Data Science from Scratch: First Principles with Python (2015)
Chapter 4. Linear Algebra
Is there anything more useless or less useful than Algebra?
Billy Connolly
Vectors
height_weight_age=[70,# inches,
170,# pounds,
40]# years
grades=[95,# exam1
80,# exam2
75,# exam3
62]# exam4
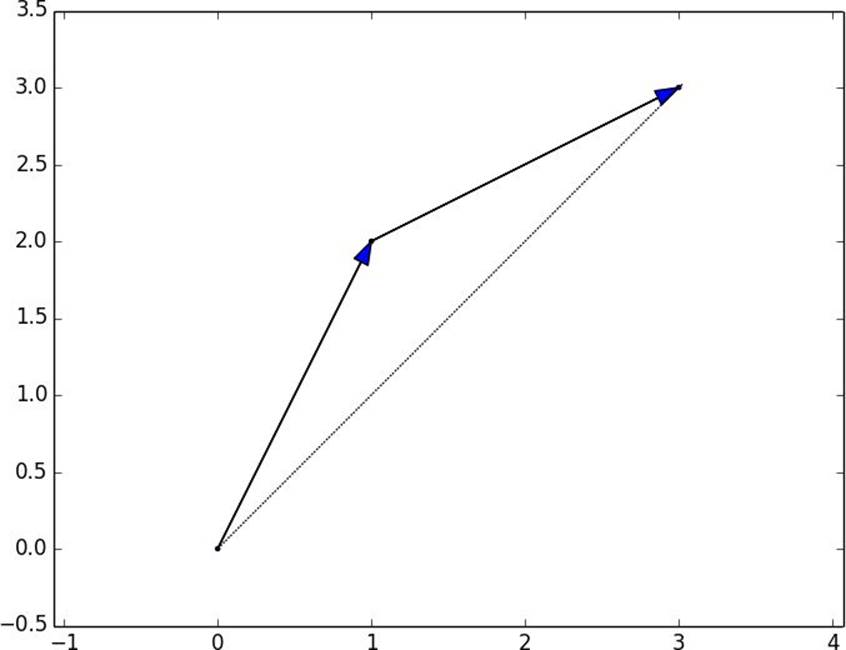
Figure 4-1. Adding two vectors
defvector_add(v,w):
"""adds corresponding elements"""
return[v_i+w_i
forv_i,w_iinzip(v,w)]
defvector_subtract(v,w):
"""subtracts corresponding elements"""
return[v_i-w_i
forv_i,w_iinzip(v,w)]
defvector_sum(vectors):
"""sums all corresponding elements"""
result=vectors[0]# start with the first vector
forvectorinvectors[1:]:# then loop over the others
result=vector_add(result,vector)# and add them to the result
returnresult
defvector_sum(vectors):
returnreduce(vector_add,vectors)
vector_sum=partial(reduce,vector_add)
defscalar_multiply(c,v):
"""c is a number, v is a vector"""
return[c*v_iforv_iinv]
defvector_mean(vectors):
"""compute the vector whose ith element is the mean of the
ith elements of the input vectors"""n=len(vectors)
returnscalar_multiply(1/n,vector_sum(vectors))
defdot(v,w):
"""v_1 * w_1 + ... + v_n * w_n"""
returnsum(v_i*w_i
forv_i,w_iinzip(v,w))
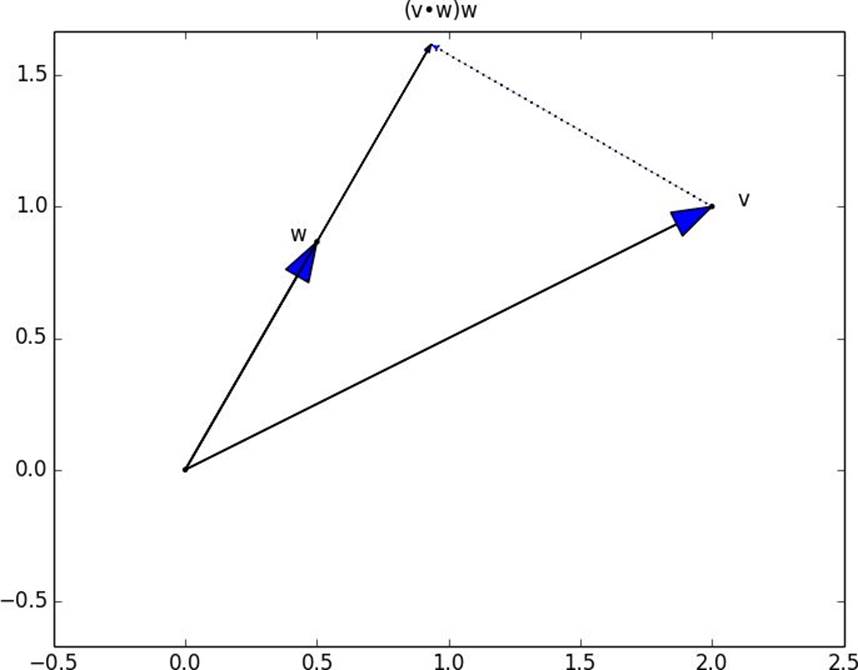
Figure 4-2. The dot product as vector projection
defsum_of_squares(v):
"""v_1 * v_1 + ... + v_n * v_n"""
returndot(v,v)
importmath
defmagnitude(v):
returnmath.sqrt(sum_of_squares(v))# math.sqrt is square root function

defsquared_distance(v,w):
"""(v_1 - w_1) ** 2 + ... + (v_n - w_n) ** 2"""
returnsum_of_squares(vector_subtract(v,w))
defdistance(v,w):
returnmath.sqrt(squared_distance(v,w))
defdistance(v,w):
returnmagnitude(vector_subtract(v,w))
NOTE
A=[[1,2,3],# A has 2 rows and 3 columns
[4,5,6]]
B=[[1,2],# B has 3 rows and 2 columns
[3,4],
[5,6]]
NOTE
defshape(A):
num_rows=len(A)
num_cols=len(A[0])ifAelse0# number of elements in first row
returnnum_rows,num_cols
If a matrix has n rows and k columns, we will refer to it as a ![]() matrix. We can (and sometimes will) think of each row of a
matrix. We can (and sometimes will) think of each row of a ![]() matrix as a vector of length k, and each column as a vector of length n:
matrix as a vector of length k, and each column as a vector of length n:
defget_row(A,i):
returnA[i]# A[i] is already the ith row
defget_column(A,j):
return[A_i[j]# jth element of row A_i
