Praise for Gray Hat Hacking: The Ethical Hacker’s Handbook, Fourth Edition (2015)
PART I. Crash Course: Preparing for the War
CHAPTER 5. World of Fuzzing
This chapter shows you how to use fuzzing techniques for software testing and vulnerability discovery. Originally fuzzing (or fuzz testing) was a class of black-box software and hardware testing in which the data used to perform the testing is randomly generated. Over the years, fuzzing evolved and came to the attention of many researchers who extended the original idea. Nowadays, fuzzing tools support black-box and white-box testing approaches and have many parameters that can be adjusted. These parameters influence the fuzzing process and are used to fine-tune the testing process for a specific problem. By understanding the different approaches and their parameters, you will be able to get the best results using this testing technique.
This chapter goes over the whole fuzzing process—from finding the software targets, to finding data templates, performing the fuzz testing, and analyzing the findings.
In this chapter, we cover the following topics:
• Choosing a good fuzzing target
• Finding suitable templates for fuzzing
• Performing mutation fuzzing with Peach
• Evaluating software crashes for vulnerabilities
Introduction to Fuzzing
One of the fastest ways to get into vulnerability research is through software testing. Traditional black-box software testing is interesting from a vulnerability research perspective because it doesn’t require an understanding of the internal software mechanisms. The only requirement to start looking for vulnerabilities is knowing which interfaces allow interaction with the software and generating the data to be passed through those interfaces.
Fuzzing or fuzz testing is a class of software and hardware testing in which the data used to perform the testing is randomly generated. This way, the problem of generating the input data is vastly simplified and doesn’t require any knowledge about the internal workings of software or the structure of the input data. This might seem like an oversimplified approach, but it has been proven to produce results and find relevant security vulnerabilities in software.
Over the years, much research has been done on improving the software testing and fuzzing techniques. Nowadays, fuzzing no longer implies the use of randomly generated data as a means of input testing, but is instead more of a synonym for any kind of automated software or hardware testing.
This chapter looks into the process of fuzzing and examines several ideas for improving the different stages in fuzzing, which should lead to finding more security vulnerabilities.
In this chapter, the following terms are used interchangeably and should be treated as equal:
• Software, program, and application
• Fuzzing, fuzz testing, and testing
• Bug, vulnerability, and fault
Choosing a Target
The first step of a fuzzing project is deciding on the target. In cases when target can be arbitrarily chosen, it is a good idea to maximize the chance of success by looking for functionality that will facilitate fuzzing.
Several heuristics can be used to order the targets based on their fuzzing potential. Following is a list of some interesting heuristics:
• Support for different input types Ensures there is enough diversion among input types so if one of them proved to be difficult to use for fuzzing, others could be examined and used.
• Ease of automation Allows the target program to be easily and programmatically automated for testing purposes. This usually means that the program can be manipulated in such a way to allow for automatic execution of the test cases generated by the fuzzer.
• Software complexity Commonly used as a heuristic to determine the likelihood that software contains a bug. This comes from the premise that complex things are more likely to contain errors due to the amount of work needed to properly verify and test their correctness. Therefore, programs that parse file formats supporting many options and parameters are more likely to contain security-related issues because they are harder to understand and thus harder to review and check for bugs.
Input Types
An important distinction between the targets is their interfacing capability, which will dictate the ease of automation of the fuzzing process. Simple interfaces, such as passing commands over the command line, are easier to use and automate than applications that only accept commands from their graphical user interface. Different types of interfaces can also dictate the availability of fuzzing strategies and configuration parameters, which results in either an easier or more complicated fuzzing setup. Note that applications can have support for multiple different input types, so it is important to distinguish between each of them and take into consideration only the ones that are of interest for the purposes of testing. An example of software that usually supports input from different types of sources is media players. One way to use them is to play music from a file on local hard drive; another would be to stream radio stations over the Internet. Depending on the type of input (file vs. network stream), a different fuzzing setup would be required. Also, it is worth noting that the complexity of fuzz testing these two input types is different. Fuzzing files is typically easier than fuzzing network protocols because the network adds another layer between the generated data and the application. This additional layer increases complexity and can influence the testing and make reproduction of vulnerabilities harder.
Here are some common types of input interfaces:
• Network (for example, HTTP protocol)
• Command line (for example, shell tools)
• File input (for example, media players)
Ease of Automation
Automation of the testing process can be simple or hard, depending on the target application. Some applications provide various mechanisms, such as exported API functions and scripting capabilities, that facilitate automation. In cases when such capabilities are not available, it is possible to use dedicated tools that specialize in software automation.
In many different scenarios, specific automation tools can simplify the fuzzing process, making it easier to perform. In this section, several automation tools will be mentioned and their common use-cases explained. The following tools represent only a small portion of the available solutions. Before committing to any of them, you should make a list of requirements for target software automation. Cross-referencing the requirements list with the functionality offered by each solution should provide the best tool for the job. Following is a list of things to keep in mind when choosing automation software:
• Price and licensing In distributed fuzzing scenarios, a single computer software license might not be enough to deploy software in a fuzzing farm made of several computers or virtual machines. Different solutions use different pricing and licensing schemes, so if budget plays a role, this should be the first filter.
• Automation language Some of the automation tools use well-known scripting languages such as LUA and Python, whereas others use proprietary languages or custom configuration files. Depending on the language, the time to deploy and develop an automation script can greatly vary, so choosing a familiar language or configuration style can help to speed up the process. However, custom languages should not be disregarded so easily because the time to learn a new language might pay off in the long run, as long as it requires less development time and provides more flexibility. A good rule of thumb is to prefer solutions that require less coding.
• Speed This requirement can sometimes be overlooked when comparing automation software because all of them can seem instantaneous. Depending on the scale of fuzzing, the speed of automation can pose a significant problem for achieving a high number of executed tests. Performing a test run of automation candidates on several thousand samples and comparing their execution speed can help in choosing the best one.
Following is a short list of some popular automation solutions:
• Selenium A browser automation framework that can be used for testing web applications as well as browsers. It supports two types of automation:
• Selenium IDE is record/playback-based testing methodology and comes as a Firefox plug-in. It is able to record user actions such as clicking a web page and entering data in forms and then replaying these actions in the same order. This type of playback automation is useful when testing web applications with complex navigation scenarios.
