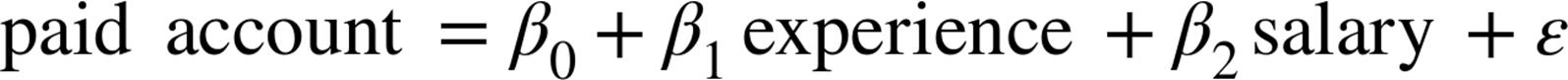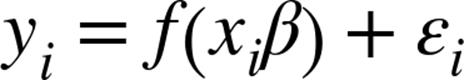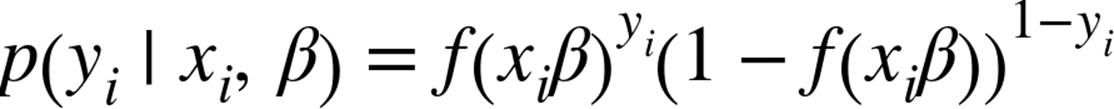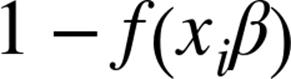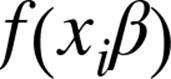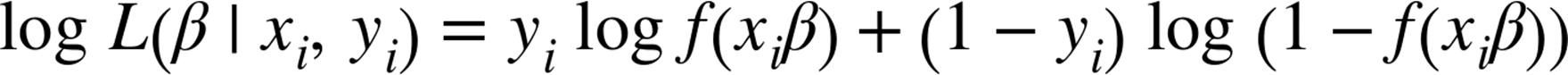Logistic Regression - Data Science from Scratch: First Principles with Python (2015)
Data Science from Scratch: First Principles with Python (2015)
Chapter 16.Logistic Regression
A lot of people say there’s a fine line between genius and insanity. I don’t think there’s a fine line, I actually think there’s a yawning gulf.
Bill Bailey
InChapter 1, we briefly looked at the problemof trying to predict which DataSciencester users paid for premium accounts. Here we’ll revisit that problem.
The Problem
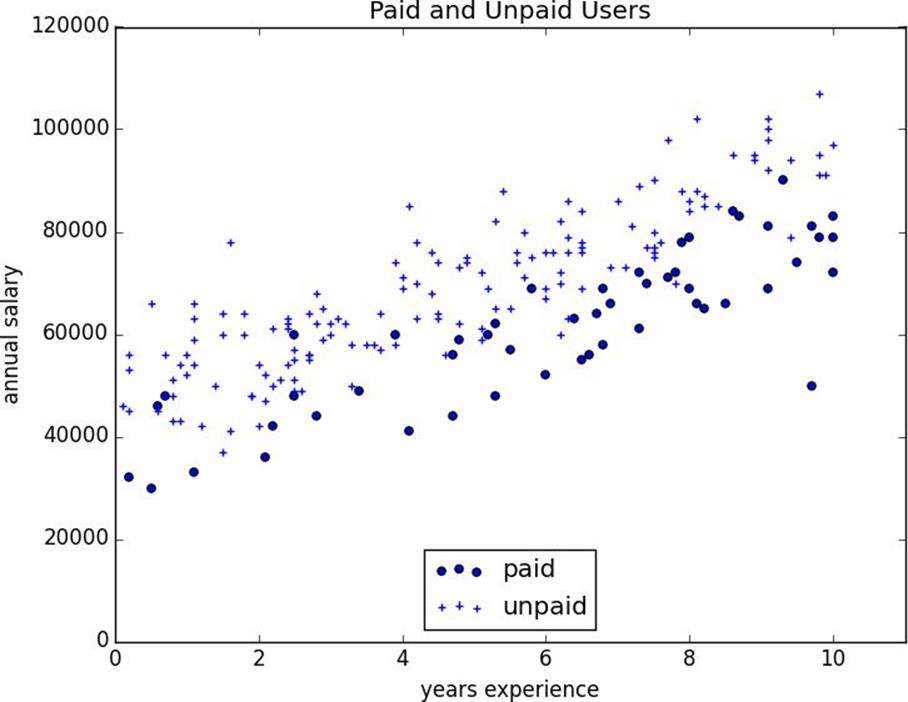
We have an anonymized data set ofabout 200 users, containing each user’s salary, her years of experience as a data scientist, and whether she paid for a premium account (Figure 16-1). As is usual with categorical variables, we represent the dependent variable as either 0 (no premium account) or 1 (premium account).
