Professional C++ (2014)
Part IVMastering Advanced Features of C++
Chapter 23Multithreaded Programming with C++
WHAT’S IN THIS CHAPTER?
· What multithreaded programming is and how to write multithreaded code
· What deadlocks and race conditions are, and how to use mutual exclusion to prevent them
· How to use atomic types and atomic operations
· Explaining thread pools
WROX.COM DOWNLOADS FOR THIS CHAPTER
Please note that all the code examples for this chapter are available as a part of this chapter’s code download on the book’s website at www.wrox.com/go/proc++3e on the Download Code tab.
Multithreaded programming is important on computer systems with multiple processor units. It allows you to write a program to use all those processor units in parallel. There are multiple ways for a system to have multiple processor units. The system can have multiple discrete processor chips, each one an independent CPU (Central Processor Unit). Or, the system can have a single discrete processor chip that internally consists of multiple independent CPUs, also called cores. These kind of processors are called multicore processors. A system can also have a combination of both. Systems with multiple processor units already exist for a long time; however, they were rarely used in consumer systems. Today, all major CPU vendors are selling multicore processors. Nowadays, multicore processors are being used for everything from servers to consumer computers and even in smartphones. Because of this proliferation of multicore processors, writing multithreaded applications is becoming more and more important. A professional C++ programmer needs to know how to write correct multithreaded code to take full advantage of all the available processor units. Writing multithreaded applications used to rely on platform- and operating system-specific APIs. This made it difficult to write platform-independent multithreaded code. C++11 solved this problem by including a standard threading library.
Multithreaded programming is a complicated subject. This chapter introduces you to multithreaded programming using the standard threading library, but it cannot go into all details due to space constraints. There are entire books written about developing multithreaded programs. If you are interested in more details, consult one of the references in the multithreading section in Appendix B.
If your compiler does not support the standard threading library, you might use other third-party libraries that try to make multithreaded programming more platform independent, such as the pthreads library and the boost::thread library. However, because they are not part of the C++ standard, they are not discussed in this book.
INTRODUCTION
Multithreaded programming allows you to perform multiple calculations in parallel. This way you can take advantage of the multiple processor units inside most systems these days. Years ago, the processor market was racing for the highest frequency, which is perfect for single-threaded applications. Around 2005, this race stopped due to a combination of power management and heat management problems. Today, the processor market is racing toward the most cores on a single processor chip. Dual- and quad-core processors are already common at the time of this writing, and announcements have already been made about 12-, 16-, 32-, and even 80-core processors.
Similarly, if you look at the processors on graphics cards, called GPUs, you’ll see that they are massively parallel processors. Today, high-end graphics cards have more than 2,000 cores, a number that will increase rapidly. These graphics cards are used not only for gaming anymore, but also to perform computationally intense tasks. Examples are image and video manipulation, protein folding (useful for discovering new drugs), processing signals as part of the SETI project (Search for Extra-Terrestrial Intelligence), and so on.
C++98/03 did not have support for multithreaded programming, and you had to resort to third-party libraries or to the multithreading APIs of your target operating system. Since C++11 included a standard multithreading library, it became easier to write cross-platform multithreaded applications. The current C++ standard targets only CPUs and not GPUs. This might change in the future.
There are two reasons to start writing multithreaded code. First, if you have a computational problem and you manage to separate it into small pieces that can be run in parallel independently from each other, you can expect a huge performance boost running it on multiple processor units. Second, you can modularize computations along orthogonal axes; for example, doing long computations in a thread instead of blocking the GUI thread, so the user interface remains responsive while a long computation occurs in the background.
Figure 23-1 shows an example of a problem perfectly suited to run in parallel. An example could be the processing of pixels of an image by an algorithm that does not require information about neighboring pixels. The algorithm could split the image into four parts. On a single-core processor, each part is processed sequentially; on a dual-core processor, two parts are processed in parallel; and on a quad-core processor, four parts are processed in parallel, resulting in an almost linear scaling of the performance with the number of cores.
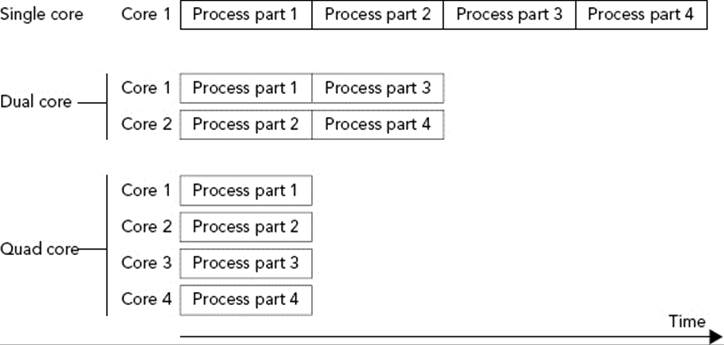
FIGURE 23-1
Of course, it’s not always possible to split the problem into parts that can be executed independently of each other in parallel. But often it can be made parallel at least partially, resulting in a performance increase. A difficult part in multithreaded programming is to make your algorithm parallel, which is highly dependent on the type of your algorithm. Other difficulties are preventing race conditions, deadlocks, tearing, and keeping cache coherency in mind. These are discussed in the following sections. They can all be solved using atomics or explicit synchronization mechanisms, as discussed later in this chapter.
WARNING To prevent these multithreading problems, try to design your programs so that multiple threads need not read and write to shared memory. Or, use a synchronization method as described in the Mutual Exclusion section, or atomic operations described in the Atomic Operations Library section.
Race Conditions
Race conditions can occur when multiple threads want to read/write to a shared memory location. For example, suppose you have a shared variable and one thread increments this value while another thread decrements it. Incrementing and decrementing the value means that the current value needs to be retrieved from memory, incremented or decremented, and stored back in memory. On older architectures, such as PDP-11 and VAX, this used to be implemented with an INC processor instruction, which was atomic. On modern x86 processors, the INC instruction is not atomic anymore, meaning that other instructions could be executed in the middle of this operation, which might cause the code to retrieve a wrong value.
The following table shows the result when the increment is finished before the decrement starts, and assumes that the initial value is 1:
|
THREAD 1 (INCREMENT) |
THREAD 2 (DECREMENT) |
|
load value (value = 1) |
|
|
increment value (value = 2) |
|
|
store value (value = 2) |
|
|
load value (value = 2) |
|
|
decrement value (value = 1) |
|
|
store value (value = 1) |
The final value stored in memory is 1. When the decrement thread is finished before the increment thread starts, the final value is also 1, as seen in the following table:
|
THREAD 1 (INCREMENT) |
THREAD 2 (DECREMENT) |
|
load value (value = 1) |
|
|
decrement value (value = 0) |
|
|
store value (value = 0) |
|
|
load value (value = 0) |
|
|
increment value (value = 1) |
|
|
store value (value = 1) |
However, when the instructions get interleaved, the result is different:
|
THREAD 1 (INCREMENT) |
THREAD 2 (DECREMENT) |
|
load value (value = 1) |
|
|
increment value (value = 2) |
|
|
load value (value = 1) |
|
|
decrement value (value = 0) |
|
|
store value (value = 2) |
|
|
store value (value = 0) |
The final result in this case is 0. In other words, the effect of the increment operation is lost. This is a race condition.
Deadlocks
If you opt to solve a race condition by using a synchronization method, such as mutual exclusion, you might run into another common problem with multithreaded programming: deadlocks. Deadlocks are threads blocking indefinitely because they are waiting to acquire access to resources currently locked by other blocked threads. For example, suppose you have two threads and two resources, A and B. Both threads require a lock on both resources, but they acquire the locks in different order. The following table shows this situation in pseudo code:
|
THREAD 1 |
THREAD 2 |
|
Lock A |
Lock B |
Now, imagine that the code in the two threads is executed in the following order:
· Thread 1: Lock A
· Thread 2: Lock B
· Thread 1: Lock B (waits, because lock held by Thread 2)
· Thread 2: Lock A (waits, because lock held by Thread 1)
Both threads are now waiting indefinitely in a deadlock situation. Figure 23-2 shows a graphical representation of this deadlock situation. Thread 1 is holding a lock on resource A and is waiting to get a lock on resource B. Thread 2 is holding a lock on resource B and is waiting to get a lock on resource A. In this graphical representation, you see a cycle that depicts the deadlock situation. Both threads will wait indefinitely.
