Praise for Gray Hat Hacking: The Ethical Hacker’s Handbook, Fourth Edition (2015)
PART I. Crash Course: Preparing for the War
CHAPTER 2. Programming Survival Skills
Why study programming? Ethical gray hat hackers should study programming and learn as much about the subject as possible in order to find vulnerabilities in programs and get them fixed before unethical hackers take advantage of them. It is very much a foot race: if the vulnerability exists, who will find it first? The purpose of this chapter is to give you the survival skills necessary to understand upcoming chapters and later find the holes in software before the black hats do.
In this chapter, we cover the following topics:
• C programming language
• Computer memory
• Intel processors
• Assembly language basics
• Debugging with gdb
• Python survival skills
C Programming Language
The C programming language was developed in 1972 by Dennis Ritchie from AT&T Bell Labs. The language was heavily used in Unix and is thereby ubiquitous. In fact, much of the staple networking programs and operating systems are based in C.
Basic C Language Constructs
Although each C program is unique, there are common structures that can be found in most programs. We’ll discuss these in the next few sections.
main()
All C programs contain a main() structure (lowercase) that follows this format:

where both the return value type and arguments are optional. If you use command-line arguments for main(), use the format
<optional return value type> main(int argc, char * argv[]){
where the argc integer holds the number of arguments and the argv array holds the input arguments (strings). The parentheses and brackets are mandatory, but white space between these elements does not matter. The brackets are used to denote the beginning and end of a block of code. Although procedure and function calls are optional, the program would do nothing without them. Procedure statements are simply a series of commands that perform operations on data or variables and normally end with a semicolon.
Functions
Functions are self-contained bundles of algorithms that can be called for execution by main() or other functions. Technically, the main() structure of each C program is also a function; however, most programs contain other functions. The format is as follows:
<optional return value type > function name (<optional function argument>){
}
The first line of a function is called the signature. By looking at it, you can tell if the function returns a value after executing or requires arguments that will be used in processing the procedures of the function.
The call to the function looks like this:
<optional variable to store the returned value =>function name (arguments if called for by the function signature);
Again, notice the required semicolon at the end of the function call. In general, the semicolon is used on all stand-alone command lines (not bounded by brackets or parentheses).
Functions are used to modify the flow of a program. When a call to a function is made, the execution of the program temporarily jumps to the function. After execution of the called function has completed, the program continues executing on the line following the call. This process will make more sense during our discussion of stack operations in Chapter 10.
Variables
Variables are used in programs to store pieces of information that may change and may be used to dynamically influence the program. Table 2-1 shows some common types of variables.
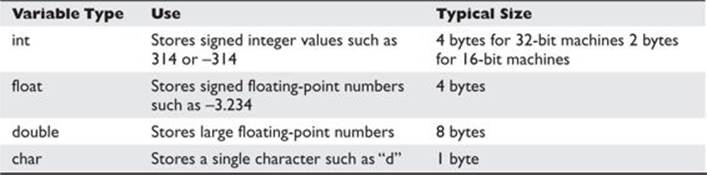
Table 2-1 Types of Variables
When the program is compiled, most variables are preallocated memory of a fixed size according to system-specific definitions of size. Sizes in Table 2-1 are considered typical; there is no guarantee that you will get those exact sizes. It is left up to the hardware implementation to define this size. However, the function sizeof() is used in C to ensure that the correct sizes are allocated by the compiler.
Variables are typically defined near the top of a block of code. As the compiler chews up the code and builds a symbol table, it must be aware of a variable before it is used in the code later. This formal declaration of variables is done in the following manner:
<variable type> <variable name> <optional initialization starting with “=”>;
For example,
int a = 0;
where an integer (normally 4 bytes) is declared in memory with a name of a and an initial value of 0.
Once declared, the assignment construct is used to change the value of a variable. For example, the statement
x=x+1;
is an assignment statement containing a variable x modified by the + operator. The new value is stored into x. It is common to use the format
destination = source <with optional operators>
where destination is the location in which the final outcome is stored.
printf
The C language comes with many useful constructs for free (bundled in the libc library). One of the most commonly used constructs is the printf command, generally used to print output to the screen. There are two forms of the printf command:
printf(<string>);
printf(<format string>, <list of variables/values>);
The first format is straightforward and is used to display a simple string to the screen. The second format allows for more flexibility through the use of a format string that can be composed of normal characters and special symbols that act as placeholders for the list of variables following the comma. Commonly used format symbols are listed and described in Table 2-2.

