Emerging Trends in Image Processing, Computer Vision, and Pattern Recognition, 1st Edition (2015)
Part II. Computer Vision and Recognition Systems
Chapter 26. A local feature-based facial expression recognition system from depth video
Md. Zia Uddin Department of Computer Education, Sungkyunkwan University, Seoul, Republic of Korea
Abstract
In this chapter, a novel approach is proposed to recognize some facial expressions from time-sequential depth videos. Local directional pattern features are extracted from the time-sequential depth faces that are followed by principal component analysis and linear discriminant analysis to make the features more robust. Finally, the local features are applied with hidden Markov models to model and recognize different facial expressions successfully. The proposed approach shows superior recognition rate against the conventional approaches.
Keywords
Depth information
LDP
PCA
LDA
HMM
FER
ACKNOWLEDGEMENT
This work was supported by Faculty Research Fund, Sungkyunkwan University, 2013.
1 Introduction
Facial expression recognition (FER) provides machines a way of sensing emotions that can be considered one of the mostly used artificial intelligence and pattern analysis applications [1–10]. In case of extracting peoples’ expression images through Red Green Blue (RGB) cameras, most of the FER works used principal component analysis (PCA), which is really well known for dimension reduction and used in many earlier works. In Padgett and Cottrell [3], PCA was used to recognize facial action units (FAUs) from the facial expression images. In Donato et al. [5] as well as Ekman and Priesen [6], PCA was used for FER with the facial action coding system.
Very recently, independent component analysis (ICA) has been extensively utilized for FER based on local face image features [5,10–21]. In Bartlett et al. [14], the authors used ICA to extract local features and then classified several facial expressions. In Chao-Fa and Shin [15], ICA was used to recognize the FAUs. Besides ICA, local binary patterns (LBP) has been used lately for FER [22–24]. The main property of LBP features is their tolerance against illumination changes as well as their computational simplicity. Later on, LBP was improved by focusing on face pixel’s gradient information and named as local directional pattern (LDP) to represent local face features [25]. As like as LBP, LDP features also have the tolerance against illumination changes but they represent much robust features than LBP due to considering the gradient information for each pixel as aforementioned [25].
Thus, LDP can be considered to be a robust approach and hence can be adopted for FER. To make LDP facial expression features more robust, linear discriminant analysis (LDA) can be applied as LDA is a strong method to be used to obtain good discrimination among the face images from different expressions by considering linear feature spaces. Hidden Markov model (HMM) is considered to be a robust tool to model and decode time-sequential events [21,26–28]. Hence, HMM seems an appropriate choice to train and recognize features of different facial expressions for FER.
For capturing face images, RGB cameras are used most widely but the faces captured through a RGB camera cannot provide the depth of the pixels based on the far and near parts of human face in the facial expression video where the depth information can be considered to contribute more to extract efficient features to describe the expression more strongly. Hence, depth videos should allow one to come up with more efficient person independent FER.
In this chapter, a novel FER approach is proposed using LDP, PCA, LDA, and HMM. Local LDP features are first extracted from the facial expression images and further extended by PCA and LDA. These robust features are then converted into discrete symbols using vector quantization and then the symbols are used to model discrete HMMs of different expressions. To compare the performance of the proposed approach, different comparison studies have been conducted such as PCA, PCA-LDA, ICA, and ICA-LDA as feature extractor in combination with HMM. The experimental results show that the proposed method shows superiority over the conventional approaches.
2 Depth Image Preprocessing
The images of different expressions are captured by a depth camera [29] where the camera generates RGB and distance information (i.e., depth) simultaneously for the objects captured by the camera. The depth video represents the range of every pixel in the scene as a gray level intensity (i.e., the longer ranged pixels have darker and shorter ones brighter values or vice versa). Figure 1 shows the basic steps of proposed FER system.
