Neo4j Essentials (2015)
Chapter 3. Pattern Matching in Neo4j
Data is not simple, it is complicated and evolving.
It is imperative to have an efficient structure to store complicated and evolving data and predominantly it should focus on "What to retrieve?", instead of "How to retrieve?". Having such an efficient structure will also help developers to focus on the domain model instead of getting lost in learning procedures/functions for accessing the database.
We could have used object-oriented principles and designed some fixed set of functions for accessing the data, but remember data in itself is evolving and not fixed, so it is cumbersome to add methods every time you add some new dimensions to your data; to make it even more complicated, sometimes you may not even know about this new data added to your system.
So, "How do we do that?" The answer is patterns and pattern matching.
Neo4j provides powerful, declarative and yet relatively simple graph query language, based on the principles of patterns and pattern matching, known as Cypher.
Cypher is a declarative graph query language, which not only provides an efficient mechanism for querying and updating graphs but also helps developers to focus on "What to query?" and hides all the complexity of "How to query?".
In this chapter, you will learn about data modeling in Neo4j and retrieving data using pattern matching in Cypher.
This chapter will cover the following topics:
· Agile data modeling with Neo4j
· Patterns and pattern matching
· Read-only Cypher queries
· Schema and legacy indexing queries
· Movie demo with GraphGists
Agile data modeling with Neo4j
Data modeling in Neo4j is evolving and flexible enough to adapt to changing business requirements. It captures the new data sources, entities, and their relationships as they naturally occur, allowing the database to easily adapt to the changes, which in turn results in an extremely agile development and provides quick responsiveness to changing business requirements.
Data modeling is a multistep process and involves the following steps:
1. Define requirements or goals in the form of questions that need to be executed and answered by the domain-specific model.
2. Once we have our goals ready, we can dig deep into the data and identify entities and their associations/relationships.
3. Now, as we have our graph structure ready, the next step is to form patterns from our initial questions/goals and execute them against the graph model.
This whole process is applied in an iterative and incremental manner, similar to what we do in agile, and has to be repeated again whenever we change our goals or add new goals/questions, which need to be answered by your graph model.
Let's see in detail how data is organized/structured and implemented in Neo4j to bring in the agility of graph models.
Based on the principles of graph data structure available at http://en.wikipedia.org/wiki/Graph_(abstract_data_type), Neo4j implements the property graph data model at storage level, which is efficient, flexible, adaptive, and capable of effectively storing/representing any kind of data in the form of nodes, properties, and relationships.
Neo4j not only implements the property graph model, but has also evolved the traditional model and added the feature of tagging nodes with labels, which is now referred to as the labeled property graph.
Essentially, in Neo4j, everything needs to be defined in either of the following forms:
· Nodes: A node is the fundamental unit of a graph, which can also be viewed as an entity, but based on a domain model, it can be something else too.
· Relationships: These defines the connection between two nodes. Relationships also have types, which further differentiate relationships from one another.
· Properties: Properties are viewed as attributes and do not have their own existence. They are related either to nodes or to relationships. Nodes and relationships can both have their own set of properties.
· Labels: Labels are used to construct a group of nodes into sets. Nodes that are labeled with the same label belong to the same set, which can be further used to create indexes for faster retrieval, mark temporary states of certain nodes, and there could be many more, based on the domain model.
Let's see how all of these four forms are related to each other and represented within Neo4j.
A graph essentially consists of nodes, which can also have properties. Nodes are linked to other nodes. The link between two nodes is known as a relationship, which also can have properties. Nodes can also have labels, which are used for grouping the nodes.
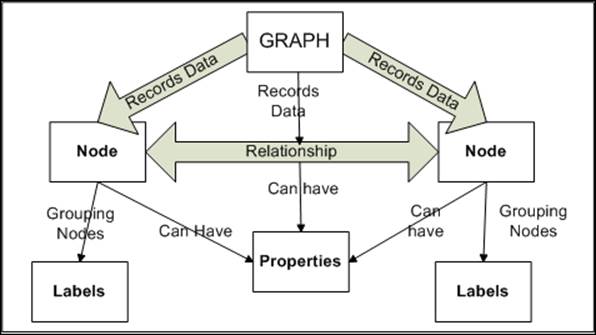
Let's take up a use case to understand data modeling in Neo4j. John is a male and his age is 24. He is married to a female named Mary whose age is 20. John and Mary got married in 2012.
Now, let's develop the data model for the preceding use case in Neo4j:
· John and Mary are two different nodes.
· Marriage is the relationship between John and Mary.
· Age of John, age of Mary, and the year of their marriage become the properties.
· Male and Female become the labels.
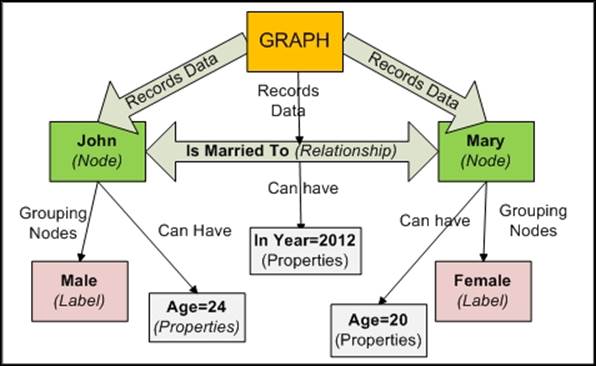
Easy, simple, flexible, and natural… isn't it?
The data structure in Neo4j is adaptive and effectively can model everything that is not fixed and evolves over a period of time.
The next step in data modeling is fetching the data from the data model, which is done through traversals. Traversals are another important aspect of graphs, where you need to follow paths within the graph starting from a given node and then following its relationships with other nodes. Neo4j provides two kinds of traversals: breadth first available at http://en.wikipedia.org/wiki/Breadth-first_search and depth first available at http://en.wikipedia.org/wiki/Depth-first_search. We will discuss traversals in detail in Chapter 5, Neo4j from Java.
