Emerging Trends in Image Processing, Computer Vision, and Pattern Recognition, 1st Edition (2015)
Part II. Computer Vision and Recognition Systems
Chapter 21. Optical flow-based representation for video action detection
Samet Akpınar; Ferda Nur Alpaslan Department of Computer Engineering, Middle East Technical University, Ankara, Turkey
Abstract
In this study, a new model to the problem of video action recognition has been proposed. The model is based on temporal video representation for automatic annotation of videos. Additionally, the generic model inspires other video information retrieval processes including temporal video segmentation. Video action recognition is a field of multimedia research enabling us to recognize the actions from a number of observations, where representation of temporal information becomes important. Visual, audio, and textual features are important sources for representation. Although textual and audio features provide high-level semantics, retrieval performance using these features highly depends on the availability and richness of the resources. Visual features such as edges, corners, and interest points are used for forming a more complicated feature, namely, optical flow. For developing methods to cope with video action recognition, we need temporally represented video information. For this reason, we propose a new temporal segment representation to formalize the video scenes as temporal information. The representation is fundamentally based on the optical flow vectors calculated for the frequently selected frames of the video scene. Weighted frame velocity concept is put forward for a whole video scene together with the set of optical flow vectors. The combined representation is used in the action-based video segment classification. Proposed method is applied to significant datasets and the results are analyzed by comparing with the state-of-the-art methods. The basic formalism mentioned in the method is also handled for video cut detection in the perspective of temporal video segmentation.
Keywords
Video action recognition
Content-based video information retrieval
Optical flow
Temporal video segment representation
Weighted frame velocity
Cut detection
1 Introduction
Video action recognition is a field of multimedia research enabling us to recognize the actions from a number of observations. The observations on video frames depend on the video features derived from different sources. While textual features include high-level semantic information, they cannot be automated. The recognition strongly depends on the textual sources which are commonly created manually. On the other hand, audio features are restricted to a supervisor role. As the audio does not contain strong information showing the actions conceptually, it can be used as an additional resource supporting visual and textual information. Visual video features provide the basic information for the video events or actions. Although it is difficult to obtain high levels of semantics by using visual information, a convincing way to construct an independent fully automated video annotation or action recognition model is to utilize visual information as the central resource. This way takes us to content-based video information retrieval.
Content-based video information retrieval is the automatic annotation and retrieval of conceptual video items such as objects, actions, and events using the visual content obtained from video frames. There are various methods to extract visual features and use them for different purposes. The visual feature sets they use vary from static image features (pixel values, color histograms, edge histograms, etc.) to temporal visual features (interest point flows, shape descriptors, motion descriptors, etc.). Temporal visual features combine the visual image features with the time information. Representing video information using temporal visual features generically means modeling the visual video information with temporal dimension, i.e., constructing temporal video information.
We need to represent the temporal video information formally for developing video action recognition methods. Visual features such as corners and visual interest points of video frames are the basics for constructing our model. These features are used for constructing a more complicated motion feature, namely, optical flow. In our work, we propose a new temporal video segment representation method to retrieve video actions for formalizing the video scenes as temporal information. The representation is fundamentally based on the optical flow vectors calculated for the frequently selected frames of the video scene. Weighted frame velocity concept is put forward for a whole video scene together with the set of optical flow vectors. The combined representation is used in the action-based temporal video segment classification. The result of the classification represents the recognized actions.
The main contribution of this work is the proposed temporal video segment representation method. It is aimed to be a generic model for temporal video segment classification for action recognition. The representation is based on optical flow concept. It uses the common way of partitioning optical flow vectors according to their angular features. An angular grouping of optical flow vectors is used for each selected frame of the video. We propose the novel concept of weighted frame velocity as the velocity of the cumulative angular grouping of a temporal video segment in order to represent the motion of the frames of the segments more descriptively.
The outline of this article is as follows. In Section 2, related work is proposed. Section 3 discusses the temporal segment representation. Optical flow is described in Section 4 and optical flow-based segment representation is discussed in Section 5. The inspiration of representation in cut detection is given in Section 6. In Section 7, experiments and results are presented. Finally, in Section 8, the conclusion is proposed.
2 Related work
There are different approaches followed for the representation of temporal video segments for content-based video information retrieval problems such as video action recognition, event detection, cut detection, etc. The studies in Refs. [1–4] focus on the perception of the visual world and bring us facts about how to detect the visual features and in which context more philosophically. Regarding the visual features, mentioned approaches can generally be figured out. Key-frame-, bag-of-words- (BoW), interest points-, and motion-based approaches are the groups of approaches reflecting the way of representation.
Key-frame-based representation approaches focus on detecting key frames in the video segments in order to use them in classification. This kind of representation is used in Refs. [5–8] for video scene detection and video summarization. The study of Vasileios et al. [5] contains the segmentation of videos into shots, and key-frames are extracted from these shots. In order to overcome the difficulty of having prior knowledge of the scene duration, the shots are assigned to visual similarity groups. Then, each shot is labeled according to its group and a sequence alignment algorithm is applied for recognizing the shot labels change patterns. Shot similarity is estimated using visual features and shot orders are kept while applying sequence alignment. In Ref. [6], a novel method for automatic annotation of images and videos is presented with keywords among the words representing concepts or objects needed in content-based image retrieval. Key-frame-based approach is used for videos. Images are represented as the vectors of feature vectors containing visual features such as color and edge. They are modeled by a hidden Markov model, whose states represent concepts. Model parameters are estimated from a training set. The study proposed in Ref. [7] deals with automatic annotation and retrieval for videos using key frames. They propose a new approach automatically annotating video shots with semantic concepts. Then, the retrieval carried out by textual queries. An efficient method extracting semantic candidate set of video shots is presented based on key frames. Extraction uses visual features. In Ref. [8], an innovative algorithm for key frame extraction is proposed. The method is used for video summarization. Metrics are proposed for measuring the quality.