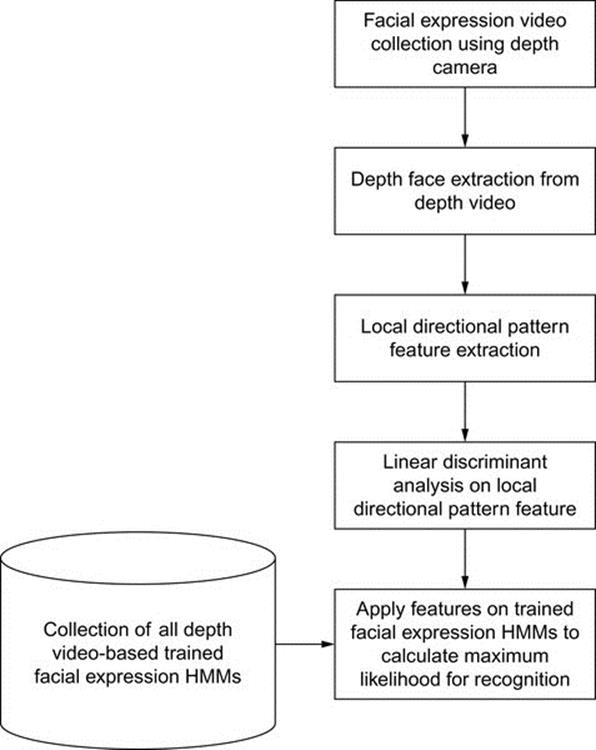
FIGURE 1 Basic steps involved in the proposed facial expression recognition system.
Figure 2(a) represents a depth image from a surprise expression. It can be noticed that in the depth image, the higher pixel value represents the near (e.g., nose) and the lower (e.g., eyes) the far distance. The pseudo-color image corresponding to the depth image in Figure 2(b) also indicates the significant differences among different face portions where the color intensities. Figure 3(a)–(c) shows five generalized depth faces from a happy, surprise, and disgust expressions, respectively.
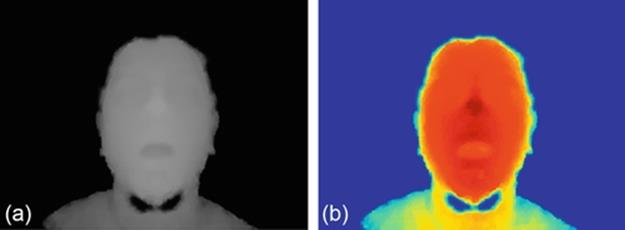
FIGURE 2 (a) A depth image and (b) corresponding pseudo color image of a surprise image.
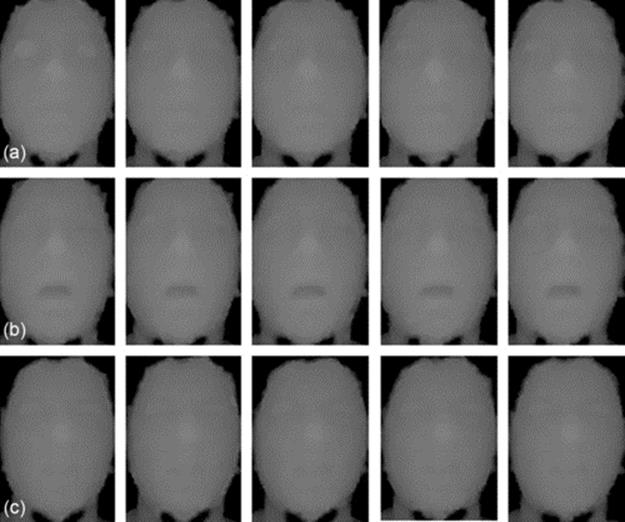
FIGURE 3 A sequential depth facial expression images of (a) happy, (b) surprise, and (c) disgust.
3 Feature extraction
The feature extraction of the proposed approach consists of three fundamental stages: (1) LDP is performed first on the depth faces of the facial expression videos, (2) PCA is applied on the LDP features for dimensionality reduction, and (3) LDA is then applied to compress the same facial expression images as close as possible and to separate the different expression class images as far as possible.
3.1 LDP Features
The LDP assigns an 8-bit binary code to each pixel of an input depth image. This pattern is then calculated by comparing the relative edge response values of a pixel in eight different directions. Kirsch, Prewitt, and Sobel edge detector are some of the different representative edge detectors that can be used. Amongst which, the Kirsch edge detector [20] detects the edges more accurately than the others as it considers all eight neighbors. Given a central pixel in the image, the eight directional edge response values {mk},k = 0, 1, …, 7 are computed by Kirsch masks Mk in eight different orientations centered on its position [18]. Figure 4 shows these masks.

FIGURE 4 Kirsch edge masks in eight directions.
The presence of a corner or an edge represents high response values in some particular directions and therefore, it is interesting to know the p most prominent directions in order to generate the LDP. Here, the top-p directional bit responses bk are set to 1. The remaining bits of 8-bit LDP pattern are set to 0. Finally, the LDP code is derived in Equation (1). Figure 5 shows the mask response as well as LDP bit positions and Figure 6 an exemplary LDP code considering five top positions, that is, p = 5.
