Digital Archaeology (2014)
9. Document Analysis
One of the great challenges for a digital investigator comes when the evidence is in plain sight but can’t be found—or isn’t recognized for what it is. Perhaps a file isn’t what it says it is. On the simplest level, a JPEG image file might be renamed with an AVI extension, making it appear to be a video file. More complex techniques employed by the bad guys include embedding files within files (alternate data streams) or even burying small files in the Windows Registry. This chapter covers some of these techniques and how to uncover the evidence.
File Identification
In theory, the easiest aspect of a file search is the process of identifying what kind of file it is. The Windows file systems (and less universally, other file systems as well) use the file extension as a file identifier. A file with the name of IMAGE.JPG is an image file using the Joint Photographic Expert Group file compression algorithm. Usually. However, file systems do not enforce extension rules. If a user changes the extension of a file in Windows, the only action the operating system takes is to present the warning shown in Figure 9.1.
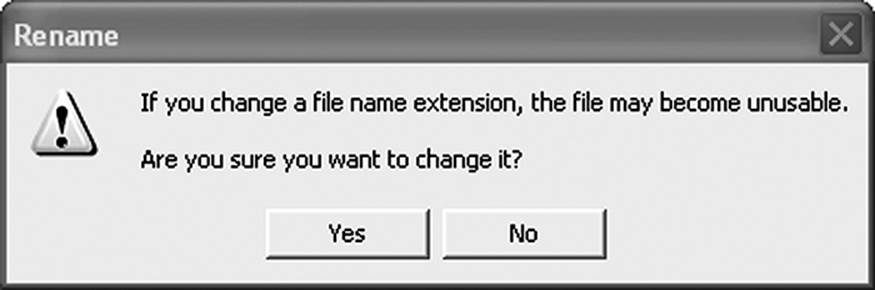
Figure 9.1 Changing a file extension in Windows only prompts a warning.
Once the extension is changed, the Windows default actions for the newly assigned extension will apply to the file. An example of a default action is the double-click of the mouse. In Windows, a double-click opens the file in the application associated with that file type. A file with a .doc extension opens in Microsoft Word. When the extension is changed, double-clicking on the file in Windows Explorer will not elicit the expected behavior. In the example shown in Figure 9.2, the file CyberControls Forensic Approach.pdf has been renamed to CyberControls Forensic Approach.tif. Double-clicking on the file in Explorer brought up the Office Picture Manager application, which could not open a PDF file. So Windows displayed a small square with a red X instead of the PDF. Right-clicking on the file and selecting Open With, and then selecting Adobe Reader opens the file correctly.
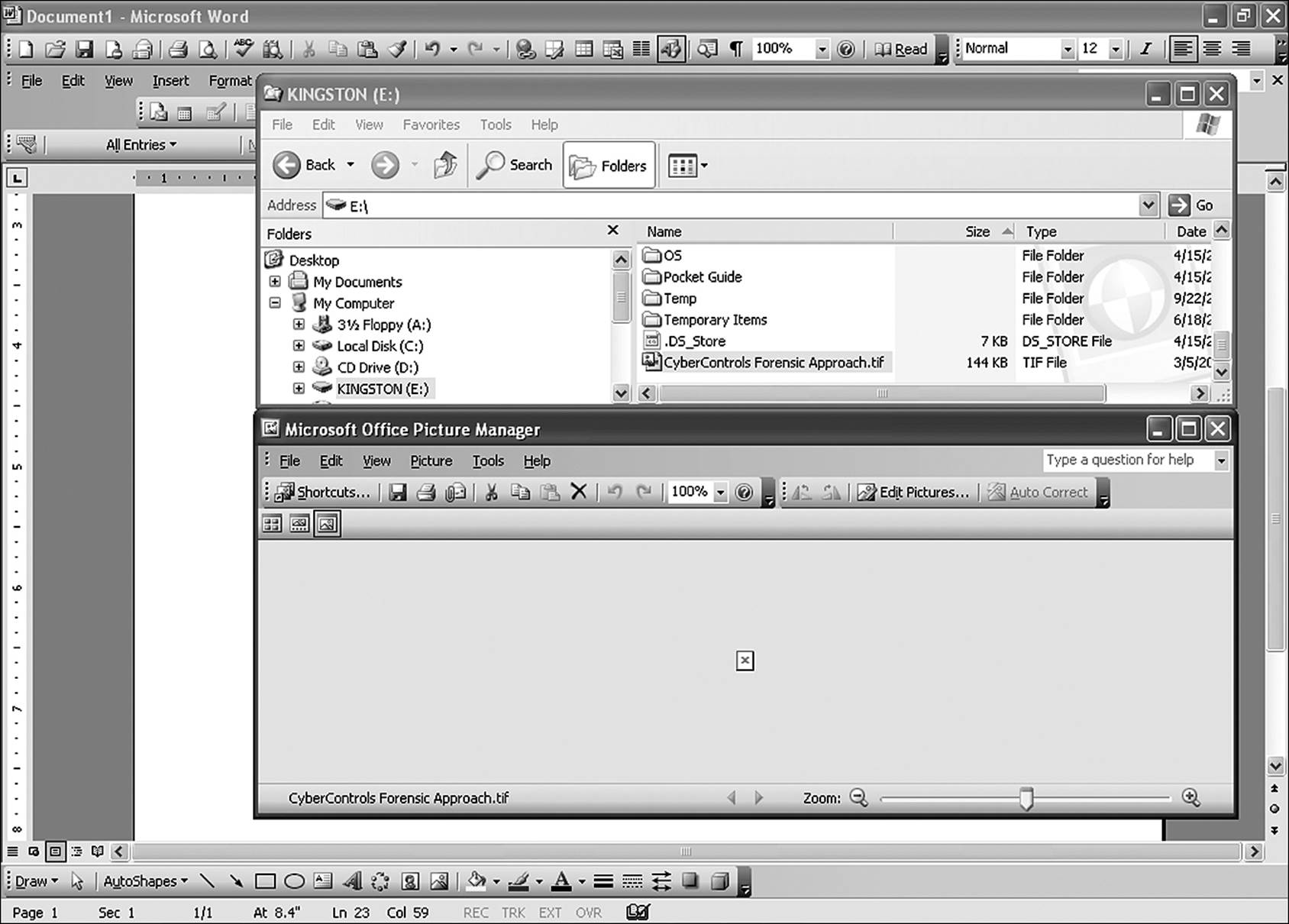
Figure 9.2 Windows default actions do not behave as expected when a file extension has been changed.
What does this little exercise imply? For one thing, it becomes clear that changing the extension does nothing to alter the structure of the file. It is doubtful anyone thought it would. Additionally, changing the extension did not affect the ability of the correct host application to open the file. Therefore, there is something else in the file structure that determines whether or not an application can open a file.
File Structure
Any file stored by any file system used by a computer must have similar structure or there can be no cross-platform compatibility. However, anyone who has experience using more than one OS knows that a Microsoft Word document can be opened with either Word for Macintosh or Word for Windows. Additionally, third-party applications such as OpenOffice have no trouble opening the files of either version of Word.
The extension, discussed briefly in the previous section, acts as a superficial identifier of file type. If unaltered, most applications have no difficulty identifying files by extension. If asked to open a file with an unfamiliar extension, the application will dig a little deeper into the file. There are several internal identifiers that files use to introduce themselves. These include file metadata and file structure.
File Metadata
Files can contain two types of metadata that applications use to recognize and open the file. Internal metadata is contained within the file and can consist of a binary string or a text string. Three commonly used metadata containers are the MFT attributes, the file header, and the magic number.
MFT Attributes
The NTFS file system used by current Windows OSs places certain information concerning the file into the metadata files. Chapter 8, “Finding Lost Files,” contains a table of the metadata files used by NTFS, along with a description of each file. The metadata files are created when the disk is first formatted to NTFS. After that, every file copied to the drive owns at least one MFT record. MFT records contain certain attributes that define the entry to the OS. Table 9.1 lists the MFT attributes used by NTFS, along with the hexadecimal value assigned to each attribute.

Table 9.1 NTFS Attributes
The reason for understanding the various attributes is that some of the utilities used key on those attributes when they search for file data. An important aspect to remember is that file content is considered an attribute of the file. It is the data attribute and carries the hex value of 0x80. This value is useful to utilities such as Directory Snoop in that it allows the application to identify the part of the file that is specifically user data. Figure 9.3 illustrates how Directory Snoop reads the file attribute types.
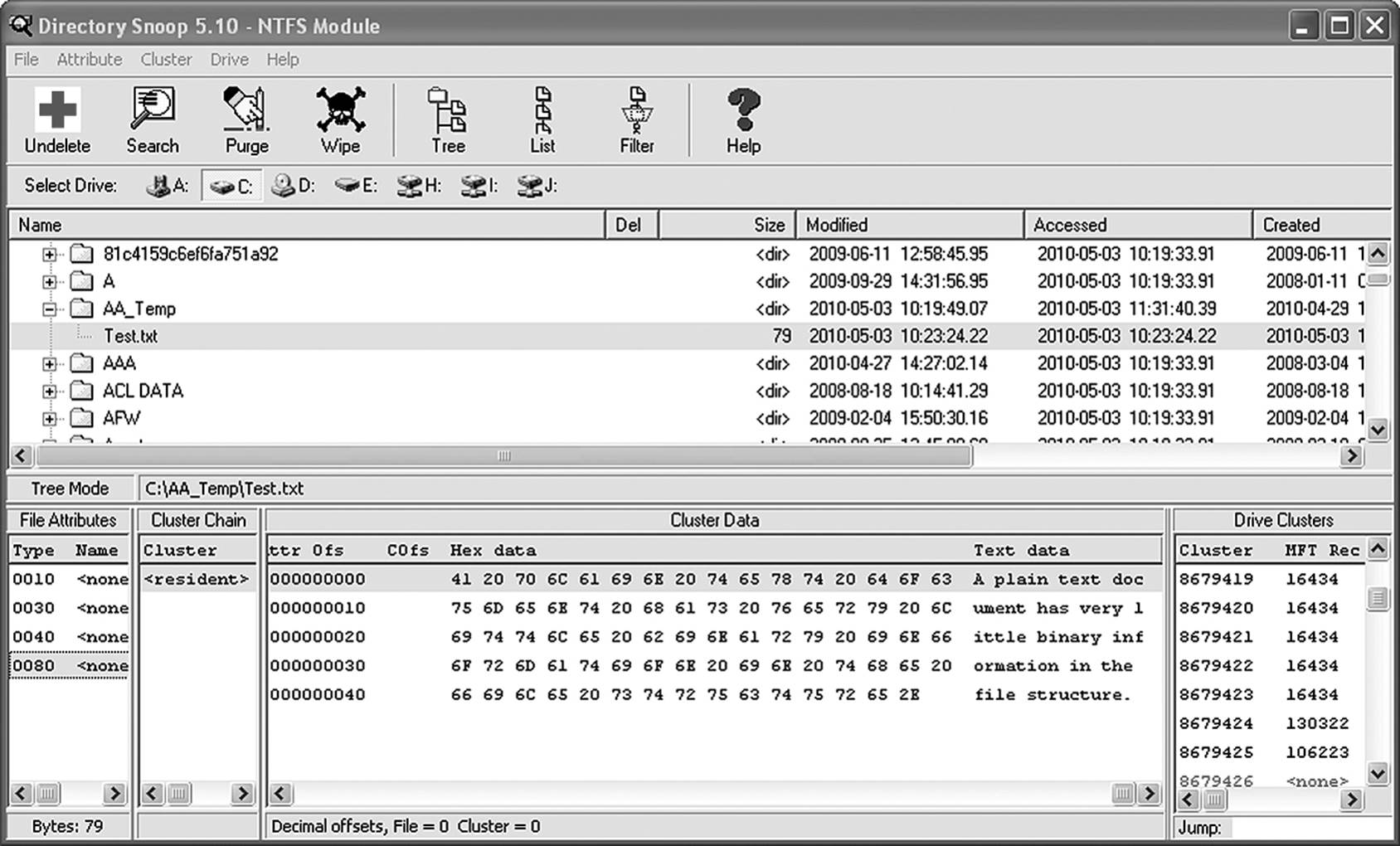
Figure 9.3 Not all files contain internal metadata.