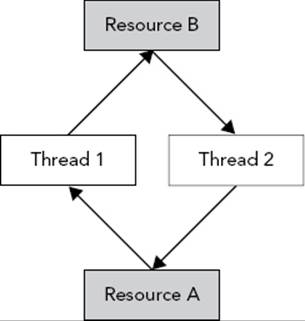
FIGURE 23-2
It’s best to always acquire locks in the same order to avoid these kinds of deadlocks. You can also include mechanisms in your program to break these kinds of deadlocks. One possible solution is to try for a certain time to acquire a lock on a resource. If the lock could not be obtained within a certain time interval, the thread stops waiting and possibly releases other locks it is currently holding. The thread might then sleep for a little bit and try again later to acquire all the resources it needs. This method might give other threads the opportunity to acquire necessary locks and continue their execution. Whether this method works or not depends heavily on your specific deadlock case.
Instead of using a workaround as described in the previous paragraph, you should try to avoid any possible deadlock situation altogether. If you need to acquire multiple locks, the recommended way is to use the standard std::lock() or std::try_lock() functions described later in the section on mutual exclusion. These functions obtain or try to obtain a lock on several resources, doing their best to prevent deadlocks.
Tearing
Tearing means that part of your data has been written to memory, while part hasn’t been written yet. If another thread reads that data at that exact moment it sees inconsistent data.
Cache Coherency
Cache coherency is important to keep in mind. If one thread writes a piece of data, that thread immediately sees this new data, but this does not mean that all threads see this new data immediately! CPUs have caches and the cache structure on multicore processors is complicated. If one core modifies your data, it is changed immediately in its cache; but, this change is not immediately visible to cores using a different cache. So, even simple data types, such as Booleans, need to be synchronized when reading and writing to them from multiple threads.
THREADS
The C++ threading library, defined in the <thread> header file, makes it very easy to launch new threads. Specifying what needs to be executed in the new thread can be done in several ways. You can let the new thread execute a global function, the operator() of a function object, a lambda expression, or even a member function of an instance of some class. The following sections give small examples of all these methods.
Thread with Function Pointer
Functions such as CreateThread(), _beginthread(), and so on, on Windows, and pthread_create() with the pthreads library, require that the thread function has only one parameter. On the other hand, a function that you want to use with the standard C++ std::threadclass can have as many parameters as you want.
Suppose you have a counter() function accepting two integers: the first representing an ID and the second representing the number of iterations that the function should loop. The body of the function is a single loop that loops the given number of iterations. On each iteration, a message is printed to standard output:
void counter(int id, int numIterations)
{
for (int i = 0; i < numIterations; ++i) {
cout << "Counter " << id << " has value ";
cout << i << endl;
}
}
You can launch multiple threads executing this function using std::thread. You can create a thread t1, executing counter() with arguments 1 and 6 as follows:
thread t1(counter, 1, 6);
The constructor of the thread class is a variadic template, which means that it accepts any number of arguments. Variadic templates are discussed in detail in Chapter 21. The first argument is the name of the function to execute in the new thread. The subsequent variable number of arguments are passed to this function when execution of the thread starts.
The following code launches two threads executing the counter() function. After launching the threads, main() calls join() on both threads. This is to make sure that the main thread keeps running until both threads are finished. A call to t1.join() blocks until the thread t1 is finished. Without these two join() calls, the main() function would finish immediately after launching the two threads. This will trigger the application to shut down; causing all other threads spawned by the application to be terminated as well, whether these threads are finished or not.
WARNING These join() calls are necessary in these small examples. In real-world applications, you should avoid using join(), because it causes the thread calling join() to block. Often there are better ways. For example, in a GUI application, a thread that finishes can post a message to the UI thread. The UI thread itself has a message loop processing messages like mouse moves, button clicks, and so on. This message loop can also receive messages from threads, and you can react to them however you want, all without blocking the UI thread with a join() call.
#include <iostream>
#include <thread>
using namespace std;
int main()
{
thread t1(counter, 1, 6);
thread t2(counter, 2, 4);
t1.join();
t2.join();
}
A possible output of this example looks as follows:
Counter 2 has value 0
Counter 1 has value 0
Counter 1 has value 1
Counter 1 has value 2
Counter 1 has value 3
Counter 1 has value 4
Counter 1 has value 5
Counter 2 has value 1
Counter 2 has value 2
Counter 2 has value 3
The output on your system will be different and it will most likely be different every time you run it. This is because two threads are executing the counter() function at the same time, so the output depends on the number of processing cores in your system and on the thread scheduling of the operating system.
By default, accessing cout from different threads is thread-safe and without any data races, unless you have called cout.sync_with_stdio(false) before the first output or input operation. However, even though there are no data races, output from different threads can still be interleaved! This means that the output of the previous example can be mixed together as in the following:
Counter Counter 2 has value 0
1 has value 0
Counter 1 has value 1
Counter 1 has value 2
Instead of:
Counter 1 has value 0
Counter 2 has value 0
Counter 1 has value 1
Counter 1 has value 2
This can be fixed using synchronization methods, which are discussed later in this chapter.
NOTE Thread function arguments are always copied into some internal storage for the thread. Use std::ref() from the <functional> header to pass them by reference.
Thread with Function Object
The previous section demonstrated how to create a thread and tell it to run a specific function in the new thread by passing a pointer to the function to execute. You can also use a function object, as shown in the following example. With the function pointer technique, the only way to pass information to the thread is by passing arguments to the function. With function objects, you can add member variables to your function object class, which you can initialize and use however you want. The example first defines a class called Counter, which has two member variables: an ID and the number of iterations for the loop. Both variables are initialized with the constructor. To make the Counter class a function object, you need to implement operator(), as discussed in Chapter 17. The implementation of operator() is the same as the counter() function in the previous section:
class Counter
{
public:
Counter(int id, int numIterations)
: mId(id), mNumIterations(numIterations)
{
}
void operator()() const
{
for (int i = 0; i < mNumIterations; ++i) {
cout << "Counter " << mId << " has value ";
cout << i << endl;
}
}
private:
int mId;
int mNumIterations;
};
Three methods for initializing threads with a function object are demonstrated in the following main(). The first uses the uniform initialization syntax. You create an instance of Counter with its constructor arguments and give it to the thread constructor between curly braces.
The second defines a named instance of Counter and gives this named instance to the constructor of the thread class.
The third looks similar to the first; it creates an instance of Counter and gives it to the constructor of the thread class, but uses parentheses instead of curly braces. The ramifications of this are discussed after the code.
int main()
{
// Using uniform initialization syntax
thread t1{ Counter{ 1, 20 }};
// Using named variable
Counter c(2, 12);
thread t2(c);
// Using temporary
thread t3(Counter(3, 10));
// Wait for threads to finish
t1.join();
t2.join();
t3.join();
}
If you compare the creation of t1 with the creation of t3, it looks like the only difference seems to be that the first method uses curly braces while the third method uses parentheses. However, when your function object constructor doesn’t require any parameters, the third method as written above will not work. For example:
class Counter
{
public:
Counter() {}
void operator()() const { /* Omitted for brevity */ }
};
int main()
{
thread t1(Counter()); // Error!
t1.join();
}
This results in a compilation error because C++ interprets the first line in main() as a declaration of a function called t1, which returns a thread object and accepts a pointer to a function without parameters returning a Counter object. For this reason, it’s recommended to use the uniform initialization syntax:
thread t1{ Counter{} }; // OK
If your compiler does not support uniform initialization, you have to add an extra set of parentheses to prevent the compiler from interpreting the line as a function declaration:
thread t1((Counter())); // OK
NOTE Function objects are always copied into some internal storage for the thread. If you want to execute operator() on a specific instance of your function object instead of copying it, you should use std::ref() from the <functional> header to pass your instance by reference.
