Threat Modeling: Designing for Security (2014)
Part IV. Threat Modeling in Technologies and Tricky Areas
Chapter 14. Accounts and Identity
If you don't get account management right, you open the door to a slew of spoofing threats. Your ability to rely on the person behind a keyboard being the person you've authorized falls away. This chapter discusses models of how computers identify and account for their users, and the interaction of those accounts with a variety of security and privacy concerns. Much of the chapter focuses on threat modeling, but some of it delves into thinking about elements of security and the building blocks that are used. The repertoire in this chapter is specialized, but frequently needed, which makes it worth working through these issues in detail.
As the world becomes more digital, we interact not with a person in front of us but with their digital avatars and their data shadows. These avatarsand shadows are models of the person. Remember: All models are wrong, and some models are useful. When the model is a model of a person, he or she may take offense at how they have been represented. The offense may be fair or misplaced, but effective threat modeling when people are involved requires an understanding of the ways in which models are wrong, and the particular ways in which wrong models can impede your security, your business, as well as the well-being, dignity, and happiness of your current or prospective customers, citizens, or visitors.
Despite the term identity being in vogue, I do not use it as a synonym for account. The English word identity has a great many meanings. At its core is the idea of oneness, a consistency of nature—that this person is the same one you spoke with yesterday. Identity refers to self, personhood, character, and the presentation of self in life. To speak of “identity issuance” reveals either a lack of grounding in sociology and psychology, or a worrisome authoritarian streak, in which the identity of a human is defined and controlled by an external authority.
It is often tempting to model accounts as permanently good or bad, as a description of the person behind it. This is risky. Accounts can change from good to bad when an attacker compromises one, or when a bad creator decides to abuse them, which may be immediate or after a long period of “reputation establishment.”
This chapter starts with the life cycle of accounts, including how they arecreated, maintained, and removed. From there, you'll learn about authentication, including login, login failures, and threats against authenticators, especially the most common authentication technology, passwords, as well as the various threats to passwords. That's followed by account recovery techniques, threat models for those, and a discussion of the trade-offs associated with them. The chapter closes with a discussion of naming and name-like systems of identifiers such as social security numbers.
Account Life Cycles
Over the lifetime of most systems, accounts will be created, maintained, and removed. Creation may take many forms, including the authorization of a federated account. Maintenance can include updating passwords or other information used for security. People are often not aware of or motivated to perform such maintenance, which has resulted in the creation of technical tools such as password expiry, which tries to either prod them or force their hand. People's awareness varies and is usually lower with lower-value accounts (when was the last time you looked at your e-mail from Friendster, or logged into your home wireless router?) Lastly, accounts will eventually need to be removed for a variety of reasons, and doing so exposes threats such as identifier re-use.
Account Creation
The life cycle of an account starts when the account is opened. Ideally, that happens with proper authorization, which means very different things in different contexts. You can roughly model this based on how deep the relationship is between the person and an organization.
For Close Relationship Accounts
Some accounts require and validate a good deal of information about a person as the account is created. These accounts are typically of very high value to the person, and incur high risk to the organization. Examples include a bank account or a work account with access to corporate e-mail and documents. Because of the sensitive nature of these accounts, the account creation process is typically more cumbersome, possibly including verification steps and approvals. Such accounts are likely to be strictly limited in terms of how many a person may have at one time.
When people understand that the security requirements for these accounts may exceed those of other types of accounts, they might use better (or at least different) passwords, and the threat of lying about key data is somewhat reduced.
For Free Accounts
There are many online accounts that require little to nothing when signing up: an e-mail address, perhaps. For these types of accounts, people will often provide personal information that is funny, aspirational, or completely inaccurate. They do this to present an identity or persona, or for political or privacy reasons. (I discovered recently that several of my online accounts say I am in Egypt, a country I haven't visited in 20 years. I likely set it during the Arab Spring, and had no reason to change it since then.) If you rely on this information, these tendencies to enter funny or aspirational information are a threat to you, while your attempts to “validate” or constrain it can seem like a threat to your customers.
Free accounts are more likely to be used by more than one person—for example, a family or team calendar. When someone leaves the team, the account management implications are less than when someone is no longer authorized to access a bank account. In the worst case scenario, the free account can be replaced trivially, although the contents might not be. Free accounts are often used for a variety of mischief, including but not limited to spam, or file-sharing for music, books, or movies. Each of these threatens to annoy you, your customers, or the Internet at large in various ways and to various degrees.
At the Factory
Systems that ship with a single default account created at the factory should require a password change at setup; otherwise, the password will be available to anyone via a search engine. You might also be able to ship with a unique password printed onto a device or a sticker.
Federated Account Creation
Accounts are often created based on an account elsewhere, such as a Facebook or Twitter login, or a corporate (active directory) account. Federation systems such as OAUTH or Active Directory Federation Services (ADFS) allow this to happen somewhat seamlessly. While federation reduces the burden on individuals who want to create new accounts, it exposes risk in that a breached federated system may be a stepping-stone to your system (depending on where and how authentication tokens are stored). It may pose privacy threats by requiring the linkage of accounts. It may also increase the impact of threats by making the federated account a more valuable target. Lastly, users are often forgetful about where they've federated, and leave federation in place even after they no longer use it.
Creating Accounts That Don't Correspond to a Person
We often want to think “one account for one person.” Security experts advise against shared accounts for good reasons of (ahem) accountability. There are many reasons why that advice is violated. Some accounts are set up for more than one person—for example, a married couple may have a joint bank account. Often times, they will share a single login/password combination, even if you've made it easy to set up several (computer) accounts to connect to a single bank account. Similarly, many people might share one work account. It is important to think about what happens when one or more participants in such a shared account are no longer authorized to use it. For the married couple with a joint bank account, what's the right system? That both spouses have a (system) account that is authorized to access the (bank) account? Similarly, a traditional landline phone is an account for a family. If you call 867–5309, you might get someone in Jenny's family.
Andrew Adams and Shirley Williams have been exploring these issues and have a short, readable paper “What's Yours Is Mine, and What's Mine Is My Own” (Adams, 2012). Taking a cue from the world of law, they suggest considering several types of joint accounts: several, shared, subordinate, and nominee. Several accounts are those that reflect the intersection of individuals where each has complete authority over the account. Shared accounts are those for which all members of a group can see information, but some subset of users can control what others can change. For example, members of an LLC could all see the financials, but only the treasurer can issue payments. Subordinate accounts might be created by a parent or guardian, and allow one or more supervisory accounts to see some, but perhaps not all, of the child's activity. (For example, parents might be able to see correspondent e-mail addresses, but not contents.) Finally, nominee accounts might allow access to the account after some circumstance, such as death. (Nominee accounts in this sense relate closely to Schechter, Egelman, and Reeder's trustees, covered later in the section “Active Social Authentication.”) In any or all of these sorts of systems, there might be one login account that is used by everyone who has access to the joint account, or one login per person—it depends primarily on your development decisions and the usability of a joint account system.
It's also important to avoid believing that there is a one-to-one correspondence between the existence of an account and a human being who controls it. This is easily forgotten, although identity masking is common enough that it has many names, such assockpuppets, astroturfing, Sybyls, and tentacles. Each of these is a way to refer to a set of fake people under the control of a group or person hoping to use social proof for the validity of their position. (Social proof is the idea that if you see a crowd doing something, you're more likely to believe it's OK.) Credit for this point belongs to Frank Stajano and Paul Wilson, as described in their paper “Understanding scam victims: seven principles for systems security” (Stajano, 2011).
Account Maintenance
Over time, it turns out that nearly everything about the person who uses an account can change, and many of those changes should be reflected with the account. For example, almost everyone will change data such as their phone number or address; but other things about them can change as well—name, gender, birthday, biometrics, social security number. (Birthdays can change because of inaccurate entry, inaccurate storage, or even discovery of a discrepancy between documents and belief.) Even biometrics can change. People can lose the body part being measured, such as a finger or an eye. Less dramatically, cuts to fingers can alter a fingerprint pattern, and older people have harder to read fingerprints.
If you store such data, you need mechanisms for changing it. It's important to align the change of these records with the security implications of a change. If you use the phone or physical mail to authenticate, ensure that you do everything appropriate to authenticate a phone number change. For a customer change of address, many wise banks send letters to both the new address and the old address, and turn their risk algorithms way up for a month or so after such a change. When users are not aware that data such as phone number will be used as an authentication channel, they are far less likely to keep it up to date. Even when they are aware that such data may be used for that purpose, they are unlikely to remember to update every system with which their phone number is associated.
Notifying the Real Person
Many services will let their customers know about unusual security events. For example, Microsoft will send text messages or e-mail to notify that additional e-mail addresses have been added to an account, and LiveJournal will sendan e-mail if a login happens from a browser without a cookie. Such notifications are helpful, insofar as your customers are probably motivated to protect their accounts; and risky, as your customers may not understand the messages. They may become more concerned than is appropriate, driving customer support costs, dissatisfaction, or brand impact. Additionally, there's a risk that attackers will fake your security messages for phishing-like attacks. The right call is a matter of good threat modeling, including good models of scenarios.
