Professional C++ (2014)
Part IIProfessional C++ Software Design
Chapter 5Designing with Objects
WHAT’S IN THIS CHAPTER?
· What object-oriented programming design is
· How you can define relationships between different objects
· The importance of abstraction and how to use it in your designs
Now that you have developed an appreciation for good software design from Chapter 4, it’s time to pair the notion of objects with the concept of good design. The difference between programmers who use objects in their code and those who truly grasp object-oriented programming comes down to the way their objects relate to each other and to the overall design of the program.
This chapter begins with a very brief description of procedural programming (C-style), followed by a detailed discussion of object-oriented programming (OOP). Even if you’ve been using objects for years, you will want to read this chapter for some new ideas regarding how to think about objects. A discussion of the different kinds of relationships between objects includes pitfalls programmers often succumb to when building an object-oriented program. You will also learn how the principal of abstraction relates to objects.
When thinking about procedural programming or object-oriented programming, the most important point to remember is that they just represent different ways of reasoning about what’s going on in your program. Too often, programmers get bogged down in the syntax and jargon of OOP before they adequately understand what an object is. This chapter is light on code and heavy on concepts and ideas. For specifics on C++ object syntax, see Chapters 7, 8, and 9.
AM I THINKING PROCEDURALLY?
A procedural language, such as C, divides code into small pieces each of which (ideally) accomplishes a single task. Without procedures in C, all your code would be lumped together inside main(). Your code would be difficult to read, and your coworkers would be annoyed, to say the least.
The computer doesn’t care if all your code is in main() or if it’s split into bite-sized pieces with descriptive names and comments. Procedures are an abstraction that exists to help you, the programmer, as well as those who read and maintain your code. The concept is built around a fundamental question about your program — What does this program do? By answering that question in English, you are thinking procedurally. For example, you might begin designing a stock selection program by answering as follows: First, the program obtains stock quotes from the Internet. Then, it sorts this data by specific metrics. Next, it performs analysis on the sorted data. Finally, it outputs a list of buy and sell recommendations. When you start coding, you might directly turn this mental model into C functions: retrieveQuotes(), sortQuotes(), analyzeQuotes(), and outputRecommendations().
NOTE Even though C refers to procedures as “functions,” C is not a functional language. The term functional is very different from procedural and refers to languages like Lisp, which use an entirely different abstraction.
The procedural approach tends to work well when your program follows a specific list of steps. In large modern applications, however, there is rarely a linear sequence of events. Often a user is able to perform any command at any time. Procedural thinking also says nothing about data representation. In the previous example, there was no discussion of what a stock quote actually is.
If the procedural mode of thought sounds like the way you approach a program, don’t worry. Once you realize that OOP is simply an alternative, more flexible, way of thinking about software, it’ll come naturally.
THE OBJECT-ORIENTED PHILOSOPHY
Unlike the procedural approach, which is based on the question What does this program do?, the object-oriented approach asks another question: What real-world objects am I modeling? OOP is based on the notion that you should divide your program not into tasks, but into models of physical objects. While this seems abstract at first, it becomes clearer when you consider physical objects in terms of their classes, components, properties, and behaviors.
Classes
A class helps distinguish an object from its definition. Consider the orange. There’s a difference between talking about oranges in general as tasty fruit that grows on trees and talking about a specific orange, such as the one that’s currently dripping juice on my keyboard.
When answering the question What are oranges? you are talking about the class of things known as oranges. All oranges are fruit. All oranges grow on trees. All oranges are some shade of orange. All oranges have some particular flavor. A class is simply the encapsulation of what defines a classification of objects.
When describing a specific orange, you are talking about an object. All objects belong to a particular class. Because the object on my desk is an orange, I know that it belongs to the orange class. Thus, I know that it is a fruit that grows on trees. I can further say that it is a medium shade of orange and ranks “mighty tasty” in flavor. An object is an instance of a class — a particular item with characteristics that distinguish it from other instances of the same class.
As a more concrete example, reconsider the stock selection application from above. In OOP, “stock quote” is a class because it defines the abstract notion of what makes up a quote. A specific quote, such as “current Microsoft stock quote,” would be an object because it is a particular instance of the class.
From a C background, think of classes and objects as analogous to types and variables. In fact, in Chapter 7, you’ll see that the syntax for classes is similar to the syntax for C structs.
Components
If you consider a complex real-world object, such as an airplane, it should be fairly easy to see that it is made up of smaller components. There’s the fuselage, the controls, the landing gear, the engines, and numerous other parts. The ability to think of objects in terms of their smaller components is essential to OOP, just as the breaking up of complicated tasks into smaller procedures is fundamental to procedural programming.
A component is essentially the same thing as a class, just smaller and more specific. A good object-oriented program might have an Airplane class, but this class would be huge if it fully described an airplane. Instead, the Airplane class deals with many smaller, more manageable, components. Each of these components might have further subcomponents. For example, the landing gear is a component of an airplane, and the wheel is a component of the landing gear.
Properties
Properties are what distinguish one object from another. Going back to the Orange class, recall that all oranges are defined as having some shade of orange and a particular flavor. These two characteristics are properties. All oranges have the same properties, just with different values. My orange has a “mighty tasty” flavor, but yours may have a “terribly unpleasant” flavor.