Thread with Lambda
Lambda expressions fit nicely with the standard C++ threading library, as demonstrated in the following example:
int main()
{
int id = 1;
int numIterations = 5;
thread t1([id, numIterations] {
for (int i = 0; i < numIterations; ++i) {
cout << "Counter " << id << " has value ";
cout << i << endl;
}
});
t1.join();
}
Thread with Member Function
You can also specify a member function of a class to be executed in a thread. The following example defines a basic Request class with a process() method. The main() function creates an instance of the Request class and launches a new thread, which executes theprocess() member function of the Request instance, req:
class Request
{
public:
Request(int id) : mId(id) { }
void process()
{
cout << "Processing request " << mId << endl;
}
private:
int mId;
};
int main()
{
Request req(100);
thread t{ &Request::process, &req };
t.join();
}
With this technique you are executing a method on a specific object in a separate thread. If other threads are accessing the same object, you need to make sure this happens in a thread-safe way to avoid race conditions. Mutual exclusion, discussed later in this chapter, can be used as synchronization mechanism to make it thread-safe.
Thread Local Storage
The standard supports the concept of thread local storage. With a keyword called thread_local, you can mark any variable as thread local, which means that each thread will have its own unique copy of the variable and it will last for the entire duration of the thread. For each thread, the variable is initialized exactly once. For example, in the following code, every thread shares one-and-only-one copy of k, while each thread has its own unique copy of n:
thread_local int n;
int k;
void doWork()
{
// perform some computation
}
Note that if the thread_local variable is declared in the scope of a function, its behavior is as if it were declared static, except that every thread has its own unique copy and is initialized exactly once per thread, no matter how many times that function is called in that thread.
Cancelling Threads
The standard does not include any mechanism for cancelling a running thread from inside another thread. The best way to achieve this is to provide some communication mechanism that the two threads agree upon. The simplest mechanism is to have a shared variable, which the target thread checks periodically to determine if it should terminate. Other threads can set this shared variable to indirectly instruct the thread to shut down. Care has to be taken to avoid race conditions and cache coherency problems with reading and writing to this shared variable. Atomic variables or condition variables, both discussed later in this chapter, can help avoid these problems.
Retrieving Results from Threads
As you saw in the previous examples, launching a new thread is pretty easy. However, in most cases you are probably interested in results produced by the thread. For example, if your thread performs some mathematical calculations, you really would like to get the results out of the thread once the thread is finished. One way is to pass a pointer or reference to a result variable to the thread in which the thread stores the results. Another method is to store the results inside a class member variable of a function object, which you can retrieve later once the thread has finished executing.
However, there is another and easier method to obtain a result from threads: futures. They also make it easier to handle errors that occur inside your threads. Futures are discussed later in this chapter.
Copying and Rethrowing Exceptions
The whole exception mechanism in C++ works perfectly, as long as it stays within one single thread. Every thread can throw its own exceptions, but they need to be caught within their own thread. Exceptions thrown in one thread cannot be caught in another thread. This introduces quite a few problems when you would like to use exception handling in combination with multithreaded programming.
Without the standard threading library it’s very difficult if not impossible to gracefully handle exceptions across threads. The standard threading library solves this issue with the following exception-related functions. These functions not only work withstd::exceptions, but with all kinds of exceptions, ints, strings, custom exceptions, and so on:
exception_ptr current_exception() noexcept;
This function is intended to be called from inside a catch block, and returns an exception_ptr object that refers to the exception currently being handled, or a copy of the currently handled exception, or a null exception_ptr object if no exception is being handled. This referenced exception object remains valid for as long as there is an object of type exception_ptr that is referencing it. exception_ptr is of type NullablePointer, which means it can easily be tested with a simple if statement, as the example later in this section demonstrates:
[[noreturn]] void rethrow_exception(exception_ptr p);
This function rethrows the exception referenced by the exception_ptr parameter. Rethrowing the referenced exception does not have to be done in the same thread that generated the referenced exception in the first place, which makes this feature perfectly suited for handling exceptions across different threads. The [[noreturn]] attribute makes it clear that this function never returns normally. Attributes are introduced in Chapter 10.
template<class E> exception_ptr make_exception_ptr(E e) noexcept;
This function creates an exception_ptr object that refers to a copy of the given exception object. This is basically a shorthand notation for the following code:
try {
throw e;
} catch(...) {
return current_exception();
}
Let’s see how handling exceptions across different threads can be implemented using these features. The following code defines a function that does some work and throws an exception. This function will ultimately be running in a separate background thread:
void doSomeWork()
{
for (int i = 0; i < 5; ++i) {
cout << i << endl;
}
cout << "Thread throwing a runtime_error exception..." << endl;
throw runtime_error("Exception from thread");
}
The following threadFunc() function wraps the call to the preceding function in a try/catch block, catching all exceptions that doSomeWork() might throw. A single argument is supplied to threadFunc(), which is of type exception_ptr&. Once an exception is caught, the function current_exception() is used to get a reference to the exception being handled, which is then assigned to the exception_ptr parameter. After that, the thread exits normally:
void threadFunc(exception_ptr& err)
{
try {
doSomeWork();
} catch (...) {
cout << "Thread caught exception, returning exception..." << endl;
err = current_exception();
}
}
The following doWorkInThread() function is called from within the main thread. Its responsibility is to create a new thread and start executing threadFunc() in it. A reference to an object of type exception_ptr is given as argument to threadFunc(). Once the thread is created, the doWorkInThread() function waits for the thread to finish by using the join() method, after which the error object is examined. Since exception_ptr is of type NullablePointer, you can easily check it using an if statement. If it’s a non-null value, the exception is rethrown in the current thread, which is the main thread in this example. By rethrowing the exception in the main thread, the exception has been transferred from one thread to another thread.
void doWorkInThread()
{
exception_ptr error;
// Launch background thread
thread t{ threadFunc, ref(error) };
// Wait for thread to finish
t.join();
// See if thread has thrown any exception
if (error)
{
cout << "Main thread received exception, rethrowing it..." << endl;
rethrow_exception(error);
}
else
cout << "Main thread did not receive any exception." << endl;
}
The main() function is pretty straightforward. It calls doWorkInThread() and wraps the call in a try/catch block to catch exceptions thrown by any thread spawned by doWorkInThread():
int main()
{
try {
doWorkInThread();
} catch (const exception& e) {
cout << "Main function caught: '" << e.what() << "'" << endl;
}
}
The output is as follows:
0
1
2
3
4
Thread throwing a runtime_error exception...
Thread caught exception, returning exception...
Main thread received exception, rethrowing it...
Main function caught: 'Exception from thread'
To keep this example compact and easier to understand, the doWorkInThread() function is using join() to block and wait until the thread is finished. Of course, in real-world applications you do not want to block your main thread. For example, in a GUI application, you might let threadFunc() send a message to the UI thread with, as argument, a copy of the result of current_exception().
ATOMIC OPERATIONS LIBRARY
Atomic types allow atomic access, which means that concurrent reading and writing without additional synchronization is allowed. Without atomic operations, incrementing a variable is not thread-safe because the compiler first loads the value from memory into a register, increments it, and then stores the result back in memory. Another thread might touch the same memory during this increment operation, which is a race condition. For example, the following code is not thread-safe and contains a race condition. This type of race condition is discussed in the beginning of this chapter:
int counter = 0; // Global variable
++counter; // Executed in multiple threads
To make this thread-safe without explicitly using any locks, use an atomic type:
atomic<int> counter(0) ; // Global variable
++counter; // Executed in multiple threads
You need to include the <atomic> header to use these atomic types. The standard defines named integral atomic types for all primitive types. The following table lists a few:
|
NAMED ATOMIC TYPE |
EQUIVALENT ATOMIC TYPE |
|
atomic_bool |
atomic<bool> |
|
atomic_char |
atomic<char> |
|
atomic_uchar |
atomic<unsigned char> |
|
atomic_int |
atomic<int> |
|
atomic_uint |
atomic<unsigned int> |
|
atomic_long |
atomic<long> |
|
atomic_ulong |
atomic<unsigned long> |
|
atomic_llong |
atomic<long long> |
|
atomic_ullong |
atomic<unsigned long long> |
|
atomic_wchar_t |
atomic<wchar_t> |
When accessing a piece of data from multiple threads, atomics also solve other problems such as cache coherence, memory ordering, compiler optimizations, and so on. Basically, it’s virtually never safe to read and write to the same piece of data from multiple threads without using atomics or explicit synchronization mechanisms.
