Emerging Trends in Image Processing, Computer Vision, and Pattern Recognition, 1st Edition (2015)
Part II. Computer Vision and Recognition Systems
Chapter 24. Gesture recognition in cooking video based on image features and motion features using Bayesian network classifier
Nguyen Tuan Hung1; Pham The Bao1; Jin Young Kim2 1 Faculty of Mathematics and Computer Science, Ho Chi Minh University of Science, Ho Chi Minh City, Viet Nam
2 School of Electrical and Computer Engineering, Chonnam National University, Gwangju, South Korea
Abstract
In this chapter, we propose an advanced method, which combines image features and motion features, for gesture recognition in cooking video. First of all, the image features including global and local features of Red-Green-Blue color images are extracted, then represented using bag of features method. Concurrently, motion features are also extracted from these videos and represented through some dense trajectories descriptors such as histogram of oriented gradient, histogram of optical flow, or motion boundary histogram. In addition, we use relative positions between objects and also their positions are detected in each frame to decrease misclassification. Next, we combine both image features and motion features to describe the cooking gestures. At the last step, Bayesian network models are applied to predict which action class a certain frame belongs to, base on the action class of previous frames and the cooking gesture in current frame. Our method has been approved through Actions for Cooking Eggs dataset that it can recognize human cooking actions as we expected. We evaluate our method as a general method for solving many different action recognition problems. In near future, therefore, we are going to apply it to solve other action recognition problems.
Keywords
Action recognition
Bayesian network
Features combination
Image features
Motion features
Depth image
Acknowledgments
We would like to thank Atsushi Shimada, Kazuaki Kondo, Daisuke Deguchi, Géraldine Morin, and Helman Stern for organizing KSCGR contest and Tomo Asakusa et al. from Kyoto University, Japan for creating and distributing Actions for Cooking Egg dataset.
1 Introduction
As you know, cooking and eating are our routines which all of us must do in order to stay healthy. Although these are simple tasks that anyone would have to go through every day in life, they account for a very important position because of healthy impact. On the other hand, in a modern society, time has become more precious than ever before. Everyone does not have much time for cooking themselves and it leads to a direct impact on the health of everyone. Therefore, the question “How could we have a delicious and nutritious dish with less cooking time?” has been raised for a while.
In recent years, researchers all over the world have been building various intelligent kitchen systems, which are anticipated as the answer for the above question. They expect that these systems can help everyone cook faster and more efficiently. In these systems, there is not only a single solution but also the solutions of many different problems such as object recognition problem, human action recognition, or nutritious meals computation which are combined together. All of the above problems have been actually raised in the “Multimedia for Cooking and Eating Activities” workshop from 2009. Until now, many complex challenges still exist and there is not any complete solution. Among these problems, we evaluated that the human’s cooking action recognition is the most challenge problem.
One of its challenges is action recognition problem. Its objection is how a computer program can recognize cooking actions based on training dataset. Furthermore, based on sequences of cooking actions, it could predict what kind of dishes. In reality, we expect that when this program is being executed, it observes actions of user(s), recognizes these actions, and either warns user(s) if there is any wrong or suggests next cooking steps. Therefore, we realize that solving problem of cooking action recognition is the most important task to complete our intelligent kitchen system. This problem has been mentioned in a contest [1] of ICPR2012 conference as an interesting topic in video retrieval field. Through this contest and many different researches, there are numerous solutions from many researchers. Moreover, plenty of dataset are created and distributed to researchers. One of them is new “Actions for Cooking Eggs” (ACE) Dataset [2], which we used for evaluating our method in experiments, was presented in contest [1].
In this chapter, a novel method for recognizing human’s actions in cooking video is proposed. Our proposed method derives from combination between image features and motion features for gesture recognition. Because of complexity of this problem, we divide it into four subproblems which include cooking action representation by image features, cooking action representation by motion features, combination of image features and motion features, and cooking action classification. From a cooking video, first, the cooking actions are represented by some image features such as pyramid histogram of oriented gradient (PHOG) [3], or scale invariant feature transform (SIFT) [4] and motion feature such as dense motion [5]. We also detect objects in each frame and compute the relative positions between them. We try to represent actions more exactly, so that classification result would be better. Hence, the feature extraction step is very important and the features must be chosen carefully. There is another subproblem which is to combine these above features. According to research from others using only one kind of feature is not good enough in accuracy and combining different features, accuracy gets higher. However, the efficient way of combination is still a complex problem since it depends on datasets and kinds of feature. In this chapter, we use both early fusion and late fusion techniques for combining features [6,7].