You can also think about properties on the class level. As recognized earlier, all oranges are fruit and grow on trees. These are properties of the fruit class whereas the specific shade of orange is determined by the particular fruit object. Class properties are shared by all objects of a class, while object properties are present in all objects of the class, but with different values.
In the stock selection example, a stock quote has several object properties, including the name of the company, its ticker symbol, the current price, and other statistics.
Properties are the characteristics that describe an object. They answer the question What makes this object different?
Behaviors
Behaviors answer either of two questions: What does this object do? Or, What can I do to this object? In the case of an orange, it doesn’t do a whole lot, but we can do things to it. One behavior is that it can be eaten. Like properties, you can think of behaviors on the class level or the object level. All oranges can pretty much be eaten in the same way. However, they might differ in some other behavior, such as being rolled down an incline, where the behavior of a perfectly round orange would differ from that of a more oblate one.
The stock selection example provides some more practical behaviors. As you recall, when thinking procedurally, we determined that our program needs to analyze stock quotes as one of its functions. Thinking in OOP, you might decide that a stock quote object can analyze itself. Analysis becomes a behavior of the stock quote object.
In object-oriented programming, the bulk of functional code is moved out of procedures and into classes. By building classes that have certain behaviors and defining how they interact, OOP offers a much richer mechanism for attaching code to the data on which it operates.
Bringing It All Together
With these concepts, you could take another look at the stock selection program and redesign it in an object-oriented manner.
As discussed, “stock quote” would be a fine class to start with. To obtain the list of quotes, the program needs the notion of a group of stock quotes, which is often called a collection. So a better design might be to have a class that represents a “collection of stock quotes,” which is made up of smaller components that represent a single “stock quote.”
Moving on to properties, the collection class would have at least one property — the actual list of quotes received. It might also have additional properties, such as the exact date and time of the most recent retrieval and the number of quotes obtained. As for behaviors, the “collection of stock quotes” would be able to talk to a server to get the quotes and provide a sorted list of quotes. This is the “retrieve quotes” behavior.
The stock quote class would have the properties discussed earlier — name, symbol, current price, and so on. Also, it would have an analyze behavior. You might consider other behaviors, such as buying and selling the stock.
It is often useful to jot down diagrams showing the relationship between components. Figure 5-1 uses multiple lines to indicate that one “collection of stock quotes” contains many “stock quote” objects.
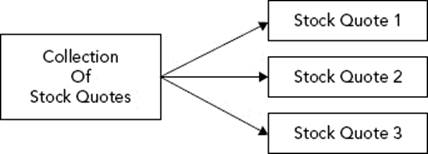
FIGURE 5-1
Another useful way of visualizing classes is to list properties and behaviors when brainstorming the object representation of a program, as in the following table:
|
CLASS |
ASSOCIATED COMPONENTS |
PROPERTIES |
BEHAVIORS |
|
Orange |
Seeds |
Color |
Eat |
|
Collection of Stock Quotes |
Made up of individual Stock Quote objects |
Individual Quotes |
Retrieve quotes |
|
Stock Quote |
None (yet) |
Company Name |
Analyze |
LIVING IN A WORLD OF OBJECTS
When programmers make the transition from thinking procedurally to the object-oriented paradigm, they often experience an epiphany about the combination of properties and behaviors into objects. Some programmers find themselves revisiting the design of programs they’re working on and rewriting certain pieces as objects. Others might be tempted to throw all the code away and restart the project as a fully object-oriented application.
There are two major approaches to developing software with objects. To some people, objects simply represent a nice encapsulation of data and functionality. These programmers sprinkle objects throughout their programs to make the code more readable and easier to maintain. Programmers taking this approach slice out isolated pieces of code and replace them with objects like a surgeon implanting a pacemaker. There is nothing inherently wrong with this approach. These people see objects as a tool that is beneficial in many situations. Certain parts of a program just “feel like an object,” like the stock quote. These are the parts that can be isolated and described in real-world terms.
Other programmers adopt the OOP paradigm fully and turn everything into an object. In their minds, some objects correspond to real-world things, such as an orange or a stock quote, while others encapsulate more abstract concepts, such as a sorter or an undoobject. The ideal approach is probably somewhere in between these extremes. Your first object-oriented program might really have been a traditional procedural program with a few objects sprinkled in. Or perhaps you went whole hog and made everything an object, from a class representing an int to a class representing the main application. Over time, you will find a happy medium.
Overobjectification
There is often a fine line between designing a creative object-oriented system and annoying everybody else on your team by turning every little thing into an object. As Freud used to say, sometimes a variable is just a variable. Okay, that’s a paraphrase of what he said.
Perhaps you’re designing the next bestselling Tic-Tac-Toe game. You’re going all-out OOP on this one, so you sit down with a cup of coffee and a notepad to sketch out your classes and objects. In games like this, there’s often an object that oversees game play and is able to detect the winner. To represent the game board, you might envision a Grid object that will keep track of the markers and their locations. In fact, a component of the grid could be the Piece object that represents an X or an O.
Wait, back up! This design proposes to have a class that represents an X or an O. That is perhaps object overkill. After all, can’t a char represent an X or an O just as well? Better yet, why can’t the Grid just use a two-dimensional array of an enumerated type? Does aPiece object just complicate the code? Take a look at the following table representing the proposed piece class:
|
CLASS |
ASSOCIATED COMPONENTS |
PROPERTIES |
BEHAVIORS |
|
Piece |
None |
X or O |
None |
The table is a bit sparse, strongly hinting that what we have here may be too granular to be a full-fledged object.
