Emerging Trends in Image Processing, Computer Vision, and Pattern Recognition, 1st Edition (2015)
Part II. Computer Vision and Recognition Systems
Chapter 20. A content-based image retrieval approach based on document queries
M. Ilie “Dunarea de Jos” University of Galati, Faculty of Automatic Control, Computers, Electrical and Electronics Engineering, Galati, Romania
Abstract
This chapter presents a new content-based image retrieval (CBIR) approach, which makes use of descriptors originating in the local and global search spaces. The algorithm extracts four color descriptors, one texture descriptor, and two local descriptors which are used to train the corresponding classifiers, based on neural networks. Subsequently, the classifiers are grouped in two weighted majority voting modules, for local and global characteristics. The system is tested on regular images and on document scans obtained from two datasets used a benchmark in previous conferences, in order to verify the architecture robustness. The experimental results demonstrate the effectiveness of the proposed model.
Keywords
CBIR
Neural networks
Image descriptors
Weighted majority voting
Acknowledgments
The authors would like to thank the Project SOP HRD/107/1.5/S/76822—TOP ACADEMIC of University “Dunarea de Jos” of Galati, Romania.
1 Introduction
The necessity of the content-based image retrieval (CBIR) phenomenon was imposed by the problems encountered in different areas. Initially, the image classification was done based on text labels, which was proven to be very time consuming and error prone. Starting from this problem, the image processing techniques have been improved, combined, and extended across a vast number of fields, like duplicate detection and copyright, creating image collections, medical applications, video surveillance and security, document analysis, face and print recognition, industrial, military, and so on. The term of “content” implies that the images are deconstructed into descriptors, which are analyzed and interpreted as image features, as opposed to image metadata, like annotations, geo-tags, file name, or camera properties (flash light on/off, exposure, etc.).
The traditional CBIR approaches try to solve this problem by extracting a set of characteristics from one image and comparing it with another one, representing a different image. The results obtained until now are promising but still far from covering all the requirements risen by a real world scenario. Also, the current approaches target specific problems in the image processing context. Because of that most of the CBIR implementations work in a rather similar way, on homogenous data. This causes significant performance drops whenever the test data originate from a different area than the training set.
This chapter proposes a CBIR architecture model with descriptors originating in different search areas. In order to be able to classify images originating in document scans, we have added an extra module, responsible for the document image segmentation stage. The user is offered the possibility of querying the engine with both document scans and regular images in order to retrieve the best N matches.
During the implementation stage we have faced multiple problems, as specified below:
• image preprocessing;
• extraction of characteristics from various spaces;
• implementation of a supervised machine learning module;
• document image segmentation;
• benchmarking the overall performance.
We have reached the conclusion that a CBIR engine can obtain better results in the presence of multiple sets of descriptors, from different search spaces or from the same one, even if the test images originate in very different areas.
2 Related Work
The CBIR engines are trying to mimic the human behavior when executing a classification process. This task is very difficult to accomplish due to a large series of factors.
The CBIR queries may take place at different levels [1]:
• feature level (find images with X% red and Y% blue);
• semantic level (find images with churches);
• affective level (find images where a certain mood prevails). There is no complete solution for the affective queries.
All the CBIR implementations use a vector of (global or local) characteristics which originate in different search spaces—color, texture, or shape.
In the color space there are many models but recently the focus is set on various normalizations of the RGB one in the attempt of obtaining invariant elements. Two of the most interesting ones are c1c2c3 (which eliminates both shadows and highlight areas) and l1l2l3 (which eliminates only the shadows, but keeps the highlight areas) [2].
There are four large categories for determining the texture descriptors [3]:
• statistical (Tamura features, Haralick's co-occurrence matrices);
• geometrical (Voronoi tesselation features);
• spectral (wavelets [4], Gabor and ICA filters);
• model based (MRFs [5], fractals).
One of the most widely embraced approach is to use local binary patterns [6].
In what regards the local descriptors, probably the most famous algorithm (scale invariant feature transform—SIFT) was introduced by Lowe [7]. Since then, many approaches have been developed. Some of the most popular ones are based on speeded up robust feature (SURF) [8], histogram of oriented gradients (HOG) [9], gradient location and orientation histogram (GLOH) [10], or local energy-based shape histogram (LESH) [11].
