Software Architecture for Developers: Technical leadership by coding, coaching, collaboration, architecture sketching and just enough up front design (2014)
III. DESIGNING SOFTWARE
This part of the book is about the overall process of designing software, specifically looking at the things that you should really think about before coding.
21 Architectural drivers
Regardless of the process that you follow (traditional and plan-driven vs lightweight and adaptive), there’s a set of common things that really drive, influence and shape the resulting software architecture.
1. Functional requirements
In order to design software, you need to know something about the goals that it needs to satisfy. If this sounds obvious, it’s because it is. Having said that, I have seen teams designing software (and even building it) without a high-level understanding of the features that the software should provide to the end-users. Some might call this being agile, but I call it foolish. Even a rough, short list of features or user stories (e.g. a Scrum product backlog) is essential. Requirements drive architecture.
2. Quality Attributes
Quality attributes are represented by the non-functional requirements and reflect levels of service such as performance, scalability, availability, security, etc. These are mostly technical in nature and can have a huge influence over the resulting architecture, particularly if you’re building “high performance” systems or you have desires to operate at “Google scale”. The technical solutions to implementing non-functional requirements are usually cross-cutting and therefore need to be baked into the foundations of the system you’re building. Retrofitting high performance, scalability, security, availability, etc into an existing codebase is usually incredibly difficult and time-consuming.
3. Constraints
We live in the real world and the real world has constraints. For example, the organisation that you work for probably has a raft of constraints detailing what you can and can’t do with respect to technology choice, deployment platform, etc.
4. Principles
Where constraints are typically imposed upon you, principles are the things that you want to adopt in order to introduce consistency and clarity into the resulting codebase. These may be development principles (e.g. code conventions, use of automated testing, etc) or architecture principles (e.g. layering strategies, architecture patterns, etc).
Understand their influence
Understanding the requirements, constraints and principles at a high-level is essential whenever you start working on a new software system or extend one that exists already. Why? Put simply, this is the basic level of knowledge that you need in order to start making design choices.
First of all, understanding these things can help in reducing the number of options that are open to you, particularly if you find that the drivers include complex non-functional requirements or major constraints such as restrictions over the deployment platform. In the words of T.S.Eliot:
When forced to work within a strict framework the imagination is taxed to its utmost - and will produce its richest ideas. Given total freedom the work is likely to sprawl.
Secondly, and perhaps most importantly, it’s about making “informed” design decisions given your particular set of goals and context. If you started designing a solution to the financial risk system without understanding the requirements related to performance (e.g. calculation complexity), scalability (e.g. data volumes), security and audit, you could potentially design a solution that doesn’t meet the goals.
Software architecture is about the significant design decisions, where significance is measured by cost of change. A high-level understanding of the requirements, constraints and principles is a starting point for those significant decisions that will ultimately shape the resulting software architecture. Understanding them early will help to avoid costly rework in the future.
22 Quality Attributes (non-functional requirements)
When you’re gathering requirements, people will happily give you a wish-list of what they want a software system to do and there are well established ways of capturing this information as user stories, use cases, traditional requirements specifications, acceptance criteria and so on. What about those pesky “non-functional requirements” though?
Non-functional requirements are often thought of as the “-ilities” and are primarily about quality of service. Alternative, arguably better yet less commonly used names for non-functional requirements include “system characteristics” or “quality attributes”. A non-exhaustive list of the common quality attributes is as follows.
Performance
Performance is about how fast something is, usually in terms of response time or latency.
· Response time: the time it takes between a request being sent and a response being received, such as a user clicking a hyperlink on a web page or a button on a desktop application.
· Latency: the time it takes for a message to move through your system, from point A to point B.
Even if you’re not building “high performance” software systems, performance is applicable to pretty much every software system that you’ll ever build, regardless of whether they are web applications, desktop applications, service-oriented architectures, messaging systems, etc. If you’ve ever been told that your software is “too slow” by your users, you’ll appreciate why some notion of performance is important.
Scalability
Scalability is basically about the ability for your software to deal with more users, requests, data, messages, etc. Scalability is inherently about concurrency and therefore dealing with more stuff in the same period of time (e.g. requests per second).
Availability
Availability is about the degree to which your software is operational and, for example, available to service requests. You’ll usually see availability measured or referred to in terms of “nines”, such as 99.99% (“four nines”) or 99.999% (“five nines”). These numbers refer to the uptime in terms of a percentage. The flip side of this coin is the amount of downtime that can be tolerated. An uptime of 99.9% (“three nines”) provides you with a downtime window of just over 1 minute per day for scheduled maintenance, upgrades and unexpected failure.
Security
Security covers everything from authentication and authorisation through to the confidentiality of data in transit and storage. As with performance, there’s a high probability that security is important to you at some level. Security should be considered for even the most basic of web applications that are deployed onto the Internet. The Open Web Application Security Project (OWASP) is a great starting point for learning about security.
Disaster Recovery
What would happen if you lost a hard disk, server or data centre that your software was running on? This is what disaster recovery is all about. If your software system is mission critical, you’ll often hear people talking about business continuity processes too, which state what should happen in the event of a disaster in order to retain continued operation.
