Professional C++ (2014)
Part IVMastering Advanced Features of C++
Chapter 22Memory Management
WHAT’S IN THIS CHAPTER?
· Different ways to use and manage memory
· The often-perplexing relationship between arrays and pointers
· A low-level look at working with memory
· Smart pointers and how to use them
· Solutions to a few memory-related problems
WROX.COM DOWNLOADS FOR THIS CHAPTER
Please note that all the code examples for this chapter are available as a part of this chapter’s code download on the book’s website at www.wrox.com/go/proc++3e on the Download Code tab.
In many ways, programming in C++ is like driving without a road. Sure, you can go anywhere you want, but there are no lines or traffic lights to keep you from injuring yourself. C++, like the C language, has a hands-off approach toward its programmers. The language assumes that you know what you’re doing. It allows you to do things that are likely to cause problems because C++ is incredibly flexible and sacrifices safety in favor of performance.
Memory allocation and management is a particularly error-prone area of C++ programming. To write high-quality C++ programs, professional C++ programmers need to understand how memory works behind the scenes. This chapter explores the ins and outs of memory management. You will learn about the pitfalls of dynamic memory and some techniques for avoiding and eliminating them.
This chapter comes late in the book because in modern C++ you should avoid low-level memory operations as much as possible. For example, instead of dynamically allocated C-style arrays you should use STL containers, such as vector, which handle all memory management automatically for you. Instead of naked pointers you should use smart pointers, such as unique_ptr and shared_ptr, which automatically free the underlying resource, such as memory, when it’s not needed anymore. Basically, you should try to avoid having calls to memory allocation routines such as new and delete in your code. Of course, it might not always be possible, and in existing code it will most likely not be the case, so a professional C++ programmer still needs to know how memory works behind the scenes.
WARNING In modern C++ you should avoid low-level memory operations as much as possible in favor of modern constructs such as containers and smart pointers.
WORKING WITH DYNAMIC MEMORY
Memory is a low-level component of the computer that sometimes unfortunately rears its head even in a high-level programming language like C++. Many programmers understand only enough about dynamic memory to get by. They shy away from data structures that use dynamic memory, or get their programs to work by trial and error. A solid understanding of how dynamic memory really works in C++ is essential to becoming a professional C++ programmer.
How to Picture Memory
Understanding dynamic memory is much easier if you have a mental model for what objects look like in memory. In this book, a unit of memory is shown as a box with a label next to it. The label indicates a variable name that corresponds to the memory. The data inside the box displays the current value of the memory.
For example, Figure 22-1 shows the state of memory after the following line is executed. The line should be in a function, so that i is a local variable:

FIGURE 22-1
int i = 7;
Since i is a local variable, it is allocated on the stack because it is declared as a simple type, not dynamically using the new keyword.
When you use the new keyword, memory is allocated on the heap. The following code creates a variable ptr on the stack, and then allocates memory on the heap to which ptr points.
int* ptr;
ptr = new int;
Figure 22-2 shows the state of memory after this code is executed. Notice that the variable ptr is still on the stack even though it points to memory on the heap. A pointer is just a variable and can live either on the stack or the heap, although this fact is easy to forget. Dynamic memory, however, is always allocated on the heap.

FIGURE 22-2
The next example shows that pointers can exist both on the stack and on the heap:
int** handle;
handle = new int*;
*handle = new int;
The preceding code first declares a pointer to a pointer to an integer as the variable handle. It then dynamically allocates enough memory to hold a pointer to an integer, storing the pointer to that new memory in handle. Next, that memory (*handle) is assigned a pointer to another section of dynamic memory that is big enough to hold the integer. Figure 22-3 shows the two levels of pointers with one pointer residing on the stack (handle) and the other residing on the heap (*handle).
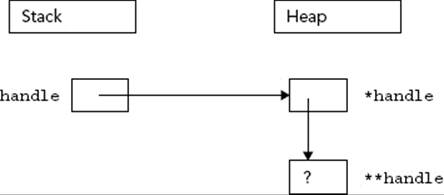
FIGURE 22-3
Allocation and Deallocation
To create space for a variable, you use the new keyword. To release that space for use by other parts of the program, you use the delete keyword. Of course, it wouldn’t be C++ if simple concepts such as new and delete didn’t have several variations and intricacies.
Using new and delete
When you want to allocate a block of memory, you call new with the type of variable for which you need space. new returns a pointer to that memory, although it is up to you to store that pointer in a variable. If you ignore the return value of new, or if the pointer variable goes out of scope, the memory becomes orphaned because you no longer have a way to access it. This is also called a memory leak.
For example, the following code orphans enough memory to hold an int. Figure 22-4 shows the state of memory after the code is executed. When there are blocks of data on the heap with no access, direct or indirect, from the stack, the memory is orphaned or leaked.
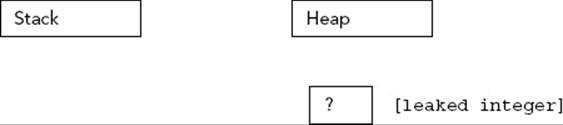
FIGURE 22-4
void leaky()
{
new int; // BUG! Orphans memory!
cout << "I just leaked an int!" << endl;
}
Until they find a way to make computers with an infinite supply of fast memory, you will need to tell the compiler when the memory associated with an object can be released and used for another purpose. To free memory on the heap, use the delete keyword with a pointer to the memory, as shown here:
int* ptr;
ptr = new int;
delete ptr;
WARNING As a rule of thumb, every line of code that allocates memory with new and that uses a naked pointer instead of storing the pointer in a smart pointer, should correspond to another line of code that releases the same memory with delete.
What about My Good Friend malloc?
If you are a C programmer, you may be wondering what is wrong with the malloc() function. In C, malloc() is used to allocate a given number of bytes of memory. For the most part, using malloc() is simple and straightforward. The malloc() function still exists in C++, but you should avoid it. The main advantage of new over malloc() is that new doesn’t just allocate memory, it constructs objects!
For example, consider the following two lines of code, which use a hypothetical class called Foo:
Foo* myFoo = (Foo*)malloc(sizeof(Foo));
Foo* myOtherFoo = new Foo();
After executing these lines, both myFoo and myOtherFoo will point to areas of memory on the heap that are big enough for a Foo object. Data members and methods of Foo can be accessed using both pointers. The difference is that the Foo object pointed to by myFoo isn’t a proper object because it was never constructed. The malloc() function only sets aside a piece of memory of a certain size. It doesn’t know about or care about objects. In contrast, the call to new allocates the appropriate size of memory and also calls an appropriate constructor to construct the object. Chapter 14 describes these two duties of new in more detail.
A similar difference exists between the free() function and the delete operator. With free(), the object’s destructor is not called. With delete, the destructor is called and the object is properly cleaned up.
WARNING You should never use malloc() and free() in C++. Use only new and delete.
When Memory Allocation Fails
Many, if not most, programmers write code with the assumption that new will always be successful. The rationale is that if new fails, it means that memory is very low and life is very, very bad. It is often an unfathomable state to be in because it’s unclear what your program could possibly do in this situation.
By default, your program will terminate if new fails. In many programs, this behavior is acceptable. The program exits when new fails because new throws an exception if there is not enough memory available for the request. Chapter 13 explains approaches to recover gracefully from an out-of-memory situation.
There is also an alternative version of new, which will not throw an exception. Instead, it will return nullptr, similar to the behavior of malloc() in C. The syntax for using this version is shown here:
int* ptr = new(nothrow) int;
Of course, you still have the same problem as the version that throws an exception — what do you do when the result is nullptr? The compiler doesn’t require you to check the result, so the nothrow version of new is more likely to lead to other bugs than the version that throws an exception. For this reason, it’s suggested that you use the standard version of new. If out-of-memory recovery is important to your program, the techniques covered in Chapter 13 give you all the tools you need.
Arrays
Arrays package multiple variables of the same type into a single variable with indices. Working with arrays quickly becomes natural to a novice programmer because it is easy to think about values in numbered slots. The in-memory representation of an array is not far off from this mental model.
