MySQL High Availability (2014)
Part II. Monitoring and Managing
Chapter 14. Replication Troubleshooting
The message subject was simply “Fix the Seattle server.” Joel knew such cryptic subject lines came from only one person. A quick scan of the message header confirmed the email was from Mr. Summerson. Joel opened the message and read the contents.
“The Seattle server is acting up again. I think the replication thingy is hosed. Make this your top priority.”
“OK,” Joel muttered to himself. Because the monitoring reports he had produced last week showed no anomalies and he was sure the replication setup was correct the last time he checked, Joel wasn’t sure how to attack the problem. But he knew where to find the answers. “It looks like I need to read that replication troubleshooting chapter after all.”
A familiar head appeared in his doorway. Joel decided to perform a preemptive maneuver by saying, “I’m on it.” This resulted in a nod and a casual salute as his boss continued down the hall.
MySQL replication is usually trouble-free and rarely needs tuning or tweaking once the topology is active and properly configured. However, there are times when things can go wrong. Sometimes an error is manifested, and you have clear evidence with which to start your investigations. Other times the condition or problem is easily understood, but the causes of the more difficult problems that can arise are not so obvious. Fortunately, you can resolve these problems if you follow some simple guidelines and practices for troubleshooting replication.
This chapter presents these ideas by focusing on techniques to resolve replication problems. We begin with a description of what can go wrong, then we discuss the basic tools available to help troubleshoot problems, and we conclude with some strategies for solving and preventing replication problems.
NOTE
Troubleshooting replication problems involving the MySQL Cluster follows the same procedures presented in this chapter. If you are having problems with MySQL Cluster, see Chapter 9 for troubleshooting cluster failures and startup issues.
Seasoned computer users understand that computing systems are prone to occasional failures. Information technology professionals make it part of their creed to prevent failures and ensure reliable access and data to users. However, even properly managed systems can have issues.
MySQL replication is no exception. In particular, the slave state is not crash-safe. This means that if the MySQL instance on the slave crashes, it is possible the slave will stop in an undefined state. In the worst case, the relay log or the master.info file could be corrupt.
Indeed, the more complex the topology (including load and database complexity) and the more diverse the roles are among the nodes in the topology, the more likely something will go wrong. That doesn’t mean replication cannot scale—on the contrary, you have seen how replication can easily scale to massive replication topologies. What we are saying is that when replication problems occur, they are usually the result of an unexpected action or configuration change.
What Can Go Wrong
There are many things that can go wrong to disrupt replication. MySQL replication is most susceptible to problems with data, be it data corruption or unintended interruptions in the replication stream. System crashes that result in an unsafe and uncontrolled termination of MySQL can also cause replication restarting issues.
You should always prepare a backup of your data before changing anything to fix the problem. In some cases, the backup will contain data that is corrupt or missing, but the benefits are still valid—specifically, that no matter what you do, you can at least return the data to the state at the time of the error. You’d be surprised how easy it is to make a bad situation worse.
In the following sections, we begin exploring replication troubleshooting by describing the most common failures in MySQL replication. These are some of the more frequently encountered replication problems. While the list can’t include all possible replication problems, it does give you an idea of the types of things that can go wrong. We include a brief statement of some likely causes for each.
Problems on the Master
While most errors will manifest on the slave, look to this section for potential solutions for problems originating on the master. Administrators sometimes automatically suspect the slave. You should take a look at both the master and the slave when diagnosing replication problems.
Master Crashed and Memory Tables Are in Use
When the master is restarted, any data for memory tables is purged, as is normal for the memory storage engine. However, if a table that uses the memory storage engine is being replicated and the slave was not restarted, the slave may have outdated data.
Fortunately, when the first access to the memory table occurs after a restart, a special delete event is sent to the slaves to signal the slaves to purge the data, thereby synchronizing the data. However, the interval between when the table is referenced and when the replication event is transmitted can result in the slave having outdated data. To avoid this problem, use a script to first purge the data, then repopulate it on the master at startup using the init_file option.
For example, if you have a memory table that stores frequently used data, create a file like the following and reference it with the init_file option:
# Force slaves to purge data
DELETE FROM db1.mem_zip;
# Repopulate the data
INSERT INTO ...
The first command is a delete query, which will be replicated to the slaves when replication is restarted. Following that are statements to repopulate the data. In this way, you can ensure there is no gap where the slave could have out-of-date information in a memory table.
Master Crashed and Binary Log Events Are Missing
It is possible for the master to fail and not write recent events to the binary log on disk. In other words, if the server crashes before MySQL flushes its binary events cache to disk (in the binary log), those cached events can be lost.
This is usually indicated by an error on the slave stating that the binary log offset event is missing or does not exist. In this case, the slave is attempting to reconnect on restart using the last known binlog file and position of the master, and while the binlog file may exist, the offset does not, because the events that incremented the offset were not written to disk.
Unfortunately, there is no way to retrieve the lost binlog events. To solve this problem, you must check the current binlog position on the master and use this information to tell the slave to start at the next known event on the master. Be sure to check the data on both your master and slave once the slave is synchronized. It should be noted that the next event may be the first event in the next binary logfile, so be sure to check to see whether the log spans multiple files.
It is also possible that some of the events that were lost on the master were applied to the data prior to the crash. You should always compare the tables in question on the master to determine if there are differences between the master and the slave. This situation is rare, but it can cause problems later on if an update for a row is executed on the master against one of these missing events, which then causes a failure when run on the slave. In this case, the slave is attempting to run an update on rows that do not exist.
For example, consider a scenario of a fictional, simplified database for an auto dealer where information about cars for sale is stored in tables corresponding to new and used cars. The tables are set up with autoincrement keys.
On the master, the following happens:
INSERT INTO auto.used_cars VALUES (2004, 'Porsche', 'Cayman', 23100, 'blue');
A crash occurs after the following statement is executed but before it is written to the binary log:
UPDATE auto.used_cars SET color = 'white' WHERE id = 17;
In this case, the update query was lost during the crash on the master. When the slave attempts to restart, an error is generated. You can resolve the problem using the suggestion just shown. A check on the number of rows on the master and slave shows the same row count. Notice the update that corrected the color of the 2004 Porsche to white instead of blue. Now consider what will happen when a salesperson tries to help a customer find the blue Porsche of her dreams by executing this query on the slave:
SELECT * FROM auto.used_cars
WHERE make = 'Porsche' AND model = 'Cayman' AND color = 'blue';
Will the salesperson who runs the query discover he has a blue Porsche Cayman for sale? A good auto salesperson always ensures he has the car on the lot by visual inspection, but for argument’s sake, let us assume he is too busy to do so and tells his customer he has the car of her dreams. Imagine his embarrassment (and loss of a sale) when his customer arrives to test-drive the car only to discover that it is white.