You can mitigate the risks by using scamicry-resistant advice (seeChapter 15 “Human Factors and Usability”), ensuring that you have low false positives, and using time as your ally. Time is an ally because you can delay authorizing important changes such as payments or backup authentication options until you have more information. That might be someone logging in from a frequently seen IP address or computer, demonstrating access to e-mail, or otherwise adding more information to your decisions. For more on delays, see “Avoiding Urgency” in Chapter 15. See also the “Account Recovery” section later in this chapter.
Account Termination
Customers may stop paying, leave, or pass away. Workers may quit or be fired. Therefore, it is important to have ways to terminate accounts fully and properly. Changing their passwords may not be enough. They might have e-mail forwarding or scheduled processes that run; or they may be able to use account recovery tools to get back in. This is actually the space in which many “identity management systems” play: helping enterprises manage the relationship between a person and the dozens to hundreds of accounts on disparate systems that they might possess. (Now get off my lawn before I hit you with my typewriter.)
When you terminate an account, you need to answer at least two important questions. First, what do you do with the objects that the account owns, including files, e-mail messages, websites, database procedures, crypto keys, and so on? Second, is the account name reserved or recycled? If you recycle account names, then confusion can result. If you don't, you risk exhausting the namespace.
Account Life-Cycle Checklist
This checklist is designed to be read aloud at a meeting. You're in a bad state if for any of these questions:
§ You can't answer yes.
§ You can't articulate and accept the implications of a no.
§ You don't know.
1. Do we have a list of how accounts will be created?
2. Do all accounts represent a single person?
3. Can we update each element of an account?
4. Does each update notify the person behind the account?
5. Do we have a way to terminate accounts?
6. Do we know what happens to all the data associated with an account when it's terminated?
Authentication
Authentication is the process of checking that someone is who they claim to be. Contrast that with authorization, which is checking what they're allowedto do. For example, the person in front of you might really be Al Cohol, but that doesn't entitle them to a free drink.
Figure 14.1 shows a simple model of the authentication process. First, a person enrolls in some way, which varies from the simple (entering a username and password on a website) to the complex (going through an extensive background check and signing paperwork to trigger a create account process). Later, someone shows up and attempts to authenticate as the person who enrolled.
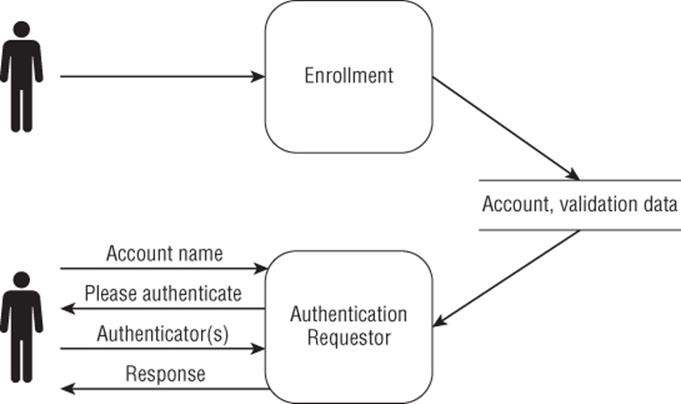
Figure 14.1 A simple model of authentication
Many of the threats covered in this chapter can be discovered by applying techniques such as STRIDE or attack trees to Figure 14.1. However, because the threats have been discovered, and the mitigations have been worked through, this chapter summarizes much of what's known so that you don't have to re-invent it.
The traditional three ways to authenticate people have required either “something you know, something you have, something you are,” or some combination of those. Passwords are an example of something you know. Something you have might include proximity cards or cryptographic devices such as RSA tokens. Something you are is measured with tools such as fingerprint or retina scanners.
These methods of authenticating people are often termed authentication factors, and multi-factor authentication refers to the use of several factors at one time. It is important that factors be independent and different. If a system consists of something you have, an ATM card, and something you know, a PIN, and you write your PIN on the card, the security of the system is substantially reduced. Similarly, if the something you have is a phone infected with malware because it's synced to a desktop computer, then the ability of the phone to add security as a second factor is greatly reduced. Using more than one of the same sort of factor is sadly frequently confused with multi-factor authentication.
These three factors have been sarcastically reframed as “something you've forgotten, something you've lost, and something you were.” (This is often attributed to Simson Garfinkel, although he does not take credit for it [Garfinkel, 2012]). This reframing stings because each is a real problem. Two additional factors are also sometimes considered: who you know, also called social authentication, and discussed later in the section “Account Recovery,” and how you get the message, sometimes called multi-channel authentication. Multi-channel is heavily threatened by the integration of communication technologies, and good modeling of the channels often reveals how they overlap. For example, if you think that a phone is a good additional channel, walking through how phones are used might uncover possible vulnerability vectors such as syncing (and associated infection risk) and how products like Google Voice are putting text messages in e-mail.
In this section, you'll learn about login and especially handling login failures, followed by threats to what you have, are, and know. Threats to what you know spans passwords and continues into the knowledge-based authentication approach to account recovery.
Login
We're all familiar with the login process: Someone presents an identifier and authenticator, and asks to be authenticated in some way. As shown in Figure 14.2, there are many spoofing threats in this simple process, including that the client or server may make false claims of identity, and the local computer may be presenting a false UI. (It's that last threat which pressing Ctrl+Alt+Delete [CAD] addresses: CAD is a secure attention sequence, one that the operating system will always respond to, rather than passing to an application.)
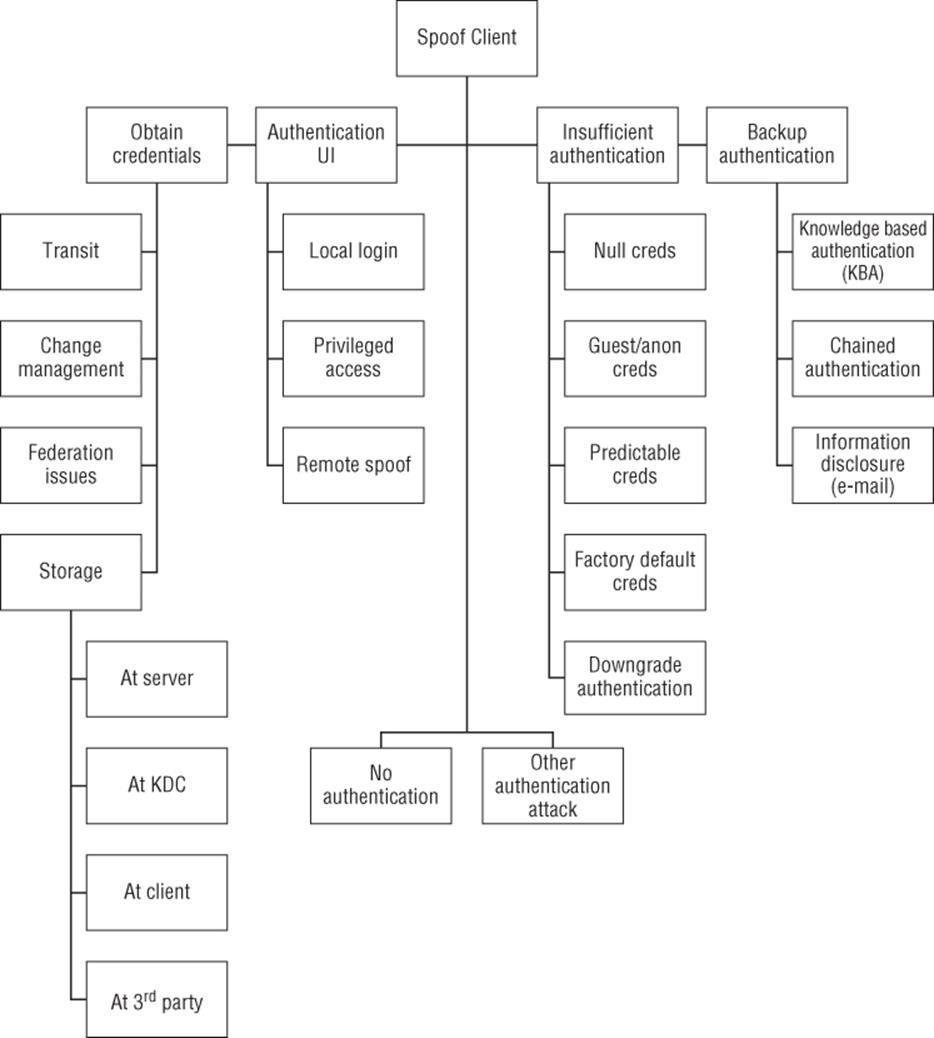
Figure 14.2 Spoofing an external entity threat tree
Let's first consider spoofing threats at the server, whether you describe the threat as threats of the server being spoofed or of the server spoofing; it's six of one, half a dozen of the other. The key is that the client is, for whatever reason, confused about the identity of the server it's talking to. As discussed previously, the key to mitigating these threats is mutual authentication, and inparticular cryptographic authentication. If you're implementing a new login system, performing a literature review of the many previous systems and their failure modes is a very worthwhile endeavor. Spoofing of the client occurs in several forms, and an attack tree is a useful way to keep track of them.
The spoofing of an external entity threat tree is discussed in detail in Appendix B, “Threat Trees.”