Last but not least, to solve cooking action classification problem, we use Bayesian network (BN) classifier. The first reason is automatic structure learning which means we do not need to concern about the network’s structure. In addition, in cooking video, the sequence of actions for each kind of dishes has its characteristics. So we can learn this feature and use it in classifier to achieve better classification results. This is the second reason for us to choose BN classifier. Other advantages are easy to update parameters of nodes in the network and modify network’s structure by adding or removing nodes in the network. For three main reasons, we have chosen BN as the classifier for our system.
To build a gesture recognition system, our main contributions are as follows:
• Representing cooking motion by image features including color histogram, local binary pattern (LBP), edge oriented histogram (EOH), PHOG, SIFT, and also the relative positions of objects.
• Representing cooking motion by motion features using dense trajectories motion feature.
• Combination of image features and motion features by both early fusion and late fusion techniques.
• Using BN classification for gesture recognition.
2 Related work
As soon as the flourishing period of computer visions, human’s action recognition problem has appeared in many applications especially for smart devices. Generally, a typical human’s action recognition system works by extracting some kind of features or/and combining them in a certain way. Most of these systems usually use both global and local image features. Until now, many researchers have been trying to answer which feature is the best for describing human’s action and whether different features are supplements for each other. These following features have been deeply studied to answer the above question for recently years.
An answer came from a successful system built by a research team from Columbia University. It used SIFT [4] as an image feature, Space-time interest points (STIP) [8] as a motion feature and Mel Frequency Cepstral Coefficients [9] as a sound feature. Overall, STIP was the best motion feature for human’s action description. However, to achieve better results, different kinds of them, which were supplemental features, should be combined together including image features, motion features, and even sound features. This is an important conclusion that other teams agree with.
Researchers from International Business Machines Corporation (IBM) built another human’s action recognition system [10]. It used many image features including SIFT [4], GIST [11], color histogram, color moment, wavelet texture, etc. For motion features, it uses STIP [8] combining with HOG/HOF [12]. According to their experiment’s result, they concluded that a combination of some features raised the accuracy of recognition. This conclusion is the same as Columbia team [13]. Besides, Nikon team’s system is a simple system [14]. It used scene cut detection to extract key frames. This method depends on kind of videos, and length of videos. Although this method is not the best method, it is a good idea that we can use in our system.
In ICPR 2012 conference, there were six systems submitted to. To describe their cooking action system, researchers from Kyushu University, Japan [15] used local features including FAST detector and CHOG3D descriptor, and combined with hand motion feature which was extracted from depth images. In that research, they achieved some spectacular results. The average accuracy for action recognition in their experiment is 50.6% in case of using depth local feature and 53.0% when they used local feature. Then, when they combine these kinds of feature, the accuracy is achieved 57.1%.
The winning entry was by a team from Chukyo University, Japan. Their method uses heuristic approach using image features with some modifications. Then, in postprocessing step, they use some methods to avoid unnatural labeling results. Their result proved that this approach is more effective than other approaches in practical use. Besides, the other recognition systems from other teams are also interesting. They use motion history image feature, spatio-temporal interest point description feature, trajectories feature, and context information. Moreover, they use one-versus-all linear Support Vector Machine (SVM) classifier as an action model. In postprocessing, they apply 1D Markov random field on the predicted class labels.
According to these methods, we could conclude that an effective action recognition method usually uses some different features and combines them to achieve the better result. Besides, the information such as context information and cooking action sequence are also important for improving the accuracy of our method.
3 Our Method
3.1 Our Recognition System Overview
Below there are two diagrams, which, respectively, shows training framework and testing framework of our recognition system. As depicted in Figure 1, the main steps in these frameworks are the same.
