Learning Nagios 4 (2014)
Chapter 8. Monitoring Remote Hosts
Nagios offers various ways of monitoring the computers and services. The previous chapter talked about passive checks and how they can be used to submit results to Nagios. It also discussed NSCA, which can be used to send check results from other machines to the Nagios server.
This chapter talks about another approach to check the service status. It uses Nagios active checks that run the actual check commands on different hosts. This approach is most useful in cases where resources local to a particular machine are to be checked. A typical example is monitoring disk or memory usage. Checking if your operating system is up-to-date is also an example of such a test. This type of data cannot be checked without running commands on the target computer.
Remote checks are usually used in combination with the Nagios plugins package that use either SSH or Nagios Remote Plugin Executor (NRPE) to run the plugins on the remote machine. This makes monitoring remote systems very similar to monitoring a local computer, with a difference only in the actual running of the commands on the remote machine. In this chapter, we will cover the following topics:
· Using SSH for monitoring the remote hosts and services and setting up the public key authentication for performing checks
· Running multiple checks at once over SSH
· Troubleshooting the SSH-based checks
· Using NRPE for performing remote checks and setting up NRPE as a system service
· Configuring NRPE-based checks in Nagios
· Passing command arguments using NRPE
· Troubleshooting NRPE-based connections
Monitoring over SSH
Very often, Nagios is used to monitor computer resources such as CPU utilization, memory, and disk space. One way in which this can be done is to connect over SSH and run a Nagios check plugin.
This requires setting up SSH to authenticate using public keys. This works because the Nagios server has an SSH private key, and the target machine is configured to allow users with that particular key to connect without prompting them for password.
Nagios offers a check_by_ssh plugin that takes the hostname and the actual command to run on the remote server. It then connects using SSH, runs the plugin, and returns both output and exit code from the actual check performed on the remote machine to Nagios running on the local server. Internally, it runs the SSH client to connect to the server, and runs the actual command to run along with its attributes on the target machine. After the check has been performed, the output along with the check command's exit code is returned to Nagios.
Thanks to this, regular plugins can be run from the same machine as the Nagios daemon, as well as remotely over SSH without any changes to the plugins. Using the SSH protocol also means that the authorization process can be automated using the key-based authentication so that each check is done without any user activity. This way, Nagios is able to log in to remote machines automatically without using any passwords. The following is an illustration of how such a check is performed:
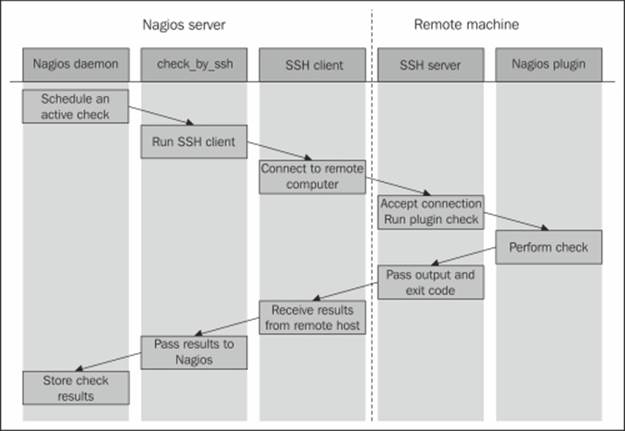
Once Nagios schedules an active check to be performed, the check_by_ssh plugin runs the ssh command to connect to the remote host's SSH server. It then runs the actual plugin, which is located on the remote host, waits for the result, and returns it to the SSH protocol. The SSH client passes this information down to the check_by_ssh plugin that, in the end, returns to the Nagios daemon.
Even though the scenario might seem a bit complicated, it works quite efficiently and requires little setup to work properly. It also works with various flavors of Unix systems as the SSH protocol, clients, and the shell syntax for commands used by the check_by_sshplugin is the same on all the systems.
Configuring the SSH connection
SSH provides multiple ways for a user to authenticate. One of them is the password-based authentication, which means that user specifies a password, the SSH client sends it to remote machine, and the remote machine checks if the password is correct.
Another form of verifying whether a user or program can access the remote machine is the public key-based authentication. It uses asymmetric cryptography (visit http://en.wikipedia.org/wiki/Public-key_cryptography for more details) to perform the authentication and provides a secure way to authenticate without specifying any credentials. It requires the user to generate an authentication key, which consists of a public and private key. By default, the file name is ~/.ssh/id_rsa for the private key and ~/.ssh/id_rsa.pub for the public key. The public key is then put on the remote machines, and it allows them to verify the user. The SSH protocol then takes care of the authentication—it only requires the client machine to have the private key and the remote machine to be configured to accept it by adding the public key to remote user's SSH authorized keys file (~/.ssh/authorized_keys in most cases).
Setting up remote checks over SSH requires a few steps. The first step is to create a dedicated user for performing checks on the machine on which the remote checks will be run. We will also need to set up directories for the user. The steps to create directory structure on the remote machine is very similar to the steps performed for the entire Nagios installation.
The first thing that needs to be performed on the Nagios server is the creation of a private and public key pair that will be used to log in to all the remote machines without using passwords. We will need to execute the ssh-keygen command to generate it. A sample session is shown in the following command snippet:
root@nagiosserver:~# su -s /bin/bash nagios
nagios@nagiosserver:~$ ssh-keygen
Generating public/private rsa key pair.
File in which to save the key (/opt/nagios/.ssh/id_rsa): <enter>
Created directory '/opt/nagios/.ssh'.
Enter passphrase (empty for no passphrase): <enter>
Enter same passphrase again: <enter>
Your identification has been saved in /opt/nagios/.ssh/id_rsa.
Your public key has been saved in /opt/nagios/.ssh/id_rsa.pub.
The key fingerprint is:
c9:68:47:bd:cd:6e:12:d3:9b:e8:0d:cf:93:bd:33:98 nagios@nagiosserver
nagios@nagiosserver:/root$
As in most cases, it was not possible to log in as the user nagios directly on which. We used the su command to switch users along with the -s flag to force the shell to be /bin/bash. The <enter> text means that the question was answered with the default reply. The private key is saved as /opt/nagios/.ssh/id_rsa, and the public key has been saved in the /opt/nagios/.ssh/id_rsa.pub file.
Next, we need to set up the remote machines that we will monitor. All the following commands should be executed on the remote machine that is to be monitored, unless explicitly mentioned. First, let's create a user and group named nagios:
root@remotehost:~# groupadd nagios
root@remotehost:~# useradd -g nagios -d /opt/nagios nagios
We do not need the nagioscmd group as we will need only the account to log in to the machine. The computer that only performs checks does not have a full Nagios installation along with the external command pipe that needs a separate group.
The next thing that needs to be done is the compiling of the Nagios plugins. You will probably also need to install the prerequisites that are needed for Nagios. Detailed instructions on how to do this can be found in Chapter 2, Installing Nagios 4. For the rest of the section, we will assume that the Nagios plugins are installed in the /opt/nagios/plugins directory, similar to how they were installed on the Nagios server.
