The C++ Programming Language (2013)
Part II: Basic Facilities
15. Source Files and Programs
Form must follow function.
– Le Corbusier
• Separate Compilation
• Linkage
File-Local Names; Header Files; The One-Definition Rule; Standard-Library Headers; Linkage to Non-C++ Code; Linkage and Pointers to Functions
• Using Header Files
Single-Header Organization; Multiple-Header Organization; Include Guards
• Programs
Initialization of Nonlocal Variables; Initialization and Concurrency; Program Termination
• Advice
15.1. Separate Compilation
Any realistic program consists of many logically separate components (e.g., namespaces; Chapter 14). To better manage these components, we can represent the program as a set of (source code) files where each file contains one or more logical components. Our task is to devise a physical structure (set of files) for the program that represents the logical components in a consistent, comprehensible, and flexible manner. In particular, we aim for a clean separation of interfaces (e.g., function declarations) and implementations (e.g., function definitions). A file is the traditional unit of storage (in a file system) and the traditional unit of compilation. There are systems that do not store, compile, and present C++ programs to the programmer as sets of files. However, the discussion here will concentrate on systems that employ the traditional use of files.
Having a complete program in one file is usually impossible. In particular, the code for the standard libraries and the operating system is typically not supplied in source form as part of a user’s program. For realistically sized applications, even having all of the user’s own code in a single file is both impractical and inconvenient. The way a program is organized into files can help emphasize its logical structure, help a human reader understand the program, and help the compiler enforce that logical structure. Where the unit of compilation is a file, all of the file must be recompiled whenever a change (however small) has been made to it or to something on which it depends. For even a moderately sized program, the amount of time spent recompiling can be significantly reduced by partitioning the program into files of suitable size.
A user presents a source file to the compiler. The file is then preprocessed; that is, macro processing (§12.6) is done and #include directives bring in headers (§2.4.1, §15.2.2). The result of preprocessing is called a translation unit. This unit is what the compiler proper works on and what the C++ language rules describe. In this book, I differentiate between source file and translation unit only where necessary to distinguish what the programmer sees from what the compiler considers.
To enable separate compilation, the programmer must supply declarations providing the type information needed to analyze a translation unit in isolation from the rest of the program. The declarations in a program consisting of many separately compiled parts must be consistent in exactly the same way the declarations in a program consisting of a single source file must be. Your system has tools to help ensure this. In particular, the linker can detect many kinds of inconsistencies. The linker is the program that binds together the separately compiled parts. A linker is sometimes (confusingly) called a loader. Linking can be done completely before a program starts to run. Alternatively, new code can be added to the running program (“dynamically linked”) later.
The organization of a program into source files is commonly called the physical structure of a program. The physical separation of a program into separate files should be guided by the logical structure of the program. The same dependency concerns that guide the composition of programs out of namespaces guide its composition into source files. However, the logical and physical structures of a program need not be identical. For example, it can be helpful to use several source files to store the functions from a single namespace, to store a collection of namespace definitions in a single file, or to scatter the definition of a namespace over several files (§14.3.3).
Here, we will first consider some technicalities relating to linking and then discuss two ways of breaking the desk calculator (§10.2, §14.3.1) into files.
15.2. Linkage
Names of functions, classes, templates, variables, namespaces, enumerations, and enumerators must be used consistently across all translation units unless they are explicitly specified to be local.
It is the programmer’s task to ensure that every namespace, class, function, etc., is properly declared in every translation unit in which it appears and that all declarations referring to the same entity are consistent. For example, consider two files:
// file1.cpp:
int x = 1;
int f() { /* do something */ }
// file2.cpp:
extern int x;
int f();
void g() { x = f(); }
The x and f() used by g() in file2.cpp are the ones defined in file1.cpp. The keyword extern indicates that the declaration of x in file2.cpp is (just) a declaration and not a definition (§6.3). Had x been initialized, extern would simply be ignored because a declaration with an initializer is always a definition. An object must be defined exactly once in a program. It may be declared many times, but the types must agree exactly. For example:
// file1.cpp:
int x = 1;
int b = 1;
extern int c;
// file2.cpp:
int x; // means "int x = 0;"
extern double b;
extern int c;
There are three errors here: x is defined twice, b is declared twice with different types, and c is declared twice but not defined. These kinds of errors (linkage errors) cannot be detected by a compiler that looks at only one file at a time. Many, however, are detectable by the linker. For example, all implementations I know of correctly diagnose the double definition of x. However, the inconsistent declarations of b are uncaught on popular implementations, and the missing definition of c is typically only caught if c is used.
Note that a variable defined without an initializer in the global or a namespace scope is initialized by default (§6.3.5.1). This is not the case for non-static local variables or objects created on the free store (§11.2).
Outside a class body, an entity must be declared before it is used (§6.3.4). For example:
// file1.cpp:
int g() { return f()+7; } // error: f() not (yet) declared
int f() { return x; } // error: x not (yet) declared
int x;
A name that can be used in translation units different from the one in which it was defined is said to have external linkage. All the names in the previous examples have external linkage. A name that can be referred to only in the translation unit in which it is defined is said to have internal linkage. For example:
static int x1 = 1; // internal linkage: not accessible from other translation units
const char x2 = 'a'; // internal linkage: not accessible from other translation units
When used in namespace scope (including the global scope; §14.2.1), the keyword static (some-what illogically) means “not accessible from other source files” (i.e., internal linkage). If you wanted x1 to be accessible from other source files (“have external linkage”), you should remove thestatic. The keyword const implies default internal linkage, so if you wanted x2 to have external linkage, you need to precede its definitions with extern:
int x1 = 1; // external linkage: accessible from other translation units
extern const char x2 = 'a'; // external linkage: accessible from other translation units
Names that a linker does not see, such as the names of local variables, are said to have no linkage.
