C++ All-in-One For Dummies (2009)
Book I
Introducing C++
Chapter 4: Dividing Your Work with Functions
In This Chapter
Calling a function
Passing things, such as variables
Writing your own great functions
Fun with strings
Manipulating main
People generally agree that most projects throughout life are easier when you divide them into smaller, more manageable tasks. That’s also the case with computer programming. If you break your code into smaller pieces, it becomes more manageable.
C++ provides many ways to divide code into smaller portions. One way is through the use of what are called functions. A function is a set of lines of code that performs a particular job.
In this chapter, we show you what functions are and how you can use them to make your programming job easier.
Dividing Your Work
If you have a big job to do that doesn’t involve a computer, you can divide your work in many ways. Over the years of studying process management, people have pretty much narrowed division of a job down to two ways: using nouns and using verbs.
Yes, that’s right. Back to good old English class, where we all learned about nouns and verbs. The idea is this: Suppose that we’re going to go out back and build a flying saucer. We can approach the designing of the flying saucer in two ways.
First, we could just draw up a plan of attack, listing all the steps to build the flying saucer from start to finish. That would, of course, be a lot of steps. But to simplify it, we could instead list all the major tasks without getting into the details. It might go something like this:
1. Build the outer shell.
2. Build and attach the engine.
That’s it. Only two steps. But when you hire a couple dozen people to do the grunt work for you while you focus on your daytrading, would that be enough for them to go on? No, probably not. Instead, you could take these two tasks and divide them into smaller tasks. For example, Step 2 might look like this:
2a. Build the antigravity lifter.
2b. Build the thruster.
2c. Connect the lifter to the thruster to form the final engine.
2d. Attach the engine to the outer shell.
That’s a little better; it has more detail. But, it still needs more. How do we do the Build the antigravity lifter part? That’s easy, but it requires more detail, as in the following:
2aa. Unearth the antigravity particles from the ground.
2ab. Compress them tightly into a superatomizing conductor.
2ac. Surround with coils.
2ad. Connect 9-volt battery clip to the coils.
And, of course, each of these requires even more detail. Eventually, after you have planned the whole thing, you will have many, many steps, but they will be organized into a hierarchy of sorts, as shown in Figure 4-1. In this drawing, the three dots represent places where other steps go, but we chose to leave them off so the diagram could fit on the page.
This type of design is called a top-down design. The idea is that you start at the uppermost step of your design (in this case, Build flying saucer) and continue to break the steps into more and more detailed steps until you have something manageable. For many years, this was how computer programming was taught.
Figure 4-1: A process can be divided into a hierarchy.
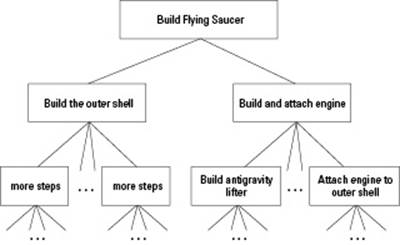
Although this process works, people have found a slightly better way. First, before breaking the steps (which are the verbs), you divide the thing you’re building into parts (the nouns). In this case, we kind of did that already in the first two steps. But instead of calling them steps, we call them objects: One object is the outer shell, and one object is the engine. This way, two different factories can work on these in sort of a division of labor. Of course, the factories would have to coordinate their activities; otherwise, the two parts may not fit together when they’re ready to go. And before figuring out exactly how to build each of these objects, it would be a good idea to describe each object: What it does, its features, its dimensions, and so on. Then, when we finally have all that done, we can list the exact features and their details. And finally, we can divide the work with each person designing or building a different part.
As you can see, this second approach makes more sense. And that’s the way programmers divide their computer programs. But at the bottom of each method is something in common: The methods are made of several little processes. These processes are called functions. When you write a computer program, after you divide your job into smaller things called objects, you eventually start giving these objects behaviors. And to code these behaviors, you do just as we did in the first approach: You break them into manageable parts, again, called functions. In computer programming terms, a function is simply a small set of code that performs a specific task. But it’s more than that: Think of a function as a machine. You can put one or more things into the machine; it processes them, and then it spits out a single answer, if anything at all. One of the most valuable diagrams we have seen draws a function in this manner, like a machine, as shown in Figure 4-2.
Figure 4-2: You can think of a function as a machine.
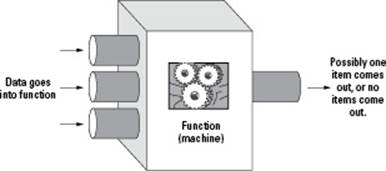
This machine (or function) has three main parts:
♦ Inputs: The function can receive data through its inputs. These data elements can be numbers, strings, or any other type. When you create such a machine, you can have as many inputs as you want (or even zero if necessary).
