Expert Oracle SQL: Optimization, Deployment, and Statistics (2014)
PART 4. Optimization
CHAPTER 18. Using Hints
In my experience, the vast majority of complex applications that involve a substantial amount of Oracle SQL are littered with hints. This is done despite the omnipresent warnings that suggest that hints are an extreme measure only to be used as a last resort. The following official warning is an example:
Hints were introduced in Oracle7, when users had little recourse if the optimizer generated suboptimal plans. Now Oracle provides a number of tools, including the SQL Tuning Advisor, SQL plan management, and SQL Performance Analyzer, to help you address performance problems that are not solved by the optimizer. Oraclestrongly recommends that you use those tools rather than hints. The tools arefar superior to hints, because when used on an ongoing basis, they providefresh solutionsas your data and databaseenvironment change.
Hints should be used sparingly, and only after you have collected statistics on the relevant tables and evaluated the optimizer plan without hints using the EXPLAIN PLAN statement. Changing database conditions as well as query performance enhancements in subsequent releases can have significant impact on how hints in your code affect performance.
Oracle 12c SQL Language Reference manual
One well-known SQL expert accepts that hinting is a fact of life but has classified hints as “good, bad, and ugly,” implying that, depending on the hint, you may be exposing yourself to substantial risks when hints are used in production code.
The sentiments expressed in these sorts of statements shouldn’t be dismissed out-of-hand but are, on occasion, misinterpreted. The fact is that there are occasions where the use of one or more hints in a SQL statement provides the best, and sometimes the only, way to ensure that performance is adequate and stable. And these occasions are far more numerous than you might think after reading all of these dire warnings.
Many of the chapters in this book include examples of how hinting can be used legitimately, most notably Chapter 14, which explains some of the many reasons why the optimizer might not arrive at an optimal execution plan all on its own. In this chapter I want to go through a few case studies that show legitimate examples of hinting as an optimization technique that don’t crop up in other chapters of the book. But before I do that, let me take a step back and try to provide some balance to the views of the foretellers of doom to help you develop your own perspective on how to approach hinting in production code. It all boils down to the one question: Are hints supportable?
Are Hints Supportable?
One of the assumptions that I know some people make is that if they have a problem with a SQL statement that includes hints, Oracle will not provide them with any support until those hints are removed. That line of reasoning suggests that hints are an inherently unsupportable feature of the SQL language. Let me go through a few real-life experiences of my own to try to determine the merit of such sentiments. Let us begin by revisiting the join subquery pushdown optimizer transformation that I covered in Chapter 13.
The PUSH_SUBQ story
If you were working on a database upgrade from 9i to 10g you would have had a nasty surprise if your code included the PUSH_SUBQ or NO_PUSH_SUBQ hints to control subquery pushdown. In 9i the hint was placed in the outer query block and applied to all subqueries referenced by the enclosing query block. In 10g the behavior of the hint was enhanced to allow each subquery to be treated differently; these days you place the hint in each subquery individually and not in the enclosing query block.
This 10g change to a hint that was documented in the 9i SQL Reference manual was not backwardly compatible with existing 9i code, thus all statements that included a PUSH_SUBQ hint needed editing at the time of the upgrade. It is experiences like this that lead some people to conclude that Oracle treats optimizer hints in a different way than it does other parts of the SQL language and that, as a result, the use of optimizer hints is a risky affair. But before you decide whether you agree with these conclusions, think about my next story.
The DML error logging story
One of the legal clauses in a PL/SQL FORALL statement is SAVE EXCEPTIONS, which is demonstrated in Listing 12-13 in the Oracle 12c PL/SQL Language Reference manual. The SAVE EXCEPTIONS clause implements what is known as batch error mode. In PL/SQL, batch error mode results in the population of the collection SQL%BULK_EXCEPTIONS, which identifies rows that couldn’t be inserted or updated because, for example, of an integrity constraint violation. An alternative approach to solving the same problem is to use DML error logging described as part of the INSERT, UPDATE and MERGE statements in the SQL Language Reference manual. The use of both batch error mode and DML error logging in the same statement is illogical, but it worked in 10g. Many customers found that when they upgraded from 10g to 11g they suddenly got ORA-38909 messages saying that their previous working code was now illegal. Just do an Internet search for this error code to see the trouble this caused.