Arrays of Basic Types
When your program allocates memory for an array, it is allocating contiguous pieces of memory, where each piece is large enough to hold a single element of the array. For example, a local array of five ints can be declared on the stack as follows:
int myArray[5];
Figure 22-5 shows the state of memory after the array is created. When creating arrays on the stack, the size must be a constant value known at compile time.
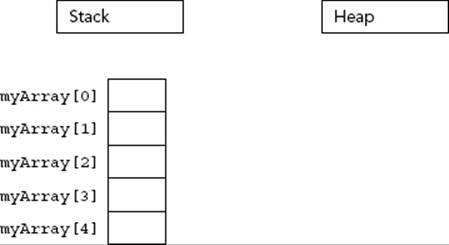
FIGURE 22-5
NOTE Some compilers allow variable-sized arrays on the stack. This is not a standard feature of C++, so I recommend cautiously backing away when you see it.
Declaring arrays on the heap is no different, except that you use a pointer to refer to the location of the array. The following code allocates memory for an array of five ints and stores a pointer to the memory in a variable called myArrayPtr.
int* myArrayPtr = new int[5];
As Figure 22-6 illustrates, the heap-based array is similar to the stack-based array, but in a different location. The myArrayPtr variable points to the 0th element of the array.
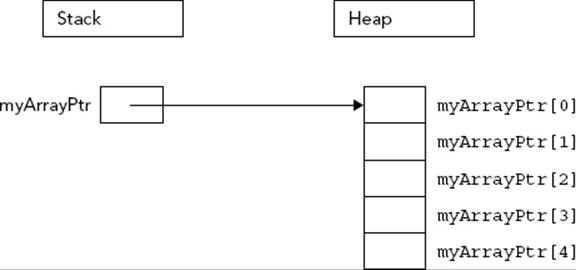
FIGURE 22-6
Each call to new[] should be paired with a call to delete[] to clean up the memory. For example:
delete [] myArrayPtr;
The advantage of putting an array on the heap is that you can use dynamic memory to define its size at run time. For example, the following function receives a desired number of documents from a hypothetical function named askUserForNumberOfDocuments() and uses that result to create an array of Document objects.
Document* createDocArray()
{
int numDocs = askUserForNumberOfDocuments();
Document* docArray = new Document[numDocs];
return docArray;
}
Remember that each call to new[] should be paired with a call to delete[], so in this example, it’s important that the caller of createDocArray() uses delete[] to clean up the returned memory. Another problem is that C-style arrays don’t know their size, thus callers ofcreateDocArray() have no idea how many elements there are in the returned array.
In the preceding function, docArray is a dynamically allocated array. Do not get this confused with a dynamic array. The array itself is not dynamic because its size does not change once it is allocated. Dynamic memory lets you specify the size of an allocated block at run time, but it does not automatically adjust its size to accommodate the data.
NOTE There are data structures, such as STL containers, that do dynamically adjust their size and that do know their actual size. You should use these STL containers instead of standard arrays because they are much safer to use.
There is a function in C++ called realloc(), which is a holdover from the C language. Don’t use it! In C, realloc() is used to effectively change the size of an array by allocating a new block of memory of the new size, copying all of the old data to the new location, and deleting the original block. This approach is extremely dangerous in C++ because user-defined objects will not respond well to bitwise copying.
WARNING Do not use realloc() in C++. It is not your friend.
Arrays of Objects
Arrays of objects are no different than arrays of simple types. When you use new[N] to allocate an array of N objects, enough space is allocated for N contiguous blocks where each block is large enough for a single object. Using new[], the zero-argument constructor for each of the objects will automatically be called. In this way, allocating an array of objects using new[] will return a pointer to an array of fully formed and initialized objects.
For example, consider the following class:
class Simple
{
public:
Simple() { cout << "Simple constructor called!" << endl; }
virtual ~Simple() { cout << "Simple destructor called!" << endl; }
};
If you allocate an array of four Simple objects, the Simple constructor is called four times.
Simple* mySimpleArray = new Simple[4];
The memory diagram for this array is shown in Figure 22-7. As you can see, it is no different than an array of basic types.
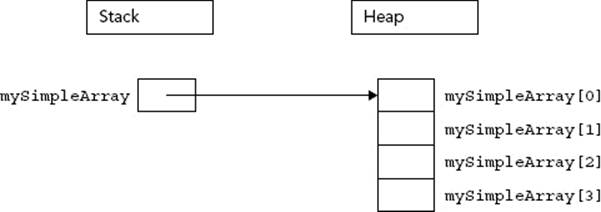
FIGURE 22-7
Deleting Arrays
As mentioned earlier, when you allocate memory with the array version of new (new[]), you must release it with the array version of delete (delete[]). This version will automatically destruct the objects in the array in addition to releasing the memory associated with them. If you do not use the array version of delete, your program may behave in odd ways. In some compilers, only the destructor for the 0th element of the array will be called because the compiler only knows that you are deleting a pointer to an object, and all the other elements of the array will become orphaned objects. In other compilers, memory corruption may occur because new and new[] can use completely different memory allocation schemes.
Simple* mySimpleArray = new Simple[4];
// Use mySimpleArray ...
delete [] mySimpleArray;
mySimpleArray = nullptr;
WARNING Always use delete on anything allocated with new, and always use delete[] on anything allocated with new[].
Of course, the destructors are called only if the elements of the array are objects. If you have an array of pointers, you will still need to delete each object pointed to individually just as you allocated each object individually, as shown in the following code:
size_t arrSize = 4;
Simple** mySimplePtrArray = new Simple*[arrSize];
// Allocate an object for each pointer.
for (size_t i = 0; i < arrSize; i++) {
mySimplePtrArray[i] = new Simple();
}
// Use mySimplePtrArray ...
// Delete each allocated object.
for (size_t i = 0; i < arrSize; i++) {
delete mySimplePtrArray[i];
}
// Delete the array itself.
delete [] mySimplePtrArray;
mySimplePtrArray = nullptr;
WARNING In modern C++ you should avoid using naked C-style pointers. Thus, instead of storing plain-old dumb pointers in plain-old dumb arrays, you should store smart pointers in modern containers. These smart pointers will automatically deallocate memory associated with them.
Multi-Dimensional Arrays
Multi-dimensional arrays extend the notion of indexed values to use multiple indices. For example, a Tic-Tac-Toe game might use a two-dimensional array to represent a three-by-three grid. The following example shows such an array declared on the stack and accessed with some test code:
char board[3][3];
// Test code
board[0][0] = 'X'; // X puts marker in position (0,0).
board[2][1] = 'O'; // O puts marker in position (2,1).
You may be wondering whether the first subscript in a two-dimensional array is the x-coordinate or the y-coordinate. The truth is that it doesn’t really matter, as long as you are consistent. A four-by-seven grid could be declared as char board[4][7] or char board[7][4]. For most applications, it is easiest to think of the first subscript as the x-axis and the second as the y-axis.
Multi-Dimensional Stack Arrays
In memory, a stack-based two-dimensional array looks like Figure 22-8. Because memory doesn’t have two axes (addresses are merely sequential), the computer represents a two-dimensional array just like a one-dimensional array. The difference is the size of the array and the method used to access it.
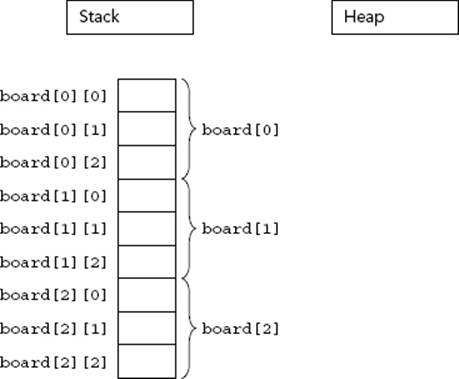
FIGURE 22-8
The size of a multi-dimensional array is all of its dimensions multiplied together, then multiplied by the size of a single element in the array. In Figure 22-8, the three-by-three board is 3 × 3 × 1 = 9 bytes, assuming that a character is 1 byte. For a four-by-seven board of characters, the array would be 4 × 7 × 1 = 28 bytes.