♦ Processor: The processor is the function itself. In terms of C++, this is actually a set of code lines.
♦ Output: A function can return something when it has finished doing its thing. In C++, this is in the form of numbers, strings, or any other type.
To make all this clear, try out the code in Listing 4-1. (Don’t forget the second line, #include <math.h>, which gives you some math capabilities.)
Listing 4-1: Seeing a Function in Action
#include <iostream>
#include <math.h>
using namespace std;
int main()
{
cout << fabs(-10.5) << endl;
cout << fabs(10.5) << endl;
return 0;
}
When you run this program, you see the following output:
10.5
10.5
In this code, you used a function or machine called fabs (usually pronounced ef-abs for floating-point absolute). This function takes a number as input and returns as output the absolute value of the number. Remember that the absolute value of a number is simply the positive version of the number. The absolute value, for example, of -5 is simply 5. The absolute value of 12 is still 12. An absolute value is always positive. And the absolute value of 0 is 0. (The reason for the f before the name abs is that it uses floating-point numbers, which are simply numbers with decimal points.)
So the first line inside main calls fabs for the value -10.5. The cout then takes the output of this function (that is, the result) and prints it to the console.
Then the second line does the same thing again, except it takes the absolute value of the number 10.5.
And where is the processor for this function? It’s not in your code; it’s in another file, and the following line ensures that your program can use this function:
#include <math.h>
You have seen functions in many places. If you use a calculator and enter a number and press the square root button, the calculator runs a function that calculates the square root.
But functions can be more sophisticated than just working with numbers. Consider this carefully: When you are using a word processor and you highlight a word and do a spelling check on the word, the program calls a function that handles the spelling check. This function does something like the following:
This is a function to check the spelling of a single word.
Inputs: A single word.
Look up the word
If the word is not found
Find some suggestions.
Open a dialog box through which you (the user)
can change the word by either typing a new word
or picking one of the selections, or just leaving
it the same.
If you made a change,
Return the new spelling.
Otherwise
Return nothing.
Otherwise
Return nothing
Notice how we grouped the if statements with indentations. The final otherwise goes with the first if statement because its indentation matches that of the if statement.
So that’s a function that performs a spelling check. But consider this: When you do not highlight a word but run the spelling checker, the spelling checker runs for the whole document. That’s another function. Here it is.
This is a function to check the spelling of the entire document
For each word in the document
Check the spelling of the single word
How does the computer do the step inside the for loop, Check the spelling of the single word? It calls the function we described earlier. This process is called code reuse. We have no reason to rewrite the entire function again if we already have it somewhere else. And that’s the beauty of functions.
Calling a Function
When you run the code in a function, computer people say you are calling the function. And just like every good person, a good function has a name. When you call a function, you do so by name.
 Often, when we’re writing a program and write code to call a function, we will say that We are calling a function. This is just partly computerspeak, and partly a strange disorder in which we computer programmers start to relate just a little too much with the computer.
Often, when we’re writing a program and write code to call a function, we will say that We are calling a function. This is just partly computerspeak, and partly a strange disorder in which we computer programmers start to relate just a little too much with the computer.
To call a function, you type its name and then a set of parentheses. Inside the parentheses, you list the items you want to send to the inputs of the function. The term we use here is pass, as in you pass the values to the function.
For example, if you want to call the fabs function, you type the name, fabs, an open parenthesis, the number you want to pass to it, and then a close parenthesis, as in the following:
fabs(-10.5)
But by itself, this does not do anything. The fabs function returns a value — the absolute value of -10.5, which comes out to be 10.5 — and you probably want to do something with that value. You could, for example, print it to the console:
cout << fabs(-10.5) << endl;
Or you could store it away in another variable. But there’s a catch. Before you can do that, you need to know the type the function returns. Just as with variables, function return values have a type. In this case, the type is a special type called double. The double type is a floating-point type that can hold many digits in a single number. To save the result of fabs, you need to have a variable of type double. The code in Listing 4-2 does this.
Listing 4-2: Seeing Another Function in Action
#include <iostream>
#include <math.h>
using namespace std;
int main()
{
double mynumber;
mynumber = fabs(-23.87);
cout << mynumber << endl;
return 0;
}
This code declares a double variable called mynumber. Then it calls fabs, passing it -23.87, and returning the value into mynumber. Next it prints the value in mynumber out to the console.
When you run this program you see the following, which is the absolute value of -23.87.