Login Failures
A login system is designed to keep the wrong people out. In a very real way, it's an interface that's intended to stymie people and present error messages, except when the right person jumps through a set of carefully designed hoops. Therefore, you have to design for failures by both those you want to see fail and those you want to see succeed. These are a first tension. Keep that tension in mind as you make choices. Do you tell the person what went wrong, and do you lock the account in some way? The second tension is that people are frustrated with security measures, and angry if their accounts are compromised. They'll be angry if their low-value accounts are compromised and used for spam or whatnot, and they'll be more deeply hurt if their bank account is drained or there are other real-world impacts.
No Such Account
“Incorrect username or password” is a common error message, based on the reasonable thinking that attackers who cannot discern if an account exists must waste energy attacking it, possibly also tripping alarms. There may well have been a time when this was commonly true, and there may yet be systems where account existence is hard to check. Today, with account recovery systems, it is harder to justify the usability loss associated with the “username or password” message. Additionally, with many systems using an e-mail address as a login mechanism, even if your system diligently hides all information disclosure threats around the existence of an account, someone else may well give it away (Roberts, 2012). It is time to accept that account existence is something an attacker can easily learn, and gain the usability benefits of telling real people that they've misspelled their account identifier.
Insufficient Authentication
As the many inadequacies of passwords become increasingly apparent, services are choosing to look at more data available at login time to make an authentication decision. With a classical web browser, this will frequently include checking the IP address, a geolocation based on that IP, browser version information, cookies, and so on. If you are going to create such a system, note that there's a threat. The specific version is cookie managers. You should plan for 20 percent–50 percent of your real customers to regularly delete their cookies (Nguyen, 2011; Young, 2011). Tell people if cookie deletion will affect the need for account recovery.
This can be generalized to a mismatch between expectations and your system. If other events will trigger account recovery, you should strongly consider setting people's expectations. Be very clear about what information you expect would be difficult for an attacker to determine about your algorithms. That's not to say you should reveal the information. Joseph Bonneau makes the claim that obscurity is an essential part of doing authentication well (Bonneau, 2012). His arguments are solid, but they resolve the tension between limiting attacker information and usability in a way that leads to frustration for the real account owners. Of course, the frustration of your having a bank account drained is also very real. For more on obscurity, see the section “Secret Systems: Kerckhoffs and His Principles” in Chapter 16 “Threats to Cryptosystems.”
Account Lockout
When a login attempt fails, you can choose to lock the account for some length of time—ranging from a few seconds to forever. The forever end of the spectrum requires some form of reset management, an exercise left to the reader. If you select shorter lengths of time, you can use fixed or increasing delays (also called backoff). You can apply delays to accounts or endpoints, such as an IP address or an address range, or both.
If the number of failures is represented as f, something like (f−3) × 10 or (f−5)2 seconds offers a reasonable mix of increasing security with each failure while not annoying people with unreasonable delays. (Of course, (f−5)2 is sort of pathological if you don't handle the small integers well.) The system designer can either expose the backoff or hide it. Hiding it (by telling the person that their attempt to log in failed) may result in people incorrectly believing that they've lost their password, and thus driving the need for backup authentication that works faster.
Requirements for scenarios of keyboard login attempts versus network login attempts may be different. It might be reasonable to allow more logins via a physical keyboard. Of course, a physical keyboard is sometimes a slippery concept, easily subject to spoofing over USB or Bluetooth.
Threats to “What You Have”
Using the authentication categories of what you have, what you are, and what you know, “what you have” includes things such as identity cards or cryptographic hardware tokens. The main threats to these are theft, loss, and destruction.
The threat of theft is in many ways the most worrisome of the threats to “what you have.” Some of these authenticators, such as proximity cards to unlock doors do not require anything else. (That is, you don't login to most doors with your handprint.) In most organizations, there is not a strong norm ensuring that the card is worn such that the face is easily visible, and an attacker who steals a card can simply put it in their wallet. Even with a “visible face” norm, matching photo to face tends to be challenging (see the next section for more discussion about this).
Other authenticator devices are often carried in bags, so someone who steals a laptop bag will obtain both the laptop and the authentication token. Some of these tokens only have a display, while others also have an input function, so using the token is a matter of what you have and what you know. The display-only tokens are cheaper, easier to use, and less secure. The appropriate trade-off is likely a matter of “chess playing.” If you use the display-only tokens, is that still what an attacker would go after, or does it make it hard enough that the attacker will attack somewhere else? As of 2012 or so, a number of companies are making authenticators that are the same size and thickness as credit cards and which have both input buttons and e-ink displays. These are more likely to be carried in a wallet than the older “credit card–size” tokens, which were very thick compared to a credit card.
The threats of loss and destruction are relatively similar. In each case, the authorized person becomes unable to authenticate. In the case of destruction or damage, there's more certainty that the authentication token wasn't stolen.
Threats to “What You Are”
Measuring “what you are” is a tremendously attractive category of authentication. There's an intuitive desire to have ways to authenticate people as people, rather than authenticate something they can loan, lose, or forget. Unfortunately, it turns out that the desire and the technical reality are different. All biometric systems involve some sort of sensors, which take measurements of a physical feature. These sensors and their properties are an important part of the threat model. The data that is stored must be stored in a way which the sensor can reliably generate. The form into which sensor data is converted is called a template. All of this is shown in Figure 14.3, which looks remarkably similar to 14–1. Clever readers may notice that neither figure contains trust boundaries. Different systems place the trust boundaries in different places. For example, if you log in to your bank over the Internet using a fingerprint reader, there's a different trust boundary than if that reader is located in their branch office. Many of the threats against biometrics can be quickly derived from a model like the one shown in Figure 14.3.
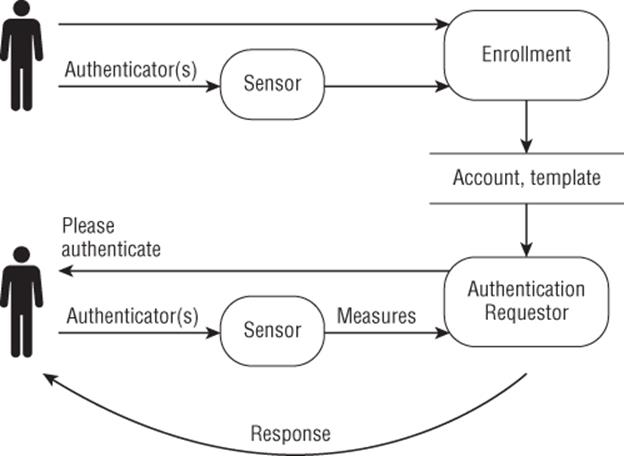
Figure 14.3 A model of biometric authentication
Some of those threats include the following:
§ Attacking templates, either tampering with them to allow impersonation, or analyzing disclosed templates to create input that will fool the system
§ Acquiring an image of the body part being measured, and using it to create input that will fool the system. This is spoofing against the sensor.
§ Adjusting the body so that the measurement changes. This is often a denial-of-service attack against the system, possibly executed for innocent reasons.
Each of these is discussed in more depth over the next several paragraphs.
Attacking templates may be easier than is comfortable for advocates of biometrics, many of who have claimed that the stored template data could not be used to reconstruct the input that will pass the biometric. This has proven to be false for fingerprints (Nagar, 2012), faces (Adler, 2004), and irises (Ross, 2005), and will likely prove false for other templates. Resisting such attacks is probably in tension with managing the false positive and false negative rates associated with the system. Worse, the people who are being authenticated are usually not given a choice about the system. Therefore, even if reconstruction-resistant templates were designed, the distribution of incentives likely argues against their use.
Acquiring an image of the body part being measured can often come from an “in the wild” image. For facial biometrics, this may be as easy as searching (ahem) Facebook or LinkedIn. Fingerprints can come from a fingerprint left on a glass, a car door, or elsewhere. A search for “fingerprint” on Flickr shows thousands of images of people's fingerprints. One person's art leads to another's artful attack. Of course, there are less artful attacks, such as chopping off the body part to be measured. This has actually happened to the owner of a Mercedes-Benz with a fingerprint reader—a Mr. Kumaran in Malaysia (see “Malaysia car thieves steal finger.” [Kent, 2005]).
Once you have a body part or an image thereof, you need to present it to the sensor in a convincing way. To reduce the incentive for taking body parts, there is sometimes “liveness” testing by the sensors. For example, fingerprint sensors might look for warmth or evidence of a pulse, while eye scanners might look for natural movements of the eye. Such testing turns out to be harder than many people expect, with facial recognition bypassed by waving a photo around; and, famously, fingerprints rendered with Gummy Bears (Matsumoto, 2002), recently repeated to some fanfare when a well known phone manufacturer experienced the same problem, possibly having failed to perform a literature review (Reiger, 2013).
Some systems measure activity, such as typing or walking, so the “image” captured needs to be more complex, and replaying it may similarly be harder, depending on where the sensor and data flows are relative to the trust boundaries. Attacks that are easy in a lab may be hard to perform in front of an alert, motivated, and attentive guard. However, in 2009, it was widely reported that Japan deported a South Korean woman who “placed special tapes on her fingers” to pass through Japan's fingerprint checks at immigration (Sydney Morning Herald, 2009).
For honest people, changing their fingerprints (or other biometrics) seems very difficult. However, there are a variety of factors and scenarios that make fingerprints harder to take or measure, including age; various professions such as surgeons, whose fingerprints are abraded by frequent scrubbing; hobbies such as woodworking, where heavy use of sandpaper can abrade the ridges; and cancer treatment drugs (Lyn, 2009).