An inline function (§12.1.3, §16.2.8) must be defined identically in every translation unit in which it is used (§15.2.3). Consequently, the following example isn’t just bad taste; it is illegal:
// file1.cpp:
inline int f(int i) { return i; }
// file2.cpp:
inline int f(int i) { return i+1; }
Unfortunately, this error is hard for an implementation to catch, and the following – otherwise perfectly logical – combination of external linkage and inlining is banned to make life simpler for compiler writers:
// file1.cpp:
extern inline int g(int i);
int h(int i) { return g(i); } // error: g() undefined in this translation unit
// file2.cpp:
extern inline int g(int i) { return i+1; }
// ...
We keep inline function definitions consistent by using header files(§15.2.2). For example:
// h.h:
inline int next(int i) { return i+1; }
// file1.cpp:
#include "h.h"
int h(int i) { return next(i); } // fine
// file2.cpp:
#include "h.h"
// ...
By default, const objects (§7.5), constexpr objects (§10.4), type aliases (§6.5), and anything declared static (§6.3.4) in a namespace scope have internal linkage. Consequently, this example is legal (although potentially confusing):
// file1.cpp:
using T = int;
const int x = 7;
constexpr T c2 = x+1;
// file2.cpp:
using T = double;
const int x = 8;
constexpr T c2 = x+9;
To ensure consistency, place aliases, consts, constexprs, and inlines in header files (§15.2.2).
A const can be given external linkage by an explicit declaration:
// file1.cpp:
extern const int a = 77;
// file2.cpp:
extern const int a;
void g()
{
cout << a << '\n';
}
Here, g() will print 77.
The techniques for managing template definitions are described in §23.7.
15.2.1. File-Local Names
Global variables are in general best avoided because they cause maintenance problems. In particular, it is hard to know where in a program they are used, and they can be a source of data races in multi-threaded programs (§41.2.4), leading to very obscure bugs.
Placing variables in a namespace helps a bit, but such variables are still subject to data races.
If you must use global variables, at least restrict their use to a single source file. This restriction can be achieved in one of two ways:
[1] Place declarations in an unnamed namespace.
[2] Declare an entity static.
An unnamed namespace (§14.4.8) can be used to make names local to a compilation unit. The effect of an unnamed namespace is very similar to that of internal linkage. For example:
// file 1.cpp:
namespace {
class X { /* ... */ };
void f();
int i;
// ...
}
// file2.cpp:
class X { /* ... */ };
void f();
int i;
// ...
The function f() in file1.cpp is not the same function as the f() in file2.cpp. Having a name local to a translation unit and also using that same name elsewhere for an entity with external linkage is asking for trouble.
The keyword static (confusingly) means “use internal linkage” (§44.2.3). That’s an unfortunate leftover from the earliest days of C.
15.2.2. Header Files
The types in all declarations of the same object, function, class, etc., must be consistent. Consequently, the source code submitted to the compiler and later linked together must be consistent. One imperfect but simple method of achieving consistency for declarations in different translation units is to #include header files containing interface information in source files containing executable code and/or data definitions.
The #include mechanism is a text manipulation facility for gathering source program fragments together into a single unit (file) for compilation. Consider:
#include "to_be_included"
The #include-directive replaces the line in which the #include appears with the contents of the file to_be_included. The content of to_be_included should be C++ source text because the compiler will proceed to read it.
To include standard-library headers, use the angle brackets, < and >, around the name instead of quotes. For example:
#include <iostream> // from standard include directory
#include "myheader.h" // from current directory
Unfortunately, spaces are significant within the < > or " " of an include directive:
#include < iostream > // will not find <iostream>
It seems extravagant to recompile a source file each time it is included somewhere, but the text can be a reasonably dense encoding for program interface information, and the compiler need only analyze details actually used (e.g., template bodies are often not completely analyzed until instantiation time; §26.3). Furthermore, most modern C++ implementations provide some form of (implicit or explicit) precompiling of header files to minimize the work needed to handle repeated compilation of the same header.
As a rule of thumb, a header may contain:

This rule of thumb for what may be placed in a header is not a language requirement. It is simply a reasonable way of using the #include mechanism to express the physical structure of a program. Conversely, a header should never contain:

Including a header containing such definitions will lead to errors or (in the case of the using-directive) to confusion. Header files are conventionally suffixed by .h, and files containing function or data definitions are suffixed by .cpp. They are therefore often referred to as “.h files” and “.cpp files,” respectively. Other conventions, such as .c, .C, .cxx, .cc, .hh, and hpp are also found. The manual for your compiler will be quite specific about this issue.
The reason for recommending that the definition of simple constants, but not the definition of aggregates, be placed in header files is that it is hard for implementations to avoid replication of aggregates presented in several translation units. Furthermore, the simple cases are far more common and therefore more important for generating good code.
It is wise not to be too clever about the use of #include. My recommendations are:
• #include only as headers (don’t #include “ordinary source code containing variable definitions and non-inline functions”).
• #include only complete declarations and definitions.
• #include only in the global scope, in linkage specification blocks, and in namespace definitions when converting old code (§15.2.4).
• Place all #includes before other code to minimize unintended dependencies.
• Avoid macro magic.
• Minimize the use of names (especially aliases) not local to a header in a header.
One of my least favorite activities is tracking down an error caused by a name being macro-substituted into something completely different by a macro defined in an indirectly #included header that I have never even heard of.
15.2.3. The One-Definition Rule
A given class, enumeration, and template, etc., must be defined exactly once in a program.