As usual, our data is in a matrix where each row is a list[experience, salary, paid_account]. Let’s turn it into the format we need:
x=[[1]+row[:2]forrowindata]# each element is [1, experience, salary]
y=[row[2]forrowindata]# each element is paid_account
An obvious first attempt is to uselinear regression and find the best model:
Figure 16-1.Paid and unpaid users
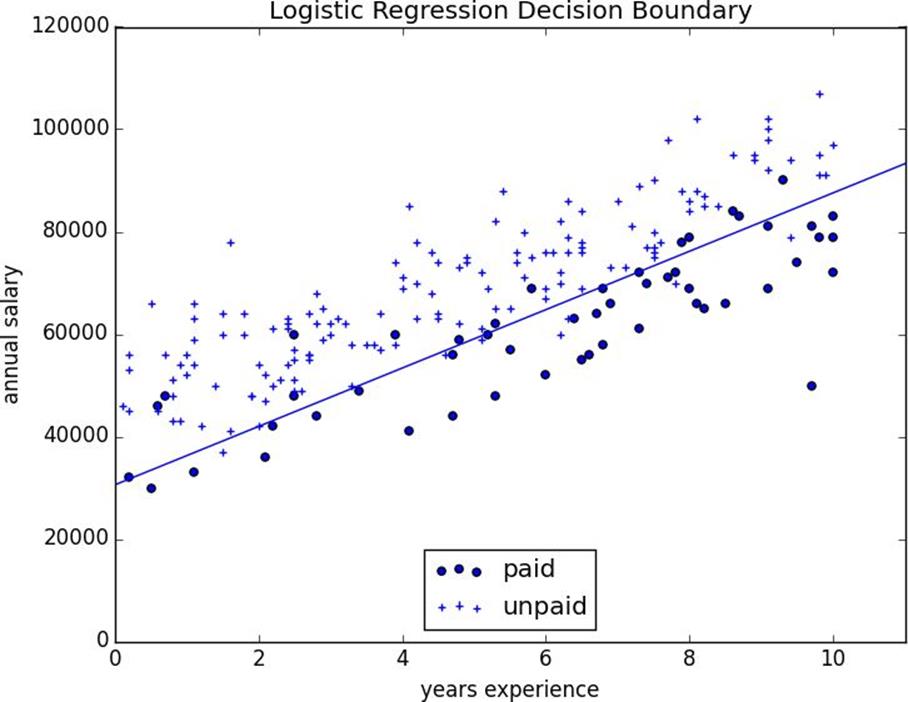
And certainly, there’s nothing preventing us from modeling the problem this way. The results are shown inFigure 16-2:
Figure 16-2.Using linear regression to predict premium accounts
But this approach leads to a couple of immediate problems:
§ We’d like for our predicted outputs to be 0 or 1, to indicate class membership. It’s fine if they’re between 0 and 1, since we can interpret these as probabilities — an output of 0.25 could mean 25% chance of being a paid member. But the outputs of the linear model can be huge positive numbers or even negative numbers, which it’s not clear how to interpret. Indeed, here a lot of our predictions were negative.
§ The linear regression model assumed that the errors were uncorrelated with the columns ofx. But here, the regression coefficent forexperienceis 0.43, indicating that more experience leads to a greater likelihood of a premium account. This means that our model outputs very large values for people with lots of experience. But we know that the actual values must be at most 1, which means that necessarily very large outputs (and therefore very large values ofexperience) correspond to very large negative values of the error term. Because this is the case, our estimate ofbetais biased.
What we’d like instead is for large positive values ofdot(x_i, beta)to correspond to probabilities close to 1, and for large negative values to correspond to probabilities close to 0. We can accomplish this by applying another function to the result.
