Digital Archaeology (2014)
11. Web Forensics
Often the focus of an investigation eventually finds its way to what a specific individual has been doing on the Internet. Internal investigations might concentrate on whether violations of company policy have occurred. Civil investigations may search for evidence of information tampering, theft of intellectual property (such as illegal downloads of music or other copyrighted material), or the uploading of corporate information to external sites. Many criminal investigations have turned on the evidence that the suspect performed searches specific to the criminal behavior under investigation. This chapter discusses how such information can be extracted from a suspect computer.
Internet Addresses
In order to access the Internet, an operating system requires an application-level interface between the user and the OS. From a purely technical standpoint, the World Wide Web is merely a very large network. But since it is so large, standard file system managers such as Windows Explorer or the OSX Finder for Macintosh are not up to the task of searching the Web for files. The Web is more complex than a local file system.
Web browsers locate objects on the Web through a Uniform Resource Locator (URL). The URL amounts to a user-friendly (sort of, anyway) address to a particular point on the Internet. A typical URL is exemplified in Figure 11.1, which shows the address of a Web page maintained by the author. There are several elements to this address.

Figure 11.1 A browser’s address line points the user to a specific URL.
The letters HTTP identify the scheme used by the resource. Generally this refers to the protocol used when accessing the resource. In this example, HTTP indicates the Hypertext Transfer Protocol. This is the standard protocol used by the vast majority of Web pages. Another common denominator is HTTPS, which stands for Hypertext Transfer Protocol Secure. This protocol incorporates encrypting algorithms and allows for the secure transfer of sensitive information such as financial data, personal identification information, and so forth. When making a purchase over the Internet, it is always critical that users verify the page in which they are entering such information employs HTTPS. There is also FTP, which is the File Transfer Protocol. Occasionally, large files are stored on FTP servers, and users are redirected to that site using the FTP protocol. Table 11.1identifies the most commonly used schemes seen across the Internet.
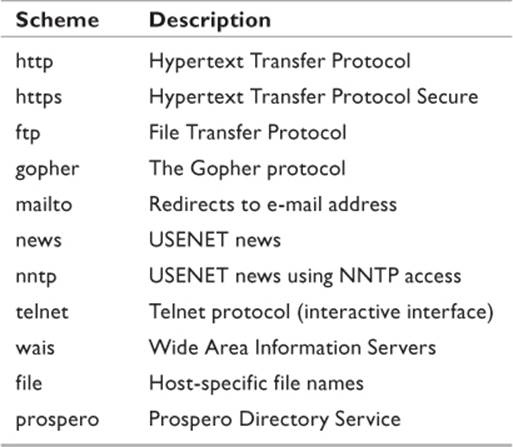
Table 11.1 URL Schemes in Use
Following the scheme will be a colon, followed by two forward slashes (://). In the example, the letters WWW indicate that the resource is located on the World Wide Web. This is the prefix of the fully qualified domain name (FQDM). Occasionally users may see prefixes such as WWW1, WWW2, or WWW3 in its place. This indicates that the browser is retrieving information from an alternative server to the one identified by the URL that serves this location. This is typical of sites that house so much information that it is stored in large server farms and not just a single machine. Many sites are not preceded by the WWW, and it is not required with most modern browsers.
MWGRAVES.COM identifies the specific domain. MWGRAVES is the domain name and COM is the URL suffix that indicates to which top-level domain it belongs. The top-level domain indicates which group of name servers will be used when searching for the site. In this example, the URL is of a commercial Web page. As of this writing, there are a total of 312 designated top-level domains (ICANN 2011), including a number of two-character extensions delegated to specific countries. There are several top-level domains (listed in Table 11.2) with which anyone should be familiar.
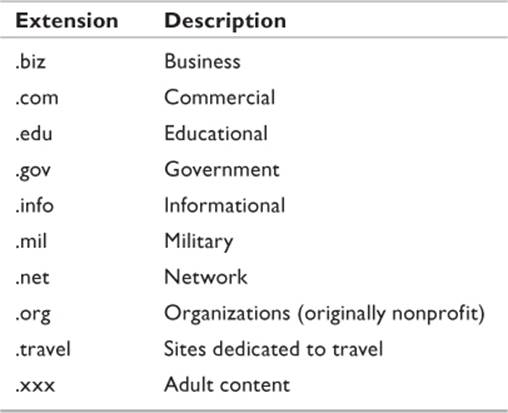
Table 11.2 Primary Top-Level Domains
That completes the minimum requirements for a fully qualified domain name. However, individual files and folders located within the domain are defined in the path segment of the full name. The example in Figure 11.1 is for a Web page located two folder levels (/Portfolios/Michael) deep in the Web site.
Web Browsers
As mentioned earlier, the Web browser is an interface between the user, the OS, and the Internet. A computer may have two or more browsers installed, but only one will be the default browser. This is the application that will open when a shortcut to a URL is activated through an application or by a user from the desktop.
When a browser is launched, it first navigates to its home page. The home page is configured in the preferences and is whatever Web site the user prefers to see when they first launch the application. This may be a personal Web site or one of the major search engines, such as Yahoo or Google.
How Web Browsers Work
A Web browser, at its most basic, interprets documents created in the Hypertext Markup Language (HTML) and displays them on a computer monitor in formatted form. A browser consists of several major components. They all work together to perform the common function of displaying a Web page.
Externally, the user interface provides the tools that allow the average person to find, download, and read Web pages. Interfaces vary among browsers but commonly include
• An address bar
• Forward and Back buttons
• Bookmarking capabilities
• Intrapage search capabilities
• Configuration utilities
The workhorse of the application is the browser engine. It processes and transmits queries and acts as a controller for the next component, which is the rendering engine. The rendering engine takes the Web page language, such as HTML, and parses it, using the information to draw the screens and display content provided by the Web page.
The networking engine talks to other services running on the computer, such as the Domain Name System, to make connections necessary for locating Web resources, connecting to them, and transferring content from source to destination and vice versa.
A key feature of Web browsers that is of relevance to the investigator is that, by default, Internet-based data systems tend to negatively impact on local system performance. In order to minimize this impact, Web browsers cache information. What that means is, when the user visits a page, a copy of the HTML for that page is stored on the local computer. Certain content, such as image files, PDFs, and multimedia content, are copied and stored as well. The reason for doing this is that when the user visits a site repeatedly, the browser does not have to duplicate the efforts of downloading all that material again. It sends out a query to the Web site, asking when was the last time the Web site content changed. If there have been no changes since the last visit, the cached content is loaded.
Browsing Web Sites
When a Web site is first opened, a couple of things happen. The URL to that site is logged in the Internet history file. This isn’t done simply to keep track of what the user is doing while on the Internet (although it certainly allows for that). This is how the browser keeps track of where to go when a user clicks on the Forward or Back buttons in the browser. Since browsers assume that speed is a critical element for most users and that many users will visit sites more than once, they create a cache of files used by Web pages. These include the HTML files and style sheets that comprise the page, individual images that make up the site, and even script files. These are the temporary Internet files.
The second thing that happens with most, but not all sites, is that a small file called a cookie is downloaded to the computer (unless that cookie already exists). A single site might load several cookies to a visitor’s computer in a single visit. Cookies are small text files that store certain information about the user and the user’s interaction with the site. This is usually information that the user voluntarily provides and not something covertly harvested by some agent launched by the Web site. While cookies can most certainly be used for nefarious purposes, for the most part they are benign tools to enhance the Web experience.
When you navigate to a favorite site and it already knows who you are . . . that is because on a previous visit it stored a cookie. When you go to Amazon.com and suddenly the page is filled with suggestions, it is because Amazon generated a cookie based on your previous searches. None of the Web site’s intimate knowledge of a user’s behavior comes from information about that person on the company’s Web servers. It is all right there on the local hard disk.
A third thing happens in Windows, but it is accomplished by the OS and not the browser. The Web site is recorded in the registry as a “most recently used” (MRU) site. Virtually every application installed in Windows maintains an MRU list in the registry. Even if the files are deleted and then forensically wiped, unless the user takes proactive measures to do so, the entry will remain in the MRU list until it is eventually overwritten.
Browser Settings
To do a complete analysis of Internet history on a system, there are several observations the investigator must make at the outset of the investigation. The browser settings must be recorded to start with. One critical setting is how the browser treats browsing history. The Internet Options (Figure 11.2) determine the default settings for how cached files are treated.
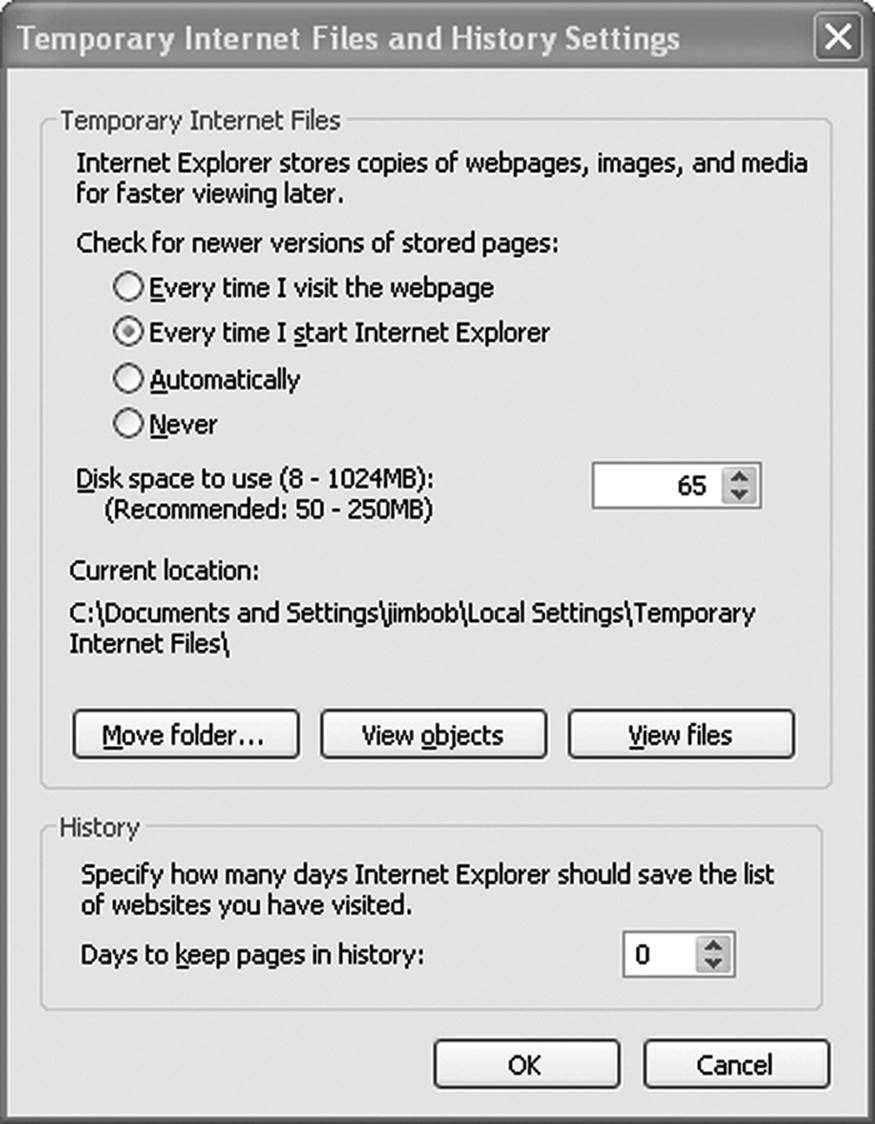
Figure 11.2 The configuration of the browser tells the investigator several things that will be useful in the investigation.
