Emerging Trends in Image Processing, Computer Vision, and Pattern Recognition, 1st Edition (2015)
Part II. Computer Vision and Recognition Systems
Chapter 22. Anecdotes extraction from webpage context as image annotation
Chuen-Min Huang Department of Information Management, National Yunlin University of Science & Technology, Yunlin, Taiwan, ROC
Abstract
Traditional feature-based or text processing techniques tend to assign the same annotation to all the images in the same cluster without considering the latent semantic anecdotes of each image. In this research, we propose the Chinese lexical chain processing method which is a bottom-up concatenating process based on the intensity and the degree of a lexical chain (LC) to extract the most meaningful LCs as anecdotes from a string. It requires minimum computation that allows sharing characters/words and facilitating their use at fine granularities without prohibitive cost. In the experiment, this method achieves a precision rate of 84.6%, and gains acceptance from expert rating and user rating of 84% and 76.6%, respectively. In performance testing, it only takes 0.007 s to process each image in a collection of 18,000 testing data set.
Keywords
Anecdotes extraction
Automatic image annotation
Chinese lexical chain processing
Lexical chain
Acknowledgments
This study was supported by the National Science Council, Taiwan, Republic of China, under the project of special research projects of free software (NSC101-2221-E-224-056).
1 Introduction
Due to the rapid growth of digital technology, it is impractical to annotate a huge amount of images manually. Traditional research in this area focuses on content based image retrieval (CBIR), however, recent research reveals a significant gap between image annotation interpretered based on visual features and image semantics understandable by humans.
A glimpse of related studies show that the typical method of bridging the semantic gap is through the automatic image annotation (AIA) which extracts semantic features using machine learning techniques including support vector machine (SVM) [1,2], Bayesian [3] and selforganizing feature map [4,5]. In addition, various text processing techniques that support content identification based on word cooccurrence, location, and lexical-chained concepts have been elaborated in [6–8]. However, the aforementioned techniques suffer the drawbacks of heavy computation for multidocument processing, which will consume lots of memory and may incur run-time overhead. Furthermore, these feature-based or text processing techniques tend to assign the same annotation to all the images in the same cluster without considering the latent semantic anecdotes of each image. Thus, many relevant images can be missed from the retrieval list if a user does not type the exactly right keyword. To alleviate this problem, we propose a customized, relatively light computation way of anecdote identification, namely “Chinese lexical chain processing (CLCP).” The CLCP method was to extract meaningful concatenated words based on lexical chain (LC) theory from the image-resided webpage that allows sharing characters/words and facilitating their use at fine granularities without prohibitive cost. Results demonstrated that applying our method can successfully generate anecdotal descriptors as image annotations. The precision rate achieves 84.6%, and the acceptance rates from experts and users reach 84% and 76.6%, respectively. The performance testing was also very promising.
The remainder of the chapter is organized as follows. Section 2 presents the related work including AIA, keyword extraction, and LC. Then, we address the intent of our experiment in Section 3. The experimental result and evaluation method are described inSection 4. Finally, in Section 5, we draw conclusions and suggest future work.
2 Literature background
2.1 Automatic Image Annotation
There have been a number of models applied for image annotation. In general, image annotation can be categorized into three types: retrieval-based, classification-based, and probabilistic-based [7]. The basic notion behind retrieval-based annotation is that semantic-relevant images are composed of similar visual features. CBIR has been proposed in 1992 [9]. Since then, more and more studies annotated the images based on this method [10].
CBIR is applied by the use of images features, including shape, color, and texture. Once images are classified into different categories, each category is annotated with a concept label such as bird, cat, mammal, and building. However, this method is limited by the training data set and the hidden semantics or abstract concepts can’t be extracted because the keywords are confined to predefined terms. Consequently, the results of CBIR are usually not satisfactory.
The second type, also known as the supervised learning approach, treats annotation as classification using multiple classifiers. The images are classified based on the extracted features. This method processes each semantic concept as an independent class, and assigns each concept as one classifier. Bayesian [3] and SVM [11] are the most often used approaches.
The third type is constructed by estimating the correlations between images and concepts with a particular emphasis on the term-term relationship and intends to solve the problem of “synonym” and “homograph.” Frequent used approaches include cooccurrence model [12], LSA [5], PLSA [13], and hidden Markov model (HMM) [14]. Notwithstanding the efforts made on the enhancement of annotation quality, the aforementioned approaches tend to assign the same annotation to all the images in the same cluster thereafter they suffered the lack of customized annotation for each image.
2.2 Keyword Extraction
In the field of information retrieval, keyword extraction plays a key role in summarization, text clustering/classification, and so on. It aims at extracting keywords that represents the text theme. One of the most prominent problems in processing Chinese texts is the identification of valid words in a sentence, since there are no delimiters to separate words from characters in a sentence. Therefore, identifying words/phrases is difficult because of segmentation ambiguities and the frequent occurrences of newly formed words.
