SEO For Dummies, 6th Edition (2016)
Part II. Building Search Engine-Friendly Sites
Chapter 9. Avoiding Things That Search Engines Hate
In This Chapter
![]() Working with frames and iframes
Working with frames and iframes
![]() Creating a readable navigation system
Creating a readable navigation system
![]() Avoiding problems with Flash and Silverlight
Avoiding problems with Flash and Silverlight
![]() Reducing page clutter
Reducing page clutter
![]() Dealing with dynamic Web pages
Dealing with dynamic Web pages
It is possible to look at your Web site in terms of its search engine friendliness. (Chapter 7 of this book does just that.) It is equally possible, however, to look at the flip side of the coin — the things people often do that hurt their Web site’s chance of ranking high within the search engines, and in some cases even making their Web sites invisible to search engines.
This tendency on the part of Web site owners to shoot themselves in the foot is very common. In fact, as you read through this chapter, you’re quite likely to find things you’re doing that are hurting you. Paradoxically, serious problems are especially likely for sites created by mid- to large-size companies using sophisticated Web technologies.
Steering you clear of major design potholes is what this chapter is all about. Guided by the principle First Do No Harm, the following sections show you the major mistakes to avoid when setting up your Web site.
Dealing with Frames
Frames were very popular a few years ago, but they’re much less so these days, I’m glad to say. A framed site is one in which the browser window is broken into two or more parts, each of which holds a Web page (see Figure 9-1).
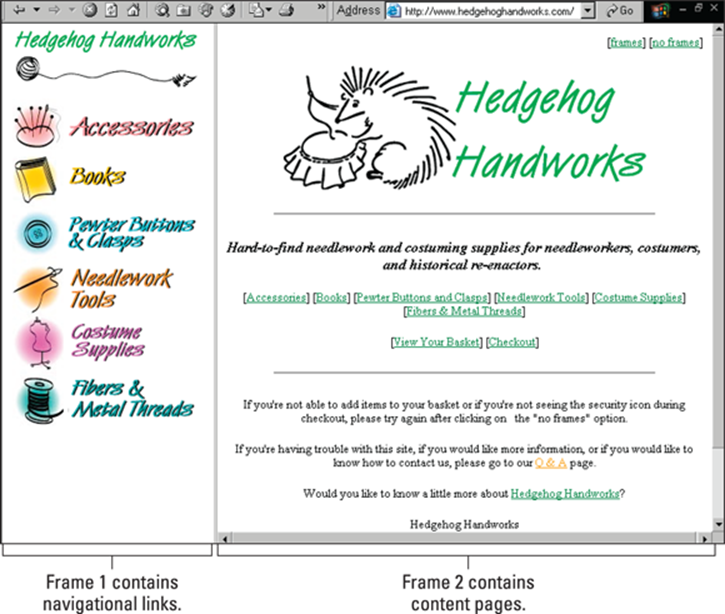
Figure 9-1: A framed Web site; each frame has an individual page. The scroll bar moves only the right frame.
 From a search engine perspective, frames create the following problems:
From a search engine perspective, frames create the following problems:
· Search engines index individual pages, not framesets. Each page is indexed separately, so pages that make sense only as part of the frameset end up in the search engines as independent pages — orphaned pages, as I like to call them. (Jump to Figure 9-2 to see an example of a page, indexed by Google, that belongs inside a frameset.)
· You can’t point to a particular page in your site. This problem may occur in the following situations:
· Linking campaigns (see Chapters 16 through 18): Other sites can link only to the front of your site; they can’t link to specific pages.
· Pay-per-click campaigns: If you’re running a pay-per-click (PPC) campaign, you can’t link directly to a page related to a particular product.
· Indexing products by shopping directories (see Chapter 15): In this case, you need to link to a particular product page.
