Implementing Cloud Storage with OpenStack Swift (2014)
Chapter 2. OpenStack Swift Architecture
OpenStack Swift is the magic that converts a set of unconnected commodity servers into a scalable, durable, easy-to-manage storage system. We will look at Swift's architecture (Havana release) in detail. First, we will look at the logical organization of objects and then how Swift completely virtualizes this view and maps it to the physical hardware.
Note
Note that we will use the terms durable and reliable synonymously.
The logical organization of objects
First, let us look at the logical organization of objects and then how Swift completely abstracts and maps objects to the physical hardware.
A tenant is assigned an account. A tenant could be any entity—a person, a department, a company, and so on. The account holds containers. Each container holds objects, as shown in the following figure. You can think of objects essentially as files.
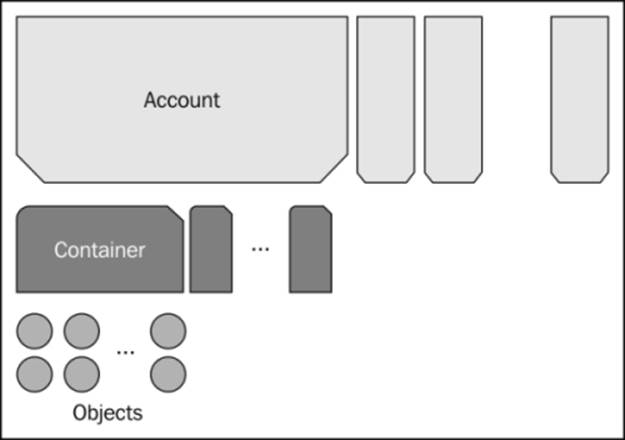
Logical organization of objects in Swift
A tenant can create additional users to access an account. Users can keep adding containers and objects within a container without having to worry about any physical hardware boundaries, unlike traditional file or block storage. Containers within an account obviously have to have a unique name, but two containers in separate accounts can have the same name. Containers are flat and objects are not stored hierarchically, unlike files stored in a filesystem where directories can be nested. However, Swift does provide a mechanism to simulate pseudo-directories by inserting a / delimiter in the object name.
The Swift implementation
The two key issues Swift has to solve are as follows:
· Where to put and fetch data
· How to keep the data reliable
We will explore the following topics to fully understand these two issues.
Key architectural principles
Some key architectural principles behind Swift are as follows:
· Masterless: A master in a system creates both a failure point and a performance bottleneck. Masterless removes this and also allows multiple members of the cluster to respond to API requests.
· Loosely coupled: There is no need for tight communication in the cluster. This is also essential to prevent performance and failure bottlenecks.
· Load spreading: Unless the load is spread out, performance, capacity, account, container, and object scalability cannot be achieved.
· Self-healing: The system must automatically adjust for hardware failures. As per the CAP theorem discussion in Chapter 1, Cloud Storage: Why Can't I be like Google? partial tolerances must be tolerated.
· Data organization: A number of object storage systems simply return a hash key for a submitted object and provide a completely flat namespace. The task of creating accounts, containers, and mapping keys to object names is left to the user. Swift simplifies life for the user and provides a well-designed data organization layer.
· Available and eventually consistent: This was discussed in Chapter 1, Cloud Storage: Why Can't I be like Google?.
