Learning Python (2013)
Part V. Modules and Packages
Chapter 22. Modules: The Big Picture
This chapter begins our in-depth look at the Python module—the highest-level program organization unit, which packages program code and data for reuse, and provides self-contained namespaces that minimize variable name clashes across your programs. In concrete terms, modules typically correspond to Python program files. Each file is a module, and modules import other modules to use the names they define. Modules might also correspond to extensions coded in external languages such as C, Java, or C#, and even to directories in package imports. Modules are processed with two statements and one important function:
import
Lets a client (importer) fetch a module as a whole
from
Allows clients to fetch particular names from a module
imp.reload (reload in 2.X)
Provides a way to reload a module’s code without stopping Python
Chapter 3 introduced module fundamentals, and we’ve been using them ever since. The goal here is to expand on the core module concepts you’re already familiar with, and move on to explore more advanced module usage. This first chapter reviews module basics, and offers a general look at the role of modules in overall program structure. In the chapters that follow, we’ll dig into the coding details behind the theory.
Along the way, we’ll flesh out module details omitted so far—you’ll learn about reloads, the __name__ and __all__ attributes, package imports, relative import syntax, 3.3 namespace packages, and so on. Because modules and classes are really just glorified namespaces, we’ll formalize namespace concepts here as well.
Why Use Modules?
In short, modules provide an easy way to organize components into a system by serving as self-contained packages of variables known as namespaces. All the names defined at the top level of a module file become attributes of the imported module object. As we saw in the last part of this book, imports give access to names in a module’s global scope. That is, the module file’s global scope morphs into the module object’s attribute namespace when it is imported. Ultimately, Python’s modules allow us to link individual files into a larger program system.
More specifically, modules have at least three roles:
Code reuse
As discussed in Chapter 3, modules let you save code in files permanently. Unlike code you type at the Python interactive prompt, which goes away when you exit Python, code in module files is persistent—it can be reloaded and rerun as many times as needed. Just as importantly, modules are a place to define names, known as attributes, which may be referenced by multiple external clients. When used well, this supports a modular program design that groups functionality into reusable units.
System namespace partitioning
Modules are also the highest-level program organization unit in Python. Although they are fundamentally just packages of names, these packages are also self-contained—you can never see a name in another file, unless you explicitly import that file. Much like the local scopes of functions, this helps avoid name clashes across your programs. In fact, you can’t avoid this feature—everything “lives” in a module, both the code you run and the objects you create are always implicitly enclosed in modules. Because of that, modules are natural tools for grouping system components.
Implementing shared services or data
From an operational perspective, modules are also useful for implementing components that are shared across a system and hence require only a single copy. For instance, if you need to provide a global object that’s used by more than one function or file, you can code it in a module that can then be imported by many clients.
At least that’s the abstract story—for you to truly understand the role of modules in a Python system, we need to digress for a moment and explore the general structure of a Python program.
Python Program Architecture
So far in this book, I’ve sugarcoated some of the complexity in my descriptions of Python programs. In practice, programs usually involve more than just one file. For all but the simplest scripts, your programs will take the form of multifile systems—as the code timing programs of the preceding chapter illustrate. Even if you can get by with coding a single file yourself, you will almost certainly wind up using external files that someone else has already written.
This section introduces the general architecture of Python programs—the way you divide a program into a collection of source files (a.k.a. modules) and link the parts into a whole. As we’ll see, Python fosters a modular program structure that groups functionality into coherent and reusable units, in ways that are natural, and almost automatic. Along the way, we’ll also explore the central concepts of Python modules, imports, and object attributes.
How to Structure a Program
At a base level, a Python program consists of text files containing Python statements, with one main top-level file, and zero or more supplemental files known as modules.
Here’s how this works. The top-level (a.k.a. script) file contains the main flow of control of your program—this is the file you run to launch your application. The module files are libraries of tools used to collect components used by the top-level file, and possibly elsewhere. Top-level files use tools defined in module files, and modules use tools defined in other modules.
Although they are files of code too, module files generally don’t do anything when run directly; rather, they define tools intended for use in other files. A file imports a module to gain access to the tools it defines, which are known as its attributes—variable names attached to objects such as functions. Ultimately, we import modules and access their attributes to use their tools.
Imports and Attributes
Let’s make this a bit more concrete. Figure 22-1 sketches the structure of a Python program composed of three files: a.py, b.py, and c.py. The file a.py is chosen to be the top-level file; it will be a simple text file of statements, which is executed from top to bottom when launched. The filesb.py and c.py are modules; they are simple text files of statements as well, but they are not usually launched directly. Instead, as explained previously, modules are normally imported by other files that wish to use the tools the modules define.