To access a value in a multi-dimensional array, the computer treats each subscript as accessing another subarray within the multi-dimensional array. For example, in the three-by-three grid, the expression board[0] actually refers to the subarray highlighted in Figure 22-9. When you add a second subscript, such as board[0][2], the computer is able to access the correct element by looking up the second subscript within the subarray, as shown in Figure 22-10.
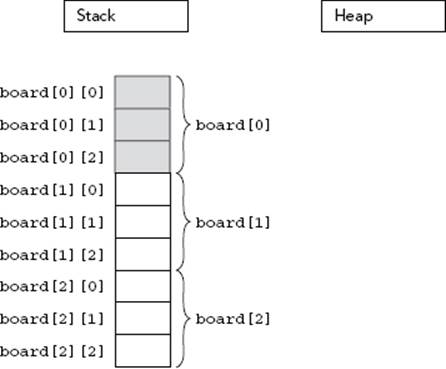
FIGURE 22-9
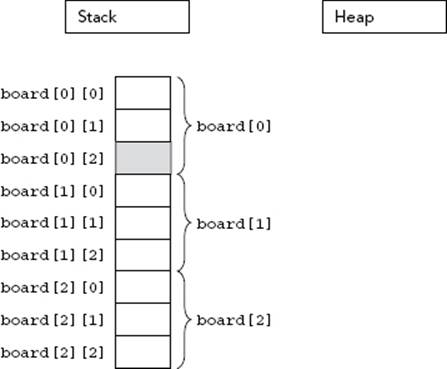
FIGURE 22-10
These techniques are extended to N-dimensional arrays, though dimensions higher than three tend to be difficult to conceptualize and are rarely useful in everyday applications.
Multi-Dimensional Heap Arrays
If you need to determine the dimensions of a multi-dimensional array at run time, you can use a heap-based array. Just as a single-dimensional dynamically allocated array is accessed through a pointer, a multi-dimensional dynamically allocated array is also accessed through a pointer. The only difference is that in a two-dimensional array, you need to start with a pointer-to-a-pointer; and in an N-dimensional array, you need N levels of pointers. At first, it might seem as if the correct way to declare and allocate a dynamically allocated multi-dimensional array is as follows:
char** board = new char[i][j]; // BUG! Doesn't compile
This code doesn’t compile because heap-based arrays don’t work like stack-based arrays. Their memory layout isn’t contiguous, so allocating enough memory for a stack-based multi-dimensional array is incorrect. Instead, you can start by allocating a single contiguous array for the first subscript dimension of a heap-based array. Each element of that array is actually a pointer to another array that stores the elements for the second subscript dimension. This layout for a two-by-two dynamically allocated board is shown in Figure 22-11.
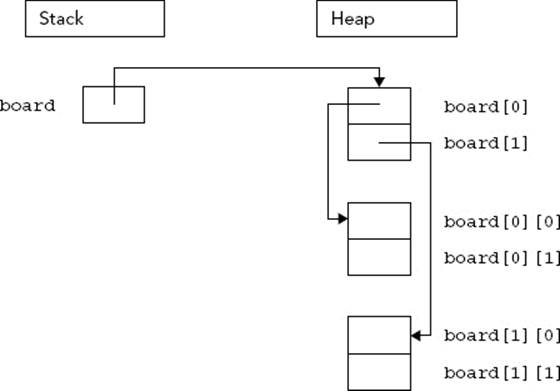
FIGURE 22-11
Unfortunately, the compiler doesn’t allocate memory for the subarrays on your behalf. You can allocate the first dimension array just like a single-dimensional heap-based array, but the individual subarrays must be explicitly allocated. The following function properly allocates memory for a two-dimensional array:
char** allocateCharacterBoard(size_t xDimension, size_t yDimension)
{
char** myArray = new char*[xDimension]; // Allocate first dimension
for (size_t i = 0; i < xDimension; i++) {
myArray[i] = new char[yDimension]; // Allocate ith subarray
}
return myArray;
}
When you wish to release the memory associated with a multi-dimensional heap-based array, the array delete[] syntax will not clean up the subarrays on your behalf. Your code to release an array should mirror the code to allocate it, as in the following function:
void releaseCharacterBoard(char** myArray, size_t xDimension)
{
for (size_t i = 0; i < xDimension; i++) {
delete [] myArray[i]; // Delete ith subarray
}
delete [] myArray; // Delete first dimension
}
WARNING Now that you know all the details to work with arrays, it is recommended to avoid these old C-style arrays as much as possible because they do not provide any memory safety. They are explained here because you will encounter them in legacy code. In new code, you should use the C++ STL containers such as std::array, std::vector, std::list, and so on. For example, use vector<T> for a one-dimensional dynamic array. Use vector<vector<T>> for a two-dimensional dynamic array and so on.
Working with Pointers
Pointers get their bad reputation from the relative ease with which you can abuse them. Because a pointer is just a memory address, you could theoretically change that address manually, even doing something as scary as the following line of code:
char* scaryPointer = (char*)7;
The previous line builds a pointer to the memory address 7, which is likely to be random garbage or memory used elsewhere in the application. If you start to use areas of memory that weren’t set aside on your behalf with new, eventually you will corrupt the memory associated with an object, or the memory involved with the management of the heap, and your program will malfunction. Such a malfunction can manifest itself in several ways. For example, it can manifest itself as invalid results because the data has been corrupted, or as hardware exceptions being triggered due to accessing non-existent memory, or attempting to write to protected memory. If you are lucky, you will get one of the serious errors that usually results in program termination by the operating system or the C++ runtime library; if you are unlucky, you will just get a wrong result.
A Mental Model for Pointers
There are two ways to think about pointers. More mathematically minded readers might view pointers as addresses. This view makes pointer arithmetic, covered later in this chapter, a bit easier to understand. Pointers aren’t mysterious pathways through memory; they are numbers that happen to correspond to a location in memory. Figure 22-12 illustrates a two-by-two grid in the address-based view of the world.
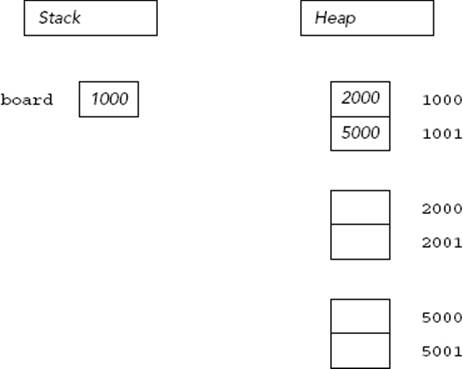
FIGURE 22-12
NOTE The addresses in Figure 22-12 are just for illustrative purposes. Addresses on a real system are highly dependent on your hardware and operating system.
Readers who are more comfortable with spatial representations might derive more benefit from the “arrow” view of pointers. A pointer is a level of indirection that says to the program, “Hey! Look over there.” With this view, multiple levels of pointers become individual steps on the path to data. Figure 22-11 shows a graphical view of pointers in memory.
When you dereference a pointer, by using the * operator, you are telling the program to look one level deeper in memory. In the address-based view, think of a dereference as a jump in memory to the address indicated by the pointer. With the graphical view, every dereference corresponds to following an arrow from its base to its head.
When you take the address of a location, using the & operator, you are adding a level of indirection in memory. In the address-based view, the program is noting the numerical address of the location, which can be stored as a pointer. In the graphical view, the &operator creates a new arrow whose head ends at the location designated by the expression. The base of the arrow can be stored as a pointer.
Casting with Pointers
Because pointers are just memory addresses (or arrows to somewhere), they are somewhat weakly typed. A pointer to an XML Document is the same size as a pointer to an integer. The compiler will let you easily cast any pointer type to any other pointer type using a C-style cast:
Document* documentPtr = getDocument();
char* myCharPtr = (char*)documentPtr;
A static cast offers a bit more safety. The compiler will refuse to perform a static cast on pointers to different data types:
Document* documentPtr = getDocument();
char* myCharPtr = static_cast<char*>(documentPtr); // BUG! Won't compile
If the two pointers you are casting are actually pointing to objects that are related through inheritance, the compiler will permit a static cast. However, a dynamic cast is a safer way to accomplish a cast within an inheritance hierarchy. Consult Chapter 10 for details on all C++ style casts.