Physical data organization
Swift completely abstracts logical organization of data from the physical organization. At a physical level, Swift classifies the physical location into a hierarchy, as shown in the following figure:
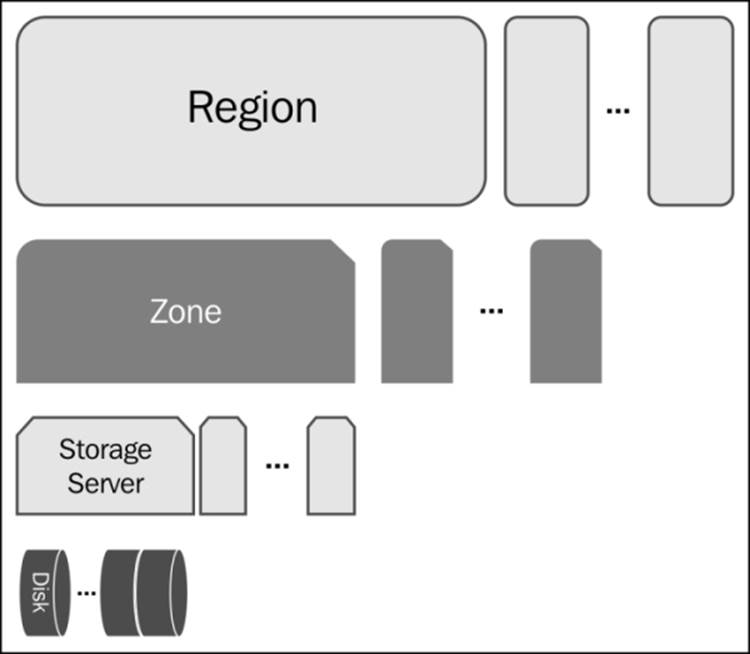
Physical data location hierarchy
· The hierarchy is as follows: Region: At the highest level, Swift stores data in regions that are geographically separated and thus suffer from a high-latency link. A user may use only one region, for example, if the cluster utilizes only one datacenter.
· Zone: Within regions, there are zones. Zones are a set of storage nodes that share different availability characteristics. Availability may be defined as different physical buildings, power sources, or network connections. This means that a zone could be a single storage server, a rack, or a complete datacenter depending on your requirements. Zones need to be connected to each other via low-latency links. Rackspace recommends having at least five zones per region.
· Storage servers: A zone consists of a set of storage servers ranging from just one to several racks.
· Disk (or devices): Disk drives are part of a storage server. These could be inside the server or connected via a JBOD.
Swift will store a number of replicas (default = 3) of an object onto different disks. Using an as-unique-as-possible algorithm, these replicas are as "far" away as possible in terms of being in different regions, zones, storage servers, and disks. This algorithm is responsible for the durability aspect of Swift.
Swift uses a semi-static table to look up where to place objects and their replicas. It is semi-static because the look-up table called a "ring" in Swift is created by an external process called the ring builder. The ring can be modified, but not dynamically; and never by Swift. It is not distributed, so every node that deals with data placement has a complete copy of the ring. The ring has entries in it called partitions (this term is not to be confused with the more commonly referred to disk partitions). Essentially, an object is mapped to a partition, and the partition provides the devices where the replicas of an object are to be stored. The ring also provides a list of handoff devices should any of the initial ones fail.
The actual storage of the object is done on a filesystem that resides on the disk, for example, XFS. Account and container information is kept in SQLite databases. The account database contains a list of all its containers, and the container database contains a list of all its objects. These databases are stored in single files, and the files are replicated just like any other object.
Data path software servers
The data path consists of the following four software servers:
· Proxy server
· Account server
· Container server
· Object server
Unless you need performance, then account, container, and object servers are often put on one physical server and called a storage server (or node), as shown in the following figure:
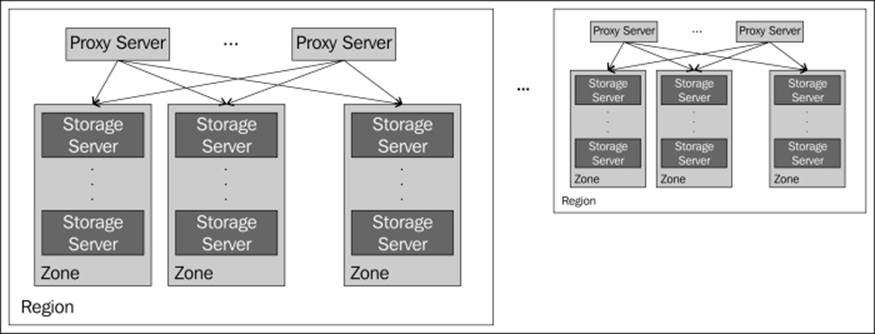
Data path software servers (a storage server includes an account, container, and object servers)
· A description of each server type is as follows: Proxy server: The proxy server is responsible for accepting HTTP requests from a user. It will look up the location of the storage server(s) where the request needs to be routed by utilizing the ring. The proxy server accounts for failures (by looking up handoff nodes) and performs read/write affinity (by sending writes or reads to the same region; Refer to A day in the life of a create operation and A day in the life of a read operation sections). When objects are streamed to or from an object server, they are streamed directly through the proxy server as well. Moreover, proxy servers are also responsible for the read/write quorum and often host inline middleware (discussed later in this chapter).