In general, Chinese texts can be parsed using dictionary lookup, statistical, or hybrid approaches [15]. The dictionary lookup approach identifies keywords of a string by mapping well-established corpus. For example, the Chinese string “![]() ” (Ying-wen Tsai went to Taipei prison to visit Shui-bian Chen and talk for an hour) will be parsed as: “[
” (Ying-wen Tsai went to Taipei prison to visit Shui-bian Chen and talk for an hour) will be parsed as: “[![]() ],” “[
],” “[![]() ],” “[
],” “[![]() ],” “[
],” “[![]() ],” “[
],” “[![]() ],” and “[
],” and “[![]() ]” by a well-known dictionary-based CKIP (Chinese Knowledge and Information Processing) segmentation system in Taiwan. This method is very efficient while it fails to identify newly formed or out-of-the-vocabulary words and it is also blamed for the triviality of the extracted words.
]” by a well-known dictionary-based CKIP (Chinese Knowledge and Information Processing) segmentation system in Taiwan. This method is very efficient while it fails to identify newly formed or out-of-the-vocabulary words and it is also blamed for the triviality of the extracted words.
Since there is no delimiters to separate words from Chinese string except for the usage of quotation marks in special occasion, word segmentation is a challenge without the aid of dictionary. The statistical technique extracts elements by using n-gram (bi-gram, tri-gram, etc.) computation for the input string. This method relies on the frequency of each segmented token and a threshold to determine the validity of the token. The above string through n-gram segmentation will produce: “[![]() ], [
], [![]() ], [
], [![]() ], [
], [![]() ], [
], [![]() ], [
], [![]() ], [
], [![]() ], [
], [![]() ], [
], [![]() ], [
], [![]() ], [
], [![]() ]”; “[
]”; “[![]() ], [
], [![]() ], …, [
], …, [![]() ]” and so on. The application of this method has the benefit of corpus-free and the capability of extracting newly formed or out-of-the-vocabulary words while at the expense of huge computations and the follow-up filtering efforts.
]” and so on. The application of this method has the benefit of corpus-free and the capability of extracting newly formed or out-of-the-vocabulary words while at the expense of huge computations and the follow-up filtering efforts.
Recently, a number of studies proposed substring [9], significant estimation [16], and relational normalization [17,18] to identify words based on statistical calculations. The hybrid method conducts dictionary mapping to process the major task of word extraction and handle the leftovers through n-gram computation, which significantly reduces the amount of terms under processing and takes care both the quality of term segmentation and the identification of unknown words. It has gained popularity and adopted by many researchers [19,20].
Since the most important task of annotation is to identify the most informative parts of a text comparatively with the rest. Consequently, a good text segmentation shall help in this identification. In the IR theory, the representation of documents is based on the vector space model [21]: A document is a vector of weighted words belonging to a vocabulary V : d = {w1, …, w|v|}. Each wv is such that 0 ≤ wv ≤ 1 and represents how much the term tn contributes to the semantics of the document d. In the term frequency-inverse document frequency model, the weight is typically proportional to the term frequency and inversely proportional to the frequency and length of the documents containing the term. Some studies [22,23] proposed other considerations to assign different weights to words, such as word length and location.
2.3 Lexical Chain
A LC is a sequence of words, which is in lexical cohesion relations with each other, and the chained words tend to indicate portions of the context that form semantic units while it is independent of the grammatical structure of the text. LCs could serve further as a basis for a segmentation [24]. This method is usually applied in a summarization generation [25]. For instance, the string “![]() ” (vector space model) may be parsed as “[
” (vector space model) may be parsed as “[![]() ],” (vector) “[
],” (vector) “[![]() ],” (space), and “[
],” (space), and “[![]() ]” (model) if there is no further merging process undergoing. Thereby the most informative compound “[
]” (model) if there is no further merging process undergoing. Thereby the most informative compound “[![]() ]” will be left out. Usually LCs are constructed in a bottom-up manner by taking each candidate word of a text, and finding an appropriate semantic relation offered by a thesaurus. Instead, the paper [26] proposes a top-down approach of linear text segmentation based on lexical cohesion of a text. Some scholars suggested to use machine learning approaches to create a set of rules to calculate the rate of forming a new word by characters for entity recognition including the maximum entropy model and HMM and claimed this method was able to achieve reasonable performance with minimal training data [27,28].
]” will be left out. Usually LCs are constructed in a bottom-up manner by taking each candidate word of a text, and finding an appropriate semantic relation offered by a thesaurus. Instead, the paper [26] proposes a top-down approach of linear text segmentation based on lexical cohesion of a text. Some scholars suggested to use machine learning approaches to create a set of rules to calculate the rate of forming a new word by characters for entity recognition including the maximum entropy model and HMM and claimed this method was able to achieve reasonable performance with minimal training data [27,28].