From a practical point of view, this means that there must be exactly one definition of, say, a class residing in a single file somewhere. Unfortunately, the language rule cannot be that simple. For example, the definition of a class may be composed through macro expansion (ugh!), and a definition of a class may be textually included in two source files by #include directives (§15.2.2). Worse, a “file” isn’t a concept that is part of the C++ language definition; there exist implementations that do not store programs in source files.
Consequently, the rule in the standard that says that there must be a unique definition of a class, template, etc., is phrased in a somewhat more complicated and subtle manner. This rule is commonly referred to as the one-definition rule (“the ODR”). That is, two definitions of a class, template, or inline function are accepted as examples of the same unique definition if and only if
[1] they appear in different translation units, and
[2] they are token-for-token identical, and
[3] the meanings of those tokens are the same in both translation units.
For example:
// file1.cpp:
struct S { int a; char b; };
void f(S*);
// file2.cpp:
struct S { int a; char b; };
void f(S* p) { /* ... */ }
The ODR says that this example is valid and that S refers to the same class in both source files. However, it is unwise to write out a definition twice like that. Someone maintaining file2.cpp will naturally assume that the definition of S in file2.cpp is the only definition of S and so feel free to change it. This could introduce a hard-to-detect error.
The intent of the ODR is to allow inclusion of a class definition in different translation units from a common source file. For example:
// s.h:
struct S { int a; char b; };
void f(S*);
// file1.cpp:
#include "s.h"
// use f() here
// file2.cpp:
#include "s.h"
void f(S* p) { /* ... */ }
or graphically:

Here are examples of the three ways of violating the ODR:
// file1.cpp:
struct S1 { int a; char b; };
struct S1 { int a; char b; }; // error: double definition
This is an error because a struct may not be defined twice in a single translation unit.
// file1.cpp:
struct S2 { int a; char b; };
// file2.cpp:
struct S2 { int a; char bb; }; // error
This is an error because S2 is used to name classes that differ in a member name.
// file1.cpp:
typedef int X;
struct S3 { X a; char b; };
// file2.cpp:
typedef char X;
struct S3 { X a; char b; }; // error
Here the two definitions of S3 are token-for-token identical, but the example is an error because the meaning of the name X has sneakily been made to differ in the two files.
Checking against inconsistent class definitions in separate translation units is beyond the ability of most C++ implementations. Consequently, declarations that violate the ODR can be a source of subtle errors. Unfortunately, the technique of placing shared definitions in headers and#includeing them doesn’t protect against this last form of ODR violation. Local type aliases and macros can change the meaning of #included declarations:
// s.h:
struct S { Point a; char b; };
// file1.cpp:
#define Point int
#include "s.h"
// ...
// file2.cpp:
class Point { /* ... */ };
#include "s.h"
// ...
The best defense against this kind of hackery is to make headers as self-contained as possible. For example, if class Point had been declared in the s.h header, the error would have been detected.
A template definition can be #included in several translation units as long as the ODR is adhered to. This applies even to function template definitions and to class templates containing member function definitions.
15.2.4. Standard-Library Headers
The facilities of the standard library are presented through a set of standard headers (§4.1.2, §30.2). No suffix is needed for standard-library headers; they are known to be headers because they are included using the #include<...> syntax rather than #include"...". The absence of a .h suffix does not imply anything about how the header is stored. A header such as <map> is usually stored as a text file called map.h in some standard directory. On the other hand, standard headers are not required to be stored in a conventional manner. An implementation is allowed to take advantage of knowledge of the standard-library definition to optimize the standard-library implementation and the way standard headers are handled. For example, an implementation might have knowledge of the standard math library (§40.3) built in and treat #include<cmath> as a switch that makes the standard math functions available without actually reading any file.
For each C standard-library header <X.h>, there is a corresponding standard C++ header <cX>. For example, #include<cstdio> provides what #include<stdio.h> does. A typical stdio.h will look something like this:
#ifdef __cplusplus // for C++ compilers only (§15.2.5)
namespace std { // the standard library is defined in namespace std (§4.1.2)
extern "C" { // stdio functions have C linkage (§15.2.5)
#endif
/* ... */
int printf(const char*, ...);
/* ... */
#ifdef __cplusplus
}
}
// ...
using std::printf; // make printf available in global namespace
// ...
#endif
That is, the actual declarations are (most likely) shared, but linkage and namespace issues must be addressed to allow C and C++ to share a header. The macro __cplusplus is defined by the C++ compiler (§12.6.2) and can be used to distinguish C++ code from code intended for a C compiler.
15.2.5. Linkage to Non-C++ Code
Typically, a C++ program contains parts written in other languages (e.g., C or Fortran). Similarly, it is common for C++ code fragments to be used as parts of programs written mainly in some other language (e.g., Python or Matlab). Cooperation can be difficult between program fragments written in different languages and even between fragments written in the same language but compiled with different compilers. For example, different languages and different implementations of the same language may differ in their use of machine registers to hold arguments, the layout of arguments put on a stack, the layout of built-in types such as strings and integers, the form of names passed by the compiler to the linker, and the amount of type checking required from the linker. To help, one can specify a linkage convention to be used in an extern declaration. For example, this declares the C and C++ standard-library function strcpy() and specifies that it should be linked according to the (system-specific) C linkage conventions:
extern "C" char* strcpy(char*, const char*);
The effect of this declaration differs from the effect of the “plain” declaration
extern char* strcpy(char*, const char*);
only in the linkage convention used for calling strcpy().
The extern "C" directive is particularly useful because of the close relationship between C and C++. Note that the C in extern "C" names a linkage convention and not a language. Often, extern "C" is used to link to Fortran and assembler routines that happen to conform to the conventions of a C implementation.
