NoSQL for Mere Mortals (2015)
Part I: Introduction
Chapter 2. Variety of NoSQL Databases
“Nothing is pleasant that is not spiced with variety.”
—FRANCIS BACON
Topics Covered In This Chapter
Data Management with Distributed Databases
ACID and BASE
A Variety of Distributed Databases
NoSQL databases solve a wide variety of data management problems by offering several types of solutions. NoSQL databases are commonly designed to use multiple servers, but this is not a strict requirement. When systems run on multiple servers, instead of on just one computer, they are known as distributed systems (see Figure 2.1).
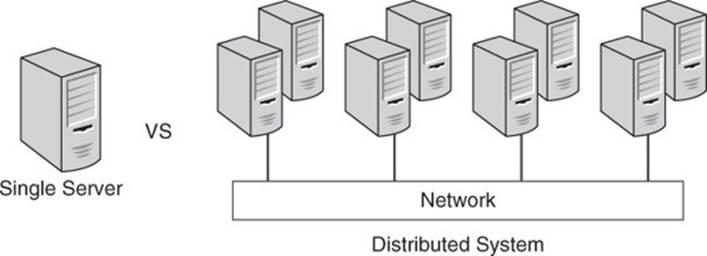
Figure 2.1 Single server versus distributed system.
This chapter starts with a review of common features and challenges faced by distributed databases. Because NoSQL databases are often used in distributed environments, this chapter spends some time examining the challenges of using multiple servers to manage data in a single logical database. Much of what is discussed in the following section on distributed systems does not apply if you run your NoSQL database on a single server.
Chapter 1, “Different Databases for Different Requirements,” introduced the motivations for NoSQL, including the need for scalability, flexibility, cost control, and availability. A common way to meet these needs is by designing data management systems to work across multiple servers, that is, as a distributed system.
In addition to the other benefits of NoSQL databases, distributed systems offer some level of operational simplicity. You can add and remove servers as needed rather than adding or removing memory, CPUs, and so on from a single server. Also, some NoSQL databases include features that automatically detect when a server is added or removed from a cluster.
Many NoSQL databases take advantage of distributed systems, but they may employ different data management strategies. There are four major types of key NoSQL databases:
• Key-value databases, for example, work with a simple model based on keys, which are identifiers for looking up data, and values, the data that is associated with keys.
• Document databases also use identifiers to look up values, but the values are typically more complex than those typically stored in key-value databases. Documents are collections of data items stored together in a flexible structure.
• Column family databases have some of the characteristics of relational databases, such as organizing data into collections of columns. Column family databases trade some of the functionality of relational databases, such as the ability to link or join tables, for improved performance.
• Graph databases are well suited to model objects and relationships between objects.
Because distributed systems are the foundation of many NoSQL databases, it is important to explore some of the issues associated with managing data in a distributed system. After I outline the challenges and limitations associated with distributed databases, you will learn about key-value, document, column family store, and graph databases and compare them with relational databases.
Data Management with Distributed Databases
Before getting into the details of distributed databases, let’s look at a simplified view of databases in general. Databases are designed to do two things: store data and retrieve data. To meet these objectives, the database management systems must do three things:
• Store data persistently
• Maintain data consistency
• Ensure data availability
In this section, you will learn how distributed systems meet these objectives. You will also learn about limitations of distributed systems, with particular attention to balancing consistency, availability, and protection for network failures that leaves some servers in a cluster unreachable.
Store Data Persistently
Data must be stored persistently; that is, it must be stored in a way that data is not lost when the database server is shut down. If data were only stored in memory—that is, RAM—then it would be lost when power to the memory is lost. Only data that is stored on disk, flash, tape, or other long-term storage is considered persistently stored, as shown in Figure 2.2.
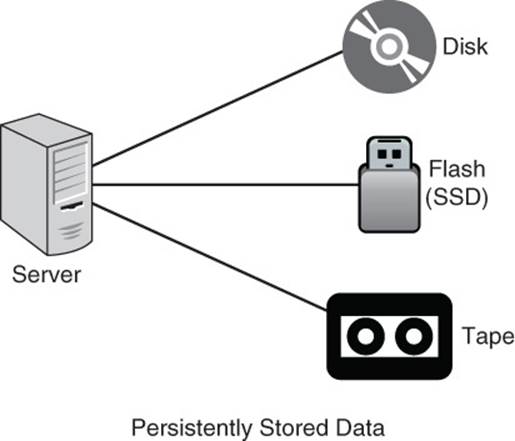
Figure 2.2 Persistently stored data is stored on disk, flash, or other long-term storage medium.
Data must be available for retrieving. You can retrieve persistently stored data in a number of different ways. Data stored on a flash device is read directly from its storage location. The movable parts of the disk and tape drives are put in position so that the read heads of the device are over the block of data to be read.
You could design your database to simply start at the beginning of a data file and search for the record you need when a read operation is performed. This would lead to painfully long response times and a waste of valuable compute resources. Rather than scan the full table for the data, you can use database indexes, which are like indexes at the end of a book, to quickly find the location of a particular piece of data. Indexes are a central element of databases.
Maintain Data Consistency
It is important to ensure that the correct data is written to a persistent storage device. If the write or read operation does not accurately record or retrieve data, the database will not be of much use. This is rarely a problem unless there is a hardware failure. A more common issue with reading and writing occurs when two or more people are using the database and want to use the same data at the same time.
Consider a small business with two partners, Alice and Bob. Alice is using a database application to update the company’s financial records. She has just received a number of payments from customers and posted them to the accounting system. The process requires two steps: updating the customer’s balance due and updating the total funds available to the business. At the same time Alice is doing that, Bob is placing an order for more supplies. Bob wants to make sure there are sufficient funds before he commits to an order, so he checks the balance of total funds available. What balance will Bob see?
Ideally, Bob would see the balance of funds available that includes the most recent payments. If he issues his query while Alice is updating the customer balance and total funds available, then Bob would see the balance without the new payments. The reason for this is that the database is designed to be consistent. Bob could see the balance before or after Alice updates both the customer balance record and the funds available record, but never when only one of the two has been updated (see Figure 2.3).
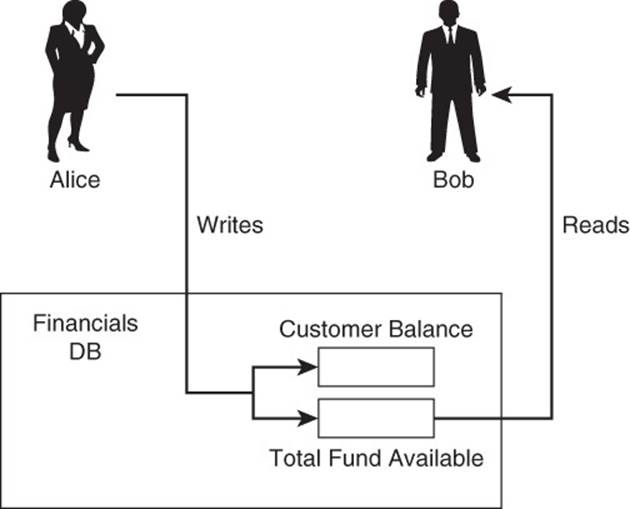
Figure 2.3 Data should reflect a consistent state.