Additionally, MFT records can be examined to see if a file that no longer exists perhaps once did. While the Windows metafiles are not directly viewable by most applications, a disk editor such as Directory Snoop allows this task to be accomplished. In Figure 9.4, we see the entry for a file called redstateicon.png. The file no longer exists on my hard disk, but a string search of the $MFT metafile in Directory Snoop found this record. While most of the information is gibberish to the average person, directory Snoop does tell us the file name and what application is the default program to open the file. Additionally, it tells us what the legacy MS-DOS file name is as well.

Figure 9.4 This Notepad file is cut and pasted from a copy of the MFT record found in the NTFS $MFT metafile.
File Header
File headers get their name as a result of being the first string of data read by the file as it loads. In Chapter 8, I discussed the concept of file headers and EOF markers. Applications read these bytes when first asked to load the file. If the header does not correspond to the file type identified, the application may have difficulty loading the file. To the digital investigator, the header also provides the starting point for carving files out of slack space or unallocated space on storage media. Table 9.2 lists a few examples of some common file types, their extension, header, and, where applicable, EOF marker. It is a very small sample—to attempt including every file type would fill an entire book.
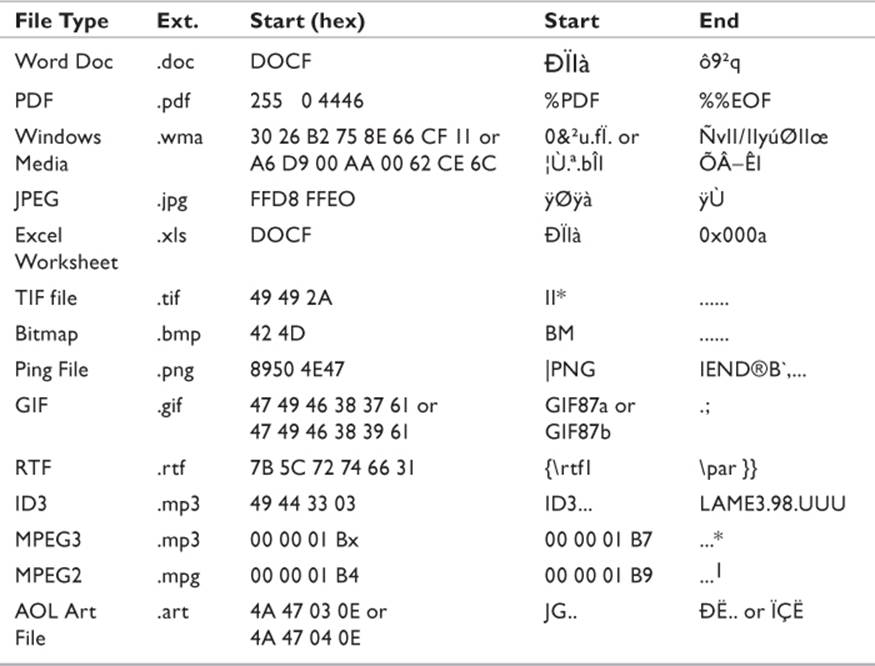
Table 9.2 Sample File Structure and Metadata
A general rule of thumb (not universally applied by all developers) is that a humanly readable file has humanly readable headers and EOF markers. A binary file has binary metadata. Notice in Table 9.2 that the PDF file has plain text metadata. An ASCII text file has no internal metadata, as seen in the Directory Snoop screenshot in Figure 9.3.
Magic Numbers
Magic numbers are really nothing more than another method of structuring a header. Files incorporating magic numbers embed a file signature consisting of hexadecimal code into the first few bytes of the file to identify the file type. The term is derived from the Linux and UNIX (*nix) file system. The Linux Information Project (LIP 2006) defines the magic number as occupying the first six bytes of the file. Many programs use the magic number as the first step in identifying a file type. However, as with the file header, there are certain files, such as ASCII text files, HTML, and source code cabinets, that do not incorporate magic numbers.
Identifying a file by the magic number method does incorporate a small degree of latency (additional processing overhead required by an application to perform a specific set of tasks). Most Linux builds have defined lists of magic numbers in various directories. Among these are (Darwin 1999)
• /usr/share/file/magic.mgc—Compiled list of magic numbers
• /usr/share/file/magic—Default list of magic numbers
• /usr/share/file/magic.mime.mgc—Default compiled list that will display mime types when the -i trigger is used
• /usr/share/file/magic.mime—Default list that will display mime types when the -i trigger is used
In Linux, the file(1) command can be used to identify a file by its type. One of the command’s first tests is to attempt to read a magic number and compare the number it finds to one or more of the magic number lists above. The digital forensic examiner can use a disk editor to view a file and examine the magic number directly in an effort to identify the file type.
Understanding Metadata
The word metadata gets thrown around a lot and is used in more than one context. Earlier in this book, a loose definition of metadata was presented that simply defined it as data that describes data. However, metadata can exist in multiple forms. The operating system maintains information about files in various repositories. As discussed in the previous chapter, the NTFS file system makes use of a series of metadata files. Individual files can also contain information stored within the file that defines the file. Additionally, many applications, such as document management systems, maintain separate files containing metadata. All of these sources can be a gold mine of information for an investigator. Aguilar v. Immigration and Customs Enforcement (2008) determined that the three types of metadata relevant to digital evidence include
• System metadata—Information generated by the file system or document management system
• Substantive metadata—Information that defines modifications to a document
• Embedded metadata—Information embedded by the application that creates or edits the file
Substantive metadata can fall within either of the other categories. Another form of metadata that exists that is important to the investigator is external metadata. Many document and image management software solutions maintain large amounts of information in the form of a database. Indexing, file modification, tracking, and auditing information is stored in separate files maintained by the application. Each of these types of metadata will be discussed over the next few pages.
System Metadata
Chapter 8 introduced the concept of metadata usage by the OS. All file systems maintain vast amounts of information about the files and directories stored on the volumes they control. The fact is—the file system is the metadata that the operating system uses to manage files on the various media it controls. To be certain, there are physical aspects of the file system, such as the mapping of file allocation units on the drive itself, but that mapping is meaningless without the directions that tell the OS or the applications how to get there from here.
It isn’t just hard disks that have volumes of metadata. CD-ROMs, DVDs, and even thumb drives need some form of file table that informs the system how and where files are store. Every computer running needs to be able to mount multiple file systems. The hard disk uses its system. As mentioned in the previous chapter, Linux systems might be formatted with the Ext2, Ext3, or Ext4 or perhaps the Reiser file system. Windows typically uses NTFS, although some legacy systems may use one of the several versions of FAT. Even an NTFS-based computer needs to be able to read FAT if that is how a USB flash drive was formatted. And in order to read CD-ROMs or DVDs, the ISO-9660 or the ECMA-167 file system must be mounted. Understanding how these files systems work is far beyond the scope of this book. However, a brief overview of how and where the system metadata is stored is essential for the digital investigator.
Value of OS Metadata
The useful aspect of OS metadata in the process of digital investigation is the ability to prove the existence of a deleted document and to research the timeline of a document. OS metadata does not help identify contents of files, aside from file type. A critical piece of information found here is the modify/access/create (MAC) data. Disks formatted with NTFS offer the additional attribute of entry modified (EM). EM notes the last time the MFT entry in the NTFS metafiles was modified. MAC information is valuable for creating a time line of events, as long as care is taken in analyzing and interpreting the data. It is important that the tools used by a forensic investigator are tested and verified to not alter MAC data.
All files stored on any file system are stamped with the time and date they were created, the last time they were accessed, and the last time they were modified. MAC data is easily viewed using a wide variety of commercial and shareware utilities. Figure 9.5 shows an example. Used in conjunction with other information found on the computer, it might be possible to identify what user was the last to access or modify a file and perhaps even who created it. A short discussion about each of the MAC attributes is in order here.
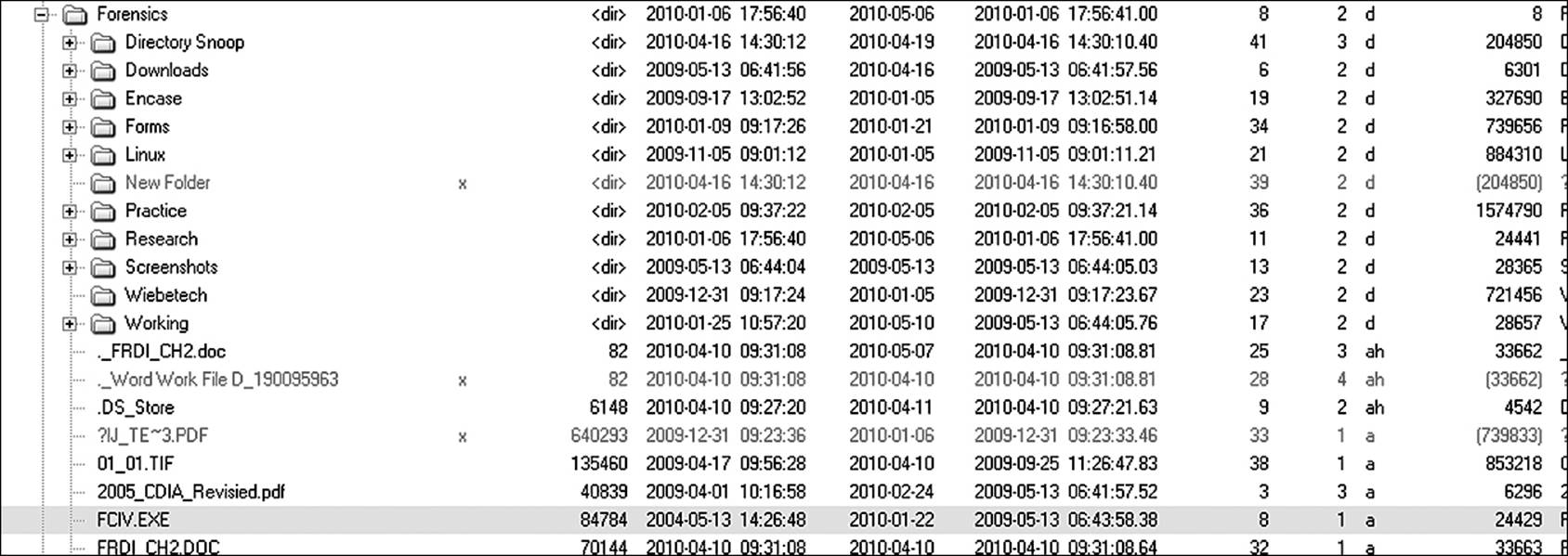
Figure 9.5 Several readily available utilities allow the user to view the currently active MAC data for a file.
Create
The create attribute on a file is generated the first time that the file is saved to the file system. Note that it is not necessarily the date that the file was originally saved. How can this be? Two things commonly affect the create date. If a user copies a file from one location to another, even though the two files are identical, each will have a different create date. The source file will show the date it was initially saved to that disk, while the new copy will have a create attribute that shows the time and date that it was first saved to the target drive.
The other way that create-attribute time stamps are modified is through a file system utility that allows a user to intentionally modify the attribute. There are several commercial and shareware applications that allow this. Therefore, by itself the create attribute doesn’t prove much of anything. It serves only as supplemental evidence to support other findings. Most applications that are used to generate files also embed creation metadata within the file. If a comparison of the two values shows a difference, there is sufficient cause for the investigator to look more deeply.
Access
The access attribute is the most volatile attribute of a file. Any time any user views, opens, copies, or backs up a file, this attribute is modified by the file system. Each time an executable is run, its access time is modified. Even the activity of antivirus scanning software has been known to alter the access time stamp. In fact, merely right-clicking on a file in Explorer and selecting Properties alters the access time stamp. There is no way for the investigator to accurately ascertain what action was invoked upon the file—only that one of them was. Many applications provide far more detail in their metadata concerning access information. For example, using the proper utilities, it is possible to identify the previous ten times that a document was accessed.
