eCommerce in the Cloud (2014)
Part II. The Rise of Cloud Computing
Chapter 3. What Is Cloud Computing?
Cloud computing is simply a new incarnation of a long-established business model: the public utility. The vast majority of households and businesses no longer invest in generating power on their own. It’s faster, better, and cheaper to allow a public utility to generate it on behalf of large groups of consumers. Public utilities benefit from being able to specialize on a very limited charter while benefitting from economies of scale. Consumers have no knowledge of how to generate power, nor should they. Yet for a nominal price, any business or individual can tap into the grid (on demand), pull as much or as little as required (elastic), and pay for only the amount that’s actually used (metered).
Power is very similar to cloud computing, both in the business model used by the vendors and the benefits it provides to individual consumers.
Generally Accepted Definition
The term cloud has come to encompass everything, to the point where it means nothing. The cloud has been so broadly redefined by marketers that any service delivered over the Internet is now considered part of the cloud. Services as mundane as online photo sharing or web-based email are now counted as cloud computing, depending on who you talk to.
Cloud computing is still maturing, both as a concept and in the technology that underlies it. But for the purposes of this book, cloud computing is best described by three adjectives:
Elastic
For given resources to be considered part of the cloud, you must be able to increase or decrease it either automatically or on demand using self-service user interfaces or APIs. A resource can include anything you have in your data center today—from commoditized hardware running Linux (Infrastructure-as-a-Service), to application servers (Platform-as-a-Service), up to applications (Software-as-a-Service). The “what” doesn’t matter all that much; it’s the fact that you can provision new resources.
On demand
Seeing as elastic is the first word used to describe the cloud, you must be able to provision a resource precisely when you need it and release it when you don’t.
Metered
You should pay for only what you use—like power. This has enormous implications as the costs directly reflect usage and can therefore be substantially lower. Because you’re renting computing power, you can also treat the costs as operational expenditures (OPEX), like power, as opposed to capital expenditures (CAPEX), like traditional hardware.
Note these are the exact same adjectives used to define power from a public utility. If a service meets all three criteria, it can generally be considered part of the cloud. Cloud solutions can be further classified by two criteria.
The first refers to how the service is made available for consumption. This is called the service model, and it comes down to how much value the vendor adds. Some vendors simply offer hardware, with you having to do all of the upper-stack work on your own. An example of this is a public Infrastructure-as-a-Service offering. In the opposite direction is Software-as-a-Service, which is where the vendor builds, deploys, and maintains the entire stack for you. An example of this is a Content Delivery Network. While there is a continuum from Infrastructure-as-a-Service to Platform-as-a-Service to Software-as-a-Service, each model is distinct.
The second refers to the deployment model, which refers to the availability of the offering. On one extreme is public, which is just as it sounds: anyone may provision its resources. The other extreme is private, where only a select group may provision. Private clouds are often built within enterprises, though their usefulness is often limited because of lack of full elasticity. Public clouds are the focus of this book.
Any cloud solution can be evaluated and classified according to the cube shown in Figure 3-1.
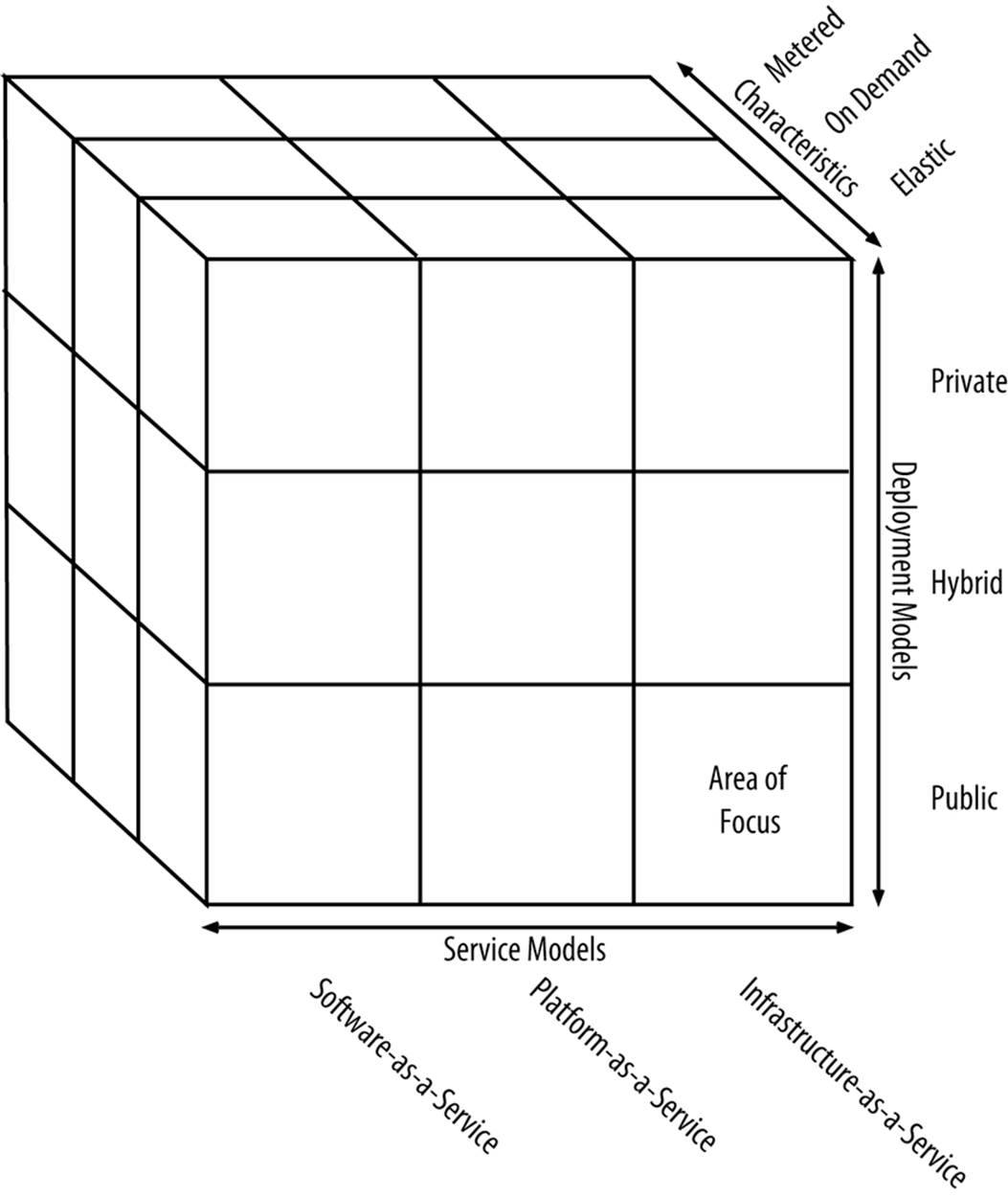
Figure 3-1. Cloud evaluation criteria
The focus of this book is largely public Infrastructure-as-a-Service. Let’s explore the adjectives further, followed by service models and, finally, deployment models.
Elastic
Elasticity refers to the ability to increase or decrease resources arbitrarily. For example, you should be able to provision more hardware for your application server tier in advance of a social media campaign or even in real-time response to a social media campaign. As traffic from the campaign tails off, you should be able to decrease your hardware to match your lower baseline of traffic. Going back to the power analogy, stadiums are able to pull as much as they please from the grid during a large event.
TIP
Elasticity is the defining characteristic of cloud.
Resources can be seen as any physical hardware or software. Any hardware or software deployed in support of an ecommerce application is technically a resource. Resources must generally be provisioned in the same ratio, though not necessarily in tandem. For example, the proportion of application servers to cache grid servers should generally remain the same, assuming the platform is scalable. More on scalability in Chapter 8.
Provisioning refers to the ability to acquire new hardware or software resources. Provisioning should be able to occur automatically or on demand using self-service user interfaces or APIs. The best provisioning is done automatically, either in reaction to or preferably in anticipation of increased demand. The next chapter is devoted exclusively to auto-scaling.
On Demand
While elasticity refers to the ability to increase or decrease resources arbitrarily, on demand refers to the ability to provision at any time. You shouldn’t have to order new hardware, sign a purchase order, or call up a vendor to get more capacity.