Table 2-2 printf Format Symbols
These format symbols may be combined in any order to produce the desired output. Except for the \n symbol, the number of variables/values needs to match the number of symbols in the format string; otherwise, problems will arise, as described in our discussion of format string exploits in Chapter 11.
scanf
The scanf command complements the printf command and is generally used to get input from the user. The format is as follows:
scanf(<format string>, <list of variables/values>);
where the format string can contain format symbols such as those shown for printf in Table 2-2. For example, the following code will read an integer from the user and store it into the variable called number:
scanf(“%d”, &number);
Actually, the & symbol means we are storing the value into the memory location pointed to by number; that will make more sense when we talk about pointers later in the chapter in the “Pointers” section. For now, realize that you must use the & symbol before any variable name withscanf. The command is smart enough to change types on-the-fly, so if you were to enter a character in the previous command prompt, the command would convert the character into the decimal (ASCII) value automatically. Bounds checking is not done in regard to string size, however, which may lead to problems as discussed later in Chapter 10.
strcpy/strncpy
The strcpy command is probably the most dangerous command used in C. The format of the command is
strcpy(<destination>, <source>);
The purpose of the command is to copy each character in the source string (a series of characters ending with a null character: \0) into the destination string. This is particularly dangerous because there is no checking of the source’s size before it is copied over to the destination. In reality, we are talking about overwriting memory locations here, something which will be explained later in this chapter. Suffice it to say, when the source is larger than the space allocated for the destination, bad things happen (buffer overflows). A much safer command is the strncpy command. The format of that command is
strncpy(<destination>, <source>, <width>);
The width field is used to ensure that only a certain number of characters are copied from the source string to the destination string, allowing for greater control by the programmer.
 CAUTION Using unbounded functions like strcpy is unsafe; however, most programming courses do not cover the dangers posed by these functions. In fact, if programmers would simply use the safer alternatives—for example, strncpy—then the entire class of buffer overflow attacks would be less prevalent. Obviously, programmers continue to use these dangerous functions since buffer overflows are the most common attack vector. That said, even bounded functions can suffer from incorrect width calculations.
CAUTION Using unbounded functions like strcpy is unsafe; however, most programming courses do not cover the dangers posed by these functions. In fact, if programmers would simply use the safer alternatives—for example, strncpy—then the entire class of buffer overflow attacks would be less prevalent. Obviously, programmers continue to use these dangerous functions since buffer overflows are the most common attack vector. That said, even bounded functions can suffer from incorrect width calculations.
for and while Loops
Loops are used in programming languages to iterate through a series of commands multiple times. The two common types are for and while loops.
for loops start counting at a beginning value, test the value for some condition, execute the statement, and increment the value for the next iteration. The format is as follows:
for(<beginning value>; <test value>; <change value>){
<statement>;
}
Therefore, a for loop like
for(i=0; i<10; i++){
printf(“%d”, i);
}
will print the numbers 0 to 9 on the same line (since \n is not used), like this: 0123456789.
With for loops, the condition is checked prior to the iteration of the statements in the loop, so it is possible that even the first iteration will not be executed. When the condition is not met, the flow of the program continues after the loop.
 NOTE It is important to note the use of the less-than operator (<) in place of the less-than-or-equal-to operator (<=), which allows the loop to proceed one more time until i=10. This is an important concept that can lead to off-by-one errors. Also, note the count was started with 0. This is common in C and worth getting used to.
NOTE It is important to note the use of the less-than operator (<) in place of the less-than-or-equal-to operator (<=), which allows the loop to proceed one more time until i=10. This is an important concept that can lead to off-by-one errors. Also, note the count was started with 0. This is common in C and worth getting used to.
The while loop is used to iterate through a series of statements until a condition is met. The format is as follows:

Loops may also be nested within each other.
if/else
The if/else construct is used to execute a series of statements if a certain condition is met; otherwise, the optional else block of statements is executed. If there is no else block of statements, the flow of the program will continue after the end of the closing if block bracket (}). The format is as follows:

The braces may be omitted for single statements.
Comments
To assist in the readability and sharing of source code, programmers include comments in the code. There are two ways to place comments in code: //, or /* and */. The // indicates that any characters on the rest of that line are to be treated as comments and not acted on by the computer when the program executes. The /* and */ pair starts and stops a block of comments that may span multiple lines. The /* is used to start the comment, and the */ is used to indicate the end of the comment block.
Sample Program
You are now ready to review your first program. We will start by showing the program with // comments included, and will follow up with a discussion of the program:

This very simple program prints “Hello haxor” to the screen using the printf function, included in the stdio.h library.
Now for one that’s a little more complex:

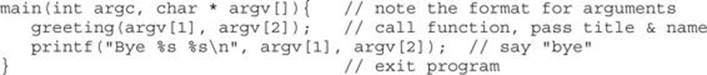
This program takes two command-line arguments and calls the greeting() function, which prints “Hello” and the name given and a carriage return. When the greeting() function finishes, control is returned to main(), which prints out “Bye” and the name given. Finally, the program exits.
Compiling with gcc
Compiling is the process of turning human-readable source code into machine-readable binary files that can be digested by the computer and executed. More specifically, a compiler takes source code and translates it into an intermediate set of files called object code. These files are nearly ready to execute but may contain unresolved references to symbols and functions not included in the original source code file. These symbols and references are resolved through a process called linking, as each object file is linked together into an executable binary file. We have simplified the process for you here.
When programming with C on Unix systems, the compiler of choice is GNU C Compiler (gcc). gcc offers plenty of options when compiling. The most commonly used flags are listed and described in Table 2-3.
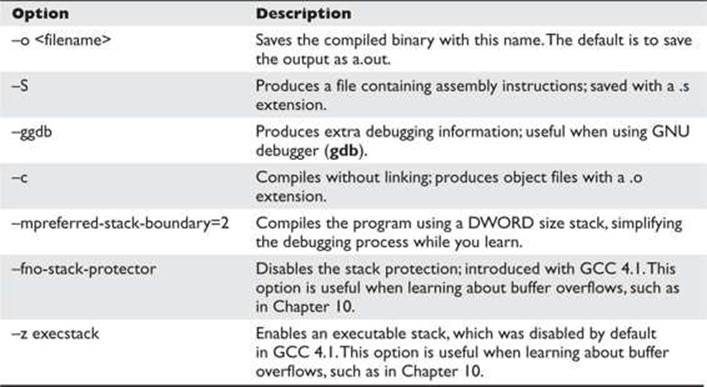
Table 2-3 Commonly Used gcc Flags
For example, to compile our meet.c program, you type
$gcc -o meet meet.c
Then, to execute the new program, you type
$./meet Mr Haxor
Hello Mr Haxor
Bye Mr Haxor
$
Computer Memory
In the simplest terms, computer memory is an electronic mechanism that has the ability to store and retrieve data. The smallest amount of data that can be stored is 1 bit, which can be represented by either a 1 or a 0 in memory. When you put 4 bits together, it is called a nibble, which can represent values from 0000 to –1111. There are exactly 16 binary values, ranging from 0 to 15, in decimal format. When you put two nibbles, or 8 bits, together, you get a byte, which can represent values from 0 to (28 – 1), or 0 to 255 in decimal. When you put 2 bytes together, you get aword, which can represent values from 0 to (216 – 1), or 0 to 65,535 in decimal. Continuing to piece data together, if you put two words together, you get a double word, or DWORD, which can represent values from 0 to (232 – 1), or 0 to 4,294,967,295 in decimal.
There are many types of computer memory; we will focus on random access memory (RAM) and registers. Registers are special forms of memory embedded within processors, which will be discussed later in this chapter in the “Registers” section.
Random Access Memory (RAM)
In RAM, any piece of stored data can be retrieved at any time—thus, the term random access. However, RAM is volatile, meaning that when the computer is turned off, all data is lost from RAM. When discussing modern Intel-based products (x86), the memory is 32-bit addressable, meaning that the address bus the processor uses to select a particular memory address is 32 bits wide. Therefore, the most memory that can be addressed in an x86 processor is 4,294,967,295 bytes.
Endian
In his 1980 Internet Experiment Note (IEN) 137, “On Holy Wars and a Plea for Peace,” Danny Cohen summarized Swift’s Gulliver’s Travels, in part, as follows in his discussion of byte order:
Gulliver finds out that there is a law, proclaimed by the grandfather of the present ruler, requiring all citizens of Lilliput to break their eggs only at the little ends. Of course, all those citizens who broke their eggs at the big ends were angered by the proclamation. Civil war broke out between the Little-Endians and the Big-Endians, resulting in the Big-Endians taking refuge on a nearby island, the kingdom of Blefuscu.1
The point of Cohen’s paper was to describe the two schools of thought when writing data into memory. Some feel that the low-order bytes should be written first (called “Little-Endians” by Cohen), whereas others think the high-order bytes should be written first (called “Big-Endians”). The difference really depends on the hardware you are using. For example, Intel-based processors use the little-endian method, whereas Motorola-based processors use big-endian. This will come into play later as we talk about shellcode in Chapters 6 and 7.
Segmentation of Memory
The subject of segmentation could easily consume a chapter itself. However, the basic concept is simple. Each process (oversimplified as an executing program) needs to have access to its own areas in memory. After all, you would not want one process overwriting another process’s data. So memory is broken down into small segments and handed out to processes as needed. Registers, discussed later in the chapter, are used to store and keep track of the current segments a process maintains. Offset registers are used to keep track of where in the segment the critical pieces of data are kept.
Programs in Memory
When processes are loaded into memory, they are basically broken into many small sections. There are six main sections that we are concerned with, and we’ll discuss them in the following sections.
.text Section
The .text section basically corresponds to the. text portion of the binary executable file. It contains the machine instructions to get the task done. This section is marked as read-only and will cause a segmentation fault if written to. The size is fixed at runtime when the process is first loaded.
.data Section
The .data section is used to store global initialized variables, such as
int a = 0;
The size of this section is fixed at runtime.
.bss Section
The below stack section (.bss) is used to store global noninitialized variables, such as
int a;
The size of this section is fixed at runtime.
Heap Section
The heap section is used to store dynamically allocated variables and grows from the lower-addressed memory to the higher-addressed memory. The allocation of memory is controlled through the malloc() and free() functions. For example, to declare an integer and have the memory allocated at runtime, you would use something like
![]()
Stack Section
The stack section is used to keep track of function calls (recursively) and grows from the higher-addressed memory to the lower-addressed memory on most systems. As we will see, the fact that the stack grows in this manner allows the subject of buffer overflows to exist. Local variables exist in the stack section.
Environment/Arguments Section
The environment/arguments section is used to store a copy of system-level variables that may be required by the process during runtime. For example, among other things, the path, shell name, and hostname are made available to the running process. This section is writable, allowing its use in format string and buffer overflow exploits. Additionally, the command-line arguments are stored in this area. The sections of memory reside in the order presented. The memory space of a process looks like this:

Buffers
The term buffer refers to a storage place used to receive and hold data until it can be handled by a process. Since each process can have its own set of buffers, it is critical to keep them straight; this is done by allocating the memory within the .data or .bss section of the process’s memory. Remember, once allocated, the buffer is of fixed length. The buffer may hold any predefined type of data; however, for our purpose, we will focus on string-based buffers, which are used to store user input and variables.
Strings in Memory
Simply put, strings are just continuous arrays of character data in memory. The string is referenced in memory by the address of the first character. The string is terminated or ended by a null character (\0 in C).
Pointers
Pointers are special pieces of memory that hold the address of other pieces of memory. Moving data around inside of memory is a relatively slow operation. It turns out that instead of moving data, keeping track of the location of items in memory through pointers and simply changing the pointers is much easier. Pointers are saved in 4 bytes of contiguous memory because memory addresses are 32 bits in length (4 bytes). For example, as mentioned, strings are referenced by the address of the first character in the array. That address value is called a pointer. So the variable declaration of a string in C is written as follows:
![]()
Note that even though the size of the pointer is set at 4 bytes, the size of the string has not been set with the preceding command; therefore, this data is considered uninitialized and will be placed in the .bss section of the process memory.
Here is another example; if you wanted to store a pointer to an integer in memory, you would issue the following command in your C program:
![]()
To read the value of the memory address pointed to by the pointer, you dereference the pointer with the * symbol. Therefore, if you wanted to print the value of the integer pointed to by point1 in the preceding code, you would use the following command:
printf(“%d”, *point1);
where the * is used to dereference the pointer called point1 and display the value of the integer using the printf() function.
Putting the Pieces of Memory Together
Now that you have the basics down, we will present a simple example to illustrate the use of memory in a program:

This program does not do much. First, several pieces of memory are allocated in different sections of the process memory. When main is executed, funct1() is called with an argument of 1. Once funct1() is called, the argument is passed to the function variable called c. Next, memory is allocated on the heap for a 10-byte string called str. Finally, the 5-byte string “abcde” is copied into the new variable called str. The function ends, and then the main() program ends.
CAUTION You must have a good grasp of this material before moving on in the book. If you need to review any part of this chapter, please do so before continuing.
Intel Processors
There are several commonly used computer architectures. In this chapter, we focus on the Intel family of processors or architecture. The term architecture simply refers to the way a particular manufacturer implemented its processor. Since the bulk of the processors in use today are Intel 80x86, we will further focus on that architecture.
Registers
Registers are used to store data temporarily. Think of them as fast 8- to 32-bit chunks of memory for use internally by the processor. Registers can be divided into four categories (32 bits each unless otherwise noted). These are listed and described in Table 2-4.
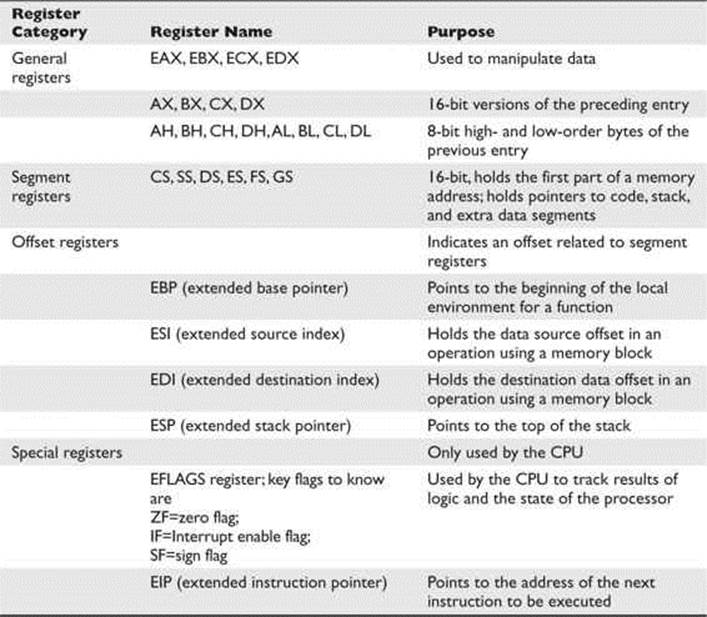
Table 2-4 Categories of Registers
Assembly Language Basics
Though entire books have been written about the ASM language, you can easily grasp a few basics to become a more effective ethical hacker.
Machine vs. Assembly vs. C
Computers only understand machine language—that is, a pattern of 1s and 0s. Humans, on the other hand, have trouble interpreting large strings of 1s and 0s, so assembly was designed to assist programmers with mnemonics to remember the series of numbers. Later, higher-level languages were designed, such as C and others, which remove humans even further from the 1s and 0s. If you want to become a good ethical hacker, you must resist societal trends and get back to basics with assembly.
AT&T vs. NASM
There are two main forms of assembly syntax: AT&T and Intel. AT&T syntax is used by the GNU Assembler (gas), contained in the gcc compiler suite, and is often used by Linux developers. Of the Intel syntax assemblers, the Netwide Assembler (NASM) is the most commonly used. The NASM format is used by many windows assemblers and debuggers. The two formats yield exactly the same machine language; however, there are a few differences in style and format:
• The source and destination operands are reversed, and different symbols are used to mark the beginning of a comment:
• NASM format CMD <dest>, <source> <; comment>
• AT&T format CMD <source>, <dest> <# comment>
• AT&T format uses a % before registers; NASM does not.
• AT&T format uses a $ before literal values; NASM does not.
• AT&T handles memory references differently than NASM.
In this section, we will show the syntax and examples in NASM format for each command. Additionally, we will show an example of the same command in AT&T format for comparison. In general, the following format is used for all commands:
<optional label:> <mnemonic> <operands> <optional comments>
The number of operands (arguments) depend on the command (mnemonic). Although there are many assembly instructions, you only need to master a few. These are described in the following sections.
mov
The mov command copies data from the source to the destination. The value is not removed from the source location.
![]()
Data cannot be moved directly from memory to a segment register. Instead, you must use a general-purpose register as an intermediate step; for example:
mov eax, 1234h; store the value 1234 (hex) into EAX
mov cs, ax; then copy the value of AX into CS.
add and sub
The add command adds the source to the destination and stores the result in the destination. The sub command subtracts the source from the destination and stores the result in the destination.

