Emerging Trends in Image Processing, Computer Vision, and Pattern Recognition, 1st Edition (2015)
Part I. Image and Signal Processing
Chapter 8. Security surveillance applications utilizing parallel video-processing techniques in the spatial domain
Leonidas Deligiannidis1; Hamid R. Arabnia2 1 Wentworth Institute of Technology, Department of Computer Science, Boston, MA, USA
2 University of Georgia, Computer Science, Athens, GA, USA
Abstract
We present several solutions to security surveillance and their applications while utilizing parallel processing of video streams for improved performance. The algorithms presented in this article are explained in detail and their implementations are provided for educational purposes. These algorithms with their implementations are being taught in our Parallel Processing course utilizing NVidia’s CUDA language and framework. We chose the topic of security surveillance in our Parallel Processing course because the results are visual and applicable in many situations such as surveillance of parking lots (e.g., monitoring our car), dormitory rooms, offices, etc. Image-processing techniques and algorithms are discussed in this article, and extended to real-time high-definition video-processing focusing on security surveillance.
Keywords
Parallel processing
Surveillance applications
Video processing
Acknowledgments
We would like to thank NVIDIA Corporation for providing equipment and financial support through their CUDA Teaching Center initiative. We would also like to thank Axis Communications for donating more than 20 network-enabled surveillance cameras. Their support is greatly appreciated.
1 Introduction
One of the most important goals of security surveillance is to collect and disseminate real-time information and provide situational awareness to operators and security analysts [1]. Only then educated decisions and future reasoning can be made and prevent undesirable incidents [2]. The need for surveillance spans in many domains, including commercial buildings, law enforcement, the military, banks, parking lots, city settings as well as hallways and entrances to buildings, etc. Most of today's surveillance is used primarily as a forensic tool, to investigate what has already happened, and not to prevent an incident. Detection of objects, people, peoples’ faces [3], cars, and their pattern of movement is necessary to enhance automated decision making and alarming. This is a difficult problem to solve [4]. One of the most common approaches to solving this problem is background subtraction [4–6] where each pixel is compared to its intensity value and if the change is above a threshold, it is marked as motion detected. In Ref. [2] the authors developed an object detection system that is based on pixel and region analysis and gives better results in sudden pixel intensity variations. Many times motion detection alone may not be enough. The identity of the object or person that triggers the motion detector may need to be identified. Other times the trajectory of the moving entity may need to be tracked [7–9].
2 Graphical Processing Unit and Compute Unified Device Architecture
Originally, graphics processors were used primarily to render images. In recent years, however, these graphical processing units (GPUs) are also used to solve problems involving massive data-parallel processing. Thus, GPUs have been transformed to general purpose graphical processing units (GPGPUs) and can be viewed as external devices that can perform parallel computations for problems that don’t only involve graphics.
Lately, GPUs have experienced a tremendous growth, mainly driven by the gaming industry. GPUs are now considered to be programmable architectures and devices consisting of several many-core processors capable of running hundreds of thousands of threads concurrently.
NVIDIA Corporation provides a new API that utilizes C/C++ to program their graphics cards. This API is called CUDA (Compute Unified Device Architecture) [10] and enables us to utilize relatively easily data-parallel algorithms [11–13]. CUDA has been used in simulations [14–16], genetic algorithms [17], DNA sequence alignment [18], encryption systems [19,20], image processing [21–29], digital forensics [30], and other fields.
CUDA is available for most operating systems, and it is freely available; CUDA is restricted to NVidia graphics cards, however, CUDA is a highly parallel computing platform and programming model and provides access to an elaborate GPU memory architecture and parallel thread execution management. Each thread has a unique identifier. Each thread can then perform the same operation on different sets of data.
A CUDA program consists of two main components. The program that runs on the host computer and functions (called kernels) that run on the GPU. Each kernel is executed as a batch of threads organized as a grid of thread blocks. The size of the grid and blocks is user configurable to fit the problem's requirements. These blocks can be configured as 1D, 2D, or 3D matrices. This architecture is built around a scalable array of multithreaded streaming multiprocessors. CUDA uses a single instruction multiple thread architecture that enables us to write thread-level parallel code.
