Digital Archaeology (2014)
8. Finding Lost Files
Here is where the actual archaeology of the digital forensics expert comes into play. Digging out the “lost data” is one of the more challenging aspects of the trade. For anyone who has been on the technical side of computers for any length of time, it is old news that a deleted file hasn’t gone anywhere. Until overwritten, the data from that file stays where it’s at. Depending on the operating system in use, it can either be very easy to restore a file or very difficult.
From a forensics point of view, however, it isn’t just deleted files that are of concern. The investigator needs to be able to recognize the presence of hidden files, disguised files, and invisible files as well. Again, how easy that is to do depends entirely upon the OS in play. This chapter describes standard file recovery techniques as well as some tricks used by more technically astute individuals for keeping files away from unwelcome eyes. Note that standard OS file recovery utilities are routine material in conventional computer books and will not be covered in detail in this chapter.
File Recovery
Once a file has been deleted and subsequently removed from the Recycle Bin or trash can or whatever adorable analogy the operating system uses, it falls to third-party utilities to regenerate the file if necessary. The vast majority of commercial file recovery applications can perform a successful recovery only if none of the sectors originally assigned by the file system to that file have been overwritten. Some of the more advanced utilities can extract partial data from unallocated space. The digital investigator is interested in those types of utilities.
Most of the forensic suites offer file-recovery options. This is one area that is blessed with several open-source applications as well. To understand how file and data recovery work, it is essential to have at least a rudimentary understanding of how the file system manages data in memory and in storage systems. While this is more thoroughly covered in a book dedicated to operating systems, a brief overview of the two main file system types are in order. The following pages will discuss file management in Windows file systems and in the various flavors of UNIX, including Linux and Macintosh OS-X.
The Microsoft File System
Over the years, Windows systems have seen several file systems evolve. The venerable old File Allocation Table (FAT) system originated with MS-DOS, and each Windows version shipped with improvements to the file system. Over the years, Microsoft has shipped OS versions using the following file systems:
• FAT12 (FAT with 12-bit file table entries)
• FAT16 (FAT with 16-bit file table entries)
• FAT32 (FAT with 32-bit file table entries)
• NTFS 1.0 (released with NT 3.1)
• NTFS 1.1 (released with NT 3.5)
• NTFS 1.2 (released with NT 3.51 and 4.0, frequently called NTFS 4.0 because of the NT version)
• NTFS 3.0 (released with Windows 2000)
• NTFS 3.1 (released with Windows XP and later)
Storage devices store data in storage units called sectors. The average magnetic device is divided in millions of sectors containing 512 bytes each. (Note that the newer Advanced Disk Format released in 2010 features a 4KB sector.) When a hard disk is formatted, it is divided into partitions and clusters. A partition is nothing more than a section of a disk. When a contractor builds a house, the main structure consists of four walls and a roof most of the time. However, it is pretty rare that those four walls contain only one room. Usually interior walls divide the house into several rooms. Hard disks can be treated the same way. A 1TB hard disk can be divided into any number of different partitions of different sizes, and each partition will be recognized by the OS as a separate drive, even though it is not.
Partitions come in one of two forms: a primary partition or an extended partition. A primary partition is one that is defined in the master boot record of the hard drive and can be turned into a bootable partition. There can only be four primary partitions on any given physical disk. Primary partitions can be further divided into extended partitions. How many extended partitions a computer can have is entirely dependent on the file system in use. With most early file systems, a system was limited by the number of letters in the alphabet. Modern file systems overcome even that limitation.
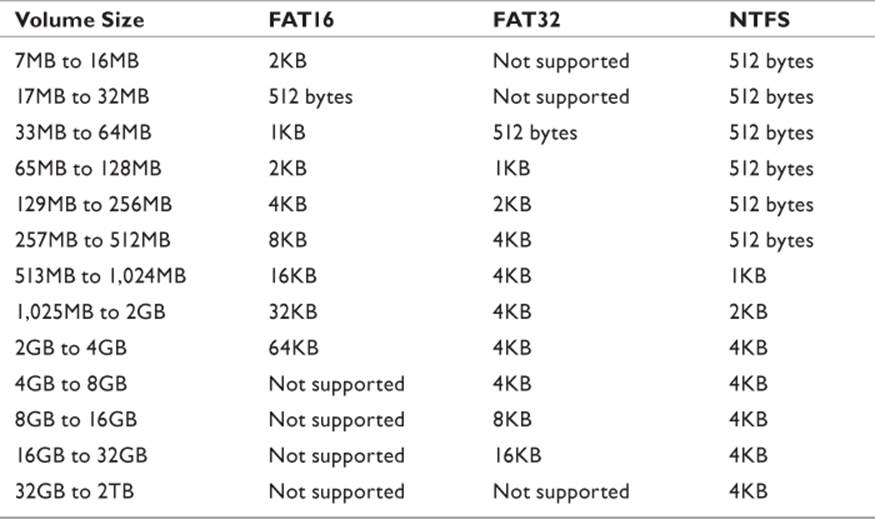
As mentioned, a hard disk is divided sectors. However, most file systems can’t read a single sector if the partition is larger than 520MB. Anywhere from 4 to as many as 64 sectors are collected together into file allocation units (FAU). A more common term used interchangeably with FAU is cluster. (This book will use the term cluster.) Table 8.1 lists some commonly seen partition sizes along with the default cluster size. No cluster can hold data from more than one file. Depending on the file system in use and the size of the formatted partition, a cluster could potentially be as large as 32KB. If a file is only 800 bytes, it occupies a full cluster, and the remaining 31KB+ become disk slack. It holds no data, yet at the same time, it is prevented from holding data. Hang onto that thought for a few pages.

Table 8.1 Common File Systems and Partition Sizing
File Allocation Tables
The File Allocation Table file system was one of the earliest of Microsoft file systems. Originally introduced with MS-DOS, it remained the default file system for the company’s operating systems up to and including Windows NT. There were several versions of the file system, described briefly as follows (Microsoft 2011).