Atomic Type Example
This section explains in more detail why you should use atomic types. Suppose you have a function called func() that increments an integer given as a reference parameter in a loop. This code uses std::this_thread::sleep_for() to introduce a small delay in each loop. The argument to sleep_for() is a std::chrono::duration, explained in Chapter 19.
void func(int& counter)
{
for (int i = 0; i < 100; ++i) {
++counter;
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
Now, you would like to run several threads in parallel, all executing this func() function. By implementing this naively without atomic types or without any kind of thread synchronization, you introduce a race condition. The following main() function launches 10 threads after which it waits for all threads to finish by calling join() on each thread.
int main()
{
int counter = 0;
std::vector<std::thread> threads;
for (int i = 0; i < 10; ++i) {
threads.push_back(std::thread{ func, std::ref(counter) });
}
for (auto& t : threads) {
t.join();
}
std::cout << "Result = " << counter << std::endl;
}
Because func() increments the integer 100 times, and main() launches 10 background threads, each of which executes func(), the expected result is 1,000. If you execute this program several times, you might get the following output but with different values:
Result = 982
Result = 977
Result = 984
This code is clearly showing race condition behavior. In this example you can use an atomic type to fix this. The following code highlights the required changes:
#include <atomic>
void func(std::atomic<int>& counter)
{
for (int i = 0; i < 100; ++i) {
++counter;
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
int main()
{
std::atomic<int> counter(0);
std::vector<std::thread> threads;
for (int i = 0; i < 10; ++i) {
threads.push_back(std::thread{ func, std::ref(counter) });
}
for (auto& t : threads) {
t.join();
}
std::cout << "Result = " << counter << std::endl;
}
The changes add the <atomic> header file, and change the type of the shared counter to std::atomic<int> instead of int. When you run this modified version, you always get 1,000 as the result:
Result = 1000
Result = 1000
Result = 1000
Without explicitly adding any locks to the code, it is now thread-safe and race-condition free because the ++counter operation on an atomic type loads the value, increments the value, and stores the value in one atomic transaction, which cannot be interrupted.
However, there is a new problem with this new code; a performance problem. You should try to minimize the amount of synchronization, either atomics or explicit synchronization, because it lowers performance. For this simple example, the best and recommended solution is to let func() calculate its result in a local variable, and only after the loop add it to the counter reference. Note that it is still required to use an atomic, because you are still writing to counter from multiple threads.
#include <atomic>
void func(std::atomic<int>& counter)
{
int result = 0;
for (int i = 0; i < 100; ++i) {
++result;
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
counter += result;
}
Atomic Operations
The standard defines a number of atomic operations. This section describes a few of those operations. For a full list, consult a Standard Library Reference; for example, http://www.cppreference.com/ or http://www.cplusplus.com/reference/.
A first example of an atomic operation is the following:
bool atomic_compare_exchange_strong(atomic<C>* object, C* expected, C desired);
It can also be called as a member of atomic<C>:
bool atomic<C>::compare_exchange_strong(C* expected, C desired);
The logic implemented atomically by this operation is as follows in pseudo-code:
if (*object == *expected) {
*object = desired;
return true;
} else {
*expected = *object;
return false;
}
A second example is atomic<T>::fetch_add(), which works for integral atomic types and fetches the current value of the atomic type, adds the given increment to the atomic value, and returns the original non-incremented value. For example:
atomic<int> value(10);
cout << "Value = " << value << endl;
int fetched = value.fetch_add(4);
cout << "Fetched = " << fetched << endl;
cout << "Value = " << value << endl;
If no other threads are touching the contents of the fetched and value variables, the output is as follows:
Value = 10
Fetched = 10
Value = 14
Atomic integral types support the following atomic operations: fetch_add(), fetch_sub(), fetch_and(), fetch_or(), fetch_xor(), ++, --, +=, -=, &=, ^=, and |=. Atomic pointer types support fetch_add(), fetch_sub(), ++, --, +=, and -=.
Most of the atomic operations can accept an extra parameter specifying the memory ordering that you would like. For example:
T atomic<T>::fetch_add(T value, memory_order = memory_order_seq_cst);
You may change the default memory_order. The standard provides: memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, and memory_order_seq_cst, all defined in the std namespace. However, it is rare that you will want to use them instead of the default. While another memory order may perform better than the default, according to some metric, if you use them slightly wrong you will again introduce race conditions or other difficult-to-track threading-related problems. If you do want to know more about memory ordering, consult one of the multithreading references in Appendix B.
MUTUAL EXCLUSION
If you are writing multithreaded applications, you have to be sensitive to sequencing of operations. If your threads read and write shared data, this can be a problem. There are many ways to avoid this problem, such as never actually sharing data between threads. However, if you can’t avoid sharing data, you must provide for synchronization so that only one thread at a time can change the data.
Scalars such as Booleans and integers can often be synchronized properly with atomic operations described earlier; but, when your data is more complex, and you need to use that data from multiple threads, you must provide explicit synchronization.
The standard library has support for mutual exclusion in the form of mutex and lock classes. These can be used to implement synchronization between threads and are discussed in the next sections.
Mutex Classes
Mutex stands for mutual exclusion. The mutual exclusion classes are all defined in the <mutex> header file and are in the std namespace. The basic mechanism of using a mutex is as follows:
· A thread that wants to use (read/write) memory shared with other threads tries to lock a mutex object. If another thread is currently holding this lock, the new thread that wants to gain access blocks until the lock is released, or until a timeout interval expires.
· Once the thread has obtained the lock, it is free to use the shared memory. Of course, this assumes that all threads that want to use the shared data all correctly acquire a lock on the mutex.
· After the thread is finished with reading/writing to the shared memory, it releases the lock to give some other thread an opportunity to obtain the lock to the shared memory. If two or more threads are waiting on the lock, there are no guarantees as to which thread is granted the lock and thus allowed to proceed.
The standard provides non-timed mutex and timed mutex classes.
Non-Timed Mutex Classes
The library has two non-timed mutex classes: std::mutex and std::recursive_mutex. Each supports the following methods:
· lock(): The calling thread tries to obtain the lock and blocks until the lock has been acquired. It blocks indefinitely. If there is a desire to limit the amount of time the thread blocks, you should use a timed mutex, discussed in the next section.
· try_lock(): The calling thread tries to obtain the lock. If the lock is currently held by another thread, the call returns immediately. If the lock has been obtained, try_lock() returns true, otherwise it returns false.
· unlock(): Releases the lock held by the calling thread, making it available for another thread.
std::mutex is a standard mutual exclusion class with exclusive ownership semantics. There can be only one thread owning the mutex. If another thread wants to obtain ownership of this mutex, it either blocks when using lock(), or fails when using try_lock(). A thread already having ownership of a std::mutex is not allowed to call lock() or try_lock() again on that mutex. This might lead to a deadlock!
std::recursive_mutex behaves almost identically to std::mutex, except that a thread already having ownership of a recursive mutex is allowed to call lock() or try_lock() again on the same recursive mutex. The calling thread should call the unlock() method as many times as it obtained a lock on the recursive mutex.
Timed Mutex Classes
The library provides three timed mutex classes: std::timed_mutex, std::recursive_timed_mutex, and std::shared_timed_mutex; all support the normal lock(), try_lock(), and unlock() methods. Additionally, they support the following:
· try_lock_for(rel_time): The calling thread tries to obtain the lock for a certain relative time. If the lock could not be obtained after the given timeout, the call fails and returns false. If the lock could be obtained within the timeout, the call succeeds and returns true.
· try_lock_until(abs_time): The calling thread tries to obtain the lock until the system time equals or exceeds the specified absolute time. If the lock could be obtained before this time, the call returns true. If the system time passes the given absolute time, the function stops trying to obtain the lock and returns false.
A thread already having ownership of a timed_mutex is not allowed to call one of the previous lock calls again on that mutex. This might lead to a deadlock!
recursive_timed_mutex behaves almost identically to timed_mutex, except that a thread already having ownership of a recursive mutex is allowed to call one of the previous lock calls again on the same mutex. The calling thread should call the unlock() method as many times as it obtained a lock on the recursive mutex.