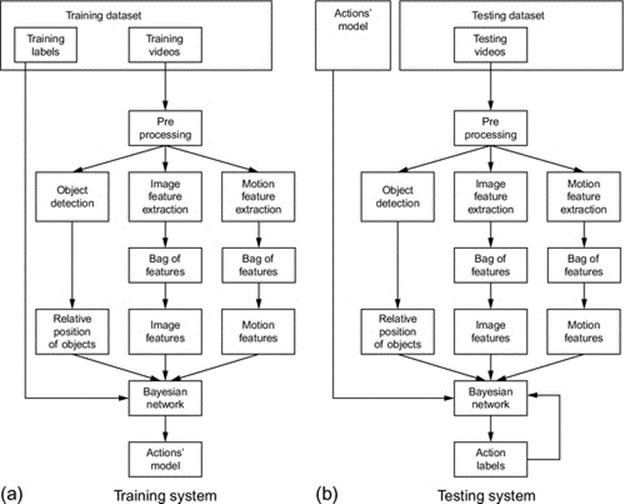
FIGURE 1 Diagrams to describe our method’s systems (a) is our training system and (b) is our testing system.
First of all, the input videos are preprocessed through some minor-steps including calibrations, segmentation, objects and human detection, and hands detection. Next, some features are extracted from both depth images and color images. According to basic action recognition methods, they extract motion features in the videos and perform discriminative analysis for action recognition. For cooking action recognition problem, however, some actions cannot be described by using a motion feature alone. Hence, we propose to extract both human’s motion feature and image features from cooking video.
For matching the feature vectors, there are some matching methods. However, for this problem, there is a large of feature vectors, which cannot be applied the original matching methods. Therefore, we use bag of feature (BoF) [16] to describe image features and motion features for speeding up the matching step. For each frame, we detect objects and also compute their relations. Moreover, using the training labels, we can learn some rules about the sequences of actions. Finally, we apply BN construction and parameters learning.
For the last step, we create three BNs first, and then train their parameters. The output of training system is a model which describes the cooking actions. In the testing system, we use the trained model to classify cooking actions. Besides, action labels of the previous actions are used as an additional input data for BN classifier. The action label of each frame is the output of testing system. Lastly, we evaluate our method based on the output by calculating accuracy score from precision and recall manner.1 Their harmonic, after that, is calculated by following formula
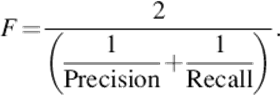 (1)
(1)
The final score is given by averaging all F-measures of all cooking motion label.
3.2 Preprocessing Input Data
In preprocessing step, we have prepared data for available to use in the following steps. First of all, we calibrate depth images because there is a distance separates depth camera and color camera. The Kinect disparity is related to a normalized disparity
![]() (2)
(2)
where d is a normalized disparity, kd is the Kinect disparity, and doff is an offset value particular to a given Kinect device. According to a technical Kinect calibration report [17], doff is typically around 1090. Moreover, in every depth image, there is a small black band on the right of the image which we expect to eliminate for mapping the depth image to color image later.
For fast segmentation, we use depth images to segment table area and floor area. We choose some first frames then find a border that separates table and floor areas. Because there is no human in these frames, it is easy for segmentation. Border detection is based on the sum of grayscale of the depth image for each row and also the ratio of disparity of two adjacent rows. In the case that this ratio is higher than a threshold, this row is the border separated table and floor areas.
For human detection, we use both depth image and segmented floor area information, which is detected in previous step. When human appears in scene, the distance from depth sensor to human body is much nearer than floor area. It means the pixels, whose grayscale are higher than average grayscale of floor area, are ones of human body.
Next step, for hand detection, we use color images and skin detection, too. First, we choose some points, which are in skin area. Based on the color of these points, we obtain the range of the color of pixels in skin area. Then, each pixel is classified by its color. Then, we eliminate areas that their size are not in range [hand_size_min, hand_size_max], which are the thresholds to determine size of hands. In case there are still more than two areas, only two largest areas are selected because the smaller areas are almost noises.
Besides, we also apply some object detection models. Objects in this case mean cooking tools such as fry pan, pan, chopstick; and ingredients such as egg, ham, and seasoning. For object detection, we use color images because they contain more information than depth images. For each object, we collect the image samples which are about 100 images. Then, image feature for each of image is calculated and a training data is made using one-versus-all SVM classification. When testing system is executed, a slide window is used to detect objects and recognize which kind of object.