Modify
The modify time stamp is arguably the most valuable of the time/date attributes contained within a file. This information tells when the contents of the file were last altered. Any change to the file content sufficient to alter its hash value (which is virtually any change at all) is sufficient to reset this value. Actions that change the access and create attributes do not impact modify times. The act of moving or copying a file has no impact. These actions, however, will likely impact the attributes of the folder containing the files. For example, if a user copies NOVEL.DOC from C:\Documents to C:\User\Documents, the attributes of NOVEL.DOC will change as follows:
• SOURCE FILE ENTITY — C:\Documents\NOVEL.DOC—Create time remains the same, access time is reset, modify time remains the same.
• SOURCE FILE CONTAINER — C:\Documents—Create time remains the same, access time is reset, modify time remains the same.
• DESTINATION FILE ENTITY — C:\User\Documents\NOVEL.DOC—Create time is reset, access time is reset, modify time remains the same.
• DESTINATION FILE CONTAINER — C:\User\Documents—Create time remains the same, access time is reset, modify time is reset.
Entry Modified
The entry modified attribute (unique to NTFS) is modified each time any of the other three attributes is changed for any reason. It basically says that something in the metadata that comprises the MFT entry for the file has changes. There is no indication of which attribute changed. By itself, this tells the investigator little, if anything. However, it does suggest that further examination is in order.
The MAC time stamps can all be easily viewed in Windows Explorer or in one of the Linux File browsers. Figure 9.6 shows these attributes displayed in the file properties of a file stored on a Windows machine. (The problem with this approach is that merely viewing the file alters the accessed time stamp and is not acceptable procedure in the investigative process.) The entry modified attribute is not so easily viewed.
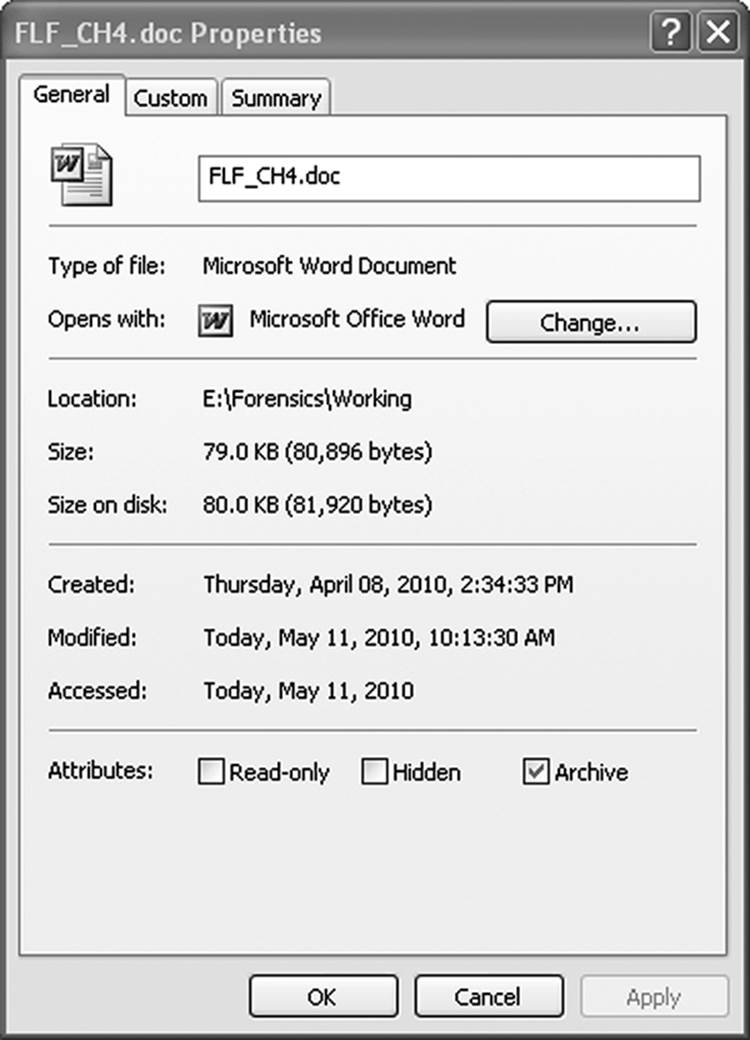
Figure 9.6 Windows Explorer is capable of displaying the Created, Accessed, and Modified file attributes.
Using MAC
One of the first things an investigator does when approaching a new inquiry is to ask “Who did what, and when did they do it?” The who part is usually the more difficult question to answer, although the when can usually be narrowed down to a relatively narrow time frame. Once a specific time has been identified, it might be possible to identify the users who had access to the data or to begin the search for who might have gained access from beyond the network. Many applications feature filtering functions that assist in this task. Figure 9.7 illustrates a simple filter (a function of Directory Snoop) to locate all document files that were modified on a specific date. Figure 9.8 shows the results of that filter.
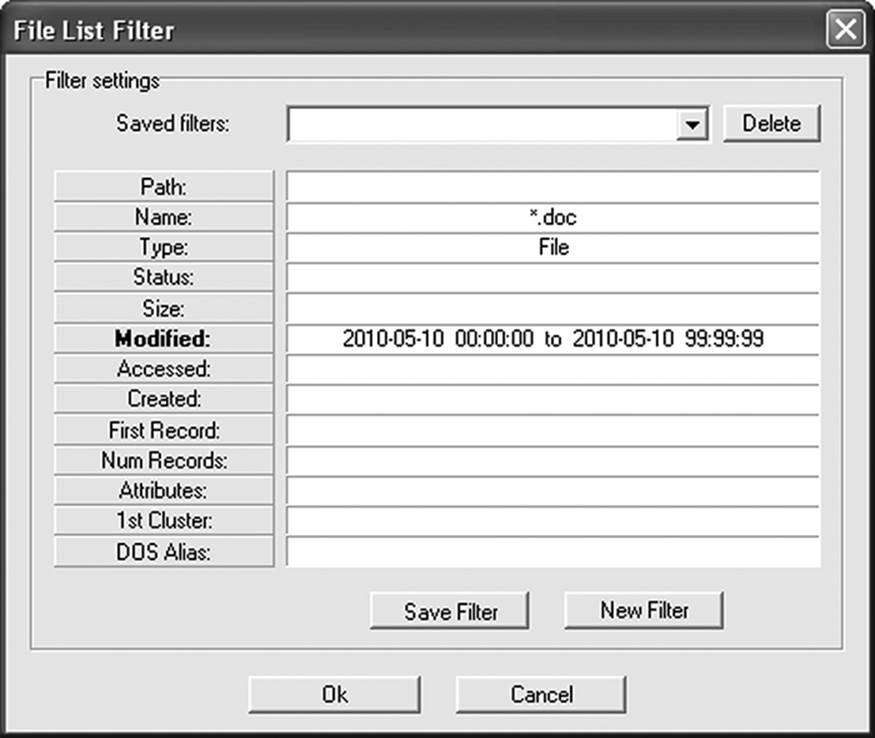
Figure 9.7 A simple filter to search for files modified on a certain date
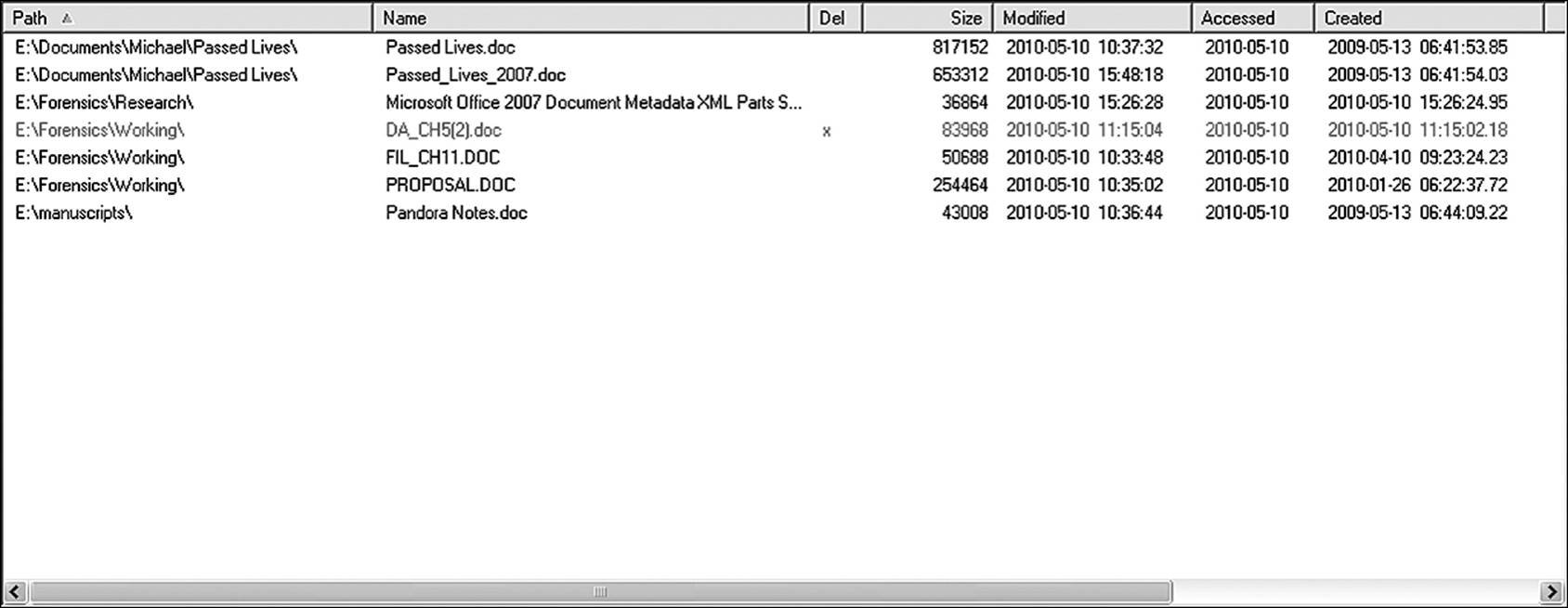
Figure 9.8 The results of the filter illustrated in Figure 9.7
Obviously, a typical investigation will involve many different file types and events. Commercial forensic software often features a timeline functionality that allows multiple queries to be processed simultaneously. Once a time frame has been identified, the investigator may want to identify all files created or modified during that window. Perhaps it is important to know that a specific application ran during that time period.
The Sleuth Kit, an open-source application running on the Linux platform, can generate timelines on virtually any file system. With The Sleuth Kit, the process consists of two parts. The fls utility collects the temporal data associated with each file on the system and collects it into a single file, called the body file. This is basically just a pipe-delimited ASCII text file that contains one line for each file, listing MAC data. (Pipe-delimited simply means that the file is a text file holding records, and each record is separated by the pipe character—the one that shares the backslash key over the right Enter key.) Once the body file has been built, the MACtime program can be used to build a timeline based on parameters selected by the investigator. The Sleuth Kit includes the ability to build the timelines as do all commercial forensic suites.
Keep in mind that the full timeline of a case is produced from more than simply file access or creation times. A full timeline includes data extracted from
• MAC data
• System logs
• Event logs
• E-mails
• Internet history
• File metadata
Analysis of these items is covered in other parts of this book. Too much reliance on file system metadata can be dangerous, since antiforensic utilities allow knowledgeable users to alter that data to read whatever they want it to.
Document Management Systems
Departmental or enterprise document management (DM) systems generate large amounts of metadata that gets stored in separate files maintained by the application. While the overall process of document management is beyond the scope of this book, it is important to understand that when such a system is in place, information that can be critical to an investigation or inquiry can be found in places other than the file system or from within the file.
Different developers approach document management in a variety of ways. Therefore, it is not possible to review every possible configuration or option; there are some generalities that are common between most products. Virtually all of them offer version control, check-in/check-out functionality, auditing, and history tracking. The actual documents are stored as files in an archive. The document archive may be called an archive, or it may be a cabinet, a repository, or a directory. It is not uncommon for an archive containing hundreds or even thousands of documents to exist as a single file managed by a database, such as Oracle or SQL Server.
The typical document management solution is client/server based. A common configuration is to have a database server handle the functions of security and indexing, and a dedicated storage device such as a Storage Area Network (SAN) or Network Attached Storage (NAS) head to warehouse the data. The files are not necessarily of the same type. A DM solution might host PDF files, TIFF files, document files, spreadsheets, and multimedia files—all in the same cabinet. The application can be programmed to automatically perform automatic document retention/destruction policies. For example, if a loan application is intended to be kept for seven years after the loan is rejected, the DM solution might automatically delete the file at seven years and one day. Any time there is potential for litigation, there should be a preservation order requested to immediately suspend such automatic destruction of documents and logs and to preserve all files that may be relevant to an investigation.