Accessibility
Accessibility usually refers to things like the W3C accessibility standards, which talk about how your software is accessible to people with disabilities such as visual impairments.
Monitoring
Some organisations have specific requirements related to how software systems should be monitored to ensure that they are running and able to service requests. This could include integrating your software with platform specific monitoring capabilities (e.g. JMX on the Java platform) or sending alerts to a centralised monitoring dashboard (e.g. via SNMP) in the event of a failure.
Management
Monitoring typically provides a read-only view of a software system and sometimes there will be runtime management requirements too. For example, it might be necessary to expose functionality that will allow operational staff to modify the runtime topology of a system, modify configuration elements, refresh read-only caches, etc.
Audit
There’s often a need to keep a log of events (i.e. an audit log) that led to a change in data or behaviour of a software system, particularly where money is involved. Typically such logs need to capture information related to who made the change, when the change was made and why the change was made. Often there is a need retain the change itself too (i.e. before and after values).
Flexibility
Flexibility is a somewhat overused and vague term referring to the “flexibility” of your software to perform more than a single task, or to do that single task in a number of different ways. A good example of a flexibility requirement would be the ability for non-technical people to modify the business rules used within the software.
Extensibility
Extensibility is also overused and vague, but it relates to the ability to extend the software to do something it doesn’t do now, perhaps using plugins and APIs. Some off-the-shelf products (e.g. Microsoft Dynamics CRM) allow non-technical end-users to extend the data stored and change how other users interact with that data.
Maintainability
Maintainability is often cited as a requirement but what does this actually mean? As software developers we usually strive to build “maintainable” software but it’s worth thinking about who will be maintaining the codebase in the future. Maintainability is hard to quantify, so I’d rather think about the architecture and development principles that we’ll be following instead because they are drivers for writing maintainable code.
Legal, Regulatory and Compliance
Some industries are strictly governed by local laws or regulatory bodies, and this can lead to additional requirements related to things like data retention or audit logs. As an example, most finance organisations (investment banks, retail banks, trust companies, etc) must adhere to a number of regulations (e.g. anti-money laundering) in order to retain their ability to operate in the market.
Internationalisation (i18n)
Many software systems, particularly those deployed on the Internet, are no longer delivered in a single language. Internationalisation refers to the ability to have user-facing elements of the software delivered in multiple languages. This is seemingly simple until you try to retrofit it to an existing piece of software and realise that some languages are written right-to-left.
Localisation (L10n)
Related to internationalisation is localisation, which is about presenting things like numbers, currencies, dates, etc in the conventions that make sense to the culture of the end-user. Sometimes internationalisation and localisation are bundled up together under the heading of “globalisation”.
Which are important to you?
There are many quality attributes that we could specify for our software systems but they don’t all have equal weighting. Some are more applicable than others, depending on the environment that you work in and the type of software systems that you build. A web-based system in the finance industry will likely have a different set of quality attributes to an internal system used within the telco industry. My advice is to learn about the quality attributes common within your domain and focus on those first when you start building a new system or modifying an existing system.
23 Working with non-functional requirements
Regardless of what you call them, you’ll often need to put some effort into getting the list of non-functional requirements applicable to the software system that you’re building.
Capture
I’ve spent most of my 15+ year career in software development working in a consulting environment where we’ve been asked to build software for our customers. In that time, I can probably count on one hand the number of times a customer has explicitly given us information about the non-functional requirements. I’ve certainly received a large number of requirements specifications or functional wish-lists, but rarely do these include any information about performance, scalability, security, etc. In this case, you need to be proactive and capture them yourself.
And herein lies the challenge. If you ask a business sponsor what level of system availability they want, you’ll probably get an answer similar to “100%”, “24 by 7 by 365” or “yes please, we want all of it”.
Refine
Once you’ve started asking those tricky questions related to non-functional requirements, or you’ve been fortunate enough to receive some information about them, you’ll probably need to refine them.
On the few occasions that I’ve received a functional requirements specification that did include some information about non-functional requirements, they’ve usually been unhelpfully vague. As an example, I once received a 125 page document from a potential customer that detailed the requirements of the software system. The majority of the pages covered the functional requirements in quite some detail and the last half page was reserved for the non-functional requirements. It said things like:
· Performance: The system must be fast.
· Security: The system must be secure.
· Availability: The system should be running 100% of the time.
Although this isn’t very useful, at least we have a starting point for some discussions. Rather than asking how much availability is needed and getting the inevitable “24 by 7” answer, you can vary the questions depending on who you are talking to. For example:
· “How much system downtime can you tolerate?”
· “What happens if the core of the system fails during our normal working hours of 9am until 6pm?”
· “What happens if the core of the system fails outside of normal working hours?”
What you’re trying to do is explore the requirements and get to the point where you understand what the driving forces are. Why does the system need to be available? When we talk about “high security”, what is it that we’re protecting? The goal here is to get to a specific set of non-functional requirements, ideally that we can explicitly quantify. For example:
· How many concurrent users should the system support on average? What about peak times?
· What response time is deemed as acceptable? Is this the same across all parts of the system or just specific features?
· How exactly do we need to secure the system? Do we really need to encrypt the data or is restricted access sufficient?