ARRAY-POINTER DUALITY
You have already seen some of the overlap between pointers and arrays. Heap-allocated arrays are referred to by a pointer to their first element. Stack-based arrays are referred to by using the array syntax ([]) with an otherwise normal variable declaration. As you are about to learn, however, the overlap doesn’t end there. Pointers and arrays have a complicated relationship.
Arrays Are Pointers!
A heap-based array is not the only place where you can use a pointer to refer to an array. You can also use the pointer syntax to access elements of a stack-based array. The address of an array is really the address of the 0th element. The compiler knows that when you refer to an array in its entirety by its variable name, you are really referring to the address of the 0th element. In this way, the pointer works just like a heap-based array. The following code creates an array on the stack, but uses a pointer to access the array:
int myIntArray[10];
int* myIntPtr = myIntArray;
// Access the array through the pointer.
myIntPtr[4] = 5;
The ability to refer to a stack-based array through a pointer is useful when passing arrays into functions. The following function accepts an array of integers as a pointer. Note that the caller will need to explicitly pass in the size of the array because the pointer implies nothing about size. In fact, C++ arrays of any form, pointer or not, have no built-in notion of size. That is another reason why you should use modern containers such as those provided by the STL.
void doubleInts(int* theArray, size_t inSize)
{
for (size_t i = 0; i < inSize; i++) {
theArray[i] *= 2;
}
}
The caller of this function can pass a stack-based or heap-based array. In the case of a heap-based array, the pointer already exists and is passed by value into the function. In the case of a stack-based array, the caller can pass the array variable, and the compiler will automatically treat the array variable as a pointer to the array, or you can explicitly pass the address of the first element. All three forms are shown here:
size_t arrSize = 4;
int* heapArray = new int[arrSize]{ 1, 5, 3, 4 };
doubleInts(heapArray, arrSize);
delete [] heapArray;
heapArray = nullptr;
int stackArray[] = { 5, 7, 9, 11 };
arrSize = sizeof(stackArray) / sizeof(stackArray[0]);
doubleInts(stackArray, arrSize);
doubleInts(&stackArray[0], arrSize);
Parameter-passing semantics of arrays are uncannily similar to that of pointers, because the compiler treats an array as a pointer when it is passed to a function. A function that takes an array as an argument and changes values inside the array is actually changing the original array, not a copy. Just like a pointer, passing an array effectively mimics pass-by-reference functionality because what you really pass to the function is the address of the original array, not a copy. The following implementation of doubleInts() changes the original array even though the parameter is an array, not a pointer:
void doubleInts(int theArray[], size_t inSize)
{
for (size_t i = 0; i < inSize; i++) {
theArray[i] *= 2;
}
}
Any number between the square brackets after theArray in the function prototype is simply ignored. The following three versions are identical:
void doubleInts(int* theArray, size_t inSize);
void doubleInts(int theArray[], size_t inSize);
void doubleInts(int theArray[2], size_t inSize);
You may be wondering why things work this way. Why doesn’t the compiler just copy the array when array syntax is used in the function definition? This is done for efficiency — it takes time to copy the elements of an array, and they potentially take up a lot of memory. By always passing a pointer, the compiler doesn’t need to include the code to copy the array.
There is a way to pass known-length stack-based arrays “by reference” to a function, although the syntax is non-obvious. This does not work for heap-based arrays. For example, the following doubleIntsStack() accepts only stack-based arrays of size 4:
void doubleIntsStack(int (&theArray)[4]);
A function template can be used to let the compiler deduce the size of the stack-based array automatically:
template<size_t N>
void doubleIntsStack(int (&theArray)[N])
{
for (size_t i = 0; i < N; i++) {
theArray[i] *= 2;
}
}
To summarize, arrays declared using array syntax can be accessed through a pointer. When an array is passed to a function, it is always passed as a pointer.
Not All Pointers Are Arrays!
Because the compiler lets you pass in an array where a pointer is expected, as in the doubleInts() function shown earlier, you may be led to believe that pointers and arrays are the same. In fact there are subtle, but important, differences. Pointers and arrays share many properties and can sometimes be used interchangeably (as shown earlier), but they are not the same.
A pointer by itself is meaningless. It may point to random memory, a single object, or an array. You can always use array syntax with a pointer, but doing so is not always appropriate because pointers aren’t always arrays. For example, consider the following code:
int* ptr = new int;
The pointer ptr is a valid pointer, but it is not an array. You can access the pointed-to value using array syntax (ptr[0]), but doing so is stylistically questionable and provides no real benefit. In fact, using array syntax with non-array pointers is an invitation for bugs. The memory at ptr[1] could be anything!
WARNING Arrays are automatically referenced as pointers, but not all pointers are arrays.
LOW-LEVEL MEMORY OPERATIONS
One of the great advantages of C++ over C is that you don’t need to worry quite as much about memory. If you code using objects, you just need to make sure that each individual class properly manages its own memory. Through construction and destruction, the compiler helps you manage memory by telling you when to do it. Hiding the management of memory within classes makes a huge difference in usability, as demonstrated by the STL classes. However, with some applications or with legacy code, you may encounter the need to work with memory at a lower level. Whether for legacy, efficiency, debugging, or curiosity, knowing some techniques for working with raw bytes can be helpful.
Pointer Arithmetic
The C++ compiler uses the declared types of pointers to allow you to perform pointer arithmetic. If you declare a pointer to an int and increase it by 1, the pointer moves ahead in memory by the size of an int, not by a single byte. This type of operation is most useful with arrays, since they contain homogeneous data that is sequential in memory. For example, assume you declare an array of ints on the heap:
int* myArray = new int[8];
You are already familiar with the following syntax for setting the value in position 2:
myArray[2] = 33;
With pointer arithmetic, you can equivalently use the following syntax, which obtains a pointer to the memory that is “2 ints ahead” of myArray and then dereferences it to set the value:
*(myArray + 2) = 33;
As an alternative syntax for accessing individual elements, pointer arithmetic doesn’t seem too appealing. Its real power lies in the fact that an expression like myArray + 2 is still a pointer to an int, and thus can represent a smaller int array. Suppose you have the following wide string:
const wchar_t* myString = L"Hello, World!";
Suppose you also have a function that takes in a string and returns a new string that contains a capitalized version of the input:
wchar_t* toCaps(const wchar_t* inString);
You can capitalize myString by passing it into this function. However, if you only want to capitalize part of myString, you can use pointer arithmetic to refer to only a latter part of the string. The following code calls toCaps() on the World part of the string by just adding 7 to the pointer, even though wchar_t is usually more than 1 byte:
toCaps(myString + 7);
Another useful application of pointer arithmetic involves subtraction. Subtracting one pointer from another of the same type gives you the number of elements of the pointed-to type between the two pointers, not the absolute number of bytes between them.
Custom Memory Management
For 99 percent of the cases you will encounter (some might say 100 percent of the cases), the built-in memory allocation facilities in C++ are adequate. Behind the scenes, new and delete do all the work of handing out memory in properly sized chunks, maintaining a list of available areas of memory, and releasing chunks of memory back to that list upon deletion.
When resource constraints are extremely tight, or under very special conditions, such as managing shared memory, implementing custom memory management may be a viable option. Don’t worry — it’s not as scary as it sounds. Basically, managing memory yourself generally means that classes allocate a large chunk of memory and dole out that memory in pieces as it is needed.
How is this approach any better? Managing your own memory can potentially reduce overhead. When you use new to allocate memory, the program also needs to set aside a small amount of space to record how much memory was allocated. That way, when you calldelete, the proper amount of memory can be released. For most objects, the overhead is so much smaller than the memory allocated that it makes little difference. However, for small objects or programs with enormous numbers of objects, the overhead can have an impact.
When you manage memory yourself, you might know the size of each object a priori, so you might be able to avoid the overhead for each object. The difference can be enormous for large numbers of small objects. The syntax for performing custom memory management is described in Chapter 14.