3 Research design
3.1 Research Model Overview
This study covers three tasks: Text processing, anecodote extraction, and annotation evaluation. Since image captions are written by journalists, it is assumed that a man-made caption would be faithful to an image scenario. We assigned the extracted anecdotes with the highest weight as the primary annotation and the second and the third places as secondary annotations. The framework of our research is depicted as Figure 1. We conducted CLCP and term weighting for the input data to extract anecodotes and evaluated the annotations by using the image caption mapping and human judgment, respectively. In the following section, we will introduce the way of anecodote extraction and the way of annotation evaluation.
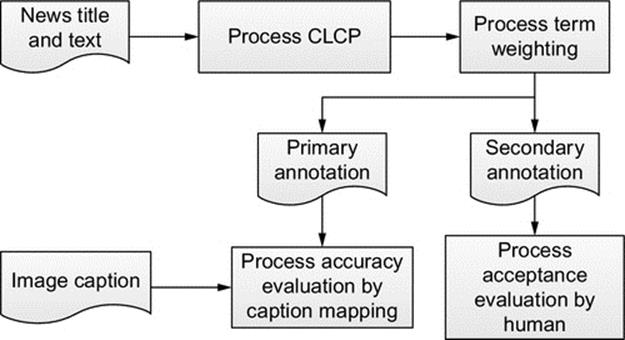
FIGURE 1 Research model.
3.2 Chinese Lexical Chain Processing
The fundamental idea of building CLCP is a bottom-up concatenating process based on the significance degree of distribution rate to extract the most meaningful LCs as anecodotes from a string. We treated a news document as a long string composed of a series of characters and punctuations.
Most of the traditional studies identify words from the whole context and store all the processed tokens for further processing as Figure 2. In this way, even a moderate-sized document may require hundreds of thousands of tokens, which will consume lots of memory and may incur unacceptable run-time overhead. Due to the number of distinct tokens processed is less than that in the document, we adopted a sharing concept to allow reuse of the identical tokens. We considered each character as a basic unit from which to build compounds as a composite, which in turn can be grouped to form larger compounds. Since the character and compound will be treated uniformly, it makes the application simple.
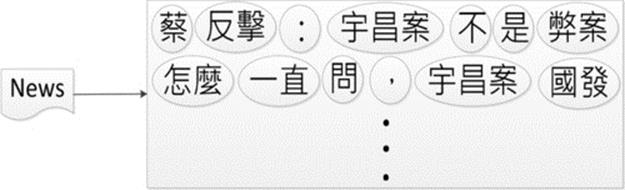
FIGURE 2 Traditional document processing.
By doing so, we adopted the concept of flyweight and composite design patterns proposed by the GOF (Gang of Four) [29] to implement this design. Figure 3 shows the flyweight as a shared object that can be used in the whole context simultaneously. Figure 4represents the part-whole hierarchy of texts and the way to use recursive composition. By applying flyweight design pattern, it supports the use of large numbers of fine-grained objects efficiently. By applying composite design pattern, it makes the application easier to add new components.
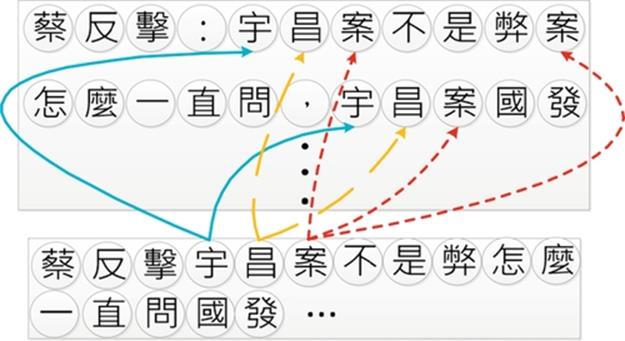
FIGURE 3 Flyweight design concept.
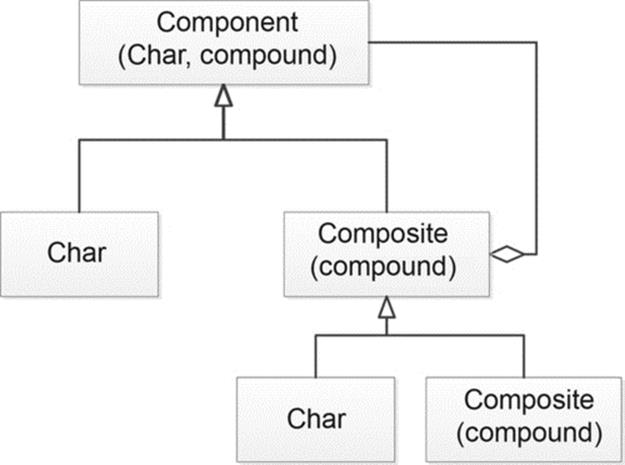
FIGURE 4 Composite text structure.
The CLCP steps are depicted as Figure 5, and Figure 6 displays a fractional code of the iterative concatenating process. The detailed description with an example is addressed next.