It is best to install plugins in the same directory on all the machines they will be running. In this case, we can use the $USER1$ macro definition when creating the actual check commands in the main Nagios configuration. The USER1 macro points to the location where Nagios plugins are installed in the default Nagios installations. This is described in more detail in Chapter 2, Installing Nagios 4. Next, we will need to create the /opt/nagios directory and set its permissions:
root@remotehost:~# mkdir /opt/nagios
root@remotehost:~# chown nagios:nagios /opt/nagios
root@remotehost:~# chmod 0700 /opt/nagios
You can make the /opt/nagios directory permissions less restrictive by setting the mode to 0755. However, it is recommended not to make the users' home directories readable for all users. We will now need to add the public key from the nagios user on the remote machine that is running the Nagios daemon, as shown in the following command snippet:
root@remotehost:~# mkdir /opt/nagios/.ssh
root@remotehost:~# echo 'ssh-rsa … nagios@nagiosserver' \>>/opt/nagios/.ssh/authorized_keys
root@remotehost:~# chown nagios.nagios \
/opt/nagios/.ssh /opt/nagios/.ssh/authorized_keys
root@remotehost:~# chmod 0700 \
/opt/nagios/.ssh /opt/nagios/.ssh/authorized_keys
When running the command, you should replace the entire text ssh-rsa … nagios@nagiosserver with the actual contents of the /opt/nagios/.ssh/id_rsa.pub file on the computer running the Nagios daemon. If your machine is maintained by more than one person, you might replace the nagios@nagiosserver string to a more readable comment such as Nagios on nagiosserver SSH check public key.
Make sure that you change the permissions for both the .ssh directory and the authorized_keys file, as many SSH server implementations ignore public key-based authorization if the files can be read or written to by other users on the system.
In order to configure multiple remote machines to be accessible over ssh without a password, you will need to perform all the steps mentioned earlier, except the key generation at the computer running the Nagios server, as a single private key will be used to access multiple machines. Assuming everything was done successfully, we can now move on to testing if the public key-based authorization actually works. To do that, we will try to run the ssh client in verbose mode and see whether using the previously generated key works fine. In order to check that our connection can now be successfully established, we need to try to connect to the remote machine from the computer that has the Nagios daemon running. We will use the ssh client with the verbose flag to make sure that our connection works properly:
nagios@nagiosserver:~$ ssh -v nagios@192.168.2.1
OpenSSH_4.6p1 Debian-5ubuntu0.2, OpenSSL 0.9.8e 23 Feb 2007
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: Applying options for *
debug1: Connecting to 192.168.2.1 [192.168.2.1] port 22.
debug1: Connection established.
debug1: identity file /opt/nagios/.ssh/id_rsa type 1
(...)
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: server->client aes128-cbc hmac-md5 none
debug1: kex: client->server aes128-cbc hmac-md5 none
debug1: SSH2_MSG_KEX_DH_GEX_REQUEST(1024<1024<8192) sent
debug1: expecting SSH2_MSG_KEX_DH_GEX_GROUP
debug1: SSH2_MSG_KEX_DH_GEX_INIT sent
debug1: expecting SSH2_MSG_KEX_DH_GEX_REPLY
The authenticity of host '192.168.2.1 (192.168.2.1)' can't be established.
RSA key fingerprint is cf:72:1e:40:03:a4:e0:9b:6c:84:4e:e1:2d:ea:56:fc.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.2.1' (RSA) to the list of known hosts.
debug1: ssh_rsa_verify: signature correct
debug1: SSH2_MSG_NEWKEYS sent
debug1: expecting SSH2_MSG_NEWKEYS
debug1: SSH2_MSG_NEWKEYS received
debug1: SSH2_MSG_SERVICE_REQUEST sent
debug1: SSH2_MSG_SERVICE_ACCEPT received
debug1: Authentications that can continue: publickey,password
debug1: Next authentication method: publickey
debug1: Offering public key: /opt/nagios/.ssh/id_rsa
debug1: Server accepts key: pkalg ssh-rsa blen 277
debug1: read PEM private key done: type RSA
debug1: Authentication succeeded (publickey).
debug1: channel 0: new [client-session]
debug1: Entering interactive session.
debug1: Sending environment.
debug1: Sending env LANG = en_US.UTF-8
$
As we were connecting to the remote machine for the first time, ssh prompted us to check whether we had accepted the remote machine's key to a list of known hosts. This needs to be done only once for a specific host.
Also, note that we need to test the connection from the Nagios account so that the keys that are used for authentication as well as the list of known hosts are the same ones that will be used by the Nagios daemon later.
Assuming that we have the Nagios plugins installed on the remote machine in the /opt/nagios/plugins directory, we can try to use the check_by_ssh plugin from the computer running Nagios to the remote machine by running the following command:
nagios@nagiosserver:~$ /opt/nagios/plugins/check_by_ssh \-H 192.168.2.1 -C "/opt/nagios/plugins/check_apt"
APT OK: 0 packages available for upgrade (0 critical updates).
We are now sure that the checking itself works fine, and we can move on to how check_by_ssh can be used and what its syntax is.
Using the check_by_ssh plugin
As mentioned earlier, Nagios uses a separate check command that connects to a remote machine over SSH and runs the actual check command on it. The command has very powerful features and can be used to query a single service status by using active checks. It can also be used to perform and report multiple checks at once as passive checks. The following is the syntax of the command:
check_by_ssh -H <host> -C <command> [-fqv] [-1|-2] [-4|-6]
[-S [lines]] [-E [lines]] [-t timeout] [-i identity]
[-l user] [-n name] [-s servicelist] [-O outputfile]
[-p port] [-o ssh-option]
The following table describes all the options accepted by the plugin. Items required are marked in bold:
|
Option |
Description |
|
-H, --hostname |
This provides the hostname or IP address of the machine to connect to; this option must be specified |
|
-C, --command |
This provides the full path of the command to be executed on the remote host along with any additional arguments; this option must be specified |
|
-l, --logname |
This lets you log in as a specific user; if omitted, it defaults to the current user (usually nagios) or any other user specified in the per-user SSH client configuration file |
|
-I, --identity |
This specifies the path to the SSH private key to be used for authorization; if omitted, then ~/.ssh/id_rsa is used by default |
|
-o, --ssh-option |
This allows passing SSH-specific options that will be passed as the -o option to the ssh command |
|
-q, --quiet |
This stops SSH from printing warning and information messages |
|
-w, --warning |
This specifies the time in seconds after which the connection should be terminated and a warning should be issued to Nagios |
|
-c, --critical |
This specifies the time in seconds after which the connection should be terminated and a critical should be issued to Nagios |
|
-t, --timeout |
This specifies the time in seconds after which the connection should be terminated and checks should be stopped; defaults to 10 seconds |
|
-p, --port |
This specifies the port to connect over SSH; defaults to 22 |
|
-1, --proto1 |
This will let you use the SSH protocol Version 1 |
|
-2, --proto2 |
This will let you use the SSH protocol Version 2; this is the default |
|
-4 |
This will let you use IPv4 protocol for SSH connectivity |
|
-6 |
This will let you use IPv6 protocol for SSH connectivity |
|
-S, --skip-stdout |
This will let you ignore all or the provided number of lines from the standard output |
|
-E, --skip-stderr |
This will let you use ignore all or the provided number of lines from the standard error |
|
-f |
This tells SSH to work in the background just after connecting, instead of using a terminal |
The only required flags are -H to specify the IP address or hostname to connect as well as -C to specify the command to be used. The remaining parameters are optional. If they are not passed, SSH defaults and the timeout of 10 seconds will be used.
The -S and -E options are used to skip messages that are written by the SSH client or the remote machine, regardless of the commands executed. For example, to properly check machines printing MOTD, even for noninteractive sessions, it is required to skip it by using one of the options.
When specifying commands, they usually need to be enclosed in single or double quotation marks. This is because the entire command that should be run needs to be passed to check_by_ssh as a single argument. If one or more arguments contain spaces, single quote characters will have to be used.
