Emerging Trends in Image Processing, Computer Vision, and Pattern Recognition, 1st Edition (2015)
Part II. Computer Vision and Recognition Systems
Chapter 19. A rough fuzzy neural network approach for robust face detection and tracking
Alfredo Petrosino; Giuseppe Salvi University “Parthenope”, Naples, Italy
Abstract
Automatic detection and tracking of human faces in video sequences are considered fundamental in many applications, such as face recognition, video surveillance, and human-computer interface. In this study, we propose a technique for real-time robust facial tracking in human facial videos based on a new algorithm for face detection in color images. The proposed face-detection algorithm extracts skin color regions in the CEILab color space, through the use of a specialized unsupervised neural network. A correlation-based method is then applied for the detection of human faces as elliptic regions. As a part of face tracking, the Kalman filter algorithm is used to predict the next face-detection window and smooth the tracking trajectory. Experiments on the five benchmark databases, namely, the CMU-PIE, color FERET, IMM, and CalTech face databases, and the standard IIT-NRC facial video database demonstrate the ability of the proposed algorithm in detecting and tracking faces in difficult conditions as complex background and uncontrolled illumination.
Keywords
Face tracking
Face detection
Rough fuzzy set
Neural clustering
Ellipse detection
Acknowledgments
This work was supported by MIUR—FIRB Project IntelliLogic (cod. RBIPO6MMBW) funded by Minister of Education, University and Research of Italy.
1 Introduction
Visual location and tracking of objects of interest, particularly, human faces in video sequences, are a critical task and an active field in computer vision applications that involves interaction with the human face by using surveillance, human-computer interface, biometrics, etc. As the face is a deformable target and its appearance easily changes because of the face-camera pose, sudden changes in illumination and complex background, tracking it is very difficult. Common methods of face detection include skin color [1,2], boosting [3,4], neural networks (NNs) [5], support vector machines (SVMs) [6,7], and template matching [8]. The results of the skin-color-based method are strongly influenced by sudden changes in lighting and the method often fails to detect people with different skin colors. In many cases, the results of the boosting, SVMs, and in particular, the NN methods suffer from the disadvantage of being strongly linked to the set of images selected for learning. For this type of approach, as face characteristics are implicitly derived from a window, a large number of face and nonface training examples are required to train a well-performed detector. To describe the face by template matching several standard patterns of a face are stored. The face detection is then computed through the correlations between an input image and the stored standard patterns. This approach, if one the one hand is simple to implement, on the other hand, has proven to be inadequate for face detection because of its extreme sensitivity to changes in both pose and orientation. Face detection may be performed on gray-scale or color images. To detect faces of different sizes and varying orientations in gray-scale images, the input image has to be rotated several times and it has to be converted to a pyramid of images [3–7] by subsampling it by a factor. Therefore, the computational complexity will increase with a complicated and time-consuming classifier. Detection using color information may be independent of face size and rotation within the color image. This approach avoids the image-scaling problem and appears to be a more promising method for a real-time face-tracking application. For this reason, in this study, we have performed face detection by using color images. The main purpose of face detection is to localize and extract with certainty a subset of pixels which satisfy some specific criteria like chromatic or textural homogeneity, the face region, from the background also to hard variations of scene conditions, such as the presence of a complex background and uncontrolled illumination. Rough set theory offers an interesting and a new mathematical approach the manage uncertainty that has been used to various soft computing techniques as: importance of features, detection of data dependencies, feature space dimensionality reduction, patterns in sample data, and classification of objects. For this reason, rough sets have been successfully employed for various image processing tasks including image classification and segmentation [9–12]. Multiscale representation is a very useful tool for handling image structures at different scales in a consistent manner. It was introduced in image analysis and computer vision by Marr and others who appreciated that multiscale analysis offers many benefits [13–18]. In this study, we have particularly proposed to make scale space according to the notion of rough fuzzy sets, realizing a system capable of efficiently clustering data coming from image analysis tasks. The hybrid notion of rough fuzzy sets comes from the combination of two models of uncertainty like coarseness by handling rough sets [19] and vagueness by handling fuzzy sets [20]. In particular the rough sets defines the contour or uniform regions in the image that appear like fuzzy sets and their comparison or combination generates more or less uniform partitions of the image. Rough fuzzy sets, and in particular C-sets first introduced by Caianiello [21], are able to capture these aspects together, extracting different kinds of knowledge in data. Based on these considerations, we report a new face-detection algorithm based on rough fuzzy sets and online learning by NN [11], able to detect skin regions in the input image at hand and thus independently from what previously seen. The extracted features at different scales by rough fuzzy sets are clustered from an unsupervised NN by minimizing the fuzziness of the output layer. The new method, named multiscale rough neural network (MS-RNN), was designed to detect frontal faces in color images and to be not sensitive to variations of scene conditions, such as the presence of a complex background and uncontrolled illumination. The proposed face-detection method has been applied to real-time face tracking using Kalman filtering algorithm [22], this filter is used to predict the next face-detection window and smooth the tracking trajectory. The article is structured as follows. In Section 2, we explain the basic theories behind the proposed method, i.e., rough sets, fuzzy sets, and their synergy. Section 3 describes the face-detection method and illustrates how these theories are applied to the process of digital images relative to the proposed method, which is specifically described in Sections 4 and 5. Section 6 introduces the proposed face-tracking method. Section 7 reports the results obtained using the proposed method, through an extensive set of experiments on CMU-PIE [23], color FERET [24,25], IMM [26], and CalTech [27] face databases; in addition, the effectiveness of the proposed model is shown when applied to the face-tracking problem on a database of YouTube video and the standard IIT-NRC [28] facial video database, comparing them with the recent results on the same topic. Lastly, some concluding remarks are presented in Section 8.