In Figure 11.2, the browser has been set to keep history for zero days. That means everything that the user views today will be gone tomorrow. The default setting is ten days. If this setting has not been changed, then the files will automatically delete ten days after it is first cached.
Another thing the configuration window tells the investigator is the directory to which cached files (temporary Internet files) are stored. This will be discussed in more detail in the next section. If a user has chosen to use a different location for any reason, the investigator learns two things. First, somebody knew enough about computer systems to change the default. This is something the prosecutor may use to her advantage later on. Second, we now know exactly where to look for cached files . . . or where to point our file recovery software in an effort to restore deleted cache files.
Browser History
Different browsers store history in different ways. Microsoft’s Internet Explorer (IE) stores information useful to the investigator in at least three different places. Users with Windows 2000 and earlier will have a cached version of the history stored in C:\Documents and Settings\@user:\Local Settings\Temporary Internet Files\Content.IE5\. This is the default location IE uses for putting pages and images viewed by that particular user. Computers used by multiple users will have a profile for each user. The purpose of this directory is to speed up access to recently or frequently visited Web pages. C:\Documents and Settings\@user:\Local Settings\History\History.IE5\ stores a noncached history without the actual pages and images. The cookies discussed earlier in the chapter are generally stored in C:\Documents and Settings\@user:\Cookies\.
Windows 7 handles cached data a little differently. By default, cached history is in C:\Users\@user:\AppData\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5. However, in previous versions of Windows, IE plug-ins failed when attempting to write data to protected folders. In order to mitigate this problem, Windows Vista and Windows 7 create virtual folders in which cached files are stored. These folders are hidden and not accessible to general users.
Cookies will be stored in one of two places, both of which are hidden. C:\Users\@user:\AppData\Roaming\Microsoft\Windows\Cookies is the default location. This is where Windows will store cookies whenever possible. In Versions 7 or later, IE offers a “protected mode” operation. If this option is turned on, cookies can only be stored in low-privilege folders. In this case, C:\Users\@user:\AppData\Roaming\Microsoft\Windows\Cookies\Low is where the cookies will land.
The above-mentioned locations are all places for the investigator to look if forced to perform a manual examination. Most well-equipped professionals will be using a specialized tool. All of the commercial forensic suites offer Internet history analysis, and all of them are quite good at what they do. On the other hand, for this particular task, it is not necessary to have an expensive tool to do an effective job. Nirsoft (www.nirsoft.net) makes available a number of different browser analysis tools as open source freeware. These include specialized history tools for IE, Mozilla, Safari, Chrome, and Opera. The popular Firefox browser is a version of Mozilla and can be analyzed by that utility. Additionally, the Linux forensic application The Sleuth Kit does an excellent job of analyzing Internet history on most browsers.
Another tool called Web Historian is useful whenever the investigator is unsure which browser may have been used. This utility scans the directory structure of the computer and identifies valid history files for IE, Mozilla, Netscape, Safari, and Opera. Web Historian (Figure 11.3) analyzes the files it finds and has the ability to output data into Excel format, HTML, or a comma-delimited text file that can be imported into virtually any database application. When data is output to a spreadsheet or database, an investigator can sort information in a variety of ways. Sorting bytimestamp and then by URL is a good way to generate a timeline of activity.
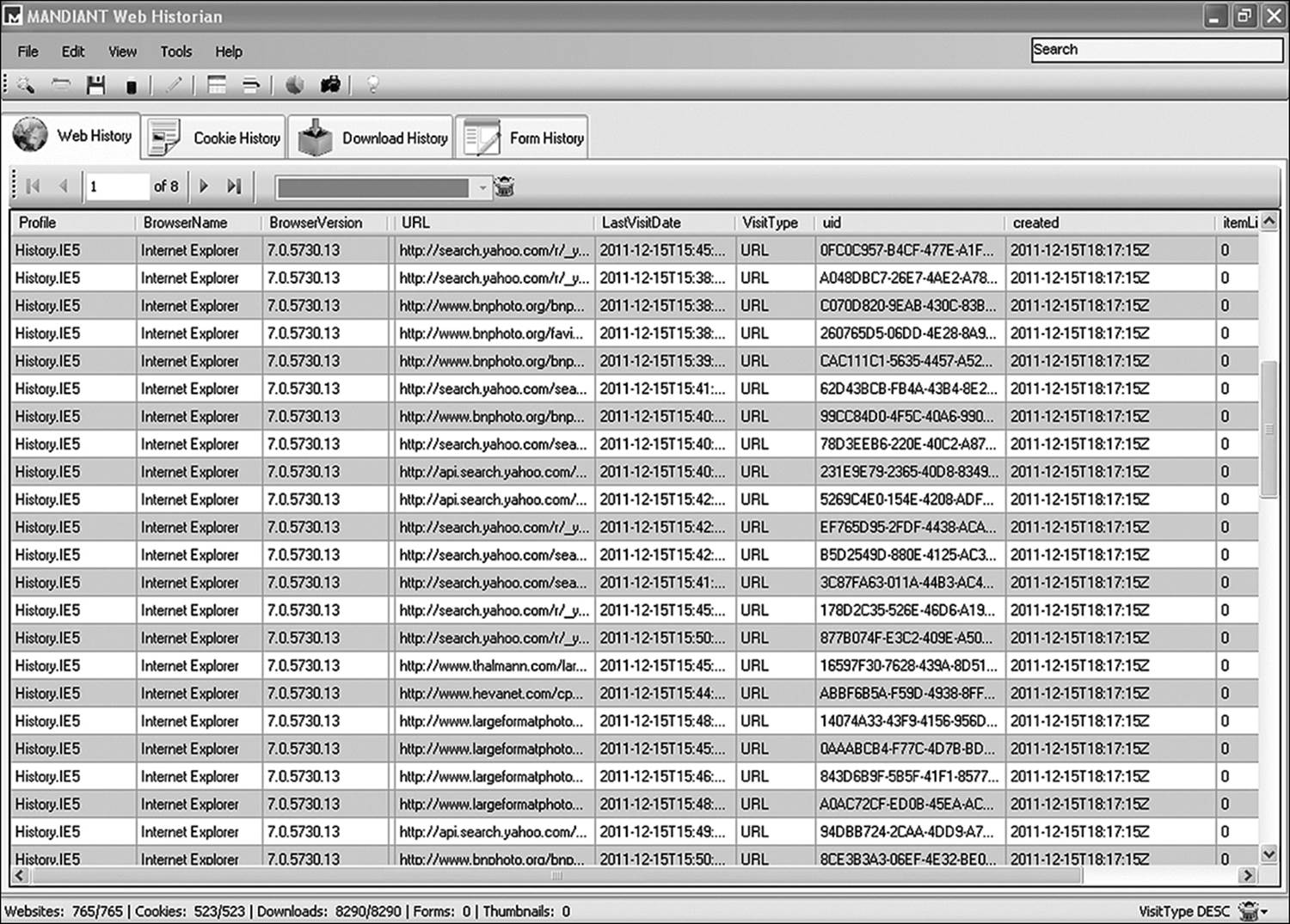
Figure 11.3 Web Historian is just one example of an application that facilitates the analysis of a user’s Internet activity.
Analyzing User Activity
The information located during browser analysis can be used to prove numerous points that a prosecutor needs to address. There are two aspects to conducting an analysis of browser history. The first part consists of finding and identifying specific records. The second aspect of the investigation is analyzing the history.
Identifying Specific Records
As mentioned earlier in this chapter, browser history can be found in more than one place in the file system. In addition to the temporary Internet files stored by the system, a history record exists in the form of .dat files. Also, the cookies stored on the system can be of importance. A user who configures her system to regularly delete history files may not eliminate cookies. Those files identify the Web site from which they originated.
The temporary Internet files will store cached Web pages, images, and PDF files that were downloaded by the browser during every session since the last time the files were cleared. Those files can be extracted and sorted by time stamp, by URL, or by file name by most browser analysis tools. DAT files require specialized software to read, but that does not necessarily mean proprietary or expensive software. Pasco is an open-source utility that will read the DAT files from Internet Explorer, Mozilla, and Netscape. It is programmed to search all of the default file locations for history files and can be told to search an entire volume. Once it finds a history file, it prepares a user-friendly file that displays the information from several different fields located within the file:
• URL: The full Web address of the record (including file name)
• File Name: The file name as it exists on the local system
• Record Type: Whether it was a browsed Web site or one to which the user was redirected
• Access Time: At what time the file was last accessed
• Modified Time: At what time the file was last changed
• Directory Name: The local directory from which the file was retrieved
• HTTP Headers: As received by the user when the Web site was first accessed
These records may be sorted in any number of ways. Sorting by URL allows the investigator to identify what files came from which source. Disparate time stamps on files from the same URL indicates that the user repeatedly visited that site—useful in refuting an argument that the user was directed there by malware and did not intend to go there. Sorting by access time allows the investigator to prepare a timeline of the user’s activities. If it is necessary to identify specific types of files that were collected, a sort by file name will be useful.
