Professional C++ (2014)
Part IIProfessional C++ Software Design
Chapter 6Designing for Reuse
WHAT’S IN THIS CHAPTER?
· The reuse philosophy: Why you should design code for reuse
· How to design reusable code
· How to use abstraction
· Three strategies for structuring your code for reuse
· Six strategies for designing usable interfaces
· How to reconcile generality with ease of use
Reusing libraries and other code in your programs is an important design strategy. However, it is only half of the reuse strategy. The other half is designing and writing the code that you can reuse in your programs. As you’ve probably discovered, there is a significant difference between well-designed and poorly designed libraries. Well-designed libraries are a pleasure to use, while poorly designed libraries can prod you to give up in disgust and write the code yourself. Whether you’re writing a library explicitly designed for use by other programmers or merely deciding on a class hierarchy, you should design your code with reuse in mind. You never know when you’ll need a similar piece of functionality in a subsequent project.
Chapter 4 introduced the design theme of reuse and explained how to apply this theme by incorporating libraries and other code in your designs. This chapter discusses the other side of reuse: designing reusable code. It builds on the object-oriented design principles described in Chapter 5 and introduces some new strategies and guidelines.
THE REUSE PHILOSOPHY
You should design code that both you and other programmers can reuse. This rule applies not only to libraries and frameworks that you specifically intend for other programmers to use, but also to any class, subsystem, or component that you design for a program.You should always keep in mind the mottos, “write once, use often,” and “avoid code duplication at all cost.” There are several reasons:
· Code is rarely used in only one program. You can be sure that your code will be used again somehow, so design it correctly to begin with.
· Designing for reuse saves time and money. If you design your code in a way that precludes future use, you ensure that you or your partners will spend time reinventing the wheel later when you encounter a need for a similar piece of functionality.
· Other programmers in your group must be able to use the code that you write. You are probably not working alone on a project. Your coworkers will appreciate your efforts to offer them well-designed, functionality-packed libraries and pieces of code to use. Designing for reuse can also be called cooperative coding.
· Lack of reuse leads to code duplication, code duplication leads to a maintenance nightmare. If ever you find yourself copy-pasting a piece of code, you have to at least consider moving it out to a helper function or class.
· You will be the primary beneficiary of your own work. Experienced programmers never throw away code. Over time, they build a personal library of evolving tools. You never know when you will need a similar piece of functionality in the future.
WARNING When you design or write code as an employee of a company, the company, not you, generally owns the intellectual property rights. It is often illegal to retain copies of your designs or code when you terminate your employment with the company. The same is also true when you are self-employed working for clients.
HOW TO DESIGN REUSABLE CODE
Reusable code fulfills two main goals. First, it is general enough to use for slightly different purposes or in different application domains. Program components with details of a specific application are difficult to reuse in other programs.
Reusable code is also easy to use. It doesn’t require significant time to understand its interface or functionality. Programmers must be able to incorporate it readily into their applications.
The means of “delivering” your library to clients is also important. You could deliver it in source form and clients just incorporate your source into their project. Another option is to deliver a static library, which they link into their application, or you could deliver a Dynamic Link Library (DLL) for Windows clients or a shared object (.so) for Linux clients. Each of these delivery mechanisms can impose additional constraints on how you code your library.
NOTE This chapter uses the term “client” to refer to a programmer who uses your interfaces. Don’t confuse clients with “users” who run your programs. The chapter also uses the phrase “client code” to refer to code that is written to use your interfaces.
The most important strategy for designing reusable code is abstraction. Chapter 4 presented the real-world analogy of a television, which you can use through its interfaces without understanding how it works inside. Similarly, when you design code, you should clearly separate the interface from the implementation. This separation makes the code easier to use, primarily because clients do not need to understand the internal implementation details in order to use the functionality.