2 Theoretical background
Let X = {x1, …, xn} be a set and ![]() an equivalence relation on X, i.e.,
an equivalence relation on X, i.e., ![]() is reflexive, symmetric, and transitive. As usual, X/
is reflexive, symmetric, and transitive. As usual, X/![]() denotes the quotient set of equivalence classes, which form a partition in X, i.e., x
denotes the quotient set of equivalence classes, which form a partition in X, i.e., x![]() y means the x and y cannot be took apart. The notion of rough set [19] borns to answer the question of how a subset T of X can be represented by means of X/
y means the x and y cannot be took apart. The notion of rough set [19] borns to answer the question of how a subset T of X can be represented by means of X/![]() . It consists of two sets:
. It consists of two sets:
![]()
![]()
where [x]![]() denotes the class of elements x, y ∈ X such that x
denotes the class of elements x, y ∈ X such that x![]() y and RS−(T) and RS−(T) are, respectively, the upper and lower approximation of T by
y and RS−(T) and RS−(T) are, respectively, the upper and lower approximation of T by ![]() , i.e.,
, i.e.,
![]()
These definitions are easily extended to fuzzy sets for dealing with uncertainty. The definition of rough fuzzy sets we propose to adopt here takes inspiration, as firstly made in Ref. [29], from the notion of composite sets [21,11]. Let ![]() a fuzzy set on T defined by adding to each element of T the degree of its membership to the set through a mapping μF : T → [0, 1]. The operations on fuzzy sets are extensions of those used for conventional sets (intersection, union, comparison, etc.). The basic operations are the intersection and union as defined as follows:
a fuzzy set on T defined by adding to each element of T the degree of its membership to the set through a mapping μF : T → [0, 1]. The operations on fuzzy sets are extensions of those used for conventional sets (intersection, union, comparison, etc.). The basic operations are the intersection and union as defined as follows:
![]()
![]()
The previous are only a restricted set of operations applicable among fuzzy sets, but they are the most significant for our aim. A composite set or C-set is a triple C = (Γ, m, M) (where Γ = {T1, …, Tp} is a partition of T in p disjoint subsets T1, …, Tp, while m and M are mappings of kind T → [0, 1] such that ![]() and
and ![]() where
where
![]() (1)
(1)
for each choice of function f : T → [0, 1]. Γ and f uniquely define a composite set. Based on these assumptions, we may formulate the following definition of rough fuzzy set:
1. If f is the membership function μF and the partition Γ is made with respect to a relation ![]() , i.e., Γ = T/
, i.e., Γ = T/![]() , a fuzzy set F gets two approximations RS−(F) and RS−(F), which are again fuzzy sets with membership functions defined as Equation (1), i.e.,
, a fuzzy set F gets two approximations RS−(F) and RS−(F), which are again fuzzy sets with membership functions defined as Equation (1), i.e., ![]() and
and ![]() . The couple of sets (RS−(F), RS−(F)) is a rough fuzzy set.
. The couple of sets (RS−(F), RS−(F)) is a rough fuzzy set.
2. Let C = (Γ, m, M) and C′ = (Γ′, m′, M′) two rough fuzzy sets related, respectively, to partitions Γ = (T1, …, Ts) and Γ′ = (T1′, …, Ts′) with m(m′) and M(M′) indicating the measures expressed in Equation (1). The product between two C-sets C and C′, denoted by ⊗, is defined as a new rough fuzzy set C′′ = C ⊗ C′ = (Γ′′, m′′, M′′) where Γ′′ is a new partition whose elements are T″i,j = Ti ∩ T′j and m′′ and M′′ are obtained by:
![]()
As shown in Ref. [29], this computation scheme generalizes the concept of fuzzy set to rough fuzzy set. It has been also demonstrated in Ref. [30,31] that recursive application of the previous operation provides a refinement of the original sets, realizing a powerful tool for measurement and a basic signal-processing technique.