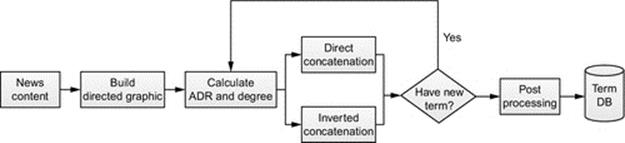
FIGURE 5 CLCP steps.

FIGURE 6 A fractional code of iterative merging.
3.2.1 Step 1: Build a directed graph
A directed graph (or digraph) is a set of nodes connected by edges, where the edges have a direction associated with them. For example, an arc (x, y) is considered to be directed from x to y, and the arc (y, x) is the inverted link. Y is a direct successor of x, and x is a direct predecessor of y.
We use the string: “![]() :
:![]() ,
,![]() ,
,![]() …” (Tsai fired back and stated that Yu Chang case is not a scandal, why did you keep asking for this and why the National Development Fund abandoned its rights repeatedly?) as an example to explain the construction process. After removing duplicate characters and replacing punctuations with new lines, a digraph is built as Figure 7, in which a solid line indicates the directed link and a dash line means the inverted link.
…” (Tsai fired back and stated that Yu Chang case is not a scandal, why did you keep asking for this and why the National Development Fund abandoned its rights repeatedly?) as an example to explain the construction process. After removing duplicate characters and replacing punctuations with new lines, a digraph is built as Figure 7, in which a solid line indicates the directed link and a dash line means the inverted link.
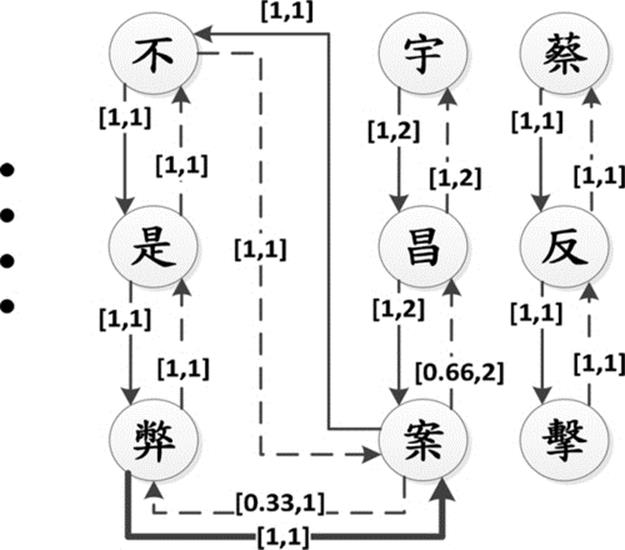
FIGURE 7 A fraction of digraph.
3.2.2 Step 2: Calculate average distribution rate and degree to concatenate vertices
This step is to calculate the average distribution rate (ADR or intensity) and the number of links (degree) of a digraph. To determine whether two vertices can be concatenated, we applied the criteria listed in (1) and (2).
![]() (1)
(1)
![]() (2)
(2)
where D(i, j) and D(p, q) represent the ADR of the arcs (i, j) and (p, q); Digraph (Nodei) and InvD (Nodep) indicate the number of direct links for vertex i and inverted links for vertex p, respectively. T is the threshold value of ADR determined by 10 runs of experiments with the value of 0.1-0.9 assigned to 500 documents and the result was verified by five subject specialists with respect to semantics of anecodotes. The result in our previous study [30] using 100 documents as a testing data set showed that 0.4 outperforms the others, while this study used five times of previous samples reveal that the accuracy rate of 0.5 reaching 82% is the best cut of intensity as Figure 8. It implies both 0.4 or 0.5 are competitive thresholds. Based on the term frequency theory, it infers that the significance of the concatenation will be proportional to its frequency. Since this study was to identify anecodotes from single documents, we set a minimum degree as 2.
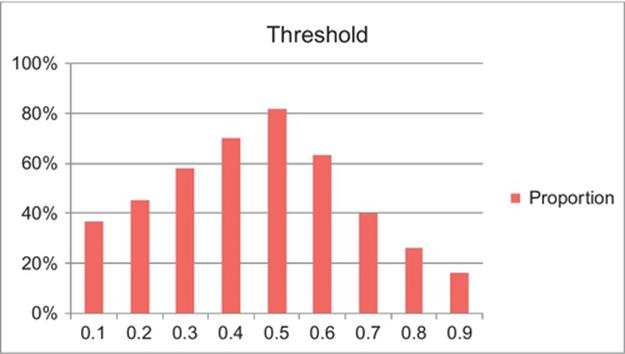
FIGURE 8 Thresholds scatter diagram of ADR.