Abstraction separates code into interface and implementation, so designing reusable code focuses on these two main areas. First, you must structure the code appropriately. What class hierarchies will you use? Should you use templates? How should you divide the code into subsystems?
Second, you must design the interfaces, which are the “entries” into your library or code that programmers use to access the functionality you provide.
Use Abstraction
You learned about the principle of abstraction in Chapter 4 and read more about its application to object-oriented design in Chapter 5. To follow the principle of abstraction, you should provide interfaces to your code that hide the underlying implementation details. There should be a clear distinction between the interface and the implementation.
Using abstraction benefits both you and the clients who use your code. Clients benefit because they don’t need to worry about the implementation details; they can take advantage of the functionality you offer without understanding how the code really works. You benefit because you can modify the underlying code without changing the interface to the code. Thus, you can provide upgrades and fixes without requiring clients to change their use. With dynamically linked libraries, clients might not even need to rebuild their executables. Finally, you both benefit because you, as the library writer, can specify in the interface exactly what interactions you expect and functionality you support. Consult Chapter 3 for a discussion on how to write documentation. A clear separation of interfaces and implementations will prevent clients from using the library in ways that you didn’t intend, which can otherwise cause unexpected behaviors and bugs.
WARNING When designing your interface, do not expose implementation details to your clients.
Sometimes libraries require client code to keep information returned from one interface in order to pass it to another. This information is sometimes called a handle and is often used to keep track of specific instances that require state to be remembered between calls. If your library design requires a handle, don’t expose its internals. Make that handle into an opaque class, in which the programmer “can’t access the internal data members, neither directly, nor through public getters or setters.” Don’t require the client code to tweak variables inside this handle. An example of a bad design would be a library that requires you to set a specific member of a structure in a supposedly opaque handle in order to turn on error logging.
NOTE Unfortunately, C++ is fundamentally unfriendly to the principle of good abstraction when writing classes. The syntax requires you to combine your public interfaces and non-public (private or protected) data members and methods together in one class definition, thereby exposing some of the internal implementation details of the class to its clients. Chapter 8 describes some techniques for working around this in order to present clean interfaces.
Abstraction is so important that it should guide your entire design. As part of every decision you make, ask yourself whether your choice fulfills the principle of abstraction. Put yourself in your clients’ shoes and determine whether or not you’re requiring knowledge of the internal implementation in the interface. You should rarely, if ever, make exceptions to this rule.
Structure Your Code for Optimal Reuse
You must consider reuse from the beginning of your design. The following strategies will help you organize your code properly. Note that all of these strategies focus on making your code general purpose. The second aspect of designing reusable code, providing ease of use, is more relevant to your interface design and is discussed later in this chapter.
Avoid Combining Unrelated or Logically Separate Concepts
When you design a library or framework, keep it focused on a single task or group of tasks, i.e., strive for high cohesion. Don’t combine unrelated concepts such as a random number generator and an XML parser.
Even when you are not designing code specifically for reuse, keep this strategy in mind. Entire programs are rarely reused on their own. Instead, pieces or subsystems of the programs are incorporated directly into other applications, or are adapted for slightly different uses. Thus, you should design your programs so that you divide logically separate functionality into distinct components that can be reused in different programs.
This program strategy models the real-world design principle of discrete, interchangeable parts. For example, you could take the tires off an old car and use them on a new car of a different model. Tires are separable components that are not tied to other aspects of the car. You don’t need to bring the engine along with the tires!
You can employ the strategy of logical division in your program design on both the macro subsystem level and the micro class hierarchy level.
Divide Your Programs into Logical Subsystems
Design your subsystems as discrete components that can be reused independently, i.e., strive for low coupling. For example, if you are designing a networked game, keep the networking and graphical user interface aspects in separate subsystems. That way you can reuse either component without dragging in the other. For example, you might want to write a non-networked game, in which case you could reuse the graphical interface subsystem, but wouldn’t need the networking aspect. Similarly, you could design a peer-to-peer file-sharing program, in which case you could reuse the networking subsystem but not the graphical user interface functionality.