Embedded and Substantive Metadata
The majority of applications that create or edit user files also generate important metadata that is contained within the file structure. Some of this information is viewable within some functionality of the program, while some of it can only be examined with specialized applications. Some of the embedded metadata is generated by the application, while some of it can be added by the user. Figure 9.9 shows some of the viewable metadata of Microsoft Word at the time of writing. Much of the metadata defined as substantive falls under the category of embedded metadata. Substantive metadata includes information such as embedded fonts, line and paragraph spacing, indents, and so forth.
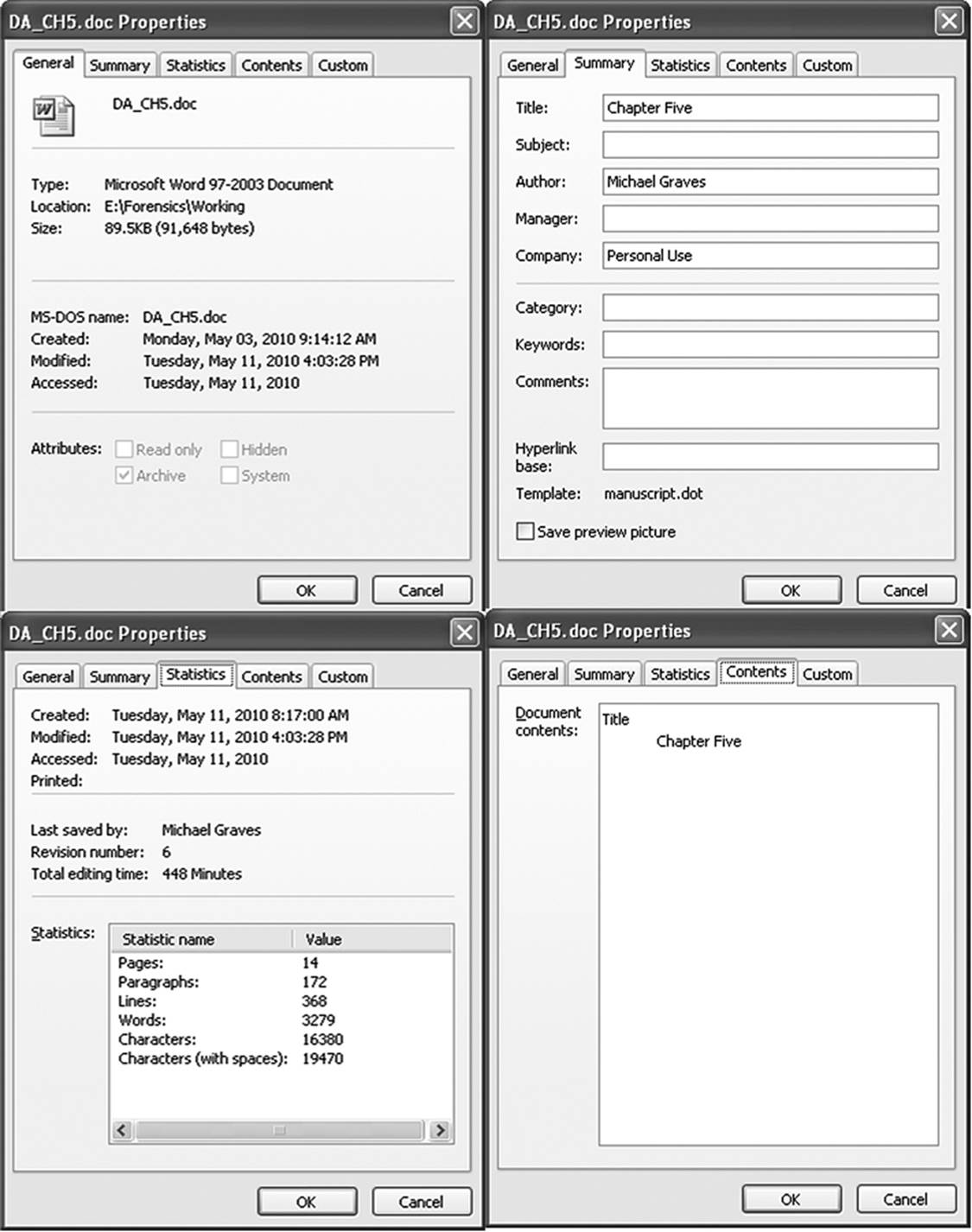
Figure 9.9 A compilation of four of the five Properties screens from a Microsoft Word document reveals the viewable metadata of this application. The fifth screen is of little or no relevance to the investigator.
An interesting thing to note in this image is that in the General Properties screen, the create date is reported as May 3, 2010, yet in the Statistics screen, it is shown as having been created on May 11, 2010. This is because the General Properties screen extracts its information from the OS metadata, while the Statistics screen represents embedded metadata. The difference is most likely the result of a fatal system error that locked up the author’s system on May 11. On reboot, the file was opened from the Microsoft document recovery option. Apparently, this altered the create date within the embedded metadata. This is a perfect example of how metadata cannot always be taken at face value, but requires intelligent analysis by the investigator.
Figure 9.10 is the final Properties screen as displayed by Microsoft. Virtually all of this information is data that can be entered by the user. These are considered custom metadata fields. For the purposes of illustration, the author has filled in some of the fields available.
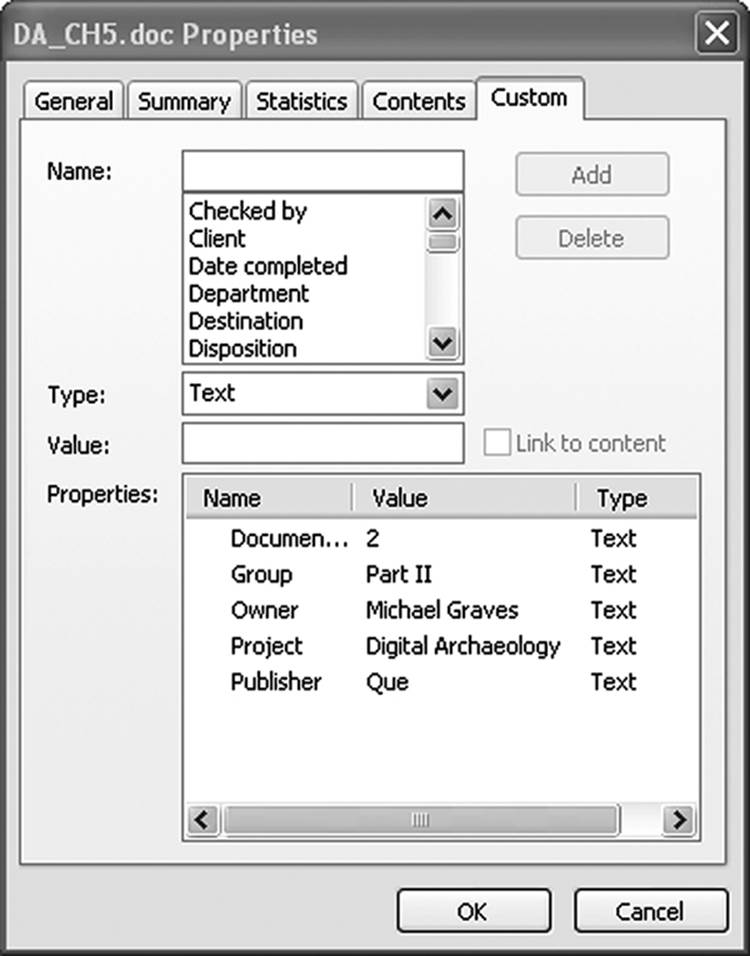
Figure 9.10 Some applications allow the user to add personalized information in custom metadata fields.
In a situation where the target of the investigation was not technically astute and paid no attention to embedded metadata, much can be gleaned from an analysis of this data. If the document is being compared to a control document, a difference in revision numbers might suggest that the document was altered between the times that the two documents were altered. Also, the field in Statistics identifying the last user to save the document might be different from the document owner, if such information is saved in the Custom field, or from the author as saved in the Summary field.
A more technically astute suspect is very likely to alter this information. There are numerous shareware and freeware applications on the Internet, as well as commercial applications, whose sole reason for existence is to alter or remove metadata from documents. Therefore, if a user wants to hide this information, it isn’t difficult.
Another thing to consider as a result of this discussion is the nefarious use that the metadata files can be put to. In this particular document, the author has embedded the first two pages of this chapter into the Comments field in the summary tab (Figure 9.11). A drug dealer could store a list of suppliers, a pimp could have a complete listing of available talent, or hundreds of phone numbers could be hidden in a similar manner.
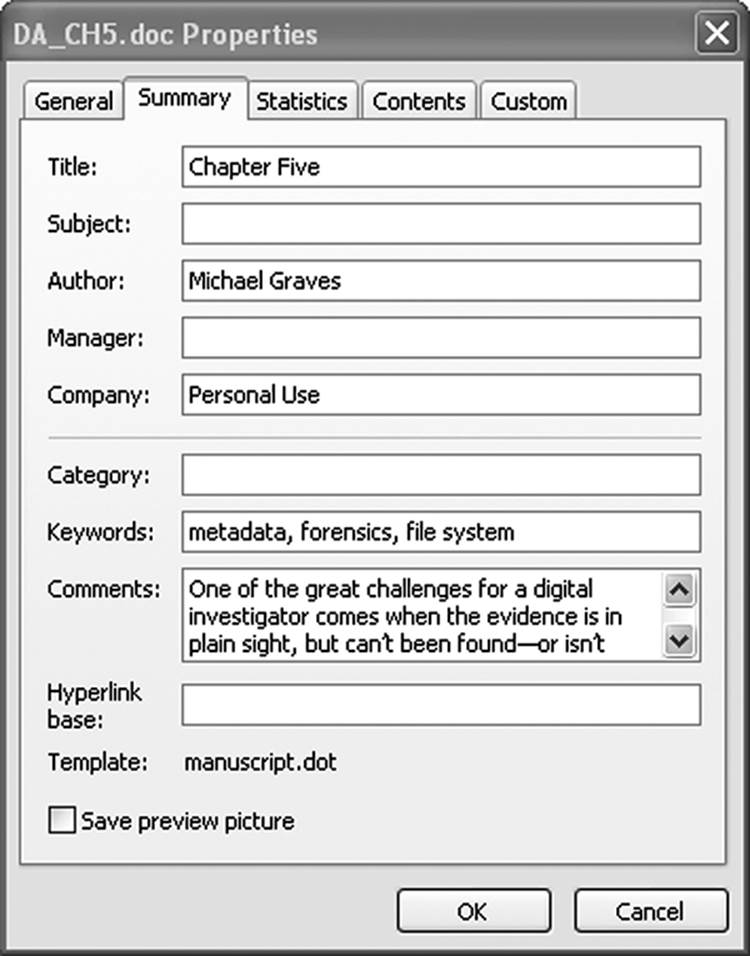
Figure 9.11 A relatively large amount of user data can be stored in the hidden metadata fields of a typical document.
Each application that creates embedded metadata can read its own. There is some compatibility between applications of a suite, but not a lot. For example, the embedded metadata of a PowerPoint file can indicate how many slides are in a presentation. Of what use is that to Word? Music files can host a large amount of data viewable in applications such as iTunes or Windows Media that identifies the song title, composer, artist, and dozens of other bits of information. Figure 9.12 shows just a fraction of the data available from the metadata of typical music files.