NOTE
To prevent loss of data should the master crash, turn on sync_binlog (set to 1) at startup or in your configuration file. This will tell the master to flush an event to the binary log immediately. While this may cause a noticeable performance drop for InnoDB, the protection afforded could be great if you cannot afford to lose any changes to the data (but you may lose the last event, depending on when the crash occurred).
While this academic example may not seem too bad, consider the possibilities of a missing update to a medical database or a database that contains scientific data. Clearly, a missing update, even a seemingly simple one, can cause problems for your users. Indeed, this scenario can be considered a form of data corruption. Always check the contents of your tables when encountering this problem. In this case, crash recovery ensures the binary log and InnoDB are consistent when sync_binlog=1, but it otherwise has no effect for MyISAM tables.
Query Runs Fine on the Master but Not on the Slave
While not strictly a problem on the master, it is sometimes possible that a query (e.g., an update or insert command) will run properly on the master but not on the slave. There are many causes of this type of error, but most point to a referential integrity issue or a configuration problem on the slave or the database.
The most common cause of this error is updating rows on the master that do not exist on the slave. It can also happen when a query refers to a table that does not exist on the slave or that has a different signature (different columns or column types). In this case, you must change the slave to match the server in order to properly execute the query. If you want to use tables that have different signatures, take care in designing the tables so that data that exists only on the master is not accessed by queries (reads) on the slaves.
In some cases, it is possible the query is referencing a table that is not replicated. For example, if you are using any of the replication filtering startup options (a quick check of the master and slave status will confirm this), it is possible that the database the query is referencing is not on the slave. In this situation, you must either adjust your filters accordingly or manually add the missing tables to the missing database on the slave.
In other cases, the cause of a failed query can be more complex, such as character set issues, corrupt tables, or even corrupt data. If you confirm your slave is configured the same as your master, you may need to diagnose the query manually. If you cannot correct the problem on the slave, you may need to perform the update manually and tell the slave to skip the event that contains the failed query.
NOTE
To skip an event on a slave, use the sql_slave_skip_counter variable and specify the number of events from the master you want to skip. Sometimes this is the fastest way to restart replication.
Table Corruption After a Crash
If your master or slave crashes and, after restarting them both, you find one or more tables are corrupt or find that they are marked as crashed by MyISAM, you will need to fix these problems before restarting replication.
You can detect which tables are corrupt by examining the server’s logfiles, looking for errors like the following:
... [ERROR] /usr/bin/mysqld: Table 'db1.t1' is marked
as crashed and should be repaired ...
You can use the following command to perform optimization and repair in one step all of the tables for a given database (in this case, db1):
mysqlcheck -u <user> -p --check --optimize --auto-repair db1
NOTE
For MyISAM tables, you can use the myisam-recover option to turn on automatic recovery. There are four modes of recovery. See the online MySQL Reference Manual for more details.
Once you have repaired the affected tables, you must also determine if the tables on the slave have been corrupted. This is necessary if the master and slave share the same data center and the failure was environmental (e.g., they were connected to the same power source).
WARNING
Always perform a backup on a table before repairing it. In some cases, a repair operation can result in data loss or leave the table in an unknown state.
It is also possible that a repair can leave the master and slave out of sync, especially if there is data loss as a result of the repair. You may need to compare the data in the affected table to ensure the master and slave are synchronized. If they are not, you may need to reload the data for the affected table on the slave if the slave is missing data, or copy data from the slave if the master is missing data.
Binary Log Is Corrupt on the Master
If a server crash or disk problem results in a corrupt binary log on the master, you cannot restart replication. There are many causes and types of corruption that can occur in the binary log, but all result in the inability to execute one or more events on the slave, often resulting in errors such as “could not parse relay log event.”
In this case, you must carefully examine the binary log for recoverable events and rotate the logs on the master with the FLUSH LOGS command. There may be data loss on the slave as a result, and the slave will most definitely fail in this scenario. The best recovery method is to resynchronize the slave with the master using a reliable backup and recovery tool. In addition to rotating the logs, you can ensure any data loss is minimized and get replication restarted without errors.
In some cases, if it is easy to determine how many events were corrupted or missing, it may be possible to skip the corrupted events by using the sql_slave_skip_counter option on the slave. You can determine this by comparing the master’s binlog reference on the slave to the current binlog position on the master and computing the number of events to skip. One way to do this is to use the mysqlbinlog tool to read the binary log of the master and count the events.
Killing Long-Running Queries for Nontransactional Tables
If you are forced to terminate a query that is modifying a nontransactional table, it is possible the query has been replicated to and executed on the slave. When this occurs, it is likely that the changes on the master will be different than on the slave.
For example, if you terminate a query that would have updated 400 out of the 600 rows in a table, allowing only 200 of the 400 changes to complete on the master, it is possible that the slave completed all 400 updates.
Thus, whenever you terminate a query that updates data on the master, you need to confirm that the change has not executed on the slave. If it has (or even as a precaution), you should resynchronize the data on the slave once you’ve corrected the table on the master. Usually in this case, you will fix the master and then make a backup of the data on the master and restore it on the slave.
Unsafe Statements
If you have databases that use both transactional and nontransactional tables, you may not encounter any problems so long as changes to the databases or tables do not occur in the same transaction. However, combining transactional and nontransactional tables is likely to cause problems. This is especially true when using unsafe statements. Although some unsafe statements may execute without errors, it is best to avoid them.
The online reference manual lists a number of unsafe statements. Essentially, these include any statement or clause that can result in a different result on the master and slave. Unsafe statements and functions include UUID(), FOUND_ROWS(), INSERT DELAYED, and LIMIT. For example, using LIMIT without an ORDER BY clause can result in different results. If you use the ORDER BY clause and the tables are the same, the results will be predictable.
For a complete list of unsafe statements, see the section “Determination of Safe and Unsafe Statements in Binary Logging” in the online reference manual.