It would be inconsistent for the database to return results that indicated a customer had paid the balance due on her account without also including that payment in the funds available record. Relational database systems are designed to support these kinds of multistep procedures that have to be treated as a single operation or transaction.
Ensure Data Availability
Data should be available whenever it is needed. This is difficult to guarantee. Hardware may fail. An operating system on the database server may need patching. You might need to install a new version of the database management system. A database that runs on a single server can be unavailable for a large number of reasons.
One way to avoid the problem of an unavailable database server is to have two database servers: One is used for updating data and responding to queries while the other is kept as a backup in case the first server fails. The server that is used for updating and responding to queries is called the primary server, and the other is the backup server. The backup server starts with a copy of the database that is on the primary server. When the database is in use, any changes to the primary database are reflected in the backup database as well.
For example, if Alice and Bob’s company used a backup database server, then when Alice updated a customer’s account, those same changes would be made to the backup server. This would require the database to write data twice: once to the disk used by the primary server and then one more time to the disk used by the backup server in an operation known as a two-phase commit (see Figure 2.4).
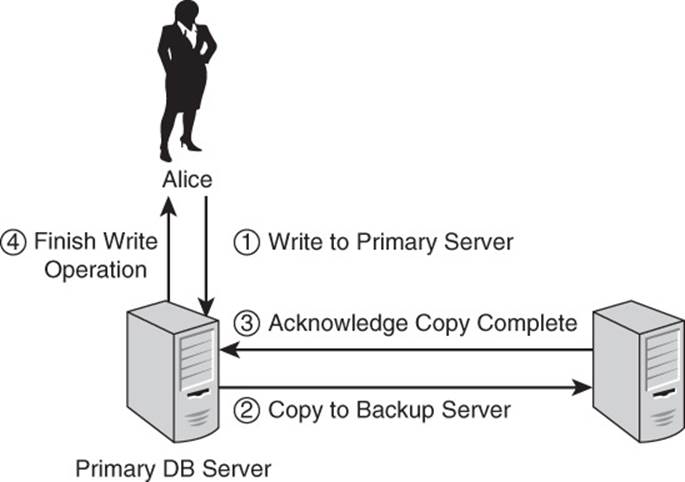
Figure 2.4 Two-phase commits are complete only when operations on both databases are complete.
Recall that a database transaction is an operation made up of multiple steps and that all steps must complete for the transaction to complete. If any one of the multiple steps fails, then the entire transaction fails. Updating two databases makes every update a multistep process.
When the company used a single server, there was just one step in updating the number of a particular product in the warehouse. For example, the number of black desk chairs could be updated from 100 to 125 in a single operation. Now that the company is using a backup database, the number of chairs would have to be updated on the primary server and the backup server.
The process for updating both databases is similar to other multistep transactions: Both databases must succeed for the operation to succeed. If the primary database is updated to reflect 125 black desk chairs in the warehouse but the update fails on the backup database, then the primary database resets the chair count back to 100. The primary and the backup databases must be consistent. This is an example of a two-phase commit. In the first phase of the operation, the database writes, or commits, the data to the disk of the primary server. In the second phase of the operation, the database writes data to the disk of the backup server.
With data consistent on two database servers, you can be sure that if the primary database fails, you can switch to using the backup database and know that you have the same data on both. When the primary database is back online, the first thing it does is to update itself so that all changes made to the backup database while the primary database was down are made to the primary database. The primary database is usable when it is consistent with the backup database.
The advantage of using two database servers is that it enables the database to remain available even if one of the servers fails. This is helpful but is not without costs. Database applications, and the people who use them, must wait while a write operation completes.
Because, in the case of a two-phase commit, a write operation is not complete until both databases are updated successfully, the speed of the updates depends on the amount of data written, the speed of the disks, the speed of the network between the two servers, and other design factors (seeFigure 2.5).
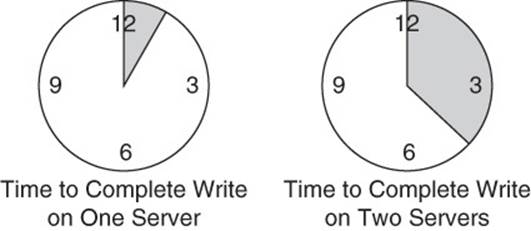
Figure 2.5 Consistency and availability require more time to complete transactions in high-availability environments.
![]() Note
Note
You can have consistent data, and you can have a high-availability database, but transactions will require longer times to execute than if you did not have those requirements.
Consistency of Database Transactions
The term consistency with respect to database transactions refers to maintaining a single, logically coherent view of data. When you transfer $100 from your savings account to your checking account, the bank’s software may subtract $100 from your savings account in one step and add $100 to your checking account in another. At no time would it be correct to say you have $100 less in your savings account without also reflecting an additional $100 in your checking account.
Consistency has also been used to describe the state of copies of data in distributed systems. For example, if two database servers each have copies of data about products stored in a warehouse, it is said they are consistent if they have the same data. This is different from the kind of consistency that is needed when updating data in a transaction.
![]() Note
Note
To avoid confusion going forward, let’s define a database server as a computer that runs database management software. That database management software will be called a database management system.
Database management systems can run on one or more computers. When the database management system is running on multiple computers, it is called a distributed database. The term database in this context is synonymous with database management system.
Availability and Consistency in Distributed Databases
You might be starting to see some of the challenges to maintaining a database management system that uses multiple servers. When two database servers must keep consistent copies of data, they incur longer times to complete a transaction. This is acceptable in applications that require both consistency and high availability at all times. Financial systems at a bank, for example, fall into this category. There are applications, however, in which the fast database operations are more important than maintaining consistency at all times. For example, an e-commerce site might want to maintain copies of your shopping cart on two different database servers. If one of the servers fails, your cart is still available on the other server.
Imagine you are programming the user interface for an e-commerce site. How long should the customer wait after clicking on an “Add to My Cart” button? Ideally, the interface would respond immediately so the customer could keep shopping. If the interface feels slow and sluggish, the customer might switch to another site with faster performance. In this case, speed is more important than having consistent data at all times.
One way to deal with this problem is to write the updates to one database and then let the program know the data has been saved. The interface can indicate to the customer that the product has been added to the cart. While the customer receives the message that the cart has been updated, the database management system is making a copy of the newly updated data and writing it to another server. There is a brief period of time when the customer’s cart on the two servers is not consistent, but the customer is able to continue shopping anyway. In this case, we are willing to tolerate inconsistency for a brief period of time knowing that eventually the two carts will have the same products in it. This is especially true with online shopping carts because there is only a small chance someone else would read that customer’s cart data anyway (see Figure 2.6).
