The C++ Programming Language (2013)
Part IV: The Standard Library
39. Locales
When in Rome, do as the Romans do.
– Proverb
• Handling Cultural Differences
• Class locale
Named locales; Comparing strings
• Class facet
Accessing facets in a locale; A Simple User-defined facet; Uses of locales and facets
• Standard facets
string Comparison; Numeric Formatting; Money Formatting; Date and Time Formatting; Character Classification; Character Code Conversion; Messages
• Convenience Interfaces
Character Classifications; Character Conversions; String Conversions; Buffer Conversions
• Advice
39.1. Handling Cultural Differences
A locale is an object that represents a set of cultural preferences, such as how strings are compared, the way numbers appear as human-readable output, and the way characters are represented in external storage. The notion of a locale is extensible so that a programmer can add new facets to a locale representing locale-specific entities not directly supported by the standard library, such as postal codes (zip codes) and phone numbers. The primary use of locales in the standard library is to control the appearance of information written to an ostream and the format of data read by an istream.
This chapter describes how to use a locale, how a locale is constructed out of facets, and how a locale affects an I/O stream.
The notion of a locale is not primarily a C++ notion. Most operating systems and application environments have a notion of locale. Such a notion is – in principle – shared among all programs on a system, independently of which programming language they are written in. Thus, the C++ standard-library notion of a locale can be seen as a standard and portable way for C++ programs to access information that has very different representations on different systems. Among other things, a C++ locale is an interface to system information that is represented in incompatible ways on different systems.
Consider writing a program that needs to be used in several countries. Writing a program in a style that allows that is often called internationalization (emphasizing the use of a program in many countries) or localization (emphasizing the adaptation of a program to local conditions). Many of the entities that a program manipulates will conventionally be displayed differently in those countries. We can handle this by writing our I/O routines to take this into account. For example:
void print_date(const Date& d) // print in the appropriate format
{
switch(where_am_I) { // user-defined style indicator
case DK: // e.g., 7. marts 1999
cout << d.day() << ". " << dk_month[d.month()] << " " << d.year();
break;
case ISO: // e.g., 1999-3-7
cout << d.year() << " – " << d.month() << " / " << d.day();
break;
case US: // e.g., 3/7/1999
cout << d.month() << "/" << d.day() << "/" << d.year();
break;
// ...
}
}
This style of code does the job. However, such code is ugly and hard to maintain. In particular, we have to use this style consistently to ensure that all output is properly adjusted to local conventions. If we want to add a new way of writing a date, we must modify the application code. Worse yet, writing dates is only one of many examples of cultural differences.
Consequently, the standard library provides an extensible way of handling cultural conventions. The iostream library relies on this framework to handle both built-in and user-defined types (§38.1). For example, consider a simple loop copying (Date,double) pairs that might represent a series of measurements or a set of transactions:
void cpy(istream& is, ostream& os)// copy (Date,double) stream
{
Date d;
double volume;
while (is >> d >> volume)
os << d << ' '<< volume << '\n';
}
Naturally, a real program would do something with the records and ideally also be a bit more careful about error handling.
How would we make this program read a file that conformed to French conventions (where a comma is the character used to represent the decimal point in a floating-point number; for example, 12,5 means twelve and a half) and write it according to American conventions? We can definelocales and I/O operations so that cpy() can be used to convert between conventions:
void f(istream& fin, ostream& fout, istream& fin2, ostream& fout2)
{
fin.imbue(locale{"en_US.UTF–8"}); // American English
fout.imbue(locale{"fr_FR.UTF–8"}); // French
cpy(fin,fout); // read American English, write French
// ...
fin2.imbue(locale{"fr_FR.UTF–8"}); // French
fout2.imbue(locale{"en_US.UTF–8"}); // American English
cpy(fin2,fout2); // read French, write American English
// ...
}
Given these streams:
Apr 12, 1999 1000.3
Apr 13, 1999 345.45
Apr 14, 1999 9688.321
...
3 juillet 1950 10,3
3 juillet 1951 134,45
3 juillet 1952 67,9
...
this program would produce:
12 avril 1999 1000,3
13 avril 1999 345,45
14 avril 1999 9688,321
...
July 3, 1950 10.3
July 3, 1951 134.45
July 3, 1952 67.9
...
Much of the rest of this chapter is devoted to describing the mechanisms that make this possible and explaining how to use them. However, most programmers will have little reason to deal with the details of locales and will never explicitly manipulate a locale. At most, they will simply retrieve a standard locale and imbue a stream with it (§38.4.5.1).
The concept of localization (internationalization) is simple. However, practical constraints make the design and implementation of locale quite intricate:
[1] A locale encapsulates cultural conventions, such as the appearance of a date. Such conventions vary in many subtle and unsystematic ways. These conventions have nothing to do with programming languages, so a programming language cannot standardize them.
[2] The concept of a locale must be extensible, because it is not possible to enumerate every cultural convention that is important to every C++ user.
[3] A locale is used in operations (e.g., I/O and sorting) from which people demand run-time efficiency.
[4] A locale must be invisible to the majority of programmers who want to benefit from facilities “doing the right thing” without having to know exactly what “the right thing” is or how it is achieved.
[5] A locale must be available to designers of facilities that deal with culture-sensitive information beyond the scope of the standard.
The mechanisms provided to compose those locales and to make them trivial to use constitute a little programming language of their own.
A locale is composed of facets that control individual aspects, such as the character used for punctuation in the output of a floating-point value (decimal_point(); §39.4.2) and the format used to read a monetary value (moneypunct; §39.4.3). A facet is an object of a class derived from class locale::facet (§39.3). We can think of a locale as a container of facets (§39.2, §39.3.1).
39.2. Class locale
The locale class and its associated facilities are presented in <locale>.

If a locale of a given name or a facet referred to doesn’t exist, the locale operation naming it throws a runtime_error.
Naming of locales is a bit curious. When you make a new locale from another plus a facet and the resulting locale has a name, that name is implementation-defined. Often, such an implementation-defined name includes the name of the locale that supplied most of the facets. For a localewithout a name, name() returns "*".
A locale can be thought of as an interface to a map<id,facet*>, that is, something that allows us to use a locale::id to find a corresponding object of a class derived from locale::facet. A real implementation of locale is an efficient variant of this idea. The layout will be something like this:
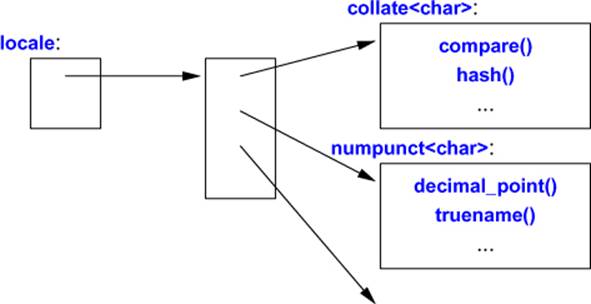
Here, collate<char> and numpunct<char> are standard-library facets (§39.4). All facets are derived from locale::facet.
A locale is meant to be copied freely and cheaply. Consequently, a locale is almost certainly implemented as a handle to the specialized map<id,facet*> that constitutes the main part of its implementation. The facets must be quickly accessible in a locale. Consequently, the specializedmap<id,facet*> will be optimized to provide array-like fast access. The facets of a locale are accessed by using the use_facet<Facet>(loc) notation; see §39.3.1.
The standard library provides a rich set of facets. To help the programmer manipulate facets in logical groups, the standard facets are grouped into categories, such as numeric and collate (§39.4):
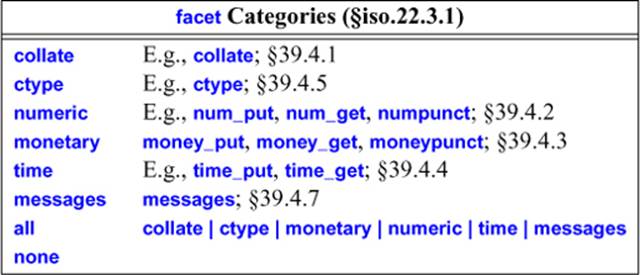
There are no facilities for a programmer to specify a name string for a newly created locale. Name strings are either defined in the program’s execution environment or created as combinations of such names by locale constructors.
A programmer can replace facets from existing categories (§39.4, §39.4.2.1). However, there is no way for a programmer to define a new category. The notion of “category” applies to standard-library facets only, and it is not extensible. Thus, a facet need not belong to any category, and many user-defined facets do not.
If a locale x does not have a name string, it is undefined whether locale::global(x) affects the C global locale. This implies that a C++ program cannot reliably and portably set the C locale to a locale that wasn’t retrieved from the execution environment. There is no standard way for a C program to set the C++ global locale (except by calling a C++ function to do so). In a mixed C and C++ program, having the C global locale differ from global() is error prone.
By far the dominant use of locales is implicitly, in stream I/O. Each istream and ostream has its own locale. The locale of a stream is by default the global locale (§39.2.1) at the time of the stream’s creation. The locale of a stream can be set by the imbue() operation, and we can extract a copy of a stream’s locale using getloc() (§38.4.5.1).
Setting the global locale does not affect existing I/O streams; those still use the locales that they were imbued with before the global locale was reset.
39.2.1. Named locales
A locale is constructed from another locale and from facets. The simplest way of making a locale is to copy an existing one. For example:
locale loc1; // copy of the current global locale
locale loc2 {""}; // copy of "the user's preferred locale"
locale loc3 {"C"}; // copy of the "C" locale
locale loc4 {locale::classic()}; // copy of the "C" locale
locale loc5 {"POSIX"}; // copy of the locale named "POSIX"
locale loc6 {"Danish_Denmark.1252"}; // copy of the locale named "Danish_Denmark.1252"
locale loc7 {"en_US.UTF–8"}; // copy of the locale named "en_US.UTF-8"
The meaning of locale{"C"} is defined by the standard to be the “classic” C locale; this is the locale that has been used throughout this book. Other locale names are implementation-defined.
The locale{""} is deemed to be “the user’s preferred locale.” This locale is set by extralinguistic means in a program’s execution environment. So to see your current “preferred locale,” write:
locale loc("");
cout << loc.name() << '\n';
On my Windows laptop, I got:
English_United States.1252
On my Linux box, I got:
en_US.UTF–8
The names of locales are not standardized for C++. Instead, a variety of organizations, such as POSIX and Microsoft, maintain their own (differing) standards across different programming languages. For example:

POSIX recommends a format of a lowercase language name, optionally followed by an uppercase country name, optionally followed by an encoding specifier, for example, sv_FI@euro (Swedish for Finland including the euro symbol).