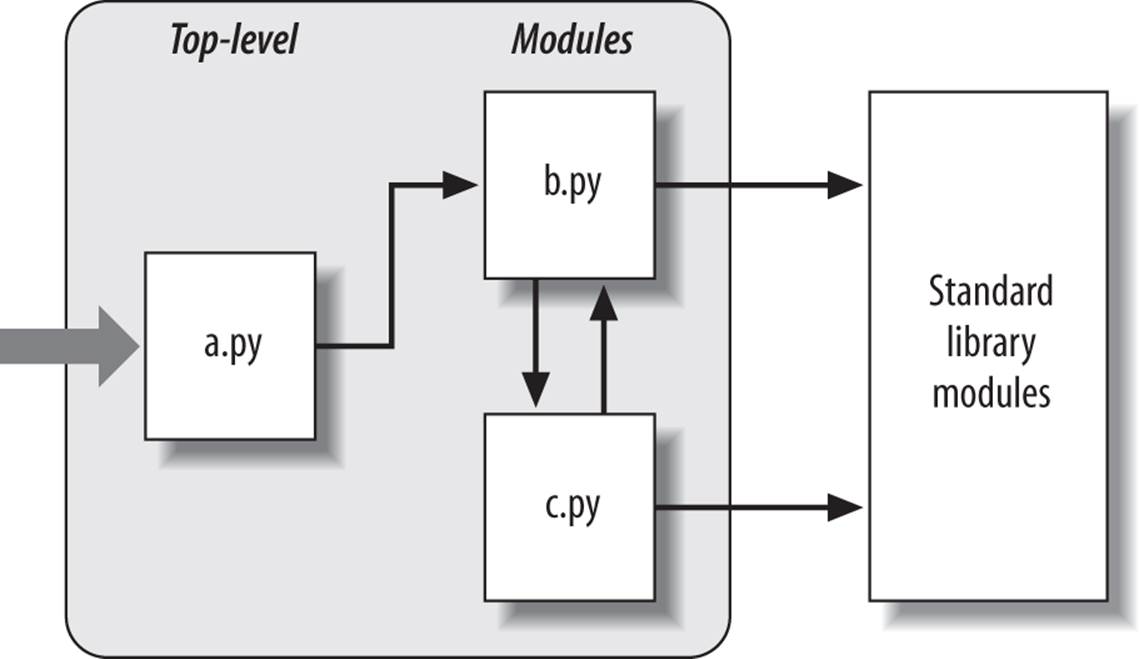
Figure 22-1. Program architecture in Python. A program is a system of modules. It has one top-level script file (launched to run the program), and multiple module files (imported libraries of tools). Scripts and modules are both text files containing Python statements, though the statements in modules usually just create objects to be used later. Python’s standard library provides a collection of precoded modules.
For instance, suppose the file b.py in Figure 22-1 defines a function called spam, for external use. As we learned when studying functions in Part IV, b.py will contain a Python def statement to generate the function, which you can later run by passing zero or more values in parentheses after the function’s name:
def spam(text): # File b.py
print(text, 'spam')
Now, suppose a.py wants to use spam. To this end, it might contain Python statements such as the following:
import b # File a.py
b.spam('gumby') # Prints "gumby spam"
The first of these, a Python import statement, gives the file a.py access to everything defined by top-level code in the file b.py. The code import b roughly means:
Load the file b.py (unless it’s already loaded), and give me access to all its attributes through the name b.
To satisfy such goals, import (and, as you’ll see later, from) statements execute and load other files on request. More formally, in Python, cross-file module linking is not resolved until such import statements are executed at runtime; their net effect is to assign module names—simple variables like b—to loaded module objects. In fact, the module name used in an import statement serves two purposes: it identifies the external file to be loaded, but it also becomes a variable assigned to the loaded module.
Similarly, objects defined by a module are also created at runtime, as the import is executing: import literally runs statements in the target file one at a time to create its contents. Along the way, every name assigned at the top-level of the file becomes an attribute of the module, accessible to importers. For example, the second of the statements in a.py calls the function spam defined in the module b—created by running its def statement during the import—using object attribute notation. The code b.spam means:
Fetch the value of the name spam that lives within the object b.
This happens to be a callable function in our example, so we pass a string in parentheses ('gumby'). If you actually type these files, save them, and run a.py, the words “gumby spam” will be printed.