Most customers running into an ORA-38909 error code were using PL/SQL and could make code changes to remove the redundant SAVE EXCEPTIONS clause from their code. However, my client was using ODP.NET, which uses batch error mode unconditionally. The use of batch error mode in ODP.NET meant that there was no way to invoke DML that included error logging clauses.
I logged a service request on my client’s behalf and after three months or so Oracle accepted that this was indeed a bug. Oracle then asked how big an impact the bug was having so that they could prioritize the fix. Since my client had already recoded their application in the intervening three months, and no other clients had reported the issue, there was no business need for a fix anymore. In 12.1.0.1 it is still not possible to invoke DML with error logging clauses from ODP.NET!
But what does this story have to do with optimizer hints? The point is that sometimes Oracle makes changes to documented features of their product that are not backwardly compatible. If the changes affect a substantial number of clients then Oracle will have to produce either a fix or a workaround. The workaround may involve customers changing their code. There isn’t anything different about documented optimizer hints or any other documented feature of the Oracle database product: 99.9% of the time an upgrade will be backwardly compatible, but once in a while something unforeseen happens.
But this book has discussed numerous undocumented hints. Should our attitude towards these hints be any different than to documented hints? Let us discuss this now.
Documented versus undocumented hints
The SQL Language Reference manual has a chapter entitled “Basic Elements of Oracle SQL” that includes a description of comments, and hints in particular. There are several dozen hints documented, but a complete (or almost complete) list of hints can be found in the view V$SQL_HINT, which has 314 rows!
You might assume that Oracle makes certain implicit guarantees about the use of documented hints but that Oracle might remove or alter the behavior of undocumented hints at any point with moral impunity. In fact, even working out what constitutes a documented hint isn’t straightforward. For example, the Data Warehousing Guide makes mention of the EXPAND_GSET_TO_UNION hint that we covered in Chapter 13 as well as other hints such as NO_MULTIMV_REWRITE and NO_BASETABLE_MULTIMV_REWRITE. None of these hints appear in the current SQL Language Reference manual, although EXPAND_GSET_TO_UNION appears in older versions of said manual. Does Oracle support the use of these hints or not?
Perhaps one of the most talked about undocumented hints is the CARDINALITY hint. At the time of writing this book, Tom Kyte is the product manager for the CBO. Although Tom hasn’t been in this role for very long his knowledge of the Oracle database product is very well known. He has published multiple excellent books on the product and has maintained the famous Ask Tom website for longer than most of us can remember. In 2010, in response to question 2233040800346569775 on the Ask Tom website, Tom said:
…correct [the cardinality hint] is not documented. However, it is—in my opinion—one of the few “safe” undocumented things to use because its use will not lead to data corruption, wrong answers, or unpredictable outcomes. If it works—it will influence a query plan, if it doesn't—it won't. That is all—it is rather “safe” in that respect.
Well, the truth is that that the vast majority of hints are optimizer hints, and the statement about the safety of the CARDINALITY hint can surely be extended to every single one of the optimizer hints can it not? Optimizer hints will either alter the execution plan. . .or not! In fact, I personally think that the CARDINALITY hint is one of the most dangerous optimizer hints to use on a production system because its effect is, in fact, unpredictable. I will cover the semantics of the CARDINALITY hint in a little while.