If you can associate some quantity to the non-functional requirements (e.g. number of users, data volumes, maximum response times, etc), you can can write some acceptance criteria and objectively test them.
Challenge
With this in mind, we all know what response we’ll get if we ask people whether they need something. They’ll undoubtedly say, “yes”. This is why prioritising functional requirements, user stories, etc is hard. Regardless of the prioritisation scale that you use (MoSCoW, High/Medium/Low, etc), everything will end up as a “must have” on the first attempt at prioritisation. You could create a “super-must have” category, but we know that everything will just migrate there.
A different approach is needed and presenting the cost implications can help focus the mind. For example:
· Architect: “You need a system with 100% uptime. Building that requires lots of redundancy to remove single points of failure and we would need two of everything plus a lot of engineering work for all of the automatic failover. It will cost in the region of $1,000,000. Alternatively we can build you something simpler, with the caveat that some components would need to be monitored and restarted manually in the event of a failure. This could cost in the region of $100,000. Which one do you need now?”
· Sponsor: “Oh, if that’s the case, I need the cheaper solution.”
Anything is possible but everything has a trade-off. Explaining those trade-offs can help find the best solution for the given context.
24 Constraints
Everything that we create as software developers lives in the real world, and the real world has constraints. Like quality attributes, constraints can drive, shape and influence the architecture of a software system. They’re typically imposed upon you too, either by the organisation that you work for or the environment that you work within. Constraints come in many different shapes and sizes.
Time and budget constraints
Time and budget are probably the constraints that most software developers are familiar with, often because there’s not enough of either.
Technology constraints
There are a number of technology related constraints that we often come up against when building software, particularly in large organisations:
· Approved technology lists: Many large organisations have a list of the technologies they permit software systems to be built with. The purpose of this list is to restrict the number of different technologies that the organisation has to support, operate, maintain and buy licenses for. Often there is a lengthy exceptions process that you need to formally apply for if you want to use anything “off list”. I’ve still seen teams use Groovy or Scala on Java projects through the sneaky inclusion of an additional JAR file though!
· Existing systems and interoperability: Most organisations have existing systems that you need to integrate your software with and you’re often very limited in the number of ways that you can achieve this. At other times, it’s those other systems that need to integrate with whatever you’re building. If this is the case, you may find that there are organisation-wide constraints dictating the protocols and technologies you can use for the integration points. A number of the investment banks I’ve worked with have had their own internal XML schemas for the exchange of trading information between software systems. “Concise” and “easy to use” weren’t adjectives that we used to describe them!
· Target deployment platform: The target deployment platform is usually one of the major factors that influences the technology decisions you make when building a greenfield software system. This includes embedded devices, the availability of Microsoft Windows or Linux servers and the cloud. Yes, even this magical thing that we call the cloud has constraints. As an example, every “platform as a service” (PaaS) offering is different, and most have restrictions on what your software can and can’t do with things like local disk access. If you don’t understand these constraints, there’s a huge danger that you’ll be left with some anxious rework when it comes to deployment time.
· Technology maturity: Some organisations are happy to take risks with bleeding edge technology, embracing the risks that such advancements bring. Other organisations are much more conservative in nature.
· Open source: Likewise, some organisations still don’t like using open source unless it has a name such as IBM or Microsoft associated with it. I once worked on a project for a high-street bank who refused to use open source, yet they were happy to use a web server from a very well-known technology brand. The web server was the open source Apache web server in disguise. Such organisations simply like having somebody to shout at when things stop working. Confusion around open source licenses also prevents some organisations from fully adopting open source too. You may have witnessed this if you’re ever tried to explain the difference between GPL and LGPL.
· Vendor “relationships”: As with many things in life, it’s not what you know, it’s who you know. Many partnerships are still forged on the golf course by vendors who wine and dine Chief Technology Officers. If you’ve ever worked for a large organisation and wondered why your team was forced to use something that was obviously substandard, this might be the reason!
· Past failures: Somewhere around the year 2000, I walked into a bank with a proposal to build them a solution using Java RMI - a technology to allow remote method calls across Java virtual machines. This was met with great resistance because the bank had “tried it before and it doesn’t work”. That was the end of that design and no amount of discussion would change their mind. Java RMI was banned in this environment due to a past failure. We ended up building a framework that would send serialized Java objects over HTTP to a bunch of Java Servlets instead (a workaround to reinvent the same wheel).
· Internal intellectual property: When you need to find a library or framework to solve some problem that you’re facing, there’s a high probability that there’s an open source or commercial product out there that suits your needs. This isn’t good enough for some people though and it’s not uncommon to find organisations with their own internal logging libraries, persistence frameworks or messaging infrastructures that you must use, despite whether they actually work properly. I recently heard of one organisation that built their own CORBA implementation.
People constraints
More often than not, the people around you will constrain the technologies and approaches that are viable to use when developing software. For example:
· How large is your development team?
· What skills do they have?
· How quickly can you scale your development team if needed?
· Are you able to procure training, consulting and specialists if needed?
· If you’re handing over your software after delivery, will the maintenance team have the same skills as your development team?
