Computer Science: A Very Short Introduction (2016)
Chapter 2 Computational artefacts
We think of the computer as the centrepiece of computing; thus, of computer science. And rightly so. But there are caveats to be noted.
First, what exactly constitutes ‘the computer’ can be debated. Some tend to think of it as the physical object they work with on a daily basis (a laptop or their workplace desktop). Others think of the total system at their disposal, including such facilities as email service, word processing, accessing databases, etc., as ‘the computer’. Still others relate it to an entirely mathematical model called the Turing machine (discussed later in this chapter).
Second, accepting that the computer is a symbol processing automaton, there are also other symbol processing artefacts associated with the computer, but which seem slightly at odds with our intuitive idea of ‘the computer’. Thus, it behoves us to be more eclectic in our view of artefacts that participate in the computing process; hence the term computational artefact. In this chapter we consider the nature of computational artefacts.
In Chapter 1, the computer appeared as (more or less) a black box. All that was said was that it is a symbol processing automaton: it accepts symbol structures (denoting information, data, or knowledge as the case may be) as input and produces (of its own impetus) symbol structures as output.
When we prise open this black box we find that it is rather like a set of nested boxes: inside we find one or more smaller boxes; opening one of these inner boxes reveals still smaller boxes nested within. And so on. Of course, the degree of nesting of black boxes is finite; sooner or later we reach the most primitive boxes.
The natural and artificial worlds both manifest instances of this phenomenon—called hierarchy. Many physical, biological, social, and technological systems are hierarchical in structure. The difference between natural hierarchies (as in living systems) and artificial ones (as in cultural or technological systems) is that scientists have to discover the former and invent the latter.
The modern computer is a hierarchically organized system of computational artefacts. Inventing, understanding, and applying rules and principles of hierarchy is, thus, a subdiscipline of computer science.
There is a reason why hierarchies exist in both natural and artificial domains, and we owe this insight, most notably, to the polymath scientist Herbert Simon. Hierarchical organization, he stated, is a means of managing the complexity of an entity. In Simon’s language, an entity is complex if it is composed of a number of components that interact in a non-trivial (that is, non-obvious) way. As we will see, the computer manifests this kind of complexity, hence it too is composed as a hierarchical system. The designers and implementers of computer systems are forced to structure them according to principles and rules of hierarchy. Computer scientists have the responsibility of inventing these rules and principles.
Compositional hierarchy
In general, a hierarchical system consists of components partitioned across two or more levels. The most common principles of hierarchy are concerned with the relationship of components both within and across levels.
Figure 1 depicts what I will call ‘MY-COMPUTER’. (Physically, this may be a desktop, a laptop, a tablet, or even a smart phone. For convenience, I will assume it is one of the first two.) Suppose I use MY-COMPUTER only for three kinds of tasks: to write texts (as I am doing now), to send emails, and to search the (World Wide) Web via the Internet. Thus, I view it as consisting of three computing tools which I will call TEXT, MAIL, and WEB-SEARCH (level 1 of Figure 1), respectively. Each is a symbol processing computational artefact. Each is defined (for me as the tool user) in terms of certain capabilities. For example, TEXT offers a user-interface allowing me to input a stream of characters, and give commands to align margins, set spacing between lines, paginate, start a new paragraph, indent, insert special symbols, add footnotes and endnotes, italicize and boldface, and so on. It also allows me to input a stream of characters which, using the commands, is set into text which I can save for later use and retrieve.
From my point of view, TEXT is MY-COMPUTER when I am writing an article or a book (as at this moment), just as MAIL or WEB-SEARCH is MY-COMPUTER when I am emailing or searching the Web, respectively. More precisely, I am afforded three different, alternative illusions of what MY-COMPUTER is. Computer scientists refer to such illusionary artefacts as virtual machines, and the creation, analysis, and understanding of such virtual machines is one of the major concerns in computer science. They constitute one of the phenomena surrounding computers that Perlis, Newell, and Simon alluded to.