FAT12
FAT12 was the original file system used by the first version of MS-DOS in 1980. It is still the file system of choice for all floppy disks and hard disks (or partitions) under 16MB. Running across a hard disk in FAT12 will be a true accomplishment for any digital archaeologist. However, it is still relatively common to encounter floppy disks.
The number 12 is derived from the fact that the OS only supported 12-bit file table entries. The 12-bit limitation meant that a FAT12 volume could only address 4,086 clusters. The astute mind notices and points out that 2 to the 12th power equals 4,096. The difference is due to reserved clusters used by the file system, and therefore not available to the OS. Clusters ranged from a single sector (512 bytes) to four sectors (2KB).
File names in FAT12 consisted of something called the 8.3 format. Up to eight characters could be used for the file name, with three characters reserved for the file extension. The “dot” character was reserved as a separator between the file name and the extension.
FAT16
With the introduction of 16-bit CPUs in the late 1980s, larger disk systems and file names became more important. FAT16 extended the file entry to 16 bits. Theoretically, the file system could address hard disks as large as 2GB. However, in that era, BIOS limitation came into play. A FAT16 volume can hold as many as 65,524 clusters, and each cluster will consist of between 4 and 64 sectors, depending on how the disk is formatted. As with FAT12, the reason the file system cannot access the full 65,536 clusters that can be theoretically addressed is because of reserved sectors.
FAT16 used exactly the same file name convention as FAT12. The 2GB limitation means that hard disks larger than 2GB had to be divided into multiple partitions. A 40GB hard disk would require 20 partitions as the very least. This rendered FAT16 of limited use as disks became larger.
FAT32
FAT32 first appeared in Windows 95, Service Pack 3. Having read the previous two sections, it is almost automatic to jump to the conclusion that FAT32 used 32-bit file table entries. To do so would be wrong. FAT32 reserves four bits of the structure for internal use, leaving a 28-bit entry. In theory, FAT32 allowed up to 2TB volumes. However, because of performance limitations introduced by system BIOS, such large file table entries are not supported by most computers of that era. The computer holds certain pieces of information in RAM at all times. The FAT structure for a 2GB partition is over two megabytes. Most computers built in the late 1990s were not suitably equipped to store this large of a file in memory and were forced to store the file tables to virtual memory. A volume with a terabyte of files would require more virtual memory than Windows could easily access.
An issue specific to FAT32 that is of significant relevance to the digital investigator is the amount of slack space caused by large partitions: 32KB clusters meant that if a file was only 2KB, there was a total of 30KB that went unused. A 2KB file that overwrote a 32KB cluster leaves behind a lot of potential evidence for the investigator to find (see Figure 8.1).
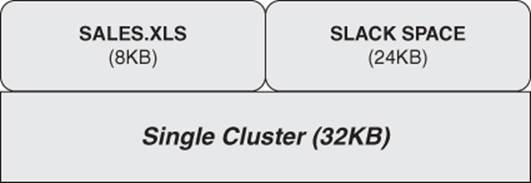
Figure 8.1 Only a single file can occupy any given cluster. Data from another file cannot coexist.
NTFS
The NTFS file system is managed by several metadata files that collectively make up a sophisticated relational database. Simply put, a metadata file is a file that contains descriptive information about other data. The Master File Table (MFT) is the file that does the most work and gets all the press, but there are several other metadata files that are essential to OS stability and that can be useful to the digital forensics investigator. Table 8.2 defines the various metadata files as defined by Microsoft. It should be noted that to the forensic investigator, the two metafiles most commonly examined are $Mft and $BadClus. The other files are included for completeness.
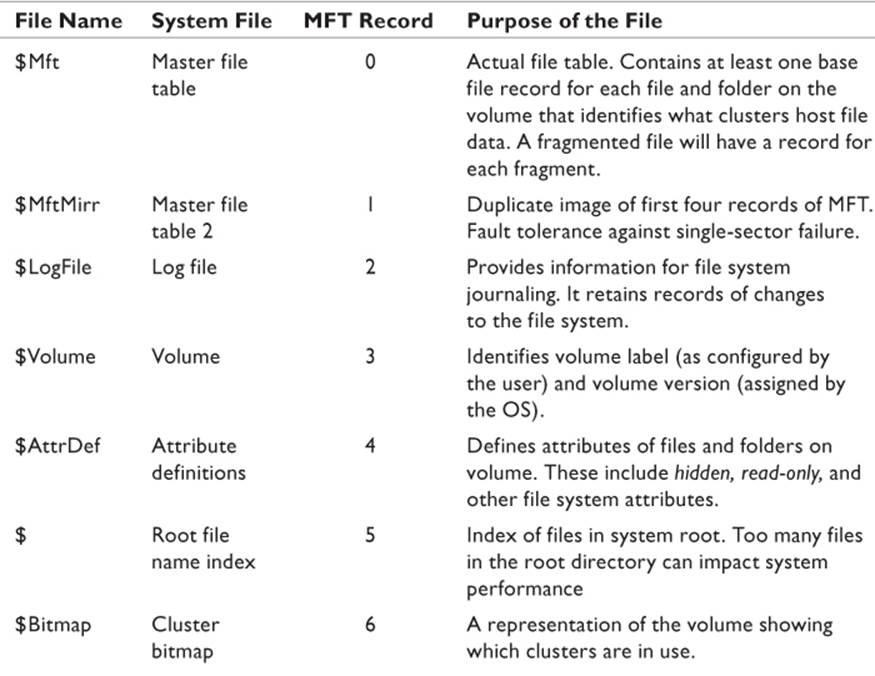
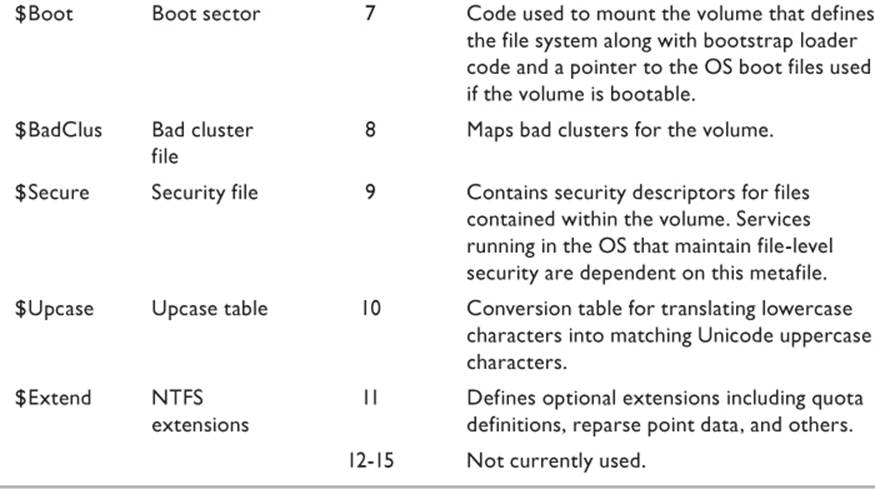
Source: Microsoft 2010.
