Understanding Context: Environment, Language, and Information Architecture (2014)
Part VI. Composing Context
Chapter 20. The Materials of Semantic Function
“When I use a word,” Humpty Dumpty said in rather a scornful tone, “it means just what I choose it to mean—neither more nor less.”
“The question is,” said Alice, “whether you can make words mean so many different things.”
“The question is,” said Humpty Dumpty, “which is to be master—that’s all.”
—LEWIS CARROLL, THROUGH THE LOOKING-GLASS
My cow is not pretty, but it’s pretty to me.
—DAVID LYNCH
Elements
TO ADDRESS HOW INFORMATION ARCHITECTURE COMPOSES CONTEXT, we need to look at what materials the practice requires for designing environments. What are the elements that it uses—the bricks and mortar, studs and joists—that create the joinery of coherently nested places?
The material for information architecture is mainly the semantic function of language. Names, categories, links, and conditional actions are not just for organizing objects but for also establishing place and shaping systemic relationships for entire environments. We can distill these elements into three categories (Figure 20-1): Labels, Relationships, and Rules.

Figure 20-1. My own take on the materials of information architecture: Labels, Relationships, and Rules[387].
I’ve mentioned these in various forms in previous chapters, but bringing them together into a three-part list helps solidify them as a model.
These three items loosely correlate with the three levels in a model developed by information architect (and colleague) Dan Klyn: Ontology, Taxonomy, and Choreography (Figure 20-2).
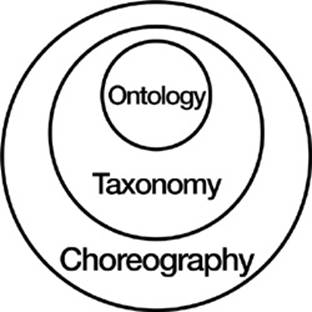
Figure 20-2. Dan Klyn’s model for information architecture: Ontology, Taxonomy, and Choreography[388]
I should note a few things about these models:
§ These are general framing devices for helping us think through what we are making, and with what elements. However, I still recommend learning about the details—topics such as controlled vocabularies, synonym rings, metadata standards, and thesauri—from methods-based resources on information architecture and information science.
§ I’m explaining the parts of these models in tandem, one pair at a time, because they resonate nicely with each other, but I don’t mean to fully equate them. Labels have a lot to do with ontology, and vice versa, but they’re lenses on how we locate specific meaning, not synonyms.
§ There are other models for these ideas that I’m not including here.[389] They are all wonderful in their own ways. I encourage everyone to investigate them all and find the perspectives that help you most.
Labels and Ontology
Label: The word sounds deceptively trivial, like something we spit out of a grocery-store pricing gun. But, as Chapter 9 points out, labels are powerful, flexible devices that make it possible for us to have language at all, allowing us to create what philosopher Andy Clark calls the “new realm of perceptible objects.”[390]
We could just as easily say “names” or “categories” or “classes” but these would be subsets of all the things we can mean by “labels.” A label can be something we add to a physical object, or it can be the mechanism we use to talk about something that isn’t specific or physical at all; for example a category, such as “jazz.” It can be the name of a person, a code for a concept, or a class in a CSS file.
Clark further explains that “the simple act of labeling the world opens up a variety of new computational opportunities and supports the discovery of increasingly abstract patterns in nature.”[391] Labeling the world structures it beyond what the structures of physical information alone can support. Ontology is a way of constructing a fully defined label; taxonomy is a way of associating labels with one another in a system of meaning.
Labels can be graphical or textual, or even gestures, but whichever way they appear, they function as language. We tend to think of labels as “extra,” because a thing is the same thing whether it has a label or not. Hopefully, though, our foray into context, cognition, and language has made it clear that labels are anything but merely extra. Labels change the experienced nature of the things they name and otherwise signify.
For information architecture, labels are central. They’re the ingredients we use for categories and classification schemes. They’re the signifiers we use to represent the function and behavior of relationships and rules as well as the effects of digital agency. Even when we add longer text as instructional information, the instructions are finally just definitions for labels.
In semantic interfaces, labels are also the environmental objects that get the attention of agent perception; users seek them out to pick up information about where they can go, how the environment is nested, and what objects and events are available there. Users look for structural cues from the graphical user interface, as well, but words are always eventually necessary for context.[392] Far beyond interfaces, the purposeful definition of every component and connection within a service, system, or organization requires the use of labels.
Ontology is the way we establish the meaning of labels in semantic systems. As I’ve mentioned before, I’m not using the word in precisely the formal, technical manner or the conceptual, philosophical manner, but in a way that involves both. As Dan Klyn puts it succinctly, ontology is about “what we mean when we say what we say.”[393]
Whether a formalized, technical ontology is necessary, there should be clarity about the semantic cornerstones that will set the alignment for everything else. Most organizations run on inherited assumptions and arbitrarily accumulated convention. They can stay in business for years, selling “product” to “customers” but never settle on what those words actually mean to the company. But, when their market is disrupted and complicates what their product is and who their customers are, the explicit definition of those terms becomes critical to survival.