On the other hand, a forward-thinking programmer might argue that while Piece is a pretty meager class as it currently stands, making it into an object allows future expansion without any real penalty. Perhaps down the road, this will be a graphical application and it might be useful to have the Piece class support drawing behavior. Additional properties could be the color of the Piece or whether the Piece was the most recently moved.
Another solution might be to think about the state of a grid square instead of using pieces. The state of a square can be Empty, X or O. To make the design future-proof to support a graphical application, you could design an abstract base class State with concrete derived classes StateEmpty, StateX and StateO which know how to render themselves.
Obviously, there is no right answer. The important point is that these are issues that you should consider when designing your application. Remember that objects exist to help programmers manage their code. If objects are being used for no reason other than to make the code “more object-oriented,” something is wrong.
Overly General Objects
Perhaps a worse annoyance than objects that shouldn’t be objects is objects that are too general. All OOP students start with examples like “orange” — things that are objects, no question about it. In real life coding, objects can get pretty abstract. Many OOP programs have an “application object,” despite the fact that an application isn’t really something you can envision in material form. Yet it may be useful to represent the application as an object because the application itself has certain properties and behaviors.
An overly general object is an object that doesn’t represent a particular thing at all. The programmer may be attempting to make an object that is flexible or reusable, but ends up with one that is confusing. For example, imagine a program that organizes and displays media. It can catalog your photos, organize your digital music collection, and serve as a personal journal. The overly general approach is to think of all these things as “media” objects and build a single class that can accommodate all of the formats. It might have a property called “data” that contains the raw bits of the image, song, or journal entry, depending on the type of media. It might have a behavior called “perform” that appropriately draws the image, plays the song, or brings up the journal entry for editing.
The clues that this class is too general are in the names of the properties and behaviors. The word “data” has little meaning by itself — you have to use a general term here because this class has been overextended to three very different uses. Similarly, “perform” will do very different things in the three different cases. Finally, this design is too general because “media” isn’t a particular object, not in the user interface, not in real life, and not even in the programmer’s mind. A major clue that a class is too general is when many ideas in the programmers mind all unite as a single object, as shown in Figure 5-2.
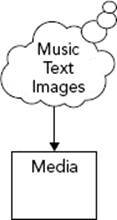
FIGURE 5-2
OBJECT RELATIONSHIPS
As a programmer, you will certainly encounter cases where different classes have characteristics in common, or at least seem somehow related to each other. For example, although creating a “media” object to represent images, music, and text in a digital catalog program is too general, these objects do share characteristics. You may want all of them to keep track of the date and time that they were last modified, or you might want them all to support a delete behavior.
Object-oriented languages provide a number of mechanisms for dealing with such relationships between objects. The tricky part is to understand what the relationship actually is. There are two main types of object relationships — a has-a relationship and an is-a relationship.
The Has-A Relationship
Objects engaged in a has-a, or aggregation, relationship follow the pattern A has a B, or A contains a B. In this type of relationship, you can envision one object as part of another. Components, as defined earlier, generally represent a has-a relationship because they describe objects that are made up of other objects.
A real-world example of this might be the relationship between a zoo and a monkey. You could say that a zoo has a monkey or a zoo contains a monkey. A simulation of a zoo in code would have a zoo object, which has a monkey component.
Often, thinking about user interface scenarios is helpful in understanding object relationships. This is so because even though not all UIs are implemented in OOP (though these days, most are), the visual elements on the screen translate well into objects. One UI analogy for a has-a relationship is a window that contains a button. The button and the window are clearly two separate objects but they are obviously related in some way. Since the button is inside the window, we say that the window has a button.
Figure 5-3 shows various real-world and user interface has-a relationships.
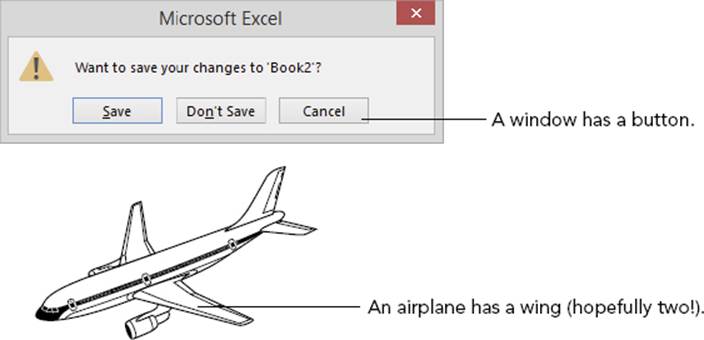
FIGURE 5-3
The Is-A Relationship (Inheritance)
The is-a relationship is such a fundamental concept of object-oriented programming that it has many names, including deriving, subclassing, extending, and inheriting. Classes model the fact that the real world contains objects with properties and behaviors. Inheritance models the fact that these objects tend to be organized in hierarchies. These hierarchies indicate is-a relationships.
Fundamentally, inheritance follows the pattern A is a B or A is really quite a bit like B — it can get tricky. To stick with the simple case, revisit the zoo, but assume that there are other animals besides monkeys. That statement alone has already constructed the relationship — a monkey is an animal. Similarly, a giraffe is an animal, a kangaroo is an animal, and a penguin is an animal. So what? Well, the magic of inheritance comes when you realize that monkeys, giraffes, kangaroos, and penguins have certain things in common. These commonalities are characteristics of animals in general.