An extern "C" directive specifies the linkage convention (only) and does not affect the semantics of calls to the function. In particular, a function declared extern "C" still obeys the C++ type-checking and argument conversion rules and not the weaker C rules. For example:
extern "C" int f();
int g()
{
return f(1); // error: no argument expected
}
Adding extern "C" to a lot of declarations can be a nuisance. Consequently, there is a mechanism to specify linkage to a group of declarations. For example:
extern "C" {
char* strcpy(char*, const char*);
int strcmp(const char*, const char*);
int strlen(const char*);
// ...
}
This construct, commonly called a linkage block, can be used to enclose a complete C header to make a header suitable for C++ use. For example:
extern "C" {
#include <string.h>
}
This technique is commonly used to produce a C++ header from a C header. Alternatively, conditional compilation (§12.6.1) can be used to create a common C and C++ header:
#ifdef __cplusplus
extern "C" {
#endif
char* strcpy(char*, const char*);
int strcmp(const char*, const char*);
int strlen(const char*);
// ...
#ifdef __cplusplus
}
#endif
The predefined macro name __cplusplus (§12.6.2) is used to ensure that the C++ constructs are edited out when the file is used as a C header.
Any declaration can appear within a linkage block:
extern "C" { // any declaration here, for example:
int g1; // definition
extern int g2; // declaration, not definition
}
In particular, the scope and storage class (§6.3.4, §6.4.2) of variables are not affected, so g1 is still a global variable – and is still defined rather than just declared. To declare but not define a variable, you must apply the keyword extern directly in the declaration. For example:
extern "C" int g3; // declaration, not definition
extern "C" { int g4; } // definition
This looks odd at first glance. However, it is a simple consequence of keeping the meaning unchanged when adding "C" to an extern-declaration and the meaning of a file unchanged when enclosing it in a linkage block.
A name with C linkage can be declared in a namespace. The namespace will affect the way the name is accessed in the C++ program, but not the way a linker sees it. The printf() from std is a typical example:
#include<cstdio>
void f()
{
std::printf("Hello, "); // OK
printf("world!\n"); // error: no global printf()
}
Even when called std::printf, it is still the same old C printf() (§43.3).
Note that this allows us to include libraries with C linkage into a namespace of our choice rather than polluting the global namespace. Unfortunately, the same flexibility is not available to us for headers defining functions with C++ linkage in the global namespace. The reason is that linkage of C++ entities must take namespaces into account so that the object files generated will reflect the use or lack of use of namespaces.
15.2.6. Linkage and Pointers to Functions
When mixing C and C++ code fragments in one program, we sometimes want to pass pointers to functions defined in one language to functions defined in the other. If the two implementations of the two languages share linkage conventions and function call mechanisms, such passing of pointers to functions is trivial. However, such commonality cannot in general be assumed, so care must be taken to ensure that a function is called the way it expects to be called.
When linkage is specified for a declaration, the specified linkage applies to all function types, function names, and variable names introduced by the declaration(s). This makes all kinds of strange – and occasionally essential – combinations of linkage possible. For example:
typedef int (*FT)(const void*, const void*); // FT has C++ linkage
extern "C" {
typedef int (*CFT)(const void*, const void*); // CFT has C linkage
void qsort(void* p, size_t n, size_t sz, CFT cmp); // cmp has C linkage
}
void isort(void* p, size_t n, size_t sz, FT cmp); // cmp has C++ linkage
void xsort(void* p, size_t n, size_t sz, CFT cmp); // cmp has C linkage
extern "C" void ysort(void* p, size_t n, size_t sz, FT cmp); // cmp has C++ linkage
int compare(const void*, const void*); // compare() has C++ linkage
extern "C" int ccmp(const void*, const void*); // ccmp() has C linkage
void f(char* v, int sz)
{
qsort(v,sz,1,&compare); // error
qsort(v,sz,1,&ccmp); // OK
isort(v,sz,1,&compare); // OK
isort(v,sz,1,&ccmp); // error
}
An implementation in which C and C++ use the same calling conventions might accept the declarations marked error as a language extension. However, even for compatible C and C++ implementations, std::function (§33.5.3) or lambdas with any form of capture (§11.4.3) cannot cross the language barrier.
15.3. Using Header Files
To illustrate the use of headers, I present a few alternative ways of expressing the physical structure of the calculator program (§10.2, §14.3.1).
15.3.1. Single-Header Organization
The simplest solution to the problem of partitioning a program into several files is to put the definitions in a suitable number of .cpp files and to declare the types, functions, classes, etc., needed for them to cooperate in a single .h file that each .cpp file #includes. That’s the initial organization I would use for a simple program for my own use; if something more elaborate turned out to be needed, I would reorganize later.
For the calculator program, we might use five .cpp files – lexer.cpp, parser.cpp, table.cpp, error.cpp, and main.cpp – to hold function and data definitions. The header dc.h holds the declarations of every name used in more than one .cpp file:
// dc.h:
#include <map>
#include<string>
#include<iostream>
namespace Parser {
double expr(bool);
double term(bool);
double prim(bool);
}
namespace Lexer {
enum class Kind : char {
name, number, end,
plus='+', minus='-', mul='*', div='/', print=';', assign='=', lp='(', rp=')'
};
struct Token {
Kind kind;
string string_value;
double number_value;
};
class Token_stream {
public:
Token(istream& s) : ip{&s}, owns(false}, ct{Kind::end} { }
Token(istream* p) : ip{p}, owns{true}, ct{Kind::end} { }
~Token() { close(); }
Token get(); // read and return next token
Token& current(); // most recently read token
void set_input(istream& s) { close(); ip = &s; owns=false; }
void set_input(istream* p) { close(); ip = p; owns = true; }
private:
void close() { if (owns) delete ip; }
istream* ip; // pointer to an input stream
bool owns; // does the Token_stream own the istream?
