Learning Web Application Development (2014)
Chapter 1. The Workflow
Creating web applications is a complicated task involving lots of moving parts and interacting components. In order to learn how to do it, we have to break down these parts into manageable chunks and try to understand how they all fit together. Surprisingly, it turns out that the component we interact with most often doesn’t even involve code!
In this chapter, we’ll explore the web application development workflow, which is the process that we use to build our applications. In doing so, we’ll learn the basics of some of the tools that make it a manageable and (mostly) painless process.
These tools include a text editor, a version control system, and a web browser. We won’t study any of these in depth, but we’ll learn enough to get us started with client-side web programming. In Chapter 2, we’ll actually see this workflow in action as we’re studying HTML.
If you’re familiar with these tools, you may want to scan the summary and the exercises at the end of the chapter and then move on.
Text Editors
The tool that you’ll interact with most often is your text editor. This essential, and sometimes overlooked, piece of technology is really the most important tool in your toolbox, because it is the program that you use to interact with your code. Because your code forms the concrete building blocks of your application, it’s really important that creating and modifying it is as easy as possible. In addition, you’ll usually be editing several files simultaneously, so it’s important that your text editor provide the ability to quickly navigate your filesystem.
In the past, you may have spent a good deal of time writing papers or editing text documents with programs like Microsoft Word or Google Docs. These are not the types of editors that we’re talking about. These editors focus more on formatting text than making it easy to edit text. The text editor that we’ll use has very few features that allow us to format text, but has an abundance of features that help us efficiently manipulate it.
At the other end of the spectrum are Integrated Development Environments (IDEs) like Eclipse, Visual Studio, and XCode. These products usually have features that make it easy to manipulate code, but also have features that are important in enterprise software development. We won’t have the occasion to use any of those features in this book, so we’re going to keep it simple.
So what kinds of text editors should we explore? Two primary categories of text editors are commonly used in modern web application development. The first are Graphical User Interface (GUI) editors. Because I’m assuming that you have some background in programming and computing, you’ve most likely experienced a Desktop GUI environment. Therefore, these editors should be relatively comfortable for you. They respond well to the mouse as an input device and they have familiar menus that allow you to interact with your filesystem as you would any other program. Examples of GUI text editors include TextMate, Sublime Text, and Coda.
The other category of text editors are terminal editors. These editors were designed before GUIs or mice even existed, so learning them can be challenging for people who are used to interacting with a computer via a GUI and a mouse. On the other hand, these editors can be much more efficient if you’re willing to take the time to learn one of them. The most commonly used editors that fall into this category are Emacs (shown in Figure 1-1) and Vim (shown in Figure 1-2).
In this book, we’ll focus on using a GUI text editor called Sublime Text, but I encourage everyone to get some experience in either Emacs or Vim. If you continue on your web application development journey, it’s highly likely you’ll meet another developer who uses one of these editors.
Installing Sublime Text
Sublime Text (or Sublime, for short) is a popular text editor with several features that make it great for web development. In addition, it has the advantage that it’s cross-platform, which means it should work roughly the same whether you’re using Windows, Linux, or Mac OS. It’s not free, but you can download an evaluation copy for free and use it for as long as you like. If you do like the editor and find that you’re using it a lot, I encourage you to purchase a license.
Figure 1-1. An HTML document opened in Emacs
Figure 1-2. An HTML document opened in Vim
To install Sublime, visit http://www.sublimetext.com and click the Download link at the top. There you’ll find installers for all major platforms. Even though Sublime Text 3 is in beta testing (at the time of this writing), I encourage you to give it a try. I used it for all the examples and screenshots in this book.
Sublime Text Basics
Once you have Sublime installed and run it, you’ll be presented with a screen that looks something like Figure 1-3.
Figure 1-3. Sublime Text, after being opened for the first time
The first thing you’ll want to do is create a new file. Do that by going to the File menu and clicking New. You can also do that by typing Ctrl-N in Windows and Linux or using Command-N in Mac OS. Now type Hello World! into the editor. The editor will look similar to Figure 1-4.
You can change the appearance of the Sublime environment by going to the Sublime Text menu and following Preferences → Color Scheme. Try out a few different color schemes and find one that is comfortable for your eyes. It’s probably a good idea to spend some time exploring the theme options because you’ll spend a lot of time looking at your text editor. Note that you can also change the font size from the Font submenu under Preferences to make the text more readable.
Figure 1-4. Sublime after a new file is opened and Hello World! is typed into the file
You probably noticed that Sublime changed the tab name from “untitled” to “Hello World!” as you typed. When you actually save, the default filename will be the text that appears in the tab name, but you’ll probably want to change it so that it doesn’t include any spaces. Once saved with a different name, the tab at the top will change to the actual filename. Notice that when you subsequently make any changes you’ll see the X on the right side of the tab change to a green circle—this means you have unsaved changes.
After you’ve changed your theme and saved your file as hello, the editor will look similar to Figure 1-5.
WARNING
Because we’ll be working from the command line, it’s a good idea to avoid spaces or special characters in filenames. We’ll occasionally save files using the underscore ( _ ) character instead of a space, but try not to use any other nonnumeric or nonalphabetic characters.
We’ll spend a lot of time editing code in Sublime, so we’ll obviously want to make sure we’re saving our changes from time to time. Because I expect that everyone has a little experience with code, I’ll assume that you’ve seen the edit-save-edit process before. On the other hand, there’s a related essential process that many new programmers don’t have experience with, and that’s called version control.