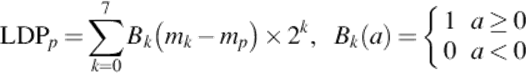 (1)
(1)
where mp is the pth most significant directional response.
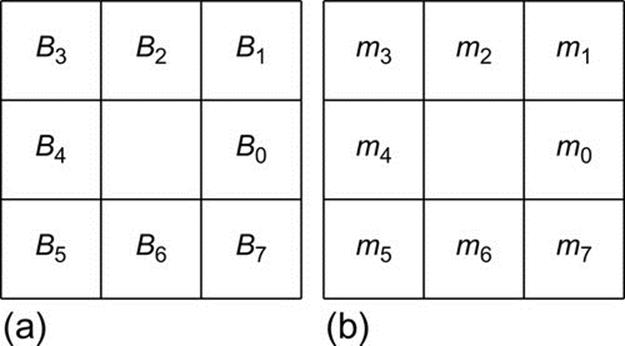
FIGURE 5 (a) Edge response to eight directions and (b) LDP binary bit positions.
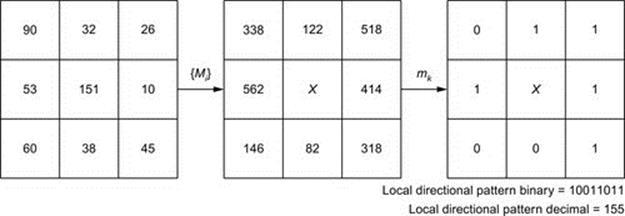
FIGURE 6 LDP code.
Thus, an image is transformed to the LDP map using LDP code. The image textual feature is presented by the histogram of the LDP map of which the qth bin can be defined as
![]() (2)
(2)
where n is the number of the LDP histogram bins (normally n = 256) for an image I. Then, the histogram of the LDP map is presented as
![]() (3)
(3)
To describe the LDP features, a depth silhouette image is divided into nonoverlapping rectangle regions and the histogram is computed for each region. Furthermore, the whole LDP feature F is expressed as a concatenated sequence of histograms
![]() (4)
(4)
where s represents the number of nonoverlapped regions in the image. After analyzing the LDP features of all the face depth images, there are some positions from all the positions corresponding to all the face images have values > 0 and hence these positions can be ignored. Thus, the LDP features from the depth faces can be represented as D.
3.2 PCA on LDP Features
PCA is very popular method to be used for data dimension reduction. PCA is a subspace projection method which transforms the high-dimensional space to a reduced space maintaining the maximum variability. The principal components of the covariance data matrix Y of the LDP features D can be calculated as
![]() (5)
(5)
where λ represents the eigenvalue matrix and P the eigenvector matrix. The eigenvector associated with the top eigenvalue means the axis of maximum variance and the next one with the second largest eigenvalue indicates the axis of second largest variance and so on. Thus, m number of eigenvectors are chosen according to the highest eigenvalues for projection of LDP features. The PCA feature space projections V of LDP features can be represented as
![]() (6)
(6)
3.3 LDA on PCA Features
To obtain more robust features, LDA is performed on the PCA feature vectors F. Basically, LDA is based on class specific information which maximizes the ratio of the within, Qw and between, Qb scatter matrix. The optimal discrimination matrix WLDA is chosen from the maximization of ratio of the determinant of the between and within class scatter matrix as
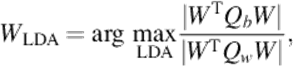 (7)
(7)
where WLDA is the discriminant feature space. Thus, the LDP-LDA feature vectors of facial expression images can be obtained as follows:
![]() (8)
(8)
Figure 7 shows an exemplar plot of 3D LDA representation of the LDP-PCA features of all the facial expression depth images that shows a good separation among the representation of the depth faces of different classes.
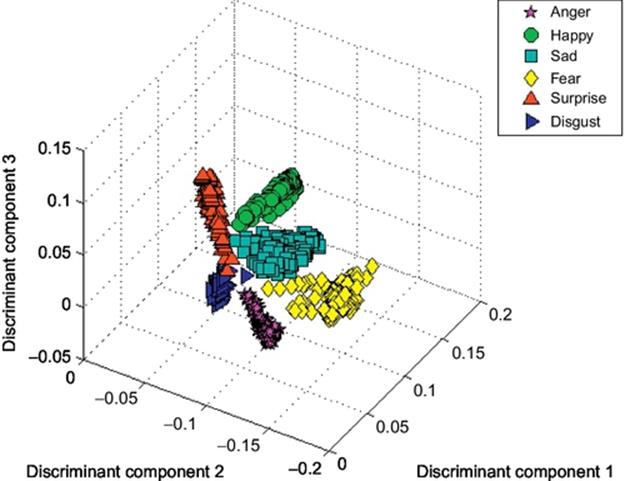
FIGURE 7 3D plot of LDP-PCA-LDA features of depth faces from six expressions.
