Professional C++ (2014)
Part IIProfessional C++ Software Design
· CHAPTER 4: Designing Professional C++ Programs
· CHAPTER 5: Designing with Objects
· CHAPTER 6: Designing for Reuse
Chapter 4Designing Professional C++ Programs
WHAT’S IN THIS CHAPTER?
· The definition of programming design
· The importance of programming design
· The aspects of design that are unique to C++
· The two fundamental themes for effective C++ design: abstraction and reuse
· The different types of code available for reuse
· The advantages and disadvantages of code reuse
· General strategies and guidelines for reusing code
· Open-source libraries
· The C++ standard library
Before writing a single line of code in your application, you should design your program. What data structures will you use? What classes will you write? This plan is especially important when you program in groups. Imagine sitting down to write a program with no idea what your coworker, who is working on the same program, is planning! In this chapter, you’ll learn how to use the Professional C++ approach to C++ design.
Despite the importance of design, it is probably the most misunderstood and underused aspect of the software-engineering process. Too often programmers jump into applications without a clear plan: they design as they code. This approach can lead to convoluted and overly complicated designs. It also makes the development, debugging, and maintenance tasks more difficult. Although counterintuitive, investing extra time at the beginning of a project to design it properly actually saves time over the life of the project.
WHAT IS PROGRAMMING DESIGN?
Your program design, or software design, is the specification of the architecture that you will implement to fulfill the functional and performance requirements of the program. Informally, the design is how you plan to write the program. You should generally write your design in the form of a design document. Although every company or project has its own variation of a desired design document format, most design documents share the same general layout, including two main parts:
1. The gross subdivision of the program into subsystems, including interfaces and dependencies between the subsystems, data flow between the subsystems, input and output to and from each subsystem, and general threading model.
2. The details of each subsystem, including subdivision into classes, class hierarchies, data structures, algorithms, specific threading model, and error-handling specifics.
The design documents usually include diagrams and tables showing subsystem interactions and class hierarchies. UML, Unified Modeling Language, is the industry standard used for diagrams. Consult one of the references in Appendix B for details. The exact format of the design document is less important than the process of thinking about your design.
NOTE The point of designing is to think about your program before you write it.
You should generally try to make your design as good as possible before you begin coding. The design should provide a map of the program that any reasonable programmer could follow in order to implement the application. Of course, it is inevitable that the design will need to be modified once you begin coding and you encounter issues that you didn’t think of earlier. Software-engineering processes have been designed to give you the flexibility to make these changes. The Spiral Model proposed by Barry W. Boehm is one example of such an iterative process whereby the application is developed according to cycles with each cycle containing at least a requirements analysis, design and an implementation part. Chapter 24 describes various software-engineering process models in more detail.
THE IMPORTANCE OF PROGRAMMING DESIGN
It’s tempting to skip the analysis and design steps, or to perform it only cursorily, in order to begin programming as soon as possible. There’s nothing like seeing code compiling and running to give you the impression that you have made progress. It seems like a waste of time to formalize a design, or to write down functional requirements when you already know, more or less, how you want to structure your program. Besides, writing a design document just isn’t as much fun as coding. If you wanted to write papers all day, you wouldn’t be a computer programmer! As a programmer myself, I understand this temptation to begin coding immediately, and have certainly succumbed to it on occasion. However, it will most likely lead to problems on all but the simplest projects. Whether or not you succeed without a design prior to the implementation depends on your experience as a programmer, your proficiency with commonly used design patterns, and how deep you understand C++, the problem domain and the requirements.
To help you understand the importance of programming design, imagine that you own a plot of land on which you want to build a house. When the builder shows up you ask to see the blueprints. “What blueprints?” he responds, “I know what I’m doing. I don’t need to plan every little detail ahead of time. Two-story house? No problem — I did a one-story house a few months ago — I’ll just start with that model and work from there.”
Suppose that you suspend your disbelief and allow the builder to proceed. A few months later you notice that the plumbing appears to run outside the house instead of inside the walls. When you query the builder about this anomaly he says, “Oh. Well, I forgot to leave space in the walls for the plumbing. I was so excited about this new drywall technology it just slipped my mind. But it works just as well outside, and functionality is the most important thing.” You’re starting to have your doubts about his approach, but, against your better judgment, you allow him to continue.
When you take your first tour of the completed building, you notice that the kitchen lacks a sink. The builder excuses himself by saying, “We were already two-thirds done with the kitchen by the time we realized there wasn’t space for the sink. Instead of starting over we just added a separate sink room next door. It works, right?”
Do the builder’s excuses sound familiar if you translate them to the software domain? Have you ever found yourself implementing an “ugly” solution to a problem like putting plumbing outside the house? For example, maybe you forgot to include locking in your queue data structure that is shared between multiple threads. By the time you realized the problem, you decided to just perform the locking manually on all places where the queue is used. Sure, it’s ugly, but it works, you said. That is, until someone new joins the project who assumes that the locking is built into the data structure, fails to ensure mutual exclusion in her access to the shared data, and causes a race condition bug that takes three weeks to track down. Note that this locking problem is just given as an example of an ugly workaround. Obviously, a professional C++ programmer would never decide to perform the locking manually on each queue access but would instead directly incorporate the locking inside the queue class, or make the queue class thread-safe in a lock-free manner.
Formalizing a design before you code helps you determine how everything fits together. Just as blueprints for a house show how the rooms relate to each other and work together to fulfill the requirements of the house, the design for a program shows how the subsystems of the program relate to each other and work together to fulfill the software requirements. Without a design plan, you are likely to miss connections between subsystems, possibilities for reuse or shared information, and the simplest ways to accomplish tasks. Without the “big picture” that the design gives, you might become so bogged down in individual implementation details that you lose track of the overarching architecture and goals. Furthermore, the design provides written documentation to which all members of the project can refer. If you use an iterative process like the Spiral Model mentioned earlier, you need to make sure to keep the design documentation up-to-date during each cycle of the process.