For example, when checking for disk usage remotely, we need to quote the entire command as well; this is because it's safer to quote the path to the drive we're checking, as shown here:
nagios@nagios1:~$ /opt/nagios/plugins/check_by_ssh -H 192.168.2.1 -C \
"/opt/nagios/plugins/check_disk -w 15% -c 10% -p '/'"
DISK OK - free space: / 243 MB (17% inode=72%)
The preceding example is a typical usage of the check_by_ssh plugin as an active check. It performs a single check and returns the status directly using the standard output and exit code. This is how it is used as an active check from within Nagios.
If you want to use check_by_ssh to deploy checks locally on the same machine as the one on which Nagios is running, you will need to add the SSH key from id_rsa.pub to the authorized_keys file on that machine as well. In order to verify that it works correctly, try logging in to the local machine over SSH. Now that the plugin works when invoked manually, we need to configure Nagios to make use of it.
Usually, for commands that will be performed both locally and remotely, the approach is to create a duplicate entry for each command with a prefix, for example, _by_ssh. Assuming that we have the command that checks swap usage locally, the definition is as follows:
define command
{
command_name check_swap
command_line $USER1$/check_swap –w $ARG1$ -c $ARG2$
}
Then, assuming that we will also check the swap usage on remote machines, we need to define the following remote counterpart:
define command
{
command_name check_swap_by_ssh
command_line $USER1$/check_by_ssh –H $HOSTADDRESS$ –C
"$USER1$/check_swap –w $ARG1$ -c $ARG2$"
}
Usually, services are defined for groups for example, a service should be defined to check swap space usage on all the Linux servers. In such cases, you can use the check_swap_by_ssh command even for checking the local machine—the overhead for such a check is larger than the one for calling the plugin directly. However, in many cases, it makes managing the configuration much easier. You can also set up two sets of services similar to the following example:
define service
{
use generic-service
host_name localhost
service_description SWAP
check_command check_swap
}
define service
{
use generic-service
host_name !localhost
hostgroup_name linux-servers
service_description SWAP
check_command check_swap_by_ssh
}
This way, localhost will use the check_swap command and all the remaining machines that are part of the linux-servers host group will use the check_swap_by_ssh check command. This way, you can slightly reduce the overhead related to monitoring the machine on which Nagios is running.
Performing multiple checks
A completely different approach is to make check_by_ssh perform multiple tests and report them directly to Nagios over the external command pipe. This way, the results are sent to Nagios as passive check results. So, specified services need to accept passive check results.
The reason for this approach is that the SSH protocol negotiations introduce a lot of overhead related to the protocol itself. For hosts with heavy load, it is more efficient to log in once and run all the checks instead of performing a complete login for each check.
A drawback of doing multiple checks is that it is not trivial to schedule these directly from Nagios. The typical approach to passive checks is to schedule checks from an external application such as cron (http://man.linuxquestions.org/index.php?query=cron).
An alternate approach is to create a dummy service that will launch passive checks in the background. The actual result for this service would also be to check whether running the tests was successful or not. Another benefit of this approach is that the checks will be performed even if the cron daemon is currently disabled, as Nagios will still take care of scheduling the checks done by it.
When using check_by_ssh to report multiple results as passive checks, the following options need to be specified:
|
Option |
Description |
|
-n, --name |
This provides the short name of the host that the tests refer; this is the name of the host that will be used when sending the results over the external command pipe |
|
-s, --services |
These are the names of the services that the tests refer, separated by colon; these are the names of services that will be used when sending results over the external pipe |
|
-O, --output |
This is the path to the external command pipe to which the results of all the checks should be sent |
The preceding options are specific to performing multiple checks only. The remaining options described earlier must also be specified—especially the -H and -C options. The second one needs to be specified multiple times, each for one check. The number of -Cparameters must match the number of entries in the -s parameter so that each result can be mapped to a service name. The following example reports disk check results for three partitions:
/opt/nagios/plugins/check_by_ssh -H 192.168.2.1 -O /tmp/out1 -n ubuntu1 \
-s "DISK /:DISK /usr:DISK /opt" \
-C "/opt/nagios/plugins/check_disk -w 15% -c 10% -p /" \
-C "/opt/nagios/plugins/check_disk -w 15% -c 10% -p /usr" \
-C "/opt/nagios/plugins/check_disk -w 15% -c 10% -p /opt"
This command will put the output into /tmp/out1, similar to the following example:
[1206096000] PROCESS_SERVICE_CHECK_RESULT;ubuntu1;DISK /:DISK CRITICAL...
[1206096000] PROCESS_SERVICE_CHECK_RESULT;ubuntu1;DISK /usr:DISK OK ...
[1206096000] PROCESS_SERVICE_CHECK_RESULT;ubuntu1;DISK /opt:DISK OK ...
As mentioned previously, it is very common to write a script that is run as an active check. This script is set up as a service that is only responsible for running multiple checks for other services. Results from those services are passed as passive check results.
The following is a sample script that runs several tests and reports their results back to Nagios:
#!/bin/sh
COMMANDFILE=$1
HOSTNAME=$2
HOSTADDRESS=$3
PLUGINPATH=$4
$PLUGINPATH/check_by_ssh –H $HOSTADDRESS –t 30 \
–o $COMMANDFILE –n $HOSTNAME \
-s "SWAP:Root Partition:Processes:System Load" \
-C "$PLUGINPATH/check_swap –w 20% -c 10%" \
-C "$PLUGINPATH/check_disk –w 20% -c 10% -p /" \
-C "$PLUGINPATH/check_procs –w 100 –c 200" \
-C "$PLUGINPATH/check_load –w 5,3,2 –c 10,8,7" \
(
echo "BYSSH CRITICAL problem while running SSH"
exit 2
)
echo "BYSSH OK checks launched"
exit 0
For the remaining part of the section, let's assume that the script is in the /opt/nagios/plugins directory and is called check_linux_services_by_ssh. The script will perform several checks, and if any of them fail, it will return a critical result as well. Otherwise, it will return an OK status and the remaining results will be passed as passive check results. We will also need to configure Nagios, both services that will receive their results as passive checks, and the service that will actually schedule the checks properly.
All the services that are checked via the check_by_ssh command itself have a very similar definition. They only need to accept passive checks and don't have any active checks scheduled. The following is a sample definition for the SWAP service:
define service
{
use generic-service
host_name !localhost
hostgroup_name linux-servers
service_description SWAP
active_checks_enabled 0
passive_checks_enabled 1
}
All other services will also need to have a very similar definition. We might also define a template for such services and only create services that use it. This will make the configuration more readable. Now, we need to define a command definition that will launch the passive check script written earlier:
define command
{
command_name check_linux_services_by_ssh
command_line $USER1$/check_linux_services_by_ssh "$COMMANDFILE$" "$HOSTNAME$" "$HOSTADDRESS$" "$USER1$"
}
All the parameters that are used by the script are passed directly from the Nagios configuration. This makes reconfiguring various paths easier. The next step is to define an actual service that will run these checks:
define service
{
use generic-service
host_name !localhost
hostgroup_name linux-servers
service_description Check Services By SSH
active_checks_enabled 1
passive_checks_enabled 0
check_command check_linux_services_by_ssh
check_interval 30
check_period 24x7
max_check_attempts 1
notification_interval 30
notification_period 24x7
notification_options c,u,r
contact_groups linux-admins
}
This will cause the checks to be scheduled every 30 minutes. It will also notify the Linux administrators if any problem occurs with the scheduling of the checks. An alternative approach is to use the cron daemon to schedule the launch of the previous script. In such a case, the Check Services By SSH service is not needed. In this case, scheduling of the checks is not done in Nagios, but we will still need to have the services for which the status will be reported.