Make sure to follow the principle of abstraction for each subsystem. Think of each subsystem as a miniature library for which you must provide a coherent and easy-to-use interface. Even if you’re the only programmer who ever uses these miniature libraries, you will benefit from well-designed interfaces and implementations that separate logically distinct functionality.
Use Class Hierarchies to Separate Logical Concepts
In addition to dividing your program into logical subsystems, you should avoid combining unrelated concepts at the class level. For example, suppose you want to write a balanced binary tree structure for a multithreaded program. You decide that the tree data structure should allow only one thread at a time to access or modify the structure, so you incorporate locking into the data structure itself. However, what if you want to use this binary tree in another program that happens to be single-threaded? In that case, the locking is a waste of time, and might require your program to link with libraries that it could otherwise avoid. Even worse, your tree structure might not compile on a different platform because the locking code might not be cross-platform. A solution is to create a class hierarchy (introduced in Chapter 5) in which a thread-safe binary tree is a derived class of a generic binary tree. That way you can use the binary tree base class in single-threaded programs without incurring the cost of locking unnecessarily. Figure 6-1 shows this hierarchy.
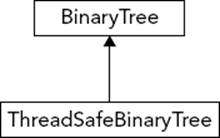
FIGURE 6-1
This strategy works well when there are two logical concepts, such as thread safety and binary trees. It becomes more complicated when there are three or more concepts. For example, suppose you want to provide both an n-ary tree and a binary tree, each of which could be thread-safe or not. Logically, the binary tree is a special-case of an n-ary tree, and so should be a derived class of an n-ary tree. Similarly, thread-safe structures could be derived classes of non-thread-safe structures. You can’t provide these separations with a linear hierarchy. One possibility is to make the thread-safe aspect a mix-in class as shown in Figure 6-2.
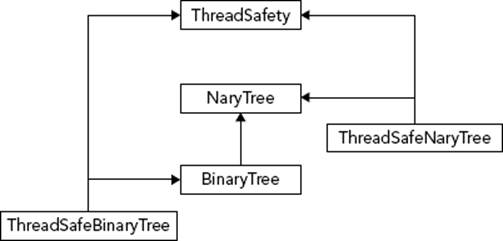
FIGURE 6-2
That hierarchy requires you to write five different classes, but the clear separation of functionality is worth the effort.
You should also avoid combining unrelated concepts at the level of methods, just as you should do at the class level. Both at the class level and the method level you should strive for high cohesion. For example, methods should not mix mutation (set) and inspection (get).
Use Aggregation to Separate Logical Concepts
Aggregation, discussed in Chapter 5, models the has-a relationship: objects contain other objects to perform some aspects of their functionality. You can use aggregation to separate unrelated or related but separate functionality when inheritance is not appropriate.
For example, suppose you want to write a Family class to store the members of a family. Obviously, a tree data structure would be ideal for storing this information. Instead of integrating the code for the tree structure in your Family class, you should write a separateTree class. Your Family class can then contain and use a Tree instance. To use the object-oriented terminology, the Family has-a Tree. With this technique, the tree data structure could be reused more easily in another program.
Eliminate User Interface Dependencies
If your library is a data manipulation library, you want to separate data manipulation from the user interface. This means that for those kinds of libraries you should never assume in which type of user interface the library will be used. As such, do not use cout, cerr, cin, stdout, stderr, or stdin, because if the library is used in the context of a graphical user interface these concepts may make no sense. For example, a Windows GUI-based application normally will not have any form of console I/O. If you think your library will only be used in GUI-based applications, you should still never pop up any kind of message box or other kind of notification to the end user; that is the responsibility of the client code to do. These kinds of dependencies not only result in poor reusability, but they prevent the client code from properly responding to an error, and handling it silently.