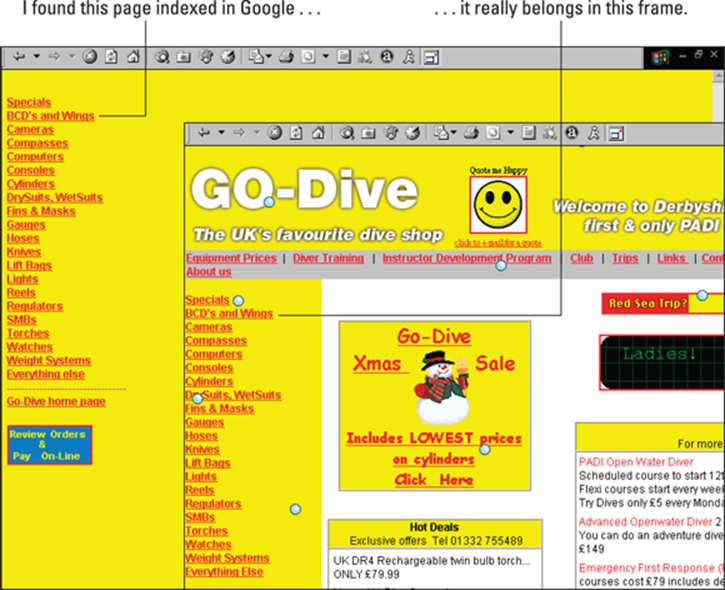
Figure 9-2: The document on the left, which I found through Google, belongs in the frameset shown on the right.
Search engines index URLs — single pages, in other words. By definition, a framed site is a collection of URLs, and search engines therefore can’t properly index the pages.
 Refraining
Refraining
Here’s how Google currently describes how they work with frames, in their Webmaster help files:
“Frames can cause problems for search engines because they don’t correspond to the conceptual model of the web. In this model, one page displays only one URL. Pages that use frames or iframes display several URLs (one for each frame) within a single page. Google tries to associate framed content with the page containing the frames, but we don’t guarantee that we will.
The HTML Nitty-Gritty of Frames
Here’s an example of a frame-definition, or frameset, document:
<HTML>
<HEAD>
</HEAD>
<FRAMESET ROWS="110,*">
<FRAME SRC="navbar.htm">
<FRAME SRC="main.htm">
</FRAMESET>
</HTML>
This document describes how the frames should be created. It tells the browser to create two rows, one 110 pixels high and the other * high — that is, it occupies whatever room is left over. The document also tells the browser to grab the navbar.htm document and place it in the first frame — the top row — and place main.htm into the bottom frame.
Search engines these days can find their way through the frameset to the navbar.htm and main.htm documents, so Google, for instance, indexes those documents.
But suppose the pages are indexed. Pages intended for use inside a frameset are individually indexed in the search engine. In Figure 9-2, you can see a page that I reached from Google — first (on the left) in the condition that I found it and then (on the right) in the frameset it was designed for.
 This is not a pretty sight — or site, as it were. But you can work around this mess by doing the following:
This is not a pretty sight — or site, as it were. But you can work around this mess by doing the following:
· Provide information in the frame-definition document to help search engines index it.
· Ensure that all search engines can find their way through this page into the main site.
· Ensure that all pages loaded into frames contain TITLE tags, meta tags, and navigation links.
· Make sure that pages are opened in the correct frameset.
However, frames are so rarely used these days — and in fact not included in the most recent HTML specification, although they are supported by most browsers — that I think that’s all I’ll say about frames.
Handling iframes
An iframe is an inline floating frame, far more common these days than regular frames. You can use an iframe to grab content from one page and drop it into another, in the same way that you can grab an image and drop it into the page. The tag looks like this:
<iframe src ="page.html">
</iframe>
I think iframes can be very useful now and then, but you should be aware of the problems they can cause. In particular, search engines index the main page and the content in an iframe separately, even though to a user they appear to be part of the same page. As with regular frames, the iframed document can be orphaned in the search results. As shown earlier in the discussion of frames, Google states that it tries to deal with iframes properly, but can’t guarantee it. You may want to add links at the bottom of the iframe content, in case someone stumbles across it when it’s orphaned.
Here’s another reason not to use frames and iframes: because you can achieve a similar effect using CSS (Cascading Style Sheets).
Fixing Invisible Navigation Systems
Navigation systems that were invisible to search engines were once a very common problem, but much less so these days because searchbots are so much smarter. Still, some search engines are smarter than others, and some navigation systems may cause problems with some systems, but you can deal with a navigation-system problem very easily.
In Chapter 7, I explain the difference between browser-side and server-side processes, and this issue is related. A Web page is compiled in two places — on the server and in the browser. If the navigation system is created “on the fly” in the browser, it may not be visible to a search engine.