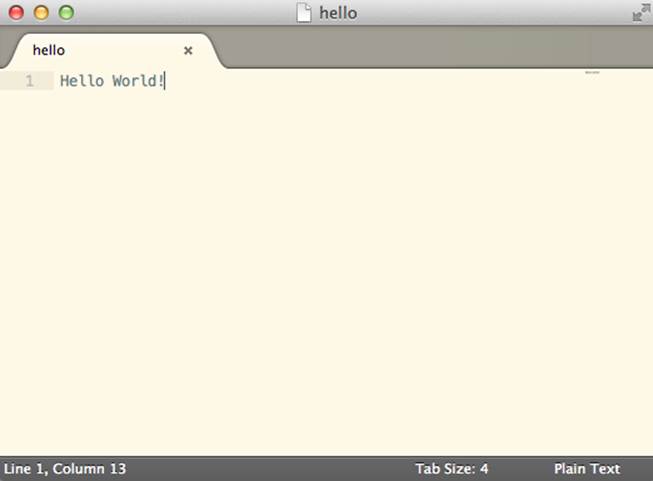
Figure 1-5. Sublime after the theme has been changed to Solarized (light) and the file has been saved as hello
Version Control
Imagine that you’re writing a long piece of fiction with a word processor. You’re periodically saving your work to avert disaster. But all of the sudden you reach a very important plot point in your story and you realize that there is a significant part of your protagonist’s backstory that is missing. You decide to fill in some details, way back near the beginning of your story. So you go back to the beginning, but realize that there are two possibilities for the character. Because you don’t have your story completely outlined, you decide to draft both possibilities to see where they go. So you copy your file into two places and save one as a file called StoryA and one as a file called StoryB. You draft out the two options of your story in each file.
Believe it or not, this happens with computer programs far more often than it happens with novels. In fact, as you continue on you’ll find that a good portion of your coding time is spent doing something that is referred to as exploratory coding. This means that you’re just trying to figure out what you have to do to make a particular feature work the way it’s supposed to before you actually start coding it. Sometimes, the exploratory coding phase can spawn changes that span multiple lines in various code files of your application. Even beginning programmers will realize this sooner rather than later, and they will often implement a solution similar to the one just described. For example, beginners might copy their current code directory to another directory, change the name slightly, and continue on. If they realize that they’ve made a mistake, they can always revert back to the previous copy.
This is a rudimentary approach to version control. Version control is a process that allows you to keep labeled checkpoints in your code so you can always refer back to them (or even revert back to them) if it becomes necessary. In addition to that, version control is an essential tool for collaborating with other developers. We won’t emphasize that as often in this book, but it’s a good idea to keep it in mind.
Many professional version control tools are available and they all have their own set of features and nuances. Some common examples include Subversion, Mercurial, Perforce, and CVS. In the web development community, however, the most popular version control system is called Git.
Installing Git
Git has straightforward installers in both Mac OS and Windows. For Windows, we’ll use the msysgit project, which is available on GitHub as shown in Figure 1-6. The installers are still available on Google Code and are linked from the GitHub page. Once you download the installer, double-click it and follow the instructions to get Git on your system.
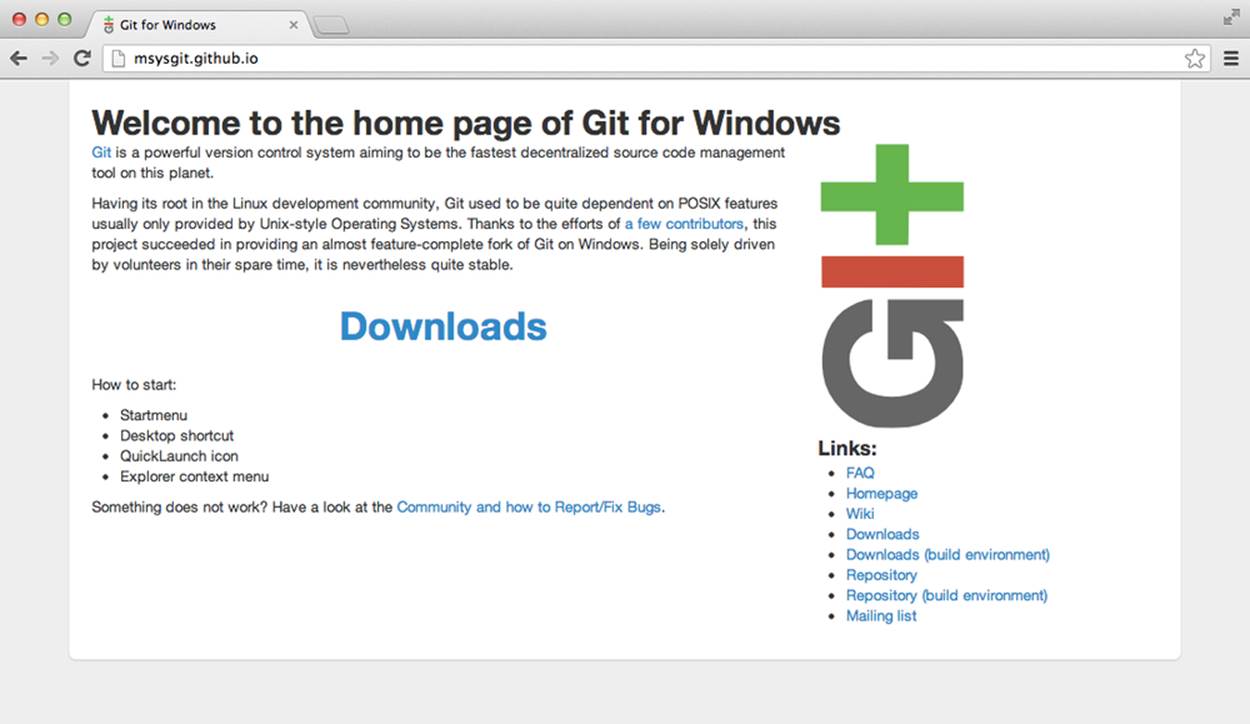
Figure 1-6. The msysgit home page
For Mac OS, I prefer using the Git OS X installer shown in Figure 1-7. You simply download the prepackaged disk image, mount it, and then double-click the installer. At the time of this writing, the installer says that it is for Mac OS Snow Leopard (10.5), but it worked fine for me on my Mountain Lion (10.8) system.