The shared_timed_mutex class supports the concept of shared lock ownership, also known as readers-writers lock. A thread can either get exclusive ownership or shared ownership of the lock. Exclusive ownership, also known as a write lock, can be acquired only when there are no other threads having exclusive or shared ownership. Shared ownership, also known as a read lock, can be acquired if there is no other thread having exclusive ownership, but other threads are allowed to have acquired shared ownership. Theshared_timed_mutex class supports lock(), try_lock(), try_lock_for(), try_lock_until(), and unlock(), all discussed earlier. These methods acquire and release exclusive locks. Additionally they have the following shared ownership-related methods:
· lock_shared(): The calling thread tries to obtain the shared ownership lock and blocks until the lock has been acquired.
· try_lock_shared(): The calling thread tries to obtain the shared ownership lock. If an exclusive lock is currently held by another thread, the call returns immediately. If the lock has been obtained, try_lock() returns true, otherwise it returns false.
· try_lock_shared_for(rel_time): The calling thread tries to obtain the shared ownership lock for a certain relative time. If the lock could not be obtained after the given timeout, the call fails and returns false. If the lock could be obtained within the timeout, the call succeeds and returns true.
· try_lock_shared_until(abs_time): The calling thread tries to obtain the shared ownership lock until the system time equals or exceeds the specified absolute time. If the lock could be obtained before this time, the call returns true. If the system time passes the given absolute time, the function stops trying to obtain the lock and returns false.
· unlock_shared(): Releases shared ownership.
A thread already having a lock on a shared_timed_mutex is not allowed to try to acquire a second lock on that mutex. This might lead to a deadlock!
WARNING Do not manually call one of the previously discussed lock and unlock methods on any of the mutex classes. Mutex locks are resources, and, as all resources, they almost exclusively should be acquired using the RAII (Resource Acquisition Is Initialization) paradigm. The standard defines a number of RAII lock classes, discussed in the next section. Using them is critical to avoid deadlocks. They automatically unlock a mutex when a lock object goes out of scope, so you don’t need to manually call unlock() at the right time.
Locks
A lock class is a RAII class that makes it easier to correctly obtain and release a lock on a mutex; the destructor of the lock class automatically releases the associated mutex. The standard defines three types of locks: std::lock_guard, std::unique_lock, andstd::shared_lock.
lock_guard
lock_guard is a simple lock with two constructors.
· explicit lock_guard(mutex_type& m);
A constructor accepting a reference to a mutex. This one tries to obtain a lock on the mutex and blocks until the lock is obtained. The keyword explicit for constructors is discussed in Chapter 8.
· lock_guard(mutex_type& m, adopt_lock_t);
A constructor accepting a reference to a mutex and an instance of the std::adopt_lock_t struct. The lock assumes that the calling thread already has obtained a lock on the referenced mutex and will manage this lock.
unique_lock
std::unique_lock is a more sophisticated lock that allows you to defer lock acquisition until later in the execution, long after the declaration. You can use the owns_lock() method to see if the lock has been acquired. A unique_lock also has a bool conversion operator, which can be used to check if the lock has been acquired. An example of using this conversion operator is given later in this chapter in the section “Using Timed Locks.” unique_lock has several constructors:
· explicit unique_lock(mutex_type& m);
A constructor accepting a reference to a mutex. This one tries to obtain a lock on the mutex and blocks until the lock is obtained.
· unique_lock(mutex_type& m, defer_lock_t) noexcept;
A constructor accepting a reference to a mutex and an instance of the std::defer_lock_t struct. The unique_lock stores the reference to the mutex, but does not immediately try to obtain a lock. A lock can be obtained later.
· unique_lock(mutex_type& m, try_to_lock_t);
A constructor accepting a reference to a mutex and an instance of the std::try_to_lock_t struct. The lock tries to obtain a lock to the referenced mutex, but if it fails it does not block.
· unique_lock(mutex_type& m, adopt_lock_t);
A constructor accepting a reference to a mutex and an instance of the std::adopt_lock_t struct. The lock assumes that the calling thread already has obtained a lock on the referenced mutex and will manage this lock.
· template <class Clock, class Duration>
· unique_lock(mutex_type& m, const chrono::time_point<Clock, Duration>& abs_time);
A constructor accepting a reference to a mutex and an absolute time. The constructor tries to obtain a lock until the system time passes the given absolute time. The Chrono library is discussed in Chapter 19.
· template <class Rep, class Period>
· unique_lock(mutex_type& m, const chrono::duration<Rep, Period>& rel_time);
A constructor accepting a reference to a mutex and a relative time. The constructor tries to get a lock on the mutex with the given relative timeout.
The unique_lock class also has the following methods: lock(), try_lock(), try_lock_for(), try_lock_until(), and unlock(), which behave as explained in the section on timed mutex classes earlier in this chapter.
shared_lock
The shared_lock class has the same type of constructors and the same methods as unique_lock. The difference is that the shared_lock class calls the shared ownership related methods on the underlying shared mutex. Thus, the methods of shared_lock are called lock(), try_lock(), and so on, but on the underlying shared mutex they call lock_shared(), try_lock_shared(), and so on. This is done so that shared_lock has the same interface as unique_lock, and can be used as a stand-in replacement for unique_lock but acquires a shared lock instead of an exclusive lock.
Acquiring Multiple Locks at Once
C++ has two generic lock functions that you can use to obtain locks on multiple mutex objects at once without the risk of creating deadlocks. Both are defined in the std namespace, and both are variadic template functions, discussed in Chapter 21.
template <class L1, class L2, class... L3> void lock(L1&, L2&, L3&...);
This generic function locks all the given mutex objects in an unspecified order without the risk of deadlocks. If one of the mutex lock calls throws an exception, unlock() is called on all locks that have already been obtained.
template <class L1, class L2, class... L3> int try_lock(L1&, L2&, L3&...);
try_lock() tries to obtain a lock on all the given mutex objects by calling try_lock() on each of them in sequence. It returns -1 if all calls to try_lock() succeed. If any try_lock() fails, unlock() is called on all locks that have already been obtained, and the return value is the zero-based index of the parameter position of the mutex on which try_lock() failed.
The following example demonstrates how to use the generic lock() function. The process() function first creates two locks, one for each mutex, and gives an instance of std::defer_lock_t as a second argument to tell unique_lock not to acquire the lock during construction. The call to lock() then acquires both locks without the risk of deadlocks:
mutex mut1;
mutex mut2;
void process()
{
unique_lock<mutex> lock1(mut1, defer_lock_t());
unique_lock<mutex> lock2(mut2, defer_lock_t());
lock(lock1, lock2);
// Locks acquired
}
int main()
{
process();
}
std::call_once
You can use std::call_once() in combination with std::once_flag to make sure a certain function or method is called exactly one time no matter how many threads try to call call_once(). Only one call_once() invocation actually calls the given function or method; this invocation is called the effective call_once(). This effective invocation on a specific once_flag instance finishes before all other call_once() invocations on the same once_flag instance. Other threads calling call_once() on the same once_flag instance block until the effective call is finished. Figure 23-3 illustrates this with three threads. Thread 1 performs the effective call_once() invocation, Thread 2 blocks until the effective invocation is finished, and Thread 3 doesn’t block because the effective invocation from Thread 1 has already finished.

FIGURE 23-3
The following example demonstrates the use of call_once(). The example launches three threads running processingFunction() that uses some shared resources. These shared resources should be initialized only once by calling initializeSharedResources() once. To accomplish this, each thread calls call_once() with a global once_flag. The result is that only one thread executes initializeSharedResources(), and exactly one time. While this call_once() call is in progress, other threads block until initializeSharedResources() returns:
once_flag gOnceFlag;
void initializeSharedResources()
{
// ... Initialize shared resources that will be used by multiple threads.
cout << "Shared resources initialized." << endl;
}
void processingFunction()
{
// Make sure the shared resources are initialized.
call_once(gOnceFlag, initializeSharedResources);
// ... Do some work, including using the shared resources
cout << "Processing" << endl;
}
int main()
{
// Launch 3 threads.
vector<thread> threads(3);
for (auto& t : threads) {
t = thread{ processingFunction };
}
// Join on all threads
for (auto& t : threads) {
t.join();
}
}
The output of this code is as follows:
Shared resources initialized.