23.87
Passing a variable
You can also pass the value of a variable into a function. The code in Listing 4-3 creates two variables; one is passed into the function, and the other receives the results of the function.
Listing 4-3: Seeing Yet Another Function in Action
#include <iostream>
#include <math.h>
using namespace std;
int main()
{
double start;
double finish;
start = -253.895;
finish = fabs(start);
cout << finish << endl;
return 0;
}
(We separated the parts of the code with blank lines to make it a little easier to follow.) This code first creates two variables; the first is called start, and the second is called finish. It then initializes start with a value of -253.895. Next, it calls fabs, passing it the value of start. It saves the return value in the finish variable, and it finally prints the value in finish. When it runs, you see the following appear on the console:
253.895
Saving a function result to a variable is useful if you need to use the result several times over. For example, if you need the absolute value of -253.895 for whatever reason and then a few lines later you need it again, you have a choice: You can either call fabs(-253.895) each time or you can call it once, save it in a variable, and then use the variable each time you need it. The advantage to saving it in a variable is that if you later, for example, say, “Oh wait! I didn’t just want the absolute value! I wanted the negative of the absolute value!” you only have to change one line of code — the line where it calls fabs. If, instead, you had called fabs several times, you would have had to change it every time you called it. And by the way, in case you’re curious about how to take the negative of the absolute value and store it in a variable, you just throw a minus sign in front of it, like so:
finish = -fabs(start);
Passing multiple variables
Some functions like to have all sorts of goodies thrown their way, such as multiple parameters. As with functions that take a single value, you put the values inside a single set of parentheses. Because you have multiple values, you separate them with commas. Listing 4-4 uses a function called pow to calculate the third power of 10. (That is, it calculates 10 times 10 times 10. Yes, POW!). Make sure that you include the math.h line in the includes section so that you can use the pow function.
Listing 4-4: Seeing Yet One More Function in Action
#include <iostream>
#include <math.h>
using namespace std;
int main()
{
double number = 10.0;
double exponent = 3.0;
cout << pow(number, exponent) << endl;
return 0;
}
When you run the program, you see 10 to the third power, which is 1,000:
1000
You can also pass a mixture of variables and numbers, or just numbers. The following code snippet also calculates the third power of 10 but passes an actual number, 3.0, for the power.
double number = 10.0;
cout << pow(number, 3.0) << endl;
Or you can pass only numbers:
cout << pow(10.0, 3.0) << endl;
Writing Your Own Functions
And now the fun begins! Calling functions is great, but you get real power (ooh!) when you write your own specialized functions. Before writing a function, remember the parts: the inputs, the main code or processor, and the single output (or no output). The inputs, however, are actually called parameters, and the output is called a return value.
Listing 4-5 shows both a custom function and code in main that calls the custom function. (The function goes outside main — before it, in fact.)
Listing 4-5: Writing Your Very Own Function
#include <iostream>
using namespace std;
int AddOne(int start)
{
int newnumber;
newnumber = start + 1;
return newnumber;
}
int main()
{
int testnumber;
int result;
testnumber = 20;
result = AddOne(testnumber);
cout << result << endl;
return 0;
}
After you get all this typed in and your fingers are feeling nice and exercised, go ahead and run it. Because there’s a good bit of code, you may get some compiler errors at first; look carefully at the lines with the errors and find the difference between your code and what’s here in the book.
After you run it, you see
21
Now before we explain the code for the function, we’ll save the fun for last. Take a look at these three lines of main:
testnumber = 20;
result = AddOne(testnumber);
cout << result << endl;
You can probably put together some facts and determine what the function does. First, we called it AddOne, which is a pretty good indication in itself. Second, when you ran the program, the number 21 appear on the console, which is one more than the value in testnumber; it added one. And that, in fact, is what the function does. It’s amazing what computers can do these days.
 When you write your own functions, try to choose a name that makes sense and describes what the function does. Writing a function and calling it something like process or TheFunction is easy, but those names do not accurately describe the function.
When you write your own functions, try to choose a name that makes sense and describes what the function does. Writing a function and calling it something like process or TheFunction is easy, but those names do not accurately describe the function.
So now take a look at the function itself. First, here are a few high-level observations about it:
♦ Position: The function appears before main. Because of the way the compiler works, it must know about a function before you call it. And thus, we put it before main. (You can do this in another way, which we discuss in “Forward references and function prototypes,” later in this chapter.)
♦ Format: The function starts with a line that seems to describe the function (which we explain later in this section), and then it has an open brace and, later, a closing brace.
♦ Code: The function has code in it that is just like the type of code you could put inside a main.
