NoSQL for Mere Mortals (2015)
Part II: Key-Value Databases
Chapter 3. Introduction to Key-Value Databases
“Everything should be made as simple as possible, but no simpler.”
—ALBERT EINSTEIN
Topics Covered In This Chapter
From Arrays to Key-Value Databases
Essential Features of Key-Value Databases
Properties of Keys
Characteristics of Values
Key-value databases are the simplest of the NoSQL databases and are a good place to start a detailed examination of NoSQL database options. As the name implies, the design of this type of data store is based on storing data with identifiers known as keys. This chapter introduces key-value data structures by starting with an even simpler data structure: the array.
A key-value data store is a more complex variation on the array data structure. Computer scientists have extended the concept of an array by relaxing constraints on the simple data structure and adding persistent data storage features to create a range of other useful data structures, including associative arrays, caches, and persistent key-value databases.
In this chapter, you learn about key characteristics of key-value data stores as well as about keys and values themselves. You also see some important operational characteristics of key-value databases.
Before jumping into database-specific topics, the next section sets the stage for key-value databases with a slight diversion into introductory data structures.
From Arrays to Key-Value Databases
Relational databases did not spring from the mind of computer scientists at the dawn of computing. Chapter 1, “Different Databases for Different Requirements,” describes the development of databases as a series of increasingly more complex systems that are better able to manage increasingly more complex data management challenges. The high points of that progression are relational and NoSQL databases.
It helps to start an examination of key-value databases by starting with a simple data structure and showing how adding features to a simple data structure can lead to a simple but even more useful type of database.
Arrays: Key Value Stores with Training Wheels
One of the first data structures taught to computer science students is the array. After scalar variables, like integers and characters, the array is one of the simplest. An array is an ordered list of values. Each value in the array is associated with an integer index. The values are all the same type. For example, an array could be an ordered list of integers, characters, or Boolean values. Figure 3.1 shows an array of 10 Boolean elements.
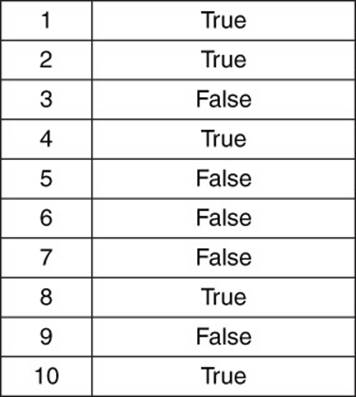
Figure 3.1 An array is an ordered list of elements. All elements are of the same type. The value of each element of the array is read and set by reference to its index.
The syntax for reading and setting array values varies by programming language. In this book, to read the first element of an array named exampleArray, you would use
exampleArray[0]
![]() Note
Note
It is common practice in programming languages to use zero instead of one as the first element of an array.
The convention for reading from an array is to use the name of the array followed by an [, an integer index, and then a ]. To set the value of an array element, use the same syntax for reading an element and follow it with an assignment symbol, in this case a ‘=’, and the value to be assigned to that element. For example,
exampleArray[0] = 'Hello world.'
sets the first element of exampleArray to the string of characters ‘Hello world.’ Additional elements can be set with the following commands:
exampleArray[1] = 'Goodbye world.'
exampleArray[2] = 'This is a test.'
exampleArray[5] = 'Key-value database'
exampleArray[9] = 'Elements can be set in any order.'
exampleArray is an array in which all elements are strings of characters. You could not, for example, set an element of exampleArray to a real number. The following command would generate an error:
exampleArray[6] = 3.1415
You might see the two following limitations when working with arrays:
• The index can only be an integer.
• The values must all have the same type.
Sometimes it is useful to have a data structure that does not have these limitations.
Associative Arrays: Taking Off the Training Wheels
An associative array is a data structure, like an array, but is not restricted to using integers as indexes or limiting values to the same type. You could, for example, have commands such as the following:
exampleAssociativeArray['Pi'] = 3.1415
exampleAssociativeArray['CapitalFrance'] = 'Paris'
exampleAssociativeArray['ToDoList'] = { 'Alice' : 'run
reports; meeting with Bob', 'Bob' : 'order inventory;
meeting with Alice' }
exampleAssociativeArray[17234] = 34468
Associative arrays generalize the idea of an ordered list indexed by an identifier to include arbitrary values for identifiers and values (see Figure 3.2). As the previous examples show, keys can be strings of characters or integers. Depending on the programming language or database, you may be able to use keys with even more complex data structures, such as a list of values.
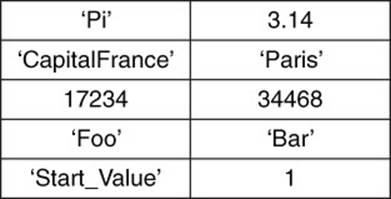
Figure 3.2 An associative array shares some characteristics of arrays but has fewer constraints on keys and values.
In addition, note that values stored in the associative array can vary. In the previous examples, there is a real number, a character string, a list, and an integer. The identifiers are generally referred to as keys. As you might have already guessed, associative arrays are the basic structure underlying the concept of key-value databases.
![]() Note
Note
Associative arrays go by a number of different names, including dictionary, map, hash map, hash table, and symbol table.