forA_iinA]# for each row A_i
defmake_matrix(num_rows,num_cols,entry_fn):
"""returns a num_rows x num_cols matrix
whose (i,j)th entry is entry_fn(i, j)"""return[[entry_fn(i,j)# given i, create a list
forjinrange(num_cols)]# [entry_fn(i, 0), ... ]
foriinrange(num_rows)]# create one list for each i
defis_diagonal(i,j):
"""1's on the 'diagonal', 0's everywhere else"""
return1ifi==jelse0
identity_matrix=make_matrix(5,5,is_diagonal)
# [[1, 0, 0, 0, 0],# [0, 1, 0, 0, 0],# [0, 0, 1, 0, 0],# [0, 0, 0, 1, 0],# [0, 0, 0, 0, 1]]First, we can use a matrix to represent a data set consisting of multiple vectors, simply by considering each vector as a row of the matrix. For example, if you had the heights, weights, and ages of 1,000 people you could put them in a ![]() matrix:
matrix:
data=[[70,170,40],
[65,120,26],
[77,250,19],
# ....
]
Second, as we’ll see later, we can use an ![]() matrix to represent a linear function that maps k-dimensional vectors to n-dimensional vectors. Several of our techniques and concepts will involve such functions.
matrix to represent a linear function that maps k-dimensional vectors to n-dimensional vectors. Several of our techniques and concepts will involve such functions.
friendships=[(0,1),(0,2),(1,2),(1,3),(2,3),(3,4),
(4,5),(5,6),(5,7),(6,8),(7,8),(8,9)]
# user 0 1 2 3 4 5 6 7 8 9
#
friendships=[[0,1,1,0,0,0,0,0,0,0],# user 0
[1,0,1,1,0,0,0,0,0,0],# user 1
[1,1,0,1,0,0,0,0,0,0],# user 2
[0,1,1,0,1,0,0,0,0,0],# user 3
[0,0,0,1,0,1,0,0,0,0],# user 4
[0,0,0,0,1,0,1,1,0,0],# user 5
[0,0,0,0,0,1,0,0,1,0],# user 6
[0,0,0,0,0,1,0,0,1,0],# user 7
[0,0,0,0,0,0,1,1,0,1],# user 8
[0,0,0,0,0,0,0,0,1,0]]# user 9
friendships[0][2]==1# True, 0 and 2 are friends
friendships[0][8]==1# False, 0 and 8 are not friends
friends_of_five=[i# only need
fori,is_friendinenumerate(friendships[5])# to look at
ifis_friend]# one row
§ Linear algebra is widely used by data scientists (frequently implicitly, and not infrequently by people who don’t understand it). It wouldn’t be a bad idea to read a textbook. You can find several freely available online:
§ Linear Algebra, from UC Davis
§ Linear Algebra, from Saint Michael’s College
§ If you are feeling adventurous, Linear Algebra Done Wrong is a more advanced introduction
§ All of the machinery we built here you get for free if you use NumPy. (You get a lot more too.)
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.