Microsoft uses a language name followed by a country name optionally followed by a code page number. A code page is a named (or numbered) character encoding.
Most operating systems have ways of setting a default locale for a program. Typically, that is done through environment variables with names such as LC_ALL, LC_COLLATE, and LANG. Often, a locale suitable to the person using a system is chosen when that person first encounters a system. For example, I would expect a person who configures a Linux system to use Argentine Spanish as its default setting will find locale{""} to mean locale{"es_AR"}. However, these names are not standardized across platforms. So, to use named locales on a given system, a programmer must refer to system documentation and experiment.
It is generally a good idea to avoid embedding locale name strings in the program text. Mentioning a file name or a system constant in the program text limits the portability of a program and often forces a programmer who wants to adapt a program to a new environment to find and change such values. Mentioning a locale name string has similar unpleasant consequences. Instead, locales can be picked up from the program’s execution environment (for example, using locale("") or reading a file). Alternatively, a program can request a user to specify alternative locales by entering a string. For example:
void user_set_locale(const string& question)
{
cout << question; // e.g., "If you want to use a different locale, please enter its name"
string s;
cin >> s;
locale::global(locale{s}); // set global locale as specified by user
}
It is usually better to let a non-expert user pick from a list of alternatives. A function implementing this would need to know where and how a system keeps its locales. For example, many Linux systems keep their locales in the directory /usr/share/locale.
If the string argument doesn’t refer to a defined locale, the constructor throws the runtime_error exception (§30.4.1.1). For example:
void set_loc(locale& loc, const char* name)
try
{
loc = locale{name};
}
catch (runtime_error&) {
cerr << "locale
// ...
}
If a locale has a name string, name() will return it. If not, name() will return string("*"). A name string is primarily a way to refer to a locale stored in the execution environment. Secondarily, a name string can be used as a debugging aid. For example:
void print_locale_names(const locale& my_loc)
{
cout << "name of current global locale: " << locale().name() << "\n";
cout << "name of classic C locale: " << locale::classic().name() << "\n";
cout << "name of "user's preferred locale": " << locale("").name() << "\n";
cout << "name of my locale: " << my_loc.name() << "\n";
}
39.2.1.1. Constructing New locales
A new locale is made by taking an existing locale and adding or replacing facets. Typically, a new locale is a minor variation on an existing one. For example:
void f(const locale& loc, const My_money_io* mio) // My_money_io defined in §39.4.3.1
{
locale loc1(locale{"POSIX"},loc,locale::monetary); // use monetary facets from loc
locale loc2 = locale(locale::classic(), mio); // classic plus mio
// ...
}
Here, loc1 is a copy of the POSIX locale modified to use loc’s monetary facets (§39.4.3). Similarly, loc2 is a copy of the C locale modified to use a My_money_io (§39.4.3.1). The resulting locales can be represented like this:
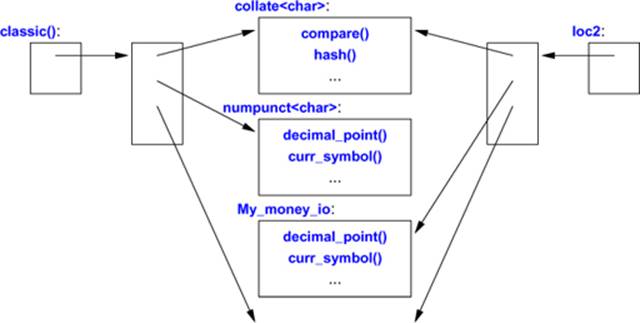
If a Facet* argument (here, My_money_io) is nullptr, the resulting locale is simply a copy of the locale argument.
In a construction locale{loc,f}, the f argument must identify a specific facet type. A plain facet* is not sufficient. For example:
void g(const locale::facet* mio1, const money_put<char>* mio2)
{
locale loc3 = locale(locale::classic(), mio1); // error: type of facet not known
locale loc4 = locale(locale::classic(), mio2); // OK: type of facet known (moneyput<char>)
// ...
}
The locale uses the type of the Facet* argument to determine the type of the facet at compile time. Specifically, the implementation of locale uses a facet’s identifying type, facet::id (§39.3), to find that facet in the locale (§39.3.1). The constructor
template<class Facet> locale(const locale& x, Facet* f);
is the only mechanism offered within the language for the programmer to supply a facet to be used through a locale. Other locales are supplied by implementers as named locales (§39.2.1). Named locales can be retrieved from the program’s execution environment. A programmer who understands the implementation-specific mechanism used for that might be able to add new locales.
The set of constructors for locale is designed so that the type of every facet is known either from type deduction (of the Facet template parameter) or because it came from another locale (that knew its type). Specifying a category argument specifies the type of facets indirectly, because the locale knows the type of the facets in the categories. This implies that the locale class can (and does) keep track of the types of facets so that it can manipulate them with minimal overhead.
The locale::id member type is used by locale to identify facet types (§39.3).
There is no way of modifying a locale. Instead, the locale operations provide ways of making new locales from existing ones. The fact that a locale is immutable after it has been created is essential for run-time efficiency. This allows someone using a locale to call virtual functions of afacet and to cache the values returned. For example, an istream can know what character is used to represent the decimal point and how true is represented without calling decimal_point() each time it reads a number and truename() each time it reads to a bool (§39.4.2). Only a call ofimbue() for the stream (§38.4.5.1) can cause such calls to return a different value.
39.2.2. Comparing strings
Comparing two strings according to a locale is possibly the most common use of a locale outside I/O. Consequently, this operation is provided directly by locale so that users don’t have to build their own comparison function from the collate facet (§39.4.1). This string comparison function is defined as locale’s operator()(). For example:
void user(const string s1, const string s2, const locale& my_locale)
{
if (my_locale(s,s2)) { // is s<s2 according to my_locale?
// ...
}
}
Having the comparison function as the () operator makes it directly useful as a predicate (§4.5.4). For example:
void f(vector<string>& v, const locale& my_locale)
{
sort(v.begin(),v.end()); // sort using < to compare elements
// ...
sort(v.begin(),v.end(),my_locale); // sort according to the rules of my_locale
// ...
}
By default, the standard-library sort() uses < for the numerical value of the implementation character set to determine collation order (§32.6, §31.2.2.1).
39.3. Class facet
A locale is a collection of facets. A facet represents one specific cultural aspect, such as how a number is represented on output (num_put), how a date is read from input (time_get), and how characters are stored in a file (codecvt). The standard-library facets are listed in §39.4.
A user can define new facets, such as a facet determining how the names of the seasons are printed (§39.3.2).
A facet is represented in a program as an object of a class derived from std::locale::facet. Like all other locale facilities, facet is found in <locale>:
class locale::facet {
protected:
explicit facet(size_t refs = 0);
virtual ~facet();
facet(const facet&) = delete;
void operator=(const facet&) = delete;
};
The facet class is designed to be a base class and has no public functions. Its constructor is protected to prevent the creation of “plain facet” objects, and its destructor is virtual to ensure proper destruction of derived-class objects.
A facet is intended to be managed through pointers stored in locales. A 0 argument to the facet constructor means that locale should delete the facet when the last reference to it goes away. Conversely, a nonzero constructor argument ensures that locale never deletes the facet. A nonzero argument is meant for the rare case in which the lifetime of a facet is controlled directly by the programmer rather than indirectly through a locale.
Each kind of facet interface must have a separate id:
class locale::id {
public:
id();
void operator=(const id&) = delete;
id(const id&) = delete;
};
The intended use of id is for the user to define a static member of type id of each class supplying a new facet interface (for example, see §39.4.1). The locale mechanisms use ids to identify facets (§39.2, §39.3.1). In the obvious implementation of a locale, an id is used as an index into a vector of pointers to facets, thereby implementing an efficient map<id,facet*>.
Data used to define a (derived) facet is defined in the derived class. This implies that the programmer defining a facet has full control over the data and that arbitrary amounts of data can be used to implement the concept represented by a facet.
A facet is intended to be immutable, so all member functions of a user-defined facet should be defined const.
39.3.1. Accessing facets in a locale
The facets of a locale are accessed using two template functions:

Think of these functions as doing a lookup in their locale argument for their template parameter F. Alternatively, think of use_facet as a kind of explicit type conversion (cast) of a locale to a specific facet. This is feasible because a locale can have only one facet of a given type. For example:
void f(const locale& my_locale)
{
char c = use_facet<numpunct<char>>(my_locale).decimal_point() // use standard facet
// ...
if (has_facet<Encrypt>(my_locale)) { // does my_locale contain an Encrypt facet?
const Encrypt& f = use_facet<Encrypt>(my_locale); // retrieve Encrypt facet
const Crypto c = f.get_crypto(); // use Encrypt facet
// ...
}
// ...
}
The standard facets are guaranteed to be available for all locales (§39.4), so we don’t need to use has_facet for standard facets.
One way of looking at the facet::id mechanism is as an optimized implementation of a form of compile-time polymorphism. A dynamic_cast can be used to get very similar results to what use_facet produces. However, the specialized use_facet can be implemented more efficiently than the general dynamic_cast.
An id identifies an interface and a behavior rather than a class. That is, if two facet classes have exactly the same interface and implement the same semantics (as far as a locale is concerned), they should be identified by the same id. For example, collate<char> andcollate_byname<char> are interchangeable in a locale, so both are identified by collate<char>::id (§39.4.1).
If we define a facet with a new interface – such as Encrypt in f() – we must define a corresponding id to identify it (see §39.3.2 and §39.4.1).
39.3.2. A Simple User-Defined facet
The standard library provides standard facets for the most critical areas of cultural differences, such as character sets and I/O of numbers. To examine the facet mechanism in isolation from the complexities of widely used types and the efficiency concerns that accompany them, let me first present a facet for a trivial user-defined type:
enum Season { spring, summer, fall, winter }; // very simple user-defined type
The style of I/O outlined here can be used with little variation for most simple user-defined types.
class Season_io : public locale::facet {
public:
Season_io(int i = 0) : locale::facet{i} { }
~Season_io() { } // to make it possible to destroy Season_io objects (§39.3)
virtual const string& to_str(Season x) const = 0; // string representation of x
virtual bool from_str(const string& s, Season& x) const = 0; // place Season for s in x
static locale::id id; // facet identifier object (§39.2, §39.3, §39.3.1)
};
locale::id Season_io::id; // define the identifier object
For simplicity, this facet is limited to strings of chars.
The Season_io class provides a general and abstract interface for all Season_io facets. To define the I/O representation of a Season for a particular locale, we derive a class from Season_io, defining to_str() and from_str() appropriately.
Output of a Season is easy. If the stream has a Season_io facet, we can use that to convert the value into a string. If not, we can output the int value of the Season:
ostream& operator<<(ostream& os, Season x)
{
locale loc {os.getloc()}; // extract the stream's locale (§38.4.4)
if (has_facet<Season_io>(loc))
return os << use_facet<Season_io>(loc).to_str(x); // string representation
return os << static_cast<int>(x); // integer representation
}
For maximum efficiency and flexibility, standard facets tend to operate directly on stream buffers (§39.4.2.2, §39.4.2.3). However, for a simple user-defined type, such as Season, there is no need to drop to the streambuf level of abstraction.
As is typical, input is a bit more complicated than output:
istream& operator>>(istream& is, Season& x)
{
const locale& loc {is.getloc()}; // extract the stream's locale (§38.4.4)
if (has_facet<Season_io>(loc)) {
const Season_io& f {use_facet<Season_io>(loc)}; // get hold of the locale's Season_io facet
string buf;
if (!(is>>buf && f.from_str(buf,x))) // read alphabetic representation
is.setstate(ios_base::failbit);
return is;
}
int i;
is >> i; // read numeric representation
x = static_cast<Season>(i);
return is;
}
The error handling is simple and follows the error-handling style for built-in types. That is, if the input string didn’t represent a Season in the chosen locale, the stream is put into the fail state. If exceptions are enabled, this implies that an ios_base::failure exception is thrown (§38.3).
Here is a trivial test program:
int main()
// a trivial test
{
Season x;
// use the default locale (no Season_io facet) implies integer I/O:
cin >> x;
cout << x << endl;
locale loc(locale(),new US_season_io{});
cout.imbue(loc); // use locale with Season_io facet
cin.imbue(loc); // use locale with Season_io facet
cin >> x;
cout << x << endl;
}
Given the input
2
summer
this program responds:
2
summer
To get this, we must derive a class US_season_io from Season_io, and define an appropriate string representation of the seasons:
class US_season_io : public Season_io {
static const string seasons[];
public:
const string& to_str(Season) const;
bool from_str(const string&, Season&) const;
// note: no US_season_io::id
};
const string US_season_io::seasons[] = {
"spring",
"summer",
"fall",
"winter"
};
Then, we override the Season_io functions that convert between the string representation and the enumerators:
const string& US_season_io::to_str(Season x) const
{
if (x<spring || winter<x) {
static const string ss = "no–such–season";
return ss;
}
return seasons[x];
}
bool US_season_io::from_str(const string& s, Season& x) const
{
const string* p = find(begin(seasons),end(seasons),s);
if (p==end)
return false;
x = Season(p–begin(seasons));
return true;
}
Note that because US_season_io is simply an implementation of the Season_io interface, I did not define an id for US_season_io. In fact, if we want US_season_io to be used as a Season_io, we must not give US_season_io its own id. Operations on locales, such as has_facet (§39.3.1), rely on facets implementing the same concepts being identified by the same id (§39.3).
The only interesting implementation question is what to do if asked to output an invalid Season. Naturally, that shouldn’t happen. However, it is not uncommon to find an invalid value for a simple user-defined type, so it is realistic to take that possibility into account. I could have thrown an exception, but when dealing with simple output intended for humans to read, it is often helpful to produce an “out-of-range” representation for an out-of-range value. Note that for input, the error-handling policy is left to the >> operator, whereas for output, the facet function to_str()implements an error-handling policy. This was done to illustrate the design alternatives. In a “production design,” the facet functions would either implement error handling for both input and output or just report errors for >> and << to handle.
This Season_io design relies on derived classes to supply the locale-specific strings. An alternative design would have Season_io itself retrieve those strings from a locale-specific repository (see §39.4.7). The possibility of having a single Season_io class to which the season strings are passed as constructor arguments is left as an exercise.
39.3.3. Uses of locales and facets
The primary use of locales within the standard library is in I/O streams. However, the locale mechanism is a general and extensible mechanism for representing culture-sensitive information. The messages facet (§39.4.7) is an example of a facet that has nothing to do with I/O streams. Extensions to the iostream library and even I/O facilities that are not based on streams might take advantage of locales. Also, a user may use locales as a convenient way of organizing arbitrary culture-sensitive information.
Because of the generality of the locale/facet mechanism, the possibilities for user-defined facets are unlimited. Plausible candidates for representation as facets are dates, time zones, phone numbers, social security numbers (personal identification numbers), product codes, temperatures, general (unit,value) pairs, postal codes (zip codes), clothing sizes, and ISBN numbers.
As with every other powerful mechanism, facets should be used with care. That something can be represented as a facet doesn’t mean that it is best represented that way. The key issues to consider when selecting a representation for cultural dependencies are – as ever – how the various decisions affect the difficulty of writing code, the ease of reading the resulting code, the maintainability of the resulting program, and the efficiency in time and space of the resulting I/O operations.
39.4. Standard facets
In <locale>, the standard library provides these facets:
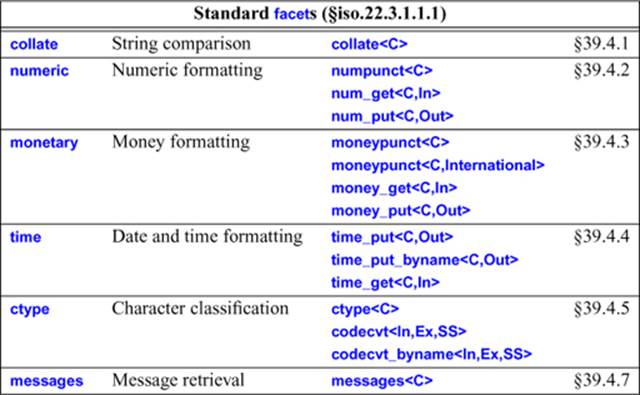
The details are explained in the referenced subsections.
When instantiating a facet from this table, C must be a character type (§36.1). These facets are guaranteed to be defined for char or wchar_t. In addition, ctype<C> is guaranteed to support char16_t and char32_t. A user who needs standard I/O to deal with another character type Xmust rely on implementation-specific facet specializations or provide suitable versions of facets for X. For example, codecvt<X,char,mbstate_t> (§39.4.6) might be needed to control conversions between X and char.
International can be true or false; true means that a three-character (plus zero terminator) “international” representation of a currency symbol is used (§39.4.3.1), such as USD and BRL.
A shift-state parameter, SS, is used to represent the shift states of a multibyte character representation (§39.4.6). In <cwchar>, mbstate_t is defined to represent any of the conversion states that can occur in an implementation-defined set of supported multibyte character encoding rules. The equivalent to mbstate_t for an arbitrary character type X is char_traits<X>::state_type (§36.2.2).
In and Out are input iterators and output iterators, respectively (§33.1.2, §33.1.4). Providing the _put and _get facets with these template arguments allows a programmer to provide facets that access nonstandard buffers (§39.4.2.2). Buffers associated with iostreams are stream buffers, so the iterators provided for those are ostreambuf_iterators (§38.6.3, §39.4.2.2). Consequently, the function failed() is available for error handling (§38.6.3).
Each standard facet has a _byname version. An F_byname facet is derived from the facet F. F_byname provides the identical interface to F, except that it adds a constructor taking a string argument naming a locale (e.g., see §39.4.1). The F_byname(name) provides the appropriate semantics for F defined in locale(name). For example:
sort(v.begin(),v.end(),collate_byname{"da_DK"}); // sort using character comparison from "da_DK"
The idea is to pick a version of a standard facet from a named locale (§39.2.1) in the program’s execution environment. This implies that _byname constructors are very slow compared to constructors that do not need to consult the environment. It is almost always faster to construct a localeand then to access its facets than it is to use _byname facets in many places in a program. Thus, reading a facet from the environment once and then using the copy in main memory repeatedly is usually a good idea. For example:
locale dk {"da_DK"}; // read the Danish locale (including all of its facets) once
// then use the dk locale and its facets as needed
void f(vector<string>& v, const locale& loc)
{
const collate<char>& col {use_facet<collate<char>>(dk)};
const ctype<char>& ctyp {use_facet<ctype<char>>(dk)};
locale dk1 {loc,&col}; // use Danish string comparison
locale dk2 {dk1,&ctyp}; // use Danish character classification and string comparison
sort(v.begin(),v.end(),dk2);
// ...
}
This dk2 locale will use Danish-style strings but will retain the default conventions for numbers.
The notion of categories gives a simpler way of manipulating standard facets in locales. For example, given the dk locale, we can construct a locale that reads and compares strings according to the rules of Danish (which has three more vowels than English) but that retains the syntax of numbers used in C++:
locale dk_us(locale::classic(),dk,collate|ctype); // Danish letters, American numbers
The presentations of individual standard facets contain more examples of facet use. In particular, the discussion of collate (§39.4.1) brings out many of the common structural aspects of facets.
Standard facets often depend on each other. For example, num_put depends on numpunct. Only if you have a detailed knowledge of individual facets can you successfully mix and match facets or add new versions of the standard facets. In other words, beyond the simple operations (such as imbue() for iostreams and using collate for sort()), the locale mechanisms are not meant to be directly used by novices. For an extensive discussion of locales, see [Langer,2000].
The design of an individual facet is often messy. The reason is partially that facets have to reflect messy cultural conventions outside the control of the library designer, and partially that the C++ standard library-facilities have to remain largely compatible with what is offered by the C standard library and various platform-specific standards.
On the other hand, the framework provided by locales and facets is general and flexible. A facet can be designed to hold any data, and the facet’s operations can provide any desired operation based on that data. If the behavior of a new facet isn’t overconstrained by convention, its design can be simple and clean (§39.3.2).
39.4.1. string Comparison
The standard collate facet provides ways of comparing arrays of characters:
template<class C>
class collate : public locale::facet {
public:
using char_type = C;
using string_type = basic_string<C>;
explicit collate(size_t = 0);
int compare(const C* b, const C* e, const C* b2, const C* e2) const
{return do_compare(b,e,b2,e2); }
long hash(const C* b, const C* e) const
{return do_hash(b,e); }
string_type transform(const C* b, const C* e) const
{return do_transform(b,e); }
static locale::id id; // facet identifier object (§39.2, §39.3, §39.3.1)
protected:
~collate(); // note: protected destructor
virtual int do_compare(const C* b, const C* e, const C* b2, const C* e2) const;
virtual string_type do_transform(const C* b, const C* e) const;
virtual long do_hash(const C* b, const C* e) const;
};
This defines two interfaces:
• The public interface for users of the facet.
• The protected interface for implementers of derived facets.
The constructor argument specifies whether a locale or a user is responsible for deleting the facet. The default (0) means “let the locale manage” (§39.3).
All standard-library facets share a common structure, so the salient facts about a facet can be summarized by the key functions:

To define a facet use collate as the pattern. To derive from a standard pattern, simply define the do_* versions of the key functions providing the facet’s functionality. The full declarations of functions are listed (rather than use patterns) to give sufficient information to write an overridingdo_* function. For an example, see §39.4.1.1.
The hash() function calculates a hash value for its imput string. Obviously, this can be useful for building hash tables.
The transform() function produces a string that, when compared to another transform()ed string, gives the same result as comparing the strings. That is:
cf.compare(cf.transform(s),cf.transform(s2)) == cf.compare(s,s2)
The purpose of transform() is to allow optimization of code in which a string is compared to many others. This is useful when implementing a search among a set of strings.
The compare() function does the basic string comparison according to the rules defined for a particular collate. It returns:
1 if the first string is lexicographically greater than the second
0 if the strings are identical
–1 if the second string is greater than the first
For example:
void f(const string& s1, const string& s2, const collate<char>& cmp)
{
const char* cs1 {s1.data()}; // because compare() operates on char[]s
const char* cs2 {s2.data()};
switch (cmp.compare(cs1,cs1+s1.size(),cs2,cs2+s2.size()) {
case 0: // identical strings according to cmp
// ...
break;
case –1: // s1 < s2
// ...
break;
case 1: // s1 > s2
// ...
break;
}
}
The collate member functions compare [b:e) ranges of C rather than basic_strings or zero-terminated C-style strings. In particular, a C with the numeric value 0 is treated as an ordinary character rather than as a terminator.
The standard-library string is not locale sensitive. That is, it compares strings according to the rules of the implementation’s character set (§6.2.3). Furthermore, the standard string does not provide a direct way of specifying comparison criteria (Chapter 36). To do a locale-sensitive comparison, we can use a collate’s compare(). For example:
void f(const string& s1, const string& s2, const string& name)
{
bool b {s1==s2}; // compare using implementation's character set values
const char* s1b {s1.data()}; // get start of data
const char* s1e {s1.data()+s1.size()} // get end of data
const char* s2b {s2.data()};
const char* s2e {s2.data()+s2.size()}
using Col = collate<char>;
const Col& global {use_facet<Col>(locale{})}; // from the current global locale
int i0 {global.compare(s1b,s1e,s2b,s2e)};
const Col& my_coll {use_facet<Col>(locale{""})}; // from my preferred locale
int i1 {my_coll.compare(s1b,s1e,s2b,s2e)};
const Col& n_coll {use_facet<Col>(locale{name})}; // from a named locale
int i2 {n_coll.compare(s1b,s1e,s2b,s2e)};
}
Notationally, it can be more convenient to use collate’s compare() indirectly through a locale’s operator() (§39.2.2). For example:
void f(const string& s1, const string& s2, const string& name)
{
int i0 = locale{}(s1,s2); // compare using the current global locale
int i1 = locale{""}(s1,s2); // compare using my preferred locale
int i2 = locale{name}(s1,s2); // compare using the named locale
// ...
}
It is not difficult to imagine cases in which i0, i1, and i2 differ. Consider this sequence of words from a German dictionary:
Dialekt, Diät, dich, dichten, Dichtung
According to convention, nouns (only) are capitalized, but the ordering is not case sensitive.
A case-sensitive German sort would place all words starting with D before d:
Dialekt, Diät, Dichtung, dich, dichten
The ä (umlaut a) is treated as “a kind of a,” so it comes before c. However, in most common character sets, the numeric value of ä is larger than the numeric value of c. Consequently, int('c')<int('ä'), and the simple default sort based on numeric values gives:
Dialekt, Dichtung, Diät, dich, dichten
Writing a compare function that orders this sequence correctly according to the dictionary is an interesting exercise.
39.4.1.1. Named collate
A collate_byname is a version of collate for a locale named by a constructor string argument:
template<class C>
class collate_byname : public collate<C> { // note: no id and no new functions
public:
typedef basic_string<C> string_type;
explicit collate_byname(const char*, size_t r = 0); // construct from named locale
explicit collate_byname(const string&, size_t r = 0);
protected:
~collate_byname(); // note: protected destructor
int do_compare(const C* b, const C* e, const C* b2, const C* e2) const override;
string_type do_transform(const C* b, const C* e) const override;
long do_hash(const C* b, const C* e) const override;
};
Thus, a collate_byname can be used to pick out a collate from a locale named in the program’s execution environment (§39.4). One obvious way of storing facets in an execution environment would be as data in a file. A less flexible alternative would be to represent a facet as program text and data in a _byname facet.
39.4.2. Numeric Formatting
Numeric output is done by a num_put facet writing into a stream buffer (§38.6). Conversely, numeric input is done by a num_get facet reading from a stream buffer. The format used by num_put and num_get is defined by a “numerical punctuation” facet called numpunct.
39.4.2.1. Numeric Punctuation
The numpunct facet defines the I/O format of built-in types, such as bool, int, and double:

The characters of the string returned by grouping() are read as a sequence of small integer values. Each number specifies a number of digits for a group. Character 0 specifies the rightmost group (the least significant digits), character 1 the group to the left of that, etc. Thus, "\004\002\003"describes a number such as 123–45–6789 (provided you use '–' as the separation character). If necessary, the last number in a grouping pattern is used repeatedly, so "\003" is equivalent to "\003\003\003". The most common use of grouping is to make large numbers more readable. Thegrouping() and thousands_sep() functions define a format for both input and output of integers and the integer part of floating-point values.
We can define a new punctuation style by deriving from numpunct. For example, I could define facet My_punct to write integer values using spaces to group the digits in sets of three and floating-point values, using a European-style comma as the “decimal point”:
class My_punct : public numpunct<char> {
public:
explicit My_punct(size_t r = 0) :numpunct<char>(r) { }
protected:
char do_decimal_point() const override { return ','; } // comma
char do_thousands_sep() const override { return '_'; } // underscore
string do_grouping() const override { return "\003"; } // 3-digit groups
};
void f()
{
cout << "style A: " << 12345678
<< " *** " << 1234567.8
<< " *** " << fixed << 1234567.8 << '\n';
cout << defaultfloat; // reset floating format
locale loc(locale(),new My_punct);
cout.imbue(loc);
cout << "style B: " << 12345678
<< " *** " << 1234567.8
<< " *** " << fixed << 1234567.8 << '\n';
}
This produces:
style A: 12345678 *** 1.23457e+06 *** 1234567.800000
style B: 12_345_678 *** 1_234_567,800000 *** 1_234_567,800000
Note that imbue() stores a copy of its argument in its stream. Consequently, a stream can rely on an imbued locale even after the original copy of that locale has been destroyed. If an iostream has its boolalpha flag set (§38.4.5.1), the strings returned by truename() and falsename() are used to represent true and false, respectively; otherwise, 1 and 0 are used.
A _byname version (§39.4, §39.4.1) of numpunct is provided:
template<class C>
class numpunct_byname : public numpunct<C> {
// ...
};
39.4.2.2. Numeric Output
When writing to a stream buffer (§38.6), an ostream relies on the num_put facet:

The value of put() is that iterator positioned one past the last character position written.
The default specialization of num_put (the one where the iterator used to access characters is of type ostreambuf_iterator<C>) is part of the standard locales (§39.4). To write elsewhere using a num_put, we must define an appropriate specialization. For example, here is a very simplenum_put for writing into a string:
template<class C>
class String_numput : public num_put<C,typename basic_string<C>::iterator> {
public:
String_numput() :num_put<C,typename basic_string<C>::iterator>{1} { }
};
I don’t mean for String_numput to go into a locale, so I used the constructor argument to retain ordinary lifetime rules. The intended use is something like this:
void f(int i, string& s, int pos) // format i into s starting at pos
{
String_numput<char> f;
f.put(s.begin()+pos,cout,' ',i); // format i into s; use cout's formatting rules
}
The ios_base argument (here, cout) provides information about formatting state and locale. For example:
void test(iostream& io)
{
locale loc = io.getloc();
wchar_t wc = use_facet<ctype<char>>(loc).widen(c); // char to C conversion
string s = use_facet<numpunct<char>>(loc).decimal_point(); // default: '.'
string false_name = use_facet<numpunct<char>>(loc).falsename(); // default: "false"
}
A standard facet, such as num_put<char>, is typically used implicitly through a standard I/O stream function. Consequently, most programmers need not know about it. However, the use of such facets by standard-library functions is interesting because they show how I/O streams work and how facets can be used. As ever, the standard library provides examples of interesting programming techniques.
Using num_put, the implementer of ostream might write:
template<class C, class Tr>
basic_ostream<C,Tr>& basic_ostream<C,Tr>::operator<<(double d)
{
sentry guard(*this); // see §38.4.1
if (!guard) return *this;
try {
if (use_facet<num_put<C,Tr>>(g etloc()).put(*this,*this,this–>fill(),d).failed())
setstate(badbit);
}
catch (...) {
handle_ioexception(*this);
}
return *this;
}
A lot is going on here. The sentry ensures that all prefix and suffix operations are performed (§38.4.1). We get the ostream’s locale by calling its member function getloc() (§38.4.5.1). We extract num_put from that locale using use_facet (§39.3.1). That done, we call the appropriate put()function to do the real work. An ostreambuf_iterator can be constructed from an ostream (§38.6.3), and an ostream can be implicitly converted to its base class ios_base (§38.4.4), so the first two arguments to put() are easily supplied.
A call of put() returns its output iterator argument. This output iterator is obtained from a basic_ostream, so it is an ostreambuf_iterator. Consequently, failed() (§38.6.3) is available to test for failure and to allow us to set the stream state appropriately.
I did not use has_facet, because the standard facets (§39.4) are guaranteed to be present in every locale. If that guarantee is violated, bad_cast is thrown (§39.3.1).
The put() function calls the virtual do_put(). Consequently, user-defined code may be executed, and operator<<() must be prepared to handle an exception thrown by the overriding do_put(). Also, num_put may not exist for some character types, so use_facet() might throw bad_cast(§39.3.1). The behavior of a << for a built-in type, such as double, is defined by the C++ standard. Consequently, the question is not what handle_ioexception() should do but rather how it should do what the standard prescribes. If badbit is set in this ostream’s exception state (§38.3), the exception is simply re-thrown. Otherwise, an exception is handled by setting the stream state and continuing. In either case, badbit must be set in the stream state (§38.4.5.1):
template<class C, class Tr>
void handle_ioexception(basic_ostream<C,Tr>& s)// called from catch-clause
{
if (s.exceptions()&ios_base::badbit) {
try {
s.setstate(ios_base::badbit); // might throw basic_ios::failure
}
catch(...) {
// ... do nothing ...
}
throw; // re-throw
}
s.setstate(ios_base::badbit);
}
The try-block is needed because setstate() might throw basic_ios::failure (§38.3, §38.4.5.1). However, if badbit is set in the exception state, operator<<() must re-throw the exception that caused handle_ioexception() to be called (rather than simply throwing basic_ios::failure).
The << for a built-in type, such as double, must be implemented by writing directly to a stream buffer. When writing a << for a user-defined type, we can often avoid the resulting complexity by expressing the output of the user-defined type in terms of output of existing types (§39.3.2).
39.4.2.3. Numeric Input
When reading from a stream buffer (§38.6), an istream relies on the num_get facet:

Basically, num_get is organized like num_put (§39.4.2.2). Since it reads rather than writes, get() needs a pair of input iterators, and the argument designating the target of the read is a reference.
The iostate variable r is set to reflect the state of the stream. If a value of the desired type could not be read, failbit is set in r; if the end-of-input was reached, eofbit is set in r. An input operator will use r to determine how to set the state of its stream. If no error was encountered, the value read is assigned through v; otherwise, v is left unchanged.
A sentry is used to ensure that the stream’s prefix and suffix operations are performed (§38.4.1). In particular, the sentry is used to ensure that we try to read only if the stream is in a good state to start with. For example, an implementer of istream might write:
template<class C, class Tr>
basic_istream<C,Tr>& basic_istream<C,Tr>::operator>>(double& d)
{
sentry guard(*this); // see §38.4.1
if (!guard) return *this;
iostate state = 0; // good
istreambuf_iterator<C,Tr> eos;
try {
double dd;
use_facet<num_get<C,Tr>>(g etloc()).g et(*this,eos,*this,state,dd);
if (state==0 || state==eofbit) d = dd; // set value only if get() succeeded
setstate(state);
}
catch (...) {
handle_ioexception(*this); // see §39.4.2.2
}
return *this;
}
I took care not to modify the target of the >> unless the read operation succeeded. Unfortunately, that cannot be guaranteed for all input operations.
Exceptions enabled for the istream will be thrown by setstate() in case of error (§38.3).
By defining a numpunct, such as My_punct from §39.4.2.1, we can read using nonstandard punctuation. For example:
void f()
{
cout << "style A: "
int i1;
double d1;
cin >> i1 >> d1; // read using standard "12345678" format
locale loc(locale::classic(),new My_punct);
cin.imbue(loc);
cout << "style B: "
int i2;
double d2;
cin >> i1 >> d2; // read using the "12_345_678" format
}
If we want to read really unusual numeric formats, we have to override do_get(). For example, we might define a num_get that reads Roman numerals, such as XXI and MM.
39.4.3. Money Formatting
The formatting of monetary amounts is technically similar to the formatting of “plain” numbers (§39.4.2). However, the presentation of monetary amounts is even more sensitive to cultural differences. For example, a negative amount (a loss, a debit), such as –1.25, should in some contexts be presented as a (positive) number in parentheses: (1.25). Similarly, color is in some contexts used to ease the recognition of negative amounts.
There is no standard “money type.” Instead, the money facets are meant to be used explicitly for numeric values that the programmer knows to represent monetary amounts. For example:
struct Money { // simple type to hold a monetary amount
using Value = long long; // for currencies that have suffered inflation
Value amount;
};
// ...
void f(long int i)
{
cout << "value= " << i << " amount= " << Money{i} << '\n';
}
The task of the monetary facets is to make it reasonably easy to write an output operator for Money so that the amount is printed according to local convention (see §39.4.3.2). The output would vary depending on cout’s locale. Possible outputs are:
value= 1234567 amount= $12345.67
value= 1234567 amount= 12345,67 DKK
value= 1234567 amount= CAD 12345,67
value= –1234567 amount= $–12345.67
value= –1234567 amount= –€12345.67
value= –1234567 amount= (CHF12345,67)
For money, accuracy to the smallest currency unit is usually considered essential. Consequently, I adopted the common convention of having the integer value represent the number of cents (pence, øre, fils, cents, etc.) rather than the number of dollars (pounds, kroner, dinar, euro, etc.). This convention is supported by moneypunct’s frac_digits() function (§39.4.3.1). Similarly, the appearance of the “decimal point” is defined by decimal_point().
The facets money_get and money_put provide functions that perform I/O based on the format defined by the money_base facet.
A simple Money type can be used to control I/O formats or to hold monetary values. In the former case, we cast values of (other) types used to hold monetary amounts to Money before writing, and we read into Money variables before converting them to other types. It is less error-prone to consistently hold monetary amounts in a Money type; that way, we cannot forget to cast a value to Money before writing it, and we don’t get input errors by trying to read monetary values in locale- insensitive ways. However, it may be infeasible to introduce a Money type into a system that wasn’t designed for that. In such cases, applying Money conversions (casts) to read and write operations is necessary.
39.4.3.1. Money Punctuation
The facet controlling the presentation of monetary amounts, moneypunct, naturally resembles the facet for controlling plain numbers, numpunct (§39.4.2.1):
class money_base {
public:
enum part { // parts of value layout
none, space, symbol, sign, value
};
struct pattern { // layout specification
char field[4];
};
};
template<class C, bool International = false>
class moneypunct : public locale::facet, public money_base {
public:
using char_type = C;
using string_type = basic_string<C>;
// ...
};
The moneypunct member functions define the layout of money input and output:

The facilities offered by moneypunct are intended primarily for use by implementers of money_put and money_get facets (§39.4.3.2, §39.4.3.3).
A _byname version (§39.4, §39.4.1) of moneypunct is provided:
template<class C, bool Intl = false>
class moneypunct_byname : public moneypunct<C, Intl> {
// ...
};
The decimal_point(), thousands_sep(), and grouping() members behave as in numpunct.
The curr_symbol(), positive_sign(), and negative_sign() members return the string to be used to represent the currency symbol (for example, $, ¥, INR, DKK), the plus sign, and the minus sign, respectively. If the International template argument is true, the intl member will also betrue, and “international” representations of the currency symbols will be used. Such an “international” representation is a four-character C-style string. For example:
"USD"
"DKK"
"EUR"
The last (invisible) character is a terminating zero. The three-letter currency identifier is defined by the ISO-4217 standard. When International is false, a “local” currency symbol, such as $, £, and ¥, can be used.
A pattern returned by pos_format() or neg_format() is four parts defining the sequence in which the numeric value, the currency symbol, the sign symbol, and whitespace occur. Most common formats are trivially represented using this simple notion of a pattern. For example:
+$ 123.45 // { sign, symbol, space, value } where positive_sign() returns "+"
$+123.45 // { symbol, sign, value, none } where positive_sign() returns "+"
$123.45 // { symbol, sign, value, none } where positive_sign() returns ""
$123.45– // { symbol, value, sign, none }
–123.45 DKK // { sign, value, space, symbol }
($123.45) // { sign, symbol, value, none } where negative_sign() returns "()"
(123.45DKK) // { sign, value, symbol, none } where negative_sign() returns "()"
Representing a negative number using parentheses is achieved by having negative_sign() return a string containing the two characters (). The first character of a sign string is placed where sign is found in the pattern, and the rest of the sign string is placed after all other parts of the pattern. The most common use of this facility is to represent the financial community’s convention of using parentheses for negative amounts, but other uses are possible. For example:
–$123.45 // { sign, symbol, value, none } where negative_sign() returns "–"
* $123.45 silly // { sign, symbol, value, none } where negative_sign() returns "* silly"
Each of the values sign, value, and symbol must appear exactly once in a pattern. The remaining value can be either space or none. Where space appears, at least one and possibly more whitespace characters may appear in the representation. Where none appears, except at the end of a pattern, zero or more whitespace characters may appear in the representation.
Note that these strict rules ban some apparently reasonable patterns:
pattern pat = { sign, value, none, none }; // error: no symbol
The frac_digits() function indicates where the decimal_point() is placed. Often, monetary amounts are represented in the smallest currency unit (§39.4.3). This unit is typically one-hundredth of the major unit (for example, a ¢ is one-hundredth of a $), so frac_digits() is often 2.
Here is a simple format defined as a facet:
class My_money_io : public moneypunct<char,true> {
public:
explicit My_money_io(size_tr=0): moneypunct<char,true>(r) { }
char_type do_decimal_point() const { return '.'; }
char_type do_thousands_sep() const { return ','; }
string do_grouping() const { return "\003\003\003"; }
string_type do_curr_symbol() const { return "USD "; }
string_type do_positive_sign() const { return ""; }
string_type do_negative_sign() const { return "()"; }
int do_frac_digits() const { return 2; } // two digits after decimal point
pattern do_pos_format() const { return pat; }
pattern do_neg_format() const { return pat; }
private:
static const pattern pat;
};
const pattern My_money_io::pat { sign, symbol, value, none };
39.4.3.2. Money Output
The money_put facet writes monetary amounts according to the format specified by moneypunct. Specifically, money_put provides put() functions that place a suitably formatted character representation into the stream buffer of a stream:

The intl argument indicates whether a standard four-character “international” currency symbol or a “local” symbol is used (§39.4.3.1).
Given money_put, we can define an output operator for Money (§39.4.3):
ostream& operator<<(ostream& s, Money m)
{
ostream::sentry guard(s); // see §38.4.1
if (!guard) return s;
try {
const money_put<char>& f = use_facet<money_put<char>>(s.g etloc());
if (m==static_cast<long long>(m)) { // m can be represented as a long long
if (f.put(s,true,s,s.fill(),m).failed())
s.setstate(ios_base::badbit);
}
else {
ostringstream v;
v << m; // convert to string representation
if (f.put(s,true,s,s.fill(),v.str()).failed())
s.setstate(ios_base::badbit);
}
}
catch (...) {
handle_ioexception(s); // see §39.4.2.2
}
return s;
}
If a long long doesn’t have sufficient precision to represent the monetary value exactly, I convert the value to its string representation and output that using the put() that takes a string.
39.4.3.3. Money Input
The money_get facet reads monetary amounts according to the format specified by moneypunct. Specifically, money_get provides get() functions that extract a suitably formatted character representation from the stream buffer of a stream:

A well-defined pair of money_get and money_put facets will provide output in a form that can be read back in without errors or loss of information. For example:
int main()
{
Money m;
while (cin>>m)
cout << m << "\n";
}
The output of this simple program should be acceptable as its input. Furthermore, the output produced by a second run given the output from a first run should be identical to its input.
A plausible input operator for Money would be:
istream& operator>>(istream& s, Money& m)
{
istream::sentry guard(s); // see _io.sentry_
if (guard) try {
ios_base::iostate state = 0; // good
istreambuf_iterator<char> eos;
string str;
use_facet<money_get<char>>(s.g etloc()).g et(s,eos,true,state,str);
if (state==0 || state==ios_base::eofbit) { // set value only if get() succeeded
long long i = stoll(str); // §36.3.5
if (errno==ERANGE) {
state |= ios_base::failbit;
}
else {
m = i; // set value only if conversion to long long succeeded
}
s.setstate(state);
}
}
catch (...) {
handle_ioexception(s); // see §39.4.2.2
}
return s;
}
I use the get() that reads into a string because reading into a double and then converting to a long long could lead to loss of precision.
The largest value that can be exactly represented by a long double may be smaller than the largest value that can be represented by a long long.
39.4.4. Date and Time Formatting
Date and time formats are controlled by time_get<C,In> and time_put<C,Out>. The representation of dates and times used is tm (§43.6).
39.4.4.1. time_put
A time_put facet takes a point in time presented as a tm and produces a sequence of characters representing it using strftime() (§43.6) or an equivalent.

A call s=put(s,ib,fill,pt,b,e) copies [b:e) onto the output stream s. For each strftime() format character x, with optional modifier mod, it calls do_put(s,ib,pt,x,mod). The possible modifier values are 0 (the default meaning “none”), E, or O. An overriding p=do_put(s,ib,pt,x,mod) is supposed to format the appropriate parts of *pt into s and return a value pointing to the position in s after the last character written.
A _byname version (§39.4, §39.4.1) of messages is provided:
template<class C, class Out = ostreambuf_iterator<C>>
class time_put_byname : public time_put<C,Out>
{
// ...
};
39.4.4.2. time_get
The basic idea is that a get_time can read what is produced by a put_time using the same strftime() format (§43.6):
class time_base {
public:
enum dateorder {
no_order, // meaning mdy
dmy, // meaning "%d%m%y"
mdy, // meaning "%m%d%y"
ymd, // meaning "%y%m%d"
ydm // meaning "%y%d%m"
};
};
template<class C, class In = istreambuf_iterator<C>>
class time_get : public locale::facet, public time_base {
public:
using char_type = C;
using iter_type = In;
// ...
}
In addition to reading according to a format, there are operations for examining the dateorder and for reading specific parts of date and time representations, such as weekday and monthname:
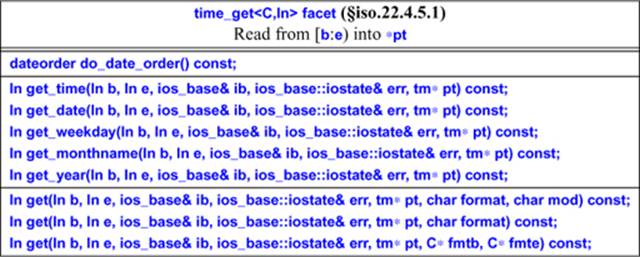
A get_*() function reads from [b:e) into *pt, getting its locale from b and setting err in case of error. It returns an iterator pointing to the first unread character in [b:e).
A call p=get(b,e,ib,err,pt,format,mod) reads as indicated by the format character format and modifier character mod, as specified by strftime(). If mod is not specified, mod==0 is used.
A call of get(b,e,ib,err,pt,fmtb,fmtb) uses a strftime() format presented as a string [fmtb:fmte). This overload, together with the one with the defaulted modifier, does not have do_get() interfaces. Instead, they are implemented by calls to the do_get() for the first get().
The obvious use of the time and date facets is to provide locale-sensitive I/O for a Date class. Consider a variant of the Date from §16.3:
class Date {
public:
explicit Date(int d ={}, Month m ={}, int year ={});
// ...
string to_string(const locale& = locale()) const;
};
istream& operator>>(istream& is, Date& d);
ostream& operator<<(ostream& os, Date d);
Date::to_string() produces a locale()-specific string using a stringstream (§38.2.2):
string Date::to_string(const locale& loc) const
{
ostringstream os;
os.imbue(loc);
return os << *this;
}
Given to_string(), the output operator is trivial:
ostream& operator<<(ostream& os, Date d)
{
return os<<to_string(d,os.getloc());
}
The input operator needs to be careful about state:
istream& operator>>(istream& is, Date& d)
{
if (istream::sentry guard{is}) {
ios_base::iostate err = goodbit;
struct tm t;
use_facet<time_get<char>>(is.getloc()).get_date(is,0,is,err,&t); // read into t
if (!err) {
Month m = static_cast<Month>(t.tm_mon+1);
d = Date(t.tm_day,m,t.tm_year+1900);
}
is.setstate(err);
}
return is;
}
The +1900 is needed because year 1900 is year zero for tm (§43.6).
A _byname version (§39.4, §39.4.1) of messages is provided:
template<class C, class In = istreambuf_iterator<C>>
class time_get_byname : public time_get<C, In> {
// ...
};
39.4.5. Character Classification
When reading characters from input, it is often necessary to classify them to make sense of what is being read. For example, to read a number, an input routine needs to know which letters are digits. Similarly, §10.2.2 showed a use of standard character classification functions for parsing input.
Naturally, classification of characters depends on the alphabet used. Consequently, a facet ctype is provided to represent character classification in a locale.
The character classes are described by an enumeration called mask:
class ctype_base {
public:
enum mask { // the actual values are implementation-defined
space = 1, // whitespace (in "C" locale: ' ', '\n', '\t', ...)
print = 1<<1, // printing characters
cntrl = 1<<2, // control characters
upper = 1<<3, // uppercase characters
lower = 1<<4, // lowercase characters
alpha = 1<<5, // alphabetic characters
digit = 1<<6, // decimal digits
punct = 1<<7, // punctuation characters
xdigit = 1<<8, // hexadecimal digits
blank = 1 << 9; // space and horizontal tab
alnum=alpha|digit, // alphanumeric characters
graph=alnum|punct
};
};
template<class C>
class ctype : public locale::facet, public ctype_base {
public:
using char_type = C;
// ...
};
This mask doesn’t depend on a particular character type. Consequently, this enumeration is placed in a (non-template) base class.
Clearly, mask reflects the traditional C and C++ classification (§36.2.1). However, for different character sets, different character values fall into different classes. For example, for the ASCII character set, the integer value 125 represents the character }, which is a punctuation character (punct). However, in the Danish national character set, 125 represents the vowel å, which in a Danish locale must be classified as an alpha.
The classification is called a “mask” because the traditional efficient implementation of character classification for small character sets is a table in which each entry holds bits representing the classification. For example:
table['P'] == upper|alpha
table['a'] == lower|alpha|xdigit
table['1'] == digit|xdigit
table[' '] == space|blank
Given that implementation, table[c]&m is nonzero if the character c is an m and 0 otherwise.
The ctype facet is defined like this:

A call is(m,c) tests whether the character c belongs to the classification m. For example:
int count_spaces(const string& s, const locale& loc)
{
const ctype<char>& ct = use_facet<ctype<char>>(loc);
int i = 0;
for(auto p = s.begin(); p!=s.end(); ++p)
if (ct.is(ctype_base::space,*p)) // whitespace as defined by ct
++i;
return i;
}
Note that it is also possible to use is() to check whether a character belongs to one of a number of classifications. For example:
ct.is(ctype_base::space|ctype_base::punct,c); // is c whitespace or punctuation in ct?
A call is(b,e,v) determines the classification of each character in [b:e) and places it in the corresponding position in the array v.
A call scan_is(m,b,e) returns a pointer to the first character in [b:e) that is an m. If no character is classified as an m, e is returned. As ever for standard facets, the public member function is implemented by a call to its do_ virtual function. A simple implementation might be:
template<class C>
const C* ctype<C>::do_scan_is(mask m, const C* b, const C* e) const
{
while (b!=e && !is(m,*b))
++b;
return b;
}
A call scan_not(m,b,e) returns a pointer to the first character in [b:e) that is not an m. If all characters are classified as m, e is returned.
A call toupper(c) returns the uppercase version of c if such a version exists in the character set used and c itself otherwise.
A call toupper(b,e) converts each character in the range [b:e) to uppercase and returns e. A simple implementation might be:
template<class C>
const C* ctype<C>::to_upper(C* b, const C* e)
{
for (; b!=e; ++b)
*b = toupper(*b);
return e;
}
The tolower() functions are similar to toupper() except that they convert to lowercase.
A call widen(c) transforms the character c into its corresponding C value. If C’s character set provides several characters corresponding to c, the standard specifies that “the simplest reasonable transformation” be used. For example:
wcout << use_facet<ctype<wchar_t>>(wcout.g etloc()).widen('e');
will output a reasonable equivalent to the character e in wcout’s locale.
Translation between unrelated character representations, such as ASCII and EBCDIC, can also be done by using widen(). For example, assume that an ebcdic locale exists:
char EBCDIC_e = use_facet<ctype<char>>(ebcdic).widen('e');
A call widen(b,e,v) takes each character in the range [b:e) and places a widened version in the corresponding position in the array v.
A call narrow(ch,def) produces a char value corresponding to the character ch from the C type. Again, “the simplest reasonable transformation” is to be used. If no such corresponding char exists, def is returned.
A call narrow(b,e,def,v) takes each character in the range [b:e) and places a narrowed version in the corresponding position in the array v.
The general idea is that narrow() converts from a larger character set to a smaller one and that widen() performs the inverse operation. For a character c from the smaller character set, we expect:
c == narrow(widen(c),0) // not guaranteed
This is true provided that the character represented by c has only one representation in “the smaller character set.” However, that is not guaranteed. If the characters represented by a char are not a subset of those represented by the larger character set (C), we should expect anomalies and potential problems with code treating characters generically.
Similarly, for a character ch from the larger character set, we might expect:
widen(narrow(ch,def)) == ch || widen(narrow(ch,def)) == widen(def) // not guaranteed
However, even though this is often the case, it cannot be guaranteed for a character that is represented by several values in the larger character set but only once in the smaller character set. For example, a digit, such as 7, often has several separate representations in a large character set. The reason for that is typically that a large character set has several conventional character sets as subsets and that the characters from the smaller sets are replicated for ease of conversion.
For every character in the basic source character set (§6.1.2), it is guaranteed that
widen(narrow(ch_lit,0)) == ch_lit
For example:
widen(narrow('x',0)) == 'x'
The narrow() and widen() functions respect character classifications wherever possible. For example, if is(alpha,c), then is(alpha,narrow(c,'a')) and is(alpha,widen(c)) wherever alpha is a valid mask for the locale used.
A major reason for using a ctype facet in general and for using narrow() and widen() functions in particular is to be able to write code that does I/O and string manipulation for any character set, that is, to make such code generic with respect to character sets. This implies that iostreamimplementations depend critically on these facilities. By relying on <iostream> and <string>, a user can avoid most direct uses of the ctype facet.
A _byname version (§39.4, §39.4.1) of ctype is provided:
template<class C>
class ctype_byname : public ctype<C> {
// ...
};
39.4.6. Character Code Conversion
Sometimes, the representation of characters stored in a file differs from the desired representation of those same characters in main memory. For example, Japanese characters are often stored in files in which indicators (“shifts”) indicate to which of the four common character sets (kanji, katakana, hiragana, and romaji) a given sequence of characters belongs. This is a bit unwieldy because the meaning of each byte depends on its “shift state,” but it can save memory because only a kanji requires more than 1 byte for its representation. In main memory, these characters are easier to manipulate when represented in a multibyte character set where every character has the same size. Such characters (for example, Unicode characters) are typically placed in wide characters (wchar_t; §6.2.3). Consequently, the codecvt facet provides a mechanism for converting characters from one representation to another as they are read or written. For example:
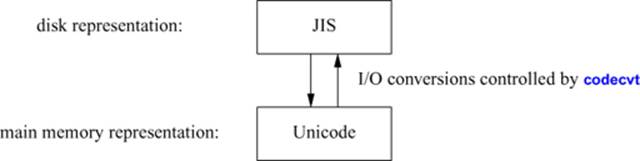
This code conversion mechanism is general enough to provide arbitrary conversions of character representations. It allows us to write a program to use a suitable internal character representation (stored in char, wchar_t, or whatever) and to then accept a variety of input character stream representations by adjusting the locale used by iostreams. The alternative would be to modify the program itself or to convert input and output files from/to a variety of formats.
The codecvt facet provides conversion between different character sets when a character is moved between a stream buffer and external storage:
class codecvt_base {
public:
enum result { // result indicators
ok, partial, error, noconv
};
};
template<class In, class Ex, class SS>
class codecvt : public locale::facet, public codecvt_base {
public:
using intern_type = In;
using extern_type = Ex;
using state_type = SS;
// ...
};

A codecvt facet is used by basic_filebuf (§38.2.1) to read or write characters. A basic_filebuf obtains this facet from the stream’s locale (§38.1).
The State template argument is the type used to hold the shift state of the stream being converted.State can also be used to identify different conversions by specifying a specialization. The latter is useful because characters of a variety of character encodings (character sets) can be stored in objects of the same type. For example:
class JISstate { /* .. */ };
p = new codecvt<wchar_t,char,mbstate_t>; // standard char to wide char
q = new codecvt<wchar_t,char,JISstate>; // JIS to wide char
Without the different State arguments, there would be no way for the facet to know which encoding to assume for the stream of chars. The mbstate_t type from <cwchar> or <wchar.h> identifies the system’s standard conversion between char and wchar_t.
A new codecvt can also be created as a derived class and identified by name. For example:
class JIScvt : public codecvt<wchar_t,char,mbstate_t> {
// ...
};
A call in(st,b,e,next,b2,e2,next2) reads each character in the range [b:e) and tries to convert it. If a character is converted, in() writes its converted form to the corresponding position in the [b2:e2) range; if not, in() stops at that point. Upon return, in() stores the position one beyond the last character read in next (the next character to be read) and the position one beyond the last character written in next2 (the next character to be written). The result value returned by in() indicates how much work was done:

Note that a partial conversion is not necessarily an error. Possibly more characters have to be read before a multibyte character is complete and can be written, or maybe the output buffer has to be emptied to make room for more characters.
The state_type argument st indicates the state of the input character sequence at the start of the call of in(). This is significant when the external character representation uses shift states. Note that st is a (non-const) reference argument: at the end of the call, st holds the shift state of the input sequence. This allows a programmer to deal with partial conversions and to convert a long sequence using several calls to in().
A call out(st,b,e,next,b2,e2,next2) converts [b:e) from the internal to the external representation in the same way the in() converts from the external to the internal representation.
A character stream must start and end in a “neutral” (unshifted) state. Typically, that state is state_type{}.
A call unshift(ss,b,e,next) looks at st and places characters in [b:e) as needed to bring a sequence of characters back to that unshifted state. The result of unshift() and the use of next are done just like out().
A call length(st,b,e,max) returns the number of characters that in() could convert from [b:e). Return values from encoding() mean:
–1 The encoding of the external character set uses state (for example, uses shift and unshift character sequences).
0 The encoding uses varying number of bytes to represent individual characters (for example, a character representation might use a bit in a byte to indicate whether 1 or 2 bytes are used to represent that character).
n Every character of the external character representation is n bytes.
A call always_noconv() returns true if no conversion is required between the internal and the external character sets and false otherwise. Clearly, always_noconv()==true opens the possibility for the implementation to provide the maximally efficient implementation that simply doesn’t invoke the conversion functions.
A call cvt.max_length() returns the maximum value that cvt.length(ss,p,q,n) can return for a valid set of arguments.
The simplest code conversion that I can think of is one that converts input to uppercase. Thus, this is about as simple as a codecvt can be and still perform a service:
class Cvt_to_upper : public codecvt<char,char,mbstate_t> { // convert to uppercase
public:
explicit Cvt_to_upper(size_t r = 0) : codecvt(r) { }
protected:
// read external representation, write internal representation:
result do_in(State& s,
const char* from, const char* from_end, const char*& from_next,
char* to, char* to_end, char*& to_next
) const override;
// read internal representation, write external representation:
result do_out(State& s,
const char* from, const char* from_end, const char*& from_next,
char* to, char* to_end, char*& to_next
) const override;
result do_unshift(State&, E* to, E* to_end, E* & to_next) const override { return ok; }
int do_encoding() const noexcept override { return 1; }
bool do_always_noconv() const noexcept override { return false; }
int do_length(const State&, const E* from, const E* from_end, size_t max) const override;
int do_max_length() const noexcept override; // maximum possible length()
};
codecvt<char,char,mbstate_t>::result
Cvt_to_upper::do_out(State& s,
const char* from, const char* from_end, const char*& from_next,
char* to, char* to_end, char*& to_next) const
{
return codecvt<char,char,mbstate_t>::do_out(s,from,from_end,from_next,to,to_end,to_next);
}
codecvt<char,char,mbstate_t>::result
Cvt_to_upper::do_in(State& s,
const char* from, const char* from_end, const char*& from_next,
char* to, char* to_end, char*& to_next) const
{
// ...
}
int main() // trivial test
{
locale ulocale(locale(), new Cvt_to_upper);
cin.imbue(ulocale);
for (char ch; cin>>ch;)
cout << ch;
}
A _byname version (§39.4, §39.4.1) of codecvt is provided:
template<class I, class E, class State>
class codecvt_byname : public codecvt<I,E,State> {
// ...
};
39.4.7. Messages
Naturally, most end users prefer to use their native language to interact with a program. However, we cannot provide a standard mechanism for expressing locale-specific general interactions. Instead, the library provides a simple mechanism for keeping a locale-specific set of strings from which a programmer can compose simple messages. In essence, messages implements a trivial read-only database:
class messages_base {
public:
using catalog = /* implementation-defined integer type */; // catalog identifier type
};
template<class C>
class messages : public locale::facet, public messages_base {
public:
using char_type = C;
using string_type = basic_string<C>;
// ...
};
The messages interface is comparatively simple:

A call open(s,loc) opens a “catalog” of messages called s for the locale loc. A catalog is a set of strings organized in an implementation-specific way and accessed through the messages::g et() function. A negative value is returned if no catalog named s can be opened. A catalog must be opened before the first use of get().
A call close(cat) closes the catalog identified by cat and frees all resources associated with that catalog.
A call get(cat,set,id,"foo") looks for a message identified by (set,id) in the catalog cat. If a string is found, get() returns that string; otherwise, get() returns the default string (here, string("foo")).
Here is an example of a messages facet for an implementation in which a message catalog is a vector of sets of “messages” and a “message” is a string:
struct Set {
vector<string> msgs;
};
struct Cat {
vector<Set> sets;
};
class My_messages : public messages<char> {
vector<Cat>& catalogs;
public:
explicit My_messages(size_t = 0) :catalogs{*new vector<Cat>} { }
catalog do_open(const string& s, const locale& loc) const; // open catalog s
string do_get(catalog cat, int s, int m, const string&) const; // get message (s,m) in cat
void do_close(catalog cat) const
{
if (catalogs.size()<=cat)
catalogs.erase(catalogs.begin()+cat);
}
~My_messages() { delete &catalogs; }
};
All messages’ member functions are const, so the catalog data structure (the vector<Set>) is stored outside the facet.
A message is selected by specifying a catalog, a set within that catalog, and a message string within that set. A string is supplied as an argument, to be used as a default result in case no message is found in the catalog:
string My_messages::do_get(catalog cat, int set, int id, const string& def) const
{
if (catalogs.size()<=cat)
return def;
Cat& c = catalogs[cat];
if (c.sets.size()<=set)
return def;
Set& s = c.sets[set];
if (s.msgs.size()<=msg)
return def;
return s.msgs[id];
}
Opening a catalog involves reading a textual representation from disk into a Cat structure. Here, I chose a representation that is trivial to read. A set is delimited by <<< and >>>, and each message is a line of text:
messages<char>::catalog My_messages::do_open(const string& n, const locale& loc) const
{
string nn = n + locale().name();
ifstream f(nn.c_str());
if (!f) return –1;
catalogs.push_back(Cat{}); // make in-core catalog
Cat& c = catalogs.back();
for(string s; f>>s && s=="<<<"; ) { // read Set
c.sets.push_back(Set{});
Set& ss = c.sets.back();
while (getline(f,s) && s != ">>>") // read message
ss.msgs.push_back(s);
}
return catalogs.size()–1;
}
Here is a trivial use:
int main()
// a trivial test
{
if (!has_facet<My_messages>(locale())) {
cerr << "no messages facet found in" << locale().name() << '\n';
exit(1);
}
const messages<char>& m = use_facet<My_messages>(locale());
extern string message_directory; // where I keep my messages
auto cat = m.open(message_directory,locale());
if (cat<0) {
cerr << "no catalog found\n";
exit(1);
}
cout << m.get(cat,0,0,"Missed again!") << endl;
cout << m.get(cat,1,2,"Missed again!") << endl;
cout << m.get(cat,1,3,"Missed again!") << endl;
cout << m.get(cat,3,0,"Missed again!") << endl;
}
If the catalog is:
<<<
hello
goodbye
>>>
<<<
yes
no
maybe
>>>
this program prints
hello
maybe
Missed again!
Missed again!
39.4.7.1. Using Messages from Other facets
In addition to being a repository for locale-dependent strings used to communicate with users, messages can be used to hold strings for other facets. For example, the Season_io facet (§39.3.2) could have been written like this:
class Season_io : public locale::facet {
const messages<char>& m; // message directory
messages_base::catalog cat; // message catalog
public:
class Missing_messages { };
Season_io(size_t i = 0)
: locale::facet(i),
m(use_facet<Season_messages>(locale())),
cat(m.open(message_directory,locale()))
{
if (cat<0)
throw Missing_messages();
}
~Season_io() { } // to make it possible to destroy Season_io objects (§39.3)
const string& to_str(Season x) const; // string representation of x
bool from_str(const string& s, Season& x) const; // place Season corresponding to s in x
static locale::id id; // facet identifier object (§39.2, §39.3, §39.3.1)
};
locale::id Season_io::id; // define the identifier object
string Season_io::to_str(Season x) const
{
return m–>get(cat,0,x,"no–such–season");
}
bool Season_io::from_str(const string& s, Season& x) const
{
for (int i = Season::spring; i<=Season::winter; i++)
if (m–>get(cat,0,i,"no–such–season") == s) {
x = Season(i);
return true;
}
return false;
}
This messages-based solution differs from the original solution (§39.3.2) in that the implementer of a set of Season strings for a new locale needs to be able to add them to a messages directory. This is easy for someone adding a new locale to an execution environment. However, sincemessages provides only a read-only interface, adding a new set of season names may be beyond the scope of an application programmer.
A _byname version (§39.4, §39.4.1) of messages is provided:
template<class C>
class messages_byname : public messages<C> {
// ...
};
39.5. Convenience Interfaces
Beyond simply imbuing an iostream, the locale facilities can be complicated to use. Consequently, convenience interfaces are provided to simplify notation and minimize mistakes.
39.5.1. Character Classification
The most common use of the ctype facet is to inquire whether a character belongs to a given classification. Consequently, a set of functions is provided for that:
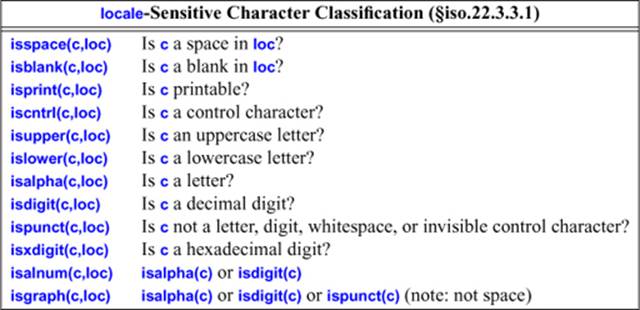
These functions are trivially implemented using use_facet. For example:
template<class C>
inline bool isspace(C c, const locale& loc)
{
return use_facet<ctype<C>>(loc).is(space,c);
}
The one-argument versions of these functions (§36.2.1) use the current C global locale. Except for the rare cases in which the C global locale and the C++ global locale differ (§39.2.1), we can think of a one-argument version as the two-argument version applied to locale(). For example:
inline int isspace(int i)
{
return isspace(i,locale()); // almost
}
39.5.2. Character Conversions
Case conversions can be locale sensitive:

39.5.3. String Conversions
Character code conversions can be locale sensitive. Class template wstring_convert performs conversions between a wide string and a byte string. It lets you specify a code conversion facet (such as codecvt) to perform the conversions, without affecting any streams or locales. For example, you might use a code conversion facet called codecvt_utf8 directly to output a UTF-8 multibyte sequence to cout without altering cout’s locale:
wstring_convert<codecvt_utf8<wchar_t>> myconv;
string s = myconv.to_bytes(L"Hello\n");
cout << s;
The definition of wstring_convert is fairly conventional:
template<class Codecvt,
class Wc = wchar_t,
class Wa = std::allocator<Wc>, // wide-character allocator
class Ba = std::allocator<char> // byte allocator
>
class wstring_convert {
public:
using byte_string = basic_string<char, char_traits<char>, Ba>;
using wide_string = basic_string<Wc, char_traits<Wc>, Wa>;
using state_type = typename Codecvt::state_type;
using int_type = typename wide_string::traits_type::int_type;
// ...
};
The wstring_convert constructors allow us to specify a character conversion facet, an initial conversion state, and values to be used in case of errors:

If a conversion to a wide_string fails, functions on a cvt constructed with a non-default w_err string return that string (as an error message); otherwise, they throw range_error.
If a conversion to a byte_string fails, functions on a cvt constructed with a non-default b_err string return that string (as an error message); otherwise, they throw range_error.
An example:
void test()
{
wstring_convert<codecvt_utf8_utf16<wchar_t>> converter;
string s8 = u8"This is a UTF–8 string";
wstring s16 = converter.from_bytes(s8);
string s88 = converter.to_bytes(s16);
if (s8!=s88)
cerr <"Insane!\n";
}
39.5.4. Buffer Conversions
We can use a code conversion facet (§39.4.6) to write directly into or to read directly from a stream buffer (§38.6):
template<class Codecvt,
class C = wchar_t,
class Tr = std::char_traits<C>
>
class wbuffer_convert
: public std::basic_streambuf<C,Tr> {
public:
using state_type = typename Codecvt::state_type;
// ...
};

39.6. Advice
[1] Expect that every nontrivial program or system that interacts directly with people will be used in several different countries; §39.1.
[2] Don’t assume that everyone uses the same character set as you do; §39.1, §39.4.1.
[3] Prefer using locales to writing ad hoc code for culture-sensitive I/O; §39.1.
[4] Use locales to meet external (non-C++) standards; §39.1.
[5] Think of a locale as a container of facets; §39.2.
[6] Avoid embedding locale name strings in program text; §39.2.1.
[7] Keep changes of locale to a few places in a program; §39.2.1.
[8] Minimize the use of global format information; §39.2.1.
[9] Prefer locale-sensitive string comparisons and sorts; §39.2.2, §39.4.1.
[10] Make facets immutable; §39.3.
[11] Let locale handle the lifetime of facets; §39.3.
[12] You can make your own facets; §39.3.2.
[13] When writing locale-sensitive I/O functions, remember to handle exceptions from user-supplied (overriding) functions; §39.4.2.2.
[14] Use numput if you need separators in numbers; §39.4.2.1.
[15] Use a simple Money type to hold monetary values; §39.4.3.
[16] Use simple user-defined types to hold values that require locale-sensitive I/O (rather than casting to and from values of built-in types); §39.4.3.
[17] The time_put facet can be used for both <chrono>- and <ctime>-style time §39.4.4.
[18] Prefer the character classification functions in which the locale is explicit; §39.4.5, §39.5.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.