When companies invoke a metaphor such as “the funnel” for marketing and retail, or “cloud”—as in cloud computing—the term eventually influences the way those companies think about and design their services.
“Cloud” has become a particularly pernicious rubric in the last few years. What’s wrong with “cloud”? It obscures complexity rather than making it understandable.
Consider Apple’s iCloud service. I’m often frustrated trying to understand how the places of iCloud work. For example, Figure 20-3 depicts a dialog box warning me if I turn off iCloud syncing for “Documents & Data, all documents stored in iCloud will be removed from this Mac.” I’ve encountered similar warnings when changing iCloud settings, and each time I’m struck with anxiety, trying to sort out the difference between “there” and “here,” and which documents on my laptop’s drive are “in iCloud” and which are on my hard drive. This message box does nothing to help me remember the specific location of my files. What if none of them are on other devices? Does it delete them entirely? If they’re on my laptop, why wouldn’t they just be left there, but disconnected from syncing with the cloud service?
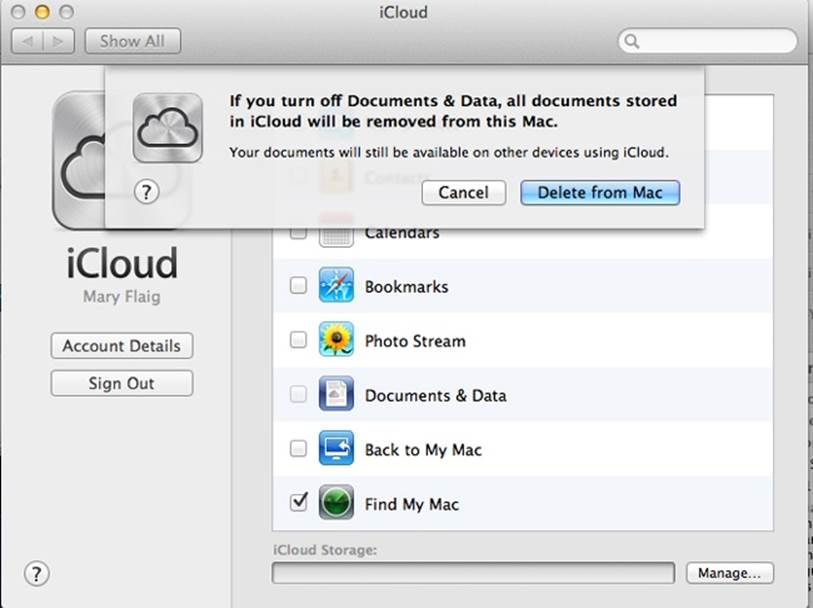
Figure 20-3. An ambiguous and not very helpful iCloud message box: iConfused
According to one study, many Americans think cloud computing has something to do with actual clouds. Of the 54 percent of those surveyed who claimed never to use cloud computing, 95 percent actually do use cloud services without realizing it. When asked to explain what the cloud is, people tend to fake their way through the explanation.[394]
Ontology is at the root of this problem. There’s no coherent invariant structure implied by the metaphor. In fact, cloud is an abdication of that architectural responsibility. It avoids the question of “where is my stuff, and what is happening to it?” by pretending as if no hard edges have to be understood—instead, the magic vapor in the sky will take care of it all for you. A cloud is, by definition, disconnected from the ground—it’s a nonplace. But the fact is, your information is definitely in one or more places, on storage media in server farms that take up acres of land and gigawatts of electricity. It has rules and boundaries associated with it, structures that most users do not see or understand. We can use buildings because we can see the joinery in them and the complexity of their structure. A cloud has no clear structure. Though it can be pretty from the outside, from within it’s just fog.
One of the more troublesome terms to define online is “account.” Every place seems to need us to have an account, but an account is not something we can really point to or put our hands on. It’s another reified idea, because an account is really just language. We can use the term for just about any sort of business relationship, which is why we end up with something like Figure 20-4, which shows an example at Kohls department store’s website.
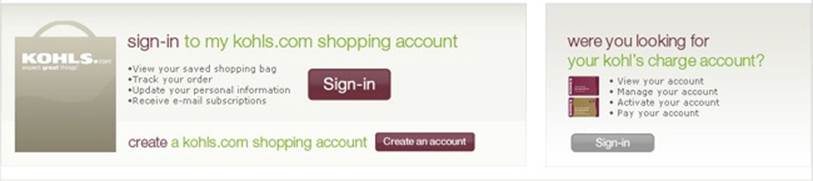
Figure 20-4. Kohl’s disambiguation of “account”
The word “groups” can also be a bedeviling bit of semantic architecture. In physical life, your body can only cluster with one group of bodies at a time, and there’s lots of tacit information about each group’s context. But online, there are only labels, links, and conditional rulesets that form the architecture of these groups. You can be logged in to many at once, and the only way to differentiate between them is through their display-based signifiers. Also, the structures and rules that make it a group can differ widely from one group to another.