The Logistic Function
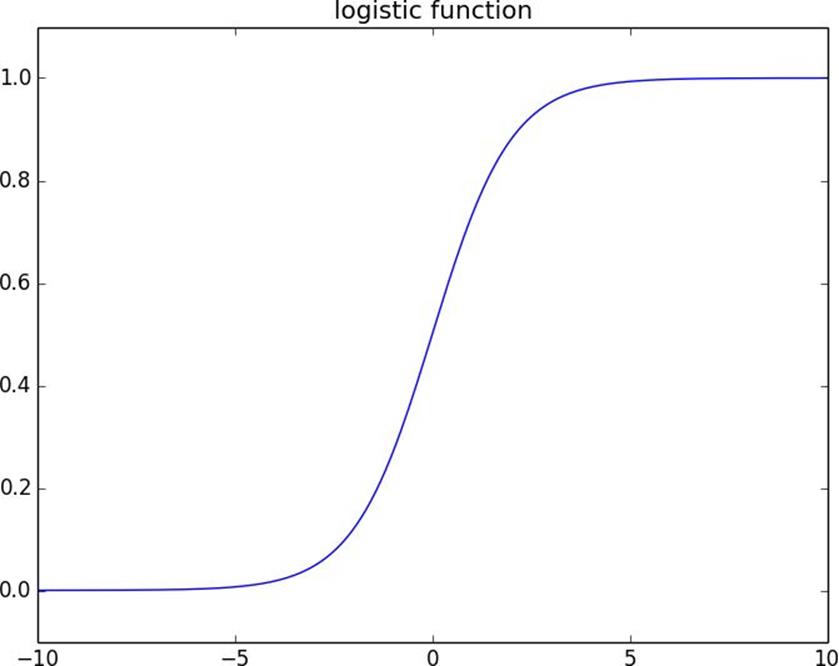
In the case of logistic regression, weuse thelogistic function, pictured inFigure 16-3:
deflogistic(x):
return1.0/(1+math.exp(-x))
Figure 16-3.The logistic function
As its input gets large and positive, it gets closer and closer to 1. As its input gets large and negative, it gets closer and closer to 0. Additionally, it has the convenient property that its derivative is given by:
deflogistic_prime(x):
returnlogistic(x)*(1-logistic(x))
which we’ll make use of in a bit. We’ll use this to fit a model:
wherefis thelogisticfunction.
Recall that for linear regression we fit the model by minimizing the sum of squared errors, which ended up choosing thethat maximized the likelihood of the data.
Here the two aren’t equivalent, so we’ll use gradient descent to maximize the likelihood directly. This means we need to calculate the likelihood function and its gradient.
Given some, our model says that eachshould equal 1 with probabilityand 0 with probability.
In particular, the pdf forcan be written as:
since ifis 0, this equals:
and ifis 1, it equals:
It turns out that it’s actually simpler to maximizethelog likelihood:
Because log is strictly increasing function, anybetathat maximizes the log likelihood also maximizes the likelihood, and vice versa.
deflogistic_log_likelihood_i(x_i,y_i,beta):
ify_i==1:
returnmath.log(logistic(dot(x_i,beta)))
else:
returnmath.log(1-logistic(dot(x_i,beta)))
If we assume different data points are independent from one another, the overall likelihood is just the product of the individual likelihoods. Which means the overall log likelihood is the sum of the individual log likelihoods:
deflogistic_log_likelihood(x,y,beta):
returnsum(logistic_log_likelihood_i(x_i,y_i,beta)
forx_i,y_iinzip(x,y))
A little bit of calculus gives us the gradient:
deflogistic_log_partial_ij(x_i,y_i,beta,j):
"""here i is the index of the data point,
j the index of the derivative"""
return(y_i-logistic(dot(x_i,beta)))*x_i[j]
deflogistic_log_gradient_i(x_i,y_i,beta):
"""the gradient of the log likelihood
corresponding to the ith data point"""
return[logistic_log_partial_ij(x_i,y_i,beta,j)
forj,_inenumerate(beta)]
deflogistic_log_gradient(x,y,beta):
returnreduce(vector_add,
[logistic_log_gradient_i(x_i,y_i,beta)
forx_i,y_iinzip(x,y)])
at which point we have all the pieces we need.
Applying the Model
We’ll want to split our datainto a training set and a test set:
These are coefficients for therescaled data, but we can transform them back to the original data as well:
beta_hat_unscaled=[7.61,1.42,-0.000249]
Unfortunately, these are not as easy to interpret as linear regression coefficients. All else being equal, an extra year of experience adds 1.42 to the input oflogistic. All else being equal, an extra $10,000 of salary subtracts 2.49 from the input oflogistic.