Histogram-based BoW approaches represent the frames of the video segments over a vocabulary of visual features. References [9,10] are the examples of such approaches. Ballan et al. [9] propose a method interpreting temporal information with the BoW approach. Video events are conceptualized as vectors composed of histograms of visual features, extracted from the video frames using BoW model. The vectors, in fact, can be behaved as the sequences, like strings, in which histograms are considered as characters. Classification of these sequences having difference in length, depending on the video scene length, is carried out by using SVM classifiers with a string kernel that uses the Needlemann-Wunsch edit distance. In Ref. [10], a new motion feature is proposed, Expanded Relative Motion Histogram of Bag-of-Visual-Words (ERMH-BoW) implementing motion relativity and visual relatedness needed in event detection. Concerning the ERMH-BoW feature, relative motion histograms are formed between visual words representing the object activities and events.
Despite their performance issues in terms of time, above approaches lack the flow features and temporal semantics of motion although they are efficient in spatial level. On the other hand, motion-based approaches deal with motion features which are important in terms of their strong information content and stability over spatiotemporal visual changes. Motion features such as interest points and optical flow are used for modeling temporal video segments. References [11–14] are the studies using motion features. Ngo et al. [11] propose a new framework in order to group the similar shots into one scene. Motion characterization and background segmentation are the most important concepts in this study. Motion characterization results in the video representation formalism, while background segmentation provides the background reconstruction which is integrated to scene change detection. These two concepts and the color histogram intersection together become the fundamental approach for calculating the similarity of scenes. The study of Sand and Teller [12] presents a new approach which implements motion estimation in video scenes. The representation of video motion is carried out by using some sort of particles. Each particle is an image point with its trajectory and other features. In order to optimize the particle trajectories, appearance stability along the particle trajectories and distortion between the particles are measured. The motion representation can be used in many areas. It cannot be constructed using the standard methods such as optical flow or feature tracking. Optical flow is a spatiotemporal motion feature describing the motion of visual features. Optical flow-based representation is especially strong for video segment classification. References [13,14] present methods for representing video segments with optical flow. Lertniphonphan et al. [13] propose a representation structure based on direction histograms of optical flow. In Ref. [14], video segments are tried to be represented by using histogram of oriented optical flow (HOOF). By the help of this representation, human actions are recognized by classifying HOOF time series. For this purpose, a generalization of the Binet-Cauchy kernels to nonlinear dynamical systems is proposed.
Temporal video segment classification is an important subproblem in content-based video information retrieval addressing video action classification in our study. By definition, it is the classification of scenes in a video. The classification highly depends on the representation of temporal video information and the classification methods working on this representation.
Authors of Refs. [15–18] propose the approaches based on 3D interest points. These methods tackle the problem of video segment classification by putting new interest points or visual features forward by enriching with time dimension. Therefore, the features in the studies can be conceptualized as space-time shapes.
The methods proposed in Refs. [19,20] view the problem from the point of spatiotemporal words. The segments are seen as bag-of-features and make the classification according to the code words.
Authors of Refs. [13,14,21–23] present optical flow-based methods for video segment classification. Optical flow histograms are constructed and utilized in segment representation. By using this representation, segment classification is carried out.
3 Temporal segment representation
Temporal video segment representation is the problem of representing video scenes as temporal video segments. While this problem generally runs through the video information including visual, audio, and textual features, our study deals with visual features only. Mentioned problem is originated from representing the temporal information. Temporal information provides a combined meaning composed of time and magnitude for a logical or physical entity. Robot sensor data, web logs, weather, video motion, and network flows are common examples of temporal information. Independent from domain, both representation and processing methods of temporal information are important in the resulting models. Regarding the processing methods, prediction, classification, and mining can be considered as first comers for the temporal information. In most cases, the representation is also a part of the processing methods due to the specific problem. While the representation and processing methods are handled together, the focus is especially on the processing methods rather than on the representation in these cases. Temporal data mining and time-series classification can be exemplified for the approaches on temporal information retrieval.
The types of the features and their quality on describing the domain knowledge also influence the temporal information processing and its application. Also, having high dimensionality makes the effective representation of temporal information with more complicated features important. Therefore, feature definitions, construction, and feature extraction methods play an important role in processing the temporal information. As the focus here is feature extraction and construction, the improvements are measured with common methods.
In content-based video information retrieval, visual video data behave like temporal information containing frame sequences over time. Each frame of the video has its visual information along with its time value. The temporal information representation highly depends on the visual content of video frames. The basic and the most primitive representation of temporal video information can be done by using the video with all pixel intensities of all frames. While this representation includes the richest visual information, processing and interpreting information is impractical. In a 600 × 480 frame size for a 10 s scene (30 frames/s, fps), 86.4M features exist with this approach. Therefore, there is a need for efficient representation formalisms.
Key-frame-based representation is one of the candidate approaches for representing temporal information in videos. For each scene, a key-frame is selected based on some calculations using visual features. The entire scene is represented and feature size of the representation is decreased by using this key frame. But, there is an important problem in key-frame-based approaches; i.e., lack of the important information resulting from the motion in videos.
Another approach is BoW approach for frame sequences. In this kind of representation, frames are behaved as code words obtained from grouping of the frames according to the visual features. With these code words, frame sequences are represented as sentences. This kind of representation contains temporal nature of the scenes. But, the most important disadvantage of this representation is the restricted nature of code words. Representing a visually rich frame with a label means losing an important amount of information. The representation is restricted with the variety of the code words. Therefore, limitless types of frames will be reduced to very limited number of labels.