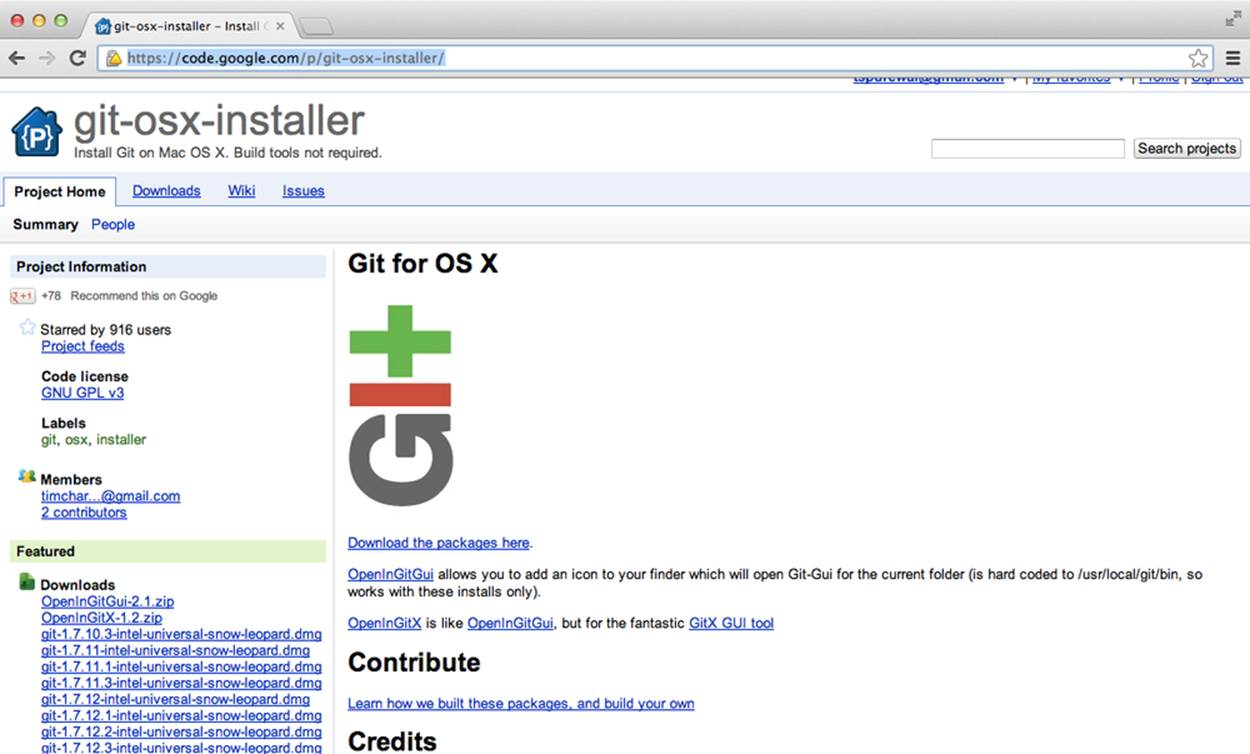
Figure 1-7. The Git for OS X home page
If you’re using Linux, you can install Git through your package management system.
Unix Command-Line Basics
There are graphical user interfaces to Git, but it’s much more efficient to learn to use it through the command line. Before you learn to do that, however, you’ll have to learn to navigate your filesystem using some basic Unix commands.
Like I mentioned before, I am assuming you have a background in computing and programming so you’ve most likely interacted with a desktop GUI environment. This means that you’ve had to use the desktop environment to explore the files and folders stored on your machine. You typically do this through a filesystem navigator such as Finder for Mac OS or Windows Explorer in Windows.
Navigating your computer’s filesystem from the command line is almost the same as navigating it using your system’s file browser. There are still files, and those files are organized into folders, but we refer to folders as directories. You can easily accomplish all the same tasks that you can accomplish in the file browser: you can move into a directory or out of a directory, see the files that are contained in a directory, and even open and edit files if you’re familiar with Emacs or Vim. The only difference is that there is no continuous visual feedback from the GUI, nor are you able to interact via a mouse.
If you’re in Windows, you’ll do the following in the Git Bash prompt that you installed with the msysgit project described in the previous section. Git Bash is a program that simulates a Unix terminal in Windows and gives you access to Git commands. To fire up the Git Bash prompt, you’ll navigate there via your Start menu. If you’re running Mac OS, you’ll use the Terminal program, which you can find in the Utilities directory of your Applications folder. If you’re using Linux, it depends a bit on the particular flavor you’re using, but there is usually an easily available Terminal program in your applications. The default Mac OS terminal window is shown in Figure 1-8.
Figure 1-8. A default terminal window in Mac OS
Once you open the terminal, you’ll be greeted with a command prompt. It may look different depending on whether you’re using Windows or Mac OS, but it usually contains some information about your working environment. For instance, it may include your current directory, or maybe your username. In Mac OS, mine looks like this:
Last login: Tue May 14 15:23:59 on ttys002
hostname $ _
Where am I?
An important thing to keep in mind is that whenever you are at a terminal prompt, you are always in a directory. The first question you should ask yourself when presented with a command-line interface is “Which directory am I in?” There are two ways to answer this question from the command line. The first way is to use the pwd command, which stands for print working directory. The output will look something like this:
hostname $ pwd
/Users/semmy
Although I do use pwd on occasion, I definitely prefer to use the command ls, which roughly translates to list the contents of the current directory. This gives me more visual cues about where I am. In Mac OS, the output of ls looks something like this:
hostname $ ls
Desktop Downloads Movies Pictures
Documents Library Music
So ls is similar to opening a Finder or Explorer window in your home folder. The result of this command clues me in that I’m in my home directory because I see all of its subdirectories printed to the screen. If I don’t recognize the subdirectories contained in the directory, I’ll use pwd to get more information.