There will be an overhead if you ask a Java team to build a Microsoft .NET solution, so you do need to take people into account whenever you’re architecting a software system.
Organisational constraints
There are sometimes other constraints that you’ll need to be aware of, including:
· Is the software system part of a tactical or strategic implementation? The answer to this question can either add or remove constraints.
· Organisational politics can sometimes prevent you from implementing the solution that you really want to.
Are all constraints bad?
Constraints usually seem “bad” at the time that they’re being imposed, but they’re often imposed for a good reason. For example, large organisations don’t want to support and maintain every technology under the sun, so they try to restrict what ends up in production. On the one hand this can reduce creativity but, on the other, it takes away a large number of potential options that would have been open to you otherwise. Software architecture is about introducing constraints too. How many logging or persistence libraries do you really want in a single codebase?
Constraints can be prioritised
As a final note, it’s worth bearing in mind that constraints can be prioritised. Just like functional requirements, some constraints are more important than others and you can often use this to your advantage. The financial risk system that I use as a case study in my training is based upon a real project that I worked on for a consulting company in London. One of the investment banks approached us with their need for a financial risk system and the basic premise behind this requirement was that, for regulatory reasons, the bank needed to have a risk system in place so that they could enter a new market segment.
After a few pre-sales meetings and workshops, we had a relatively good idea of their requirements plus the constraints that we needed to work within. One of the major constraints was an approved list of technologies that included your typical heavyweight Java EE stack. The other was a strict timescale constraint.
When we prepared our financial proposal, we basically said something along the lines of, “yes, we’re confident that we can deliver this system to meet the deadline, but we’ll be using some technologies that aren’t on your approved technology list, to accelerate the project”. Our proposal was accepted. In this situation, the timescale constraint was seen as much more important than using only the technologies on the approved technology list and, in effect, we prioritised one constraint over the other. Constraints are usually obstacles that you need to work around, but sometimes you can trade the off against one another.
Listen to the constraints
Every software system will be subject to one or more constraints, and part of the software architecture role is to seek these out, understand why they are being imposed and let them help you shape the software architecture. Failing to do this may lead to some nasty surprises.
25 Principles
While constraints are imposed upon you, principles are the things that you want to adopt in order to introduce standard approaches, and therefore consistency, into the way that you build software. There are a number of common principles, some related to development and others related to architecture.
Development principles
The principles that many software developers instantly think of relate to the way in which software should be developed. For example:
· Coding standards and conventions: “We will adopt our in-house coding conventions for [Java|C#|etc], which can be found on our corporate wiki.”
· Automated unit testing: “Our goal is to achieve 80% code coverage for automated unit tests across the core library, regardless of whether that code is developed using a test-first or test-last approach.”
· Static analysis tools: “All production and test code must pass the rules defined in [Checkstyle|FxCop|etc] before being committed to source code control.”
· etc
Architecture principles
There are also some principles that relate to how the software should be structured. For example:
· Layering strategy: A layered architecture usually results in a software system that has a high degree of flexibility because each layer is isolated from those around it. For example, you may decompose your software system into a UI layer, a business layer and a data access layer. Making the business layer completely independent of the data access layer means that you can (typically) switch out the data access implementation without affecting the business or UI layers. You can do this because the data access layer presents an abstraction to the business layer rather than the business layer directly dealing with the data storage mechanism itself. If you want to structure your software this way, you should ensure that everybody on the development team understands the principle. “No data access logic in the UI components or domain objects” is a concrete example of this principle in action.
· Placement of business logic: Sometimes you want to ensure that business logic always resides in a single place for reasons related to performance or maintainability. In the case of Internet-connected mobile apps, you might want to ensure that as much processing as possible happens on the server. Or if you’re integrating with a legacy back-end system that already contains a large amount of business logic, you might want to ensure that nobody on the team attempts to duplicate it.
· High cohesion, low coupling, SOLID, etc: There are many principles related to the separation of concerns, focussing on building small highly cohesive building blocks that don’t require too many dependencies in order to do their job.
· Stateless components: If you’re building software that needs to be very scalable, then designing components to be as stateless as possible is one way to ensure that you can horizontally scale-out your system by replicating components to share the load. If this is your scalability strategy, everybody needs to understand that they must build components using the same pattern. This will help to avoid any nasty surprises and scalability bottlenecks in the future.
· Stored procedures: Stored procedures in relational databases are like Marmite - you either love them or you hate them. There are advantages and disadvantages to using or not using stored procedures, but I do prefer it when teams just pick one approach for data access and stick to it. There are exceptions to every principle though.
· Domain model - rich vs anaemic: Some teams like having a very rich domain model in their code, building systems that are very object-oriented in nature. Others prefer a more anaemic domain model where objects are simply data structures that are used by coarse-grained components and services. Again, consistency of approach goes a long way.
· Use of the HTTP session: If you’re building a website, you may or may not want to use the HTTP session for storing temporary information between requests. This can often depend on a number of things including what your scaling strategy is, where session-backed objects are actually stored, what happens in the event of a server failure, whether you’re using sticky sessions, the overhead of session replication, etc. Again, everybody on the development team should understand the desired approach and stick to it.