If you are from the RDBMS world, then you must now be wondering, "What about the schema?" and you will be surprised to know that Neo4j is a schemaless or schema-optional graph database. We do not have to define the schema unless we are at a stage where we want to provide some structure to our data for performance gains. Once performance becomes a focus area, then you can define a schema and create indexes/constraints/rules over data. We will read more about indexing and its capabilities in the upcoming sections.
Unlike the traditional models where we freeze requirements and then draw our models, Neo4j embraces data modeling in an agile way so that it can be evolved over a period of time and is highly responsive to the dynamic and changing business requirements.
Patterns and pattern matching
Patterns and pattern matching is one of the important components for extracting data from the graph databases. Let's first talk about the definition of patterns and pattern matching and then we will see how these are implemented in the context of Neo4j:
· Pattern: In simple language and to make it even simpler to understand, a pattern is an occurrence of sequence of characters/numbers, word or group of words, literals that need to be found in a given dataset.
· Pattern matching: The process or algorithm used for finding or matching a pattern or sequence of patterns against a given dataset or data structure is called pattern matching. In other words, pattern matching consists of specifying patterns to which some data should conform and then checking to see if it does and deconstructing the data according to those patterns. Pattern matching should not be confused with pattern recognition, in which the match usually has to be exact.
There are well-known graph query languages which implement pattern matching and can be used to query graphs, but they are tedious and involve a lot of work in maintenance/modifications and enhancements. A few of the well-known graph query languages include:
· SPARQL: http://en.wikipedia.org/wiki/SPARQL
· GREMLIN: http://gremlin.tinkerpop.com/
· Metaweb Query Language (MQL): https://developers.google.com/freebase/v1/mql-overview
They also failed to meet one or more of the primary goals of the query language for the Neo4j database which are as follows:
· Declarative
· ASCII art pattern
· External DSL
· SQL familiarity
· Closures
Considering all the preceding goals, Neo4j implemented the concepts of patterns and pattern matching and provided a new declarative graph query language, Cypher, as a query language for the Neo4j graph database. Cypher is specifically designed to be a humane query language, which is focused on making things simpler for developers. Another benefit of being a declarative language is that it focuses on "What to retrieve?" and not "How to retrieve?", which is in contrast to the other imperative languages such as Java and Gremlin.
Patterns and pattern matching are the core components of Cypher; so, being effective with Cypher requires a good understanding of the patterns and their implementation in Cypher.
Patterns are used to describe the shape of the data and also provide the path from where it should start searching for occurrences of the provided pattern.
Let's see how the patterns are defined for nodes, properties, labels, and relationships followed by examples.
Pattern for nodes
Pattern for nodes is one of the most basic and simplest one. Pattern for nodes are defined using a pair of parentheses and a name is given between the parentheses as follows:
(n)
Here, a pair of parentheses define a single node and n is the identifier of that node.
Pattern for more than one node
More than one node is defined in the same way as we do for a single node, but when two or more nodes are used, then we also need to define the relationship between these two nodes. Consider the following code as an example:
(n)-->(n1)
In the preceding example, we have defined two nodes, n and n1, and both the nodes are connected to each other through a directed arrow --> which is known as the directed relationship between n and n1.
Pattern for paths
A series of connected nodes is known as a path. All the following examples define the path in a particular pattern:
· (n)-[:REL_TYPE]->(n1)
· (n)-->()<--(n1)
· (n)-->(x)<--(n1)
We can also assign a path identifier and store the pattern in a variable as follows:
Var = (n)-[:REL_TYPE]->(n1)
Pattern for labels
As we define the pattern for nodes, we can also define the pattern for labels. Labels are the identifiers for a node, which can also be used to group the related nodes.
A node can have one or more labels:
(n:Male)-->(b) or (a: Artist:Male)-->(b)
Pattern for relationships
Relationships can be of two types: unidirectional and bidirectional.
· Unidirectional: This is defined using an arrow sign, with an arrow head defining the direction of the relationship as shown in the following example:
(n)-->(n1)
This example defines a relationship between n and n1, which starts from node n and ends at node n1.
· Bidirectional: This is defined using an arrow sign with NO arrow head as shown in the following example:
(n)--(n1)
This example defines a relationship between n and n1, which can flow from either end.
As with nodes, relationships can also have names or identifiers. Names or identifiers for relationships are defined in a pair of square brackets as follows:
· (n)-[r]->(n1)
· (n)-[r]-(n1)
We can also define one or more than one relationship in a pattern:
· (n)-[r:REL_TYPE]->(n1)
· (n)-[r:REL_TYPE | REL_TYPE]-(n1)
As we do in nodes, we can also omit the names or identifiers in relationships:
· (n)-[:REL_TYPE]->(n1)
· (n)-[]-(n1)
Pattern for properties
Properties are defined in nodes and relationships, which in turn help in developing richer models.
Properties are defined in a key/value format separated with a comma, where the key is the string and the value can either be a primitive data type such as Boolean, int, double, long, char, string, and so on, or an array of primitive data type such as boolean[], int[], double[], long[], char[], string[], except NULL, which is not a valid value of a property. One or more properties can be defined using curly braces either within the node or within the relationship. The following examples show the format for defining properties in a node and in a relationship:
Structure / syntax for defining the property of a node.
(n:Artist {Name:"John"}) OR (n:Artist {Name:"John", Age: 24})
Structure / syntax for defining the property of a node.
[r:FRIEND {Since: 2004, LastVisited:"Jan-2015"}]
Expressions
Cypher supports a variety of expressions. The following is the list of such expressions that can be used within Cypher queries:
· Decimal, hexadecimal, or octal integer literals
· String literals "Hello" or 'Hey'
· Boolean literals true/false or TRUE/FALSE.
