Selenium Design Patterns and Best Practices (2014)
Chapter 8. Growing the Test Suite
|
"To succeed, planning alone is insufficient. One must improvise as well." |
||
|
--Isaac Asimov, Foundation Series |
||
Writing tests is fun! This may seem contrary to the first sentence in Chapter 1, Writing the First Test, of this book. However, once we solve the difficult problems such as test stability, test data, and the framework design, writing a new test case is the most gratifying experience one can have in our field.
Once we have a good grasp of Selenium and are ready to grow our test suite, we will face some new challenges. Questions such as what test needs to be written next or what CI tool to choose from will naturally come up. In this chapter, we will discuss the following topics about the long-term growth and maintenance of the test suite:
· Strategies for writing test suites
· Different types of tests
· Different types of test suites
· Continuous Integration
· Testing in multiple browsers
· Selenium Grid
· Managing build nodes
· Build node virtualization
· Frequently Asked Questions
Strategies for writing test suites
A common question during a job interview for test automation is "How do you plan to build the test suite?" When I was new to software test automation, I would answer that 99 percent coverage is critical. After reality had a chance to catch up, it became apparent that such high coverage is impossible due to obvious time constraints.
Instead of having 100 percent test coverage, the best that can be done is to prioritize the growth of the test suites. In this section, we will discuss the order in which test suits should be built. As we build our test suites, some tests will cross multiple boundaries, which is perfectly normal. However, it is best to have a way to group certain tests together so they can be executed individually. For example the smoke test suite is a subset of the regression suite, but we need ability to execute it without having to run the regression suite.
Note
All of the strategies listed are in order from highest priority to lowest, but they are not mutually exclusive.
Different types of tests
Before we dive into the different Selenium test suites, let's define several types of automated tests. This will help us understand where Selenium tests belong in the development cycle. The following definitions are commonly used to describe a type of an individual test; however, they are slightly redefined with Selenium bias:
· Unit test: This is, by definition, the smallest test unit. This type of a test is written to test an individual object and even individual methods of said object. Unit testing is highly important because it prevents bugs from creeping in at the lowest level. These tests rarely use any production-like test data and often solely rely on mock data. Since unit tests are at a low level of the application, Selenium tests are not applicable here.
Note
Low level is a phrase commonly used to describe code that has a low level of abstraction. Likewise, high level describes code with a high level of abstraction. For example, a method that adds 1 and 1 would be described as low level and a method that registers a new user in the database is a high-level method.
· Integration test: This consists of several modules of code put together, allowing them to pass data between each other. The purpose of this type of test is to make sure that all modules integrate and work with each other. In terms of Selenium, integration might be checking that the store module of our website can pass the product information into the cart module. The tests that run in CI after every commit to test only our application and stubbing all third-party services is considered integration build.
Note
Integration tests are sometimes referred to as functional tests, since they test the functionality of an application.
· End-to-end: This is the highest-level of test. This type of test is executed in production or a production-like environment, such as staging. Similar to integration tests, an end-to-end test tries to verify that all of the components, including third-party services, can communicate well with each other.
Note
End-to-end tests are sometimes referred to as Verification and Validation (V&V)
The majority of Selenium tests will fall into the integration category. By blocking as much instability caused by test data and third-party dependencies as possible, our tests can concentrate on testing only one piece of functionality at the time. However, a well-written test that is properly hermetically sealed should be able to run in both integration and end-to-end environments.
Note
See Hermetic Test Pattern in Chapter 3, Refactoring Tests, for more information.
The smoke test suite
Smoke testing is a very common and popular concept in the quality assurance world. The idea is to plug in the new code, let it run, and see whether it runs or catches on fire. Out of all the test suites, a smoke suite will by far be the smallest in size, since it needs to give a close to instantaneous pass or fail verdict. This test suite is best used in the first few minutes after new code is deployed to any environment. Use this small test suite to make sure that the production environment is up and running.
Tests in the smoke test suite should look for the following:
· Running application: Does the website load or does it give a 500 error? This is by far the simplest question and could be answered by navigating to several key pages, such as the home page or the online store.
· Database connection: Database issues happen more often than anyone cares to admit. After the deployment of the new code, we realize that the database was not properly migrated. Test should do several read only checks against the database, such as log in with an existing user.
· Abnormal amount of exception: This question is a little bit more involving than others. The starting point is to make sure no page returns an error code when it should not. It can evolve into dumping the JavaScript console logs to check whether new JavaScript errors start to appear.
Smoke test suite should almost be like a feather in a boxing fight. It should touch the application without leaving a single dent or scratch. We should keep the following in mind:
· Avoid writing to a database if you cannot clean it up after: It is normal to register new users or make purchases on a staging environment. However, this is typically a bad idea in production, since it is difficult to clean up the test data after the test is complete. To stay on the safe side, the test should only perform actions that read from the database, never write to it.
· Don't test too much: We want to have an answer about the state of the environment as fast as possible. Leave the more extensive testing to other test suites.
The money path suite
Money path is one or several core key pathway through our application. In the case of an online store, it is the ability to add items to the cart and receive payment information. In an inventory management system, it's the ability to retrieve and update current inventory. Noncritical functionality, such as updating user's email preferences, is to be left out of this test suite.