3 Our approach
The proposed approach targets to classify a mixed set of images, containing real world scenes and document scans. The system mainly follows the standard CBIR architecture as it can be seen in Figure 1. It is composed of two interconnected submodules:
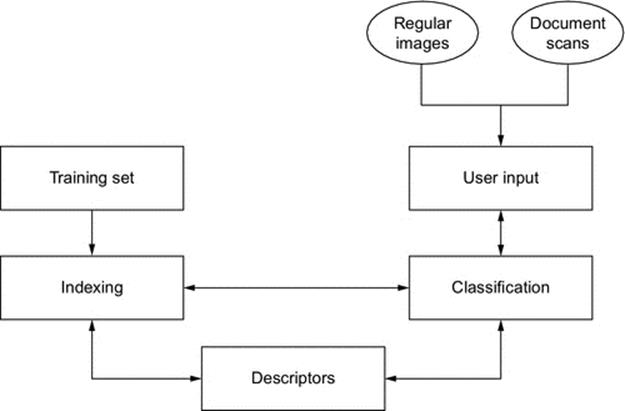
FIGURE 1 The basic system architecture.
• the training and learning module;
• the document classification module.
A valid use case scenario contains the below stages:
• the system is trained on a set of images;
• each image is analyzed and decomposed in relevant descriptors;
• the descriptors are provided as input to a machine learning module, which is in charge of setting the class boundaries;
• each new regular image (not document) is decomposed and classified accordingly;
• each new document scan is preprocessed and segmented. The extracted images are then classified;
• the system extracts the 10 most relevant results and provides them as an answer to the user query.
The indexing process is based on supervised machine learning and is conducted on regular images. The user is allowed to enter queries based on both image types.
We are using a mixed set of image characteristics:
• different color spaces;
• texture space;
• local descriptors.
We have not used any shape descriptors, as the preliminary tests showed that in this area these do not produce a noticeable improvement. The main problem was caused by the fact that the objects contained in the images may be affected by problems like occlusion or clutter.
In the color descriptors area, we have used four sets of characteristics, as it follows:
• c1c2c3 and l1l2l3. As explained above, these color spaces are very useful when applied on real world images. The coordinates are described by the equations below:
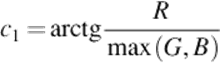 (1)
(1)
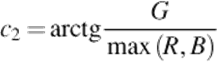 (2)
(2)
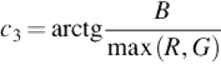 (3)
(3)
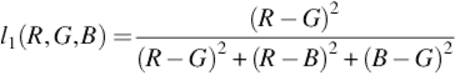 (4)
(4)
(5)
(6)
• the whole image in RGB coordinates;
• the RGB histogram, with 256 bins.
Each of the four sets of characteristics is used as an input for a standard feed forward/back propagation neural network. The neural networks' outputs are then collected by a simplified weighted majority voting module, as it can be observed in Figure 2.
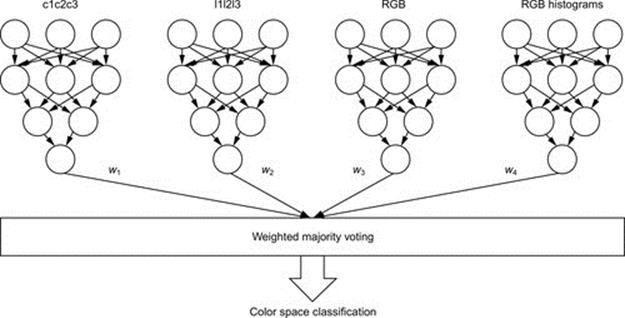
FIGURE 2 Color space classification.
The weighted module works according to the below algorithm:
• let n be the number of accepted classes and k be the number of classifiers;
• each neural network will produce on the final layer a vector Cx = {c1, c2, …, cn}, where 1 ≤ x ≤ k;
• the weight associated to the output layer will be W = {w1, w1, …, wk};
• the weighted result will be provided by the wiCi sum, as specified below, where R ε [1, n], max(C) represents the maximum value obtained for a certain class, and idx represents the position of this class in the final vector
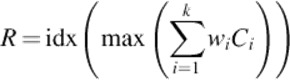 (7)
(7)
In the texture space area we have chosen an approach based on local binary pattern descriptors, mainly because of their invariant properties for color or rotation.