push and pop
The push and pop commands push and pop items from the stack.

xor
The xor command conducts a bitwise logical “exclusive or” (XOR) function—for example, 11111111 XOR 11111111 = 00000000. Therefore, you use XOR value, value to zero out or clear a register or memory location.
![]()
jne, je, jz, jnz, and jmp
The jne, je, jz, jnz, and jmp commands branch the flow of the program to another location based on the value of the eflag “zero flag.” jne/jnz jumps if the “zero flag” = 0; je/jz jumps if the “zero flag” = 1; and jmp always jumps.

call and ret
The call command calls a procedure (not jumps to a label). The ret command is used at the end of a procedure to return the flow to the command after the call.

inc and dec
The inc and dec commands increment or decrement the destination, respectively.

lea
The lea command loads the effective address of the source into the destination.
![]()
int
The int command throws a system interrupt signal to the processor. The common interrupt you will use is 0x80, which signals a system call to the kernel.
![]()
Addressing Modes
In assembly, several methods can be used to accomplish the same thing. In particular, there are many ways to indicate the effective address to manipulate in memory. These options are called addressing modes and are summarized in Table 2-5.

Table 2-5 Addressing Modes
Assembly File Structure
An assembly source file is broken into the following sections:
• .model The .model directive indicates the size of the .data and .text sections.
• .stack The .stack directive marks the beginning of the stack section and indicates the size of the stack in bytes.
• .data The .data directive marks the beginning of the data section and defines the variables, both initialized and uninitialized.
• .text The .text directive holds the program’s commands.
For example, the following assembly program prints “Hello, haxor!” to the screen:

Assembling
The first step in assembling is to make the object code:
$ nasm -f elf hello.asm
Next, you invoke the linker to make the executable:
$ ld -s -o hello hello.o
Finally, you can run the executable:
$ ./hello
Hello, haxor!
Debugging with gdb
When programming with C on Unix systems, the debugger of choice is gdb. It provides a robust command-line interface, allowing you to run a program while maintaining full control. For example, you may set breakpoints in the execution of the program and monitor the contents of memory or registers at any point you like. For this reason, debuggers like gdb are invaluable to programmers and hackers alike.
gdb Basics
Commonly used commands in gdb are listed and described in Table 2-6.
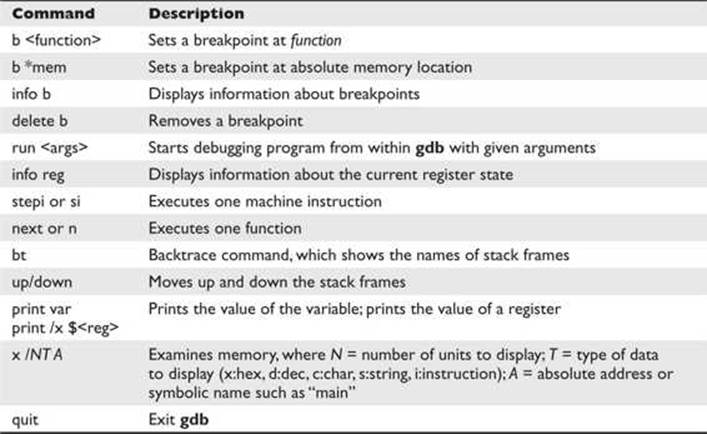
Table 2-6 Common gdb Commands
To debug our example program, we issue the following commands. The first will recompile with debugging and other useful options (refer to Table 2-3).
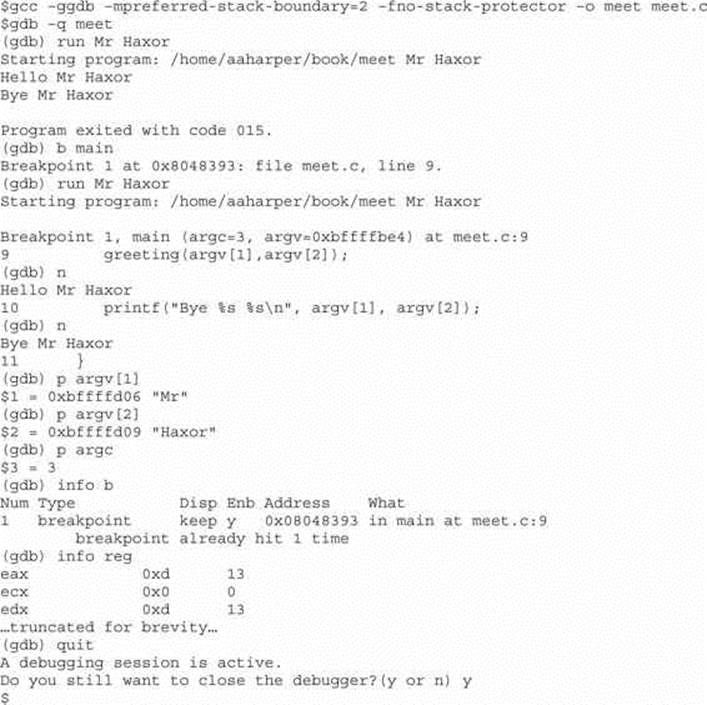
Disassembly with gdb
To conduct disassembly with gdb, you need the two following commands:
![]()
The first command toggles back and forth between Intel (NASM) and AT&T format. By default, gdb uses AT&T format. The second command disassembles the given function (to include main if given). For example, to disassemble the function called greeting in both formats, you type
![]()
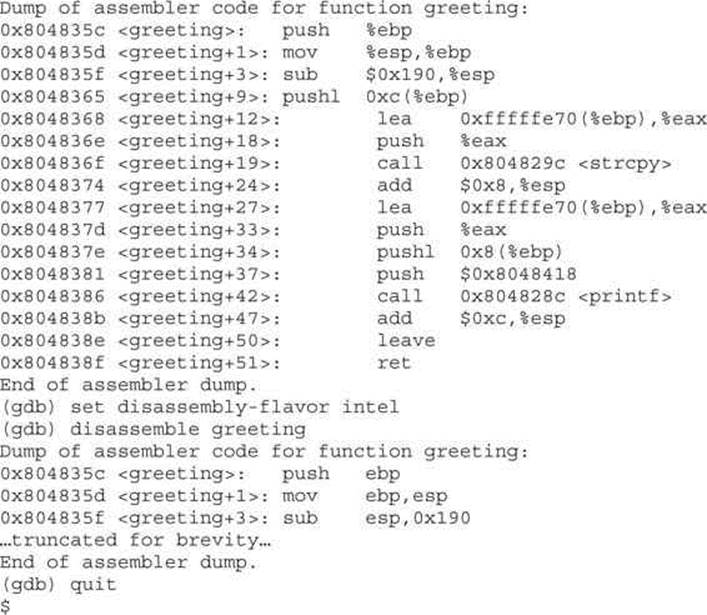
Python Survival Skills
Python is a popular interpreted, object-oriented programming language similar to Perl. Hacking tools (and many other applications) use Python because it is a breeze to learn and use, is quite powerful, and has a clear syntax that makes it easy to read. This introduction covers only the bare minimum you’ll need to understand. You’ll almost surely want to know more, and for that you can check out one of the many good books dedicated to Python or the extensive documentation at www.python.org.
Getting Python
We’re going to blow past the usual architecture diagrams and design goals spiel and tell you to just go download the Python version for your OS from www.python.org/download/ so you can follow along here. Alternately, try just launching it by typing python at your command prompt—it comes installed by default on many Linux distributions and Mac OS X 10.3 and later.
NOTE For you Mac OS X users, Apple does not include Python’s IDLE user interface, which is handy for Python development. You can grab that from www.python.org/download/mac/. Or you can choose to edit and launch Python from Xcode, Apple’s development environment, by following the instructions at http://pythonmac.org/wiki/XcodeIntegration.
Because Python is interpreted (not compiled), you can get immediate feedback from Python using its interactive prompt. We’ll use it for the next few pages, so you should start the interactive prompt now by typing python.
Hello World in Python
Every language introduction must start with the obligatory “Hello, world” example and here is Python’s:

Or if you prefer your examples in file form:

Pretty straightforward, eh? With that out of the way, let’s roll into the language.
Python Objects
The main thing you need to understand really well is the different types of objects that Python can use to hold data and how it manipulates that data. We’ll cover the big five data types: strings, numbers, lists, dictionaries (similar to lists), and files. After that, we’ll cover some basic syntax and the bare minimum on networking.
Strings
You already used one string object in the prior section, “Hello World in Python.” Strings are used in Python to hold text. The best way to show how easy it is to use and manipulate strings is to demonstrate:


Those are basic string-manipulation functions you’ll use for working with simple strings. The syntax is simple and straightforward, just as you’ll come to expect from Python. One important distinction to make right away is that each of those strings (we named them string1, string2, and string3) is simply a pointer—for those familiar with C—or a label for a blob of data out in memory someplace. One concept that sometimes trips up new programmers is the idea of one label (or pointer) pointing to another label. The following code and Figure 2-1 demonstrate this concept:
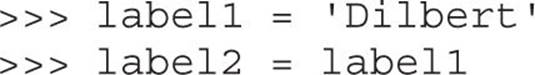
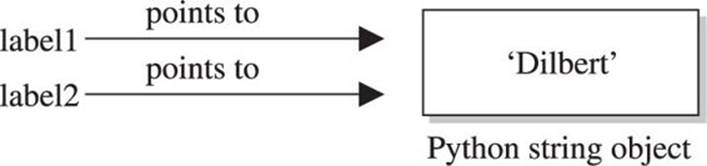
Figure 2-1 Two labels pointing at the same string in memory
At this point, we have a blob of memory somewhere with the Python string ‘Dilbert’ stored. We also have two labels pointing at that blob of memory. If we then change label1’s assignment, label2 does not change:

As you see next in Figure 2-2, label2 is not pointing to label1, per se. Rather, it’s pointing to the same thing label1 was pointing to until label1 was reassigned.
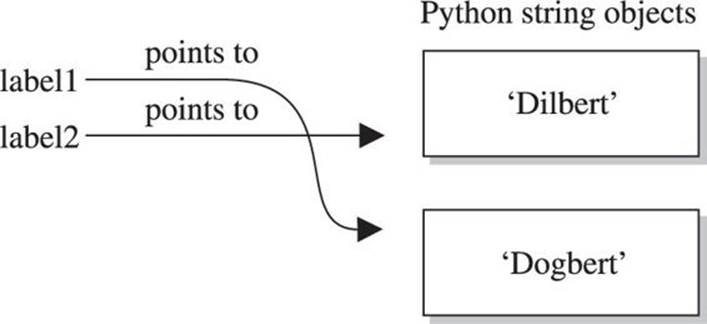
Figure 2-2 Label1 is reassigned to point to a different string.
Numbers
Similar to Python strings, numbers point to an object that can contain any kind of number. It will hold small numbers, big numbers, complex numbers, negative numbers, and any other kind of number you could dream up. The syntax is just as you’d expect:

Now that you’ve seen how numbers work, we can start combining objects. What happens when we evaluate a string plus a number?

Error! We need to help Python understand what we want to happen. In this case, the only way to combine ‘abc’ and 12 is to turn 12 into a string. We can do that on-the-fly:

When it makes sense, different types can be used together:
![]()
And one more note about objects—simply operating on an object often does not change the object. The object itself (number, string, or otherwise) is usually changed only when you explicitly set the object’s label (or pointer) to the new value, as follows:

Lists
The next type of built-in object we’ll cover is the list. You can throw any kind of object into a list. Lists are usually created by adding [ and ] around an object or a group of objects. You can do the same kind of clever “slicing” as with strings. Slicing refers to our string example of returning only a subset of the object’s values, for example, from the fifth value to the tenth with label1[5:10]. Let’s demonstrate how the list type works:
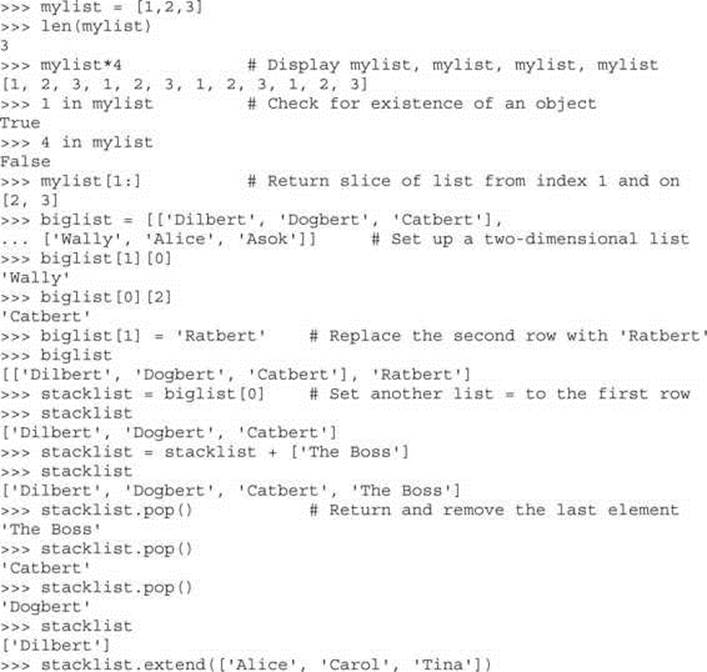

Next, we’ll take a quick look at dictionaries and then files, and then we’ll put all the elements together.
Dictionaries
Dictionaries are similar to lists except that objects stored in a dictionary are referenced by a key, not by the index of the object. This turns out to be a very convenient mechanism to store and retrieve data. Dictionaries are created by adding { and } around a key-value pair, like this:

We’ll use dictionaries more in the next section as well. Dictionaries are a great way to store any values that you can associate with a key where the key is a more useful way to fetch the value than a list’s index.
Files with Python
File access is as easy as the rest of Python’s language. Files can be opened (for reading or for writing), written to, read from, and closed. Let’s put together an example using several different data types discussed here, including files. This example assumes we start with a file named targets and transfer the file contents into individual vulnerability target files. (We can hear you saying, “Finally, an end to the Dilbert examples!”)