Although it is possible to detect when these statements are used by monitoring warnings closely, you could have a situation where you encounter these statements through user naïveté. For example, consider the following table:
CREATE TABLE test.t1 (a int, b char(20)) ENGINE=InnoDB;
Now suppose the following updates are occurring on different clients writing to the master and that statement-based binary logging is enabled. The clients are identified by different mysql prompts. Assume that the order the statements are executed represents the order in which the statements were executed:
client_1> BEGIN;
client_1> INSERT INTO test.t1
VALUES (1, 'client_1'), (2, 'client_1'), (3, 'client_1');
client_2> BEGIN;
client_2> INSERT INTO test.t1
VALUES (4, 'client_2'), (5, 'client_2'), (6, 'client_2');
client_2> COMMIT;
client_1> COMMIT;
Notice that although client 1 started its transaction first, client 2 completed (committed) its transaction first. Because InnoDB preserves the order of insert based on when the transacton started, the resulting table will look like the following (in this case, the rows are in the order in which they were inserted in the InnoDB caching mechanism; this is how it would appear in a SELECT without using indexes on the master):
mysql> SELECT * FROM test.t1;
+------+----------+
| a | b |
+------+----------+
| 1 | client_1 |
| 2 | client_1 |
| 3 | client_1 |
| 4 | client_2 |
| 5 | client_2 |
| 6 | client_2 |
+------+----------+
6 rows in set (0.00 sec)
However, because the transaction on client 2 actually executed first, that is the order reflected in the binary log and therefore the order read by a slave. Thus, on a connected slave, the same table will have a slightly different original, unindexed order (but the same data):
mysql> SELECT * FROM test.t1;
+------+----------+
| a | b |
+------+----------+
| 4 | client_2 |
| 5 | client_2 |
| 6 | client_2 |
| 1 | client_1 |
| 2 | client_1 |
| 3 | client_1 |
+------+----------+
6 rows in set (0.00 sec)
Now let’s consider an unsafe statement executed on the master like the following:
UPDATE test.t1 SET b='this_client' LIMIT 3;
Here, the intention is to change only the first three rows correcting column b. On the master, this works as expected:
mysql> SELECT * FROM test.t1;
+------+-------------+
| a | b |
+------+-------------+
| 1 | this_client |
| 2 | this_client |
| 3 | this_client |
| 4 | client_2 |
| 5 | client_2 |
| 6 | client_2 |
+------+-------------+
6 rows in set (0.00 sec)
However, on the slave, we get an entirely different result when the statement is replicated. As you can see, this sort of unsafe statement can lead to some really interesting and frustrating data inconsistencies:
mysql> SELECT * FROM test.t1;
+------+-------------+
| a | b |
+------+-------------+
| 4 | this_client |
| 5 | this_client |
| 6 | this_client |
| 1 | client_1 |
| 2 | client_1 |
| 3 | client_1 |
+------+-------------+
6 rows in set (0.00 sec)
Clearly, unsafe statements should be avoided. One of the best ways to do so is to educate users as to which statements are unsafe, monitor your replication warnings, and consider using all transactional tables and row-based binary logging.
Problems on the Slave
Most problems you will encounter will be the result of some error on the slave. In some situations, like those described in the previous section, it may be a problem that originated on the master, but it almost always will be seen on the slave in one form or another. The following sections list some of the common problems on the slave.
USE BINARY LOGGING ON THE SLAVE
One way to ensure a more robust slave is to turn on binary logging using the log-slave-updates option. This will cause the slave to log the events it executes from its relay log, thereby creating a binary log that you can use to replay events on the slave in the event that the relay log (or the data) becomes corrupt.
Slave Server Crashed and Replication Won’t Start
When a slave server crashes, it is usually easy to reestablish replication with the master once you determine the last known good event executed on the slave. You can see this by examining the SHOW SLAVE STATUS output.
However, when you encounter errors regarding account access, it may become impossible to restart replication. This can be the result of authentication problems, such as if the slave had to be rebuilt and the replication account (the account used in the CHANGE MASTER command) was not created or the password is incorrect. Replication may also not be able to start due to corrupted tables on the master or slave(s). In these cases, you are likely to see connection errors in the console and logs for the slave MySQL server.
When this occurs, always check the permissions of the replication user on the master. Ensure the proper privileges are granted to the user defined in either your configuration file or on your CHANGE MASTER command. The privileges should be similar to the following:
GRANT REPLICATION SLAVE ON *.*
TO 'rpl_user'@'192.168.1.%' IDENTIFIED BY 'password_here';
You can change this command to suit your needs as a means to solve this problem.
Slave Connection Times Out and Reconnects Frequently
If you have multiple slaves in your topology and have either not set the server_id option or have the same value for server_id for two or more of your slaves, you may have conflicting server IDs. When this happens, one of the slaves may exhibit frequent timeouts or drop and reconnect sequences.
This problem is simply due to the nonunique IDs among your slaves. But it can be difficult to diagnose (or, we should say, it’s easy to misdiagnose as a connection problem). You should always check the error log of the master and slave for error messages. In this case, it is likely the error will contain the nature of the timeout.
To prevent this type of problem, always ensure that all of your servers have a server_id option set either in the configuration file or in the startup command line.
Query Results Are Different on the Slave than on the Master
One of the more difficult problems to detect occurs when the results of a query performed on one or more slaves do not match that of the master. It is possible you may never notice the problem. The problem could be as simple or innocuous as sort order issues, or as severe as missing or extra rows in the result set.
The main causes of this type of error are the execution of unsafe statements, writes sent to the slave, mixing transactional and nontransactional storage engines, and different query options set on the master and slave (e.g., SQL_MODE).
A less common cause for this problem is differing character sets between the master and slave. For example, the master can be configured with one character set and collation defaults, while one or more slaves are configured with another. In most cases, this is fine so long as the character sets are compatible (same number of bytes for character storage). However, if your users start complaining of extra or missing rows or differing result orders, you should check the data carefully for rows that differ between the master and slaves.
Another possible cause of this problem is using different default storage engines on the master and slave (e.g., using the MyISAM storage engine on the master and the InnoDB storage engine on the slave). In this case, it is entirely likely that the query results will be in different orders if there are no primary key or any indexes to ensure correct order (and no ORDER BY clause).
Perhaps a more subtle cause of this type of problem is differing table definitions on the master and slave. For example, it is possible to leave some initial columns or ending columns missing on the slave. A solution to this problem is to ensure you always include the columns in each SELECTstatement. For example, if the slave has more columns than the master, a SELECT * query executed on the slave will result in more data than what is on the master. This can be complicated if the slave has extra initial columns. In this case, the results of a SELECT * query will not align to the same query executed on the master.
Similar, and perhaps more serious, is the case where you execute an INSERT INTO query on the master without specifying the columns. Again, if the slave has more initial columns, the data may not align and the query may fail. It is best to write the query as INSERT INTO <table> (a, b, c) …, explicitly listing the columns.
NOTE
Column order is important. Tables with different structures on the master and slave must have a common set of columns that appear at the beginning or end of the table.
There are many potential errors when you use this feature. For example, if the master has more columns than the slave, users could expect that the data for all columns is replicated but only those columns present on the slave are replicated. Sometimes you actually want fewer columns on the slave, and can make it work by careful querying. But a careless user can achieve this accidentally by dropping columns in such a way that replication can still proceed. In some cases, the SELECT queries executed on the slave will fail when referencing the missing columns, thereby giving you a clue to the problem. Other times, you can simply be missing data in your applications.
A common user error, which can result in different results from queries delivered to the master and to the slave, is making other types of changes to the tables or databases executed on the slave but not executed on the master (i.e., a user performs some non-replicated data manipulation on the slave that changes a table signature but does not execute the same statement on the master). When this occurs, queries can return wrong results, wrong columns, wrong order, or extra data, or simply fail due to referencing missing columns. It is always a good precaution to check the layout of a table involved in these types of problems to ensure it is the same on the master and slave. If it is not, resynchronize the table and retry the query.