· Collection of expressions: ["x", "z"] or [4,5,6] or ["a", 2, n.property, {param}], [ ]
· Function call and aggregate functions such as count (*), avg(x), sum(y)
· Mathematical, comparison, Boolean, string, and collection operators
· CASE expressions
All the preceding defined patterns are used in conjunction with the CRUD operations within Cypher queries. Cypher pattern matching borrows the approach to expressions from SPARQL and a few of the other collection semantics have been borrowed from languages such as Haskell and Python. Cypher also borrows much of its structure from SQL itself and made it easy to understand for developers who are already familiar with SQL. It also helped them to achieve one of their critical goals of SQL familiarity.
Let's see the similarity between the structure of Cypher and SQL:
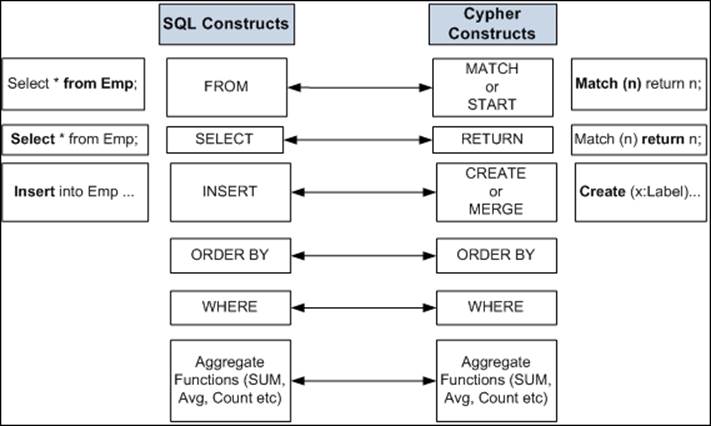
Usage of pattern
Let's see how queries are constructed and the way the patterns are used within the Cypher queries:
1. Open your Unix/ Linux shell and open Neo4j shell by executing <$NEO4J_HOME>/bin/neo4j-shell.
2. Execute the following commands on your Neo4j shell:
3. CREATE (n:MALE {Name:"John", Age:"24"});
4. MATCH (n:MALE) RETURN n;
You will see the following output on your screen:
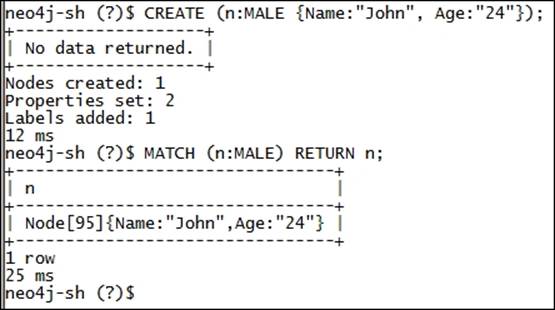
In the previous step, we created a node with a label and properties, and then in the next statement we searched for the same node. Refer to the following illustration which explains the different parts of preceding Cypher query and also similarity with SQL:
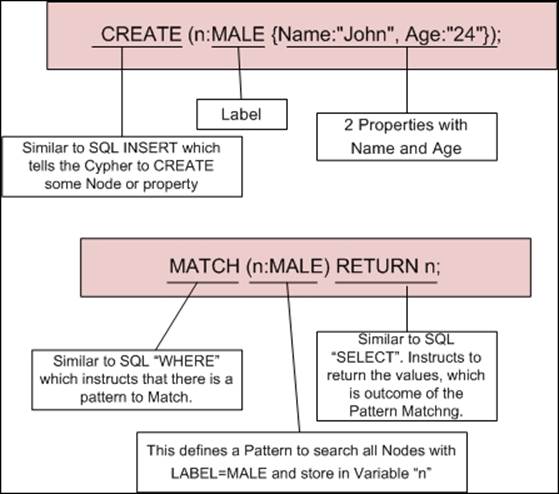
In this section, we discussed the basic usage of patterns/pattern matching and implementation of these in Cypher, including its syntax. In the upcoming sections/chapter, we will get into the nitty-gritties of Cypher queries and will use various illustrations to show the usage of Cypher constructs.
Read-only Cypher queries
In the previous section, we have discussed the heart of Cypher, that is, patterns and pattern matching, and in this section, we will discuss one of the most important aspects of Neo4j, that is, read-only Cypher queries.
Read-only Cypher queries are not only the core component of Cypher but also help us in exploring and leveraging various patterns and pattern matching constructs. It either begins with MATCH, OPTIONAL MATCH, or START, which can be used in conjunction with the WHEREclause and further followed by WITH and ends with RETURN. Constructs such as ORDER BY, SKIP, and LIMIT can also be used with WITH and RETURN.
We will discuss in detail about read-only constructs, but before that, let's create a sample dataset and then we will discuss constructs/syntax of read-only Cypher queries with illustration.