Money path and smoke test strategies can have multiple tests in common; however, tests that write to the database in the money path suite should probably not be included in the Smoke Test suite.
The money path suite should answer the following question: is the customer prevented from giving us money? This is by far the most important part of this suite. Every single test in this test suite should aim to answer that question, if it's not it should be moved to another test suite.
New feature growth strategy
Smoke test suite and money path suites are the top priority when writing tests. However, those test suites are relatively small and will go into maintenance mode pretty quickly. After they are finished, we will spend the majority of our time in this mode. The idea of the new feature strategy is to keep up with the development of the application. As a new feature is added, we add a new test. This strategy does not try to write tests for an already existing functionality such as regression strategy.
By far, this new feature strategy is most effective when the test writer is embedded in the development team.
Tip
Some of the teams I've personally worked on, the developers themselves were responsible for the creation of new tests as the application got new features. This gave an up-to-date Selenium test support for all new features and gave the QA team a starting point to add and improve the said tests. This setup has been extremely successful.
Being part of the team on a daily basis and seeing the direction of development is an important part in keeping up with new features. The classic over-the-wall approach to quality assurance will not work well because by the time the test developer starts writing tests for newly delivered feature, the development team has moved on to new tasks.
Note
The over-the-wall testing approach consists of the Development and QA teams being completely separate. After a new set of features has been added to the application, the new build is given to the QA team to test. The QA members are not involved in daily testing as each commit happens.
When writing tests for new features, the tests should concentrate on answering the following questions:
· Is this the most important and critical feature to be tested?
There are new features that enhance the application slightly and there are critical features. When pressed for time, as we always are, the new tests should aim to test mission critical features and leave the enhancements to the regression suite.
· Are the new tests useful right away?
As soon as a new test is written, even for an unfinished feature, it should be added to CI. Features that are in active development have the maximum instances of instability and bugs by far. Having the new tests added in step with new code and running on every commit provides a good foundation for stability.
Bug-driven growth strategy
Bug-driven and new feature strategies are extremely compatible with each other. The new feature strategy concentrates on adding a new test for every new feature. The bug-driven strategy concentrates on adding a new test for every bug discovered and fixed.
Every new release of the application comes with a list of new features or bug fixes, and more often than not, both at the same time. Most people who will be testing the new release of the application will concentrate on testing the new features, while giving the bug fixes a cursory glance. Having an automated test case for every bug fixed in the current build is a great safety net. Furthermore, sometimes when a new release branch is being created in the Version Control System (VCS), bug fixes are sometimes overwritten or reverted by accident. A single test might prevent an emergency deploy!
Tip
An accidental revert of a bug fix may not be the most common occurrence on a team familiar with their VCS tool; when it does happen, it happens at the worst possible time.
The regression suite
Regression tests are all of the tests in our suite that test features developed in the past; this is not to be confused with features actively being developed. Following the previously-described strategies, we will add new tests to the regression test suite.
Sadly, more often than not, our teams will always be too understaffed to write new tests against already existing features. When pressed for time, we should always concentrate on new features, since this part of the code will prove to be most unstable. As new bugs are discovered in older code and feature set, the regression suite will slowly grow. However, spending too much time writing tests for sections of code that were not touched in years will probably prove to be a waste of time.
The 99 percent coverage suite
A test suite that covers 99 percent of new and existing features in an application is the dream of every tester. However, it often proves to be nothing but a pipe dream. Unless we are on the team writing tests for the space station or a nuclear power plant, we will never have enough resources to test everything. Thus, for most automated test creators, this strategy is not only wasteful but can be extremely harmful.
Any piece of the application that has not been touched in a long time and has not had any bugs in that time is unlikely to randomly start producing bugs. Writing a test for that code may be harmful because it takes time away from writing a test for new code that more than likely will break. However, if the said old code starts to be updated with a bug fix or a new feature, it's a good idea to write tests for it.
On the other hand, if you are in a very fortunate position where you can afford to keep updating the test suite, bringing it closer and closer to full coverage, consider yourself extremely lucky and keep going!
One last thought about adding new tests to our application before we move on, is that it is always better to have a smaller test suite that is reliable and is executed often, than to have a large test suite that fails randomly and makes everyone on the team lose faith in its usefulness.
Tip
As soon as we start to add any test to our suite, it's a good time to start thinking about CI.
Continuous Integration
The most amazing test suite ever written is useless if it sits on someone's laptop and is never executed! Having our tests in CI is not only beneficial to the quality of the application, but it is also beneficial to the quality of the test suite itself. By executing the test suite dozens of times a day we can discover test instabilities, which occur once in a while.
There are five components to setting up a Continuous Integration system. They are listed in order of importance here:
· Test environment: In order to execute the tests, we need to have an application we are trying to test. Without a test environment, the tests are just pieces of code that cannot be executed. We talked about different types of test environments in the Data relevance versus data accessibility section of Chapter 4, Data-driven Testing.
Tip
Even if it is possible to execute a more complicated test suite than a smoke test in a production environment, it is an anti-pattern that should be avoided.
· Test data: Having access to reliable test data is very important. After all, the test's only role is to pass data from one location in our application to another and check the outcome. We discussed the Test Data problems and solutions in Chapter 4, Data-driven Testing.