As we’ve seen, the object.attribute notation appears throughout Python code—most objects have useful attributes that are fetched with the “.” operator. Some reference callable objects like functions that take action (e.g., a salary computer), and others are simple data values that denote more static objects and properties (e.g., a person’s name).
The notion of importing is also completely general throughout Python. Any file can import tools from any other file. For instance, the file a.py may import b.py to call its function, but b.py might also import c.py to leverage different tools defined there. Import chains can go as deep as you like: in this example, the module a can import b, which can import c, which can import b again, and so on.
Besides serving as the highest organizational structure, modules (and module packages, described in Chapter 24) are also the highest level of code reuse in Python. Coding components in module files makes them useful in your original program, and in any other programs you may write later. For instance, if after coding the program in Figure 22-1 we discover that the function b.spam is a general-purpose tool, we can reuse it in a completely different program; all we have to do is import the file b.py again from the other program’s files.
Standard Library Modules
Notice the rightmost portion of Figure 22-1. Some of the modules that your programs will import are provided by Python itself and are not files you will code.
Python automatically comes with a large collection of utility modules known as the standard library. This collection, over 200 modules large at last count, contains platform-independent support for common programming tasks: operating system interfaces, object persistence, text pattern matching, network and Internet scripting, GUI construction, and much more. None of these tools are part of the Python language itself, but you can use them by importing the appropriate modules on any standard Python installation. Because they are standard library modules, you can also be reasonably sure that they will be available and will work portably on most platforms on which you will run Python.
This book’s examples employ a few of the standard library’s modules—timeit, sys, and os in last chapter’s code, for instance—but we’ll really only scratch the surface of the libraries story here. For a complete look, you should browse the standard Python library reference manual, available either online at http://www.python.org, or with your Python installation (via IDLE or Python’s Start button menu on some Windows). The PyDoc tool discussed in Chapter 15 is another way to explore standard library modules.
Because there are so many modules, this is really the only way to get a feel for what tools are available. You can also find tutorials on Python library tools in commercial books that cover application-level programming, such as O’Reilly’s Programming Python, but the manuals are free, viewable in any web browser (in HTML format), viewable in other formats (e.g., Windows help), and updated each time Python is rereleased. See Chapter 15 for more pointers.
How Imports Work
The prior section talked about importing modules without really explaining what happens when you do so. Because imports are at the heart of program structure in Python, this section goes into more formal detail on the import operation to make this process less abstract.
Some C programmers like to compare the Python module import operation to a C #include, but they really shouldn’t—in Python, imports are not just textual insertions of one file into another. They are really runtime operations that perform three distinct steps the first time a program imports a given file:
1. Find the module’s file.
2. Compile it to byte code (if needed).
3. Run the module’s code to build the objects it defines.
To better understand module imports, we’ll explore these steps in turn. Bear in mind that all three of these steps are carried out only the first time a module is imported during a program’s execution; later imports of the same module in a program run bypass all of these steps and simply fetch the already loaded module object in memory. Technically, Python does this by storing loaded modules in a table named sys.modules and checking there at the start of an import operation. If the module is not present, a three-step process begins.
1. Find It
First, Python must locate the module file referenced by an import statement. Notice that the import statement in the prior section’s example names the file without a .py extension and without its directory path: it just says import b, instead of something like import c:\dir1\b.py. Path and extension details are omitted on purpose; instead, Python uses a standard module search path and known file types to locate the module file corresponding to an import statement.[43] Because this is the main part of the import operation that programmers must know about, we’ll return to this topic in a moment.
2. Compile It (Maybe)
After finding a source code file that matches an import statement by traversing the module search path, Python next compiles it to byte code, if necessary. We discussed byte code briefly in Chapter 2, but it’s a bit richer than explained there. During an import operation Python checks both file modification times and the byte code’s Python version number to decide how to proceed. The former uses file “timestamps,” and the latter uses either a “magic” number embedded in the byte code or a filename, depending on the Python release being used. This step chooses an action as follows:
Compile
If the byte code file is older than the source file (i.e., if you’ve changed the source) or was created by a different Python version, Python automatically regenerates the byte code when the program is run.
As discussed ahead, this model is modified somewhat in Python 3.2 and later—byte code files are segregated in a __pycache__ subdirectory and named with their Python version to avoid contention and recompiles when multiple Pythons are installed. This obviates the need to check version numbers in the byte code, but the timestamp check is still used to detect changes in the source.
Don’t compile
If, on the other hand, Python finds a .pyc byte code file that is not older than the corresponding .py source file and was created by the same Python version, it skips the source-to-byte-code compile step.