Interest points-based representation is an alternative formalism for temporal video information. Interest points are the “important” features that may best represent the video frames invariant from the scale and noise. This representation alternative is very successful in reducing the huge frame information into small but descriptive patterns. But, it is again disadvantageous in detecting motion features despite its descriptiveness. As the motion features include flow with time, it is important to track the features along the time. Using interest points for representation lacks the motion-based information.
State-space methods are also used for representing temporal video information. The state-space methods define features which span the time. The space-time interest point concept is proposed by Laptev and Lindeberg [16]. Interest points that are spatially defined and extracted in 2D are extended with time. With this extension, interest points gain a 3D structure with time. Therefore, a space-time 3D sketch of frame patterns can be obtained and they are ready for processing. State-space approaches best fit the representation of video information temporally as they can associate the time with the visual information in a descriptive and integrated way.
In our study, a state-space-based representation approach is proposed. Optical flow is the motion feature—integrating time with visual features—utilized for constituting the state-space method.
4 Optical flow
Theoretically, optical flow is the motion of visual features such as points, objects, and shapes through a continuous view of the environment. It represents the motion of the environment relative to an observer. James Jerome Gibson first introduced the optical flow concept in the 1940s, during World War II [24]. He was working on pilot selection, training, and testing. He intended to train the perception of pilots during the war. Perception was considered for the effect of the motion on the observer. In this context, shape of objects, movement of entities, etc. are handled for perception. During his study on aviation, he discovered optical flow patterns. He found that the environment observed by the pilot tends to move away from the landing point, while the landing point does not move according to the pilot. Therefore, he joined this concept with the pilot perception on the observed environment.
In the perception of an observer, there may be two options for approaching/departing optical flow around a point. In the first option, the observer may be moving through the target point. This makes the optical flow departing from the point. In the second option, the environment around the point may be moving through the motionless observer. This also gives the same effect, having the optical flow departing from the point. These two options are also valid for approaching optical flow. If the observer departs from the target point or the point departs from the motionless observer, the optical flow is seen as approaching through the point.
In video domain, optical flow is commonly known as the apparent motion of brightness patterns in the images. More specifically, it can be conceptualized as the motion of visual features such as corners, edges, ridges, and textures. through the consecutive frames of a video scene. Optical flow, here, is materialized by optical flow vectors. An optical flow vector is defined for a point (pixel) of a video frame. In optical flow estimation of a video frame, selection of “descriptive” points is important. This selection is done using visual features. It is clear that using an edge point or corner point is more informative than using an ordinary point semantically as the motion perception of human is based on prominent entities instead of ordinary ones. Optical flow vectors are, then, the optical flow of video frame feature instances instead of all frame points.
Two problems arise in the optical flow estimation of video frames: (1) detection and extraction of the features to be tracked, (2) calculation of the optical flow vectors of the extracted features. Optical flow estimation aims to find effective solutions to these problems. Calculation of optical flow vectors of the extracted features can be reduced to the following problem; Given a set of points in a video frame, finding the same points in another frame.
4.1 Derivation of Optical Flow
There are various approaches concerning the estimation of optical flow. Differential, region-based, energy-based, and phased-based methods are the main groups of approaches [25]. All of these groups include many algorithms proposed so far. Each of these algorithms reflects the theoretical background of its group of approach.
Here, the meaning of optical flow estimation is discussed from a differential point of view. The explanation is based on the change of pixels with respect to time. The solution of the problem can be reduced to the solution of the following equation [26]:
![]() (1)
(1)
The equation is written for a point in a video frame. The point is assumed to change its pixel value over time. (x, y, t) is defined as the 3D point composed of the 2D coordinates (pixel value) of the given point at time t. I represents the intensity function giving the image intensity value of a given pixel value at a given time. The equation is based on the assumption that enormously small amount of change in the pixel position of the point in enormously small amount of time period converges to zero change in the intensity value. In other words, the intensity value of a pixel in a frame is equal to the intensity value of another pixel having the same point (the point in the former pixel) in the next frame. The point moves enormously small amount of distance (pixel change) in enormously small amount of time.
LHS of the equation is expanded by using the Taylor Series Expansion [26]:
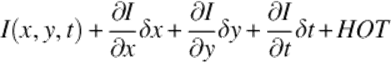 (2)
(2)
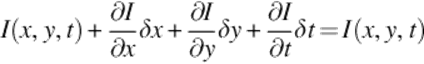 (3)
(3)
By some further derivations on Equation (3), we obtain Equations (7) (8). The variables represented by Ix, Iy, It are the derivatives of intensity function according to all dimensions.
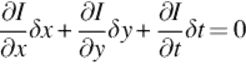 (4)
(4)
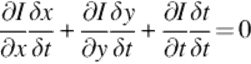 (5)
(5)
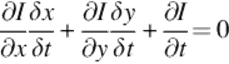 (6)
(6)
![]() (7)
(7)
![]() (8)
(8)
Now, the problem converges to the solution of ![]() . The solution will be the estimation of optical flow. As there are two unknowns in the equation, it cannot be solved; additional constraints and approaches are needed for solution. This problem is known asaperture problem.
. The solution will be the estimation of optical flow. As there are two unknowns in the equation, it cannot be solved; additional constraints and approaches are needed for solution. This problem is known asaperture problem.
4.2 Algorithms
Many algorithms according to different approaches have been proposed for optical flow estimation. According to Barron et al. [25], optical flow estimation algorithms can be grouped according to the theoretical approach while interpreting optical flow. These aredifferential techniques, region-based matching, energy-based methods and phase-based techniques.