Caches: Adding Gears to the Bike
Key-value databases build on the concept of an associative array, but there are important differences. Many key-value data stores keep persistent copies of data on long-term storage, such as hard drives or flash devices. Some key-value data stores only keep data in memory. These are typically used so programs can access data faster than if they had to retrieve data from disk drives (see Figure 3.3). The first time a piece of data is retrieved from a disk, for example, as the result of a SQL query in a relational database, it is stored in the cache along with a set of unique keys. A SQL query such as the following retrieves name and shipping address information from a relational table called customers:
SELECT
firstName,
lastName,
shippingAddress,
shippingCity,
shippingState,
shippingZip
from
customers
where
customerID = 1982737
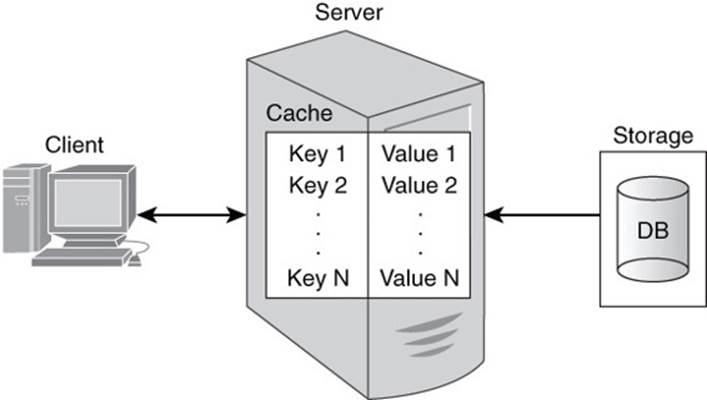
Figure 3.3 Caches are associative arrays used by application programs to improve data access performance.
Only the information for the customer with the customerID of 1982737 is retrieved.
The program could run faster if it retrieved data from memory rather than from the database. The first time the program fetches the data, it will need to read from the disk but after that the results can be saved in memory.
![]() Tip
Tip
If the program is relatively simple and only needs to track one customer at a time, then the application programmer could use character-string variables to store the customer name and address information. When a program must track many customers and other entities at the same time, then using a cache makes more sense.
An in-memory cache is an associative array. The values retrieved from the relational database could be stored in the cache by creating a key for each value stored. One way to create a unique key for each piece of data for each customer is to concatenate a unique identifier with the name of the data item. For example, the following stores the data retrieved from the database in an in-memory cache:
customerCache['1982737:firstname'] = firstName
customerCache['1982737:lastname'] = lastName
customerCache['1982737:shippingAddress'] = shippingAddress
customerCache['1982737:shippingCity'] = shippingCity
customerCache['1982737:shippingState'] = shippingState
customerCache['1982737:shippingZip'] = shippingZip
Because the customerID is part of the key, the cache can store data about as many customers as needed without creating separate program variables for each set of customer data.
Programs that access customer data will typically check the cache first for data and if it is not found in the cache, the program will then query the database. Here is sample pseudocode for a getCustomer function:
define getCustomer(p_customerID):
begin
if exists(customerCache['1982737:firstName]),
return(
customerCache[p_customerID
+':lastname'],
customerCache[p_customerID
+':shippingAddress'],
customerCache[p_customerID
+':shippingCity'],
customerCache['p_customerID
+':shippingState'],
customerCache[p_customerID
+'':shippingZip']
);
else
return(addQueryResultsToCache(p_customerID,
'SELECT
firstName,
lastName,
shippingAddress,
shippingCity,
shippingState,
shippingZip
FROM
customers
WHERE
customerID = p_customerID')
end;
);
The pseudocoded function takes one parameter, p_customerID, which is a unique identifier of the customer. The if statement checks if there exists a key in the cache that consists of the customer identifier passed in as a parameter and the character string 'firstName'. If it does exist, then it is safe to assume that all the attributes about the customer are in the cache and can be returned from the cache. If the customer’s first name is not in the cache, the function executes another function called addQueryResultsToCache. This function takes a key, and SQL query returns the data associated with that key. The function also stores a copy of the returned data in the cache so it is available next time the getCustomer function is called.
![]() Caution
Caution
Like arrays in programming languages, when the server is shut down or the cache terminates, the data in memory is lost. The next time the application starts, it will have to reload the cache with data by executing statements like the SQL statement in the getCustomer function.
Although caches are types of key-value data stores, they are outside the scope of this book. The following discussion about key-value databases applies to key-value stores that save data persistently.
In-Memory and On-Disk Key-Value Database: From Bikes to Motorized Vehicles
Caches are helpful for improving the performance of applications that perform many database queries. Key-value data stores are even more useful when they store data persistently on disk, flash devices, or other long-term storage. They offer the fast performance benefits of caches plus the persistent storage of databases.
Key-value databases impose a minimal set of constraints on how you arrange your data. There is no need for tables if you do not want to think in terms of groups of related attributes.
![]() Note
Note
The one design requirement of a key-value database is that each value has a unique identifier in the form of the key. Keys must be unique within the namespace defined by the key-value database. The namespace can be called a bucket, a database, or some other term indicating a collection of key-value pairs (see Figure 3.4).
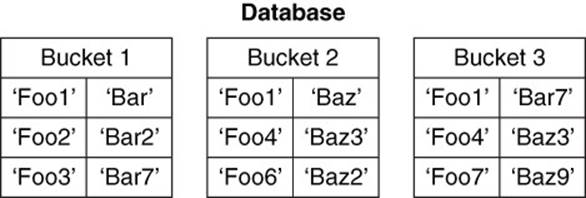
Figure 3.4 Keys of a key-value database must be unique within a namespace.
Developers tend to use key-value databases when ease of storage and retrieval are more important than organizing data into more complex data structures, such as tables or networks.
![]() Note
Note
Developers could readily implement networks and table-like data structures using key-value databases as a foundation. A developer could use a key-naming convention that uses a table name, primary key value, and an attribute name to create a key to store the value of an attribute, as shown in the following example:
customer:1982737:firstName
customer:1982737:lastName
customer:1982737:shippingAddress
customer:1982737:shippingCity
customer:1982737:shippingState
customer:1982737:shippingZip
Next, the developer can create a set of functions that emulate the operations performed on a table, such as creating, reading, updating, or deleting a row. One example of pseudocode for a create function is
define addCustomerRow(p_tableName, p_primaryKey,
p_firstName, p_lastName, p_shippingAddress,
p_shippingCity, p_shippingState, p_shippingZip)
begin
set [p_tableName+p_primary+'firstName'] = p_firstName;
set [p_tableName+p_primary+'lastName'] = p_lastName;
set [p_tableName+p_primary+'shippingAddress'] =
p_shippingAddress;
set [p_tableName+p_primary+'shippingCity'] =
p_shippingCity;
set [p_tableName+p_primary+'shippingState'] =
p_shippingState;
set [p_tableName+p_primary+'shippingZip'] =
p_shippingZip;
end;
The reading, updating, and deleting functions are equally as easy to write. (You will write a delete function later in the chapter as an exercise.)