In reality, a lot of hints aren’t documented simply because Oracle hasn’t gotten around to documenting them. I discussed the GATHER_PLAN_STATISTICS hint in Chapter 4, but this hint didn’t appear in the Oracle documentation until 12c! To give another example, it is quite clear that Oracle wants us to be able to use hints to control join order and join method, hence the documentation of the LEADING, USE_NL, USE_MERGE, and USE_HASH hints. But any time we use the LEADING and USE_HASH hints together we absolutely must use a SWAP_JOIN_INPUTS orNO_SWAP_JOIN_INPUTS hint so as to be unambiguous in our intentions. The only reason that SWAP_JOIN_INPUTS and NO_SWAP_JOIN_INPUTS haven’t been documented is because Oracle hasn’t gotten around to documenting them. There is absolutely no supportability issue involved at all.
By this stage in the discussion you might be thinking that my view is that you should have no qualms at all about using any hint, documented or undocumented, and that the number of such hints that float around application code has no impact on the supportability of the application. That would be taking things too far. In fact, there are support implications of using hints but they aren’t the ones we have discussed so far. Let me use an analogy to make my point.
The MODEL clause corollary
If you feel the need to use the HAVING clause in a SQL statement, go right ahead. If you want to use an analytic function, don’t feel inhibited. Whether 1% or 90% of SQL statements in an application contain HAVING clauses is of no concern to the supportability of the application, although if 90% of statements had HAVING clauses it would be a strange application! If someone is reading your code and they don’t understand the basic features of the SQL language, that is their problem. They should just go home and read the manual.
But what happens if you feel the urge to use the MODEL clause? Should you just go ahead and start using it with as little thought as when you use an analytic function? Absolutely not. The MODEL clause is used in very few applications, and most programmers have absolutely no knowledge of it. Your colleagues can’t just go home and read a couple of pages about the MODEL clause before they go to bed and expect to wake up an expert. It is a complex beast!
So if you want to use the MODEL clause, take a breath. Can you use traditional SQL syntax to obtain the results you need with adequate performance? If so, and if the MODEL clause is not already in use in your application, then you should probably refrain from being the first to introduce it. On the other hand, if you have a clearly defined need (such as the moving median example that I discussed in Chapter 7) then you shouldn’t be afraid to use the MODEL clause just because it is unfamiliar. Just make sure that you comment your code and explain to your colleagues what you are doing and why.
A similar thought process should go through your head when you feel the urge to slap one of those plus signs at the start of your comment. You should be asking yourself these sorts of questions:
· Do I know the reason why I need to hint this code? Why has the CBO picked a different plan to the one I think is best?
· Do I know that hinting the code will actually make a positive difference, or am I making a potentially incorrect assumption?
· Are there alternative approaches? Are these alternative approaches better or worse than the use of hints?
· Do I understand what the hints that I plan to use do?
· Are the hints an appropriate and complete set?
· Will my colleagues understand what I have done and why?
If you find that you have satisfactory answers to all of the above questions then go ahead. If not, then try to get satisfactory answers or find an alternative solution to your problem.
So where do all the analogies and anecdotes leave us? Here is a summary of my personal thoughts on the use of hints.
Supportability conclusion
If you have a functional or performance problem with your Oracle database product then the response that you get from Oracle will depend upon the extent of your business impact and the number of customers affected by similar problems. By its very nature, a problem with the performance of a single SQL statement is almost always much less serious than, for example, a data corruption issue that prevents a database from starting up. As a consequence, there is a limit to the level of support you will get from Oracle for SQL performance issues regardless of whether the issues are caused by optimizer hints or by other features of the database product and regardless of whether the hints are documented or not.
This is not a dig at Oracle. It is how business works. Indeed, you will find that deprecated hints like ORDERED and AND_EQUAL that are widespread in code written by many customers years ago still work perfectly well in 12c, despite having been removed from the SQL Language Reference manual years ago.
The real issues relating to the supportability of hints are focused closer to home and involve you and your colleagues. The sad fact is that even the documented hints aren’t usually documented very well, and there are all sorts of hidden restrictions and limitations that mean that we are all working somewhat in the dark.
At Oracle Open World in 2013, Jonathan Lewis said the words we don’t know how to hint in one of his talks. These words are still ringing in my ears because they are not false modesty! Nobody, and I mean nobody, knows all the ins and outs of every optimizer hint. This means that with the exception of the most trivial of SQL statements, nobody can say with absolute certainty that they have the correct set of hints that will provide optimal and stable performance forever.