· Always consistent vs eventually consistent: Many teams have discovered that they often need to make trade-offs in order to meet complex non-functional requirements. For example, some teams trade-off data consistency for increased performance and/or scalability. Provided that wedo see all Facebook status updates, does it really matter if we all don’t see them immediately? Your context will dictate whether immediate or delayed consistency is appropriate, but a consistent approach is important.
Beware of “best practices”
If you regularly build large enterprise software systems, you might consider most of the principles that I’ve just listed to be “best practices”. But beware. Even the most well-intentioned principles can sometimes have unintended negative side-effects. That complex layering strategy you want to adopt to ensure a complete separation of concerns can suck up a large percentage of your time if you’re only building a quick, tactical solution. Principles are usually introduced for a good reason, but that doesn’t make them good all of the time.
The size and complexity of the software you’re building, plus the constraints of your environment, will help you decide which principles to adopt. Context, as always, is key. Having an explicit list of principles can help to ensure that everybody on the team is working in the same way but you do need to make sure these principles are helping rather then hindering. Listening to the feedback from the team members will help you to decide whether your principles are working or not.
26 Technology is not an implementation detail
I regularly run training classes where I ask small groups of people to design a simple financial risk system. Here are some of the typical responses I hear when I ask people why their diagrams don’t show any technology decisions:
· “the [risk system] solution is simple and can be built with any technology”.
· “we don’t want to force a solution on developers”.
· “it’s an implementation detail”.
· “we follow the ‘last responsible moment’ principle”.
I firmly believe that technology choices should be included on architecture diagrams but there’s a separate question here about why people don’t feel comfortable making technology decisions. Saying that “it can be built with any technology” doesn’t mean that it should. Here’s why.
1. Do you have complex non-functional requirements?
True, most software systems can be built with pretty much any technology; be it Java, .NET, Ruby, Python, PHP, etc. If you look at the data storage requirements for most software systems, again, pretty much any relational database is likely to be able to do the job. Most software systems are fairly undemanding in terms of the non-functional characteristics, so any mainstream technology is likely to suffice.
But what happens if you do have complex non-functional requirements such as high performance and/or scalability? Potentially things start to get a little trickier and you should really understand whether your technology (and architecture) choices are going to work. If you don’t consider your non-functional requirements, there’s a risk that your software system won’t satisfy its goals.
2. Do you have constraints?
Many organisations have constraints related to the technologies that can be used and the skills (people) that are available to build software. Some even dictate that software should be bought and/or customised rather than built. Constraints can (and will) influence the software architecture that you come up with. Challenge them by all means, but ignore them and you risk delivering a software system that doesn’t integrate with your organisation’s existing IT environment.
3 Do you want consistency?
Imagine you’re building a software system that stores data in a relational database. Does it matter how individual members of the development team retrieve data from and store data to the database when implementing features? I’ve seen a Java system where there were multiple data access techniques/frameworks adopted in the same codebase. And I’ve seen a SharePoint system where various components were configured in different ways. Sometimes this happens because codebases evolve over time and approaches change, but often it’s simply a side-effect of everybody on the development team having free rein to choose whatever technology/framework/approach they are most familiar with.
People often ask me questions like, “does it really matter which logging framework we choose?”. If you want everybody on the development team to use the same one, then yes, it does. Some people are happy to allow anybody on the development team to download and use any open source library that they want to. Others realise this can lead to problems if left unchecked. I’m not saying that you should stifle innovation, but you should really only have a single logging, dependency injection or object-relational mapping framework in a codebase.
A lack of a consistent approach can lead to a codebase that is hard to understand, maintain and enhance. Increasing the number of unique moving parts can complicate the deployment, operation and support too.
Deferral vs decoupling
It’s worth briefly talking about deferring technology decisions and waiting until “the last responsible moment” to make a decision. Let’s imagine that you’re designing a software system where there aren’t any particularly taxing non-functional requirements or constraints. Does it matter which technologies you choose? And shouldn’t a good architecture let you change your mind at a later date anyway?
Many people will say, for example, that it really doesn’t matter which relational database you use, especially if you decouple the code that you write from a specific database implementation using an object-relational mapping layer such as Hibernate, Entity Framework or ActiveRecord. If you don’t have any significant non-functional requirements or constraints, and you truly believe that all relational databases are equal, then it probably doesn’t matter which you use. So yes, you can decouple the database from your code and defer the technology decision. But don’t forget, while your choice of database is no longer a significant decision, your choice of ORM is. You can decouple your code from your ORM by introducing another abstraction layer, but again you’ve made a significant decision here in terms of the structure of your software system.
Decoupling is a great approach for a number of reasons plus it enables technology decisions to be deferred. Of course, this doesn’t mean that you should defer decisions though, especially for reasons related to the presence of non-functional requirements and constraints.
Every decision has trade-offs
Much of this comes back to the fact that every technology has it’s own set of advantages and disadvantages, with different options not necessarily being swappable commodities. Relational database and web application frameworks are two typical examples of a technology space that is often seen as commoditised. Likewise with many cloud providers, but even these have their trade-offs related to deployment, monitoring, management, cost, persistent access to disk and so on.