3.3 Image Feature Extraction
Image feature has an important role in motion representing and they are extracted faster than other features. To solve our problems, we use image feature as one of main features for fast motion describing. In addition, there are many kinds of image feature can be used to solve our problem. We need to consider which features are the most characteristic for motion representing.
Following preprocessing step, first, image features are extracted from every frame in video. However, in practice, we only extract feature from key-frames which are chosen by one frame for each k frames in video. In our experiment, we use k = 10 to reduce the amount of computation because in ten continuous frames there are not many differences. In our research, LBP [18], EOH [19], PHOG [3], and SIFT [4] are used because they can characterize the content of frames including information about the context and are easy to be extracted.
To extract image feature more detail, each image feature is extracted from cells of a 4 × 8 grid of frame. For PHOG feature, we extract with eight gradient bins and the highest level l = 2. Moreover, for SIFT features, we apply BoF method [16] to increase the effectiveness of recognition. After key point detection step, histogram of these keypoints is calculated based on codebook which is the collection of millions of keypoints. Then, we gain many different kinds of feature vectors. Next, we apply early fusion technique in [6] to join these feature vectors together to obtain only one feature vector, which is known as the image feature vector characterized for a frame in video.
3.4 Motion Feature Extraction
For solving our problem, motion feature is indispensable because of their efficient in motion representation. However, this feature requires an enormous computation and is much more complex than image feature. Therefore, in our research, we use one of fastest and most density motion feature which was studied by Wang et al. [5].
Being parallel with the image features extraction, we extract motion features from videos. In our method, we use dense trajectories and motion boundary histogram (MBH) description [5] for action representation. The main reason for choosing this motion feature is every cooking actions are characterized by different simple motions, such as cutting action is related to vertical motions while mixing action is almost described by turn around motions. Moreover, there are many fine motions in cooking videos, so that we use dense trajectories feature that is the best feature for representing even the fine motions. Besides, MBH descriptor expresses only boundary of foreground motion and eliminates background and camera motion. Thus, it is completely appropriate to be applied in this step for action representation.
To compute the optical flow from above dense samples, we use FarneBack algorithm [20] because it is one of the fastest algorithm to compute a dense optical flow. Next, we track in optical flows to find out trajectories in a sequence of 15 continuous frames. To describe motion feature, each video is separated to many blocks, which are N × M × L-size blocks. It means scaling each optical flow matrix to size N × M and each block containing L optical flow. Then, each block is divided into nσ × nσ × nt cells. Lastly, we calculate MBH feature for each cell and join them together. For motion feature, we also use BoFs [16] to increase effectiveness of recognition as SIFT feature from image features.
3.5 BNs Training
Because of three main reasons in the first section, we choose BNs as our classifier. In our approach, we use three separate networks that play different roles in this classification step. Since there are some categories of features from label information, image features and motion features, we use different BNs for training and classifying each of categories. By using three different BNs, the classification result would be better than using only one network. Moreover, we can train three different networks at the same time which means training time could be reduced.
In this step, we create three BNs to classify feature vectors into a certain action class. First of all, we have a BN from ground-truth label data which represents the possibility of subsequence action’s label based on previous identified action labels. It is calculated by using Bayes’s theorem formula
![]() (3)
(3)
where Ai is the ith action and PALs are previous action labels.
For the second BN, we have a graph in which nodes’ value are extracted from high-level feature. In this BN, see Figure 2, we have human node which determines whether human exists in this frame. Similarly, hand node is node which determines whether hands are in frame or not. Besides, nodes including tool using node, container using node, and food using node are determined based on the relative position between the hands and the objects. In addition, there is a status changing node, which expresses the changing of ingredient inside cooking container. Finally, the action label nodes are based on the above-identified nodes, whose conditional probability formula is below
![]() (4)
(4)
where SC is status changing, TU is tool using, CU is container using, FU is food using, Hd is hand, and Hm is Human.