The Model-View-Controller (MVC) paradigm, introduced in Chapter 4, is a well-known design pattern to separate storing data from visualizing the data. With this paradigm, the model can be in the library, while the client code can provide the view and the controller.
Use Templates for Generic Data Structures and Algorithms
C++ has a concept called templates allowing you to create structures that are generic with respect to a type or class. For example, you might have written code for an array of integers. If you subsequently would like an array of doubles, you need to rewrite and replicate all the code to work with doubles. The notion of a template is that the type becomes a parameter to the specification, and you can create a single body of code that can work on any type. Templates allow you to write both data structures and algorithms that work on any types.
The simplest example of this is the std::vector class which is part of the C++ Standard Template Library (STL). To create a vector of integers, you write std::vector<int>; to create a vector of doubles you write std::vector<double>. Template programming is in general extremely powerful but can be very complex. Luckily, it is possible to create rather simple usages of templates that parameterize according to a type. Chapters 11 and 21 explain the techniques to write your own templates, while this section discusses some of their important design aspects.
Whenever possible, you should use a generic design for data structures and algorithms instead of encoding specifics of a particular program. Don’t write a balanced binary tree structure that stores only book objects. Make it generic, so that it can store objects of any type. That way you could use it in a bookstore, a music store, an operating system, or anywhere that you need a balanced binary tree. This strategy underlies the standard template library. The STL provides generic data structures and algorithms that work on any types.
Why Templates Are Better Than Other Generic Programming Techniques
Templates are not the only mechanism for writing generic data structures. You can write generic structures in C and C++ by storing void* pointers instead of a specific type. Clients can use this structure to store anything they want by casting it to a void*. However, the main problem with this approach is that it is not type-safe: the containers are unable to check or enforce the types of the stored elements. You can cast any type to a void* to store in the structure, and when you remove the pointers from the data structure, you must cast them back to what you think they are. Because there are no checks involved, the results can be disastrous. Imagine a scenario where one programmer stores pointers to int in a data structure by first casting them to void*, but another programmer thinks they are pointers to Process objects. The second programmer will blithely cast the void* pointers to Process* pointers and try to use them as Process*s. Needless to say, the program will not work as expected.
A second approach is to write the data structure for a specific class. Through polymorphism, any derived class of that class can be stored in the structure. Java takes this approach to an extreme: it specifies that every class derives directly or indirectly from the Objectclass. The Java containers store Objects, so they can store objects of any type. However, this approach is also not truly type-safe. When you remove an object from the container, you must remember what it really is and down-cast it to the appropriate type.
Templates, on the other hand, are type-safe when used correctly. Each instantiation of a template stores only one type. Your program will not compile if you try to store different types in the same template instantiation. Java does support the concept of generics which are type-safe just as C++ templates. Java does support the concept of generics which are type-safe just as C++ templates.
Problems with Templates
Templates are not perfect. First of all, their syntax is confusing, especially for someone who has not used them before. Second, the parsing is difficult, and not all compilers fully support the entire C++ standard. If your compiler does not fully support the C++ standard regarding templates, your compiler might also not support the entire feature set of the STL. On the other hand, any compiler that fully supports the STL should be sufficiently powerful to support most template programming.
Furthermore, templates require homogeneous data structures, in which you can store only objects of the same type in a single structure. That is, if you write a templatized balanced binary tree, you can create one tree object to store Process objects and another tree object to store ints. You can’t store both ints and Processes in the same tree. This restriction is a direct result of the type-safe nature of templates.
Templates versus Inheritance
Programmers sometimes find it tricky to decide whether to use templates or inheritance. Here are some tips to help you make the decision.
Use templates when you want to provide identical functionality for different types. For example, if you want to write a generic sorting algorithm that works on any type, use templates. If you want to create a container that can store any type, use templates. The key concept is that the templatized structure or algorithm treats all types the same. However, if required, templates can be specialized for specific types to treat those types differently. Template specialization is discussed in Chapter 11.