There are also a few threats that are harder to see in the simple model. The first is “insult rates,” the second is suitability and externalities. The biometrics industry has long had a problem with what they call the “insult rate.” People are deeply offended when the machine doesn't “recognize” them, and if the people being measured are members of the general public, staff need to be trained to handle the problem gracefully. The second insult issue is that many people associate fingerprinting with being treated like a criminal. Is it suitable to treat your customers in a way that may be so perceived? Organizations should carefully consider the issue of offense, and well-meaning people should also consider the issue of desensitization caused by overuse of biometrics. This is an externality, where the act of an organization has a cost on others.
Many of the desirable properties of authenticators are not available in biometrics. Biometric sensors are less precise than a keyboard, which makes it harder to derive cryptographic keys. Another property that you'd like for your authentication secrets is that they are shared between one person and one organization, and you want to change those secrets now and then. But most people only have 10 fingers. (A few have more, and more have less.) Therefore, the threat of information disclosure by anyone who has a copy of your fingerprint has an impact on everyone who relies on your fingerprint to authenticate you. Of course, that applies to all biometrics, not just fingerprints. Overuse of biometrics makes these threats more serious for everyone who needs to rely on them.
One last comment on biometrics before moving on: Photographs are also a biometric, one that people can use very well, if the photograph is shown to motivated people in a high quality and reasonable size. People do an excellent job of recognizing family and friends. However, using photographs to match strangers to their ID photos turns out to be far more difficult, at least when the photograph is the size that appears on a credit card. (See Ross Anderson's Security Engineering, Second Edition [Wiley, 2008] for a multi-page discussion of the issue. To summarize, participants in an experiment rarely detected that a photo ID did not match the person using it. However, it appears that the use of such photos may act as a deterrent to casual crime.)
Threats to “What You Know”
Passwords are the worst authentication technology imaginable, except for all those others that have been tried from time to time. We all have too many of them, decent ones are hard to remember, and they're static and exposed to a potentially untrustworthy other party. They are also memorizable, require no special software, can be easily transmitted over the phone, and are more crisp than a biometric, which allows us to algorithmically derive keys from them. For a detailed analysis of these trade-offs, see Joseph Bonneau's “The quest to replace passwords” (Bonneau, 2012c). These tradeoffs mean that passwords are unlikely to go away, and most systems that have accounts are going to need to store passwords, or something like them, in some way.
In the aforementioned paper, Bonneau and colleagues lay out a framework for evaluating the usability, deployability, and security of authentication systems. Their security characteristics are outlined in the form of a security properties checklist, which will be useful to anyone considering the design of a new authentication scheme. They are listed here without discussion because anyone considering such a task should read their paper:
1. Resilient to physical observation
2. Resilient to targeted impersonation (such as attacks against knowledge-based backup authentication)
3. Resilient to throttled guessing (this is my online attacks category)
4. Resilient to unthrottled guessing (this is offline attacks)
5. Resilient to internal observation (such as keylogging malware)
6. Resilient to leaks from other verifiers
7. Resilient to phishing
8. Resilient to theft
9. No trusted third party
10.Requiring explicit consent
11.Unlinkable
Threats to Passwords
Threats to password security can be categorized in several different ways, and which is most useful depends on your scenario. I'll offer up a simple enumeration:
§ Unintentional disclosure, including passwords on sticky notes, wikis, or SharePoint sites, and phishing attacks
§ Online attacks against the login system
§ Offline attacks against the stored passwords
Online attacks are attempts to guess the password through defenses such as rate limiting. Offline attacks bypass those defenses and test passwords as quickly as possible, often many orders of magnitude faster. Password leaks are a common problem these days, and they're a problem because they enable offline attacks, ranging from simple lookups to rainbow tables to more complex cracking. Good password storage approaches can help guard against offline attacks. Passwords stored on web servers is a common issue in larger operational environments. Phishing attacks come in a spectrum from untargetted to carefully crafted after hours of research on sites such as Facebook or LinkedIn. There's a model of online social engineering attacks is in Chapter 15.
Password Storage
This section walks you through information disclosure threats to stored passwords, building up layers of threats and cryptographic mitigations to bring you to an understanding of the modern approaches to password storage.
If you don't cryptographically protect your list of usernames and passwords, then all that's required to exploit it after information disclosure is to look up the account the attacker wishes to spoof, and then use the associated login. The naive defense against this is to store a one-way hash of the password. (A one-way hash is a cryptographic function that takes an arbitrary input and produces a fixed-length output.) The way to attack such a list is to take a list of words and for each word in the list, hash the word, and search for that hash in the list of hashed passwords. The list of words is called a dictionary, and the attack is called a dictionary attack. Each hashed dictionary word can be compared to each stored password. (If it matches, then you know what word you hashed, and that's the password.)
The defense against the speedup from comparing to each stored password is to add a salt to the password before hashing it. A salt is a random string intended to be different with different account passwords. Using a salt slows down an attacker from comparing each hash to all stored passwords to comparing each hash to that one password with the same salt (or those few passwords with the same salts). Salts should be random so that Alice@example.com has a different salt at different systems, and thus her stored, hashed password will be different even if she's using the same password at different systems. Salts are normally stored as plaintext with the hashed passwords.
Attackers might try to use modified versions of dictionary words. Software has been available for a long time that will take a list and permute each word in it, by changing o to 0, l (the letter, el) to 1, adding punctuation, and so on. Dictionaries are available for a wide variety of common languages, ranging from Afrikaans to Yiddish. There are also password-cracking lists of proper names, sports teams, and even Klingon. It's possible to store the hashed wordlist for a given hash, engaging in a “time-memory trade-off.” These lists are called rainbow tables, and many are downloadable from the Internet. (Technically, rainbow tables store a special form of chains of hashes, which matter more if you are going to design your own storage mechanism; but given that smart people have spent time on this, you should use a standard mitigation approach.)
Unless you're implementing an operating system, it's almost certain that you'll want to store passwords that have been hashed and salted. The best pattern for this is roughly to take a password and salt, and shove them through a hash function thousands of times. The goal is to ensure that there's time after the detection of an accidental information disclosure for your customers to change their passwords. There are three common libraries for this: bcrypt, scrypt, and PBKDF2. All are likely to be better than anything you'd whip up yourself, and they are freely available in many languages.
§ bcrypt: This is what I recommend. There is more freely available code, which is better documented and has more examples (Muffett, 2012). The bcrypt library also has an adaptive feature, which enables password storage to be strengthened over time without access to the cleartext (Provos, 1999). Do note that the name bcrypt is overloaded; at least one Linux package named bcrypt performs Blowfish file cryptography.
§ scrypt: This may offer more security if you use it correctly. However, while documentation explains how to use the function for file encryption, it does not clearly address its use as a password storage tool (as opposed to a file encryption tool).
§ PBKDF2 (Password-Based Key Derivation Function 2): This offers less defense, does not offer adaptivity, and there's only one reason to use it when bcrypt is available for your platform: because it's a NIST Standard (Percival, 2012; Openwall, 2013).
Even after you hash the passwords, you want to ensure that the hashes are hard to get. Even with salting, modern password cracking with dictionaries of common passwords is shockingly fast, on the order of eight billion MD5 passwords tested per second (Hashcat, 2013). At that speed, testing the million most common passwords with 100 variants of each takes less than a second.
If you are implementing an operating system, then the storage of passwords (or password equivalents) is a more complex issue. There are good usability reasons to keep authenticators in memory. This allows for the authenticator to be used without bothering the user. For example, Windows domain members can authenticate to a file share or Exchange without retyping their password, and unix users will often use ssh-agent, or the Mac OS keychain to help them authenticate. These patterns also lead to issues where an attacker can impersonate the account if they're inside the appropriate trust boundary.
There is no great solution short of keeping them out, which is, empirically, challenging. Relying on hardware such as smartcards or TPMs to ensure that the secrets don't leave the machine is helpful, as it provides a temporal bound, but an attacker who can execute code as the user can still authenticate as the user. The alternative of requiring action per authentication is highly inconvenient and would probably not solve the problem, because frequent authentication requests would desensitize people to requests for authentication data.
Using static strings for authentication means that the system to which a person is authenticating can spoof that person. There are a variety of clever cryptographic ways to avoid this, all of which have costs at deployment time, or other issues that make them harder to deploy than passwords (as noted earlier in “Authentication”).
Password Expiration
In an attempt to respond to the threat of information disclosure involving passwords, many systems will expire them. By forcing regular changes, an attacker who comes into possession of a password has a limited window of time in which to use it. When systems force password changes, there are a few predictable ways in which people respond. Those include changing their password and then changing it back, transforming it to generate a new password (password1 becomes password2, or Decsecret becomes Jansecret), or picking a completely new password. (Hey, it could happen, and the person might not even write down the new password.)
This leads to an argument for controlling those human behaviors by storing password history, and sometimes also limiting the rate of password change. Systems that store password history create an additional risk, which is that the stored passwords might be obtained, and an attacker who has access to a series of passwords can use either human or algorithmic pattern recognition to make very accurate guesses about what a person's next password is likely to be (Thorsheim, 2009; Zhang 2010). If you must store history, it is probably sensible to use an in-place adaptive algorithm such as bcrypt to store the historical passwords with a level of protection that would lead to unacceptable performance in interactive login.