Changing directories
The next thing that you’ll want to do is navigate to a different directory than the one you’re currently in. If you’re in a GUI file browser, you can do this by simply double-clicking the current directory.
It’s not any harder from the command line; you just have to remember the name of the command. It’s cd, which stands for change directory. So if you want to go into your Documents folder, you simply type:
hostname $ cd Documents
And now if you want to get some visual feedback on where you are, you can use ls:
hostname $ ls
Projects
This tells you that there’s one subdirectory in your Documents directory, and that subdirectory is called Projects. Note that you may not have a Projects directory in your Documents directory unless you’ve previously created one. You may also see other files or directories listed if you’ve used your Documents directory to store other things in the past. Now that you’ve changed directories, running pwd will tell you your new location:
hostname $ pwd
/Users/semmy/Documents
What happens if you want to go back to your home directory? In the GUI file browser, there is typically a back button that allows you to move to a new directory. In the terminal there is no such button. But you can still use the cd command with a minor change: use two periods (..) instead of a directory name to move back one directory:
hostname $ cd ..
hostname $ pwd
/Users/semmy
hostname $ ls
Desktop Downloads Movies Pictures
Documents Library Music
Creating directories
Finally, you’ll want to make a directory to store all of your projects for this book. To do this, you’ll use the mkdir command, which stands for make directory:
hostname $ ls
Desktop Downloads Movies Pictures
Documents Library Music
hostname $ mkdir Projects
hostname $ ls
Desktop Downloads Movies Pictures
Documents Library Music Projects
hostname $ cd Projects
hostname $ ls
hostname $ pwd
/Users/semmy/Projects
In this interaction with the terminal, you first look at the contents of your home directory to make sure you know where you are with the ls command. After that, you use mkdir to create the Projects directory. Then you use ls to confirm that the directory has been created. Next, you use cdto enter the Projects directory, and then ls to list the contents. Note that the directory is currently empty, so ls has no output. Last, but not least, you use pwd to confirm that you are actually in the Projects directory.
These four basic Unix commands are enough to get you started, but you’ll learn more as we move forward. I’ve included a handy table at the end of this chapter that describes and summarizes them. It’s a good idea to try to memorize them.
Filesystems and trees
Web development (and programming in general) is a very abstract art form. This roughly means that to do it effectively and efficiently, you’ll need to improve your abstract thinking skills. A big part of thinking abstractly is being able to quickly attach mental models to new ideas and structures. And one of the best mental models that can be applied in a wide variety of situations is a tree diagram.
A tree diagram is simply a way of visualizing any kind of hierarchical structure. And because the Unix filesystem is a hierarchical structure, it’s a good idea to start practicing our mental visualizations on it. For example, consider a directory called Home that contains three other directories:Documents, Pictures, and Music. Inside the Pictures directory are five images. Inside the Documents directory is another directory called Projects.
A tree diagram for this structure might look something like Figure 1-9.
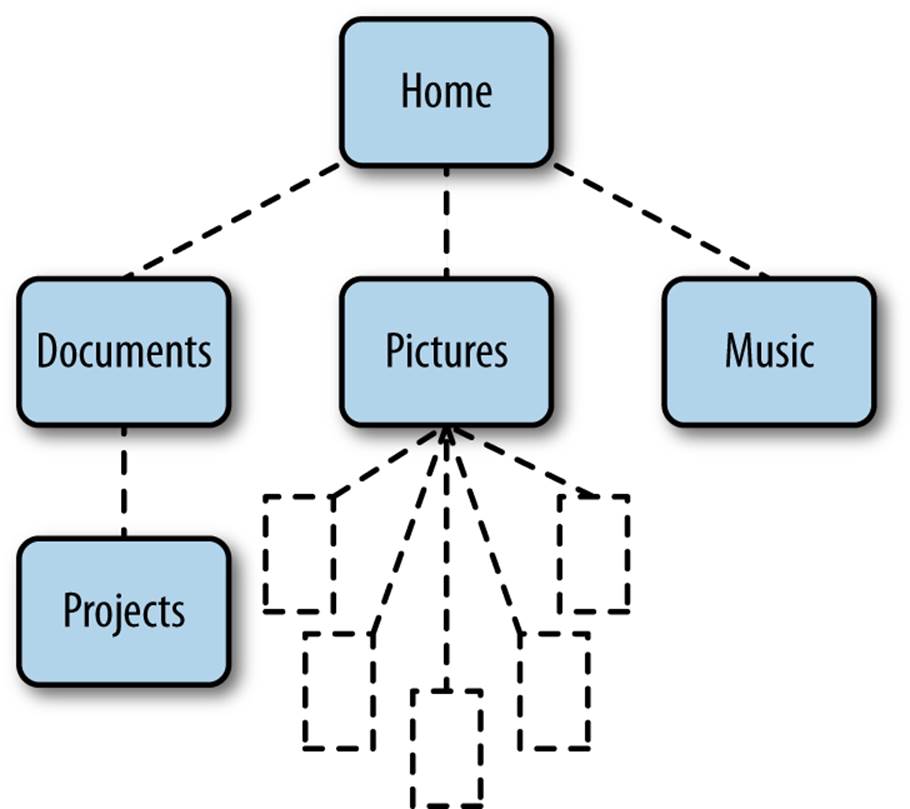
Figure 1-9. A tree diagram representing a file hierarchy
It’s a good idea to keep this mental model in your head while you’re navigating the filesystem. In fact, I would recommend adding an asterisk (or something similar) that denotes your current directory and have that move as you’re moving through the filesystem.