The impact on the output, however, depends on the other inputs as well. Ifdot(beta, x_i)is already large (corresponding to a probability close to 1), increasing it even by a lot cannot affect the probability very much. If it’s close to 0, increasing it just a little might increase the probability quite a bit.
What we can say is that — all else being equal — people with more experience are more likely to pay for accounts. And that — all else being equal — people with higher salaries are less likely to pay for accounts. (This was also somewhat apparent when we plotted the data.)
Goodness of Fit
We haven’t yet used the test data that we held out.Let’s see what happens if we predictpaid accountwhenever the probability exceeds 0.5:
This gives a precision of 93% (“when we predictpaid accountwe’re right 93% of the time”) and a recall of 82% (“when a user has a paid account we predictpaid account82% of the time”), both of which are pretty respectable numbers.
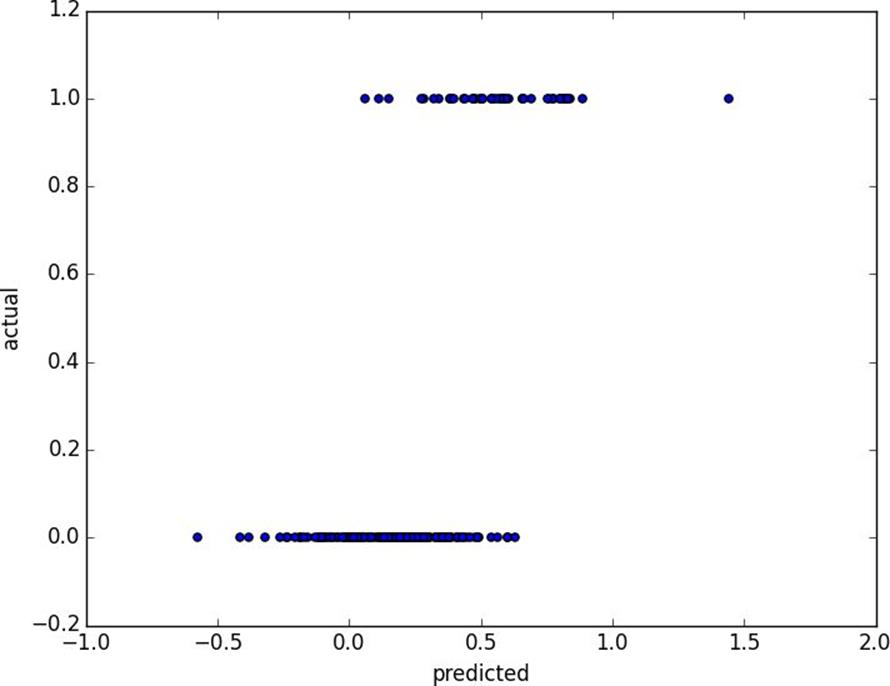
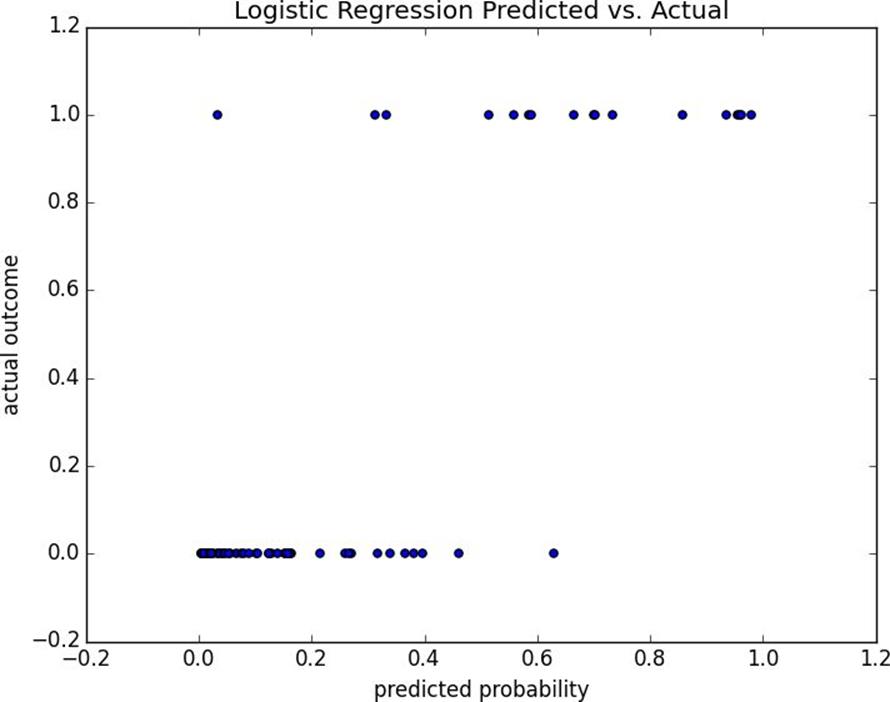
We can also plot the predictions versus the actuals (Figure 16-4), which also shows that the model performs well:
plt.title("Logistic Regression Predicted vs. Actual")
plt.show()
Figure 16-4.Logistic regression predicted versus actual
Support Vector Machines
The set of points wheredot(beta_hat, x_i)equals 0 is the boundary between our classes. We can plot this to see exactly what our model is doing (Figure 16-5).