Essential Features of Key-Value Databases
A variety of key-value databases is available to developers, and they all share three essential features:
• Simplicity
• Speed
• Scalability
These characteristics sound like an ideal combination that should be embraced by every database, but as you will see, there are limitations that come along with these valued features.
Simplicity: Who Needs Complicated Data Models Anyway?
Key-value databases use a bare-minimum data structure. You might wonder, why would anyone want to use a bare-minimum database when you could use a feature-rich relational database? The answer is that sometimes you do not need all those extra features.
Think about word processors. Microsoft Word, for example, has an impressive list of features, including a wide array of formatting options, spelling and grammar checkers, and even the ability to integrate with other tools like reference and bibliography managers.
These are just the kinds of tools you want in your word processor if you are writing a book or lengthy term paper. But what if you are writing a six-item to-do list on your phone? A full-featured word processor is more than you need. A simple text editor would do the job just as well. The same kind of situation can occur when design applications use a database for storage.
Often, developers do not need support for joining tables or running queries about multiple entities in the database. If you were implementing a database to store information about a customer’s online shopping cart, you could use a relational database, but it would be simpler to use a key-value database. You would not have to define a database schema in SQL. You would not have to define data types for each attribute you’d like to track.
If you discover that you would like to track additional attributes after you have written your program, you can simply add code to your program to take care of those attributes. There is no need to change database code to tell the database about the new attribute. Key-value databases have no problem working with adding new attributes as they come along.
In key-value databases, you work with a simple data model. The syntax for manipulating data is simple. Typically, you specify a namespace, which could be a database name, a bucket name, or some other type of collection name, and a key to indicate you want to perform an operation on a key-value pair. When you specify only the namespace name and the key, the key-value database will return the associated value. When you want to update the value associated with a key, you specify the namespace, key, and new value.
Key-value databases are flexible and forgiving. If you make a mistake and assign the wrong type of data, for example, a real number instead of an integer, the database usually does not complain. This feature is especially useful when the data type changes or you need to support two or more data types for the same attribute. If you need to have both numbers as strings for customer identifiers, you can do that with code such as the following:
shoppingCart[cart:1298:customerID] = 1982737
shoppingCart[cart:3985:customerID] = 'Johnson, Louise'
One of the advantages of simple data structures in computer science is that they are often associated with fast operations.
Speed: There Is No Such Thing as Too Fast
Major database vendors create tools to help developers and database administrators identify slow-running queries. Books are written on tuning databases. Software engineers comb their code for opportunities to cut down on the time required to run their code. It seems like no one wants to wait for his or her data.
Key-value databases are known for their speed. With a simple associative array data structure and design features to optimize performance, key-value databases can deliver high-throughput, data-intensive operations.
One way to keep database operations running fast is to keep data in memory. Reading and writing data to RAM is much faster than writing to a disk. Of course, RAM is not persistent storage, so if you lose power on your database server, you will lose the contents of RAM. Key-value databases can have the advantages of fast write operations to RAM and the persistence of disk-based storage by using both.
When a program changes the value associated with a key, the key-value database can update the entry in RAM and then send a message to the program that the updated value has been saved. The program can then continue with other operations. While the program is doing something else, the key-value database can write the recently updated value to disk. The new value is saved to disk unless there is a power loss or some other failure between the time the application updates the value and the key-value database stores the value on disk (see Figure 3.5).
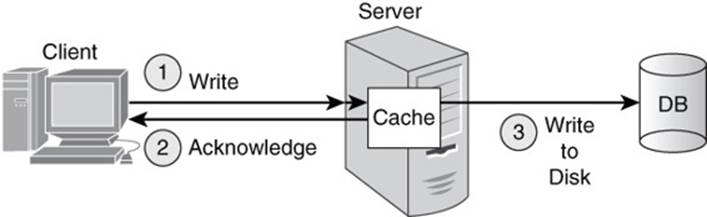
Figure 3.5 Write operations can return control to the calling application faster by first writing inserts and updates to RAM and then updating disk storage.
Similarly, read operations can be faster if data is stored in memory. This is the motivation for using a cache, as described earlier. Because the size of the database can exceed the size of RAM, key-value stores have to find ways of managing the data in memory.
![]() Tip
Tip
Compressing data is one way of increasing the effective storage capacity of memory, but even with compression there may not be sufficient memory to store a large key-value database completely in RAM.
When the key-value database uses all the memory allocated to it, the database will need to free some of the allocated memory before storing copies of additional data. There are multiple algorithms for this, but a commonly used method is known as least recently used (LRU). The idea behind the LRU algorithm is that if data has not been used in a while, it is less likely to be used than data that has been read or written more recently. This intuition makes sense for many application areas of key-value databases (see Figure 3.6).
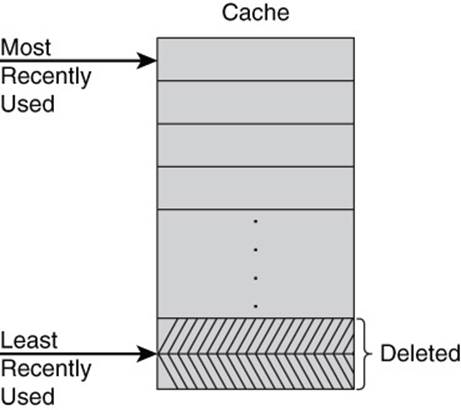
Figure 3.6 Least recently used algorithms delete data that has not been read or written as recently as other data.