Garbage Collection
At the other end of the memory hygiene spectrum lies garbage collection. With environments that support garbage collection, the programmer rarely, if ever, explicitly frees memory associated with an object. Instead, objects to which there are no references anymore will be cleaned up automatically at some point by the runtime library.
Garbage collection is not built into the C++ language as it is in C# and Java. In modern C++ you use smart pointers to manage memory, while in legacy code you will see memory management at the object level through new and delete. It is possible but not easy to implement garbage collection in C++, but freeing yourself from the task of releasing memory would probably introduce new headaches.
One approach to garbage collection is called mark and sweep. With this approach, the garbage collector periodically examines every single pointer in your program and annotates the fact that the referenced memory is still in use. At the end of the cycle, any memory that hasn’t been marked is deemed to be not in-use and is freed.
A mark-and-sweep algorithm could be implemented in C++ if you were willing to do the following:
1. Register all pointers with the garbage collector so that it can easily walk through the list of all pointers.
2. Derive all objects from a mixin class, perhaps GarbageCollectible, that allows the garbage collector to mark an object as in-use.
3. Protect concurrent access to objects by making sure that no changes to pointers can occur while the garbage collector is running.
As you can see, this approach to garbage collection requires quite a bit of diligence on the part of the programmer. It may even be more error-prone than using delete! Attempts at a safe and easy mechanism for garbage collection have been made in C++, but even if a perfect implementation of garbage collection in C++ came along, it wouldn’t necessarily be appropriate to use for all applications. Among the downsides of garbage collection are the following:
· When the garbage collector is actively running, the program might become unresponsive.
· With garbage collectors, you have so called non-deterministic destructors. Because an object is not destroyed until it is garbage collected, the destructor is not executed immediately when the object leaves its scope. This means that cleaning up resources (such as closing a file, releasing a lock, etc.), which is done by the destructor, is not performed until some indeterminate time in the future.
Object Pools
Garbage collection is like buying plates for a picnic and leaving any used plates out in the yard where the wind will conveniently blow them into the neighbor’s yard. Surely, there must be a more ecological approach to memory management.
Object pools are the analog of recycling. You buy a reasonable number of plates, and after using a plate, you clean it so that it can be reused later. Object pools are ideal for situations where you need to use many objects of the same type over time, and creating each one incurs overhead.
Chapter 25 contains further details on using object pools for performance efficiency.
Function Pointers
You don’t normally think about the location of functions in memory, but each function actually lives at a particular address. In C++, you can use functions as data. In other words, you can take the address of a function and use it like you use a variable.
Function pointers are typed according to the parameter types and return type of compatible functions. One way to work with function pointers is to use a type alias, discussed in Chapter 10. A type alias allows you to assign a type name to the family of functions that have the given characteristics. For example, the following line defines a type called MatchFcn that represents a pointer to any function that has two int parameters and returns a bool:
using MatchFcn = bool(*)(int, int);
This type alias is equivalent to the following old-school, less readable, typedef:
typedef bool(*MatchFcn)(int, int);
Now that this new type exists, you can write a function that takes a MatchFcn as a parameter. For example, the following function accepts two int arrays and their size, as well as a MatchFcn. It iterates through the arrays in parallel and calls the MatchFcn on corresponding elements of both arrays, printing a message if the MatchFcn function returns true. Notice that even though the MatchFcn is passed in as a variable, it can be called just like a regular function:
void findMatches(int values1[], int values2[], size_t numValues, MatchFcn inFunc)
{
for (size_t i = 0; i < numValues; i++) {
if (inFunc(values1[i], values2[i])) {
cout << "Match found at position " << i <<
" (" << values1[i] << ", " << values2[i] << ")" << endl;
}
}
}
Note that this implementation requires that both arrays have at least numValues elements. To call the findMatches() function, all you need is any function that adheres to the defined MatchFcn type — that is, any type that takes in two ints and returns a bool. For example, consider the following function, which returns true if the two parameters are equal:
bool intEqual(int inItem1, int inItem2)
{
return inItem1 == inItem2;
}
Because the intEqual() function matches the MatchFcn type, it can be passed as the final argument to findMatches(), as follows:
int arr1[] = { 2, 5, 6, 9, 10, 1, 1 };
int arr2[] = { 4, 4, 2, 9, 0, 3, 4 };
int arrSize = sizeof(arr1) / sizeof(arr1[0]);
cout << "Calling findMatches() using intEqual():" << endl;
findMatches(arr1, arr2, arrSize, &intEqual);
The intEqual() function is passed into the findMatches() function by taking its address. Technically, the & character is optional — if you put the function name, the compiler will know that you mean to take its address. The output is as follows:
Calling findMatches() using intEqual():
Match found at position 3 (9, 9)
The benefit of function pointers lies in the fact that findMatches() is a generic function that compares parallel values in two arrays. As it is used above, it compares based on equality. However, because it takes a function pointer, it could compare based on other criteria. For example, the following function also adheres to the definition of MatchFcn:
bool bothOdd(int inItem1, int inItem2)
{
return inItem1 % 2 == 1 && inItem2 % 2 == 1;
}
The following code calls findMatches() using bothOdd:
cout << "Calling findMatches() using bothOdd():" << endl;
findMatches(arr1, arr2, arrSize, &bothOdd);
The output is:
Calling findMatches() using bothOdd():
Match found at position 3 (9, 9)
Match found at position 5 (1, 3)
By using function pointers, a single function, findMatches(), is customized to different uses based on a parameter, inFunc.
NOTE Instead of using these old-style function pointers, you can also use std::function, which is explained in Chapter 19.
Pointers to Methods and Data Members
You can create and use pointers to both variables and functions. Now, consider pointers to class data members and methods. It’s perfectly legitimate in C++ to take the addresses of class data members and methods in order to obtain pointers to them. However, you can’t access a non-static data member or call a non-static method without an object. The whole point of class data members and methods is that they exist on a per-object basis. Thus, when you want to call the method or access the data member via the pointer, you must dereference the pointer in the context of an object. Here is an example:
SpreadsheetCell myCell(123);
double (SpreadsheetCell::*methodPtr) () const = &SpreadsheetCell::getValue;
cout << (myCell.*methodPtr)() << endl;
Don’t panic at the syntax. The second line declares a variable called methodPtr of type pointer to a non-static const method of SpreadsheetCell that takes no arguments and returns a double. At the same time, it initializes this variable to point to the getValue() method of the SpreadsheetCell class. This syntax is quite similar to declaring a simple function pointer, except for the addition of SpreadsheetCell:: before the *methodPtr. Note also that the & is required in this case.
The third line calls the getValue() method (via the methodPtr pointer) on the myCell object. Note the use of parentheses surrounding myCell.*methodPtr. They are needed because () has higher precedence than *.
The second line can be simplified with a type alias:
SpreadsheetCell myCell(123);
using PtrToGet = double (SpreadsheetCell::*) () const;
PtrToGet methodPtr = &SpreadsheetCell::getValue;
cout << (myCell.*methodPtr)() << endl;
Using auto it can be simplified even further:
SpreadsheetCell myCell(123);
auto methodPtr = &SpreadsheetCell::getValue;
cout << (myCell.*methodPtr)() << endl;
Pointers to methods and data members usually won’t come up in your programs. However, it’s important to keep in mind that you can’t dereference a pointer to a non-static method or data member without an object. Every so often, you’ll find yourself wanting to try something like passing a pointer to a non-static method to a function such as qsort() that requires a function pointer, which simply won’t work .
NOTE C++ does permit you to dereference a pointer to a static data member or method without an object.
SMART POINTERS
Memory management in C++ is a perennial source of errors and bugs. Many of these bugs arise from the use of dynamic memory allocation and pointers. When you extensively use dynamic memory allocation in your program and pass many pointers between objects, it’s difficult to remember to call delete on each pointer exactly once and at the right time. The consequences of getting it wrong are severe: When you free dynamically allocated memory more than once you can cause memory corruption or a fatal run-time error, and when you forget to free dynamically allocated memory you cause memory leaks.