Table 8.2 Metadata Files of the NTFS File System
Every file or directory ever created in NTFS has at least one record. If a file is fragmented, it will have at least as many entries as there are fragments. Additionally, as attributes are piled onto the resource, it is possible that new entries will be required to accommodate the additional metadata generated.
The metadata files do not reside within the confines of the traditional file system. Even if an advanced user selects options in Windows Explorer to view hidden files, system files, and so forth, the metadata files will not be visible in Explorer. However, a cluster-level search tool, such as Briggs Software’s Directory Snoop, will allow you to view and even edit them (a highly dangerous operation and definitely not recommended). Figure 8.2 shows Directory Snoop revealing the metadata files. As is easy to see, some of these are not small files. On this particular machine, the $MFT file is in excess of 135MB.
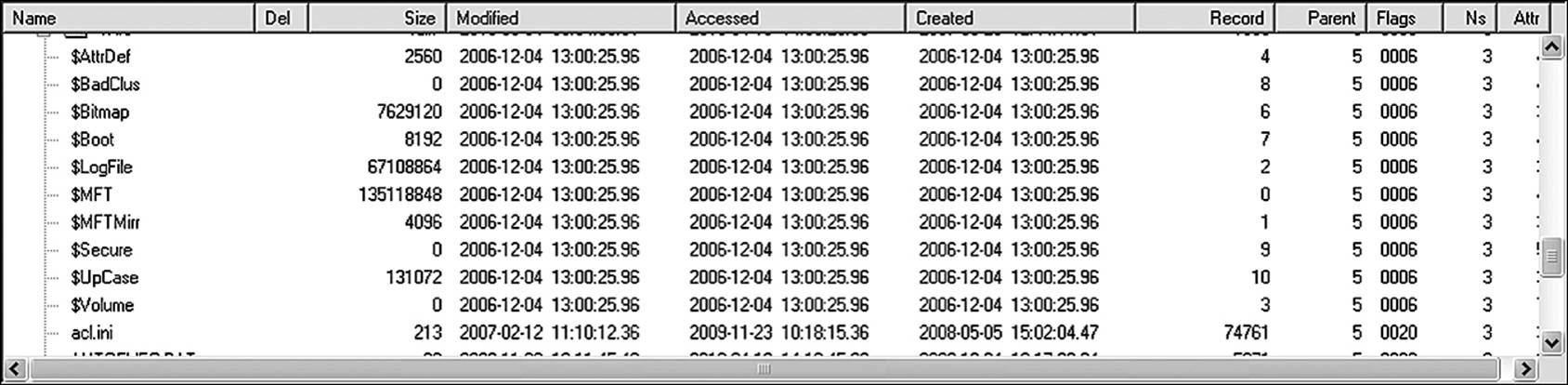
Figure 8.2 A third-party utility, such as Directory Snoop, allows the investigator to access cluster-level information, including the NTFS metadata files.
UNIX/Linux File System Metadata
Linux operating systems can use Ext2, Ext3, Ext4, or Reiser file systems. UNIX uses the UNIX File System (UFS). Each file system approaches the issue of data storage and mapping in slightly different ways. However, the overall process and theory are similar between the Linux and UNIX systems. The following is only a brief discussion from a balloonist’s view.
Most Linux systems employ one of the Ext file systems. Ext2 is a legacy system and rarely used in new installations. Ext3 and Ext4 have different levels of complexity but can coexist on the same system. Their basic structure is the same, and therefore the following discussion pertains to those two versions.
Linux treats all file systems as though they are a common set of objects. In Ext*, these objects are
• Superblock
• Inode
• Dentry
• File
At the root of each file system is the superblock. The superblock is the “master node.” It contains information about the file system itself. Size, status, and definitions of other objects within the file system, such as the inodes and dentries, are contained in the superblock. The objects that a user recognizes as “the file system,” such as files or directories, are represented in Linux as an inode. The inode (short for index node) contains all the metadata used by the file system to manage objects. This information includes
• File owner
• File type
• File permissions
• Modify/Access/Create (MAC) information
• File size
• Pointers to the blocks hosting the file
• Number of links to the file
The dentries act like a telephone book, identifying what inode numbers are assigned to specific file names. The file is the container that is viewable by the user. Ext3 maintains a directory cache of the most recently used items to speed up performance.
Understanding Slack Space
A digital investigator will spend a great deal of time digging information out of slack space. Therefore, it is essential to know precisely what slack space is, and how to read it. Slack space is disk space allocated to a file but not actually used by the file. To understand this requires a brief discussion of disk geometry.
Disks store information in clusters, which are built out of sectors. Operating systems format disks into clusters, which, depending on the file system chosen and the partition size created, could range from 1 to 64 sectors. Table 8.3 lists various combinations of file system, partition size, and cluster size an investigator is likely to encounter. For the purposes of this explanation, the 64-sector cluster will be used. That represents a data unit of 32KB.
Source: Technet 2011.
Table 8.3 Cluster Sizes in Different File Systems
Any individual cluster can be assigned to only a single file. Think of each cluster as being a kitchen canister with rigorously enforced standards. The one labeled “Salt” can only contain salt. Your 32-ounce container can contain up to 32 ounces of salt. But if you have only 2 ounces, you cannot fill the remaining space with flour. If you try to put flour in, all of the contents would be unusable. Your kitchen containers might let you make that mistake, but the file system won’t.