3.4 HMM for Expression Modeling and Recognition
To decode the depth information-based time-sequential facial expression features, discrete HMMs are employed. HMMs have been applied extensively to solve a large number of complex problems in various applications such as speech recognition [30].
An HMM is a collection of states where each state is characterized by transition and symbol observation probabilities. A basic HMM can be expressed as H = {S, π, R, B} where S denotes possible states, π the initial probability of the states, R the transition probability matrix between hidden states, and B observation symbols’ probability from every state. If the number of activities is N then there will be a dictionary (H1, H2, …, HN) of N trained models. We used the Baum-Welch algorithm for HMM parameter estimation as applied in [21]. Figure 8 shows the structure and transition probabilities of a sad HMM after training.
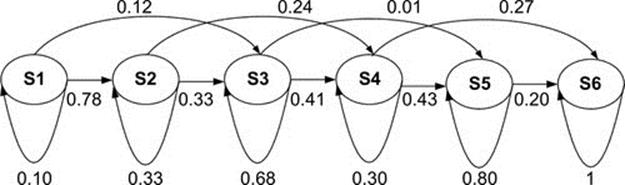
FIGURE 8 A HMM transition probabilities for sad expression after training.
To test a facial expression video for recognition, the obtained observation sequence O from the corresponding depth image sequence is used to determine the proper model by highest likelihood L computation of all N trained expression HMMs as follows:
![]() (9)
(9)
4 Experiments and results
The FER database was built for six expressions: namely Surprise, Sad, Happy, Disgust, Anger, and Fear. Each expression video clip was of variable length and each expression in each video starts and ends with neutral expression. A total of 20 sequences from each expression were used to build the feature space. To train and test each facial expression model, 20 and 40 image sequences were applied, respectively.
The average recognition rate using PCA on depth faces is 62.50% as shown in Table 1. Then, we applied LDA on PCA features and obtained 65.83% average recognition rate as shown in Table 2. As PCA-based global features showed poor recognition performance, we tried ICA-based local features for FER and obtained 83.33% average recognition rate as reported in Table 3. To improve ICA features, we applied LDA on the ICA features and as shown in Table 4, the average recognition rate utilizing ICA representation on the depth facial expression images is 83.50%, which is higher than that of depth face-based FER applying PCA-based features.
Table 1
FER Confusion Matrix Using Depth Faces with PCA
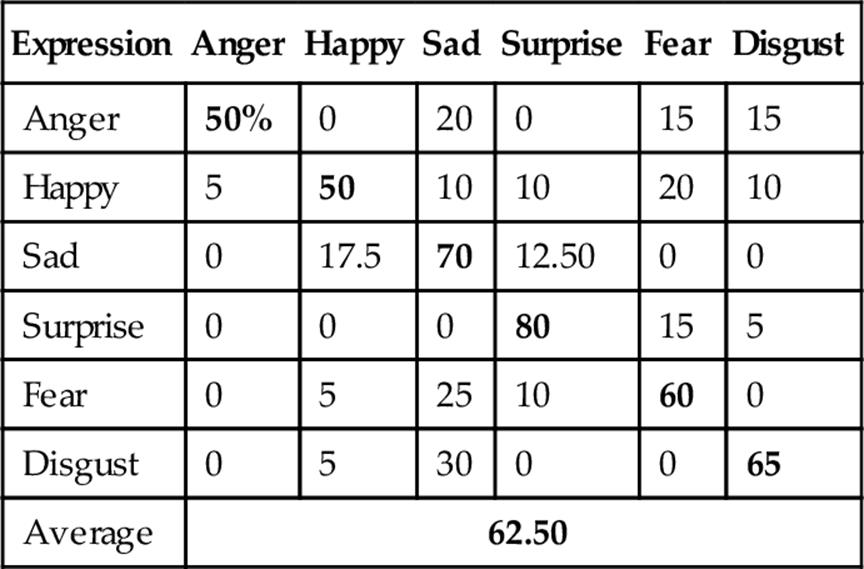
Bold values indicate correct expression recognition and others indicate incorrect recognition.