More generally speaking, if you try to attach a tree diagram to any hierarchical structure you’ll most likely find that it’s easier to understand and analyze. Because a large part of being an effective programmer comes from the programmer’s ability to quickly build mental models, it’s a good idea to practice attaching these tree diagrams to real-world hierarchical systems whenever they make sense. We’ll do that in a few instances throughout the rest of the book.
Git Basics
Now that we can navigate the command line, we’re ready to learn how to keep our project under version control with Git.
Configuring Git for the first time
Like I mentioned before, Git is actually designed for large-scale collaboration among many programmers. Even though we’re going to use it for our personal projects, it will need to be configured so that it can track our changes with some identifying information, specifically our name and email address. Open your terminal and type the following commands (changing my name and email address to yours, of course):
hostname $ git config --global user.name "Semmy Purewal"
hostname $ git config --global user.email "semmy@semmy.me"
We’ll only need to do this once on our system! In other words, we don’t need to do this every time we want to create a project that we’re tracking with Git.
Now we’re ready to start tracking a project with Git. We’ll begin by navigating to our Projects folder if we’re not already there:
hostname $ pwd
/Users/semmy
hostname $ cd Projects
hostname $ pwd
/Users/semmy/Projects
Next we’ll create a directory called Chapter1, and we’ll list the contents of the directory to confirm that it’s there. Then we’ll enter the directory:
hostname $ mkdir Chapter1
hostname $ ls
Chapter1
hostname $ cd Chapter1
hostname $ pwd
/Users/semmy/Projects/Chapter1
Initializing a Git repository
Now we can put the Chapter1 directory under version control by initializing a Git repository with the git init command. Git will respond by telling us that it created an empty repository:
hostname $ pwd
/Users/semmy/Projects/Chapter1
hostname $ git init
Initialized empty Git repository in /Users/semmy/Projects/Chapter1/.git/
Now try typing the ls command again to see the files that Git has created in the directory, and you’ll find there’s still nothing there! That’s not completely true—the .git directory is there, but we can’t see it because files prepended by a dot ( . ) are considered hidden files. To solve this, we can use ls with the -a (all) flag turned on by typing the following:
hostname $ ls -a
. .. .git
This lists all of the directory contents, including the files prepended with a dot. You’ll even see the current directory listed (which is a single dot) and the parent directory (which is the two dots).
If you’re interested, you can list the contents of the .git directory and you’ll see the filesystem that Git prepares for you:
hostname $ ls .git
HEAD config hooks objects
branches description info refs
We won’t have the occasion to do anything in this directory, so we can safely ignore it for now. But we will have the opportunity to interact with hidden files again, so it’s helpful to remember the -a flag on the ls command.
Determining the status of our repository
Let’s open Sublime Text (if it’s still open from the previous section, close it and reopen it). Next, open the directory that we’ve put under version control. To do this, we simply select the directory in Sublime’s Open dialog box instead of a specific file. When you open an entire directory, a file navigation pane will open on the left side of the editor window—it should look similar to Figure 1-10.
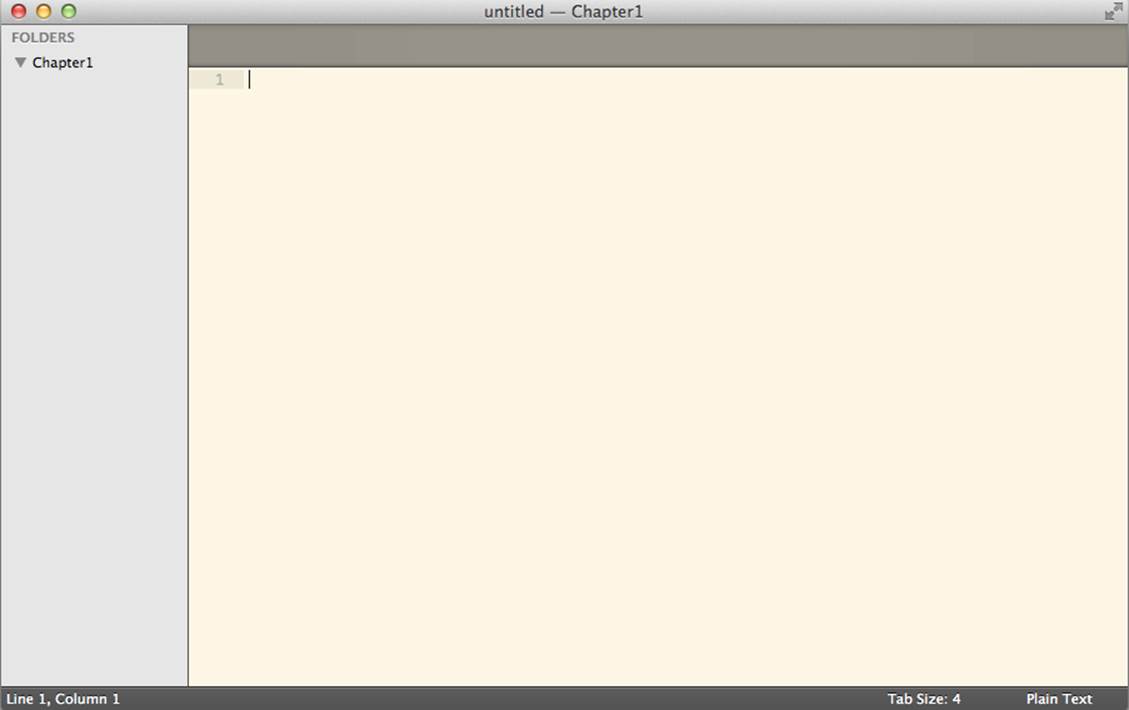
Figure 1-10. Sublime with the Chapter1 directory opened
To create a new file in the Chapter1 directory, right-click (or Command-click on Mac OS) Chapter1 in the file navigation pane and select New File from the context menu. This will open a new file as before, but when you save it, by default it will use the Chapter1 directory. Let’s save it asindex.html.