Google’s use of the groups label is widespread, as is amply demonstrated in Figure 20-5. There are groups that you can create in your Contacts for use in Gmail; there are Google Groups (based on the long-acquired Deja News, which was a UseNet mirror); the Groups in the Google Apps for Business email platform, like personal Gmail groups but for businesses and custom domains; and others. You can convert a Business Apps Email Group to a Google Groups for Business Group, but doing so is daunting and requires comprehending both administrative paradigms. All this is not to mention the new Google Plus dimension of Circles that now intersects most of the Google ecosystem.
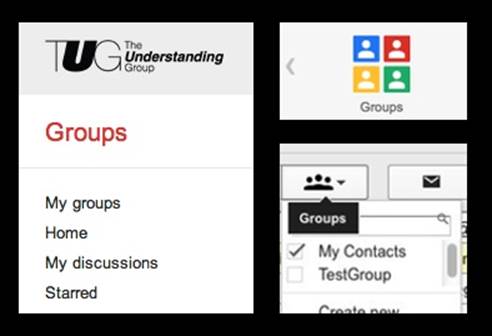
Figure 20-5. Just a few examples of groups among the many in the Google ecosystem
Undoubtedly, Google has defined formal ontologies for all these species of group in their backend systems. Yet, Google’s environment struggles to establish coherent semantic function on the frontend, for human users. Data architecture does not equal information architecture, though each certainly depends on the other for user success.
Making multicontextual structures understandable is a difficult architectural problem to solve, especially when adding multiuser access. What users need is for those problems to be solved, not ignored. Rather than pretending everything is “seamless,” we instead need well-crafted seams that we can see and understand how to use. In the words of Mark Weiser, one of the early pioneers of ubiquitous computing, we should make “beautiful seams” that transparently reveal the inner workings of these clockworks we now inhabit.[395] Our bodies can perceive how stairs work because of the structure implicit in the seams joining their surfaces. Likewise, semantic environments need seams that clearly indicate where and how one context joins to another. Seams demand the work of ontology, because seams are possible only if the edges of elements are defined in the first place.
Relationships and Taxonomy
Relationships are the associations between elements in an environment. A relationship is really an abstraction. Even with physical information, we don’t perceive relationships, per se; we perceive surfaces and objects, which are nested as layouts. But the context of one thing’s relation to another brings additional meaning for those elements.[396]
Sometimes, it’s the nested relationships of superordinal to subordinal places and objects, as in a smartphone where an app is contained in a home screen, contained in the mobile device itself, all aggregating into the compound object we call “smartphone.”
Moreover, sometimes these relationships are about the connections between separate objects or places. Ecologically, we evolved to depend upon these connections as stable paths. Thus, we tend to expect even our digital connections—from hyperlinks to API calls—to be invariant, even when we perceive only the outer effects of their digital inner workings.
Just as a river can connect various cities with trade, digital connections can make relationships that entire markets depend on. Consider when Twitter changed its API in 2012, removing support for RSS and limiting the API’s usage by certain third-party clients: app developers who had depended on the old API as an invariant part of the environment found themselves without a product anymore.[397]
To work with semantic relationships, we use signifiers that indicate what is related. These signifiers are also labels, with all the qualities of labels, as previously outlined. In user interfaces, we pay a lot of attention to these semantic signifiers because they have to do all the heavy lifting for expressing relationships. A bakery on the street can be called “Jane’s” on the sign, but the smell of bread and the baked goods in the window can do the rest of the work. Online, though, we need semantic equivalents of the smell of bread and the shop window, from the company name to the metadata for Yelp, Google, and the rest.
In fact, with digital information, we can make relationships between things that we can’t even see but whose well-defined relationships are crucial for infrastructure. The relationships defined in database schemas are arguably now the majority of important semantic-information relationships in our world.
Web-centered information architecture has long been concerned with hyperlinks and their relationships; but hyperlinks—though revolutionary in their own way—are only one way we establish relationships online or off. Here’s a question I find myself asking often in projects: in what way can information architecture use semantic information to shape and clarify the relationships between physical life and digital function? Starting with that frame of mind can open up many opportunities for great work, beyond hyperlinks.
A general term we use for making relationships with language is taxonomy. There’s a common assumption that a taxonomy is always a hierarchical classification scheme—a “tree-shaped” structure, with the broadest category at the top, and subsequently narrower categories on the way down. That’s a common type of taxonomy, but not the only one.