Consider a key-value database used to store items in customers’ online carts. Assume that once a customer adds an item to the cart, it stays there until the customer checks out or the item is removed by a background cleanup process. A customer who finished shopping several hours ago may still have data in memory. More than likely, that customer has abandoned the cart and is not likely to continue shopping. Compare that scenario with a customer who last added an item to the cart five minutes ago. There is a good chance that customer is still shopping and will likely add other items to the cart or continue to the checkout process shortly.
Scalability: Keeping Up with the Rush
It is important for key-value databases, and other types of NoSQL databases used in web and other large-scale applications, to scale with minimal disruption to operations. Remember from Chapter 2, “Variety of NoSQL Databases,” that scalability is the capability to add or remove servers from a cluster of servers as needed to accommodate the load on the system. When you scale databases, the capability to accommodate both reads and writes is an important property. Key-value databases take different approaches to scaling read and write operations. Let’s consider two options:
• Master-slave replication
• Masterless replication
Scaling with Master-Slave Replication
One way to keep up with a growing demand for read operations is to add servers that can respond to queries. It is easy to imagine applications that would have many more reads than writes. During the World Cup finals, football fans around the world (and soccer fans in the United States) who have to work instead of watch the game would be checking their favorite sport score website for the latest updates. News sites would similarly have a greater proportion of reads than writes. Even e-commerce sites can experience a higher ratio of page views than data writes because customers may browse many descriptions and reviews for each item they ultimately end up adding to their shopping carts.
In applications such as this, it is reasonable to have more servers that can respond to queries than accept writes. A master-slave replication model works well in this case.
The master is a server in the cluster that accepts write and read requests. It is responsible for maintaining the master record of all writes and replicating, or copying, updated data to all other servers in the cluster. These other servers only respond to read requests. As Figure 3.7 shows, master-slave architectures have a simple hierarchical structure.
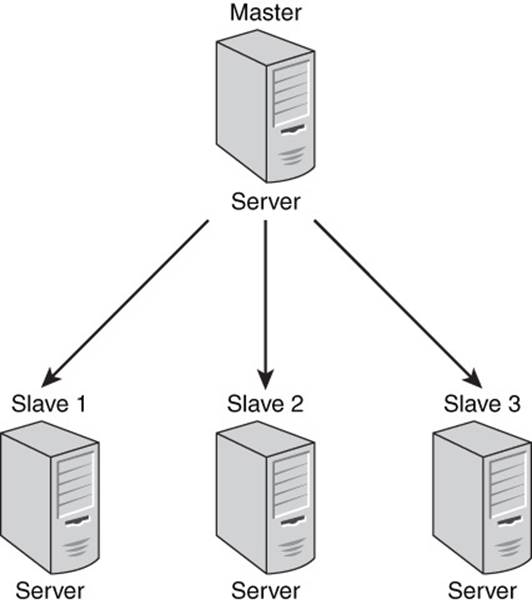
Figure 3.7 Master-slave architectures have a simple communication pattern during normal operations.
An advantage of master-slave models is simplicity. Except for the master, each node in the cluster only needs to communicate with one other server: the master. The master accepts all writes, so there is no need to coordinate write operations or resolve conflicts between multiple servers accepting writes.
A disadvantage of the master-slave replication model is that if the master fails, the cluster cannot accept writes. This can adversely impact the availability of the cluster The master server is known as a single point of failure—that is, a single component in a system that if it fails, the entire system fails or at least loses a critical capacity, such as accepting writes.
Designers of distributed systems have developed protocols so active servers can detect when other servers in the cluster fail. For example, a server may send a simple message to ask a random server in the cluster if it is still active. If the randomly selected server replies, then the first server will know the other server is active.
In the case of master-slave configurations, if a number of slave servers do not receive a message from the master within some period of time, the slaves may determine the master has failed. At that point, the slaves initiate a protocol to promote one of the slaves to master (see Figure 3.8). Once active as the master, the new master server begins accepting write operations and the cluster would continue to function, accepting both read and write operations.
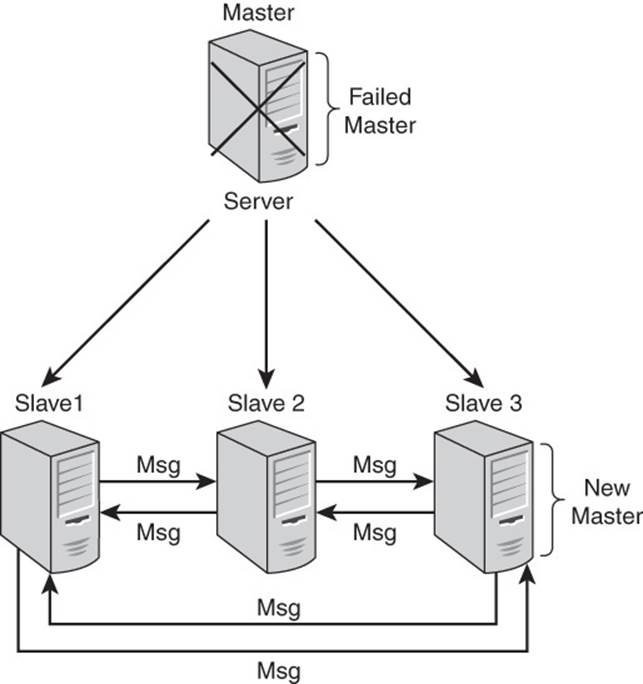
Figure 3.8 Once a failed master server is detected, the slaves initiate a protocol to elect a new master.
Scaling with Masterless Replication
The master-slave replication model with a single server accepting writes does not work well when there are a large number of writes. Imagine the Rolling Stones decide to have one more world tour. Fans around the world flock to buy concert tickets. The fans would generate a large number of reads when they look up the cities that will be hosting concerts, but once they find one or two close cities, they are ready to purchase tickets.
The software engineers who write the concert ticket program have a lot to think about, including
• Storing concert locations and dates.
• Available seats in each venue.
• Cost of seats in various sections.
• Any limits on the number of tickets purchased by a single customer.