CUDA also features several high-bandwidth memory spaces to meet the performance requirements of a program. For example, Global memory is memory accessed by the host computer and by the GPU. Other memory types are only accessible by the kernels and reside within the chip and provide a much lower latency: a read-only constant memory, shared memory (which is private for each block of threads only), a texture cache and, finally, a two-level cache that is used to speed up accesses to the global memory. Coordination between threads within a kernel is achieved through synchronization barriers. However, as thread blocks run independently from all others, their scope is limited to the threads within the thread block. CPU-based techniques can be used to synchronize multiple kernels.
Generally, in a CUDA program, data are copied from the host memory to the GPU memory across the PCI bus. Once in the GPU memory, data are processed by kernels (functions that run in the GPU), and upon completion of a task the data need to be copied back to the host memory. Newer GPUs support host page-locked memory where host memory can be accessed directly by kernels, but that reduces the available memory to the rest of the applications running on the host computer. On the other hand, this eliminates the time needed to copy back and forth data from host to GPU memory and vice versa. Additionally, for image generation and manipulation application, we can use the interoperability functionality of OpenGL with CUDA to improve further the performance of an application. This is because we can render an image directly on the graphics card and avoid copying the image data from the host to GPU, and back, for each frame.
3 Parallel algorithms for image processing
Spatial domain filtering (or image processing and manipulation in the spatial domain) can be implemented using CUDA where each pixel can be processed independently and in parallel. The spatial domain is a plane where a digital image is defined by the spatial coordinates of its pixels. Another domain considered in image processing is the frequency domain where a digital image is defined by its decomposition into spatial frequencies participating in its formation. Many image-processing operations, particularly spatial domain filtering, are reduced to local neighborhood processing [31].
Let Sxy be the set of coordinates of a neighborhood (normally a 3 × 3 or 5 × 5 matrix) that is centered on an arbitrary pixel (x,y) of an image f.
Processing a local neighborhood generates a pixel (x,y) in the output image g. The intensity of the generated pixel value is determined by a specific operation involving the pixel in the input image at the same coordinates [32]. The spatial domain processing can be described by the following expression:
![]()
where f(x, y) is the intensity value of the pixel (x,y) of the input image, g(x, y) is the intensity value of the pixel (x,y) of the output image, and T is an operator defined on a local neighborhood of the pixel with coordinates (x,y), shown in Figure 1.
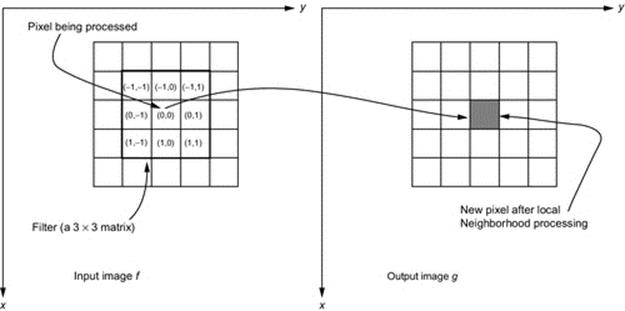
FIGURE 1 Local neighborhood processing with a 3 × 3 filter of an input pixel (x,y). New pixel value is stored in the output image at the same coordinates.
Because an operation of local neighborhood in the spatial domain is based on processing the local and limited area (typically a 3 × 3 or 5 × 5 matrix; also called filter kernel) around every pixel of the input image, these operations can be implemented separately and independently for each pixel, which provides the opportunity for these operations to be performed in parallel. The linear spatial filtering of an image of size N × M with a filter of size m × n is defined by the expression:

where f(x, y) is the input image, w(s, t) are the coefficients of the filter, and ![]() , and
, and ![]() .
.
The pseudo-code of the algorithm is shown below. An image f of size N × M is being processed where a filter w of size n × m is applied, and the result is placed in the output image g (see Pseudo-code 1).