Once it has been named, double-click it and add the line “Hello World!” to the top of the file, as shown in Figure 1-11.
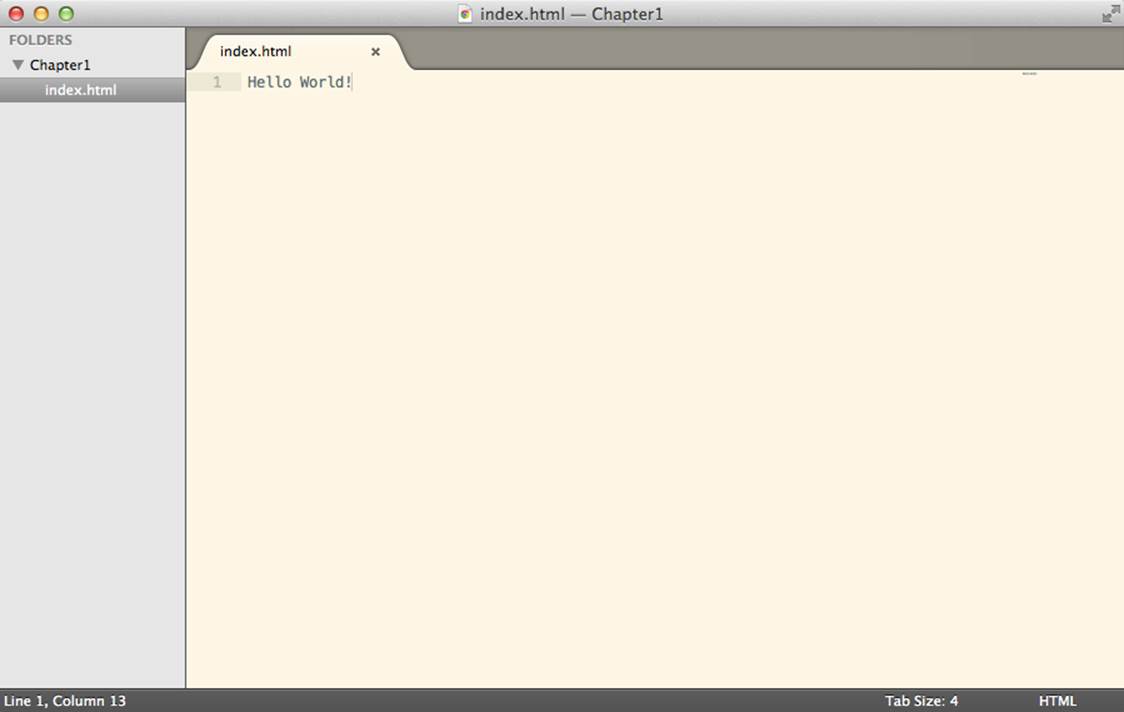
Figure 1-11. Sublime after the index.html file is added, edited, and saved
Let’s see what has happened with our Git repo. Return to your terminal window and confirm you’re in the correct directory:
hostname $ pwd
/Users/semmy/Projects/Chapter1
hostname $ ls
index.html
Now type git status and you’ll see a response that looks something like this:
hostname $ git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# index.html
There’s a lot of information here. We’re most interested in the section labeled Untracked files. Those are the files that are in our working directory, but are not currently under version control.
Notice that our index.html file is there, ready to be committed to our Git repository.
Our first commits!
We’re interested in tracking changes in our index.html file. To do that, we follow the instructions Git gave us and add it to the repo with the git add command:
hostname $ git add index.html
Notice that Git doesn’t respond at all. That’s okay. We can double-check that everything worked by typing git status again:
hostname $ git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: index.html
#
This gives us the feedback we were looking for. Notice that index.html is now listed under the Changes to be committed heading.
Once we’ve added the new files to the repository, we would like to commit the initial state of the repository. To do this, we use the git commit command along with the -m flag and a meaningful message about what has changed since the last commit. Our initial commit often looks something like this:
hostname $ git commit -m "Initial commit"
[master (root-commit) 147deb5] Initial commit
1 file changed, 1 insertion(+)
create mode 100644 index.html
This creates a snapshot of our project in time. We can always revert back to it later if something goes wrong down the road. If we now type git status, we’ll see that index.html no longer appears because it is being tracked and no changes have been made. When we have no changes since our last commit, we say we have a “clean working directory”:
hostname $ git status
# On branch master
nothing to commit (working directory clean)
WARNING
It’s easy to forget to include the -m and a commit message when committing. If that happens, however, you’ll most likely find yourself inside the Vim text editor (which is typically the default system editor). If that happens you can get out of it by hitting a colon (:) and then typing q! and pressing Enter to exit.
Next, let’s modify index.html with a minor change. We’ll add a second line that says “Goodbye World!” Go ahead and do that and save the file using the appropriate keyboard shortcut. Now let’s see how git status responds to this change:
hostname $ git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: index.html
#
no changes added to commit (use "git add" and/or "git commit -a")
Notice that Git tells us that index.html has been modified, but that it’s not staged for the next commit. To add our modifications to the repository, we have to first git add the modified file and then we have to git commit our changes. We may want to verify the add has correctly happened by typing git status before the commit. This interaction might look something like this:
hostname $ git add index.html
hostname $ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
#
hostname $ git commit -m "Add second line to index.html"
[master 1c808e2] Add second line to index.html
1 file changed, 1 insertion(+)
Viewing the history of our repo
So now we’ve made two commits to our project and we can revert to those snapshots at any time. In More Practice and Further Reading, I’ll link to a reference that will show you how to revert to a previous commit and start coding from there. But for now, there’s one other command that may come in useful. We can look at our commit history by using git log:
hostname $ git log
commit 1c808e2752d824d815929cb7c170a04267416c04
Author: Semmy Purewal <semmy@semmy.me>
Date: Thu May 23 10:36:47 2013 -0400
Add second line to index.html
commit 147deb5dbb3c935525f351a1154b35cb5b2af824
Author: Semmy Purewal <semmy@semmy.me>
Date: Thu May 23 10:35:43 2013 -0400
Initial commit
Like the four Unix commands that we learned in the previous section, it’s really important to memorize these four Git commands. A handy chart in Summary covers these commands.
