Data Science from Scratch: First Principles with Python (2015)
Chapter 24. MapReduce
The future has already arrived. It’s just not evenly distributed yet.
William Gibson
1. Use a mapper function to turn each item into zero or more key-value pairs. (Often this is called the map function, but there is already a Python function called map and we don’t need to confuse the two.)
2. Collect together all the pairs with identical keys.
3. Use a reducer function on each collection of grouped values to produce output values for the corresponding key.
Example: Word Count
defword_count_old(documents):
"""word count not using MapReduce"""
returnCounter(word
fordocumentindocuments
forwordintokenize(document))
defwc_mapper(document):
"""for each word in the document, emit (word,1)"""
forwordintokenize(document):
yield(word,1)
defwc_reducer(word,counts):
"""sum up the counts for a word"""
yield(word,sum(counts))
defword_count(documents):
"""count the words in the input documents using MapReduce"""
# place to store grouped values
collector=defaultdict(list)
fordocumentindocuments:
forword,countinwc_mapper(document):
collector[word].append(count)
return[output
forword,countsincollector.iteritems()
foroutputinwc_reducer(word,counts)]
{"data":[1,1],
"science":[1,1],
"big":[1],
"fiction":[1]}
[("data",2),("science",2),("big",1),("fiction",1)]
Why MapReduce?
NOTE
§ Have each machine run the mapper on its documents, producing lots of (key, value) pairs.
§ Distribute those (key, value) pairs to a number of “reducing” machines, making sure that the pairs corresponding to any given key all end up on the same machine.
§ Have each reducing machine group the pairs by key and then run the reducer on each set of values.
§ Return each (key, output) pair.
MapReduce More Generally
defmap_reduce(inputs,mapper,reducer):
"""runs MapReduce on the inputs using mapper and reducer"""
collector=defaultdict(list)
forinputininputs:
forkey,valueinmapper(input):
collector[key].append(value)
return[output
forkey,valuesincollector.iteritems()
foroutputinreducer(key,values)]
word_counts=map_reduce(documents,wc_mapper,wc_reducer)
defreduce_values_using(aggregation_fn,key,values):
"""reduces a key-values pair by applying aggregation_fn to the values"""
yield(key,aggregation_fn(values))
defvalues_reducer(aggregation_fn):
"""turns a function (values -> output) into a reducer
that maps (key, values) -> (key, output)"""returnpartial(reduce_values_using,aggregation_fn)
sum_reducer=values_reducer(sum)
max_reducer=values_reducer(max)
min_reducer=values_reducer(min)
count_distinct_reducer=values_reducer(lambdavalues:len(set(values)))
Example: Analyzing Status Updates
{"id":1,
"username":"joelgrus",
"text":"Is anyone interested in a data science book?",
"created_at":datetime.datetime(2013,12,21,11,47,0),
"liked_by":["data_guy","data_gal","mike"]}
defdata_science_day_mapper(status_update):
"""yields (day_of_week, 1) if status_update contains "data science" """
if"data science"instatus_update["text"].lower():
day_of_week=status_update["created_at"].weekday()
yield(day_of_week,1)
data_science_days=map_reduce(status_updates,
data_science_day_mapper,
sum_reducer)
§ Put the username in the key; put the words and counts in the values.
§ Put the word in key; put the usernames and counts in the values.
§ Put the username and word in the key; put the counts in the values.