Analyzing Browser History
The goal of the forensic investigator is to support or disprove the hypothesis that someone is either innocent or guilty of the crime for which they have been accused. Simply finding contraband on a computer is not always sufficient evidence to convict someone of a crime. Let us consider a hypothetical case involving illegally downloaded music. In this situation, the prosecutor needs to be able to prove several things:
• The defendant had knowledge of possession of illegal materials (contraband).
• The defendant took specific actions in order to obtain the contraband.
• The defendant had control over the contraband.
• If deleted, the defendant took active measures to destroy the actual materials and/or evidence that such materials once existed.
• There was sufficient quantity of contraband to justify prosecution.
It is not the job of the investigator to prosecute or defend the case. Therefore, this discussion will not explore the legal issues surrounding how each of the above points is defined. The investigator’s job is to provide the information the prosecution—or defense, if that is the side being examined—will use in preparing an argument.
Note
For the purposes of this discussion, consider executive management to be the prosecutor in regards to an internal investigation.
Establishing Knowledge of Possession
Simply having a copy of a file on a computer is not proof that the owner of the computer had knowledge of its existence. Two common defenses are these: “It was an unwanted pop-up,” and “Somebody else was on my machine.” Two approaches can be made to demonstrate knowledge of possession. The present possession concept states that since the object is currently in the suspect’s possession, that person must know it is there. Therefore, under this precept, simply finding a cached image of the file on the computer’s hard disk is not necessarily proof of knowledge.
Many users have no idea that Internet data is stored on their computer. The idea that the user doesn’t know about cache can be refuted if that person admits to having cleared the browser cache in the past. If the investigator can find evidence that the user has cleared the cache in the past, this defense is refuted. The presence, or the evidence of past presence in any directory other than the default directories used by the browser, is strong evidence that the file was intentionally saved to that location.
Evidence of deleted files has been accepted as evidence that the user knew of the material’s existence. In The United States v. Tucker (2001), the defendant claimed that he had no knowledge of possession because the computer automatically stored the images in cache without any intervention on his part. The court finding disagreed with that argument, stating in its decision that possession “is not only evidenced by his showing and manipulation of the images, but also by the telling fact that he took the time to delete the image links from his computer cache file.” This demonstrated knowledge of existence and the ability to control the image.
Tools such as Directory Snoop can locate the Master File Table (MFT) entries in the file system metadata long after the file itself has been wiped or overwritten (see Figure 11.4). This concept falls short, however, when the files are deleted by an automatic process such as the IE function that automatically clears cache at predetermined intervals. In this case, intent belongs to the automated process. Corroborating evidence to show that the file was deleted in some other fashion might be needed by the prosecutor. A comparison of the create dates and the delete dates on many of the images in Figure 11.4 shows that the file was deleted on the same day as it was created. If the browser is only configured to flush the cache every several days, this is evidence of intentional deletion. Unfortunately, it is not much help if the default browser is set to clear the cache upon closing the application.
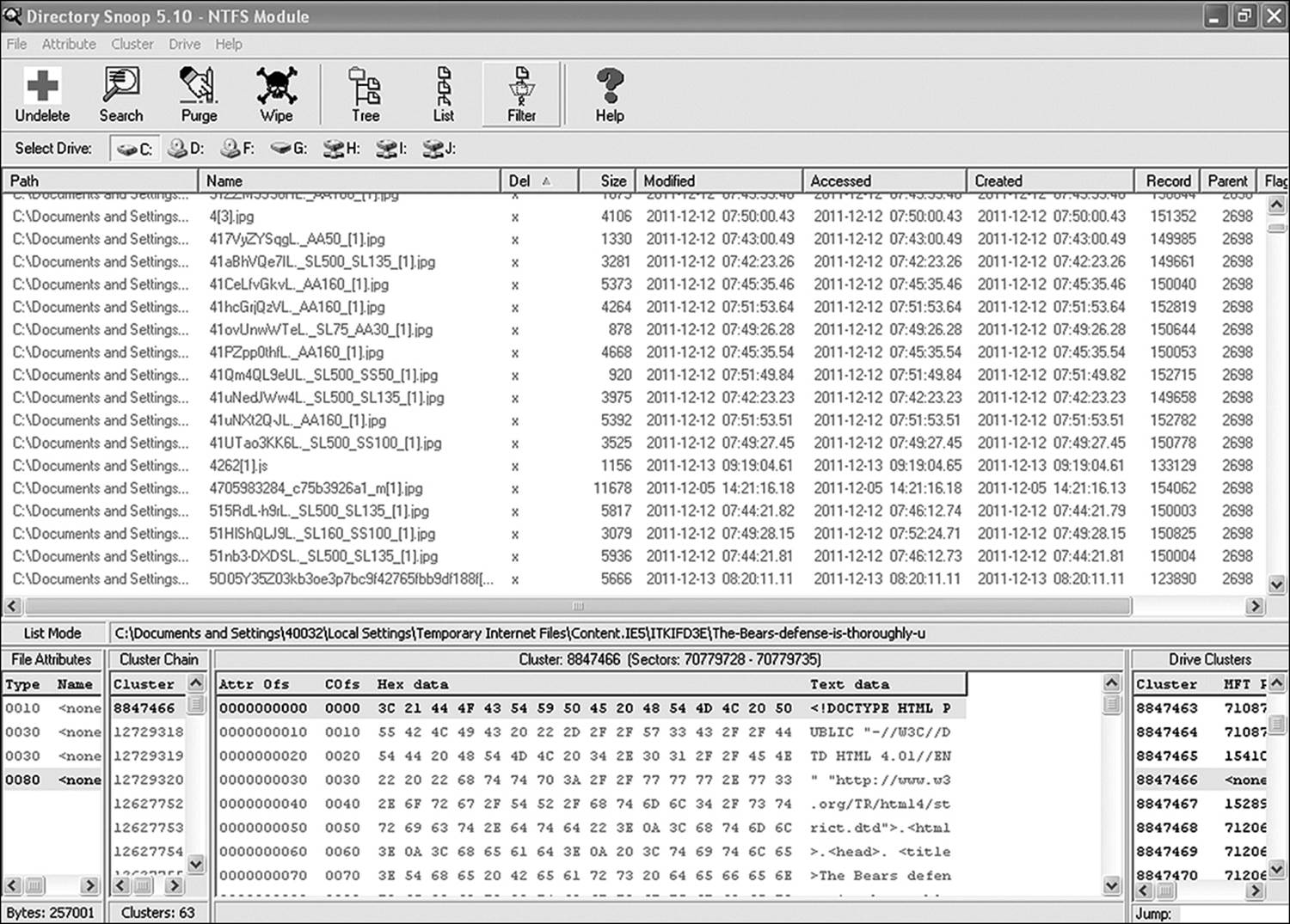
Figure 11.4 Most low-level disk editors, such as Directory Snoop, allow the investigator to view evidence of the previous existence of files long after they are gone.
The idea that another person was on the machine at the time can be a little trickier to disprove. This generally requires the collection of corroborating evidence. Log files showing that the user accessed password-protected information or Web sites are one bit of evidence that can be used. In a Windows system, the Security tab of the Event Viewer might be helpful if it contains data records for that period of time. These logs show log-on and log-off times for every individual who has accessed the computer over time. However, event logs are set to a certain size, and older data moves out as the log fills.
Establishing User Actions
The browser history goes a long way in establishing the intent of a user. It is true that many Web sites launch obnoxious pop-up windows that the user did not wish to see and had no intention of launching; however, repeated searches can reveal intent. In The State of Florida v. Casey Marie Anthony (2008), the digital investigators were able to demonstrate that Anthony had performed numerous searches for chloroform and its effects. This was in spite of the fact that Anthony had made a concerted effort to erase her browser’s history. Prosecutors used the searches as the foundation for showing premeditation in the act. While the defendant was found not guilty in this particular case, it is still a good illustration of how this type of evidence is used in real-life situations.
Web history needs to be examined carefully, with both sides of the argument carefully considered. Occasionally the most innocent of searches brings up the worst sites. And many Web sites generate income for each mouse click they draw for the client Web site (in particular, those specializing in pornographic materials). Less scrupulous Webmasters design pages that instantly generate hundreds of unsolicited pop-ups. This is often referred to as a pop-up bomb. While these are often the result of navigating to the type of Web page the prosecutor is hoping to prove, they can also be the result of a Trojan horse received through an e-mail or other innocuous source. The unsuspecting person who has this happen to them is not someone who deserves prosecution. The guilty party may use this as an argument for how an image got on his computer.
A pop-up is an example of a redirect. In other words, the user browsed to one URL but either the client or the server responds to the browser application with an HTTP 300 response. This is a message that tells the browser that the requested resource has been moved to a different location and subsequently sends the browser to the new location. Another culprit is the fast meta refresh. This is where the Web programmer puts code in the header that automatically sends a refresh command to the browser, and redirects the page to a new URL. One URL is chosen by the user, but the Web page opens one or many alternate pages the person never intended to visit.
A redirected URL of any sort will be identified as such in applications such as Web Historian (see Figure 11.5). The application extracts information from the header to accomplish this. It should be noted, however, that the fact that a page is identified as a redirect is no indication that the resultant artifact is not the result of intent. Redirects can be the result of moved Web pages. If the owners of a Web site move to a different host provider, they certainly don’t want to lose traffic because of a new URL. Therefore, they will program redirects for their old URL. Once again, the investigator is looking for corroborating evidence. Pop-up bombs will generate a burst of redirects. A long series of automatic downloads not identified as a redirect, followed by one or two redirects, is not a very strong indication of the user being victimized by a pop-up storm. Conversely, several dozen redirects in a very short period is strong evidence of such an incident.