Creating a sample dataset – movie dataset
Let's perform the following steps to clean up our Neo4j database and insert some data which will help us in exploring various constructs of Cypher queries:
1. Open your Command Prompt or Linux shell and open the Neo4j shell by typing <$NEO4J_HOME>/bin/neo4j-shell.
2. Execute the following commands on your Neo4j shell for cleaning all the previous data:
3. //Delete all relationships between Nodes
4. MATCH ()-[r]-() delete r;
5. //Delete all Nodes
6. MATCH (n) delete n;
7. Now we will create a sample dataset, which will contain movies, artists, directors, and their associations. Execute the following set of Cypher queries in your Neo4j shell to create the list of movies:
8. CREATE (:Movie {Title : 'Rocky', Year : '1976'}); CREATE (:Movie {Title : 'Rocky II', Year : '1979'});
9. CREATE (:Movie {Title : 'Rocky III', Year : '1982'});
10.CREATE (:Movie {Title : 'Rocky IV', Year : '1985'});
11.CREATE (:Movie {Title : 'Rocky V', Year : '1990'});
12.CREATE (:Movie {Title : 'The Expendables', Year : '2010'});
13.CREATE (:Movie {Title : 'The Expendables II', Year : '2012'});
14.CREATE (:Movie {Title : 'The Karate Kid', Year : '1984'});
15.CREATE (:Movie {Title : 'The Karate Kid II', Year : '1986'});
16. Execute the following set of Cypher queries in your Neo4j shell to create the list of artists:
17.CREATE (:Artist {Name : 'Sylvester Stallone', WorkedAs : ["Acto
18.r", "Director"]});
19.CREATE (:Artist {Name : 'John G. Avildsen', WorkedAs : ["Director"]});
20.CREATE (:Artist {Name : 'Ralph Macchio', WorkedAs : ["Actor"]});
21.CREATE (:Artist {Name : 'Simon West', WorkedAs : ["Director"]});
22. Execute the following set of cypher queries in your Neo4j shell to create the relationships between artists and movies:
23.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "Rocky"}) CREATE (artist)-[:ACTED_IN {Role : "Rocky Balboa"}]->(movie);
24.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "Rocky II"}) CREATE (artist)-[:ACTED_IN {Role : "Rocky Balboa"}]->(movie);
25.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "Rocky III"}) CREATE (artist)-[:ACTED_IN {Role : "Rocky Balboa"}]->(movie);
26.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "Rocky IV"}) CREATE (artist)-[:ACTED_IN {Role : "Rocky Balboa"}]->(movie);
27.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "Rocky V"}) CREATE (artist)-[:ACTED_IN {Role : "Rocky Balboa"}]->(movie);
28.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "The Expendables"}) CREATE (artist)-[:ACTED_IN {Role : "Barney Ross"}]->(movie);
29.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "The Expendables II"}) CREATE (artist)-[:ACTED_IN {Role : "Barney Ross"}]->(movie);
30.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "Rocky II"}) CREATE (artist)-[:DIRECTED]->(movie);
31.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "Rocky III"}) CREATE (artist)-[:DIRECTED]->(movie);
32.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "Rocky IV"}) CREATE (artist)-[:DIRECTED]->(movie);
33.Match (artist:Artist {Name : "Sylvester Stallone"}), (movie:Movie {Title: "The Expendables"}) CREATE (artist)-[:DIRECTED]->(movie);
34.Match (artist:Artist {Name : "John G. Avildsen"}), (movie:Movie {Title: "Rocky"}) CREATE (artist)-[:DIRECTED]->(movie);
35.Match (artist:Artist {Name : "John G. Avildsen"}), (movie:Movie {Title: "Rocky V"}) CREATE (artist)-[:DIRECTED]->(movie);
36.Match (artist:Artist {Name : "John G. Avildsen"}), (movie:Movie {Title: "The Karate Kid"}) CREATE (artist)-[:DIRECTED]->(movie);
37.Match (artist:Artist {Name : "John G. Avildsen"}), (movie:Movie {Title: "The Karate Kid II"}) CREATE (artist)-[:DIRECTED]->(movie);
38.Match (artist:Artist {Name : "Ralph Macchio"}), (movie:Movie {Title: "The Karate Kid"}) CREATE (artist)-[:ACTED_IN {Role:"Daniel LaRusso"}]->(movie);
39.Match (artist:Artist {Name : "Ralph Macchio"}), (movie:Movie {Title: "The Karate Kid II"}) CREATE (artist)-[:ACTED_IN {Role:"Daniel LaRusso"}]->(movie);
40.Match (artist:Artist {Name : "Simon West"}), (movie:Movie {Title: "The Expendables II"}) CREATE (artist)-[:DIRECTED]->(movie);
41. Next, browse your data through the Neo4j browser. Click on Get some data from the left navigation pane and then execute the query by clicking on the right arrow sign that will appear on the extreme right corner just below the browser navigation bar, and it should look something like this:
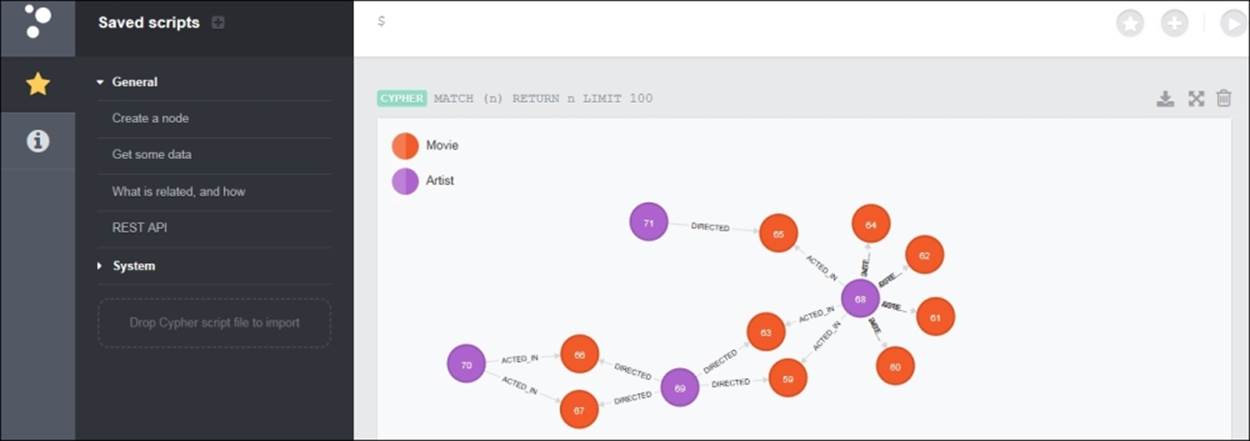
Now, let's understand the different pieces of read-only queries and execute those against our movie dataset.