I am not aware of any evidence that password expiration systems have any impact on the rate at which compromises happen. There is excellent evidence that normal people do not change their passwords unless forced, and as such there is a cost to password expiry that is hard to justify. The main reason to pay the cost of such a system is because a compliance program insists on it.
Authentication Checklist
This checklist is designed to be read aloud at a meeting. You're in a bad state if for any of these questions:
§ You can't answer yes.
§ You can't articulate and accept the implications of a no.
§ You don't know.
1. Do we have an explicit list of what data is used in authentication?
2. Is it easy for us to add factors to that list?
3. Do we have easy to understand error messages?
4. If we're hiding authentication factors, what is our estimate of how long it would take for an attacker to find out about each?
5. Have we reviewed at least the information in the book for each authentication factor?
a. Have we looked up the relevant references?
b. Have we looked for additional threats based on those references?
6. Are we storing passwords using a cryptographically strong approach?
Account Recovery
We've all seen the “Forgot your password?” feature that so many sites offer. There are many varieties of this, including the following:
§ E-mail authentication
§ Social authentication
§ Knowledge-based authentication
§ Secret question/secret answer (or)
§ Data from public records, such as your address on a given date
There are many varieties of these systems because, much like passwords, they are highly imperfect. This section provides an overview of the trade-offs involved. It begins with a discussion of time in account recovery, then explains account recovery via e-mail and social authentication, both of which are simple and relatively secure when compared to the more familiar knowledge-based (“secret question”) systems covered at the end of this section.
All of these systems are abused by attackers. Famous examples include U.S. vice presidential candidate Sarah Palin's e-mail being taken over (the questions were birth date, zip code, and “Where did you meet your husband?” [Campanile, 2008]).
These systems should focus on recovering the account. The focus on “forgotten passwords” often leads system designers into the trap of giving people their previous password. This leads to the plaintext storage of passwords, which is usually not needed. Customers don't really care about their password or need it back. They care about the account (or what it enables) and need access to the account. Therefore, you should focus on restoring account access. The only substantial exception to this is encrypted data, for which it may be the case that an encryption key is derived from the password. You should investigate other ways to back up those encryption keys, such that you don't need to store passwords in plaintext.
When an account is recovered, it may be possible to throw away information that an attacker could exploit, such as payment information or mailing address. This information is usually easy to re-enter and has value to an attacker. (Addresses are useful for chained authentication attacks and stalking.) If you inform people why the data is gone, they are likely to be understanding. What data you choose to destroy as part of the account recovery process will depend on your business.
Time and Account Recovery
Time is an important and underrated ally in account recovery systems. The odds that users will need to use their account recovery option within five minutes (or even five days) of their last successful login are low. You might want the account recovery options for an account to be disabled until some specified amount of time has elapsed since the last successful login. (This point was made by my colleague and usable security expert Rob Reeder.) It is tempting to suggest offering fake account recovery options until then, but that might frustrate your real users.
The person driving an account recovery process might be the authorized account holder or an attacker. Your process should balance ease of use with challenge, and speed with an opportunity for the real account holder to intervene. For example, if you send password recovery e-mails, you should notify the person via every channel available to you. These notifications should contain instructions for the case that the receiver didn't initiate the account recovery, and possibly an explanation of why you're “spamming” them. These notifications and delays are more important when other risk factors are visible (for example, the account logs in from one IP address 90 percent of the time, but today logged in from the other side of the world).
Time also plays into account recovery in terms of what happens after the instant of getting into the account. Some system designers think they're done when a new password has been set. If the password was changed by an attacker, how does your customer recover his or her account? Perhaps after account recovery (but not normal password changes) the old password could work for some time period? However, then an attacker with the password is not locked out. There is no single obvious answer, and the right answer will differ for accounts associated with close relationships (work, banks, etc.) versus casual accounts.
Time is also a threat to account recovery systems. Over time, information that people have given you will decay. Their credit cards will become invalid, and their e-mail addresses, billing addresses, and phone numbers will likely change. If you rely on such information, consider allowing it to decay over time, being revalidated or removed from the system's recovery options.
E-mail for Account Recovery
If you have an e-mail address for your customer, you can send mail to it. That mail can contain a password or a token of some form. If you e-mail the customer a password, you should e-mail a new, randomly generated password. In fact, that should be all you can do, because you should take the preceding advice and not be able to e-mail them their old password. However, e-mailing them a password exposes the password to information disclosure threats on a variety of network connections and in storage at the other end. Some people will argue that it's better to not expose the password, but instead use a one-use token that allows the person to reset their password. The token should be a large random number, say 128–1,024 bits. You can send this either as a string they copy and paste into a browser form or as a URL. Hopefully it is obvious that the code which actually resets the password must confirm that the account actually requested a password reset, that the e-mail didn't bounce, and that the token is the one that was sent.
Either approach is vulnerable to information disclosure attacks. These attacks rely on either network sniffing or access to the backup e-mail address. You can partially mitigate these threats by crafting a message that does not contain all the information needed to recover the account. For example, if the system sends a URL with a recovery token, then it should not contain the account name. Thus, someone who intercepts or obtains the e-mail would need additional information if the account name is not the e-mail address. In systems where the e-mail address is the account name, that obviously doesn't work. You can add a layer of mitigation by checking cookies and possibly also by confirming that the browser they're using is sending the same headers as it was when someone requested a password reset. If you do that, there is a cookie deletion threat, which can be managed by telling people that they need to keep the page where they've requested a password reset.
Knowledge-Based Authentication
A variety of systems use various non-password information, which, it is hoped, only the real person behind the account knows. Of course, such information isn't really perfect for authentication. It must be known by the relying party so that it can be confirmed. Such information has the weakness that it may be known to other relying parties, or it may be discoverable by an attacker. The spectrum of such information runs from information that's widely available to the public through information that might be known only to the relying party. (Known only to the relying parties is a property that many hope is true of passwords.) This section considers three forms of knowledge-based authentication:
§ Secret questions/secret answers
§ Data from public records, such as your address on a given date
§ Things only a few groups other than the organization and customer know, such as the dollar amount of a given transaction. “What is your password?” is one logical end of this knowledge-based authentication spectrum.
As mentioned earlier, ideally, the answers to these questions are known only to the real person behind the account, are exposed only to the proper account system, and people know they should keep it secret. Each of these systems can be threat modeled in the same ways.
Security
There are several classes of attack on the security of questions. The biggest ones are guessing and observation. The difficulty of each can be quantified, (possibly with respect to a specific category of attacker). Guessing difficulty is based on the number of possible answers. For example, “what color are your eyes?” has very few possible answers. Guessing difficulty is also based on probability. Brown eyes outnumber blue, which outnumber green. There are also attacks where the answer to the question can be found (observed) elsewhere. For example, information about addresses is generally public. This approach to measurement has been formalized by Bonneau, Just, and Matthews (Bonneau, 2010). They measured the guessing difficulty for people's names (parent names, grandparent names, teacher names, best friends) and place names (where you went to school, last vacation). They also comment on the relatively small number of occupations that our grandparents engaged in, and the small number of movies that are common favorites.
Observation difficulty refers to how hard it would be to find the answer from a given perspective. For example, mothers' maiden names are often accessible because of genealogy websites. Some questions are also subject to attack by memes such as “Your Porn Star Name” or “20 Facts About Me.” The current first search result for “porn star name” suggests that you should form it from “your first pet's name and the street you grew up on.” Relying on such information being secret is a bad choice. It is a bad choice because people don't expect that the information in question will need to be kept private. No one would find it entertaining to be asked for a password in order to generate a porn star name; they'd find it worrisome. Observation difficulty can only be measured in relation to some set of possible observers. Therefore, attacker-centered modeling makes sense for measuring observation difficulty.
Usability
Knowledge-based authentication systems also suffer many usability problems, including the following:
§ Applicability: Does the item apply to the whole population? Questions about the color of your first car only apply to those who have owned cars; questions about the name of your first pet only apply to pet owners.
§ Memorability: Will people remember their answer? Studies have shown that 20 percent or so will forget their answers within three months (Schechter, 2009).
§ Repeatability: Can someone correctly re-enter their answer (“Main St” vs. “Main Street”), and is the answer still the same as it was 10 years ago? (Is Avril Lavigne still your favorite singer?) Repeatability is also called stability in some analyses.
§ Facts versus preferences: There is some evidence that preferences are more stable over time. However, entropy, and thus resistance to guessing attacks, is lower, and some preferences may be revealed to observation.
§ Privacy: Some questions can seem intrusive, creepy, or too personal to users. Also, under the privacy laws of many countries, information can only be used for the purpose for which it was collected. Using such information for authentication may run afoul of such laws.
§ Internationalization: The meaning of some questions does not carry across cultures. Facebook has reported that people in Indonesia don't name their pets, and so the usual answer to that question is “cat” (Anderson, 2013).
Aligning security with the mental models of your customers is great if you can manage it, but it may be sufficient to avoid surprising your customer. To illustrate the difference, a website decided that cookies were part of the login process, and if your cookies were deleted, you would need not only your password, but also your secret question. Because my secret answer was something like “asddsfdaf,” this presented a problem. The design surprised me, and prevented me from logging back in, which is the state my account is probably in to this day.