What this means for the programmer is that you can define an Animal class that encapsulates all of the properties (size, location, diet, etc.) and behaviors (move, eat, sleep) that pertain to every animal. The specific animals, such as monkeys, become derived classes ofAnimal because a monkey contains all the characteristics of an animal. Remember, a monkey is an animal plus some additional characteristics that make it distinct. Figure 5-4 shows an inheritance diagram for animals. The arrows indicate the direction of the is-a relationship.
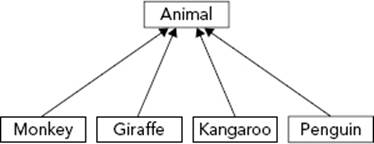
FIGURE 5-4
Just as monkeys and giraffes are different types of animals, a user interface often has different types of buttons. A checkbox, for example, is a button. Assuming that a button is simply a UI element that can be clicked and performs an action, a Checkbox extends theButton class by adding state — whether the box is checked or unchecked.
When relating classes in an is-a relationship, one goal is to factor common functionality into the base class, the class that other classes extend. If you find that all of your derived classes have code that is similar or exactly the same, consider how you could move some or all of the code into the base class. That way, any changes that need to be made only happen in one place and future derived classes get the shared functionality “for free.”
Inheritance Techniques
The preceding examples cover a few of the techniques used in inheritance without formalizing them. When deriving classes, there are several ways that the programmer can distinguish a class from its parent class or base class or superclass. A derived class may use one or more of these techniques and they are recognized by completing the sentence A is a B that . . . .
Adding Functionality
A derived class can augment its parent by adding additional functionality. For example, a monkey is an animal that can swing from trees. In addition to having all of the behaviors of Animal, the Monkey class also has a swing from trees behavior, which is specific to only the Monkey class.
Replacing Functionality
A derived class can replace or override a behavior of its parent entirely. For example, most animals move by walking, so you might give the Animal class a move behavior that simulates walking. If that’s the case, a kangaroo is an animal that moves by hopping instead of walking. All the other properties and behaviors of the Animal base class still apply, but the Kangaroo derived class simply changes the way that the move behavior works. Of course, if you find yourself replacing all of the functionality of your base class, it may be an indication that inheriting was not the correct thing to do after all, unless the base class is an abstract base class. An abstract base class forces each of the derived classes to implement a certain behavior. You cannot create instances of an abstract base class. Abstract classes are discussed in Chapter 9.
Adding Properties
A derived class can also add new properties to the ones that were inherited from the base class. A penguin has all the properties of an animal but also has a beak size property.
Replacing Properties
C++ provides a way of overriding properties similar to the way you can override behaviors. However, doing so is rarely appropriate, because it hides the property from the base class, i.e. the base class can have a specific value for a property with a certain name, while the derived class can have another value for the property with the same name. Hiding is explained in more details in Chapter 9. It’s important not to get the notion of replacing a property confused with the notion of derived classes having different values for properties. For example, all animals have a diet property that indicates what they eat. Monkeys eat bananas and penguins eat fish, but neither of these is replacing the diet property — they simply differ in the value assigned to the property.
Polymorphism versus Code Reuse
Polymorphism is the notion that objects that adhere to a standard set of properties and behaviors can be used interchangeably. A class definition is like a contract between objects and the code that interacts with them. By definition, any monkey object must support the properties and behaviors of the monkey class.
This notion extends to base classes as well. Because all monkeys are animals, all Monkey objects support the properties and behaviors of the Animal class as well.
Polymorphism is a beautiful part of object-oriented programming because it truly takes advantage of what inheritance offers. In a zoo simulation, you could programmatically loop through all of the animals in the zoo and have each animal move once. Since all animals are members of the Animal class, they all know how to move. Some of the animals have overridden the move behavior, but that’s the best part — our code simply tells each animal to move without knowing or caring what type of animal it is. Each one moves whichever way it knows how.
There is another reason to use inheritance besides polymorphism. Often, it’s just a matter of leveraging existing code. For example, if you need a class that plays music with an echo effect, and your coworker has already written one that plays music without any effects, you might be able to extend the existing class and add in the new functionality. The is-a relationship still applies (an echo music player is a music player that adds an echo effect), but you didn’t intend for these classes to be used interchangeably. What you end up with are two separate classes, used in completely different parts of the programs (or maybe even in different programs entirely) that happen to be related only to avoid reinventing the wheel.
The Fine Line between Has-A and Is-A
In the real world, it’s pretty easy to classify has-a and is-a relationships between objects. Nobody would claim that an orange has a fruit — an orange is a fruit. In code, things sometimes aren’t so clear.
Consider a hypothetical class that represents a hash table. A hash table is a data structure that efficiently maps a key to a value. For example, an insurance company could use a Hashtable class to map member IDs to names so that given an ID, it’s easy to find the corresponding member name. The member ID is the key and the member name is the value.