Pseudo-code 1
for x = 1 to N do
for y = 1 to M do
Out = 0;
for s = -a to a do
for t = -b to b do
// calculate the weighted sum
Out = Out + f(x + s, y + t) * w(s,t)
g(x,y) = Out
Normally, the filter size is small in size, ranging from 3 × 3 to 5 × 5 matrices. The image size is, however, could be in thousands of pixels especially when we are working with high-definition images and video. In the above algorithm, we see four nested loops. However, only the outer two loops need to be iterated many times; since the inner two loops iterate nine times total for a 3 × 3 filter. Thus, to speed up performance we need to parallelize the outer two loops first, before even considering to parallelize the two inner loops. We can visualize the entire image as a long one-dimensional array of pixels; that's how it is stored in memory anyway. Now we can rewrite the above algorithm as such (see Pseudo-code 2).
Pseudo-code 2
foreach pixel p in f do
x = p.getXcoordinates()
y = p.getYcoordinates()
Out = 0
for s = -a to a do
for t = -b to b do
// calculate the weighted sum
Out = Out + f(x + s, y + t) * w(s,t)
g(x,y) = Out
The above algorithm collapses the two outer loops. Now, using Cuda's built-in thread and block identifiers, we can launch N × M threads where each thread will be processing a single pixel and thus eliminating the expensive two outer loops. Note that the two inner loops are not computationally expensive and can be left alone. So the revised parallel algorithm will look like Pseudo-code 3:
Pseudo-code 3
x = getPixel(threadID).getXcoordinates()
y = getPixel(threadID).getYcoordinates()
Out = 0
for s = -a to a do
for t = -b to b do
// calculate the weighted sum
Out = Out + f(x + s, y + t) * w(s,t)
g(x,y) = Out
The same CUDA function can be called for different filtering effects by passing a reference to a filter. Since the filters do not change, they can be placed in Constant memory for decreased access time. The Cuda kernel is shown below in Code 1. The filter is placed in Constant memory for increased performance. *ptr is a pointer to the input image, and *result is a pointer to the output image. Since this kernel is invoked on RGB images, the filter is applied on all three colors and the result is constrained to values from 0 to 255 using our T() function.
4 Applications for surveillance using parallel video processing
Based on the topics described earlier, we can implement several algorithms for practical surveillance applications. These algorithms that we will describe can run serially, but for improved performance we can run them in parallel. To implement and execute these algorithms we used a Lenovo W530 running Windows 8 Pro 64-bit, equipped with an i7@2.6GHz CPU, and 8GB of memory. The GPU is an NVIDIA Quadro K1000M with 192 CUDA cores.
Code 1
__global__ void Parallel_kernel(uchar4 *ptr, uchar4 *result,
const int filterWidth, const int filterHeight) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
if( offset >= N*M ) return; // in case we launched more threads than we need.
int w = N;
int h = M;
float red = 0.0f, green = 0.0f, blue = 0.0f;
//multiply every value of the filter with corresponding image pixel.
//Note: filter dimensions are relatively very small compared to the dimensions of an image.
for(int filterY = 0; filterY < filterHeight; filterY++) {
for(int filterX = 0; filterX < filterWidth; filterX++) {
int imageX = ((offset%w) - filterWidth / 2 + filterX + w) % w;
int imageY = ((offset/w) - filterHeight / 2 + filterY + h) % h;
red += ptr[imageX + imageY*w].x * filterConst[filterX+filterY*filterWidth];
green += ptr[imageX + imageY*w].y * filterConst[filterX+filterY*filterWidth];
blue += ptr[imageX + imageY*w].z * filterConst[filterX+filterY*filterWidth];
}
}
//truncate values smaller than zero and larger than 255, and store the result.
result[offset].x = T(int(red));
result[offset].y = T(int(green));
result[offset].z = T(int(blue));
}
For a camera, we used an Axis P13 series network camera attached to a Power Over Ethernet 100 Gbit switch. We wrote software that communicates with the camera using the HTTP protocol, to instruct the camera when to begin and end the video feed as well as changing the resolution of the feed. The camera transmits the video in Motion JPG format. Each frame is delimited with special tags and the header for each image frame contains the length of the data frame. We used the std_image (http://nothings.org/stb_image.c) package to decode each JPG image before passing the image frame to our processing algorithms.