Working with the MATCH clause
MATCH is the most important clause used to fetch data from the database. It accepts a pattern, which defines "What to search?" and "From where to search?". If the latter is not provided, then Cypher will scan the whole tree and use indexes (if defined) in order to make searching faster and performance more efficient.
Working with nodes
Let's start asking questions from our movie dataset and then form Cypher queries, execute them on <$NEO4J_HOME>/bin/neo4j-shell against the movie dataset and get the results that will produce answers to our questions:
· How do we get all nodes and their properties?
· Answer: MATCH (n) RETURN n;
· Explanation: We are instructing Cypher to scan the complete database and capture all nodes in a variable n and then return the results, which in our case will be printed on our Neo4j shell.
· How do we get nodes with specific properties or labels?
· Answer: Match with label, MATCH (n:Artist) RETURN n; or MATCH (n:Movies) RETURN n;
· Explanation: We are instructing Cypher to scan the complete database and capture all nodes, which contain the value of label as Artist or Movies.
· Answer: Match with a specific property MATCH (n:Artist {WorkedAs:["Actor"]}) RETURN n;
· Explanation: We are instructing Cypher to scan the complete database and capture all nodes that contain the value of label as Artist and the value of property WorkedAs is ["Actor"]. Since we have defined the WorkedAs collection, we need to use square brackets, but in all other cases, we should not use square brackets.
Note
We can also return specific columns (similar to SQL). For example, the preceding statement can also be formed as MATCH (n:Artist {WorkedAs:["Actor"]}) RETURN n.name as Name;.
Working with relationships
Let's understand the process of defining relationships in the form of Cypher queries in the same way as you did in the previous section while working with nodes:
· How do we get nodes that are associated or have relationships with other nodes?
· Answer: MATCH (n)-[r]-(n1) RETURN n,r,n1;
· Explanation: We are instructing Cypher to scan the complete database and capture all nodes, their relationships, and nodes with which they have relationships in variables n, r, and n1 and then further return/print the results on your Neo4j shell. Also, in the preceding query, we have used - and not -> as we do not care about the direction of relationships that we retrieve.
· How do we get nodes, their associated properties that have some specific type of relationship, or the specific property of a relationship?
· Answer: MATCH (n)-[r:ACTED_IN {Role : "Rocky Balboa"}]->(n1) RETURN n,r,n1;
· Explanation: We are instructing Cypher to scan the complete database and capture all nodes, their relationships, and nodes, which have a relationship as ACTED_IN and with the property of Role as Rocky Balboa. Also, in the preceding query, we do care about the direction (incoming/outgoing) of a relationship, so we are using ->.
Note
For matching multiple relations replace [r:ACTED_IN] with [r:ACTED_IN | DIRECTED] and use single quotes or escape characters wherever there are special characters in the name of relationships.
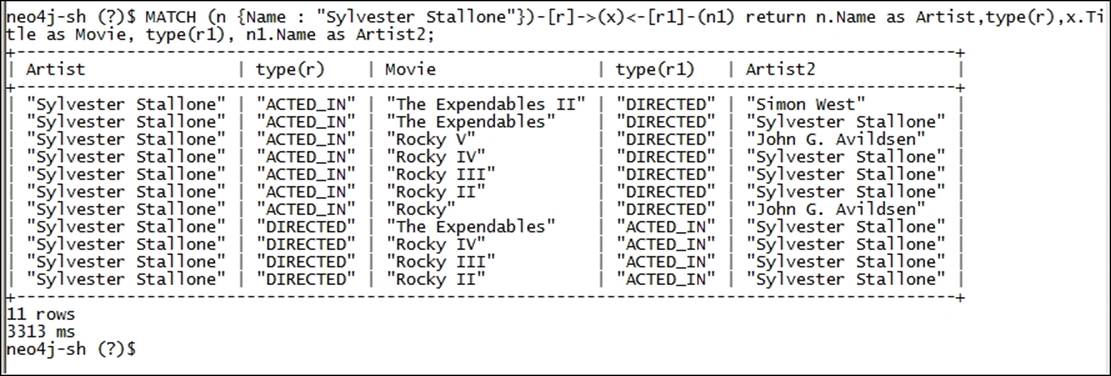
· How do we get a coartist?
· Answer: MATCH (n {Name : "Sylvester Stallone"})-[r]->(x)<-[r1]-(n1) return n.Name as Artist,type(r),x.Title as Movie, type(r1), n1.Name as Artist2;
· Explanation: We are trying to find out all artists that are related to Sylvester Stallone in some manner or the other. Once you run the preceding query, you will see something like the following image, which should be self-explanatory. Also, see the usage of as and type. as is similar to the SQL construct and is used to define a meaningful name to the column presenting the results, and type is a special keyword that gives the type of relationship between two nodes.
· How do we get the path and number of hops between two nodes?
· Answer: MATCH p = (:Movie{Title:"The Karate Kid"})-[:DIRECTED*0..4]-(:Movie{Title:"Rocky V"}) return p;
· Explanation: Paths are the distance between two nodes. In the preceding statement, we are trying to find out all paths between two nodes, which are between 0 (minimum) and 4 (maximum) hops away from each other and are only connected through the relationship DIRECTED. You can also find the path, originating only from a particular node and re-write your query as MATCH p = (:Movie{Title:"The Karate Kid"})-[:DIRECTED*0..4]-() return p;.
Working with the OPTIONAL MATCH clause
The OPTIONAL MATCH clause is similar to MATCH but the only difference is that OPTIONAL MATCH is "not strict" while evaluating the pattern against a given dataset.