Table 2
FER Confusion Matrix Using Depth Faces with PCA-LDA
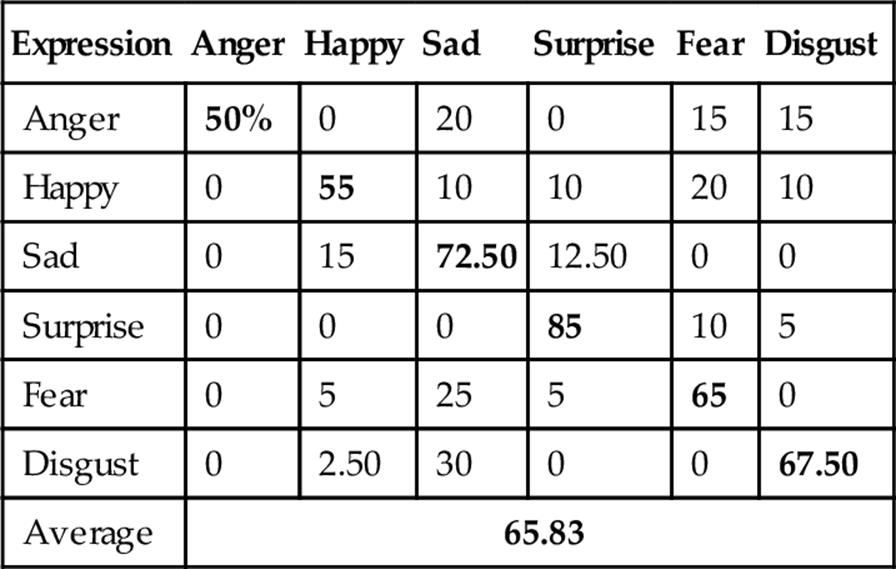
Bold values indicate correct expression recognition and others indicate incorrect recognition.
Table 3
FER Confusion Matrix Using Depth Faces with ICA
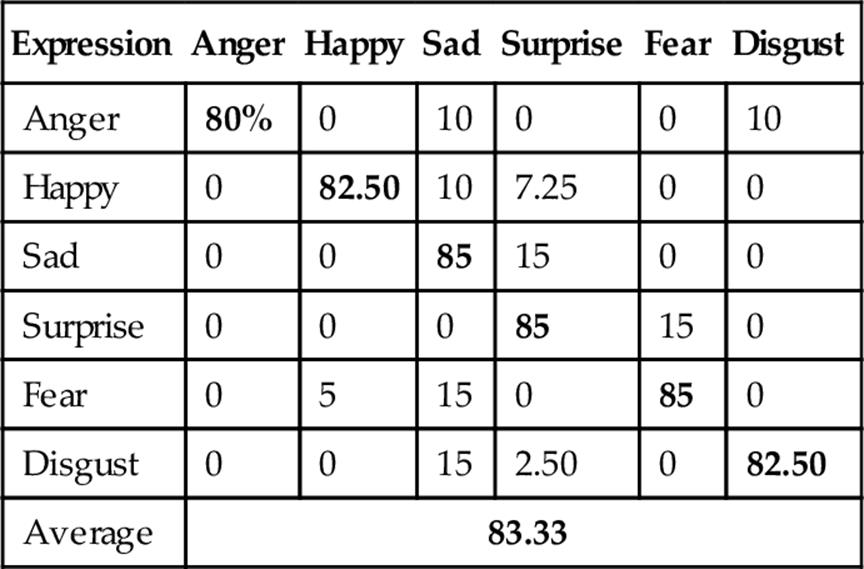
Bold values indicate correct expression recognition and others indicate incorrect recognition.
Table 4
FER Confusion Matrix Using Depth Faces with ICA-LDA
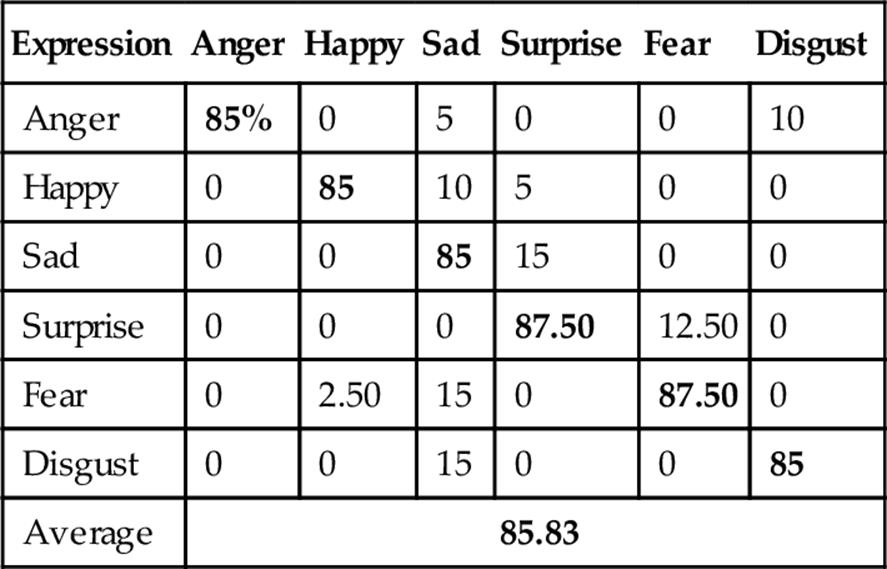
Bold values indicate correct expression recognition and others indicate incorrect recognition.