4.1 Motion Detector
The first algorithm detects motion in the field of view of the camera. To implement this algorithm, we need to keep track of the previous frame to see if the current and the previous frames differ and by how much. We first calculate the square difference of the previous and the current frame; this operation is done for every pixel.
If this difference is above a set threshold, we fire a "Motion Detected" event, which can activate a sound alarm, etc., to get the attention of the operator. We can adjust the threshold value to make the detector more or less sensitive to pixel value changes. We can also display the pixels that triggered the alarm visually. The parallel algorithm is shown in Pseudo-code 4:
Pseudo-code 4
//one thread for each pixel
foreach pixel p do
color_diff = prev_color(p) - curr_color(p)
// square of different
color_diff * = color_diff
// update previous color
prev_color(p) = curr_color(p)
// empirically chosen value.
// can be adjusted to make detector more
// or less sensitive to changes.
threshold = 5000
if( color_diff > threshold ) then
fire "Motion Detected" event
current_color(p) = RED
else
leave pixel unchanged
OR make pixel gray
OR anything you want
4.2 Over a Line Motion Detector
Even though the Motion Detector algorithm presented earlier is a simple and useful algorithm, many times we are interested only in a section of the live video feed. This algorithm is applicable when, for example, there is a busy road on the left and a restricted area on the right of the field of view of the camera. A single line can divide the live video feed into two areas. Since a line is defined but only two points, an operator only needs to define these two points. Alarm events get generated only if there is motion above the user-defined line. To implement this algorithm, we will use the dot product of two vectors. There are two ways of calculating the dot product of two vectors:
![]()
![]()
We will use the second formula to calculate the dot product. To determine if a pixel C with coordinates (Cx,Cy) is above the user-specified line, which is defined by points A and B with coordinates (Ax,Ay) and (Bx,By) respectively, we need to do the following, as illustrated in Figure 2.
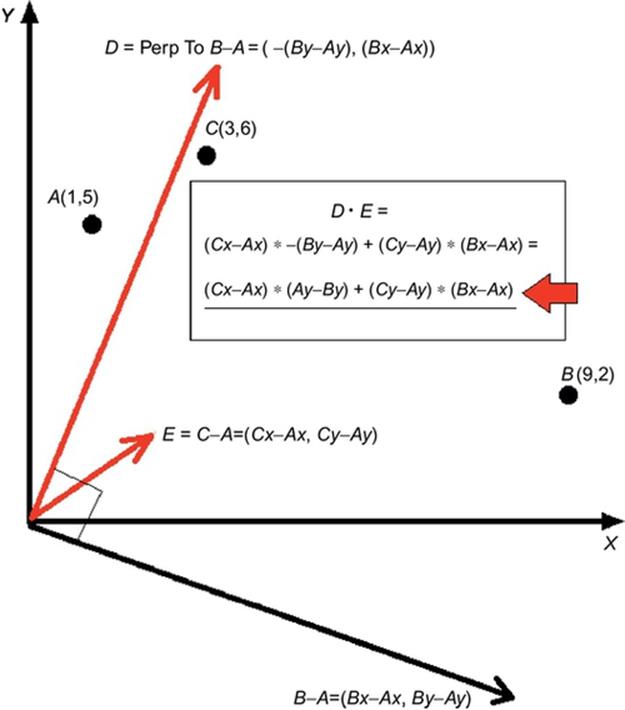
FIGURE 2 Using dot product to determining if a point is over or below a user-specified line.
First we need to find the vector that is perpendicular to the line that is defined by points A and B; we will call it vector D. We then need to find the vector E that is equal to the difference of vectors C and A. If the dot product of D and E is greater than 0, point C is above the line defined by points A and B. If it is equal to 0, point C is right on the line, otherwise point C is below the line. The parallel algorithm in pseudo-code is shown in Pseudo-code 5.
4.3 Line Crossing Detector
Line Crossing Detector is a similar algorithm to Over a Line Detector.
Pseudo-code 5
//one thread for each pixel
foreach pixel p do
color_diff = prev_color(p) - curr_color(p)
// square of different
color_diff *= color_diff
// update previous color
prev_color(p) = curr_color(p)
// empirically chosen value.