In such a case, we need to make sure that cron is running to have up-to-date results for the checks. Such verification can be done by monitoring the daemon using Nagios and the check_procs plugin. The first thing that needs to be done is to adapt the script to not print out the results in case everything worked fine and hardcode paths to the Nagios files:
#!/bin/sh
COMMANDFILE=/vat/nagios/rw/nagios.cmd
PLUGINPATH=/opt/nagios/plugins
HOSTNAME=$1
HOSTADDRESS=$2
$PLUGINPATH/check_by_ssh –H $HOSTADDRESS –t 30 \
–o $COMMANDFILE –n $HOSTNAME \
-s "SWAP:Root Partition:Processes:System Load" \
-C "$PLUGINPATH/check_swap –w 20% -c 10%" \
-C "$PLUGINPATH/check_disk –w 20% -c 10% -p /" \
-C "$PLUGINPATH/check_procs –w 100 –c 200" \
-C "$PLUGINPATH/check_load –w 5,3,2 –c 10,8,7" \
|| (
echo "BYSSH CRITICAL problem while running SSH"
exit 2
)
#echo "BYSSH OK checks launched"
exit 0
Actual changes have been highlighted. The next step is to add entry to the Nagios user, crontab. This can be done by running the crontab -e command as the nagios user or the crontab -u nagios -e command as the administrator. Assuming that the check should be performed every 30 minutes, the crontab entry should be as follows:
*/30 * * * * /opt/nagios/plugins/check_linux_services_by_ssh
For more details on how an entry in crontab should look, please consult the manual page (http://linux.die.net/man/5/crontab).
Troubleshooting the SSH-based checks
If you have followed the steps from the previous sections carefully, then most probably, everything should be working smoothly. However, in some cases, your setup might not be working properly, and you will need to find the root cause of the problem.
The first thing that you should start with is using the check_ssh plugin to make sure that SSH is accepting connections on the host that we are checking. For example, we can run the following command:
root@ubuntu1:~# /opt/nagios/plugins/check_ssh -H 192.168.2.51
SSH OK - OpenSSH_4.7p1 Debian-8ubuntu1.2 (protocol 2.0)
Where, 192.168.2.51 is the name of the IP address of the remote machine we want to monitor. If no SSH server is set up on the remote host, the plugin will return Connection refused status, and if it failed to connect, the result will state No route to host. In these cases, you need to make sure that the SSH server is working and all routers and firewalls do not filter out connections for SSH, which is TCP port 22.
Assuming that the SSH server is accepting connections, the next thing that can be checked is whether the SSH key-based authorization works correctly. To do this, switch to the user the Nagios process is running as. Next, try to connect to the remote machine. The following are sample commands to perform this check:
root@ubuntu1:~# su nagios -
$ ssh -v 192.168.2.51
This way, you will check the connectivity as the same user at which Nagios is running checks. You can also analyze the logs that will be printed to the standard output, as described earlier in this chapter. If the SSH client will prompt you for a password, then your keys are not set up properly. It is a common mistake to set up keys on the root account instead of setting them up on the nagios account. If this is the case, then create a new set of keys as the correct user and verify whether these keys are working correctly now. Assuming this step worked fine, the next thing to be done is checking whether invoking an actual check command produces correct results. For example:
root@ubuntu1:~# su nagios -
$ ssh 192.168.2.51 /opt/nagios/plugins/check_procs
PROCS OK: 51 processes
This way, you will check the connectivity as the same user at which Nagios is running checks. The last check is to make sure that the check_by_ssh plugin also returns correct information. An example of this is given as follows:
root@ubuntu1:~# su nagios -
$ /opt/nagios/plugins/check_by_ssh -H 192.168.2.1 \
/opt/nagios/plugins/check_procs
PROCS OK: 52 processes
If the last step also worked correctly, it means that all check commands are working correctly. If you still have issues with the running of the checks, then the next thing you should investigate is if Nagios has been properly configured and whether all commands, hosts, and services are set up in the correct way.
Monitoring using NRPE
Nagios Remote Plugin Executor (NRPE) is a daemon for running check commands on remote computers. It is designed explicitly to allow the central Nagios server to trigger checks on other machines in a secure manner.
NRPE offers a very good security mechanism along with encryption mechanisms. It is possible to specify a list of machines that can run checks via NRPE and which plugins can be run along with aliases that should be used by the central Nagios server.
The main difference is that the communication overhead is much smaller than for the SSH checks. This means that both the central Nagios server and the remote machine need less CPU time to perform a check. This is mainly important for Nagios servers that deal with a lot of checks that are performed remotely on machines. If the SSH overhead compared to NRPE is only 1 second, then for performing 20,000 checks, we can save 5.5 hours that would be spent on negotiations.
It also offers a better level of security than SSH mechanisms in terms of the remote machine's safety. It does not provide complete access to the destination machines from the Nagios central server and forbids running any commands outside the predefined check commands. This is very important in situations where Nagios is monitoring machines that might store sensitive information. In such a case, SSH-based solution might not be acceptable due to security policies.
NRPE checks work in the same way as SSH checks in many aspects. In both the cases, the Nagios check command connects to the remote machine and sends a request to run a plugin installed on that machine. NRPE uses a custom protocol. It offers more flexibility in terms of which checks can be executed (and which checks not) as well as which hosts can connect to the NRPE daemon running on the remote machine. It also requires much less overhead to send the command to NRPE and receive output from it as compared to performing checks using the SSH protocol.
Another difference between NRPE and the SSH-based checks is that NRPE allows running only a single command and can be used so that the results are passed back as active checks. However, the ability to perform multiple checks that the check_by_ssh plugin offers is not possible using NRPE.
NRPE uses the TCP protocol with SSL encryption on top of it. Enabling encryption is optional, but it is recommended for companies that require security to be at a high level. By default, NRPE communicates on port 5666. The connection is always made from the machine running the Nagios daemon to the remote machine. If your company has firewalls set up for local connectivity, make sure that you allow communications from port 5666 of your Nagios server. The following is an illustration of how such a check is performed:
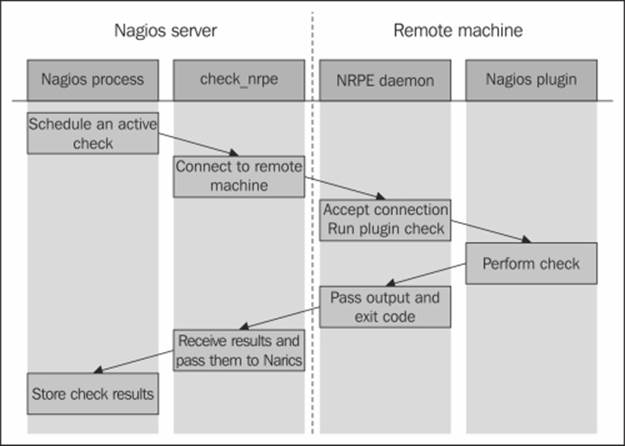
Nagios determines that an active check should be performed. It runs the check_nrpe plugin that connects to the remote host's NRPE daemon. After the NRPE daemon accepts this as a valid host to send commands to, check_nrpe sends the command to be run along with any parameter to the remote machine.
Next, the NRPE daemon translates these into the actual system command to be run. In case the specified command is not configured to be run, the NRPE daemon will reject this request. Otherwise, it will run the command and pass the results back to check_nrpe on the machine hosting the Nagios daemon. This information is then passed back to the Nagios daemon and stored in the data files and/or databases.
The NRPE package consists of two parts: the NRPE daemon and the NRPE check command. The first one needs to be running on all remote machines that are to be monitored using this method. The NRPE check command (check_nrpe) is a Nagios plugin to perform active checks and needs to be installed on the machine on which the Nagios daemon is running.