After noting these high-level things, take a look at the code inside the function. The first part of it looks like this:
int newnumber;
newnumber = start + 1;
So far, this is pretty straightforward. It declares an integer variable called newnumber. Then it initializes it to start plus one. But what is start? That’s one of the inputs.
Finally, this line is at the end of the function, before the closing brace:
return newnumber;
This is the output of the function, or the return value. When you want to return something from a function, you just put the word return and then indicate what you want to return. From the preceding two lines, you can see that newnumber is one more than the number passed into the function. So this line returns the newnumber. Thus, we have covered all three parts: We have taken the input or parameter; we have processed it by creating a variable and adding one to the parameter; and we have returned the output, which is one more than the parameter.
But what is the parameter? It’s called start. And where did that come from? Here’s the very first line of the function:
int AddOne(int start)
The stuff in parentheses is the list of parameters. Notice that it looks just like a variable declaration; it’s the word int (the type, or integer) followed by a variable name, start. That’s the parameter — the input — to the function, and you can access this parameter throughout the function by simply using a variable called start.
We think that’s rather ingenious, if we do say so ourselves. Okay, so we didn’t invent it, but nevertheless, we think it’s ingenious: You can use the input to the function as a variable itself.
And so, if down in main we had written
result = AddOne(25);
then throughout the function, the value of start would be 25.
But if we had written
result = AddOne(152);
then throughout the function, the value of start would be 152.
But here’s the really great thing about functions. Or, at least, one of the loads of really great things about functions! We can call the function several times over. In the same main, we can have the following lines
cout << AddOne(100) << endl;
cout << AddOne(200) << endl;
cout << AddOne(300) << endl;
which would result in this output:
101
201
301
Arguing over parameters
Technically, the term parameter refers strictly to the inputs to the function, from the function’s perspective. When you call the function, the things you place in parentheses in the call line are not called parameters; rather, they are called arguments. Thus, in the following function header the variables first and last are parameters. But in the following call to this function
ConnectNames(“Bill”, “Murray”)
the strings “Bill” and “Murray” are arguments of the call.
In the first call to AddOne, the value of start would be 100. During the second call, the value would be 200, and during the third call, it would be 300.
Now take another look at the header:
int AddOne(int start)
The word AddOne is the name of the function, as you probably figured out already. And that leaves that thing at the beginning, the int. That’s the type of the return value. The final line in the function before the closing brace is
return newnumber;
The variable newnumber inside the function is an integer. And the return type is integer. That’s no accident: As we’ve all heard before, friends don’t let friends return something other than the type specified in the function header. The two must match in type. And further, take a look at this line from inside main:
result = AddOne(testnumber);
What type is the result variable? It’s also an integer. All three match. Again, no accident. You can copy one thing to another (in this case the function’s return value to the variable called result) only if they match in type. And here, they do. They’re both integers.
And notice one more thing about the function header: It has no semicolon after it. This is one of the places you do not put a semicolon. If you do, the compiler gets horribly confused. The CodeBlocks compiler shows an error that says, “error: expected unqualified-id before ‘{‘ token.”
 Here’s a recap of some of the rules we just mentioned regarding functions:
Here’s a recap of some of the rules we just mentioned regarding functions:
♦ Header line: The header line starts with a value for the return type, the name of the function, and the list of parameters.
♦ Parameters: The parameters are written like variable declarations, and indeed, you can use them as variables inside the function.
♦ Return type: Whatever you return from the function must match in type with the type you specified in your function header.
♦ More on format: The function header does not have a semicolon after it.
♦ Even more on format: After the function header, you use an open brace. The function ends with a closing brace. The final brace tells the compiler where the function ends.
Finally, ponder this line of code for a moment:
testnumber = AddOne(testnumber);
This takes the value stored inside testnumber, passes it into AddOne, and gets back a new number. It then takes that new number and stores it back into testnumber. Thus, testnumber’s value changes based on the results of the function AddOne.
Multiple parameters or no parameters
You don’t need to write your functions with only one parameter each. You can have several parameters, or you can have none at all. It may seem a little strange that you would want a function — a machine — that takes no inputs. But you may run into lots of cases where this may be a good idea. Here are some ideas:
♦ Day function: This would be a function that figures out the day and returns it as a string, as in “Monday” or “Tuesday”.
♦ Number-of-users function: This could be a function that figures out the current number of users logged into a Web-server computer.
♦ Current font function: This function would be in a text editor program (such as Notepad) and would return a string containing the current font name, such as “Arial”.
♦ Editing time function: This function would return the amount of time you have been using the word processor program.