3 Face-detection method
The RGB color space is considered native to computer graphics (the encoding of files, CRT monitors, CCD cameras and scanners, and the rasterization of graphics cards usually use this model), and is therefore the most widespread. It is an additive model, in which the colors are produced by adding, the primary colors red, green, and blue, with white having all the colors present and black representing the absence of any color. RGB is a good space for computer graphics but not so for image processing and analysis. RGB’s major defects are the high correlation between the three channels (varying the intensities, all three components change) and the fact that it is not perceptually uniform. However, this color space can be used to generate other alternative color formats, includingYCbCr, HSI, and CIELab. CIELab is the most complete color space specified by the International Commission on Illumination (CIE). This color space is based on the opponent-colors theory of color vision, which says that a single values can be used to describe the red/green and the yellow/blue attributes as two colors cannot be both green and red at the same time, nor blue and yellow at the same time. When a color is expressed in CIELab, L defines lightness (L = 0 denotes black and L = 100 indicates diffuse white), the chromaticity coordinates (a, b), which can take both positive and negative values, denote, respectively, the red (+ a)/green (− a) value and the yellow (+ b)/blue (− b) value. The CIELab color space covers the entire spectrum visible to the human eye and represents it in a uniform way. It thus enables description of the set of visible colors independent of any graphics technology. This color space has two advantages:
1. It was designed to be perceptually uniform, i.e., perceptually similar images have the same chromaticity components.
2. The chromaticity coordinates (a, b) are distinct and independent of the lightness L.
The smooth shape and curve of a face, in some cases, may be varied considerably the intensity of the light reflected from it. The chromaticity components, instead, remain relatively unchanged and it can be used to detect skin regions. For this reason, to separate the skin from the non-skin regions, we analyze only the chromaticity distribution of an image, in particular, those relating to the chromaticity component a regardless of the lightness component. After detection of the skin regions, the luminance component of the colors is used to capture the details of the face (eyes, nose, lips, eyebrows, beard, etc.). The overall algorithm for face detection is given as a flow chart in Figure 1, where the input to the algorithm is an RGB image.
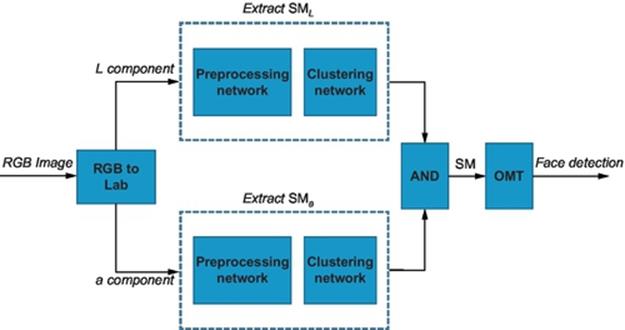
FIGURE 1 Overall face-detection method.
The luminance component L and the chrominance components a are used to create the skin map at each pixel (x, y) as follows:
![]()
where SML(x, y) and SMa(x, y) are obtained as the output of a specialized NN incurred from the integration of the rough-fuzzy-set-based scale space transform and neural clustering, and separately applied to the L component image, and a component image, as depicted in Figure 1. Finally, the skin map SM is fed as input to an algorithm for the detection of elliptical objects, as an extension of the technique reported in Ref. [32].
In Figure 2, we have presented the results obtained by applying this method to some images of CalTech database. It can be observed from the figures that the a component identifies the skin region, while the L component is used mainly to obtain the details of the face (eyes, nose, lips, eyebrows, beard, etc.).


FIGURE 2 L component, a component, and skin map (SM).
3.1 The Proposed Multiscale Method
Let us consider an image as a set X of picture elements, i.e., a Cartesian product [0, …, N − 1] × [0, …, M − 1]. X/![]() is a discretization grid in classes of pixels, such that [x]
is a discretization grid in classes of pixels, such that [x]![]() denotes the class of pixels containing x and μ is the luminance function of each pixel. Given a subset T of the image not necessarily included or equal to any [x]
denotes the class of pixels containing x and μ is the luminance function of each pixel. Given a subset T of the image not necessarily included or equal to any [x]![]() , various approximations (RS−(T) and RS−(T)) of this subset can be obtained. As instance, this subset defines the contour or uniform regions in the image. On the contrary, regions appear rather like fuzzy sets of gray levels and their comparison or combination generates more or less uniform partitions of the image. Rough fuzzy sets, and in particular C-sets, seem to capture these aspects together, trying to extract different kinds of knowledge in data. In particular, let us consider four different partitions Υi, i = 1, 2, 3, 4, of the set-image X, such that each element of Υi is a sub-image of dimension w × w and Υ2, Υ3, Υ4 are taken as shifted versions of Υ1 in the directions of 0 °, − 45 °, and − 90 ° of w − 1 pixels. In such a case, each pixel of the image can be seen as the intersection of four corresponding elements of the partitions Y1, Y2, Y3, Y4 as shown in Figure 3.
, various approximations (RS−(T) and RS−(T)) of this subset can be obtained. As instance, this subset defines the contour or uniform regions in the image. On the contrary, regions appear rather like fuzzy sets of gray levels and their comparison or combination generates more or less uniform partitions of the image. Rough fuzzy sets, and in particular C-sets, seem to capture these aspects together, trying to extract different kinds of knowledge in data. In particular, let us consider four different partitions Υi, i = 1, 2, 3, 4, of the set-image X, such that each element of Υi is a sub-image of dimension w × w and Υ2, Υ3, Υ4 are taken as shifted versions of Υ1 in the directions of 0 °, − 45 °, and − 90 ° of w − 1 pixels. In such a case, each pixel of the image can be seen as the intersection of four corresponding elements of the partitions Y1, Y2, Y3, Y4 as shown in Figure 3.