• Ensuring that seats that appear to be available to a user are still available when the user chooses to purchase the ticket. This assumes the customer opts to buy the ticket almost immediately after seeing the availability.
There are probably many more requirements, but these are sufficient to give you a basic idea of the challenges the software engineers are up against.
With the possibility of a surge in the number of customers trying to write to the database, a single server accepting writes will limit scalability. A better option for this application is a masterless replication model in which all nodes accept reads and writes. An immediate problem that comes to mind is: How do you handle writes so that two or more servers do not try to sell the same seat in a concert venue to multiple customers? (See Figure 3.9.)
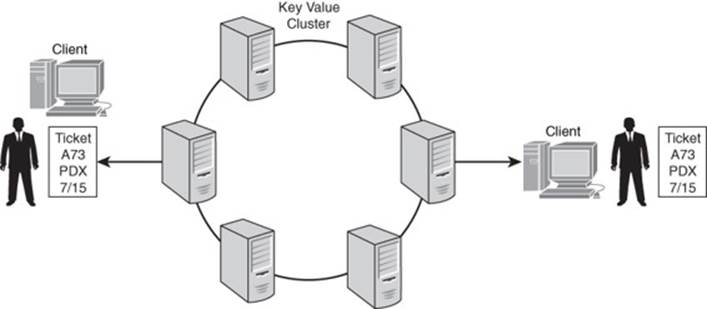
Figure 3.9 A fan’s worst nightmare: Multiple fans are able to purchase tickets for the same seat.
There is an elegant solution to this problem that is described later in the “Keys: More Than Meaningless Identifiers” section. For now, let’s assume that only one customer can purchase a seat at a concert venue at a particular date and time. There is still the problem of scaling reads.
In a masterless replication model, there is not a single server that has the master copy of updated data, so no single server can copy its data to all other servers. Instead, servers in a masterless replication model work in groups to help their neighbors.
Consider a set of eight servers configured in a masterless replication model and set up in a ring structure. For simplicity, assume that the servers are named 1, 2, 3, and so on up to Server 8. In the ring structure, Server 1 is logically linked to Servers 2 and 8, Server 2 is linked to Servers 1 and 3, Server 3 is linked to Servers 2 and 4, and so on. Figure 3.10 shows the full configuration.
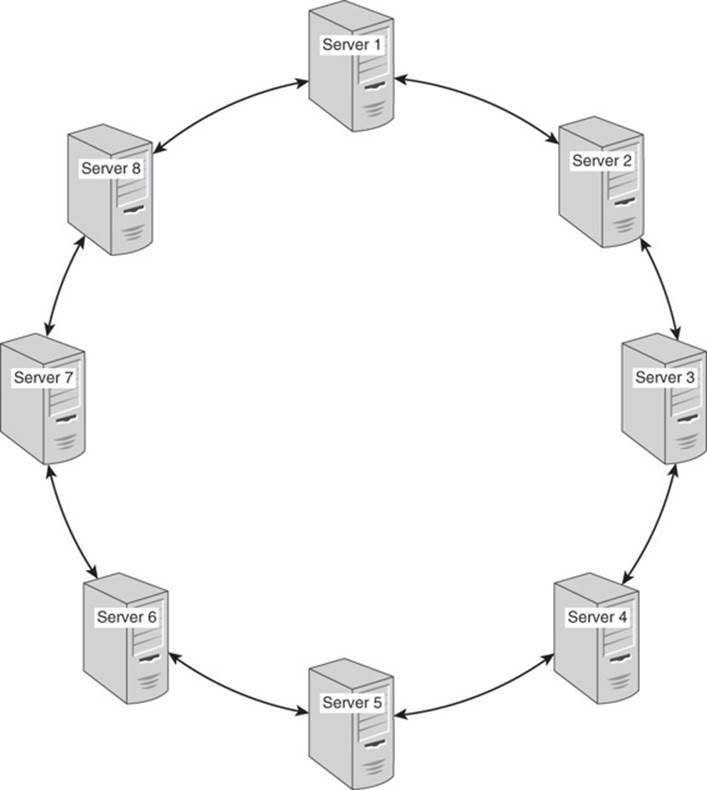
Figure 3.10 An eight-server cluster in a ring configuration.
![]() Note
Note
The ring structure is a useful abstraction for discussing replication in a masterless model. In a data center, the eight servers would probably all be connected to a single network hub and able to directly communicate with each other.
Database administrators can configure a key-value database to keep a particular number of replicas. In this scenario, the administrator has decided that four replicas are sufficient. Each time there is a write operation to one of the servers, it replicates that change to the three other servers holding its replica. In this scenario, each server replicates to its two neighbors and to the server two links ahead. For example, Server 2 replicates to its neighbors Server 1 and Server 3 as well as Server 4, which is two links ahead. Figure 3.11 shows the full replication pattern.
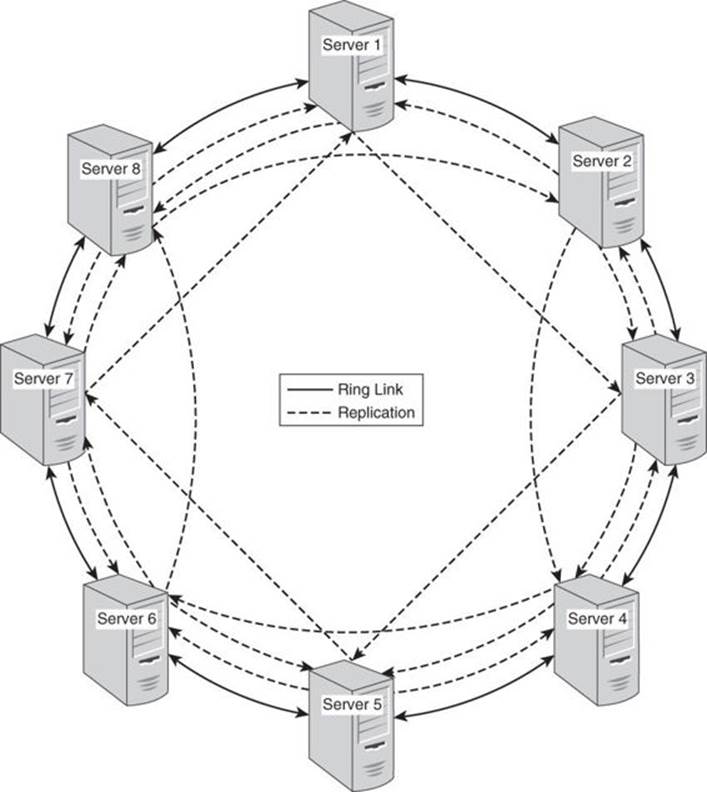
Figure 3.11 An eight-server cluster in a ring configuration with a replication factor of 4.