The term architecture is used generically by computer scientists to mean the logical or functional structure of computational artefacts. (The term computer architecture has a more specialized meaning which will be discussed later.) From my (or any other user’s) point of view, the computing tool TEXT has a certain architecture which is visible to me: it has an interpreter that interprets and executes commands; a temporary or working memory whose content is the text I am composing; a permanent or long-term memory which holds all the different texts as files I have chosen to save; input channels that transmits my character streams and commands to the machine, and output channels that allow the display of texts on a screen or as printed matter (‘hardcopy’). These components are ‘functional’: I may not know (or particularly care) about the actual media in which these components exist. And because they characterize all I (as the user) need to know about TEXT to be able to use it, we will call it TEXT’s architecture.
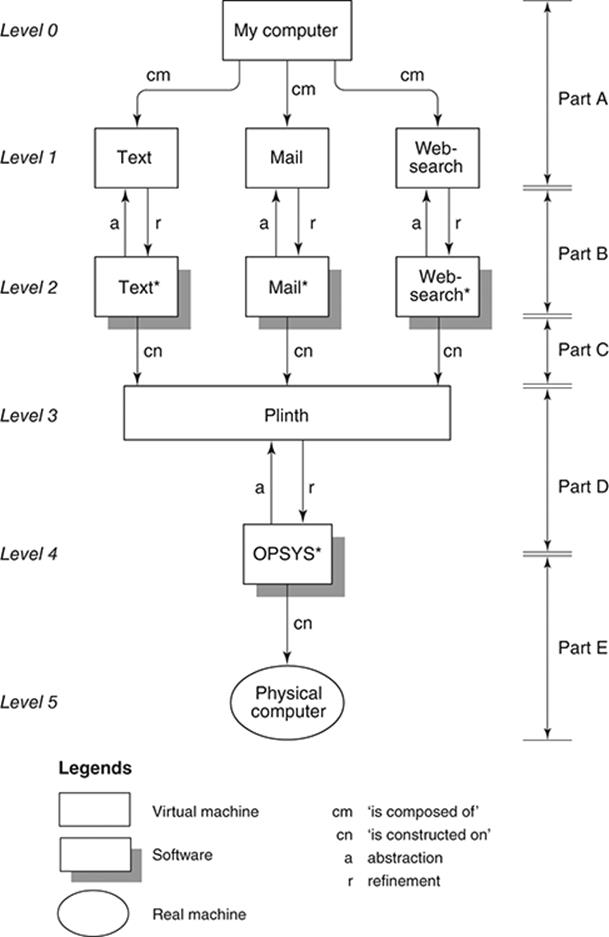
1. Abstraction and hierarchy inside a computer system.
Likewise, when emailing, the tool MAIL is MY-COMPUTER: a virtual computational artefact. This too is a symbol processor. It manifests a user-interface that enables me to specify one or more recipients of a message; link one or more other symbol structures (texts, pictures) as attachments that accompany the message; compose the message; and send it to the recipient(s). Its architecture resembles that of TEXT in that it manifests the same kinds of components. It can interpret commands, has an input channel enabling character streams to be assembled in a working memory, a long-term memory to hold, as long as I want, my messages, and output channels for displaying the contents of the email on the screen and printing it out. In addition, MAIL has access to other kinds of long-term memory which hold the symbol structures (texts and images) that can be attached to the message; however, one of these long-term memories is private to MY-COMPUTER and so, can only be accessed by me, while the other is public—that is, shared with users of other computers.
Finally, there is WEB-SEARCH. Its architecture is similar: an interpreter of the commands; a shared/public memory (the Web) whose contents (‘web pages’) are accessible; a private working memory that (temporarily) holds the contents accessed from shared memory; a private long-term memory which can save these contents; and input and output channels.
The hierarchy shown in part A of Figure 1 is two-levelled. At the upper level (0) is a single computational artefact, MY-COMPUTER; but the lower level (1) shows that MY-COMPUTER is composed of three independent tools. This lower level constitutes my tool box as it were. This type of hierarchy, when an entity A is composed of entities α, β, γ, … , is ubiquitous in complex systems of any kind, natural or artificial. It is certainly a characteristic of computational artefacts. There is no commonly accepted term for it, so let us call it compositional hierarchy.
Abstraction/refinement
As we have noted, the three computing tools at level 1 of Figure 1 are similar in their respective architectures. Each comprises of shared and private long-term memories, private working memory, input and output channel(s), and interpreter(s) of commands.