In addition, if Python finds only a byte code file on the search path and no source, it simply loads the byte code directly; this means you can ship a program as just byte code files and avoid sending source. In other words, the compile step is bypassed if possible to speed program startup.
Notice that compilation happens when a file is being imported. Because of this, you will not usually see a .pyc byte code file for the top-level file of your program, unless it is also imported elsewhere—only imported files leave behind .pyc files on your machine. The byte code of top-level files is used internally and discarded; byte code of imported files is saved in files to speed future imports.
Top-level files are often designed to be executed directly and not imported at all. Later, we’ll see that it is possible to design a file that serves both as the top-level code of a program and as a module of tools to be imported. Such a file may be both executed and imported, and thus does generate a .pyc. To learn how this works, watch for the discussion of the special __name__ attribute and __main__ in Chapter 25.
3. Run It
The final step of an import operation executes the byte code of the module. All statements in the file are run in turn, from top to bottom, and any assignments made to names during this step generate attributes of the resulting module object. This is how the tools defined by the module’s code are created. For instance, def statements in a file are run at import time to create functions and assign attributes within the module to those functions. The functions can then be called later in the program by the file’s importers.
Because this last import step actually runs the file’s code, if any top-level code in a module file does real work, you’ll see its results at import time. For example, top-level print statements in a module show output when the file is imported. Function def statements simply define objects for later use.
As you can see, import operations involve quite a bit of work—they search for files, possibly run a compiler, and run Python code. Because of this, any given module is imported only once per process by default. Future imports skip all three import steps and reuse the already loaded module in memory. If you need to import a file again after it has already been loaded (for example, to support dynamic end-user customizations), you have to force the issue with an imp.reload call—a tool we’ll meet in the next chapter.[44]
[43] It’s syntactically illegal to include path and extension details in a standard import. However, package imports, which we’ll discuss in Chapter 24, allow import statements to include part of the directory path leading to a file as a set of period-separated names. Package imports, though, still rely on the normal module search path to locate the leftmost directory in a package path (i.e., they are relative to a directory in the search path). They also cannot make use of any platform-specific directory syntax in the import statements; such syntax only works on the search path. Also, note that module file search path issues are not as relevant when you run frozen executables (discussed in Chapter 2), which typically embed byte code in the binary image.
[44] As described earlier, Python keeps already imported modules in the built-in sys.modules dictionary so it can keep track of what’s been loaded. In fact, if you want to see which modules are loaded, you can import sys and print list(sys.modules.keys()). There’s more on other uses for this internal table in Chapter 25.
Byte Code Files: __pycache__ in Python 3.2+
As mentioned briefly, the way that Python stores files to retain the byte code that results from compiling your source has changed in Python 3.2 and later. First of all, if Python cannot write a file to save this on your computer for any reason, your program still runs fine—Python simply creates and uses the byte code in memory and discards it on exit. To speed startups, though, it will try to save byte code in a file in order to skip the compile step next time around. The way it does this varies per Python version:
In Python 3.1 and earlier (including all of Python 2.X)
Byte code is stored in files in the same directory as the corresponding source files, normally with the filename extension .pyc (e.g., module.pyc). Byte code files are also stamped internally with the version of Python that created them (known as a “magic” field to developers) so Python knows to recompile when this differs in the version of Python running your program. For instance, if you upgrade to a new Python whose byte code differs, all your byte code files will be recompiled automatically due to a version number mismatch, even if you haven’t changed your source code.
In Python 3.2 and later
Byte code is instead stored in files in a subdirectory named __pycache__, which Python creates if needed, and which is located in the directory containing the corresponding source files. This helps avoid clutter in your source directories by segregating the byte code files in their own directory. In addition, although byte code files still get the .pyc extension as before, they are given more descriptive names that include text identifying the version of Python that created them (e.g., module.cpython-32.pyc). This avoids contention and recompiles: because each version of Python installed can have its own uniquely named version of byte code files in the __pycache__ subdirectory, running under a given version doesn’t overwrite the byte code of another, and doesn’t require recompiles. Technically, byte code filenames also include the name of the Python that created them, so CPython, Jython, and other implementations mentioned in the preface and Chapter 2 can coexist on the same machine without stepping on each other’s work (once they support this model).
In both models, Python always recreates the byte code file if you’ve changed the source code file since the last compile, but version differences are handled differently—by magic numbers and replacement prior to 3.2, and by filenames that allow for multiple copies in 3.2 and later.