• The Selenium WebDriver API exposes a very powerful programmatic interface designed for browser automation. It provides better support for dynamic web content and controls the browser directly using the browser’s built-in automation support. WebDriver should be used when IDE functionality is not enough to perform the desired tasks.
• AutoIt This popular software supports writing automation scripts for Windows operating systems in a BASIC-like scripting language. The simplicity of its scripting language, coupled with many resources and documentation of its usage, makes it a very popular candidate. This software might be a good choice for any kind of automation on Windows.
• Expect A program that is able to communicate with other interactive programs and automate the interaction on Linux. The Except configuration language supports Tcl (Tool Command Language) but also some additional Except-specific commands. Also, the library libexpect exposes Expect functionality to C/C++.
Complexity
A common way to judge the fuzzing potential of software is to determine its complexity. For example, an Echo service has much lower complexity and fuzzing potential than an HTTP service. The HTTP protocol is an order of magnitude more complex, which also implies more code and functionality. This complexity usually introduces gray areas that are harder for engineers to understand, in which case security vulnerabilities can be overlooked.
One good way to judge the complexity of software is to check for any available resources for the program or protocol that will be tested, such as the following:
• Software documentation
• RFC specifications for the supported protocols
• Number of supported file types
• Technical specifications for the supported file types
• Size of the application
Types of Fuzzers
We mentioned already that fuzzers have evolved over time and are no longer solely based on random data generation. This section explains different types of fuzzers and their respective strong and weak points. Because fuzzing is not an exact science, experimentation with different fuzzing types and parameters is encouraged.
Following is a list of common fuzzer classifications based on the data-generation algorithms:
• Mutation fuzzers
• Generation fuzzers
Mutation Fuzzers
Mutation-based fuzzers, also called dumb fuzzers, are the simplest variant and closest to the original idea of randomizing the input data. The name comes from changing (mutating) the input data, usually in a random way. The mutated data is then used as input for the target software in order to try and trigger software crash.
Mutation fuzzers usually have two parameters that can be fine-tuned:
• Mutation segments These are parts or sections of the data that will be modified during the fuzzing. This can be full data modification, in which all parts of the file are treated equally and will be modified during the testing. Not all data segments are equally important, so it can be a good idea to skip fuzzing certain parts of the file. File formats usually have magic values that distinguish the file type. These magic values can be several bytes long and located at the beginning of the file. Fuzzing and randomly modifying these parts would only result in corrupted files that cannot be opened or processed by the software. In such cases, it can be a good idea to skip the magic values (or other parts of the file that should remain immutable) to reduce the number of irrelevant test cases. This will greatly improve the number of valid tests and increase the speed of fuzzing.
There are two common types of mutation segment configurations:
• Full All the data is mutated, and no part of the file is treated specially.
• Pros This type of coverage ensures that most of vulnerabilities are covered and tested for.
• Cons The amount of combinations that have to be tested is huge and results in long runtimes. This can also result in a lot of test cases being ignored by the software because of the malformations that can result from modifying special parts or segments of data.
• Segmented In this case, not all data segments are treated equally, and some parts will be handled by special rules.
• Pros The fuzzing process can be directed to specifically test interesting parts of the target. In this case, the “interesting” part is subjective and usually comes from a hunch or educated guess. This hunch can also be enhanced by taking into consideration the list mentioned in the “Complexity” section.
• Cons Fuzzing coverage is limited and depends on correctly identifying interesting parts of the data format.
• Mutation algorithms Commonly, there are three different ways to mutate or modify data while fuzzing, each with different tradeoffs in terms of speed and coverage:
• Randomization This is the easiest and probably most common way to perform fuzzing. Data is modified by replacing portions with randomly generated patterns from a predefined alphabet (for example, printable characters). In this case, the mutation is only restricted by the generating alphabet and desired size of new data. This type of mutation is the most comprehensive because it has the potential to cover all possible combinations and find all bugs. The problem is that combinatorial explosion prevents one from actually testing all possible combinations in a reasonable amount of time, so this approach is opportunistic and can take a lot of time. It is usually a good idea to combine random testing with a set-based approach so that the most common types of vulnerability triggers are performed before starting the extensive random testing.
• Time to deploy: Quick (Quick/Medium/Slow)
• Test coverage: Full (Full/Partial/Minimal)
• Running time: Slow (Fast/Medium/Slow)
• Set based This type of mutation tries to solve the problem of extremely large numbers of combinations in randomization testing, which poses a serious problem to the speed of the testing. The full range of possible mutations present in a random mutation is reduced to a much smaller set that is usually handpicked. This representative set is chosen in such a way to have properties that can trigger or test common vulnerability types.
• Time to deploy: Medium
• Test coverage: Minimal/Partial (depending on the set quality)
• Running time: Fast
• Rule based This type of mutation is a tradeoff between a full randomized search and a minimal hand-picked set. In this case, a set of rules is written to generate patterns or number ranges that will be used for testing. This approach usually extends the created set by writing more general rules that would also explore the patterns similar to the ones determined as “interesting” by the set-based approach.
• Time to deploy: Medium
• Test coverage: Medium
• Running time: Medium
Generation Fuzzers
Generation fuzzers are also called grammar-based or white-box testing. This approach is based on the premise that efficient testing requires understanding the internal workings of the target being tested. Generation fuzzers don’t need examples of valid data inputs or protocol captures like the mutation-based ones. They are able to generate test cases based on data models that describe the structure of the data or protocol. These models are usually written as configuration files whose formats vary based on the fuzzing tools that use them.
One of the main problems with generation fuzzers is writing data models. For simple protocols or data structures for which documentation is available, that is not a major problem, but such cases are rare and not so interesting because of their simplicity.
In reality, things are much more complicated, and the availability of specifications and documentation still requires significant effort to correctly translate to a fuzzing model. Things get even more complicated when software companies don’t follow the specifications and slightly modify them or even introduce new features not mentioned in the specification. In such cases, it is necessary to customize the model for the target software, which requires additional effort.
Most proprietary file formats and protocols don’t even have any public specifications, so a reverse engineering of the format has to be performed. All these things significantly raise the amount of preparation time and can make it very expensive to use this approach.