♦ Username function: If you are logged onto a computer, this function would give back your username as a string, such as “Elisha”.
All the functions in this list have something in common: They look something up. Because no parameters are in the code, for the functions to process some information, they have to go out and get it themselves. It’s like sending people out into the woods to find food but not giving them any tools: It’s totally up to them to do it, and all you can do is sit back and watch and wait for your yummy surprise.
If a function takes no parameters, you write the function header as you would for one that takes parameters, and you include the parentheses; you just don’t put anything in the parentheses, as Listing 4-6 shows. So if nothing good is going in, there really can be something good coming back out, at least in the case of a function with no parameters.
Listing 4-6: Taking No Parameters
#include <iostream>
using namespace std;
string Username()
{
return “Elisha”;
}
int main()
{
cout << Username() << endl;
return 0;
}
When you run Listing 4-6, you see the following output:
Elisha
Your function can also take multiple parameters. Listing 4-7 shows this. Notice that the function, ConnectNames, takes the two strings as parameters and combines them, along with a space in the middle. Notice also that the function uses the two strings as variables.
Listing 4-7: Taking Multiple Parameters
#include <iostream>
using namespace std;
string ConnectNames(string first, string last)
{
return first + “ “ + last;
}
int main()
{
cout << ConnectNames(“Richard”, “Nixon”) << endl;
return 0;
}
In the function header in Listing 4-7, we had to put the type name string for each parameter. If we only listed it for the first, we would get a compile error. (Okay, we admit it — we did forget it, and that’s how we remembered to tell you. But that shows that even experienced programmers came make mistakes. Occasionally.)
Now here are some points about this code:
♦ We didn’t create variables for the two names in main. Instead, we just typed them as string constants (that is, as actual strings surrounded by quotes).
♦ You can do calculations and figuring right inside the return statement. That saves the extra work of creating a variable. In the function, we could have created a return variable of type string, set it to first + “ “ + last, and then returned that variable, as in the following code:
string result = first + “ “ + last;
return result;
But instead, we chose to do it all on one line, as in this:
return first + “ “ + last;
Although you can save yourself the work of creating an extra variable and just put the whole expression in the return statement, sometimes this is a bad thing. If the expression is really long like the following
return (mynumber * 100 + somethingelse / 200) *
(yetanother + 400 / mynumber) / (mynumber + evenmore);
then it can get just a tad complicated. Breaking it into variables, such as this, is best:
double a = mynumber * 100 + somethingelse / 200;
double b = yetanother + 400 / mynumber;
double c = mynumber + evenmore;
return a * b / c;
Returning nothing
In the preceding section, “Multiple parameters or no parameters,” we presented a list of functions that take no parameters; these functions go and bring back something, whether it’s a number, a string, or some other type of food.
One such example gets the username of the computer you’re logged into. But what if you are the great computer guru, and you are writing the program that actually logs somebody in? In that case, your program doesn’t ask the computer what the username is — your program tells the computer what the username is, by golly!
In that case, your program would call a function, like SetUsername, and pass the new username. And would this function return anything? It could; it could return the name back, or it could return a message saying that the username is not valid or something like that. Or, it may not return anything at all.
Take a look at the case where a function doesn’t return anything at all. In C++, the way you state that the function doesn’t return anything is by using the word void as the return type in the function header. Listing 4-8 shows this.
Listing 4-8: Returning Nothing at All
#include <iostream>
using namespace std;
void SetUsername(string newname)
{
cout << “New user is “ << newname << endl;
}
int main()
{
SetUsername(“Harold”);
return 0;
}
When you run the program, you see
New user is Harold
Notice the function header: It starts with the word void, which means that it returns nothing at all. It’s like in outer space: There’s just a big void with nothing there, and nothing is returned, except for static from the alien airwaves, but we won’t go there. Also notice that, because this function does not return anything, there is no return statement.
Now, of course, this function really doesn’t do a whole lot other than print the new username to the console, but that’s okay; it shows you how you can write a function that does not return anything.
A function of return type void returns nothing at all.
Do not try to return something in a function that has a return type of void. Void means the function returns nothing at all. If you try to put a return statement in your function, you get a compile error.
Keeping your variables local
Everybody likes to have their own stuff, and functions are no exception. When you create a variable inside the code for a function, that variable will be known only to that particular function. When you create such variables, they are called local variables, and people say that they are local to that particular function. (Well, computer people say that, anyway.)