Now, here is where the analogy breaks down. If you relabel the salt canister with the name “Flour,” you can now fill the container with 32 ounces of flour. The average person washes the canister thoroughly before changing contents. The file system does not. It simply replaces the salt in the canister with flour—and worse yet, it starts from the bottom and works upward. So if you have a 32-ounce container of salt, change the name to Flour, and start filling it, a whole bunch of salt remains. In other words, the data in a reallocated cluster is not overwritten.
Figure 8.3 illustrates this concept. In this illustration, the nursery rhyme Twinkle, Twinkle, Little Star was hosted by cluster 154926645. The file was erased and replace by Mary Had a Little Lamb, which did not require as much space. So the file system overwrote the bytes it required, but left certain characters from the previous file behind. The astute investigator can retrieve the remaining characters from the erased file to determine if they have any relevance to the investigation at hand. While such information may not be the proverbial smoking gun, it may provide powerful evidence of where the smoke came from.
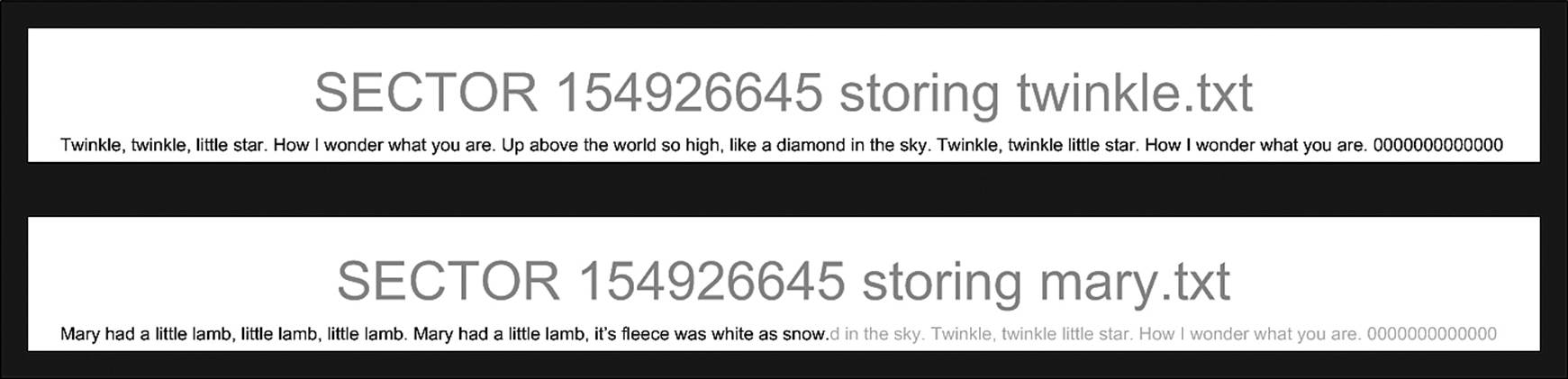
Figure 8.3 An example of slack space. The faded text represents data left behind by a previous file.
Up until recently, a disk sector was 512 bytes. Of that 512 bytes, about 40 bytes were used for sector mapping and 40 bytes for error correction. The International Disk Drive Equipment and Materials Association (IDEMA) developed the Long Block Data (LBD) standard that defined 4KB sectors. Disk drive manufacturers have incorporated this new standard in the Advanced Format. Since file systems such as NTFS, ext3, and HFS all use 4KB as a default cluster, once usage of LBD becomes universal, the concept of the cluster will be reexamined.
Understanding Unallocated Space
Occasionally, a beginning practitioner has difficulty understanding the difference between slack space and unallocated space. In a way, they are similar, but realistically, they are quite different. Unallocated space can be considered as slack space for the entire volume. It is any hard disk space that is not currently identified within the file system as hosting live file data. Those clusters have not been assigned, or “allocated” as it were, to any given file. It is available for use, should the operating system need to store a new file or to extend an existing file into additional clusters.
Just because a cluster is unallocated does not necessarily mean it is empty. When a user deletes a file, the clusters assigned by the file system to that file are marked as free, and the space is now unallocated. The data is not affected unless one of two things happen. The first is if the file system identifies the cluster as free and uses it for another file. In that case, if the cluster is not completely overwritten, it may be possible to extract data from the part of the cluster not completely overwritten. This is the “slack space” that was discussed in the previous section.
The second thing that can destroy the data in unallocated clusters is to use a wipe utility. Such a utility overwrites the data repeatedly with 0s and 1s, deleting the data between each pass. Some utilities perform as many as 32 passes. The average digital forensic lab will be unable to retrieve any data from clusters subjected to such a wipe. However, some highly specialized facilities have equipment that can extract information from drives on a molecular level. This, however, is far beyond the scope of this book.
Assuming that a wipe utility has not been used, most forensic suites have the capability of searching slack space as though it were a file. They can search for text using string searches. Data-carving utilities (discussed later in the chapter) can find entire files as long as they exist intact.
Sometimes it is a matter of finding specific data, and not recovering an entire file. To find text strings in slack space, a couple of utilities are quite useful—GREP and strings. Both utilities are available in either *nix or Windows variations.
GREP
GREP is an acronym for Global/Regular Express/Print. Originally developed for UNIX, all flavors of Linux support it as well. It is a command-line utility and requires at least a rudimentary understanding of using a terminal emulator. Terminal emulators are programs that operate within the graphical environment of the OS, but provide pure command-line services. This is frequently called simply the shell. Such shells include Terminal, XTerm, BASH, Konsole, and about a thousand others.
GREP has over 40 different command-line tags that modify its behavior. Therefore, a complete discussion would require a small book on its own. To get the condensed version of the GREP manual, type MAN GREP at the Linux command prompt, and it will display a detailed description of each trigger.
The tricks that GREP can perform that are of interest to the investigator are somewhat simpler. It can extract strings of text from binary files. This is useful if data has been embedded in another file. For example, a music file might have strings of text embedded between the file header and the sample blocks. GREP can look for specific patterns. This is useful if you are looking for files that contain certain words.