TIP
While elasticity is the defining characteristic of cloud, it is predicated on the ability to provision at any time. Traditional noncloud deployments could technically be considered elastic because you can add more capacity; it just takes weeks or even months. On-demand refers to the ability to provision at any time.
Like power generation, cloud computing generally works because consumers of the respective services have their peaks at different times. Individual consumers are around the world in different time zones, in different verticals, running different workloads. Resource utilization should remain fairly constant for the cloud vendor but may vary greatly for individual consumers. For example, you will use a lot more resources on Black Friday or Boxing Day than on a Sunday morning in January. Should all individual consumers try to provision a large quantity of resources simultaneously, there wouldn’t be enough resources available for everyone. This is formally defined as over-subscription, meaning the same resources are promised to multiple tenants. The business models for cloud vendors (and public utilities) work because of this principle.
Many workloads in a public Infrastructure-as-a-Service cloud do not have to be executed at a given time. Among workloads, ecommerce is unique in that a customer is waiting on the other end for an HTTP request to be executed. You can’t defer the execution of an HTTP request. Many cloud workloads are batch and can be executed whenever. To even out overall demands on a cloud, some vendors offer the ability to bid on unused computing capacity in an auction format. On Black Friday, when ecommerce applications require a lot of processing power, the demands for resources would be very high and the bid price of spare capacity would also be very high. Workloads that are not time sensitive can then run on, say, Christmas day, when demands on the entire system and the prices are likely to be very low. This allows consumers of cloud resources to get lower prices while allowing the vendors to even out their traffic and purchase less overall hardware than would otherwise be necessary. A great analogy is congestion pricing for freeways, where tolls increase as more people are on the roads.
In addition to being able to provision resources, resources should be provisioned in a timely manner. It should take only a few minutes to provision.
Metered
Another central tenet of the cloud is the ability to pay for what you use. If you provision a server for three hours, you should pay for only the three hours you actually use it. Paying for resources you haven’t provisioned isn’t cloud computing. Going back to the power analogy, you pay only for the power you use. The price per kilowatt-hour is known, and you can look at your meter or online to see how much power you’ve consumed. It would be ludicrous to pay for your peak power utilization of the year for the entire year, yet that’s how most ecommerce resources are paid for today. You scale for peaks and pay for those resources the entire year.
A requirement to charging for the resources actually consumed is the ability to accurately measure. Table 3-1 lists the common usage metrics.
Table 3-1. Common usage metrics for metering/charge-back
|
Resource |
Usage metrics |
|
Global Server Load Balancing (GSLB) |
DNS lookups |
|
Content Delivery Network (CDN) |
HTTP requests, bandwidth |
|
Load balancing |
HTTP requests, bandwidth, time |
|
Software-as-a-Service |
HTTP requests, bandwidth, time, application-specific metrics like orders per day |
|
Platform-as-a-Service |
HTTP requests, bandwidth, time |
|
Infrastructure-as-a-Service |
Number of physical servers, capabilities of each server, time |
Unit costs should be the same or less as you add each instance. In other words, you should pay the same or less per unit as you consume more.
As disruptive as the cloud is from a technology standpoint, it’s even more disruptive and potentially advantageous to the finance people. Traditional hardware that’s purchased up front is treated as a CAPEX, which is a fixed cost that must be paid for up front and depreciated over a period of years. An OPEX, like power, is paid for incrementally, when value is actually realized.
Cost matched with value looks like Figure 3-2.
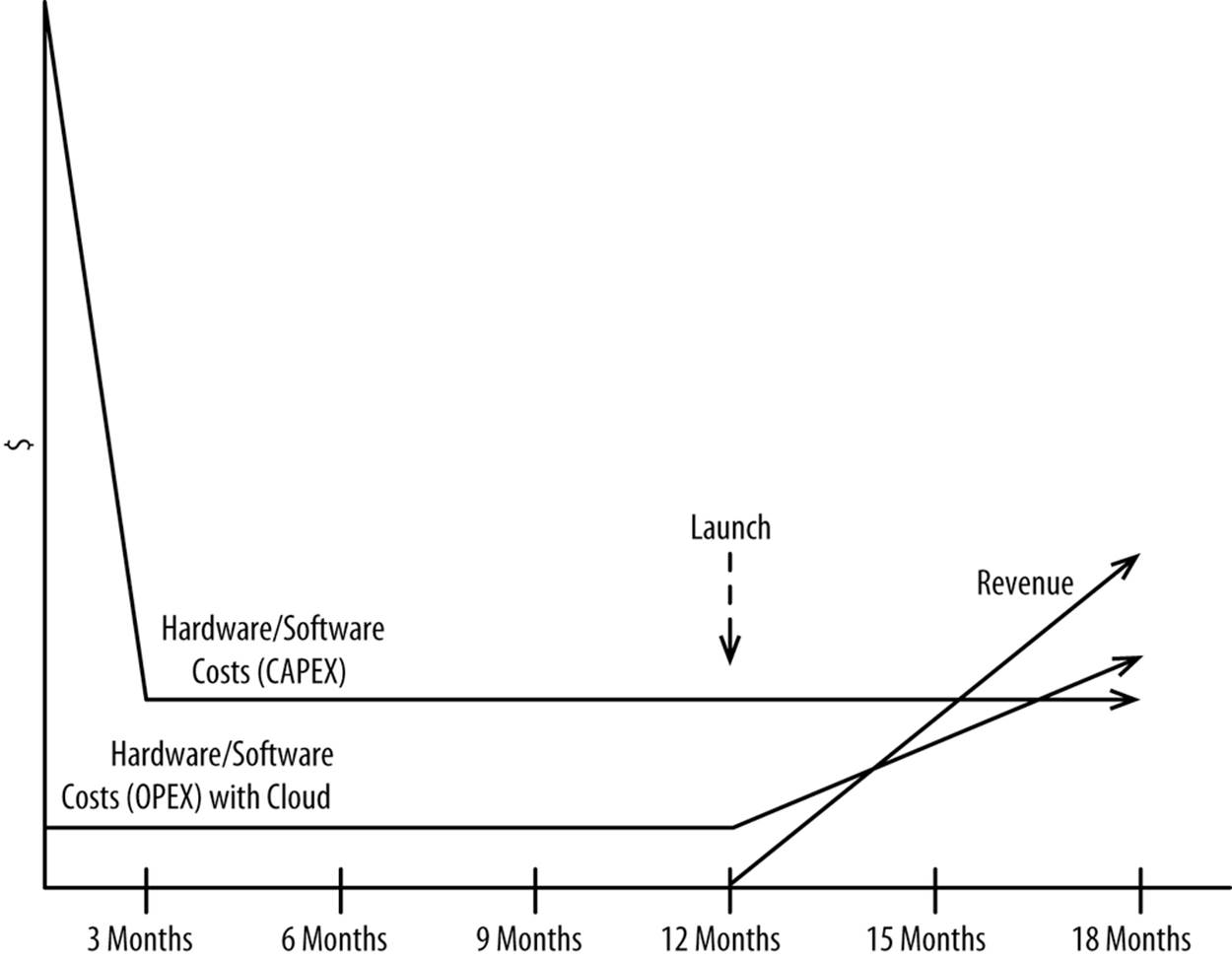
Figure 3-2. Hardware/software costs—CAPEX versus OPEX
Most other businesses require large sums of capital before they can start earning revenue. Think of retail, healthcare, manufacturing, software, and telecommunications—which all require large sums of capital to be invested before they earn a dollar. While this is partially true of ecommerce, at least the large static infrastructures of the past are no longer necessary.
TIP
The cloud is much more than just technology. It’s a fundamental change to the economics of IT.
Service Models
Service models come down to how much value the vendor adds. Each layer provided allows the vendor to add more value. Figure 3-3 shows the three most common service models.