Examples of such systems include those created by using
· JavaScripts
· Adobe Flash animation format
· Microsoft’s Silverlight animation format
· Java applets
So do you need to worry about these issues? I say you don’t, unless you know for sure you are having problems; if, for instance, the search engines aren’t indexing your Web site, despite the fact that you have more than just one or two links pointing to the site (I discuss this issue in detail in Chapter 3), one question you should ask yourself is how the navigation system was created. If it’s just basic HTML links, you don’t have a problem; move on. If the navigation system is built into the JavaScript, then there might be a problem. That’s unlikely to be a problem with Google, as it reads JavaScript quite well; Bing, however, still warns Webmasters that it may not be able to read JavaScript (and that affects Yahoo!, of course, as Bing feeds results to Yahoo!). If the site is being indexed by Google but not Bing, and your navigation structure is within JavaScript, maybe that’s the problem.
As for Adobe Flash, Google generally reads Flash pretty well; again, Bing states it may not be able to find links in Flash. Both search engines still state they have problems with this format.
What about Java applets? I assume that if your navigation is built into an applet, the search engines can’t see the links. But using Java applets for navigation is pretty rare.
Some other more obscure format? Assume that search engines can’t read it.
Fixing the problem
But let’s say you think you have this problem: One or more search engines are having problems finding their way through your site, because you’re using some format other than HTML for your navigation system. Or perhaps you just want to be conservative, and make sure you don’t have problems. What do you do?
The fix is easy: Just, to quote Bing, “implement a down-level experience which includes the same content elements and links as your rich version does. This will allow anyone ([including] Bingbot) without rich media enabled to see and interact with your website.”
Let me translate the geekspeak. By “down-level,” they mean simply use add links in a simpler format (that is, HTML). Add a secondary form of navigation that duplicates the top navigation.
You can duplicate the navigation structure by using simple text links at the bottom of the page, for instance, or perhaps in a navigation bar on the side of the page. If you have long pages or extremely cluttered HTML, you may want to place small text links near the top of the page, perhaps in the leftmost column, to make sure that search engines get to them.
Flush the Flash Animation
Adobe Flash animation is a very useful tool. But you should be aware of the SEO problems related to using it.
Many Web designers place fancy Flash animations on their home pages just to make them look cool. Often these animations serve no purpose beyond making site visitors wait a little longer to see the site. (This design flaw is falling out of favor, but you still see it here and there.) Major search engines can now read and index Flash content (albeit not always well — Bing warns that it might not be able to read it), but Flash animations often don’t contain any useful text for indexing. So, if you built your entire home page — the most important page on your site — by using Flash, the page is worthless from a search engine perspective.
Some designers even create entire Web sites using Adobe Flash (generally because they are Flash designers, not Web designers). Do this, and your site will almost certainly not do well in search results.
However, there are ways around the problem, by providing alternate content. In effect, you’re placing the code containing the Flash near the top of your HTML and then follow it with basic HTML that will be seen by browsers without Flash enabled and will be read by the search engines.
I’m no Flash expert, but one solution I’m aware of is the use of SWFObject, which is a method for embedding Flash content into Web pages using JavaScript. SWFObject includes the ability to define an alternate-content element and put the HTML text into a <div> tag of the same name as that element. Search for swfobject for details. Site visitors will see the Flash, but searchbots will see the alternate content.
Using SWFObject sounds remarkably like cloaking (see the section “Using Session IDs in URLs,” later in this chapter, and Chapter 10 for more detail). However, Google is aware of SWFObject and even recommends it.
(By the way, many home-page Flash animations automatically forward the browser to the next page — the real home page — after they finish running. If you really have to have a Flash intro, make sure that you include a clearly visible Skip Intro link somewhere on the page.)
Flash has many good uses, and search engines can index Adobe Flash files … but generally not well. And here’s the proof. Ask yourself how often you find Flash files, or pages that are mostly Flash components, at the top of the search results. The answer is virtually never. I’ve received a lot of criticism over the years from fans of Flash, and they sometimes point me to documents (generally on the Adobe Web site), talking about how well Flash files work with the search engines. Sure, those files can be indexed, but they almost certainly will not rank well. Furthermore, they may on occasion be orphaned — that is, the search engine may provide a link in the search results to the Flash file itself, rather than the page containing the file. A much better strategy is to provide alternate HTML content on the page, using a method such as the SWFObject script I describe earlier.
