C# in Depth (2012)
Part 4. C# 4: Playing nicely with others
Chapter 16. C# 5 bonus features and closing thoughts
This chapter covers
· Changes to captured variables
· Caller information attributes
· Closing thoughts
C# 2 had a bunch of small but disparate features, along with the major ones. C# 3 had several minor features building up to LINQ. Even C# 4 had relatively small features worth going into some detail about.
C# 5 has almost no features beyond asynchrony. It has just two little extras, both tiny. The C# design team always weighs the cost of a feature (in terms of design, implementation, testing, documentation, and developer education) against its benefits. I’m sure there are plenty of outstanding feature requests the team would like to satisfy, so presumably the costs of these bite-sized features were just small enough to allow them to make the cut.
The first change isn’t so much a feature as a correction to an earlier mistake in the language design...
16.1. Changes to captured variables in foreach loops
Back in section 5.5.5 I gave a warning about code that used an anonymous function (typically a lambda expression) within a foreach loop, capturing the loop variable. The following listing shows a simple example of such code, which looks as if it will output x, then y, and then z.
Listing 16.1. Using captured iteration variables
string[] values = { "x", "y", "z" };
var actions = new List<Action>();
foreach (string value in values)
{
actions.Add(() => Console.WriteLine(value));
}
foreach (Action action in actions)
{
action();
}
In C# 3 and C# 4, this would actually print z three times—the loop variable (value) would be captured by the lambda expression, and there was notionally just one variable “instance” that changed value on each iteration of the loop. All three delegates would refer to the same variable, and by the time they were executed at the end, the value of that variable would be z. This wasn’t an implementation mistake in the compiler; it was how the language was specified to behave.
In C# 5, the language works as you’d probably have expected it to in the first place: each iteration of the loop effectively introduces a separate variable. Each of the delegates will refer to a different variable, with the value from that iteration of the loop.
There’s not a lot more to say about this feature—it’s really just correcting an area of the language that caused problems for a lot of developers. (You’d probably be amazed at how many Stack Overflow questions this caused.)
I want to give one word of warning, though: if you’re in the fairly unusual position of writing code that needs to be compiled with various different versions of the C# compiler, you need to be aware that the behavior will vary. The code from listing 16.1 doesn’t produce any warnings in any versions of C#—the behavior just changes silently for C# 5. Be careful, and make sure you have unit tests to fall back on!
On to the final feature...
16.2. Caller information attributes
Some features are very general—lambda expressions, implicitly typed local variables, generics, and the like. Others are more specific—LINQ is really meant to be about querying data of some form or other, even though it’s aimed to generalize over many different data sources. The final C# 5 feature is extremely targeted: there are two significant use cases (one obvious, one slightly less so), and I really don’t expect it to be used much outside those situations.
16.2.1. Basic behavior
.NET 4.5 introduces three new attributes: CallerFilePathAttribute, CallerLineNumberAttribute, and CallerMemberNameAttribute, all in the System.Runtime .-CompilerServices namespace. Just as with other attributes, when you apply any of these, you can omit the Attribute suffix, and as that’s the most common way of using attributes, I’ll abbreviate the names appropriately for the rest of the book.
All three attributes can only be applied to parameters, and they’re only useful when they’re applied to optional parameters. The idea is simple: if the call site doesn’t provide the argument, the compiler will use the current file, line number, or member name to fill in the argument, instead of taking the normal default value. If the caller does supply an argument, the compiler will leave it alone.
The following listing shows an example of both cases.
Listing 16.2. Using caller information attributes properly, and abusing them
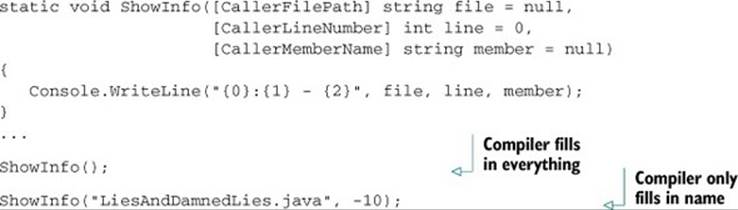
The output from listing 16.2 would be something like this:
c:\Users\Jon\Code\Chapter16\CallerInfoDemo.cs:21 - Main
LiesAndDamnedLies.java:-10 - Main
Of course, you wouldn’t usually give a fake value for any of these arguments, but it’s useful to be able to pass the value explicitly, particularly if you want to log the current method’s caller, using the same attributes.