Obtaining NRPE
NRPE is a core add-on for Nagios, and it is maintained by the Nagios development team. NRPE can be downloaded as both source code and binary packages. In the first case, you can compile NRPE from sources by yourself. In the binary packages, you have a ready-to-use set of binaries.
The NRPE source package can be downloaded from the Nagios download page (http://www.nagios.org/download/addons). NRPE can be found in the Addons section of the page. The file is named in the form of nrpe-2.15.tar.gz.
Many Linux distributions already contain prebuilt NRPE binaries. If you want to use precompiled packages instead of building them yourself, then this is the way to go.
For Ubuntu Linux, the package names are nagios-nrpe-server and nagios-nrpe-plugin for the daemon and client, respectively. For Ubuntu, the command to install the client and the server is as follows:
apt-get install nagios-nrpe-server nagios-nrpe-plugin
For Red Hat Enterprise Linux (RHEL), CentOS, and Fedora systems that have yum installed, the package names are nagios-nrpe and nagios-plugins-nrpe for the daemon and the client respectively. The command to install both client and server is as follows:
yum install nagios-nrpe nagios-plugins-nrpe
Microsoft Windows version of the NRPE daemon can be found in the NRPE_NT project on SourceForge (http://sourceforge.net/projects/nrpent/). It offers the same functionality as its Unix version and is configured in the same way.
The Nagios plugins do not provide the Windows version, so you will need to compile Nagios plugins using the Cygwin package (visit http://www.cygwin.com/). You can also provide only your own check commands and set up NRPE_NT to use those. In the case of Microsoft Windows, it is important to remember that your plugins need to be command-line tools and cannot be created as GUI–based tools.
Monitoring Microsoft Windows-based machines and using the NRPE protocol for performing the checks is described in more detail in Chapter 10, Advanced Monitoring.
Compiling NRPE
If you are using NRPE from prebuilt packages, you can skip this section and resume with the NRPE configuration information. Compiling NRPE requires a standard compiler, linker, and similar tools to be present on your system. It also needs the OpenSSL package along with the actual openssl command line, which is used to generate the Diffie-Hellman key for each instance.
On an Ubuntu Linux system, installing the prerequisite packages can be done by performing the following command:
apt-get install gcc make binutils cpp pkg-config libc6-dev \
libssl-dev openssl
For other systems, the commands and package names might differ a bit, but should be very similar. It is also recommended to install the same prerequisites as those for compiling Nagios and the Nagios plugins. These packages should already be there from when the actual plugins were built. However, in case the compilation fails, it would be a good idea to install all packages that were also used for the Nagios build. For Ubuntu Linux, this would require running the following command:
apt-get install gcc make binutils cpp libpq-dev libmysqlclient15-dev \
libssl0.9.8 libssl-dev pkg-config apache2 \
libgd2-xpm libgd2-xpm-dev libgd-tools \
libpng12-dev libjpeg62-dev \
perl libperl-dev libperl5.8 libnet-snmp-perl
More information on what packages should be installed on other operating systems and how to do this can be found in Chapter 2, Installing Nagios 4.
Now that our packages are set up, the next step is to run the configure script that will set up the NRPE parameters and create the Diffie-Hellman key.
For standard paths and users that were used in Chapter 2, Installing Nagios 4, the command is as follows:
sh configure \
--sysconfdir=/etc/nagios \
--libexecdir=/opt/nagios/plugins \
--prefix=/opt/nagios \
--localstatedir=/var/nagios \
--with-nrpe-user=nagios \
--with-nrpe-group=nagios \
--with-nagios-user=nagios \
--with-nagios-group=nagios \
--enable-ssl
If running the configure script failed, it is probably because one or more of the required packages are missing. If this happens, verify whether all the packages mentioned earlier in the chapter have been installed, and then try again. Also, if you know that the package is properly installed, it may require additional options to be passed. In such cases, it is recommended to check for the exact error code on the Internet. The next step is to actually build the NRPE client and daemon. To do this, run the following command:
make all
This command will build both the binaries and then create the sample configuration files for the NRPE daemon.
It is a very common problem that the build fails, claiming that the get_dh512 function could not be found. The problem is not obvious. In this case, please make sure that the openssl command is installed, the directory where it is located is added to the PATHenvironment variable, and then run all of the steps again—starting with the configure script.
The problem is that the configure script tries to generate a Diffie-Hellman key if a problem exists during this step. Then the script itself does not fail to complete, but the build process eventually fails. Please make sure that somewhere at the end of the output from theconfigure script, a text similar to the one that follows is printed out:
*** Generating DH Parameters for SSL/TLS ***
Generating DH parameters, 512 bit long safe prime, generator 2
This is going to take a long time
+..............+...........+........++*+*++*++*++*++*
If the openssl command is not present, the following error will show up instead:
*** Generating DH Parameters for SSL/TLS ***
configure: line 6703: /usr/bin/openssl: No such file or directory
If the compilation process fails for any other reason, it is most probably due to the missing libraries or header files. In this case, installing the packages mentioned earlier will help.
Assuming that the build succeeded, the next step is to install either the NRPE client or the daemon. On the machine that is running the Nagios daemon, we need to install the client check_nrpe command. To do this, type the following command:
make install-plugin
This command will copy the check_nrpe command to the /opt/nagios/plugins directory. NRPE does not require any configuration file for the NRPE client, and hence, no additional file needs to be copied. For all of the remaining machines, please run the following command to install the NRPE daemon:
make install-daemon
This command will copy the nrpe binary to the /opt/nagios/bin directory.
Because the NRPE daemon requires configuration, it is recommended that you copy the sample-config/nrpe.cfg file as /etc/nagios/nrpe.cfg.
Configuring the NRPE daemon
Our NRPE daemon is now built and ready to be deployed on the remote machines. We need to configure it and set up the system so that it accepts connections from other computers.
The NRPE daemon should use a separate user and password. First, let's create a user and a group named nagios:
groupadd nagios
useradd -g nagios -d /opt/nagios nagios
We also need to create a home directory for the user, and it is a good idea to lock out access for that user if no checks are to be performed over SSH. To do this, run the following commands:
mkdir /opt/nagios
chown nagios:nagios /opt/nagios
passwd -l nagios
There are many ways of setting this up—NRPE can work either as a standalone process that handles incoming connections, or as part of the inetd setup (http://en.wikipedia.org/wiki/inetd) or the xinetd (http://www.xinetd.org/) setup. In all cases, a configuration file is needed. This file specifies the commands to be used and the additional options to run the NRPE daemon standalone.
The configuration file is similar to the main Nagios configuration file—all parameters are written in the form of <name>=<value>. If you have compiled NRPE from the source, then a default configuration can be found in the sample-config/nrpe.cfg file.
A sample NRPE configuration script that will work for both standalone installations as well as under inetd is as follows:
log_facility=daemon
pid_file=/var/run/nrpe.pid
server_port=5666
nrpe_user=nagios
nrpe_group=nagios
allowed_hosts=192.168.2.51
command_timeout=60
connection_timeout=300
debug=0
The first series of parameters includes information related to logging. NRPE uses standard Unix logging mechanisms. The log_facility parameter specifies the syslog facility name to be used for logging. The default value is daemon, but it can be set to any of the predefined syslog facility names.
A standalone NRPE daemon also allows the setting up of the IP address and the port to listen, as well as the user and group names to be used. In order to specify that NRPE should listen only on a specific IP address, you need to use the server_address parameter.If this parameter is omitted, then the NRPE will listen on all the network interfaces. The server_port parameter is used to specify the port number on which NRPE should listen. If NRPE should accept connections only from a predefined list of machines, you need to specify the allowed_hosts parameter, which will contain a list of all the IP addresses of these machines, separated by commas.