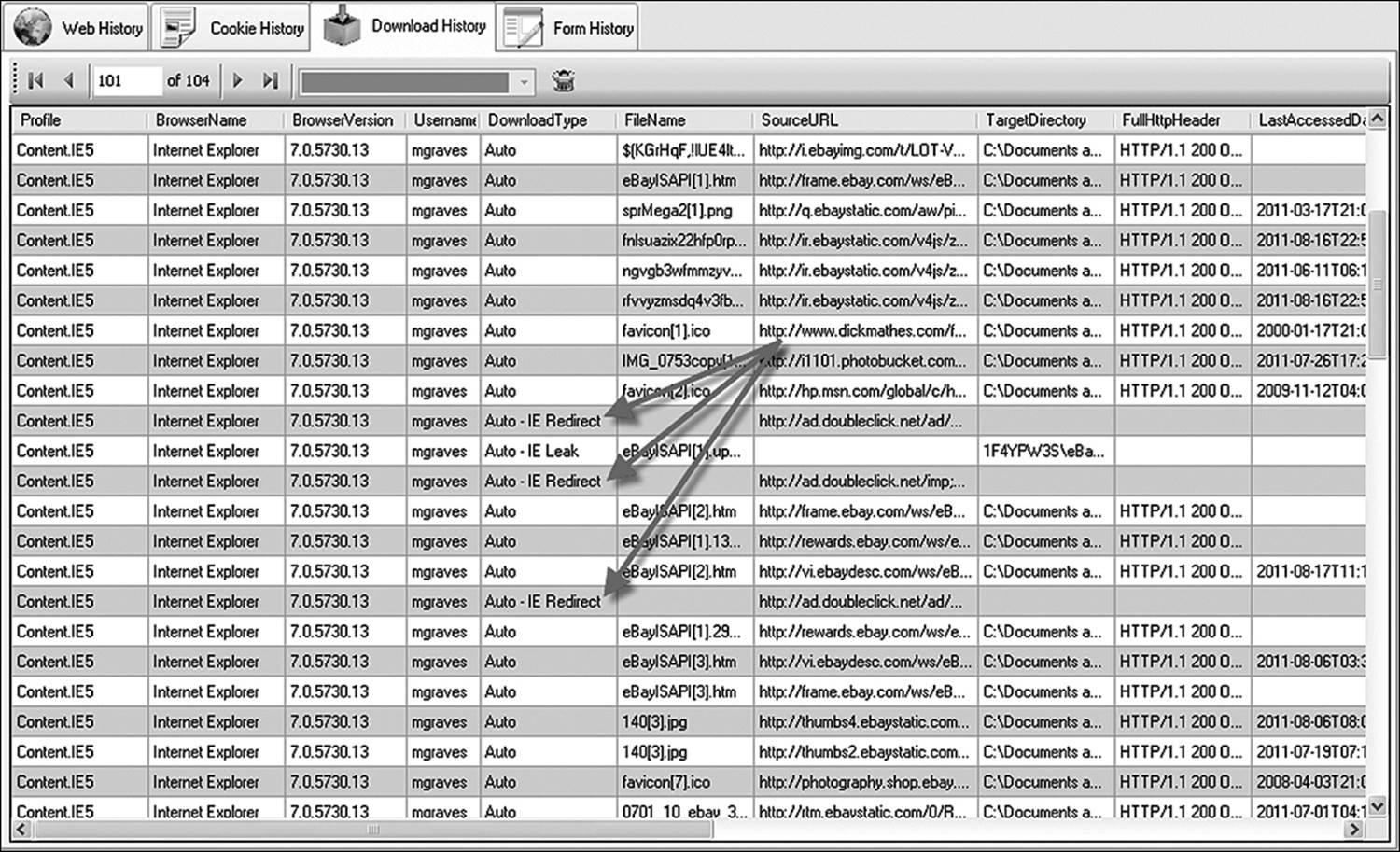
Figure 11.5 An application such as Web Historian can not only display the browser history but can also identify redirects and IE Leaks.
Another source of potential evidence on a Windows machine is the registry. One can access the Windows registry by clicking Start then Run and typing REGEDIT at the prompt. One registry entry in particular that is of some use is HKEY_CURRENT_USER\Software\Microsoft\Internet Explorer\TYPEDURLs. Another location to examine is HKEY_USERS\.Default\Software\Microsoft\Internet Explorer\TYPEDURLs. This registry entry stores values that are typed into the browser’s address window by an active user. When examining the Typed URL list in the Registry (Figure 11.6), keep two things in mind. Quite a number of these URLs can be stored, and deleting the history or the temporary files in IE does nothing to eliminate them. More importantly, a URL recorded here is a URL that was not very likely “accidentally” accessed. A key point to remember is that typed URLs may not necessarily represent the exact URL typed in by the user. If Auto-Complete is turned on, and the user starts to type a Web address, and then accepts Auto-Complete’s “suggestion” of a Web site, that site will now appear in the TYPEDURL registry entry.
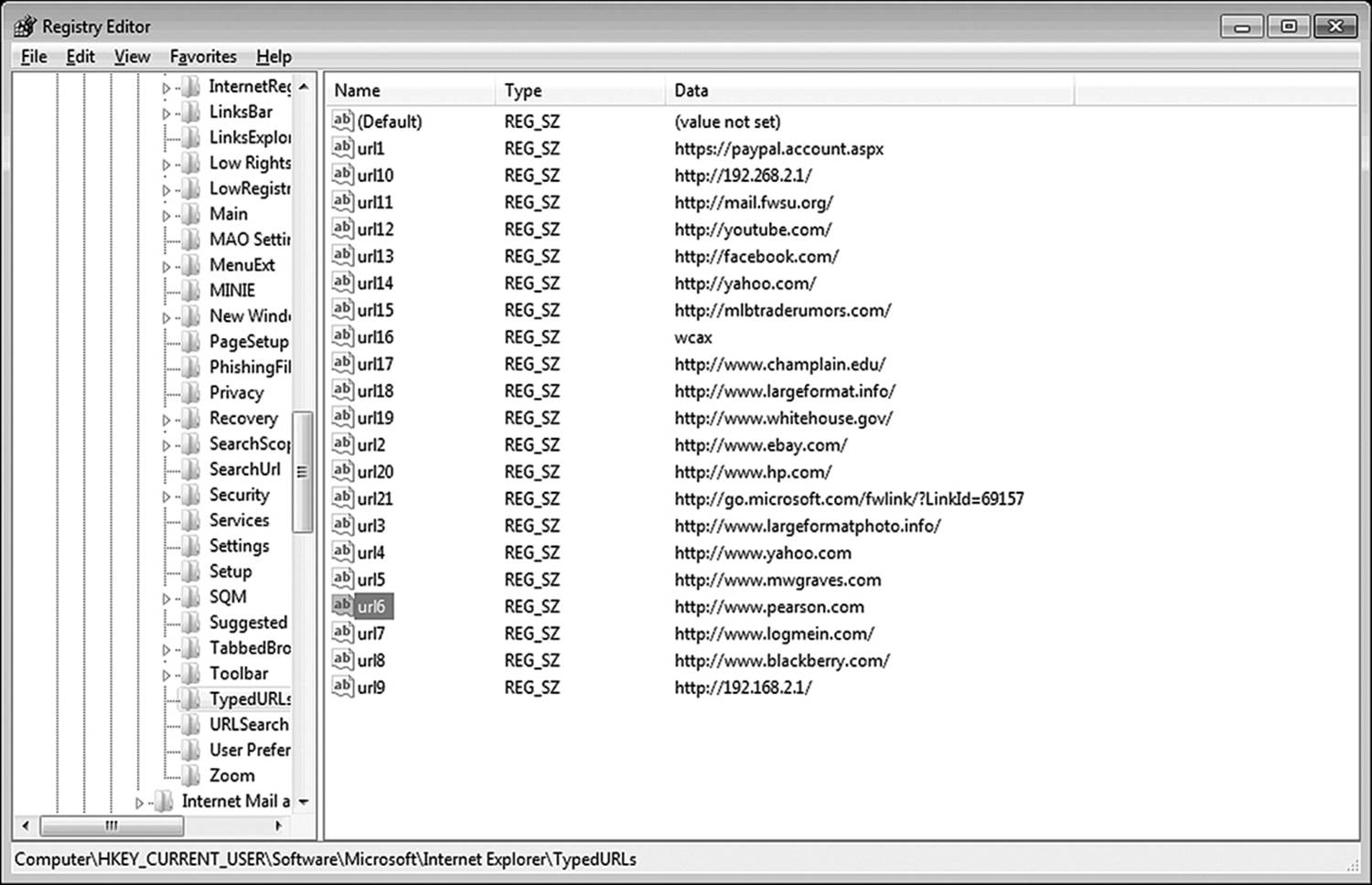
Figure 11.6 The TYPEDURL registry entry shows addresses that were accessed via the address bar of Internet Explorer.
Establishing Control of Digital Material
In the Tucker case mentioned earlier, the question arose whether the defendant had any actual control over the files found in the locations managed by the OS and by the browser. His claim was that since the browser saved files against his will, he was not responsible for their presence. The previous sections of this chapter discussed how to ascertain whether sites on a computer were intentionally accessed or were the result of redirects. Another defense frequently mounted is the “Trojan horse” defense: Malware made me do it.
If the investigator is able to demonstrate that the user intentionally navigated to a Web site that downloaded files to the hard drive, they will have a good foundation for proving both intent and control. If the contraband is stored anywhere else on the computer, such presence indicates the user actively manipulated and controlled the files.
The Trojan horse defense presupposes the existence of malware. Proving the existence of malware is easy enough. Many applications exist that will scan a computer system and report the presence of viruses, worms, and Trojan horses. Such a scan would be the first line of defense for a suspect. However, it should be noted that the presence of malware at the time of the seizure is not sufficient defense. It is essential for the defense to prove that it existed on the computer at the time the contraband materials appeared on the system.
When attempting to establish control over digital information, the investigator needs to establish the exact time the material first appeared on the computer. That would appear in the file properties as the create date. If the last access date is within a few seconds of the create date, there is strong evidence that the file was copied to the file system as part of the browser’s automated process. An access date several hours (or days) later is difficult to defend.
Determining Active Measures Were Taken
Did the user delete the browser history files, or were they deleted during an automated purge? That can be difficult to prove. Many document management solutions automatically audit file deletions and indicate what user initiated the action, along with an exact time and date. Unless specifically configured in advance, most file systems do not audit file deletion information. Therefore, it is difficult to prove the exact time at which a file disappeared from the system. Once again, the investigator needs to look for corroborative evidence.
Simply deleting a file does not wipe it. A file wipe eliminates the data from the surface of the drive. Look for the presence of file-wiping software on the system. Such software works by overwriting files with 1s, 0s, or random sequences of 1s and 0s. Files that are wiped are generally difficult, if not impossible, to recover. However, the fact that a file was wiped proves intent.
Disk editing software, such as Directory Snoop, helps to establish whether a file was wiped, rather than simply deleted. A few other indicators can show intent. In Figures 11.7 through 11.9, a file has been deleted in one instance and wiped in another. In Windows there are a couple of significant differences between the wiped file and the deleted file. A file deleted by means of Windows file system methods is moved to the Recycle Bin and continues to store data until overwritten by another file. A file wiped by a file-wiping utility remains in its original directory but no longer contains data.