Additionally, systems can be open question or open answer. Open-question systems are of the form “please enter your question.” It turns out that such systems result in questions with few answers (e.g., “What color are my eyes?”; “What bank is this?”).
If You Must Use a Knowledge-Based Authentication System
Look for information in your system that can be used, such as “What was the dollar amount of your last transaction?” The information should be available to few parties;, thus, the last LinkedIn connection you added is poor. If your organization has features to enable social sharing, nothing that is shared should be usable to authenticate. It should also be hard for an attacker to influence; thus, “Who was the last person who e-mailed you?” is bad. Finally, it should be hard for an attacker who has broken in to extract all the information they would need to retake the account.
One way to reduce the chance that the attacker can extract all the information from the account is to augment the last dollar amount question with a financial account number question. If you use financial account numbers, be sure to require more than five digits. (Four digits is the U.S. limit to how many may be displayed; using five means an attacker only needs to guess, on average, five times to get in. Consider asking for six or eight.) When someone gets the answers right, consider sending a message to all the backup contact information you have, offering the real account owner a chance to challenge the authentication. That said, however, consider using social authentication, covered in the section of the same name, in place of knowledge-based authentication.
Chained Authentication Failures
As many organizations develop backup authentication schemes, avoiding chained and interlock authentication failures is an important issue. A chained failure is where an attacker who takes over an account at one site can see all the information they'll need to authenticate to another site. An interlocking failure is where that's bi-directional. For example, if you set your Gmail account recovery to Yahoo mail, and your Yahoo mail to recover with Gmail, then your recovery options are interlocked. Unfortunately, it's normally an issue that end users must manage for themselves.
Note
This issue came to widespread attention after an August 2012 article in Wired, “How Apple and Amazon Security Flaws Led to My Epic Hacking” (Honan, 2012). It's worth recounting the details and then analyzing them. The names of the companies are taken from the Wired story. Note that these are large, mature companies with employees focused on security. The story is presented solely to help others learn. The steps that led to the “epic hacking” are as follows:
1. Attacker calls Amazon and partially authenticates with victim's name, e-mail address, and billing address. Attacker adds a credit card number to the account.
2. Attacker calls Amazon again, authenticating with victim's name, e-mail address, billing address, and the credit card number added in step 1. Attacker adds a new e-mail address to the account.
3. Attacker visits Amazon.com, and sends password reset e-mail to e-mail address from step 2.
4. Attacker logs in to Amazon with the new password. Attacker gathers last four digits of real credit card numbers.
5. Attacker calls Apple with e-mail address, billing address, and last four digits of the credit card. Apple issues a temporary credential for an iCloud account.
6. Attacker logs into iCloud and changes passwords.
7. Attacker visits Gmail and sends account reset e-mail to compromised Apple account.
8. Attacker logs into Gmail.
So what went wrong here?
§ All the attacks used backup authentication methods.
§ Several places used data that's mostly public to authenticate.
§ Amazon allowed information that can be used to authenticate to be added with less authentication.
§ The Wired writer took the advised approach and interlinked all of his accounts.
Returning to the issue of chained authentication failures, it is hard to prevent people from using their preferred e-mail provider. It is perhaps impossible for a company to determine where it stands in a daisy chain of authentications. It might be possible to detect authentication loops, manage the privacy concerns such a process could raise, and handle the loop in a clever way.
Social Authentication
As mentioned earlier, the traditional methods of authentication are what you have, what you know, and what you are. In a 2006 paper, John Brainard and colleagues suggested a fourth: who you know, presenting it as a way to handle primary authentication (Brainard, 2006).
Social authentication is authentication based on social contact of various forms. It is already in use at a great many businesses that send a replacement password to your manager if you're locked out. This leverages the expectation that managers ought to be able to get in touch with their employees and authenticate them. Social authentication may also help with making your system more viral. When someone is selected as a trustee, you might want to round-trip an e-mail message to them to ensure that the details are valid, and you may want to recheck that address from time to time. Such messages can have the added value of marketing your service, as you might need to explain what the service is. Try hard to not eliminate the security value by spamming.
Passive Social Authentication
In early 2012, Facebook deployed a backup authentication mechanism that asks users to identify a set of people connected to that user (Fisher, 2012; Rice, 2011). This is passive authentication in the sense that your Facebook contacts are not actively involved in the authentication process. Such systems are easier to deploy if you have a rich social graph of some type.
However, the data needed to bypass such a system is sometimes available to (and perhaps via) Facebook, LinkedIn, Google, and a growing number of other companies. Other problems include photos that don't include an identifiable face and photos that contain a name badge (for example, from a conference). Facebook also explored use of their social graph to make collaboration more difficult, selecting people who are less likely to be known to a single attacker, or friends of the attacker. Of course, because the attacker is unknown, they can only do this by looking for distinct subgraphs (Rice, 2011).
Active Social Authentication
Active social authentication uses a real-world relationship to recover access to an account. Such systems are most obvious when a manager gets a new password and provides it to an employee, but it's possible to build deeper systems that use a variety of account “trustees.” One such system was developed experimentally by Stuart Schechter, Serge Egelman, and Rob Reeder (Schechter, 2009). It is reviewed here in depth because it's superior in many ways to knowledge-based systems, and because many of the details show interesting design points.
They use a system of trustees who reauthorize access to an account. Their test used a system of four trustees selected by the account holder, and required concurrence of three trustees. When an account goes into recovery, each trustee is sent an e-mail with a subject line of “**FOR YOU ONLY**.” The body of the message starts with “Do not forward any part of this e-mail to anyone,” and continues with an explanation of what to do. The e-mail then goes on to encourage the recipient to visit a given URL. When the recipient does so, he or she is asked to explain why an account recovery code is being requested. The reasons are listed from riskiest to least risky so that someone who selects the first option(s) will see an additional level of warning before being allowed to get a recovery code. The reasons given are as follows:
§ Someone helping William Shakespeare (or who claimed to be helping) asked for the code
§ An e-mail, IM, SMS, or other text message that appears to be from William Shakespeare asked for the code
§ William Shakespeare left me a voicemail asking for the code, and I will call him back to provide it
§ I am speaking to William Shakespeare by phone right now and he has asked for the code
§ William Shakespeare is here with me in person right now and he has asked me for the code
§ None of the above reasons applies. I will provide my own:
After selecting one of these, and possibly seeing additional warnings about signs of fraud, the trustee is asked to pledge to the veracity of the answer and their understanding of the consequences of being duped. They are required to type their name and then press a button that says “I promise the above pledge is true.” The trustee is then given a six-character code, and instructed to provide it either in person or in a phone call. The system will then e-mail all the other trustees, encouraging them to call or visit the account holder. This process has several useful properties, including increased security and alerting the account holder if they didn't initiate the account recovery.
There are a number of issues with the system as presented. One is time. This social approach takes longer to complete than knowledge-based approaches. Another is that in the initial reliability experiment, many participants did not succeed at recovering their account. Of 43 participants in the weeklong reliability experiment, 17 abandoned the experiment. Of the 26 who actively participated, 65 percent were able to recover their account. Two of the failures didn't remember their trustees or use the “look them up” feature, and another two were too busy to participate in the study. Looking at the 22 who actively participated, 77 percent of them succeeded at account recovery, which seems poor, but it's comparable to knowledge-based systems. It seems likely that more people would succeed if they really were trying to recover their account, and had nominated appropriate trustees.
Despite these concerns, social authentication is a promising area for account recovery, and I am optimistic that new systems will be developed and deployed, replacing knowledge-based account recovery for casual accounts.
Attacker-Driven Analysis of Account Recovery
Knowing who is attacking is a useful lens into how account recovery systems work, because there are sets of attackers who obviously have more access to data. Spouses or ex-spouses, family members, and others will often know (or be able to tease out information about) your first car, the street you grew up on, and so on. Attackers include, but are not limited to, the following:
§ Spouses
§ Friends
§ Social network “friends” and contacts
§ Attackers with current access to your account
§ Attackers with access to an account on another system
§ Attackers with access to a data broker's data
In “It's No Secret: Measuring the Security and Reliability of Authentication via ‘Secret’ Questions” (Schechter, 2009), the authors categorize 25 percent of question/answer pairs in use at large service providers as vulnerable to guessing by family, friends, or coworkers. Spouses generally have unfettered access to records, financial instruments such as credit cards, and the like. Friends will often know about biographical information. Social network contacts can use attacks like the “Your Porn Star Name” game to get access to elements of personal history that social networks such as Facebook don't make public. The social networks themselves change what information they show as public, meaning your analysis of knowledge-based account recovery must be regularly revisited.
Another important set of attackers is online criminals, who have found ways to access information stored by data brokers. This information is often marketed as “out of wallet” authentication. That criminals have access to such data emphasizes the need to use data known only to you and your customers (Krebs, 2013).
Multi-Channel Authentication
Many systems claim to use additional channels for authentication. Some of them even do, but modeling what counts as a channel in a converged world is challenging. In particular, when a smartphone is synced to a computer, the act of syncing often involves giving one computer full authority to read or write to anything in the other. This means that smartphones are a risky source of additional channels. The computer is a threat to the smartphone, and vice versa. Physical mail is a fine example of an additional channel, with the obvious issue that it's quite slow.