Slave Issues Errors when Attempting to Restart with SSL
Problems related to SSL connections are typically the usual permission issues described previously. In this case, the privileges granted must also include the REQUIRE SSL option, as shown here (be sure to check that the replication user exists and has the correct privileges):
GRANT REPLICATION SLAVE ON *.*
TO 'rpl_user'@'%' IDENTIFIED BY 'password_here' REQUIRE SSL;
Other issues related to restarting replication when SSL connections are used are missing certificate files or incorrect values for the SSL-related options in the configuration file (e.g., ssl-ca, ssl-cert, and ssl-key) or the related options in the CHANGE MASTER command (e.g.,MASTER_SSL_CA, MASTER_SSL_CAPATH, MASTER_SSL_CERT, and MASTER_SSL_KEY). Be sure to check your settings and paths to ensure nothing has changed since the last time replication was started.
Memory Table Data Goes Missing
If one or more of your databases uses the memory storage engine, the data contained in these tables will be lost when a slave server is restarted (the server, not the slave threads). This is expected, as data in memory tables does not survive a restart. The table configuration still exists and the table can be accessed, but the data has been purged.
It is possible that when a slave server is restarted, queries directed to the memory table fail (e.g., UPDATE) or query results are inaccurate (e.g., SELECT). Thus, the error may not occur right away and could be as simple as missing rows in a query result.
To avoid this problem, you should carefully consider the use of memory tables in your databases. You should not create memory tables on the master to be updated on the slaves via replication without procedures in place to recover the data for the tables in the event of a crash or planned restart of the server. For example, you can execute a script before you start replication that copies the data for the table from the master. If the data is derived, use a script to repopulate the data on the slave.
Other things to consider are filtering out the table during replication or possibly not using the memory storage engine for any replicated table.
Temporary Tables Are Missing After a Slave Crash
If your replicated databases and queries make use of temporary tables, you should consider some important facts about temporary tables. When a slave is restarted, its temporary tables are lost. If any temporary tables were replicated from the master and you cannot restart the slave from that point, you may have to manually create the tables or skip the queries that reference the temporary tables.
This scenario often results in the case where a query will not execute on one or more slaves. The resolution to this problem is similar to missing memory tables. Specifically, in order to get the query to execute, you may have to manually recreate the temporary tables or resynchronize the data on the slave with the data on the master and skip the query when restarting the slave.
Slave Is Slow and Is Not Synced with the Master
In slave lag, also called excessive lag, the slave cannot process all of the events from the master fast enough to avoid delays in updates of the data. In the most extreme cases, the updates to the data on the slave become out of date and cause incorrect results. For example, if a slave server in a ticketing agency is many minutes behind the master, it is possible the ticketing agency can sell seats that are no longer available (i.e., they have been marked as “sold” on the master but the slave did not get the updates until too late).
We discussed this problem in previous chapters, but a summary of the resolution is still relevant here. To detect the problem, monitor the slave’s SHOW SLAVE STATUS output and examine the Seconds_Behind_Master column to ensure the value is within tolerance for your application. To solve the problem, consider moving some of the databases to other slaves, reducing the number of databases being replicated to the slave, improving network delays (if any), and making data storage improvements.
For example, you can relieve the slave of processing extraneous events by using an additional slave for bulk or expensive data updates. You can relieve the replication load by making updates on a separate slave and applying the changes using a reliable backup and restore method on all of the other machines in the topology.
Data Loss After a Slave Crash
It is possible that a slave server may crash and not record the last known master binlog position. This information is saved in the relay_log.info file. When this occurs, the slave will attempt to restart at the wrong (older) position and therefore attempt to execute some queries that may have already been executed. This normally results in query errors; you can handle this by skipping the duplicate events.
However, it is also possible these duplicate events can cause the data to be changed (corrupted) so that the slave is no longer in sync with the master. Unfortunately, these types of problems are not that easy to detect. Careful examination of the logfiles may reveal that some events have been executed, but you may need to examine the binlog events and the master’s binary log to determine which ones were duplicated.
NOTE
There is a set of Python-based tools called MySQL Utilities for working with MySQL servers. They include a utility that can be used to identify differences in data and structure. MySQL Utilities are discussed in more detail in Chapter 17.
Table Corruption After a Crash
When you restart a master following a crash, you may find one or more tables are corrupt or marked as crashed by MyISAM. You need to resolve these issues before restarting replication. Once you have repaired the affected tables, ensure the tables on the slave have not suffered any data loss as a result of the repair. It is very unusual for this to occur, but it is something that you should check. When in doubt, always manually resynchronize these tables with the master using a backup and restore or similar procedure before restarting replication.
WARNING
Data loss after a repair operation is a very real possibility for MyISAM when a partial page write occurs during a hardware or server crash. Unfortunately, it is not always easy to determine if the data has been lost.
Relay Log Is Corrupt on the Slave
If a server crash or disk problem results in a corrupt relay log on the slave, replication will stop with one of several errors related to the relay log. There are many causes and types of corruption that can occur in the relay log, but all result in the inability to execute one or more events on the slave.
When this occurs, your best choice for recovery is identifying where the last known good event was executed from the master’s binary log and restarting replication using the CHANGE MASTER command, providing the master’s binlog information. This will force the slave to recreate a new relay log. Unfortunately, this means any recovery from the old relay log can be compromised.
Multiple Errors During Slave Restart
One of the more difficult problems to detect and fix is multiple errors on the slave during initial start or a later restart. There are a variety of errors that occur and sometimes they occur at random or without a clearly identifiable cause.
When this occurs, check the error log and the output of SHOW SLAVE STATUS, looking for messages concerning errors reported during slave connection and replication startup. You can also check the size of the max_allowed_packet on both the master and the slave. If the size is larger on the master than on the slave, it is possible the master has logged an event that exceeds the slave’s size. This can cause random and seemingly illogical errors.
Consequences of a Failed Transaction on the Slave
Normally when there is a failed transaction, the changes are rolled back to avoid problems associated with partial updates. However, this is complicated when you mix transactional and nontransactional tables—the transactional changes are rolled back, but the nontransactional changes are not. This can lead to problems such as data loss or duplicated, redundant, or unwanted changes to the nontransactional tables.
The best way to avoid this problem is to avoid mixing transactional and nontransactional table relationships in your database and to always use transactional storage engines.
I/O Thread Problems
There are three common issues related to the I/O thread:
§ Dropped connection to the master
§ Intermittent connection to the master
§ Slave lagging severely behind the master
You will find master connection errors in the slave status output in the Last_IO_Errno and Last_IO_Error fields. It is also likely that the state of the Slave_IO_Running will be No. The causes for these errors should be apparent in the error description. If the error is not easily understood, you should follow these steps to isolate the problem:
§ Check the CHANGE MASTER command to ensure the correct user credentials are used.