For example, consider the following code:
#include <iostream>
using namespace std;
void PrintName(string first, string last)
{
string fullname = first + “ “ + last;
cout << fullname << endl;
}
int main()
{
PrintName(“Thomas”, “Jefferson”);
return 0;
}
Notice in the PrintName function that we declared a variable called fullname. We then use that variable in the second line in that function, the one starting with cout. But we cannot use the variable inside main. If we try to, as in the following code, we would get a compile error:
int main()
{
PrintName(“Thomas”, “Jefferson”);
cout << fullname << endl;
return 0;
}
However, we can declare a variable called fullname inside main, as in the following code. But, if we do that, this fullname is local only to main, while the other variable, also called fullname, is local only to the PrintName function. In other words, each function has its own variable; they just happen to share the same name. But they are two separate variables.
int main()
{
string fullname = “Abraham Lincoln”;
PrintName(“Thomas”, “Jefferson”);
cout << fullname << endl;
return 0;
}
When two functions declare variables by the same name, they are two separate variables. If you store a value inside one of them, the other function will not know about it. The other function only knows about its own variable by that name. Think of it the way two people could each have a storage bin in the closet labeled “tools.” If Sally puts a hammer in her bin labeled “tools” and Hal opens another bin also labeled “tools” at his house, he won’t see the very same hammer in Sally’s bin, will he? We hope not, or something is seriously awry in the universe. With variables it works the same way.
 If you use the same variable name in two different functions, forgetting that you’re working with two different variables is very easy. Only do this if you’re sure that no confusion can occur.
If you use the same variable name in two different functions, forgetting that you’re working with two different variables is very easy. Only do this if you’re sure that no confusion can occur.
If you use the same variable name in two different functions (such as a counter variable called index, which you use in a for loop), matching the case is usually a good idea. Don’t use count in one function, and Count in another. Although you can certainly do that, you may find yourself typing the name wrong when you need it. But that won’t cause you to access the other one. (You can’t because it’s in a different function.) Instead, you get a compile error, and you have to go back and fix it. Being consistent is a timesaver.
Forward references and function prototypes
In all the examples in this chapter, we have put the code for any function we write above the code for main. The reason is that the compiler scans through the code from start to finish. If it has not encountered a function yet but sees a call to it, it won’t know what it’s seeing, and it issues a good old compile error.
Such an error can be especially frustrating and could cause you to spend hours yelling at your computer (or, if you’re like us, running to the refrigerator and getting something sweet and fattening). Nothing is more frustrating than looking at your program, being told by the compiler it’s wrong, yet knowing it’s right because you know you wrote the function.
You can, however, put your functions after main; or you can even use this method to put your functions in other source-code files (something we talk about in Minibook I, Chapter 5).
What you can do is include a function prototype. A function prototype is nothing more than a copy of the function header. But instead of following it with an open brace and then the code for the function, you follow the function header with a semicolon and are finished. A function prototype, for example, looks like this:
void PrintName(string first, string last);
Then you actually write the full function (header, code, and all) later. The full function can even be later than main or later than any place that makes calls to it.
Notice that this looks just like the first line of a function. In fact, we cheated! To write it, we simply copied the first line of the original function we wrote and added a semicolon.
So where would you use this fellow? Take a look at Listing 4-9.
Listing 4-9: Using a Function Prototype
#include <iostream>
using namespace std;
void PrintName(string first, string last);
int main()
{
PrintName(“Thomas”, “Jefferson”);
return 0;
}
void PrintName(string first, string last)
{
string fullname = first + “ “ + last;
cout << fullname << endl;
}
Notice, in this listing, that we have the function header copied above main and ending with a semicolon. Then we have main. Finally we have the function itself (again, with the header but no semicolon this time). Thus, the function comes after main.
“Whoop-de-do,” we can hear you saying. The function comes after. But why bother when now we have to type the function header twice?
But rest assured, dear readers, that this step is useful. If you have a source code file with, say, 20 functions, and these functions all make various calls to each other, it could be difficult to carefully order them so that each function calls only functions that are above it in the source code file. Instead, most programmers put the functions in some logical order (or maybe not), but they don’t worry much about the calling order. Then they have all the function prototypes toward the top of the source code file, as we did earlier in Listing 4-9.
When you type a function prototype, many people say that you are specifying a forward reference. This phrase simply means that you are providing a reference to something that happens later. It’s not a big deal, and it mainly comes from some of the older programming languages. But some people use the jargon, and we hope that if you hear that phrase, it will trigger happy memories of this book.
Writing two versions of the same function
There may be times when you want to write two versions of the same function, the only difference being that they take different parameter types. For example, you may want a function called Combine. One version takes two strings and puts the two strings together, but with a space in the middle. It then prints the resulting string to the console. Another version takes two numbers, adds them, and writes all three numbers — the first two and the sum — to the console.