![]()
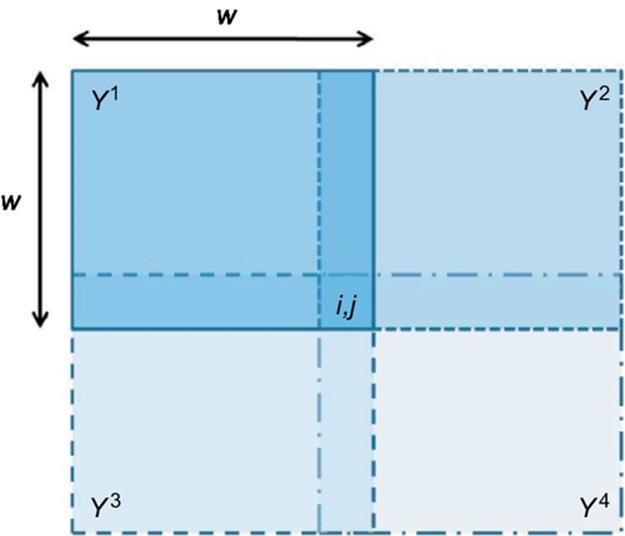
FIGURE 3 Each image pixel can be seen as the intersection of four elements of the partitions.
Since for each partition, it is possible to define a C-set, each pixel can be seen as belonging to the partition obtained by the product of the original four C-set:
![]()
where Ci is the composite set corresponding to partition Υi. We shall define as scale the size w of each partition element. The product operator is neither idempotent nor increasing. The fact that this operator is not idempotent allows it to be iteratively applied to the input signal in order to construct the scales pace. The multiscale construction follows that of a fuzzy NN [33,34]. Specifically, it consists of two pyramidal-layered networks with fixed weights, each looking upon an 2n × 2n image. By fixing the initial dimension ofCRC (Candidate Region to be Categorized), each pyramidal network is constituted by n − R multiresolution levels. Each processing element (i, j) at the rth level of the first pyramid (respectively, second pyramid) computes the minimum value (respectively maximum value) over a 2w × 2w area at the (r − 1)th level. The pyramidal structures are computed in a top-down manner, firstly analyzing regions as large as possible and then proceeding by splitting regions turned out to be not of interest. The mechanism of splitting operates as follows. If we suppose to be at the rth level of both pyramid-networks and analyze a region w × w which is the intersection of four 2w × 2w regions, the minimum and maximum values computed inside are denoted by ms,t and Ms,t,s = i, …, i + w, t = j, …, j + w. The combination of the minima and maxima values is made up at the output layer, i.e.,
![]()
If ci,j1 and ci,j2 satisfy a specific constraint, the region under consideration is seen as RC (Region to be Categorize) and the values are retained as elementary features of such a region. Otherwise, the region is divided in four sub-regions each of dimension equal tow/2. The preprocessing subnetwork is applied again to the newly defined regions. The fuzzy intersections computed by the preprocessing subnetwork are fed to a clustering subnetwork which is described in the following.
3.2 Clustering Subnetwork
Each node in the clustering sub network receives, as shown in Figure 4, two input values from each corresponding neuron at the previous layer. In particular, at each iteration, a learning step is applied to the clustering subnetwork according to the minimization of a Fuzzines Index (FI), applying, and somewhere extending, the learning mechanism proposed in Ref. [35].
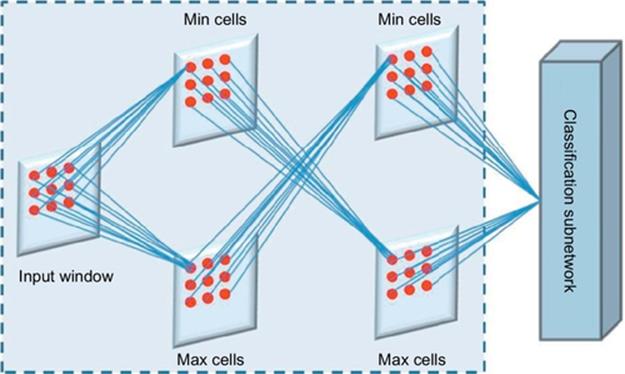
FIGURE 4 The preprocessing networks.
The output of a node j is then obtained as:
![]()
where ![]() and
and ![]() , where wj,iq indicates the connection weight between the jth node of the output layer and the ith node of the previous layer in the qth cell-plane, q = 1, 2. Each sum is intended over all nodes i in the neighborhood of the jth node at the upper hidden layer. f (the membership function) can be sigmoidal, hyperbolic, Gaussian, Gaborian, etc. with the accordance that if oj takes the value 0.5, a small quantity (usually 0.001) is added; this reflects into dropping out instability conditions. g is a similarity function, e.g. correlation, Minkowsky distance, etc. To retain the value of each output node oj in [0, 1], we apply the following mapping to each input image pixel g:
, where wj,iq indicates the connection weight between the jth node of the output layer and the ith node of the previous layer in the qth cell-plane, q = 1, 2. Each sum is intended over all nodes i in the neighborhood of the jth node at the upper hidden layer. f (the membership function) can be sigmoidal, hyperbolic, Gaussian, Gaborian, etc. with the accordance that if oj takes the value 0.5, a small quantity (usually 0.001) is added; this reflects into dropping out instability conditions. g is a similarity function, e.g. correlation, Minkowsky distance, etc. To retain the value of each output node oj in [0, 1], we apply the following mapping to each input image pixel g:
![]()
where gmin and gmax are the lowest and highest gray levels in the image.