In a standard hash table implementation, every key has a single value. If the ID 14534 maps to the member name “Kleper, Scott”, it cannot also map to the member name “Kleper, Marni”. In most implementations, if you tried to add a second value for a key that already has a value, the first value would go away. In other words, if the ID 14534 mapped to “Kleper, Scott” and you then assigned the ID 14534 to “Kleper, Marni”, then Scott would effectively be uninsured, as shown in the following sequence, which shows two calls to a hypothetical hash table insert() behavior and the resulting contents of the hash table. The notation hash.insert jumps ahead a bit to C++ object syntax. Just think of it as saying “use the insert behavior of the hash object.”
hash.insert(14534, "Kleper, Scott");
|
KEYS |
VALUES |
|
14534 |
“Kleper, Scott” [string] |
hash.insert(14534, "Kleper, Marni");
|
KEYS |
VALUES |
|
14534 |
“Kleper, Marni” [string] |
It’s not difficult to imagine uses for a data structure that’s like a hash table, but allows multiple values for a given key. In the insurance example, a family might have several names that correspond to the same ID. Because such a data structure is very similar to a hash table, it would be nice to leverage that functionality somehow. A hash table can have only a single value as a key, but that value can be anything. Instead of a string, the value could be a collection (such as an array or a list) containing the multiple values for the key. Every time you add a new member for an existing ID, add the name to the collection. This would work as shown in the following sequence.
Collection collection; // Make a new collection.
collection.insert("Kleper, Scott"); // Add a new element to the collection.
hash.insert(14534, collection); // Insert the collection into the table.
|
KEYS |
VALUES |
|
14534 |
{“Kleper, Scott”} [collection] |
Collection collection = hash.get(14534);// Retrieve the existing collection.
collection.insert("Kleper, Marni"); // Add a new element to the collection.
hash.insert(14534, collection); // Replace the collection with the updated one.
|
KEYS |
VALUES |
|
14534 |
{“Kleper, Scott”, “Kleper, Marni”} [collection] |
Messing around with a collection instead of a string is tedious and requires a lot of repetitive code. It would be preferable to wrap up this multiple-value functionality in a separate class, perhaps called a MultiHash. The MultiHash class would work just like Hashtableexcept that behind the scenes, it would store each value as a collection of strings instead of a single string. Clearly, MultiHash is somehow related to Hashtable because it is still using a hash table to store the data. What is unclear is whether that constitutes an is-a or a has-a relationship.
To start with the is-a relationship, imagine that MultiHash is a derived class of Hashtable. It would have to override the behavior that adds an entry into the table so that it would either create a collection and add the new element, or retrieve the existing collection and add the new element. It would also override the behavior that retrieves a value. It could, for example, append all the values for a given key together into one string. This seems like a perfectly reasonable design. Even though it overrides all the behaviors of the base class, it will still make use of the base class’s behaviors by using the original behaviors within the derived class. This approach is shown in Figure 5-5.
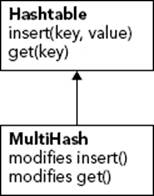
FIGURE 5-5
Now consider it as a has-a relationship. MultiHash is its own class, but it contains a Hashtable object. It probably has an interface very similar to Hashtable, but it need not be the same. Behind the scenes, when a user adds something to the MultiHash, it is really wrapped in a collection and put in a Hashtable object. This also seems perfectly reasonable and is shown in Figure 5-6.

FIGURE 5-6
So, which solution is right? There’s no clear answer, though a friend of mine who has written a MultiHash class for production use, viewed it as a has-a relationship. The main reason was to allow modifications to the exposed interface without worrying about maintaining hash table functionality. For example, in Figure 5-6, the get behavior was changed to getAll, making it clear that this would get all the values for a particular key in a MultiHash. Additionally, with a has-a relationship, you don’t have to worry about any hash table functionality bleeding through. For example, if the hash table class supported a behavior that would get the total number of values, it would report the number of collections unless MultiHash knew to override it.
That said, one could make a convincing argument that a MultiHash actually is a Hashtable with some new functionality, and it should have been an is-a relationship. The point is that there is sometimes a fine line between the two relationships, and you will need to consider how the class is going to be used and whether what you are building just leverages some functionality from another class or really is that class with modified or new functionality.
The following table represents the arguments for and against taking either approach for the MultiHash class.
|
IS-A |
HAS-A |
|
|
Reasons For |
|
|
|
Reasons Against |
MultiHash overrides both behaviors of Hashtable, a strong sign that something about the design is wrong.
|
|
The reasons against using an is-a relationship in this case are pretty strong. In fact, after years of experience, I recommend to opt for a has-a relationship over an is-a relationship if you have the choice.
Note that the Hashtable and MultiHash are used here to demonstrate the difference between the is-a and has-a relationships. In your own code, it is recommended to use one of the standard hash table classes instead of writing your own. The C++ standard library provides an unordered_map class, which you should use instead of the Hashtable and an unordered_multimap class, which you should use instead of the MultiHash. Both of these standard classes are discussed in Chapter 16.
The Not-A Relationship
As you consider what type of relationship classes have, consider whether or not they actually have a relationship at all. Don’t let your zeal for object-oriented design turn into a lot of needless class/derived class relationships.
One pitfall occurs when things are obviously related in the real world but have no actual relationship in code. OO hierarchies need to model functional relationships, not artificial ones. Figure 5-7 shows relationships that are meaningful as ontologies or hierarchies, but are unlikely to represent a meaningful relationship in code.