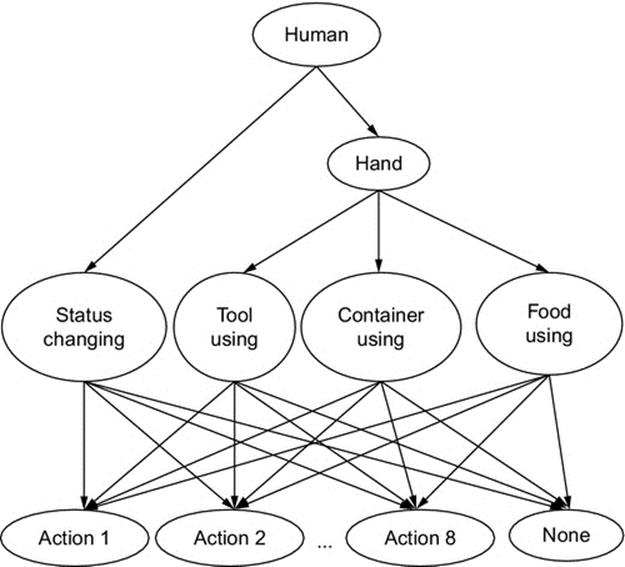
FIGURE 2 The second Bayesian network in our method.
The last BN represents the possibility of an action based on motion features of sequence of images surround the current frame.
![]() (5)
(5)
where MF is motion feature.
The probability of the ith action class calculated by the first BN is called PNEXT(Ai), by the second BN is called PIMAGE(Ai), and by the last one is called PMOTION(Ai). We can compute the probability of an action label based on PNEXT and PIMAGE only by multiply probabilities, or PNEXT and PMOTION. After that, we combine these probability values to obtain the probability of the ith action
![]() (6)
(6)
4 Experiments
4.1 Dataset
In our experiments, we use ACE dataset, which contains five sets for training and two sets for testing. There are five menus of cooking eggs and eight kinds of cooking actions performed by actors in dataset. In addition, the ingredients and cooking utensils, which are used in dataset, are egg, ham, milk, oil, salt and frying pan, saucepan, bowl, knife, chopsticks, etc. The videos were captured by a Kinect sensor, which provides synchronized color and depth image sequences. Each of the videos was from 5 to 10 min long containing from 2000 to over 10,000 frames. Each frame is 480 × 640-size and is assigned to a certain action label indicating type of action performed by the actors in video.
In this dataset, all dishes are based on egg, sometimes ham or some seasons are added to. Each dish has its own color such as boiled egg has white or brown color from eggshell color while omelet has yellow and pink color from egg and ham. Therefore, we used image features such as color histogram, color moment feature which are extracted to classify different dish. Besides, because each cooking action requires different cooking tool, which has characterized shape, we use image features related to edge features such as cutting action requires knife while mixing action requires chopsticks.
4.2 Parameter Setting
There are some parameters throughout our processes such as in preprocessing step, the parameter doff = 1090 which depends on a certain Kinect device. Other parameters are the thresholds determining hands are hand_size_min and hand_size_max which are obtained from training data. For motion extraction, there are also some other parameter including N × M = 480 × 640, L = 20, nσ = 2, and nt = 3.
Lastly, we simply use w1 = w2 = 1 in Equation (6) because the problem of optimizing value for w1 and w2 is hard problem. However, by using w1 = w2 = 1 we also obtain a good result as we expected.
4.3 Results
Our original work which was published as paper in IPCV2014 [21] has been extended by adding some more features. We evaluate the recognition precision of image features, motion features, and combination of them in ACE dataset. The evaluation results of using either image features or motion features singly are shown in the first and the second columns of Table 1. When using only image features, some actions such as boiling, breaking, and seasoning cannot be classified, which precision is 0%. While other actions include baking action and cutting action achieved has better precisions which are 36.9 and 26.1%. However, in case we apply only motion features, all actions have better precision than using only image features.