Getting Started
To get started with fuzzing, you can follow these steps:
1. Choose the target application.
2. Find the fuzzing templates.
3. Choose the optimal template set.
4. Mutate the templates and test the target application.
5. Validate and group the crash results.
Finding the Fuzzing Templates
The success of mutation fuzzers depends on two main factors:
• The data that will be used as a template and mutated
• The algorithms used to perform the mutation
When talking about data used as a mutation template, the notion of quality should be discussed. Quality can be measured by the amount or percentage of the program functionality that is affected or utilized. While the data is being processed, different parts of code will be affected. The affected code can be measured with two metrics: code coverage and code importance.
Code coverage is an easy way to assign a metric to the quality of the template by measuring the amount of code that is executed while processing the template data. This measure is usually a number of executed basic blocks or functions in a program.
Another way to determine the template metric is to measure code importance instead of concentrating only on quantitative information such as the number of executed functions in the code coverage. A template can be said to have higher importance if it covers a set of function or basic blocks that are not covered by any other template.
Therefore, in a nutshell, two important metrics can be used to score templates and determine which should be prioritized when performing mutations:
• Quantitative coverage measurement based on the number of functions or basic blocks executed in the target software while the input data is being processed. In this case, the higher the number of covered functions, the more suited that data is as a mutation template.
• Uniqueness coverage measurement based on maximizing the total code coverage area of the minimal template set. In this scenario, the value of the specific template is measured by how much it improves code coverage relative to the other samples. This will result in a high-scoring data template that covers a small number of functions but whose functions are not covered by other templates.
Before we look at how to classify and choose template importance, it is necessary to collect as many samples as possible.
Crawling the Web for Templates
The previous chapter mentioned that not all data samples are equally valuable for mutation fuzzing purposes. A good approach is to select a small set of valuable data samples and use them as templates for fuzzing. Finding the best samples for templates is a very important prerequisite for successful fuzzing. The templates used will determine the amount of code that will be tested and can make the difference between rich or nonexistent findings.
Finding data samples can be very easy for popular file formats but tricky for those data formats that are not so popular. Definitely one of the best starting points is the Internet. Many file-sharing services and data repositories allow for easy searching and downloading of content.
One good resource of various media formats is the MPlayer website (http://samples.mplayerhq.hu/). It offers free download of samples of various file formats used for testing and fuzzing purposes.
The Internet Archive
The Internet Archive (www.archive.org) was created as an Internet library and contains a large amount of text, audio, video, and software as well as archived web pages in its collection. All content is easily and freely accessible over the JSON API, which makes it a great resource for finding data to be used as templates for fuzzing. As a side note, as of October 2012, Internet Archive contained over 10 petabytes of data.
Level and Jonathan Hardin have made a handy Python script called Pilfer-Archive that will crawl Internet Archive and download all data samples related to specific file types.
Search Engine APIs
Finding things on the Internet is a well-known problem that many companies are trying to solve. Search engines such as Google, Bing, and Yahoo! are among the most popular search engines, and all of them expose some kind of API that allows developers to benefit from all the information collected in their databases. Unfortunately, using such APIs is not free, and pricing models usually depend on the number of searches per day. Depending on the scale of the sample collection, these might still be an interesting solution. Following is a list of the search engines and companies that provide access to their information through an API:
• Google Custom Search Engine and Google Site Search are two solutions available for programmatically exploring Google’s Web index. Licensing and pricing are different for both products, but a limited number of free queries is available. More information can be found athttps://developers.google.com/custom-search/.
• Yahoo! BOSS Search API is a commercial solution for custom web search queries. This paid service is based on the number of searches. More information is available at http://developer.yahoo.com/boss/search/.
• Bing Search API is a commercial solution for web queries that includes 5,000 free searches. More information is available at http://datamarket.azure.com/dataset/bing/search.
• IndexDen This is a full-text search engine tuned for searching and storing textual data. It also exposes an API for the most popular languages, including Python, Ruby, PHP, Java, and .NET. More information is available at http://indexden.com/pricing.
• Faroo This web search engine is based on peer-to-peer technology. Its free API service is marketed as allowing one million free queries per month. More information can be found at http://www.faroo.com/hp/api/api.html.
 Lab 5-1: Collecting Samples from the Internet Archive
Lab 5-1: Collecting Samples from the Internet Archive
 NOTE This lab, like all of the labs, has a unique README file with instructions for setup. See the Appendix for more information.
NOTE This lab, like all of the labs, has a unique README file with instructions for setup. See the Appendix for more information.
In this lab, we will use the Pilfer-Archive script to acquire Real Media (RM) files to be used for fuzzing in the following sections. Here is the list of steps necessary to complete this lab:
1. Install Python 2.7 or later.
2. Download pilfer-archive-new.py from https://github.com/levle/pilfer-archive and save it in the created folder c:\pilfer-archive\.
3. Create a folder called repo in c:\pilfer-archive\.
4. The Pilfer-Archive script contains many different data types that will be downloaded by the default. In this lab, we will concentrate only on one media type: Real Media.
NOTE Data type names used in the script and by the Internet Archive search engine are coming from the MIME media types and can be looked up on at http://www.iana.org/assignments/media-types.
First, open c:\pilfer-archive\pilfer-archive-new.py and replace the line itemz = [‘3g2’, … following the main() function with the following code:
itemz = [‘rm’, ‘rmvb’]
The final code should look like this:

NOTE In case you are having problems executing pilfer-archive-new.py and encounter the error “AttributeError: Queue instance has no attribute ‘clear’,” replace the two instances of searchQueue.clear() with searchQueue.queue.clear().
5. Run the script by executing it from the command line, like in the following example:


It can take a very long time to download all the samples that the script finds, so after collecting approximately 20 samples in the repo directory, you can terminate the script by killing the process.
A high-quality sample set is a requirement for a successful fuzzing session. Because it’s very difficult to individually score a sample, scoring is usually done relative to the other samples in the set. For this kind of scoring, it is best to gather as many samples as possible. This lab should provide a starting point for collecting various file formats in large numbers but should not be regarded as the only source. Samples should be collected from as many different sources as possible so that the following steps in the fuzzing process can generate better results.
Choosing the Optimal Template Set with Code Coverage
Having thousands of data templates to use for the mutation doesn’t guarantee success. On the contrary, it can slow down the testing process because multiple similar files will be mutated and tested for the same modifications, which doesn’t improve the quality of testing and instead just wastes time.