At the end of the day, every technology choice you make will have a trade-off whether that’s related to performance, scalability, maintainability, the ability to find people with the right experience, etc. Understanding the technology choices can also assist with high-level estimating and planning, which is useful if you need to understand whether you can achieve your goal given a limited budget.
If you don’t understand the trade-offs that you’re making by choosing technology X over Y, you shouldn’t be making those decisions. It’s crucial that the people designing software systems understand technology. This is why software architects should be master builders.
Technology isn’t just an “implementation detail” and the technology decisions that you make are as important as the way that you decompose, structure and design your software system. Defer technology decisions at your peril.
27 More layers = more complexity
One of the key functional requirements of the financial risk system case study that we run through on the training course is that the solution should be able to distribute data to a subset of users on a corporate LAN. Clearly there are 101 different ways to solve this problem, with one of the simplest being to allow the users to access the data via an internal web application. Since only a subset of the users within the organisation should be able to see the data, any solution would need some sort of authentication and authorisation on the data.
Given the buzz around Web 2.0 and Rich Internet Applications in recent times, one of the groups on a training course decided that it would be nice to allow the data to be accessed via a Microsoft Silverlight application. They’d already thought about building an ASP.NET application but liked the additional possibilities offered by Silverlight, such as the ability to slice and dice the data interactively. Another driving factor for their decision was that the Silverlight client could be delivered “for free” in that it would take “just as long to build as an ASP.NET application”. “For free” is a pretty bold claim, especially considering that they were effectively adding an extra architectural layer into their software system. I sketched up the following summary of their design to illustrate the added complexity.
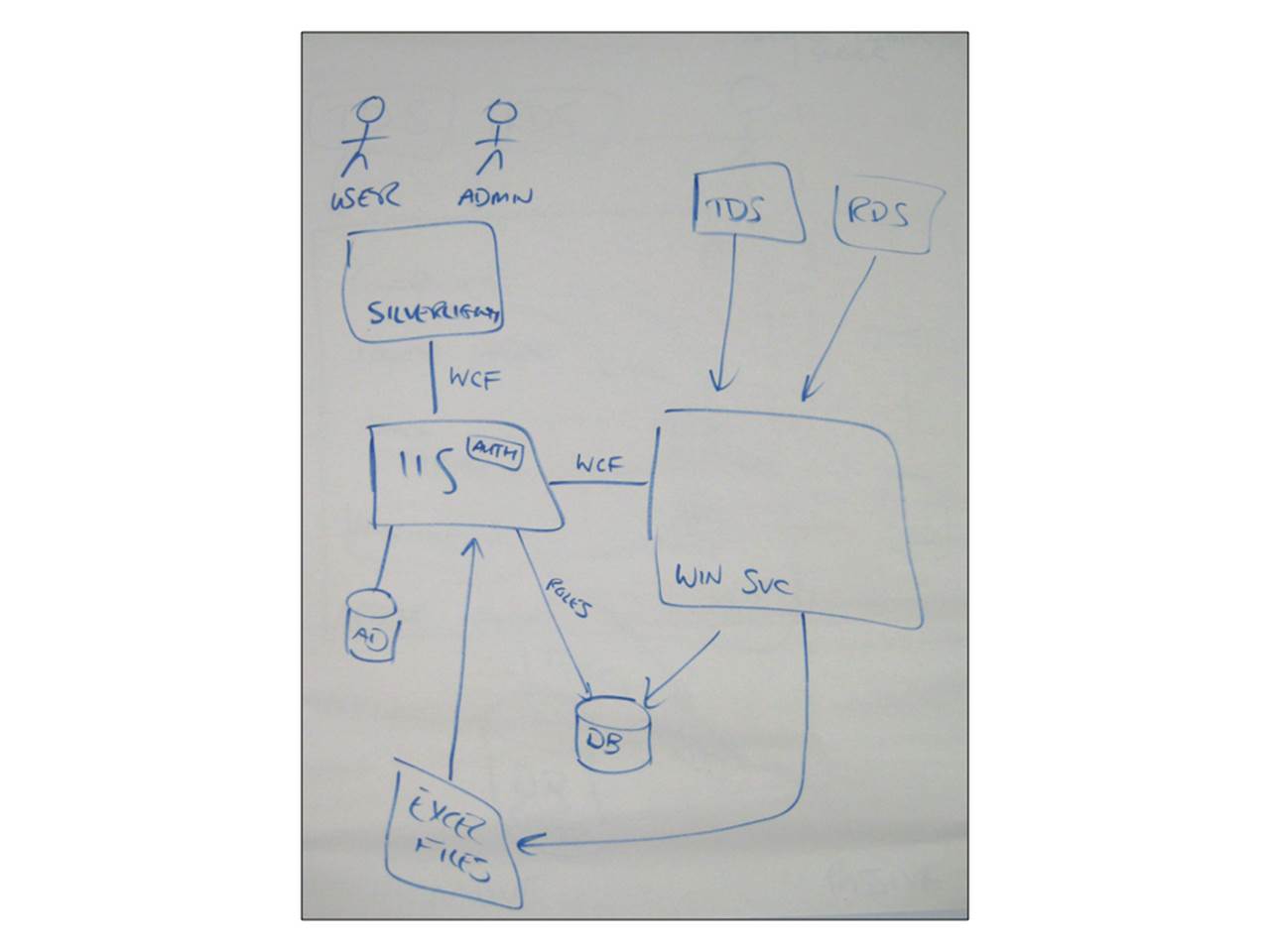
While I don’t disagree that Silverlight applications aren’t hard to build, the vital question the group hadn’t addressed was where the data was going to come from. As always, there are options; from accessing the database directly through to exposing some data services in a middle-tier. The group had already considered deploying some Windows Communication Foundation (WCF) services into the IIS web server as the mechanism for exposing the data, but this led to yet further questions.