If the investigator is looking for passwords in a live memory capture, GREP can be used to find all text strings that fall within a size range. For example, if one knows that the password policy requires passwords between 8 and 15 characters, then the memory image file can be search for all text strings in that range and ignore all others.
Strings
Strings is available in both the *nix and the Windows platforms and is equally useful. By default, the utility will display any text string longer than four characters. However, as with the GREP utility, command-line triggers allow the user to modify this behavior. The –n trigger allows the user to specify a minimum string length. Strings can search individual files, or it can search folders. If the folders option is used, it can be told to search folders recursively. This means that all nested folders within folders within folders can be searched using the parameters specified.
The Deleted File
The best way to understand how files can be recovered is to understand what happens when they are deleted. Different operating systems deal with the deleted file in different ways.
FAT16 deleted the file simply by replacing the first character of the file name with an illegal character. The file name was then rendered “invisible” to the operating system and did not show up in directory listings, nor are the file names visible to applications. The data remained intact on all clusters until the file system needed that cluster for another file. Recovering a deleted file required only that the user have disk-level access in order to replace the illegal character at the beginning of the file name with a legal character. It did not matter if the correct character was used or not. However, the OS has no way of dealing with partially overwritten clusters. So if a cluster had been reallocated, one of two things would happen. Either the file would be reported as corrupt and the application would fail to load it, or it would load the file, and where foreign data had replaced original data, the information would appear as gibberish.
Later versions of Windows introduced the Recycle Bin. In those versions, when a user deletes a file it is reallocated to the Recycle Bin. It is not “placed” or “moved” there. The actual data that comprises the file stays precisely where it was before the user elected to delete it. The FAT entries are simply rewritten to place the file in a hidden folder called Recycled. (Note that if you have more than one drive in your computer, you’ll have a Recycled folder for each drive.) The file is then renamed. The original name and location of the file are stored in a hidden index file, called INFO2 (or INFO, if you’re using Windows 95), located in the Recycled folder. When you open the Recycle Bin, click a file, and choose Restore, the original path is read from the INFO file, the file is renamed, and its directory entry restored.
A file is in no danger of being lost until it is removed from the Recycle Bin. Even then, the file data is not deleted. What happens is that Windows changes the name of the file by changing the first character of the file name to an illegal character (as previously discussed in the previous section). The file system alters the file’s directory entry to indicate the space occupied by this file is no longer needed and is available for use. Until that space is needed, it still remains intact. However, if the operating system needs space for another file, those clusters may be overwritten. Until it is overwritten, the raw data still exists on the hard disk and may be recoverable by third-party applications.
The implications of this are twofold. If the deleted file contains information that must never again see the light of day, then steps must be taken to permanently erase the data. There are a number of utilities available that will accomplish this task. Note that many file deletion products claim to meet Department of Defense specifications for a clean file wipe, citing a need for data to be overwritten seven times. In fact the Clearing and Sanitizing Matrix (U.S. DoD 2006) generally referenced does not make such a statement. In fact, it states that in order to sanitize a disk containing classified information, the disk must be degaussed with a Type I or Type II degausser or destroyed.
For acceptable destruction methods, incineration, melting, disintegrating, pulverizing, or shredding are all listed as acceptable methods. These latter methods are not very conducive to data recovery. Only for nonclassified information is any method involving overwriting considered to be acceptable. The method of deleting nonclassified information from a disk is to “overwrite all addressable locations with a character, its complement, then a random character and verify” (U.S. DOD 2006). The implication here is that even data that has been overwritten is potentially recoverable.
Implication number two is that if there is need to recover that file, one can dramatically increase the chances of being able to recover a deleted file by halting any subsequent disk activity. If the OS decides it wants to recycle one or more of the sectors used by the file, the difficulty of recovering it increases by several magnitudes. That is why many published guidelines suggest turning off a suspect computer by pulling the power plug from the back of the system. A graceful shutdown writes a myriad of files to the hard disk in the process of shutting down. These new files, or newly relocated files, can potentially overwrite sectors that the investigator might want to later recover.
The File Recovery Process
The author assumes that readers of this book are already familiar with the process of recovering a file from standard Recycle and Trash bins. This text will concentrate on locating and extracting files that have been removed from those locations.
There are numerous third-party utilities that can successfully restore files from the NTFS file system. An inexpensive option that the reader can use to follow along is Directory Snoop from Briggs Software. A free download allows 25 uses before a license is required. As of this writing the licensed version, as used here, is around $40.
In this example, a file named Test_Document.doc was saved to the DA_Temp folder. The file was subsequently deleted. For the purposes of this demonstration, the Recycle Bin was emptied prior to deletion, making Test_Document.doc the only file present. Windows Explorer still reports this file as present in the Recycle folder (Figure 8.4). Next, the file was removed from the Recycle Bin. As one might expect, there are no longer any entries in Explorer. However, the data remain intact on the clusters it occupied until overwritten by another file. Additionally, the MFT entries may still exist.