Processing
Processing
Processing
Of course, in this example, you could call initializeSharedResources() once in the beginning of the main() function before the threads are launched; however, that wouldn’t demonstrate the use of call_once().
Examples Using Mutual Exclusion Objects
Thread-Safe Writing to Streams
Earlier in this chapter, in the section about threads, there is an example with a class called Counter. That example mentions that C++ streams are race-condition free by default, but that the output from multiple threads can be interleaved. To solve this interleaving issue, you can use a mutual exclusion object to make sure that only one thread at a time is reading/writing to the stream object.
The following example synchronizes all accesses to cout in the Counter class. For this, a static mutex object is added to the class. It should be static, because all instances of the class should use the same mutex instance. lock_guard is used to obtain a lock on the mutexbefore writing to cout. Changes compared to the earlier version are highlighted:
class Counter
{
public:
Counter(int id, int numIterations)
: mId(id), mNumIterations(numIterations)
{
}
void operator()() const
{
for (int i = 0; i < mNumIterations; ++i) {
lock_guard<mutex> lock(mMutex);
cout << "Counter " << mId << " has value ";
cout << i << endl;
}
}
private:
int mId;
int mNumIterations;
static mutex mMutex;
};
mutex Counter::mMutex;
This code creates a lock_guard instance on each iteration of the for loop. It is recommended to limit the time a lock is held as much as possible, otherwise you are blocking other threads for too long. For example, if the lock_guard instance would be created once right before the for loop, then you basically lose all multithreading in this code because one thread holds a lock for the entire duration of its for loop, and all other threads wait for this lock to be released.
Using Timed Locks
The following example demonstrates how to use a timed mutex. It is the same Counter class as before, but this time it uses a timed_mutex in combination with a unique_lock. A relative time of 200 milliseconds is given to the unique_lock constructor, causing it to try to obtain a lock for 200 milliseconds. If the lock could not be obtained within this timeout interval, the constructor returns. Afterward you can check whether or not the lock has been acquired, which can be done with an if statement on the lock variable because theunique_lock class defines a bool conversion operator. The timeout is specified using the Chrono library, discussed in Chapter 19.
class Counter
{
public:
Counter(int id, int numIterations)
: mId(id), mNumIterations(numIterations)
{
}
void operator()() const
{
for (int i = 0; i < mNumIterations; ++i) {
unique_lock<timed_mutex> lock(mTimedMutex, 200ms);
if (lock) {
cout << "Counter " << mId << " has value ";
cout << i << endl;
} else {
// Lock not acquired in 200 ms
}
}
}
private:
int mId;
int mNumIterations;
static timed_mutex mTimedMutex;
};
timed_mutex Counter::mTimedMutex;
If your compiler does not yet support the C++14 standard user-defined literals, then instead of 200ms, you have to write the following:
chrono::milliseconds(200)
Double-Checked Locking
You can use locks to implement the double-checked locking pattern.
WARNING The double-checked locking pattern is explained here because you might encounter it in existing code. Double-checked locking is sensitive to race conditions, cache coherency, and so on; It is hard to get right. It’s recommended to avoid this pattern as much as possible in new code. Instead, use other mechanisms such as simple locks, atomic variables, and call_once() without any double checking.
Double-checked locking could for example, be used to make sure that a variable is initialized exactly once. The following example shows how you can implement this. It is called the double-checked locking algorithm because it is checking the value of the initializedvariable twice, once before acquiring the lock and once right after acquiring the lock. The first initialized check is to prevent obtaining a lock when it is not needed and will increase performance. The second check is required to make sure that no other thread performed the initialization between the first initialized check and acquiring the lock:
void initializeSharedResources()
{
// ... Initialize shared resources that will be used by multiple threads.
cout << "Shared resources initialized." << endl;
}
atomic<bool> initialized(false);
mutex mut;
void func()
{
if (!initialized) {
unique_lock<mutex> lock(mut);
if (!initialized) {
initializeSharedResources();
initialized = true;
}
}
cout << "OK" << endl;
}
int main()
{
vector<thread> threads;
for (int i = 0; i < 5; ++i) {
threads.push_back(thread{ func });
}
for (auto& t : threads) {
t.join();
}
}
The output clearly shows that only one thread has initialized the shared resources:
Shared resources initialized.
OK
OK
OK
OK
OK
NOTE For this example, it’s recommended to use call_once() as demonstrated earlier in this chapter, instead of double-checked locking.
CONDITION VARIABLES
Condition variables allow a thread to block until a certain condition is set by another thread or until the system time reaches a specified time. They allow for explicit inter-thread communication. If you are familiar with multithreaded programming using the Win32 API, you can compare condition variables with event objects in Windows.
There are two kinds of condition variables available, both defined in the <condition_variable> header file:
· std::condition_variable: A condition variable that can wait only on a unique_lock<mutex>, which, according to the standard, allows for maximum efficiency on certain platforms.
· std::condition_variable_any: A condition variable that can wait on any kind of object, including custom lock types.
The condition_variable class supports the following methods.
· notify_one();
Wakes up one of the threads waiting on this condition variable. This is similar to an auto-reset event in Windows.
· notify_all();
Wakes up all threads waiting on this condition variable.
· wait(unique_lock<mutex>& lk);
The thread calling wait() should already have acquired a lock on lk. The effect of calling wait() is that it atomically calls lk.unlock() and then blocks the thread, waiting for a notification. When the thread is unblocked by a notify_one() or notify_all() call in another thread, the function calls lk.lock() again, possibly blocking on the lock and then returning.
· wait_for(unique_lock<mutex>& lk, const chrono::duration<Rep, Period>& rel_time);
Similar to the previous wait() method, except that the thread is unblocked by a notify_one() call, a notify_all() call, or when the given timeout has expired.
· wait_until(unique_lock<mutex>& lk, const chrono::time_point<Clock, Duration>& abs_time);
Similar to wait(), except that the thread is unblocked by a notify_one() call, a notify_all() call, or when the system time passes the given absolute time.
There are also versions of wait(), wait_for(), and wait_until() that accept an extra predicate parameter. For instance, the version of wait() accepting an extra predicate is equivalent to the following:
while (!predicate())
wait(lk);
The condition_variable_any class supports the same methods as the condition_variable class except that it accepts any kind of lock class instead of only a unique_lock<mutex>. Your lock class should have a lock() and unlock() method.
Threads waiting on a condition variable can wake up when another thread calls notify_one() or notify_all(), or with a relative timeout, or when the system time reaches a certain time, but can also wake up spuriously. This means that a thread can wake up even if no other thread has called any notify method. Thus, when a thread waits on a condition variable and wakes up, it needs to check whether it woke up because of a notify or not. One way to check for this is using one of the versions of wait() accepting a predicate.
As an example, condition variables can be used for background threads processing items from a queue. You can define a queue in which you insert items to be processed. A background thread waits until there are items in the queue. When an item is inserted into the queue, the thread wakes up, processes the item, and goes back to sleep, waiting for the next item. Suppose you have the following queue:
std::queue<std::string> mQueue;
You need to make sure only one thread is modifying this queue at any given time. You can do this with a mutex:
std::mutex mMutex;
To be able to notify a background thread when an item is added, you need a condition variable:
std::condition_variable mCondVar;
A thread that wants to add an item to the queue first acquires a lock on the mutex, adds the item to the queue, and notifies the background thread. You can call notify_one() or notify_all() whether you currently have the lock or not. Both will work.
// Lock mutex and add entry to the queue.
unique_lock<mutex> lock(mMutex);
mQueue.push(entry);
// Notify condition variable to wake up thread.
mCondVar.notify_all();
The background thread waits for notifications in an infinite loop, as follows. Note the use of wait() accepting a predicate to correctly handle spurious wake-ups. The predicate checks if there is something in the queue. When the call to wait() returns, you are sure there is something in the queue.
unique_lock<mutex> lock(mMutex);
while (true) {
// Wait for a notification.
mCondVar.wait(lock, []{ return !mQueue.empty(); });
// Condition variable is notified, so something is in the queue.
// Process queue item...
}
The section, “Example: Multithreaded Logger Class,” toward the end of this chapter provides a complete example of how to use condition variables to send notifications to other threads.