1. What operations do you need to expose to the Silverlight client?
2. Which technology binding and protocol would you use?
3. How do you ensure that people can’t plug in their own bespoke WCF client and consume the services?
4. How do you deploy and test it?
5. etc
Non-functional requirements
In the context of the case study, the third question is important. The data should only be accessible by a small number of people and we really don’t want to expose a web service that anybody with access to a development tool could consume.
Most security conscious organisations have their self-hosted public facing web servers firewalled away in a DMZ, yet I’ve seen some software systems where those same secured web servers subsequently access unsecured web services residing on servers within the regular corporate LAN. Assuming that I can connect a laptop to the corporate LAN, there’s usually nothing to stop me firing up a development tool such as Microsoft Visual Studio, locating the service definition (e.g. a WSDL file) and consuming the web service for my own misuse. In this case, thought needs to be given to authentication and authorisation of the data service as well as the Silverlight client. A holistic view of security needs to be taken.
Time and budget - nothing is free
Coming back to the claim that building a Silverlight client won’t take longer than building an ASP.NET application; this isn’t true because of the additional data services that need to be developed to support the Silverlight client. In this situation, the benefits introduced by the additional rich client layer need to be considered on the basis that additional complexity is also being introduced. All architecture decisions involve trade-offs. More moving parts means more work designing, developing, testing and deploying. Despite what vendor marketing hype might say, nothing is ever free and you need to evaluate the pros and cons of adding additional layers into a design, particularly if they result in additional inter-process communication.
28 Collaborative design can help and hinder
Let’s imagine that you’ve been tasked with building a 3-tier web application and you have a small team that includes people with specialisms in web technology, server-side programming and databases. From a resourcing point of view this is excellent because collectively you have experience across the entire stack. You shouldn’t have any problems then, right?
The effectiveness of the overall team comes down to a number of factors, one of them being people’s willingness to leave their egos at the door and focus on delivering the best solution given the context. Sometimes though, individual specialisms can work against a team; simply through a lack of experience in working as a team or because ego gets in the way of the common goal. If there’s a requirement to provide a way for a user to view and manipulate data on our 3-tier web application, you’ll probably get a different possible approach from each of your specialists.
· Web developer: Just give me the data as JSON and we can do anything we want with it on the web-tier. We can even throw in some JQuery to dynamically manipulate the dataset in the browser.
· Server-side developer: We should reuse and extend some of the existing business logic in the middle-tier service layer. This increases reuse, is more secure than sending all of the data to the web-tier and we can write automated unit tests around it all.
· Database developer: You’re both idiots. It’s way more efficient for me to write a stored procedure that will provide you with exactly the data that you need. :-)
Experience influences software design
Our own knowledge, experience and preferences tend to influence how we design software, particularly if it’s being done as a solo activity. In the absence of communication, we tend to make assumptions about where components will sit and how features will work based upon our own mental model of how the sofware should be designed. Getting these assumptions out into the open as early as possible can really help you avoid some nasty surprises before it’s too late. One of the key reasons I prefer using a whiteboard to design software is because it encourages a more collaborative approach than somebody sitting on their own in front of their favourite modelling tool on a laptop. If you’re collaborating, you’re also communicating and challenging each other.
Like pair programming, collaborating is an effective way to approach the software design process, particularly if it’s done in a lightweight way. Collaboration increases quality plus it allows us to discuss and challenge some of the common assumptions that we make based our own knowledge, experience and preferences. It also paves the way for collective ownership of the code, which again helps to break down the silos that often form within software development teams. Everybody on the team will have different ideas and those different ideas need to meet.
29 Software architecture is a platform for conversation
If you’re writing software as a part of your day-to-day job, then it’s likely that your software isn’t going to live in isolation. We tend to feel safe in our little project teams, particularly when everybody knows each other and team spirits are high. We’ve even built up development processes around helping us communicate better, prioritise better and ultimately deliver better software. However, many software projects are still developed in isolation by teams that are locked away from their users and their operational environments.
The success of agile methods has shown us that we need to have regular communication with the end-users or their representatives so we can be sure we’re building software that will meet their needs. But what about all of those other stakeholders? Project teams might have a clear vision about what the software should do but often you’ll hear phrases like this, often late in the delivery cycle.
· “Nobody told us you needed a production database created on this server.”
· “We can’t upgrade to [Java 7|.NET 4] on that server until system X is compatible.”
· “We don’t have spare production licenses.”
· “Sorry, that contravenes our security policy.”