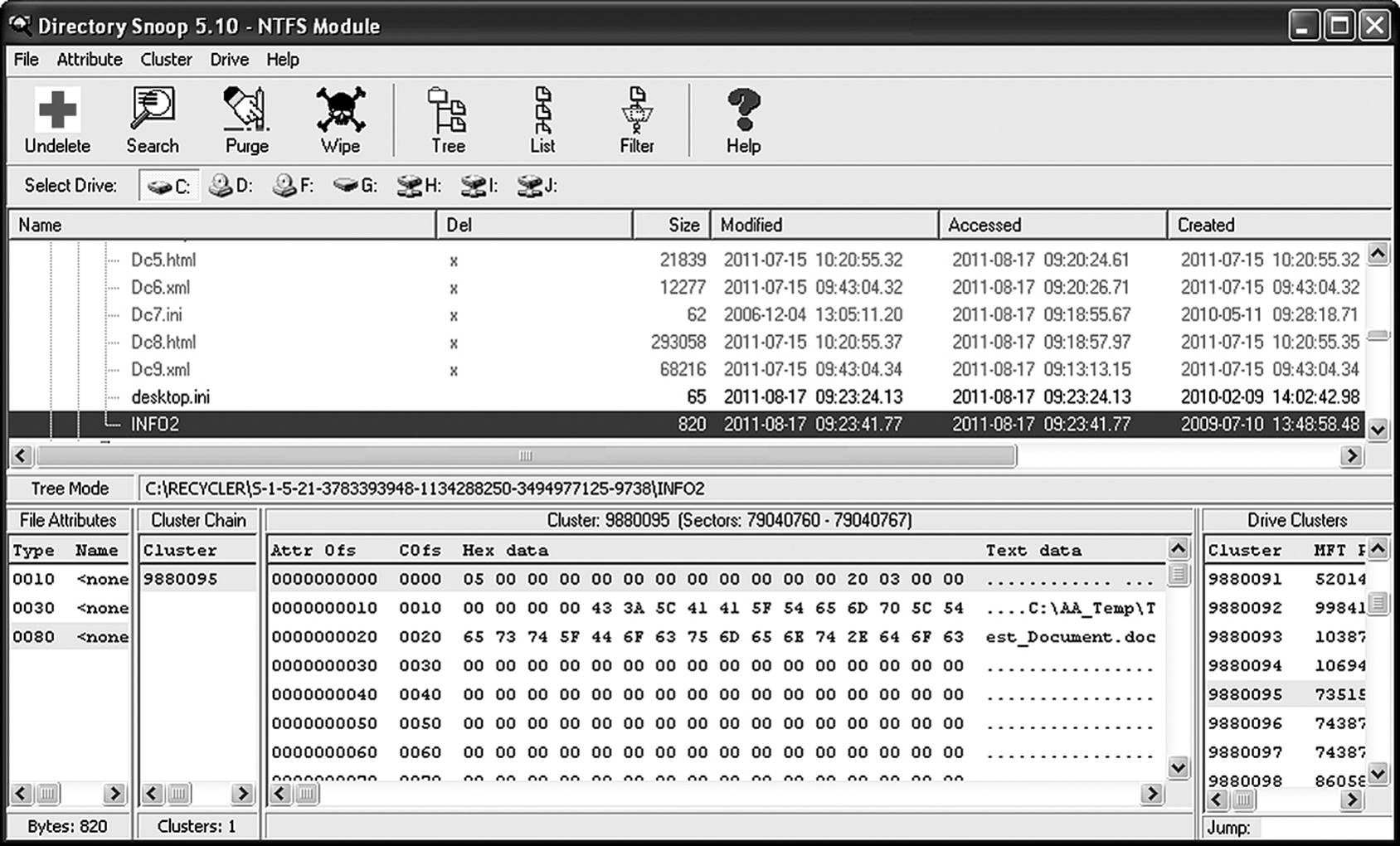
Figure 8.4 The INFO2 directory holds recycled files.
So how does one go about finding this ephemeral data? Numerous file recovery utilities exist that, with varying degrees of success, can restore a file that has not been overwritten. A few more sophisticated utilities can restore the data from partially overwritten files. All of the major forensic suites provide functionality for recovering deleted data.
MFT entries are not immediately deleted after a file is erased. The entries are simply marked as free, becoming available if needed. Disk editors enable the investigator to read and copy into a file the information contained by MFT entries remaining from deleted files. This can include information such as file name, file extension, and possibly a pointer to the next MFT entry. This suggests the size of the file was larger than the cluster size in use by the file system.
In this example, Directory Snoop finds two entries that correspond to the deleted file. The file names do not correspond. The author knew to look in the Recycle Bin for the deleted file rather than in the original directory. Why? As mentioned earlier, the initial erasure of the file simply moved the file from its original director to the Recycle directory. The Windows 7 file system maintains a hidden, read-only file called $Recycle Bin where deleted files are maintained. (Windows XP and earlier utilized INFO2 files.) They are renamed by the file system to prevent naming conflicts in the inevitable case where the user recreates the file under the same name. When the Recycle Bin is emptied, the files are simply deleted from that directory, and the space is allocated by the file system as available.
Notice in Figure 8.5 that there are multiple subdirectories of Recycle Bin. Each of those folders is the recycle bin for a specific user account on the machine. This explains why each user sees only her deleted files and not those of other users who share the machine. The deleted files continue to appear, and using the utility are easily restored as long as the file has not been overwritten. With this utility and several others like it, it is possible to restore the remaining data from slack space even after a cluster has been allocated to a new file.