But these three computing tools must have been implemented for them to be actual working artefacts: For instance, someone must have designed and implemented a computational artefact which when activated performs as TEXT, hiding the details of the mechanisms by which TEXT was realized. Let us denote this implemented artefact TEXT* (level 2 of Figure 1); this is a computer program, a piece of software. The relationship between TEXT and TEXT* is one of abstraction/refinement (part B of Figure 1):
An abstraction of an entity E is itself another entity e that reveals only those characteristics of E considered relevant in some context while suppressing other characteristics deemed irrelevant (in that context). Conversely, a refinement of an entity e is itself another entity E such that E reveals characteristics that were absent or suppressed in e.
TEXT is an abstraction of TEXT*; conversely, TEXT* is a refinement of TEXT. Notice that abstraction/refinement is also a principle of hierarchy in which abstraction is at the upper level and refinement at the lower level. Notice also that abstractions and refinements are context-dependent. The same entity E may be abstracted in different ways to yield two or more higher level entities e1, e2, … , eN. Conversely, the same entity e may be refined in two more different ways to yield different lower level entities E1, E2,…, En.
The principle of abstraction/refinement as a way of managing the complexity of computational artefacts has a rich history from the earliest years of computing. Perhaps the person who made the emerging computer science community in the 1960s most conscious about the importance of this principle of hierarchy was Edsger Dijkstra. Later we will see its particular importance in the process of building computational artefacts, but for the present it is enough for the reader to appreciate how a complex computational artefact can be understood in terms of the abstraction/refinement principle, just as a complex computational artefact can be understood in terms of the compositional hierarchy.
Hierarchy by construction
We are no longer ‘seeing’ MY-COMPUTER from my perspective as a user. We are now in the realm of those who have actually created MY-COMPUTER: the tool builders or artificers. And they are not, incidentally, a homogenous lot.
In particular, TEXT*, MAIL*, and WEB-SEARCH* are computer programs—software—which programmers (software developers, as they are now preferably called), have constructed upon an infrastructure which I call here PLINTH (part C and level 3 of Figure 1). This particular infrastructure also consists of a collection of computing tools the builders of TEXT* et al. could use. Here, then, is a third type of hierarchy: hierarchy by construction.
Ever since the earliest days of the digital computer, designers and researchers have sought to protect the user, as far as possible, from the gritty, and sometimes nasty, realities of the physical computer, to make the user’s life easier. The ambition has always been to create a smooth, pleasant user interface that is close to the user’s particular universe of discourse, and remains within the user’s comfort zone. A civil or a mechanical engineer wants to perform computations that command the computer to solve the equations of engineering mechanics; a novelist wants his computer to function as a writing instrument; the accountant desires to ‘offload’ some of her more tedious calculations to the computer; and so on. In each case, the relevant user desires an illusion that their computer is tailor-made for his or her need. Much debate has ensued over the years as to whether such user tools and infrastructures should be incorporated into the physical machine (‘hardwired’) or provided in more flexible fashion by way of software. In general, the partitioning of infrastructures and tools across this divide has been rationalized by the particular needs of the communities for whom computers are developed.
As we have noted, MY-COMPUTER offers such illusions to the user whose sole concerns are typing text, sending and receiving emails, and searching the Web. MY-C0MPUTER offers an infrastructure for the user to write texts, compose and send emails, and search for information on the Web, just as PLINTH (at a lower level) offers such an infra-structure for the construction of programs that function as the user’s toolkit.
But even the software developers, who created these abstractions by implementing the programs TEXT* et al., must have their own illusions: they too are users of the computer though their engagement with the computer is far more intense than mine when I am using TEXT or MAIL. We may call them ‘application programmers’ or ‘application software developers’, and they too must be shielded from some of the realities of the physical computer. They too need an infrastructure with which they can work, upon which they can create their own virtual machines.
In Figure 1, the entity named PLINTH is such a foundation. It is, in fact, an abstraction of a collection of programs (a ‘software system’), shown here as OPSYS* (level 4) which belongs to a class of computational artefacts called operating systems.