Then, LBP was tried on the same database that achieved the average recognition rate of 89.20% as shown in Table 5. Furthermore, LDP was employed and achieved the better recognition rate than LBP, that is, 90.83% as shown in Table 6. Finally, LDP-PCA-LDA was applied with HMM that showed superiority over the other feature extraction methods achieving the highest recognition rate (i.e., 98.33%) as shown in Table 7. Figure 9 shows FER performances using different approaches where LDP-PCA-LDA shows its superiority.
Table 5
FER Confusion Matrix Using Depth Faces with LBP
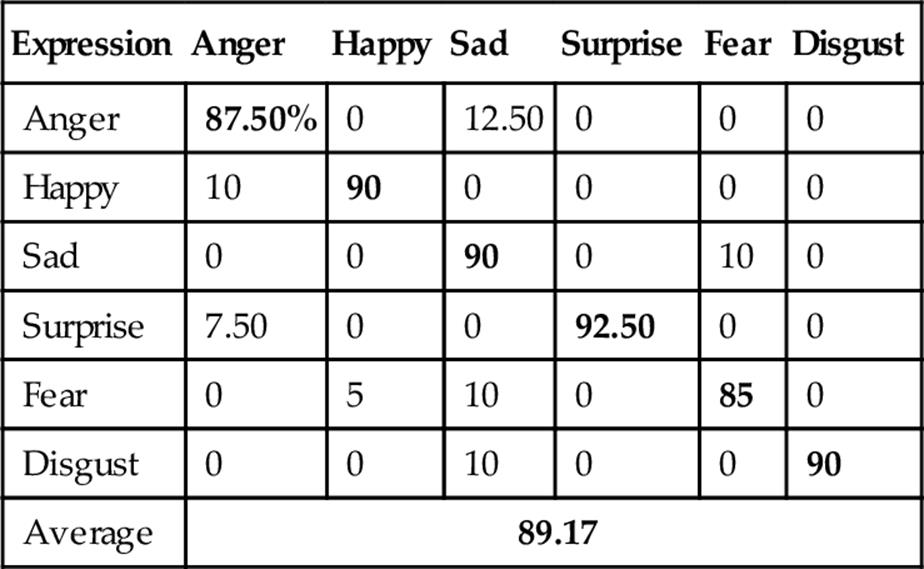
Bold values indicate correct expression recognition and others indicate incorrect recognition.
Table 6
FER Confusion Matrix Using Depth Faces with LDP
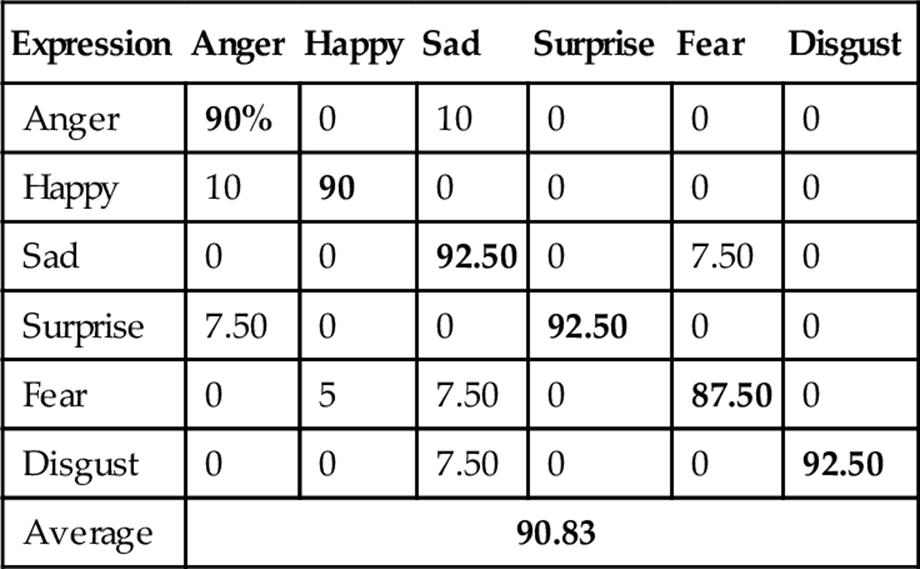
Bold values indicate correct expression recognition and others indicate incorrect recognition.