In MATCH, it is all or nothing but OPTIONAL MATCH uses NULLs for missing parts of the pattern for those scenarios where no match is found. It is similar to the functionality provided by the outer joins in SQL.
Let's consider that in the movie dataset, we want to get all outgoing relationships from the movie Rocky II. The following is our Cypher query:
OPTIONAL MATCH (n:Movies {Title: "Rocky II"})-[r]->()
return r;
The result is shown in the following screenshot:
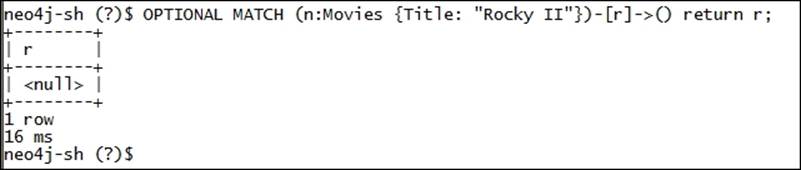
The preceding query returned 1 row and the <null> values because there were no matching records for the given pattern.
Working with the START clause
START is used in cases where we have multiple starting points and you need to specifically provide a starting point for evaluating your pattern. Starting points are introduced by legacy index lookups or by the ID. However, trying to use a legacy index that doesn't exist will generate an exception.
START is only used when we are dealing with legacy indexes (refer to the next section for more information on legacy indexes), otherwise Cypher is intelligent enough to find out the starting point from your pattern by looking at nodes or labels and its predicates.
Starting Neo4j 2.0 START is not recommended and is only used for backward compatibility with the prior versions of Neo4j. It is advised to not use START for all versions of Neo4j 2.0+.
Let's consider an example where we need to get details of a node with ID 10. Your query would be:
start n=node(10) return n;
The results of the preceding query may vary from database to database as the IDs are internal to Neo4j and are re-used whenever a node or relationship is deleted.
Working with the WHERE clause
WHERE, as the name suggests, is used to filter the given set of results.
Let's consider our movie dataset and take an example where we need to fetch all relationships that have some value of attribute Role, so our Cypher query would be:
MATCH (n)-[r]-() where r.Role is NOT NULL return n,r;
Another example would be where we want a count of relationships for a particular node, which does have a value of attribute Role:
MATCH (n)-[r]-() where r.Role is NOT NULL return n,count(r);
We could also consider an example where we want only those nodes that have count (r) is greater than 1:
MATCH (n)-[r]-() WITH n, count(r) AS countRel
WHERE countRel>1 return n,countRel;
See the usage of the WITH clause in the preceding statement, which is used to introduce the aggregate function count(r) for counting the relationships for all nodes within our database.
WITH is like the event horizon—it is a barrier between a plan and the finished execution of that plan. Apart from the aggregate functions, WITH can also be used to chain together two reading query parts. For example, let's assume that we need to get the count of Moviefor all Artist that are related to Movie by ACTED_IN relationship, but we should consider only for those Artist that are linked to movies by the DIRECTED relationship:
MATCH (m:Movie)<-[r:ACTED_IN]-(a:Artist)-[d:DIRECTED]->(m)
WITH a
MATCH (a)-[:ACTED_IN]->(m1:Movie)
WITH a,count( DISTINCT m1) as TotalMovies
return a.Name as Artist,TotalMovies;
In the preceding query, we have chained two reading query parts: the first one does the filtering and gets the Artist that are related to Movie by DIRECTED and ACTED_IN relationships, and the second one counts the movies of the selected Artist that are related to Movieby the ACTED_IN relationship. We have also used DISTINCT so that, while aggregating, we consider only unique records.
There is no limit and depending on the available memory you can chain together as many query parts as you like using WITH.
Working with the RETURN clause
RETURN is used to return the results of Cypher statements to the program, which is requesting Neo4j to execute queries or statements. It is similar to SQL SELECT. But in Cypher it needs to be the last statement of the query.
Except the CREATE statement, every other Cypher statement should end with RETURN, otherwise it is treated as an invalid statement and the compiler will throw an error.
There are clauses such as ORDER BY, SKIP, and LIMIT, which can be used with RETURN for getting the results in a desired format.
Let's take an example where we need to get all nodes marked with the label Artist in a particular order (ascending or descending) and also retrieve only the top two rows:
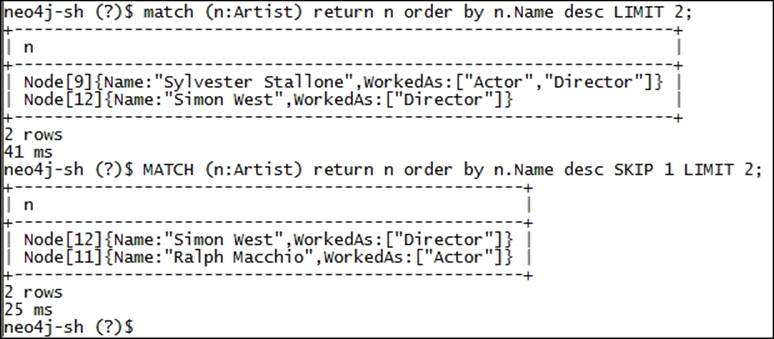
MATCH (n:Artist) return n order by n.Name desc LIMIT 2;
Remove desc from the preceding statement to get the results in ascending order. You can also use SKIP with RETURN for ignoring a particular number of specified rows starting from the top of the results.
Let's rewrite our previous query and use to SKIP 1 record:
MATCH (n:Artist) return n order by n.Name desc SKIP 1 LIMIT 2;
The results of the preceding query will skip a record from the top; then it will show the second and third rows of the result set, as shown in the following screenshot:
Schema and legacy indexing
Neo4j 2.0+ supports two different ways of indexing the data; legacy indexing and schema level indexing. Let's discuss both the indexing techniques.