For the local descriptors we have chosen two sets of characteristics, based on SIFT and histogram of oriented gradients (HOG). Traditionally, the HOG descriptors are used in order to train an SVM classifier, but since we are dealing with a multiple classification problem, we have used neural networks in the learning stage for both descriptors. The two types of local descriptors produced similar results during the tests, therefore the combined classifier for SIFT and HOG uses equal weights of 50%.
The final classifier includes an additional weighted majority voting module, as shown in Figure 3.
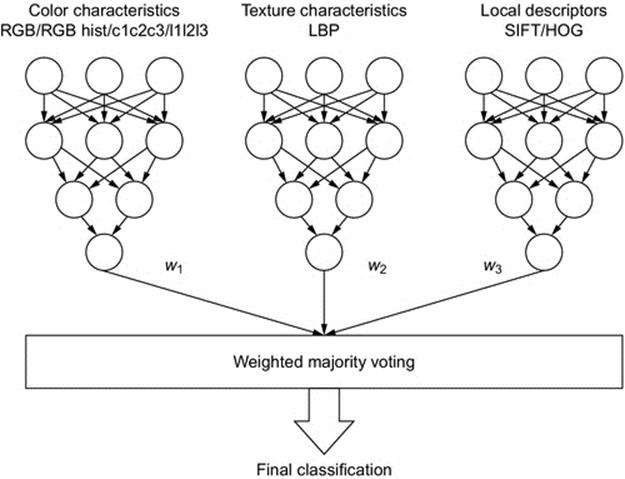
FIGURE 3 The final classification.
Since the aim is to classify document scans as well as regular images, we have also included an additional document analysis module. Its purpose is to process the scans and extract the images included in the document, in order to pass them subsequently to the module in charge of extraction of descriptors and to classify them accordingly. We are not interested in text segmentation, therefore this module will only binarize the document and go through a bottom-up [12] image segmentation stage, based on the below steps:
• text filtering, implemented as a simplified XY axis projection module [13];
• the document is split in tiles, which are analyzed according to their average intensity and variance. The decision criteria is that in a particular tile, an image tends to be more uniform than the text;
• the remaining tiles are clustered through a K-Means algorithm, which uses as a decision metric the Euclidean distance;
• the clusters are filtered according to their connectivity and scarcity scores in order to eliminate tiles containing text areas with different fonts, affected by noise/poor illumination or by page curvature;
• the final clusters are exposed to a reconstruction stage and merged into a single image, which is provided as an input to the modules in charge of descriptors extraction/classification (Figure 4).

FIGURE 4 Document image segmentation results.
All the neural networks have the same structure. The transfer function is sigmoid and the images in the training set have been split in three groups:
• 60% for training;
• 20% for cross-validation;
• 20% for testing.
In order to validate the neural network progress, we have used gradient checking on the cost function specified below:
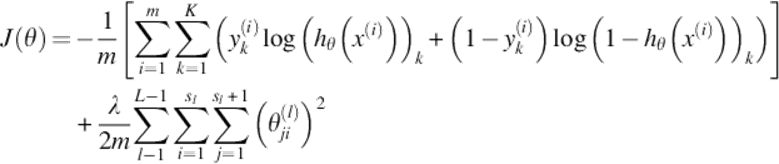 (8)
(8)
with the following notations:{(x(1), y(1)), (x(2), y(2)), … , (x(m), y(m))} is the (input, output) vector, hθ(x) ∈ RK is the hypothesis function, L is the number of layers, sl is the number of neurons in a specific layer l, K is the number of classes, with y ∈ RK, and Θ, the matrix which stores the weights for each layer.
4 Experimental setup
We aimed to create a scalable application, portable between different architectures and operating systems. Therefore, in what regards the programming language, we have chosen python over Matlab or Octave, for practical reasons, especially for the libraries which facilitate the user interface generation, socket management, and data processing. The operating system is a 12.04 LTS 32 bit Ubuntu, running on a machine with two cores with hyper threading and 4 GB of RAM. The software architecture is modular to facilitate any subsequent refactoring; each sub-module is implemented in a class. In order to make better use of the hardware, the modules that require resources intensively use multi-threading and multi-processing techniques. The data are stored in a MySQL database, based on MyISAM. The application follows the standard client-server architecture, in order to facilitate the exposure of functionalities to multiple users at once. So far, we have disregarded the user management problems.