Table 7
FER Confusion Matrix Using Depth Faces with LDP-PCA-LDA
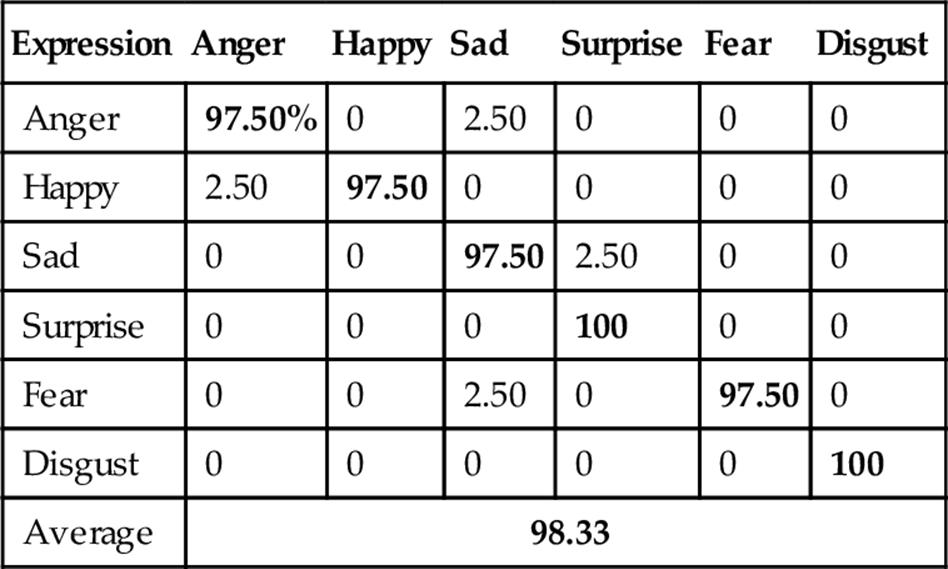
Bold values indicate correct expression recognition and others indicate incorrect recognition.
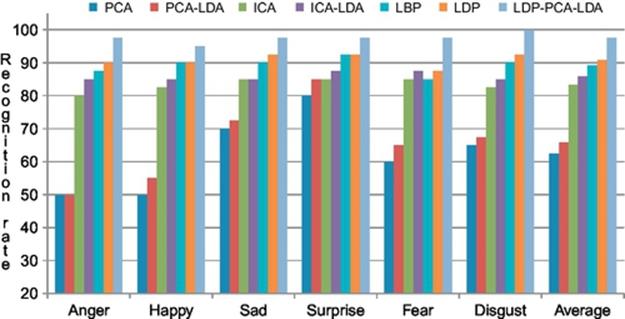
FIGURE 9 Depth image-based FER performances using different approaches.
5 Concluding Remarks
A depth video-based robust FER system has been proposed in this work using LDP-PCA-LDA features for facial expression feature extraction and HMM for recognition. The proposed method was compared with other traditional approaches and the recognition performance showed its superiority over others. However, the proposed system can be implemented in many systems such as smart home applications.
References
[1] Uddin MZ, Jehad Sarkar AM. A facial expression recognition system from depth video. In: Proc. 2014 international conference on image processing, computer vision, & pattern recognition (IPCV’14), July 21–24, Las Vegas; 2014.
[2] Kim D-S, Jeon I-J, Lee S-Y, Rhee P-K, Chung D-J. Embedded face recognition based on fast genetic algorithm for intelligent digital photography. IEEE Trans Consum Electron. 2006;52(3):726–734.
[3] Padgett C, Cottrell G. Representation face images for emotion classification. Cambridge, MA: MIT Press; . Advances in neural information processing systems. 1997;vol. 9.
[4] Mitra S, Acharya T. Gesture recognition: a survey. IEEE Trans Syst Man Cybern C Appl Rev. 2007;37(3):311–324.