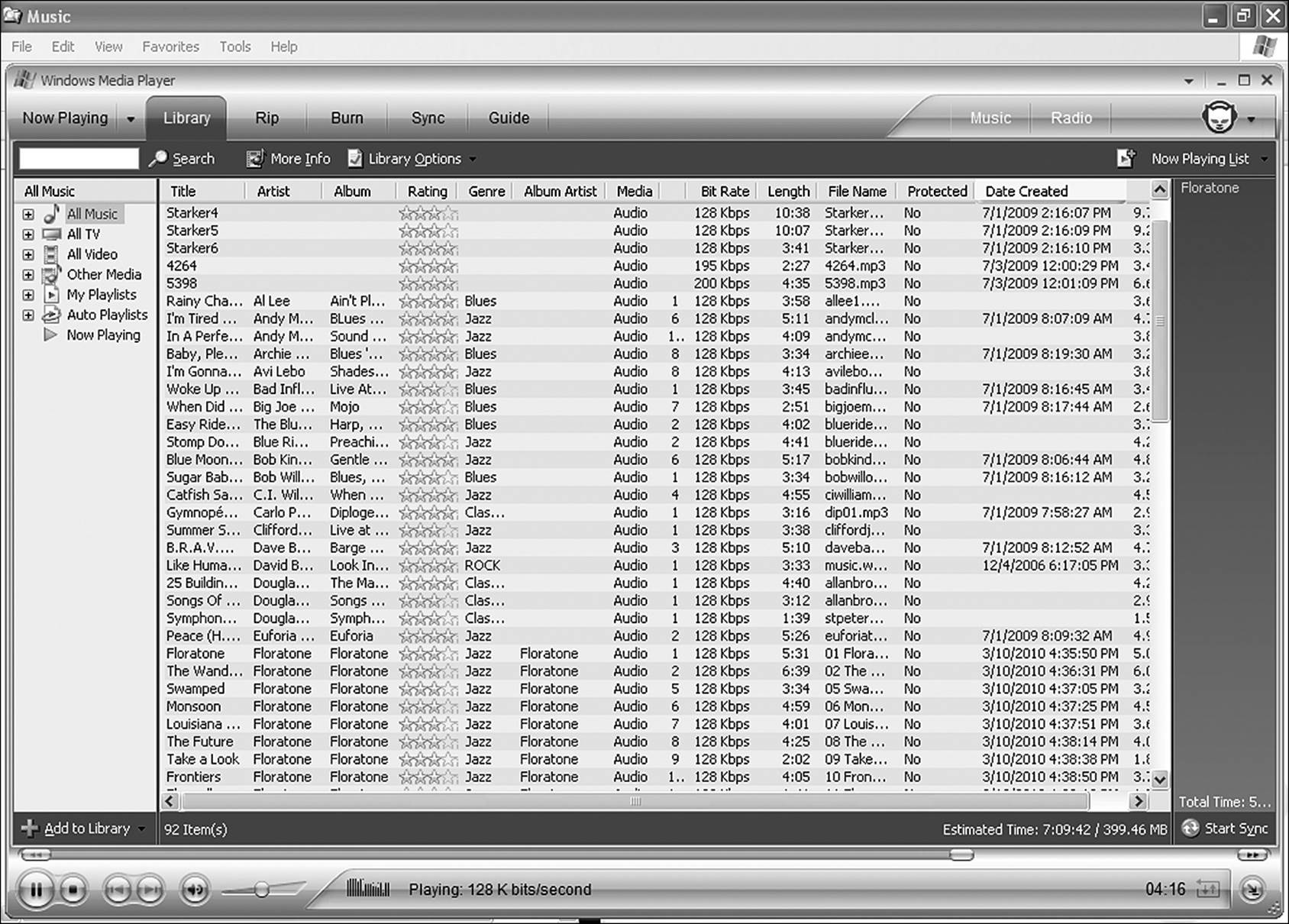
Figure 9.12 Most files created by user applications embed large amounts of custom metadata into the file package.
The majority of document metadata is easily viewable from within the application that created the file. Viewing the document properties exposes most of the metadata in Word, and there is a wide variety of metadata editors out there for image and music files.
Some critical metadata is hidden. A rather embarrassing incident happened to the British government in 2003, when a spokesperson released a dossier supposedly produced by their intelligence services. Dr. Glen Rangwala of Cambridge University was able to prove that the document was actually produced by a U.S. researcher by extracting the revision logs from the document (Thompson 2003). These logs are not visible through any conventional method but can be viewed by way of several third-party utilities. One utility called DocScrubber is a free utility from Java-Cool Software that can do this. Figure 9.13 shows the metadata uncovered from a document by this utility that reveals eight different revisions by three authors (only two of which appear in the screenshot).
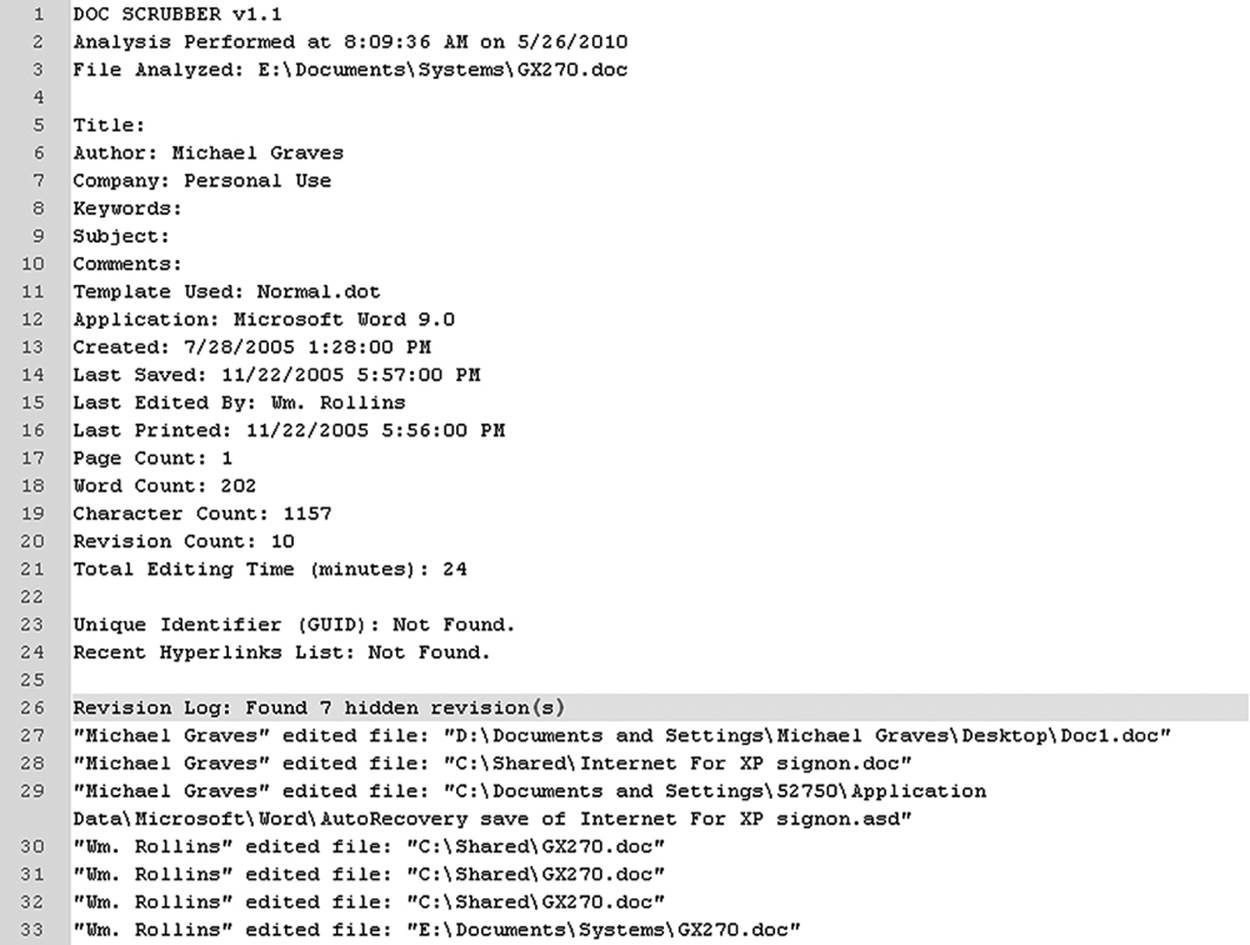
Figure 9.13 Revision logs can reveal much about a document that is not visible from the application.
A sample of useful data that can be extracted from a documents metadata includes
• User name
• User initials
• Organization name (if configured on the system)
• Computer name
• Document storage location
• Names of previous authors
• Revision log (Word, Excel)
• Version log (Word)
• Template file name (Word, PowerPoint)
• Hidden text (Word, Excel)
• Globally Unique Identifiers (GUIDs)
Most applications can be configured to not save certain information, and there are also third-party utilities that can “cleanse” a document of this information. Therefore, it should not be expected that every document will expose each and all of these bits of data. For an example of examining a specific document, see the sidebar entitled Digging Deeper into the Document History.
Digging Deeper into the Document History
For the forensic investigator, finding a file is only the beginning of the search. After that, the real fun begins. Who really created it, and was it altered in the meantime? Are there other versions out there somewhere? In this exercise, the reader should refer to Figure 9.12 and look at some of the information that DocScrubber provided in its analysis of the sample document.
The metadata shows that the original author was the same person as the one who wrote this book. However, it was last edited by Wm. Rollins, and in fact, the last several edits were done by Mr. or Ms. Rollins. This may be meaningless, unless of course, Mr. Graves insists that he did all of the work on the document and that there was no opportunity for anyone to make any changes . . . or unless M. Rollins is claiming to be the original author.
One piece of information that requires a bit of interpretation is found in lines 20 and 21. DocScrubber reports 10 versions of this file, but an editing time of 24 minutes. Even if the revision logs are not available, this suggests that the file has been renamed at some time. Why is that? Unless one is a very fast editor and typist, 2.4 minutes per edit seems to suggest very fast work on somebody’s part. On the other hand, if a file is renamed and then reopened, it is seen as a new file the first time it is opened and the editing clock starts over. Perhaps the investigator might find another copy of this file elsewhere under a different name. Do a strings search for some text extracted from the file.
The file was also printed on 11/22. That suggests that the possibility that hard copy of the file has been distributed. Only the investigator will know if this is a significant factor or not, but it certainly brings suspicion to the claim “Nobody else has seen this file.”
The metadata log also tells us the file changed names twice along the way. The first change, from Doc1.doc to Internet for XP Signon.doc, won’t come as any surprise. That shows the creation of the document and the first file name it was saved under. Then after M. Rollins takes control of the file, it suddenly becomes GX270.doc. So this is where the reported editing time began. Now, if this was a large file with only 22 minutes of editing time, we would have additional reason to be suspicious of any claim that Rollins was the author.
We also see an autorecovery file (Internet for XP Signon.asd) listed. Can we find a temporary file on the system that contains a different version of this file? Does the file still exist under its original name, and what differences can we find?
Additional embedded metadata that can be found in documents includes a substantial amount of user data that “hides” in the file. The formulae used in a spreadsheet are contained within the file. Unless it is hidden, a user can view the syntax of a formula by clicking on a cell that contains a formula. A document with the Track Changes feature enabled might contain large amounts of information embedded in the file. Some of the embedded metadata contained in a file includes
• Formulae
• Hyperlinks
• Hidden columns
• Tracked edits
• Fields
• Database links
• Embedded object information
• Hidden text or numbers
• Alternate streams
Mining the Temporary Files
Modern operating systems rely very heavily on the services of temporary files that are created in the process of running an application, editing files, or performing searches. The general idea is that once a temporary file is no longer needed, the OS automatically deletes that file. However, not all temporary files are successfully deleted by the OS. An improper shutdown of the system results in a large number of temporary files that are permanently stored on the hard disk. So in essence, they are no longer temporary. By knowing the extension and default locations of temporary files created by specific applications, the investigator can go looking for specific types of files. According to a Microsoft article (Technet 2005), there are three sets of circumstances that result in temporary files:
• Files created by desktop applications to facilitate editing (undo files, scratch files, and so forth)
• Backwardly compatible applications that require swap files in order to run on the current system (such as MS-DOS files running on a Windows system)
• Spooler files created when a print job is sent to the printer
Internet Explorer, as well as virtually all other Internet browsers, also keeps a cache of files from recently visited Web sites so that the page will load more quickly if the user returns to that site. Additionally, many applications create “autosave” files so that if the system crashes while the user is working on a document, all unsaved work will not necessarily be lost. Some temporary files can be identified by characters added to the file name. Table 9.3 is a list of some of the commonly produced temporary files that can be found on a typical system. Note that the default locations listed can be changed by the user with most, if not all, of the applications listed. A little searching might be required on the part of the investigator.