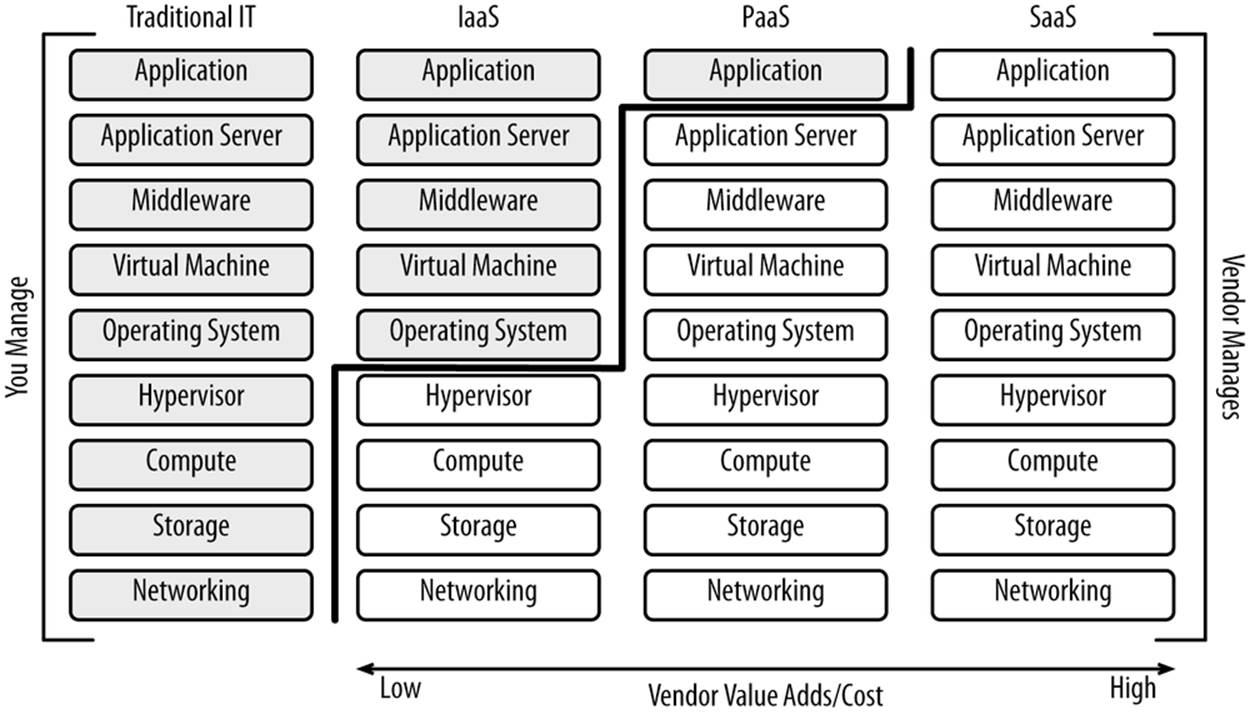
Figure 3-3. Vendor value adds and their cost
Vendors are always trying to move up the value chain—that is, adding more value to more layers of the stack so they can generate higher margins and increase their revenue per customer. Vendors that move up the value chain toward Software-as-a-Service offerings can charge higher margins while offering better service at a better price than what you would be able to do yourself. The vendors generally save you money and make some money themselves through labor specialization (it helps if you can hire the world’s top experts in each specialization) and economies of scale (you can benefit from automation and higher purchasing power). This desire to move up the value chain is why most Infrastructure-as-a-Service vendors now have Platform-as-a-Service and Software-as-a-Service offerings that complement their core Infrastructure-as-a-Service offerings. Most vendors don’t fit neatly into one category, as often each vendor has multiple offerings.
CASE STUDY: AMAZON WEB SERVICES
Amazon first started its foray into the cloud in 2006 with EC2, its public Infrastructure-as-a-Service offering. It quickly added complementary services, from storage to load balancing. Since 2010, Amazon.com’s flagship ecommerce platform has been hosted on its own cloud offerings.
In 2011, Amazon announced its Platform-as-a-Service offering, named Beanstalk. Beanstalk vertically integrates a host of offerings across Amazon’s portfolio:
§ Amazon Elastic Cloud Compute (Amazon EC2)
§ Amazon Simple Storage Service (Amazon S3)
§ Amazon Simple Notification Service (Amazon SNS)
§ Amazon CloudWatch
§ Amazon Elastic Load Balancing
Customers pay for the underlying Amazon services they use, but there is no additional fee for Beanstalk itself.[39] Customers pay for an additional five or more Amazon services with Beanstalk that they might otherwise not use. The alternative to Platform-as-a-Service (five vertically integrated Amazon services) is often just Infrastructure-as-a-Service (EC2). Customers get a fully vertically integrated platform, and Amazon is able to earn more revenue. It works for everyone.
It’s best to determine all of the services you’ll need to deliver your ecommerce platform and then decide which ones you can perform better than your competition. For example, you could provision some bare Linux servers from an Infrastructure-as-a-Service vendor, install a web server, and serve static content from there. Or you could outsource this to an actual Content Delivery Network. Content Delivery Networks can serve static content better, faster, and cheaper than you can, in addition to providing other added value that you could not.
TIP
Anything that you can’t do better than your competition should be outsourced when possible, preferably to a vendor that has the highest offerings up the value chain.
Let’s explore these models further, in order of value added by the vendor (highest value listed first).
Software-as-a-Service
In Software-as-a-Service (SaaS), vendors offer a service as opposed to the raw platform or hardware required to deliver a service. For example, DNS vendors and Content Delivery Network vendors often sell their software this way. The consumers of software delivered this way don’t care how the vendor builds the service. The application server, hardware, operating system, and database don’t matter so long as the service is compliant with agreed-upon service-level agreements. Service-level agreements define terms like expected availability and performance. Figure 3-4shows what SaaS vendors offer.
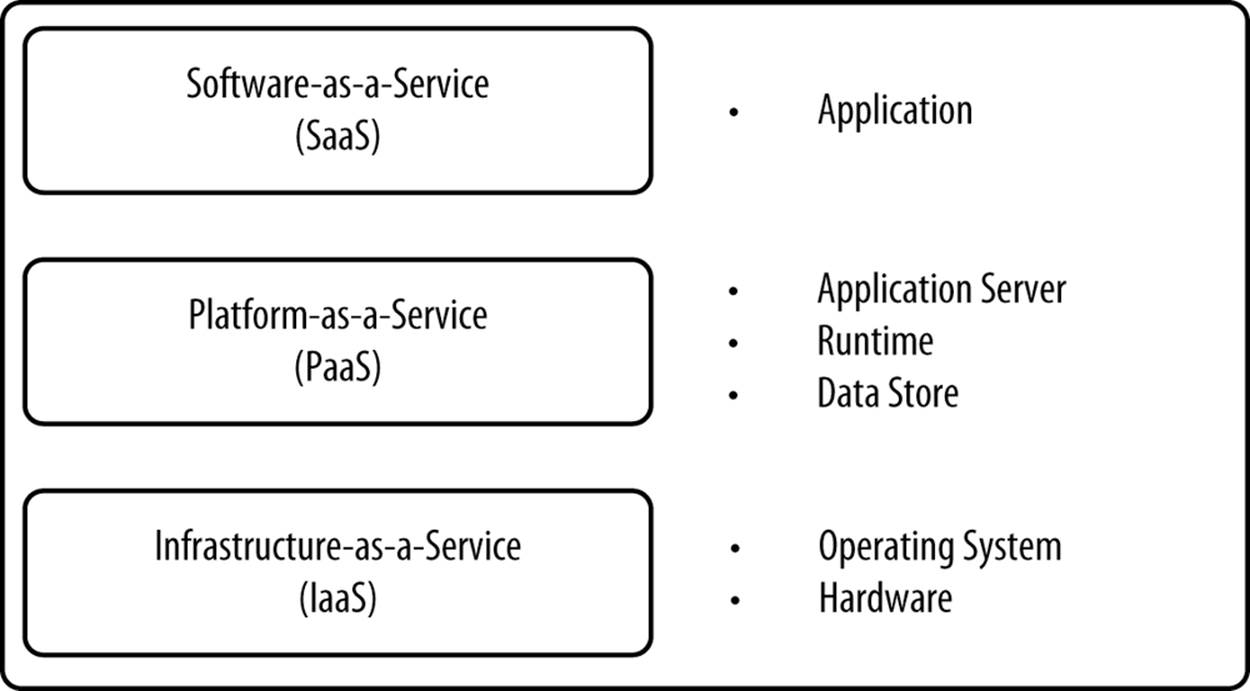
Figure 3-4. What SaaS vendors offer
Vendors that offer SaaS have the luxury of specializing in doing one thing exceptionally well. The platform underneath the service can be tuned and optimized specifically for a single workload. They can, in a few circumstances, make the hardware work better with the software to ensure a fully vertically integrated experience. This may be possible with PaaS or IaaS but it would require more work.