However, writing this book has made me realize that writing good SQL is very difficult, and so is coming up with a good physical database design. So not only do we not know how to hint, but also we don’t know how to write SQL and we don't know how to design our database either! We simply have to assess each situation on its merits and provide the simplest and most supportable solution that we can find for our business problem based upon our knowledge.
I think I have said enough about philosophy; it’s now time to return to detailed technical content and look at the different types of hints at our disposal.
Types of Hints
In the preceding paragraphs I have sometimes talked about hints in general and sometimes talked specifically about optimizer hints. There is a difference because there are a few hints that aren’t directed at the optimizer at all. Furthermore, there are a couple of different types of optimizer hints. Let me first talk briefly about the hints that aren’t directed at the optimizer.
Edition -based redefinition hints
Edition-based redefinition (EBR) was probably the most talked about new feature of 11gR2 and is needed by customers that want to do rolling application upgrades. I use the term “rolling application upgrade” to mean changing application code and DDL specifications without shutting down your application. An integral part of EBR is a set of three hints that change the semantics of a SQL statement. These hints are:
· IGNORE_ROW_ON_DUPKEY_INDEX
· CHANGE_DUPKEY_ERROR_INDEX
· RETRY_ON_ROW_CHANGE
Let me emphasize that these hints change what the SQL statement does and are in that respect quite unlike the vast majority of optimizer hints; optimizer hints are generally intended to have an impact on the performance of the statement and nothing else.
The documentation of EBR hints in the SQL Language Reference manual takes care to point out that the normal dire warnings of a potential performance meltdown do not apply to this special type of hint; if you are using EBR you are encouraged to and indeed have no choice but to use these special hints.
A detailed discussion of EBR is beyond the scope of this book, but if you are interested in reading more there is a chapter dedicated to the topic in the Advanced Application Developer’s Guide.
It is almost time to turn our attention to optimizer hints, but the discussion of EBR prompts me to take a brief diversion to discuss a somewhat unusual topic.
Hints that cause errors
If you have experience with hinting you will know that, barring bugs, if a hint is used erroneously it will not cause the associated SQL statement to fail; the SQL statement will just ignore the hint. But did you know that if the hint is valid it may cause the statement to fail or it may prevent it from failing? I have come across three examples of this. Two of these examples relate to EBR and one to materialized view rewrite. Take a look at the examples in Listing 18-1.
Listing 18-1. Hints that cause errors
CREATE TABLEt1
AS
SELECT 1 c1, 1 c2 FROM DUAL;
CREATE UNIQUE INDEX t1_i1
ON t1 (c1);
CREATE UNIQUE INDEX t1_i2
ON t1 (c2);
INSERT /*+ change_dupkey_error_index(t1 (c1)) */
INTO t1
SELECT 2, 1 FROM DUAL;
ORA- 00001: unique constraint (BOOK. T1_I2) violated
INSERT /*+ change_dupkey_error_index(t1 (c1)) */
INTO t1
SELECT 1, 2 FROM DUAL;
ORA- 38911: unique constraint (BOOK. T1_I1) violated
INSERT /*+ ignore_row_on_dupkey_index(t1 (c1)) */
INTO t1
SELECT ROWNUM + 1, 1
FROM DUAL
CONNECT BY LEVEL <= 3;
ORA- 00001: unique constraint (BOOK. T1_I2) violated
INSERT /*+ ignore_row_on_dupkey_index(t1 (c1)) */
INTO t1
SELECT ROWNUM, ROWNUM + 1
FROM DUAL
CONNECT BY LEVEL <= 3;
2 rows created
ALTER SESSION SET query_rewrite_integrity=enforced;
SELECT /*+ rewrite_or_error */
t.calendar_month_desc, SUM (s.amount_sold) AS dollars
FROM sh.sales s, sh.times t
WHERE s.time_id = t.time_id
GROUP BY t.calendar_month_desc;
ORA-30393: a query block in the statement did not rewrite
Listing 18-1 begins by creating a table T1 that has a single row with two columns, C1 and C2. The values of C1 and C2 in this single row are both 1. We now create two indexes, T1_I1 and T1_I2, that ensure that the values of C1 and C2 respectively remain unique.