The member name works for all members, normally in the obvious way, with the following reasonably predictable special names:
· Static constructor: .cctor
· Constructor: .ctor
· Finalizer: Finalize
The name used as part of a method call during a field initializer is the name of the field.
There are two situations in which caller member information isn’t populated. The first is attribute initialization; listing 16.3 provides an example of an attribute that you might expect to be given the name of the member it was applied to, but unfortunately the compiler doesn’t fill anything in automatically in this case.
Listing 16.3. Attempting to use caller information attributes in an attribute declaration
[AttributeUsage(AttributeTargets.All)]
public class MemberDescriptionAttribute : Attribute
{
public MemberDescriptionAttribute([CallerMemberName] string member = null)
{
Member = member;
}
public string Member { get; set; }
}
This could definitely be useful. I’ve seen situations where developers have found attributes via reflection, but had to populate their own data structure to maintain a mapping between the member name and the attribute, which could be done automatically by the compiler.
The dynamic typing omission is more easily forgivable. The following listing demonstrates the kind of usage that unfortunately doesn’t work.
Listing 16.4. Attempting to use caller information attributes with dynamic invocation
class TypeUsedDynamically
{
internal void ShowCaller([CallerMemberName] string caller = "Unknown")
{
Console.WriteLine("Called by: {0}", caller);
}
}
...
dynamic x = new TypeUsedDynamically();
x.ShowCaller();
Listing 16.3 just prints Called by: Unknown as if the attribute weren’t present. Although this may seem disappointing, consider the alternative: in order to work, the compiler would need to embed the member name, filename, and line number into every dynamic call that could possiblyend up requiring the information. Overall, I think the costs would outweigh the benefits for most developers.
16.2.2. Logging
The most obvious case where caller information is useful is when writing to a log file. Previously when logging, you would usually construct a stack trace (using System .Diagnostics.StackTrace, for example) to find out where the log information came from. This is normally hidden from view in logging frameworks, but it’s still there—and ugly. It’s potentially an issue in terms of performance, and it’s brittle in the face of JIT compiler inlining.
It’s easy to see how a logging framework could make use of the new feature to allow caller-only information to be logged very cheaply, even preserving line numbers and member names in the face of a build that had debug information stripped, and even after obfuscation. This doesn’t help in cases where you want to log a full stack trace, of course, but it doesn’t take away your ability to do that either.
As I write, I’m not aware of any logging frameworks that have taken advantage of this; it would require a build specifically targeting .NET 4.5, to start with, or a framework with the attributes declared explicitly, as you’ll see in section 16.2.4. But it should be easy to write your own wrapper classes that make use of whichever logging framework you prefer and provide caller information. Over time, I’m sure the frameworks will catch up and provide this functionality out of the box.
16.2.3. Implementing INotifyPropertyChanged
The less obvious use of just one of these attributes, [CallerMemberName], may be very obvious to you if you happen to implement INotifyPropertyChanged frequently.
The interface is very simple—it’s a single event of type PropertyChangedEventHandler. This is a delegate type with the following signature:
public delegate void PropertyChangedEventHandler(Object sender,
PropertyChangedEventArgs e)
PropertyChangedEventArgs, in turn, has a single constructor:
public PropertyChangedEventArgs(string propertyName)
A typical implementation of INotifyPropertyChanged before C# 5 might look something like the following.
Listing 16.5. Implementing INotifyPropertyChanged the old way
class OldPropertyNotifier : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged;
private int firstValue;
public int FirstValue
{
get { return firstValue; }
set
{
if (value != firstValue)
{
firstValue = value;
NotifyPropertyChanged("FirstValue");
}
}
}
// Other properties with the same pattern
private void NotifyPropertyChanged(string propertyName)
{
PropertyChangedEventHandler handler = PropertyChanged;
if (handler != null)
{
handler(this, new PropertyChangedEventArgs(propertyName));
}
}
}
The purpose of the helper method is to avoid having to put the nullity check in each property. You could easily make it an extension method to avoid repeating it on each implementation, of course.
This isn’t just long-winded (which hasn’t changed)—it’s brittle. The problem is that the name of the property (FirstValue) is specified as a string literal, and if you refactor the property name to something else, you could easily forget to change the string literal. If you’re lucky, your tools and tests will help you spot the mistake, but it’s still very ugly.
With C# 5, the majority of the code stays the same, but you can make the compiler fill in the property name by using CallerMemberName in the helper method, as follows.