When you want to provide different behaviors for related types, use inheritance. For example, use inheritance if you want to provide two different, but similar, containers such as a queue and a priority queue.
Note that you can combine inheritance and templates. You could write a templatized queue that stores any type, with a derived class that is a templatized priority queue. Chapter 11 covers the details of the template syntax.
Provide Appropriate Checks and Safeguards
There are two opposite styles for writing safe code. The optimal programming style is probably using a healthy mix of both of them. The first is called design-by-contract which means that the documentation for a function or a class represents a contract with a detailed description of what the responsibility of the client code is and what the responsibility of your function or class is. This is often used in the STL. For example, std::vector defines a contract for using the array notation to get a certain element from a vector. The contract says that the vector will not perform any bounds checking, but that this is the responsibility of the client code. This is done to increase performance for client code that knows their indices are within bounds. The vector also defines an at() method to get a specific element which does perform bounds checking. So client code can choose whether it uses the array notation without, or the at() method with bounds checking.
The second style is that you design your functions and classes to be as safe as possible. The most important aspect of this guideline is to perform error checking in your code. For example, if your random number generator requires a non-negative integer for a seed, don’t just trust the user to correctly pass a non-negative integer. Check the value that is passed in, and reject the call if it is invalid.
As an analogy, consider an accountant who prepares income tax returns. When you hire an accountant, you provide him or her with all your financial information for the year. The accountant uses this information to fill out forms from the IRS. However, the accountant does not blindly fill out your information on the form, but instead makes sure the information makes sense. For example, if you own a house, but forget to specify the property tax you paid, the accountant will remind you to supply that information. Similarly, if you say that you paid $12,000 in mortgage interest, but made only $15,000 gross income, the accountant might gently ask you if you provided the correct numbers (or at least recommend more affordable housing).
You can think of the accountant as a “program” where the input is your financial information and the output is an income tax return. However, the value added by an accountant is not just that he or she fills out the forms. You choose to employ an accountant also because of the checks and safeguards that he or she provides. Similarly in programming, you could provide as many checks and safeguards as possible in your implementations.
There are several techniques and language features that help you incorporate checks and safeguards in your programs. First, you can return an error code or a distinct value like false or nullptr or throw an exception to notify the client code of an error. Chapter 13 covers exceptions in detail. Second, use smart pointers that help you manage your dynamically allocated memory. Conceptually, a smart pointer is a pointer to dynamically allocated memory that remembers to free the memory when it goes out of scope. Third, use safe memory techniques as discussed in Chapter 22.
Design Usable Interfaces
In addition to abstracting and structuring your code appropriately, designing for reuse requires you to focus on the interface with which programmers interact. If you have the most beautiful and most efficient implementation, your library will not be any good if it has a wretched interface.
Note that every subsystem and class in your program should have good interfaces, even if you don’t intend them to be used in multiple programs. First of all, you never know when something will be reused. Second, a good interface is important even for the first use, especially if you are programming in a group and other programmers must use the code you design and write.
The main purpose of interfaces is to make the code easy to use, but some interface techniques can help you follow the principle of generality as well.
Design Interfaces That Are Easy to Use
Your interfaces should be easy to use. That doesn’t mean that they must be trivial, but they should be as simple and intuitive as the functionality allows. You shouldn’t require consumers of your library to wade through pages of source code in order to use a simple data structure, or go through contortions in their code to obtain the functionality they need. This section provides four specific strategies for designing interfaces that are easy to use.
Develop Easy-To-Use Interfaces
The best strategy for developing easy-to-use interfaces is to follow standard and familiar ways of doing things. When people encounter an interface similar to something they have used in the past, they will understand it better, adopt it more readily, and be less likely to use it improperly.