This boundary is ahyperplanethat splits the parameter space into two half-spaces corresponding topredict paidandpredict unpaid. We found it as a side-effect of finding the most likely logistic model.
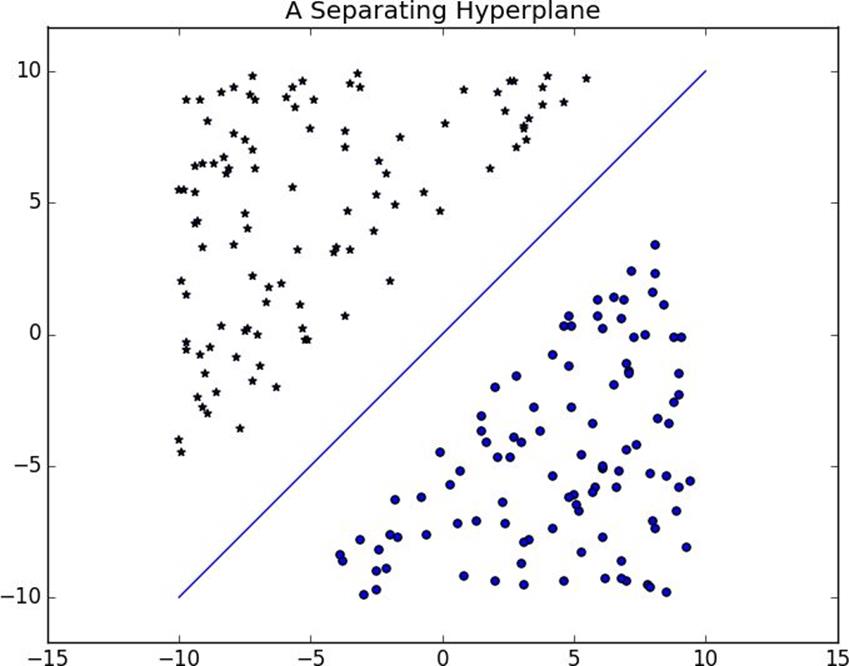
An alternative approach to classification is to just look for the hyperplane that “best” separates the classes in the training data.This is the idea behind thesupport vector machine, which finds the hyperplane that maximizes the distance to the nearest point in each class (Figure 16-6).
Figure 16-5.Paid and unpaid users with decision boundary
Finding such a hyperplane is an optimization problem that involves techniques that are too advanced for us. A different problem is that a separating hyperplane might not exist at all. In our “who pays?” data set there simply is no line that perfectly separates the paid users from the unpaid users.