Now that you have had a basic introduction to the essential features of key-value data stores, it is time to drill down into some of the properties of two components: keys and values.
Keys: More Than Meaningless Identifiers
As already stated, keys are used to identify, index, or otherwise reference a value in a key-value database. The one essential property of a key is that it must be unique within a namespace. This makes keys sound pretty simple, and they are—sometimes.
How to Construct a Key
If you have worked with relational databases, you may have used counters or sequences to generate keys. Counters and sequences are functions that return a new unique number each time the function is called. Database application designers use these routinely to make keys for rows of data stored in a table. Each generated number is a unique identifier used by a row in a table.
Designers could use one counter to generate primary keys for all tables, or they could use a different counter or sequence for each table. Either way, each row in a table has a unique identifier. Just as keys in key-value databases must be unique in a namespace, the primary key of a row of data must be unique to the table.
![]() Tip
Tip
It is considered good practice to use meaningless keys in relational database design.
The sole purpose of a primary key, the reasoning goes, is to uniquely identify a row. If you were to use a property of the data, such as the last name and first initial of a customer, you might run into problems with duplicates. Also, values stored in rows may change.
For example, consider how quickly the meaning of a primary key would change if you used the two-letter state abbreviation of the state in which a customer lives as part of a key for that customer. You could have a key such as ‘SMITH_K_TX’ for a Katherine Smith who lives in Texas. If Katherine Smith moves to Illinois, then the primary key is no longer meaningful.
![]() Caution
Caution
Primary keys should not be changed, so you could not simply change the key to ‘SMITH_K_IL.’ That would violate the principle that primary keys are immutable. You could conceivably change a primary key (if the database management system allowed such updates), but you would have to update all references to that key in other tables.
Storing a primary key to a row in another table is known as a foreign key. As you can see, the way relational databases work, it makes sense to have meaningless keys.
In NoSQL databases, and key-value databases in general, the rules are different. Key-value databases do not have a built-in table structure. With no tables, there are no columns. With no columns, there is no way to know what a value is for except for the key. Consider a shopping cart application using a key-value database with meaningless keys:
Cart[12387] = 'SKU AK8912j4'
This key is the type of identifier you would likely see in a relational database. This key-value pair only tells you that a cart identified by number 12387 has an item called 'SKU AK8912j4'. You might assume from the value that SKU stands for stock keeping unit, a standard term in retail to refer to a specific type of product. However, you don’t know who this cart belongs to or where to ship the product.
One way to solve this problem is to create another namespace, such as custName. Then you could save a value such as
CustName[12387] = 'Katherine Smith'
This would solve the immediate problem of identifying who owns the cart, but you can see that this approach does not generalize well. Every attribute tracked in the application would need a separate namespace. Alternatively, you can use meaningful keys that entail information about attributes.
As discussed earlier, you can construct meaningful names that entail information about entity types, entity identifiers, and entity attributes. For example:
Cust:12387:firstName
could be a key to store the first name of the customer with customerID 12387. This is not the only way to create meaningful names, but it is the one used throughout this book. Again, the basic formula is
Entity Name + ':' + Entity Identifier +':' + Entity
Attribute
The delimiter does not have to be a ':' but it is a common practice.
Using Keys to Locate Values
Up to this point, there has been a fair amount of discussion about how to construct keys, why keys must be unique within a namespace, and why meaningful keys are more useful in key-value databases than relational databases. There has been some mention of the idea that keys are used to look up associated values, but there has been no explanation about how that happens. It is time to address that topic.
If key-value database designers were willing to restrict you to using integers as key values, then they would have an easy job of designing code to fetch or set values based on keys. They could load a database into memory or store it on disk and assume that the first value stored in a namespace is referenced by key 1, the next value by key 2, and so on. Fortunately, key-value designers are more concerned with designing useful data stores than simplifying data access code.
Using numbers to identify locations is a good idea, but it is not flexible enough. You should be able to use integers, character strings, and even lists of objects as keys if you want. The good news is that you can. The trick is to use a function that maps from integers, character strings, or lists of objects to a unique string or number. These functions that map from one type of value to a number are known as hash functions.
![]() Note
Note
Not all key-value databases support lists and other complex structures. Some are more restricted in the types and lengths of keys than others.
Hash Functions: From Keys to Locations
A hash function is a function that can take an arbitrary string of characters and produce a (usually) unique, fixed-length string of characters.
![]() Note
Note
Actually, the value returned by the hash function is not always unique; sometimes two unrelated inputs can generate the same output. This is known as a collision.
![]() Refer to Chapter 4, “Key-Value Database Terminology,” for information on how to deal with collisions.
Refer to Chapter 4, “Key-Value Database Terminology,” for information on how to deal with collisions.
For example, the keys mentioned earlier in the chapter to describe customer shipping information are mapped to hash values listed in Table 3.1.