Account Recovery Checklist
This checklist is designed to be read aloud at a meeting. You're in a bad state if for any of these questions:
§ You can't answer yes.
§ You can't articulate and accept the implications of a no.
§ You don't know.
1. Do we have explicit reasons that we need an online account recovery feature?
2. Have we investigated active social authentication as an approach?
3. If you're using active social authentication, then have we tried to address the attacks by friends problem?
4. Have we tested the usability and efficacy of our approach for both the authorized customer and one or more sorts of attacker?
If you've decided to use a knowledge-based authentication system, you'll probably jump from #2 to the following list:
1. Will our system use only information that only we and our customer should know?
2. Will our system resist attacks like “Your Porn Star Name” game?
3. Will our system resist attack by spouses?
4. Will our system resist attackers who have broken in and scraped the account?
5. Will our system resist attackers who have access to information bought and sold by data brokers?
6. Have we considered the various usability aspects of knowledge-based authentication?
7. Do we use time and account-holder notification as allies?
Names, IDs, and SSNs
A great many technological systems seem to end up using human names and identifiers. The designers of these systems often make assumptions that are not true, or are perhaps even dangerous. A good model of names, identifiers, and related topics helps you threat model effectively, limiting what you expect to gain from using these identifiers. Many reliability and usability threats are associated with these topics. In this section, you'll learn about names, identity cards and documents, social security numbers and their misuse, and identity theft.
Names
“What's in a name?” asked Shakespeare, for a very good reason. A name is an identifier, and between diminutives, nicknames, and married names, many people use more than one name in the course of their life. Useful names are also relative. You and I mean something different by “mom”‘ or “my wife.” I often mean different people when I say “Mike.” (At work, my three-person team has a Mike, and my boss's boss is named Mike; and that's just at work.)
“Real Names”
It is tempting to set up a new system that requires people to use their “real names.” It is widely believed that a real-name system is easier to validate, and that people will comment more usefully under their real names. Both of these claims are demonstrably false. South Korea rolled out and then scrapped a regulation requiring real names, having found that it did not prevent people “from posting abusive messages or spreading false rumors” (Chosunilbo, 2011). Internet comment management company Disqus has analyzed its data and discovered that 61 percent of its commenters were obviously using pseudonyms, and only 4 percent used what appeared to be a real name. They also found that both real name and pseudonym comments were marked as spam at approximately the same rates (9 percent and 11 percent respectively).
However, the cost of real name requirements can be high. Google's G+ system required real names on rollout. They did so with a set of “name police,” who rejected real names and violated their own policies. These “nymwars” as they came to be known had a dramatic effect on the adoption of Google+, and I've argued elsewhere that it was singularly responsible for G+ not killing Facebook (Shostack, 2012b). Germany has a law forbidding such policies (Essers, 2012). Both demands for real names and attempts to impose rules on those names continues to happen and cause outrage. For example, see “Please Enter a Valid Last Name” (Neilsen Hayden, 2012).
Patrick McKenzie published a list titled “Falsehoods Programmers Believe About Names.” The list is worth reading in full, but here are the first nine items (McKenzie, 2010):
1. People have exactly one canonical full name.
2. People have exactly one full name which they go by.
3. People have, at this point in time, exactly one canonical full name.
4. People have, at this point in time, one full name which they go by.
5. People have exactly N names, for any value of N.
6. People's names fit within a certain defined amount of space.
7. People's names do not change.
8. Peoples names change, but only at a certain enumerated set of events.
9. Peoples names are written in ASCII, or some other single character set.
The list continues through another 30 false assumptions. Two items can be added to the list, based on reading the comments. First, you can exclude certain characters from people's names without offending them. Second, the name people give you is one they use outside your system. Many programmers seem offended at being asked to deal with this. A great many comments are of the form “people should just deal with it and offer a Romanized version of their name.” Other commenters point out that lying about your name is in some instances a felony, and how changes in names or transliteration can lead to real problems. Many Americans were introduced to this by the TSA (airport security) when they checked that identity documents matched names on tickets. Discrepancies such as “Mike/Michael” lead to trouble. At best, a system that refuses people's preferred names threatens to appear arrogant and offensive to those who are mis-addressed.
So what should you do? Don't use human names as account names. Treat human names as a single field, and use what people enter. If you'd like to be informal, ask your customers for both a full name and how the system should address them.
Account Names
Unlike human names, it is possible to make account names unique by having some authority that approves names before they can be used. (I am aware of some countries that do this at birth, but none that require a renaming when someone moves there.) Names can be unique or currently unique. Someone had my microsoft.com e-mail before me. The last I heard, his kids were knocking it out of the little league park, and his wife still loved him (muscle memory on typing his e-mail address, or so she claimed). Therefore, uniqueness is helpful, but it leads to all the easily remembered e-mail addresses being taken.
If your account system relies on someone else maintaining uniqueness forever, while in fact they maintain uniqueness at a given time, you can run into trouble. For example, if that other Adam and I both sign up for LinkedIn with our @microsoft.com addresses, what should LinkedIn do? They can probably handle that by now, and you'll need to do so as well. (A draft of this section threatened to magnify this problem by including my e-mail address.)
“Meaningful ID”
Carl Ellison has coined the term meaningful ID and defined it as follows: “A meaningful ID for use by some human being is an identifier that calls to that human user's mind the correct identified entity” (Ellison, 2007). This is a good model for an important use case for names, which is to call to mind a specific person.
Ellison provides some requirements for meaningful IDs:
1. Calling a correct entity to the human's mind implies that the human being has a body of memories about the correct entity. If there are no such memories, then no ID can be a meaningful ID.
2. What works to call those memories to one observer's mind may not work for another observer. Therefore, a meaningful ID is in general a function of both the identified entity and the person looking at it.
3. The meaningful ID needs to attract attention or be presented without distracting clutter, so that it has the opportunity to be perceived.
4. When a security decision is to be made, the meaningful ID(s) must be derived in a secure manner, and competing IDs that an attacker could introduce at-will should not be displayed.
Ellison suggests that the best identifier to present to a person is probably a nickname selected by the person who must rely on it, or a picture taken by that relying party. Implicitly, a system must perform the translation, and be designed to mitigate spoofing threats around the nickname shown.
Zooko's Triangle
You may have noticed that the requirements for a meaningful ID are in tension with the requirements for account names. Meaningful IDs are selected by people, to be evocative for themselves, while account names are mediated by some authority. It turns out that there are many such tensions associated with names. One very useful model of these tensions is “Zooko's Triangle,” named after its creator, Zooko Wilcox-O'Hearn, and shown in Figure 14.4. The triangle shows the properties of decentralized, secure, and human-meaningful (Zooko, 2006).
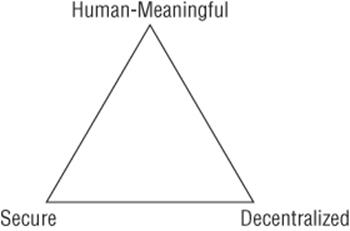
Figure 14.4 Zooko's Triangle
The idea is that every system design focuses on one or two of these properties, which requires a trade-off with the others. The choice can be implicit or explicit, and the Triangle is a useful model for making it explicit.
Identity Documents
Deferring the issue of identifying your users to a government agency is attractive. Having someone look at or make a copy of a government-issued identity document may constitute sufficient due diligence, especially if you are in a regulated industry. Looking at the documents and storing copies exposes you to very different threats. If you store them and lose control of the storage, you'll need to notify those people if you lose control of the documents (under a wide variety of state breach disclosure laws). This is an information disclosure threat against a data store, and the risk elimination mitigation is to not have that data store. It may be sufficient to ensure that you check the documents. If you are not required by law to expose yourself to such liabilities, then having copies of identity documents seems foolishly risky.
Another issue with identity documents is that many people lack them for a wide variety of reasons. Many American citizens lack identity documents. This issue gained attention in the run-up to the 2012 election, as many states passed voter ID laws. Setting aside the emotional political questions, these laws drew attention to the fact that roughly 11 percent of voting-age Americans do not have current and valid government-issued photo ID (Brenner, 2012). It is important to consider how you'll handle those customers without valid ID, or whose ID is not of the form you expect. For example, 20 million Americans don't have a driver's license (Swire, 2008). Your response to those without the ID you want might be to threaten to or actually refuse them service, but check with your sales and marketing departments before cutting off so many of your potential customers.
Many times, it seems attractive to address fraud issues by asking people to show copies of such documents. If the document is shown over the Internet, any fool with a printer can make a spoof that's good enough for their webcam. Similarly, any college student or illegal immigrant can acquire a document that's good enough to fool the majority of people paid to check the documents. As the value of such documents increases, so does the motivation to either forge them or corrupt the official issuance process. This is an economic threat to both your system and the integrity of the system as a whole. Regardless, knowing what an ID card says does not mean that the person with a given ID card is the same person who opened the account. This is a spoofing threat. (After all, given the breaches that happen, all the data on a given ID card may be available to a fraudster.)
In short, looking at ID cards may be a helpful step, but it would reflect poor threat modeling to assume that it will solve all your authentication problems.