Taxonomies are always semantic in nature, and they always have to do with the relationships between elements. But, they can take many forms, such as lists, hierarchies, matrices, facets, and even continuums or systemic maps.[398] Many of the models in this book are actually taxonomies, expressed as diagrams.
The term comes from two Greek roots: “taxis,” which means the ordering or arrangement of things; and “nomos,” which is “anything assigned, usage or custom, law or ordinance.” In Organising Knowledge: Taxonomies, Knowledge, and Organisational Effectiveness (Chandos Publishing), Patrick Lambe defines taxonomy as “the rules or conventions of order or arrangement.”[399] Taxonomy creates relationships that arrange and order units of meaning. And, it can do so using an explicitly defined rule, or through tacitly emergent convention, or through some means between those extremes.
Hence, taxonomies are the ways we arrange the world with language. They’re what we use to represent the physical and semantic information of our environment, creating structures and relationships, classifications and nested places. They’re the way we put joinery between semantic surfaces into the environment.
Ontologies and taxonomies have a symbiotic relationship; arguably you can’t truly create one without the other. Ontologies require defining, and definitions are (by definition!) about relationships that give context to the thing defined; taxonomies have a hard time being very solid until at least some of the key terms in them have been well delineated, or else they can become too porous, absorbing generalities until they lose specific utility.
Taxonomies follow some physical, ecological principles, even though they’re semantic. In an insight that echoes J. J. Gibson, Lambe explains how people usually start with “basic-level categories” that are not “the most granular, atomistic elements in our world. They tend to be whole objects we can identify and act upon in a direct way. Linguistically, we have shorter and simpler names for them compared to other objects, and they tend to be accessible things that populate our everyday world.”[400]
We begin with things such as “apple” and “clock.” We then work our way out and up to larger, broader categories (fruit, orchard, harvest, timepiece, engineering) or inward and down to smaller bits (tyrosinase enzyme, fructose, molecule, pinion, spring, atomic structure of brass). This pattern we have with language correlates with the way we perceive physical information: at the body-relevant level first, and then working our way beyond that level to the broadest canopy around us and down to tiny objects—attention that we augment with telescopes and microscopes.
When we navigate an environment, we pay attention first to the objects that are most relevant to our needs as well as our bodies, even when considering semantic information. When I visit a hospital or other building with medical offices, I need to figure out which office has the doctor I want to see. Hopefully, I find a directory of some sort in the lobby, where I can find my doctor’s name and office number. I’m not interested in learning the entire building, and I’m not interested in how my doctor is related to all the others. Likewise, I don’t care just yet what rooms are inside my doctor’s suite—I won’t worry about that until I’m in the waiting room. We treat all sorts of environments this way, from websites and cable TV guides to subways and cities.
Taxonomies can help us translate between different perspectives—serving as a Rosetta stone between cultural umwelts. For example, in an effort to help scientists better explain climate change, some have been creating guides to improving the way scientists translate the language of theory to the language of laypeople, as shown in Figure 20-6.
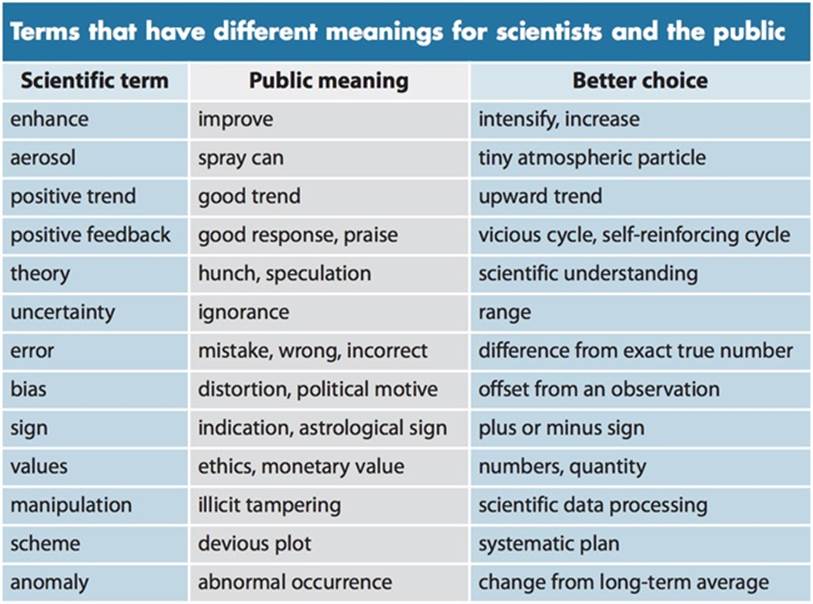
Figure 20-6. A table of terms and their public meanings, with recommendations for more accurate communication of the intended meanings[401]
This table reminds us that there is often no one way to label something that has the same information scent or explicit definition to everyone—it can even mean opposite things in different contexts.