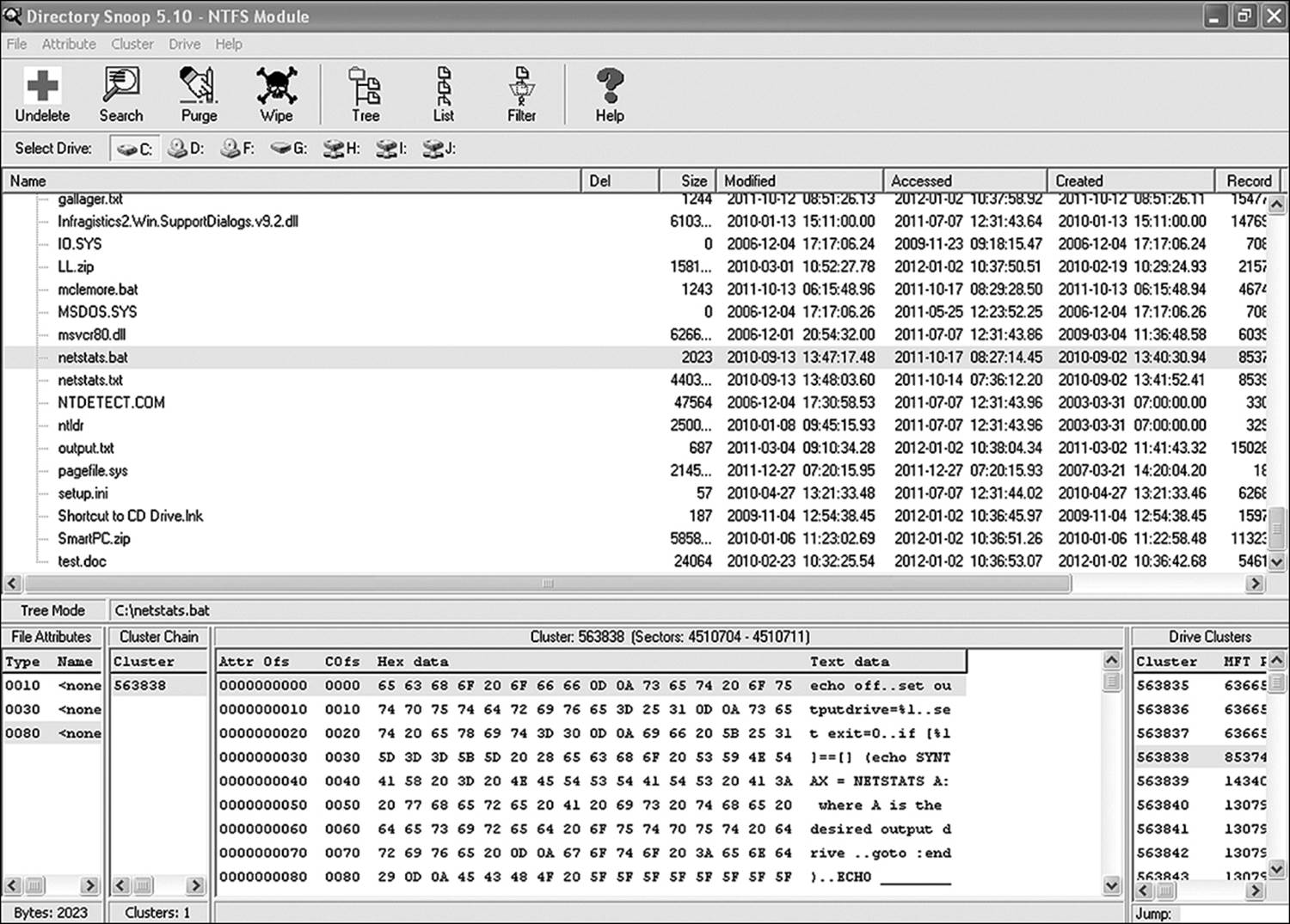
Figure 11.7 A file before deletion
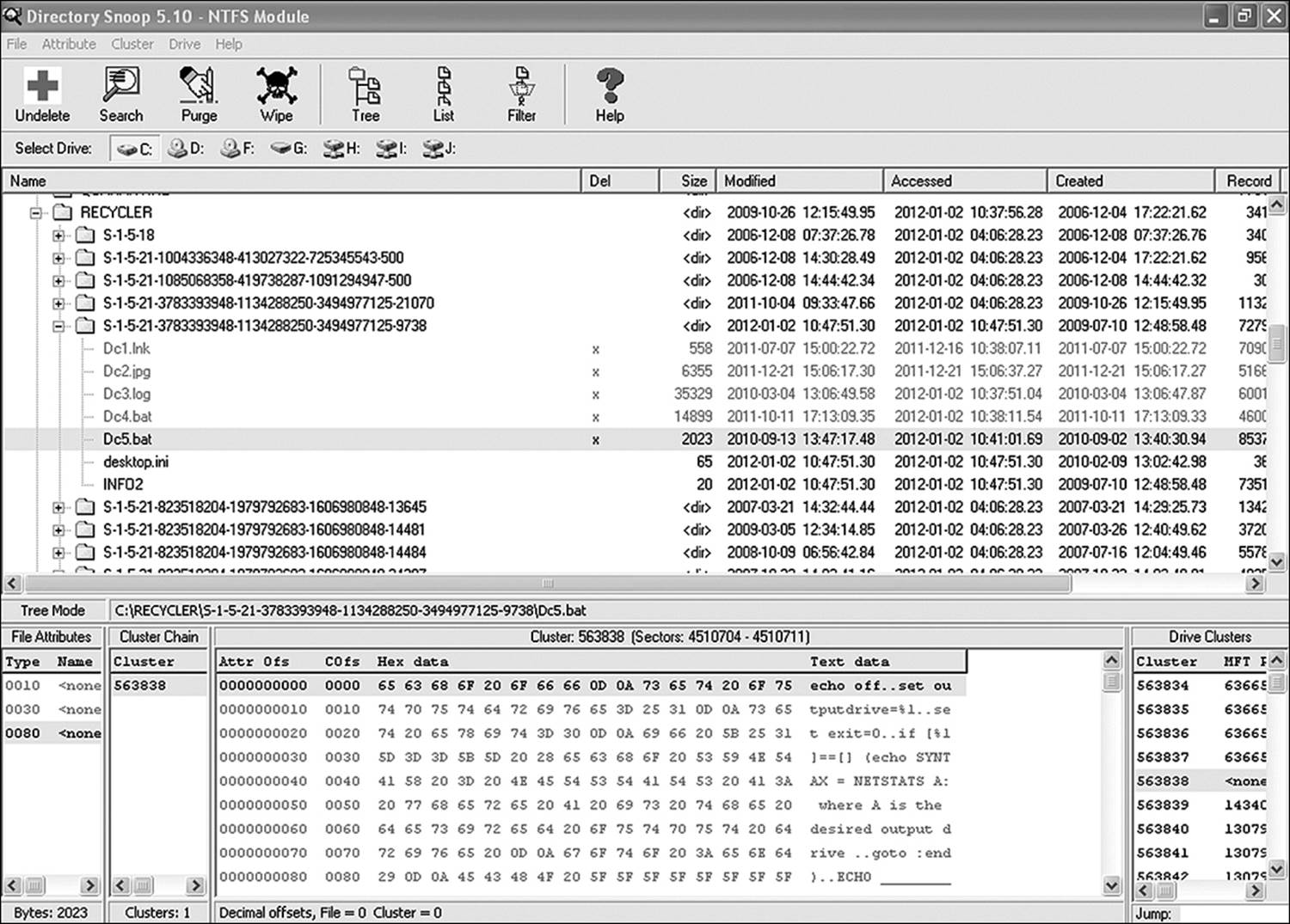
Figure 11.8 A file deleted by means of Windows file system
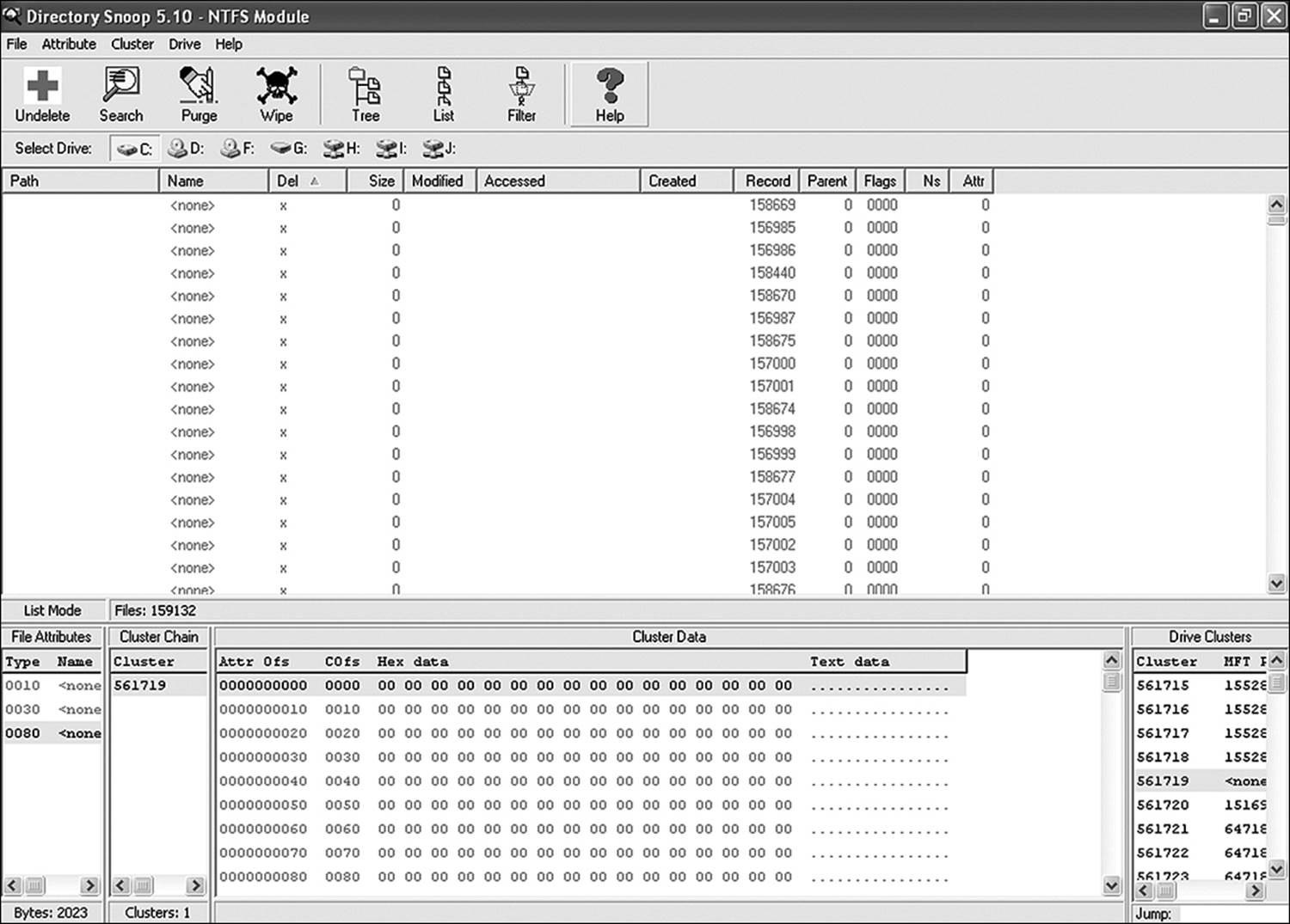
Figure 11.9 A file wiped by a file-wiping utility
The initial file was the netstats.bat file described elsewhere in this text. The original file was deleted, using Windows Explorer, and then emptied from the Recycle Bin. The file showed up in the Recycler folder as DC5.bat. Finding it was simply a matter of knowing to check for deleted files in that folder and then doing a text search for a string known to exist in the file. The deleted file was no longer found in its original directory. An investigator who does not know exactly where to look for a file can either search for a string, for a file name, or for a known hash value (if the file is from one of the national databases of known contraband files). Examining Figure 11.8 shows that the data still exists in the deleted file. A file that is partially overwritten will very likely contain data from the new file that owns the cluster, but may be able to provide evidentiary material from the slack space.