Token ct {Kind::end}; // current_token
};
extern Token_stream ts;
}
namespace Table {
extern map<string,double> table;
}
namespace Error {
extern int no_of_errors;
double error(const string& s);
}
namespace Driver {
void calculate();
}
The keyword extern is used for every variable declaration to ensure that multiple definitions do not occur as we #include dc.h in the various .cpp files. The corresponding definitions are found in the appropriate .cpp files.
I added standard-library headers as needed for the declarations in dc.h, but I did not add declarations (such as using-declarations) needed only for the convenience of an individual .cpp file.
Leaving out the actual code, lexer.cpp will look something like this:
// lexer.cpp:
#include "dc.h"
#include <cctype>
#include <iostream> // redundant: in dc.h
Lexer::Token_stream ts;
Lexer::Token Lexer::Token_stream::get() { /* ... */ }
Lexer::Token& Lexer::Token_stream::current() { /* ... */ }
I used explicit qualification, Lexer::, for the definitions rather that simply enclosing them all in
namespace Lexer { /* ... */ }
That avoids the possibility of accidentally adding new members to Lexer. On the other hand, had I wanted to add members to Lexer that were not part of its interface, I would have had to reopen the namespace (§14.2.5).
Using headers in this manner ensures that every declaration in a header will at some point be included in the file containing its definition. For example, when compiling lexer.cpp the compiler will be presented with:
namespace Lexer { // from dc.h
// ...
class Token_stream {
public:
Token get();
// ...
};
}
// ...
Lexer::Token Lexer::Token_stream::get() { /* ... */ }
This ensures that the compiler will detect any inconsistencies in the types specified for a name. For example, had get() been declared to return a Token, but defined to return an int, the compilation of lexer.cpp would have failed with a type-mismatch error. If a definition is missing, the linker will catch the problem. If a declaration is missing, some .cpp files will fail to compile.
File parser.cpp will look like this:
// parser.cpp:
#include "dc.h"
double Parser::prim(bool get) { /* ... */ }
double Parser::term(bool get) { /* ... */ }
double Parser::expr(bool get) { /* ... */ }
File table.cpp will look like this:
// table.cpp:
#include "dc.h"
std::map<std::string,double> Table::table;
The symbol table is a standard-library map.
File error.cpp becomes:
// error.cpp:
#include "dg.h"
// any more #includes or declarations
int Error::no_of_errors;
double Error::error(const string& s) { /* ... */ }
Finally, file main.cpp will look like this:
// main.cpp:
#include "dc.h"
#include <sstream>
#include <iostream> // redundant: in dc.h
void Driver::calculate() { /* ... */ }
int main(int argc, char* argv[]) { /* ... */ }
To be recognized as the main() of the program, main() must be a global function (§2.2.1, §15.4), so no namespace is used here.
The physical structure of the system can be presented like this:
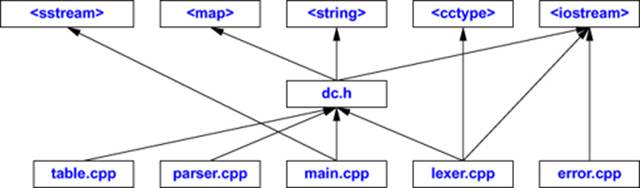
The headers on the top are all headers for standard-library facilities. For many forms of program analysis, these libraries can be ignored because they are well known and stable. For tiny programs, the structure can be simplified by moving all #include directives to the common header. Similarly, for a small program, separating out error.cpp and table.cpp from main.cpp would often be excessive.
This single-header style of physical partitioning is most useful when the program is small and its parts are not intended to be used separately. Note that when namespaces are used, the logical structure of the program is still represented within dc.h. If namespaces are not used, the structure is obscured, although comments can be a help.
For larger programs, the single-header-file approach is unworkable in a conventional file-based development environment. A change to the common header forces recompilation of the whole program, and updates of that single header by several programmers are error-prone. Unless strong emphasis is placed on programming styles relying heavily on namespaces and classes, the logical structure deteriorates as the program grows.
15.3.2. Multiple-Header Organization
An alternative physical organization lets each logical module have its own header defining the facilities it provides. Each .cpp file then has a corresponding .h file specifying what it provides (its interface). Each .cpp file includes its own .h file and usually also other .h files that specify what it needs from other modules in order to implement the services advertised in the interface. This physical organization corresponds to the logical organization of a module. The interface for users is put into its .h file, the interface for implementers is put into a file suffixed _impl.h, and the module’s definitions of functions, variables, etc., are placed in .cpp files. In this way, the parser is represented by three files. The parser’s user interface is provided by parser.h:
// parser.h:
namespace Parser { // interface for users
double expr(bool get);
}
The shared environment for the functions expr(), prim(), and term(), implementing the parser is presented by parser_impl.h:
// parser_impl.h:
#include "parser.h"
#include "error.h"
#include "lexer.h"
using Error::error;
using namespace Lexer;
namespace Parser { // interface for implementers
double prim(bool get);
double term(bool get);
double expr(bool get);
}
The distinction between the user interface and the interface for implementers would be even clearer had we used a Parser_impl namespace (§14.3.3).
The user’s interface in header parser.h is #included to give the compiler a chance to check consistency (§15.3.1).