If the preceding analogy hasn’t convinced you to design before you code, here is an example where jumping directly into coding fails to lead to an optimal design. Suppose that you want to write a chess program. Instead of designing the entire program before you begin programming, you decide to jump in with the easiest parts and move slowly to the more difficult parts. Following the object-oriented perspective introduced in Chapter 1 and covered in more detail in Chapter 5, you decide to model your chess pieces with classes. You figure the pawn is the simplest chess piece, so you opt to start there. After considering the features and behaviors of a pawn, you write a class with the properties and behaviors shown in the following table:
|
CLASS |
PROPERTIES |
BEHAVIORS |
|
Pawn |
Location on Board |
Move |
Of course, you didn’t actually write the table. You went straight to the implementation. Happy with that class you move on to the next easiest piece: the bishop. After considering its attributes and functionality, you write a class with the properties and behaviors shown in the next table:
|
CLASS |
PROPERTIES |
BEHAVIORS |
|
Bishop |
Location on Board |
Move |
Again, you didn’t generate a table, because you jumped straight to the coding phase. However, at this point you begin to suspect that you might be doing something wrong. The bishop and the pawn look similar. In fact, their properties are identical and they share many behaviors. Although the implementations of the move behavior might differ between the pawn and the bishop, both pieces need the ability to move. If you had designed your program before jumping into coding, you would have realized that the various pieces are actually quite similar, and that you should find some way to write the common functionality only once. Chapter 5 explains the object-oriented design techniques for doing that.
Furthermore, several aspects of the chess pieces depend on other subsystems of your program. For example, you cannot accurately represent the location on the board in a chess piece class without knowing how you will model the board. On the other hand, perhaps you will design your program so that the board manages pieces in a way that doesn’t require them to know their own locations. In either case, encoding the location in the piece classes before designing the board leads to problems. To take another example, how can you write a draw method for a piece without first deciding your program’s user interface? Will it be graphical or text-based? What will the board look like? The problem is that subsystems of a program do not exist in isolation — they interrelate with other subsystems. Most of the design work determines and defines these relationships.
DESIGNING FOR C++
There are several aspects of the C++ language that you need to keep in mind when designing for C++.
· C++ has an immense feature set. It is almost a complete superset of the C language, plus classes and objects, operator overloading, exceptions, templates, and many other features. The sheer size of the language makes design a daunting task.
· C++ is an object-oriented language. This means that your designs should include class hierarchies, class interfaces, and object interactions. This type of design is quite different from “traditional” design in C or other procedural languages. Chapter 5 focuses on object-oriented design in C++.
· C++ has numerous facilities for designing generic and reusable code. In addition to basic classes and inheritance, you can use other language facilities such as templates and operator overloading for effective design. Design techniques for reusable code are discussed in more details further in this chapter.
· C++ provides a useful standard library, including a string class, I/O facilities, and many common data structures and algorithms. All of these facilitate coding in C++.
· C++ is a language that readily accommodates many design patterns, or common ways to solve problems.
Tackling a design can be overwhelming. I have spent entire days scribbling design ideas on paper, crossing them out, writing more ideas, crossing those out, and repeating the process. Sometimes this process is helpful, and, at the end of those days (or weeks), leads to a clean, efficient design. Other times it can be frustrating, and leads nowhere, but it is not a waste of effort. You will most likely waste more time if you have to re-implement a design that turned out to be broken. It’s important to remain aware of whether or not you are making real progress. If you find that you are stuck, you can take one of the following actions:
· Ask for help. Consult a coworker, mentor, book, newsgroup, or web page.
· Work on something else for a while. Come back to this design choice later.
· Make a decision and move on. Even if it’s not an ideal solution, decide on something and try to work with it. An incorrect choice will soon become apparent. However, it may turn out to be an acceptable method. Perhaps there is no clean way to accomplish what you want to with this design. Sometimes you have to accept an “ugly” solution if it’s the only realistic strategy to fulfill your requirements. Whatever you decide, make sure you document your decision, so that you and others in the future know why you made it. This includes documenting designs that you have rejected and the rationale behind the rejection.
NOTE Keep in mind that good design is hard, and getting it right takes practice. Don’t expect to become an expert overnight, and don’t be surprised if you find it more difficult to master C++ design than C++ coding.
TWO RULES FOR C++ DESIGN
There are two fundamental design rules in C++: abstraction and reuse. These guidelines are so important that they can be considered themes of this book. They come up repeatedly throughout the text, and throughout effective C++ program designs in all domains.
Abstraction
The principle of abstraction is easiest to understand through a real-world analogy. A television is a simple piece of technology found in most homes. You are probably familiar with its features: you can turn it on and off, change the channel, adjust the volume, and add external components such as speakers, VCRs, and DVD players. However, can you explain how it works inside the black box? That is, do you know how it receives signals over the air or through a cable, translates them, and displays them on the screen? Most people certainly can’t explain how a television works, yet are quite capable of using it. That is because the television clearly separates its internal implementation from its external interface. We interact with the television through its interface: the power button, channel changer, and volume control. We don’t know, nor do we care, how the television works; we don’t care whether it uses a cathode ray tube or some sort of alien technology to generate the image on our screen. It doesn’t matter because it doesn’t affect the interface.
Benefiting from Abstraction
The abstraction principle is similar in software. You can use code without knowing the underlying implementation. As a trivial example, your program can make a call to the sqrt() function declared in the header file <cmath> without knowing what algorithm the function actually uses to calculate the square root. In fact, the underlying implementation of the square root calculation could change between releases of the library, and as long as the interface stays the same, your function call will still work. The principle of abstraction extends to classes as well. As introduced in Chapter 1, you can use the cout object of class ostream to stream data to standard output like this:
cout << "This call will display this line of text" << endl;
In this line, you use the documented interface of the cout insertion operator (<<) with a character array. However, you don’t need to understand how cout manages to display that text on the user’s screen. You only need to know the public interface. The underlying implementation of cout is free to change as long as the exposed behavior and interface remain the same.
Incorporating Abstraction in Your Design
You should design functions and classes so that you and other programmers can use them without knowing, or relying on, the underlying implementations. To see the difference between a design that exposes the implementation and one that hides it behind an interface, consider the chess program again. You might want to implement the chess board with a two-dimensional array of pointers to ChessPiece objects. You could declare and use the board like this:
ChessPiece* chessBoard[8][8];
...
ChessBoard[0][0] = new Rook();
However, that approach fails to use the concept of abstraction. Every programmer who uses the chess board knows that it is implemented as a two-dimensional array. Changing that implementation to something else, such as an array of vectors, would be difficult, because you would need to change every use of the board in the entire program. There is no separation of interface from implementation.
A better approach is to model the chess board as a class. You could then expose an interface that hides the underlying implementation details. Here is an example of the ChessBoard class:
class ChessBoard
{
public:
// This example omits constructors, destructors, and assignment operator.
void setPieceAt(ChessPiece* piece, int x, int y);
ChessPiece& getPieceAt(int x, int y);
bool isEmpty(int x, int y) const;
private:
// This example omits data members.
};
Note that this interface makes almost no commitment to any underlying implementation. The ChessBoard could easily be a two-dimensional array, but the interface does not require it. Changing the implementation does not require changing the interface. Furthermore, the implementation can provide additional functionality, such as bounds checking.