 Use Flash when necessary, but don’t rely on it for search engine indexing.
Use Flash when necessary, but don’t rely on it for search engine indexing.
Waiting for Silverlight (to Disappear)
Microsoft’s answer to Flash was Silverlight, released in 2007. One occasionally runs across Silverlight applications here and there, but it never quite caught on, and is unlikely to be used much in the future for two main reasons. Many browsers either don’t, or soon won’t, support Silverlight, and Microsoft has ended development.
So, you’re unlikely to run into problems with Silverlight. But if your site does use Silverlight, you should understand that the problems are the same as with Flash, but much worse.
Anything in the Silverlight animation probably isn’t being indexed by the search engines.
Avoiding Embedded Text in Images
Many sites use images heavily. The overuse of images is often the sign of an inexperienced Web designer — in particular, one who’s quite familiar with graphic design tools (perhaps a graphic artist who has accidentally encountered a Web project). Such designers often create entire pages, including the text, in a graphical design program and then save images and insert them into the Web page.
The advantage of this approach is that it gives the designer much more control over the appearance of the page — and is often much faster than using HTML to lay out a few images and real text.
Putting text into graphics has significant drawbacks, though. Such pages transfer across the Internet much more slowly, and because the pages contain no real text, search engines don’t have anything to index. And don’t believe the “Google is magic” hype; Google does not read text in the images it finds online and is unlikely to do so for a number of years yet.
 I don’t see this happening anywhere near as much as it did in the past. A decade ago I had a pro bono client, a nationally recognized ballet theatre that, I discovered, had a Web site that was nothing but images. These days, this kind of thing is much rarer, though I still run across sites with significant portions created using images. It’s a shame to see blocks of text, full of useful keywords, that aren’t doing the site any good in the search engines because they’re images.
I don’t see this happening anywhere near as much as it did in the past. A decade ago I had a pro bono client, a nationally recognized ballet theatre that, I discovered, had a Web site that was nothing but images. These days, this kind of thing is much rarer, though I still run across sites with significant portions created using images. It’s a shame to see blocks of text, full of useful keywords, that aren’t doing the site any good in the search engines because they’re images.
Reducing the Clutter in Your Web Pages
This is another of those “this used to be pretty important … probably not so much these days” things.
It used to be that simple was good; cluttered was bad, because the more cluttered your pages, the more work it is for search engines to dig through them. What do I mean by clutter? I’m referring to everything in a Web page that is used to create the page but that is not actual page content.
For instance, one of my clients had a very cluttered site. The HTML source document for the home page had 21,414 characters, of which 19,418 were characters other than spaces. However, the home page didn’t contain a lot of text: 1,196 characters, not including the spaces between the words.
So, if 1,196 characters were used to create the words on the page, what were the other 18,222 characters used for? They were used for elements such as these:
· JavaScripts: 4,251 characters
· JavaScript event handlers on links: 1,822 characters
· The top navigation bar: 6,018 characters
· Text used to embed a Flash animation near the top of the page: 808 characters
The rest is the normal clutter that you always have in HTML: tags used to format text, create tables, and so on. The problem with this page was that a search engine had to read 18,701 characters (including spaces) before it ever reached the page content. Of course, the page didn’t have much content, and what was there was hidden away below all that HTML.
This clutter above the page content meant that some search engines might not reach the content. But is this important today? Probably not so much. On the other hand, there are several things you can do to unclutter your pages that are good for other reasons, such as page loading speeds, so why not? (In my preceding client example. I was able to remove around 11,000 characters without much effort.)
Use external JavaScripts
You don’t need to put JavaScripts inside a page. JavaScripts generally should be placed in an external file — a tag in the Web page calls a script that is pulled from another file on the Web server — for various reasons:
· They’re safer outside the HTML file. That is, they’re less likely to be damaged while making changes to the HTML.
· They’re easier to manage externally. Why not have a nice library of all the scripts in your site in one directory?
· The download time is slightly shorter. If you use the same script in multiple pages, the browser downloads the script once and caches it.
· They’re easier to reuse. You don’t need to copy scripts from one page to another and fix all the pages when you have to make a change to the script. Just store the script externally and change the external file to automatically change the script in any number of pages.
· Doing so removes clutter from your pages!
Creating external JavaScript files is easy: Simply save the text between the <SCRIPT></SCRIPT> tags in a text editor and copy that file to your Web server (as a .js file — mouseover_script.js, for instance).