§ Check the replication user’s credentials on the master.
§ Check the network to ensure the master is reachable by using ping hostname on a client, where hostname is the hostname of the master.
§ Check that the port used on the server is reachable using telnet hostname n, where n is the master’s port.
If the connection to the master drops but the slave is able to reestablish the connection, you most likely are encountering problems with network bandwidth. In this case, use your network testing tools to ensure there is sufficient bandwidth and take appropriate steps to reduce excessive bandwidth use.
If the slave is very far behind the master, you should ensure there is no corruption in the relay log, there are no errors or warnings on the slave, and the slave is performing correctly (a common problem is that the system is burdened with another process). If all of these check out, you can consider using a multithreaded slave or replication filtering to isolate databases among groups of slaves.
SQL Thread Problems: Inconsistencies
The most common problem found with the SQL thread is a statement that has failed to execute on the slave. In this case, the slave’s SQL thread will stop and the error will be presented in the slave status. You should look there for clues to why the statement failed and take corrective action.
Causes for statement errors on the slave but not the master were addressed earlier. They are often caused by key collisions, inadvertent writes to the slave, or by different data on the slave and master. Whenever you encounter these issues, you should trace the cause of the problem if possible to try and prevent it from happening in the future. One key step is to identify an application or user that issued data changes to a slave.
The cure for most of these problems is bringing the slave back into synchronization with the master. A nifty tool for checking consistency between the master and slave is the MySQL Utilities mysqldbcompare script. This utility is an offline tool that you can run on your slave during periods of low activity or when it is safe to lock the tables for a period of time. The utility will not only identify which objects differ in structure or are missing, it will also identify the data rows that differ and permit you to generate transformation statements that you can use to bring the slave into consistency with the master. This utility and several other replication utilities are discussed in more detail in Chapter 17.
Different Errors on the Slave
Although rare, it is possible you could encounter a situation where a statement results in a different error presented on the slave than the master. This is normally manifested as an error that reads, “Query X caused different errors on master and slave…” The message will present the error, but it might appear simply as something like “Error 0,” which indicates that the statement succeeded on the slave but that there was an error on the master.
The most likely cause of this problem is an error during a trigger or event on the master. For example, if a trigger on the master failed but either the equivalent trigger succeeded on the slave or the trigger was missing on the slave (a common practice). In this case, the best way to solve the problem is to correct the error on the master, then tell the slave to skip the statement.
However, it is also possible the problem is related to a deadlock in the trigger brought on by data inconsistencies. If this occurs, you may need to correct the inconsistencies first and retry or skip the statement.
Advanced Replication Problems
There are some natural complications with some of the more advanced replication topologies. In this section, we examine some of the common problems you might encounter while using an advanced feature of replication.
A Change Is Not Replicated Among the Topology
In some cases, changes to a database object are not replicated. For example, ALTER TABLE may be replicated, while FLUSH, REPAIR TABLE, and similar maintenance commands are not. Whenever this happens, consult the limitations of data manipulation (DML) commands and maintenance commands.
This problem is typically the result of an inexperienced administrator or developer attempting database administration on the master, expecting the changes to replicate to the slaves.
Whenever there are profound changes to a database object that change its structure at a file level or you use a maintenance command, execute the command or procedure on all of the slaves to ensure the changes are propagated throughout your topology.
Savvy administrators often use scripts to accomplish this as routine scheduled maintenance. Typically, the scripts stop replication in an orderly manner, apply the changes, and restart replication automatically.
Circular Replication Issues
If you are using circular replication and you have recovered from a replication failure whereby one or more servers were taken out of the topology, you can encounter a problem in which an event is executed more than once on some of the servers. This can cause replication to fail if the query fails (e.g., a key violation). This occurs because the originating server was among those servers that were removed from the topology.
When this happens, the server designated as the originating server has failed to terminate the replication of the event. You can solve this problem by using the IGNORE_SERVER_IDS option (available in MySQL versions 5.5.2 and later) with the CHANGE MASTER command, supplying a list of server IDs to ignore for an event. When the missing servers are restored, you must adjust this setting so that events from the replaced servers are not ignored.
Multimaster Issues
As with circular replication (which is a specific form of multimaster topology), if you are recovering from a replication failure, you may encounter events that are executed more than once. These events are typically events from a removed server. You can solve this problem the same way as you would with circular replication—by placing the server IDs of the removed servers in the list of the IGNORE_SERVER_IDS option with the CHANGE MASTER command.
Another possible problem with multimaster replication crops up when changes to the same table occur on both masters and the table has an autoincrement column for the primary key. In this case, you can encounter duplicate key errors. If you must insert new rows on more than one master,use the auto_increment_increment and auto_increment_offset options to stagger the increments. For example, you can allow one server to use only even numbers while the other uses only odd numbers. It can be even more complicated to get more than two masters to update the same table with an autoincrement primary key. Not only does it make it more difficult to stagger the increments, it becomes an administrative problem if you need to replace a server in the topology that is updating the table. If you make the increment too large (and you have massive amounts of data), you could exceed the maximum values of the data type for the key in a large table.
The HA_ERR_KEY_NOT_FOUND Error
This is a familiar error encountered in a row-based replication topology. The most likely cause of this error is a conflict whereby the row to be updated or deleted is not present or has changed, so the storage engine cannot find it. This can be the result of an error during circular replication or changes made directly to a slave on replicated data. When this occurs, you must determine the source of the conflict and repair the data or skip the offending event.
GTID Problems
The addition of Globally Unique Transaction Identifiers (GTID) is a recent feature for replication. As we discussed earlier in the book, GTIDs can solve the problem of failover for the loss of the master in a topology. Fortunately, there are few cases where replication encounters problems with GTIDs. Their very nature makes them stable. However, it is still possible to run into problems when working with slaves on topologies that have GTID enabled.
Most often you will not encounter errors but will find that the slave has an incomplete set of transactions. In this case, you will use the techniques discussed previously to identify which GTIDs have been executed on the slave. If it is not possible to wait for the slave to catch up to the master, you can use the new replication protocol to catch a slave up by making it a slave of another up-to-date slave. This will make the slave that is behind request those missing GTIDs from its new master. Once the slave is up-to-date, you can return it to its original master.
The one situation where you may encounter an error related to GTIDs is when you attempt to provision a slave. If you have a slave that is behind or does not have all of the data on the master, you would ordinarily perform a restore on the slave of a most recent backup of the master. You can still do this, but you also need to set the gtid_purged variable on the slave to include all of the GTIDs executed on the master (the value of the masters gtid_executed system variable).