The functions implementing the parser are stored in parser.cpp together with #include directives for the headers that the Parser functions need:
// parser.cpp:
#include "parser_impl.h"
#include "table.h"
using Table::table;
double Parser::prim(bool get) { /* ... */ }
double Parser::term(bool get) { /* ... */ }
double Parser::expr(bool get) { /* ... */ }
Graphically, the parser and the driver’s use of it look like this:
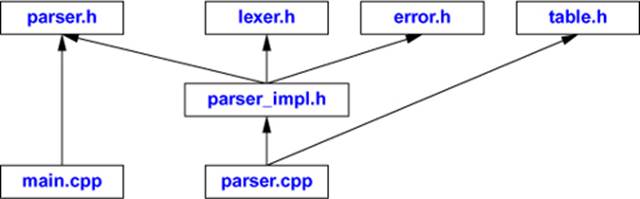
As intended, this is a rather close match to the logical structure described in §14.3.1. To simplify this structure, we could have #included table.h in parser_impl.h rather than in parser.cpp. However, table.h is an example of something that is not necessary to express the shared context of the parser functions; it is needed only by their implementation. In fact, it is used by just one function, prim(), so if we were really keen on minimizing dependencies we could place prim() in its own .cpp file and #include table.h there only:
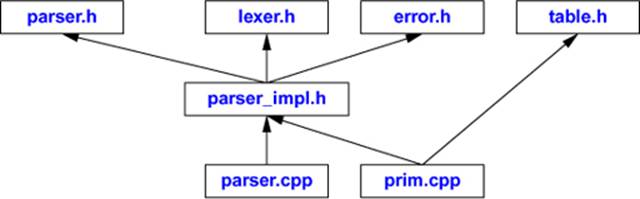
Such elaboration is not appropriate except for larger modules. For realistically sized modules, it is common to #include extra files where needed for individual functions. Furthermore, it is not uncommon to have more than one _impl.h, since different subsets of the module’s functions need different shared contexts.
Please note that the _impl.h notation is not a standard or even a common convention; it is simply the way I like to name things.
Why bother with this more complicated scheme of multiple header files? It clearly requires far less thought simply to throw every declaration into a single header, as was done for dc.h.
The multiple-header organization scales to modules several magnitudes larger than our toy parser and to programs several magnitudes larger than our calculator. The fundamental reason for using this type of organization is that it provides a better localization of concerns. When analyzing and modifying a large program, it is essential for a programmer to focus on a relatively small chunk of code. The multiple-header organization makes it easy to determine exactly what the parser code depends on and to ignore the rest of the program. The single-header approach forces us to look at every declaration used by any module and decide if it is relevant. The simple fact is that maintenance of code is invariably done with incomplete information and from a local perspective. The multiple-header organization allows us to work successfully “from the inside out” with only a local perspective. The single-header approach – like every other organization centered around a global repository of information – requires a top-down approach and will forever leave us wondering exactly what depends on what.
The better localization leads to less information needed to compile a module, and thus to faster compiles. The effect can be dramatic. I have seen compile times drop by a factor of 1000 as the result of a simple dependency analysis leading to a better use of headers.
15.3.2.1. Other Calculator Modules
The remaining calculator modules can be organized similarly to the parser. However, those modules are so small that they don’t require their own _impl.h files. Such files are needed only where the implementation of a logical module consists of many functions that need a shared context (in addition to what is provided to users).
The error handler provides its interface in error.h:
// error.h:
#include<string>
namespace Error {
int Error::number_of_errors;
double Error::error(const std::string&);
}
The implementation is found in error.cpp:
// error.cpp:
#include "error.h"
int Error::number_of_errors;
double Error::error(const std::string&) { /* ... */ }
The lexer provides a rather large and messy interface:
// lexer.h:
#include<string>
#include<iostream>
namespace Lexer {
enum class Kind : char {/* ... */ };
class Token { /* ... */ };
class Token_stream { /* ... */ };
extern Token_stream is;
}
In addition to lexer.h, the implementation of the lexer depends on error.h and on the character-classification functions in <cctype> (§36.2):
// lexer.cpp:
#include "lexer.h"
#include "error.h"
#include <iostream> // redundant: in lexer.h
#include <cctype>
Lexer::Token_stream is; // defaults to "read from cin"
Lexer::Token Lexer::Token_stream::get() { /* ... */ };
Lexer::Token& Lexer::Token_stream::current() { /* ... */ };
We could have factored out the #include directive for error.h as the Lexer’s _impl.h file. However, I considered that excessive for this tiny program.
As usual, we #include the interface offered by the module – in this case, lexer.h – in the module’s implementation to give the compiler a chance to check consistency.
The symbol table is essentially self-contained, although the standard-library header <map> could drag in all kinds of interesting stuff to implement an efficient map template class:
// table.h:
#include <map>
#include <string>
namespace Table {
extern std::map<std::string,double> table;
}
Because we assume that every header may be #included in several .cpp files, we must separate the declaration of table from its definition:
// table.cpp:
#include "table.h"
std::map<std::string,double> Table::table;
I just stuck the driver into main.cpp:
// main.cpp:
#include "parser.h"
#include "lexer.h" // to be able to set ts
#include "error.h"
#include "table.h" // to be able to predefine names
#include <sstream> // to be able to put main()'s arguments into a string stream
namespace Driver {
void calculate() { /* ... */ }
}
int main(int argc, char* argv[]) { /* ... */ }
For a larger system, it is usually worthwhile to separate out the driver and minimize what is done in main(). That way main() calls a driver function placed in a separate source file. This is particularly important for code intended to be used as a library. Then, we cannot rely on code in main()and must be prepared for the driver to be called from a variety of functions.