The first version would look like this:
void Combine(string first, string second)
{
cout << first << “ “ << second << endl;
}
There’s nothing magical or particularly special about this function. It’s called Combine; it takes two strings as parameters; it does not return anything. The code for the function prints the two strings with a space between them.
Now the second version looks like this:
void Combine(int first, int second)
{
int sum = first + second;
cout << first << “ “ << second << “ “ << sum << endl;
}
Again, nothing spectacular here. The function name is Combine, and it does not return anything. But this version takes two integers, not two strings, as parameters. The code is also different from the previous code in that it first figures the sum of the two and then it prints the different numbers.
Well this is all fine and dandy, but can you have two functions by the same name like this? Yup! Listing 4-10 shows the entire code. Both functions are present in the listing.
Listing 4-10: Writing Two Versions of a Function
#include <iostream>
using namespace std;
void Combine(string first, string second)
{
cout << first << “ “ << second << endl;
}
void Combine(int first, int second)
{
int sum = first + second;
cout << first << “ “ << second << “ “ << sum << endl;
}
int main()
{
Combine(“David”,”Letterman”);
Combine(15,20);
return 0;
}
Note in main that we called each function. How did we specify which one we want? By simply passing the right types. Take a close look at the first call:
Combine(“David”,”Letterman”);
This call includes two strings. so the compiler knows to use the first version, which takes two strings. Now look at the second function call:
Combine(15,20);
This call takes two integers, so the compiler knows to use the second version of the function.
This process of writing two versions of the same function is called overloading the function. Normally, overloading is a bad thing, like when we go to a nice restaurant and overload our stomachs. But here it’s a good thing and even useful.
When you overload a function, the parameters must differ. For example, the functions can take the same type of information but use a different number of parameters. Of course, the previous example shows that the parameters can also vary by type. You can also have different return types, but they must differ by more than just the return type.
Calling All String Functions
To get the most out of strings, you need to make use of some special functions that cater to the strings. However, using these functions is a little different from the other functions used so far in the chapter. Instead of just calling the function, you type first the variable name that holds the string, then a period (or dot, as the netheads prefer to call it), and then the function name along with any parameters (arguments, if any purists are reading).
 The reason you code string functions differently is because you’re making use of some object-oriented programming features. Minibook I, Chapter 7 describes in detail how these types of functions (called member functions) work.
The reason you code string functions differently is because you’re making use of some object-oriented programming features. Minibook I, Chapter 7 describes in detail how these types of functions (called member functions) work.
One function that you can use is called insert. You can use this function if you want to insert more characters into another string. For example, if you have the string “Something interesting and bizarre” and you insert the string “seriously ” (with a space at the end) into the middle of it starting at index 10, you’ll get the string “Something seriously interesting and bizarre”.
When you work with strings, the first character is the 0th index, and the second character is the 1st index, and so on.
The following lines of code perform an insert by using the insert function:
string words = “Something interesting and bizarre”;
words.insert(10, “seriously “);
The first of these lines simply creates a string called words and stuffs it full with the phrase “Something interesting and bizarre”. The second line does the insert. Notice the strange way of calling the function: You first specify the variable name, words, and then a dot, and then the function name, insert. Next, you follow it with the parameters in parentheses, as usual. For this function, the first parameter is the index where you want to insert the string. The second parameter is the actual string you are going to insert.
After these two lines run, the string variable called words contains the string “Something seriously interesting and bizarre”.
You can also erase parts of a string by using a similar function called, believe it or not, erase. Although computer folks like to obfuscate through their parlance (that is, confuse people through choices of words!), they do occasionally break down and pick names that actually make sense.
The following line of code erases from the string called words 16 characters starting with the 20th index:
words.erase(19,16);
Consequently, if the variable called words contains the string “Something seriously interesting and bizarre”, after this line runs, it will contain “Something seriously bizarre”.
Another useful function is replace. This function replaces a certain part of the string with another string. To use this, you specify where in the string you want to start the replacement and how many characters you want to replace. Then you specify the string you want to replace the old, worn-out parts with.
So, for example, if your string is “Something seriously bizarre” and you want to replace the word “thing” with the string “body”, you would tell replace to start at index 4, and replace 5 characters with the word “body”. To do this, you would enter:
words.replace(4, 5, “body”);
Notice the number of characters you replace does not have to be the same as the length of the new string. If the string starts out with “Something seriously bizarre”, after this replace statement runs, the string will contain “Somebody seriously bizarre”. But the string will not actually contain somebody who is seriously bizarre; it contains just the string.