Table 1
Action Recognition Precision (%)
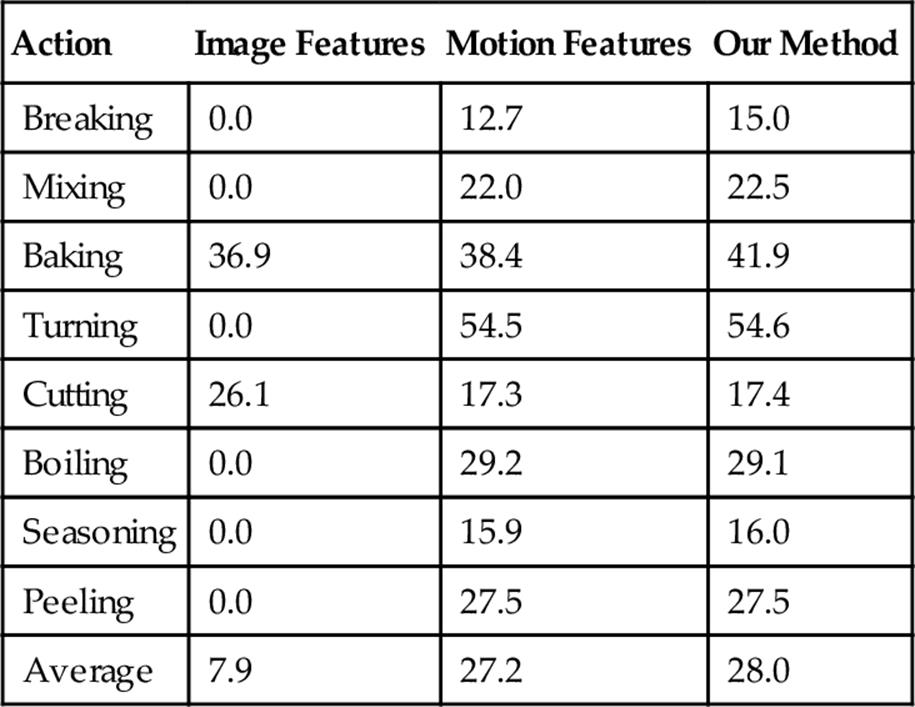
Therefore, we find out that the motion features are more efficient to represent the cooking actions than the image features, especially for the actions with large amplitude such as baking or cutting using a big cooking tool as a knife. It is successful to recognize based on the image features. However, they do not describe the other actions which have small amplitude or use tiny cooking tools. On the other hand, when we use only image features, the actions with no color changing or no use any cooking tools such as boiling, breaking, or seasoning could not be recognized by image features including color feature or edge feature. After that, we combine both of image features and motion features to obtain better results as we have expected.
The result of a combination is shown in the last column of Table 1. Compared with two first cases, the combination of the two features improves the recognition results. In this case, some actions are also well recognized, especially the actions “baking” and “turning,” because they are the ones with large amplitude. However, some action recognitions are not improved while comparing with motion features because image features may not describe exactly these actions. To solve the problems, one way is to modify the high-level image feature extraction to describe more exactly such as determining exactly which cooking tools are being used. The other way is to combine these features in more efficient way such as trying to find better parameters w1 and w2.
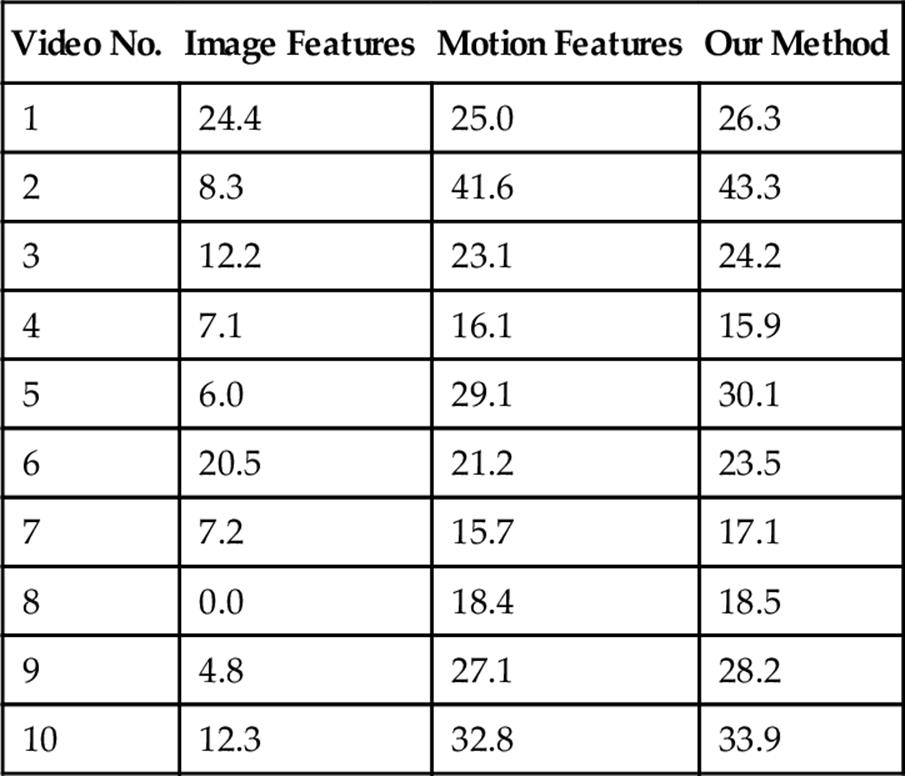
Moreover, the recognition results of each testing video are shown in Table 2. Each video contains a sequence of actions to cook a certain dish. In our experiment, the best precision is over 40% for all frames in a video. Although the average of precision is approximate 30%, it proves that our approach is appropriate. If we optimize the parameters and improve our implementation, the result would be definitely improved. Therefore, our works still need to be continued in near future.