15.3.2.2. Use of Headers
The number of headers to use for a program is a function of many factors. Many of these factors have more to do with the way files are handled on your system than with C++. For example, if your editor/IDE does not make it convenient to look at several files simultaneously, then using many headers becomes less attractive.
A word of caution: a few dozen headers plus the standard headers for the program’s execution environment (which can often be counted in the hundreds) are usually manageable. However, if you partition the declarations of a large program into the logically minimal-size headers (putting each structure declaration in its own file, etc.), you can easily get an unmanageable mess of hundreds of files even for minor projects. I find that excessive.
For large projects, multiple headers are unavoidable. In such projects, hundreds of files (not counting standard headers) are the norm. The real confusion starts when they begin to be counted in the thousands. At that scale, the basic techniques discussed here still apply, but their management becomes a Herculean task. Tools, such as dependency analysers, can be of great help, but there is little they can do for compiler and linker performance if the program is an unstructured mess. Remember that for realistically sized programs, the single-header style is not an option. Such programs will have multiple headers. The choice between the two styles of organization occurs (repeatedly) for the parts that make up the program.
The single-header style and the multiple-header style are not really alternatives. They are complementary techniques that must be considered whenever a significant module is designed and must be reconsidered as a system evolves. It’s crucial to remember that one interface doesn’t serve all equally well. It is usually worthwhile to distinguish between the implementers’ interface and the users’ interface. In addition, many larger systems are structured so that providing a simple interface for the majority of users and a more extensive interface for expert users is a good idea. The expert users’ interfaces (“complete interfaces”) tend to #include many more features than the average user would ever want to know about. In fact, the average users’ interface can often be identified by eliminating features that require the inclusion of headers that define facilities that would be unknown to the average user. The term “average user” is not derogatory. In the fields in which I don’t have to be an expert, I strongly prefer to be an average user. In that way, I minimize hassles.
15.3.3. Include Guards
The idea of the multiple-header approach is to represent each logical module as a consistent, self-contained unit. Viewed from the program as a whole, many of the declarations needed to make each logical module complete are redundant. For larger programs, such redundancy can lead to errors, as a header containing class definitions or inline functions gets #included twice in the same compilation unit (§15.2.3).
We have two choices. We can
[1] reorganize our program to remove the redundancy, or
[2] find a way to allow repeated inclusion of headers.
The first approach – which led to the final version of the calculator – is tedious and impractical for realistically sized programs. We also need that redundancy to make the individual parts of the program comprehensible in isolation.
The benefits of an analysis of redundant #includes and the resulting simplifications of the program can be significant both from a logical point of view and by reducing compile times. However, it can rarely be complete, so some method of allowing redundant #includes must be applied. Preferably, it must be applied systematically, since there is no way of knowing how thorough an analysis a user will find worthwhile.
The traditional solution is to insert include guards in headers. For example:
// error.h:
#ifndef CALC_ERROR_H
#define CALC_ERROR_H
namespace Error {
// ...
}
#endif // CALC_ERROR_H
The contents of the file between the #ifndef and #endif are ignored by the compiler if CALC_ERROR_H is defined. Thus, the first time error.h is seen during a compilation, its contents are read and CALC_ERROR_H is given a value. Should the compiler be presented with error.h again during the compilation, the contents are ignored. This is a piece of macro hackery, but it works and it is pervasive in the C and C++ worlds. The standard headers all have include guards.
Header files are included in essentially arbitrary contexts, and there is no namespace protection against macro name clashes. Consequently, I choose rather long and ugly names for my include guards.
Once people get used to headers and include guards, they tend to include lots of headers directly and indirectly. Even with C++ implementations that optimize the processing of headers, this can be undesirable. It can cause unnecessarily long compile time, and it can bring lots of declarations and macros into scope. The latter might affect the meaning of the program in unpredictable and adverse ways. Headers should be included only when necessary.
15.4. Programs
A program is a collection of separately compiled units combined by a linker. Every function, object, type, etc., used in this collection must have a unique definition (§6.3, §15.2.3). A program must contain exactly one function called main() (§2.2.1). The main computation performed by the program starts with the invocation of the global function main() and ends with a return from main(). The return type of main() is int, and the following two versions of main() are supported by all implementations:
int main() { /* ... */ }
int main(int argc, char* argv[]) { /* ... */ }
A program can only provide one of those two alternatives. In addition, an implementation can allow other versions of main(). The argc, argv version is used to transmit arguments from the program’s environment; see §10.2.7.
The int returned by main() is passed to whatever system invoked main() as the result of the program. A nonzero return value from main() indicates an error.
This simple story must be elaborated on for programs that contain global variables (§15.4.1) or that throw an uncaught exception (§13.5.2.5).
15.4.1. Initialization of Nonlocal Variables
In principle, a variable defined outside any function (that is, global, namespace, and class static variables) is initialized before main() is invoked. Such nonlocal variables in a translation unit are initialized in their definition order. If such a variable has no explicit initializer, it is by default initialized to the default for its type (§17.3.3). The default initializer value for built-in types and enumerations is 0. For example:
double x = 2; // nonlocal variables
double y;
double sqx = sqrt(x+y);
Here, x and y are initialized before sqx, so sqrt(2) is called.
There is no guaranteed order of initialization of global variables in different translation units. Consequently, it is unwise to create order dependencies between initializers of global variables in different compilation units. In addition, it is not possible to catch an exception thrown by the initializer of a global variable (§13.5.2.5). It is generally best to minimize the use of global variables and in particular to limit the use of global variables requiring complicated initialization.
Several techniques exist for enforcing an order of initialization of global variables in different translation units. However, none are both portable and efficient. In particular, dynamically linked libraries do not coexist happily with global variables that have complicated dependencies.