Then add an src= attribute to your <SCRIPT> tag to refer to the external file, like this:
<script language="JavaScript" type="text/javascript" src="/scripts/mouseover_script.js"></script>
Use external CSS files
If you can stick JavaScript stuff into an external file, it shouldn’t surprise you that you can do the same thing — drop stuff into a file that’s then referred to in the HTML file proper — with Cascading Style Sheet (CSS) information. For reasons that are unclear to me, many designers place huge amounts of CSS information directly into the page, despite the fact that the ideal use of a style sheet is generally external. One of the original ideas behind style sheets was to allow you to make formatting changes to an entire site very quickly. If you want to change the size of the body text or the color of the heading text, for example, you make one small change in the CSS file and it affects the whole site immediately. If you have CSS information in each page, though, you have to change each and every page. (Rather defeats the object of CSS, doesn’t it?)
Here’s how to remove CSS information from the main block of HTML code. Simply place the targeted text in an external file — everything between and including the <STYLE></STYLE> tags — and then call the file in your HTML pages by using the <LINK> tag, like this:
<link rel="stylesheet" href="site.css" type="text/css">
Move image maps to the bottom of the page
An image map (described in detail later in this chapter) is an image that contains multiple links. One way to clean up clutter in a page is to move the code that defines the links to the bottom of the Web page, right before the </BODY> tag. Doing so doesn’t remove the clutter from the page — it moves the clutter to the end of the page, where it doesn’t get placed between the top of the page and the page content. That makes it more likely that the search engines will reach the content.
Avoid the urge to copy and paste from MS Word
That’s right. Don’t copy text directly from Microsoft Word and drop it into a Web page. You’ll end up with all sorts of formatting clutter in your page!
Here’s one way to get around this problem:
1. Save the file as an HTML file.
Word provides various options to do this, but you want to use the simplest: Web Page (Filtered).
2. In your HTML-authoring program, look for a Word-cleaning tool.
Word has such a bad reputation that some HTML programs have tools to help you clean the text before you use it. Dreamweaver has such a tool, for instance (Clean Up Word HTML).
Managing Dynamic Web Pages
Chapter 7 explains how your standard, meat-and-potatoes Web page gets assembled in your browser so that you, the surfer, can see it. But you can assemble a Web page in more than one way. For example, the process can go like this:
1. The Web browser requests a Web page.
2. The Web server sends a message to a database program requesting the page.
3. The database program reads the URL to see exactly what is requested, compiles the page, and sends it to the server.
4. The server reads any instructions inside the page.
5. The server compiles the page, adding information specified in server-side includes (SSIs) or scripts.
6. The server sends the file to the browser.
Pages pulled from databases are known as dynamic pages, as opposed to normal static pages, which are individual files saved on the hard drive. The pages are dynamic because they’re created on the fly, when requested. The page doesn’t exist until a browser requests it, at which point the data is grabbed from a database by some kind of program — a CGI, ASP, or PHP script, for instance, or from some kind of content-management system — and dropped into a Web page template and then sent to the browser requesting the file.
Dynamic pages often caused problems in the past. Even the best search engines often didn’t read them. Of course, a Web page is a Web page, whether it was created on the fly or days earlier. After the searchbot receives the page, the page is already complete, so the searchbots could read them if they wanted to, but sometimes, based on what the page URL looked like, they choose not to. So it isn’t the page itself that’s the problem; static or database, the final Web page is the same thing. It’s the structure of the URL that’s the problem, because the search engines can look at the URL and recognize that the page is a dynamic page.
Search engine programmers discovered that dynamic pages were often problem pages. Here are a few of the problems that searchbots were running into while reading dynamic pages:
· Dynamic pages often have only minor changes in them. A searchbot reading these pages may end up with hundreds of pages that are almost exactly the same, with nothing more than minor differences to distinguish one from each other.
· Search engines were concerned that databased pages might change frequently, making search results inaccurate.
· Searchbots sometimes get stuck in the dynamic system, going from page to page to page among tens of thousands of pages. On occasion, this happens when a Web programmer hasn’t properly written the link code, and the database continually feeds data to the search engine, even crashing the Web server.
· Hitting a database for thousands of pages can slow down the server, so searchbots often avoided getting into situations in which that is likely to happen.