Figure 9 shows a digraph with ADR and degree, the arc (![]() ,
, ![]() ) (Yu, Chang) with the expression [1, 2] indicating that the intensity is 1 and the degree is 2, therefore it will be concatenated as “[
) (Yu, Chang) with the expression [1, 2] indicating that the intensity is 1 and the degree is 2, therefore it will be concatenated as “[![]()
![]() ]” (Yu Chang) because it meets the criteria (1). In [31], we considered only on directed links but failed in detecting significant concatenations from inverted links. For example, the LC “[
]” (Yu Chang) because it meets the criteria (1). In [31], we considered only on directed links but failed in detecting significant concatenations from inverted links. For example, the LC “[![]()
![]() ]” (Scandal) with the value [0.33, 2] of the direct link (
]” (Scandal) with the value [0.33, 2] of the direct link (![]() ,
, ![]() ) will not be concatenated if we don’t consider its inverted link (
) will not be concatenated if we don’t consider its inverted link (![]() ,
,![]() ) with the value [1,2] which meets the criteria (2).
) with the value [1,2] which meets the criteria (2).
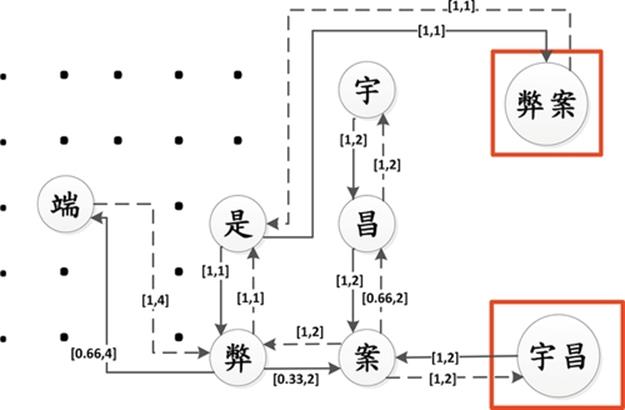
FIGURE 9 Digraph with concatenate vertices.
3.2.3 Step 3: Run iteration
The above steps will be iterated until no concatenation can be found, and this iteration process will generate a series of short and long LCs as anecdotes. A long LC is believed to carry more anecdotes than a short LC could possibly do. For example, it is obvious that “[![]() ]” is a better anecdote than its substring “[
]” is a better anecdote than its substring “[![]() ]” or “[
]” or “[![]() ]” or “[
]” or “[![]() ].” To enhance the semantics of candidate anecdotes, we will take a further concatenation process as the last step to finalize the CLCP.
].” To enhance the semantics of candidate anecdotes, we will take a further concatenation process as the last step to finalize the CLCP.
3.2.4 Step 4: Execute postprocessing
In the final step, significant words are determined by observing the information mutually shared by two-overlapped LCs using the following significance estimation (SE) function as (3)
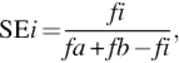 (3)
(3)
where i denotes the LCi to be estimated, that is, i = ii· i2, …, in; a and b represent the two longest compound substrings of LCi with the length n− 1, that is, a = ii· i2, …, in− 1 and b = i2· i3, …, in. The fa, fb and fi are the frequencies of a, b, and i, respectively. In the above example, the term i, “[![]() ]” (Yu Chang case), shall gain the SE value of 0.83 based on its frequency 5 and the frequency 6 of its substring a, “[
]” (Yu Chang case), shall gain the SE value of 0.83 based on its frequency 5 and the frequency 6 of its substring a, “[![]() ]” (Yu Chang), as well as the frequency 5 of the other substring “[
]” (Yu Chang), as well as the frequency 5 of the other substring “[![]()
![]() ]” (Chang case). In this case, we will retain term i “[
]” (Chang case). In this case, we will retain term i “[![]() ]” and its substring a “[
]” and its substring a “[![]() ]” because the frequency of “[
]” because the frequency of “[![]() ]” is less than “[
]” is less than “[![]() ]” indicating “[
]” indicating “[![]() ]” carries useful meanings. Likewise, we will discard the substring b “[
]” carries useful meanings. Likewise, we will discard the substring b “[![]()
![]() ]” because both terms have the same frequency indicating the long term “[
]” because both terms have the same frequency indicating the long term “[![]()
![]() ]” can replace its substring “[
]” can replace its substring “[![]() ].” As stated above, since fi < fa, we retain both terms, and discard “[
].” As stated above, since fi < fa, we retain both terms, and discard “[![]() ]” because fi = fb.
]” because fi = fb.
3.2.5 Term weighting
It is suggested that the most significant content description often appears in the title and the first paragraph. In addition, word frequency and word length are also accepted as the indicators of term discrimination value in a document. Given a word LCi, the term weighting algorithm may be defined as (4).
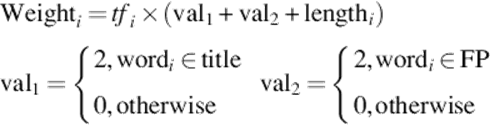 (4)
(4)
where tfi represents the frequency of LCi; val1 and val2 express the added double weights on the news title and the first paragraph, respectively.