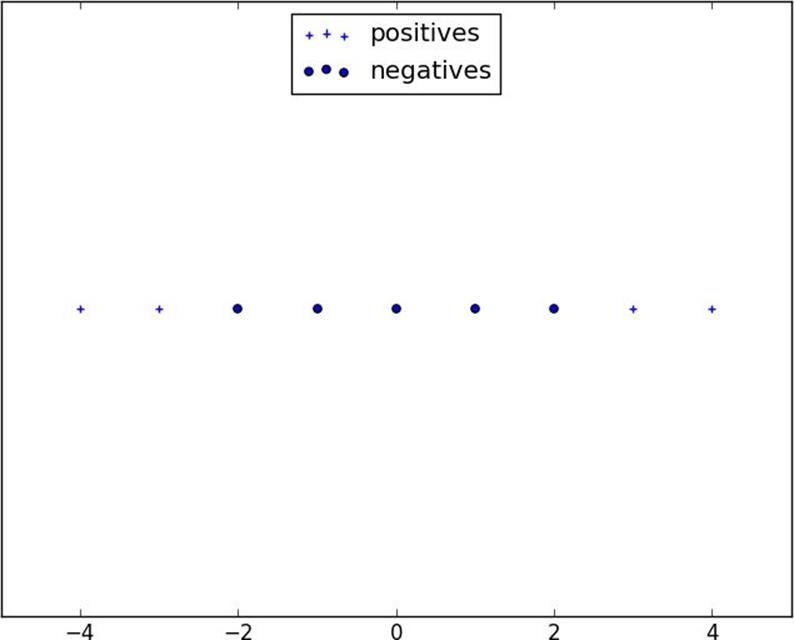
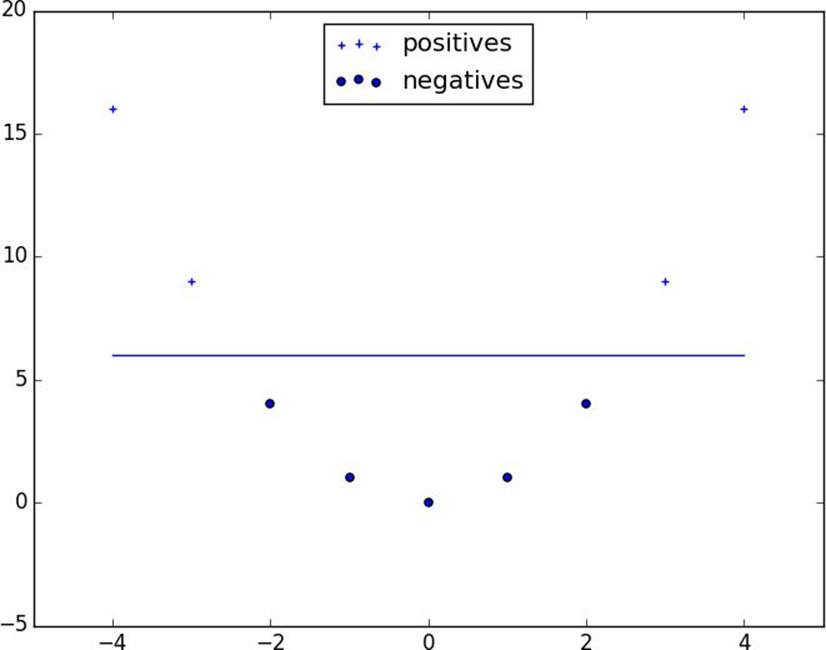
We can (sometimes) get around this by transforming the data into a higher-dimensional space. For example, consider the simple one-dimensional data set shown inFigure 16-7.
Figure 16-6.A separating hyperplane
It’s clear that there’s no hyperplane that separates the positive examples from the negative ones. However, look at what happens when we map this data set to two dimensions by sending the pointxto(x, x**2). Suddenly it’s possible to find a hyperplane that splits the data (Figure 16-8).
This is usually calledthekernel trickbecause rather than actually mapping the points into the higher-dimensional space (which could be expensive if there are a lot of points and the mapping is complicated), we can use a “kernel” function to compute dot products in the higher-dimensional space and use those to find a hyperplane.
Figure 16-7.A nonseparable one-dimensional data set
It’s hard (and probably not a good idea) tousesupport vector machines without relying on specialized optimization software written by people with the appropriate expertise, so we’ll have to leave our treatment here.
Figure 16-8.Data set becomes separable in higher dimensions
For Further Investigation
§ scikit-learn has modules for bothLogistic RegressionandSupport Vector Machines.
§ libsvmis the support vector machine implementation that scikit-learn is using behind the scenes. Its website has a variety of useful documentation about support vector machines.