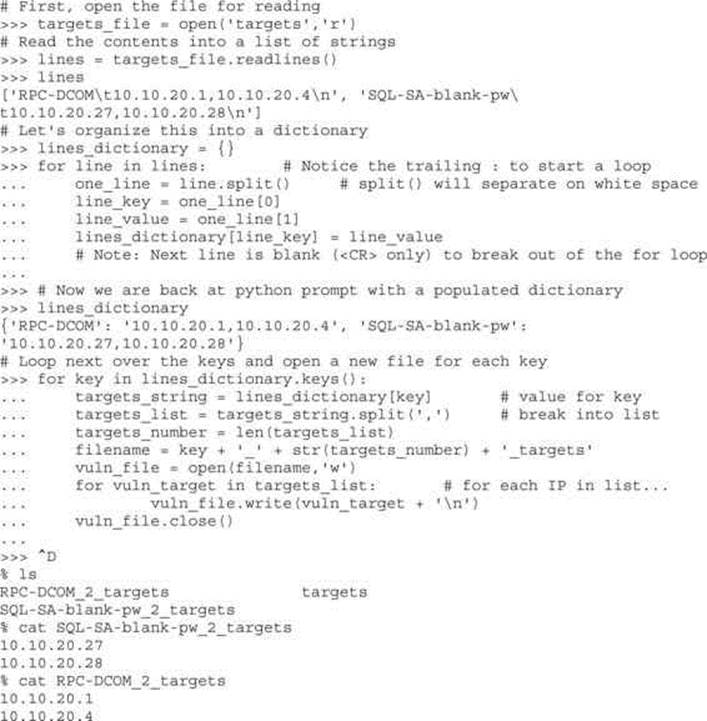
This example introduced a couple of new concepts. First, you now see how easy it is to use files. open() takes two arguments. The first is the name of the file you’d like to read or create, and the second is the access type. You can open the file for reading (r) or writing (w).
And you now have a for loop sample. The structure of a for loop is as follows:

CAUTION In Python, white space matters, and indentation is used to mark code blocks.
Un-indenting one level or a carriage return on a blank line closes the loop. No need for C-style curly brackets. if statements and while loops are similarly structured. Here is an example:

Sockets with Python
The final topic we need to cover is Python’s socket object. To demonstrate Python sockets, let’s build a simple client that connects to a remote (or local) host and sends ‘Hello, world’. To test this code, we’ll need a “server” to listen for this client to connect. We can simulate a server by binding a netcat listener to port 4242 with the following syntax (you may want to launch nc in a new window):
% nc -l -p 4242
The client code follows:

Pretty straightforward, eh? You do need to remember to import the socket library, and then the socket instantiation line has some socket options to remember, but the rest is easy. You connect to a host and port, send what you want, recv into an object, and then close the socket down. When you execute this, you should see ‘Hello, world’ show up on your netcat listener and anything you type into the listener returned back to the client. For extra credit, figure out how to simulate that netcat listener in Python with the bind(), listen(), and accept() statements.
Congratulations! You now know enough Python to survive.
Summary
This chapter prepares you, our readers, for the war! An ethical hacker must have programming skills to create exploits or review source code; he or she needs to understand assembly code when reversing malware or finding vulnerabilities; and, last but not least, debugging is a must-have skill in order to analyze the malware at run time or to follow the execution of a shellcode in memory. All these basic requirements for becoming an ethical hacker were taught in this chapter, so now you are good to go!
References
1. Cohen, Danny (1980, April 1). “On Holy Wars and a Plea for Peace.” Internet Experiment Note (IEN) 137. Retrieved from IETF: www.ietf.org/rfc/ien/ien137.txt.
For Further Reading
“A CPU History,” PC Mech, March 23, 2001 (David Risley) www.pcmech.com/article/a-cpu-history.
Art of Assembly Language Programming and HLA (Randall Hyde) webster.cs.ucr.edu/.
Debugging with NASM and gdb www.csee.umbc.edu/help/nasm/nasm.shtml.
Endianness, Wikipedia en.wikipedia.org/wiki/Endianness.
Good Python tutorial docs.python.org/tut/tut.html.
“How C Programming Works,” How Stuff Works (Marshall Brain) computer.howstuffworks.com/c.htm.
Introduction to Buffer Overflows,” May 1999 www.groar.org/expl/beginner/buffer1.txt.
Introduction to C Programming, University of Leicester (Richard Mobbs) www.le.ac.uk/users/rjm1/c/index.html.
“Little Endian vs. Big Endian,” Linux Journal, September 2, 2003 (Kevin Kaichuan He) www.linuxjournal.com/article/6788.
Notes on x86 assembly, 1997 (Phil Bowman) www.ccntech.com/code/x86asm.txt.
“Pointers: Understanding Memory Addresses,” How Stuff Works (Marshall Brain) computer.howstuffworks.com/c23.htm.
Programming Methodology in C (Hugh Anderson) www.comp.nus.edu.sg/~hugh/TeachingStuff/cs1101c.pdf.
Python home page www.python.org.
“Smashing the Stack for Fun and Profit” (Aleph One) www.phrack.org/issues.html?issue=49&id=14#article.
x86 Registers www.eecg.toronto.edu/~amza/www.mindsec.com/files/x86regs.html.