· Tests and test stability: Developing the test suite the next item on the list. We discussed some strategies on prioritizing the order of the tests earlier in this chapter. Remember, do not let the pace of test suite growth reduce the quality of individual tests and the test suite as a whole. We discussed improving test stability and reliability in Chapter 5, Stabilizing the Tests.
· Test nodes: Managing the computers that host the test environment and the testing nodes is important. Having a stable application and test suite can be completely negated by a test environment, which randomly deletes the database or test nodes that restart at will. We will cover these issues further in the Managing the test environments and nodes section.
· CI system: Choosing the right CI tool seems like the top priority; how can we execute our tests without it? However, if the preceding four points are properly resolved, the tool that executes the tests can be completely interchangeable; thus, it is the least important item on our list. We will talk more about choosing the right CI tool in the Choosing the CI tool section.
Note
The statement made in this bullet can only remain true if the investment made into the current CI tool is minimal. We will discuss some ways to reduce dependency on a specific CI tool in the Choosing the CI tool section.
Managing the test environments and nodes
The management of CI and testing environments is often ignored. The development team is often too busy or doesn't want to play the role of a systems administrator. The production system administrators might be able to help with managing the hardware and the operating system of staging and testing environments, but making dozens of deployments of new code to those environments can become taxing on them.
For these reasons, the quality assurance and test automation teams must fill in that role. They are the ones who care the most about these environments and having a more intimate knowledge of how the application is deployed can provide a lot of insight on why certain bugs occur; not to mention a more detailed bug report, for which all of the developers are eternally grateful! There are two aspects of environment management that naturally fall into this field: the testing environment and the CI environment.
Deploying new builds
Being able to reliably deploy new code into a testing environment at the drop of a hat is extremely useful both for manual and automated testing. Testing new features or verifying that a bug is fixed as soon as the new build released is great for a fast feedback cycle and reduction in frustration for all parties involved.
Luckily for us, we do not necessarily have to do a lot of work to make this a reality. Most of the time, the production operations administrators have scripts written to help them deploy new versions. By working with those teams, it is possible to get a hold of those scripts and adopt them to work with Integration and Staging testing environments. Combining those deployments scripts with CI build, we are able to deploy the latest build into our test environment and automatically trigger a Selenium smoke test suite. Depending on the test environment, we even are able to run the whole regression test suite.
We do not necessarily need to have system administrator experience to have the tools to make our day-to-day life easier. Convincing all parties involved that a QA team, which is independent, is a huge time and money saver. Very few people can argue against that logic.
CI environment management
Managing the CI environment can be slightly more involved compared to having deployment scripts to a testing environment. We need to manage the build nodes, the test data, and the scripts to execute the test build. There is a lot of work to do in this area, but keeping these items stable will prevent a lot of flakey builds. Let's talk about node management first.
Build node management
Whether we are talking about CI build nodes or Selenium Grid nodes, in an ideal world, all of them would be identical to each other. Having the same version of all tools and environment settings, such as the version of Java or the same version of Firefox, will prevent failures that cannot be easily replicated or explained. There are several ways to approach this problem:
· Configuration Management System
· Virtualization
Configuration management system
There are several commercial and open source configuration management systems available. These tools take care of managing third-party applications, dependencies, and configurations on large quantities of computers. These tools will not only help you manage the testing nodes, but will also help you to manage the computers used by both development and testing teams. Having all of the environments in sync with production will prevent odd surprises once the code is deployed for the customers.
Early on in my career, I was a manual and automated tester on a Java-based web project. When the whole website overhaul effort was completed and deployed to production, we noticed some poor performance and strange bugs that were never seen in testing environments. After further inspection, it was discovered that the version of Java used on production severs was one minor version behind from development and testing environment. The difference caused a forced rollback and delay of this major undertaking, not to mention embarrassment for the whole team involved.
After learning this valuable lesson, it has always been my priority to manage all of the build nodes properly. Here are the tools that I was able to use successfully in the past to avoid instability:
· Chef: This is a Ruby cross-platform tool that allows you to group computers on your network into groups and assign which applications and versions of said applications are to be installed on per-group basis. Find more information about Chef at http://www.getchef.com/chef/.
· Puppet: This is a Ruby-based configuration management, which is a direct competitor to Chef. Both have an analogous feature set; you can find more information about Puppet at http://puppetlabs.com/.
· Shell scripts: When you do not have ability to use a full configuration management system, having some shell scripts is drastically better than trying to manage each node by hand. You can use Bash scripts on Linux-based systems and batch and PowerShell scripts on Windows-based systems. Having a script that downloads, installs the correct tools, and manages the configuration of the operating system is a worthwhile initial investment that will pay off in the long run.
Note
If you wish to use Bash scripts on a Windows node instead of writing it as a batch or PowerShell file, installing Cygwin is a great solution. Cygwin can be found at https://www.cygwin.com/install.html.
Virtualization
Virtualization is another way to manage build nodes. It can be combined with a configuration management system or by itself. By setting up a base Virtual Machine (VM) image of a testing node, we can configure an environment to be optimal for testing. After the base image has been created, we can copy it to create as many nodes as necessary without spending any time in configuring individual ones. Furthermore, VMs are great for periodically deleting the whole OS and starting again from an optimal environment!