· “Sorry, we’ll need to undertake some operational acceptance testing before we promote your application into the production environment.”
· “How exactly are we supposed to support this application?”
· “I don’t care if you have a completely automated release process … I’m not giving you the production database credentials for your configuration files.”
· “We need to run this past the risk and compliance team.”
· “There’s no way your system is going on the public cloud.”
Software development isn’t just about delivering features
The people who use your software are just one type of stakeholder. There are usually many others including:
· Current development team: The current team need to understand the architecture and be aware of the drivers so that they produce a solution that is architecturally consistent and “works”.
· Future development team: Any future development/maintenance teams need to have the same information to hand so that they understand how the solution works and are able to modify it in a consistent way.
· Other teams: Often your software needs to integrate with other systems within the environment, from bespoke software systems through to off-the-shelf vendor products, so it’s crucial that everybody agrees on how this will work.
· Database administrators: Some organisations have separate database teams that need to understand how your solution uses their database services (e.g. from design and optimisation through to capacity planning and archiving).
· Operations/support staff: Operational staff typically need to understand how to run and support your system (e.g. configuration and deployment through to monitoring and problem diagnostics).
· Compliance, risk and audit: Some organisations have strict regulations that they need to follow and people in your organisation may need to certify that you’re following them too.
· Security team: Likewise with security; some organisations have dedicated security teams that need to review systems before they are permitted into production environments.
These are just some of the stakeholders that may have an interest in your architecture, but there are probably others depending on your organisation and the way that it works. If you think you can put together a software architecture in an ivory tower on your own, you’re probably doing it wrong. Software architectures don’t live in isolation and the software design process is a platform for conversation. A five minute conversation now could help capture those often implied architectural drivers and improve your chance of a successful delivery.
30 SharePoint projects need software architecture too
Although the majority of my commercial experience relates to the development of bespoke software systems, I’ve seen a number of SharePoint and other product/platform implementations where the basic tenets of software architecture have been forgotten or neglected. Here’s a summary of why software architecture is important for SharePoint projects.
1. Many SharePoint implementations aren’t just SharePoint
Many of the SharePoint solutions I’ve seen are not just simple implementations of the SharePoint product where end-users can create lists, share documents and collaborate. As with most software systems, they’re a mix of new and legacy technologies, usually with complex integration points into other parts of the enterprise via web services and other integration techniques. Often, bespoke .NET code is also a part of the overall solution, either running inside or outside of SharePoint. If you don’t take the “big picture” into account by understanding the environment and its constraints, there’s a chance that you’ll end up building the wrong thing or building something that doesn’t work.
2. Non-functional requirements still apply to SharePoint solutions
Even if you’re not writing any bespoke code as a part of your SharePoint solution, that doesn’t mean you can ignore non-functional requirements. Performance, scalability, security, availability, disaster recovery, audit, monitoring, etc are all potentially applicable. I’ve seen SharePoint projects where the team has neglected to think about key non-functional requirements, even on public Internet-facing websites. As expected, the result was a solution that exhibited poor response times and/or severe security flaws (e.g. cross-site scripting). Such issues were identified at a late stage in the project lifecycle.
3. SharePoint projects are complex and require technical leadership too
Like any programming language, SharePoint is a complex platform and there are usually a number of different ways to solve a single problem. In order to get some consistency of approach and avoid chaos, SharePoint projects need strong technical leadership. The software architecture role is applicable regardless of whether you’re implementing a platform or writing a software system from scratch. If you’ve ever seen SharePoint projects where a seemingly chaotic team has eventually delivered a poor quality solution, you’ll appreciate why this is important.
4. SharePoint solutions still need to be documented
With all of this complexity in place, I’m continually amazed to see SharePoint solutions that have no documentation. I’m not talking about hefty 200+ page documents here, but there should be at least some lightweight documentation to provide an overview of the solution. Some diagrams to show how the SharePoint solution works at a high-level are also useful. My C4 approach works well for SharePoint too and some lightweight documentation can be a great starting point for future support, maintenance and enhancement work; particularly if the project team changes or if the project is delivered under an outsourcing agreement.
Strong leadership and discipline aren’t just for software development projects
If you’re delivering software solutions then you need to make sure that you have at least one person undertaking the technical leadership role. If not, you’re doing it wrong. As an aside, all of this applies to other platform products such as SAP and Microsoft Dynamics CRM, especially if you’re “just tacking on an Internet-facing ASP.NET website to expose some data via the Internet”.
I’ve mentioned this to SharePoint teams in the past and some have replied “but SharePoint isn’t software development”. Regardless of whether it is or isn’t software development, successful SharePoint projects need strong technical leadership and discipline. SharePoint projects need software architecture too.
31 Questions
1. What are the major factors that influence the resulting architecture of a software system? Can you list those that are relevant to the software system that you are working on?
2. What are non-functional requirements and why are they important? When should you think about non-functional requirements?
3. Time and budget are the constraints that most people instantly relate to, but can you identify more?
4. Is your software development team working with a well-known set of architectural principles? What are they? Are they clearly understood by everybody on the team?
5. How to you approach the software design process? Does your team approach it in the same way? Can it be clearly articulated? Can you help others follow the same approach?
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.