4 Evaluation
In this experiment, we collected 18,000 images-resided web pages from Taiwan news website udn.com including the categories of politics, society, local news, world news, finance, and life as the data sets. To verify the effectiveness of our proposed CLCP method, we used the image caption as the ground truth label for the primary annotation to understand the degree to which it matches the caption. We also invited subject experts and users to assess the appropriateness of the secondary annotations. In the end, we measured the performance of the CLCP method in a real-time mode.
4.1 Evaluation of Primary Annotation
Due to the fact of discrepancy in interpreting the context semantics by humans, therefore the exact number of correct annotations of an image may not be easily identified. For example, the LC “[![]() ]” (President Ma Ying-jiu) is better than its substrings “[
]” (President Ma Ying-jiu) is better than its substrings “[![]() ]” and “[
]” and “[![]() ]” even though these two substrings are also valid annotations. Thus, the recall measurement did not apply to this study. A precision measurement was used to understand the proportion of primary annotations actually matched the image captions as (5).
]” even though these two substrings are also valid annotations. Thus, the recall measurement did not apply to this study. A precision measurement was used to understand the proportion of primary annotations actually matched the image captions as (5).
![]() (5)
(5)
where PAs represent the primary annotations from 18,000 documents. After the CLCP processing, the total number of matched PAs in captions are 15,228. We obtained a precision rate of 84.6%.
4.2 Expert Evaluation of Secondary Annotation
To evaluate the validity of the secondary annotations, we invited five subject experts to participate in the assessment. Thirty pieces of news were randomly selected from which we extracted 60 secondary annotations. To reduce ambiguous judgements, each annotation was evaluated based on a method of dichotomic classification to which the annotation represents the image content. Each expert could only identify either “agree” or “disagree” for each annotation. The result showed that the number of check marks of consent is 252 of 300. It implies that the agreement of the appropriateness of the secondary annotations to the images achieves 84%.
4.3 User Evaluation of Secondary Annotation
To evaluate the appropriateness of the secondary annotation, we conducted another survey to understand the differences between the image annotation and the users’ expectation. Sixty graduate and undergraduate students were recruited from National Yunlin University of Science & Technology, Taiwan to participate in the assessment. One hundred pieces of news were randomly selected from which we collected 200 secondary annotations. Students were divided into four groups, and each group was given 25 images for the evaluation. To assist the assessment, we provided news title, text and caption for references. Each annotation was evaluated by three participants to understand the degree to which the annotations appropriately address the image content. The result in Table 1shows that the number of check marks of agreement is much higher than that of disagreement. The agreement rate of user evaluation reaches 76.6%.
Table 1
Results of User Agreement

4.4 Results of Image Annotation
The following three examples display the results after conducting CLCP. For copyright consideration, we refer the indicated image to its url address for reference. Table 2 is a local news entitled “![]() ” (The automobile life-saving buoy, Europe science competition won the gold medal). The primary and secondary annotations were generated, including “[
” (The automobile life-saving buoy, Europe science competition won the gold medal). The primary and secondary annotations were generated, including “[![]()
![]() ]” (Dr. Zhang Faxian, Department of Electronic Engineering at Cheng Shiu University), “[
]” (Dr. Zhang Faxian, Department of Electronic Engineering at Cheng Shiu University), “[![]() ]” (Combined Type of Rescue buoyancy Suite), and “[
]” (Combined Type of Rescue buoyancy Suite), and “[![]() ]” (The automobile life-saving buoy). Note that our method extracts “[
]” (The automobile life-saving buoy). Note that our method extracts “[![]() ],” the inventor of this awarded buoy, is not mentioned in the news title and it is so specific and completely fit the picture. Table 3 is an international news entitled “
],” the inventor of this awarded buoy, is not mentioned in the news title and it is so specific and completely fit the picture. Table 3 is an international news entitled “![]() ” (The First Lady of Taiwan Chow Mei-Ching attends the exhibition of the Imperial Palace in Tokyo). The primary and secondary annotations were generated, including “[
” (The First Lady of Taiwan Chow Mei-Ching attends the exhibition of the Imperial Palace in Tokyo). The primary and secondary annotations were generated, including “[![]()
![]() ]” (Special exhibition of the Treasured masterpieces from National Palace Museum, Taipei), “[
]” (Special exhibition of the Treasured masterpieces from National Palace Museum, Taipei), “[![]() ]” (Taiwan), and “[
]” (Taiwan), and “[![]()
![]() ]” (Chow Mei-Ching’s visit to Japan). Note that our method extracts “[
]” (Chow Mei-Ching’s visit to Japan). Note that our method extracts “[![]()
![]() ],” the complete description of the exhibition, is the main theme of the visit. With the three annotations, it clearly describes the picture. Table 4 is an international news entitled “
],” the complete description of the exhibition, is the main theme of the visit. With the three annotations, it clearly describes the picture. Table 4 is an international news entitled “![]()
![]() ” (France committed to deal with the flight crash in Algeria). The primary and secondary annotations were generated, including “[
” (France committed to deal with the flight crash in Algeria). The primary and secondary annotations were generated, including “[![]() 5017
5017![]() ]” (Algeria Airlines Flight 5017), “[
]” (Algeria Airlines Flight 5017), “[![]() ]” (Three days of national mourning), and “[118
]” (Three days of national mourning), and “[118![]() ]” (118 victims). Note that the three extracted annotations depict the implicit content of the press conference, which enhance understanding the picture.