There is only one small commitment to the underlying implementation because of the interface. The getPieceAt() function returns a reference, so it is recommended for the underlying implementation to not directly store objects in a collection, but pointers or better yet smart pointers to objects, to avoid bizarre aliasing problems, which can be hard to track down. For example, suppose a client of the ChessBoard class stores a reference received by a call to getPieceAt(). If the ChessBoard class directly stores objects in the underlying collection, this returned reference can become invalid when the ChessBoard class needs to reallocate memory for the collection. Storing pointers or smart pointers in the collection avoids this reference-invalidation problem.
This example, hopefully, has convinced you that abstraction is an important technique in C++ programming. Chapter 5 covers abstraction and object-oriented design in more detail, and Chapters 7 and 8 provide all the details about writing your own classes.
Reuse
The second fundamental rule of design in C++ is reuse. Again, it is helpful to examine a real-world analogy to understand this concept. Suppose that you give up your programming career in favor of work as a baker. On your first day of work, the head baker tells you to bake cookies. In order to fulfill his orders you find the recipe for chocolate-chip cookies, mix the ingredients, form cookies on the cookie sheet, and place the sheet in the oven. The head baker is pleased with the result.
Now, I’m going to point out something so obvious that it will surprise you: you didn’t build your own oven in which to bake the cookies. Nor did you churn your own butter, mill your own flour, or form your own chocolate chips. I can hear you think, “That goes without saying.” That’s true if you’re a real cook, but what if you’re a programmer writing a baking simulation game? In that case, you would think nothing of writing every component of the program, from the chocolate chips to the oven. Or, you could save yourself time by looking around for code to reuse. Perhaps your office-mate wrote a cooking simulation game and has some nice oven code lying around. Maybe it doesn’t do everything you need, but you might be able to modify it and add the necessary functionality.
Something else you took for granted is that you followed a recipe for the cookies instead of making up your own. Again, that goes without saying. However, in C++ programming, it does not go without saying. Although there are standard ways of approaching problems that arise over and over in C++, many programmers persist in reinventing these strategies in each design.
Reusing Code
The idea of using existing code is not new. You’ve been reusing code from the first day you printed something with cout. You didn’t write the code to actually print your data to the screen. You used the existing cout implementation to do the work.
Unfortunately, programmers generally do not take advantage of available code. Your designs should take into account existing code and reuse it when appropriate. How to reuse existing code is discussed in depth later in this chapter.
Writing Reusable Code
The design theme of reuse applies to code you write as well as to code that you use. You should design your programs so that you can reuse your classes, algorithms, and data structures. You and your coworkers should be able to use these components in both the current project and in future projects. In general, you should avoid designing overly specific code that is applicable only to the case at hand.
One language technique for writing general-purpose code in C++ is the template. The following example shows a templatized data structure. If you’ve never seen this syntax before, don’t worry! Chapter 11 explains the syntax in depth.
Instead of writing a specific ChessBoard class that stores ChessPieces, as shown earlier, consider writing a generic GameBoard template that can be used for any type of two-dimensional board game such as chess or checkers. You would need only to change the class declaration so that it takes the piece to store as a template parameter instead of hard-coding it in the interface. The template could look something like this:
template <typename PieceType>
class GameBoard
{
public:
// This example omits constructors, destructors, and assignment operator.
void setPieceAt(PieceType* piece, int x, int y);
PieceType& getPieceAt(int x, int y);
bool isEmpty(int x, int y) const;
private:
// This example omits data members.
};
With this simple change in the interface, you now have a generic game board class that you can use for any two-dimensional board game. Although the code change is simple, it is important to make these decisions in the design phase, so that you are able to implement the code effectively and efficiently.
Chapter 6 goes into more details on how to design your code with reuse in mind.
Reusing Ideas
As the baker example illustrates, it would be ludicrous to reinvent recipes for every dish that you make. However, programmers often make an equivalent mistake in their designs. Instead of using existing “recipes,” or patterns, for designing programs, they reinvent these techniques every time they design a program. However, many design patterns appear in myriad different C++ applications. As a C++ programmer, you should familiarize yourself with these patterns so that you can incorporate them effectively into your program designs.
For example, you might want to design your chess program so that you have a single ErrorLogger object that serializes all errors from different components to a log file. When you try to design your ErrorLogger class, you realize that it would be disastrous to have more than one object instantiated from the ErrorLogger class in a single program. You also want to be able to access this ErrorLogger object from anywhere in your program. These requirements of a single, globally accessible, instance of a class arise frequently in C++ programs, and there is a standard strategy to implement them, called the singleton. Thus, a good design at this point would specify that you want to use the singleton pattern. A detailed discussion of design patterns and techniques is outside the scope of this book. If you are interested, consult one of the references from Appendix B.
REUSING CODE
Experienced C++ programmers never start a project from scratch. They incorporate code from a wide variety of sources, such as the standard template library, open-source libraries, proprietary code bases in their workplace, and their own code from previous projects. In addition, good C++ programmers reuse approaches or strategies to address various common design issues. These strategies can range from a technique that worked for a past project to a formal design pattern. You should reuse code liberally in your designs. In order to make the most of this rule, you need to understand the types of code that you can reuse and the tradeoffs involved in code reuse. Note that reusing code does not mean copy-pasting existing code! In fact it means quite the opposite, reusing code without duplicating it.
A Note on Terminology
Before analyzing the advantages and disadvantages of code reuse, it is helpful to specify the terminology involved and to categorize the types of reused code. There are three categories of code available for reuse:
· Code you wrote yourself in the past
· Code written by a coworker
· Code written by a third party outside your current organization or company
There are also several ways that the code you use can be structured:
· Stand-alone functions or classes. When you reuse your own code or coworkers’ code, you will generally encounter this variety.
· Libraries. A library is a collection of code used to accomplish a specific task, such as parsing XML, or to handle a specific domain, such as cryptography. Other examples of functionality usually found in libraries include threads and synchronization support, networking, and graphics.
· Frameworks. A framework is a collection of code around which you design a program. For example, the Microsoft Foundation Classes (MFC) provide a framework for creating graphical user interface applications for Microsoft Windows. Frameworks usually dictate the structure of your program.
NOTE A program uses a library but fits into a framework. Libraries provide specific functionality, while frameworks are fundamental to your program design and structure.
Another term that arises frequently is application programming interface, or API. An API is an interface to a library or body of code for a specific purpose. For example, programmers often refer to the sockets API, meaning the exposed interface to the sockets networking library, instead of the library itself.