The wiped file shown in Figure 11.9 still exists in the original directory (the root directory in this example). No data remains, as the software completely overwrote the data. Note, however, that the file name remains intact. The software used to delete this file did nothing to alter the MFT metadata. Much of the freely available software used to wipe files works in this manner. More recent products, however, are not so investigator friendly. Some products wipe the metadata as well. The Purge function in Directory Snoop is an example of that. As the name implies, the utility purges the MFT record completely. Recovering the file is out of the question (by any conventional forensic tool, that is), but the fact that it was wiped is a sure sign that user action was taken on the file. Now it is up to the investigator to connect a specific user to that action. As before, that is a matter of identifying what user was logged on at the time of the action.
Determining a Sufficient Quantity of Contraband Exists
It is not the responsibility of the investigator to prove what is or is not sufficient material to justify prosecution of the case. In an internal investigation looking into employee misconduct, a single image or music file may be sufficient cause. In criminal prosecution, the investigator will simply indicate how many of what types of files were located in the suspect media. Let the prosecutor take it from there.
Tools for Browser Analysis
Most of the tasks described in the previous sections can be performed by automated tools. Some task-specific tools were mentioned in various sections. Table 11.3 lists several readily available tools for analyzing specific browsers.
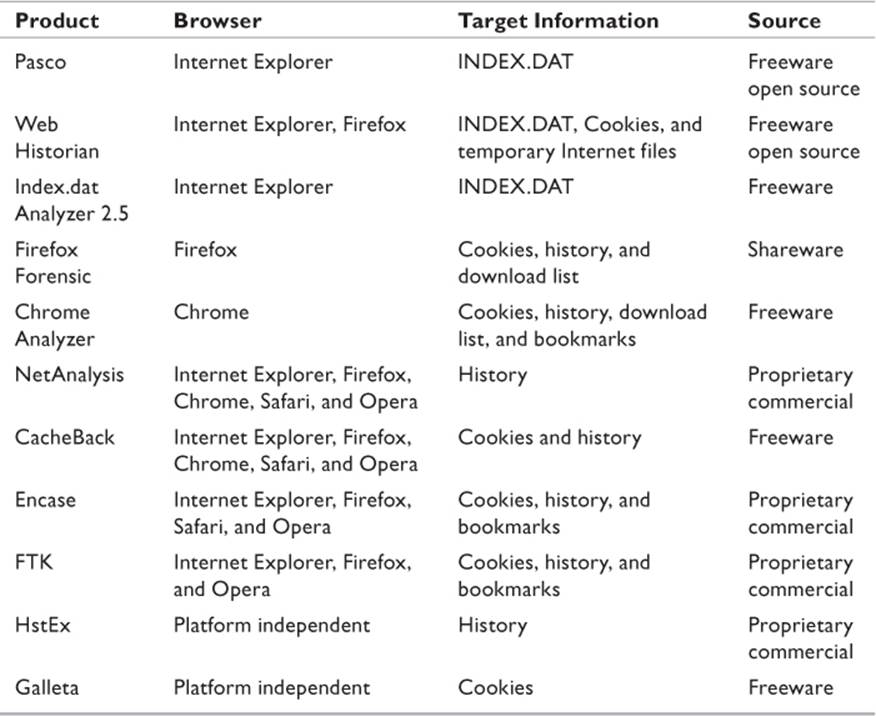
Table 11.3 Forensic Tools for Browser Analysis
Running Web Historian
Web Historian is a powerful yet free tool that provides a wealth of information about a user’s activity on the Internet. As of this writing, it is available for download at www.mandiant.com/resources/download/web-historian. Once it is installed on the investigator’s computer, history files can be imported and analyzed, or a local profile can be analyzed. If installed on the target system, it can analyze all profiles present on the system. Additionally, it can analyze local files. If an image file is mounted on the system, you can essentially treat that system as a mapped drive.
Information found is stored in XML format. Therefore, it is not only viewable in Web Historian, but can be imported into a database application or into a spreadsheet.
Before scanning a system, configure the options to clarify what it is you are examining. Click on the Settings tab, and select from one of the three options (Figure 11.10):
• Scan my local system
• Profile folder:
• History file:
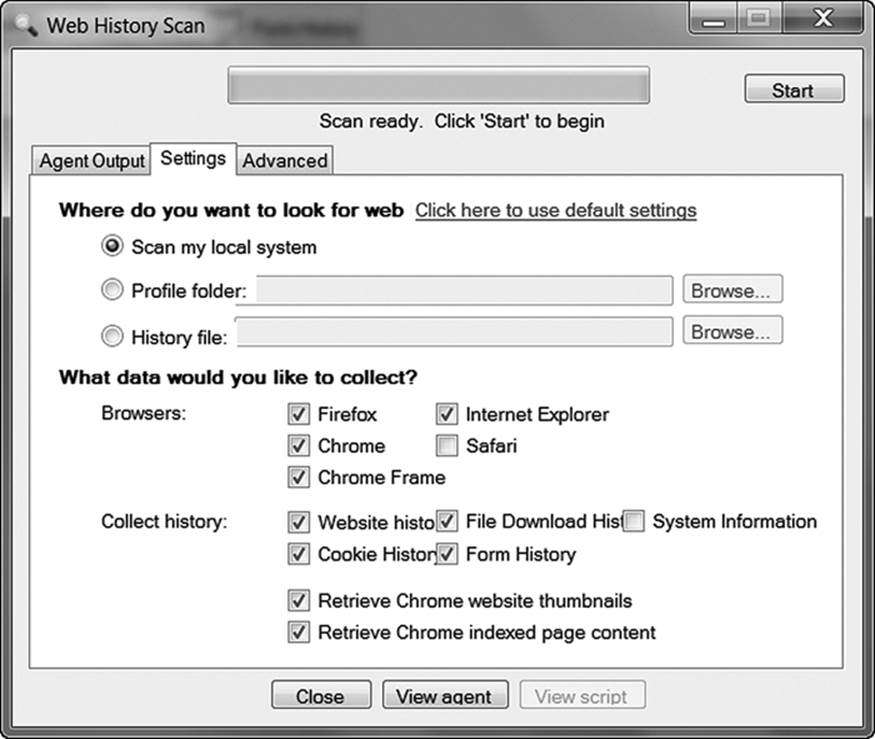
Figure 11.10 Web Historian settings
The first option will analyze every profile it finds on the system from which the executable is running. To analyze mapped drives, one of the other two options must be used. Profile folder requires that you browse to the folder where the profile is housed (which can be on the local machine or a network share). The same applies to the History file option. Then, click on the Start button in the upper right-hand corner of the screen. It can take a while to analyze a system with an extensive history, so be patient.
Once the scan is completed, the various filters configured in the application can help limit the viewable output to such records as fit into predefined parameters. In addition to the built-in filters, the application allows the user to build custom filters based on specific requirements. Some of the filter options just for Web history appear in Figure 11.11. By default, all options are selected. To narrow the search, deselect all options except for the one that interests you. For example, in a multiuser machine, it would be a good idea to sort by UserName. Or you might want to find out how many of your employees are visiting Monster.Com and submitting resumes. Filter by URL to do that.
Figure 11.11 A few of the filter options in Web Historian
Another valuable tool is the Website Profiler. Make sure the history scan has already been run and is loaded in Web Historian. Click on Tools. Website Profiler. Type in a domain name that you wish to analyze, and press Enter. The tool will tell you how many cookies have been downloaded from the site, provide a summary of all temporary files found from the site, and tell you how many users have visited it, how often it was visited, and how recently it was visited.
Web Servers
On the server side, there may be multiple searches for an investigator to perform. A complex Web site will have a Web server application such as Apache as well as one or more Web-based applications. There may be chat logs to analyze as well as authentication logs.
How a Web Server Works
When the client browser on a user’s workstation makes a request to access any resource on the Internet, it sends an HTTP request to the Internet service provider (ISP). The ISP maintains a DNS server that examines the URL, extracts the domain name out of the address, and translates it to an IP address. The ISP then forwards the request to the IP address it found. This IP address is the physical address of the server hosting the Web site. This may or may not be an individual server. Web server applications are very I/O intensive, but not so very much processor intensive. Most companies that host Web sites for small to mid-sized companies use virtual machines to host each site. One physical server might host a hundred or more individual Web sites.