Social Security Numbers and Other National Identity Numbers
This section reviews risks associated with the United States social security number (SSN). Over the last five to ten years, the use of SSNs has declined substantially as a result of new laws. As of this writing, it is illegal to deny someone goods or services because they will not give you their SSN in Alaska, Kansas, Maine, New Mexico, and Rhode Island (Hillebrand, 2008). A large number of state laws also restrict their use, too numerous to list here (Bovbjerg, 2005). The first problem is that many developers are unaware of these laws, and their lack of awareness may put their employers at risk. The second problem with SSNs is that some organizations use them as identifiers, while others use them for authenticators. (Recall that an identifier is a label for a person or other entity. An authenticator is how you prove that claim.) A few remarkable organizations manage to use them for both, but that's not a model you want to emulate.
SSNs Are Poor Identifiers
Social security numbers make poor identifiers even if all your customers are American citizens who happen to be willing to give you their SSN. Not every American has an SSN, and not everyone legally residing in the United States is a citizen. For example, many teachers participate in the Teacher Retirement System, which does not use SSNs. Many legal residents are not able to get an SSN. Second, SSNs lack a check digit, so it's easy to accidentally transpose or mistype digits. When you do, you have a roughly one-in-three chance of getting someone else's SSN. (Roughly 300–400 million SSNs have been issued, and the number space is nine digits.) Third, except for those who work at the Social Security Administration, the identifiers are outside your control.
SSNs Are Poor Database Keys
Even if you collect SSNs, you should ensure that your account identifier and database keys are ones that you control. Otherwise, you'll need to deal with a way to change your account identifier. As the Social Security Administration notes, “Applying for a new number is a big decision. It may impact your ability to interact with federal and state agencies, employers, and others. This is because your financial, medical, employment and other records will be under your former Social Security number . . .” (Social Security Administration, 2011). It is unclear whether the SSA is using SSNs as account identifiers, or if they are warning that many others do so. If they are using the SSA as an account identifier, that might be reasonable, but it would also seem reasonable that they have a way to manage an update. If they have chosen a mitigation strategy of risk transfer to citizens, then reasonable people might be skeptical that that's a decision a government should be making.
SSNs Are Poor Authenticators
SSNs are known to many parties. As stated earlier in the discussion of knowledge-based authentication, answers to authentication questions should be known to only a few parties. Unfortunately, between schools, banks, insurance companies, utility companies, employers, tax preparation, gyms, and other entities that have made SSNs a condition of participation, the SSNs of most Americans are available fairly widely, and are often leaked in data breaches.
Even if they were not, Alessandro Acquisti and Ralph Gross have shown that they can predict many SSNs based on date and location of birth. They could “identify in a single attempt the first five digits for 44 percent of deceased individuals who were born after 1988 and for 7 percent of those born between 1973 and 1988.” They were also able to “identify all nine digits for 8.5 percent of those individuals born after 1988 in less than 1,000 attempts” (Power, 2009). In further work with Fred Stutzman, they were able to add facial recognition, using a dataset of faces on Facebook and an online dating site to find names and birth dates. They were able to guess a substantial number of SSNs or partial SSNs from three webcam pictures (Acquisti, 2011). As they point out, this technology will get better and better as facial recognition technology improves, and as labeled face data becomes more widely available.
Finally, social security numbers are routinely published by the Social Security Administration after people die, in the Social Security Death Master File (SSDMF) [Social Security Administration, 2012]. Some organizations check the SSDMF to prevent new account fraud. However, when someone dies, their account does not necessarily go away. For example, bank accounts might be maintained by an estate during probate. A phone might be kept active for several months to enable people to get in touch. If you are using SSNs or some portion of the SSN as an authenticator, it will have been made public, making your authenticator far less useful.
Why Not Publish the SSN List?
One innovative response to the issue of “are SSNs well known?” is to simply publish the list, thus clarifying the true state of the system (Lindstrom, 2006). This is attractive in a number of ways. However, the law states “Social security account numbers and related records that are obtained or maintained by authorized persons pursuant to any provision of law enacted on or after October 1, 1990, shall be confidential, and no authorized person shall disclose any such social security account number or related record” (42 USC 405(c)(2)(C)(viii)). Therefore, any source with an authoritative list is legally prohibited from publishing it. Rather than change the law to allow publication of the list, a sane new law should prohibit the use of SSNs as identifiers or authenticators, and restrict their use in both the public and private sectors. (Given the lack of a check digit, associating two records based on an SSN should probably be treated as negligent.)
Other National Identity Schemes
The preceding section is very U.S.-centric, and may therefore seem irrelevant to those in other countries, but it is not. The same sorts of issues crop up with any national identifier scheme, although the semi-private nature of the SSN seems to have exacerbated the conflation of its use as both identifier and authenticator.
Wherever you are considering using a government-issued identifier, (or other identifier provided by another organization) you should ask the following questions:
§ Does everyone have one?
§ Does it have a check digit?
§ Will you ever serve tourists, students, refugees, or other foreigners?
§ Can an individual get a new ID, and if so does it have the same field values?
§ How will the system handle identity fraud in the future? (Even if the citizen can't change their number now, they may be able to in the future. You should store it as a field, not as your identifier or database key.)
If you want to use it as an authenticator, perhaps as part of an electronic ID scheme, ask how many people have access to the authentication data associated with the card.
Identity Theft
There is a common worry in the United States, referred to as identity theft. Elsewhere, I've written that the term fraud by impersonation is a more accurate description of the crime, and that it's a crime facilitated by inappropriate allocation of costs and benefits (Shostack, 2003). In particular, it's easy for organizations that trade in information to be paid even when the information turns out to be highly inaccurate. The cost to them is that they may need to update it. The threat to a data subject may be denial of credit, denial of a job or a volunteer opportunity, or even an inappropriate arrest. Other cost distributions would likely result in more socially desirable outcomes.
However, the term identity theft may be appropriate when you consider its emotional impact on a subset of victims where records with information about them have become inextricably linked to those of the perpetrator, and whose ability to engage in normal activities is inhibited by the emotional burden of further false accusations, and the fear of those accusations. Those people really have had their “good name” stolen (Identity Theft Resource Center, 2009). There may be a good case that their good name isn't stolen by the impersonator, but by those who intermix records and re-distribute the misinformation.
How does this play into threat modeling? Linkage is a threat to your data integrity and to your customer's satisfaction. System designers should take care when linking information from disparate sources. If your system has features or processes that allow people to access and correct information you store, you should ensure that those corrections are not accidentally overridden by the same data from a source whose data has been corrected. (That is, if Alice tells you that Bob is a deadbeat, and Bob shows you his cancelled checks paying his debt to Alice, you'll correct your record. Next month, Alice may well include Bob in her list of deadbeats again. Do you want Bob to be a happy customer? If so, you should be careful to not require that he correct your data repeatedly.) Tracking where your data is from can help with these issues. If you sell data about people, you can provide information about where you got the data to help your customers deliver better service. The most important distinction is between your direct observation and information you receive from elsewhere. You can either name the source, or, if the source is commercially sensitive, give them an alias.
Names, IDs, and SSNs Checklist
This checklist is designed to be read aloud at a meeting. You're in a bad state if for any of these questions:
§ You can't answer yes.
§ You can't articulate and accept the implications of a no.
§ You don't know.
1. Do we know who controls our account namespace?
2. Do we have a way for our customers to assign a meaningful ID to things they need to securely identify?
3. Do we know what trade-offs we've made between global, meaningful, and secure?
4. Are we relying on identity documents? If so, are we storing copies of those documents, and who has signed off on that risk?
5. Are we using SSNs or similar identifiers at all?
Summary
In a good model of accounts, they exist at the intersection of the human and the machine, and threats are abundant at that boundary. Those threats include authentication threats and confusion about names and identifiers.
Accounts are a focal point for threats, which occur throughout the account life cycle, including account creation, maintenance, and termination. Risks of information disclosure to bad actors cause many systems to treat the people behind the accounts as attackers, rather than allies. Many of the authentication factors that are hidden are easily learned by a motivated attacker, while your real customers are left frustrated and in the dark. Good modeling that exposes how easy or hard it is to learn the obscured elements of authentication can help you make good choices, especially about notifying the person behind the account of what's happening.
Authentication is hard. Creating a workable authentication system that satisfies both an organization and its customers is hard. The framework of what you know, what you have, and what you are gives you a way to think about authentication, with “what channel are we using?” and “who you know” being interesting additions to the framework. However, each of these elements has threats against it, which have been worked through in great depth, and there are established patterns and limits for each.
If authentication is hard, backup authentication is even harder. A variety of knowledge-based authentication techniques can be used to recover access to an account. When you use one, you should focus on account recovery, not password recovery, because you should not store passwords in plaintext. There are many problems with knowledge-based authentication, including security and usability. It may be preferable to use a social authentication technique; although they are new and less familiar, they are likely more secure.
Unlike authentication, names are relatively easy, once you accept that they lack certain properties, and you understand the risks that they carry. Avoid the “real name” trap, and consider where on Zooko's Triangle your system should be: Are names memorable, globally unique, or secure? (Pick any two.) It is tempting to defer the problem to identity documents, which can help a carefully designed system but carry risks of their own. Designers often want to use social security numbers, which are poor identifiers, poor database keys, and poor authenticators. Despite those flaws, they are often used, bringing privacy and security threats along with them. One of those threats is identity theft, and there are patterns that can help you avoid contributing to the problem.