// can be adjusted to make detector more
// or less sensitive to changes.
threshold = 5000
Cx = p.getXcoordinates()
Cy = p.getYcoordinates()
// calculate dot product, see Figure 2
r = (Cx-Ax)*(Ay-By) + (Cy-Ay)*(Bx-Ax)
if( r > 0 ) then // OVER THE LINE
if ( color_diff > threshold ) then
fire "Motion Detected" event
current_color(p) = RED
else
over the line but below threshold.
could make pixel transparent
else // BELOW THE LINE
do nothing, we are not
interested in this area
Pseudo-code 6
//one thread for each pixel
foreach pixel p do
color_diff = prev_color(p) - curr_color(p)
// square of different
color_diff *= color_diff
// update previous color
prev_color(p) = curr_color(p)
// empirically chosen value.
// can be adjusted to make detector more
// or less sensitive to changes.
threshold = 5000
Cx = p.getXcoordinates()
Cy = p.getYcoordinates()
// calculate dot product, see Figure 2
r = (Cx-Ax)*(Ay-By) + (Cy-Ay)*(Bx-Ax)
if( r >= -200 && r <= 200 ) then
if ( color_diff > threshold ) then
fire "On Line Motion Detected" event
current_color(p) = RED
else
pixel on line, but no motion detected.
could make pixel green to show line
else // OVER or BELOW THE LINE
do nothing, we are not
interested in these areas
It is similar in that this algorithm is also using a line defined by two points and the dot product. However, if the dot product computed in Over a Line Motion Detector is equal to zero, then the pixel in question is located on the line.
This algorithm detects motion on the line. Because the line could be very skinny, depending on its slope, only a few pixels could end up exactly on the line. For this reason, we can make the line thicker by adjusting the limits of the dot product. Instead of checking if the dot product is equal to exactly zero, we can check if the dot product is between the positive and negative n, where n is a user-specified value. The algorithm in Pseudo-code 6 illustrates the Line Crossing Detector.
One problem with this algorithm is that the thickness of the line depends on the distance between the points A and B that specify the line. To fix this, we need to calculate the distance (length) between the two points as shown below:
// find length of line
distX=Ax-Bx;
distY=Ay-By;
LEN = sqrt(distX*distX+distY*distY);
if(LEN equals 0) then
LEN=0.001;
and then we need to replace in Pseudo-code 6
if ( r >= -200 && r <= 200 ) then
with
X=4.0
if (r/LEN >= -X && r/LEN <= X) then
Now the width of the line does not depend on the distance of the A and B points. The value of X specifies the thickness of the line, and it does not depend on the length of the vector ![]() . This is very useful when the user wants to dynamically adjust the position and orientation of the line by manipulating the points A and B.
. This is very useful when the user wants to dynamically adjust the position and orientation of the line by manipulating the points A and B.
Figure 3 is a snapshot of our application showing motion detection above a user-specified line and also motion on the line, in real time on a video feed with resolution 1920 × 1080.

FIGURE 3 Snapshot showing motion detected above a user-specified line and on the line.
4.4 Area Motion Detector
We can modify the Over a Line Motion Detector algorithm and instead of specifying one line, we can specify multiple lines. We can specify several detached areas or one area defined by a polygon. This algorithm can be used easily to define an area of interest or exclude the defined area; this can be done by simply reversing the order of the points that define the area. We will need to compute N number of dot products where N is the number of lines.
4.5 Fire Detection
As a next step, we wanted to detect not only motion but also some type of an emergency event such as fire. If we classify the pixels that contain fire, then we can highlight these pixels (change their color, enhance their brightness, etc.) and also notify an operator. This is a difficult problem to solve as it is not very trivial to classify and recognize pixels that contain fire, flame, or smoke. We used Refs. [33,34] to figure out how to detect fire in a video stream. Then we implemented the algorithm in Ref. [33] which produced relatively accurate results as shown in Figure 4. The angle of the camera seemed to influence the fire detection, but if the fire was close to the camera, this algorithm seemed to produce accurate results. We should note here that we did not incorporate the "Compute Area" part of the algorithm presented in [33] and that could be the reason of not having our implementation producing very accurate results.

FIGURE 4 Fire detection in a video stream.