For example, suppose that you are designing the steering mechanism of a car. There are a number of possibilities: a joystick, two buttons for moving left or right, a sliding horizontal lever, or a good-old steering wheel. Which interface do you think would be easiest to use? Which interface do you think would sell the most cars? Consumers are familiar with steering wheels, so the answer to both questions is, of course, the steering wheel. Even if you developed another mechanism that provided superior performance and safety, you would have a tough time selling your product, let alone teaching people how to use it. When you have a choice between following standard interface models and branching out in a new direction, it’s usually better to stick to the interface to which people are accustomed.
Innovation is important, of course, but you should focus on innovation in the underlying implementation, not in the interface. For example, consumers are excited about the innovative hybrid gasoline-electric engine in some car models. These cars are selling well in part because the interface to use them is identical to cars with standard engines.
Applied to C++, this strategy implies that you should develop interfaces that follow standards to which C++ programmers are accustomed. For example, C++ programmers expect the constructor and destructor of a class to initialize and clean up an object, respectively. When you design your classes, you should follow this standard. If you require programmers to call initialize() and cleanup() methods for initialization and cleanup instead of placing that functionality in the constructor and destructor, you will confuse everyone who tries to use your class. Because your class behaves differently from other C++ classes, programmers will take longer to learn how to use it and will be more likely to use it incorrectly by forgetting to call initialize() or cleanup().
NOTE Always think about your interfaces from the perspective of someone using them. Do they make sense? Are they what you would expect?
C++ provides a language feature called operator overloading that can help you develop easy-to-use interfaces for your objects. Operator overloading allows you to write classes such that the standard operators work on them just as they work on built-in types like intand double. For example, you can write a Fraction class that allows you to add, subtract, and stream fractions like this:
Fraction f1(3,4);
Fraction f2(1,2);
Fraction sum;
Fraction diff;
sum = f1 + f2;
diff = f1 – f2;
cout << f1 << " " << f2 << endl;
Contrast that with the same behavior using method calls:
Fraction f1(3,4);
Fraction f2(1,2);
Fraction sum;
Fraction diff;
sum = f1.add(f2);
diff = f1.subtract(f2);
f1.print(cout);
cout << " ";
f2.print(cout);
cout << endl;
As you can see, operator overloading allows you to provide an easier to use interface for your classes. However, be careful not to abuse operator overloading. It’s possible to overload the + operator so that it implements subtraction and the – operator so that it implements multiplication. Those implementations would be counterintuitive. This does not mean that each operator should always implement exactly the same behavior. For example, the string class implements the + operator to concatenate strings, which is an intuitive interface for string concatenation. See Chapters 8 and 14 for details on operator overloading.
Don’t Omit Required Functionality
This strategy is twofold. First, include interfaces for all behaviors that clients could need. That might sound obvious at first. Returning to the car analogy, you would never build a car without a speedometer for the driver to view his or her speed! Similarly, you would never design a Fraction class without a mechanism for client code to access the nominator and denominator values.
However, other possible behaviors might be more obscure. This strategy requires you to anticipate all the uses to which clients might put your code. If you are thinking about the interface in one particular way, you might miss functionality that could be needed when clients use it differently. For example, suppose that you want to design a game board class. You might consider only the typical games, such as chess and checkers, and decide to support a maximum of one game piece per spot on the board. However, what if you later decide to write a backgammon game, which allows multiple pieces in one spot on the board? By precluding that possibility, you have ruled out the use of your game board as a backgammon board.
Obviously, anticipating every possible use for your library is difficult, if not impossible. Don’t feel compelled to agonize over potential future uses in order to design the perfect interface. Just give it some thought and do the best you can.
The second part of this strategy is to include as much functionality in the implementation as possible. Don’t require client code to specify information that you already know in the implementation, or could know if you designed it differently. For example, if your library requires a temporary file, don’t make the clients of your library specify that path. They don’t care what file you use; find some other way to determine an appropriate temporary file path.