The subnetwork has to self-organize by minimizing the fuzziness of the output layer. Since the membership function is chosen to be sigmoidal, minimizing the fuzziness is equivalent to minimizing the distances between corresponding pixel values in both cell-planes at the upper hidden layer. Since random initialization acts as noise, all the weights are initially set to unity. The adjustment of weights is done using the gradient descent search, i.e., the incremental change Δwj,il, l = 1, 2, is taken as proportional to the sum of the negative gradient − η(∂E/∂oi)f′(Ii)oj. The adjustment rule is then the following:
![]()
Specifically, we adopted the Linear Index of Fuzziness (LIF), whose updating rules look as follows, where E indicates the energy-fuzziness of our method and n = M × N. LIF learning:
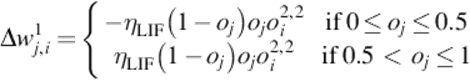
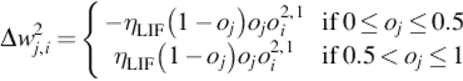
where ηLIF = η × 2/n.
The previous rules hold also for the determination of an exact threshold value, θ, adopted for dividing the image into skin regions and nonskin regions, when convergence is reached. According to the properties of fuzziness, the initial threshold is set to be 0.5; this value allows to determine an hard decision from an unstable condition to a stable one. As said before, the updating of weights is continued until the network stabilizes. The method is said stable (the learning stops) when:
![]()
where E(t) is the method fuzziness computed at the tth iteration, γ is a prefixed very small positive quantity and ![]() . After convergence, the pixels j with oj > θ are considered to constitute the skin map of the image; they are set to take value 255, in contrast with the remaining which will constitute the background (value 0). Figure 5 shows, with a 3D representation, the segmentation process (b) and (c) performed by the MS-RNN method on the input image depicted in (a).
. After convergence, the pixels j with oj > θ are considered to constitute the skin map of the image; they are set to take value 255, in contrast with the remaining which will constitute the background (value 0). Figure 5 shows, with a 3D representation, the segmentation process (b) and (c) performed by the MS-RNN method on the input image depicted in (a).

FIGURE 5 (a) Original images, (b) L component, (c) a component, and (d) skin map (SM).
4 Skin Map Segmentation
We transformed the image model into CEILab and normalized the luminance component L and the chrominance components a in the range of [0, 255]. To realize multiclass image segmentation, the CRC must satisfy a homogeneity constraint, i.e., the difference between ci,j1 and ci,j2 must be less than or equal to a prefixed threshold. In such a case, the region is seen as uniform and becomes RC otherwise, the CRC is split into four newly defined CRC, letting w be w/2. The parameters of the preprocessing subnetwork have been set to the following values:
• w0 = 8, wt = wt − 1/2 (t denotes iteration)
• θ = 50
The output of the preprocessing subnetwork normalized in the [0, 1] range is fed to a clustering subnetwork. The parameters of the clustering subnetwork have been set to the following values:
• η = 0.2 (learning rate)
• γ = 0.001 (convergence rate)
The reason for these choices resides in a most successful skin-detection system, both for detecting skin and suppressing noise, while requiring the minimum amount of computation or, equivalently, minimum number of iterations to converge.
4.1 Skin Map Segmentation Results
Several experiments were performed on real images to test the efficacy of the proposed method. In Figures 6 and 7, we present the results obtained by applying this method to some images.


FIGURE 6 Images of CalTech, IMM, and CMU face database and skin map obtained by the algorithm proposed.

FIGURE 7 Multiface image and the skin map obtained by the algorithm proposed.
5 Face detection
Face detection is achieved by detecting elliptical regions in the skin map by properly modifying the Orientation Matching (OM) technique reported in Ref. [32]. The technique detects circular objects of radius in the interval [rm, rM], computing the OM transform of the input image and taking the peaks of the transform, which correspond to the centers of the circular patterns. To customize the technique for handling our problem of detecting elliptical pattern in the skin map, we performed a statistical analysis on 500 images taken from the databases used to test the method to find a proper ratio between major and minor semi-axis of ellipses around faces. We statistically found this ratio as 0.75. In Figures 8 and 9, we present the results achieved by applying this method to the binary skin map obtained as the output of the multiscale method.

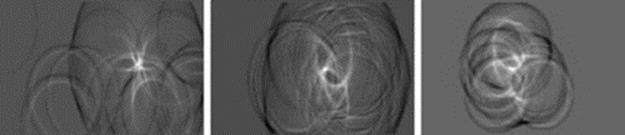
FIGURE 8 Images of CalTech, IMM, and CMU face database and the results of the OM technique.

FIGURE 9 Multiface image and the result of the OM technique.