An operating system is the great facilitator; it is the great protector; it is the great illusionist. In its early days of development, in the 1960s, it was called ‘supervisor’ or ‘executive’ and these terms capture well what its responsibilities are. Its function is to manage the resources of the physical computer and provide a uniform set of services to all users of the computer whether layperson or software developer. These services include ‘loaders’ which will accept programs to be executed and allocating them to appropriate locations in memory; memory management (ensuring that one user program does not encroach upon, or interfere with, the memory used by another program); providing virtual memory (giving users the illusion of unlimited memory); controlling physical devices (such as disks, printers, monitors) that perform input and output functions; organizing the storage of information (or data or knowledge) in long-term memories so as to make it easily and speedily accessible; executing procedures according to standardized rules (called ‘protocols’) that enable a program on one computer to request service from a program in another computer communicated through a network; protecting a user’s program from being corrupted by another user’s program either accidentally or by the latter user’s malice. The infrastructure called PLINTH in Figure 1 provides such services—a set of computing tools; it is an abstraction of the operating system OPSYS*.
Yet, an operating system is not exactly a firewall forbidding all interaction between a program constructed atop it (such as MAIL*) and the physical computer beneath it. After all, a program will execute by issuing instructions or commands to the physical computer, and most of these instructions will be directly interpreted by the physical computer (in which situation, these instructions are called ‘machine instructions’). What the operating system will do is ‘let through’ machine instructions to the physical computers in a controlled fashion, and interpret other instructions itself (such as those for input and output tasks).
Which brings us to (almost) the bottom of the hierarchy depicted in Figure 1. OPSYS*, the operating system software, is shown here as constructed—on top of the physical computer (level 5). For the present we will assume that the physical computer (commonly and crudely calledhardware) is (finally) the ‘real thing’; that there is nothing virtual about it. We will see that this too is an illusion, that the physical computer has its own internal hierarchy and it too has its own levels of abstraction, composition, and construction. But at least we can complete the present discussion on this note: that the physical computer provides an infrastructure and a toolbox comprising a repertoire of instructions (machine instructions), a repertoire of data types (see Chapter 1), modes of organizing and accessing instructions and data in memory, and certain other basic facilities which enable the implementation of programs (especially the operating system) that can be executed by the physical computer.
Three classes of computational artefacts
In a recent book narrating the history of the birth of computer science I commented that a peculiarity of computer science lies in its three classes of computational artefacts.
One class is material. These artefacts, like all material objects encountered through history, obey the physical laws of nature (such as Ohm’s law, the laws of thermodynamics, Newton’s laws of motion, etc.). They consume power, generate heat, entail (in some cases) physical motion, decay physically and chemically over time, occupy physical space, and consume physical time when operational. In our example of Figure 1, the physical computer at level 5 is an instance. Obviously, all kinds of computer hardware are material computational artefacts.
Some computational artefacts, however, are entirely abstract. They not only process symbol structures, they themselves are symbol structures and are intrinsically devoid of any physicality (though they may be made visible via physical media such as marks on paper or on the computer screen). So physico-chemical laws do not apply to them. They neither occupy physical space nor do they consume physical time. They ‘neither toil nor spin’ in physical space-time; rather, they exist in their own space-time frame. There are no instances of the abstract artefact in Figure 1. In the next section, I cite examples, and will discuss some of them in chapters to follow. But if you recall the mention of procedures that I as a user of TEXT or MAIL can devise to deploy these tools, such procedures exemplify abstract artefacts.
The third class of computational artefacts are the ones that most lend strangeness to computer science. These are abstract and material. To be more precise, they are themselves symbol structures, and in this sense they are abstract; yet their operations cause changes in the material world: signals transmitted across communication paths, electromagnetic waves to radiate in space, physical states of devices to change, and so on; moreover, their actions depend on an underlying material agent to execute the actions. Because of this nature, I have called this class liminal (meaning a state of ambiguity, of between and betwixt). Computer programs or software is one vast class of liminal computational artefacts, for example, the programs TEXT*, MAIL*, WEB-SEARCH*, and the operating system OPSYS* of Figure 1.
Later, we will encounter another important kind of liminal artefact. For the present, what makes computer science both distinctive and strange is not only the presence of liminal artefacts but also that what we call ‘the computer’ is a symbiosis of the material, the abstract, and the liminal.