There are dozens of free and enterprise VM solutions available on the market. Each comes with its own feature set and some might work much better for your individual situation than others. Here are several free virtualization solutions:
· Xen project: This is an open source virtualization product that allows users to host multiple concurrent VMs. This allows users to host both Linux-and Windows-based VMs. This is a lightweight, highly stable and highly reliable solution to host multiple simple build nodes. The biggest drawback of Xen is that it can only be hosted on a Linux-based host computer, and requires some system administrator skills; simply put, it is not overly user friendly. More information about Xen project can be found at http://www.xenproject.org.
· Virtual box: This is an open source project by Oracle. It runs on many host operating systems such as Windows, Linux, and Mac OSX. Virtual Box supports many types of guest VMs, such as Windows, Linux, and Mac OSX. Virtual box is user friendly and easy to get started with. More information on virtual box can be found at https://www.virtualbox.org.
· Windows virtual PC: This is a free VM host provided by Microsoft. This can only be run on a Windows host, and have only provided Windows guest VMs. For more information about Windows virtual PC, please refer to http://www.microsoft.com/windows/virtual-pc/.
Selenium Grid
While we are on the topic of build nodes, let's briefly visit Selenium Grid. So far, we have been writing our tests and executing them only on our local computers. This type of test execution is called the standalone mode of execution. The downside of standalone mode is that the resources available limit us on our current computer. For example, we can only use the browsers currently installed on the computer; basically, running your tests in Internet Explorer from a Mac is impossible. Selenium Grid solves these limitations by allowing our tests to take over other computers on our network. Thus, we are no longer limited by the resources on our computer, but can increase the coverage and reach of our test suite!
Understanding standalone and grid modes
To clear up any misconceptions on how Selenium Grid works, let's take a closer look at how WebDriver controls the web browser. Understanding the internal workings will help you set up a much more stable grid in the long run. Let's first take a look at how Selenium WebDriver controls a web browser with the JsonWire protocol.
JsonWire protocol
The JsonWire protocol (also known as the WebDriver Wire protocol) is a standard set of API calls that is used to communicate with the WebDriver server. Basically, when our test wants the browser to navigate to a certain page or click on a certain link, the language binding translates the click method call into the JsonWire protocol and sends it as an HTTP request to the WebDriver server.
Note
Detailed documentation on the JsonWire API can be found at https://code.google.com/p/selenium/wiki/JsonWireProtocol.
Since the JsonWire protocol is simple to understand and use, anyone can write a language binding to drive any browser!
Note
Throughout this book, we used Ruby bindings to control the browser; however, there's a binding for every major programming language. In some cases, there are multiple implementations of WebDriver bindings for a given programming language.
Standalone mode
When we run our Selenium tests in standalone mode, an instance of WebDriver server is started on our computer. This server controls the browser we are testing and we control the server through the language bindings. The following figure demonstrates the flow of commands from the test to the browser:
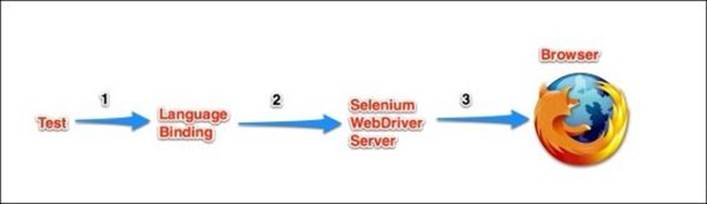
The click command follows these steps:
1. Our test finds the element it wants to click on and calls the click method.
2. The language binding, where the click method is defined, builds a simple JSON snippet. This snippet explains what action needs to be performed and what the target of the action is to the WebDriver server.
3. Selenium WebDriver server tells the web driver what action to perform.
Grid mode
Selenium Grid manages multiple computers, called nodes. Instead of connecting to a local instance of the Selenium WebDriver server, our tests connect to a central hub. The hub keeps track of all available nodes. The grid hub has the following responsibilities:
· Keep track of all available nodes
· Manage the creation and clean-up of test sessions
· Forward JsonWire communication between test bindings and nodes
When running tests using Selenium Grid, our tests are executed on a remote node in a remote browser, but everything acts as if we are running in standalone mode. The following diagram demonstrates how a click command works in the grid mode:
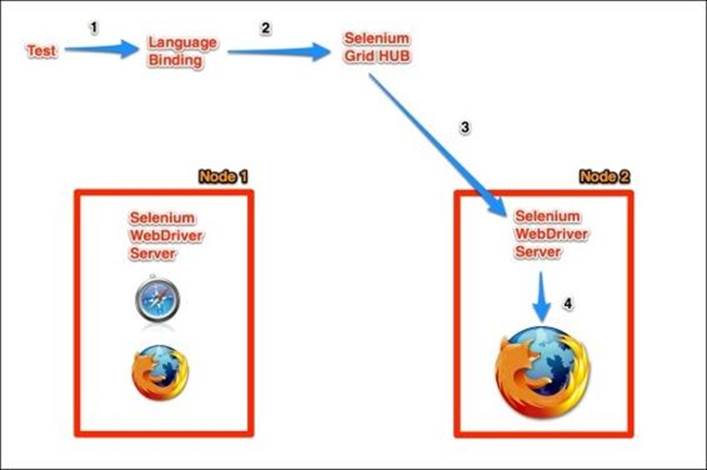
There are two things to note about the preceding diagram:
· As node 2 executes our tests, node 1 is idle; this means that we can start another test suite to run against node 1.