defwords_per_user_mapper(status_update):
user=status_update["username"]
forwordintokenize(status_update["text"]):
yield(user,(word,1))
defmost_popular_word_reducer(user,words_and_counts):
"""given a sequence of (word, count) pairs,
return the word with the highest total count"""word_counts=Counter()
forword,countinwords_and_counts:
word_counts[word]+=count
word,count=word_counts.most_common(1)[0]
yield(user,(word,count))
user_words=map_reduce(status_updates,
words_per_user_mapper,
most_popular_word_reducer)
defliker_mapper(status_update):
user=status_update["username"]
forlikerinstatus_update["liked_by"]:
yield(user,liker)
distinct_likers_per_user=map_reduce(status_updates,
liker_mapper,
count_distinct_reducer)
Example: Matrix Multiplication
Recall from “Matrix Multiplication” that given a ![]() matrix A and a
matrix A and a ![]() matrix B, we can multiply them to form a
matrix B, we can multiply them to form a ![]() matrix C, where the element of C in row i and column j is given by:
matrix C, where the element of C in row i and column j is given by:
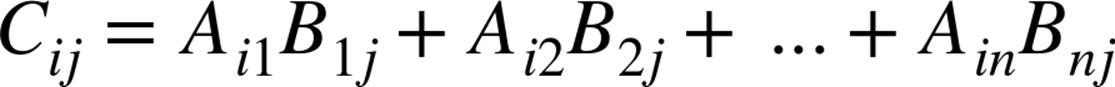
As we’ve seen, a “natural” way to represent a ![]() matrix is with a
matrix is with a list of lists, where the element ![]() is the jth element of the ith list.
is the jth element of the ith list.
To motivate our algorithm, notice that each element ![]() is only used to compute the elements of C in row i, and each element
is only used to compute the elements of C in row i, and each element ![]() is only used to compute the elements of C in column j. Our goal will be for each output of our
is only used to compute the elements of C in column j. Our goal will be for each output of our reducer to be a single entry of C, which means we’ll need our mapper to emit keys identifying a single entry of C. This suggests the following:
defmatrix_multiply_mapper(m,element):
"""m is the common dimension (columns of A, rows of B)
element is a tuple (matrix_name, i, j, value)"""name,i,j,value=element
ifname=="A":
# A_ij is the jth entry in the sum for each C_ik, k=1..m
forkinrange(m):
# group with other entries for C_ik
yield((i,k),(j,value))
else:
# B_ij is the i-th entry in the sum for each C_kj
forkinrange(m):
# group with other entries for C_kj
yield((k,j),(i,value))
defmatrix_multiply_reducer(m,key,indexed_values):
results_by_index=defaultdict(list)
forindex,valueinindexed_values:
results_by_index[index].append(value)
# sum up all the products of the positions with two results
sum_product=sum(results[0]*results[1]
forresultsinresults_by_index.values()
iflen(results)==2)
ifsum_product!=0.0:
yield(key,sum_product)
A=[[3,2,0],
[0,0,0]]
B=[[4,-1,0],
[10,0,0],
[0,0,0]]
entries=[("A",0,0,3),("A",0,1,2),
("B",0,0,4),("B",0,1,-1),("B",1,0,10)]
mapper=partial(matrix_multiply_mapper,3)
reducer=partial(matrix_multiply_reducer,3)
map_reduce(entries,mapper,reducer)# [((0, 1), -3), ((0, 0), 32)]
For Further Exploration
§ The most widely used MapReduce system is Hadoop, which itself merits many books. There are various commercial and noncommercial distributions and a huge ecosystem of Hadoop-related tools.
In order to use it, you have to set up your own cluster (or find someone to let you use theirs), which is not necessarily a task for the faint-hearted. Hadoop mappers and reducers are commonly written in Java, although there is a facility known as “Hadoop streaming” that allows you to write them in other languages (including Python).
§ Amazon.com offers an Elastic MapReduce service that can programmatically create and destroy clusters, charging you only for the amount of time that you’re using them.
§ mrjob is a Python package for interfacing with Hadoop (or Elastic MapReduce).
§ Hadoop jobs are typically high-latency, which makes them a poor choice for “real-time” analytics. There are various “real-time” tools built on top of Hadoop, but there are also several alternative frameworks that are growing in popularity. Two of the most popular are Spark and Storm.
§ All that said, by now it’s quite likely that the flavor of the day is some hot new distributed framework that didn’t even exist when this book was written. You’ll have to find that one yourself.