4.2.1 Differential Techniques
Differential techniques utilize a kind of velocity estimation from spatial and temporal derivatives of image intensity [25]. They are based on the theoretical approach proposed by Horn and Schunck [26]. The proposed approach results in Equation (3). Differential techniques are used for solving the problem generally represented by this equation. Horn-Shunck method [26] is a fundamental method among the differential techniques. Global smoothness concept is also used in the approach. Lucas-Kanade method [27] is also an essential method solving the mentioned differential equation for a set of neighboring pixels together by using a weighted window. Nagel [28] and Uras et al. [29] use second-order derivatives generating the optical flow equations. Global smoothness concept is also used as well as the Horn-Shunck method. Niebles et al. [30] propose a distance-based method efficient for real-time systems. The method is analyzed according to time-space complexity and its tradeoff. Harris and Stephens Proesmans et al. [31] suggest a classical differential approach. But, it is combined with correlation-based motion descriptors.
4.2.2 Region-Based Matching
Region-based matching approaches alternate the differential techniques in case differentiation and numerical operations is not useful due to noise or small number of frames [25]. In region-based matching, the concepts such as velocity and similarity are defined between image regions. Shi and Tomasi [32] and Ali [33] propose region-based matching methods for optical flow estimation. In Ref. [32], the matching is based on Laplacian pyramid while [33] recommends a method based on sum of squared distance computation.
4.2.3 Energy-Based Methods
Energy-based methods are based on the output energy of filters tuned by the velocity [25]. Laptev and Lindeberg [34] propose an energy-based method fitting spatiotemporal energy to a plane in frequency space. Gabor filtering is used in the energy calculations.
4.2.4 Phase-Based Techniques
Different from energy-based methods velocity is defined as filter outputs having phase behavior. References [35–37] are the examples of phase-based techniques using spatiotemporal filters.
5 Optical flow-based segment representation
In this study, an optical flow-based temporal video information representation is proposed. Optical flow vectors are needed to be calculated for the selected sequential frames. Optical flow estimation is important as the basic element of the model is optical flow vectors. As mentioned in Section 4, detection of features and estimation of optical flow according to these features are the main steps of optical flow estimation. The methods and approaches for both steps are discussed below [38].
5.1 Optical Flow Estimation
In our approach, Shi-Tomasi algorithm proposed in Ref. [39] is used for feature detection. As it is mentioned before, Shi-Tomasi algorithm is based on Harris corner detector [40] and finds corners as interest points. Harris matrix shown in Equation (10) is obtained from the Harris corner detector:
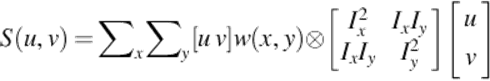 (9)
(9)
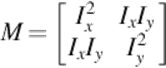 (10)
(10)
Shi-Tomasi algorithm uses the eigenvalues of the Harris matrix. In this context, it differs from Harris corner detector. The algorithm assumes that minimum of two eigenvalues of Harris matrix determines the cornerness (C) of the point. Therefore, the corner decision is done using the eigenvalues of the matrix. Shi-Tomasi algorithm gives more accurate results compared with Harris detector. The algorithm is also more stable for tracking.
For estimating optical flow, Lucas-Kanade algorithm is selected [27]. With videos having sufficient information and excluding noise, Lucas-Kanade algorithm is successful. The algorithm works for the corners obtained from Shi-Tomasi algorithm. Basically, the following function should be minimized for each detected corner point as seen in differential approaches:
![]() (11)
(11)
With suitable δx and δy, optical flow vectors can be obtained. But, aperture problem is not solved yet with this minimization. The solution approach for aperture problem is reflected to the function definition ε(δx, δy)as follows:
![]() (12)
(12)
Summation on the x − y direction is a solution for the aperture problem. By using a window w centering the point (x, y), the estimation of optical flow of the point is extended with the neighboring points.
In our approach, Lucas-Kanade algorithm is applied to the corner points detected with Shi-Tomasi algorithm. Video frames are selected according to a frequency of 6 fps (30 fps videos are used) from Hollywood Human Actions dataset [41]. In Figure 1, two frequently sequential frames obtained from the mentioned dataset are shown.

FIGURE 1 Consecutive frames for optical flow estimation.
Figure 2 shows the optical flow vectors estimated for the detected points in the former video frame in the sequence.

FIGURE 2 Frame with optical flow vectors.
In our method, optical flow vectors are calculated for every detected point in all frequently selected frames. The set of optical flow vectors is the temporal information source for our representation.
The model below forms the back bone for our representation formalism. Optical flow vector set with an operator constructs the representation.
![]() (13)
(13)
S(V) is the set of optical flow vectors while Φ is the descriptor operator. Operator defines the relation of the elements of the optical flow vector set of the frames. This relation exposes the temporal representation of video information. The operator may change according to the complexity of the model. It may vary from just counting the vectors to complex relations between the optical flow vectors. This generic representation can easily be adapted to different problems such as segment classification or cut detection. Choice of the operator and the optical flow representation may change drastically in different problems.
5.2 Proposed Representation
Usage of optical flow in video information representation is encountered in many studies including [14,17,42]. These studies are the state-of-the-art techniques motivating us for an optical flow-based representation. Optical flow histogram is the most common way of optical flow-based video representation. In [42], optical flow histograms are used for characterizing the motion of a soccer player in a soccer video. A motion descriptor based on optical flow is proposed and a similarity measure for this descriptor is described. The study of Barron et al. [17] uses optical flow by splitting it into horizontal and vertical channels. The histogram is calculated on these channels. Each channel is integrated over the angularly divided bins of optical flow vectors. In Ref. [14], HOOF is simply used according to angular segments for each frame. The feature vectors are constructed with these angular values and combined for all frames of the video segment. The essential part for contribution here is the classification method. The classification is done with a proposed novel time-series classification method including a metric for comparing optical flow histograms. The study in Ref. [21] proposes an optical flow-based representation which groups the optical flow vectors of whole video segment according to angular values. Then, average histogram is computed for each of these angular groups. The resulting histogram is the feature vector.