5 Conclusion
In this article, we presented several algorithms that are easily implemented even by undergraduate students. These algorithms have many applications in Security and more specifically in security surveillance. Using CUDA, these algorithms can be executed in parallel for increased performance. This can be done because using CUDA we can launch one thread per pixel. So, a high-resolution image or video feed can be processed in almost the same amount of time as a low resolution image or video stream. When our students implemented these algorithms as programming assignments we found that the biggest delay in the application was the network feeding the camera video stream to the application. In this paper we present the extended results of our paper initially published in Ref. [35].
References
[1] Olsina L, Dieser A, Covella G. Metrics and indicators as key organizational assets for ICT security assessment. In: Akhgar B, Arabnia HR, eds. Emerging trends in computer science & applied computing. Elsevier Inc.; 2013:978-0-12-411474-6. Emerging trends in ICT security.
[2] Collins RT, Lipton AJ, Fujiyoshi H, Kanade T. Algorithms for cooperative multisensor surveillance. Invited paper Proc IEEE. 2001;89(10):1456–1477.
[3] Introna LD, Wood D. Picturing algorithmic surveillance: the politics of facial recognition systems. In: Norris C, McCahill M, Wood D, eds. 177–198. Surveillance & Society CCTV Special. 2004;vol. 2 2/3.
[4] Toyama K, Krumm J, Brumitt B, Meyers B. Wallflower: principles and practice of background maintenance. In: Proceedings of the international conference computer vision, Corfu, Greece; 1999:255–261.
[5] Haritaoglu I, Harwood D, Davis LS. W4: Real-time surveillance of people and their activities. IEEE Trans Pattern Anal Mach Intell. 2000;22:809–830.
[6] Stauffer C, Grimson WEL. Learning patterns of activity using real-time tracking. IEEE Trans Pattern Anal Mach Intell. 2000;22:747–757.
[7] Jiang X, Motai Y, Zhu X. Predictive fuzzy logic controller for trajectory tracking of a mobile robot. In: Proceedings of IEEE mid-summer workshop on soft computing in industrial applications; 2005.
[8] Klancar G, Skrjanc I. Predictive trajectory tracking control for mobile robots. In: Proceedings of power electronics and motion control conference; 2006:373–378.
[9] Ma J. Using event reasoning for trajectory tracking. In: Akhgar B, Arabnia HR, eds. Emerging trends in computer science & applied computing. Elsevier Inc.; 2013:978-0-12-411474-6. Emerging trends in ICT security.
[10] Nvidia Corporation's CUDA download page. https://developer.nvidia.com/cuda-downloads. Retrieved Nov. 26 2013.
[11] Husselmann AV, Hawick, KA. Spatial agent-based modeling and simulations—a review. Technical Report CSTN-153, Computer Science, Massey University, Albany, Auckland, New Zealand, October 2011. In Proc. IIMS Postgraduate Student Conference, October 2011.
[12] Husselmann AV, Hawick KA. Simulating species interactions and complex emergence in multiple flocks of birds with gpus”. In: Gonzalez T, ed. Proceedings IASTED international conference on parallel and distributed computing and systems (PDCS 2011), Dallas, USA, 14-16 Dec 2011. IASTED; 2011:100–107.
[13] Husselmann AV, Hawick KA. Parallel parametric optimization with firefly algorithms on graphical processing units. In: Proceedings of the international conference on genetic and evolutionary methods (GEM’12), number CSTN-141, Las Vegas, USA; 2012:77–83.
[14] Sang J, Lee C-R, Rego V, King C-T. A fast implementation of parallel discrete-event simulation. In: Proceedings of the international conference on parallel and distributed processing techniques and applications (PDPTA); 2013.
[15] Rego VJ, Sunderam VS. Experiments in concurrent stochastic simulation: the eclipse paradigm. J Parallel Distrib Comput. 1992;14(1):66–84.
[16] Johnson MGB, Playne DP, Hawick KA. Data-parallelism and GPUs for lattice gas fluid simulations. In: Proc. of the Int. Conf. on Parallel and Distributed Processing Techniques and Applications (PDPTA); 2010.