Now then, what happens when we try to insert rows into T1 that violate these integrity constraints? The first insertion attempts to generate a duplicate value for C2, violating the constraint enforced by T1_C2. As we would expect, we get an ORA-00001 error. But when we try a second insertion that attempts to duplicate values for C1 in violation of the integrity constraint enforced by T1_C1, we get a different error: ORA-38911! This difference is because of the CHANGE_DUPKEY_ERROR_INDEX hint that specifies the C1 column (and implicitly the constraint enforced by the T1_C1 index), thus causing a different error that can be treated in a special way by an EBR-related exception handler.
The third insertion in Listing 18-1 attempts to insert three rows into T1, one of which is a duplicate of C1. This time, the offending row is ignored and we insert the remaining two rows without error. This behavior arises as a result of the IGNORE_ROW_ON_DUPKEY_INDEX hint that once again specifies the integrity constraint should be ignored.
The final SQL statement in Listing 18-1 has nothing to do with EBR and yet also causes a statement failure. The fact that the referential integrity constraint on the TIME_ID column in SH.SALES is not enforced means that the final query in Listing 18-1 cannot be rewritten to use the materialized view CAL_MONTH_SALES_MV when QUERY_REWRITE_INTEGRITY is ENFORCED. Normally, the query would just run against the base tables, but because of the REWRITE_OR_ERROR hint the statement fails. An EXPLAIN PLAN statement specifying the query also fails with the ORA-30393 error.
I hope you found this distraction interesting, but it is time now to return to performance-related matters. We are not yet, however, ready to discuss optimizer hints. We need to look at runtime engine hints first.
Runtime engine hints
There are one or two hints that affect the behavior of a SQL statement at runtime but bear no relationship to the decisions the CBO makes in relation to transformations and final state optimization, including the following:
· We discussed the GATHER_PLAN_STATISTICS hint in Chapter 4 and also in this chapter. This hint causes the runtime engine to gather actual performance statistics at runtime but has no impact on the execution plan.
· We discussed the NO_GATHER_OPTIMIZER_STATISTICS hint in Chapter 9. This hint, and its counterpart GATHER_OPTIMIZER_STATISTICS, controls whether an OPTIMIZER STATISTICS GATHERING operation is added to the execution for direct-path loads.
· The MONITOR hint can be used to force the collection of data that can be referenced using the DBMS_SQLTUNE.REPORT_SQL_MONITOR function. By default, such data isn’t collected for statements that run for less than five seconds. The NO_MONITOR hint can be used to suppress the collection of data for statements running for longer than five seconds. Like the GATHER_PLAN_STATISTICS, (NO_)GATHER_OPTIMIZER_STATISTICS, and the (NO_)MONITOR hints have no impact on the execution plan generated by the CBO.
· The DRIVING_SITE hint can be used to change the way a distributed query runs. Although the DRIVING_SITE hint does change the execution plan produced by the CBO, it does so in a way that is independent of the cost-based or heuristic decisions the CBO makes. I will give an example of the legitimate use of the DRIVING_SITE hint in a moment.
· Like the DRIVING_SITE hint, the APPEND and APPEND_VALUES hints alter the appearance of the execution plan generated by the CBO in ways unrelated to the optimization process, but unlike the DRIVING_SITE hint, the APPEND and APPEND_VALUES hints affect the semantics of the statement, as I will demonstrate shortly.
Listing 18-2 makes use of the loopback link that we created in Listing 8-1 to demonstrate the DRIVING_SITE hint.