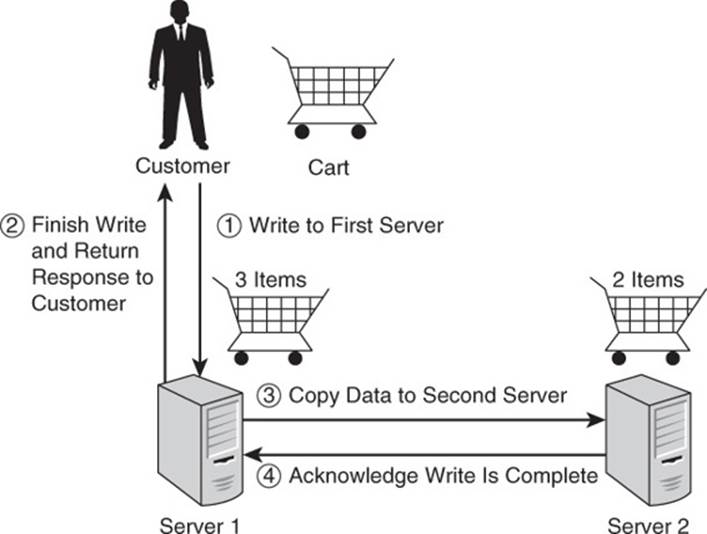
Figure 2.6 Data structures, such as shopping carts, can be inconsistent for short periods of time without adversely affecting system effectiveness. In this example, Server 2 is inconsistent with Server 1 until step 3 is complete.
Balancing Response Times, Consistency, and Durability
NoSQL databases often implement eventual consistency; that is, there might be a period of time where copies of data have different values, but eventually all copies will have the same value. This raises the possibility of a user querying the database and getting different results from different servers in a cluster. For example, assume Alice has updated a customer’s address in a database that implements eventual consistency. Immediately after Alice updates the address, Bob reads that customer’s address. Will he see the new or old address? The answer is not as simple as it is when working with a relational database and strict consistency.
NoSQL databases often use the concept of quorums when working with reads and writes. A quorum is the number of servers that must respond to a read or write operation for the operation to be considered complete.
When a read is performed, the NoSQL database reads data from, potentially, multiple servers. Most of the time, all of the servers will have consistent data. However, while the database copies data from one of the servers to the other servers storing replicas, the replica servers may have inconsistent data.
One way to determine the correct response to any read operation is to query all servers storing that data. The database counts the number of distinct response values and returns the one that meets or exceeds a configurable threshold. For example, assume data in a NoSQL database is replicated to five servers and you have set the read threshold to 3 (see Figure 2.7). As soon as three servers respond with the same response, the result is returned to the user.
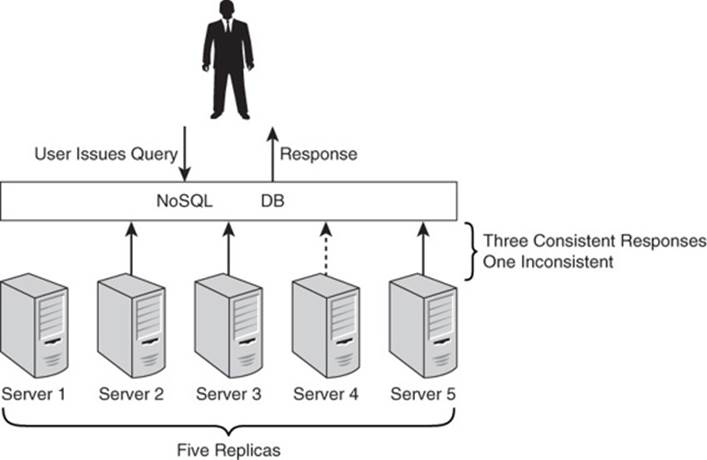
Figure 2.7 NoSQL databases can mitigate the risk of inconsistent data by having servers vote on the correct response to a query.
You can vary the threshold to improve response time or consistency. If the read threshold is set to 1, you get a fast response. The lower the threshold, the faster the response but the higher the risk of returning inconsistent data.
In the preceding example, if you set the read threshold to 5, you would guarantee consistent reads. In that case, the query would return only after all replicas have been updated and could lead to longer response times.
Just as you can adjust a read threshold to balance response time and consistency, you can also alter a write threshold to balance response time and durability. Durability is the property of maintaining a correct copy of data for long periods of time. A write operation is considered complete when a minimum number of replicas have been written to persistent storage.
![]() Caution
Caution
If the write threshold is set to 1, then the write is complete once a single server writes the data to persistent storage. This leads to fast response times but poor durability. If that one server or its storage system fails, the data is lost.
Assume you are working the five-server cluster described previously. If data is replicated across three servers and you set the write threshold to 3, then all three copies would be written to persistent storage before the write completes. If you set the threshold to 2, your data would be written to two servers before completing the write operation and the third copy would be written at a later time.
Setting the write threshold to at least 2 provides for durability while setting the number of replicas higher than the threshold helps improve durability without increasing the response time of write operations.
Consistency, Availability, and Partitioning: The CAP Theorem
This book is one of many books written “for mere mortals,” that is, people who are not necessarily specialists in the subject area. In these books, technical terminology is kept to a minimum and discussions are designed to provide practical, useful knowledge. There are times, however, when a brief discussion of a fundamental principle is worth the need to delve into a more subject-oriented discussion. This is one of those times.
The CAP theorem, also known as Brewer’s theorem after the computer scientist who introduced it, states that distributed databases cannot have consistency (C), availability (A), and partition protection (P) all at the same time. Consistency, in this case, means consistent copies of data on different servers. Availability refers to providing a response to any query. Partition protection means if a network that connects two or more database servers fails, the servers will still be available with consistent data.
You saw in a previous example of the e-commerce shopping cart that it is possible to have a backup copy of the cart data that is out of sync with the primary copy. The data would still be available if the primary server failed, but the data on the backup server would be inconsistent with data on the primary server if the primary server failed prior to updating the backup server (see Figure 2.8).