We have restricted the number of recognized classes at 10 so far. The training was conducted on a CIFAR data set, provided by Ref. [14]; it includes 60,000 small (32 × 32 pixels) color images. The author's tests involved feed forward neural networks as well, with performances revolving around 87%.
The document scans data consisted of 1380 images, obtained from two sources:
• scans of old, degraded documents, used as a benchmark in the ICDAR 2007 conference [15];
• high quality copies, containing mostly manuals and documentation for the Ubuntu 12.04 operating system. In order to be able to use them, we have previously converted them from the pdf format to the jpeg one.
Initially we have tried replicating the CIFAR benchmark results. We have also used a neural network approach, based on RGB descriptors only; we obtained similar performances (85%). However, when we tried to classify an image originating from a different image set (document scans), the accuracy dropped significantly, by more than 10%. Therefore, we started experimenting with various combinations of RGB/c1c2c3/l1l2l3 descriptors. The results are described in Table 1 [16].
Table 1
Color Space Experiments
|
Combined Descriptors |
Results (%) |
|
RGB + l1l2l3 |
82 |
|
RGB + c1c2c3 |
84 |
|
RGB + RGB histograms |
69 |
|
RGB |
71 |
As we can observe, the presence of the c1c2c3 and l1l2l3 color spaces produces an improvement of over 10%, leading to the below conclusions:
• the experiments conducted on real world images confirm the necessity of additional color space descriptors;
• c1c2c3 produces the most solid performance boost. After analyzing the images in the data set, we have observed the presence of many pictures with shady areas, which shows that this color space is adequate for these conditions. Figure 5 shows the effects of the c1c2c3 normalization on an image containing highlight and shadow areas;
FIGURE 5 c1c2c3 normalization.
• introducing the RGB histograms as a global descriptor actually produced a performance drop, as two different images may have very similar color histograms, yet a very different content. This was mainly caused by the surrounding conditions in which the picture of a certain object was taken. Also, the presence of the shadow areas affects the histograms and implicitly the classification result.
After experimenting with various color space weight values we have chosen the below values:
• the RGB histograms weights have been set to w4 = 10%, which improved the overall performance. We have kept this set of descriptors for situations where the color plays a more important role in the classification process. In this case, the user will be able to adjust this value accordingly;
• the rest of the weights have been set to w[1:3] = 30% (for the RGB/c1c2c3/l1l2l3 descriptors). This lead to a combined overall performance of 86%. As we mentioned before, the UI offers the user the possibility of manually adjusting the global color relevance (associated to the RGB histograms) in the final result. As an example, the user can choose a combination like w1 = 20%, w2 = 20%, w3 = 20%, and w4 = 40%.
The next set of experiments was conducted in the texture space, with the LBP descriptor. The main problems in this area were related to choosing the cell shape and size, along with the number of pixels which compose the final descriptor. After a series of tests we concluded the below:
• choosing radial cells over square cells produces an overall performance increase of over 10%, going over 95%;
• the execution times are larger when using radial cells, especially due to the trigonometric calculus;
• over-increasing the cell size leads to performance drops, as the small textures are ignored.
The conclusion was that we will use square cells of 3 × 3 pixels and 8 pixels to compose the local texture descriptor.
Subsequently, we have started experimenting with the rest of the descriptors. For the HOG and SIFT algorithms we have used the authors' implementations. The tests involved the usage of singular descriptors and combining all of them together; the final weights have been set as it follows:
• W1 = 30% for the color space;
• W2 = 30% for the texture space;
• W3 = 40% for the local descriptors. These have been considered more representative than the global descriptors.
The results are presented in Table 2 [16].
Table 2
Experiments Involving All Descriptor Spaces
|
Descriptor Type |
Results (%) |
|
Color space |
86 |
|
Texture space (LBP) |
85 |
|
SIFT |
82 |
|
HOG |
85 |
|
All of the above |
92 |
The results show that combining multiple types of descriptors from multiple search spaces lead to performance improvements. On the above-mentioned data set, the results are promising and show an increase of over 5%. Also, the proposed architecture is able to correctly classify images obtained from document scans as well as regular images.
All the experiments conducted so far have been performed on document images which have been correctly segmented. The next set of experiments have used images affected by different types of noise, specific for the document analysis and recognition area.