]” (118 victims). Note that the three extracted annotations depict the implicit content of the press conference, which enhance understanding the picture.
Table 2
Example 1
|
News title |
The automobile life-saving buoy, Europe science competition seizes the gold medal |
|
Image link |
https://s2.yimg.com/bt/api/res/1.2/sPmFSiNcFapEMkRGOuZVdg--/YXBwaWQ9eW5ld3M7Y2g9MjQwO2NyPTE7Y3c9MzIwO2R4PTA7ZHk9MDtmaT11bGNyb3A7aD0xNDM7cT04NTt3PTE5MA--/http://media.zenfs.com/zh_hant_tw/News/ftv/2014526U02M1.jpg |
|
Caption |
The automobile life-saving buoy, Europe science competition won the gold medal, special award |
|
CLCP |
Dr. Zhang Faxian, Department of Electronic Engineering at Cheng Shiu University | Combined Type of Rescue buoyancy Suite | The automobile life-saving buoy |
Table 3
Example 2
|
News title |
The First Lady of Taiwan Chow Mei-Ching attends the exhibition of the Imperial Palace in Tokyo |
|
Image link |
http://wscdn.bbc.co.uk/worldservice/assets/images/2014/08/04/140804110249_cn_chow_mei_ching_tokyo_624x351_afp.jpg |
|
Caption |
Chow Mei-Ching’s visit to Japan but was ultimately received a cold-should by the media |
|
CLCP |
Special Exhibition of the Treasured Masterpieces from National Palace Museum, Taipei | Taiwan | Chow Mei-Ching’s visit to Japan |
Table 4
Example 3
|
News title |
France committed to deal with the flight crash in Algeria |
|
Image link |
http://wscdn.bbc.co.uk/worldservice/assets/images/2014/07/26/140726222034_francois_hollande_624x351_reuters.jpg |
|
Caption |
After meeting with the families of the victims François Hollande made a commitment |
|
CLCP |
Algeria Airlines Flight 5017 | Three days of national mourning | 118 victims |
4.5 Performance Testing
After the annotation validity and acceptance evaluation, we conducted a performance testing with respect to the time spent of processing from an event trigger to system response. Often real-time response times are understood to be in milliseconds and sometimes microseconds. Our testing data sets consist of 18,000 pieces of news; the processing time is 126 s in total with 0.007 s on average for each piece of news.
5 Conclusion
Unlike recent feature-based or text processing techniques tend to assign the same annotation to all the images in the same cluster without considering the latent semantic anecdotes of each image. This study proposed a corpus-free, relatively light computation of term segmentation, namely “CLCP method” to identify pertinent anecdotes for image annotation.
This chapter contributes to image annotation research in several ways. First, it demonstrates that a corpus-free, lightweight computation of a single document can effectively generate pertinent anecdotes for image annotation. This finding indicates that a greater deployment of the CLCP needs to be undertaken in order to provide customized image annotation that has been neglected by current CBIR and text-based image processing. Second, for performance consideration, this method adopted the concept of flyweight and composite design patterns that allows sharing characters/words and facilitating their use at fine granularities without prohibitive cost. This finding implies that whether the CLCP applied to a single document or multidocument processing will gain the same benefit. Third, this study demonstrates that the extracted anecdotes truly depict the implicit content of the news, which enhance understanding the picture.
Results showed that this method achieves a significant precision rate and gains high acceptance from experts and users. The performance testing was also very promising. The proposed model, along with the empirical findings, sheds new light on AIA.
References
[1] Gao S, Wang D-H, Lee C-H. Automatic image annotation through multi-topic text categorization. In: 2006 IEEE international conference on acoustics, speech and signal processing; 2006.
[2] Lei Z, Jun M. Image annotation by incorporating word correlations into multi-class SVM. Soft Comput. 2011;15:917–927.
[3] Luong-Dong N, Ghim-Eng Y, Ying L, Ah-Hwee T, Liang-Tien C, Joo-Hwee L. A Bayesian approach integrating regional and global features for image semantic learning. In: IEEE international conference on multimedia and expo 2009, 28 June to 3 July 2009; 2009:546–549.
[4] Chow TWS, Rahman MKM. A new image classification technique using tree-structured regional features. Advanced Neurocomput Theory Methodol. 2007;70:1040–1050.
[5] Huang C-M, Chang C-C, Chen C-T. Automatic image annotation by incorporating weighting strategy with CSOM classifier. In: The 2011 international conference on image processing, computer vision, & pattern recognition (IPCV’11). Monte Carlo Resort, Las Vegas, Nevada, USA; 2011.