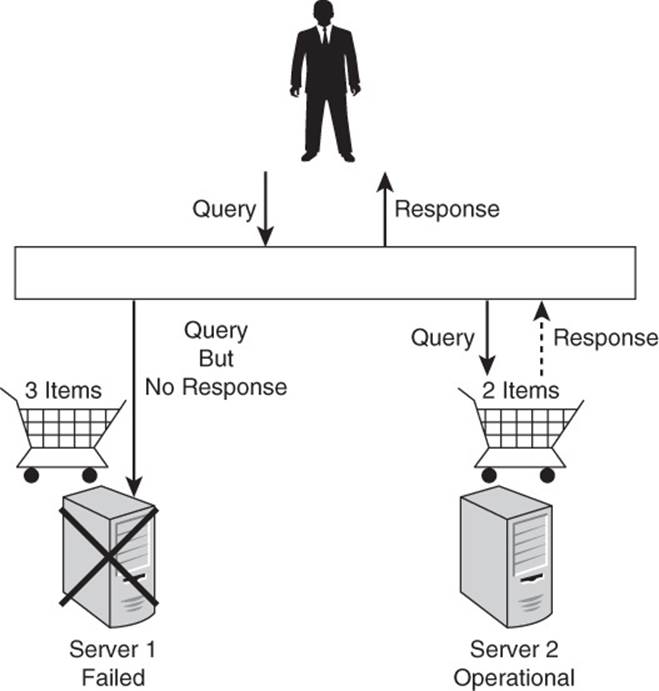
Figure 2.8 Data can be available but not consistent.
You also saw in an earlier example of the two-phase commit that you can have consistency but at the risk of the most recent data not being available for a brief period of time. While the two-phase commit is executing, other queries to the data are blocked. The updated data is unavailable until the two-phase commit finishes. This favors consistency over availability (see Figure 2.9).
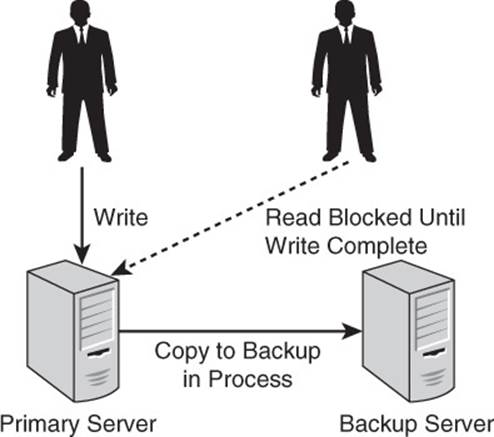
Figure 2.9 Data can be consistent but not available.
Partition protection deals with situations in which servers cannot communicate with each other. This would be the case in the event of a network failure. This splitting of the network into groups of devices that can communicate with each other from those that cannot is known as partitioning. (Partitioning, like consistency, has multiple meanings in data management. It is important to remember that when talking about the CAP theorem, partitioning has to do with the inability to send messages between database servers.) If database servers running the same distributed database are partitioned by a network failure, then you could continue to allow both to respond to queries and preserve availability but at the risk of them becoming inconsistent. Alternatively, you could disable one so that only one of the servers responds to queries. This would avoid returning inconsistent data to users querying different servers but at the cost of availability to some users.
From a practical standpoint, network partitions are rare, at least in local area networks. You can imagine a wide area network with slow network connections and low throughput (for example, older satellite connections to remote areas) that could experience network outages. This means that from a pragmatic perspective, database application designers have to deal with the trade-offs between consistency and availability more than issues with partitioning.
Designers of NoSQL database management systems have to determine how to balance varying needs for consistency, availability, and partitioning protection. This is not a one-time decision for the database management system. NoSQL database designers can provide configuration mechanisms that allow users of the database to specify their preferred settings rather than making a single choice for all users of the database management system.
Application designers could make use of NoSQL database configuration options to make the availability-consistency trade-off decision at fine-grained levels, such as based on different types of data in the database. The only limitation is the configuration options provided in the NoSQL database management system used by the application.
ACID and BASE
In the world of chemistry, acids are chemicals with a pH of less than 7 and bases are chemicals that have a pH of greater than 7. However, the use of the terms ACID and BASE when discussing databases has nothing to do with chemistry. ACID is an acronym derived from four properties implemented in relational database management systems. BASE is an acronym for properties common to NoSQL databases.
ACID: Atomicity, Consistency, Isolation, and Durability
A is for atomicity. Atomicity, as the name implies, describes a unit that cannot be further divided. The word atom comes from the Greek atomos, which means indivisible. In the earlier discussion about transactions, such as transferring funds from your savings account to your checking account, you learned that all the steps had to complete or none of them completed. In essence, the set of steps is indivisible. You have to complete all of them as a single indivisible unit, or you complete none of them.
C is for consistency. In relational databases, this is known as strict consistency. In other words, a transaction does not leave a database in a state that violates the integrity of data. Transferring $100 from your savings account to your checking account must end with either (a) $100 more in your checking account and $100 less in your savings account or (b) both accounts have the same amount as they had at the start of the transaction. Consistency ensures no other possible state could result after a transfer operation.
I is for isolation. Isolated transactions are not visible to other users until transactions are complete. For example, in the case of a bank transfer from a savings account to a checking account, someone could not read your account balances while the funds are being deducted from your savings account but before they are added to your checking account. Databases can allow different levels of isolation. This can allow, for example, lost updates in which a query returns data that does not reflect the most recent update because the update operation has not completely finished.
D is for durability. This means that once a transaction or operation is completed, it will remain even in the event of a power loss. In effect, this means that data is stored on disk, flash, or other persistent media.
Relational database management systems are designed to support ACID transactions. NoSQL databases typically support BASE transactions, although some NoSQL databases also provide some level of support for ACID transactions.
BASE: Basically Available, Soft State, Eventually Consistent
BA is for basically available. This means that there can be a partial failure in some parts of the distributed system and the rest of the system continues to function. For example, if a NoSQL database is running on 10 servers without replicating data and one of the servers fails, then 10% of the users’ queries would fail, but 90% would succeed. NoSQL databases often keep multiple copies of data on different servers. This allows the database to respond to queries even if one of the servers has failed.
S is for soft state. Usually in computer science, the term soft state means data will expire if it is not refreshed. Here, in NoSQL operations, it refers to the fact that data may eventually be overwritten with more recent data. This property overlaps with the third property of BASE transactions, eventually consistent.
E is for eventually consistent. This means that there may be times when the database is in an inconsistent state. For example, some NoSQL databases keep multiple copies of data on multiple servers. There is, however, a possibility that the multiple copies may not be consistent for a short period of time. This can occur when a user or program updates one copy of the data and other copies continue to have the old version of the data. Eventually, the replication mechanism in the NoSQL database will update all copies, but in the meantime, the copies are inconsistent.
The time it takes to update all copies depends on several factors, such as the load on the system and the speed of the network. Consider a database that maintains three copies of data. A user updates her address in one server. The NoSQL database management system automatically updates the other two copies. One of the other copies is on a server in the same local area network, so the update happens quickly. The other server is in a data center thousands of miles away, so there is a time delay in updating the third copy. A user querying the third server while the update is in progress might get the user’s old address while someone querying the first server gets the new address.
Types of Eventual Consistency
Eventual consistency is such an important aspect of NoSQL databases, it is worth further discussion.