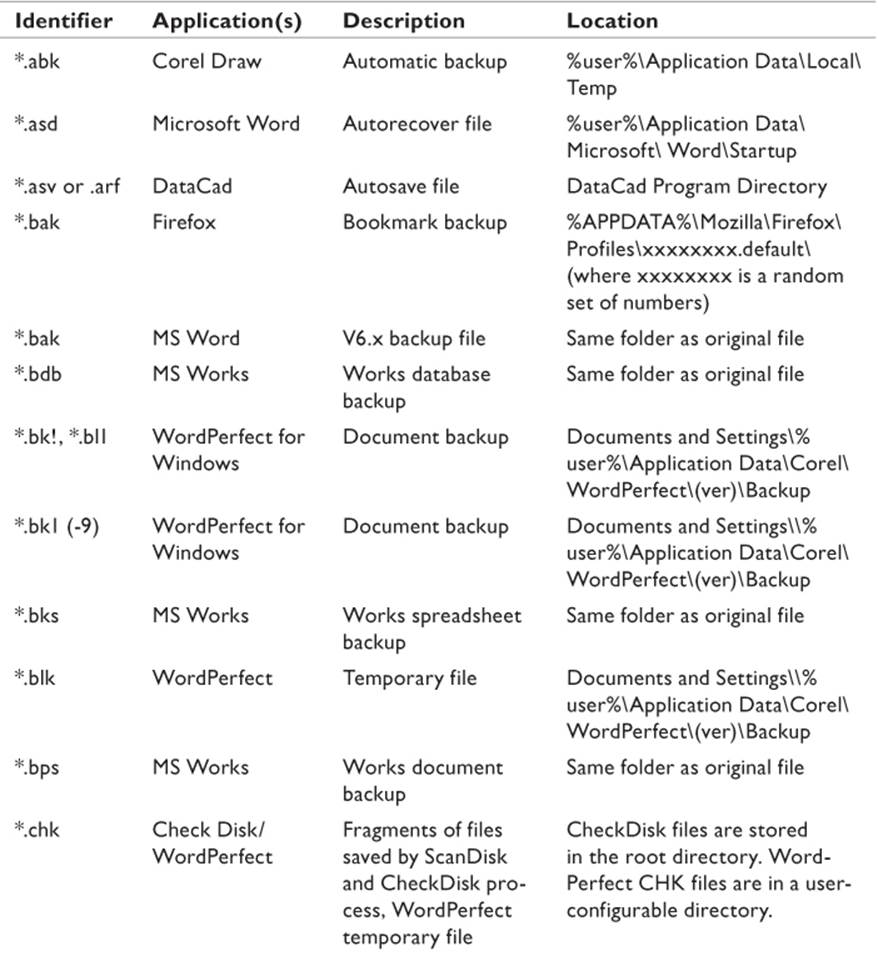
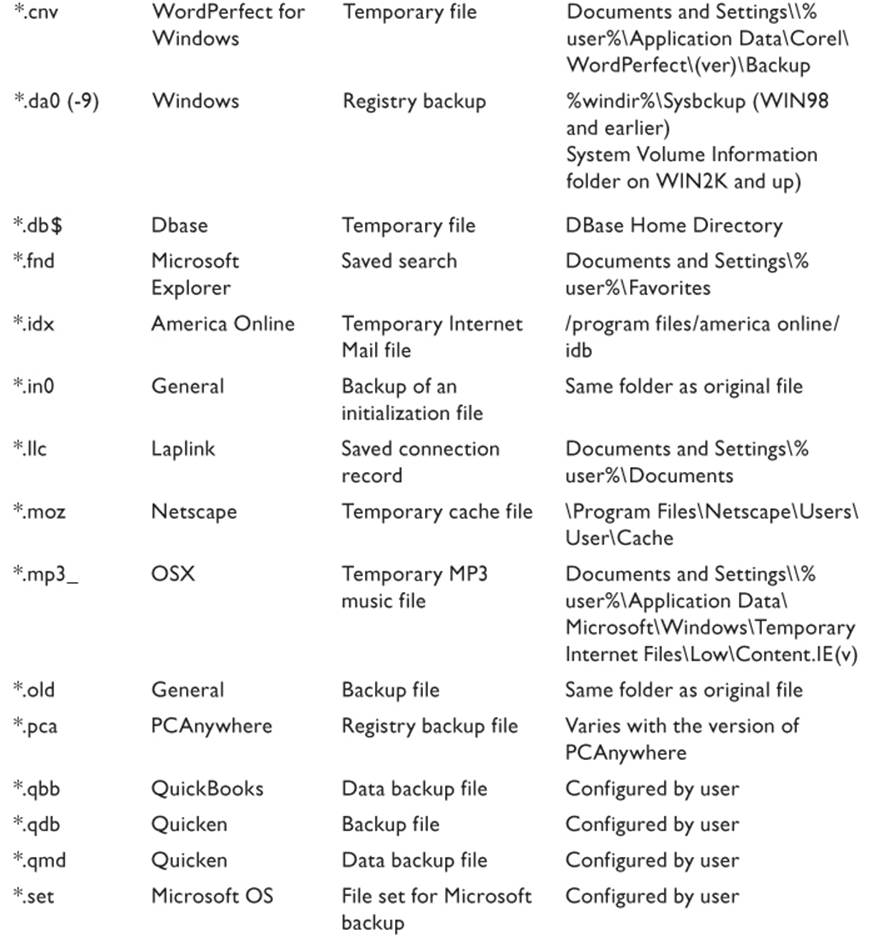
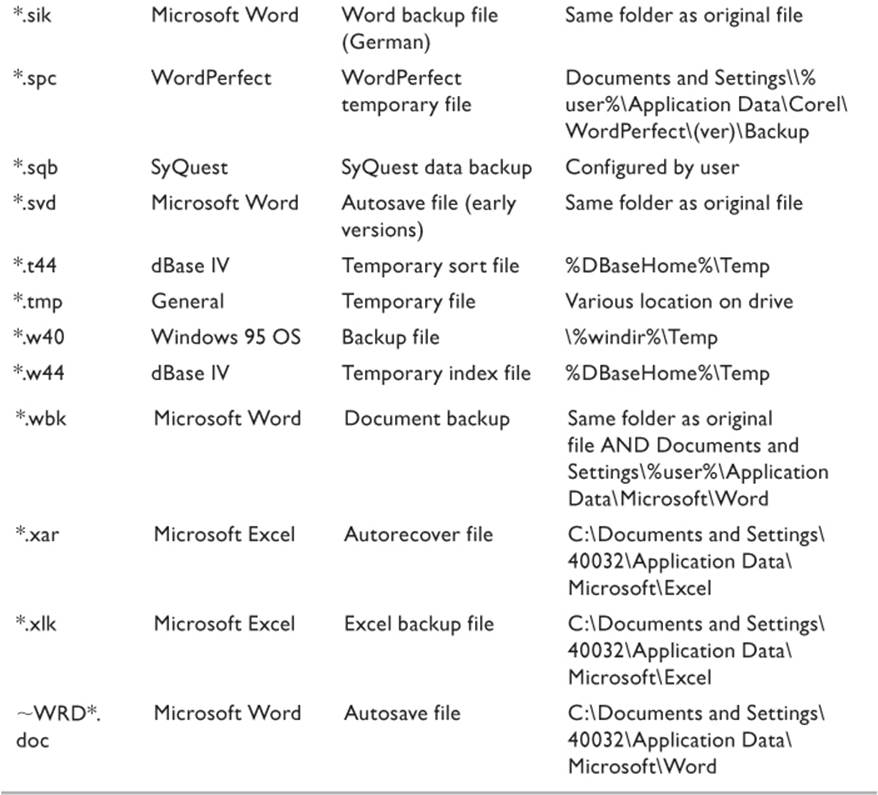
Table 9.3 Some Common Temporary Files
This is only a brief list of the most commonly found files and is not intended to be all inclusive. The investigator should be aware of the applications running on the target system and research the types of files created by the application.
Temporary files are automatically deleted by the application or the OS when the system or application is gracefully shut down. However, these files are treated as any other deleted file and, if not overwritten by later files, can still be recovered by most forensic software. Figure 9.14 is a partial listing of automatically deleted files found by Directory Snoop that could potentially be recovered if there was a need.
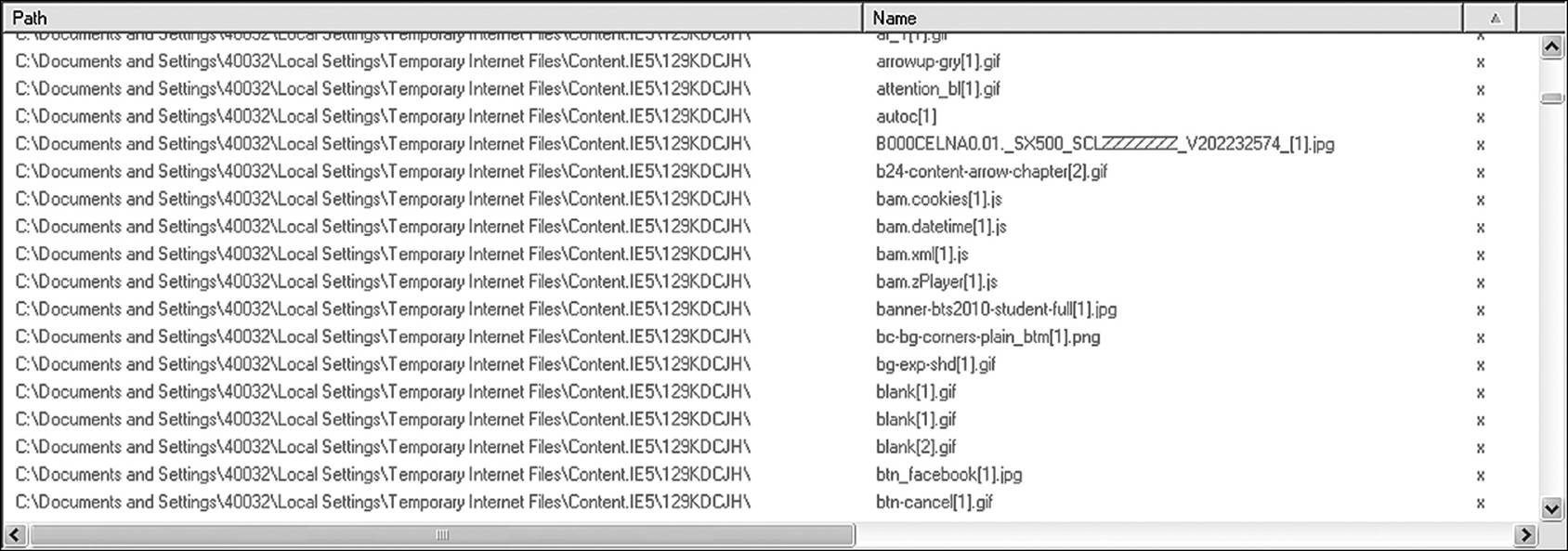
Figure 9.14 Temporary files that are automatically deleted can often still be recovered.
Identifying Alternate Hiding Places of Data
So far the discussion of document analysis has centered on examining or finding entire files. For the average user, this is as far as a search needs to go. However, more technically astute individuals will know of other ways to keep information stored on a computer that will completely elude the casual observer, and might possibly escape the notice of a professional if not specifically sought. There are four common repositories for hiding data that an investigator should routinely check (if possible):
• Registry entries
• Document metadata fields
• Bad clusters
• Alternate data streams
There are tools for searching all of these areas. The following pages will discuss some methods for uncovering the intentionally hidden files. The use of bad clusters and alternate data streams for concealing data is not a function of document analysis and will be covered in Chapter 15, “Fighting Antiforensics.”
Finding Data in the Registry
The designated use of the Windows registry is to control how Windows functions. It typically deals with configuration issues, compatibility, functionality, and behavior of the OS and installed applications. It also contains a lot of user-specific data. The nature of registry entries and a Windows applet called regedit allows users to embed data in certain types of registry entry.