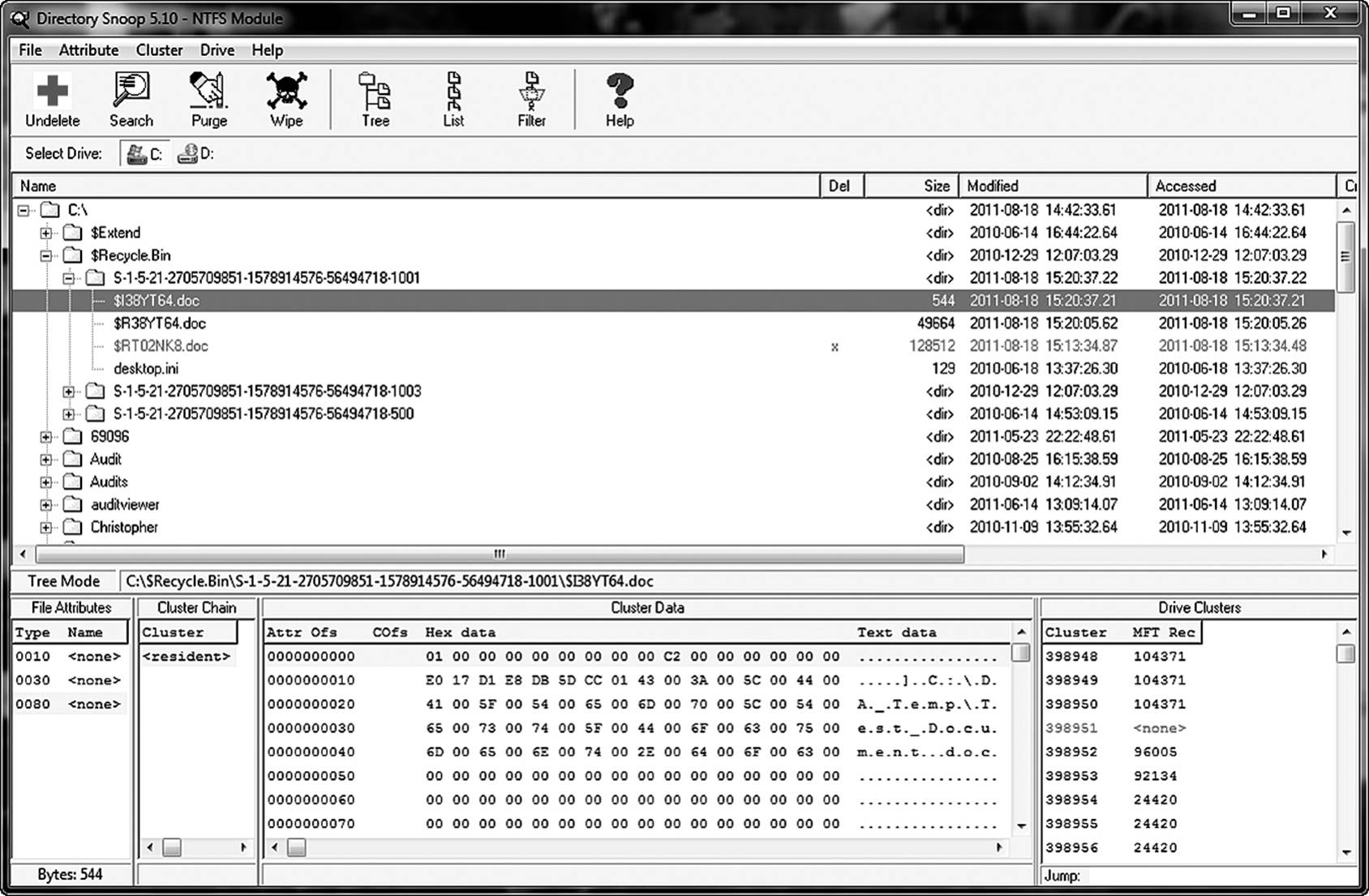
Figure 8.5 Every user on the system has a separate folder in the Recycle Bin.
Data Carving
It has been mentioned numerous times in this book that until overwritten, files continue to exist on most media. However, without the support of a file system in place, a file must be returned to an approximation of its original structure before it can be opened. The process of data carvingextracts the string of binary code that makes up a file and copies it into a contiguous file that is readable by the file system. By nature, each type of file has a specific file structure. The file header is unique to each type of file. Additionally, different file types support different classes of metadata. The payload contains the actual data.
How Data Carving Works
Forensic investigators make use of special utilities to extract complete files from slack space or unallocated space. They utilize an understanding of basic file structure in order to perform their magic. Every file has a header, and every file has an end of file (EOF) marker. Headers for any given file are a specific string that tells the OS what type of data is contained within. The utility finds files in slack space by locating the string and copying all data between that point and the EOF marker for that file type. It maintains a table of common header and EOF strings.
An example of how a carving utility works can be seen in how it would dig a JPEG file out of unallocated space. The JPEG header consists of a series of hexadecimal characters that translate into a symbol set that looks like ÿØÿà..JFIF. The EOF string is ÿÙ. The carving utility scans unallocated space looking for ÿØÿà..JFIF, and when it finds this string, it copies it—along with all the data that follows—until it finds the string ÿÙ. It copies the EOF to the end of the new file and saves it as a file with a JPEG extension.
Another advantage of these tools is that they can find files embedded inside of other files. Image files embedded in a word processing document are an example of this. The image file may no longer exist as an independent file on the hard disk but be part of a composite document.
There are some limitations to the investigator’s ability to uncover files using this method. The vast majority of utilities can only recover files that are part of a contiguous space. If the file is fragmented on the hard disk, they will fail. Other utilities can find the extended sectors, patch them together, and present the file completely. This technique, known as SmartCarving, was first demonstrated by Pal, Sencar, and Memon (2008) in response to the 2007 Digital Forensics Research Workshop (DFRWS) challenge. A company called Digital Assembly now distributes a suite of utilities called Adroit Photo Forensics that incorporates this technology.
Conventional data carving utilities rely on certain conditions to be successful. Those parameters in part depend on the technique used by the file carving utility. The most common utilities use either block-based or header/footer analysis. However, in general the following applies to all except SmartCarving utilities. The file signature (that part of the header that identifies the type of file) must be present and intact. The file is not fragmented. The utility must be able to account for file block size variables. A condition that does not preclude success, but can make life difficult for the investigator is when the file signature is so common that it is likely to appear repeatedly as a character string in numerous files. This causes a great number of false positives to be reported.
A block-based file carver starts out by finding a known header string. Then, it examines each block of data in turn, using data modeling to determine if the next block scanned meets the expected data for that type of file. Each data block that fits the model is added to the file.
Header/footer utilities start out by using a search string engine to scan the unallocated space, looking for known file headers. Next, the utility performs a mapping function. It bounces down the input file, one block at a time, looking for the first occurrence of the file footer identified with that file. By default, most applications use the 512-byte block to match the sector size of most hard drives. All of the data between the header and footer is assumed to be associated with that file and is “cut and pasted” into a new file and given an arbitrary name, followed by the default extension for that file type. Any data remaining in a 512-byte block that follows the EOF marker is dropped. The file is copied to the target evidence drive into a folder selected by the investigator. As mentioned earlier, common header strings result in false positives.
Each invalid header results in a new file being started. When the footer is reached, the new file is copied to the target drive. If a single contiguous stream of data yields a dozen “headers” before finding a valid footer, then 12 files will be generated. Only one will be the actual file, but all of the others will still be copied to the target evidence drive. On a large project this can have a major impact on resources.
Another source of failure for data carving utilities is the fragmented file. The header and footer of the file may be separated by one or more clusters owned by a different file.