There are several types of eventual consistency:
• Casual consistency
• Read-your-writes consistency
• Session consistency
• Monotonic read consistency
• Monotonic write consistency
Casual Consistency
Casual consistency ensures that the database reflects the order in which operations were updated. For example, if Alice changes a customer’s outstanding balance to $1,000 and one minute later Bob changes it to $2,000, all copies of the customer’s outstanding balance will be updated to $1,000 before they are updated to $2,000.
Read-Your-Writes Consistency
Read-your-writes consistency means that once you have updated a record, all of your reads of that record will return the updated value. You would never retrieve a value inconsistent with the value you had written. Let’s say Alice updates a customer’s outstanding balance to $1,500. The update is written to one server and the replication process begins updating other copies. During the replication process, Alice queries the customer’s balance. She is guaranteed to see $1,500 when the database supports read-your-writes consistency.
Session Consistency
Session consistency ensures read-your-writes consistency during a session. You can think of a session as a conversation between a client and a server or a user and the database. As long as the conversation continues, the database “remembers” all writes you have done during the conversation. If the session ends and you start another session with the same server, there is no guarantee it will “remember” the writes you made in the previous session. A session may end if you log off an application using the database or if you do not issue commands to the database for so long that the database assumes you no longer need the session and abandons it.
Monotonic Read Consistency
Monotonic read consistency ensures that if you issue a query and see a result, you will never see an earlier version of the value. Let’s assume Alice is yet again updating a customer’s outstanding balance. The outstanding balance is currently $1,500. She updates it to $2,500. Bob queries the database for the customer’s balance and sees that it is $2,500. If Bob issues the query again, he will see the balance is $2,500 even if all the servers with copies of that customer’s outstanding balance have not updated to the latest value.
Monotonic Write Consistency
Monotonic write consistency ensures that if you were to issue several update commands, they would be executed in the order you issued them. Let’s consider a variation on the outstanding balance example. Alice is feeling generous today and decides to reduce all customers’ outstanding balances by 10%. Charlie, one of her customers, has a $1,000 outstanding balance. After the reduction, Charlie would have a $900 balance. Now imagine if Alice continues to process orders. Charlie has just ordered $1,100 worth of material. His outstanding balance is now the sum of the previous outstanding balance ($900) and the amount of the new order ($1,100) or $2,000.
Now consider what would happen if the NoSQL database performed Alice’s operations in a different order. Charlie started with a $1,000 outstanding balance. Next, instead of having the discount applied, his record was first updated with the new order ($1,100). His outstanding balance becomes $2,100. Now, the 10% discount operation is executed and his outstanding balance is set to $2,100–$210 or $1890.
Monotonic write consistency is obviously an important feature. If you cannot guarantee the order of operations in the database, you would have to build features into your program to guarantee operations execute in the order you expect.
Four Types of NoSQL Databases
Distributed databases come in several forms. Distributed relational databases exist but are not within the scope of this book. Instead, the focus here is on NoSQL databases. The most widely used types of NoSQL databases are
• Key-value pair databases
• Document databases
• Column family store databases
• Graph databases
NoSQL databases do not have to be implemented as distributed systems. Many can run on a single server. Some of the most interesting and appealing features of NoSQL databases, however, require a distributed implementation. When availability and scalability are top concerns, it makes sense to implement a NoSQL database across multiple servers. As soon as you enter the realm of distributed systems, you are faced with decisions and trade-offs not found in single-server implementations. As you design your NoSQL databases and related applications, consider how you want to balance your need for scalability, availability, consistency, partition protection, and durability. These topics are central to NoSQL databases and are addressed repeatedly throughout this book.
Key-Value Pair Databases
Key-value pair databases are the simplest form of NoSQL databases. These databases are modeled on two components: keys and values.
Keys
Keys are identifiers associated with values. They are analogous to tags you get when you check luggage at the airport. The tag you receive has an identifier associated with your luggage. With your tag, you can find your luggage more efficiently than without it. Imagine you have a connecting flight and your luggage did not make it to your connecting flight. If your luggage doesn’t have a tag, an airline employee searching for your bag would have to look through all undelivered bags to determine which is yours.
Now imagine that the airline organizes undelivered bags by tag number. If the airline employee knows your ticket number, she or he could go right to that spot in the luggage area to retrieve your bag.
Airlines generate luggage tags when you check a bag. If you were assigned the task of designing a ticket-generating program, you might decide to have tickets with two parts: a flight number and a sequential number.
![]() Note
Note
This is an oversimplified scheme because it does not account for flights with the same number that occurs on different days, but we will continue with it anyway.
The first customer checking bags on flight 1928 might be assigned ticket 1928.1 for her first bag and 1928.2 for her second bag. The second customer also has two bags and he is assigned 1928.3 and 1928.4 (see Figure 2.10).
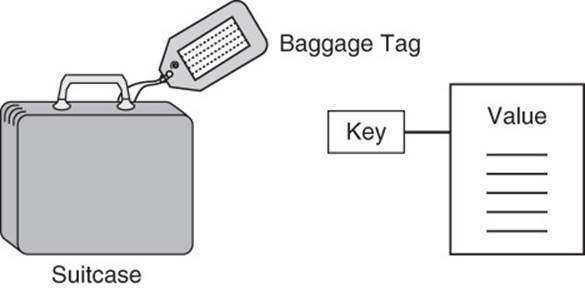
Figure 2.10 Airline tags for checked bags are analogous to keys used to store data in a key-value database.
You can use a similar approach when generating keys in a key-value database. Let’s assume you are building a key-generating program for an e-commerce website. You realize you need to track five pieces of information about each visitor to your site: the customer’s account number, name, address, number of items in the shopping cart, and customer type indicator. The customer type indicator identifies customers enrolled in the company’s loyalty program.
All of these values are associated with a customer, so you can generate a sequential number for each customer. For each item you are storing, you create a new key by appending the name of the item you are storing to the customer number. For example, data about the first customer in the system would use keys 1.accountNumber, 1.name, 1.address, 1.numItems, and 1.custType (see Figure 2.11).
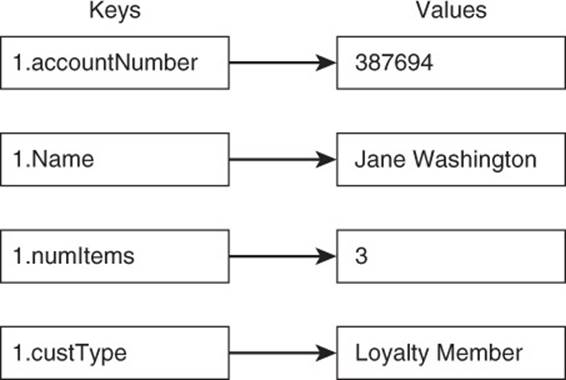
Figure 2.11 Key-value databases are modeled on a simple, two-part data structure consisting of an identifier and a data value.