6 Face Tracking
The use of our MS-RNN method for face tracking relies on the fact that the skin color is invariant to face orientation and is insensitive to partial occlusion. Also, our system proved insensitive to variations of scene conditions, such as the presence of a complex background and uncontrolled illumination. Based on these considerations, we applied the MS-RNN method at any frames of video sequences and the Kalman filter algorithm [22]. Kalman filtering helps to predict the next face-detection window and smooth the tracking trajectory. Face detection is performed within a predicted window instead of an entire image region to reduce computation costs. The x − y coordinates and height of the face region are initially set to the values given by the face-detection process, while the velocity values of the state vector are set to 1. The face motion model used in our tracking method can be defined by the following set of space-state equations:
![]()
where xk represents the state vector at the time k, characterized by five parameters consisting of the x − y coordinates of the center point of the face region (cx, cy), the velocity in the x and y directions (vx, vy), and the height Hk of the face-bounded region. The width of the face-bounded region is always assumed to be 0.75 times the size of the calculated height. The transition matrix, Φ, which relates the current state to the predicted state after the time interval Δt is given as:
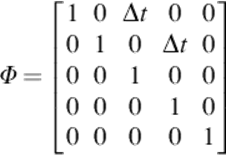
The vector zk ∈ ![]() 3 represents the face position and height observed with the observation matrix:
3 represents the face position and height observed with the observation matrix:
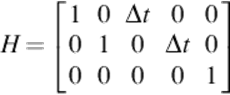
and wk and vk are the zero-mean, white, Gaussian random processes modeling the system noise. The whole filtering procedure consists of prediction and correction steps, which are carried out alternatively. The state in the next time step is predicted from the current state using:
![]()
Face detection is performed on the window of height Hk + 1|k and width 0.75Hk + 1|k centered at a predicted position. Detection within the window instead of the whole image helps to reduce the detection time, which is important for real-time operations. The Kalman corrector is
![]()
where Kk + 1 is the Kalman gain, computed as
![]()
The covariance matrix P is updated as follows:
![]()
where Qk = E[wkwkT], Rk = E[vkvkT] and P0|0 = E[x0x0T]. The face detector and the tracker are used simultaneously. The overall algorithm for face tracking is given as a flow chart in Figure 10.
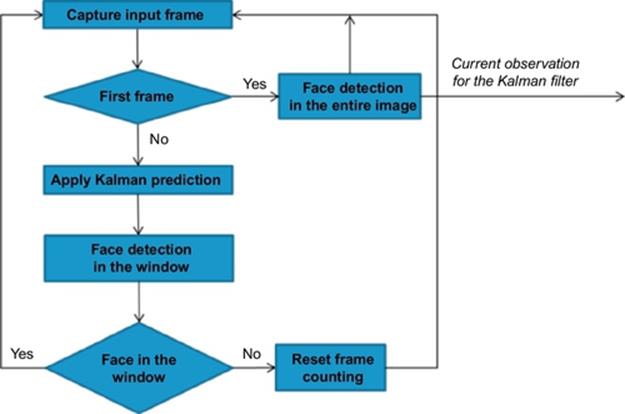
FIGURE 10 Overall face-tracking algorithm.
7 Experiments
7.1 Face-Detection Experiments
7.1.1 Experiment 1
To form an experimental dataset and evaluate the effectiveness of the proposed color face-detection method in terms of face-detection performance, a total of 7266 facial images from 980 subjects were collected from three publicly available face databases, CMU-PIE [23], color FERET [24,25], and IMM [26]. A total of 2847 face images of 68 subjects were collected from CMU-PIE; for one subject, the images had different expressions and 21 lighting variations with "room lighting on" conditions. From Color FERET, a total of 4179 face images of 872 subjects were collected; for one subject, the images included five different pose variations. Specifically, the pose angles were in the range from − 45° to + 45°. From IMM, a total of 240 face images of 40 subjects were collected; for 1 subject, the images include 6 different pose variations. Specifically, the pose angles were in the range from − 30° to + 30°. The face images used in Experiment 1 were scaled down to their one-fourth size. Figure 11 shows some of the test images and SM results.


FIGURE 11 Eight of the 7266 images in Experiment 1 and skin map segmentation results.
To evaluate the performance of the face-detection algorithm, a number of detection rates and false alarms are used. The detection rate is defined as the ratio between the number of faces correctly detected and the actual number of faces, while a false alarm is a detection of the face where there is no face. Table 1 shows the results of the MS-RNN face-detection method on CMU-PIE, color FERET, and IMM databases.
Table 1
Experimental Results on CMU-PIE, Color FERET, and IMM Databases
|
Database |
Detection Rate (%) |
False Alarms |
|
CMU-PIE |
92.16 |
175 |
|
color FERET |
96.53 |
16 |
|
IMM |
98.65 |
0 |
Table 1 shows that the proposed algorithm for face-detection exhibits very good performance in detecting faces, which is also affected by scene condition variations, such as the presence of a complex background and uncontrolled illumination. However, the MS-RNN method is noted to be sensitive to the images where the background (neutral illumination) is turned off, mainly those obtained from CMU-PIE database.
7.1.2 Experiment 2
This experiment used the CalTech [27] face database. A total of 450 frontal images of 27 people of different races and facial expressions were included. Each image was of 896 × 592 pixels. The experiment employed detection and false alarms to evaluate the face-detection performance. Figure 12 shows some detection results.


FIGURE 12 Face-detection results by the proposed method in Experiment 2.