Byte Code File Models in Action
The following is a quick example of these two models in action under 2.X and 3.3. I’ve omitted much of the text displayed by the dir directory listing on Windows here to save space, and the script used here isn’t listed because it is not relevant to this discussion (it’s from Chapter 2, and simply prints two values). Prior to 3.2, byte code files show up alongside their source files after being created by import operations:
c:\code\py2x> dir
10/31/2012 10:58 AM 39 script0.py
c:\code\py2x> C:\python27\python
>>> import script0
hello world
1267650600228229401496703205376
>>> ^Z
c:\code\py2x> dir
10/31/2012 10:58 AM 39 script0.py
10/31/2012 11:00 AM 154 script0.pyc
However, in 3.2 and later byte code files are saved in the __pycache__ subdirectory and include versions and Python implementation details in their names to avoid clutter and contention among the Pythons on your computer:
c:\code\py2x> cd ..\py3x
c:\code\py3x> dir
10/31/2012 10:58 AM 39 script0.py
c:\code\py3x> C:\python33\python
>>> import script0
hello world
1267650600228229401496703205376
>>> ^Z
c:\code\py3x> dir
10/31/2012 10:58 AM 39 script0.py
10/31/2012 11:00 AM <DIR> __pycache__
c:\code\py3x> dir __pycache__
10/31/2012 11:00 AM 184 script0.cpython-33.pyc
Crucially, under the model used in 3.2 and later, importing the same file with a different Python creates a different byte code file, instead of overwriting the single file as done by the pre-3.2 model—in the newer model, each Python version and implementation has its own byte code files, ready to be loaded on the next program run (earlier Pythons will happily continue using their scheme on the same machine):
c:\code\py3x> C:\python32\python
>>> import script0
hello world
1267650600228229401496703205376
>>> ^Z
c:\code\py3x> dir __pycache__
10/31/2012 12:28 PM 178 script0.cpython-32.pyc
10/31/2012 11:00 AM 184 script0.cpython-33.pyc
Python 3.2’s newer byte code file model is probably superior, as it avoids recompiles when there is more than one Python on your machine—a common case in today’s mixed 2.X/3.X world. On the other hand, it is not without potential incompatibilities in programs that rely on the prior file and directory structure. This may be a compatibility issue in some tools programs, for instance, though most well-behaved tools should work as before. See Python 3.2’s “What’s New?” document for details on potential impacts.
Also keep in mind that this process is completely automatic—it’s a side effect of running programs—and most programmers probably won’t care about or even notice the difference, apart from faster startups due to fewer recompiles.
The Module Search Path
As mentioned earlier, the part of the import procedure that most programmers will need to care about is usually the first—locating the file to be imported (the “find it” part). Because you may need to tell Python where to look to find files to import, you need to know how to tap into its search path in order to extend it.
In many cases, you can rely on the automatic nature of the module import search path and won’t need to configure this path at all. If you want to be able to import user-defined files across directory boundaries, though, you will need to know how the search path works in order to customize it. Roughly, Python’s module search path is composed of the concatenation of these major components, some of which are preset for you and some of which you can tailor to tell Python where to look:
1. The home directory of the program
2. PYTHONPATH directories (if set)
3. Standard library directories
4. The contents of any .pth files (if present)
5. The site-packages home of third-party extensions
Ultimately, the concatenation of these four components becomes sys.path, a mutable list of directory name strings that I’ll expand upon later in this section. The first and third elements of the search path are defined automatically. Because Python searches the concatenation of these components from first to last, though, the second and fourth elements can be used to extend the path to include your own source code directories. Here is how Python uses each of these path components:
Home directory (automatic)
Python first looks for the imported file in the home directory. The meaning of this entry depends on how you are running the code. When you’re running a program, this entry is the directory containing your program’s top-level script file. When you’re working interactively, this entry is the directory in which you are working (i.e., the current working directory).
Because this directory is always searched first, if a program is located entirely in a single directory, all of its imports will work automatically with no path configuration required. On the other hand, because this directory is searched first, its files will also override modules of the same name in directories elsewhere on the path; be careful not to accidentally hide library modules this way if you need them in your program, or use package tools we’ll meet later that can partially sidestep this issue.
PYTHONPATH directories (configurable)
Next, Python searches all directories listed in your PYTHONPATH environment variable setting, from left to right (assuming you have set this at all: it’s not preset for you). In brief, PYTHONPATH is simply a list of user-defined and platform-specific names of directories that contain Python code files. You can add all the directories from which you wish to be able to import, and Python will extend the module search path to include all the directories your PYTHONPATH lists.