As shown in Ref. [17], the document scans can be affected by different alterations:
• extra characters or images being present in the scan, due to the paper transparency;
• page curvature introduces distortions;
• incorrect exposure to light;
• machine malfunctioning;
• additional ink spots, water stains, anchoring devices, other marks, etc.
Each of the above factors may affect the segmentation process and the overall classification results. Therefore we have used the CVSEG algorithm presented in Ref. [17] applied on a mixed set of documents.
There are two areas which may be affected by the problems described above—the binarization stage or the segmentation stage. In what follows, we will describe how the binarization results affect the segmentation stage and the overall performance.
The CVSEG binarization tests have used four types of binarization algorithms. The experiments showed that the best options are NLBIN (a nonlinear binarization algorithm, recommended by the authors of the Ocropus library [18]) and Sauvola’s algorithm [19]. Both algorithms have similar results and are usually affected as described below:
• the binarized image includes large black areas, especially in old scan documents;
• rotated images introduce skew angle estimation errors; these are usually introduced by the human operator or by the anchoring devices;
• threshold-related problems (usually these are caused by the low contrast or by the quality of the paper), which cause some details to be eroded and others to be enhanced.
The classification algorithm was then tested only against documents which contained the problems described above (the segmentation process was 100% accurate). The overall classification results have been affected as it is presented in Table 3.
Table 3
Binarization Experiments
|
Binarization Problem |
Overall Results (%) |
|
Large black areas |
75.5 |
|
Skew angle estimation |
90.8 |
|
Threshold problems |
89.1 |
The most impacting effect is caused by the old document area in the context of the binarization stage. When the large black areas are introduced, they usually cover the images as well, not only the text. This causes all the next processing stages (segmentation and classification) to fail. Figure 6 is affected by this problem—the drawing in the upper area has been completely covered and the only visible area is the one containing text.

FIGURE 6 Binarization problems.
The next performance drop is caused by the threshold problems, which may erode some details until they completely vanish. Specifically, in the over-dilated images the small details are usually merged into black tiles and in the over-eroded images the details composed of thin line disappear completely. Under these circumstances, the classification algorithm is not be able to extract the same amount of descriptors therefore the accuracy dropped by 3%.
There is also a small performance drop when processing rotated images but usually this problem is solved by the rotation invariance characteristic in the descriptors.
In what regards the segmentation experiments, we have used the CVSEG algorithm [17]. We have also found some problems in what regards processing the images at this stage. Usually they are caused by:
• incorrect binarization results—this may lead to segmentation results which include too much or too little from the original image;
• usage of different font types—some of the larger fonts may get included in the result;
• page layout, borders, page rotation, objects which did not belong in the original document, etc.
The results are described in Table 4.
Table 4
Segmentation Experiments
|
Segmentation Problem |
Overall Results (%) |
|
Binarization |
74.2 |
|
Font type |
91.0 |
|
Page layout |
91.1 |
Again, the binarization results have an important impact on the overall performance. As mentioned before, the segmentation module cannot extract the correct image from a document which has not been correctly binarized, because in many cases the original drawings/images have been masked by the large black areas. Subsequently, the classification module cannot extract the appropriate descriptors and fails to correctly classify the image.
There are some small performance drops in the remaining two areas as well but usually, even the segmentation results contain erroneous areas (page borders or extra text) they have little or no impact at all in the classification stage. Most of the problems in this area have been caused by the incomplete images originating in the segmentation results.
The last experiments have been conducted on mixed images, with problems in both the binarization and segmentation stages, or no problems at all, originating from the ICDAR dataset and from the Ubuntu documentation. The combined results are described inTable 5.
Table 5
Overall Classification Performance Fluctuations
|
Images |
Average Results (%) |
Performance Drop (%) |
|
Binarization problems |
85.13 |
6.87 |
|
Segmentation problems |
85.43 |
6.57 |
|
Mixed images |
89.58 |
2.42 |
As expected, the overall performance dropped especially because of the results obtained in the binarization stage, which impact the remaining stages as well. The difference however is not very large, mostly because the classification module can still identify over-dilated images or incomplete images.
5 Future research
In the future we would like to continue the research conducted so far. There are many areas which can be improved and also, upon refactoring they can provide new functionalities:
• we intend to add a module in charge of collecting a user score for the result vector, which can be used later for altering automatically the default weights in the majority voting module. This way, the CBIR engine will be able to provide more representative results for the user.