· Sometimes URLs can change (I talk about session IDs a little later in this chapter), so even if the search engine indexed the page, the next time someone tried to get there, it would be gone, and search engines don’t want to index dead links.
All these problems were more common a few years ago, and, in fact, the major search engines are now far more likely to index databased pages than they were back then. Databased pages may still limit indexing by some search engines, though in particular, URLs with very long, complicated structures.
Understanding dynamic-page URLs
What does a dynamic-page URL look like? Go deep into a large ecommerce site; if it’s a product catalog, for instance, go to the farthest subcategory you can find. Then look at the URL. Suppose that you have a URL like this:
http://www.yourdomain.edu/march/rodent-racing-scores.php
This URL is a normal one that should have few problems. It’s a static page — or at least it looks like a static page, which is what counts. (It might be a dynamic, or databased, page, but there’s no way to tell from the URL.) Compare this URL with the next one:
http://www.yourdomain.edu/march/scores.php?prg=1
This filename ends with ?prg=1. This page is almost certainly a databased dynamic page; ?prg=1 is a parameter that’s being sent to the server to let it know which piece of information is needed from the database. This URL is okay, especially for the major search engines, although a few smaller search engines may not like it; it almost certainly won’t stop a searchbot from indexing it. It’s still not very good from a search engine perspective, though, because it doesn’t contain good keywords.
Now look at the following URL:
http://yourdomain.com/march/index.html?&DID=18&CATID=13&ObjectGroup_ID=79
Now the URL is getting more complicated. It contains three parameters: DID=18, CATID=13, and ObjectGroup_ID=79. These days, Google will probably index this page; at one point, a number of years ago, it likely wouldn’t have.
Today, I wouldn’t worry much about dynamic-page URLs not being indexed, unless yours are particularly complicated. However, there’s another good reason for not using dynamic-page URLs: They generally don’t contain useful keywords, and the URL is an important place to put keywords. If a search engine sees rodent-racing in a URL, that’s a really good signal to the search engines that the page is in some way related to racing rodents, rather than, say, dental surgery or baseball.
What does Google say? Its SEO Starter Guide (see Chapter 23) says “Creating descriptive categories and filenames for the documents on your website can not only help you keep your site better organized, but it could also lead to better crawling of your documents by search engines.” Elsewhere, a document about dynamic URLs discourages Webmasters from changing them, while in another document it states “rewriting dynamic URLs into user-friendly versions is always a good practice when that option is available to you.”
So, despite the document discouraging changing URLs, I believe there are real advantages to doing so, and Google has itself stated this. In addition, many in the SEO business agree; “rewriting” URLs (explained in the following section) is common practice.
Fixing your dynamic Web page problem
If you do have problems, how do you make search engines read your state-of-the-art dynamic Web site? Here are a few ideas:
· Find out whether the database program has a built-in way to create static HTML. Some ecommerce systems, for instance, spit out a static copy of their catalog pages, which is intended for search engines. When visitors click the Buy button, they’re taken back into the dynamic system. Google has even on occasion recommended this process; however, this is probably not a process used very frequently nowadays.
· Modify URLs so that they don’t look like they’re pointing to dynamic pages. You can often help fix the problem by removing characters such as ?, #, !, *, %, and & and reducing the number of parameters to one. For the specifics, talk with the programmer responsible for the database system.
· Use a URL rewrite trick — a technique for changing the way URLs look. Different servers have different tools available; the mod_rewrite tool, for instance, is used by the Apache Web server (a very popular system), and ISAPI Rewrite can be used on Windows servers.Rewriting is a process whereby the server can convert fake URLs into real URLs. The server might see, for instance, a request for a page at
http://yourdomain.com/march/rodent-racing-scores.html
· The server knows that this page doesn’t exist and that it really refers to, perhaps, the following URL:
http://yourdomain.com/showprod.cfm?&DID=7&User_ID=2382175&st=6642&st2=45931500&st3=-43564544&topcat_id=20018&catid=20071&objectgroup_id=20121.
· In other words, this technique allows you to use what appear to be static URLs yet still grab pages from a database. Furthermore, the URLs then contain nice keywords, which is an SEO advantage. This topic is complicated, so if your server administrator doesn’t understand it, it may take him a few days to figure it all out; for someone who understands URL rewriting, however, it’s fairly easy and can take just a few hours to set up.