SaaS is an easy-to-deploy, cost-effective, and technically superior way of deploying standalone services such as the following:
§ Global Server Load Balancing (GSLB) or DNS
§ Proxying requests from the edge back to the data center running your code
§ Static content serving
§ Distributed denial-of-service (DDoS) attack mitigation (request scrubbing)
§ Web application firewalls
SaaS doesn’t always meet all of the requirements of cloud computing:
§ Elastic
§ On demand
§ Metered
SaaS usually meets the first two but it doesn’t always meet the last one. For example, many vendors offer monthly subscriptions to their services, where you can consume all you need. There are often multiyear contracts involved. While not technically cloud computing, these services should still be considered. Pragmatism should rule your decision making.
Platform-as-a-Service
In Platform-as-a-Service (PaaS), vendors offer a platform you can use to deploy your own application. With the vendor responsible for the application server, runtime environment, database, and hardware, you’re freed up to concentrate on your application. Many vendors also offer complementary services like integrated testing, messaging, monitoring, application modeling, and other services required to accelerate the development and deployment of applications and keep them up in production, as listed in Figure 3-5.
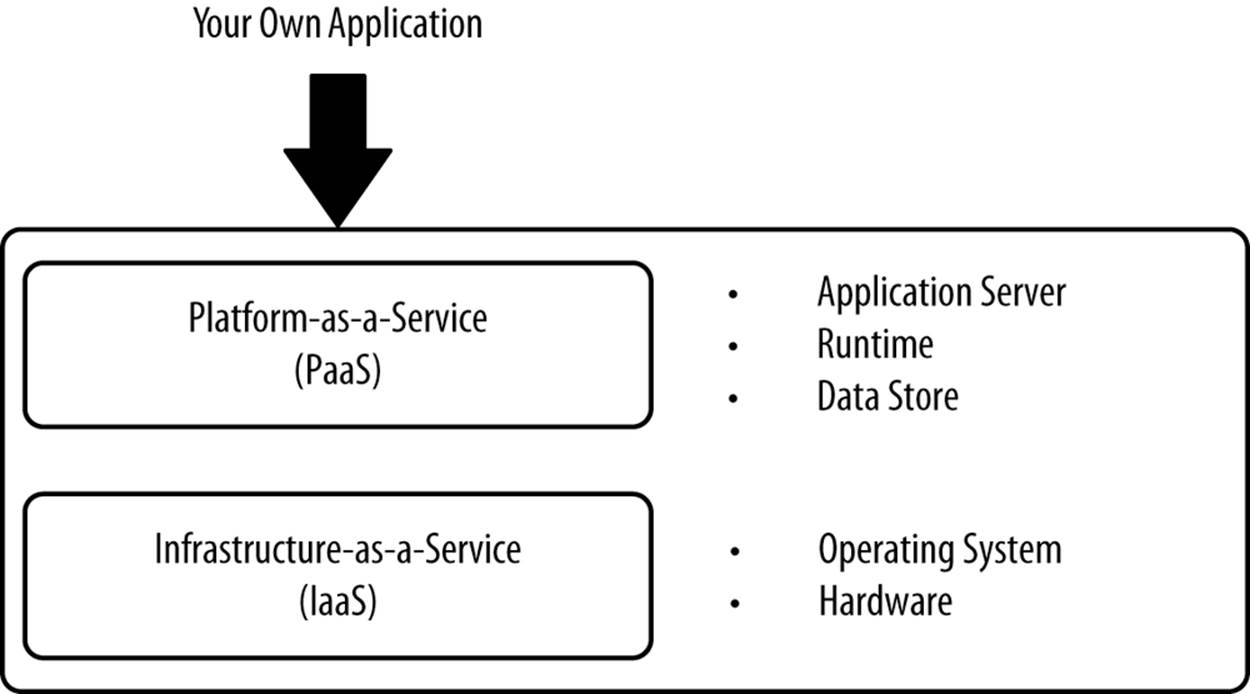
Figure 3-5. What PaaS vendors offer
PaaS is an entire package that you buy and build your application for. If you buy in all the way, you can save an enormous amount of time and money because the PaaS vendor does everything for you. Many vendors even set up auto-scaling for you, allowing them to monitor each tier of your application and scale up and down based on demand. But this all comes at the expense of flexibility. The experience inside the vendor’s walled garden is generally very good because of tight vertical integration. But if you venture out and need something that your vendor doesn’t support, you’re often out of luck. For example, some PaaS vendors don’t allow you to write from your application to a local filesystem. If your application needs to write to a local filesystem, you won’t be able to use that vendor. This inherently leads to relying on multiple PaaS vendors, which adds complexity.
PaaS tends to work well for small applications, perhaps in support of a larger ecommerce application. For example, PaaS would be great if you wanted to build a standalone pricing engine. PaaS generally does not work well for an entire enterprise-level ecommerce application. Few ecommerce applications fit neatly inside the boundaries offered by many PaaS vendors. There are always ancillary applications, middleware, and agents of various types that must be deployed in support of an ecommerce application.
The most common challenge with PaaS is a lack of flexibility. Vendors are able to deliver the most value by standardizing on a single stack and then vertically integrating that stack. This standardization and vertical integration means, for example, you probably can’t swap out the database that’s provided for one you like more. It also means you can’t deploy applications that don’t fit neatly into their stack, like third-party monitoring agents. Either you take what’s provided or you’re out of luck. Vertical integration can also lead to vendor lock-in if you’re not careful. Vendors are responding to these shortcomings, but you’ll never have as much flexibility as you do with IaaS.
Infrastructure-as-a-Service
In Infrastructure-as-a-Service (IaaS), vendors offer hardware and a hypervisor with a connection to the Internet, and that’s it. You have to build out everything above the operating system, though this is often preferable because it gives you nearly total flexibility. See Figure 3-6 for what IaaS vendors offer. We’ll spend Chapter 5 discussing how to rapidly build up newly provisioned servers.
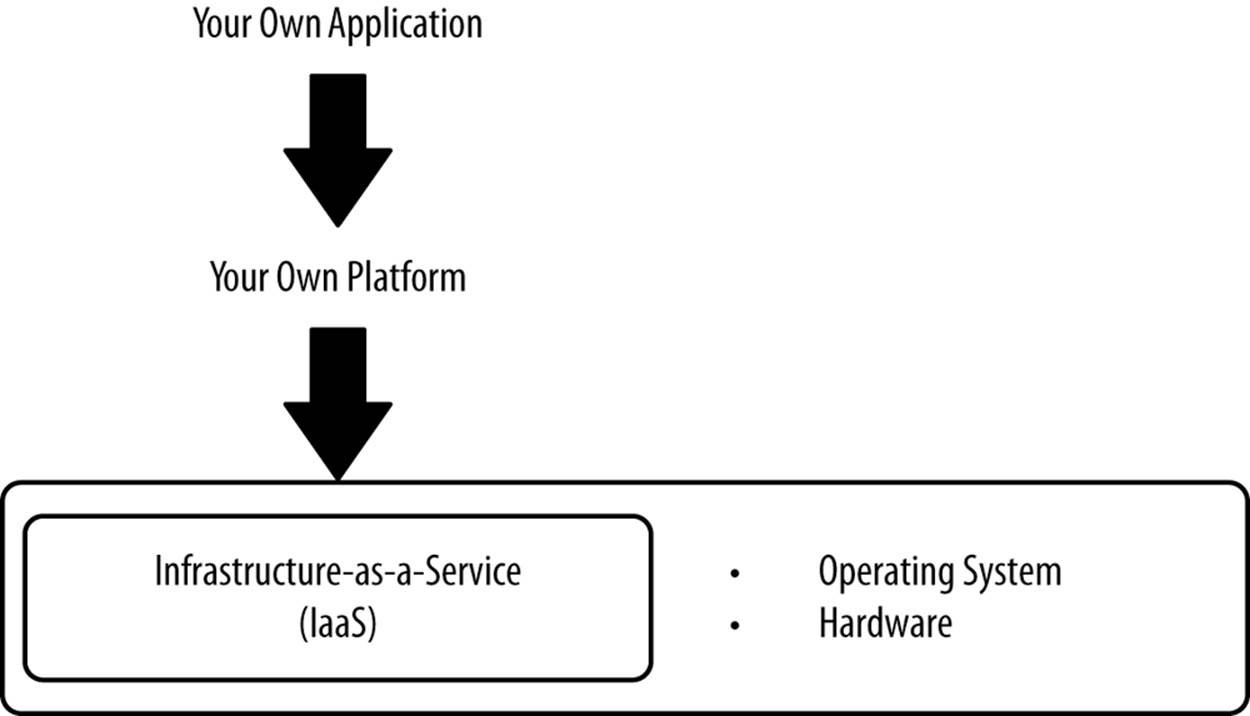
Figure 3-6. What IaaS vendors offer
IaaS is valuable because it gives you complete flexibility in what software you deploy and how you configure it all to work together. You can install any version of any software and configure it as you please. You’ll never be stuck because a vendor you use has stopped supporting a layer of the stack used by your PaaS vendor. Because the vendor is just offering commoditized hardware, it generally costs much less than comparable PaaS or SaaS. But you have to spend more to make it work.