When we design environments in which different perspectives are in play, we can use taxonomies to create thesauri to do these translations. We can also use faceted classification, an especially powerful taxonomical form. Developed in 1932 by Indian librarian S.R. Ranganathan, this “colon classification” approach gives us a technique to create highly scalable, adaptive classes based on combinations of mutually exclusive category lists. For example, we could use three simple categories to string together the classes for an online document repository: Author :: Date/Time :: File Type. There is no superordinal or subordinal structure; there is only a string of attributes, in unique combinations (ensured here by the fact that no one author will have created more than one file at exactly the same time). If more metadata were needed, we could add more facets.
Faceted classification is an excellent invention for accommodating the nested, nonlinear ways we experience context. It can expand and recombine to take on new perspectives and permutations, and provides us with the means to come at the world from multiple angles of entry. It’s essentially categorization as collage rather than a single lens.
But be prepared: it can be surprising how resistant business and technology partners can be to a non-single-hierarchy worldview. The Cartesian habits that make us want a single hierarchy are deeply ingrained.
Rules and Choreography
By rules, I mean prescribed principles, guidelines, or conditional procedures for action. Like relationships, rules themselves are not perceived directly. We instead perceive the information we use to make them, or we perceive their effects, but the logic that makes a rule work is abstract. The etymology of the word “rule” tells us that it’s always been about language: pronouncements, directives, orders, stipulations, and so on.
Although rules are language-based, they can be embodied in the environment. The simple wall in the field shown in Chapter 1 instantiates a rule about what can move from one side to the other, or perhaps the ownership of the land. A complex rule, with conditional logic, can determine that cars can cross a drawbridge until a boat needs to be let through. The bridge’s action makes the rule manifest, but the semantic expression of the rule came first.
We also use semantic information to put rules into our environment all the time. The line painted down the middle of the road is a semantic expression that we treat as if it were physical. Likewise, the law stating we should not cross over that line is another semantically expressed rule. When we make a contractual agreement, we are agreeing to abide by semantic environmental structures—many of which are signified by defined labels, or “terms” of the agreement.[402] And, as we’ve seen, software is made of rules, and its conditional logic works as a sort of legislation for software-dependent environments.
It is important that we expand the concept of information architecture as sharing responsibility for rule definition. The early focus on the arrangement of content for browsing, searching, and retrieving is only a microcosm of the larger concern: planning and structuring environments for habitation.
One way of thinking about the rules is as a set of instructions for how environments should behave—a sort of choreography for the coupled dance between agents, the elements we design, and the elements of the environment that are already there.
We can think of choreography as a predefined set of instructions, as in traditional ballet. But, we can also think of it as a set of patterns to be recombined and improvised, as in tap and swing dancing. As Klyn puts it, “The essence of choreography is the placement of meaning and structure into a flow with a specific context.”[403] The flow is the continual action of the agent’s embodied engagement with the elements of the environment; the context is ultimately how the agent understands those elements and how they relate.
Consider a quintessential, traditional information architecture project such as designing the taxonomy and search for a retailer. Even though this sort of design problem has had known solutions for many years now, we’re still evolving the way websites handle the nonlinear, idiosyncratic actions of “shoppers.” For one thing, retailers must learn that not everyone is actually a shopper. Site visitors are often using products as proxies for learning, dreaming, or solving a problem. And they come at the task of looking at products from many different situational contexts.
People satisfice when they browse and search—they engage whatever most immediately triggers the “scent” related to their present situation. In fact, “browse” and “search” are reified ideas that have more to do with the way the system constrains choice of action than the sorts of actions a user might take without such constraints. Everything a user does boils down to taking action in the environment, seeing what happens, and calibrating further action based on that feedback loop. Putting words in a search field or tapping on a label are both just different forms of tossing language at the world and seeing what the world gives you back. We can’t choreograph those activities in a linear, predefined manner. All we can do is have the right patterns to gracefully dance along with whatever moves the user might make.
Information architecture must accommodate the way people actually find and create their own meaning. So, for example, if we define “navigation” as the reified menus of lists found in sites and apps, we miss the point entirely. As Resmini and Rosati memorably say, “We say navigate, but really mean understand.”[404] Navigation isn’t really about the “chrome”—the fly-outs, mega-menus, and sidebar lists. It’s about taking action in the whole environment toward discovering the next needed action and the next after that. People look for the right “scent” of semantic function, and resort to the machinery of navigation menus mainly when other actions aren’t improving the scent.