• we have started to develop a user interface which will allow the user to configure the classification module according to his/her needs—this involves selecting the desired binarization/segmentation algorithms and tuning the majority voting modules. The user score module and this module can be combined with a user management module so that the system can recall the user's preferences;
• we also intend to insert a module that can analyze a certain image and compute how many shadow areas it contains. This module would help in deciding which color space is more adequate for each particular situation;
• the number of characteristics is very large; only the SIFT descriptors may go over 100,000 for 640 × 480 images. In order to be able to compute the results much faster, we are considering the possibility of adding a module in charge of reducing the dimensionality;
• in the document processing area, the system is currently cropping out the images from a scan. In order to have more accurate results, we intend to add an OCR module, which can extract the text content as well. The text can be later on reduced to keywords, which can be used in the classification and retrieval process.
References
[1] Sebe, N. Feature extraction & content description—DELOS—MUSCLE Summer School on Multimedia digital libraries, Machine learning and cross-modal technologies for access and retrieval. www.videolectures.net. [Online] February 25, 2007.www.videolectures.net/dmss06_sebe_fecd/.
[2] Gevers T, Smeulders AW. Colour-based object recognition. Pattern Recogn. 1999;32:453–464.
[3] Vassilieva, N. RuSSIR—Russian Summer School in Information Retrieval. [Online] 2012. http://videolectures.net/russir08_vassilieva_cbir/.
[4] Cao X, Shen W, Yu LG, Wang YL, Yang JY, Zhang ZW. Illumination invariant extraction for face recognition using neighboring wavelet coefficients. Pattern Recogn. 2012;45:1299–1305.
[5] Bhavsar AV, Rajagopalan AN. Range map superresolution-inpainting, and reconstruction from sparse data. Comput Vis Image Underst. 2012;116(4):572–591.
[6] Wikipedia. Local binary patterns. www.wikipedia.org. [Online] November 08, 2011. http://en.wikipedia.org/wiki/Local_binary_patterns.
[7] Lowe DG. Object recognition from local scale-invariant features. In: International Conference on Computer Vision. 1999:1150–1157.
[8] Bay H, Tuytelaars T, Van Gool L. Speeded-up robust features (SURF). Comput Vis Image Underst. 2008;110:346–359 Zurich, Leuven, Belgia: s.n.
[9] Dalal N, Triggs B. Histograms of oriented gradients for human detection. Int Conf Comput Vis Pattern Recognit. 2005;1:886–893.
[10] Mikolajczyk K, Schmid C. A performance evaluation of local descriptors. IEEE Trans Pattern Anal Mach Intell. 2005;27:1615–1630.
[11] Sarfraz S, Hellwich O. Madeira, Portugal. Head pose estimation in face recognition across pose scenarios. Proceedings of VISAPP 2008, Int. Conference on Computer Vision Theory and Applications; 2008, p. 235–242.
[12] Chen N, Blostein D. A survey of document image classification: problem statement, classifier architecture and performance evaluation. IJDAR. 2007;10:1–16.
[13] Ha J, Haralick RM. Recursive X-Y cut using bounding boxes of connected components. Doc Anal Recognit. 1995;2:952–955.
[14] Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. In: Pereira F, Burges CJC, Bottou L, Weinberger KQ, eds. Curran Associates, Inc; 1097–1105. Advances in neural information processing systems. 2012;25.
[15] Antonacopoulos A, Bridson D, Papadopoulos C. ICDAR 2007 Page Segmentation Competition. ICDAR. [Online] 2007. http://www.primaresearch.org/ICDAR2007_competition/.
[16] Ilie M. A content based image retrieval approach based on document queries, IPCV'14—The 2014 International Conference on Image Processing, Computer Vision, and Pattern Recognition; 2014.
[17] Ilie M. Document image segmentation through clustering and connectivity analysis, The International Conference on Multimedia and Network Information Systems—MISSI’14; 2014.
[18] Google. Ocropus, April 21, 2013, http://code.google.com/p/ocropus/.
[19] Sauvola J, Seppanen T, Haapakoski S, Pietikainen M. Adaptive document binarization, Ulm, Germany: s.n., 1997. International Conference on Document Analysis and Recognition. p. 147–152.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.