Furthermore, don’t require library users to perform unnecessary work to amalgamate results. If your random number library uses a random number algorithm that calculates the low-order and high-order bits of a random number separately, combine the numbers before giving them to the user.
Present Uncluttered Interfaces
In order to avoid omitting functionality in their interfaces, some programmers go to the opposite extreme: they include every possible piece of functionality imaginable. Programmers who use the interfaces are never left without the means to accomplish a task. Unfortunately, the interface might be so cluttered that they never figure out how to do it!
Don’t provide unnecessary functionality in your interfaces; keep them clean and simple. It might appear at first that this guideline directly contradicts the previous strategy of avoiding omitting necessary functionality. Although one strategy to avoid omitting functionality would be to include every imaginable interface, that is not a sound strategy. You should include necessary functionality and omit useless or counterproductive interfaces.
Consider cars again. You drive a car by interacting with only a few components: the steering wheel, the brake and accelerator pedals, the gearshift, the mirrors, the speedometer, and a few other dials on your dashboard. Now, imagine a car dashboard that looked like an airplane cockpit, with hundreds of dials, levers, monitors, and buttons. It would be unusable! Driving a car is so much easier than flying an airplane that the interface can be much simpler: you don’t need to view your altitude, communicate with control towers, or control the myriad components in an airplane such as the wings, engines, and landing gear.
Additionally, from the library development perspective, smaller libraries are easier to maintain. If you try to make everyone happy, then you have more room to make mistakes, and if your implementation is complicated enough so that everything is intertwined, even one mistake can render the library useless.
Unfortunately, the idea of designing uncluttered interfaces looks good on paper, but is remarkably hard to put into practice. The rule is ultimately subjective: you decide what’s necessary and what’s not. Of course, your clients will be sure to tell you when you get it wrong!
Provide Documentation and Comments
Regardless of how easy to use you make your interfaces, you should supply documentation for their use. You can’t expect programmers to use your library properly unless you tell them how to do it. Think of your library or code as a product for other programmers to consume. Your product should have documentation explaining its proper use.
There are two ways to provide documentation for your interfaces: comments in the interfaces themselves and external documentation. You should strive to provide both. Most public APIs provide only external documentation: comments are a scarce commodity in many of the standard Unix and Windows header files. In Unix, the documentation usually comes in the form of online manuals called man pages. In Windows, the documentation usually accompanies the integrated development environment.
Despite the fact that most APIs and libraries omit comments in the interfaces themselves, I actually consider this form of documentation the most important. You should never give out a “naked” header file that contains only code. Even if your comments repeat exactly what’s in the external documentation, it is less intimidating to look at a header file with friendly comments than one with only code. Even the best programmers still like to see written language every so often!
Some programmers use tools to create documentation automatically from comments. Chapter 3 discusses this technique in more detail.
Whether you provide comments, external documentation, or both, the documentation should describe the behavior of the library, not the implementation. The behavior includes the inputs, outputs, error conditions and handling, intended uses, and performance guarantees. For example, documentation describing a call to generate a single random number should specify that it takes no parameters, returns an integer in a previously specified range, and should list all the exceptions that might be thrown when something goes wrong. This documentation should not explain the details of the linear congruence algorithm for actually generating the number. Providing too much implementation detail in interface comments is probably the single most common mistake in interface development. Many developers have seen perfectly good separations of interface and implementation ruined by comments in the interface that are more appropriate for library maintainers than clients.
Of course you should also document your internal implementation, just don’t make it publicly available as part of your interface. Chapter 3 provides details on the appropriate use of comments in your code.
Design General-Purpose Interfaces
The interfaces should be general purpose enough that they can be adapted to a variety of tasks. If you encode specifics of one application in a supposedly general interface, it will be unusable for any other purpose. Here are some guidelines to keep in mind.
Provide Multiple Ways to Perform the Same Functionality
In order to satisfy all your “customers,” it is sometimes helpful to provide multiple ways to perform the same functionality. Use this technique judiciously, however, because overapplication can easily lead to cluttered interfaces.