Accessing a Web server for investigative purposes is a lot more complex than getting into an individual computer. For the purposes of this chapter, it is assumed that the investigator has already successfully navigated the various hoops and legal snarls and now has access to the system. At this point in time, the biggest road block will be the fact that it will in all probability not be possible to bring down the server long enough to image it. And in most cases, the “server” will consist of a cluster of multiple servers with RAID arrays for drives—or perhaps a SAN. Therefore, one of two approaches must be taken.
It may be possible to directly access the server and work directly on the system. If this is the case, The Coroner’s Toolkit—an open-source collection of forensic tools that includes a utility—can be used to analyze the data. In most cases, however, live acquisition will be the order of the day. As of this writing, very few forensic analysis tools are available to do live analysis remotely. Encase Enterprise is one tool that supports remote live analysis. From a Linux-based forensics system, PyFlag is a powerful utility that works with static images or live analysis. Lacking either capability, the investigator is likely to be reduced to acquiring the files targeted for analysis and making copies to be examined on a forensic workstation.
Server Log Files
Web servers store a significant number of files in various directories that keep track of different events that occur. These events include authentication success, authentication failure, IP addresses, connection history, and many others. Different applications use different formats for their log files. The two most popular servers are the Windows Web Server and Apache Web server systems.
Windows Log Files
Windows Web servers support the use of the following file formats (Technet 2005):
• W3C: ASCII format that allows customized properties. Time is recorded in Coordinated Universal Time (UTC), which is based on Greenwich Mean Time. Individual logged properties are separated by spaces.
• IIS: Fixed ASCII format that does not allow customization. Time is recorded as local time, based on the internal clock chip on the host device. Individual fields are comma delimited, making the file easy to export into a spreadsheet application.
• NCSA (Common Log): NCSA (National Center for Supercomputing Applications) uses a fixed ASCII format that does not allow customization. Time is recorded as local time, based on the internal clock chip on the host device. Individual fields are separated by spaces.
• IIS ODBC: ODBC (Open Database Connectivity) logging must be enabled before logs will be generated. A database must be configured to accept incoming data, and the database to be monitored must be configured. Since this function degrades server performance, it is not as frequently used.
• BIN (Centralized Binary): This method, used with IIS 5.1 and earlier, used binary data to store information and was able to log the activities of several Web sites at once.
• XML: XML (Extensible Markup Language) is a file format easily read by humans, but designed for moving data back and forth between applications.
Some specific log files to look for include
• IIS Log Files: These files are generally the most interesting to the investigator, as they contain information about all client requests against the Web server. By default, these files are located in the c:\%system%\system32\LogFiles\W3SVC1 directory. However, this location can be reconfigured by the administrator to reside anywhere on the system. The files have a conventional naming system of EXxxxxxx.log, where xxxxxx is a number generated by IIS.
• IISMSID: Logs Mobile Station Identifiers. A mobile station identifier is a number associated with a wireless service provider that identifies a particular unit on the network. This log is only present on a Microsoft Web server if the MSIDFILT or CLOGFILT functions are enabled.
• HTTPERR: HTTPERR logs record all invalid requests made to the Web server. These files are stored in the %systemroot%\System32\LogFiles\HTTPERR directory.
• URLSCAN: The URLSCAN tool is a utility that can be installed on a Microsoft Web server that allows the administrator to block specific HTTP requests. If the tool is installed on the Web server (and unless logging is disabled), a log file records all denied requests. By default the file is located in the directory %systemroot%\inetsrv\urlscan\logs.
Apache Log Files
Apache HTTP Server (currently version 2.2) uses the Common Log Format. As described above, the files are standard text files, readable in any text processing application. Fields are separated by spaces. The time is represented in local time, as reported by the device’s clock chip, with an offset recorded for GMT. Two log files are of interest to the investigator:
• Access Log: On Unix/Linux systems, this file is called access_log. The default path to this file is /var/log/httpd/access_log on most distributions. It may also be located at /var/log/Apache2/access_log. On a Windows system, look for %systemroot%\System32\LogFiles\access.log. This file records all access requests processed by the server.
• Error Log: On Unix/Linux systems, this file is called error_log. The default path to this file is /var/logs/httpd/error_log on most distributions. It may also be located at /var/logs/Apache2/error_log. On a Windows system, the file name is error.log and is located in the %systemroot%\System32\LogFiles\directory. This file records any event that the system reports as an error. Entries may describe application errors or errors encountered in processing client requests.
Other log files located on an Apache server include the httpd.pid file, which records the process ID of an HTTP process. The Script log records the results of processing CGI scripts and is generally found only on test servers. The Rewrite log is used by developers for debugging. None of these files are particularly useful to the investigator.
Parsing Log Files
Comma-delimited or XML logs can be opened in a spreadsheet application. Even though these log files are human readable, to get the most information in the least time, the forensic investigator is going to want a more specialized tool. There are a wide variety options available.
Log Parser 2.2 is a tool distributed by Microsoft that reads most log file formats. As one might imagine, it only runs on Microsoft OSs. It is a command-line utility that not only extracts IIS log files, but also works with Event Viewer logs and SQL logs. Since it is a command-line utility, it is necessary for the user to be fully familiar with command syntax and the various modifiers that dictate how the utility works. Downloading and using Visual Log Parser from Serialcoder (currently found at http://visuallogparser.codeplex.com/) will relieve much of the pain. It is a GUI for the utility that allows the investigator to configure queries from simple-to-understand menus, and outputs results to easily read tables.
AWSTATS is an open-source log file for Web servers. The user can configure reports to show unique visitor lists, the results of error logs, and numerous other pieces of critical information. It works with IISW3C, NCSA, XML, and CLF.
A tool that is not precisely a parser but is very useful in conjunction with one is Webscavator. It takes the output of any parser that can generate CSV files and can generate graphs and charts using the data. Using this tool allows a person to visualize timelines, most frequently visited sites, and more. Most importantly, it allows the investigator to generate a timeline using the data collected.
Analyzing Log Files
The server logs provide a large amount of information about any given HTTP transaction that the investigator can use in determining what happened and the order of events. While each type of Web server differs somewhat in how it records its log files, Microsoft Internet Information Service is fairly typical of most server logs. Table 11.4 lists the significant fields recorded in an IIS server log. It should be noted that since IIS uses W3C format, the content contained by the files may be customized by the Webmaster. Some of these fields may be absent.
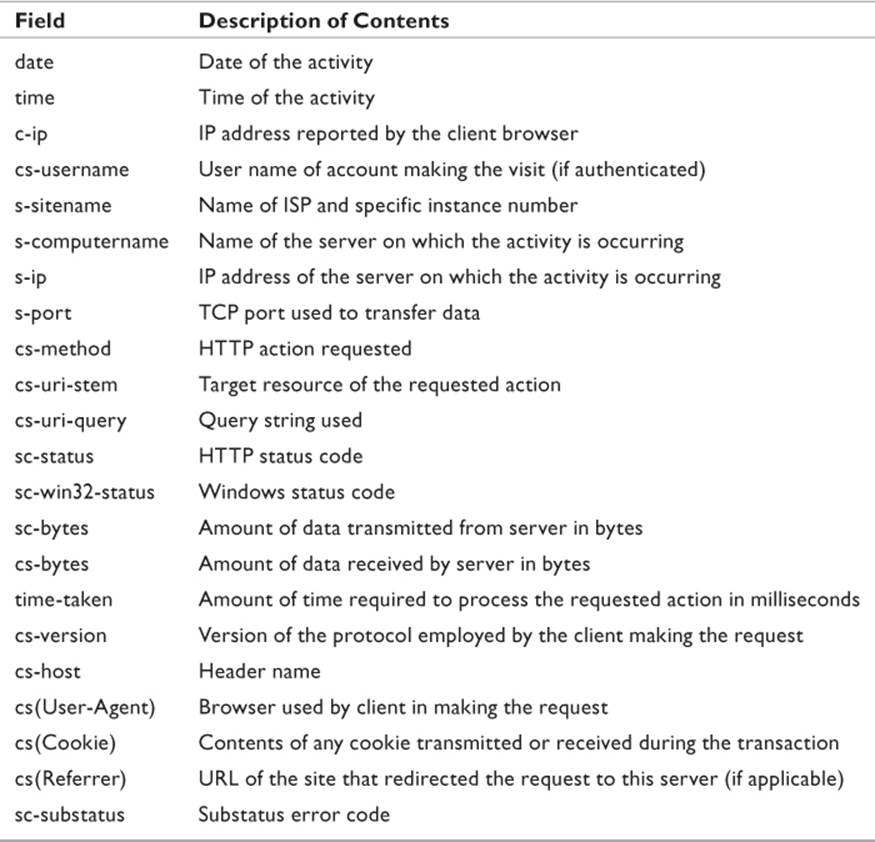
Table 11.4 W3C Extended Log File Fields
The prefix of the field name determines the direction the data travels. The letter c indicates that the action resides solely on the client, while s indicates it is an exclusive server action. The letters sc indicate server to client, while cs indicates client to server.
Logs on a server get very large and are therefore rotated frequently. A typical scenario would be that the Webmaster is rotating logs every 24 hours. The old log file is renamed, using some naming convention selected by the administrator. In Apache, the file name is typically appended with a long number that basically represents the number of seconds that have passed between January 1, 1970, UTC and the instant the log file is created. For example, a few seconds ago, I ran an Epoch time conversion utility against the current time, and it read 1325787761. Now it reads 1325787802, and so on and so forth. There is a Web site located at www.epochconverter.com/ that provides a handy Web tool that will convert those numbers into easily read time/date formats. If the investigator knows a specific time and date range for which the log files need to be analyzed, it is easy enough to use this method to narrow down the log files to those created during that time.
IIS approaches logging a little differently. The administrator can select centralized login, which allows for logging per server. With this option, a singularly large binary file is created that represents every site on the system. This may be advantageous if the Web server is internally hosted and only supports a small number of sites. ISPs will generally favor logging by site, which generates separate log files for each site hosted on the system. A commonly seen approach is to roll over log files daily. However, an enterprise site that gets a million hits a day can grow log files larger than a gigabyte before the day is through. On such servers, log rotation might be configured to roll over more frequently.