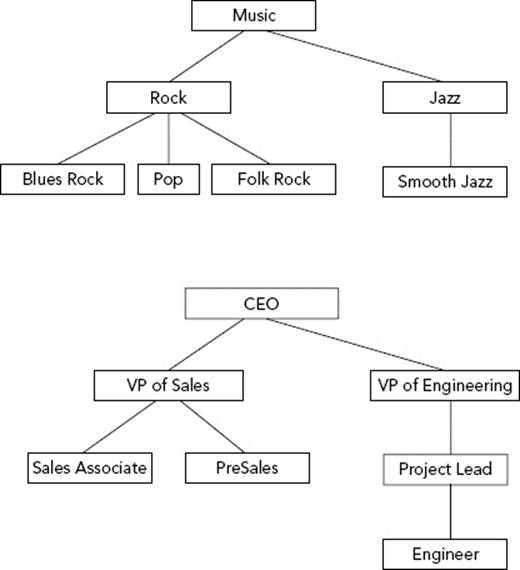
FIGURE 5-7
The best way to avoid needless inheritance is to sketch out your design first. For every class and derived class, write down what properties and behaviors you’re planning on putting there. You should rethink your design if you find that a class has no particular properties or behaviors of its own, or if all of those properties and behaviors are completely overridden by its derived classes, except when working with abstract base classes as mentioned earlier.
Hierarchies
Just as a class A can be a base class of B, B can also be a base class of C. Object-oriented hierarchies can model multilevel relationships like this. A zoo simulation with more animals might be designed with every animal as a derived class of a common Animal class as shown in Figure 5-8.
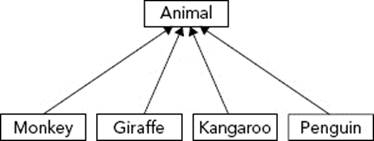
FIGURE 5-8
As you code each of these derived classes, you might find that a lot of them are similar. When this occurs, you should consider putting in a common parent. Realizing that Lion and Panther both move the same way and have the same diet might indicate a possibleBigCat class. You could further subdivide the Animal class to include WaterAnimal, and Marsupial. A more hierarchical design that leverages this commonality is shown in Figure 5-9.
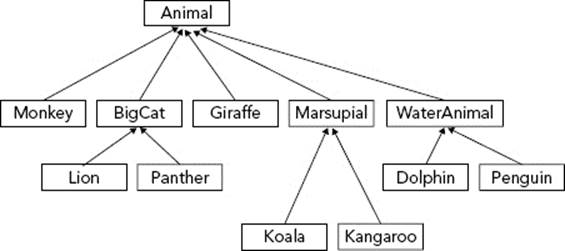
FIGURE 5-9
A biologist looking at this hierarchy may be disappointed — a penguin isn’t really in the same family as a dolphin. However, it underlines a good point — in code, you need to balance real-world relationships with shared functionality relationships. Even though two things might be very closely related in the real world, they might have a not-a relationship in code because they really don’t share functionality. You could just as easily divide animals into mammals and fish, but that wouldn’t factor any commonality to the base class.
Another important point is that there could be other ways of organizing the hierarchy. The preceding design is organized mostly by how the animals move. If it were instead organized by the animals’ diet or height, the hierarchy could be very different. In the end, what matters is how the classes will be used. The needs will dictate the design of the object hierarchy.
A good object-oriented hierarchy accomplishes the following:
· Organizes classes into meaningful functional relationships
· Supports code reuse by factoring common functionality to base classes
· Avoids having derived classes that override much of the parent’s functionality, unless the parent is an abstract class.
Multiple Inheritance
Every example so far has had a single inheritance chain. In other words, a given class has, at most, one immediate parent class. This does not have to be the case. Through multiple inheritance, a class can have more than one base class.
Figure 5-10 shows a multiple inheritance design. There is still a base class called Animal, which is further divided by size. A separate hierarchy categorizes by diet, and a third takes care of movement. Each type of animal is then a derived class of all three of these classes, as shown by different lines.
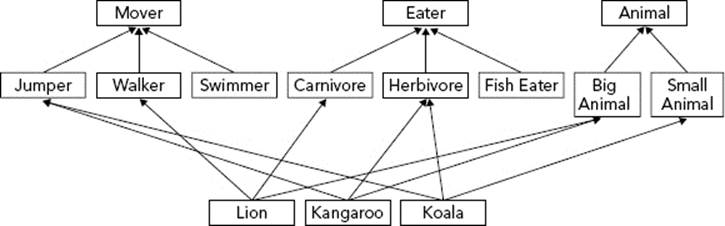
FIGURE 5-10
In a user interface context, imagine an image that the user can click on. This object seems to be both a button and an image so the implementation might involve inheriting from both the Image class and the Button class, as shown in Figure 5-11.
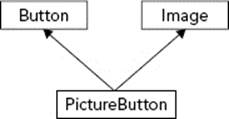
FIGURE 5-11
Multiple inheritance can be very useful in certain cases, but it also has a number of disadvantages that you should always keep in mind. Many programmers dislike multiple inheritance. C++ has explicit support for such relationships, though the Java language does away with them altogether, except for inheriting from multiple interfaces (abstract base classes). There are several reasons to which multiple inheritance critics point.