· Account server: The account server tracks the names of containers in a particular account. Data is stored in SQLite databases; database files are further stored on the filesystem. This server also tracks statistics, but does not have any location information about containers. The location information is determined by the proxy server based on the ring. Normally, this server is hosted on the same physical server with container and object servers. However, in large installations, this may need to be on a separatephysical server.
· Container server: This server is very similar to the account server, except that it deals with object names in a particular container.
· Object server: Object servers simply store objects. Each disk has a filesystem on it, and objects are stored in those filesystems.
Let us stitch the physical organization of the data with the various software components and explore the four basic operations: create, read, update, and delete (known as CRUD). For simplicity, we are focusing on the object server, but it may be further extrapolated to both account and container servers too.
A day in the life of a create operation
A create request is sent via an HTTP PUT API call to a proxy server. It does not matter which proxy server gets the request since Swift is a distributed system and all proxy servers are created equal. The proxy server interacts with the ring to get a list of disks and associated object servers to write data to. As we covered earlier, these disks will be as unique as possible. If certain disks have failed or are unavailable, the ring provides handoff devices. Once the majority of disks acknowledge the write (for example, two out of three disks), the operation is returned as being successful. Assuming the remaining writes complete successfully, we are fine. If not, the replication process, shown in the following figure, ensures that the remaining copies are ultimately created:
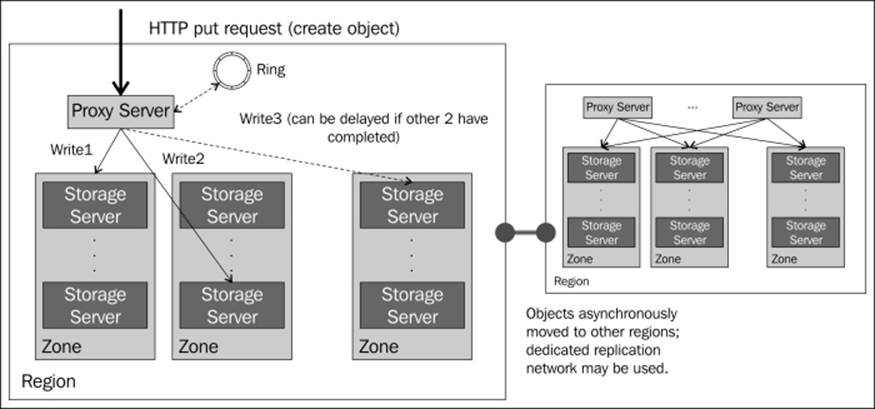
A day in the life of a create operation
The create operation operation works slightly differently in a multiregion cluster. All copies of the object are written to the local region. This is called write affinity. The object is then asynchronously moved to other region(s). A dedicated replication network may be used for this operation.
A day in the life of a read operation
A read request is sent via an HTTP GET API call to a proxy server. Again, any proxy server can receive this request. Similar to the create operation, the proxy server interacts with the ring to get a list of disks and associated object servers. The read request is issued to object servers in the same region as the proxy server. This is called read affinity. For a multiregion implementation, eventual consistency presents a problem since different regions might have different versions of an object. To get around this issue, a read for an object with the latest timestamp may be requested. In this case, proxy servers first request the time stamp from all the object servers and read from the server with the newest copy. Similar to the write case, in the case of a failure, handoff devices may be requested.
A day in the life of an update operation
An update request is handled in the same manner as a write request. Objects are stored with their timestamp to make sure that when read, the latest version of the object is returned. Swift also supports a versioning feature on a per-container basis. When this is turned on, older versions of the object are also available in a special container called versions_container.
A day in the life of a delete operation
A delete request sent via an HTTP DELETE API call is treated like an update but instead of a new version, a "tombstone" version with zero bytes is placed. The delete operation is very difficult in a distributed system since the system will essentially fight a delete by recreating deleted copies. The Swift solution is indeed very elegant and eliminates the possibility of deleted objects suddenly showing up again.