Saving versus committing
In case it’s confusing, I want to take a moment to clearly differentiate between saving a file (through your text editor) and actually committing a change. When you save a file, you actually overwrite the file on your computer’s disk. That means that unless your text editor offers you some sort of built-in revision history, you can no longer access the old version of the file.
Committing to a Git repository allows you to keep track of all the changes you made since the last time you committed the file. This means that you can always go back to a previous version of the file if you find that you’ve made an unrecoverable mistake in your file’s current state.
At this point, it probably looks as though Git stores your code as a linear sequence of commits. That makes sense right now because you’ve learned a subset of Git that allows you to create a repository of where every commit follows exactly one other commit. We refer to the first commit as aparent commit and the second commit as a child commit. A Git repository with four commits looks similar to Figure 1-12.
It’s worth noting, however, that a commit is a series of instructions for taking your project to the next version. In other words, a Git commit doesn’t actually store the entire contents of your repository in the way that you would if you were to copy a directory to another directory. Instead, it only stores what needs to be changed: for example, a commit might store information like “add a line with Goodbye World" instead of storing the entire file. So it’s better to imagine a Git repository as a sequence of instructions. That’s why we write our commit messages in the present imperative tense—you can think of a commit as a series of instructions for taking your project from one state to the next.
Why does all this matter? Actually, a Git repository may have a much more complex structure. A commit may have more than one child, and—in fact—more than one parent. Figure 1-13 shows an example of a more complex Git repository where both of those are true.
Figure 1-12. A Git repository with four commits
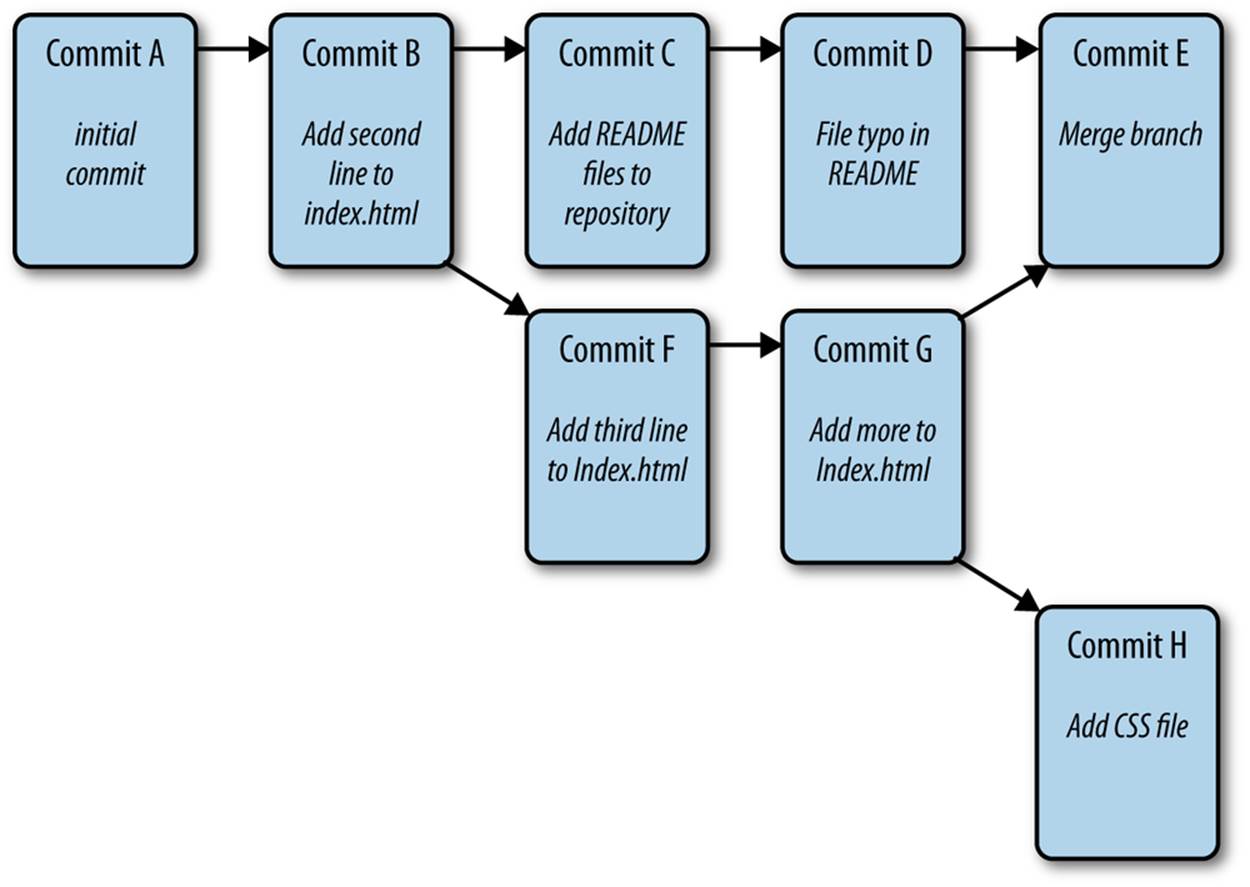
Figure 1-13. A more complex Git repository
Right now, we don’t know any Git commands that will allow us to create a structure like this, but if you continue on in your web app development journey, you’ll have to learn them eventually. The point is that this should motivate you to start picturing your Git repo in a more visual way so that when things do get complex, you don’t get overwhelmed.