Look to IaaS for your core application and supporting software. Generally, only IaaS offers the flexibility required to deploy and configure an enterprise-level ecommerce platform. Specifically, consider using it for the following:
§ Your core ecommerce application—the one you build or buy/customize
§ Application server
§ Runtime environment
§ Database, like a relational or NoSQL database
Whereas IaaS is flexible and inexpensive relative to the other service models, it requires that you have the ability to implement the recommendations contained in this book. You’re given some tools from vendors but you’re basically on your own. For a small organization or one that isn’t particularly adept at making big changes, this is a tall order.
Deployment Models
While service models are about the value that each vendor adds, deployment models describe who can consume each offering. Any service model may technically be delivered using any deployment model, but in practice certain service models lend themselves better to certain deployment models. A public cloud is consumable by anybody. A private cloud is consumable by only designated organizations or individuals, and it can be deployed on or off premises. A hybrid cloud is the dynamic bursting to a public cloud from either a private cloud or a traditional on- or off-premises deployment.
Table 3-2 shows the attributes that these deployment models can be evaluated on.
Table 3-2. Attributes of common deployment models
|
Criteria |
Public |
Hybrid |
Private |
|
Most common service models |
SaaS, PaaS, IaaS |
PaaS, IaaS |
PaaS, IaaS |
|
Who may consume |
Anybody |
Designated organizations/individuals |
Designated organizations/individuals |
|
Who owns data centers/hardware |
Public cloud vendor |
You + public cloud vendor |
You (owned by you or a colo) |
|
Control |
Low |
Medium |
High |
|
Who manages stack |
Public cloud vendor |
You + public cloud vendor |
You |
|
Accounting model |
OPEX |
OPEX (for public cloud) + CAPEX (for private cloud) |
CAPEX |
The definitions of each deployment model are fairly simple, but the implications can be substantial. Let’s discuss further.
Public Cloud
A public cloud is exactly what it sounds like: it’s public. Anybody may consume its services. By definition, a public cloud is owned and operated by a third party in data centers belonging to or under contract by the vendor. In other words, the data centers aren’t yours. Public cloud vendors typically operate out of many different data centers, with consumers of the service able to choose where they want to provision their resources.
Vendors offering public clouds benefit greatly from economies of scale. They can buy vast quantities of hardware, bandwidth, and power, and then build advanced automation on top of their stack. This allows them to deliver their software, platform, or infrastructure to you faster, better, and cheaper than you can. Public cloud vendors, especially IaaS vendors, also benefit by signing up a wide range of customers and ending up using the resources for different purposes at different times. This allows the resources to be oversubscribed. Higher oversubscription means less cost to you.
A public cloud is often used when large amounts of resources must be marshaled. For example, large-scale weather simulations may use thousands of servers but only for a few hours. It doesn’t make sense for a university to buy a few thousand machines and use them for only a few hours a year. Or in the case where you get hit with a distributed denial-of-service attack and need to handle 1,000 times your traffic—that’s where public clouds excel. It is for the exact same reason that public clouds excel for ecommerce.
Elasticity is a defining characteristic of public clouds. Cloud vendors provide easy-to-use APIs to scale up or down the use of a platform or infrastructure. Or in the case of SaaS, you can consume as much as you need and then pay for what you actually use. That elasticity and the ability to consume vast amounts of resources is important for workloads like ecommerce.
Public clouds offer their services to anyone, so security tends to be a concern. Depending on the service model, your data may be colocated with other tenants. Your data may be traversing countries that can intercept it. You can’t physically see and touch the servers on which your sensitive data is traversing. Security can definitely be a concern, but as we’ll discuss in Chapter 9, public clouds can make it easier to be secure.
Hybrid Cloud
A hybrid cloud is a combination of traditional on or off-premises deployment that bursts to a public cloud. “Build the base, rent the peak” is the phrase most often used to describe a hybrid cloud. What’s key about a hybrid is the bursting component—not whether the part of your environment that you directly oversee and manage is a private cloud. Hybrid clouds are often used in the following scenarios:
§ Software or hardware is unable to be deployed in a cloud for technical reasons. For example, you may need a physical appliance, or an application may not work well in a virtualized environment. With this model, you could, for example, keep your backend in-house and put your more variable frontend in a public cloud.
§ You want to keep sensitive data under your control on hardware that’s yours, with your own badged employees serving as administrators.
§ Software is unable to be deployed in a cloud for commercial reasons. For example, you may be using software whose licensing doesn’t work well with a cloud.
NOTE
For the purposes of this book, the frontend is defined as a user interface and the backend is defined as server-side code that contains business logic.
A hybrid cloud is great for ecommerce, where you have a steady baseline of traffic yet want to scale dynamically for peaks. You save money, gain flexibility, yet retain full control over your sensitive data. Not everybody will deploy a full ecommerce platform out to a public cloud. A hybrid model is sometimes desired because the core of the platform holding the sensitive data can remain under your firm control, while the nonsensitive parts of the application can be deployed out to a cloud.
While a step in the right direction and a good option for many, hybrid clouds aren’t perfect. Hybrid clouds require that you break your application into two pieces: the piece that’s managed in-house and the piece that’s deployed out to a public cloud. Splitting an existing application in two pieces isn’t easy, but the benefits can easily outweigh the costs. We’ll discuss this further in Chapter 11.
Private Cloud
A private cloud is basically a public cloud that is limited to your own organization. While typically deployed on hardware that you own in your own data center, it can also be deployed on hardware that you don’t own in a colo. To be a private cloud, it has to meet the requirements of cloud computing: elastic, on demand, and metered. Traditional static deployments of hardware and software don’t meet the definition of cloud computing. Likewise, the use of virtualization doesn’t make it a private cloud either, as we’ll discuss in Chapter 6.
To build a private cloud and have the econommics work out, you need a large pool of software that you can deploy to this private cloud. With only one application (say, ecommerce) deployed to a private cloud, you have to buy enough hardware to handle your peak, and by doing that, you’ve cancelled all of the benefits of cloud computing. With varied workloads, a private cloud becomes more worthwhile, but only if each workload has its peak at different times. If you’re a retailer and you use a private cloud for all of your retail applications, you’re going to quickly run out of capacity on Black Friday. To solve that, you have to buy a lot more hardware than you need at steady state and let it sit idle for all but a few hours of the year, which defeats the purpose of cloud computing.
A private cloud is often used for consolidation within large enterprises. If the different workloads you have deployed to a private cloud each have their peaks at different times throughout the day, week, month, or year, you could end up saving money. But, again, if your workloads all have their peaks at the same time, you just incur unnecessary overhead.
A private cloud is used primarily for three reasons:
§ You have many workloads to consolidate.
§ You’re especially security conscious and don’t yet trust public clouds to be secure (see Chapter 9).
§ You want to “try cloud computing at home” before going out to a public cloud.
Unless you have many workloads to consolidate, a private cloud doesn’t offer a strong value proposition.
Hardware Used in Clouds
Clouds are often comprised of commoditized x86 hardware, with the commoditized components assembled by off-brand manufacturers or even assembled in-house. Commodity hardware is used because it’s cheap and general-purpose. The hardware is cheap because it’s produced in enormous volumes and assembled by manufacturers who add very little value (cost) to it. The hardware used in clouds is meant to be nearly disposable. In the classic cost/quality/fit-for-purpose trade-off, cost is the deciding factor.
While commodity hardware is most often used in cloud computing, it need not be a defining feature of cloud computing. Cloud computing is defined as elastic, on demand, and metered. Commodity hardware is not among those three attributes.