First, visualizing multiple inheritance is complicated. As you saw in Figure 5-10, even a simple class diagram can become very complicated when there are multiple hierarchies and crossing lines. Class hierarchies are supposed to make it easier for the programmer to understand the relationships between code. With multiple inheritance, a class could have several parents that are in no way related to each other. With so many classes contributing code to your object, can you really keep track of what’s going on?
Second, multiple inheritance can destroy otherwise clean hierarchies. In the animal example, switching to a multiple inheritance approach means that the Animal base class is less meaningful because the code that describes animals is now separated into three separate hierarchies. While the design illustrated in Figure 5-10 shows three clean hierarchies, it’s not difficult to imagine how they could get messy. For example, what if you realize that not only do all Jumpers move in the same way, they also eat the same things? Because there are separate hierarchies, there is no way to join the concepts of movement and diet without adding yet another derived class.
Third, implementation of multiple inheritance is complicated. What if two of your base classes implement the same behavior in different ways? Can you have two base classes that are themselves a derived class of a common base class? These possibilities complicate the implementation because structuring such intricate relationships in code is difficult both for the author and a reader.
The reason that other languages can leave out multiple inheritance is that it is usually avoidable. By rethinking your hierarchy you can often avoid introducing multiple inheritance when you have control over the design of a project.
Mixin Classes
Mixin classes represent another type of relationship between classes. In C++, a mixin class is implemented syntactically just like multiple inheritance, but the semantics are refreshingly different. A mixin class answers the question “What else is this class able to do?” and the answer often ends with “-able.” Mixin classes are a way that you can add functionality to a class without committing to a full is-a relationship. You can think of it as a shares-with relationship.
Going back to the zoo example, you might want to introduce the notion that some animals are “pettable.” That is, there are some animals that visitors to the zoo can pet, presumably without being bitten or mauled. You might want all pettable animals to support the behavior “be pet.” Since pettable animals don’t have anything else in common and you don’t want to break the existing hierarchy you’ve designed, Pettable makes a great mixin class.
Mixin classes are used frequently in user interfaces. Instead of saying that a PictureButton class is both an Image and a Button, you might say that it’s an Image that is Clickable. A folder icon on your desktop could be an Image that is Draggable. Software developers tend to make up lots of fun adjectives.
The difference between a mixin class and a base class has more to do with how you think about the class than any code difference. In general, mixin classes are easier to digest than multiple inheritance because they are very limited in scope. The Pettable mixin class just adds one behavior to any existing class. The Clickable mixin class might just add “mouse down” and “mouse up” behaviors. Also, mixin classes rarely have a large hierarchy so there’s no cross-contamination of functionality.
ABSTRACTION
In Chapter 4, you learned about the concept of abstraction — the notion of separating implementation from the means used to access it. Abstraction is a good idea for many reasons explored earlier. It’s also a fundamental part of object-oriented design.
Interface versus Implementation
The key to abstraction is effectively separating the interface from the implementation. Implementation is the code you’re writing to accomplish the task you set out to accomplish. Interface is the way that other people use your code. In C, the header file that describes the functions in a library you’ve written is an interface. In object-oriented programming, the interface to a class is the collection of publicly accessible properties and behaviors. A good interface contains only public behaviors. Properties/variables of a class should never be made public but can be exposed through public behaviors also called getters and setters.
Deciding on an Exposed Interface
The question of how other programmers will interact with your objects comes into play when designing a class. In C++, a class’s properties and behaviors can each be public, protected, or private. Making a property or behavior public means that other code can access it. protected means that other code cannot access the property or behavior but derived classes can access them. private is a stricter control, which means that not only are the properties or behaviors locked for other code, but even derived classes can’t access them.
Designing the exposed interface is all about choosing what to make public. When working on a large project with other programmers, you should view the exposed interface design as a process.
Consider the Audience
The first step in designing an exposed interface is to consider for whom you are designing it. Is your audience another member of your team? Is this an interface that you will personally be using? Is it something that a programmer external to your company will use? Perhaps a customer or an off-shore contractor? In addition to determining who will be coming to you for help with the interface, this should shed some light on some of your design goals.
If the interface is for your own use, you probably have more freedom to iterate on the design. As you’re making use of the interface, you can change it to suit your own needs. However, you should keep in mind that roles on an engineering team change and it is quite likely that, some day, others will be using this interface as well.
Designing an interface for other internal programmers to use is slightly different. In a way, your interface becomes a contract with them. For example, if you are implementing the data store component of a program, others are depending on that interface to support certain operations. You will need to find out all of the things that the rest of the team wants your class to do. Do they need versioning? What types of data can they store? As a contract, you should view the interface as slightly less flexible. If the interface is agreed upon before coding begins, you’ll receive some groans from other programmers if you decide to change it after code has been written.
If the client is an external customer, you will be designing with a very different set of requirements. Ideally, the target customer will be involved in specifying what functionality your interface exposes. You’ll need to consider both the specific features they want as well as what customers might want in the future. The terminology used in the interface will have to correspond to the terms that the customer is familiar with, and the documentation will have to be written with that audience in mind. Inside jokes, codenames, and programmer slang should probably be left out of your design.
Consider the Purpose
There are many reasons for writing an interface. Before putting any code on paper or even deciding on what functionality you’re going to expose, you need to understand the purpose of the interface.
Application Programming Interface (API)
An API is an externally visible mechanism to extend a product or use its functionality within another context. If an internal interface is a contract, an API is closer to a set-in-stone law. Once people who don’t even work for your company are using your API, they don’t want it to change unless you’re adding new features that will help them. So, care should be given to planning the API and discussing it with customers before making it available to them.