The standard also defines a helper function called std::notify_all_at_thread_exit(cond, lk) where cond is a condition variable and lk is a unique_lock<mutex> instance. A thread calling this function should already have acquired the lock lk. When the thread exits, it automatically executes the following:
lk.unlock();
cond.notify_all();
NOTE The lock lk stays locked until the thread exits. So, you need to make sure that this does not cause any deadlocks in your code, for example due to wrong lock ordering. Deadlocks are discussed earlier in this chapter.
FUTURES
As discussed earlier in this chapter, using std::thread to launch a thread that calculates a single result does not make it easy to get the computed result back once the thread has finished executing. Another problem with std::thread is handling errors like exceptions. If a thread throws an exception and this exception is not handled by the thread itself, the C++ runtime calls std::terminate, which usually terminates the whole application. You can avoid this by using std::future, which is able to transport an uncaught exception to another thread, which can then handle the exception however it wants. Of course, it’s good practice to always try to handle exceptions in the threads themselves as much as possible, preventing them from leaving the thread.
std::future and std::promise work together to make it easier to retrieve a result from a function that ran in the same thread or in another thread. Once a function, running in the same thread or in another thread, has calculated the value that it wants to return, it puts this value in a promise. This value can then be retrieved through a future. You can think of a future/promise pair as an inter-thread communication channel for a result.
A thread that launches another thread to calculate a value can get this value as follows. T is the type of the calculated result:
future<T> fut = ...; // Is discussed later
T res = fut.get();
The call to get() retrieves the result and stores it in the variable res. If the other thread has not yet finished calculating the result, the call to get() blocks until the value becomes available. You can avoid blocking by first asking the future if there is a result available:
if (fut.wait_for(0)) { // Value is available
T res = fut.get();
} else { // Value is not yet available
...
}
A promise is the input side for the result; future is the output side. A promise is something where a thread stores its calculated result. The following code demonstrates how a thread might do this:
promise prom = ...; // Is discussed later
T val = ...; // Calculate result value
prom.set_value(val);
If a thread encounters some kind of error during its calculation, it can store an exception in the promise instead of the value:
prom.set_exception(runtime_error("message"));
A thread that launches another thread to calculate something should give the promise to the newly launched thread, so that it can store the result in it. This is made easy with std::packaged_task, which automatically links a future and a promise. The following code demonstrates this feature. It creates a packaged_task, which executes the given lambda expression in a separate thread. The lambda expression accepts two arguments and returns the sum of them as the result. The future is retrieved from the packaged_task by callingget_future(). The thread is started by the third line, and the last line uses the get() function to wait for and retrieve the result from the launched thread:
packaged_task<int(int, int)> task([](int i1, int i2) { return i1 + i2; });
auto fut = task.get_future(); // Get the future
task(2, 3); // Launch the task
int res = fut.get(); // Retrieve the result
NOTE This code is just for demonstration purposes. It launches a separate thread and then calls get(), which blocks until the result is calculated. This sounds like a very expensive function call. In real-world applications you use the promise/futuremodel by periodically checking if there is a result available in the future (using wait_for() as discussed earlier), or by using a synchronization mechanism such as a condition variable. When the result is not yet available, you can do something else in the meantime, instead of blocking.
If you want to give the C++ runtime more control over whether or not a thread is created to calculate something, you can use std::async(). It accepts a function to be executed and returns a future that you can use to retrieve the result. There are two ways in whichasync() can call your function:
· Creating a new thread to run your function asynchronously
· Running your function at the time you call get() on the returned future
If you call async() without additional arguments, the runtime automatically chooses one of the two methods depending on factors like the number of processors in your system and the amount of concurrency already taking place. You can force the runtime to use one or the other method by specifying a launch::async (create a new thread) or launch::deferred (use current thread) policy argument. The following example demonstrates the use of async():
int calculate()
{
return 123;
}
int main()
{
auto fut = async(calculate);
//auto fut = async(launch::async, calculate);
//auto fut = async(launch::deferred, calculate);
// Do some more work...
// Get result
int res = fut.get();
cout << res << endl;
}
As you can see in this example, std::async() is one of the easiest methods to perform some calculations in another thread or the same thread, and retrieve the result afterwards.
NOTE A future returned by a call to async() blocks in its destructor until the result is available.
Exception Handling
A big advantage of using futures is that they automatically transport exceptions between threads. At the time you call get() on a future, you receive the requested result, or, any exception that occurred in the thread is rethrown in the thread calling get() and you can catch them using a normal try/catch block. Here is an example:
int calculate()
{
throw runtime_error("Exception thrown from a thread.");
}
int main()
{
// Use launch::async policy to force a new thread.
auto fut = async(launch::async, calculate);
// Do some more work...
// Get result
try {
int res = fut.get();
cout << res << endl;
} catch (const exception& ex) {
cout << "Caught exception: " << ex.what() << endl;
}
}
EXAMPLE: MULTITHREADED LOGGER CLASS
This section demonstrates how to use threads, the mutual exclusion and lock classes, and condition variables to write a multithreaded Logger class. The class allows log messages to be added to a queue from different threads. The Logger class itself processes this queue in another background thread that serially writes the log messages to a file. The class will be designed in two iterations to show you some examples of problems you will encounter when writing multithreaded code.
The C++ standard does not have a thread-safe queue, thus it is obvious that you have to protect access to the queue with a mutex to prevent multiple threads from reading/writing to the queue at the same time. Based on that, you might define the Logger class as follows:
class Logger
{
public:
// Starts a background thread writing log entries to a file.
Logger();
// Prevent copy construction and assignment.
Logger(const Logger& src) = delete;
Logger& operator=(const Logger& rhs) = delete;
// Add log entry to the queue.
void log(const std::string& entry);
private:
// The function running in the background thread.
void processEntries();
// Mutex and condition variable to protect access to the queue.
std::mutex mMutex;
std::condition_variable mCondVar;
std::queue<std::string> mQueue;
// The background thread.
std::thread mThread;
};
The implementation is as follows. Note that this initial design has a couple of problems and when you try to run it, it might behave strangely or even crash. This is discussed and solved in the next iteration of the Logger class. The inner while loop in theprocessEntries() method is also worth looking at. It processes all messages in the queue one at a time, and acquires and releases the lock on each iteration. This is done to make sure the loop doesn’t keep the lock for too long, blocking other threads.
Logger::Logger()
{
// Start background thread.
mThread = thread{ &Logger::processEntries, this };
}
void Logger::log(const std::string& entry)
{
// Lock mutex and add entry to the queue.
unique_lock<mutex> lock(mMutex);
mQueue.push(entry);
// Notify condition variable to wake up thread.
mCondVar.notify_all();
}
void Logger::processEntries()
{
// Open log file.
ofstream ofs("log.txt");
if (ofs.fail()) {
cerr << "Failed to open logfile." << endl;
return;
}
// Start processing loop.
unique_lock<mutex> lock(mMutex);
while (true) {
// Wait for a notification.
mCondVar.wait(lock);
// Condition variable is notified, so something might be in the queue.
lock.unlock();
while (true) {
lock.lock();
if (mQueue.empty()) {
break;
} else {
ofs << mQueue.front() << endl;
mQueue.pop();
}
lock.unlock();
}
}
}
This Logger class can be tested with the following test code. It launches a number of background threads, all logging a few messages to the same Logger instance:
void logSomeMessages(int id, Logger& logger)
{
for (int i = 0; i < 10; ++i) {
stringstream ss;
ss << "Log entry " << i << " from thread " << id;
logger.log(ss.str());
}
}
int main()
{
Logger logger;
vector<thread> threads;
// Create a few threads all working with the same Logger instance.
for (int i = 0; i < 10; ++i) {
threads.emplace_back(logSomeMessages, i, ref(logger));
}
// Wait for all threads to finish.
for (auto& t : threads) {
t.join();
}
}
If you build and run this naïve initial version on a multicore machine, you will notice that the background Logger thread is terminated abruptly when the main() function finishes. This means that messages still in the queue are not written to the file on disk. Some runtime libraries even issue an error or generate a crash dump when the background Logger thread is abruptly terminated. You need to add a mechanism to gracefully shut down the background thread and wait until the background thread is completely shut down before terminating the application itself. This can be done by adding a destructor and an atomic Boolean member variable to the class. The new definition of the class is as follows:
class Logger
{
public:
// Gracefully shut down background thread.