If you use mysqldump or the mysqldbcopy, mysqldbexport, and mysqldbimport commands from MySQL Utilities, the correct GTID statements will be generated for you. However, if you attempt to set the gtid_purged variable on the slave, you may encounter an error similar to "GTID_PURGED can only be set when GTID_EXECUTED is empty.” This occurs because the destination server is not in a clean replication state. To correct the error, you must first issue the RESET MASTER command on the slave to clear the gtid_purged variable, then set the gtid_purgedvariable.
WARNING
Never issue RESET MASTER on your master for an active replication topology using GTIDs. Be very careful when using this command.
Tools for Troubleshooting Replication
If you have used or set up replication or performed maintenance, many of the tools you need to successfully diagnose and repair replication problems are familiar to you.
In this section, we discuss the tools required to diagnose replication problems along with a few suggestions about how and when to use each:
SHOW PROCESSLIST
When encountering problems, it is always a good idea to see what else is running. This command tells you the current state of each of the threads involved in replication. Check here first when examining the problem.
SHOW MASTER STATUS and SHOW SLAVE STATUS
These SQL commands are your primary tool for diagnosing replication problems. Along with the SHOW PROCESSLIST command, you should execute these commands on the master and then on the slave, then examine the output. The slave command has an extended set of parameters that are invaluable in diagnosing replication problems.
SHOW GRANTS FOR < replication user >
Whenever you encounter slave user access problems, you should first examine the grants for the slave user to ensure they have not changed.
CHANGE MASTER
Sometimes the configuration files have been changed, either knowingly or accidentally. Use this SQL command to override the last known connection parameters, which can correct slave connection problems.
STOP/START SLAVE
Use these SQL commands to start and stop replication. It is sometimes a good idea to stop a slave if it is in an error state.
Examine the configuration files
Sometimes the problem occurs as a result of an unsanctioned or forgotten configuration change. Check your configuration files routinely when diagnosing connection problems.
Examine the server logs
You should make this a habit whenever diagnosing problems. Checking the server logs can sometimes reveal errors that are not visible elsewhere. As cryptic as they can sometimes be, the error and warning messages can be helpful.
SHOW SLAVE HOSTS
Use this command to identify the connected slaves on the master if they use the report-host option.
SHOW BINLOG EVENTS
This SQL command displays the events in the binary log. If you use statement-based replication, this command will display the changes using SQL statements.
mysqlbinlog
This utility allows you to read events in the binary or relay logs, often indicating when there are corrupt events. Don’t hesitate to use this tool frequently when diagnosing problems related to events and the binary log.
PURGE BINARY LOGS
This SQL command allows you to remove certain events from the binary log, such as those that occur after a specific time or after a given event ID. Your routine maintenance plan should include the use of this command for purging older binary logs that are no longer needed. You should use a specific time duration to prevent purging binary logs accidentally or too frequently.
Now that we have reviewed the problems you can encounter in replication and have seen a list of the tools available in a typical MySQL release, we turn our attention to strategies for attacking replication problems.
Best Practices
Reviewing the potential problems that can occur in replication and listing the tools available for fixing the problems is only part of the complete solution. There are some proven strategies and best practices for resolving replication problems quickly.
This section describes the strategies and best practices you should cultivate when diagnosing and repairing replication problems. We present these in no particular order—depending on the problem you are trying to solve, one or more may be helpful.
Know Your Topology
If you are using MySQL replication on a small number of servers, it may not be that difficult to commit the topology configuration to memory. It may be as simple as a single master and one or more slaves, or as complex as two servers in a multimaster topology. However, there is a point at which memorizing the topology and all of its configuration parameters becomes impossible.
The more complex the topology and the configuration, the harder it is to determine the cause of a problem and where to begin your repair operations. It would be very easy to forget a lone slave in a topology of hundreds of slave servers.
It is always a good idea to have a map of your topology and the current configuration settings. You should keep a record of your replication setup in a notebook or file and place it where you and your colleagues or subordinates can find it easily. This information will be invaluable to someone who understands replication administration but may have never worked with your installation.
You should include a textual or graphical drawing of your topology and indicate any filters (master and slave), as well as the role of each server in the topology. You should also consider including the CHANGE MASTER command, complete with options, and the contents of the configuration files for all of your servers.
A drawing of your topology need not be sophisticated or an artistic wonder. A simple line drawing will do nicely. Figure 14-1 shows a hybrid topology, complete with notations for filters and roles.
Note that the production relay slave (192.168.1.105) has two masters (192.168.1.100 and 192.168.1.101). This is strange, because no slave can have more than one master. To achieve this level of integration—consuming data from a third party—you would need a second instance of a MySQL server on the production relay slave to replicate the data from the strategic partner (192.168.1.101) and use a script to conduct periodic transfers of the data from the second MySQL instance to the primary MySQL instance on the production relay slave. This would achieve the integration depicted in Figure 14-1 with some manual labor and a time-delayed update of the strategic partner data.
There are certain problems inherent in certain topologies. We have already discussed many of these in this and previous chapters. What follows is a list of the types of topologies, including a short description and some common issues to be aware of concerning known vulnerabilities:
Star (also called single master)
This is the typical single master, many slaves topology. There are no special limitations or problems other than those that apply to replication as a whole. However, the process of promoting a slave to a master can be complicated in that you must use the slave that is most up-to-date with the master. This can be difficult to determine and may require examination of the state of every slave.
Chain
In this configuration, a server is a master to one slave, which is in turn a master to another slave, and so on, with the end point being a simple slave. Other than the server ID issue mentioned earlier, there is also the problem of determining which position an intermediate master/slave was at when it failed. Promoting a new master/slave node can require additional work to ensure consistency.
Circular (also called ring)
This is the same as the chain topology except there is no end point. This topology requires careful setup so that events are terminated at the originating server.
Multimaster
This is similar to a circular topology, but in this case, each master is a slave of every other master. This topology has all of the limitations and problems of circular replication as well as being one of the most complex topologies to manage due to the possibility of conflicting changes. To avoid this problem, you must ensure you make changes using only one of the masters. If a conflicting change occurs, say an UPDATE on one master and a DELETE statement on the other master, it is possible the DELETE statement will execute before the UPDATE, which will prevent theUPDATE from updating any rows.
Hybrid
A hybrid topology uses elements of some or all of the other topologies. You typically see this topology in a large organization that has compartmentalized functions or divisions that require similar but often isolated elements of the infrastructure. Isolation is accomplished using filtering whereby data is divided among several slaves from an original master (sometimes called the prime or master master) that contains all of the data sent to the slaves, which become masters to their own star topologies. This is by far the most complex topology and requires careful notation and diligence to keep your documentation updated.
