in as a symbol).
stores the move as a string (in case it comes in as a symbol).
RPS has a spaceship operator (<=>) method definition ![]() that specifies what happens when this instance of RPS is compared to another instance. If the two have equal moves, the result is 0—the signal that the two terms of a spaceship comparison are equal. The rest of the logic looks for winning combinations using the WINS array, returning -1 or 1 depending on whether this instance or the other instance has won. If it doesn’t find that either player has a win, and the result isn’t a tie, it raises an exception.
that specifies what happens when this instance of RPS is compared to another instance. If the two have equal moves, the result is 0—the signal that the two terms of a spaceship comparison are equal. The rest of the logic looks for winning combinations using the WINS array, returning -1 or 1 depending on whether this instance or the other instance has won. If it doesn’t find that either player has a win, and the result isn’t a tie, it raises an exception.
Now that RPS objects know how to compare themselves, it’s easy to play them against each other, which is what the play method does ![]() . It’s simple: whichever player is higher is the winner, and if it’s a tie, the method returns false.
. It’s simple: whichever player is higher is the winner, and if it’s a tie, the method returns false.
We’re now ready to incorporate the RPS class in a threaded, networked version of the game, thread keys and all.
Using the RPS class in a threaded game
The following listing shows the networked RPS program. It waits for two people to join, gets their moves, reports the result, and exits. Not glitzy—but a good way to see how thread keys might help you.
Listing 14.4. Threaded, networked RPS program using thread keys

This program loads and uses the Games::RPS class, so make sure you have the RPS code in the file rps.rb in the same directory as the program itself.
As in the chat-server example, we start with a server ![]() along with an array in which threads are stored
along with an array in which threads are stored ![]() . Rather than loop forever, though, we gather only two threads, courtesy of the 2.times loop and the server’s accept method
. Rather than loop forever, though, we gather only two threads, courtesy of the 2.times loop and the server’s accept method ![]() . For each of the two connections, we create a thread
. For each of the two connections, we create a thread ![]() .
.
Now we store some values in the thread’s keys: a number for this player (based off the times loop, adding 1 so that there’s no player 0) and the connection. We then welcome the player and store the move in the :move key of the thread.
After both players have played, we grab the two threads in the convenience variables a and b and join both threads ![]() . Next, we parlay the two thread objects, which have memory of the players’ moves, into two RPS objects
. Next, we parlay the two thread objects, which have memory of the players’ moves, into two RPS objects ![]() . The winner is determined by playing one against the other. The final result of the game is either the winner or, if the game returned false, a tie
. The winner is determined by playing one against the other. The final result of the game is either the winner or, if the game returned false, a tie ![]() .
.
Finally, we report the results to both players ![]() . You could get fancier by inputting their names or repeating the game and keeping score. But the main point of this version of the game is to illustrate the usefulness of thread keys. Even after the threads have finished running, they remember information, and that enables us to play an entire game as well as send further messages through the players’ sockets.
. You could get fancier by inputting their names or repeating the game and keeping score. But the main point of this version of the game is to illustrate the usefulness of thread keys. Even after the threads have finished running, they remember information, and that enables us to play an entire game as well as send further messages through the players’ sockets.
We’re at the end of our look at Ruby threads. It’s worth noting that threads are an area that has undergone and continues to undergo a lot of change and development. But whatever happens, you can build on the grounding you’ve gotten here as you explore and use threads further.
Next on the agenda, and last for this chapter, is the topic of issuing system commands from Ruby.
14.6. Issuing system commands from inside Ruby programs
You can issue system commands in several ways in Ruby. We’ll look primarily at two of them: the system method and the `` (backticks) technique. The other ways to communicate with system programs involve somewhat lower-level programming and are more system-dependent and therefore somewhat outside the scope of this book. We’ll take a brief look at them nonetheless, and if they seem to be something you need, you can explore them further.
14.6.1. The system method and backticks
The system method calls a system program. Backticks (``) call a system program and return its output. The choice depends on what you want to do.
Executing system programs with the system method
To use system, send it the name of the program you want to run, with any arguments. The program uses the current STDIN, STDOUT, and STDERR. Here are three simple examples. cat and grep require pressing Ctrl-d (or whatever the “end-of-file” key is on your system) to terminate them and return control to irb. For clarity, Ruby’s output is in bold and user input is in regular font:
>> system("date")
Sat Jan 18 07:32:11 EST 2014
=> true
>> system("cat")
I'm typing on the screen for the cat command.
I'm typing on the screen for the cat command.
=> true
>> system('grep "D"')
one
two
David
David
When you use system, the global variable $? is set to a Process::Status object that contains information about the call: specifically, the process ID of the process you just ran and its exit status. Here’s a call to date and one to cat, the latter terminated with Ctrl-c. Each is followed by examination of $?:
>> system("date")
Sat Jan 18 07:32:11 EST 2014
=> true
>> $?
=> #<Process::Status: pid 28025 exit 0>
>> system("cat")
^C=> false
>> $?
=> #<Process::Status: pid 28026 SIGINT (signal 2)>
And here’s a call to a nonexistent program:
>> system("datee")
=> nil
>> $?
=> #<Process::Status: pid 28037 exit 127>
The $? variable is thread-local: if you call a program in one thread, its return value affects only the $? in that thread:

The Process::Status object reporting on the call to date is stored in $? in the main thread ![]() . The new thread makes a call to a nonexistent program
. The new thread makes a call to a nonexistent program ![]() , and that thread’s version of $? reflects the problem
, and that thread’s version of $? reflects the problem ![]() . But the main thread’s $? is unchanged
. But the main thread’s $? is unchanged ![]() . The thread-local global variable behavior works much like it does in the case of the $n regular-expression capture variables—and for similar reasons. In both cases, you don’t want one thread reacting to an error condition that it didn’t cause and that doesn’t reflect its actual program flow.
. The thread-local global variable behavior works much like it does in the case of the $n regular-expression capture variables—and for similar reasons. In both cases, you don’t want one thread reacting to an error condition that it didn’t cause and that doesn’t reflect its actual program flow.
The backtick technique is a close relative of system.
Calling system programs with backticks
To issue a system command with backticks, put the command between backticks. The main difference between system and backticks is that the return value of the backtick call is the output of the program you run:
>> d = `date`
=> "Sat Jan 18 07:32:11 EST 2014\n"
>> puts d
Sat Jan 18 07:32:11 EST 2014
=> nil
>> output = `cat`
I'm typing into cat. Since I'm using backticks,
I won't see each line echoed back as I type it.
Instead, cat's output is going into the
variable output.
=> "I'm typing into cat. Since I'm using backticks,\nI won't etc.
>> puts output
I'm typing into cat. Since I'm using backticks,
I won't see each line echoed back as I type it.
Instead, cat's output is going into the
variable output.
The backticks set $? just as system does. A call to a nonexistent method with backticks raises a fatal error:
>> `datee`
Errno::ENOENT: No such file or directory - datee
>> $?
=> #<Process::Status: pid 28094 exit 127>
>> `date`
=> "Sat Jan 18 07:35:32 EST 2014\n"
>> $?
=> #<Process::Status: pid 28095 exit 0>
Some system command bells and whistles
There’s yet another way to execute system commands from within Ruby: the %x operator. %x{date}, for example, will execute the date command. Like the backticks, %x returns the string output of the command. Like its relatives %w and %q (among others), %x allows any delimiter, as long as bracket-style delimiters match: %x{date}, %x-date-, and %x(date) are all synonymous.
Both the backticks and %x allow string interpolation:
command = "date"
%x(#{command})
This can be convenient, although the occasions on which it’s a good idea to call dynamically evaluated strings as system commands are, arguably, few.
Backticks are extremely useful for capturing external program output, but they aren’t the only way to do it. This brings us to the third way of running programs from within a Ruby program: open and Open.popen3.
14.6.2. Communicating with programs via open and popen3
Using the open family of methods to call external programs is a lot more complex than using system and backticks. We’ll look at a few simple examples, but we won’t plumb the depths of the topic. These Ruby methods map directly to the underlying system-library calls that support them, and their exact behavior may vary from one system to another more than most Ruby behavior does.
Still—let’s have a look. We’ll discuss two methods: open and the class method Open.popen3.
Talking to external programs with open
You can use the top-level open method to do two-way communication with an external program. Here’s the old standby example of cat:

The call to open is generic; it could be any I/O stream, but in this case it’s a two-way connection to a system command ![]() . The pipe in front of the word cat indicates that we’re looking to talk to a program and not open a file. The handle on the external program works much like an I/O socket or file handle. It’s open for reading and writing (the w+ mode), so we can write to it
. The pipe in front of the word cat indicates that we’re looking to talk to a program and not open a file. The handle on the external program works much like an I/O socket or file handle. It’s open for reading and writing (the w+ mode), so we can write to it ![]() and read from it
and read from it ![]() . Finally, we close it
. Finally, we close it ![]() .
.
It’s also possible to take advantage of the block form of open and save the last step:
>> open("|cat", "w+") {|p| p.puts("hi"); p.gets }
=> "hi\n"
A somewhat more elaborate and powerful way to perform two-way communication between your Ruby program and an external program is the Open3.popen3 method.
Two-way communication with Open3.popen3
The Open3.popen3 method opens communication with an external program and gives you handles on the external program’s standard input, standard output, and standard error streams. You can thus write to and read from those handles separately from the analogous streams in your program.
Here’s a simple cat-based example of Open.popen3:

After loading the open3 library ![]() , we make the call to Open3.popen3, passing it the name of the external program
, we make the call to Open3.popen3, passing it the name of the external program ![]() . We get back three I/O handles and a thread
. We get back three I/O handles and a thread ![]() . (You can ignore the thread.) These I/O handles go into and out of the external program. Thus we can write to the STDINhandle
. (You can ignore the thread.) These I/O handles go into and out of the external program. Thus we can write to the STDINhandle ![]() and read lines from the STDOUT handle
and read lines from the STDOUT handle ![]() . These handles aren’t the same as the STDIN and STDOUT streams of the irb session itself.
. These handles aren’t the same as the STDIN and STDOUT streams of the irb session itself.
The next example shows a slightly more elaborate use of Open.popen3. Be warned: in itself, it’s trivial. Its purpose is to illustrate some of the basic mechanics of the technique—and it uses threads, so it reillustrates some thread techniques too. The following listing shows the code.
Listing 14.5. Using Open.popen3 and threads to manipulate a cat session

The program opens a two-way pipe to cat and uses two threads to talk and listen to that pipe. The first thread, t ![]() , loops forever, listening to STDIN—your STDIN, not cat’s—and writing each line to the STDIN handle on the cat process. The second thread, u
, loops forever, listening to STDIN—your STDIN, not cat’s—and writing each line to the STDIN handle on the cat process. The second thread, u ![]() , maintains a counter (n) and a string accumulator (str). When the counter hits a multiple of 3, as indicated by the modulo test
, maintains a counter (n) and a string accumulator (str). When the counter hits a multiple of 3, as indicated by the modulo test ![]() , the u thread prints out a horizontal line, the three text lines it’s accumulated so far, and another horizontal line. It then resets the string accumulator to a blank string and goes back to listening.
, the u thread prints out a horizontal line, the three text lines it’s accumulated so far, and another horizontal line. It then resets the string accumulator to a blank string and goes back to listening.
If you run this program, remember that it loops forever, so you’ll have to interrupt it with Ctrl-c (or whatever your system uses for an interrupt signal). The output is, predictably, somewhat unexciting, but it gives you a good, direct sense of how the threads are interacting with the in and out I/O handles and with each other. In this output, the lines entered by the user are in italics:
One
Two
Three
--------
One
Two
Three
--------
Four
Five
Six
--------
Four
Five
Six
--------
As stated, we’re not going to go into all the details of Open.popen3. But you can and should keep it in mind for situations where you need the most flexibility in reading from and writing to an external program.
14.7. Summary
In this chapter you’ve seen
· Proc objects
· The lambda “flavor” of process
· Code block-to-proc (and reverse) conversion
· Symbol#to_proc
· Method objects
· Bindings
· eval, instance_eval, and class_eval
· Thread usage and manipulation
· Thread-local “global” variables
· The system method
· Calling system commands with backticks
· The basics of the open and Open.popen3 facilities
Objects in Ruby are products of runtime code execution but can, themselves, have the power to execute code. In this chapter, we’ve looked at a number of ways in which the general notion of callable and runnable objects plays out. We looked at Proc objects and lambdas, the anonymous functions that lie at the heart of Ruby’s block syntax. We also discussed methods as objects and ways of unbinding and binding methods and treating them separately from the objects that call them. The eval family of methods took us into the realm of executing arbitrary strings and also showed some powerful and elegant techniques for runtime manipulation of the program’s object and class landscape, using not only eval but, even more, class_eval and instance_eval with their block-wise operations.
Threads figure prominently among Ruby’s executable objects; every program runs in a main thread even if it spawns no others. We explored the syntax and semantics of threads and saw how they facilitate projects like multiuser networked communication. Finally, we looked at a variety of ways in which Ruby lets you execute external programs, including the relatively simple system method and backtick technique, and the somewhat more granular and complex open and Open.popen3 facilities.
There’s no concrete definition of a callable or runnable object, and this chapter has deliberately taken a fairly fluid approach to understanding the terms. On the one hand, that fluidity results in the juxtaposition of topics that could, imaginably, be handled in separate chapters. (It’s hard to argue any direct, close kinship between, say, instance_eval and Open.popen3.) On the other hand, the specifics of Ruby are, to a large extent, manifestations of underlying and supervening principles, and the idea of objects that participate directly in the dynamism of the Ruby landscape is important. Disparate though they may be in some respects, the topics in this chapter all align themselves with that principle; and a good grounding in them will add significantly to your Ruby abilities.
At this point we’ll turn to our next—and last—major topic: runtime reflection, introspection, and callbacks.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.