For security reasons, NRPE usually runs as a separate user. The options to specify the user and group names that should be used by NRPE are nrpe_user and nrpe_group, respectively.
We can also specify the file to which NRPE should write the PID of the daemon process—this is useful in the startup scripts that can read this file to terminate any NRPE processes during a restart of the service. The option name is pid_file.
We can also tell NRPE for how long a command can run. The first option is command_timeout, and it tells NRPE how many seconds a command can run before it should be stopped. If a command is running for more than the specified number of seconds, it is terminated and a CRITICAL status is sent back to the NRPE client.
The connection_timeout option specifies the time in seconds after which a connection should be closed if no data has been received. This does not change the way the command times out, it only specifies how much time NRPE should wait for a command to be sent.
NRPE also offers a debug option that can specify whether it should record a large amount of information in the system log. A value of 1 enables verbose logging and 0 disables it. This should be disabled in production, but can be useful during the initial runs in case you run into a problem.
The next step is to configure the commands that can be used by the other machines. The NRPE commands define aliases for the actual commands that will be executed. All commands have a unique name and the actual command line to be run.
Usually, command names are the plugin names or the plugin names with some description appended. For example, the check_disk command that checks the /home directory could be called check_disk_home.
Each command is defined as command[<command_name>]=<command_to_execute>. Each command_name can be used only once, and there is no possibility of defining which hosts can run which commands. The same set of commands can be run by all hosts specified in theallowed_hosts parameter. An example command definition to use check_disk and to verify the space on the root partition is as follows:
command[check_disk_sys]=/opt/nagios/plugins/check_disk -w 20% -c 10% -p /
It would be a good idea to create a template configuration that will contain the typical checks and the hosts that should be allowed to run the checks. These can be modified later for individual hosts, but using a template makes it easier to deploy the checks for a large number of boxes. A typical set of commands would be as follows:
command[check_rootdisk]=/opt/nagios/plugins/check_disk -w 20% -c 10% -p /
command[check_swap]=/opt/nagios/plugins/check_disk -w 40% -c 20%
command[check_sensors]=/opt/nagios/plugins/check_sensors
command[check_users]=/opt/nagios/plugins/check_users -w 10 -c 20
command[check_load]=/opt/nagios/plugins/check_load -w 10,8,5 -c 20,18,15
command[check_zombies]=/opt/nagios/plugins/check_procs -w 5 -c 10 -s Z
command[check_all_procs]=/opt/nagios/plugins/check_procs -w 150 -c 200
Note
The parameters for several plugins may be changed according to your preferences, but they do represent reasonable defaults.
In case you need to troubleshoot why a check is failing, it would be a good idea to set the debug parameter to 1 in nrpe.cfg. If NRPE is running in standalone mode, it will need to be restarted for the changes to take effect. An example log from a connection is as follows:
Apr 21 20:07:29 ubuntu2 nrpe[5569]: Handling the connection...
Apr 21 20:07:29 ubuntu2 nrpe[5569]: Host is asking for command
'check_root_disk' to be run...
Apr 21 20:07:29 ubuntu2 nrpe[5569]: Running command:
/opt/nagios/plugins/check_disk -w 20% -c 10% -p /
Apr 21 20:07:29 ubuntu2 nrpe[5569]: Command completed with return code 0
and output: DISK OK - free space: / 7211 MB (90% inode=96%);|
/=759MB;6717;7557;0;8397
Apr 21 20:07:29 ubuntu2 nrpe[5569]: Return Code: 0, Output: DISK OK - free space: / 7211 MB (90% inode=96%);| /=759MB;6717;7557;0;8397
Another requirement for using NRPE is that the commands need to be specified using the full path to the plugin, and no macro substitution can take place. Not being able to use any macro definitions requires more attention when writing macros. It also requires that any change to the command is edited in the NRPE configuration on the remote machine, and not in the Nagios configurations on the central server. This introduces a very strict security model, but makes NRPE a bit harder to maintain.
In some cases, it is better to be able to pass arguments to NRPE from the Nagios server and have NRPE put these into the command definition. Even though this functionality is disabled for security reasons, it is possible to enable it. How NRPE can be set up to accept parameters from the Nagios server is described in the Using command arguments with NRPE section in this chapter.
Setting up NRPE as a system service
The easiest way to get NRPE up and running is to add it to startup in a standalone mode. In this case, it will handle listening on the specified TCP port and changing the user and group by itself. To do this, simply run the NRPE binary with the following parameters:
/opt/nagios/bin/nrpe -c /etc/nagios/nrpe.cfg -d
You can also add NPRE to the init.d file so that NPRE will start automatically at system start. Usually, this file is located in /etc/init.d/nrpe or /etc/rc.d/init.d/nrpe.
The NRPE source code provides two init.d scripts: init-script.debian that can be used for Ubuntu and Debian distributions and init-script.suse that can be used for SUSE/openSUSE Linux distributions. The scripts can be found in the NRPE source directory and are customized as a part of configuring the NRPE sources so that they contain appropriate paths.
If you are running a different Linux distribution, it may be worth checking if either of the scripts work properly in your case. If not, a simple script that starts up and shuts down NRPE is as follows:
#! /bin/sh
case "$1" in
start)
echo -n "Starting NRPE daemon..."
/opt/nagios/bin/nrpe -c /etc/nagios/nrpe.cfg -d
echo " done."
;;
stop)
echo -n "Stopping NRPE daemon..."
pkill -u nagios nrpe
echo " done."
;;
restart)
$0 stop
sleep 2
$0 start
;;
*)
echo "Usage: $0 start|stop|restart"
;;
esac
exit 0
The script does not have proper error handling or verification that the process is terminated, but should work properly on all Linux distributions. The next step is to set up a system to stop and start this service when changing to appropriate run levels. Depending on your system, the command to add nrpe as a service can be one of the following:
chkconfig --add nrpe ; chkconfig nrpe on
update-rc.d nrpe defaults
NRPE can also be run either from inetd or xinetd. To do this, we first need to add the following line to the /etc/services file:
nrpe 5666/tcp
This will indicate that the TCP port 5666 maps to the service name, nrpe. This specification is used by both inetd and xinetd to map the service name to the actual protocol and port definition.
If we're using inetd, we need to add the following service configuration to the /etc/inetd.conf file—a sample definition is as follows:
nrpe stream tcp nowait nagios /opt/nagios/bin/nrpe -c /etc/nagios/nrpe.cfg -i
The preceding entry should be stored as a single line. Next, we should restart inetd by running the following command:
/etc/init.d/inetd reload
This will make inetd reload the service definition. The NRPE daemon should now be accepting connections whenever one comes on TCP port 5666.
Configuring the NRPE daemon for xinetd can be done similarly. We will need to create a file called /etc/xinetd.d/nrpe with the following contents:
service nrpe
{
flags = REUSE
socket_type = stream
wait = no
user = nagios
group = nagios
server = /opt/nagios/bin/nrpe
server_args = -c /etc/nagios/nrpe.cfg -i
log_on_failure += USERID
disable = no
}
Next, we need to reload xinetd by running the following command:
/etc/init.d/xinetd reload
As with the previous reloading of inetd, the NRPE daemon should now accept connections on port 5666.
When NRPE is working under inetd or xinetd, the server ignores the server_address, server_port, nrpe_user, and nrpe_group parameters from the configuration files. This is because inetd and xinetd handle these internally.