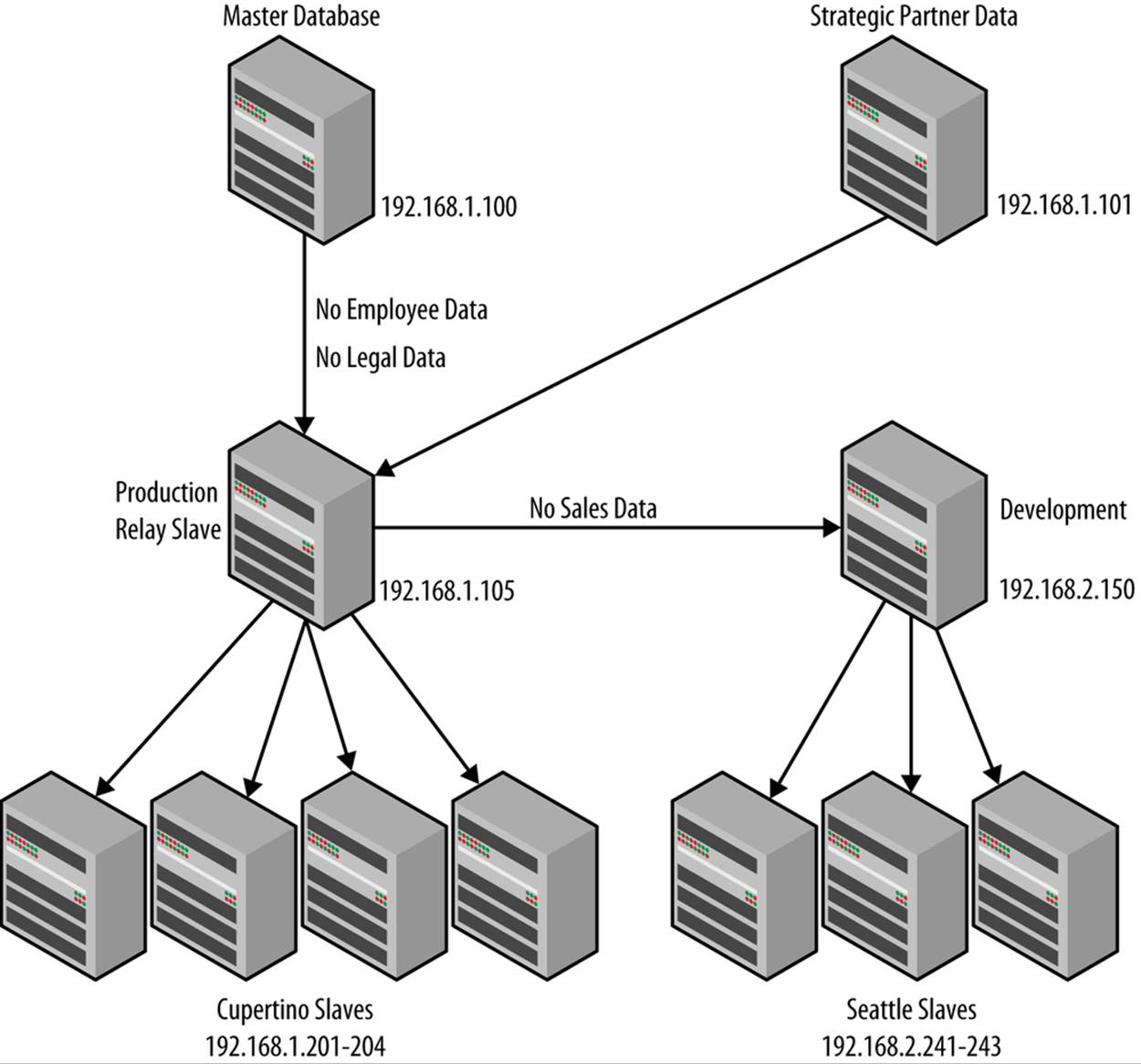
Figure 14-1. Sample topology map
Check the Status of All of Your Servers
One of the best preventive tasks you can perform is to regularly check the status of all of the servers in your topology. This need not be complicated. For instance, you can set up a scheduled task that launches the MySQL client and issues a SHOW MASTER STATUS or SHOW SLAVE STATUSand prints out or emails the results.
Keeping a close eye on your server status is a good way to stay informed when there is a potential problem. It also gives you a chance to react more quickly when errors occur.
You should look for errors, monitor the slave lag, check your filters to see that they match your records, and ensure all of your slaves are running and not reporting warnings or connection errors.
Check Your Logs
Along with checking your server status regularly, you should also consider checking the logs of your servers periodically. You can accomplish this easily using the MySQL Workbench GUI to connect to each server in turn and look at the most recent entries in the logs.
If you are diligent in this effort, it will pay dividends in the form of early problem detection. Sometimes errors or warnings—which, at the time, do not manifest in anything detectable—are written to the log. Catching these telltale signs early can make your repair work much easier.
We recommend examining your logs at the same time you examine the status of your servers.
Check Your Configuration
Along with the servers and logfiles, you should also routinely examine your configuration files to ensure your documentation is up-to-date. This isn’t as critical as checking the logs, but it is often overlooked. We recommend checking your configuration files and updating your documentation at least once a week if you have a lot of changes, and at least once a month if you have few changes to the topology or servers. If you have an environment in which there is more than one administrator, you may want to consider doing this more frequently.
Conduct Orderly Shutdowns
Sometimes it is necessary to stop replication while you diagnose and repair a problem. If replication has already stopped, you may not need to do anything, but if you have a complex topology and the error is related to data loss, it may be safer to stop replication across the topology. But you should do so in a controlled and safe manner.
There are several strategies for doing a controlled shutdown of your replication topology. If data loss is an issue and slave lag is not, you may want to lock the tables on your master and flush the binary logs, then wait for all of the (remaining) slaves to catch up and then shut the slaves down. This will ensure all events are replicated and executed on the slaves that are operational.
On the other hand, if the problem is severe, you may want to start with the slaves on the leaves of your topology and work your way up the topology, leaving the master running. However, if you leave the master running (i.e., you don’t lock all of the tables) and you have a heavy load of updates running and your diagnostic and repair takes a long time, your slaves will be lagging behind your master when you restart replication. It is better to stop updates on the master if you think your repair will take a long time.
If you are faced with a difficult problem or (worse) a problem that appears randomly or without warning, you may want to consider shutting down replication completely. This is especially true if you have a problem with only one of your slaves. Shutting down replication will allow you to isolate the server while you diagnose the problem.
Conduct Orderly Restarts After a Failure
It is also important to restart replication in an orderly manner. It is often best to restart the replication topology under controlled conditions, such as on only one master and one slave. Even if your topology is more complex, having the most basic building blocks of replication started initially will allow you to test and ensure the problem is fixed before restarting all of your servers.
Isolation is essential when dealing with problems that are confined to a single slave or a set of events. It is also helpful to start with a single master and a single slave so that if you cannot fix the problem, you can get help from MySQL professionals more easily because you have isolated the problem to the smallest set of parameters as possible. See Reporting Replication Bugs for more details.