Using legacy indexes
Legacy indexes are also known as manual indexes that are managed at the application level via IndexManager API available at http://neo4j.com/docs/2.1.5/javadocs/org/neo4j/graphdb/index/package-summary.html. Legacy indexes are created by a unique user-defined name and can be created either on nodes or relationships.
Searching or retrieving the data from legacy indexes is also a manual process and can be done in two ways:
· org.neo4j.graphdb.index.Index.get: This will return the exact matches for a given key-value pair.
· org.neo4j.graphdb.index.Index.query: Exposes querying capabilities from the backend indexing APIs used for indexing the data. Neo4j leverages Lucene (http://lucene.apache.org/) and Lucene query syntax can be directly used for querying the database.
We will discuss in detail the various kinds of searches exposed by legacy indexes in the next chapter.
We can also use the autoindexing mechanism for enabling legacy indexing by enabling properties such as node_auto_indexing, node_keys_indexable, relationship_auto_indexing, and relationship_keys_indexable in neo4j.properties.
Maintaining or querying with legacy or manual indexes is a complicated process. Everything needs to be managed by the application itself, which is against the principles of databases where indexes should be automatically populated/updated and used once it is defined by the users. So, to improve the efficiency and ease of use, Neo4j 2.0 introduced a new mechanism for indexing and deprecated the old process of manual indexing, though it is still supported but only for backward compatibility for Neo4j applications which are developed and running on earlier versions of Neo4j (=<Neo4j1.9.9).
Using schema-level indexing
Neo4j 2.0 introduced indexes and constraints on labels which together define the schema for Neo4j. Cypher CREATE constructs can be used to define constraints on the attributes and indexes on labels. Creation of schema or defining schema is optional and can be deferred until you want to provide structure to your data and focus is on performance.
Defining schema/index improves the speed of searching and is leveraged implicitly during execution of the queries. Indexes are eventually available, that is, they are being populated asynchronously without impacting the user operations. The decision of whether indexes need to be used in a query will depend upon the state of the index. If an index is in the available state, then it will be used, otherwise not. All these complexities of indexes are hidden from developers and usually there is no need to specifically provide any hints in our queries. There are APIs that can tell you the status and availability of indexes and constraints in your database.
Further in this section, we will leverage our movie dataset that we created in the previous section and will create schema (indexes/constraints) using Cypher.
Creating schema with Cypher
Let's create some indexes and constraints using Cypher on our movie dataset:
· Create the index on the property Name for all the nodes that have the Label Artist:
· CREATE index on :Artist(Name);
· Drop index which was created on :Artist(Name):
· DROP index on :Artist(Name);
· Create unique Constraint on :Movies(Title):
· CREATE Constraint on (movies:Movie) ASSERT movies.Title IS UNIQUE;
· Drop unique Constraint on :Movies(Title):
· Drop Constraint on (movies:Movie) ASSERT movies.Title IS UNIQUE;
· Query the status of all indexes and constraints within your database:
· Schema
· Query the status of index :Artist(Name)
· schema -l :Artist -p Name
In the preceding statement, -l will list all indexes on a given label. –p will list indexes on a given property and –v is to print errors for the indexes that are in the failed state.
· Forcing queries to use indexes:
· MATCH (n:Artist)
· USING INDEX n:Artist(Name)
· WHERE n.Name = 'Sylvester Stallone' RETURN n;
Note
Creating constraints also creates a unique index on the same column, so there is no need to explicitly create an index on unique columns.
Movie Demo with GraphGists
Gist (https://help.github.com/articles/about-gists/) is one of the wonderful features of GitHub, which provides a quick-and-easy way of sharing code, text, and files. It provides support for rendering a huge number of programming languages and facilitates rich syntax highlighting.
Neo4j leveraged the same thought process developed by Neo4j Gist http://gist.neo4j.org/ for sharing and rendering the graphs.
In this section, we will re-use the same movie dataset and will see how Neo4j Gists can be leveraged to share our data with the community.
Let's follow the steps to create our Movie Demo and share it with the other users on Neo4j Gist:
1. Create a GitHub user ID and password and log in to https://gist.github.com/.
2. Create ASCIIDoc, then enter the text given in the following screenshot:
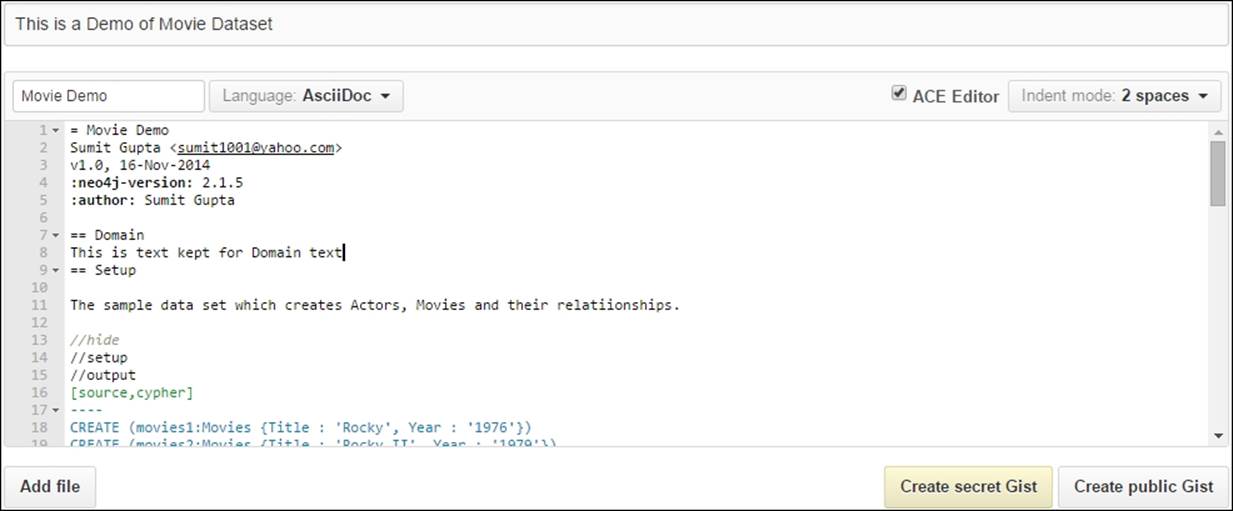
3. Next, just below the [source, cypher] statement, drop in your Cypher queries for creating the movie dataset. Your Cypher queries should be in between ----, as shown in row 17 in the preceding screenshot. You can use the same queries that we used in theRead-only Cypher queries section to create our movie database.