Carefully selecting a subset of the collected files will ensure that every modification of different data templates will result in a test that covers a different part or functionality of the code. That way, more code is tested and the chances of finding vulnerabilities are higher.
The Peach fuzzing framework has a useful tool for selecting a minimum number of data samples that have the best coverage of target software. Code coverage is determined by using each data sample as an input for the software and then calculating how many basic blocks were executed during the execution time.
PeachMinset is a tool from the Peach framework that automates the process of collecting code coverage traces and calculates the minimal set. The generated trace file contains information about which code path was taken in the program during the program execution. The process is divided into two parts:
• Collecting code coverage traces for each of the data samples
• Calculating the minimal set of data samples that should be used for fuzzing
Lab 5-2: Selecting the Best Samples for Fuzzing
To successfully complete the lab, follow these steps:
1. Download and install the Peach fuzzer from http://peachfuzzer.com/.
2. Download and install the VLC media player, which will be used as a sample fuzzing target in this chapter (www.videolan.org/vlc/).
3. Copy the RM files downloaded in Lab 5-1 from the repo folder to the newly created folder rm_samples. This folder should be located under the Peach installation directory (for example, c:\peach3\rm_samples).
4. Run the PeachMinset.exe command to calculate the trace files and select the best samples located in rm_samples directory. In this case, a VLC player is used to calculate the trace file as we are choosing sample templates to fuzz the VLC later on.
NOTE Remember to perform the minimum set calculations for each target application. It is important to do that because the resulting minimum set can be different across applications due to their different implementations and support for file types.
5. An example of PeachMinset execution is presented in the following listing:
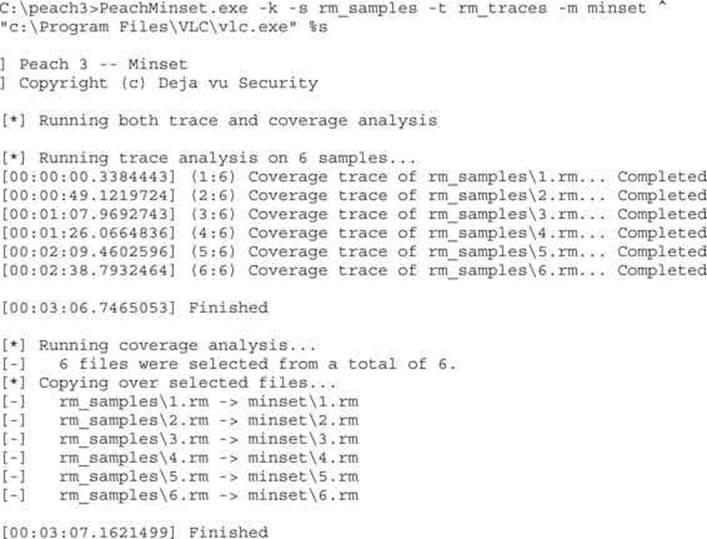
The PeachMinset command will select the best samples, which in this example are 1.rm through 6.rm. Selected samples will be moved to the minset directory. After the best samples have been chosen, the mutation fuzzing process can be started using these files, which will be explained in the following sections.
Selecting the best samples from a starting set is meant to minimize the amount of work done by the fuzzer by removing similar or duplicate samples. Code coverage with tools such as PeachMinset is one of the better metrics that can be used for scoring and selecting samples, but it should never be trusted blindly. In cases where there is an indication that a sample might possess interesting properties, it should be included in the final set no matter what the scoring says. Playing it safe and spending more time on testing should pay off in the long run.
Peach Fuzzing Framework
This section provides an overview of the Peach mutation fuzzer. This should provide you with enough information to start experimenting with fuzzing and looking for vulnerabilities.
The Peach framework can be used on Windows, Linux, and OS X operating systems. On Linux and OS X, a cross-platform .NET development framework called Mono is necessary to run Peach. In this section, all examples will be based on Peach for Windows because this is the most common scenario.
As mentioned previously, mutation fuzzing is an extremely interesting idea because it usually doesn’t require much work from the user’s perspective. A set of samples has to be chosen as input to the mutation program and then the fuzzing can begin.
To start fuzzing with Peach, a file called Pit has to be created. Peach Pit files are XML documents that contain the entire configuration for the fuzzing session. Typical information that is contained in Pit file includes the following:
• General configuration Defines things not related to the fuzzing parameters (for example, the Python path).
• Data model Defines the structure of the data that will be fuzzed in the Peach specification language.
• State model Defines the state machine needed to correctly represent protocols where a simple data model is not enough to capture all the protocol specification.
• Agents and monitors Defines the way Peach will distribute the fuzzing workload and monitor the target software for signs of failure/vulnerabilities.
• Test configuration Defines the way Peach will create each test case and what fuzzing strategies will be used to modify data.
Mutation Pits are fairly easy to create, and Peach provides several templates that can be examined and modified to suit different scenarios. Pit configurations can be created and modified using any text editor—or more specifically, one of the XML editors. Peach documentation suggests using Microsoft Visual Studio Express, but even Notepad++ or Vim can suffice for this task.
The following is the rm_fuzz.xml Peach Pit file:


The Pit file consists of several important sections that will influence and determine the fuzzing process. Following is a list of these sections and how each one of them influences the fuzzing process for the previously presented Pit file:
• DataModel (![]() and
and ![]() ) Defines the structure of data that will be fuzzed. In case of black-box testing, the DataModel is typically unknown and will be represented by a single data entry, <Blob/>, that describes an arbitrary binary data unit and doesn’t enforce any constraints on the data (be it values or order). If you omit the data model, Peach will not be able to determine the data types and their respective sizes, resulting in a somewhat imprecise data modification approach. On the other hand, omitting data model reduces the time needed to start the fuzzing. Because black-box fuzzing is very quick and cheap to set up, it is usually worth it to start the black-box testing while working on a better data model.
) Defines the structure of data that will be fuzzed. In case of black-box testing, the DataModel is typically unknown and will be represented by a single data entry, <Blob/>, that describes an arbitrary binary data unit and doesn’t enforce any constraints on the data (be it values or order). If you omit the data model, Peach will not be able to determine the data types and their respective sizes, resulting in a somewhat imprecise data modification approach. On the other hand, omitting data model reduces the time needed to start the fuzzing. Because black-box fuzzing is very quick and cheap to set up, it is usually worth it to start the black-box testing while working on a better data model.