The ecommerce use case is fairly unique among cloud workloads. If you’re sequencing DNA in the cloud, for example, it doesn’t matter whether you sequence 300 bases a second or 400. But in ecommerce, milliseconds matter because a real (potentially) paying customer is waiting on the other end for that response. Many clouds offer different types of hardware optimized for different workloads. Besides commodity, clouds now offer hardware optimized for the following:
§ Memory
§ Computing
§ GPU
§ Storage
§ Networking
You may, for example, want to deploy your ecommerce application on hardware optimized for computing, and your database on hardware optimized for fast access to storage. The hardware you choose is a trade-off between performance and cost, with your architecture sometimes mandating specialized hardware. Vendors also offer general-purpose small, medium, and large instances, with cost, memory, and computing power rising in tandem.
Hardware Sizing
The vertical scalability of software on any given hardware is always limited. It’s hard to find software that will deliver the same throughput (e.g., HTTP requests per second) for CPU core number 1 and for CPU core number 64. Software always performs optimally when deployed across a certain number of CPU cores. For example, the graph in Figure 3-7 shows the marginal vertical scalability of a hypothetical single Java Virtual Machine (JVM).
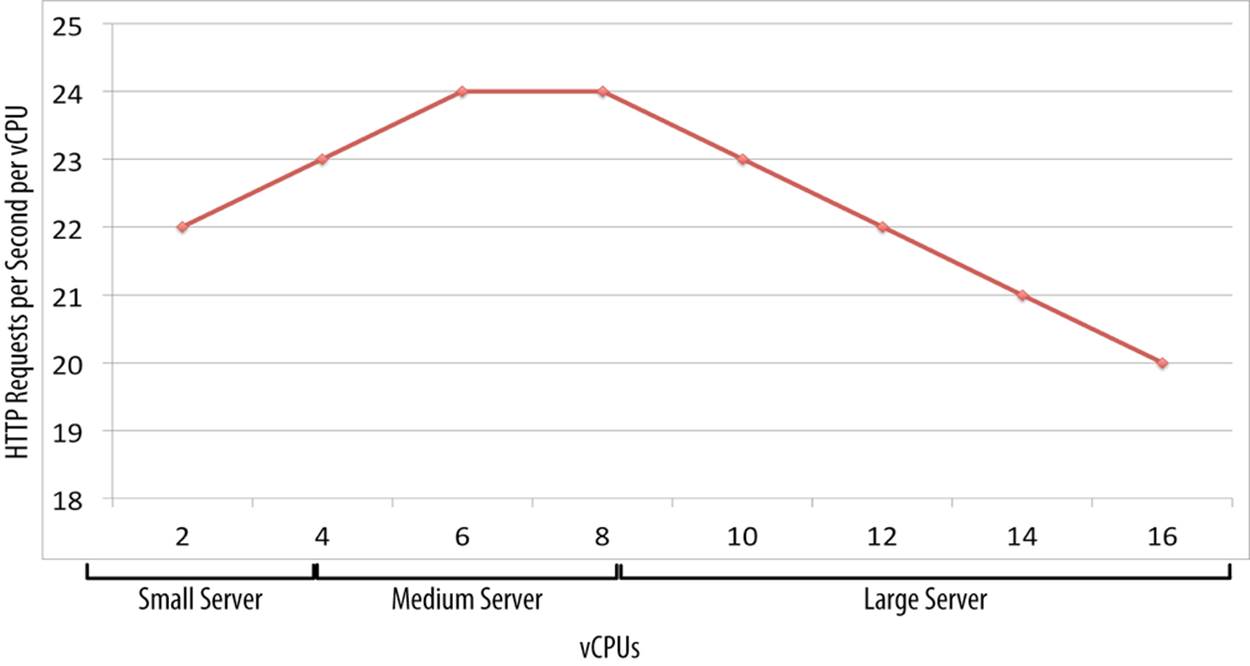
Figure 3-7. Marginal vertical scalability of a hypothetical single JVM
At the lower end of the x-axis, you’ll find that a JVM doesn’t deliver as much throughput as it could because the limited CPU and memory is consumed by the overhead of starting up each JVM and performing garbage collection. JVMs, like all software, have runtime overhead. At the high end of the x-axis, you’ll suffer from thread contention as too many threads are competing to lock on the same objects, or you’ll run out of CPU as your garbage collection algorithm works exponentially harder.
So long as you’re meeting your necessary service-level agreements, pick the instance type that offers the lowest price per the metric that makes the most sense for each workload. For example, calculate the number of HTTP requests per second each instance type can generate and then divide that by the number of virtual CPUs, or vCPUs. That should lead you to data similar to Table 3-3.
Table 3-3. Calculations required to find optimal server size
|
Server size |
Cost per hour |
vCPUs |
HTTP requests/second |
Cost/100 HTTP requests/second |
|
Small |
$0.15 |
4 |
92 (4 vCPUs × 23 HTTP requests/sec) |
$0.163 |
|
Medium |
$0.25 |
8 |
192 (8 vCPUs × 24 HTTP requests/second) |
$0.130 |
|
Large |
$0.50 |
16 |
320 (16 vCPUs × 20 HTTP requests/second) |
$0.156 |
From this simple exercise, it’s clearly best to choose the medium instance type because the cost per 100 HTTP requests per second is the least. It may also make sense to choose a compute-intensive server. Perhaps the premium you’re paying could be offset by the marginal capacity it offers. Do this for each of your workloads. Cloud vendors offer many options—it’s up to you to pick the most cost-effective one for each of your workloads.
Complementary Cloud Vendor Offerings
Cloud vendors have traditionally offered PaaS and/or IaaS, with pure play vendors offering the various SaaS components as well. Most IaaS vendors have an entire portfolio of SaaS and PaaS offerings in order to appeal to different market segments and be able to upsell to their customers. Once a vendor’s platform is in place, the marginal cost of a new offering is very small, as shown in Figure 3-8.
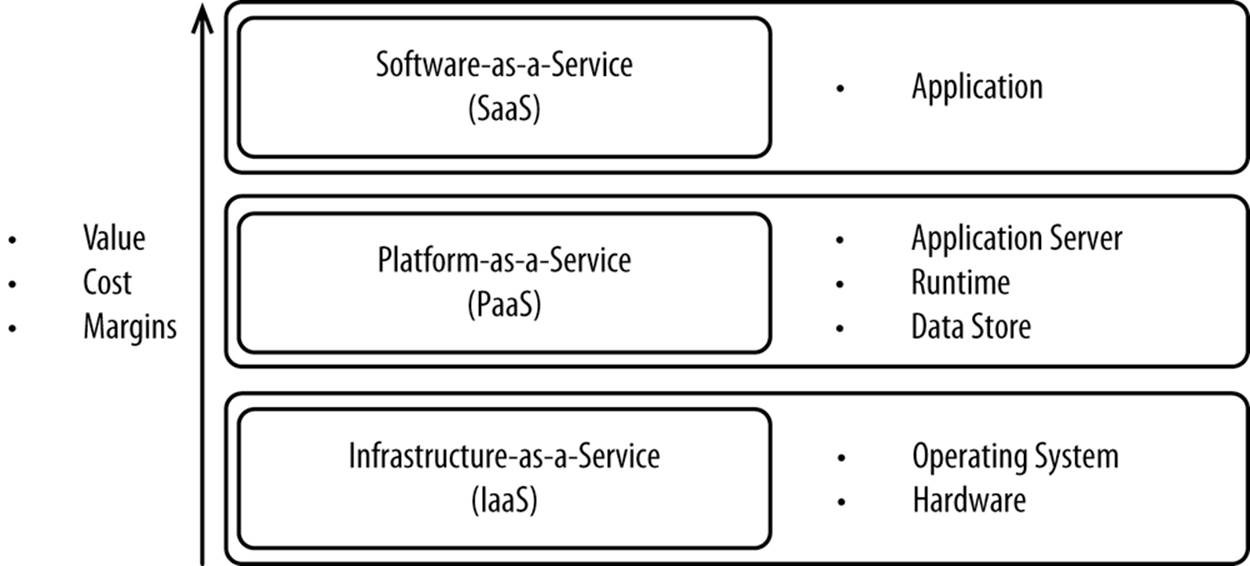
Figure 3-8. Service models versus value/cost/margins
The most capital-intensive part is building out the IaaS layer. That involves building, buying, or leasing data centers, as well as buying hardware. Once that’s in place, building a PaaS layer is relatively easy. Once PaaS is built, SaaS is even easier because each layer builds on the layer before it.