Prior to version 7.0, IIS file names were based on a base file name defined by the administrator when logging was initially configured with the time and date appended. For example, if the base file name was initially defined as IISLOGFILE, each file would be IISLOGFILE_timestamp.log. The timestamp was defined by the frequency of the rotation. A server configured to roll logs over every hour would use the syntax IISLOGFILE_yymmddhh.log. A daily log would eliminate the hh portion, while a weekly log would be IISLOG_yymmww.log. In 7.0 and later, instead of a preconfigured base file name, the first letters of the log file format are used, followed by a similarly defined timestamp. Table 11.5 shows common naming syntax for the different file formats (Microsoft 2008).

Table 11.5 File Naming Conventions for IIS 7.0 Log Files
Proxy Servers
Many larger organizations employ proxy servers to separate their internal network from the outside world. Proxy servers serve two functions. With the appropriate software installed, they can serve as firewalls, keeping the outside world from accessing the internal network. They also act as a powerful Web cache that serves all users on the network.
Just like Web servers, proxy servers maintain libraries of log files that record activity. However, the proxy server records information regarding traffic specific to the network to which it is attached. In addition to history logs and user authentication logs, proxy server logs can also provide information on how much bandwidth each user utilized. If configured to do so, it can also keep track of how much time the server spent processing requests for each user it serviced. In an internal investigation, proxy server logs can identify attempts to access forbidden or undesirable Web sites.
Proxy log files exist in a variety of formats. One format common to Web servers is the W3C log file format. Servers configured to use this format can be analyzed with the same software used to analyze IIS Web servers. Other log file formats include
• Microsoft Web Proxy Server 2.0
• Squid
• Netscape Proxy
• Proxy+
• CCProxy
• CCProxy v2010
Different proxy software builds maintain different logs. Two common approaches are those of Microsoft (IIS) and those of Novell. A third one of which investigators should be aware is Squid. IS proxies use a logging scheme similar to that of IIS Web servers, so no further discussion is required.
Novell Proxy Logs
Novell’s BorderManager is capable of maintaining three types of logs. A fully configured proxy keeps a Common Log, an Indexed Log, and an Extended Log. The Common Log provides all of the basic information needed by an investigation. However, in order to generate the most complete reports, extended or indexed logs are desirable. It is possible to configure BorderManager to run without a log, but it is unlikely that any administrator would ever do this. Additionally, the destination of log files can be modified from those described in the following sections. This might be the case in large organizations where log files are frequently rotated and archived.
Common Log Files
Common files are typically maintained in the \ETC\PROXY\LOG\HTTP\COMMON directory. The Common Log maintains the following fields:
• IP Address: The private IP address used by the machine accessing the BorderManager server.
• Authenticated User Name: User name of the individual accessing the Border-Manager server. The syntax of this entry makes use of full context (mgraves.mwgraves.com, where mgraves is the user ID and mwgraves.com is the domain). This entry is only included if authentication using the Single Sign-On (SSO) method (CLNTRUST.EXE) or Secure Socket Layer (SSL) method is configured.
• Date: The date on which the request was made.
• Time: The time (in local time) at which the request was made.
• Time Zone: The time zone configured on the server formatted as an offset from Greenwich Mean Time (for example, +0000).
• HTTP Request: HTTP code for the specific request being made in the individual transaction.
• URL: The URL of the site being accessed, including a fully qualified domain name along with the full path within the site for the file being accessed.
• HTTP Version: The version of HTTP employed by the client making the request.
• Status Code: The number that indicates the results of the client request. (See Table 11.6.)
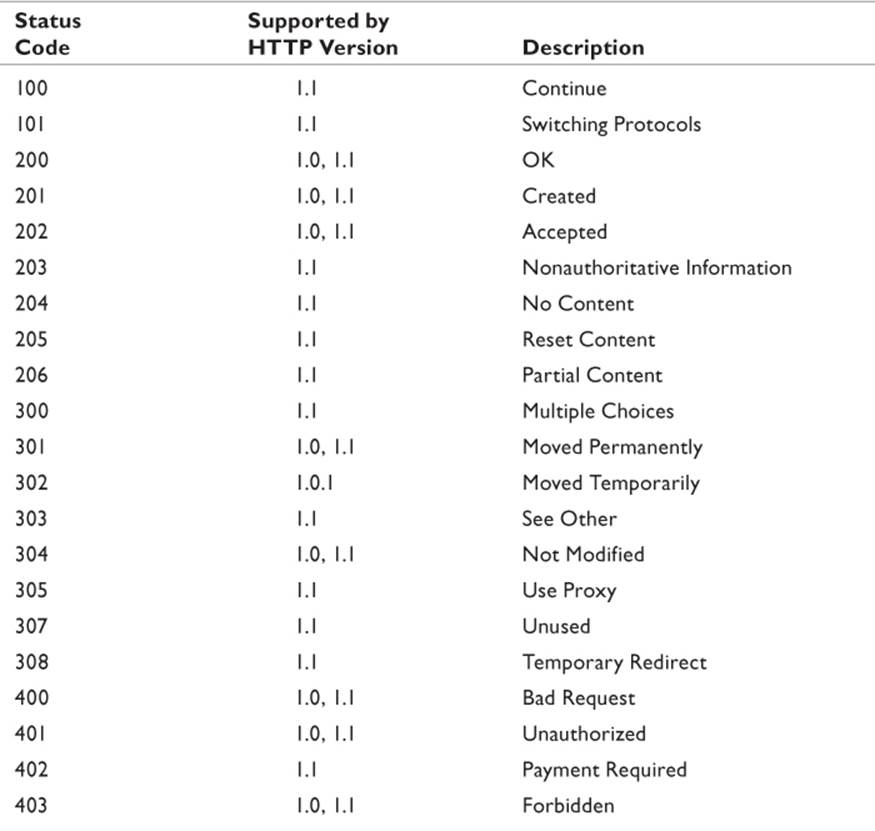

Source: Williamson 2002.
Table 11.6 HTTP Status Codes
• File Size: The size of the log file in bytes.
Extended Log Files
The Extended Log contains all of the information stored in a Common Log, plus the following additional five fields:
• Cached: Indicates whether the URL was retrieved from cache or represents dynamic content. Possible values are: cache miss, cache hit, noncachable pattern (dynamic content).
• [date-time]: The date and time of the entry in local time, including the time zone offset relative to GMT.
• c-ip: The IP address of the requesting client.
• cs-method: The HTTP request type.
• cs-uri: The URL of the site being accessed represented as a fully qualified domain, with full path to the file.
The Extended Log files are stored in \ETC\PROXY\LOG\HTTP\EXTENDED. An administrator will generally select one type of log file.
Indexed Log Files
Indexed Log files are different from Common or Extended in that they are not stored as plain text. Either of the other two files can be viewed in Notepad or a similar plain text editor in a pinch. Indexed files are generated by a database engine based on Btrieve. Specialized tools are required for viewing or analyzing these files. Four tools provided by Novell for this purpose are
• NWAdmin
• ODBC
• CSAUDIT
• BUTIL
NWAdmin can export the file into ASCII format. So if the file is to be analyzed away from the server, this tool should be utilized first. Otherwise, a third-party tool might be useful.
Squid
Squid is a Linux-based proxy server that is popular with many organizations. There are also Windows and OSX versions. The logging methodology is similar to all versions, and the following information is specific to the Linux version. Squid maintains three logs of significance:
• Cache Log (var/log/squid/cache.log): Squid stores error messages and information used for debugging in this file. This is useful for tracking failed authentication attempts.
• Configuration Log (/var/log/squid/squid.out): This file only exists when Squid is run from a built-in RunCache script. This file stores information about the Squid application and any fatal errors it has encountered.
• Access Log (/var/log/squid/access.log): This is the file most useful for forensic analysis. This contains records of all traffic back and forth between the client workstations and the Internet.
By default, Squid uses its own native format. If the administrator so desires, this can be changed to the Common Log Format.
Tools for Analyzing Proxy Logs
Common or Extended log files are based on plain text and can be viewed in a standard text editor. However, careful analysis of the files requires specialized tools. As mentioned, the Indexed file is in Btrieve format and requires conversions. Novell recommends WebTrends for this purpose (although it is also useful for a variety of other proxy servers). WebTrends reads any Novell Web server, firewall, or proxy server file and allows several layers of detailed analysis. Web activity can be divided between incoming and outgoing traffic. A standard, detailed summary report generated by the application provides information on
• General statistics
• Visited sites
• Top users
• Resources accessed
• Activity statistics
• Technical statistics
Another powerful tool, which can also be used for Web and application server analysis, is Sawmill. Sawmill can read virtually any log file format currently used. Its powerful tools include the ability to monitor multiple sites simultaneously, to generate reports on the fly from a running server, and much more. It also reports on penetration attempts and several other types of attack on the network. While not an inexpensive tool, its professional interface and results will make the investigator’s job significantly easier.
Chapter Review
1. Based on what you read in this chapter, explain why a cookie can show that a user has visited a specific site even if the browser history has been deleted.
2. Of all the information collected by a tool such as Web Historian, which field will tell you if a site popped up in a user’s browser as a result of a redirect? What are some of the other fields of a temporary Internet file that Web Historian reads and reports that are of value?
3. Explain the concept of knowledge of possession. What are a couple of techniques an investigator can employ to demonstrate that a user knew that a particular file existed on her computer?
4. What are pop-up bombs, and how can they complicate an investigation?
5. How can server log files be used to corroborate evidence found on a suspect’s computer?
Chapter Exercises
1. Download a copy of Web Historian, and run it against the Web history on a machine that has had Internet access for some time. Locate a Web site that seems to get a lot of traffic, and run Website Profiler report against it. See if you can identify a specific user who has accessed the site. How many cookies were stored on the system by the site? How many temporary Internet files?
2. Using Web Historian, put together a list of every Web site visited by a specific user.
References
ICANN. 2011. List of top level domains. http://data.iana.org/TLD/tlds-alpha-by-domain.txt (accessed December 23, 2011).
Technet. 2005. Log file formats in IIS. http://technet.microsoft.com/en-us/library/cc785886(WS.10).aspx (accessed January 3, 2011).
The State of Florida v. Casey Marie Anthony, Circuit Court, Fla. 9th Jud. Cir., Oct. 14, 2008.
The United States v. Tucker, 150 F. Supp. 2d 1263 (D. Utah 2001).
Williamson, M. 2002. Understanding Novell Border Manager’s HTTP proxy logs. http://support.novell.com/techcenter/articles/ana20020102.html (accessed January 6, 2011).