Some preexisting entries exist that are open for storing user data. An example of this is the time zone information key, located at HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\TimeZoneInformation. The purpose of this key is to record the difference between the local time zone, as configured on the computer, and the Universal Time Zone, which acts as the control value. It also contains information used by the OS to calculate changes in times caused by Daylight Savings Time. There are two entries that are allowed to be empty and can contain text values as well as binary data. These entries are entitled StandardName and DaylightName (Figure 9.15).
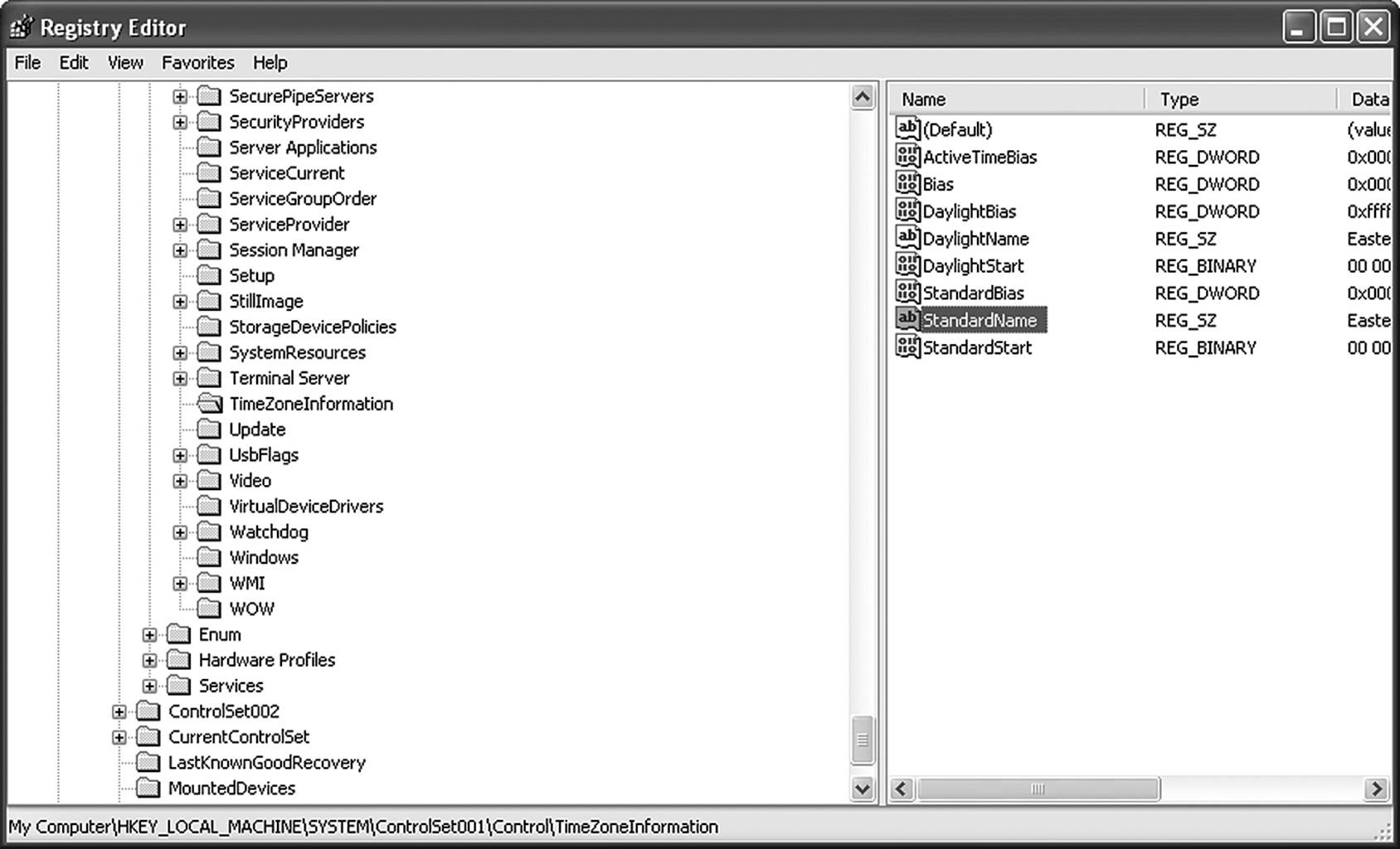
Figure 9.15 Many existing registry entries can be used to conceal user data.
In Figure 9.16, two new keys have been generated called Password and Text. In the Password key, the text string Passw0rd1 has been entered. This can just as easily be an actual password to an encrypted volume or a server. An entire line of text is stored in the Text key. Why couldn’t a drug dealer put the name and phone number of his Columbian supplier in a place like this?
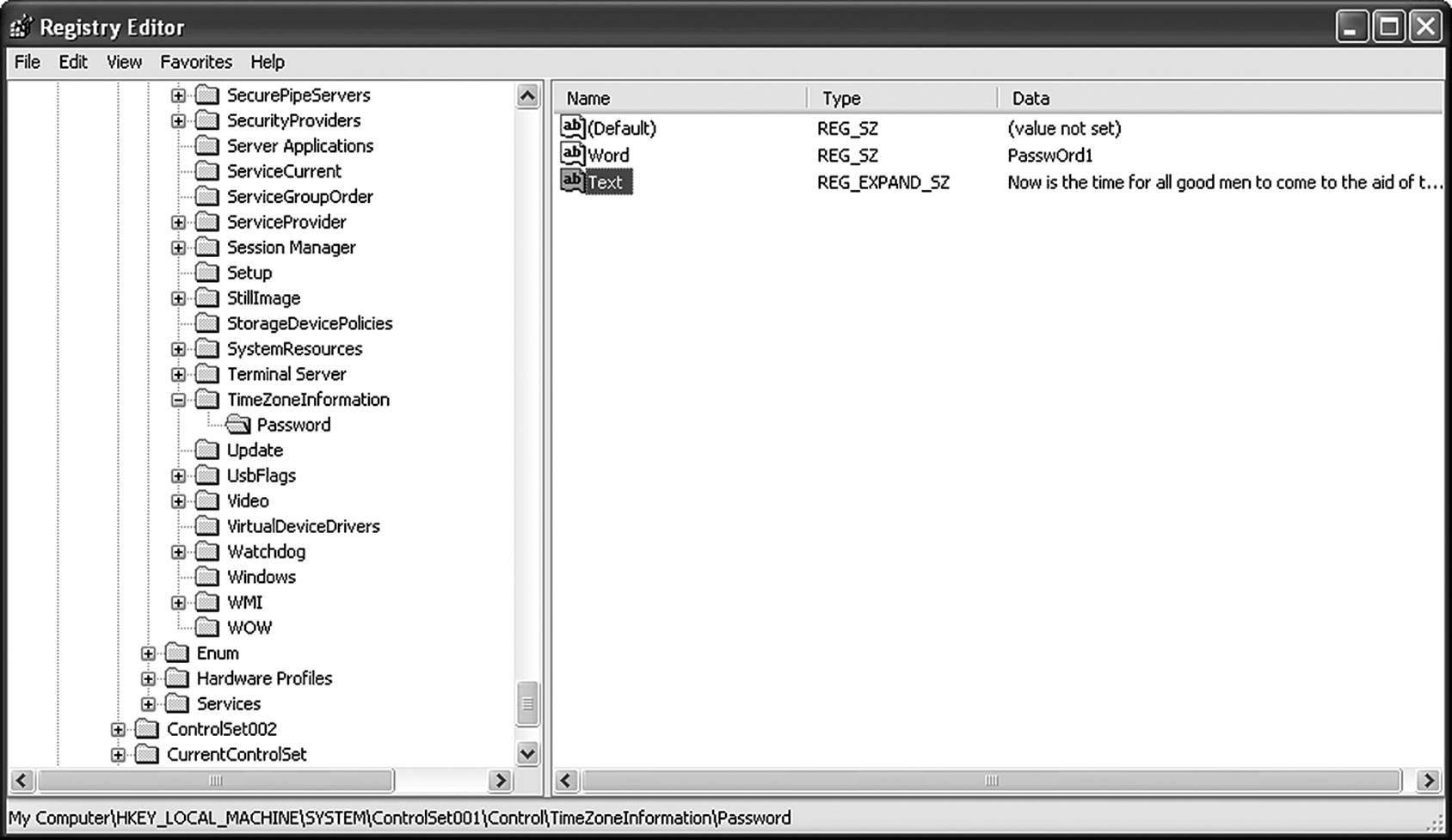
Figure 9.16 The advanced user can create custom fields to house information.
How does the investigator find such information? There is no easy way. Using the regedit utility, it might be possible to do a string search for certain key words or phrases and hope for the best. Another way is to use a registry analyzer to search for unused entries. Since there can easily be hundreds or even thousands of such entries in a system that has been used for a while, this might get a bit tedious, but it also might find the data that a string search leaves out. Paraben Software manufactures an advanced registry analyzer called (conveniently enough) Registry Analyzer as part of their P2 Command Kit. Most forensic suites offer a similar utility.
Document Metadata
In the earlier discussion about metadata, one of the examples included a document in which several pages of text were included in the metadata. That example shows that a fairly significant amount of data can be hidden in a document. To the professional investigator, finding the information in a single document is no challenge when there is some reason to believe it is there. On a system containing thousands of documents, finding a single document containing hidden data is more of a challenge.
Different files have different types of metadata and require different tools to extract or display this information. The National Library of New Zealand created a universal Metadata Extraction Tool that works on a wide variety of documents and once mastered is a valuable addition to the investigator’s toolkit. For the most part, a different tool will be used for different file types. Table 9.4 lists several common files and information regarding the metadata they contain. Note that this list is not exhaustive, but intended to be a representative example.
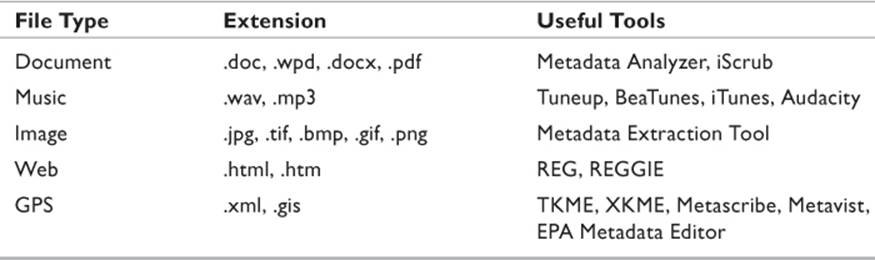
Table 9.4 Common File Metadata
Several utilities allow the investigator to search for specific strings of data. The Microsoft utility called (conveniently enough) strings is an example of such a utility. While preparing this chapter, the author embedded the sentence “Hidden data in the metadata fields can be a problem to find in large collections of documents.” into the document’s description metadata. Now that the sentence has also been placed into the general text, a general content search in Windows Explorer using any phrase contained in the sentence would find this document. Figure 9.17 shows a search based on the phrase “large collections.” As it found several documents, the search string may have been too generic.