If you want to find out more about URL rewriting, simply search for url rewrite, and you’ll find tons of information.
Using Session IDs in URLs
Just as dynamic Web pages can throw a monkey wrench into the search engine machinery, session IDs can make search engine life equally interesting. A session ID identifies a particular person visiting the site at a particular time, which enables the server to track which pages the visitor looks at and which actions the visitor takes during the session.
If you request a page from a Web site — by clicking a link on a Web page, for instance — the Web server that has the page sends it to your browser. Then if you request another page, the server sends that page, too, but the server doesn’t know that you’re the same person. If the server needs to know who you are, it needs a way to identify you each time you request a page. It does that by using session IDs.
Session IDs are used for a variety of reasons, but their main purpose is to allow Web developers to create various types of interactive sites. For instance, if developers have created a secure environment, they may want to force visitors to go through the home page first. Or, the developers may want a way to resume an unfinished session. By setting cookies containing the session ID on the visitor’s computer, developers can see where the visitor was in the site at the end of the visitor’s last session. (A cookie is a text file containing information that can be read only by the server that set the cookie.)
Session IDs are common when running software applications that have any kind of security procedure (such as requiring a login), that need to store variables, or that want to defeat the browser cache — that is, ensure that the browser always displays information from the server, never from its own cache. Shopping cart systems typically use session IDs — that’s how the system can allow you to place an item in the shopping cart and then go away and continue shopping. It recognizes you based on your session ID.
A session ID can be created in two ways:
· Store it in a cookie.
· Display it in the URL itself.
Some systems are set up to store the session ID in a cookie but then use a URL session ID if the user’s browser is set to not accept cookies. (Relatively few browsers, perhaps 1 or 2 percent, don’t accept cookies.) Here’s an example of a URL containing a session ID:
http://yourdomain.com/index.jsp;jsessionid=07D3CCD4D9A6A9F3CF9CAD4F9A728F44
The 07D3CCD4D9A6A9F3CF9CAD4F9A728F44 piece of the URL is the unique identifier assigned to the session.
If a search engine recognizes a URL as including a session ID, it probably doesn’t read the referenced page because each time the searchbot returns to your site, the session ID will have expired, so the server will do one of the following:
· Display an error page rather than the indexed page or perhaps display the site’s default page (generally the home page). In other words, the search engine has indexed a page that isn’t there if someone clicks the link in the search results page.
· Assign a new session ID. The URL that the searchbot originally used has expired, so the server replaces the ID with another one and changes the URL. So, the spider could be fed multiple URLs for the same page.
Even if the searchbot reads the referenced page (and sometimes it does), it may not index it. Webmasters sometimes complain that a search engine entered their site, requested the same page over and over, and left without indexing most of the site. The searchbot simply got confused and left. Or, sometimes the search engine doesn’t recognize a session ID in a URL. One of my clients had hundreds of URLs indexed by Google, but because they were all long-expired session IDs, they all pointed to the site’s main page.
These are all worst-case scenarios, as the major search engine’s searchbots do their best to recognize session IDs and work around them. Furthermore, Google recommends that if you are using session IDs, you use the canonical directive to tell the search engines the correct URL for the page. For instance, let’s say you’re using session IDs, and your URLs look something like this:
http://www.youdomain.com/product.php?item=rodent-racing-gear&xyid=76345&sessionid=9876
A search engine might end up with hundreds of URLs effectively referencing the same page. So, you can put the <link> tag in the <head> section of your Web pages to tell the search engines the correct URL, like this:
<link rel="canonical" href="http://www.yourdomain.com/product.php?item= rodent-racing-gear " />
Session ID problems are rarer than they once were; in the past, fixing a session ID problem was like performing magic: Sites that were invisible to search engines suddenly become visible! One site owner in a search engine discussion group described how his site had never had more than 6 pages indexed by Google, yet within a week of removing session IDs, Google had indexed over 600 pages.
If your site has a session ID problem, there are a couple of other things you can do, in addition to using the canonical directive:
· Rather than use session IDs in the URL, store session information in a cookie on the user’s computer. Each time a page is requested, the server can check the cookie to see whether session information is stored there. (Few people change their browser settings to block cookies.) However, the server shouldn’t require cookies, or you may run into further problems.