Listing 16.6. Implementing INotifyPropertyChanged using caller information
// Within the setter
if (value != firstValue)
{
firstValue = value;
NotifyPropertyChanged();
}
...
void NotifyPropertyChanged([CallerMemberName] string propertyName = null)
{
// Exactly the same code as before
}
I’ve only shown the sections of the code that have changed—it’s that simple. Now when you change the name of the property, the compiler will use the new name instead. It’s not an earth-shattering improvement, but it’s nicer nonetheless.
16.2.4. Using caller information attributes without .NET 4.5
Like extension methods, caller information attributes just let you ask the compiler to mess with your code very slightly during the compilation process. They don’t use any information you couldn’t provide yourself—you’d just need to be careful as you did so. Just like extension methods, it’s possible to use them when targeting an earlier version of .NET than the one that really contains the attributes—you just have to declare the attributes yourself. This is as simple as copying the declaration from MSDN. The attributes themselves don’t have any parameters, so you just need to provide an empty body for the class declaration, which still has to be in the System.Runtime.CompilerServices namespace.
The C# compiler will treat your user-provided attributes in exactly the same way as it would treat the real ones in .NET 4.5. The downside of this approach is that you’ll run into problems if you ever build the same code against .NET 4.5. You’ll need to remove your hand-crafted attributes at that point, to avoid confusing the compiler.
If you’re using .NET 4, Silverlight 4 or 5, or Windows Phone 7.5, another option is to use the Microsoft.Bcl NuGet package. This provides these attributes along with several other handy types you might otherwise be pining for.
And that’s it—C# 5 all wrapped up.
16.3. Closing thoughts
The first two editions of C# in Depth closed with a chapter dedicated to the future as I perceived it at the time of writing. If you own either (or both!) of those editions, you may want to look back and have a quiet chuckle to yourself. I don’t think I said anything outrageously wrong, but I clearly had little idea of how much things could change in just a couple of years.
I’d also like to point out that I had no clue what would be coming in either C# 4 or C# 5 until they were announced by Microsoft. Both dynamic typing and asynchronous functions came as big surprises to me. I had the good fortune of presenting my ideas for C# 5 at a conference, with a few members of the C# team in attendance, and I’m hugely pleased that they went their own way instead. In case I haven’t made myself clear yet, async/await rocks as a feature, and it’s far beyond anything I could have come up with.
What’s in store for the industry? More mobile, more touch input, more distributed cloud services, possibly augmented reality—these are all reasonably safe bets by now. But if those are the most disruptive forces in the industry by the end of 2014, I’ll be very disappointed. The best things in computing seem to come out of nowhere—after many years of hard effort by the people involved, of course—and surprise everyone.
The same sort of thing can be said for C#. I still have my wish-list of minor features, and maybe C# 6 will be a tidy-up release, with many minor features instead of the huge ones we’ve seen in the past. Maybe the language will be expanded in an extendable way, allowing other developers to create those minor features themselves. Or maybe the new killer feature will be something that I didn’t even know I needed—yet again.
The C# and .NET teams have certainly not been idle. Even leaving aside C# 5 and all the work required integrating .NET into the Windows 8 UI, we do know one project they’ve been working hard on: Roslyn. Named as a pun on the orientation of Eric Lippert’s office when he worked on the project, Roslyn is another name for the “compiler as a service” idea that’s been talked about for so long. Roslyn will provide an API that developers can use to analyze C# (or VB) code, modify it programmatically, compile it into IL, and so on. I suspect relatively few developers will have any need for this, but those who do will be immensely glad of it, and they’ll create wonderful things for the rest of us. Imagine being able to write your own refactoring tools, more sophisticated code convention analysis, code generation, and more—all with an API designed to be powerful and performant enough to be the engine for future releases of Visual Studio. Perhaps more important for most of us, Roslyn gives the C# team a playground in which it’s relatively easy to implement new features. Maybe they’ll become even more adventurous and ambitious in the future!
I can state one thing with a fair degree of certainty, though: I’ll continue to enjoy writing about, talking about, and using C# for quite some time, whether or not the language evolves any further. I find it hard to believe that programming will become less interesting in the next decade.
As in previous editions, I urge you to do awesome things. Write fabulously clear code that your colleagues will love to work with. Develop the Next Big Thing in the open source world. Help other developers on Stack Overflow. Talk to user groups, conferences, friends, and anyone who will listen about whatever your passion may be. I wish you the very best of luck in however many of these you undertake, and I hope this book has provided some small measure of help in achieving your ambitions.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.