Smart pointers help you manage your dynamically allocated memory and are the recommended technique for avoiding memory leaks. Smart pointers are a notion that arose from the fact that most memory-related issues are avoidable by putting everything on the stack. The stack is much safer than the heap because stack variables are automatically destructed and cleaned up when they go out of scope. Smart pointers combine the safety of stack variables with the flexibility of heap variables. There are several kinds of smart pointers. The simplest type of smart pointer takes sole ownership of the memory and when the smart pointer goes out of scope, it frees the referenced memory, for example, unique_ptr.
However, managing pointers presents more problems than just remembering to delete them when they go out of scope. Sometimes several objects or pieces of code contain copies of the same pointer. This problem is called aliasing. In order to free all memory properly, the last piece of code to use the memory should call delete on the pointer. However, it is often difficult to know which piece of code uses the memory last. It may even be impossible to determine the order when you code because it might depend on run-time inputs. Thus, a more sophisticated type of smart pointer implements reference counting to keep track of its owners. When all owners are finished using the pointer, the number of references drops to 0 and the smart pointer calls delete on its underlying dumb pointer. The standard shared_ptr smart pointer discussed later includes reference counting. It is important to be familiar with this concept.
C++ provides several language features that make smart pointers attractive. First, you can write a type-safe smart pointer class for any pointer type using templates. Second, you can provide an interface to the smart pointer objects using operator overloading that allows code to use the smart pointer objects as if they were dumb pointers. Specifically, you can overload the * and -> operators such that client code can dereference a smart pointer object the same way it dereferences a normal pointer.
The Old Deprecated auto_ptr
The old, pre-C++11 standard library included a basic implementation of a smart pointer, called auto_ptr. Unfortunately, auto_ptr has some serious shortcomings. One of these shortcomings is that it does not work correctly when used inside STL containers likevectors. C++ has now officially deprecated auto_ptr and replaced it with unique_ptr and shared_ptr, discussed in the next section. auto_ptr is mentioned here to make sure you know about it and to make sure you never use it.
WARNING Do not use the old auto_ptr smart pointer anymore. Instead use unique_ptr or shared_ptr!
The unique_ptr and shared_ptr Smart Pointers
The difference between shared_ptr and unique_ptr is that shared_ptr is a reference-counted smart pointer, while unique_ptr is not reference counted. This means that you can have several shared_ptr instances pointing to the same dynamically allocated memory and the memory will only be deallocated when the last shared_ptr goes out of scope. shared_ptr is also thread-safe. See Chapter 23 for a discussion on multithreading.
unique_ptr on the other hand means ownership. When the single unique_ptr goes out of scope, the underlying memory is freed.
Your default smart pointer should be unique_ptr. Use only shared_ptr when you need to share the resource.
Both smart pointers require you to include the <memory> header file.
WARNING Never assign the result of a memory allocation to a dumb pointer. Whatever memory allocation method you use, always immediately give the memory pointer to a smart pointer, unique_ptr or shared_ptr.
unique_ptr
As a rule of thumb, always store dynamically allocated objects in stack-based instances of unique_ptr. For example, consider the following function that blatantly leaks memory by allocating a Simple object on the heap and neglecting to release it:
void leaky()
{
Simple* mySimplePtr = new Simple(); // BUG! Memory is never released!
mySimplePtr->go();
}
Sometimes you might think that your code is properly deallocating dynamically allocated memory. Unfortunately, it most likely is not correct in all situations. Take the following function:
void couldBeLeaky()
{
Simple* mySimplePtr = new Simple();
mySimplePtr->go();
delete mySimplePtr;
}
The above function dynamically allocates a Simple object, uses the object, and then properly calls delete. However, you can still have memory leaks in this example! If the go() method throws an exception, the call to delete is never executed, causing a memory leak.
In both cases you should use a unique_ptr. The object is not explicitly deleted; but when the unique_ptr instance goes out of scope (at the end of the function, or because an exception is thrown) it automatically deallocates the Simple object in its destructor:
void notLeaky()
{
auto mySimpleSmartPtr = make_unique<Simple>();
mySimpleSmartPtr->go();
}
This code uses make_unique() from C++14, in combination with the auto keyword, so that you only have to specify the type of the pointer, Simple in this case, once. If the Simple constructor requires parameters, you put them in between the parentheses of themake_unique() call.
If your compiler does not yet support make_unique() you can create your unique_ptr as follows. Note that Simple must be mentioned twice.
unique_ptr<Simple> mySimpleSmartPtr(new Simple());
WARNING Always use make_unique() to create a unique_ptr, if your compiler supports it.
One of the greatest characteristics of smart pointers is that they provide enormous benefit without requiring the user to learn a lot of new syntax. As you can see in the preceding code, the smart pointer can still be dereferenced (using * or ->) just like a standard pointer.
A unique_ptr is suitable to store a dynamically allocated old C-style array. For example, the following example creates a unique_ptr that holds a dynamically allocated C-style array of 10 integers:
auto myVariableSizedArray = make_unique<int[]>(10);
Even though it is possible to use a unique_ptr to store a dynamically allocated C-style array, it’s recommended to use an STL container instead, such as std::array or std::vector.
By default, unique_ptr uses the standard new and delete operators to allocate and deallocate memory. You can change this behavior as follows:
int* malloc_int(int value)
{
int* p = (int*)malloc(sizeof(int));
*p = value;
return p;
}
int main()
{
auto deleter = [](int* p){ free(p); };
unique_ptr<int, decltype(deleter)> myIntSmartPtr(malloc_int(42), deleter);
return 0;
}
This code allocates the memory for the integer with malloc_int(). The unique_ptr deallocates the memory by calling the named lambda, deleter, which uses the standard free() function. As said before, in C++ you should never use malloc() but new instead. However, this feature of unique_ptr is available because it is useful to manage other resources instead of just memory. For example, it can be used to automatically close a file or network socket or anything when the unique_ptr goes out of scope.
Unfortunately, the syntax for a custom deleter with unique_ptr is a bit clumsy. Using a custom deleter with shared_ptr is much easier. The following section on shared_ptr demonstrates how to use a shared_ptr to automatically close a file when it goes out of scope.
shared_ptr
shared_ptr is used in a similar way as unique_ptr. To create one, you use make_shared(), which is more efficient than creating a shared_ptr directly. For example:
auto mySimpleSmartPtr = make_shared<Simple>();
WARNING Always use make_shared() to create a shared_ptr.
A difference with unique_ptr is that a shared_ptr cannot be used to store a pointer to a dynamically allocated old C-style array.
WARNING Never use a shared_ptr to manage a pointer to a C-style array. Use unique_ptr to manage the C-style array, or better yet, use STL containers instead of C-style arrays.
The following functions are available to cast shared_ptrs: const_pointer_cast(), dynamic_pointer_cast(), and static_pointer_cast(). For example, suppose you have a Base class, and a Derived class that derives from Base. You can then write:
shared_ptr<Base> myBasePtr(new Derived);
shared_ptr<Derived> myDerivedPtr = dynamic_pointer_cast<Derived>(myBasePtr);
Just as unique_ptr, shared_ptr by default uses the standard new and delete operators to allocate and deallocate memory. You can change this behavior as follows:
// Implementation of malloc_int() as before.
int main()
{
shared_ptr<int> myIntSmartPtr(malloc_int(42), free);
return 0;
}
As you can see, this is much easier than a custom deleter with unique_ptr.
The following example uses a shared_ptr to store a file pointer. When the shared_ptr goes out of scope, the file pointer is automatically closed with a call to the CloseFile() function. Remember that C++ has proper object-oriented classes to work with files (see Chapter 12). Those classes already automatically close their files when they go out of scope. This example using the old C fopen() and fclose() functions is just to give a demonstration for what shared_ptrs can be used for besides pure memory:
void CloseFile(FILE* filePtr)
{
if (filePtr == nullptr)
return;
fclose(filePtr);
cout << "File closed." << endl;
}
int main()
{
FILE* f = fopen("data.txt", "w");
shared_ptr<FILE> filePtr(f, CloseFile);
if (filePtr == nullptr) {
cerr << "Error opening file." << endl;
} else {
cout << "File opened." << endl;
// Use filePtr
}
return 0;
}
The Need for Reference Counting
As a general concept, reference counting is the technique for keeping track of the number of instances of a class or particular object in use. A reference-counting smart pointer is one that keeps track of how many smart pointers have been built to refer to a single real pointer, or single object. This way, smart pointers can avoid double deletion.