In our approach, histogram-based optical flow approaches are enriched with a newly defined velocity concept, Weighted Frame Velocity. The idea, here, is originated from the inadequacy of optical flow histograms for interpreting information. Using optical flow histogram is discarded as the most important drawback of using histograms in segment representation is that the histogram similarity does not always mean the real similarity for motion characterization. Optical flow vectors are divided into angular groups and according to these groups, optical flow vectors are summed and integrated with the new velocity concept instead of a histogram-based approach.
Estimating the optical flow vectors for each frame is the first step. Then, Equation (6) giving the generic representation is adapted to segment representation. In this aspect, Φ is the operator defining the relations between the optical flow vectors and giving their meaning for representing the video segment composed of the set of optical flow vectors S(V).
In our adaptation of the above representation to segment representation, the description of Φ is important. The parameters used in the definition are shown in Table 1.
Table 1
Segment Representation Model Parameters
|
Parameter |
Definition |
|
F |
Set of frames in the video segment |
|
S(Vf) |
Set of optical flow vectors in frame f |
|
S(Vf, α, β) |
Set of optical flow vectors having angle between α − β in frame f |
|
A(α, β) |
Weighted frame velocity of the whole segment direction having angle between α − β |
|
τf(α, β) |
Threshold function for optical flow vectors having angle between α − β in frame f |
|
V(r, ∠ φ) |
Optical flow vector having magnitude r and angle φ |
The parameters above are the basic building blocks for constructing the representation model and the descriptor operator Φ. The following definitions are done for this purpose. The definition of S(Vf, α, β) is made as follows:
![]() (14)
(14)
Let’s assume that |F| = n, m is the number of angle intervals and l is the length of the video segment in terms of seconds. With these assumptions, the representation of a video segment using average of optical flow vectors with angular grouping can be formulized as
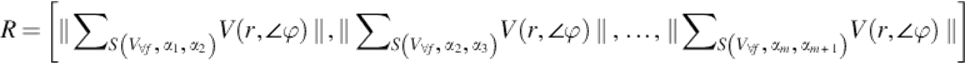 (15)
(15)
Above vector representation is composed of m dimensions each of which is the magnitude of the sum of optical flow vectors for angle intervals. This is the common way of optical flow representation except the usage of vectors instead of histograms. This representation is descriptive as it utilizes the movement of a segment in different angel intervals by using the vector sum and magnitude calculation. But, it lacks the temporal information in terms of velocity. This means that the flow details throughout the frame sequence are discarded by only looking at the resulting direction and magnitude information. If this vector is extracted for each frame and combined for solving the problem as it is done in Ref. [14], curse of dimensionality problem arises. The dimension of the resulting vector will be mxnxl. For a 30-fps video of 5 s length with 30 angular intervals, for example, a vector of 4500 features is obtained for representing a segment. Using a frequency filter of 0.2 (6 frames selected from a second of the video) will decrease the dimension into 900, but the problem will not be able to be solved yet. This yields to the need for tackling the curse of dimensionality problem as it is handled in Ref. [14] with the newly proposed time-series classification method including the new distance metric for the feature vectors.
In our approach, we enrich the representation to make the temporal information more descriptive without causing the curse of dimensionality problem. For this purpose, a new component is needed for the above feature representation based on movement magnitude of the segment in different directions. Velocity is selected as the fundamental idea for the new component as the velocity of the frames strongly affects the nature of video motion such as in walk and run events. For this purpose, weighted frame velocity concept is proposed. Abstractly, the velocity component is added to the feature vector to contain distance-velocity pair.
Weighted frame velocity is a metric which measures the velocity of a segment in a given dimension. It is weighted with the vector count in its direction. Theoretically, weighted frame velocity is formulated inspiring from the general velocity calculation ![]() :
:
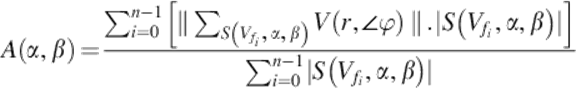 (16)
(16)
Equation (9) calculates the weighted distance for each angular interval of each frame. Weight concept, here, is the weight of the frame to the segment. The weighted distances are summed up and averaged according to the number of vectors in the segment. The resulting value is the weighted velocity of the frames.
When this approach is analyzed, one can notice that another problem occurs. As the velocity is weighted according to the number of vectors in the given angle interval of the frame, the noise or errors resulting from optical flow estimation and insignificant number of vectors in one dimension unfairly dominate the values of that feature. In order to avoid this problem, thresholding is used as a common way of noise reduction. Therefore, a threshold function depending on the frame and angle interval is proposed to be used in the weighted frame velocity function.
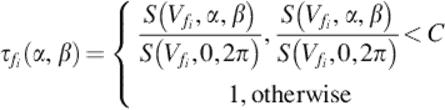 (17)
(17)
The above function is based on the ratio of the optical flow vectors of the given angle interval for the given frame. This ratio’s being smaller or bigger according to the threshold value C directly determines the result of the function. At this point, estimation of threshold becomes important. The estimation will be done during the classification phase. Thus, the weighted frame velocity function is updated accordingly.
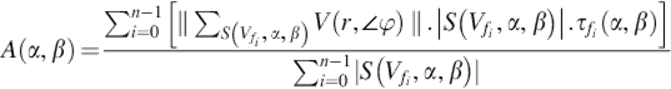 (18)
(18)
The function affects the weighted contribution of each frame into the velocity of the segment in an angle interval according to whether its vectors’ are noisy or not.