Over the approximately six decades during which computer science as an autonomous, scientific discipline evolved, many distinct subclasses of these three classes of computational artefacts have emerged. Four instances—user tool and infrastructure, software, and physical computer—are shown in Figure 1. Of course, some subclasses are more central to computing than others because they are more universal in their scope and use than others. Moreover, the classes and subclasses form a compositional hierarchy of their own.
Here is a list of some of these classes and subclasses presently recognized in computer science. The numbering convention demonstrates the hierarchical relationship between them. While the reader may not be familiar with many of these elements, I will explain the most prominent of them in the course of this book.
[1] Abstract artefacts
[1.1] Algorithms
[1.2] Abstract automata
[1.2.1] Turing machines
[1.2.2] Sequential machines
[1.3] Metalanguages
[1.4] Methodologies
[1.5] Languages
[1.5.1] Programming languages
[1.5.2] Hardware description languages
[1.5.3] Microprogramming languages
[2] Liminal artefacts
[2.1] User tools and interfaces
[2.2] Computer architectures
[2.2.1] Uniprocessor architectures
[2.2.2] Multiprocessor architectures
[2.2.3] Distributed computer architectures
[2.3] Software (programs)
[2.3.1] Von Neumann style
[2.3.2] Functional style
[3] Material artefacts
[3.1] Physical computers/hardware
[3.2] Logic circuits
[3.3] Communication networks
The ‘great unifier’
There is one computational artefact that must be singled out. This is the Turing machine, an abstract machine named after its originator—logician, mathematician, and computer theorist Alan Turing. Let me first describe this artefact and then explain why it deserves special attention.
The Turing machine consists of a tape that is unbounded in length and divided into squares. Each square can hold one of a vocabulary of symbols. At any point in time a read/write head is positioned on one square of the tape which becomes the ‘current’ square. The symbol in the current square (including the ‘empty’ symbol or ‘blank’) is the ‘current symbol’. The machine can be in one of a finite number of states. The state of the machine at any given time is its ‘current state’. Depending on the current symbol and the current state, the read/write head can write (an output) symbol on the current square (overwriting the current symbol), move one square left or right, or effect a change of state, called the ‘next state’. The cycle of operation repeats with the next state as the current state, the new current square holding the new current symbol. The relationships between the (possible) current states (CS), (possible) current (input) symbols (I), the (possible) output symbols (O), movements of the read/write head (RW), and the (possible) next states (NS) are specified by a ‘state table’. The behaviour of the machine is controlled by the state table and the invisible mechanism that effects the reads and writes, moves the read/write head, and effects changes of state.
Figure 2 depicts a very simple Turing machine which reads an input string of 0s and 1s written on the tape, replaces the input string with 0s except that when the entire string has been scanned, it writes a 1 if the number of 1s in the input string is odd, and 0 otherwise. The machine then comes to a halt. A special symbol, say #, on the tape indicates the end of the input string. This machine would be called a ‘parity detector’: it replaces the entire input string with 0s and replaces # with a 1 or a 0 depending on whether the parity of (the number of 1s in) the input string is odd or even.
This machine needs three states: So signifies that an odd number of 1s have been detected in the input string at any point in the machine’s operation. Se represents the detection of an even number of 1s up to any point in the machine’s operation. The third state H is the halting state: it causes the machine to halt. When the machine begins operation, its read/write head is pointing to the square holding the first digit in the input string.
The potential behaviour of the Turing machine is specified by the state table (see Table 1).