· Node 1 supports both the Firefox and Safari browsers. Our test suite can drive the Safari browser from any computer, even if that computer does not support Safari.
Note
SauceLabs is a company that set up a Grid-like infrastructure in the cloud. If you want to be able to test multiple browsers but do not have access or do not want to manage the grid nodes, they might be the right solution for you. Find more information at https://saucelabs.com/.
Installing Selenium Grid
Installing Selenium Grid on your network is as simple as finding several computers, downloading the Selenium WebDriver JAR file, and running the start command. If your IT department has several old computers that are out of date to be used in development but can still run at least one modern browser, you can build a large grid for your tests! Follow these steps to get started:
1. Download the latest version of the Selenium server from http://docs.seleniumhq.org/download/.
2. In the terminal, run the following command to start the Selenium hub (replacing PATH-TO-SELENIUM-JAR with the path to the downloaded JAR file):
3. java -jar PATH-TO-SELENIUM-JAR.jar -role hub
The terminal output should look something like this:

Note
This command is using all default settings, such as port number, for the hub to start on. To see all available settings, add the –help flag to the preceding command.
3. Now that the hub server has been started, let's add a node. In a new terminal window, run the following command:
4. java -jar PATH-TO-SELENIUM-JAR.jar -role wd -hub http://localhost:4444 -port 5555
We added the –role wd flag to tell our JAR to start in WebDriver mode. The –hub flag is used to point the node to the hub location. Finally, the –port parameter is used to tell the node which port to listen on. The default port is 4444, which was occupied by the hub, so we use5555 instead.
We have a small Selenium Grid up and running! Let's take a look at the grid console by navigating to http://localhost:4444/grid/console in our browser. We will see a summary of available nodes and browsers; it will look similar to this:
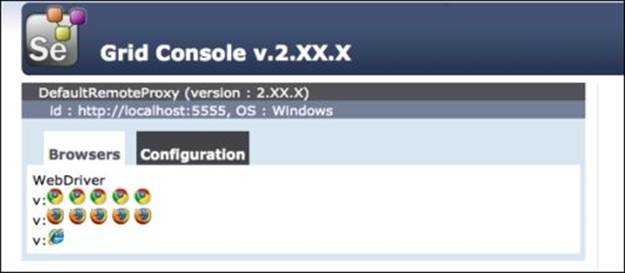
As we can see, our grid has one node that can run five instances of Chrome, five instances of Firefox, and one instance of Internet Explorer. Now that we have an active grid, we can point our tests at it.
Using Selenium Grid
It is very easy to start using our tests in grid mode. In Chapter 1, Writing the First Test, we used the following code to acquire a new instance of Firefox:
selenium = Selenium::WebDriver.for(:firefox)
By adding several new parameters to the WebDriver.for method call, we can request the new session to come from the Selenium Grid:
selenium = Selenium::WebDriver.for(:remote,
:url => "http://localhost:4444",
:desired_capabilities => :firefox)
The :remote parameter declares that the tests will run in Grid mode, and the Grid is located in the :url parameter. Finally, :desired_capabilities specifies the browser we want to use.
Selenium Grid Extras
Managing Selenium Grid can become quite involving. There are a lot of options and preferences for session management, timeouts, and much more. Selenium Grid can only control the web browsers on the nodes it manages. This means that someone has to manually manage all OS-level tasks on the Grid nodes. To help with the node management tasks, the Selenium Grid Extras project was created.
Selenium Grid Extras takes care of many aspects of grid management. Things such as automatically downloading new versions of WebDriver, periodically restarting the nodes, and viewing system resource usage can be handled by this project. To get more information about Selenium Grid Extras, please visit https://github.com/groupon/Selenium-Grid-Extras.
Whether we choose to use Selenium Grid for our testing in CI or not, we need to take environment maintenance seriously. In the next section, we will talk about managing both the test environments and the CI environments.
Choosing the CI tool
Since there are multiple open source and enterprise CI tools available on the market, the task of choosing one can be quite daunting. We can spend weeks comparing tables of features, licenses, capabilities, and User Interface (UI). This task might feel monumental; after all, once the tool is selected we are stuck with it forever! However, as it turns out, the tool itself is the least important part of setting up a CI environment.
After all, a CI tool is nothing but a glorified cron job, with a UI attached to it. At its core, a CI tool runs on a set interval to check whether any updates were made to the code base; if changes are detected, it executes a saved script that we call test suite. We can set up a single script file on a computer, which executes on a cron and achieves the exact same results as the most expensive enterprise tool available on the market!
Note
A cron job is a software utility on Unix-like systems, which executes a specified task at a specified interval. Windows has an analogous utility called Task Scheduler.