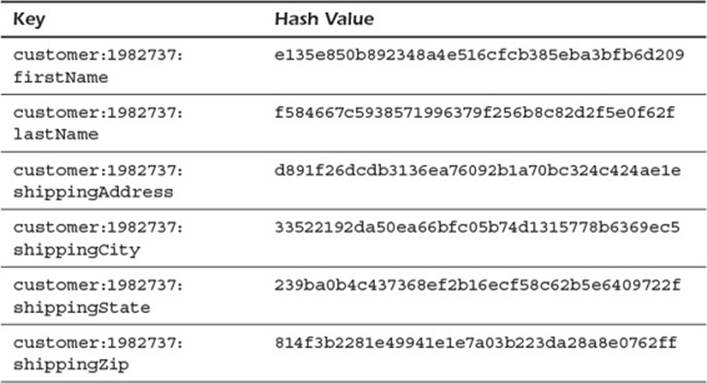
Table 3.1 Key to Hash Value Mappings
Each hash value is quite different from the others, although they all have the same 'customer:1982737:' prefix. One of the properties of hash functions is that they map to what appear to be random outputs. In this example, the SHA-1 hash function is used to generate the hash values.
The values are all numbers in hexadecimal, a base-16 number system. The hexadecimal integers are 0–9 and a–f, which represent 10–15. This is about 1.4615016e+48 different values. Needless to say, this should be plenty for any key-value database application.
Keys Help Avoid Write Problems
Now, let’s see how you can use the numbers returned by the hash function to map to a location. To keep things simple, the discussion focuses on using the number returned by a hash function to determine which server in a cluster should be used to store the value associated with the key. An actual key-value implementation would have to map to a location on disk or in memory, but that is beyond the scope of this discussion.
Assume you are working with the eight-server cluster that you saw in Figure 3.10. You can take advantage of the fact that the hash function returns a number. Because the write load should be evenly distributed across all eight servers, you can send one eighth of all writes to each server. You could send the first write to Server 1, the second to Server 2, the third to Server 3, and so on in a round-robin fashion, but this would not take advantage of the hash value.
One way to take advantage of the hash value is to start by dividing the hash value by the number of servers. Sometimes the hash value will divide evenly by the number of servers. (For this discussion, assume the hash function returns decimal numbers, not hexadecimal numbers, and that the number of digits in the number is not fixed.)
If the hash function returns the number 32 and that number is divided by 8, then the remainder is 0. If the hash function returns 41 and it is divided by 8, then the remainder is 1. If the hash function returns 67, division by 8 leaves a remainder of 3.
As you can see, any division by 8 will have a remainder between 0 and 7. Each of the eight servers can be assigned a number between 0 and 7.
In this discussion, the remainder will be called the modulus after the modulo arithmetic operation that returns a remainder. Figure 3.12 shows how to assign each modulus to a server.
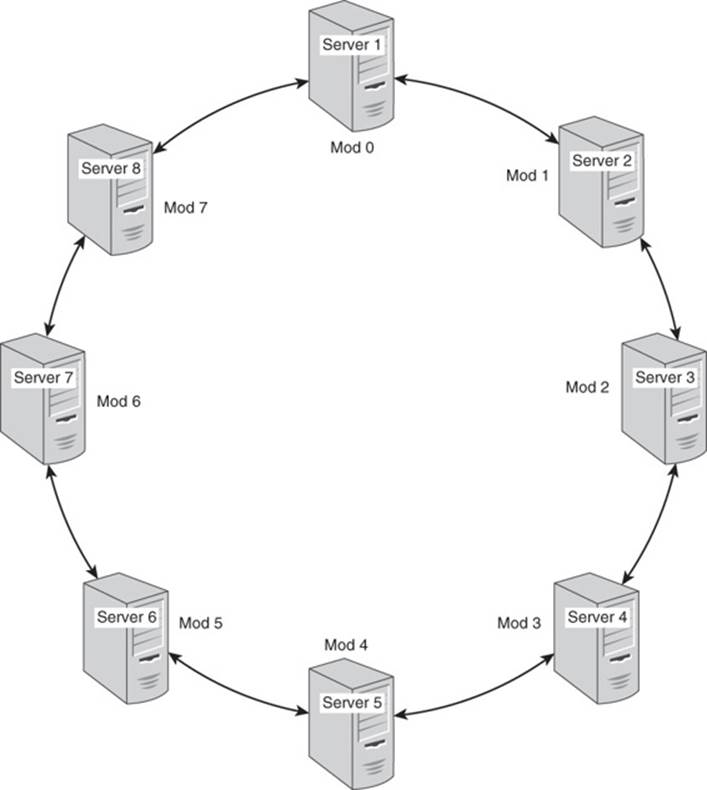
Figure 3.12 An eight-server cluster in a ring configuration with modulo number assigned.
Let’s return to the concert ticket application. A challenge was to ensure that two servers did not sell tickets to the same seat, at the same venue, in the same city, on the same night to more than one person. Because key-value databases running in a masterless configuration can accept writes from all servers, such a mistake could happen. The solution is to make sure any requests for the same seat, at the same venue, in the same city, on the same night all go to the same server.
You can do this by making a key based on seat, venue, city, and date. For example, two fans want to purchase set A73 at the Civic Center in Portland, Oregon, on July 15. You could construct keys using the seat, an abbreviation for the venue (CIvCen in this case), the airport code for the city (PDX in this case), and a four-digit number for the date. In this example, the key would be
A73:CivCen:PDX:0715
Anyone trying to purchase that same seat on the same day would generate the same key. Because keys are mapped to servers using modulo operations, all requests for that seat, location, and date combination would go to the same server. There is no chance for another server to sell that seat, thus avoiding the problem with servers competing to sell the same ticket.
Keys, of course, are only half the story in key-value databases. It is time to discuss values.
Values: Storing Just About Any Data You Want
This chapter started with the theme of simplicity. Key-value data stores are the simplest form of NoSQL database. That is in part because the foundational data structure of the associative array is so simple. NoSQL databases are also simple with respect to the way they store data.
Values Do Not Require Strong Typing
Unlike strongly typed programming languages that require you to define variables and specify a type for those variables, key-value databases do not expect you to specify types for the values you store.