· Get your programmer to omit session IDs if the device requesting a Web page from the server is a searchbot. The server delivers the same page to the searchbot but doesn’t assign a session ID, so the searchbot can travel throughout the site without using session IDs. (Every device requesting a page from a Web server identifies itself, so it’s possible for a programmer to send different pages according to the requestor.) This process is known as user agent delivery, in which user agent refers to the device — browser, searchbot, or other program — that is requesting a page.
The user agent method has one potential problem: In the technique sometimes known as cloaking, a server sends one page to the search engines and another to real site visitors. Search engines generally don’t like cloaking because some Web sites try to trick them by providing different content from the content that site visitors see. Of course, in the context of using this technique to avoid the session-ID problem, that’s not the intent; it’s a way to show the same content that the site visitor sees, so it isn’t true cloaking. However, the (very slight) danger is that the search engines may view it as cloaking if they discover what is happening. (I don’t believe that the risk is big, though some people in the SEO business will tell you that it is.) For more on cloaking, see Chapter 10.
Fixing Bits and Pieces
Forwarded pages, image maps, and special characters can also cause problems for search engines.
Forwarded pages
Search engines don’t want to index pages that automatically forward to other pages. You’ve undoubtedly seen pages telling you that a page has moved to another location and that you can click a link or wait a few seconds for the page to automatically forward the browser to another page. This is often done with a REFRESH meta tag, like this:
<meta http-equiv="refresh" content="0; url=http://yourdomain.com">
This meta tag forwards the browser immediately to yourdomain.com. Quite reasonably, search engines don’t like these pages. Why index a page that doesn’t contain information but instead forwards visitors to the page with the information? Why not index the target page? That’s just what search engines do.
If you use the REFRESH meta tag, you can expect search engines to ignore the page (unless it’s a very slow refresh rate of over ten seconds, which is specified by the number immediately after content=). But don’t listen to the nonsense that you’ll hear about your site being penalized for using refresh pages: Search engines don’t index the page, but there’s no reason for them to penalize your entire site. (On the other hand, there’s an old trick using JavaScript in which the search engines are shown one page, but the visitor is instantly forwarded to another page with different content; the theory is that the search engines won’t see the JavaScript redirect, so they’ll index the heavily keyworded initial page and not realize users are going to a different one. Search engines don’t appreciate that, and often catch it these days! As noted earlier, Google especially is quite good at reading JavaScript.)
Image maps
An image map is an image that has multiple links. You might create the image like this:
<img name="main" src="images/main.gif" usemap="#m_main">
The usemap= parameter refers to the map instructions. You can create the information defining the hotspots on the image — the individual links — by using a <MAP> tag, like this:
<map name="m_main">
<area shape="rect" coords="238,159,350,183" href="page1.html">
<area shape="rect" coords="204,189,387,214" href=" page2.html">
<area shape="rect" coords="207,245,387,343" href=" page3.html">
<area shape="rect" coords="41,331,155,345" href=" page4.html">
<area shape="rect" coords="40,190,115,202" href=" page5.html">
<area shape="rect" coords="42,174,148,186" href=" page6.html">
<area shape="rect" coords="40,154,172,169" href=" page7.html">
<area shape="rect" coords="43,137,142,148" href=" page8.html">
<area shape="rect" coords="45,122,165,131" href=" page9.html">
<area shape="rect" coords="4,481,389,493" href=" page10.html">
<area shape="rect" coords="408,329,588,342" href=" page11.html">
<area shape="rect" cords="410,354,584,391" href=" page12.html">
</map>
There was a time when search engines wouldn’t read the links, but that time is long gone; major search engines now read image maps, though some smaller ones may not. A more important problem these days is that links in images don’t provide the benefit of keywords that search engines can read. The solution is simple: Use additional simple text links in the document.
Special characters
The issue of using special characters is a little complicated. Currently Google seems to handle special-character searches well. Search for rôle and for role, and you’ll get different results. Try the test at Bing, and you’ll get almost the same result both times.
Consider, then, that when people search, they don’t use special characters. They simply type the search term with the keyboard characters in front of them. Almost nobody would search for shakespearean rôles; people would search for shakespearean roles (even if they realized that the word role has an accented o). Thus, if you use the word rôle, your page won’t match searches for role.
My general advice is to avoid special characters when possible, particularly in really SEO-valuable fields such as the <Title> tag and DESCRIPTION meta tag.