To make these additional services more appealing, vendors vertically integrate the solutions to work together. When taken together, the ancillary services offered by each vendor create compelling solutions. Vertically integrated solutions are almost always better than individual services offered by different vendors.
Here are some examples of ancillary services offered by many vendors:
§ Global Server Load Balancing (GSLB)/DNS (Chapter 10)
§ Proxying requests from the edge back to the data center running your code (Chapter 7)
§ Static content serving (Chapter 7)
§ DDoS attack mitigation (request scrubbing) (Chapter 9)
§ Web application firewalls (Chapter 9)
§ Storage
§ Load balancing
§ Virtual private clouds within a larger public cloud (Chapter 9)
§ Auto-scaling (Chapter 4)
§ Monitoring (Chapter 4)
§ Backup
§ Databases (Chapter 8)
§ Cache grids (Chapter 8)
Many of these services come with high service-level agreements and enterprise-level 24/7 support.
Challenges with Public Clouds
Public clouds, the focus of this book, provide strong advantages as well as disadvantages. The disadvantages of public clouds often stem from what’s known as the agency dilemma in economics, whereby the two parties (you and your public cloud vendor) have different interests and information. For example, you may lock down your environments and disallow any further changes (called a holiday freeze) beginning in October and ending after Christmas because you earn much of your annual revenue in the weeks before, during, and after Black Friday. With no changes to your environment, you’re less likely to have outages. But a cloud vendor is unlikely to have the same incentives to avoid downtime and may decide to do maintenance when you have your annual peak. Of course, both parties have an interest in maintaining availability, but an outage on Black Friday is going to cost you a lot more than it will cost your cloud vendor. That agency problem is at the root of many of these challenges.
Let’s discuss some of these issues.
Availability
As we discussed in Chapter 2, availability is of utmost importance for ecommerce. While rare, public clouds will always suffer from server-level failures, data center–wide failures, and cloud-wide failures. Let’s look at these each individually.
Server-level failures are common. It is known expected that hardware will fail:[40]
In each cluster’s [of 10,000 servers] first year, it’s typical that 1,000 individual machine failures will occur; thousands of hard drive failures will occur; one power distribution unit will fail, bringing down 500 to 1,000 machines for about 6 hours; 20 racks will fail, each time causing 40 to 80 machines to vanish from the network; 5 racks will “go wonky,” with half their network packets missing in action; and the cluster will have to be rewired once, affecting 5 percent of the machines at any given moment over a 2-day span, Dean said. And there’s about a 50 percent chance that the cluster will overheat, taking down most of the servers in less than 5 minutes and taking 1 to 2 days to recover.
— Jeff Dean Google Fellow
Cloud vendors have the same challenges that Google has. Hardware is cheap and unreliable. To compensate for the unreliability, resiliency is (or should be) built in to software through the use of clustering and similar technology. Almost without exception, you can deploy any software across two or more physical servers to minimize the impact of any one server failing.
While rare, entire data centers do go offline. For example, Hurricane Sandy took out data centers across the East Coast of the US in 2012. Natural disasters and human error (including cable cuts) are often to blame. No data center should be seen as immune to going entirely offline. This is why most ecommerce vendors have an off-site replica of production, either in an active/passive or active/active configuration across two or even more data centers (discussed in Chapter 10). To avoid these issues, most vendors group together data centers into partitions that are (supposedly) entirely separated from each other. By deploying your software across multiple partitions, you should be fairly safe.
While exceptionally unlikely, cloud-wide failures do occur. For example, a large cloud vendor recently suffered a complete worldwide outage because they forgot to renew their SSL certificate. Clouds are supposed to span multiple physical data centers and be partitioned to avoid outages propagating from one data center to another, but you can never be 100% certain that there are no dependencies between data centers. Cloud-wide outages may be due to the following:
§ A reliance on shared resources, coupled with the failure of a shared resource. That resource may even be something as simple as an SSL certificate.
§ Technical issues that propagate across data centers.[41]
§ Operational missteps, like patching all data centers at the same time only to discover there was a bug in one of the patches applied.
§ Malicious behavior, like DDoS attacks or hacking.
The only way to completely protect your ecommerce platform against entire cloud-wide outages is to deploy your software across multiple clouds, though most vendors do a pretty good job of isolation. Deploying across multiple data centers and multiple clouds is covered in Chapter 10.
Performance
Performance is always a concern for ecommerce because revenue depends so much on it. In responding to customer feedback, Google increased the number of results on its search engine result page from 10 to 50. Immediately after implementing that change, the company saw a 20% decline in page views and corresponding ad revenue. What Google didn’t control for was the extra 500 milliseconds of latency introduced by the larger response. When 500 milliseconds of response time was artificially added to the standard page with 10 results, the same 20% decline in traffic (and therefore revenue) was also seen.[42] Amazon.com saw conversion rates drop 1% for every 100 milliseconds of additional response time.[43] Customers may say they want more functionality, but real-world testing has repeatedly shown that they value performance as much, if not even more than, additional functionality.
In your own data center, you can optimize performance of your hardware and software stack. Need to make 1,000 synchronous calls back to your cache grid to build a page? No problem, so long as you use specialized networking technology like InfiniBand, bypass the kernel, and have submicrosecond round-trip latency. In a cloud environment, you can’t change very much. You’re stuck with the stack you’re given, for better or worse. Every time you have to communicate with another machine, as is increasingly common, your data takes the journey shown in Figure 3-9.
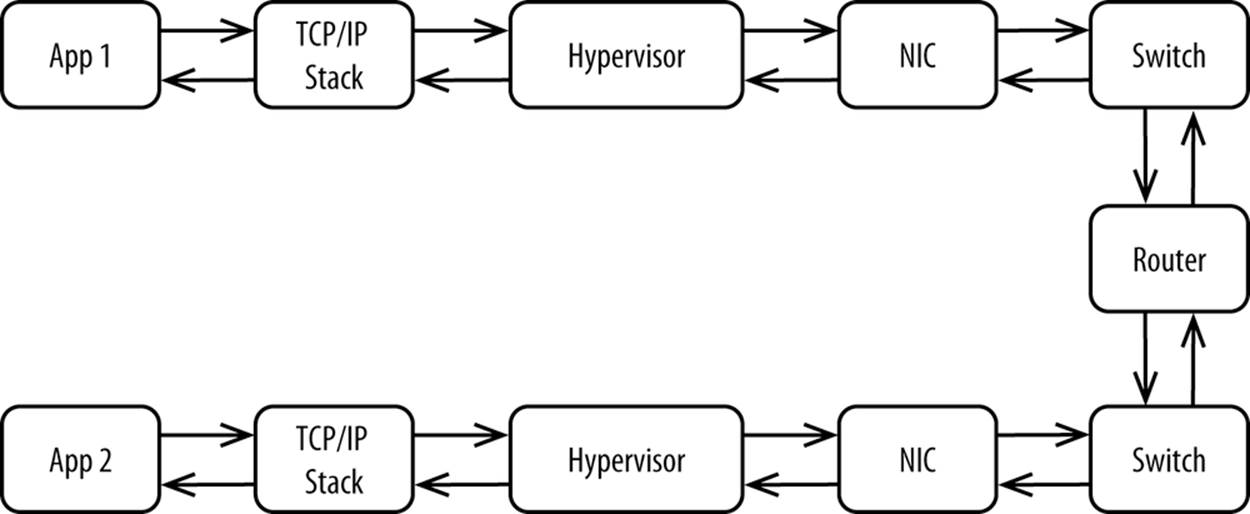
Figure 3-9. Layers involved in making a call to a remote host
The hardware and software used in public clouds is designed to be general-purpose because public clouds need to support so many workloads.
Now take that page with 1,000 synchronous calls to your cache grid and deploy it in a cloud with four milliseconds of latency between your application server and cache grid and you have a big problem, as shown in Figure 3-10.