Listing 18-2. The DRIVING_SITE hint
SELECT /*+ driving_site(s) */
cust_id
,c.cust_first_name
,c.cust_last_name
,SUM (s.amount_sold) sum_sales
FROM sh.customers c JOIN sh.sales@loopback s USING (cust_id)
GROUP BY cust_id, c.cust_first_name, c.cust_last_name;
--------------------------------------------------------------------
| Id | Operation | Name | Rows | Pstart| Pstop |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT REMOTE| | 918K| | |
| 1 | HASH GROUP BY | | 918K| | |
|* 2 | HASH JOIN | | 918K| | |
| 3 | REMOTE | CUSTOMERS| 55500 | | |
| 4 | PARTITION RANGE ALL | | 918K| 1 | 28 |
| 5 | TABLE ACCESS FULL | SALES | 918K| 1 | 28 |
--------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A2"."CUST_ID"="A1"."CUST_ID")
Note
-----
- fully remote statement
- this is an adaptive plan
The query in Listing 18-2 joins the local SH.CUSTOMERS table to SH.SALES, which is accessed over a database link. Without the DRIVING_SITE hint, all 918,843 rows from the SH.SALES table would be pulled over the link to join with the local SH.CUSTOMERS table locally. As a consequence of using the DRIVING_SITE hint, the query is actually run at the remote site, and rather than the 918,843 rows from SH.SALES being pulled over the database link, the 55,500 rows from SH.CUSTOMERS are pushed over the link instead. With the hint in place the join and aggregation are performed at the remote site, and the resulting 7,059 rows are returned from the remote side to the local side.
The use of the DRIVING_SITE hint reduces the amount of data sent over the database link and is a perfectly reasonable thing to do, but as of yet this is not an approach that the CBO even considers in an unhinted query. The only time that an unhinted query is run from a remote site is when all the row sources are at that site—in other words, when the query isn’t really distributed at all.
It is, of course, possible for a query to reference multiple remote locations. It is for this reason that the DRIVING_SITE hint takes a parameter that specifies the row source associated with the remote site that is expected to drive the query.
That’s enough about DRIVING_SITE—let us now move on to APPEND and APPEND_VALUES. Parallel DML statements usually result in direct-path writes, but the APPEND and APPEND_VALUES statements are required when trying to cause direct-path loads to occur for serialINSERT statements.
The APPEND hint has been around for many years, but the hint has always been illegal when a VALUES clause was supplied. However, the VALUES clause can be used to insert large numbers of records, and an APPEND_VALUES hint is now available, as demonstrated in Listing 18-3.
Listing 18-3. Use of the APPEND_VALUES hint
CREATE /*+ NO_GATHER_OPTIMIZER_STATISTICS */
TABLE t2
AS
SELECT *
FROM all_objects
WHERE 1 = 0;
DECLARE
TYPE obj_table_type IS TABLE OF all_objects%ROWTYPE;
obj_table obj_table_type;
BEGIN
SELECT *
BULK COLLECT INTO obj_table
FROM all_objects;
FORALL i IN 1 .. obj_table.COUNT
INSERT /*+ TAGAV append_values */
INTO t2
VALUES obj_table (i);
COMMIT;
END;
/
SET LINES 200 PAGES 0
SELECT p.*
FROM v$sql s
,TABLE (DBMS_XPLAN.display_cursor (s.sql_id, s.child_number, 'BASIC')) p
WHERE s.sql_text LIKE 'INSERT /*+ TAGAV%';
INSERT /*+ TAGAV append_values */ INTO T2 VALUES (:B1 ,:B2 ,:B3 ,:B4
,:B5 ,:B6 ,:B7 ,:B8 ,:B9 ,:B10 ,:B11 ,:B12 ,:B13 ,:B14 ,:B15 ,:B16
,:B17 ,:B18 )
Plan hash value: 3581094869
---------------------------------
| Id | Operation | Name |
---------------------------------
| 0 | INSERT STATEMENT | |
| 1 | LOAD AS SELECT | |
| 2 | BULK BINDS GET | |
---------------------------------
Unless I am specifically interested in runtime statistics, this book uses the EXPLAIN PLAN statement and the DBMS_XPLAN.DISPLAY function to obtain the execution plan for a statement, and I don’t usually show the calls. But in Listing 18-3 the SQL statement under analysis is buried in a PL/SQL block, and it is more convenient to obtain the execution plan by means of the DBMS_XPLAN.DISPLAY_CURSOR in conjunction with a tagged SQL statement and a lateral join, as I have shown.