The main tradeoff in designing an API is usually ease of use versus flexibility. Because the target audience for the interface is not familiar with the internal working of your product, the learning curve to use the API should be gradual. After all, your company is exposing this API to customers because the company wants it to be used. If it’s too difficult to use, the API is a failure. Flexibility often works against this. Your product may have a lot of different uses, and you want the customer to be able to leverage all the functionality you have to offer. However, an API that lets the customer do anything that your product can do may be too complicated.
As a common programming adage goes, “A good API makes the easy case easy and the hard case possible.” That is, APIs should have a simple learning curve. The things that most programmers will want to do should be accessible. However, the API should allow for more advanced usage, and it’s acceptable to trade off complexity of the rare case for simplicity of the common case.
Utility Class or Library
Often, your task is to develop some particular functionality for general use elsewhere in the application. It could be a random number library or a logging class. In these cases, the interface is somewhat easier to decide on because you tend to expose most or all of the functionality, ideally without giving too much away about its implementation. Generality is an important issue to consider. Since the class or library is general purpose, you’ll need to take the possible set of use cases into account in your design.
Subsystem Interface
You may be designing the interface between two major subsystems of the application, such as the mechanism for accessing a database. In these cases, separating the interface from the implementation is paramount because other programmers are likely to start implementing against your interface before your implementation is complete. When working on a subsystem, first think about what its one main purpose is. Once you have identified the main task your subsystem is charged with, think about specific uses and how it should be presented to other parts of the code. Try to put yourself in their shoes and not get bogged down in implementation details.
Component Interface
Most of the interfaces you define will probably be smaller than a subsystem interface or an API. These will be classes that you use within other code that you’ve written. In these cases, the main pitfall is when your interface evolves gradually and becomes unruly. Even though these interfaces are for your own use, think of them as though they weren’t. As with a subsystem interface, consider the one main purpose of each class and be cautious of exposing functionality that doesn’t contribute to that purpose.
Consider the Future
As you are designing your interface, keep in mind what the future holds. Is this a design you will be locked into for years? If so, you might need to leave room for expansion by coming up with a plug-in architecture. Do you have evidence that people will try to use your interface for purposes other than what it was designed for? Talk to them and get a better understanding of their use case. The alternative is rewriting it later, or worse, attaching new functionality haphazardly and ending up with a messy interface. Be careful though! Speculative generality is yet another pitfall. Don’t design the be-all end-all logging class if the future uses are unclear, because it might unnecessarily complicate the design, the implementation and its public interface.
Designing a Successful Abstraction
Experience and iteration are essential to good abstractions. Truly well-designed interfaces come from years of writing and using other abstractions. You can also leverage someone else’s years of writing and using abstractions by reusing existing, truly well designed abstractions in the form of standard design patterns. As you encounter other abstractions, try to remember what worked and didn’t work. What did you find lacking in the Windows file system API you used last week? What would you have done differently if you had written the network wrapper, instead of your coworker? The best interface is rarely the first one you put on paper, so keep iterating. Bring your design to your peers and ask for feedback. If your company uses code reviews, start the code review by doing a review of the interface specifications before the implementation starts. Don’t be afraid to change the abstraction once coding has begun, even if it means forcing other programmers to adapt. Hopefully, they’ll realize that a good abstraction is beneficial to everyone in the long term.
Sometimes you need to evangelize a bit when communicating your design to other programmers. Perhaps the rest of the team didn’t see a problem with the previous design or feels that your approach requires too much work on their part. In those situations, be prepared both to defend your work and to incorporate their ideas when appropriate.
A good abstraction means that the interface has only public behaviors. All code should be in the implementation file and not in the class definition file. This means that the interface files containing the class definitions are stable and will not change.
Beware of single-class abstractions. If there is significant depth to the code you’re writing, consider what other companion classes might accompany the main interface. For example, if you’re exposing an interface to do some data processing, consider also writing a result object that provides an easy way to view and interpret the results.
Always turn properties into behaviors. In other words, don’t allow external code to manipulate the data behind your class directly. You don’t want some careless or nefarious programmer to set the height of a bunny object to a negative number. Instead, have a “set height” behavior that does the necessary bounds checking.
Iteration is worth mentioning again because it is the most important point. Seek and respond to feedback on your design, change it when necessary, and learn from mistakes.
SUMMARY
In this chapter, you’ve gained an appreciation for the design of object-oriented programs without a lot of code getting in the way. The concepts you’ve learned are applicable in almost any object-oriented language. Some of it may have been a review to you, or it may be a new way of formalizing a familiar concept. Perhaps you picked up some new approaches to old problems or new arguments in favor of the concepts you’ve been preaching to your team all along. Even if you’ve never used objects in your code, or have used them only sparingly, you now know more about how to design object-oriented programs than many experienced C++ programmers.
The relationships between objects are important to study, not just because well-linked objects contribute to code reuse and reduce clutter, but also because you will be working in a team. Objects that relate in meaningful ways are easier to read and maintain. You may decide to use the “Object Relationships” section as a reference when you design your programs.
Finally, you learned about creating successful abstractions and the two most important design considerations — audience and purpose.
The next chapter continues the design theme by explaining how to design your code with reuse in mind.