As it is mentioned before, the weighted frame velocity is, now, a new component of the feature vector representation based on the movement of the segment. Thus, the new representation is as follows:
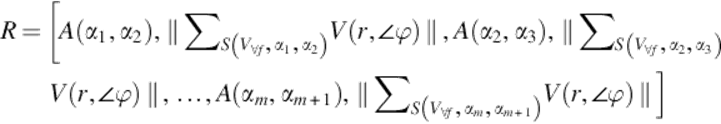 (19)
(19)
Now, the operator Φ in the generic optical-based representation model R = [S(V), Φ] is defined in this specific problem. The operator maps the optical flow vector set S(V) to the feature vector R for a video scene.
![]() (20)
(20)
The function of the above mapping is shown in the obtained final representation. Mainly, it constructs the representation by applying the operator to the optical flow vectors. The operator Φ, in fact, is the symbolic representation of our method.
The practical use of the representation is classifying the segments. The representation is used for each video segment and has the size mx2. The segment classification, constant estimations, and experiments with results and comparisons will be held in Section 7.
6 Cut Detection Inspiration
Temporal video segmentation is the problem of splitting the video information temporally into coherent scenes. Temporal video segmentation is generally originated from the needs of video segment classification. As it is needed in our study, the video scenes are needed to be extracted from whole video information in many cases in order to classify them semantically as segments. On the other hand, in some cases, video segment classification and temporal video segmentation are held together. This kind of methods tackles the problem with an integrated approach by trying to carry out the scene extraction with the classification of related semantic information.
As temporal video information is composed of visually complicated and continuous sequence of video frames, analyzing the temporal boundaries of video events, actions, etc. is an important field of study. From this point of view, event boundary detection, temporal video segmentation, cut detection, etc. are similar concepts dealing with this problem.
Again, textual and audio features together with visual features are important sources of information for temporal video segmentation likewise in temporal video segment representation. Our main concern about automaticity and dependency of textual features to manual creation also continues here. Therefore, visual features’ domination proceeds in this problem, too.
Regarding this domination, detecting the cuts between video scenes using visual features is an important problem. Optical flow is the key concept behaving as an operator inspiring from the representation proposed for action recognition in this study. The fundamental idea, here, is that some sort of change in optical flow character determines the cuts. In detail, the hypothesis is that the difference of intensity values between the pixels (mapped with optical flow vectors) of consecutive frames changes at the cut points. Calculated optical flow vectors in the first phase, video segment representation, can also be used here as building block features operating on pixel difference calculations to represent scene changes. This yields to a decrease in the computational complexity because of the fact that the feature base, optical flow vectors, is same and singularly calculated for both phases.
Estimated optical flow vectors for each frame in the previous part can be used. The equation R = [S(V), Φ] giving the optical flow-based generic representation, defined in Section 5, can be handled and adapted to cut detection. From this point of view, Φ is the operator defining the relations between the optical flow vectors S(V) and giving their meaning for representing cuts.
In our adaptation of the above representation to temporal video segmentation—cut detection, the description of Φ is important. In order to make this description, the parameters used in the definition should be described.
7 Experiments and results
Temporal segment classification for action recognition uses the vector representation proposed in Section 5. Support Vector Machines (SVM) is used for nonlinear classification. Gaussian radial basis function—using standard deviation σ for two feature vectors xi, xj- —is selected as SVM kernel.
![]() (21)
(21)
Hollywood Human Actions dataset [41] is used for evaluation. Hollywood dataset includes video segments composed of human actions from 32 movies. Each segment is labeled with one or more of 8 action classes: AnswerPhone, GetOutCar, HandShake, HugPerson, Kiss, SitDown, SitUp, and StandUp. While, the test set is obtained from 20 movies, training set is obtained from 12 other movies different from those in the test set. The training set contains 219 video segments and the test set contains 211 samples with manually created labels.
After the optical flows are estimated, the calculations for constructing feature vectors are carried out accordingly and feature vectors are obtained for the test data. The number of angular intervals is taken as 30 as in Ref. [14]. The threshold C in the threshold function below, as discussed in this section, was determined experimentally.
(22)
The result of the experiments for determining the best threshold value which is 0.025 is shown in Figure 3. The experiments on Hollywood dataset were carried out using this threshold value.
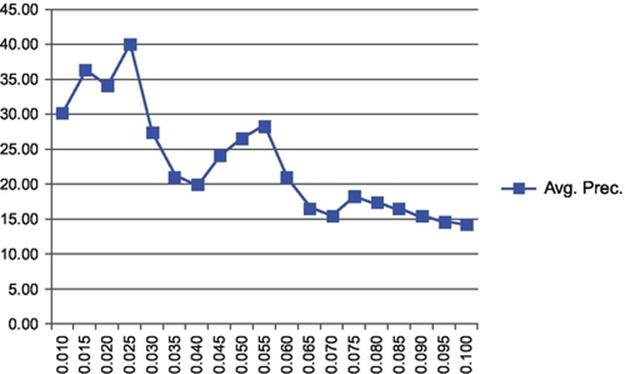
FIGURE 3 Threshold estimation in segment representation for Hollywood Human Actions.
Comparison is made with the popular state-of-the-art Weizmann dataset. The dataset contains the actions “walk,” “run,” “jump,” “side,” “bend,” “one-hand wave,” “two-hands wave,” “pjump,” “jack,” and “skip.”
First, the threshold estimation is carried out for this set again. As shown in Figure 4, the threshold values 0.020 − 0.025 gave the best results. These values were used in evaluating the results over this dataset.
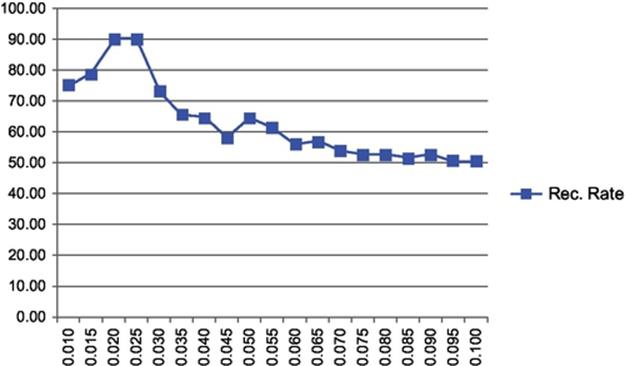
FIGURE 4 Threshold estimation in segment representation for Weizmann dataset.