Data modeling for most file formats and protocols is unfortunately a tedious process of reading the specification documents and translating it to the correct model in the Peach Pit format. It should be noted that in most scenarios it is not necessary to closely follow the specification documents because the implementations can introduce additional changes and extend the format specifications with custom changes.
• StateModel (![]() and
and ![]() ) Defines the different states the data can go through while fuzzing the application. State model is very simple for file fuzzing because only a single file is generated and used for testing purposes.
) Defines the different states the data can go through while fuzzing the application. State model is very simple for file fuzzing because only a single file is generated and used for testing purposes.
Fuzzing network protocols is a good example in which the state model plays an important role. To explore the different states in the protocol implementation, it is necessary to correctly traverse the state graph. Defining StateModel will instruct the fuzzer how to walk through the state graph and allow for testing more code and functionality, thus improving the chances for finding vulnerabilities.
• Agent (![]() and
and ![]() ) Defines the debugger that will be used to monitor execution of the target program and collect information about crashes. The collected crash data then has to be manually reviewed and classified as relevant or irrelevant. Relevant crashes should then be additionally reviewed to check for exploitable conditions and to determine their value.
) Defines the debugger that will be used to monitor execution of the target program and collect information about crashes. The collected crash data then has to be manually reviewed and classified as relevant or irrelevant. Relevant crashes should then be additionally reviewed to check for exploitable conditions and to determine their value.
• Test (![]() and
and ![]() ) Defines configuration options relevant to the testing (fuzzing) process. In this case, it will define the filename for the generated test cases as fuzzed.rm and define logs as the logging directory containing data about program crashes.
) Defines configuration options relevant to the testing (fuzzing) process. In this case, it will define the filename for the generated test cases as fuzzed.rm and define logs as the logging directory containing data about program crashes.
To test that the written Pit has a valid structure, Peach offers several solutions. The first thing to do is to test and validate Pit with the --test command, which will perform a parsing pass over the Pit file and report any problems found. Following is an example of how to test Pit XML:

In cases where the Pit test reports an error, it is possible to debug the parsing of the configuration by running the XML parser with enabled debugging output. The following shows what debugging output looks like for a broken XML file:


Another, probably nicer way of testing Pit files is using a PeachValidator, which provides a visual tool for troubleshooting Pit configurations. PeachValidator can be used to explore the XML elements of the Pit file and provide a more structured overview of the configuration.
After you have verified the Pit file and ensured that the configuration file has the correct syntax, it is time to start fuzzing. Starting a new fuzzing session in Peach is very easy and requires only a path to the desired Pit file as an argument.
The following shows how to start a new Peach session with the previously created Pit file:


Sometimes it is necessary to stop the fuzzer and perform maintenance on the machine it’s running on. For such cases, Peach allows for easy stopping and resuming of the session. To stop the current Peach session, it is sufficient to press CTRL-C in its terminal window. Suspending the session will result in the following Peach output:

The results of a terminated session can be examined in the session folder under the Peach “logs” directory. Folders in the logs directory use the following naming scheme: Timestamp with the current time at the directory creation moment is appended to the filename of the Pit XML configuration used for fuzzing (for example “rm_fuzz.xml_2013101623016”). Inside the session directory is the status.txt file, which contains the information about the session, such as the number of test cases tested and information about times and filenames that generated crashes. If the session was successful, an additional folder named Faults would also exist in the session folder. The Faults directory contains a separate folder for each class of crash that was detected. Inside each of these crash clusters, one or more test cases are located that contain the following information:
• The mutated test case that triggered the crash.
• A debugging report collected about the program state at the time of the crash. This report includes information about the state and values of the processor register, a portion of stack content, as well as information gathered from the WinDbg plugin !exploitable, which provides automated crash analysis and security risk assessment.
• The original test case name that was mutated to create this specific mutation.
The session can be resumed by skipping the already preformed test. Information about which was the last test case performed by the fuzzer can be seen in the logs folder under the session name in the file status.txt:

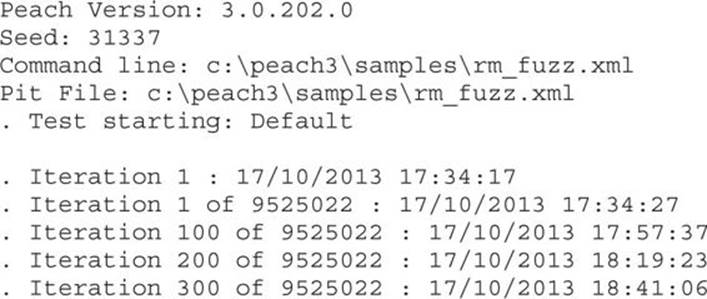
Another way to see the progress and number of iterations performed by Peach is in the command-line output during fuzzing, which will show in the first entry of a list iteration number. In the following example, the iteration number of the current test is 13:

One thing to have in mind is that resuming the fuzzing session only has real value if the fuzzing strategy chosen is deterministic. When you use the “random” strategy, resuming the previous session doesn’t make much difference.