Manually Execute Failed Queries
One of the most frequently overlooked strategies is examining the queries in the relay log or binary log for clues as to what has gone wrong. It is easy to get stuck on researching the error on the slave and diagnosing all of the many things that can go wrong, but sometimes (especially when there is a query involved) you can gain far more information about the problem by isolating the slave server in question and attempting the query manually.
If you are using statement-based replication, this is an easy task because the query is human-readable in the binary or relay log. If you use row-based replication, you can still execute the query, but you cannot read the query itself. In this case, a malformed query or a query that uses a missing, incorrect, or corrupt reference may not be obvious until you execute the query manually.
Remember, you should always make a backup of your data before attempting diagnostics that could result in changes to the data. Running a broken query is definitely one of those cases. We have seen queries that cause replication errors but sometimes succeed when run manually. When this occurs, it is usually indicative of a slave configuration error or binary or relay log issue rather than a problem with the query itself.
Don’t Mix Transactional and Nontransactional Tables
This may be an obvious best practice to many, but it is good to remind ourselves nonetheless. Mixing transactional and nontransactional table updates in a transaction can lead to a host of problems, not the least of which is the inability to rollback changes to a nontransactional table. You should avoid this practice entirely.
That being said, it is possible that some mixing of nontransactional statements can be considered safe. For example, if your nontransactional tables are lookup tables that rarely get updated and, more important, are not updated in the course of the transaction, it may be safe to execute these statements.
The best way to avoid problems associated with mixing transactional and nontransactional tables is to convert all of your tables to InnoDB, thereby making them transactional. In most cases, this is perfectly reasonable and you will notice no ill effects. However, if your data requires a different storage engine (e.g., the Archive or CSV storage engines), it may not be convenient or even possible to convert them.
Common Procedures
There are also some common procedures you can use to execute the practices just discussed. These include troubleshooting replication and pausing replication on the master.
Troubleshooting replication failures
The following is a stepwise procedure you can use when attacking replication problems (most of these steps have been described elsewhere in this book or may already be familiar to you):
1. Check the status on the master. Record any anomalies.
2. Check the status on each slave. Record any anomalies.
3. Read the error logs on all of your servers.
4. Examine the process list on each server. Look for anomalies in status.
5. If no errors are reported, attempt to restart the slave. Record any errors presented.
6. Check the configuration of the server in question to ensure nothing has changed.
7. Examine your notes and form a plan to research and fix the problem.
This procedure is oversimplified, but it should help you diagnose the replication problem more quickly than chasing the errors presented will (if there are any errors to chase).
NOTE
You should write down or electronically record all observations while you conduct this procedure. Seeing the information consolidated in one place can sometimes present a much clearer body of evidence.
Pausing replication
To pause replication, execute the following steps on each of your master servers, starting with the prime master (the first master):
On the master:
1. Run the FLUSH TABLES WITH READ LOCK command.
2. Run the SHOW MASTER STATUS command.
3. Record the master binary log and position.
On the slaves:
1. Run SELECT MASTER_POS_WAIT (binary_log_name, position).
On each remaining active slave connected to this master, examine the results of SHOW SLAVE STATUS until the slave has synchronized with the master. Once the slave reaches this state, it is safe to shut down the slave.
When you restart your replication topology, all slaves will automatically start without any lag. This procedure is useful in cases where there has been a disruption and you want to get things going again to avoid a prolonged slave lag.
Reporting Replication Bugs
Once in a while you may encounter a replication problem that you cannot solve or there is no solution. In this case, you should report the problem to the MySQL developers, who may be better equipped to diagnose the problem (and correct it if it is a defect). Even if you do not have a support agreement in place, you can report a bug for the MySQL release you are using.
That is not to say that the bug database is a “free help” resource. It is reserved for reporting and tracking defects. The best advice for tricky problems is to check all MySQL database forums for ideas and solutions first. Only when it is clear that the problem is unique and unrelated to your environment or application should you report it as a defect.
The best bug reports are those that describe errors that can be demonstrated or repeated using an isolated test case (e.g., a replication problem that can be demonstrated on a test master and slave), and that have a minimal set of data needed for the problem. Often this is nothing more than a complete and accurate report of the configuration and event in question.
To report a bug, visit http://bugs.mysql.com and (if you have not done so already) register for an account. When you enter your bug report, be sure to describe the problem as completely as possible. For fastest results and a quick resolution, include as many of the following details as possible:
§ Record all error messages verbatim.
§ Include the binary log (in full or an excerpt).
§ Include the relay log (in full or an excerpt).
§ Record the configuration of the master and slave.
§ Copy the results of the SHOW MASTER STATUS and SHOW SLAVE STATUS commands.
§ Provide copies of all error logs.
NOTE
Be sure to exhaust all of these techniques and explore the problem using all of the available tools.
The MySQL bug tracking tool will keep you apprised of your bug submission by sending you email alerts whenever the bug report is updated.
Conclusion
This chapter includes suggestions for solving some of the common problems that can arise when using replication. We examined some of the ways replication can fail and discussed how to solve the problems and prevent them in the future. We also examined some tools and best practices for troubleshooting MySQL replication.
One resource that is often overlooked is the section titled “Replication Features and Issues” in the online reference manual. This section includes very important information about limitations with replication and how it interacts with certain server features, settings, and the design and implementation choices of your databases. You may want to read this section whenever a new version of the server is released to ensure you are informed about how new features may affect replication.
Joel smiled as he heard his boss coming toward his door. He was ready this time and started speaking as soon as he saw Mr. Summerson’s polished wingtips. “I’ve got the Seattle server back online, sir. It was a problem with a couple of queries that failed because the tables were changed on the slave. I have advised the Seattle office to direct all schema changes and table maintenance to the master here. I will keep a watch on it from now on and let you know if the problem returns.”
Mr. Summerson smiled. Joel could feel perspiration beading on his forehead. “Great! Good work.”
Joel was relieved. “Thank you, sir.”
His boss started to leave, but performed one of his now-routine pause, turn, and task maneuvers. “One more thing.”
“Sir?” Joel said a little too quickly.
“It’s Bob.”
Joel was confused. Mr. Summerson’s tasking usually involved a complete sentence. “Sir?” he said hesitantly.
“You can call me Bob. I think we’re well past the ‘sir’ stuff.”
Joel sat for a few moments until he realized he was staring into the middle distance of space. He blinked and realized his friend Amy from the development staff was standing in front of his desk.
“Are you OK, Joel?”
“What?”
“You were zoned out there. What were you thinking about?”
Joel smiled and reclined his chair. “I think I finally got to him.”
“Who? Mr. Summerson?”
“Yeah, he just told me to call him Bob.”
Amy smiled and crossed her arms, then jokingly said, “Well, I suppose we’ll be calling you Mr. Joel from now on.”
Joel laughed and said, “Have you had lunch yet?”
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.