This approach would work when you have a relatively simple database. If you need to track other entities, such as product information, warehouses, and shipping providers, you might want to use a similar sequential numbering system. Take warehouses, for example. You might want to track the closest warehouse to a customer that has the products listed in the shopping cart. This can help determine an estimated delivery date. For each warehouse, you need to track its warehouse number and its address. If you use a sequential number generator for warehouses that is different from the one used with customers, you could generate the following keys for the first warehouse: 1.number and 1.address.
The 1.address key is used for both a customer and a warehouse. This will cause problems because data about customers and warehouses will be saved with the same key. If you add a warehouse to your key-value database using 1.address and then save a customer’s address using 1.address, the next time you look up the warehouse’s address, you will find a customer’s address instead.
One way to address this problem is to use a key-naming convention that includes the entity type. For example, you could use the prefix cust for customer and wrhs for warehouse. You can append the sequentially generated numbers to these prefixes to create unique keys. The keys for the customer data would look like the following:
• cust1.accountNumber
• cust1.name
• cust1.address
• cust1.numItems
• cust1.custType
• cust2.accountNumber
• cust2.name
• cust2.address
• cust2.numItems
• cust2.custType
and so on. Similarly, the keys for the warehouse data would be
• wrhs1.number
• wrhs1.address
• wrhs2.number
• wrhs2.address
The important principle to remember about keys is that they must be unique. Of course, someone building a key-value database at Company A might use the same keys as someone at Company B. This is not a problem because the two databases are separate. There is no chance of one company reading or writing to the other database. In database terminology, the keys in these two companies are in different namespaces. A namespace is a collection of identifiers. Keys must be unique within a namespace.
A namespace could correspond to an entire database. In this case, all keys in the database must be unique. Some key-value databases provide for different namespaces within a database. This is done by setting up data structures for separate collections of identifiers within a database. This book refers to these data structures as buckets (see Figure 2.12).
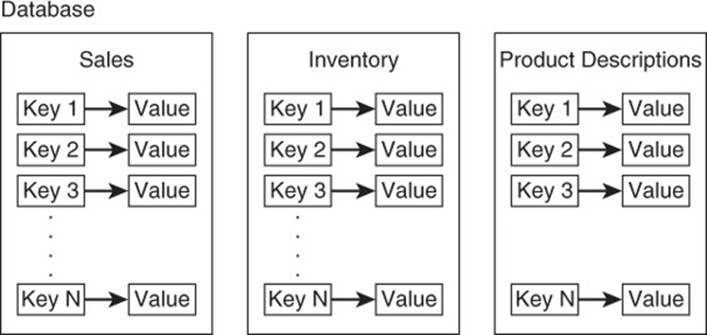
Figure 2.12 Key-value databases may support separate namespaces within a single database.
![]() Note
Note
If you are familiar with SQL databases, you might notice a similarity to schemas in relational databases.
Values
Values are data stored along with keys. Like luggage, values in a key-value database can store many different things. Values can be as simple as a string, such as a name, or a number, such as the number of items in a customer’s shopping cart. You can store more complex values, such as images or binary objects, too.
Key-value databases give developers a great deal of flexibility when storing values. For example, strings can vary in length. Cust123.address could be “543 N. Main St.” or “543 North Main St. Portland, OR 97222.” Values can also vary in type. An employee database might include photos of employees using keys such as Emp328.photo. That key could have a picture stored as a binary large object (BLOB) type or a string value such as “Not available.” Key-value databases typically do not enforce checks on data types of values.
Because key-value databases allow virtually any data type in values, it is important for software developers to implement checks in their programs. For example, a program that expects either a BLOB or a string with a value of “Not available” might not function as expected if the string “No photo” is used instead. A programmer might decide to support any BLOB or string as valid values, but it is up to the programmer to determine the range of valid values and enforce those choices as needed.
Differences Between Key-Value and Relational Databases
Key-value databases are modeled on minimal principles for storing and retrieving data. Unlike in relational databases, there are no tables, so there are no features associated with tables, such as columns and constraints on columns. There is no need for joins in key-value databases, so there are no foreign keys. Key-value databases do not support a rich query language such as SQL.
Some key-value databases support buckets, or collections, for creating separate namespaces within a database. This can be used to implement something analogous to a relational schema, especially when combined with a key-naming convention like the one described previously.
If you have developed relational data models, you might have noticed parallels between the key-naming convention and tables, primary keys, and columns. The key-naming convention described previously basically uses the convention of concatenating a table name or symbol, a primary key, and a column name. For example, the key ‘cust123.address’ would be equivalent to a relational table named cust or customer, with a column called address, and a row identified by the primary key ID of 123 (see Figure 2.13).
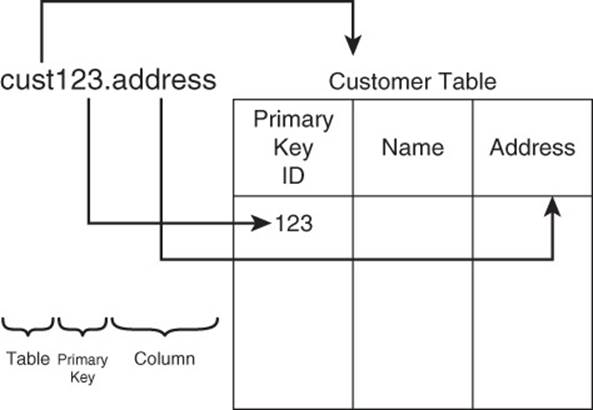
Figure 2.13 The key-naming convention outlined above maps to patterns seen in relational database tables.
Document Databases
Document databases, also called document-oriented databases, use a key-value approach to storing data but with important differences from key-value databases. A document database stores values as documents. In this case, documents are semistructured entities, typically in a standard format such as JavaScript Object Notation (JSON) or Extensible Markup Language (XML). It should be noted that when the term document is used in this context, it does not refer to word processing or other office productivity files. It refers to data structures that are stored as strings or binary representations of strings.
Documents
Instead of storing each attribute of an entity with a separate key, document databases store multiple attributes in a single document.
Here is a simple example of a document in JSON format:
{
firstName: "Alice",
lastName: "Johnson",
position: "CFO",
officeNumber: "2-120",
officePhone: "555-222-3456",
}
One of the most important characteristics of document databases is you do not have to define a fixed schema before you add data to the database. Simply adding a document to the database creates the underlying data structures needed to support the document.
The lack of a fixed schema gives developers more flexibility with document databases than they have with relational databases. For example, employees can have different attributes than the ones listed above. Another valid employee document is
{
firstName: "Bob",
lastName: "Wilson",
position: "Manager",
officeNumber: "2-130",
officePhone: "555-222-3478",
hireDate: "1-Feb-2010",
terminationDate: "12-Aug-2014"
}
The attributes hireDate and terminationDate are in Bob’s document but not Alice’s. This is not a problem from the database perspective. Developers can add attributes as needed, but their programs are responsible for managing them. If you expect all employee documents to have first and last names, you should implement a check in your code that adds employee documents to ensure that the rule is enforced.