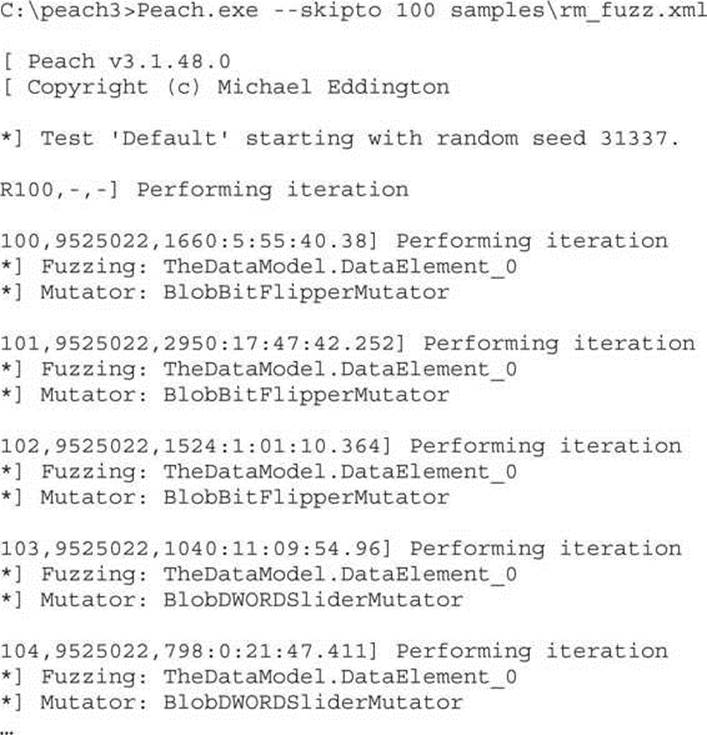
To resume a session, it is enough to run the Pit file, as previously shown, and use the --skipto option to jump to a specific test case number. An example of skipping 100 tests is shown here:
Peach Fuzzing Strategies
Peach supports three different fuzzing strategies:
• Sequential
• Random deterministic
• Random
The sequential strategy will fuzz each element defined in the data models in their respective order. This strategy is deterministic, which means that a single session will always have the same number of test that will be identical among different sessions. A sequential type of strategy should be avoided in cases where it is not possible to estimate the time available for testing. If it’s not evident whether the whole sequence of tests will be performed before finishing the session, sequential strategy should not be used. The reason for this is that parts of the data model will not be tested at all, and the parts that have been tested might not have as much fuzzing potential as the ones later on. When in doubt, one of the random strategies should be used.
The random deterministic strategy is the default strategy for Peach. This strategy is the same as sequential, but it solves its shortcoming by randomizing the order of elements that will be fuzzed. Like sequential strategy, this one is also deterministic and will have a relatively small number of test cases when compared with a pure random strategy.
The random strategy is the most generic of the strategies and will randomly generate test cases forever. Two parameters are available to fine tune this strategy:
• MaxFieldsToMutate Defines the maximum number of fields that can be modified per test case. The default value of this parameter is 6.
• SwitchCount Defines the number of tests that will be performed for each of the mutator algorithms used in that session. The default value of this parameter is 200.
Following is an example of the random strategy with modified parameters:

Speed Does Matter
After you have set up a testing environment and have gotten some experience with fuzzing, it is time to take the setup to another level. After committing to a specific fuzzing strategy, the next thing to improve is the scale of testing and the number of test cases that are executed. The easiest way to improve the speed of the fuzzer is to parallelize the fuzzing process and increase the number of fuzzers working together.
The Peach fuzzing framework supports parallelization of testing in a very easy way. To split fuzzing work among an arbitrary number of machines, two things must be specified. First, you have to know the total number of available machines (or workers) that will execute Peach and perform fuzzing. This number allows Peach to correctly calculate which test cases a specific worker instance has to perform. Next, each worker has to know its own position in the worker order to know which portion of tests it has to perform. These two parameters are passed to Peach in the command line during startup. The --parallel M, N command tells Peach that it should be run in parallel mode and that the workload has to be split between a total of M machines, and that this specific machine instance is at Nth position in the line. There is no requirement for how the machines have to be ordered, but each machine has to have a unique position in the line. In a scenario with three machines available for fuzzing, the following parallel Peach commands can be executed:
Machine #1: peach -p 3,1 peach_pit_xml_config
Machine #2: peach -p 3,2 peach_pit_xml_config
Machine #3: peach -p 3,3 peach_pit_xml_config
Crash Analysis
During a fuzzing session, if everything is going as planned, there should be some logs for the target application crashes. Depending on the fuzzer used, different traces of a crash will be available. Here are some of the usual traces of crashes available:
• Sample file or data records that can be used to reproduce the crash. In the case of a file fuzzer, a sample file that was used for testing will be stored and marked for review. In the case of a network application fuzzer, a PCAP file might be recorded and stored when an application crash was detected. Sample files and data records are the most rudimentary way to keep track of application crashes and provide no context about the crash.
• Application crash log files can be collected in many ways. Generally, a debugger is used to monitor the target application state and detect any sign of a crash. When the crash is detected, the debugger will collect information about the CPU context (for example, the state of registers and stack memory), which will be stored along with the crash sample file. The crash log is useful for getting a general idea about the type of crash as well as for crash clustering. Sometimes an application can crash hundreds of times because of the same bug. Without some context about the crash, it is very hard to determine how much different the vulnerabilities are. Crash logs provide a great first step in filtering and grouping crashes into unique vulnerabilities.
• Many custom scripts can be run when an application crash is detected that collect specific types of information. The easiest way to implement such scripts is by extending the debugger. !exploitable is one such useful debugger extension. It was developed by Microsoft for WinDbg and can be used for checking whether or not a crash is exploitable. It should be noted that even though !exploitable is useful and can provide valuable information regarding the crash and its classification, it should not be fully trusted. To thoroughly determine whether or not a crash is exploitable, you should perform the analysis manually because it is often up to the researcher to determine the value of the vulnerability.
Using Peach as the framework produces some nice benefits when you’re dealing with crashes. Peach uses WinDbg and the !exploitable extension to gather contextual information about a crash and to be able to perform some crash clustering.