So, architectures can’t always engineer people’s actions; they have to accommodate and assist them, instead. Resmini and Rosati refer to this capability as resilience, an information architecture heuristic they define as “the capability of a pervasive information architecture model to shape and adapt itself to specific users, needs, and seeking strategies.”[405] It doesn’t require space-age intelligent systems. Often, resilience is just a matter of creating simple structures that have facets and options that catch users where they are, from their particular points of view. A website might not need some advanced algorithm to get a user to the right input form if the site’s structure simply uses better information scent and instructional content. Likewise, a cross-channel service can accommodate great complexity just by providing the right hubs of service interaction, clearly orchestrated, to allow customers to move among them in their own idiosyncratic ways. Resilient conditional frameworks can make the difference between a dead, static museum of information and a living, breathing environment that the user experiences as an embodied conversation through action.
Sometimes, a linear path is necessary—for trained workers doing rote data entry, perhaps. But most software isn’t being made for those situations anymore. Some amount of wandering is often the most valuable part of the experience. Information architectures are constructs that help people understand their own actions, situations, and needs; good information architecture helps people discover their ultimate narrative along their own, uniquely wandering path.
We’ve mainly learned these lessons on websites for the last 20-odd years. Now we need to use these lessons in how we use information to ground, inform, scaffold, and nudge people’s understanding beyond the confines of individual computer screens, or within just one piece of software.
IFTTT (If This Then That) is accessed by users through a website or an app, but it’s actually a cross-channel service framework that has the potential to let users create architectures of their own for any networked device. For users to understand how to use IFTTT (see Figure 20-7), the service has to articulate itself in a way that provides clear instruction. Consequently, it crafted a clear taxonomy for the building blocks and functions available: Channels, Triggers, Actions, and so on. A “channel” is one of the cloud-based services; a “trigger” is the “this” object in “if this then that.” “On/Off” is binary mode setting for whether the recipe is active or inactive. These work almost like facets do—mutually exclusive sorts of elements that, like noun, verb, and adjective, perform specific roles in a grammar of digital-agent assembly.
The choreography here is twofold: the rules packaged into a kit of digital objects, and the dance the user can create by playing with the parts to make new, soft machines.
Service design brings a comprehensive approach to choreography, where designers consider every context in a service ecosystem. Service designs don’t necessarily involve digital information, but it is telling that the discipline has grown so much in the post-Internet age, when services can involve so many channels and information layers not previously available. With smartphones and ambient devices, services can be choreographed intimately with individual user action, on the fly.

Figure 20-7. Taxonomy of functions on IFTTT, from the service’s website at IFTTT.com
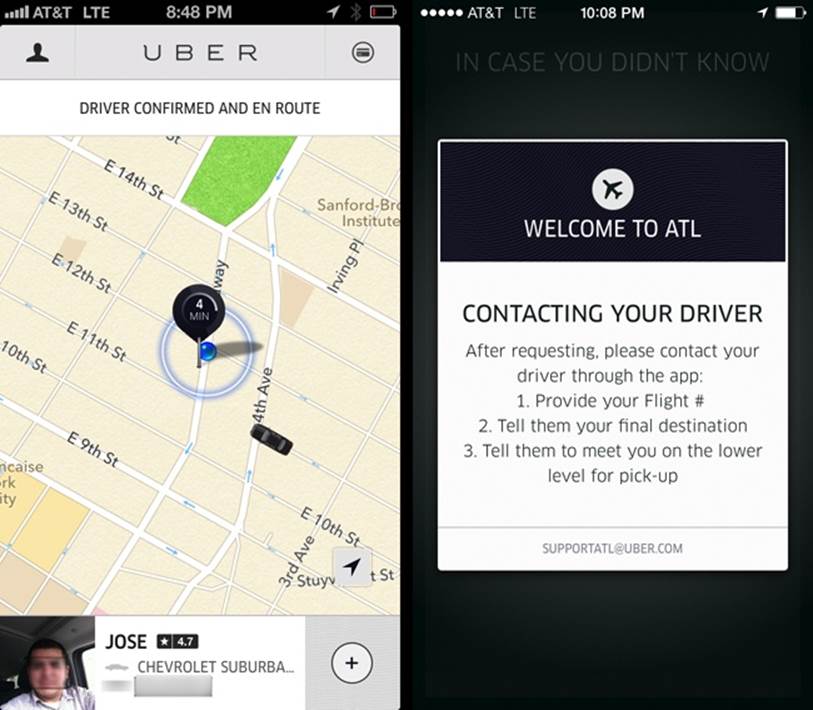
The Uber car service is a recent favorite example of service design. Uber uses a smartphone app as a customer’s interface to a service that helps find a ride from a group of Uber cab drivers near the customer’s location, as shown in Figure 20-8, left.
 New York City map" width="650" height="568" />
New York City map" width="650" height="568" />
Figure 20-8. After requesting a car, I can watch my driver (identity obscured here) on the way to pick me up, live on a New York City map
Even though I’m standing in the midst of the unplanned, open environment of a busy cityscape, as soon as I engage the Uber service, I’m gently lifted into a service experience in which nearly everything is automated and requires very little of my effort. The driver arrives where I am—I don’t have to chase and hail cabs. I have contextual information about the driver’s identity, vehicle, and arrival. And when I get to my destination, I don’t have to fuss with a tip—the service is set up to pay its drivers without bothering the customer. The “tip” comes in the form of a quick one- to five-star review I can choose to complete in the app.