NRPE also ignores the allowed_hosts directive when it is running from any inetd flavor. In this way, you can configure which hosts are allowed to access this particular service in the inetd/xinetd file. For xinetd, this can be done by using the only_from statement in the service definition. For inetd, this can be done using the tcpd wrapper (http://linux.about.com/library/cmd/blcmdl8_tcpd.htm) to achieve this.
Configuring Nagios for NRPE
The next step is to set up Nagios to use NRPE for performing checks via a remote machine. Using NRPE to perform checks requires the creation of one or more commands that will use the check_nrpe plugin to send actual check requests to a remote machine.
The syntax of the plugin is as follows:
check_nrpe -H <host> [-n] [-u] [-p <port>] [-t <timeout>]
[-c <command>] [-a <arglist...>]
The following table describes all of the options accepted by the plugin. The items required are marked in bold:
|
Option |
Description |
|
-H, --host |
This provides the hostname or IP address of the machine to connect; this option must be specified |
|
-c, --command |
This is the name of the command that should be executed; the command needs to be defined in the nrpe.cfg file on the remote machine |
|
-n, --no-ssl |
This disables SSL for communication |
|
-p, --port |
This connects to the specified port; defaults to 5666 |
|
-t, --timeout |
This is the number of seconds after which a connection will be terminated; defaults to 10 |
|
-u, --unknown-timeout |
If a timeout occurs, this will return an UNKNOWN state; if not specified, then CRITICAL status is returned in case of timeout |
The only two required attributes are -H and -c, which specify the host and the command alias to run on that machine, respectively.
The next thing we should do is make sure that the NRPE server on the remote machine is working correctly. Assuming that check_swap is a valid command defined in NRPE on a remote machine, we can now try to connect from the Nagios server. The first thing that's worth checking is whether calling check_nrpe directly works:
$ /opt/nagios/plugins/check_nrpe -H 192.168.2.52 -c check_swap
SWAP OK - 100% free (431 MB out of 431 MB) |swap=431MB;86;43;0;431
In our example, 192.168.2.52 is the IP address of the remote computer. As the connection was successful, NRPE passed the actual plugin output to the standard output. After a successful check, we can now define a command in the Nagios configuration that will perform a check over NRPE.
define command
{
command_name check_swap_nrpe
command_line $USER1$/check_nrpe –H "$HOSTADDRESS$"
-c "check_swap"
}
We can then use the check_swap_nrpe command in a service definition. NRPE has a much lower overhead as compared to SSH. So, in some cases, it would be a good idea to use NRPE even for performing local checks.
In case we are defining a service for a group of hosts, we can use the same trick as those for checks over SSH to perform checks on a local machine by using the plugins directly and checking all of the remaining machines using NRPE. This will reduce the overhead related to monitoring the local machine and remove the need to install NRPE on the local host.
The following is a sample configuration that defines a check for swap usage locally for the computer on which it is defined, and over NRPE for all the remaining machines:
define service
{
use generic-service
host_name localhost
service_description SWAP
check_command check_swap
normal_check_interval 15
}
define service
{
use generic-service
host_name !localhost
hostgroup_name linux-servers
service_description SWAP
check_command check_swap_nrpe
normal_check_interval 30
}
Using command arguments with NRPE
By default, NRPE is configured to run only the predefined commands, and it is not possible to pass any arguments to the commands that will be run. In some cases, for example with a large number of partitions mounted on various servers, this is hard to manage as changes to the command configurations need to be done at the remote machine level, and not at the central Nagios server level.
In such cases, it might be worth investigating an option included in NRPE to pass arguments to commands. This option is disabled by default as it is considered to be a large security concern. This is because it is possible to send malicious arguments to a check command and make it perform actions other than the ones it should be doing. It is recommended that you keep the option disabled as this is a more secure option.
However, if lowering the level of security is not a concern, it is possible to enable this functionality within the NRPE daemon. This allows easier management of NRPE and the Nagios configuration.
The first thing that needs to be done is the rebuilding of the NRPE daemon with this option enabled. To do this, run the configure script again with the --enable-command-args flag added. For the same invocation that was used previously to build NRPE, the command would be:
sh configure \
--sysconfdir=/etc/nagios \
--libexecdir=/opt/nagios/plugins \
--prefix=/opt/nagios \
--localstatedir=/var/nagios \
--with-nrpe-user=nagios \
--with-nrpe-group=nagios \
--with-nagios-user=nagios \
--with-n agios-group=nagios \
--enable-command-args \
--enable-ssl
Of course, it is also necessary to rebuild the NRPE daemon and reinstall the binary. If you are running NRPE as a standalone daemon, then you need to restart the daemon after overwriting the binary. Only the daemon on remote machine needs to be reconfigured and recompiled. It is not necessary to rebuild the NRPE client as it always supports the passing of arguments to the NRPE daemon.
The next step is to add the dont_blame_nrpe option to the nrpe.cfg file and set it to 1. This option, despite its strange name, enables the functionality to use arguments in the command definitions. When both NRPE is compiled with this option and the option is enabled in the NRPE configuration, this option is enabled.
After that, it is possible to use the $ARGn$ macros in the NRPE configuration, similar to how they are defined in Nagios. This works in the same way as Nagios, where $ARG1$ indicates the first argument, $ARG2$ the second one, and so on for up to 16 arguments. For example, a check command that checks the disk space on any partition looks like the following:
command[check_disk]=/opt/nagios/plugins/check_disk -w $ARG1$ -c $ARG2$ -p $ARG3$
This requires that the warning and critical levels are passed during the check. The actual path to the mount point, which is specified as a third parameter, is essential. Arguments are passed to check_nrpe by specifying the -a flag and passing all required arguments after it, with each argument as a separate parameter. An example invocation of the check command as a standalone command would be as follows:
$ /opt/nagios/plugins/check_nrpe -H 10.0.0.1 -c check_disk –a 10% 5% /usr
DISK OK - free space: /usr 7209 MB (90% inode=96%)
After making sure that the check works, we can now define a command and the corresponding service definition. The command will pass the arguments specified in the actual service definition:
define command
{
command_name check_disk_nrpe
command_line $USER1$/check_disk –H "$HOSTADDRESS$"
-c "check_disk" –a $ARG1$ $ARG2$ $ARG3$
}
And, the actual service definition is as follows:
define service
{
use generic-service
host_name !localhost
hostgroup_name linux-servers
service_description Disk space on /usr
check_command check_disk_nrpe!10%!5%!/usr
}
This way, you can define multiple partition checks without any modifications on the remote machines. Of course, arguments can also be used for various plugins, for example, to be able to configure the load, user, and process thresholds in a central location.
Passing arguments to NRPE is a very useful feature. However, it comes at the price of a lower security level. If the machines you deploy NRPE do not require very strict limitations, then it would be a good idea to enable it.
Having a strict source IP address policy in both the firewalls and the remote machine is a good way of limiting security issues related to the passing of arguments down to the actual check commands.
Troubleshooting NRPE
Our NRPE configuration should now be complete and working as expected. However, in some cases, for example, if there is a firewall issue or an issue of invalid configuration, the NRPE-based checks may not work correctly. There are some steps that you can take to determine the root cause of the problem.
The first thing that should be checked is whether Nagios server can connect to the NRPE process on the remote machine. Assuming that we want to use NRPE on 192.168.2.1, we can check if NRPE accepts connections by using check_tcp from the Nagios plugins. By default, NRPE uses port 5666, which we'll also use in the following example that shows how to check:
$ /opt/nagios/plugins/check_tcp -H 192.168.2.1 -p 5666
TCP OK - 0.009 second response time on port 5666|time=0.008794s;;;0.000000;10.000000
If NRPE is not set up on the remote host, the plugin will return Connection refused. If the connection could not be established, the result will be No route to host. In these cases, you need to make sure that the NRPE server is working and the traffic that the TCP port NRPE is listening is not blocked by the firewalls.