As previously mentioned, Peach will organize all crash data in the folders under the Fault directory. An example of Peach’s Fault directory structure is shown here:
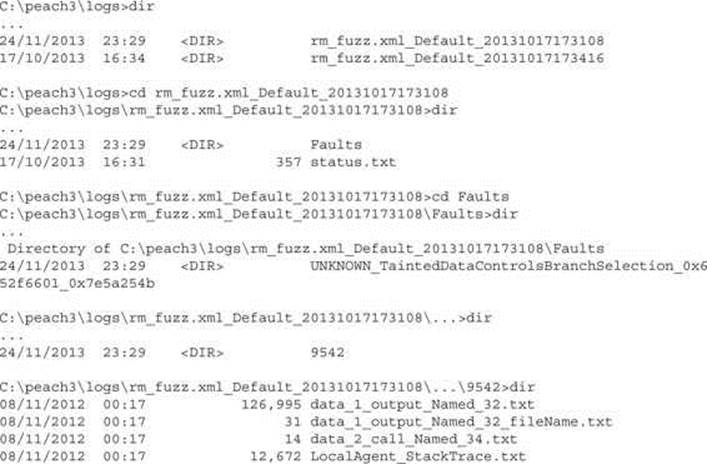
Out of the four files located under the test case 9542 folder file, LocalAgent_StackTrace.txt contains information about the crash. An example of a crash log (with some lines removed for brevity) is presented next:

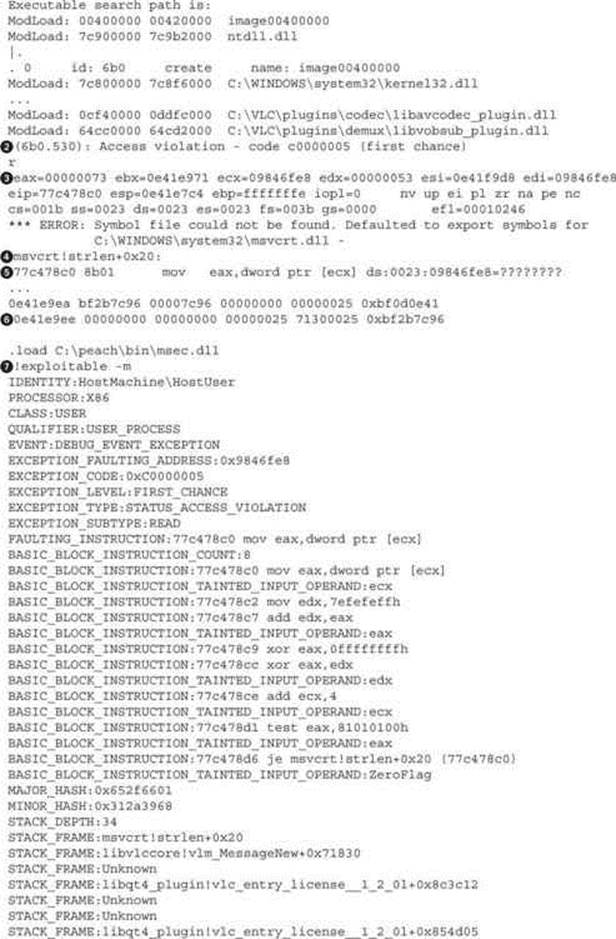
The file consists of two main sections:
• Crash information collected from the debugger, including loaded modules names, information about CPU registers, and an excerpt from memory. This information spans from ![]() to
to ![]() in the preceding log.
in the preceding log.
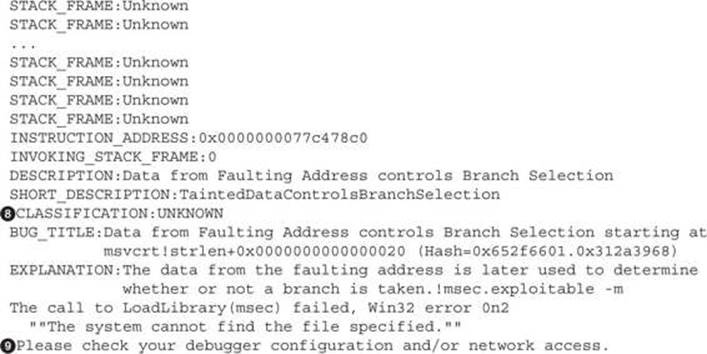
• An !exploitable report, which contains information and a classification of the crash. Information that can be found in this part of the log gives more context to the crash and includes exception code, stack frames information, bug title, and classification. Classification is the !exploitableconclusion about the potential exploitability of the crash. It can contain one of four possible values: Exploitable, Probably Exploitable, Probably Not Exploitable, or Unknown. This information spans from ![]() to
to ![]() in the preceding log.
in the preceding log.
Quickly glancing over the exception type at line ![]() will give us information on how the debugger detected the crash and will give us a hint about the type of bug. The next thing to examine is the code that generated the exception. Line
will give us information on how the debugger detected the crash and will give us a hint about the type of bug. The next thing to examine is the code that generated the exception. Line ![]() reveals that the exception happened in the msvcrt library—more precisely, the strlen function. Line
reveals that the exception happened in the msvcrt library—more precisely, the strlen function. Line ![]() gives the exact assembly instruction that generated the exception as well as more low-level perspective about the bug:
gives the exact assembly instruction that generated the exception as well as more low-level perspective about the bug:
mov eax, dword ptr [ecx] ds:0023:09846fe8=????????
This line is interpreted as “eax was supposed to be assigned the data pointed to by the ecx register but the address to which ecx is pointing cannot be found, ds:0023:09846fe8=????????.” The value of ecx=0x09846fe8 can be confirmed by checking line ![]() , where values of all registers at the crash time are recorded. The strlen() function calculates the length of a pointer to an array of characters, so it can be safely assumed that ecx was supposed to point to some string, but it got corrupted and is pointing to an invalid memory location. Taking into consideration this information, it means that the exploitability depends on the ability to control the value of ecx and that the result of the strlen() operation can be used in a way to lead to an exploitable scenario. This specific case is probably not exploitable, but to confirm that, it would be necessary to check the following things:
, where values of all registers at the crash time are recorded. The strlen() function calculates the length of a pointer to an array of characters, so it can be safely assumed that ecx was supposed to point to some string, but it got corrupted and is pointing to an invalid memory location. Taking into consideration this information, it means that the exploitability depends on the ability to control the value of ecx and that the result of the strlen() operation can be used in a way to lead to an exploitable scenario. This specific case is probably not exploitable, but to confirm that, it would be necessary to check the following things:
• Isolate part of the sample file that influences the value of the ecx register and determine which values it can contain.
• Reverse engineer and analyze the function calling strlen() and how the string pointed to by ecx is used as well as if it can be manipulated in a way to make this scenario exploitable.
• Craft a file based on the crash sample that would trigger and exploit the found vulnerability.
NOTE Crash sample that can be used to reproduce the crash is located in the same folder as the crash log. In the previous listing, file data_1_output_Named_32.txt is the sample data file that triggered the crash. The file named data_1_output_Named_32_fileName.txt contains the full file path to the template that the crash sample was mutated from (for example, C:\peach3\rm_samples\template1.rm).
Because this process can take a very long time, !exploitable can provide a valuable report that heuristically classifies the crash in several exploitability categories. The report is located after the debugger part and starts from line ![]() . The !exploitable classification ofUNKNOWN is located on line
. The !exploitable classification ofUNKNOWN is located on line ![]() and doesn’t provide any more insight into the exploitability except that it isn’t trivially exploitable based on Microsoft heuristics.
and doesn’t provide any more insight into the exploitability except that it isn’t trivially exploitable based on Microsoft heuristics.