[6] Barnard K, Duygulu P, Forsyth D, De Freitas N, Blei DM, Jordan MI. Matching words and pictures. J Mach Learn Res. 2003;3:1107–1135.
[7] Su JH, Chou CL, Lin CY, Tseng VS. Effective image semantic annotation by discovering visual-concept associations from image-concept distribution model. In: Proc. IEEE international conference on multimedia; 2010:42–47.
[8] Zhu S, Liu Y. Semi-supervised learning model based efficient image annotation. IEEE Signal Process Lett. 2009;16:989–992.
[9] Kato T. Database architecture for content-based image retrieval. In: Proc. SPIE 1662, image storage and retrieval systems; 1992:112–123.
[10] Jing L, Shao-Ping M, Min Z. Automatic image annotation based-on model space. In: Proc. 2005 IEEE international conference on natural language processing and knowledge, engineering 30 Oct–1 Nov 2005; 2005:455–460.
[11] Gao Y, Fan J, Xue X, Jain R. Automatic image annotation by incorporating feature hierarchy and boosting to scale up SVM classifiers. In: Proc. of the 14th annual ACM international conference on multimedia; Santa Barbara, CA: ACM; 2006.
[12] Mori Y, Takahashi H, Oka R. Image-to-word transformation based on dividing and vector quantizing images with words. In: First international workshop on multimedia intelligent storage and retrieval management; 1999.
[13] Monay F, Gatica-Perez D. PLSA-based image auto-annotation: constraining the latent space. In: Proc. 12th annual ACM international conference on multimedia; New York, NY: ACM; 2004.
[14] Carneiro G, Vasconcelos N. Formulating semantic image annotation as a supervised learning problem. In: IEEE computer society conference on computer vision and pattern recognition, USA; 2005.
[15] Wang Z, Xu J, Araki K, Tochinai K. Word segmentation of Chinese text with multiple hybrid methods. In: 2009 International conference on computational intelligence and software engineering; 2009.
[16] Horng JT, Yeh CC. Applying genetic algorithms to query optimization in document retrieval. Inform Process Manag. 2000;36:737–759.
[17] Fuketa M, Fujisawa N, Bando H, Morita K, Aoe JI. A retrieval method of similar strings using substrings. In: 2010 Second international conference on computer engineering and applications; 2010.
[18] Kim MS, Whang KY, Lee JG, Lee MJ. Structural optimization of a full-text n-gram index using relational normalization. VLDB J. 2008;17:1485–1507.
[19] Hong C-M, Chen C-M, Chiu C-Y. Automatic extraction of new words based on Google News corpora for supporting lexicon-based Chinese word segmentation systems. Expert Syst Appl. 2009;36:3641–3651.
[20] Tsai R.T.-H. Chinese text segmentation: a hybrid approach using transductive learning and statistical association measures. Expert Syst Appl. 2010;37:3553–3560.
[21] Salton G, Mcgill MJ. Introduction to modern information retrieval. New York: McGraw-Hill Book Company; 1983.
[22] Troy AD, Zhang G-Q. Enhancing relevance scoring with chronological term rank. In: Proc. 30th annual international ACM SIGIR conference on research and development in information retrieval; Amsterdam, The Netherlands: ACM; 2007.
[23] Yan H, Ding S, Suel T. Compressing term positions in web indexes. In: Proc. 32nd international ACM SIGIR conference on research and development in information retrieval; Boston, MA: ACM; 2009:147–154 1571969.
[24] Tatar D, Kapetanios E, Sacarea C, Tanase D. Text segments as constrained formal concepts. In: 12th international symposium on symbolic and numeric algorithms for scientific computing (SYNASC), 23–26 Sept. 2010; 2010:223–228.
[25] Shanthi V, Lalitha S. Lexical chaining process for text generations. In: International conference on process automation, control and computing (PACC); 2011.
[26] Tatar D, Mihis AD, Czibula GS. Lexical chains segmentation in summarization. In: 10th international symposium on symbolic and numeric algorithms for scientific computing, 26–29 Sept. 2008; 2008:95–101.
[27] Ageishi R, Miura T. Named entity recognition based on a hidden Markov model in part-of-speech tagging. In: First international conference on the applications of digital information and web technologies; 2008.
[28] Chiong R, Wang W. Named entity recognition using hybrid machine learning approach. In: The 5th IEEE international conference on cognitive informatics; 2006.
[29] Gamma E, Helm R, Johnson R, Vlissides J. Design patterns: elements of reusable object-oriented software. Indianapolis, IN: Pearson Education Co; 1995.
[30] Huang C-M. Applying a lightweight Chinese lexical chain processing in web image annotation. In: The 2014 international conference on image processing, computer vision, & pattern recognition (IPCV’14), Las Vegas, Nevada, USA; 2014.
[31] Huang C-M, Chang Y-J. Applying a lightweight iterative merging Chinese segmentation in web image annotation. In: Perner P, ed. 2013 International conference on machine learning and data mining, New York, USA; Berlin Heidelberg: Springer; 2013:183–194.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.