Often, a function returning a reference is a good alternative to a global variable. For example:
int& use_count()
{
static int uc = 0;
return uc;
}
A call use_count() now acts as a global variable except that it is initialized at its first use (§7.7). For example:
void f()
{
cout << ++use_count(); // read and increment
// ...
}
Like other uses of static, this technique is not thread-safe. The initialization of a local static is thread-safe (§42.3.3). In this case, the initialization is even with a constant expression (§10.4), so that it is done at link time and not subject to data races (§42.3.3). However, the ++ can lead to a data race.
The initialization of nonlocal (statically allocated) variables is controlled by whatever mechanism an implementation uses to start up a C++ program. This mechanism is guaranteed to work properly only if main() is executed. Consequently, one should avoid nonlocal variables that require run-time initialization in C++ code intended for execution as a fragment of a non-C++ program.
Note that variables initialized by constant expressions (§10.4) cannot depend on the value of objects from other translation units and do not require run-time initialization. Such variables are therefore safe to use in all cases.
15.4.2. Initialization and Concurrency
Consider:
int x = 3;
int y = sqrt(++x);
What could be the values of x and y? The obvious answer is “3 and 2!” Why? The initialization of a statically allocated object with a constant expression is done at link time, so x becomes 3. However, y’s initializer is not a constant expression (sqrt() is no constexpr), so y is not initialized until run time. However, the order of initialization of statically allocated objects in a single translation unit is well defined: they are initialized in definition order (§15.4.1). So, y becomes 2.
The flaw in this argument is that if multiple threads are used (§5.3.1, §42.2), each will do the run-time initialization. No mutual exclusion is implicitly provided to prevent a data race. Then, sqrt(++x) in one thread may happen before or after the other thread manages to increment x. So, the value of y may be sqrt(4) or sqrt(5).
To avoid such problems, we should (as usual):
• Minimize the use of statically allocated objects and keep their initialization as simple as possible.
• Avoid dependencies on dynamically initialized objects in other translation units (§15.4.1).
In addition, to avoid data races in initialization, try these techniques in order:
[1] Initialize using constant expressions (note that built-in types without initializers are initialized to zero and that standard containers and strings are initialized to empty by link-time initialization).
[2] Initialize using expressions without side effects.
[3] Initialize in a known single-threaded “startup phase” of computation.
[4] Use some form of mutual exclusion (§5.3.4, §42.3).
15.4.3. Program Termination
A program can terminate in several ways:
[1] By returning from main()
[2] By calling exit()
[3] By calling abort()
[4] By throwing an uncaught exception
[5] By violating noexcept
[6] By calling quick_exit()
In addition, there are a variety of ill-behaved and implementation-dependent ways of making a program crash (e.g., dividing a double by zero).
If a program is terminated using the standard-library function exit(), the destructors for constructed static objects are called (§15.4.1, §16.2.12). However, if the program is terminated using the standard-library function abort(), they are not. Note that this implies that exit() does not terminate a program immediately. Calling exit() in a destructor may cause an infinite recursion. The type of exit() is:
void exit(int);
Like the return value of main() (§2.2.1), exit()’s argument is returned to “the system” as the value of the program. Zero indicates successful completion.
Calling exit() means that the local variables of the calling function and its callers will not have their destructors invoked. Throwing an exception and catching it ensures that local objects are properly destroyed (§13.5.1). Also, a call of exit() terminates the program without giving the caller of the function that called exit() a chance to deal with the problem. It is therefore often best to leave a context by throwing an exception and letting a handler decide what to do next. For example, main() may catch every exception (§13.5.2.2).
The C (and C++) standard-library function atexit() offers the possibility to have code executed at program termination. For example:
void my_cleanup();
void somewhere()
{
if (atexit(&my_cleanup)==0) {
// my_cleanup will be called at normal termination
}
else {
// oops: too many atexit functions
}
}
This strongly resembles the automatic invocation of destructors for global variables at program termination (§15.4.1, §16.2.12). An argument to atexit() cannot take arguments or return a result, and there is an implementation-defined limit to the number of atexit functions. A nonzero value returned by atexit() indicates that the limit is reached. These limitations make atexit() less useful than it appears at first glance. Basically, atexit() is a C workaround for the lack of destructors.
The destructor of a constructed statically allocated object (§6.4.2) created before a call of atexit(f) will be invoked after f is invoked. The destructor of such an object created after a call of atexit(f) will be invoked before f is invoked.
The quick_exit() function is like exit() except that it does not invoke any destructors. You register functions to be invoked by quick_exit() using at_quick_exit().
The exit(), abort(), quick_exit(), atexit(), and at_quick_exit() functions are declared in <cstdlib>.
15.5. Advice
[1] Use header files to represent interfaces and to emphasize logical structure; §15.1, §15.3.2.
[2] #include a header in the source file that implements its functions; §15.3.1.
[3] Don’t define global entities with the same name and similar-but-different meanings in different translation units; §15.2.
[4] Avoid non-inline function definitions in headers; §15.2.2.
[5] Use #include only at global scope and in namespaces; §15.2.2.
[6] #include only complete declarations; §15.2.2.
[7] Use include guards; §15.3.3.
[8] #include C headers in namespaces to avoid global names; §14.4.9, §15.2.4.
[9] Make headers self-contained; §15.2.3.
[10] Distinguish between users’ interfaces and implementers’ interfaces; §15.3.2.
[11] Distinguish between average users’ interfaces and expert users’ interfaces; §15.3.2.
[12] Avoid nonlocal objects that require run-time initialization in code intended for use as part of non-C++ programs; §15.4.1.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.