4. Now we will define a couple of read-only Cypher queries to fetch the data and show the results in the graph and table format, and click on Create public Gist and save our Movie Demo script.
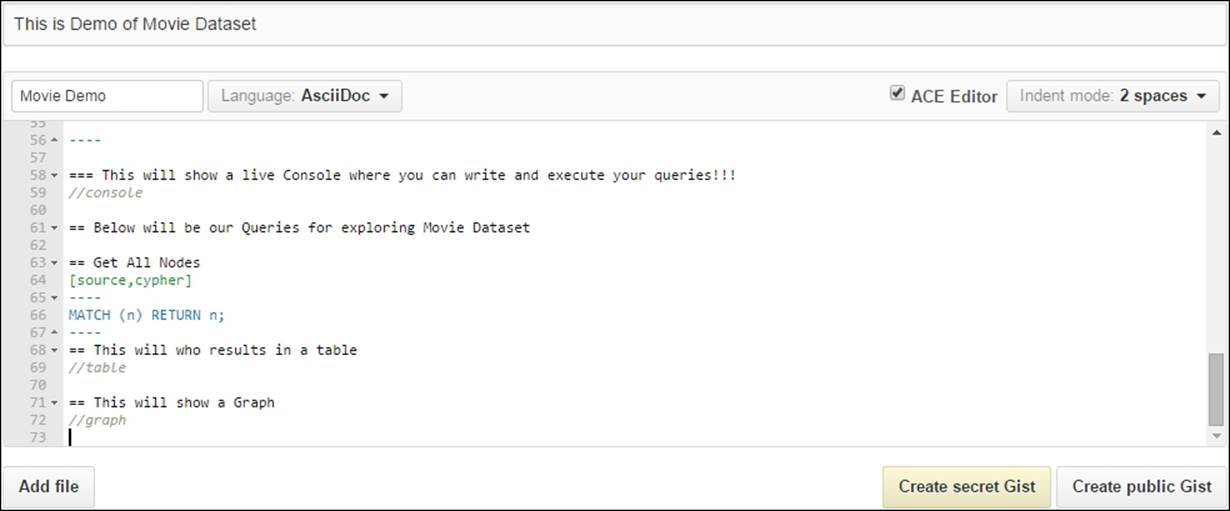
Visit https://gist.github.com/sumit1001/c12f2049a6356a6bf664 and download the code of ASCIIDoc referred to in the preceding example.
5. Copy the URL as shown in your browser navigation bar.
6. Open a new browser window/tab and browse gist.neo4j.org.
7. Next in the top right-hand corner, just below the browser navigation bar, paste your GitHub Gist URL, which we copied in step 5, and click on Enter.
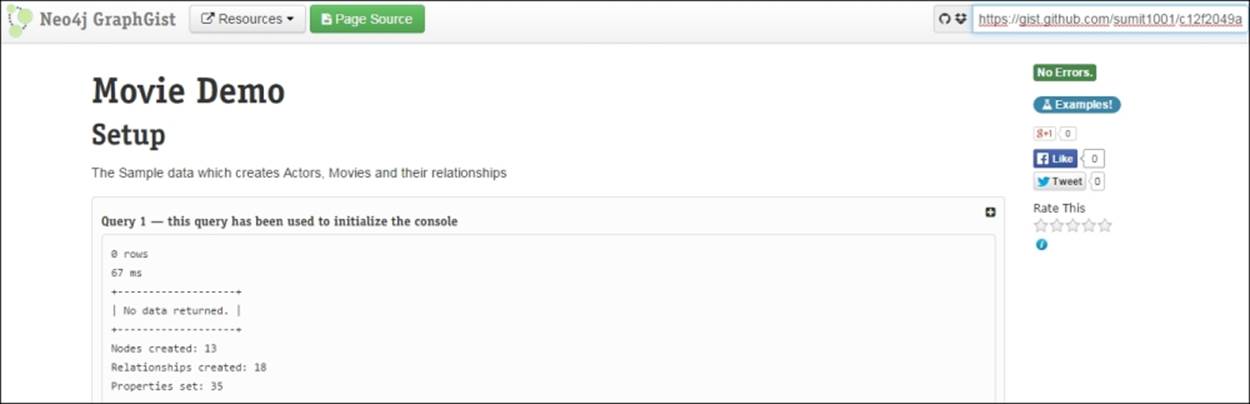
And we are done!!! Scroll down to see the Live Console, Graph, and Table.
Note
Share your GitHub Gist URL with community members and they will be able to execute, contribute, and appreciate your work.
Summary
In this chapter, you have learned the basic concepts of data modeling in Neo4j and implementation of patterns and pattern matching in the Neo4j query language, that is, Cypher. We also talked about a new indexing feature, that is, schema over legacy indexing and, lastly, you learned a powerful way to share your work with the members of the Graph community.
In the next chapter, we will discuss Cypher queries for inserting data, creating/searching indexes, and also optimization techniques for writing performance-efficient queries.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.