NOTE Although people use the terms API and library interchangeably, they are not equivalent. The library refers to the implementation, while the API refers to the published interface to the library.
For the sake of brevity, the rest of this chapter uses the term library to refer to any reused code, whether it is really a library, framework, or random collection of functions from your office-mate.
Deciding Whether or Not to Reuse Code
The rule to reuse code is easy to understand in the abstract. However, it’s somewhat vague when it comes to the details. How do you know when it’s appropriate to reuse code, and which code to reuse? There is always a tradeoff, and the decision depends on the specific situation. However, there are some general advantages and disadvantages to reusing code.
Advantages to Reusing Code
Reusing code can provide tremendous advantages to you and to your project.
· You may not know how to, or may not be able to justify the time to write the code you need. Would you really want to write code to handle formatted input and output? Of course not: that’s why you use the standard C++ I/O streams.
· Your designs will be simpler because you will not need to design those components of the application that you reuse.
· The code that you reuse usually requires no debugging. You can often assume that library code is bug-free because it has already been tested and used extensively.
· Libraries handle more error conditions than would your first attempt at the code. You might forget obscure errors or edge cases at the beginning of the project, and would waste time fixing these problems later. Library code that you reuse has generally been tested extensively and used by many programmers before you, so you can assume that it handles most errors properly.
· Libraries generally are designed to be suspect of bad user inputs. Invalid requests, or requests not appropriate for the current state, usually result in suitable error notifications. For example, a request to seek to a nonexistent record in a database, or to read a record from a database which is not open, would have well-specified behavior from a library.
· Reusing code written by domain experts is safer than writing your own code for that area. For example, you should not attempt to write your own security code unless you are a security expert. If you need security or cryptography in your programs, use a library. Many seemingly minor details in code of that nature could compromise the security of the entire program if you got them wrong.
· Library code is constantly improving. If you reuse the code, you receive the benefits of these improvements without doing the work yourself. In fact, if the library writers properly separated the interface from the implementation, you can obtain these benefits by upgrading your library version without changing your interaction with the library. A good upgrade modifies the underlying implementation without changing the interface.
Disadvantages to Reusing Code
Unfortunately, there are also some disadvantages to reusing code.
· When you use only code that you wrote yourself, you understand exactly how it works. When you use libraries that you didn’t write yourself, you must spend time understanding the interface and correct usage before you can jump in and use it. This extra time at the beginning of your project will slow your initial design and coding.
· When you write your own code, it does exactly what you want. Library code might not provide the exact functionality that you require.
· Even if the library code provides the exact functionality you need, it might not give you the performance that you desire. The performance might be bad in general, poor for your specific use case, or completely undocumented.
· Using library code introduces a Pandora’s box of support issues. If you discover a bug in the library, what do you do? Often you don’t have access to the source code, so you couldn’t fix it even if you wanted to. If you have already invested significant time learning the library interface and using the library, you probably don’t want to give it up, but you might find it difficult to convince the library developers to fix the bug on your time schedule. Also, if you are using a third-party library, what do you do if the library authors drop support for the library before you stop supporting the product that depends on it? Think carefully about this before you decide to use a library for which you cannot get source code.
· In addition to support problems, libraries present licensing issues which cover topics such as disclosure of your source, redistribution fees (often called binary license fees), credit attribution, and development licenses. You should carefully inspect the licensing issues before using any library. For example, some open-source libraries require you to make your own code open-source.
· Another consideration with reusing code is cross-platform portability. If you want to write a cross-platform application, make sure the libraries you use are also cross-platform portable.
· Reusing code requires a trust factor. You must trust whoever wrote the code by assuming that he or she did a good job. Some people like to have control over all aspects of their project, including every line of source code.
· Upgrading to a new version of the library can cause problems. The upgrade could introduce bugs which could have fatal consequences in your product. A performance related upgrade might optimize performance in certain cases but make it worse in your specific use-case.
Putting It Together to Make a Decision
Now that you are familiar with the terminology, advantages, and disadvantages of reusing code, you are better prepared to make the decision about whether or not to reuse code. Often, the decision is obvious. For example, if you want to write a graphical user interface (GUI) in C++ for Microsoft Windows, you should use a framework such as MFC or QT. You probably don’t know how to write the underlying code to create a GUI in Windows, and more importantly, you don’t want to waste the time to learn it. You will save person-years of effort by using a framework in this case.
However, other times the choice is less obvious. For example, if you are unfamiliar with a library or framework, and need only a simple data structure, it might not be worth the time to learn the entire framework to reuse only one component that you could write in a few days.
Ultimately, the decision is a choice that you need to make for your own particular needs. It often comes down to a tradeoff between the time it would take to write it yourself and the time required to find and learn how to use a library to solve the problem. Carefully consider how the advantages and disadvantages listed previously apply to your specific case, and decide which factors are most important to you. Finally, remember that you can always change your mind, which might even be not too much work if you handled the abstraction correctly.
Strategies for Reusing Code
When you use libraries, frameworks, coworkers’ code, or your own code, there are several guidelines you should keep in mind.
Understand the Capabilities and Limitations
Take the time to familiarize yourself with the code. It is important to understand both its capabilities and its limitations. Start with the documentation and the published interfaces or APIs. Ideally, that will be sufficient to understand how to use the code. However, if the library doesn’t provide a clear separation between interface and implementation, you may need to explore the source code itself if provided. Also, talk to other programmers who have used the code and who might be able to explain its intricacies. You should begin by learning the basic functionality. If it’s a library, what behaviors does it provide? If it’s a framework, how does your code fit in? What classes should you derive from? What code do you need to write yourself? You should also consider specific issues depending on the type of code.
Here are some points to keep in mind:
· Is the code safe for multithreaded programs?
· Does the library impose any specific compiler settings on code using the library? If so, is that acceptable in your project?
· What initialization calls does the library or framework need? What cleanup does it need?
· On what other libraries does the library or framework depend?
· If you derive from a class, which constructor should you call on it? Which virtual methods should you override?
· If a call returns memory pointers, who is responsible for freeing the memory: the caller or the library? If the library is responsible, when is the memory freed? It’s highly recommended to find out if you can use smart pointers to manage memory allocated by the library. Smart pointers are introduced in Chapter 1.
· What error conditions does the library call check for, and what does it assume? How does it handle errors? How does it notify the client program about errors? Avoid using libraries that pop up message boxes, issue messages to stderr/cerr or stdout/cout, or terminate the program.
· What are all the return values (by value or reference) from a call?
· What are all the possible exceptions thrown?