Table 2
Recognition Precision (%) on Testing Videos
As we have mentioned in the first section, this problem has been raised in the contest [1]. Until the end of contest, there are five teams who submit their works and results. We compare our method with their results as in Figures 3 and 4. Although in general our method’s result is not as high as top of results, there are some advantages comparing with other methods. Some other methods cannot recognize some action but our method can recognize every kind of action. Therefore, in future, we can improve to achieve higher accuracy for all actions which can be easy to obtain by applying postprocess into test framework.
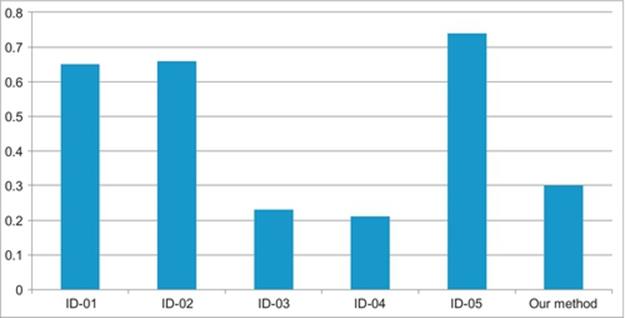
FIGURE 3 Comparing evaluation result with other researches.
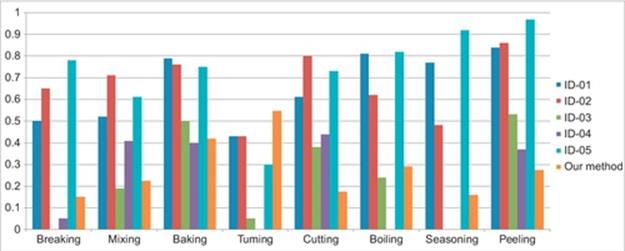
FIGURE 4 Comparing evaluation result in each gesture with other researches.
In addition, our method has achieved the best result in “tuning” action recognition which is one of the hardest actions for correctly recognizing. Because our method uses the appropriate features including image features and motion features, it achieves a good result in this action. However, for some other action, its performance is not as good as other methods because the combination method needs improving to achieve better result. Hence, in next our research, we keen on studying some different way to combine the different feature vectors.
In our research, we use a PC with CPU Intel core i7-2600 3.4 GHz, 8 GB RAM, and MATLAB 7.12.0 (R2011a) 64-bit on Windows 7 64-bit OS. Most of time is used to extract motion features although we have applied one of the fastest optical flow computing algorithms. It requires much more running time because dense trajectories in each sequence of images are extracted. In addition, we only use one PC in our research. If our method is applied on a parallel system such as the clusters or the high performance computing using GPU-CPU, the result will be improved more.
5 Conclusions
In this chapter, we proposed a method using both image features and motion features for gesture recognition in cooking video. It means the motions in cooking video are represented by image feature vector and motion feature vectors. In our method, BN model is model to predict which action class a certain frame belongs to based on the action class of previous frames and cooking gesture in present frame. Additional information such as the sequence of actions is also applied into BN model to improve classification result.
According to our results, our proposed method is a good approach for solving action recognition in video. Although its performance is not good enough when comparing with the best method, we are certain this method can be improved to achieve higher performance. In addition, it is a completely flexible method as we can add easily more action or other features. Furthermore, we can also reconstruct BNs and update their parameters in nodes easily too. Thus, our method can be applied for other action recognition systems even there are many complex actions.