It is too easy to get carried away with research and acquisition of the perfect tool that we hope will fulfill all of our needs. However, if we decouple our test suite from the CI tool, we will be able to switch tools at will. This allows us the flexibility to start with a free solution at first and migrate to a paid solution if the feature set in said solution is overwhelmingly positive.
Decoupling tests from tools
As we discussed in Chapter 5, Stabilizing the Tests, Chapter 6, Testing the Behavior, and Chapter 7, The Page Objects Pattern, our tests need to be as independent from the application and tools as possible. Decoupling tests from the implementation details of the application and reusing methods in a DRY pattern makes them easy to maintain in the long run and gives us flexibility to change things without breaking everything. The same principle applies to running our tests in CI.
To prevent a situation where we are locked into a given CI tool and cannot migrate to a better option, we need to separate the tool's tasks from the tests themselves. We will let the CI tool do what it was designed to do and nothing else. Here are the three primary functions of the CI tool:
· Looking for code changes in VCS
· Managing build node availability
· Providing some rudimentary security system to prevent accident modifications to builds
Treating the build configuration and execution with same care and respect as application code is a great way to separate the tests from the tool. Here is how we will approach the setup of the CI environment for our website:
1. Set up a separate VCS repository whose only job is to store test execution scripts.
2. Migrate any common set-up tasks, such as database migration or starting of third-party services, into the shared spaces in our VCS.
Note
Whether we are using Bash scripts or PowerShell scripts, it is a great idea to split different set-up tasks into functions and keep things DRY.
3. Add a script for each new job. Each script uses the shared code to set up the environment prebuild. It is the script's responsibility to trigger the build, whether it is a Rake, Maven, or Shell script.
Note
Some CI tools provide support for Maven, Rake, and ant builds. If we choose to use the tool's support to execute the tests, we can still use the setup scripts as part of the prebuild to configure the environment.
4. Each new build job in CI will use this repository to call the appropriate script to start the build. Since all of the setup is done within our build scripts, we no longer rely on any tool to provide all of the needed support; thus, the CI tool becomes interchangeable.
Tip
If we are careful in the naming of build scripts in the repository to match the build name in CI, we can copy and paste the same execution commands to all of our builds and let the CI tool choose the correct script at run time.
In Jenkins, the build command would look like this: sh ${JOB_NAME}.sh.
By separating the test execution away from the CI tool's UI, we are free to sample any tool and settle down on the one we want. The other great advantage of having a script execute our test suite is that we can execute it on our local machine without the CI. This is a great way to debug test failures that occur only when the whole suite is executed but not when we run a single test. The script will set up the database and other environment settings in an identical way to CI, thus making the illusive test failures that much easier to find.
This approach to configuring the CI job is not the only one. As you set up your own, you will find what works best for you and what does not. Whatever approach you do decide to take, just keep in mind that locking yourself into a single tool might not be the best solution in the long run, especially when you find out that the competitor's test reporting view is much more pleasing to the eye.
Note
I will not be listing all of the currently available enterprise and open source CI tools. Since I started working on this book, at least one more free and paid for tool was released, and many more will be released by the time you read this. Thus, a simple Internet search will provide a much better list of current tools and a feature set comparison between all of them.
Frequently Asked Questions
Even though this book is about writing tests in Selenium, most of the ideas and topics apply to test automation in general. Having said that, Selenium is not necessarily the best solution for every problem that comes along. In this section, I would like to discuss some of the most common questions I've heard asked. We will discuss each scenario, followed by problems most commonly associated with that scenario and a possible solution or possible solutions that may apply.
How to test on multiple browsers?
Testing in multiple browsers is by far the most frustrating part of working with Selenium. Certain browsers cause more problems than others by default; I'm looking at Internet Explorer. There have been multiple situations where Firefox and Chrome build would pass but Internet Explorer build will fail due to idiosyncrasies in how Microsoft decided to interpreted common web standards.
Problem
More and more web applications are hosted in Unix-like environments. Thus, the development environments are shifting away from Windows to Linux-based computers, which cannot support a local instance of Internet Explorer for quick local testing.
Possible solutions
There are multiple approaches to testing in Internet Explorer and other browsers. We will list them in order of speed and overall stability here. The first applicable choice is usually by far the best.
Localhost testing
The most reliable way to test on Internet Explorer is to have the tests execute locally on the CI node. If it is possible to add a Windows node to your CI that will execute the Selenium tests, then this is the solution for you. Having the Windows node connected to CI directly gives access to a lot of operating system level tasks that will help you make the tests stable. In the Decoupling tests from tools section of this chapter, we discussed a prebuild setup script that will set up the test environment. Part of that script can be terminating any orphan IE processes that may have been left over from a previous run. These orphan processes can cause a lot of environment instability for you.
Setting up Selenium Grid
Sometimes, setting up a Windows node in CI is not an option. For example, if we want to run the tests against a local instance of a website but the application stack is not compatible with Windows architecture. We will need to host the application stack on a different computer and have the Internet Explorer run against that local instance instead. This approach lacks the same amount of prebuild control; however, we discussed some possible work-around for it in the Selenium Grid section of this chapter.