The double deletion problem is easy to provoke. Consider the following class, Nothing, which prints out messages when an object is created and destroyed:
class Nothing
{
public:
Nothing() { cout << "Nothing::Nothing()" << endl; }
virtual ~Nothing() { cout << "Nothing::~Nothing()" << endl; }
};
If you were to create two standard shared_ptrs and have them both refer to the same Nothing object as follows, both smart pointers would attempt to delete the same object when they go out of scope:
void doubleDelete()
{
Nothing* myNothing = new Nothing();
shared_ptr<Nothing> smartPtr1(myNothing);
shared_ptr<Nothing> smartPtr2(myNothing);
}
Depending on your compiler, this piece of code might crash! If you do get output, the output can be:
Nothing::Nothing()
Nothing::~Nothing()
Nothing::~Nothing()
Yikes! One call to the constructor and two calls to the destructor? You get the same problem with unique_ptr and with the old deprecated auto_ptr. You might be surprised that even the reference-counted shared_ptr class behaves this way. However, this is correct behavior according to the C++ standard. You should not use shared_ptr like in the previous doubleDelete() function to create two shared_ptrs pointing to the same object. Instead, you should use make_shared(), and use the copy constructor to make a copy as follows:
void noDoubleDelete()
{
auto smartPtr1 = make_shared<Nothing>();
shared_ptr<Nothing> smartPtr2(smartPtr1);
}
The output of this code is:
Nothing::Nothing()
Nothing::~Nothing()
Even though there are two shared_ptrs pointing to the same Nothing object, the Nothing object is destroyed only once. Remember that unique_ptr is not reference counted. In fact, unique_ptr will not allow you to use the copy constructor as in the noDoubleDelete()function.
NOTE If your program uses smart pointers by copying them, assigning them, or passing them by value as arguments to functions, the shared_ptr is the perfect solution.
If you really need to write code as shown in the previous doubleDelete() function, you will need to implement your own smart pointer to prevent double deletion. But again, it is recommended to use the standard shared_ptr template for sharing a resource. Simply avoid code as in the doubleDelete() function, and use the copy constructor instead:
shared_ptr<Nothing> smartPtr2(smartPtr1);
Move Semantics
Both shared_ptr and unique_ptr support move semantics discussed in Chapter 10 to make them efficient. Because of this, it is also efficient to return a shared_ptr or a unique_ptr from a function. For example, you can write the following func() function and use it as demonstrated in main():
// ... definition of Simple not shown for brevity
shared_ptr<Simple> func()
{
auto ptr = make_shared<Simple>();
// Do something with ptr...
return ptr;
}
int main()
{
shared_ptr<Simple> mySmartPtr = func();
return 0;
}
This is efficient because C++ automatically calls std::move() on the return statement in func(), which triggers the move semantics of shared_ptr. The same happens if you use unique_ptr instead of shared_ptr. unique_ptr does not support the normal copy assignment operator and copy constructor, but it does support the move assignment operator and move constructor, which explains why you can return a unique_ptr from a function.
Take a look at the following unique_ptr statements:
auto p1 = make_unique<int>(42);
unique_ptr<int> p2 = p1; // Error: does not compile
unique_ptr<int> p3 = move(p1); // OK
The line defining p2 will not compile because it is trying to use the copy constructor, which is not available for unique_ptr. The definition of p3 is good because std::move() (defined in the <utility> header file, see Chapter 10) is used to trigger the move constructor ofunique_ptr. After p3 is created, p1 is reset to nullptr and you will be able to access the integer 42 only through p3; ownership has been moved from p1 to p3.
weak_ptr
There is one more class in C++ that is related to shared_ptr; called weak_ptr. A weak_ptr can contain a reference to memory managed by a shared_ptr. The weak_ptr does not own the memory, so the shared_ptr is not prevented from deallocating the memory. A weak_ptrdoes not destroy the pointed to memory when it goes out of scope; however, it can be used to determine if the memory has been deallocated by the associated shared_ptr or not. The constructor of a weak_ptr requires a shared_ptr or another weak_ptr as argument. To get access to the pointer stored in a weak_ptr you need to convert it to a shared_ptr. There are two ways to do this:
· Use the lock() method on a weak_ptr instance, which returns a shared_ptr, or
· Create a new shared_ptr instance and give a weak_ptr as argument to the shared_ptr constructor.
In both cases, this new shared_ptr will be nullptr if the shared_ptr associated with the weak_ptr has been deallocated in the meantime.
COMMON MEMORY PITFALLS
It is difficult to pinpoint the exact situations that can lead to a memory-related bug. Every memory leak or bad pointer has its own nuances. There is no magic bullet for resolving memory issues, but there are several common categories of problems and some tools you can use to detect and resolve them.
Underallocating Strings
The most common problem with C-style strings is underallocation. In most cases, this arises when the programmer fails to allocate an extra character for the trailing '\0' sentinel. Underallocation of strings also occurs when programmers assume a certain fixed maximum size. The basic built-in C-style string functions do not adhere to a fixed size — they will happily write off the end of the string into uncharted memory.
The following code demonstrates underallocation. It reads data off a network connection and puts it in a C-style string. This is done in a loop because the network connection receives only a small amount of data at a time. On each loop, getMoreData() is called, which returns a pointer to dynamically allocated memory. When nullptr is returned from getMoreData(), all of the data has been received. strcat() is a C function which concatenates the C-style string given as a second argument to the end of the C-style string given as a first argument. It expects the destination buffer to be big enough.
char buffer[1024] = {0}; // Allocate a whole bunch of memory.
while (true) {
char* nextChunk = getMoreData();
if (nextChunk == nullptr) {
break;
} else {
strcat(buffer, nextChunk); // BUG! No guarantees against buffer overrun!
delete [] nextChunk;
}
}
There are three ways to resolve the possible underallocation problem. In decreasing order of preference, they are:
1. Use C++-style strings, which handle the memory associated with concatenation on your behalf.
2. Instead of allocating a buffer as a global variable or on the stack, allocate it on the heap. When there is insufficient space left, allocate a new buffer large enough to hold at least the current contents plus the new chunk, copy the original buffer into the new buffer, append the new contents, and delete the original buffer.
3. Create a version of getMoreData() that takes a maximum count (including the '\0' character) and returns no more characters than that; then track the amount of space left and the current position in the buffer.
Accessing Out-of-Bounds Memory
Earlier in this chapter, you read that since a pointer is just a memory address, it is possible to have a pointer that points to a random location in memory. Such a condition is quite easy to fall into. For example, consider a C-style string that has somehow lost its '\0'termination character. The following function, which fills the string with all 'm' characters, continues to fill the contents of memory following the string with 'm's:
void fillWithM(char* inStr)
{
int i = 0;
while (inStr[i] != '\0') {
inStr[i] = 'm';
i++;
}
}
If an improperly terminated string is handed to this function, it is only a matter of time before an essential part of memory is overwritten and the program crashes. Consider what might happen if the memory associated with the objects in your program is suddenly overwritten with 'm's. It’s not pretty!
Bugs that result in writing to memory past the end of an array are often called buffer overflow errors. Such bugs have been exploited by several high-profile malware programs; for example, viruses and worms. A devious hacker can take advantage of the ability to overwrite portions of memory to inject code into a running program.
Many memory-checking tools detect buffer overflows. Also, using higher-level constructs like C++ strings and vectors help prevent numerous bugs associated with writing to C-style strings and arrays.
WARNING Avoid using old C-style strings and arrays that offer no protection whatsoever. Instead, use modern and safe constructs like C++ strings and vectors that manage all their memory for you.
Memory Leaks
Finding and fixing memory leaks can be one of the more frustrating parts of programming in C or C++. Your program finally works and appears to give the correct results. Then, you start to notice that your program gobbles up more and more memory as it runs. Your program has a memory leak. The use of smart pointers to avoid memory leaks is a good first approach to solving the problem.