virtual ~Logger();
// Other public members omitted for brevity
private:
// Boolean telling the background thread to terminate.
std::atomic<bool> mExit;
// Other members omitted for brevity
};
The Logger constructor needs to initialize mExit. The destructor sets it to true, wakes up the thread, and then waits until the thread is shut down. The destructor acquires a lock on mMutex before setting mExit to true and before calling notify_all(). This is to prevent a race condition and deadlock with processEntries(). processEntries() could be at the beginning of its while loop right after having checked mExit and right before the call to wait(). If the main thread calls the Logger destructor at that very moment, and the destructor wouldn’t acquire a lock on mMutex, then the destructor sets mExit to true and calls notify_all() after processEntries() has checked mExit and before processEntries() is waiting on the condition variable, thus processEntries() will not see the new value of mExit and it will miss the notification. In that case, the application is in a deadlock situation, because the destructor is waiting on the join() call and the background thread is waiting on the condition variable. Note that the destructor must release the lock on mMutex before callingjoin(), which explains the extra code block using curly brackets.
Logger::Logger() : mExit(false)
{
// Start background thread.
mThread = thread{ &Logger::processEntries, this };
}
Logger::~Logger()
{
{
unique_lock<mutex> lock(mMutex);
// Gracefully shut down the thread by setting mExit
// to true and notifying the thread.
mExit = true;
// Notify condition variable to wake up thread.
mCondVar.notify_all();
}
// Wait until thread is shut down. This should be outside the above code
// block because the lock on mMutex must be released before calling join()!
mThread.join();
}
The processEntries() method needs to check this Boolean variable and terminate the processing loop when it’s true:
void Logger::processEntries()
{
// Open log file.
ofstream ofs("log.txt");
if (ofs.fail()) {
cerr << "Failed to open logfile." << endl;
return;
}
// Start processing loop.
unique_lock<mutex> lock(mMutex);
while (true) {
if (!mExit) { // Only wait for notifications if we don’t have to exit.
// Wait for a notification.
mCondVar.wait(lock);
}
// Condition variable is notified, so something might be in the queue
// and/or we need to shut down this thread.
lock.unlock();
while (true) {
lock.lock();
if (mQueue.empty()) {
break;
} else {
ofs << mQueue.front() << endl;
mQueue.pop();
}
lock.unlock();
}
if (mExit) {
break;
}
}
}
Note that you cannot just check for mExit in the condition for the outer while loop because even when mExit is true, there might still be log entries in the queue that need to be written.
You can add artificial delays on specific places in your multithreaded code to trigger certain behavior. Note that such delays should only be added for testing, and should be removed from your final code! For example, to test that the race-condition with the destructor is solved, you can remove any calls to log() from the main program causing it to almost immediately call the destructor of the Logger class, and add the following delay:
void Logger::processEntries()
{
// Omitted for brevity
// Start processing loop.
unique_lock<mutex> lock(mMutex);
while (!mExit) {
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
// Wait for a notification.
mCondVar.wait(lock);
// Omitted for brevity
}
}
THREAD POOLS
Instead of creating and deleting threads dynamically throughout your program lifetime, you can create a pool of threads that can be used as needed. This technique is often used in programs that want to handle some kind of event in a thread. In most environments, the ideal number of threads is equal to the number of processing cores. If there are more threads than cores, threads will have to be suspended to allow other threads to run, and this will ultimately add overhead. Note that while the ideal number of threads is equal to the number of cores, this applies only in the case where the threads are compute bound and cannot block for any other reason, including I/O. When threads can block, it is often appropriate to run more threads than there are cores. Determining the optimal number of threads in such cases may involve throughput measurements.
Because not all processing is identical, it is not uncommon to have threads from a thread pool receive, as part of their input, a function object or lambda expression that represents the computation to be done.
Because threads from a thread pool are pre-existing, it is vastly more efficient for the operating system to schedule one to run than it is to create one in response to an input. Furthermore, the use of a thread pool allows you to manage the number of threads created, so depending on the platform, you may have just one thread or thousands of threads.
There are several libraries available that implement thread pools; for example, Intel Threading Building Blocks (TBB), Microsoft Parallel Patterns Library (PPL), and so on. It’s recommended to use such a library for your thread pools instead of writing your own implementation. If you do want to implement a thread pool yourself, it can be done in a similar way as an object pool. Chapter 25 gives an example implementation of an object pool.
THREADING DESIGN AND BEST PRACTICES
This section briefly lists a couple of best practices related to multithreaded programming.
· Before terminating the application, always use join() to wait for background threads to finish: Make sure you use join() on all background threads before terminating your application. This will make sure all those background threads have the time to do proper cleanup. Background threads for which there is no join() will terminate abruptly when the main thread is terminated.
· The best synchronization is no synchronization: Multithreaded programming becomes much easier if you manage to design your different threads in such a way that all threads working on shared data read only from that shared data and never write to it, or only write to parts never read by other threads. In that case there is no need for any synchronization and you cannot have problems like race conditions or deadlocks.
· Try to use the single-thread ownership pattern: This means that a block of data is owned by no more than one thread at a time. Owning the data means that no other thread is allowed to read/write to the data. When the thread is finished with the data, the data can be passed off to another thread, which now has sole and complete responsibility/ownership of the data. No synchronization is necessary in this case.
· Use atomic types and operations when possible: Atomic types and atomic operations make it easier to write race-condition and deadlock-free code, because they handle synchronization automatically. If atomic types and operations are not possible in your multithreaded design, and you need shared data, you have to use a mutual exclusion mechanism to ensure proper synchronization.
· Use locks to protect mutable shared data: If you need mutable shared data to which multiple threads can write, and you cannot use atomic types and operations; you have to use a locking mechanism to make sure reads and writes between different threads are synchronized.
· Release locks as soon as possible: When you need to protect your shared data with a lock, make sure you release the lock as soon as possible. While a thread is holding a lock, it is blocking other threads waiting for the same lock, possibly hurting performance.
· Make sure to acquire multiple locks in the same order: If multiple threads need to acquire multiple locks, they must be acquired in the same order in all threads to prevent deadlocks. You should use the generic std::lock() or std::try_lock() to minimize the chance of violating lock ordering restrictions.
· Use a multithreading-aware profiler: Use a multithreading-aware profiler to find performance bottlenecks in your multithreaded applications and to find out if your multiple threads are indeed utilizing all available processing power in your system. An example of a multithreading-aware profiler is the profiler in certain editions of Microsoft Visual Studio.
· Understand the multithreading support features of your debugger: Most debuggers have at least basic support for debugging multithreaded applications. You should be able to get a list of all running threads in your application, and you should be able to switch to any one of those threads to inspect their call stack. You can use this, for example, to inspect deadlocks because you can see exactly what each thread is doing.
· Use thread pools instead of creating and destroying a lot of threads dynamically: Your performance decreases if you dynamically create and destroy a lot of threads. In that case it’s better to use a thread pool to reuse existing threads.
· Use higher-level multithreading libraries: Where possible, use higher-level multithreading libraries such as Intel Threading Building Blocks (TBB), Microsoft Parallel Patterns Library (PPL), and so on, rather than reinventing the wheel. Multithreaded programming is hard to get right and is error prone. More often than not, your wheel may not be as round as you think.
SUMMARY
This chapter gave a brief overview of multithreaded programming using the standard C++ threading library. It explained how you can use atomic types and atomic operations to operate on shared data without having to use explicit locks. In case you cannot use these atomic types and operations, you learned how to use mutual exclusion mechanisms to ensure proper synchronization between different threads that need read/write access to shared data. You also saw how promises and futures represent a simple inter-thread communication channel; you can use futures to more easily get a result from a background thread. The chapter finished with a number of best practices for multithreaded application design.
As mentioned in the introduction, this chapter tried to touch on all the functionality provided by the standard C++ threading library, but due to space constraints, it cannot go into all the details of multithreaded programming. There are books available that discuss nothing but multithreading. See Appendix B for a few references.