Setting up SauceLabs Grid
Setting up a Selenium Grid might not always be the practical solution. Managing the Windows nodes is a very involved process, and having a dedicated Windows node for each version of Internet Explorer makes this even more difficult. SauceLabs takes care of hosting multiple versions of Internet Explorer and administration of the Windows nodes. The only downside is reduced performance speed, since the communication between the local instance of the website and remote browsers can become very slow. However, all of the positive features SauceLabs provides outweigh the reduction in test speed. For more information, visit the SauceLabs website at https://saucelabs.com/.
Note
SauceLabs was one of the first companies to provide Selenium nodes as a service in the cloud. Since then, several new companies started to offer this service, and the two most recent examples are Spoonium (https://spoonium.net/) and BrowserStack (http://www.browserstack.com/).
Which programming language to write tests in?
Selenium has a WebDriver implementation in every major programming language. This means that choosing the language and testing framework for your test suite should be relatively easy. You do not have to use the same language to write tests that was used to write the application itself. However, there are obvious advantages of doing so:
· Closer integration: If the application being tested is written on a JVM platform, it makes a lot of sense to write tests in a JVM-compatible language. This could give us closer integration with the application, making the testing effort that much easier.
Tip
Why not reuse the existing database connection object already written to query the database and find out the contents required for the test?
· Programming help: If you are new to programming in a given language or programming in general, never underestimate the help you can receive from the developers on your team. A single question with the right person on your team might save you days of research.
· Developer involvement: If the tests are written in a language developers understand and are comfortable with, they are much more willing to write and improve the tests themselves. Having a team of developers writing their own tests as they develop the feature is the best possible solution for a good quality test suite. Do not be afraid that the developers will take your job if they are also writing tests. There is always plenty to do to make sure the test suite remains stable, and you might become the Selenium guru on your team and everyone will come to you for help.
Once we have picked out the programming language and toolset we will use, we can start writing tons of new tests! At some point we will want to test on platforms and browsers other than Firefox. To help us diversify the browser coverage, let's talk about Selenium Grid.
Should we use Selenium to test the JS functionality?
Using Selenium to only test a single validation pop up on the registration page is like using a canon to kill a mosquito. However, if we review any large test suite, we will find a lot of canons used. Is Selenium the right tool to use to test a small piece of JavaScript?
Problem
Selenium is a very resource-intensive testing tool and loading the programming language, the databases, and the browser is inefficient if we are only testing JavaScript validations on a single form.
Possible solution
If we are testing the JavaScript functions on a form, we should try to isolate the code and test it by itself. There are multiple JavaScript testing tools, such as Jasmine, that allow the functions to be tested without loading the whole page. By moving the majority of tests from Selenium to Jasmine, we were able to execute 1,000+ JavaScript-only tests in under 2 minutes (4 minutes on Internet Explorer).
Note
Jasmine is a JavaScript BDD tool that uses Selenium WebDriver to load a web browser and all of the JavaScript functions into a single page. A user writes tests in JavaScript in an RSpec-like syntax. For more information on Jasmine, visit http://jasmine.github.io/.
Why should I use a headless browser?
We do not need to open up an instance of Firefox to execute our Selenium tests. Having the tests run in a browser allows us to view the execution as it is happening, which helps in the writing and debugging stages of a given test. However, once the test is complete and is reliably running in CI, we don't always need to physically watch it run. A headless browser is a solution for these scenarios.
The web browser has to render the whole Domain Object Model (DOM) as the user navigates from page to page. The rendering is a slow and resource-intensive process. Furthermore, the operating system needs to provide a windowing service in which to render the browser. Windows can only support a single window at the time; thus, concurrent browsers end up stacking on top of each other.
Possible solution
Using a headless browser, such as HTMLUnit Driver or PhatntomJS, increases the execution speed of the test suite, since the browser is not required to render the whole DOM. Furthermore, using a headless browser is a lot less resource-intensive, allowing a higher quantity of parallel-running tests.
Note
More information on HTMLUnit Driver can be found at https://code.google.com/p/selenium/wiki/HtmlUnitDriver.
PhantomJS
PhantomJS is a relatively new OSS project, which uses the WebKit engine to render web pages in memory only, and no browser window is attached. It is newer and better compared to HTMLUnit driver because it uses the actual WebKit engine instead of emulating the behavior of JavaScript. Having a real browser engine rendering the headless browser leads to much more reliable and consistent results compared to emulation.
Note
WebKit is a web page layout engine written by Apple for its Safari web browser. It is dramatically faster than the Trident engine used by Internet Explorer. Google has forked the WebKit project, calling it Blink engine. Currently, the Google Chrome and Opera browsers use the Blink engine.
Because PhantomJS is relatively easy to set up and the decreased suite execution time, it becomes a perfect solution for running the whole test suite on the developer's computer before committing new code to the VCS. Running a headless test suite locally and handing off the real browser execution to the real web browsers in CI can be the solution your team is looking for.
Note
Since PhantomJS is a relatively new project, it might not have Selenium bindings implemented for every programming language. However, the team is very active and is adding new language and frameworks all the time. For more information on PhantomJS, visithttp://phantomjs.org/.
Which BDD tool should I use on my team?
BDD tools can provide a good starting point for any framework we want. But with so many tools to choose from, which one is the best for us?