Understand the Performance
It is important to know the performance guarantees that the library or other code provides. Even if your particular program is not performance sensitive, you should make sure that the code you use doesn’t have awful performance for your particular use.
Big-O Notation
Programmers generally discuss and document algorithm and library performance using big-O notation. This section explains the general concepts of algorithm complexity analysis and big-O notation without a lot of unnecessary mathematics. If you are already familiar with these concepts, you may skip this section.
Big-O notation specifies relative, rather than absolute, performance. For example, instead of saying that an algorithm runs in a specific amount of time, such as 300 milliseconds, big-O notation specifies how an algorithm performs as its input size increases. Examples of input sizes include the number of items to be sorted by a sorting algorithm, the number of elements in a hash table during a key lookup, and the size of a file to be copied between disks.
NOTE Note that big-O notation applies only to algorithms whose speed depends on their inputs. It does not apply to algorithms that take no input or whose running time is random. In practice, you will find that the running times of most algorithms of interest depend on their input, so this limitation is not significant.
To be more formal: big-O notation specifies algorithm run time as a function of its input size, also known as the complexity of the algorithm. However, that’s not as complicated as it sounds. For example, an algorithm with a performance that is linear as a function of its input size takes twice as long to process twice as many elements. Thus, if it takes 2 seconds to process 500 elements, it will take 4 seconds to process 1000 elements. That is, you could graph the performance versus input size as a straight line. Big-O notation summarizes the algorithm performance like this: O(n). The O just means that you’re using big-O notation, while the n represents the input size. O(n) specifies that the algorithm speed is a direct linear function of the input size.
Unfortunately, not all algorithms have performance that is linear with respect to the input size. Computer programs would run a lot faster if that were true. The following table summarizes the common complexities, in order of their performance from best to worst:
|
ALGORITHM COMPLEXITY |
BIG-O NOTATION |
EXPLANATION |
EXAMPLE ALGORITHMS |
|
Constant |
O(1) |
Running time is independent of input size. |
Accessing a single element in an array |
|
Logarithmic |
O(log n) |
The running time is a function of the logarithm base 2 of the input size. |
Finding an element in a sorted list using binary search |
|
Linear |
O(n) |
The running time is directly proportional to the input size. |
Finding an element in an unsorted list |
|
Linear Logarithmic |
O(n log n) |
The running time is a function of the linear times the logarithmic function of the input size. |
Merge sort |
|
Quadratic |
O(n2) |
The running time is a function of the square of the input size. |
A slower sorting algorithm like selection sort |
|
Exponential |
O(2n) |
The running time is an exponential function of the input size. |
Optimized traveling salesman problem |
There are two advantages to specifying performance as a function of the input size instead of in absolute numbers:
1. It is platform independent. Specifying that a piece of code runs in 200 milliseconds on one computer says nothing about its speed on a second computer. It is also difficult to compare two different algorithms without running them on the same computer with the exact same load. On the other hand, performance specified as a function of the input size is applicable to any platform.
2. Performance as a function of input size covers all possible inputs to the algorithm with one specification. The specific time in seconds that an algorithm takes to run covers only one specific input, and says nothing about any other input.
Sometimes the statistical expectations are taken into account when working with big-O notation in which case big-O represents the expected time. For example, a linear search is often said to be O(n/2) because statistically about half of the elements need to be searched each time. The number of cases that are found in less than O(n/2) are compensated for by the number of cases that require more than O(n/2) time.
Tips for Understanding Performance
Now that you are familiar with big-O notation, you are prepared to understand most performance documentation. The C++ standard template library in particular describes its algorithm and data structure performance using big-O notation. However, big-O notation is sometimes insufficient or even misleading. Consider the following issues whenever you think about big-O performance specifications:
· If an algorithm takes twice as long to work on twice as much data, it doesn’t say anything about how long it took in the first place! If the algorithm is written badly but scales well, it’s still not something you want to use. For example, suppose the algorithm makes unnecessary disk accesses. That probably wouldn’t affect the big-O time but would be very bad for overall performance.
· Along those lines, it’s difficult to compare two algorithms with the same big-O running time. For example, if two different sorting algorithms both claim to be O(n log n), it’s hard to tell which is really faster without running your own tests.
· The big-O notation describes the time complexity of an algorithm asymptotically, as the input size grows to infinity. For small inputs, big-O time can be very misleading. An O(n2) algorithm might actually perform better than an O(log n) algorithm on small input sizes. Consider your likely input sizes before making a decision.
In addition to considering big-O characteristics, you should look at other facets of the algorithm performance. Here are some guidelines to keep in mind:
· You should consider how often you intend to use a particular piece of library code. Some people find the “90/10” rule helpful: 90 percent of the running time of most programs is spent in only 10 percent of the code (Hennessy and Patterson, “Computer Architecture, A Quantitative Approach, Fourth Edition”, 2006, Morgan Kaufmann, 2002). If the library code you intend to use falls in the oft-exercised 10 percent category of your code, you should make sure to analyze its performance characteristics carefully. On the other hand, if it falls into the oft-ignored 90 percent of the code, you should not spend much time analyzing its performance because it will not benefit your overall program performance very much.
· Don’t trust the documentation. Always run performance tests to determine if library code provides acceptable performance characteristics.
Understand Platform Limitations
Before you start using library code, make sure that you understand on which platforms it runs. That might sound obvious, but even libraries that claim to be cross-platform might contain subtle differences on different platforms.
Also, platforms include not only different operating systems but different versions of the same operating system. If you write an application that should run on Solaris 8, Solaris 9, and Solaris 10, ensure that any libraries you use also support all those releases. You cannot assume either forward or backward compatibility across operating system versions. That is, just because a library runs on Solaris 9 doesn’t mean that it will run on Solaris 10 and vice versa.
Understand Licensing and Support
Using third-party libraries often introduces complicated licensing issues. You must sometimes pay license fees to third-party vendors for the use of their libraries. There may also be other licensing restrictions, including export restrictions. Additionally, open-source libraries are sometimes distributed under licenses that require any code that links with them to be open source as well. A number of licenses commonly used by open-source libraries are discussed later in the chapter.
WARNING Make sure that you understand the license restrictions of any third-party libraries you use if you plan to distribute or sell the code you develop. When in doubt, consult a legal expert.
Using third-party libraries also introduces support issues. Before you use a library, make sure that you understand the process for submitting bugs, and that you realize how long it will take for bugs to be fixed. If possible, determine how long the library will continue to be supported so that you can plan accordingly.
Interestingly, even using libraries from within your own organization can introduce support issues. You may find it just as difficult to convince a coworker in another part of your company to fix a bug in his or her library as you would to convince a stranger in another company to do the equivalent. In fact, you may even find it harder, because you’re not a paying customer. Make sure that you understand the politics and organizational issues within your own organization before using internal libraries.