Memory leaks occur when you allocate memory and neglect to release it. At first, this sounds like the result of careless programming that could easily be avoided. After all, if every new has a corresponding delete in every class you write, there should be no memory leaks, right? Actually, that’s not always true. In the following code, the Simple class is properly written to release any memory that it allocates. Keep in mind that this Simple class implementation is only for demonstration purposes. In real code, you should make themIntPtr a unique_ptr.
When doSomething() is called, the outSimplePtr pointer is changed to another Simple object without deleting the old one. The doSomething() function doesn’t delete the old object on purpose to demonstrate memory leaks. Once you lose a pointer to an object, it’s nearly impossible to delete it.
class Simple
{
public:
Simple() { mIntPtr = new int(); }
virtual ~Simple() { delete mIntPtr; }
void setIntPtr(int inInt) { *mIntPtr = inInt; }
private:
int* mIntPtr;
};
void doSomething(Simple*& outSimplePtr)
{
outSimplePtr = new Simple(); // BUG! Doesn't delete the original.
}
int main()
{
Simple* simplePtr = new Simple(); // Allocate a Simple object.
doSomething(simplePtr);
delete simplePtr; // Only cleans up the second object.
return 0;
}
In cases like the preceding example, the memory leak probably arose from poor communication between programmers or poor documentation of code. The caller of doSomething() may not have realized that the variable was passed by reference and thus had no reason to expect that the pointer would be reassigned. If they did notice that the parameter is a non-const reference to a pointer, they may have suspected that something strange was happening, but there is no comment around doSomething() that explains this behavior.
Finding and Fixing Memory Leaks in Windows with Visual C++
Memory leaks are hard to track down because you can’t easily look at memory and see what objects are not in use and where they were originally allocated. However, there are programs that can do this for you. Memory leak detection tools range from expensive professional software packages to free downloadable tools. If you already work with Microsoft Visual C++, its debug library has built-in support for memory leak detection. This memory leak detection is not enabled by default, unless you create an MFC project. To enable it in other projects, you need to start with including the following three lines at the beginning of your code:
#define _CRTDBG_MAP_ALLOC
#include <cstdlib>
#include <crtdbg.h>
These lines should be in the exact order as shown. Next, you need to redefine the new operator as follows:
#ifdef _DEBUG
#ifndef DBG_NEW
#define DBG_NEW new ( _NORMAL_BLOCK , __FILE__ , __LINE__ )
#define new DBG_NEW
#endif
#endif // _DEBUG
Note that this is within a “#ifdef _DEBUG” statement so the redefinition of new is done only when compiling a debug version of your application. This is what you normally want. Release builds usually do not do any memory leak detection.
The last thing you need to do is to add the following line as the first line in your main() function:
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF);
This tells the Visual C++ CRT (C RunTime) library to write all detected memory leaks to the debug output console when the application exits. For the previous leaky program, the debug console will contain lines similar to the following:
Detected memory leaks!
Dumping objects ->
c:\leaky\leaky.cpp(15) : {147} normal block at 0x014FABF8, 4 bytes long.
Data: < > 00 00 00 00
c:\leaky\leaky.cpp(33) : {146} normal block at 0x014F5048, 8 bytes long.
Data: < O > 9C CC 97 00 F8 AB 4F 01
Object dump complete.
The output clearly shows in which file and on which line memory was allocated but never deallocated. The line number is between parentheses immediately behind the filename. The number between the curly brackets is a counter for the memory allocations. For example, {147} means the 147th allocation in your program since it started. You can use the VC++ _CrtSetBreakAlloc() function to tell the VC++ debug runtime to break into the debugger when a certain allocation is performed. For example, add the following line to the beginning of your main() function to let the debugger break on the 147th allocation:
_CrtSetBreakAlloc(147);
In this leaky program, there are two leaks — the first Simple object that is never deleted and the heap-based integer that it creates. In the Visual C++ debugger output window, you can simply double click on one of the memory leaks and it will automatically jump to that line in your code.
Of course, programs like Microsoft Visual C++ discussed in this section, and Valgrind discussed in the next section, can’t actually fix the leak for you — what fun would that be? These tools provide information that you can use to find the actual problem. Normally, that involves stepping through the code to find out where the pointer to an object was overwritten without the original object being released. Most debuggers provide “watch point” functionality that can break execution of the program when this occurs.
Finding and Fixing Memory Leaks in Linux with Valgrind
Valgrind is an example of a free open-source tool for Linux that, amongst other things, pinpoints the exact line in your code where a leaked object was allocated.
The following output, generated by running Valgrind on the previous leaky program, pinpoints the exact locations where memory was allocated but never released. Valgrind finds the same two memory leaks — the first Simple object never deleted and the heap-based integer that it creates:
==15606== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
==15606== malloc/free: in use at exit: 8 bytes in 2 blocks.
==15606== malloc/free: 4 allocs, 2 frees, 16 bytes allocated.
==15606== For counts of detected errors, rerun with: -v
==15606== searching for pointers to 2 not-freed blocks.
==15606== checked 4455600 bytes.
==15606==
==15606== 4 bytes in 1 blocks are still reachable in loss record 1 of 2
==15606== at 0x4002978F: __builtin_new (vg_replace_malloc.c:172)
==15606== by 0x400297E6: operator new(unsigned) (vg_replace_malloc.c:185)
==15606== by 0x804875B: Simple::Simple() (leaky.cpp:4)
==15606== by 0x8048648: main (leaky.cpp:24)
==15606==
==15606==
==15606== 4 bytes in 1 blocks are definitely lost in loss record 2 of 2
==15606== at 0x4002978F: __builtin_new (vg_replace_malloc.c:172)
==15606== by 0x400297E6: operator new(unsigned) (vg_replace_malloc.c:185)
==15606== by 0x8048633: main (leaky.cpp:20)
==15606== by 0x4031FA46: __libc_start_main (in /lib/libc-2.3.2.so)
==15606==
==15606== LEAK SUMMARY:
==15606== definitely lost: 4 bytes in 1 blocks.
==15606== possibly lost: 0 bytes in 0 blocks.
==15606== still reachable: 4 bytes in 1 blocks.
==15606== suppressed: 0 bytes in 0 blocks.
WARNING It is strongly recommended to use smart pointers as much as possible to avoid memory leaks.
Double-Deleting and Invalid Pointers
Once you release memory associated with a pointer using delete, the memory is available for use by other parts of your program. Nothing stops you, however, from attempting to continue to use the pointer, which is now a dangling pointer. Double deletion is also a problem. If you use delete a second time on a pointer, the program could be releasing memory that has since been assigned to another object.
Double deletion and use of already released memory are both hard problems to track down because the symptoms may not show up immediately. If two deletions occur within a relatively short amount of time, the program might work indefinitely because the associated memory is not reused that quickly. Similarly, if a deleted object is used immediately after being deleted, most likely it will still be intact.
Of course, there is no guarantee that such behavior will work or continue to work. The memory allocator is under no obligation to preserve any object once it has been deleted. Even if it does work, it is extremely poor programming style to use objects that have been deleted.
Many memory leak-checking programs, such as Microsoft Visual C++ and Valgrind, will also detect double deletion and use of released objects.
If you disregard the recommendation for using smart pointers and instead still use dumb pointers, at least set your pointers to nullptr after deallocating their memory. This prevents you from accidentally deleting the same pointer twice or to use an invalid pointer. It’s worth noting that you are allowed to call delete on a nullptr pointer; it simply will not do anything.
SUMMARY
In this chapter, you learned the ins and outs of dynamic memory. Aside from memory-checking tools and careful coding, there are two key takeaways to avoid dynamic memory-related problems. First, you need to understand how pointers work under the hood. After reading about two different mental models for pointers, hopefully you are now confident that you know how the compiler doles out memory. Second, you can avoid all sorts of dynamic memory issues by obscuring pointers with stack-based objects, like the C++string class, vector class, smart pointers, and so on.
If there is one thing that you should have learned from this chapter it is that you should try to avoid using old C-style constructs and functions as much as possible, and use the safe C++ alternatives.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.