[5] Donato G, Bartlett MS, Hagar JC, Ekman P, Sejnowski TJ. Classifying facial actions. IEEE Trans Pattern Anal Mach Intell. 1999;21(10):974–989.
[6] Ekman P, Priesen WV. Facial action coding system: a technique for the measurement of facial movement. Palo Alto, CA: Consulting Psychologists Press; 1978.
[7] Meulders M, Boeck PD, Mechelen IV, Gelman A. Probabilistic feature analysis of facial perception of emotions. Appl Stat. 2005;54(4):781–793.
[8] Calder AJ, Burton AM, Miller P, Young AW, Akamatsu S. A principal component analysis of facial expressions. Vision Res. 2001;41:1179–1208.
[9] Dubuisson S, Davoine F, Masson M. A solution for facial expression representation and recognition. Sign Process Image Commun. 2002;17:657–673.
[10] Buciu I, Kotropoulos C, Pitas I. ICA and Gabor representation for facial expression recognition. In: Proc. IEEE; 2003:855–858.
[11] Chen F, Kotani K. Facial expression recognition by supervised independent component analysis using MAP estimation. IEICE Trans Inf Syst. 2008;E91-D(2):341–350.
[12] Hyvarinen A, Karhunen J, Oja E. Independent component analysis. New York: John Wiley & Sons; 2001.
[13] Karklin Y, Lewicki MS. Learning higher-order structures in natural images. Network: Comput Neural Syst. 2003;14:483–499.
[14] Bartlett MS, Donato G, Movellan JR, Hager JC, Ekman P, Sejnowski TJ. Face image analysis for expression measurement and detection of deceit. In: Proc. sixth joint symposium on neural computation; 1999:8–15.
[15] Chao-Fa C, Shin FY. Recognizing facial action units using independent component analysis and support vector machine. Pattern Recognit. 2006;39:1795–1798.
[16] Calder AJ, Young AW, Keane J. Configural information in facial expression perception. J Exp Psychol Hum Percept Perform. 2000;26(2):527–551.
[17] Lyons MJ, Akamatsu S, Kamachi M, Gyoba J. Coding facial expressions with Gabor wavelets. In: Proc. third IEEE international conference on automatic face and gesture recognition; 1998:200–205.
[18] Bartlett MS, Movellan JR, Sejnowski TJ. Face recognition by independent component analysis. IEEE Trans Neural Netw. 2002;13(6):1450–1464.
[19] Liu C. Enhanced independent component analysis and its application to content based face image retrieval. IEEE Trans Syst Man Cybern B Cybern. 2004;34(2):1117–1127.
[20] Phillips PJ, Wechsler H, Huang J, Rauss P. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis Comput. 1998;16:295–306.
[21] Uddin MZ, Lee JJ, Kim T-S. An enhanced independent component-based human facial expression recognition from video. IEEE Trans Consum Electr. 2009;55(4):2216–2224.
[22] Ojala T, Pietikäinen M, Mäenpää T. Multiresolution gray scale and rotation invariant texture analysis with local binary patterns. IEEE Trans Pattern Anal Mach Intell. 2002;24:971–987.
[23] Shan C, Gong S, McOwan P. Robust facial expression recognition using local binary patterns. In: Proc. IEEE international conference on image processing (ICIP); 2005:370–373.
[24] Shan C, Gong S, McOwan P. Facial expression recognition based on local binary patterns: a comprehensive study. Image Vis Comput. 2009;27:803–816.
[25] Jabid T, Kabir MH, Chae O. Local directional pattern (LDP): a robust image descriptor for object recognition. In: Proc. IEEE advanced video and signal based surveillance (AVSS); 2010:482–487.
[26] Zhu Y, De Silva LC, Ko CC. Using moment invariants and HMM in facial expression recognition. Pattern Recognit Lett. 2002;23(1-3):83–91.
[27] Cohen I, Sebe N, Garg A, Chen LS, Huang TS. Facial expression recognition from video sequences: temporal and static modeling. Comput Vis Image Underst. 2003;91:160–187.
[28] Aleksic PS, Katsaggelos AK. Automatic facial expression recognition using facial animation parameters and multistream HMMs. IEEE Trans Inform Sec. 2006;1:3–11.
[29] Iddan GJ, Yahav G. 3D imaging in the studio (and elsewhere…). Proc. SPIE. 2001;4298:48–55.
[30] Rabiner LR. A tutorial on hidden markov modes and selected application in speech recognition. Proc. IEEE. 1989;77:257–286.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.