Know Where to Find Help
Using libraries and frameworks can sometimes be daunting at first. Fortunately, there are many avenues of support available. First of all, consult the documentation that accompanies the library. If the library is widely used, such as the standard template library (STL), or the MFC, you should be able to find a good book on the topic. In fact, for help with the STL, consult Chapters 15 and later of this book. If you have specific questions not addressed by books and product documentation, try searching the web. Type your question in your search engine of choice to find web pages that discuss the library. For example, when you search for the phrase “introduction to C++ STL” you will find several hundred websites about C++ and the STL. Also, many websites contain their own private newsgroups or forums on specific topics for which you can register.
WARNING A note of caution: don’t believe everything you read on the web! Web pages do not necessarily undergo the same review process as printed books and documentation, and may contain inaccuracies.
Prototype
When you first sit down with a new library or framework, it is often a good idea to write a quick prototype. Trying out the code is the best way to familiarize yourself with the library’s capabilities. You should consider experimenting with the library even before you tackle your program design so that you are intimately familiar with the library’s capabilities and limitations. This empirical testing will allow you to determine the performance characteristics of the library as well.
Even if your prototype application looks nothing like your final application, time spent prototyping is not a waste. Don’t feel compelled to write a prototype of your actual application. Write a dummy program that just tests the library capabilities you want to use. The point is only to familiarize yourself with the library.
WARNING Due to time constraints, programmers sometimes find their prototypes morphing into the final product. If you have hacked together a prototype that is insufficient as the basis for the final product, make sure that it doesn’t get used that way.
Bundling Third-Party Applications
Your project might include multiple applications. Perhaps you need a web server front end to support your new e-commerce infrastructure. It is possible to bundle third-party applications, such as a web server, with your software. This approach takes code reuse to the extreme in that you reuse entire applications. However, most of the caveats and guidelines for using libraries apply to bundling third-party applications as well. Specifically, make sure that you understand the legality and licensing ramifications of your decision.
NOTE Consult a legal expert whose specialty is Intellectual Property before bundling third-party applications with your software distributions.
Also, the support issue becomes more complex. If customers encounter a problem with your bundled web server, should they contact you or the web server vendor? Make sure that you resolve this issue before you release the software.
Open-Source Libraries
Open-source libraries are an increasingly popular class of reusable code. The general meaning of open-source is that the source code is available for anyone to look at. There are formal definitions and legal rules about including source with all your distributions, but the important thing to remember about open-source software is that anyone (including you) can look at the source code. Note that open-source applies to more than just libraries. In fact, the most famous open-source product is probably the Linux operating system. Google Chrome and Mozilla Firefox are two examples of famous open-source web browsers.
The Open-Source Movements
Unfortunately, there is some confusion in terminology in the open-source community. First of all, there are two competing names for the movement (some would say two separate, but similar, movements). Richard Stallman and the GNU project use the term free software. Note that the term free does not imply that the finished product must be available without cost. Developers are welcome to charge as much or as little as they want. Instead, the term free refers to the freedom for people to examine the source code, modify the source code, and redistribute the software. Think of the free in free speech rather than the free in free beer. You can read more about Richard Stallman and the GNU project at www.gnu.org.
The Open Source Initiative uses the term open-source software to describe software in which the source must be available. As with free software, open-source software does not require the product or library to be available without cost. However, an important difference with free software is that open-source software is not required to give you the freedom to use, modify, and redistribute it. You can read more about the Open Source Initiative at www.opensource.org.
There are several licensing options available for open-source projects. One of them is the GNU Public License (GPL). However, using a library under the GPL requires you to make your own product open-source as well. On the other hand, an open-source project can use a licensing option like Boost, OpenBSD, CodeGuru, Boost Software License, BSD, Code Project Open License, CodeProject, Creative Commons License, and so on, which allow using the open-source library in a closed-source product.
Because the name “open-source” is less ambiguous than “free software,” this book uses “open-source” to refer to products and libraries with which the source code is available. The choice of name is not intended to imply endorsement of the open-source philosophy over the free software philosophy: it is only for ease of comprehension.
Finding and Using Open-Source Libraries
Regardless of the terminology, you can gain amazing benefits from using open-source software. The main benefit is functionality. There are a plethora of open-source C++ libraries available for varied tasks: from XML parsing to cross-platform error logging.
Although open-source libraries are not required to provide free distribution and licensing, many open-source libraries are available without monetary cost. You will generally be able to save money in licensing fees by using open-source libraries.
Finally, you are often but not always free to modify open-source libraries to suit your exact needs.
Most open-source libraries are available on the web. For example, searching for “open-source C++ library XML parsing” results in a list of links to XML libraries in C and C++. There are also a few open-source portals where you can start your search, including:
· www.boost.org
· www.gnu.org
· www.sourceforge.net
Guidelines for Using Open-Source Code
Open-source libraries present several unique issues and require new strategies. First of all, open-source libraries are usually written by people in their “free” time. The source base is generally available for any programmer who wants to pitch in and contribute to development or bug fixing. As a good programming citizen, you should try to contribute to open-source projects if you find yourself reaping the benefits of open-source libraries. If you work for a company, you may find resistance to this idea from your management because it does not lead directly to revenue for your company. However, you might be able to convince management that indirect benefits, such as exposure of your company name, and perceived support from your company for the open-source movement, should allow you to pursue this activity.
Second, because of the distributed nature of their development, and lack of single ownership, open-source libraries often present support issues. If you desperately need a bug fixed in a library, it is often more efficient to make the fix yourself than to wait for someone else to do it. If you do fix bugs, you should make sure to put the fixes into the public source base for the library. Even if you don’t fix any bugs, make sure to report problems that you find so that other programmers don’t waste time encountering the same issues.
The C++ Standard Library
The most important library that you will use as a C++ programmer is the C++ standard library. As its name implies, this library is part of the C++ standard, so any standards-conforming compiler should include it. The standard library is not monolithic: it includes several disparate components, some of which you have been using already. You may even have assumed they were part of the core language. Chapters 15 and later go into more details about the standard library.
C Standard Library
Because C++ is mostly a superset of C, most of the C library is still available. Its functionality includes mathematical functions such as abs(), sqrt(), and pow(), and error-handling helpers such as assert() and errno. Additionally, the C library facilities for manipulating character arrays as strings, such as strlen() and strcpy(), and the C-style I/O functions, such as printf() and scanf(), are all available in C++.