Consider cars again. Most new cars these days provide remote keyless entry systems, with which you can unlock your car by pressing a button on a key fob. However, these cars always provide a standard key that you can use to physically unlock the car, for example when the battery in the key fob is empty. Although these two methods are redundant, most customers appreciate having both options.
Sometimes there are similar situations in program interface design. For example, suppose that one of your methods takes a string. You might want to provide two interfaces: one that takes a C++ string object and one that takes a C-style character pointer. Although it’s possible to convert between the two, different programmers prefer different types of strings, so it’s helpful to cater to both approaches.
Note that this strategy should be considered an exception to the “uncluttered” rule in interface design. There are a few situations where the exception is appropriate, but you should most often follow the “uncluttered” rule.
Provide Customizability
In order to increase the flexibility of your interfaces, provide customizability. Customizability can be as simple as allowing a client to turn on or off error logging. The basic premise of customizability is that it allows you to provide the same basic functionality to every client, but gives clients the ability to tweak it slightly.
You can allow greater customizability through function pointers and template parameters. For example, you could allow clients to set their own error-handling routines. This technique is an application of the decorator pattern.
The STL takes this customizability strategy to the extreme and actually allows clients to specify their own memory allocators for containers. If you want to use this feature, you must write a memory allocator object that follows the STL guidelines and adheres to the required interfaces. Each container in the STL takes an allocator as one of its template parameters. Chapter 20 provides more details.
Reconciling Generality and Ease of Use
The two goals of ease of use and generality sometimes appear to conflict. Often, introducing generality increases the complexity of the interfaces. For example, suppose that you need a graph structure in a map program to store cities. In the interest of generality, you might use templates to write a generic map structure for any type, not just cities. That way, if you need to write a network simulator in your next program, you could employ the same graph structure to store routers in the network. Unfortunately, by using templates, you made the interface a little clumsier and harder to use, especially if the potential client is not familiar with templates.
However, generality and ease of use are not mutually exclusive. Although in some cases increased generality may decrease ease of use, it is possible to design interfaces that are both general purpose and straightforward to use. Here are two guidelines you can follow.
Supply Multiple Interfaces
In order to reduce complexity in your interfaces while still providing enough functionality, you can provide two separate interfaces. For example, you could write a generic networking library with two separate facets: one presents the networking interfaces useful for games, and one presents the networking interfaces useful for the Hypertext Transport Protocol (HTTP) for web browsing.
Make Common Functionality Easy To Use
When you provide a general-purpose interface, some functionality will be used more often than other functionality. You should make the commonly used functionality easy to use, while still providing the option for the more advanced functionality. Returning to the map program, you might want to provide an option for clients of the map to specify names of cities in different languages. English is so predominant that you could make that the default but provide an extra option to change languages. That way most clients will not need to worry about setting the language, but those who want to will be able to do so.
SUMMARY
By reading this chapter, you learned why you should design reusable code and how you should do it. You read about the philosophy of reuse, summarized as “write once, use often,” and learned that reusable code should be both general purpose and easy to use. You also discovered that designing reusable code requires you to use abstraction, to structure your code appropriately, and to design good interfaces.
This chapter presented three specific tips for structuring your code: avoid combining unrelated or logically separate concepts, use templates for generic data structures and algorithms, and provide appropriate checks and safeguards.
The chapter also presented six strategies for designing interfaces: develop easy-to-use interfaces, don’t omit required functionality, present uncluttered interfaces, provide documentation and comments, provide multiple ways to perform the same functionality, and provide customizability. It concluded with two tips for reconciling the often-conflicting demands of generality and ease of use: supply multiple interfaces and make common functionality easy to use.
This chapter concludes the second part of this book which focuses on discussing design themes on a higher level. The next part delves into the implementation phase of the software engineering process with details of C++ coding.