The LOAD AS SELECT operation in Listing 18-3 signifies the use of direct-path insertion. As with parallel direct-path inserts, serial direct-path inserts will result in what is, in this case, the slightly misleading ORA-12838: cannot read/modify an object after modifying it in parallel error message if an attempt is made to access the object before a COMMIT statement.
What is perhaps a little surprising in Listing 18-3 is that there is no OPTIMIZER STATISTICS GATHERING operation visible in the execution plan and no object statistics are gathered by the INSERT ... VALUES statement as they would have been with an INSERT ... SELECT statement when the APPEND hint is supplied. This behavior cannot be changed by the use of any GATHER_OPTIMIZER_STATISTICS hint.
Incidentally, the GATHER_OPTIMIZER_STATISTICS hint is in some way akin to the NO_SET_TO_JOIN hint that we discussed in Chapter 13. Because both hints specify default behavior, neither hint has any effect under normal circumstances. However, just as theNO_SET_TO_JOIN hint can be used to disable the set-to-join transformation if you set "_convert_set_to_join" to TRUE, so too can GATHER_OPTIMIZER_STATISTICS can be used to force statistics gathering if you set "_optimizer_gather_stats_on_load" toFALSE!
Unlike the three EBR hints, the GATHER_PLAN_STATISTICS, (NO_)MONITOR, (NO_)GATHER_OPTIMIZER_STATISTICS, DRIVING_SITE, APPEND, and APPEND_VALUES hints are not exempt from the health warning in the SQL Language Reference manual. However, you should think of these eight hints in the same way as you do the three EBR hints, namely as extensions of the SQL language that allow you to express what you want to do, not as a way to express how it should be done.
Like most of the optimizer hints that we will discuss in this chapter, the three EBR hints and the eight hints described here are more like directives than hints: there is no discretion allowed in their application. But you shouldn’t think of all optimizer hints as directives. Let us look now at some of the optimizer hints that really are hints and not directives.
Optimizer hints that are hints
Most optimizer hints should properly be regarded as directives in that they tell the CBO either that it must do something or that it must not. Of course, the directives are conditional in nature. For example, the USE_HASH (T) hint says: “Assuming that T is not the leading row source in the join tree, and assuming that T has not been eliminated by the join elimination transformation, or undergone any other transformation rendering this directive moot, then join T with a hash join.” Similarly, the PARALLEL (T) hint says: “Assuming that you access T with a full table scan, then perform the scan in parallel.”
There are, however, one or two optimizer hints that contain no prescriptive component and really are hints. Let us begin our look at these hints now with OPT_PARAM.
OPT_PARAM
We have just discussed two hidden parameters—"_convert_set_to_join" and "_optimizer_gather_stats_on_load"—that allow specific features of the CBO to be enabled, disabled, or forced. In fact, there are scores of such hidden parameters that control optimizer behavior, and officially you need agreement from Oracle support to change any of them. There are also a few documented parameters that are not hidden that affect optimizer behavior, such as OPTIMIZER_INDEX_COST_ADJ. Documented or not, I would repeat my recommendation that, with the exception of the few parameters that I mentioned in Chapter 9, you leave all optimizer-related initialization parameters well alone unless you have a really convincing reason to use non-default values.
If you just want to override default CBO behavior for one statement, then you have the option to use the OPT_PARAM hint as an alternative to changing the initialization parameter for the entire session. The OPT_PARAM hint has been around forever but is documented in 12cR1 for the first time. As you might expect, the documentation for OPT_PARAM only authorizes overrides to documented initialization parameters such as OPTIMIZER_INDEX_COST_ADJ. Listing 18-4 shows the OPT_PARAM hint in action.