NOTE C++ provides better strings and I/O support than C. Even though the C-style strings and I/O routines are available in C++, you should avoid them in favor of C++ strings (Chapter 2) and I/O streams (Chapter 12).
Note that the C header files have different names in C++. These names should be used instead of the C library names, because they are less likely to result in name conflicts. For details of the C libraries, consult a Standard Library Reference, for examplehttp://www.cppreference.com/ or http://www.cplusplus.com/reference/.
Deciding Whether or Not to Use the STL
The STL was designed with functionality, performance, and orthogonality as its priorities. The benefits of using it are substantial. Imagine having to track down pointer errors in linked list or balanced binary tree implementations, or debug a sorting algorithm that isn’t sorting properly. If you use the STL correctly, you will rarely, if ever, need to perform that kind of coding. Chapters 15 and later provide in-depth information on the STL functionality.
DESIGNING WITH PATTERNS AND TECHNIQUES
Learning the C++ language and becoming a good C++ programmer are two very different things. If you sat down and read the C++ standard, memorizing every fact, you would know C++ as well as anybody else. However, until you gain some experience by looking at code and writing your own programs, you wouldn’t necessarily be a good programmer. The reason is that the C++ syntax defines what the language can do in its raw form, but doesn’t say anything about how each feature should be used.
As they become more experienced in using the C++ language, C++ programmers develop their own individual ways of using the features of the language. The C++ community at large has also built some standard ways of leveraging the language, some formal and some informal. Throughout this book, I point out these reusable applications of the language, known as design techniques and design patterns. Some patterns and techniques will seem obvious to you because they are simply a formalization of the obvious solution. Others describe novel solutions to problems you’ve encountered in the past. Some present entirely new ways of thinking about your program organization.
It is important for you to familiarize yourself with these patterns and techniques so that you can recognize when a particular design problem calls for one of these solutions. There are many more techniques and patterns applicable to C++ than those described in this book. A detailed discussion of design techniques and design patterns is outside the scope of this book. If you are interested in more details, consult a reference from Appendix B.
DESIGNING A CHESS PROGRAM
This section introduces a systematic approach to designing a C++ program in the context of a simple chess game application. In order to provide a complete example, some of the steps refer to concepts covered in later chapters. You should read this example now, in order to obtain an overview of the design process, but you might also consider rereading it after you have finished later chapters.
Requirements
Before embarking on the design, it is important to possess clear requirements for the program’s functionality and efficiency. Ideally, these requirements would be documented in the form of a requirements specification. The requirements for the chess program would contain the following types of specifications, although in more detail and number:
· The program will support the standard rules of chess.
· The program will support two human players. The program will not provide an artificially intelligent computer player.
· The program will provide a text-based interface:
· The program will render the game board and pieces in plain text.
· Players will express their moves by entering numbers representing locations on the chessboard.
The requirements ensure that you design your program so that it performs as its users expect.
Design Steps
You should take a systematic approach to designing your program, working from the general to the specific. The following steps do not always apply to all programs, but they provide a general guideline. Your design should include diagrams and tables as appropriate. An industry standard for making diagrams is called UML (Unified Modeling Language). UML defines a multitude of standard diagrams you can use for documenting software designs, for example class diagrams, sequence diagrams, and so on. I recommend using UML or at least UML-like diagrams where applicable. However, I’m no advocate of strictly adhering to the UML syntax because having a clear, understandable diagram is more important than a syntactically correct one.
Divide the Program into Subsystems
Your first step is to divide your program into its general functional subsystems and to specify the interfaces and interactions between the subsystems. At this point, you should not worry about specifics of data structures and algorithms, or even classes. You are trying only to obtain a general feel for the various parts of the program and their interactions. You can list the subsystems in a table that expresses the high-level behaviors or functionality of the subsystem, the interfaces exported from the subsystem to other subsystems, and the interfaces consumed, or used, by this subsystem on other subsystems. The recommended design for this chess game is to have a clear separation between storing the data and displaying the data by using the Model-View-Controller (MVC) paradigm. This paradigm models the notion that many applications commonly deal with a set of data, one or more views on that data, and manipulation of the data. In MVC, a set of data is called the model, a view is a particular visualization of the model, and the controller is the piece of code that changes the model in response to some event. The three components of MVC interact in a feedback loop; Actions are handled by the controller, which adjusts the model, resulting in a change to the view(s). Using this paradigm, you can easily switch between having a text-based interface and a graphical user interface. A table for the chess game subsystems could look like this:
|
SUBSYSTEM NAME |
INSTANCES |
FUNCTIONALITY |
INTERFACES EXPORTED |
INTERFACES CONSUMED |
|
GamePlay |
1 |
Starts game |
Game Over |
Take Turn (on Player) |
|
ChessBoard |
1 |
Stores chess pieces |
Get Piece At |
Game Over (on GamePlay) |
|
ChessBoardView |
1 |
Draws the associated ChessBoard |
Draw |
Draw (on ChessPieceView) |
|
ChessPiece |
32 |
Moves itself |
Move |
Get Piece At (on ChessBoard) |
|
ChessPieceView |
32 |
Draws the associated ChessPiece |
Draw |
None |
|
Player |
2 |
Interacts with user: prompts user for move, obtains user’s move |
Take Turn |
Get Piece At (on ChessBoard) |
|
ErrorLogger |
1 |
Writes error messages to log file |
Log Error |
None |
As this table shows, the functional subsystems of this chess game include a GamePlay subsystem, a ChessBoard and ChessBoardView, 32 ChessPieces and ChessPieceViews, two Players, and one ErrorLogger. However, that is not the only reasonable approach. In software design, as in programming itself, there are often many different ways to accomplish the same goal. Not all solutions are equal: some are certainly better than others. However, there are often several equally valid methods.
A good division into subsystems separates the program into its basic functional parts. For example, a Player is a subsystem distinct from the ChessBoard, ChessPieces, or GamePlay. It wouldn’t make sense to lump the players into the GamePlay subsystem because they are logically separate subsystems. Other choices might not be as obvious.
In this MVC design, the ChessBoard and ChessPiece subsystems are part of the Model. The ChessBoardView and ChessPieceView are part of the View and the Player is part of the Controller.
Because it is often difficult to visualize subsystem relationships from tables, it is usually helpful to show the subsystems of a program in a diagram where arrows represent calls from one subsystem to another.