Postprocessing software components
There are three key postprocessing software components that run in the background, as opposed to being part of the data path.
Replication
Replication is a very important aspect of Swift. Replication ensures that the system is consistent, that is, all servers and disks assigned by the ring to hold copies of an object or database do indeed have the latest version. The process protects against failures, hardware migration, and ring rebalancing (where the ring is changed and data has to be moved around). This is done by comparing local data with the remote copy. If the remote copy needs to be updated, the replication process "pushes" a copy. The comparison process is pretty efficient and is carried out by simply comparing hash lists rather than comparing each byte of an object (or account or container database). Replication uses rsync, a Linux based remote file synchronization utility, to copy data but there are plans to replace it with a faster mechanism.
Updaters
In certain situations, account or container servers may be busy due to heavy load or being unavailable. In this case, the update is queued onto the storage server's local storage. There are two updaters to process these queued items. The object updater will update objects in the container database while the container updater will update containers in the account database. This situation could lead to an interesting eventual consistency behavior where the object is available, but the container listing does not have it at that time. These windows of inconsistency are generally very small.
Auditors
Auditors walk through every object, container, and account to check their data integrity. This is done by computing an MD5 hash and comparing it to the stored hash. If the item is found corrupted, it is moved to a quarantine directory and in time, the replication process will create a clean copy. This is how the system is self-healing. The MD5 hash is also available to the user so they can perform operations such as comparing the hash of their location object with the one stored on Swift.
Other processes
The other background processes are as follows:
· Account reaper: This process runs in the background and is responsible for deleting an entire account once it is marked for deletion in the database.
· Object expirer: Swift allows users to set retention policies by providing "delete-at" or "delete-after" information for objects. This process ensures that expired objects are deleted.
· Drive audit: This is another useful background process that looks out for bad drives and unmounts them. This can be more efficient than letting the auditor deal with this failure.
· Container to container synchronization: Finally using the container to container synchronization process, all contents of a container to be mirrored to another container. These containers can be in different clusters and the operation uses a secret sync key. Before multiregion support, this feature was the only way to get multiple copies of your data in two or more regions, and thus this feature is less important now than before. However, it is still very useful for hybrid (private-public combination) or community clouds (multiple private clouds).
Inline middleware options
In addition to the mentioned core data path components, other items may also be placed in the data path to extend Swift functionality. This is done by taking advantage of Swift's architecture, which allows middleware to be inserted. The following is a non-exhaustive list of various middleware modules. Most of them apply only to the proxy server, while some modules such as logging and recon do apply to other servers as well.
Auth
Authentication is one of the most important inline functions. All Swift middleware is separate and is used to extend Swift; thus auth systems are separate projects and one of several may be chosen. Keystone auth is the official OpenStack identity service and may be used in conjunction with Swift, though there is nothing to prevent a user from creating their own auth system or using others such as Swauth or TempAuth.
Authentication works as follows:
1. A user presents credentials to the auth system. This is done by executing an HTTP REST API call.
2. The auth system provides the user with an AUTH token.
3. The AUTH token is not unique for every request, but expires after a certain duration.
4. Every request made to Swift has to be accompanied by the AUTH token.
5. Swift validates the token with the Auth system and caches the result. The result is flushed upon expiration.
6. The Auth system generally has the concept of administrator accounts and non-admin accounts. Administrator requests are obviously passed through.
7. Non-admin requests are checked against container level Access Control Lists (ACL). These lists allow the administrator to set read and write ACLs for each non-admin user.
8. Therefore, for non-admin users, the ACL is checked before the proxy server proceeds with the request. The following figure illustrates the steps involved when Swift interacts with the Auth system:
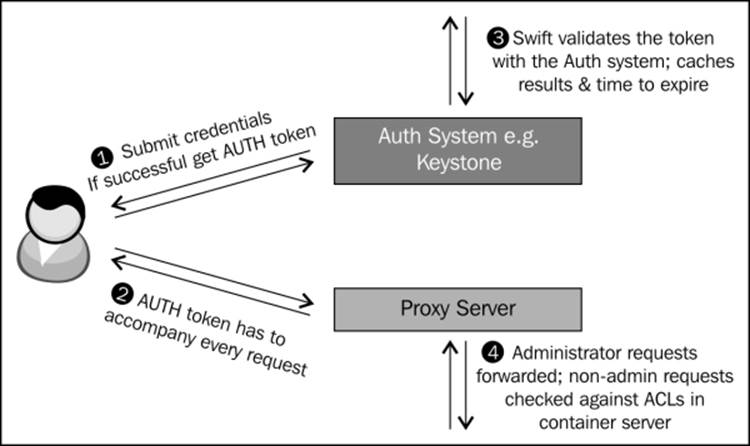
Swift and its interaction with the Auth system
Logging
Logging is a very important module. This middleware provides logging. A user may insert their custom log handler as well.