Table 2 shows the comparison of the results of the MS-RNN face-detection method on CalTech databases with other fast face-detection methods reported in Refs. [6,9], which may be applied to real-time face tracking. Specifically, the first method used for comparison extends the detection in gray-images method presented in Ref. [6] to detection in color images. The second method segments skin colors, in the HSV color space, using a self-organizing Takagi-Sugeno fuzzy network with support vector learning [9]. A fuzzy system is used to eliminate the effects of illumination, to adaptively determine the fuzzy classifier segmentation threshold according to the illumination of an image. The proposed method showed the highest detection rate as well as the smallest number of false alarms, when compared with other methods.
Table 2
Experimental Results on CalTech Database
|
Method |
Detection Rate (%) |
False Alarms |
|
Texture + SVM [6] |
95.7 |
91 |
|
SOTFN-SV + IFAT [9] |
95.7 |
67 |
|
Proposed method |
98.43 |
20 |
7.2 Face-Tracking Experiments
The proposed system was written in Visual C++ and implemented on a personal computer with an Intel Core i3 3.1 GHz CPU and Windows 7 operating system. The proposed detection system took 0.516 (s) for an image measuring 720 × 576 pixels. During the tracking process, the detection window size was 200 × 200 pixels, and the detection time was about 0.08 s if only the detection operation was conducted. The real-time tracking system uses a SONY CCD camera to capture images, and each image measured 720 × 576 pixels. At the start, a face was detected from the whole captured image, and subsequently, a face was detected within a predicted search region measuring 200 × 200 pixels.
7.2.1 Experiment 1
In this experiment, we tested the quality of the proposed face-tracking system on the standard IIT-NRC facial video database compared with the incremental visual tracker (IVT). This database contains short videos that show large changes in facial expression and orientation of the users taken from a web-cam placed on the computer monitor. In Figure 13, we have illustrated the tracking results of our approach and IVT on the IIT-NRC facial video database. We noted that our method, unlike the IVT approach, is capable of tracking the target presenting a pose (190, 206), expression (89, 104), and size (89) variation, and maintaining the size of the face detected, which allows the use of the frames tracked in the recognition.


FIGURE 13 Results of our approach and IVT tracker on the IIT-NRC facial video database.
7.2.2 Experiment 2
In this experiment, we tested the quality of the proposed face-tracking system on a set of 500 video clips collected from YouTube. The frame size ranged from (320 × 240) to (240 × 180) pixels. Despite the heavy rate of noise in the video used, mostly due to the low resolution and high compression rate, our tracker successfully tracked 90 % of the video clips. In Figure 14, we have presented examples of well-tracked videos. The level of performance obtained by our tracker is more than satisfactory by taking into account the low quality and high variability in the data tested.


FIGURE 14 Face-tracking results on YouTube video clips.
7.2.3 Experiment 3
Figure 15 shows the tracking results for a succession of captured frames. These results show that, the proposed system can correctly track a subject under various complex motion and partial occlusion. By tracing the center point of the face detected in each frame, we obtained a motion signature as shown in Figure 16. Such motion signatures can be used to characterize human activities.

FIGURE 15 Face tracking of a subject under various complex motion and partial occlusion.
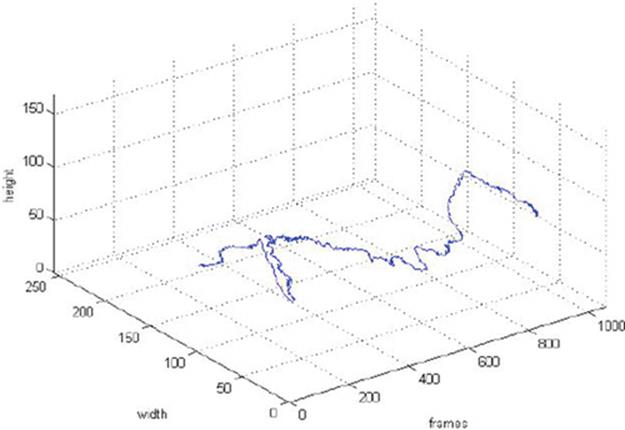
FIGURE 16 The motion signature obtained by tracing the center point of the face detected in each frame.
8 Conclusions and Future Works
A new method for face tracking and detection has been presented in this study, which has been designed to detect frontal faces in color images without a priori knowledge about the number of faces or the size of the faces in a given image. All our experiment results show that the proposed method can obtain high detection rates in the presence of both simple and complex backgrounds. SM detection may not be suitable for certain cases, such as when there are colors in the image that resemble the skin, but are not skin pixels. To overcome this problem OM transform could be employed to correctly detect the face region in the SM image. The ongoing work involves increasing the speed of our proposed method as well as adopting parallel processing provided by GPUs. In addition, the method is also being adopted as a pre-processor for a face recognition system, such that false positives may be rejected by the face validation process of the recognition system.
References
[1] Sun YB, Kim JT, Lee WH. Extraction of face objects using skin color information. In: Proceedings of the IEEE international conference on communications, circuits and systems and West Sino expositions; 2002:1136–1140.
[2] Soriano M, Martinkauppi B, Huovinen S, Laaksonen M. Adaptive skin color modeling using the skin locus for selecting training pixels. Pattern Recogn. 2003;36(3):681–690.