Choose Threading Models
It’s too early in the design phase to think about how to multithread specific loops in algorithms you will write. However, in this step, you choose the number of high-level threads in your program and specify their interactions. Examples of high-level threads are a UI thread, an audio-playing thread, a network communication thread, and so on. In multithreaded designs, you should try to avoid shared data as much as possible because it will make your designs simpler and safer. If you cannot avoid shared data, you should specify locking requirements. If you are unfamiliar with multithreaded programs, or your platform does not support multithreading, then you should make your programs single-threaded. However, if your program has several distinct tasks, each of which could work in parallel, it might be a good candidate for multiple threads. For example, graphical user interface applications often have one thread performing the main application work and another thread waiting for the user to press buttons or select menu items. Multithreaded programming is covered in Chapter 23.
The chess program needs only one thread to control the game flow.
Specify Class Hierarchies for Each Subsystem
In this step, you determine the class hierarchies that you intend to write in your program. The chess program needs a class hierarchy to represent the chess pieces. The hierarchy could work as shown in Figure 4-1.

FIGURE 4-1
In this hierarchy, a generic ChessPiece class serves as the abstract base class. A similar hierarchy is required for the ChessPieceView class.
Another class hierarchy can be used for the ChessBoardView class to make it possible to have a text-based interface or a graphical user interface for the game. Figure 4-2 shows an example hierarchy that allows the chess board to be displayed as text on a console or as a 2D or 3D rendering.
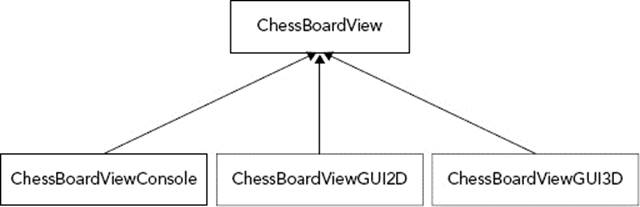
FIGURE 4-2
A similar hierarchy is required for the Player controller and for the individual classes of the ChessPieceView hierarchy.
Chapter 5 explains the details of designing classes and class hierarchies.
Specify Classes, Data Structures, Algorithms, and Patterns for Each Subsystem
In this step, you consider a greater level of detail, and specify the particulars of each subsystem, including the specific classes that you write for each subsystem. It may well turn out that you model each subsystem itself as a class. This information can again be summarized in a table:
|
SUBSYSTEM |
CLASSES |
DATA STRUCTURES |
ALGORITHMS |
PATTERNS |
|
GamePlay |
GamePlay class |
GamePlay object includes one ChessBoard object and twoPlayer objects. |
Gives each player a turn to play |
None |
|
ChessBoard |
ChessBoard class |
ChessBoard object stores a two-dimensional representation of 32 ChessPieces. |
Checks for win or tie after each move |
None |
|
ChessBoardView |
ChessBoardView abstract base class |
Stores information on how to draw a chess board |
Draws a chess board |
Observer |
|
ChessPiece |
ChessPiece abstract base class |
Each piece stores its location on the chess board. |
Piece checks for legal move by querying chess board for pieces at various locations. |
None |
|
ChessPieceView |
ChessPieceView abstract base class |
Stores information on how to draw a chess piece |
Draws a chess piece |
Observer |
|
Player |
Player abstract base class |
None |
prompt user for move, check if move is legal, and move piece. |
Mediator |
|
ErrorLogger |
One ErrorLogger class |
A queue of messages to log |
Buffers messages and writes them to a log file |
Singleton pattern to ensure only oneErrorLogger object |
This section of the design document would normally present the actual interfaces for each class, but this example will forgo that level of detail.
Designing classes and choosing data structures, algorithms, and patterns can be tricky. You should always keep in mind the rules of abstraction and reuse discussed earlier in this chapter. For abstraction, the key is to consider the interface and the implementation separately. First, specify the interface from the perspective of the user. Decide what you want the component to do. Then decide how the component will do it by choosing data structures and algorithms. For reuse, familiarize yourself with standard data structures, algorithms, and patterns. Also, make sure you are aware of the standard library code in C++, as well as any proprietary code available in your workplace.
Specify Error Handling for Each Subsystem
In this design step, you delineate the error handling in each subsystem. The error handling should include both system errors, such as memory allocation failures, and user errors, such as invalid entries. You should specify whether each subsystem uses exceptions. You can again summarize this information in a table:
|
SUBSYSTEM |
HANDLING SYSTEM ERRORS |
HANDLING USER ERRORS |
|
GamePlay |
Logs an error with the ErrorLogger, shows a message to the user and gracefully shuts down the program if unable to allocate memory for ChessBoard or Players |
Not applicable (no direct user interface) |
|
ChessBoard |
Logs an error with the ErrorLogger and throws an exception if unable to allocate memory |
Not applicable (no direct user interface) |
|
ChessBoardView |
Logs an error with the ErrorLogger and throws an exception if something goes wrong during rendering |
Not applicable (no direct user interface) |
|
Player |
Logs an error with the ErrorLogger and throws an exception if unable to allocate memory |
Sanity-checks user move entry to ensure that it is not off the board; prompts user for another entry. Checks each move legality before moving the piece; if illegal, prompts user for another move. |
|
ErrorLogger |
Attempts to log an error, informs user, and gracefully shuts down the program if unable to allocate memory |
Not applicable (no direct user interface) |
The general rule for error handling is to handle everything. Think hard about all possible error conditions. If you forget one possibility, it will show up as a bug in your program! Don’t treat anything as an “unexpected” error. Expect all possibilities: memory allocation failures, invalid user entries, disk failures, and network failures, to name a few. However, as the table for the chess game shows, you should handle user errors differently from internal errors. For example, a user entering an invalid move should not cause your chess program to terminate.
Chapter 13 discusses error handling in more depth.
SUMMARY
In this chapter, you learned about the professional C++ approach to design. Hopefully it convinced you that software design is an important first step in any programming project. You also learned about some of the aspects of C++ that make design difficult, including its object-oriented focus, its large feature set and standard library, and its facilities for writing generic code. With this information, you are better prepared to tackle C++ design.
This chapter introduced two design themes. The concept of abstraction, or separating interface from implementation, permeates this book and should be a guideline for all your design work.
The notion of reuse, both of code and ideas, also arises frequently in real-world projects, and in this text. You learned that your C++ designs should include both reuse of code, in the form of libraries and frameworks, and reuse of ideas, in the form of techniques and patterns. You should write your code to be as reusable as possible. Also remember about the tradeoffs and about specific guidelines for reusing code, including understanding the capabilities and limitations, the performance, licensing and support models, the platform limitations, prototyping, and where to find help. You also learned about performance analysis and big-O notation. Now that you understand the importance of design and the basic design themes, you are ready for the rest of Part II. Chapter 5 describes strategies for using the object-oriented aspects of C++ in your design.