Querying Documents
You might be wondering, why couldn’t you store JSON or XML documents in key-value databases? Because key-value databases have few restrictions on the type of data stored as a value, you could store a JSON document as a value. The only way to retrieve such a document is by its key, however.
Document databases provide application programming interfaces (APIs) or query languages that enable you to retrieve documents based on attribute values. For example, if you have a database with a collection of employee documents called “employees,” you could use a statement such as the following to return the set of all employees with the position Manager:
db.employees.find( { position:"Manager" })
As with relational databases, document databases typically support operators such as AND, OR, greater than, less than, and equal to.
Differences Between Document and Relational Databases
As noted, a key distinction between document and relational databases is that document databases do not require a fixed, predefined schema.
Another important difference is that documents can have embedded documents and lists of multiple values within a document. For example, the employee documents might include a list of previous positions an employee held within the company. For example:
{
firstName: "Bob",
lastName: "Wilson",
positionTitle: "Manager",
officeNumber: "2-130",
officePhone: "555-222-3478",
hireDate: "1-Feb-2010",
terminationDate: "12-Aug-2014"
PreviousPositions: [
{ \position: "Analyst",
StartDate:"1-Feb-2010",
endDate:"10-Mar-2011"
} {
position: "Sr. Analyst",
startDate: "10-Mar-2011"
endDate:"29-May-2013"
} ]
}
Embedding documents or lists of values in a document eliminates the need for joining documents the way you join tables in a relational database. If there are cases where you stored a list of document identifiers in a document and want to look up attributes in the documents associated with those identifiers, then you would have to implement that operation in your program.
Document databases are probably the most popular type of NoSQL database. They offer support for querying structures with multiple attributes, like relational databases, but offer more flexibility with regard to variation in the attributes used by each document.
The next section discusses the column family database, which is another type of NoSQL database that shares some important characteristics with relational databases.
Column Family Databases
Column family databases are perhaps the most complex of the NoSQL database types, at least in terms of the basic building block structures. Column family databases share some terms with relational databases, such as rows and columns, but you must be careful to understand important differences between these structures.
These differences are discussed in Chapters 9 through 11. In the meantime, let’s examine the basic building blocks of column family databases.
Columns and Column Families
A column is a basic unit of storage in a column family database. A column is a name and a value. (Some column family databases keep a time stamp along with a name and value, but let’s ignore that for now.) See Figure 2.14.
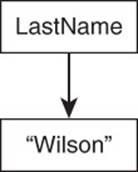
Figure 2.14 A column consists of a name and a value. In this example, the column is named lastName and has a value of “Wilson.”
A set of columns makes up a row. Rows can have the same columns, or they can have different columns, as shown in Figure 2.15.
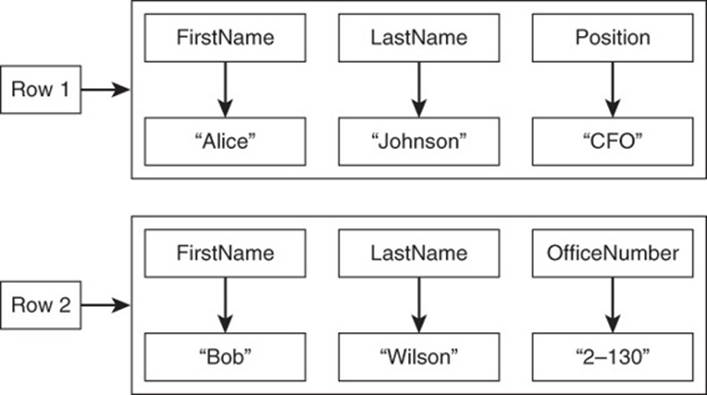
Figure 2.15 A row consists of one or more columns. Different rows can have different columns.
When there are large numbers of columns, it can help to group them into collections of related columns. For example, first and last name are often used together, and office numbers and office phone numbers are frequently needed together. These can be grouped in collections called column families.
As in document databases, column family databases do not require a predefined fixed schema. Developers can add columns as needed. Also, rows can have different sets of columns and super columns. Column family databases are designed for rows with many columns. It is not unusual for column family databases to support millions of columns.
Differences Between Column Family and Relational Databases
Column family databases and relational databases are superficially similar. They both make use of rows and columns, for example. There are important differences in terms of data models and implementation details.
One thing missing from column family databases is support for joining tables. You might have noticed that the term table has not been used when describing column family databases. This is intentional. Tables in relational databases have a relatively fixed structure, and the relational database management system can take advantage of that structure when optimizing the layout of data on drives and when retrieving data for read operations. Unlike a relational database table, however, the set of columns in a column family table can vary from one row to another.
In relational databases, data about an object can be stored in multiple tables. For example, a customer might have name, address, and contact information in one table; a list of past orders in another table; and a payment history in another. If you needed to reference data from all three tables at once, you would need to perform a join operation between tables. Column family databases are typically denormalized, or structured so that all relevant information about an object is in a single, possibly very wide, row.
Query languages for column family databases may look similar to SQL. The query language can support SQL-like terms such as SELECT, INSERT, UPDATE, and DELETE as well as column family–specific operations, such as CREATE COLUMNFAMILY.
The next section discusses a fourth type of NoSQL databases known as graph databases, which are well suited for addressing problems that require representing many objects and links between those objects. Social media, a transportation network, and an electric grid are just a few examples of areas where graph databases may be used.
Graph Databases
Graph databases are the most specialized of the four NoSQL databases discussed in this book. Instead of modeling data using columns and rows, a graph database uses structures called nodes and relationships (in more formal discussions, they are called vertices and edges). A node is an object that has an identifier and a set of attributes. A relationship is a link between two nodes that contain attributes about that relation.
Nodes and Relationships
There are many ways to use graph databases. Nodes can represent people, and relationships can represent their friendships in social networks. A node could be a city, and a relationship between cities could be used to store information about the distance and travel time between cities. Figure 2.16 includes an example of flying times between several cities.
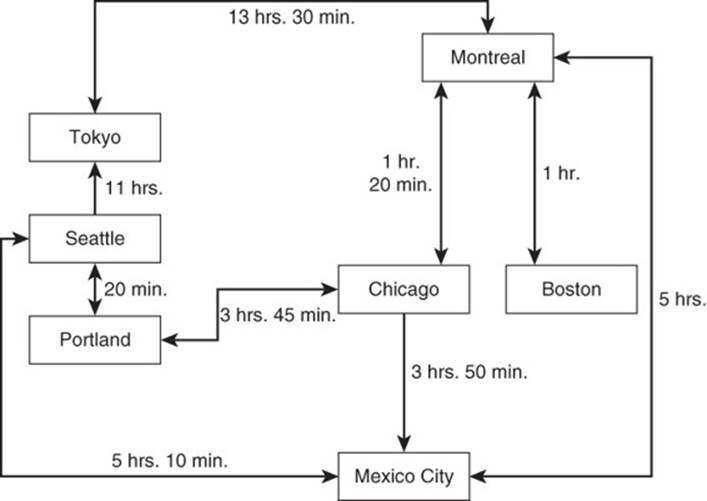
Figure 2.16 Properties of relationships or nodes store attributes about relations between linked nodes. In this case, attributes include flying times between cities.