[3] Viola P, Jones MJ. Robust real-time face detection. Int J Comput Vis. 2004;57(2):137–154.
[4] Lienhart R, Maydt J. An extended set of Haar-like features for rapid object detection. 900–903. Proceedings of the IEEE international conference on image processing. 2002;vol. 1.
[5] Rowley H, Baluja S, Kanade T. Neural network-based face detection. IEEE Trans Pattern Anal Mach Intell. 1998;20(1):23–38.
[6] Sun Z, Bebis G, Miller R. Object detection using feature subset selection. Pattern Recogn. 2004;37(11):2165–2176.
[7] Juang CF, Chang SW. Fuzzy system-based real-time face tracking in a multi-subject environment with a pan-tilt-zoom camera. Expert Syst Appl. 2010;37(6):4526–4536.
[8] Kim HS, Kang WS, Shin JI, Park SH. Face detection using template matching and ellipse fitting. IEICE Trans Inf Syst. 2000;11:2008–2011.
[9] Hassanien AE. Fuzzy-rough hybrid scheme for breast cancer detection. Image Comput Vis J. 2007;25(2):172–183.
[10] Mitra S, Banka H, Pedrycz W. Rough-fuzzy collaborative clustering systems. IEEE Trans Man Cybern B. 2006;36(4):795–805.
[11] Petrosino A, Salvi G. Rough fuzzy set based scale space transforms and their use in image analysis. Int J Approx Reasoning. 2006;41:212–228.
[12] Sarkar M. Rough-fuzzy functions in classification. Fuzzy Sets Syst. 2002;132(3):353–369.
[13] Marr D, Ullman S, Poggio T. Bandpass channels, zero-crossing, and early visual information processing. J Opt Soc Am. 1979;69:914–916.
[14] Bangham JA, Ling PD, Harvey R. Scale-space from nonlinear filters. IEEE Trans Pattern Anal Mach Intell. 1996;18:520–528.
[15] Cantoni V, Cinque L, Guerra C, Levialdi S, Lombardi L. 2-D object recognition by multiscale tree matching. Pattern Recogn. 1998;31(10):1443–1454.
[16] Dyer CR. Multiscale image understanding. In: Uhr L, ed. Parallel computer vision. New York: Academic Press; 1987:171–213.
[17] Rosenfeld A, ed. Multiresolution image processing and analysis. Berlin: Springer; 1984.
[18] Ueda N, Suzuki S. Learning visual models from shape contours using multi-scale convex/concave structure matching. IEEE Trans Pattern Anal Mach Intell. 1993;15(4):337–352.
[19] Pawlak Z. Rough sets. Int J Comput Inform Sci. 1982;11(5):341–356.
[20] Zadeh LA. Fuzzy sets. Inform Control. 1965;8:338–353.
[21] Caianiello ER. A calculus of hierarchical systems. In: Proceedings of the international conference on pattern recognition, Washington, DC; 1973:1–5.
[22] Catlin DE. Estimation, control, and the discrete Kalman filter. New York: Springer-Verlag; 1989.
[23] Sim T, Baker S. The CMU pose illumination and expression database. IEEE Trans Pattern Anal Mach Intell. 2003;25(12):1615–1617.
[24] Phillips PJ, Wechsler H, Huang J, Rauss P. The FERET database and evaluation procedure for face recognition algorithms. Image Vis Comput J. 1998;16(5):295–306.
[25] Phillips PJ, Moon H, Rizvi SA, Rauss PJ. The FERET evaluation methodology for face recognition algorithms. IEEE Trans Pattern Anal Mach Intell. 2000;22(10):1090–1104.
[26] Stegmann MB, Ersbøll BK, Larsen R. FAME–a flexible appearance modeling environment. IEEE Trans Med Imag. 2003;22(10):1319–1331.
[27] Markus W. Face database collection of Markus Weber. [Online] 02 February 2006. Available: http://www.vision.caltech.edu/Image_Datasets/faces/.
[28] Gorodnichy DO. Associative neural networks as means for low resolution video-based recognition. In: International joint conference on neural networks (IJCNN); 2005.
[29] Dubois D, Prade H. Rough fuzzy sets and fuzzy rough sets. In: International conference on fuzzy sets in informatics, Moscow, September 20–23; 1993.
[30] Caianiello ER, Ventre A. A model for C-calculus. Int J General Syst. 1985;11:153–161.
[31] Caianiello ER, Petrosino A. Neural networks, fuzziness and image processing. In: Cantoni V, ed. Machine and human perception: analogies and divergencies. New York: Plenum Press; 1994:355–370.
[32] Ceccarelli M, Petrosino A. The orientation matching approach to circular object detection. In: Proceedings of the IEEE international conference on image processing; 2001:712–715.
[33] Lee S, Lee E. Fuzzy neural networks. Math Biosci. 1975;23:151–177.
[34] Simpson PK. Fuzzy min-max neural networks—part I: classification. IEEE Trans Neural Netw. 1992;3:776–786.
[35] Ghosh A, Pal NR, Pal SK. Self-organization for object extraction using a multilayer neural network and fuzziness measures. IEEE Trans Fuzzy Systems. 1993;1:54–68.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.