Depending on the type of the target application and the purpose of testing, the findings will have different values. In the best-case scenario, all findings should be reported and fixed in the code. When you’re looking only for exploitable security vulnerabilities, it can be very hard to determine the true impact and significance of a bug. In such cases, additional analysis and reverse engineering of code where the crash happened might be necessary.
Lab 5-3: Mutation Fuzzing with Peach
In this lab, we look at mutation fuzzing with Peach using Pit files. To successfully complete the lab, follow these steps:
1. Copy the rm_fuzz.xml file listed in the “Peach Fuzzing Framework” section of this chapter to C:\peach3\samples\.
2. If you completed Lab 5-2, you should have a directory called C:\peach3\minset\ containing fuzzing templates chosen by PeachMinset as the most suitable for fuzzing. To use those samples, change
<Data fileName=“C:\peach3\rm_samples\*.rm” />
to
<Data fileName=“C:\peach3\ minset\*.rm” />
3. Specify the desired fuzzing target by installing some media player software capable of processing Real Media files and change the following two lines referencing the VLC media player in the rm_fuzz.xml Pit file:
<Param name=“Executable” value=“vlc.exe”/>
<Param name=“CommandLine” value=” c:\Program Files\VLC\vlc.exe fuzzed.rm” />
4. Start the fuzzer by executing following command:
C:\peach3>Peach.exe samples\rm_fuzz.xml Default
5. Leave the fuzzer running for a while and then stop it by issuing CTRL-C in the process window.
6. To continue the fuzzing, first check the status.txt file of the last session, as explained in the previous section. Replace the <test_number> tag within the following command and resume the fuzzing:
C:\peach3>Peach.exe --skipto <test_number> samples\rm_fuzz.xml
7. Periodically check for crashes in the Faults directory under the session folder located in C:\peach3\logtest\. Examine the crash log files for any obviously exploitable vulnerabilities by looking at the !exploitable report. Crashes that should be investigated first would have aCLASSIFICATION tag value of Exploitable or Probably Exploitable (check line ![]() in LocalAgent_StackTrace.txt from the “Crash Analysis” section, for example).
in LocalAgent_StackTrace.txt from the “Crash Analysis” section, for example).
The benefit of using a fuzzing framework like Peach is that it contains almost all the tools you will need during a fuzzing session. Because of this versatility, it can seem a little overwhelming at first. This lab hopefully shows that Peach is very simple and that you can start fuzzing in a matter of minutes. As you get more comfortable with the fuzzing setup and want to try new things, it is easy to iterate and evolve a Peach session. This allows for easy experimentation and slowly building up more complex testing scenarios.
Other Mutation Fuzzers
Many fuzzers and fuzzing frameworks are available that support mutation-style fuzzing. Here’s a list of some of them:
• Radamsa https://code.google.com/p/ouspg/wiki/Radamsa
• Zzuf http://caca.zoy.org/wiki/zzuf
• Sulley https://github.com/OpenRCE/sulley
Generation Fuzzers
As mentioned previously, writing configuration files for generation fuzzers is a complex and time-consuming task. Most fuzzing tools and frameworks use their own configuration formats and languages, making it very difficult to write generic configurations that are acceptable for multiple tools. Following is a list of popular fuzzers that support generation-based testing:
• Peach A generic fuzzing framework that supports generation- and mutation-based fuzzing. Generation-based fuzzing uses Pit configuration, which is XML files describing the data model. Pit files have support for various data types and also allow for state modeling, which makes them applicable for file and protocol fuzzing.
• Sulley A fuzzing framework that has support for generation-based fuzzing and has good support for target monitoring and automation. Generation-based configurations are Python programs that utilize Sulley’s API to model data types and state. The use of a well-known scripting language for data modeling also allows for the use of the language’s capabilities and makes the model more flexible.
In some scenarios, it is possible to overcome the problems of describing the data structure for generation-based fuzzer by cheating. Analyzing the target software and understanding its inner workings are never a waste of time. Information collected about the target can be used to cheat and perform a somewhat hybrid approach of white-box testing.
Summary
Fuzzing as a testing methodology gained popularity because of its simplicity and ease of setup. Today’s fuzzing frameworks, such as Peach, build on top of the original idea of random testing. They constantly evolve by keeping track of the latest advances in the fuzzing community. To efficiently use these new functionalities, it is necessary to understand them. This chapter should give you the necessary language and an overview of the fuzzing world to get you started with testing and hunting for vulnerabilities.
For Further Reading
!exploitable WinDbg plug-in msecdbg.codeplex.com/.
“Analysis of Mutation and Generation-Based Fuzzing” (C. Miller and Z. N. J. Peterson) securityevaluators.com/files/papers/analysisfuzzing.pdf.
“Babysitting an Army of Monkeys” (C. Miller) fuzzinginfo.files.wordpress.com/2012/05/cmiller-csw-2010.pdf.
Bind search engine developer resources datamarket.azure.com/.
Corelan Peach fuzz templates redmine.corelan.be/projects/corelanfuzztemplates/repository/show/peach.
Faroo search engine www.faroo.com/.
Google search engine developer resources developers.google.com/.
IANA Media Types www.iana.org/assignments/media-types.
IndexDen search service indexden.com/.
Internet Archive download script github.com/levle/pilfer-archive.
Internet Archive storage size archive.org/web/petabox.php.
The Internet Archive www.archive.org/.
Microsoft Visual Studio Express www.microsoft.com/visualstudio/eng/products/visual-studio-express-products.
Mono, open source .NET framework www.mono-project.com/.
Notepad++ editor notepad-plus-plus.org/.
Peach fuzzing framework peachfuzzer.com/.
Peach fuzzing framework peachfuzzer.com/.
Peach MinSet tool peachfuzzer.com/v3/minset.html.
Python language www.python.org/.
Radamsa fuzzer code.google.com/p/ouspg/wiki/Radamsa.
Repository for multimedia samples samples.mplayerhq.hu/.
Sulley fuzzing framework github.com/OpenRCE/sulley.
VIM editor www.vim.org/.
Yahoo search engine developer resources developer.yahoo.com/.
Zzuf fuzzer caca.zoy.org/wiki/zzuf.