[17] Tadaiesky VWA, de Santana Á.L., Dias L.d.J.C., Oliveira I.d.I.d., Jacob Jr. AFL, Lobato FMF. Runtime performance evaluation of GPU and CPU using a genetic algorithm based on neighborhood model. In: Proceedings of the international conference on parallel and distributed processing techniques and applications (PDPTA); 2013.
[18] He J, Zhu M, Wainer M. Parallel sequence alignments using graphics processing unit. In: Proceedings of the international conference on bioinformatics and computational biology (BIOCOMP); 2009.
[19] Wang Z, Graham J, Ajam N, Jiang H. Design and optimization of hybrid MD5-blowfish encryption on GPUs. In: Proceedings of the international conference on parallel and distributed processing techniques and applications (PDPTA); 2011.
[20] Bobrov M, Melton R, Radziszowski S, Lukowiak M. Effects of GPU and CPU loads on performance of CUDA applications. In: Proceedings of international conference on parallel and distributed processing techniques and applications, PDPTA'11, July 2011, Las Vegas, NV, vol. II; 2011:575–581.
[21] Colantoni P, Boukala N, Da Rugna J. Fast and accurate color image processing using 3d graphics cards. In: 8th International Fall Workshop: Vision Modeling and Visualization; 2003.
[22] Ahmadvand M, Ezhdehakosh A. GPU-based implementation of JPEG2000 encoder. In: Proceedings of the international conference on parallel and distributed processing techniques and applications (PDPTA); 2012.
[23] Sánchez MG, Vidal V, Bataller J, Verdú G. Performance analysis on several GPU architectures of an algorithm for noise removal. In: Proceedings of the international conference on parallel and distributed processing techniques and applications (PDPTA); 2012.
[24] Sánchez MG, Vidal V, Bataller J, Arnal J. A fuzzy metric in GPUs: fast and efficient method for the impulsive image noise removal. In: Proceedings of the international symposium on computer and information sciences (ISCIS); 2011.
[25] Stone SS, Haldar JP, Tsao SC, Hwu WW, Liang Z-P, Sutton BP. Accelerating advanced MRI reconstructions on GPUs. In: Proceedings of the 5th international conference on computing, frontiers; 2008.
[26] Xu W, Mueller D. Learning effective parameter settings for iterative ct reconstruction algorithms. In: Fully 3D image reconstruction in radiology and nuclear medicine conference; 2009.
[27] Li L, Li X, Tan G, Chen M, Zhang P. Experience of parallelizing cryo-EM 3D reconstruction on a CPU-GPU heterogeneous system. In: Proceeding HPDC 11 proceedings of the 20th international symposium on high performance distributed computing; 2011.
[28] Anderson RF, Kirtzic JS, Daescu O. New York: Springer-Verlag New York Inc. Applying parallel design techniques to template matching with GPUs. 2011;vol. 6449.
[29] Sánchez MG, Vidal V, Bataller J, Arnal J. Implementing a GPU fuzzy filter for impulsive image noise correction. In: Proceedings of the international conference computational and mathematical methods in science and engineering (CMMSE); 2010.
[30] Chen C-h, Wu F. An efficient acceleration of digital forensics search using GPGPU. In: Proceedings of the 2013 international conference on security and management (SAM); 2012.
[31] Gonzalez RC, Woods RE. Digital image processing. 3rd ed. Prentice Hall; Upper Saddle River, NJ; 2008.9780131687288.
[32] Shiffman D. Learning processing: a beginner's guide to programming images, animation, and interaction. In: Morgan Kaufmann series in computer graphics. USA: Morgan Kaufmann, Elsevier; 2008:9780123736024.
[33] Patel P, Tiwari S. Flame detection using image processing techniques. Int J Comput Appl. 2012;58(18):13–16.
[34] Çelik T, Özkaramanlı H, Demirel H. Fire and smoke detection without sensors: image processing based approach. In: 15th European signal processing conference (EUSIPCO 2007), Poznan, Poland; 2007.
[35] Deligiannidis L, Arabnia HR. Parallel video processing techniques for surveillance applications. In: Proceedings of the 2014 international conference on computational science and computational intelligence (CSCI'14), Las Vegas, NV, USA; 2014:183–189.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.