Data Carving Tools
As previously mentioned, all commercial forensic suites offer powerful file recovery tools. This includes data carving. For those not blessed with the budget for such fancy toys, there are two open-source utilities that are worth examining: Foremost and Scalpel. The following is a brief overview of these tools.
Foremost
Foremost (downloaded from http://foremost.sourceforge.net/) is a Linux data carving utility that can extract files from their entirety from unallocated space (assuming, of course that the file still exists in its entirety.) Originally developed by the U.S. Air Force Office of Special Investigations, it has been released to the public domain for general use. It is primarily header/footer based but does examine block content to verify file type. The utility can work on a live system or a forensic image file.
Foremost is a command-line utility that must be run with root privileges for maximum success. Several triggers allow the investigator to customize the output of the results. While not a conclusive list of triggers, the more useful to the investigator include
• -i Input file. Allows the user to specify a specific file for Foremost to analyze.
• -o Output directory. Allows user to specify the directory in which the output file will be stored.
• -v Verbose. Runs in verbose mode, providing more information about running state and file statistics.
• -q Quick mode. Only searches each block for header information. Speeds up the search but misses embedded files.
• -Q Quiet mode. Suppresses error messages.
• -w Write audit mode. Creates a list of files found without extracting any files.
• -k Allows the user to specify the size of the data chunk scanned by Foremost. (Note that there must be sufficient free RAM for whatever size is specified.)
• -b Block size. Specifies the block size to be used. Allows known cluster sizes to be configured, speeding up the process. Default is 512 bytes.
• -t File type. Specifies the type of file for the search (DOC, JPEG, TIF, etc.).
• -s Skip blocks. Specifies how many data blocks to scan past before beginning the search for header information. Useful for scanning images of large drives where boot sectors, file system metadata, and root directories can be skipped.
An example of Foremost at work follows (note that the command is typed all one line):
FOREMOST –t jpeg, tif, bmp – /usr/documents/
evidence/diskimage.dd –o/usr/documents/evidence/results
In the above example, the utility has been asked to search for all JPEG, TIF, and BMP images located in a disk image created by the DD utility. The image file named diskimage.dd, located in the /usr/documents/evidence directory of the mounted drive, is the file being examined. If diskimage.dd is located in a different directory or on a different partition, Foremost will generate a “file not found” error.
The output of the search will be stored in directory named /usr/documents/evidence/results. Files will be stored with randomly generated names followed by the appropriate extension. For example, the output directory might contain files such as 65544361.jpg, 35719997.jpg, 44002899.jpg, and so forth.
If the audit trigger is specified, an additional file named audit.txt will be generated by Foremost and stored in the target directory. A cautionary note here is that Foremost is not intelligent enough to create a directory that does not exist. Therefore, the investigator must first create the desired target direct prior to running the utility.
Carver-Recovery
Carver-recovery is another open-source utility (download from https://carver-recovery.googlecode.com/files/Portable_Executable.zip) that looks for file headers and footers in order to perform its function. Scalpel scans the target drive twice. In the first pass, it is reading data in large chunks. While the chunk size is user definable, the default setting is 10MB. As the application performs this scan, it keeps a log of the location of each header it finds for which it was configured to search. It also looks for footers, creating a log of each hit. On the second pass, the indexes created during the first pass are used to determine what chunks hold potential files and is able to skip over all chunks that do not offer potential evidence. This process makes for a somewhat faster operation in theory. In practice, the results varied widely.
The author used three sample image files and used Foremost and Scalpel to look for images. The images consisted of
• 2GB USB drive: 6 undeleted and 2 deleted images
• 40MB partition from a FAT32 hard disk: 20 undeleted and 10 deleted images
• 40GB hard disk: 20 undeleted and 10 deleted images (source of partition above)
The test results were rather interesting. On the 2GB USB drive, Foremost finished the job about 27 minutes and 45 seconds (27m45s), whereas Scalpel took 26m17s. Both utilities extracted the undeleted files with ease, while neither was able to identify or extract the deleted files. While Scalpel was somewhat faster, it was not a significant difference. The reason that the flash drive did not allow for the recovery of deleted drives was that flash memory is not magnetic media and stores data in a completely different manner. It uses microtransistors to store data, and when a file is deleted, all transistors are set to “off.”
The 40MB file took 38m47s for Scalpel to process. Foremost beat it out with a 22m17s time. The time savings came at a cost, however. Foremost found but nine of the ten deleted files, whereas Scalpel identified all of them. The 40GB test was particularly revealing. Scalpel finished the job, finding all files in 4h32m38s. Processing the image file in Foremost was unsuccessful.
Chapter Review
1. Explain in your own words how the file system in use on a computer system can be significant to the investigator when looking for evidence. What makes the search approach different between file systems? What makes a search more or less difficult with any given file system?
2. You have to find any files on a computer that are related to a specific case. You know that the suspect’s name is Priscilla, that she was dealing in the international pornography trade, and that one of the suspected suppliers is in the state of Georgia. What utilities can help you find files, and how is it that they can help?
3. Why is it that a file that has been deleted by the user can be recovered intact? Shouldn’t the data be permanently erased when a file is deleted?
4. How does slack space differ from unallocated space? How are they similar?
5. What process is used to recover files intact out of unallocated space?
Chapter Exercises
1. Using either online resources or the library, research at least two criminal or civil cases in which recovered files played a significant role in how the case played out.
2. On your own hard disk, try to find some files that were deleted in the past and recover them. Are you able to use them?
References
Microsoft. 2010. The NTFS file system. Technet. http://technet.microsoft.com/en-us/library/cc976808.aspx (accessed July 22, 2011).
Microsoft. 2011. File systems. Technet. http://technet.microsoft.com/en-us/library/cc938437.aspx (accessed July 18, 2011).
Pal, A., T. Sencar, and N. Memon. 2008. Detecting file fragmentation point using sequential hypothesis testing. Digital Investigations (Fall). http://digital-assembly.com/technology/research/pubs/dfrws2008.pdf (accessed August 24, 2011).
U.S. Department of Defense. 2006. Clearing and sanitizing matrix. DoD 5220.22-M.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.