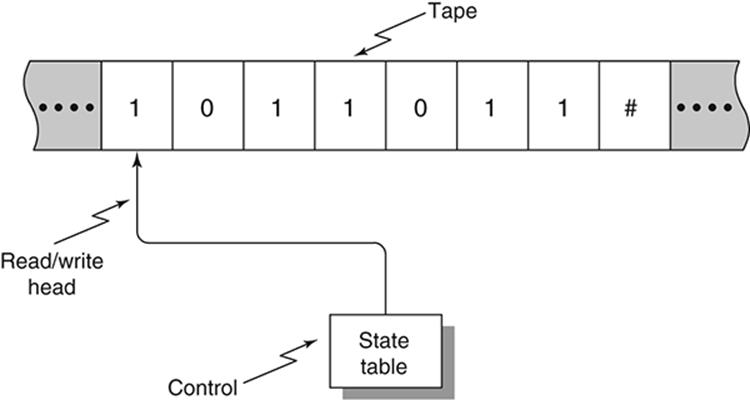
2. General structure of the Turing machine.
Table 1. The state table
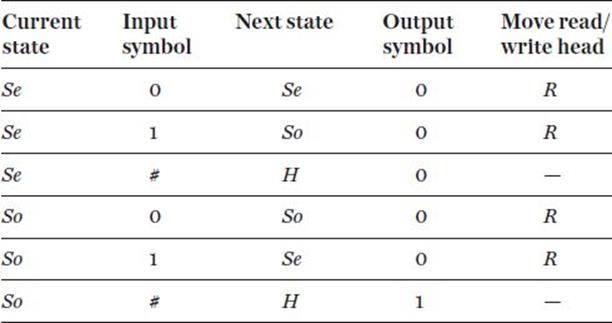
Each row in this table specifies a distinct operation on the part of the machine and must be interpreted independently. For example, the first row says that: if the current state is Se and the current input symbol is 0 then the next state will (also) be Se and output symbol 0 is written on the tapeand the read/write head is moved one position right. The last row tells us that that if the current state is So and the input symbol is # then replace the # with a 1 and make the next state the halt state H. There is no further motion of the read/write head.
Suppose the input string is as shown in Figure 2, and the machine is set to the state Se. The reader can easily verify that the sequence of states and the contents of the tape in successive cycles of the machine’s operation will be as follows. The position of the read/write head in each cycle is indicated by the asterisk to the right of the ‘current’ input symbol:
Se: 1*011011# ➔ So: 00*11011# ➔ So: 001*1011# ➔ Se: 0001*011# ➔
So: 00000*11# ➔ So: 000001*1# ➔ Se: 0000001*# ➔ So: 0000000#* ➔
H: 00000001*
There will be, then, a distinct Turing machine (Turing himself called this, simply, a ‘computing machine’) for each distinct symbol processing task. Each such (special purpose) Turing machine will specify the alphabet of symbols that the machine will recognize, the set of possible states, the initial square on which the read/write head is positioned, the state table, and the initial current state. At the end of the machine’s operation (when it reaches the ‘halt’ state, if there is one) the output written onto the tape gives the result of the symbol processing task.
Thus, for example, a Turing machine can be built to add two numbers n, m, represented by n 1s followed by a blank followed by m 1s, leaving the result n + m (as a string of n + m 1s) on the tape. Another Turing machine with a single string composed of the symbols a, b, and c as input will replace this input string with a ‘mirror image’ (called a ‘palindrome’) of the input string. For example if the input string is ‘aaabbbccc’ then the output will be ‘cccbbbaaa’. A Turing machine is, thus, a symbol processing machine. It is, of course, an abstract artefact in the ‘purest’ sense since the machine itself is a symbol structure. No one would dream of making a physical version of a Turing machine as a practical artefact.
But Turing went further. He also showed that one can build a single computing machine U that can simulate every other Turing machine. If U is provided with a tape containing the description of the state table for a specific Turing machine, U will interpret that description and perform the same task as that particular machine would do. Such a machine U is called a universal Turing machine.
The significance of Turing’s invention lies in a claim he made that any procedure that we ‘intuitively’ or ‘naturally’ think of as a computing procedure can be realized by a Turing machine. It follows that a universal Turing machine can perform anything we think of as computing. This claim is called the Turing thesis (or sometimes as the Church–Turing thesis, since another logician, Alonzo Church, arrived at the same conclusion using an entirely different line of thinking).
We may think of the Turing machine as the ‘great unifier’. It is what binds all computational artefacts; that is, all computational artefacts and their behaviours can be reduced to the workings of a Turing machine.
Having said this, and also recognizing that an entire branch of computer science called automata theory exists which studies the structure and behaviour, the power and limitations of the Turing machine in all its conceivable manifestations (e.g. in confining the tape to a finite length, or in introducing multiple tapes with multiple read/write heads), we must also recognize the paradoxical situation that the Turing machine has had almost no impact on the invention, design, implementation, and behaviour of any practical (or practicable) computational artefact whatsoever, or on the thinking and practice of computer scientists who deal with such artefacts!