Browsers
The last tool that we’ll interact with regularly is the web browser. Because we’re learning to build applications that run in the web browser, it’s essential that we learn how to effectively use our browser as a developer tool, and not just as a window into the Internet.
There are several excellent web browsers including Firefox, Safari, and Chrome. I would recommend becoming proficient in using the developer tools available in all of these browsers. But to keep everyone on the same page and to keep things simple, we’ll use Google Chrome as our browser of choice.
Installing Chrome
Whether you’re on Windows, Mac OS, or Linux, you can install Google Chrome easily by going to the Google Chrome web page. The installation process will, of course, vary, but the instructions are very clear. Once you install Chrome and run it for the first time, it should look something like Figure 1-14.

Figure 1-14. Default Chrome window
Summary
One of the most important aspects of web application development is getting used to an efficient and effective workflow. A modern workflow involves three important tools: a text editor, a version control system, and a web browser. Sublime Text is a popular, cross-platform text editor that is useful for editing source code. Git is a commonly used version control system that has a command-line interface. Chrome is an excellent web browser for web development.
Before moving on, you should have all of the previously described tools installed on your computer. You should also memorize the commands in Table 1-1 and Table 1-2, which allow you to navigate your filesystem and interact with Git from the command line.
Table 1-1. Unix commands
|
Command |
Description |
|
pwd |
Print your current directory |
|
ls |
List the contents of your current directory |
|
ls -a |
List including all hidden files |
|
cd [dir] |
Change to the directory called [dir] |
|
mkdir [dir] |
Create a new directory called [dir] |
Table 1-2. Git commands
|
Command |
Description |
|
git init |
Initialize your repository |
|
git status |
Display the status of your repository |
|
git add [file(s)] |
Stage [files] for the next commit |
|
git commit -m [msg] |
Commit your staged files with message [msg] |
|
git log |
Show the commit history |
More Practice and Further Reading
Memorization
In teaching and learning, memorization often has a negative connotation. In my mind, this view is mostly misguided, particularly when it relates to computer programming. If you follow the mindset that “well, I can just look that up when I need it,” you’ll spend more time looking up basic stuff than focusing on the more challenging things that arise. Imagine, for instance, how much more difficult long division would be if you didn’t have your multiplication tables memorized!
With that in mind, I’m going to include a “Memorization” section at the end of the first few chapters that will cover the basic things that you should memorize before moving on to the next chapter. For this chapter, those things are all related to Git and the Unix command line. You should repeatedly do the following things until you can do them without looking at any documentation:
1. Create a new folder using the command line.
2. Enter that folder on the command line.
3. Create a text file in your text editor and save it as index.html in the new directory.
4. Initialize a Git repository from the command line.
5. Add and commit that file to the repository from the command line.
What’s the best way to memorize this sequence of tasks? Simple: do it over and over again. I’ll pile more onto this task throughout the next few chapters, so it’s important to master these steps now.
Sublime Text
As I mentioned before, you’ll be spending a lot of time in your text editor, so it’s probably a good idea to move a little beyond the basics. The Sublime website has a great support page that has links to documentation and videos that demonstrate advanced features of the editor. I suggest that you explore the page and see if you can level up your Sublime skills.
Emacs and Vim
Nearly every web developer will eventually have to edit a file on a remote server. This means that you won’t be able to use a text editor that requires a GUI. Emacs and Vim are incredibly powerful editors that make doing so a breeze, but the learning curve on both is relatively steep. If you can find the time, it is really worthwhile to learn the basics of both editors, but it seems to me that Vim has become more common among web developers in recent years (full disclosure: I’m an Emacs user).
The GNU home page has an excellent overview of Emacs, including a tutorial for beginners. O’Reilly also has several books on Emacs and Vim including Learning the vi and Vim Editors by Arnold Robbins, Elbert Hannah, and Linda Lamb and Learning GNU Emacs by Debra Cameron, James Elliott, Marc Loy, Eric S. Raymond, and Bill Rosenblatt.
It would be to your benefit to learn how to do the following things in both editors:
1. Open and exit the editor.
2. Open, edit, and save an existing file.
3. Open multiple files simultaneously.
4. Create a new file from within the editor and save it.
5. Search a file for a given word or phrase.
6. Cut and paste portions of text between two files.
If you take the time to do that, you’ll get a pretty good sense of which editor you would prefer to spend more time with.
Unix Command Line
The Unix command line takes ages to master, but you’ve learned enough to get started. In my experience, it’s far better to learn things in the context of solving specific problems, but there are a few other basic commands that I use regularly. Using a Google search, learn about some of these common commands: cp, mv, rm, rmdir, cat, and less. These will all come in handy at various times.
More About Git
Git is an extraordinarily powerful tool—we’ve only barely scratched the surface of its capabilities. Fortunately, Scott Chacon has written Pro Git (Apress, 2009), a great book that covers many aspects of Git in a lot of detail. The first two chapters cover several features that will help you move through this book more efficiently, including reverting to previously committed versions of your repository.
The third chapter of Chacon’s book covers the concept of branching in detail. Branching is a bit beyond the scope of this book, but I hinted at it earlier. I encourage you to explore this topic because the ability to easily and quickly branch your repository is really one of the best features of Git.
GitHub
GitHub is an online service that will host your Git repositories. If you keep your code open source, it’s free. If you want to create private Git repositories, GitHub’s cheapest plan is about $7 per month. I encourage you to sign up for the free plan and explore storing Git repositories on GitHub.
GitHub’s help page walks you through setting up a GitHub account and connecting it to your Git repository. It also has a ton of useful information on both Git and GitHub in general. Use it to get started.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.