In the future, we are going to improve motion feature extraction, which is acceleration of feature extraction because now it account to over 80% of the running time. Another problem that we can improve in near future is using high level features. In our research, at present, there is still limitation in high-level features application because they still require more computation and time now.
References
[1] ICPR 2012 Contest, Kitchen Scene Context based Gesture Recognition http://www.murase.m.is.nagoya-u.ac.jp/KSCGR/index.html.
[2] Shimada A. Kitchen scene context based gesture recognition: a contest in ICPR2012. In: Advances in depth image analysis and applications. Berlin Heidelberg/New York: Springer; 2013.
[3] Bosch A, Zisserman A, Munoz X. Representing shape with a spatial pyramid kernel. In: Proc. of the 6th international conference on image and video retrieval (CIVR), Amsterdam; 2007.
[4] Lowe DG. Distinctive image features from scale-invariant keypoints. Int J Comput Vis. 2004;60:91–110.
[5] Wang H, Klaser A, Schmid C, Liu CL. Action recognition by dense trajectories. In: IEEE conference on computer vision & pattern recognition, Colorado Springs, USA, June; 2011:3169–3176.
[6] Snoek C, Worring M, Geusebroek JM, Koelma DC, Seinstra FJ. The MediaMill TRECVID 2004 semantic video search engine. In: Proc. TRECVID Workshop. Gaithersburg, MD: NIST Special Publication; 2004.
[7] Westerveld T, de Vries AP, Ballegooij A, de Jong F, Hiemstra D. A probabilistic multimedia retrieval model and its evaluation. EURASIP JASP. 2003;186–197.
[8] Laptev I. On space-time interest points. Int J Comput Vis. 2005;64:107–123.
[9] Mermelstein P. Distance measures for speech recognition, psychological and instrumental. In: Chen CH, ed. Pattern recognition and artificial intelligent. New York: Academic Press; 1976:374–388.
[10] Matthew H, Gang H, Apostol N, John RS, Lexing X, Bert H, et al. IBM research trecvid-2010 video copy detection and multimedia event detection system. In: NIST TRECVID Workshop, Gaithersburg, MD, USA; 2010.
[11] Oliva A, Torralba A. Modeling the shape of the scene: a holistic representation of the spatial envelope. Int J Comput Vis. 2001;42:145–175.
[12] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: CVPR; 2005:886–893 vol. 1.
[13] Yu GJ, Xiaohong Z, Guangnan Y, Subhabrata B, Dan E, Mubarak S, et al. Columbia-UCF TRECVID2010 multimedia event detection: combining multiple modalities, contextual concepts, and temporal matching. In: NIST TRECVID Workshop, Gaithersburg, MD, USA; 2010.
[14] Matsuo T, Nakajima S. Nikon multimedia event detection system. In: NIST TRECVID Workshop, Gaithersburg, MD, USA; 2010.
[15] Ji Y, Ko Y, Shimada A, Nagahara H, Taniguchi R. Cooking gesture recognition using local feature and depth image. In: ICPR; 2012.
[16] Cruska G, Dance CR, Fan L, Willamowski J, Bray C. Visual categorization with bags of keypoints. In: Workshop on statistical learning in computer vision, ECCV; 2004:886–893.
[17] Bueno JG, Slupska PJ, Burrus N, Moreno L. Textureless object recognition and arm planning for a mobile manipulator. In: 2011 Proc. ELMAR, 14–16 September; 2011 p. 59, 62.
[18] Ojala T, Pietikainen M, Harwood D. A comparative study of texture measures with classification based on feature distributions. Pattern Recognit. 1996;29:51–59.
[19] Freeman WT, Michal R. Orientation histograms for hand gesture recognition. In: IEEE international workshop on automatic face and gesture recognition, Zurich, June; 1995.
[20] Farneback G. Two-frame motion estimation based on polynomial expansion. Lect Notes Comput Sci. 2003;2749:363–370.
[21] Tuan Hung N, Thanh Binh N, Bao PT, Young Kim J. Gesture recognition in cooking video based on image features and motion features using Bayesian network classifier. In: The 2014 international conference on image processing, computer vision, and pattern recognition (IPCV2014); 2014.
1 http://www.murase.m.is.nagoya-u.ac.jp/KSCGR/evaluation.html.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.