Because Python searches the home directory first, this setting is only important when importing files across directory boundaries—that is, if you need to import a file that is stored in a different directory from the file that imports it. You’ll probably want to set your PYTHONPATH variable once you start writing substantial programs, but when you’re first starting out, as long as you save all your module files in the directory in which you’re working (i.e., the home directory, like the C:\code used in this book) your imports will work without you needing to worry about this setting at all.
Standard library directories (automatic)
Next, Python automatically searches the directories where the standard library modules are installed on your machine. Because these are always searched, they normally do not need to be added to your PYTHONPATH or included in path files (discussed next).
.pth path file directories (configurable)
Next, a lesser-used feature of Python allows users to add directories to the module search path by simply listing them, one per line, in a text file whose name ends with a .pth suffix (for “path”). These path configuration files are a somewhat advanced installation-related feature; we won’t cover them fully here, but they provide an alternative to PYTHONPATH settings.
In short, text files of directory names dropped in an appropriate directory can serve roughly the same role as the PYTHONPATH environment variable setting. For instance, if you’re running Windows and Python 3.3, a file named myconfig.pth may be placed at the top level of the Python install directory (C:\Python33) or in the site-packages subdirectory of the standard library there (C:\Python33\Lib\site-packages) to extend the module search path. On Unix-like systems, this file might be located in usr/local/lib/python3.3/site-packages or /usr/local/lib/site-pythoninstead.
When such a file is present, Python will add the directories listed on each line of the file, from first to last, near the end of the module search path list—currently, after PYTHONPATH and standard libraries, but before the site-packages directory where third-party extensions are often installed. In fact, Python will collect the directory names in all the .pth path files it finds and will filter out any duplicates and nonexistent directories. Because they are files rather than shell settings, path files can apply to all users of an installation, instead of just one user or shell. Moreover, for some users and applications, text files may be simpler to code than environment settings.
This feature is more sophisticated than I’ve described here. For more details, consult the Python library manual, and especially its documentation for the standard library module site—this module allows the locations of Python libraries and path files to be configured, and its documentation describes the expected locations of path files in general. I recommend that beginners use PYTHONPATH or perhaps a single .pth file, and then only if you must import across directories. Path files are used more often by third-party libraries, which commonly install a path file in Python’s site-packages, described next.
The Lib\site-packages directory of third-party extensions (automatic)
Finally, Python automatically adds the site-packages subdirectory of its standard library to the module search path. By convention, this is the place that most third-party extensions are installed, often automatically by the distutils utility described in an upcoming sidebar. Because their install directory is always part of the module search path, clients can import the modules of such extensions without any path settings.
Configuring the Search Path
The net effect of all of this is that both the PYTHONPATH and path file components of the search path allow you to tailor the places where imports look for files. The way you set environment variables and where you store path files varies per platform. For instance, on Windows, you might use your Control Panel’s System icon to set PYTHONPATH to a list of directories separated by semicolons, like this:
c:\pycode\utilities;d:\pycode\package1
Or you might instead create a text file called C:\Python33\pydirs.pth, which looks like this:
c:\pycode\utilities
d:\pycode\package1
These settings are analogous on other platforms, but the details can vary too widely for us to cover in this chapter. See Appendix A for pointers on extending your module search path with PYTHONPATH or .pth files on various platforms.
Search Path Variations
This description of the module search path is accurate, but generic; the exact configuration of the search path is prone to changing across platforms, Python releases, and even Python implementations. Depending on your platform, additional directories may automatically be added to the module search path as well.
For instance, some Pythons may add an entry for the current working directory—the directory from which you launched your program—in the search path before the PYTHONPATH directories. When you’re launching from a command line, the current working directory may not be the same as the home directory of your top-level file (i.e., the directory where your program file resides), which is always added. Because the current working directory can vary each time your program runs, you normally shouldn’t depend on its value for import purposes. See Chapter 3 for more on launching programs from command lines.[45]
To see how your Python configures the module search path on your platform, you can always inspect sys.path—the topic of the next section.
The sys.path List
If you want to see how the module search path is truly configured on your machine, you can always inspect the path as Python knows it by printing the built-in sys.path list (that is, the path attribute of the standard library module sys). This list of directory name strings is the actual search path within Python; on imports, Python searches each directory in this list from left to right, and uses the first file match it finds.
Really, sys.path is the module search path. Python configures it at program startup, automatically merging the home directory of the top-level file (or an empty string to designate the current working directory), any PYTHONPATH directories, the contents of any .pth file paths you’ve created, and all the standard library directories. The result is a list of directory name strings that Python searches on each import of a new file.