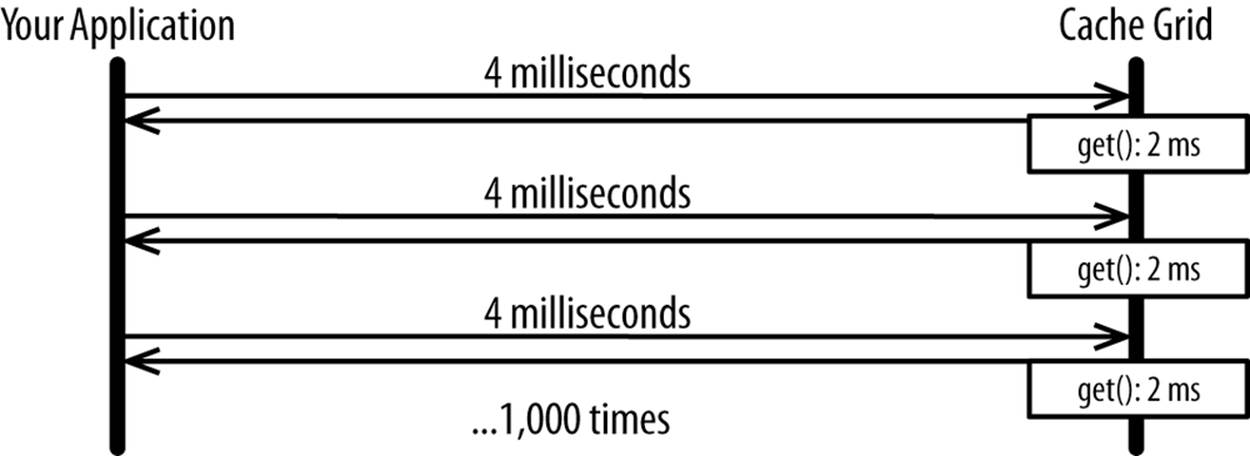
Figure 3-10. Impact of latency with multiple calls
Applications written to deal with latency, usually through the use of batching, shouldn’t have a problem. Most software now supports the equivalent of getAll() calls (as opposed to simple get()). That all but eliminates this as a challenge, as Figure 3-11 shows.

Figure 3-11. Impact of using a getAll() equivalent
CASE STUDY: REDDIT
Reddit, an online discussion community with two billion page views per month,[44] had this issue when it moved to a public IaaS cloud.[45] Reddit was calling its cache grid, Memcached, up to 1,000 times per page view when hosted out of its own data center. In a public IaaS cloud, Reddit’s latency between servers increased by 10 times, which made that old approach unusable in a cloud. The company had to batch up requests to Memcached to avoid the overhead of synchronously going back and forth to Memcached. Doing this completely eliminated the impact of the latency that its cloud vendor introduced.
Oversubscription
Public SaaS, PaaS, and IaaS work as business models because each consumer of the respective service uses the service at roughly different times. Most shared utility-based services work like this, from power to roads to physical retail stores. Problems arise for service providers when everybody tries to use a shared resource at the same time—as when everybody turns their air conditioning on during the hottest day of the year.
Some vendors have this problem because they’re used heavily by one industry. For example, Content Delivery Networks are used by nearly every major ecommerce vendor, and most ecommerce vendors have their spikes on the same few days: Black Friday (US, Brazil, China), Singles’ Day (China), Boxing Day (UK, Australia), and El Buen Fin (Mexico).[46] On these few days, traffic can spike hundreds of times over the average.
To make matters worse, cloud vendors tend to have a few endpoints in each country. So El Buen Fin in Mexico, for example, taxes the few data centers each Content Delivery Network has in Mexico. Fortunately, Content Delivery Networks, as with SaaS offerings, have the benefit of you being able to hold the vendor to meeting predetermined service-level agreements. Those vendors then have to scale and have a lot of hardware sit idle throughout the year. Although you pay for it, it’s not as direct of a cost as if you had the hardware sitting idle in your own data centers.
When looked at globally, large public IaaS vendors are relatively protected against these spikes because their customers come from various industries and run a wide range of workloads. Demand-based pricing, as discussed earlier, also helps to smooth out load.
While vendors claim you can always provision, and have a good track record of allowing customers to provision at any time, it is theoretically possible that a vendor could run out of capacity. For example, a cloud vendor could run out of capacity during a news event as people look online for more information and websites auto-scale to handle the increased demand. For example, web traffic more than doubled following Michael Jackson’s death in 2009.[47]
To guard against this, various strategies may be employed, including:
§ Pre-provisioning hours ahead of your big events. Traffic from special events is often predictable.
§ Buying dedicated capacity. Most vendors offer this.
§ Being able to provision and run smoothly across multiple data centers within the same cloud vendor’s network.
§ Being able to provision from multiple clouds.
You need to take proactive steps to ensure that your vendor(s) has enough capacity available to handle your peaks.
Cost
While cloud computing is generally less expensive than traditional on-premises computing, it may be more expensive, depending on how you use it. Cloud computing excels in handling elastic workloads. Highly static workloads may or may not make sense, depending on whether your organization can cost-effectively deploy and manage hardware and software.
If you calculate the cost of a server on a public IaaS cloud over the expected useful life of a server (say, three years) and compare that to the cost to acquire the same hardware/software, the cost of a cloud-based solution is likely to be more. But you need to look at costs holistically. That hourly price you’re being quoted includes the following:
§ Data center space
§ Power
§ Bandwidth out to the Internet
§ Software
§ Supporting network infrastructure
§ Patching (firmware and possibly operating system)
§ All of the labor required to rack/stack/cable/maintain the hardware
§ A baseline of support
These costs can be considerable. You’re generally renting capacity for hours at a time to handle big spikes in traffic. The cost of building up all of that capacity in-house and then letting it sit idle for most of the year is exponentially greater than the cost you would pay to a cloud vendor. You also have to take into consideration that your organization’s core competency is unlikely to be building out hardware and/or software infrastructure. Your organization is likely to be a retailer of some variety. Straying too far away from your organization’s core competency is never a good thing in the longrun.
Cloud vendors often offer better prices than what you could do in-house because their core competency is delivering large quantities of resources like infrastructure. When you can specialize and offer one service exceptionally well, you do it better than an organization whose focus is elsewhere. Specifically, cloud vendors benefit from the following:
§ Economies of scale—you can purchase hardware, software, and data center space at much better rates if you buy in bulk.
§ Being able to hire the world’s experts in various topics.
§ Heavy automation—it makes sense to automate patching if you have 100,000 servers but not if you have 10, for example.
§ Organizational alignment around delivering your core competency.
While most of these principles are applicable to public IaaS vendors, they apply equally to PaaS and SaaS vendors.
Cloud vendors are also able to offer flexible pricing by allowing you to rapidly scale up/down, select your preferred server type, and purchase capacity by the hour or on a fixed basis throughout the year.
For more information on the cloud, read Cloud Architecture Patterns by Bill Wilder (O’Reilly).
Summary
In this chapter, we’ve defined cloud and its benefits, reviewed the concepts of service and deployment models, discussed complementary offerings, and covered the challenges of public clouds. In the next chapter, we’ll explore auto-scaling, the enabler of cloud’s central promise: elasticity.
[39] Amazon Web Services, “AWS Elastic Beanstalk Pricing,” http://aws.amazon.com/elasticbeanstalk/pricing/.
[40] Stephen Shankland, “Google Spotlights Data Center Inner Workings,” CNet (30 May 2008), http://cnet.co/MrUH9A.
[41] Matthew Prince, “Today’s Outage Post Mortem,” CloudFlare (3 March 2013), http://bit.ly/1k7yxbx.
[42] Greg Linden, “Marissa Mayer at Web 2.0,” Geeking with Greg (9 November 2006), http://bit.ly/QnOcHH.
[43] Todd Hoff, “Latency Is Everywhere And It Costs You Sales—How To Crush It,” High Scalability (25 July 2009), http://bit.ly/1hEgNOK.
[44] Todd Hoff, “Reddit: Lessons Learned From Mistakes Made Scaling To 1 Billion Pageviews A Month,” High Scalability (26 August 2013), http://bit.ly/1kmFZke.
[45] Todd Hoff, “How Can Batching Requests Actually Reduce Latency?” High Scalability (4 December 2013), http://bit.ly/MrUHq1.
[46] Akamai Technologies, “Facts and Figures” (2014), http://www.akamai.com/html/about/facts_figures.html.
[47] Andy Jordan, “The Day the Internet Almost Died,” The Wall Street Journal Online (26 June 2009), http://on.wsj.com/P93I93.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.