The next step is to try to run an invalid command and check the output from the plugin. The following is an example that assumes that dummycommand is not defined in the NRPE configuration on the remote machine:
$ /opt/nagios/plugins/check_nrpe -H 192.168.2.1 -c dummycommand
NRPE: Command 'dummycommand' not defined
If you received a CHECK_NRPE: Error - Could not complete SSL handshake error or something similar, it means that NRPE is not configured to accept connections from your machine—either via the allowed_hosts option in the NRPE configuration or in the inetd configuration.
In order to check this, log on to the remote machine and search the system logs for nrpe. For example, on most systems, to check if the NRPE is configured we need to execute the following command:
# grep nrpe /var/log/syslog /var/log/messages
(...)
ubuntu1 nrpe[3023]: Host 192.168.2.13 is not allowed to talk to us!
This indicates that your Nagios server is not added to the list of allowed hosts in the NRPE configuration. Add it in the allowed_hosts option and restart the NRPE process.
Another error message that could be returned by the check_nrpe command is CHECK_NRPE: Received 0 bytes from daemon. Check the remote server logs for error messages. This message usually means that you have passed arguments or invalid characters in the command name and the NRPE server refused the request because of these. Looking at the remote server's logs will usually provide more detailed information:
# grep nrpe /var/log/syslog /var/log/messages
(...)
ubuntu1 nrpe[3023]: Error: Request contained command arguments!
ubuntu1 nrpe[3023]: Client request was invalid, bailing out...
In this situation, you need to make sure that you enable arguments or change the Nagios configuration to not to use arguments over NRPE. Another possibility is that the check returns CHECK_NRPE: Socket timeout after 10 seconds or a similar message. In this case, the check command has not been completed within the configured time. You may need to increase command_timeout in the NRPE configuration.
Comparing NRPE and SSH
Both SSH and NRPE are used to perform checks on remote machines. They can be set up to perform the same tasks; however, there are some differences and each solution is better in certain conditions. Depending on what the critical issues are for your network, the choice is usually to either use SSH or NRPE to perform the checks on other machines.
The first is easier to set up from a network and administrative perspective. All that is needed is to put a set of plugins on the machine, create a public key-based authentication, and you are all set to go! The main advantage of this method is that it uses the existing network protocol, which is usually running and enabled on all Unix-based machines. This way, it is not necessary to configure firewalls to pass traffic related to the Nagios checks if the server that Nagios is running on can already connect to other hosts using the SSH protocol.
Security and performance are the trade-offs. As SSH is a generic protocol, the Nagios server can run any command on any of the machines that it can access. Many institutions may consider using a generic service such as SSH. One way of limiting this problem is to set up a restricted shell for the user that performs the checks, which will make sure that only Nagios plugins are run.
Another problem with this approach is that SSH is a complex protocol, and the overheads related to connecting to a remote machine and running a plugin are high. The main problem occurs where one central Nagios server performs a large volume of tests over SSH. The problem will not be significant on remote computers, but the central server will require more processing power to handle all of the checks in a timely manner.
NRPE is an alternative to SSH. It is a daemon that is installed on remote computers that allow the running of checks. The main advantage of this approach is that it offers much better security. The administrator of the remote computer can configure NRPE to accept connections only from certain IP addresses and to allow the execution of only predefined commands. By default, it is not even possible to pass any arguments to them. So, there is very little chance of a security issue on account of NRPE. Another advantage is that the NRPE protocol requires much less overhead and frequent checks do not affect the central Nagios server too much.
There are some downsides to NRPE. The first one is that it needs to be set up on all of the machines that will be monitored in a remote manner. In addition, all configurations for the checks are kept on the remote machines. In such cases, it is much harder to maintain changes in the configuration when monitoring multiple computers.
There are many other options for monitoring machines and the services on them. They are not as popular, but they can be also used to get the job done. There are various agent-based systems that offer to run commands remotely. They can be used to create check commands that are executed on remote machines. Another approach is to use existing protocols such as HTTP for deploying checks on the remote host. Common solutions, such as PHP, CGI, or various scripting languages, can be leveraged to perform these kinds of tests. This is mainly useful if you already have a stable web server that is also used for other purposes. All that is needed is to install the scripts and configure the server to accept connections, either from all addresses or just from specific ones.
Usually, it is quite obvious which solution should be used in which case. There may be cases where it's easier to use the existing SSH daemons. In other cases, security or performance is more of an issue and NRPE is a better choice. In some other cases, a custom solution will work best. How you should proceed is a matter of knowing the best tool for a particular case. In all cases, doing checks from the remote computers is not as easy as doing it locally. But, it is also not very difficult if you are using the right tools.
Alternatives to SSH and NRPE
This chapter focuses mainly on using SSH and NRPE for performing the remote checks. This is because Nagios is widely used to perform checks on the remote machines. There are also various alternate approaches that people take to invoke checks remotely. A very popular approach is to use frameworks for working remotely. In such cases, you might need to create some scripts or jobs that perform the checks, but the entire network communication along with authentication and authorization are already implemented in them.
One such framework is the Software Testing Automation Framework (STAF) available at http://staf.sourceforge.net/. This is a peer-to-peer-based framework that allows you to write code that performs specific jobs on remote machines. As the system is not centralized, there is no critical resource that can make your entire system malfunction if it is down.
STAF can be used from various languages such as Java, Perl, Python, Tcl, and Ant. This means that pieces of the checks can be done in languages that best fit a specific scenario. Another approach is to use check_http and web-based communication. This is a very common scenario when doing a check for web applications. This way, you can invoke a specific URL that will perform a check on the remote machine and provide the results over the HTTP protocol.
In such a case, an application can have a URL that is accessible only from specific IP addresses and returns diagnostic information about the website. This can mean performing a test SQL query to the database and checking the file permissions and available disk space. The application can also perform a sanity check of critical data either in the files or in a database.
The web page can return a predefined string if all of the tests are passed correctly and will return an error message otherwise. In this case, it is possible to perform the check with the check_http plugin.
A typical scenario is when a check is done for both the string preset in the answer and a page size range. For example, a check for the OK string combined with a page size ranging from two to eight will check whether the result contains information about the correct test and will also detect any additional messages preset in the output.
Summary
Checking whether a service is available over a network can be done from a single machine. In such cases, using a single, dedicated machine to do all of these checks would be a good idea as it also reduces the load to be on just a single computer on your network. In reality, this is not enough for a robust computer and failure monitoring solution.
In this chapter, we have learned how to perform checks on the remote machines using the SSH protocol. We have set up our SSH private key, added the corresponding public key to remote machine, and performed the checks using this approach. We have also learned how to perform multiple checks over the SSH protocol using a single check invocation, which can be used to reduce the number of connections and load on the remote machine.
This chapter also covers the NRPE protocol and how to set up the NRPE server and client. We have configured an NRPE server that allows specific checks from the remote machines. We have also learned how to use NRPE to perform checks and how to pass arguments to the checks, such as using a single check definition to allow checking the disk space for multiple volumes. The chapter also discussed the differences between the SSH-based and NRPE-based approaches and when it is better to use one or the other. It also mentions other less popular alternatives to automate performing remote checks.
The next chapter talks about Simple Network Management Protocol (SNMP), which is a protocol for monitoring and managing various types of devices connected to a network. The protocol supports both querying the device as well as receiving information from the devices regarding the failure. The SNMP protocol is used by a large variety of devices, from network switches and routers to mainframe servers.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.