You could, for example, store a string along with a key for a customer’s address:
'1232 NE River Ave, St. Louis, MO'
or you could store a list of the form:
('1232 NE River Ave', 'St. Louis', 'MO')
or you could store a more structured format using JavaScript Object Notation, such as
{ 'Street:' : '1232 NE River Ave', 'City' : 'St. Louis',:
'State' : 'MO' }
Key-value databases make minimal assumptions about the structure of data stored in the database.
While in theory, key-value databases allow for arbitrary types of values, in practice database designers have to make implementation choices that lead to some restrictions. Different implementations of key-value databases have different restrictions on values. For example, some key-value databases will typically have some limit on the size of values. Some might allow multiple megabytes in each value, but others might have smaller size limitations.
Even in cases in which you can store extremely large values, you might run into performance problems that lead you to work with smaller data values.
![]() Note
Note
It is important to consider the design characteristics of the key-value database you choose to use. Consult the documentation for limitations on keys and values. Part of the process in choosing a key-value database is considering the trade-off of various features. One key-value database might offer ACID transactions but limit you to small keys and values. Another key-value data store might allow for large values but limit keys to numbers or strings. Your application requirements should be considered when weighing the advantages and disadvantages of different database systems.
Limitations on Searching for Values
Keep in mind that in key-value databases, operations on values are all based on keys. You can retrieve a value by key, you can set a value by key, and you can delete values by key. That is pretty much the repertoire of operations. If you want to do more, such as search for an address in which the city is “St. Louis,” you will have to do that with an application program. If you were using a relational database, you could issue a SQL query, such as the following:
SELECT
address,
city,
state,
zip
FROM
Customer
WHERE
city = 'St. Louis'
Key-value databases do not support query languages for searching over values. There are two ways to address this limitation.
You, as an application developer, could implement the required search operations in your application. For example, you could generate a series of keys, query for the value of each key, and test the returned value for the pattern you seek.
Let’s assume you decided to store addresses as a string such as '1232 NE River Ave, St. Louis, MO' and you store it like this:
appData[cust:9877:address] = '1232 NE River Ave, St.
Louis, MO'
A pseudocode function for searching for customers in a particular city is
define findCustomerWithCity(p_startID, p_endID, p_City):
begin
# first, create an empty list variable to hold all
# addresses that match the city name
returnList = ();
# loop through a range of identifiers and build keys
# to look up address values then test each address
# using the inString function to see if the city name
# passed in the p_City parameter is in the address
# string. If it is, add it to the list of addresses
# to return
for id in p_startID to p_endID:
address = appData['cust:' + id + ':address'];
if inString(p_City, Address):
addToList(Address,returnList );
# after checking all addresses in the ranges specified
# by the start and end ID return the list of addresses
# with the specified city name.
return(returnList);
end;
This method enables you to search value strings, but it is inefficient. If you need to search large ranges of data, you might retrieve and test many values that do not have the city you are looking for.
Some key-value databases incorporate search functionality directly into the database. This is an additional service not typically found in key-value databases but can significantly add to the usefulness of the database. A built-in search system would index the string values stored in the database and create an index for rapid retrieval. Rather than search all values for a string, the search system keeps a list of words with the keys of each key-value pair in which that word appears. Figure 3.13 shows a graphical depiction of what such an index might look like.

Figure 3.13 A search index helps efficiently retrieve data when selecting by criteria based on values.
Summary
Key-value databases are simple and flexible. They are based on the associative array, which is a more generalized data structure than arrays. Associative arrays allow for generalized index values, or keys. Keys may be integers, strings, lists of values, or other types.
An important constraint on keys is that they must be unique within a namespace. Keys are used to look up values and those values can vary by type. There are some practical limitations on the size of values and those limitations can vary by implementation. Some of the limitations of key-value databases, such as lack of query language, are mitigated with additional features such as search tools.
Key-value databases lend themselves to scalable designs based on both master-slave and masterless replication models. Master-slave architectures typically have a single node that accepts writes and multiple nodes that support read operations. Masterless architectures allow for multiple nodes to accept write and support reads.
Chapter 4 includes additional terminology and concepts needed to understand both the design and the use of key-value databases. Then, Chapter 5, “Designing for Key-Value Databases,” discusses the use of key-value databases in application design and describes a number of useful design patterns to help you develop robust applications based on key-value databases.
Review Questions
1. How are associative arrays different from arrays?
2. How can you use a cache to improve relational database performance?
3. What is a namespace?
4. Describe a way of constructing keys that captures some information about entities and attribute types.
5. Name three common features of key-value databases.
6. What is a hash function? Include important characteristics of hash functions in your definition.
7. How can hash functions help distribute writes over multiple servers?
8. What is one type of practical limitation on values stored in key-value databases?
9. How does the lack of a query language affect application developers using key-value databases?
10. How can a search system help improve the performance of applications that use key-value databases?
References
Basho Technologies, Inc. Riak Documentation: http://docs.basho.com/riak/latest/
Carlson, Josiah L. Redis in Action. Shelter Island, NY: Manning Publications Co., 2013.
Meyer, Mathias. Riak Handbook. Seattle, WA: Amazon Digital Services, Inc., 2013.
FoundationDB, FoundationDB Documentation: https://foundationdb.com/key-value-store/documentation/index.html
Macedo, Tiago, and Fred Oliveira. Redis Cookbook. Sebastopol, CA: O’Reilly Media, Inc., 2011.
Oracle Corporation. Oracle NoSQL Documentation: http://www.oracle.com/technetwork/database/database-technologies/nosqldb/documentation/index.html.
Redis. io Documentation: http://redis.io/documentation
Bibliography
Hernandez, Michael J. Database Design for Mere Mortals: A Hands-On Guide to Relational Database Design. Reading, MA: Addison-Wesley, 2003.
Viescas, John L., and Michael J. Hernandez. SQL Queries for Mere Mortals. Reading, MA: Addison-Wesley, 2007.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.