Both the nodes and relationships can have complex structures. For example, each city can have a list of airports along with demographic and geographic data about the city, as shown in Figure 2.17.

Figure 2.17 Nodes can also have attributes to describe the node. In this case, attributes include information about the airports in the city along with population and geographic area.
Graph databases get their name from a branch of mathematics called graph theory. Graph theory is the study of objects represented by vertices and relations represented by edges. Graph theory is not related to the study of charts and other visualizations sometimes referred to as graphs.
Differences Between Graph and Relational Databases
Graph databases are designed to model adjacency between objects. Every node in the database contains pointers to adjacent objects in the database. This allows for fast operations that require following paths through a graph.
For example, if you wanted to find all possible ways to fly from Montreal to Mexico City using the graph you saw in Figure 2.16, you could start at the Montreal node and follow each of the adjacent nodes to Boston, Chicago, and Tokyo, and then to Mexico City. At the Boston node, you would find no relationship with Mexico City and assume that there are no direct flights available from Boston to Mexico City. From Chicago, a direct flight to Mexico City would take 3 hours and 50 minutes. That time, plus the 1 hour and 20 minutes to fly to Chicago would leave a total flying time of 5 hours and 10 minutes.
Flying from Montreal to Tokyo to get to Mexico City is possible but hardly efficient. Because the relationship between Montreal and Tokyo shows a 13 hour 30 minute flight, over twice as long as the Montreal to Chicago to Mexico City route, you can safely stop following other routes from Tokyo to Mexico City. From Chicago, you could fly to Portland, but like Boston, this does not lead to a direct flight to Mexico City. Finally, a direct flight from Montreal to Mexico City would take 5 hours, the fastest route available.
Performing this same kind of analysis in a relational database would be more involved. We could easily represent the same data shown in Figure 2.16 using a table such as the one shown in Table 2.1.
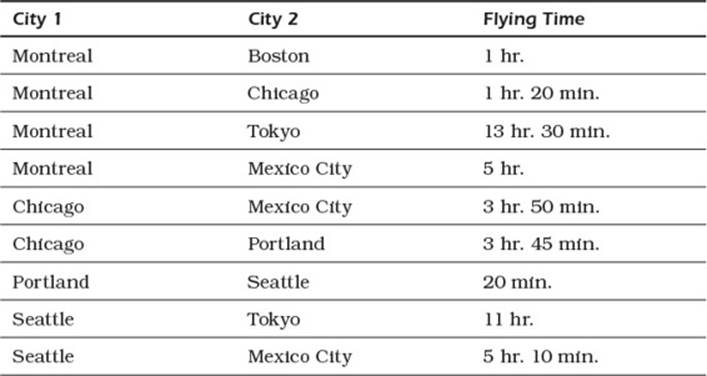
Table 2.1 Flight Times Between Cities Modeled as a Relational Table
Querying is more difficult. You would have to write multiple SQL statements or use specialized recursive statements if they are provided (for example, Oracle’s CONNECT BY clause in SELECT statements) to find paths using the table representation of the data.
Graph databases allow for more efficient querying when paths through graphs are involved. Many application areas are efficiently modeled as graphs and, in those cases, a graph database may streamline application development and minimize the amount of code you would have to write.
The most widely used types of NoSQL databases are key-value, document, column family, and graph databases. The following chapters describe each of these in depth and present examples of typical use cases for each.
Summary
NoSQL databases are often deployed using clusters of servers. When applications run on multiple servers and coordinate their work across servers, they are known as distributed systems. When you use NoSQL databases in a distributed manner, you will have to decide how to address the challenges that come with that type of implementation. Distributed systems help improve scalability and availability but make it more difficult to ensure consistency of data across servers. There are also potential problems if there is a network failure and some servers cannot send messages to other servers in the distributed database system.
The nature of distributed systems has led NoSQL database designers to choose a different set of principles for building data management systems. Rather than support atomic, consistent, isolated, and durable transactions (ACID), NoSQL databases achieve basic availability, soft state, eventually consistent (BASE). (Some NoSQL databases are working to support ACID transactions, at least in some cases.)
The four types of NoSQL databases described in this chapter all must address the challenges of distributed systems. The types of NoSQL database systems differ primarily in the basic data structures used to model data. The different data structure choices lead to different implementation details. Developers who work with NoSQL databases should understand how the nature of distributed systems could affect their applications, and they should know how to choose among NoSQL databases for their requirements. The rest of this book is dedicated to informing you about those topics.
Review Questions
1. What is a distributed system?
2. Describe a two-phase commit. Does it help ensure consistency or availability?
3. What do the C and A in the CAP theorem stand for? Give an example of how designing for one of those properties can lead to difficulties in maintaining the other.
4. The E in BASE stands for eventually consistent. What does that mean?
5. Describe monotonic write consistency. Why is it so important?
6. How many values can be stored with a single key in a key-value database?
7. What is a namespace? Why is it important in key-value databases?
8. How do document databases differ from key-value databases?
9. Describe two differences between document databases and relational databases.
10. Name two data structures used in column family databases.
11. What are the two fundamental data structures in a graph database?
12. You are assigned the task of building a database to model employees and who they work with in your company. The database must be able to answer queries such as how many employees does Employee A work with? And, does Employee A work with anyone who works with Employee B? Which type of NoSQL database would naturally fit with these requirements?
References
Brewer, Eric. “CAP Twelve Years Later: How the ‘Rules’ Have Changed.” Computer vol. 45, no. 2 (Feb 2012): 23–29
Chodorow, Kristina. MongoDB: The Definitive Guide. Sebastopol, CA: O’Reilly Media, Inc., 2013.
Hewitt, Eben. Cassandra: The Definitive Guide. Sebastopol, CA: O’Reilly Media, Inc., 2010.
Robinson, Ian, Jim Webber, and Emil Eifrem. Graph Databases. Sebastopol, CA: O’Reilly Media, Inc., 2013.
Vogel, Werner. 2008. “Eventually Consistent—Revisited” (December). http://www.allthingsdistributed.com/2008/12/eventually_consistent.html
Bibliography
Hernandez, Michael J. Data Design for Mere Mortals: A Hands-On Guide to Relational Database Design. Reading, MA: Addison-Wesley, 2007.
Viescas, John L., and Michael J. Hernandez. SQL Queries for Mere Mortals. Reading, MA: Addison-Wesley, 2007.