The comparison of our method in terms of recognition rates with the essential studies having different viewpoints in human action recognition and segment classification is shown in Table 2.
Table 2
Comparison of the Results of Video Segment Classification for Weizmann Dataset
|
Methods |
Recognition Rates (%) |
|
Chaudry et al. [14] |
94.44 |
|
Ali et al. [15] |
92.60 |
|
This article |
90.32 |
|
Niebles et al. [20] |
90.00 |
|
Lertniphonphan [13] |
79.17 |
|
Niebles and Fei-Fei [19] |
72.80 |
The methods shown in Table 2 are some of the well-known reference studies tackling with the temporal segment classification problem. The approach in Ref. [15] uses new interest point features having time dimension. The classification is done according to these novel 3D features. Royden and Moore [13] and Gianluigi and Raimondo [14] propose optical flow-based classification, whereas Gianluigi and Raimondo [14] focuses on representing the segments frame by frame optical flows with high dimensions causing curse of dimensionality problem. Instead of dealing with the representation, the method aims to contribute by finding new metrics and time-series patterns in this high-dimensional data. Royden and Moore [13], on the other hand, propose a representation structure based on direction histograms of optical flow. Niebles et al. [20] presents a model based on spatiotemporal words. This method sees the segments as bag-of-features and makes the classification according to the code words. A bag-of-features method is also proposed in Ref. [19] where interest points are extracted and used as bag-of-features.
When we analyze the results, we have seen that the methods proposing interest point-based new 3D features are more successful than the other models. But, the features are specific to the dataset which makes the solution dependent on dataset types. Methods focusing on mining the highly over-descriptive data in terms of time domain exhibit high success rates as they develop the model independent from the contributions in video features. But, they are disadvantageous with their high-dimensional representation regarding time complexity. Our optical flow-based method better results than the approaches using optical flow-based segment representation. It is also more successful than the BoW-based methods.
8 Conclusion
In this study, we tried to solve a combination of different problems on action recognition. The fundamental problem inspires us is the representation of temporal information. In many fields, representation of temporal information is essential to retrieve information from a temporal dataset. The solution to the problem varies from representing each temporal entity in a different time slice to representing a simple summary of the whole time interval. Efforts for finding a solution between these two endpoints should try to tackle the problem from different point of views. This is because, the level of representation changes with the source of the problem. For instance, to represent all the information in all time slices for symbolizing the temporal information having high-frequency over time, one should handle the curse of dimensionality problem. On the other hand, representing a single summary will cause the problem of lacking the flow of temporal information. In these cases, the focus of approaches will be finding supportive information from different sources and integration of these sources in a singular representation.
We aimed to solve the temporal information representation problem in video domain. As the video information is a perfect example of high-frequency temporal information, representation of video information is essential for the purposes based on video information retrieval. Video action recognition is selected as our specific domain. The problem domain is reduced to the temporal video segment classification. The study is shaped on visual features of the video information for the automaticity concerns. As it is mentioned below, the representation level determines the reduced problem. In this context, our aim is to represent the video scenes avoiding the lack of temporal information flow while without causing the curse of dimensionality problem. Therefore, using more descriptive and high-level visual features having the ability to host the additional temporal nature of the simpler features such as color, edge, corner, etc. becomes unavoidable. This will pass the high load of temporal information residing in high-dimensional representation to the mentioned high-level features.
The discussion summarized above took us to the complex visual features having temporal dimension. In our research, we observed that space-time related 3D features obtained from combining 2D features with temporal information [16,18] are proved to be successful. Space-time interest points and space-time shapes for actions are proposed in these studies. We also observed high-level state-of-the-art features such as optical flow describing the motion of frame features are calculated and used in temporal video information representation as in Refs. [13,14,21]. Curse of dimensionality problem occurs as all frames are represented using optical flow vectors [14]. The problem is solved by using time-series analysis and metrics.
An optical flow-based approach is proposed in this paper for representing temporal video information by inspiring from the above studies. This generic approach is applied in both temporal video segment classification and temporal video segmentation. The adaptation of the model to video segment classification is presented. The weighted frame velocity concept is proposed to strengthen the representation with the velocity of video frames. This representation formalism is tested with SVM-based classification of video segments. The results show that the proposed method produces encouraging results.
The main advantage of the method is the multipurpose temporal video representation model proposed for video action recognition domain. The new formalism described here is especially important for simplifying the computational complexity for high-dimensional information.
References
[1] Burton A, Radford J. Thinking in perspective: critical essays in the study of thought processes. London, UK: Routledge; 1978.
[2] Warren DH, Strelow ER. In: Electronic spatial sensing for the blind: contributions from perception, rehabilitation, and computer vision. Dordrecht, Netherlands: Martinus Nijhoff Publishers; 1985: Nato Science Series.
[3] Ibson JJ. The perception of the visual world. Boston, MA, USA: Houghton Mifflin; 1950.
[4] Royden CS, Moore KD. Use of speed cues in the detection of moving objects by moving observers. Vis Res. 2012;59:17–24.
[5] Vasileios TC, Aristidis CL, Nikolaos PG. Scene detection in videos using shot clustering and sequence alignment. IEEE Trans Multimed. 2009;11(1):89–100.
[6] Ghoshal A, Ircing P, Khudanpur S. Hidden Markov models for automatic annotation and content based retrieval of images and video. In: Proceedings of SIGIR; 2005.