Speaking of context, when I finish my New York trip and arrive in Atlanta, the Uber app is ready with a helpful instructional message (Figure 20-8, right) specifically designed for the Atlanta airport context—complete with which level of the airport I should use for pickup.
Although any service has opportunities for improvement, there is much to appreciate in the Uber experience, at least based on my interactions as a customer. It turns a regular car into a digital object, along with the driver and the passenger, but without making the customer feel like an object. It doesn’t hide seams that users need to see but does hide the ones they don’t.
There are well-considered interactions at the level of interface here, and a great deal of technical prowess enabling the service. But there’s an architecture at work, as well: the labels, relationships, and rules that choreograph the coordination between physical location, semantic sensemaking, and digital systems. Whether anyone on Uber’s design team calls these aspects information architecture or not, this is information in the service of environmental structure and understanding. It requires an architecturally coherent system for placemaking and sensemaking, through and through.
The Organization as Medium
The level of choreography we see with services such as Uber is very difficult to achieve, even for a start-up that has no “legacy” baggage to corrupt its mission. But, like it or not, most of our work tends to be with existing companies that have longer histories—full of barnacles, cluttered basements, and skeletons in the closet.
Because organizations are essentially made of information—they are what they are because they’re “organized” after all—there’s no reason why they can’t be used as raw material for creating great contextual experiences, contextually aware capabilities, and clear, beautifully “seamful” architectures. However, doing it requires facing some truths about the nature of organizations.
There’s an adage called Conway’s law, named after Melvin Conway, who introduced the idea in 1968. It states that organizations that design systems “are constrained to produce designs which are copies of the communication structures of these organizations.”[406] The nested structures of the organizational environment become a collectively binding map of the way that organization sees the world, nudging it into creating all environments in its image.
The organizational map is often bound up with its existing machinery—the dysfunctional plumbing of its infrastructure. The map is in turn further etched into the organization by those stubbornly influential systems. Kohls can’t magically make a single, consolidated place where a customer can manage both the credit card account and the web-shopping account, because they’re fundamentally separate businesses—a bank and a retailer—merely portraying themselves under one brand. Delta has millions of customers and deep legacy data structures that already understand “Silver, Gold, Platinum”; it’s beyond nontrivial to blow it all up and start over with a more scalable loyalty structure, so they resort to bolting on new dimensions that don’t nest coherently.
Google can’t easily change what it means by “groups,” partly because some of the features are acquired systems that had to be grafted onto decade-old infrastructure. Apple, as disciplined as it might be in its design aesthetic, is only mortal, and struggles to create a coherent layout between its many deep silos and existing services infrastructures. Organizations are organisms of a sort, with their own perceptions, learned habits, and joints that bend only one way or another.
Technology departments tend not to concern themselves with how everything relates to everything else, but to focus mainly on the mechanics of engineering for defined requirements. Rather than composition, computer science—and IT engineering—is often more focused on what it callsdecomposition, whereby a complex system is broken down into parts in order to better organize its work and maintain it. This is certainly a necessary effort, but it often becomes an end in itself, losing the original holistic context of the system. As Paul Dourish notes, “The typical conception of context in technical systems is of information of a middling relevance.”[407] When the environment is “decomposed” into tiny objects, they become the most relevant elements in the work, losing the composed context for why the parts should exist.
In built-environment architecture, this effort of establishing the full purpose and context of a building before designing it is called programming. (Alas, this word has other uses in IT departments.) Different from something like a project charter—which is normally used only until resources are assigned and a project has kicked off—an architectural program (or “brief”) is a constant touchstone throughout the process. It’s the first articulation of why a building is to exist and what its functional value should be, and it’s the continually updated standard by which the specifics of design are evaluated.
The way we document and articulate our work shapes the way the work is done. No matter how much more advanced our technology becomes, our failure to grasp the importance of “language as infrastructure” will undermine our ability to solve contextual problems.
And, when companies define their business rules, they are using language to establish how the world will work, long before anyone is explicitly “designing” anything. In my experience, however, more often than not I’ve seen the business side of the organization abdicate much of the responsibility for the rigor of business rules, opting instead to just generally state vague wishes and leave the hard details to IT.
Making complex, pervasive systems work well contextually will require more and better effort from business and design stakeholders in collaboratively composing business rules. That’s because business rules are architecture. They are blueprints—maps—that describe the natural laws of the to-be-made territory. They use language to create molds, which will then be used to cast the gears and armatures of the machinery upon which the business depends.