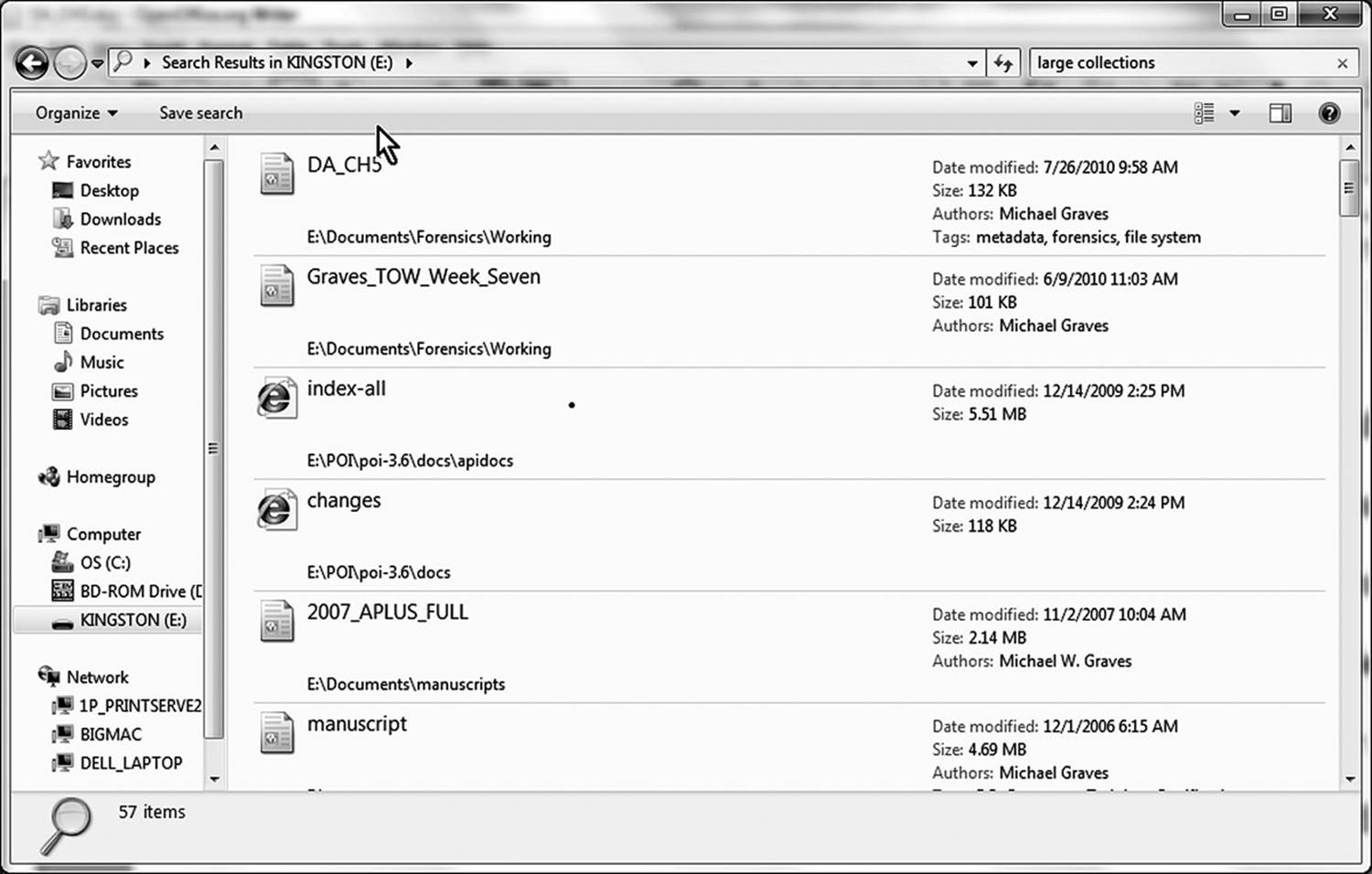
Figure 9.17 Most operating systems allow generic searches for phrases in the general content of files.
For the moment, pretend that the sentence is not in the actual document, but resides only in the metadata. The investigator suspects that a document exists with a word, phrase, or name embedded somewhere, but it isn’t showing up in a general content search. The strings utility might help if you have a unique string to search by. For the purpose of this example, the author has now embedded the word “dirigible” into the metadata. The reason for such an interesting selection was to simplify the results for this example. The results are shown in Figure 9.18.
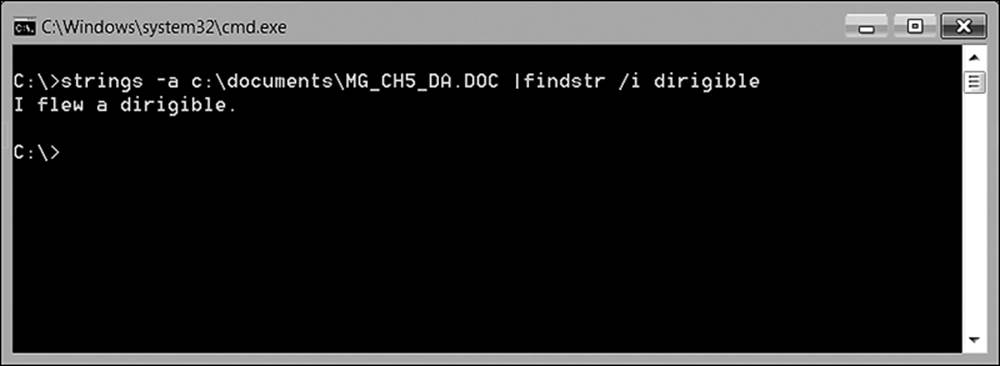
Figure 9.18 The strings command will find a desired text string even if concealed in the metadata.
The command is used in this manner:
strings [-trigger] [file or directory name]
Available triggers include
• -s Searches subdirectories
• -o Displays the offset within the file where the string is located
• -a Looks for ASCII characters only
• -u Looks for UNICODE characters only
• -b [bytes] Limits the number of bytes of file to scan
• -n X Sets a minimum length of strings to display, X characters long.
An asterisk can be used in place of the file name to search all files in a specific directory. For example, strings -a e:\documents\forensics\working\* searches every file in the e:\documents\forensics\working\ directory that consists of ASCII code.
A specific text string can be the target of the search by adding a pipe, followed by the findstr trigger, followed by the text string desired. The limitation of this method is that it hiccups when spaces are used. If a string is offered with no quotations marks, such as in strings -a e:\documents\forensics\working\* | findstr find text, it returns the error, “Cannot open text.” If you try to outsmart it by using “find text” with quotes, it returns every file it finds with either word. A search string that is too general can return so many results that they are tedious to sort through.
A similar utility available to the Linux user is GREP. (Note that there is a utility in Linux called string, but it performs a completely different function, not related to text strings.) Grep turns the same tricks as strings in Windows. It does, however, offer a few more options and is considered by many to be a more powerful tool. The following triggers are available to GREP:
• -A num Displays specified number of lines after the matched pattern
• -B num Displays specified number of lines before the matched pattern
• -c Displays number of matches found for specified text
• -C Displays two lines before and after each match
• -e pattern Searches for pattern (e.g., eixeixeix)
• -f file Uses a pattern from a file
• -i Ignores case
• -l Lists names of files that contain matches
• -L Lists files that have no matches
• -w Lists whole words that are matched
• -x Lists only whole lines that are matched
If the investigator is simply trying to find documents with suspicious embedded metadata, regardless of content, a better solution is one of the various metadata analysis tools on the market. Virtually all of the professional digital forensic suites sold commercially have some version of a metadata analyzer. Investigators with these at their disposal are well equipped to perform a thorough analysis.
If one finds oneself in the field without such a tool, there are some utilities that will help. Metadata Analyzer can examine an entire folder of Microsoft Word or Excel documents and extract all the conventional fields from the file header, such as author, last editor, file creation date, and so forth. It will also report if there are custom fields containing user-added information. While it does not display that information, at least the investigator knows which files contain user-generated metadata. Figure 9.19 shows a selected document displayed by a report generated by the author. In this example, 33 documents from a folder were analyzed. The one displayed contents four custom fields and is worth further examination. This tool is offered as a free utility by Smart PC Solutions (located at www.smartpctools.com/metadata/).
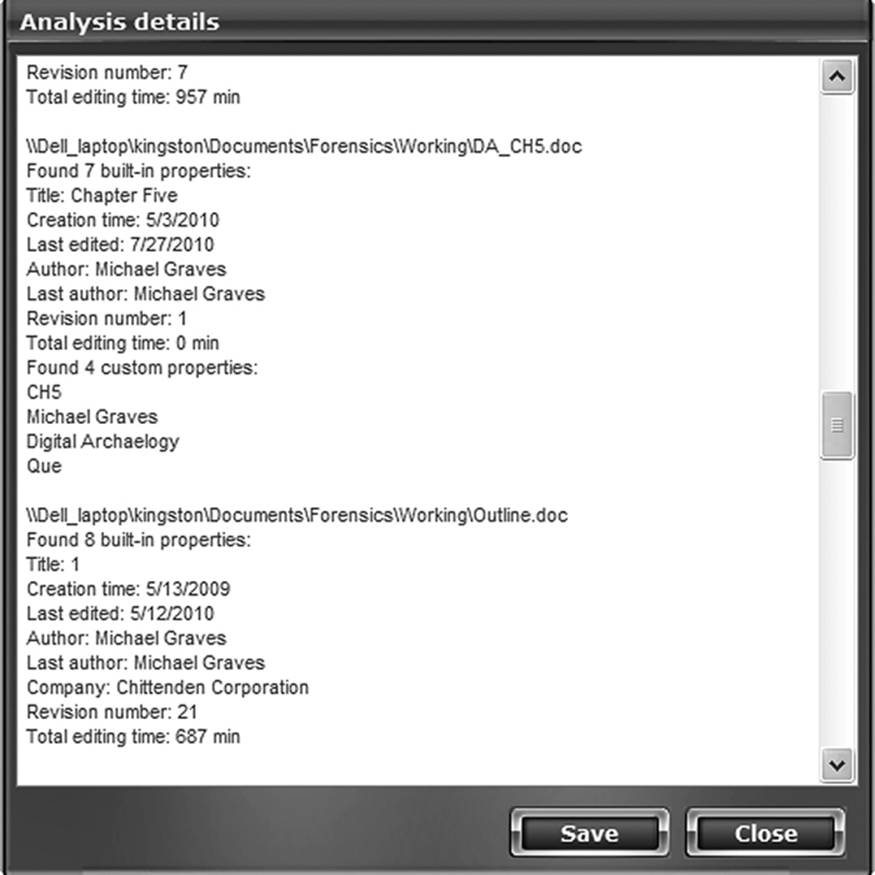
Figure 9.19 Metadata Analyzer is but one of several tools that can extract document metadata and display it.
Finding Data in the Bad Clusters
Using bad clusters as a way to hide data is more of a theoretical trick than one that is generally seen in the field. The NTFS file system maintains a list and a bitmap of bad clusters it finds during disk checks in the file system’s $Badclus metadata file. Since the release of IDE drives back in the late 1990s, hard disks have managed bad clusters through the firmware. By editing the $Badclus file to include a block of sectors, these sectors will be excluded from those available to the file system and will not be seen by any traditional tools.
The Metasploit suite has the ability to do this. However, the difficulty of the process, combined with the subsequent difficulty of retrieving the data at will, has all but rendered the technique obsolete. It is very easy to detect that bad clusters are being used. All the investigator has to do is view the contents of the $Badclus file. In a typical Windows system, it is a zero-byte file with no entries. If there are entries, virtually any disk editing tool can easily locate those clusters, and the investigator simply cuts and pastes the data into a new file, saved to any media.
Chapter Review
1. What are three forms of metadata that can be useful to an investigator, and how are they of use?
2. Discuss the differences and similarities between Windows file headers and the Linux magic numbers.
3. What is it about MAC data that makes it critically important that an investigator be very careful about how it is used and applied?
4. What types of metadata does Microsoft Word store in documents? Of what value is this information to an investigation?
5. List several types of temporary files that are of use in an investigation, and explain how they can be used.
Chapter Exercises
1. Download a copy of DocScrubber from www.brightfort.com/docscrubber.html, and install it on a computer. Create a document in Microsoft Word, and have each person in the class copy the file to his or her computer and pass it on to the next person. After the last edit has been made, use Doc-Scrubber to analyze the document. What do you learn from this exercise?
2. Open the file created in the above exercise on each person’s computer. After a few minutes, the file will autosave. Try to find the file it creates. (Hint: It carries an extension of .asd.)
References
Aguilar v. Immigration and Customs Enforcement Div. of U.S. Dept. of Homeland Sec., 255 F.R.D. 350 (S.D.N.Y. 2008) (No. 07 Civ. 8224 (JGK)(FM)).
Darwin, I. 1999. File(1). www.fileformat.info/info/man-pages/man1/file.1 (accessed May 4, 2010).
Linux Information Project. 2006. Magic number definition. www.linfo.org/magic_number.html (accessed May 4, 2010).
Technet. 2005. Windows temporary files. http://support.microsoft.com/kb/92635 (accessed June 8, 2010).
Thompson, C. 2003. Microsoft word accidentally reveals Iraq-dossier writers. Collision Detection. www.collisiondetection.net/mt/archives/2003/07/microsoft_word.php (accessed May 26, 2010).