[7] Chang LW, Lie WN, Chiang R. Automatic annotation and retrieval for videos. In: Proceedings of PSIVT 2006; 1030–1040. Lecture Notes in Computer Science. 2006;vol. 4319.
[8] Gianluigi C, Raimondo S. An innovative algorithm for key frame extraction in video summarization. J Real-Time Image Procees. 2006;1(1):69–88.
[9] Ballan L, Bertini M, Del Bimbo A, Serra G. Video event classification using string kernels. Multimed Tools Appl. 2009;48:69–87.
[10] Wang F, Jiang Y, Ngo C. Video event detection using motion relativity and visual relatedness. In: ACM Multimedia '08, October 26-31; 2008.
[11] Ngo C, Pong T, Zhang H. Motion-based video representation for scene change detection. Int J Comput Vis. 2002;50(2):127–142.
[12] Sand P, Teller S. Particle video: long-range motion estimation using point trajectories. Int J Comput Vis. 2008;80:72–91.
[13] Lertniphonphan K, Aramvith S, Chalidabhongse T. Human action recognition using direction histograms of optical flow. In: ISCIT; 2011.
[14] Chaudry R, Ravichandran A, Hager G, Vidal R. Histograms of oriented optical flow and Binet-Cauchy kernels on nonlinear dynamical systems for the recognition of human actions. In: Proceedings of CVPR’09, Miami, US; 2009.
[15] Ali S, Basharat A, Shah M. Chaotic invariants for human action recognition. In: IEEE international conference on computer vision; 2007.
[16] Laptev I, Lindeberg T. Space-time interest points. In: Proceedings of ICCV'03, Nice, France; 2003:432–439.
[17] Tran D, Sorokin A. Human activity recognition with metric learning. In: European conference on computer vision; 2008.
[18] Gorelick L, Blank M, Shechtman E, Irani M, Basri R. Actions as space-time shapes. IEEE Trans Pattern Anal Mach Intellig. 2007;29(12):2247–2253.
[19] Niebles JC, Fei-Fei L. A hierarchical model of shape and appearance for human action classification. In: IEEE international conference on computer vision and pattern recognition, June; 2007.
[20] Niebles JC, Wang H, Fei-Fei L. Unsupervised learning of human action categories using spatial-temporal words. Int J Comput Vis. 2008;79:299–318.
[21] Erciş F. Comparison of histograms of oriented optical flow based action recognition methods [MS thesis]. Turkey: Middle East Technical University; 2012.
[22] Little S, Jargalsaikhan I, Clawson K, Nieto M, Li H, Direkoglu C, et al. An information retrieval approach to identifying infrequent events in surveillance video. In: Proceedings of the 3rd ACM Conference on International Conference on Multimedia Retrieval (ICMR '13); New York, NY, USA: ACM; 2013.
[23] Wang T, Snoussi H. Histograms of optical flow orientation for abnormal events detection. In: IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS); 2013:45–52.
[24] Gibson JJ. The perception of the visual world. Boston, MA, USA: Houghton Mifflin; 1950.
[25] Barron J, Fleet D, Beauchemin S. Performance of optical flow techniques. Int J Comput Vis. 1994;12:43–47.
[26] Horn BKP, Schunck BG. Determining optical flow. Artif Intell. 1981;17:185–203.
[27] Lucas B, Kanade T. An iterative image registration technique with an application to stereo vision. In: Proceedings of DARPA IU Workshop; 1981:121–130.
[28] Nagel HH. On the estimation of optical flow relations between different approaches and some new results. Artif Intell. 1987;33:299–324.
[29] Uras S, Girosi F, Verri A, Torre V. A computational approach to motion perception. Biol Cybern. 1988;60:79–97.
[30] Camus T. Real-time quantized optical flow. J Real-Time Imaging. 1997;3:71–86 Special Issue on Real-Time Motion Analysis.
[31] Proesmans M, Van Gool L, Pauwels E, Oosterlinck A. Determination of optical flow and its discontinuities using non-linear diffusion. In: 3rd European conference on computer vision, ECCV’94, vol. 2; 1994:295–304.
[32] Anandan P. A computational framework and an algorithm for the measurement of visual motion. Int J Comput Vis. 1989;2:283–310.
[33] Singh A. An estimation-theoretic framework for image-flow computation. In: Proceedings of ICCV, Osaka; 1990:168–177.
[34] Heeger DJ. Optical flow using spatiotemporal filters. Int J Comput Vis. 1988;1:279–302.
[35] Waxman AM, Wuand J, Bergholm F. Convected activation proles and receptive fields for real time measurement of short range visual motion. In: Proceedings of IEEE CVPR, Ann Arbor; 1988:717–723.
[36] Fleet DJ, Jepson AD. Computation of component image velocity from local phase information. Int J Comput Vis. 1990;5:77–104.
[37] Buxton B, Buxton H. Computation of optical flow from the motion of edge features in image sequences. Image Vis Comput. 1984;2:59–74.
[38] Akpınar S, Alpaslan FN. Video action recognition using an optical flow based representation. In: International conference on image processing, computer vision, and pattern recognition (IPCV '14), Las Vegas, USA; 2014.
[39] Shi J, Tomasi C. Good features to track. In: IEEE conference on computer vision and pattern recognition (CVPR’94), Seattle, June; 1994.
[40] Harris C, Stephens M. A combined corner and edge detector. In: Proceedings of the 4th Alvey Vision conference; 1988:147–151.
[41] Laptev I, Marszalek M, Schmid C, Rozenfeld B. Learning realistic human actions from movies. In: Proceedings of CVPR’08, Anchorage, US; 2008.
[42] Efros A, Berg A, Mori G, Malik J. Recognizing action at a distance. In: IEEE international conference on computer vision; 2003:726–733.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.