So, one challenge for information architecture practitioners is to not only understand the end user, but to understand the organization that is making something for the user to begin with. Large organizations especially have trouble with semantic confusion because there are so many different political factions and cultural silos involved. Departments of engineers, marketing professionals, and executive management all tend to understand language from different perspectives. Any user-experience designer who has tried to explain why “research” is necessary, even though the Marketing/Communications department has done lots of “research” already, has experienced the pain of these disconnects.
As information architect Abby Covert says in her book How to Make Sense of Any Mess:
I once had a project where the word “asset” was defined three different ways across five teams.
I once spent three days defining the word “customer.”
I once defined and documented over a hundred acronyms in the first week of a project for a large company, only to find 30 more the next week.
I wish I could say that I’m exaggerating or that any of this effort was unnecessary. Nope. Needed.
Language is complex. But language is also fundamental to understanding our direction.[408]
Meaning is a participatory sport, in which the game can seem completely different depending on the perspective of any given player. But, we can minimize risks if we work to understand the collage of perspectives and learned meanings that will be perceiving the structures we introduce to the world. Semantic information is also the territory. There’s already a map driving the creation of new environment, whether we acknowledge it or not. Semantics are never “just semantics.”
I like the thought of the organization as a medium for understanding—a material we can reframe, recalibrate, refine. This is basically what we’re doing when we introduce new language into organizations; powerful semantic function can get into the body politic and change its shape, like stem cells that grow new bones over time. No joke; I’ve seen it happen!
But even if we don’t change the organization as a whole, we still need to change parts of it enough to accommodate and support the new architectures it needs; otherwise, the new organs are easily rejected, abandoned, or neutralized through assimilation.
[387] Icons by webalys.com
[388] Interpreted from a version by Abby Covert.
[389] I should mention that Jorge Arango also has a three-part model: Links, Nodes, and Order, that I really like as well. There is no single, right model for all this. I see all models as provisional, contextual, and nested among one another. Jorge’s model is available at http://www.jarango.com/blog/2013/04/07/links-nodes-order/.
[390] Clark, Andy. Supersizing the Mind: Embodiment, Action, and Cognitive Extension (Philosophy of Mind). London: Oxford University Press, 2010:1145-6, Kindle locations.
[391] ———. Supersizing the Mind: Embodiment, Action, and Cognitive Extension (Philosophy of Mind). London: Oxford University Press, 2010:1128-32
[392] It is telling that, in the current move toward “flat” design, it’s the simulated objects such as buttons that are being removed, putting even more weight on labels for establishing invariant structure.
[393] Klyn, Dan. “Understanding Information Architecture.” January 13, 2014 (http://bit.ly/1x5o8Ql).
[394] Citrix. “Most Americans Confused By Cloud Computing According to National Survey” August 28, 2012 (http://bit.ly/125vdXZ).
[395] Greenfield, Adam. “On the ground running: Lessons from experience design.” June 22, 2007 (http://bit.ly/1oqMMvQ).
[396] In previous work, I’ve used “connections” here, but I now think “relationships” is a better way to frame the idea.
[397] Warren, Christina. “New Twitter API Drops Support for RSS, Puts Limits on Third-Party Clients.” Mashable.com Sept 5, 2012 (http://mashable.com/2012/09/05/twitter-api-rss/).
[398] Lambe, Patrick. Organising Knowledge: Taxonomies, Knowledge and Organisational Effectiveness. Oxford, England: Chandos Publishing, 2007:10.
[399] ———. Organising Knowledge: Taxonomies, Knowledge and Organisational Effectiveness. Oxford, England: Chandos Publishing, 2007:4.
[400] ———. Organising Knowledge: Taxonomies, Knowledge and Organisational Effectiveness. Oxford, England: Chandos Publishing, 2007:16.
[401] Somerville, Richard C. J., and Susan Joy Hassol. “Communicating the science of climate change.” Physics Today, October, 2011:51.
[402] The use of the word “terms” as part of a contractual agreement is one of the lovely examples of synecdoche (essentially conflating a signifier with the whole of what it represents) we rely on to both communicate and create our environment.
[403] Klyn, Dan. “Understanding Information Architecture,” January 13, 2014 (http://bit.ly/1x5o8Ql).
[404] Resmini, Andrea, and Luca Rosati. Pervasive Information Architecture: Designing Cross-Channel User Experiences. Burlington, MA: Morgan Kaufmann, 2011:66.
[405] ———. Pervasive Information Architecture: Designing Cross-Channel User Experiences. Burlington, MA: Morgan Kaufmann, 2011:113.
[406] Conway, Melvin E. “How do Committees Invent?” Datamation April, 1968; 14(5):28-31. (Retrieved 2009-04-05)
[407] Dourish, Paul. What We Talk About When We Talk About Context. 2004.
[408] Covert, Abby. How to Make Sense of Any Mess. (Author) 2014.