Python exposes this list for two good reasons. First, it provides a way to verify the search path settings you’ve made—if you don’t see your settings somewhere in this list, you need to recheck your work. For example, here is what my module search path looks like on Windows under Python 3.3, with my PYTHONPATH set to C:\code and a C:\Python33\mypath.pth path file that lists C:\Users\mark. The empty string at the front means current directory, and my two settings are merged in; the rest are standard library directories and files and the site-packages home for third-party extensions:
>>> import sys
>>> sys.path
['', 'C:\\code', 'C:\\Windows\\system32\\python33.zip', 'C:\\Python33\\DLLs',
'C:\\Python33\\lib', 'C:\\Python33', 'C:\\Users\\mark',
'C:\\Python33\\lib\\site-packages']
Second, if you know what you’re doing, this list provides a way for scripts to tailor their search paths manually. As you’ll see by example later in this part of the book, by modifying the sys.path list, you can modify the search path for all future imports made in a program’s run. Such changes last only for the duration of the script, however; PYTHONPATH and .pth files offer more permanent ways to modify the path—the first per user, and the second per installation.
On the other hand, some programs really do need to change sys.path. Scripts that run on web servers, for example, often run as the user “nobody” to limit machine access. Because such scripts cannot usually depend on “nobody” to have set PYTHONPATH in any particular way, they often set sys.path manually to include required source directories, prior to running any import statements. A sys.path.append or sys.path.insert will often suffice, though will endure for a single program run only.
Module File Selection
Keep in mind that filename extensions (e.g., .py) are omitted from import statements intentionally. Python chooses the first file it can find on the search path that matches the imported name. In fact, imports are the point of interface to a host of external components—source code, multiple flavors of byte code, compiled extensions, and more. Python automatically selects any type that matches a module’s name.
Module sources
For example, an import statement of the form import b might today load or resolve to:
§ A source code file named b.py
§ A byte code file named b.pyc
§ An optimized byte code file named b.pyo (a less common format)
§ A directory named b, for package imports (described in Chapter 24)
§ A compiled extension module, coded in C, C++, or another language, and dynamically linked when imported (e.g., b.so on Linux, or b.dll or b.pyd on Cygwin and Windows)
§ A compiled built-in module coded in C and statically linked into Python
§ A ZIP file component that is automatically extracted when imported
§ An in-memory image, for frozen executables
§ A Java class, in the Jython version of Python
§ A .NET component, in the IronPython version of Python
C extensions, Jython, and package imports all extend imports beyond simple files. To importers, though, differences in the loaded file type are completely irrelevant, both when importing and when fetching module attributes. Saying import b gets whatever module b is, according to your module search path, and b.attr fetches an item in the module, be it a Python variable or a linked-in C function. Some standard modules we will use in this book are actually coded in C, not Python; because they look just like Python-coded module files, their clients don’t have to care.
Selection priorities
If you have both a b.py and a b.so in different directories, Python will always load the one found in the first (leftmost) directory of your module search path during the left-to-right search of sys.path. But what happens if it finds both a b.py and a b.so in the same directory? In this case, Python follows a standard picking order, though this order is not guaranteed to stay the same over time or across implementations. In general, you should not depend on which type of file Python will choose within a given directory—make your module names distinct, or configure your module search path to make your module selection preferences explicit.
Import hooks and ZIP files
Normally, imports work as described in this section—they find and load files on your machine. However, it is possible to redefine much of what an import operation does in Python, using what are known as import hooks. These hooks can be used to make imports do various useful things, such as loading files from archives, performing decryption, and so on.
In fact, Python itself makes use of these hooks to enable files to be directly imported from ZIP archives: archived files are automatically extracted at import time when a .zip file is selected from the module import search path. One of the standard library directories in the earlier sys.pathdisplay, for example, is a .zip file today. For more details, see the Python standard library manual’s description of the built-in __import__ function, the customizable tool that import statements actually run.
NOTE
Also see Python 3.3’s “What’s New?” document for updates on this front that we’ll mostly omit here for space. In short, in this version and later, the __import__ function is now implemented by importlib.__import__, in part to unify and more clearly expose its implementation.
The latter of these calls is also wrapped by importlib.import_module—a tool that, per Python’s current manuals, is generally preferred over __import__ for direct calls to import by name string, a technique discussed in Chapter 25. Both calls still work today, though the __import__ function supports customizing imports by replacement in the built-in scope (see Chapter 17), and other techniques support similar roles. See the Python library manuals for more details.