Interactive computing
Moreover, since Turing’s time there have emerged computational artefacts that work interactively with each other or with other natural or artificial systems. ‘Interaction’ refers here to the mutual or reciprocal influence amongst artificial (including social) and/or natural agents that together form a system of some sort.
Consider, for example, my paying a utilities bill: this entails an interaction between me and my laptop, and my bank’s computer system and that of the utility company. In this situation four agents (three computational artefacts and myself) are effecting information transfers and computations interactively, by exchanging messages, commands, and data.
Or consider the abstract computational artefact TEXT in Figure 1. This constitutes a human–computer interface whereby the human user of TEXT and the software system TEXT* interact with each other. Commands afforded by TEXT and issued by the user causes TEXT* to respond (initiating a new line of text, creating a space between words, adding characters to form words in the text, indenting for a new paragraph, italicizing a word, etc.) and this latter response prompts, in turn, the human user to respond.
Such interactive systems do not conform to the ‘standard’ idea of the Turing machine which is essentially a stand-alone artefact with inputs already inscribed on its tape before the activation of the machine and whose output is only visible when the Turing machine halts. Interactive computational artefacts (such as my bank’s or my utility company’s system) may never halt.
It is because of such considerations that some computer scientists insist that the study of Turing machines—automata theory—properly belongs to the realm of mathematics and mathematical logic than to computer science proper, while others question the validity of seeing the Turing thesis as encompassing the whole of computing.
Computer science as a science of the artificial
To summarize the discussion so far, computational artefacts are made things; they process symbol structures signifying information, data, or knowledge (depending on one’s point of view and context). Computer science is the science of computational artefacts.
Clearly, computational artefacts are not part of the natural world in the sense that rocks, minerals and fossils, plants and animals, stars, galaxies and black holes, elementary particles, atoms and molecules are. Human beings bring these artefacts into existence. Thus, computer science is not anatural science. So what kind of science is it?
One view is that since computational artefacts are utilitarian, thus technological, computer science is not ‘really’ a science at all. Rather, it is a branch of engineering. However, the traditional engineering sciences such as strength of materials, theory of structures, thermodynamics, physical metallurgy, circuit theory, as well as such new engineering sciences as bioengineering and genetic engineering are directly constrained by the laws of nature. Liminal and abstract computational artefacts seem a far cry from the uncompromisingly material artefacts—structures, machine tools, engines, integrated circuits, metals, alloys, and composite materials, etc.—studied by engineering scientists. This is one of the reasons why material computational artefacts (computer hardware) often belong to the domain of engineering schools while liminal and abstract ones are in the domain of schools of science.
However, all artefacts—engineering and computational—have something in common: they are the products of human thought, human goals, human needs, human desires. Artefacts are purposive: they reflect the goals of their creators.
Herbert Simon called all the sciences concerned with artefacts (abstract, liminal, or material) the sciences of the artificial. They stand apart from the natural sciences because they must take into account goals and purposes. A natural object has no purpose: rocks and minerals, stars and galaxies, atoms and molecules, plants and organisms have not come into the world with a purpose. They just are. The astronomer does not ask: ‘What is a galaxy for?’ The geologist does not ask: ‘What is the purpose of an igneous intrusion?’ The task of the natural scientist is to discover the laws governing the structures and behaviours of natural phenomena, inquire into how they came into being, but not ask why—for what purpose—they came into existence.
In contrast, artefacts have entered the world reflecting human needs and goals. It is not enough to ask what are the laws and principles governing the structure and behaviour of a computational artefact (or, for that matter, of pyramids, suspension bridges, particle accelerators, and kitchen knives) if we then ignore the reason for their existence.
The sciences of the artificial entail the study of the relationship between means and ends: the goals or needs for which an artefact is intended, and the artefact made to satisfy the needs. The ‘science’ in computer science is, thus, a science of means and ends. It asks: given a human need, goal, or purpose, how can a computational artefact demonstrably achieve such a purpose? That is, how can one demonstrate, by reason or observation or experiment that the computational artefact satisfies that purpose?
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.