Listing 4-11 shows all these functions working together.
Listing 4-11: Operating on Strings
#include <iostream>
using namespace std;
int main()
{
string words = “Something interesting and bizarre”;
cout << words << endl;
words.insert(10, “seriously “);
cout << words << endl;
words.erase(19,16);
cout << words << endl;
words.replace(4, 5, “body”);
cout << words << endl;
return 0;
}
When you run this program, you see the following output:
Something interesting and bizarre
Something seriously interesting and bizarre
Something seriously bizarre
Somebody seriously bizarre
The first line is the original string. The second line is the result of the insert function. The third line is the result of the erase function. And the final line is the result of the replace function.
Understanding main
All the programs so far have had a main. This main is actually a function. Notice its header, which is followed by code inside braces:
int main()
You can see that this is definitely a function header: It starts out with a return type, then the function name, main. This is just one form of the main function — the form that CodeBlocks uses by default. However, you may decide that you want to give users the ability to provide input when they type the name of your program at the console. In this case, you use this alternative form of the main function that includes two parameters.
int main(int argc, char *argv[])
Who, what, where, and why return?
The main function header starts with the type int. This means the function main returns something. But what? And to whom? And why and when and all those w words?
The result of main is sometimes used by the computer to return error messages if the program, for some reason, didn’t work or didn’t do what it was supposed to do. But here’s the inside scoop: Outputting a return value just doesn’t work — at least, not in the graphical environment that most of you use.
It’s true. For many computers, particularly Windows computers, the return value is of very little use to anybody. The return type is specifically designed to work with batch files (files with a BAT extension that originally appeared as part of DOS, or Disk Operating System). Consequently, unless you plan to work with batch files (and many people still do), just return 0.
On some high-powered Unix systems, the return value of main is used. Some of these systems running so-called mission-critical applications (a fancy word that means the computer programmers feel like what they’re doing is important to the safety of the universe) do indeed use the return values from main. These computers may run hundreds of programs. If one of these programs returns something other than 0, another program detects this and notifies somebody (usually by sending the poor sap a page in the middle of the night). When you’re still learning C++, you’re not likely to need to return things other than 0, but if you’re lucky enough to be working for a company that builds applications vital to the well-being of the universe, you may want to find out from your teammates if you do, in fact, need to return something other than 0.
So what about those seriously bizarre looking parameters in main? The first is reasonably straightforward; it’s an integer variable with the goofy name argv, which sounds like something Scooby-Doo would say. But what about that second goofiness? To understand the second, you need to know that these two parameters are actually used as command-line parameters. When you run a program, especially from the command prompt, you type the name of the program and press Enter. But before pressing Enter, you can follow the program name with other words. Many of the commands you use in Unix and in the Windows command-line tool (also known as DOS) have a program name and then various parameters. For example, on Unix you could type the following command to copy the file called myfile to a new file called yourfile:
cp myfile yourfile
On Windows, you could type the following command to copy the file called myfile to a new file called yourfile:
copy myfile yourfile
When you run such a command, you are actually running a program called copy. The program takes two command-line parameters, in this case “myfile” and “yourfile” and passes these two strings into the main function as parameters.
For the main function, the first parameter in the header is argc, pronounced arg-SEE, which represents the number of command-line parameters. In the case of the copy or cp command (see the two preceding lines of code), you have two (“myfile” and “yourfile”), so argcwould be 2.
The second parameter in the main function is the cryptic-looking char *argv[]. The name of the variable is called argv, and it is pronounced arg-VEE. Minibook I, Chapter 8, deals with a topic called an array. An array is a sequence of variables stored under one name. The argvvariable is one such animal. To access the individual variables stored under the single umbrella known as argv, you do something like this:
cout << argv[0] << endl;
cout << argv[1] << endl;
(In the preceding example, you’re using brackets as you did similarly with accessing the individual characters in a string.)
In the case of the two command-line parameters myfile and yourfile, these two lines of code would print the lines
myfile
yourfile
You can access the command-line parameters using a for loop. Listing 4-12 shows how.
Listing 4-12: Accessing the Command-Line Parameters
#include <iostream>
#include <stdlib.h>
int main(int argc, char *argv[])
{
for (int index=0; index < argc; index++)
{
cout << argv[index] << endl;
}
return 0;
}
When we run this program from the prompt using the following command-line parameters
CommandLineParameters Command Line Parameters
we see the following output:
c:\CommandLineParameters Command Line Parameters
CommandLineParameters
Command
Line
Parameters
The first item in the argv list is always the name of the program.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.