Other modules
A number of other Swift and third-party middleware modules are available; the following are a few examples:
· Health check: This module provides a simple way to monitor if the proxy server is alive. Simply access the proxy server with the path / health check and the server will respond with OK.
· Domain remap: This middleware allows you to remap the account and container name from the path into the host domain name. This allows you to simplify domain names.
· CNAME lookup: Using this software, you can create friendly domain names that remap directly to your account or container. CNAME lookup and domain remap may be used in conjunction.
· Rate limiting: Rate limiting is used to limit the rate of requests that result in database writes to account and container servers.
· Container and account quotas: An administrator can set container or account quotas by using these two middleware modules.
· Bulk delete: This middleware allows bulk operations such as deletion of multiple objects or containers.
· Bulk archive auto-extraction: For bulk expansion of TAR (TAR, tar.gz, tar.bz2) files to be performed with a single command, use this software.
· TempURL: The TempURL middleware allows you to create a URL that provides temporary access to an object. This access is not authenticated but expires after a certain duration of time. Furthermore, the access is only to a single object and no other objectscan be accessed via the URL.
· Swift origin server: This is a module that allows the use of Swift as an origin server to a Content Delivery Network (CDN).
· Static web: This software converts Swift into a static web server. You can also provide CSS stylesheets to get full control over the look and feel of your pages. Obviously, requests can be from anonymous sources.
· Form post: Using the form post middleware, you get the ability to upload objects to Swift using standard HTML form posts. The middleware converts the different POST requests to different PUT requests, and the requests do not go through authentication to allow collaboration across users and non-users of the cluster.
· Recon: Recon is software useful for management. It provides monitoring and returns various metrics about the cluster.
Additional features
Swift has additional features not covered in the previous sections. The following sections detail some of the additional features.
Large object support
Swift places a limit on the size of a single uploaded object (default is 5 GB), yet allows for the storage and downloading of virtually unlimited size objects. The technique used is segmentation. An object is broken up into equal-size segments (except the last one) and uploaded. These uploads are efficient since no one segment is unreasonably large and data transfers can be done in parallel. Once uploads are complete, a manifest file, which shows how the segments form one single large object, is uploaded. The download is a single operation where Swift concatenates the various segments to recreate the single large object.
Metadata
Swift allows custom metadata to be attached to accounts, containers, or objects that are set and retrieved in the form of custom headers. The metadata is simply a key (name) value pair. Metadata may be provided at the time of creating an object (using PUT) or updated later (using POST). Metadata may be retrieved independently of the object by using the HEAD method.
Multirange support
The HTTP specification allows for a multirange GET operation, and Swift supports this by retrieving multiple ranges of an object rather than the entire object.
CORS
CORS is a specification that allows JavaScript running in a browser to make a request to domains other than where it came from. Swift supports this, and this feature makes it possible for you to host your web pages with JavaScript on one domain and request objects from a Swift cluster on another domain. Swift also supports a broader cross-domain policy file where other client-side technologies such as Flash, Java, and Silverlight can also interact with Swift that is in a different domain.
Server-side copies
Swift allows you to make a copy of an object using a different container location and/or object name. The entire copy operation is performed on the server side, thus offloading the client.
Cluster health
A tool called swift-dispersion-report may be used to measure the overall cluster health. It does so by ensuring that the various replicas of an object and container are in their proper places.
Summary
In summary, Swift takes a set of commodity servers and creates a reliable and scalable storage system that is simple to manage. In this chapter, we reviewed the Swift architecture and major functionalities. The next chapter shows how you can install Swift on your own environment using multiple servers.