Optimized byte code files
Finally, Python also supports the notion of .pyo optimized byte code files, created and run with the -O Python command-line flag, and automatically generated by some install tools. Because these run only slightly faster than normal .pyc files (typically 5 percent faster), however, they are infrequently used. The PyPy system (see Chapter 2 and Chapter 21), for example, provides more substantial speedups. See Appendix A and Chapter 36 for more on .pyo files.
THIRD-PARTY SOFTWARE: DISTUTILS
This chapter’s description of module search path settings is targeted mainly at user-defined source code that you write on your own. Third-party extensions for Python typically use the distutils tools in the standard library to automatically install themselves, so no path configuration is required to use their code.
Systems that use distutils generally come with a setup.py script, which is run to install them; this script imports and uses distutils modules to place such systems in a directory that is automatically part of the module search path (usually in the Lib\site-packages subdirectory of the Python install tree, wherever that resides on the target machine).
For more details on distributing and installing with distutils, see the Python standard manual set; its use is beyond the scope of this book (for instance, it also provides ways to automatically compile C-coded extensions on the target machine). Also check out the third-party open source eggs system, which adds dependency checking for installed Python software.
Note: as this fifth edition is being written, there is some talk of deprecating distutils and replacing it with a newer distutils2 package in the Python standard library. The status of this is unclear—it was anticipated in 3.3 but did not appear—so be sure to see Python’s “What’s New” documents for updates on this front that may emerge after this book is released.
[45] Also watch for Chapter 24’s discussion of the new relative import syntax and search rules in Python 3.X; they modify the search path for from statements in files inside packages when “.” characters are used (e.g., from . import string). By default, a package’s own directory is not automatically searched by imports in Python 3.X, unless such relative imports are used by files in the package itself.
Chapter Summary
In this chapter, we covered the basics of modules, attributes, and imports and explored the operation of import statements. We learned that imports find the designated file on the module search path, compile it to byte code, and execute all of its statements to generate its contents. We also learned how to configure the search path to be able to import from directories other than the home directory and the standard library directories, primarily with PYTHONPATH settings.
As this chapter demonstrated, the import operation and modules are at the heart of program architecture in Python. Larger programs are divided into multiple files, which are linked together at runtime by imports. Imports in turn use the module search path to locate files, and modules define attributes for external use.
Of course, the whole point of imports and modules is to provide a structure to your program, which divides its logic into self-contained software components. Code in one module is isolated from code in another; in fact, no file can ever see the names defined in another, unless explicitimport statements are run. Because of this, modules minimize name collisions between different parts of your program.
You’ll see what this all means in terms of actual statements and code in the next chapter. Before we move on, though, let’s run through the chapter quiz.
Test Your Knowledge: Quiz
1. How does a module source code file become a module object?
2. Why might you have to set your PYTHONPATH environment variable?
3. Name the five major components of the module import search path.
4. Name four file types that Python might load in response to an import operation.
5. What is a namespace, and what does a module’s namespace contain?
Test Your Knowledge: Answers
1. A module’s source code file automatically becomes a module object when that module is imported. Technically, the module’s source code is run during the import, one statement at a time, and all the names assigned in the process become attributes of the module object.
2. You only need to set PYTHONPATH to import from directories other than the one in which you are working (i.e., the current directory when working interactively, or the directory containing your top-level file). In practice, this will be a common case for nontrivial programs.
3. The five major components of the module import search path are the top-level script’s home directory (the directory containing it), all directories listed in the PYTHONPATH environment variable, the standard library directories, all directories listed in .pth path files located in standard places, and the site-packages root directory for third-party extension installs. Of these, programmers can customize PYTHONPATH and .pth files.
4. Python might load a source code (.py) file, a byte code (.pyc or .pyo) file, a C extension module (e.g., a .so file on Linux or a .dll or .pyd file on Windows), or a directory of the same name for package imports. Imports may also load more exotic things such as ZIP file components, Java classes under the Jython version of Python, .NET components under IronPython, and statically linked C extensions that have no files present at all. In fact, with import hooks, imports can load arbitrary items.
5. A namespace is a self-contained package of variables, which are known as the attributes of the namespace object. A module’s namespace contains all the names assigned by code at the top level of the module file (i.e., not nested in def or class statements). Technically, a module’s global scope morphs into the module object’s attributes namespace. A module’s namespace may also be altered by assignments from other files that import it, though this is generally frowned upon (see Chapter 17 for more on the downsides of cross-file changes).
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.