Problem
There are multiple BDD tools available and all try to accomplish the same goal: making the functionality of the application easy to understand and decoupled from implementation. However, each tool has its own format for describing the behavior and tends to be more resource-intensive than a simpler framework. Furthermore, it might be difficult to get the whole team to agree on which description format to use; not everyone likes the Given, When, Then format of describing the features.
Possible solutions
If the intention of the test suite is to have a simple no frills test suite that only runs the tests without any BDD methodologies, then choosing a simple framework such as Test::Unit or JUnit might be more than sufficient. The downside is that you get what you pay for; this approach will not have all the easy-to-understand features that a BDD tool might have.
If the intended consumer of the test is from a nontechnical team, such as a project manager or manual testers, then a framework such as Cucumber or JBehave is great. It helps to specify intended behavior in clear, easy-to understand language. This is especially useful if the team uses some form of agile development methodology. The story can be directly translated into a Given, When, Then format. However, the tremendous amount of wordiness might not be idea for all teams.
A compromise between the preceding two options is a framework like RSpec. This tool provides a human-readable test description but in a much more precise and less wordy manner. This seems to be a lot more popular among purely development-minded people who might be turned off by the Given, When, Then style of behavior description.
Note
MiniTest is another tool that uses the RSpec style of feature description but is much more lightweight and faster than RSpec. MiniTest is automatically bundled with Ruby, starting from version 1.9. For more information on this tool, visit https://github.com/seattlerb/minitest.
In the end, it does not matter which tool is chosen as long as the test suite is growing with good reliable tests. The best tool is not the one that has the most features, but the one that everyone will use to grow and maintain the test suite.
Can I use Selenium for performance testing?
When releasing a new version of the website, we want to make sure that the new version does not perform slower than existing code. If we do not pay attention to the website performance, it will not take a long time for our fast and new website to become slow and unpleasant to use.
Problem
Technically, we can use Selenium for performance testing. However, just because we can technically do something, a question should always be nagging us at the back of our mind: should we do it? Using Selenium for performance testing is similar to using a butter knife to cut a steak; effective but unpleasant. The following factors make Selenium unsuitable for performance testing:
· Inaccurate: When testing page load performance, we are not testing the server response times but page load times. Even if our website is fully loaded, some asset from a third-party application might still be loading. Timing the page load times will give inflated results.
· Testing JavaScript performance: Selenium is not the best tool to use to test the performance of JavaScript on the page. First of all, it is too big and clumsy to give any results worth noting. Since JavaScript is technically a single-threaded language, that means that our site's scripts will have to share resources with any third-party JavaScript loaded in the browser. The slower than expected results might be coming from something outside of our control.
· Testing asset performance: If we cannot reliably test JavaScript performance and the performance of complete page loads, maybe we can test the asset loading. Selenium will not be able to tell you accurately how fast a certain image or video downloaded and rendered in the browser. Browser performance depends on so many factors outside of the current page, such as the amount of windows currently open, available RAM, disk usage, and CPU usage by background processes. Not to mention the asset caching performed by the browser and the caching performed by a network caching proxy that your IT department installed for the whole company. It is close to impossible to get consistent download and render time results without using Selenium.
· Testing server load: By far, testing the server load with Selenium is the least helpful experience. In order to generate noticeable load on the web server we need dozens, if not hundreds of Selenium instances, and even then, it might not be enough.
In conclusion, Selenium is a terrible solution for performance testing. There are simpler and better solutions available.
Possible solutions
Depending on the type of performance testing we are trying to accomplish, there are specialized tools to accomplish just about any goal. For example, to put a server under heavy load and record the response times from it, JMeter is a great tool. It simulates user behavior by recording the HTTP interactions your browser makes as you normally browse the website and replays these interactions with thousands of concurrent requests.
Note
For more information on the JMeter project, visit at http://jmeter.apache.org/.
To test the performance of the JavaScript on a given page, Google provides the V8 Benchmark Suite (http://v8.googlecode.com/svn/data/benchmarks/v7/run.html).
If we want to have a cross-browser solution for checking what assets are slow to load, YSlow (http://yslow.org/) is a great tool for that. Furthermore, most modern browsers provide a built-in test suite for JavaScript and asset performance.
Finally, if none of the tools mentioned satisfy your needs, we can write our own scripts. Using Ruby or Bash, we can write a simple script that makes HTTP requests against different API endpoints or assets and records the time it took to complete a purchase request or for an image to download. At the end of the day, a simple shell script will provide a much more accurate performance report than a Selenium test.
Summary
This concludes Selenium Design Patterns and Best Practices. The goal of this book was to demonstrate that Selenium testing is more than just clicking on links. To test a complicated application in a reliable and repeatable way requires a sophisticated Selenium test suite. Throughout this book, we touched upon some of the most difficult problems that I and people like myself have been encountering in the field of test automation. I hope that our collected knowledge will help save you weeks or months of frustration and confusion that I have personally experienced.
In conclusion, technical solutions provided in this book might not be the best solution in your individual case. However, I hope they will send you on the right path to something that fits perfectly for you. Improvising is a large part of this new field, so find out what works for you and share your accumulated knowledge with the Selenium community. Together, we can make test automation into an integral part of software development.
Now, go write some tests!