Listing 18-4. The OPT_PARAM hint
ALTER SESSION SET star_transformation_enabled=temp_disable;
SELECT /*+ opt_param('_optimizer_adaptive_plans','false')
opt_param('_optimizer_gather_feedback','false')
*/
* FROM t2;
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100K| 35M| 426 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T2 | 100K| 35M| 426 (1)| 00:00:01 |
--------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$1 / T2@SEL$1
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
FULL(@"SEL$1" "T2"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
ALL_ROWS
OPT_PARAM('star_transformation_enabled' 'temp_disable')
OPT_PARAM('_optimizer_gather_feedback' 'false')
OPT_PARAM('_optimizer_adaptive_plans' 'false')
DB_VERSION('12.1.0.1')
OPTIMIZER_FEATURES_ENABLE('12.1.0.1')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/
Listing 18-4 sets an initialization parameter at the session level before running a query that includes two OPT_PARAM hints that turn off default CBO features. Interestingly, the outline data section in the displayed execution plan includes an OPT_PARAM hint for the non-default session-level parameter. This is necessary because by default the OPTIMIZER_FEATURES_ENABLE ('12.1.0.1') hint, itself a non-prescriptive hint, implicitly resets the value of most optimizer parameters to the default values for the specified release. Because theOPTIMIZER_FEATURES_ENABLE ('12.1.0.1') hint did not appear in the original query, OPT_PARAM hints are added to the outline data for any non-default session-level settings to override the OPTIMIZER_FEATURES_ENABLE ('12.1.0.1') hint.
The OPT_PARAM hint can be used to enable or disable certain optimizer features, and when used this way OPT_PARAM can be regarded as a directive. However, when parameters like OPTIMIZER_INDEX_COST_ADJ are overridden, the CBO isn’t being explicitly told to do or not to do anything. It is just being given some additional information to feed into its deliberations.
Incidentally, the initialization parameter OPTIMIZER_DYNAMIC_SAMPLING can be controlled at the statement level either by the OPT_PARAM hint or by the DYNAMIC_SAMPLING hint. Many of us in the Oracle community were highly amused by the fact that in 12cR1 the maximum value of OPTIMIZER_DYNAMIC_SAMPLING was increased from 10 to 11. There is an old movie with the name This is Spinal Tap, and if you look at the YouTube clip entitled “spinal tap: these go to eleven,” you will see why many of us giggled somewhat childishly when we learned about the new value of OPTIMIZER_DYNAMIC_SAMPLING!
FIRST_ROWS and ALL_ROWS
As of 12cR1 the valid values of the initialization parameter OPTIMIZER_MODE are FIRST_ROWS_1, FIRST_ROWS_10, FIRST_ROWS_100, FIRST_ROWS_1000, or ALL_ROWS. The last of these is, effectively, FIRST_ROWS_INFINITY and is the default value.
When OPTIMIZER_MODE has a non-default value, default CBO behavior can be obtained at the statement level by use of the ALL_ROWS hint. The FIRST_ROWS hint is more flexible than the initialization parameter setting in that you can specify any positive integer as an argument.Listing 18-5 demonstrates.
Listing 18-5. The FIRST_ROWS hint
SELECT /*+ first_rows(2000) */
*
FROM sh.sales s JOIN sh.customers c USING (cust_id)
ORDER BY cust_id;
-------------------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | TABLE ACCESS BY INDEX ROWID | CUSTOMERS |
| 4 | INDEX FULL SCAN | CUSTOMERS_PK |
| 5 | PARTITION RANGE ALL | |
| 6 | BITMAP CONVERSION TO ROWIDS | |
|* 7 | BITMAP INDEX SINGLE VALUE | SALES_CUST_BIX |
| 8 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
-------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("S"."CUST_ID"="C"."CUST_ID")
SELECT /*+ first_rows(3000) */
*
FROM sh.sales s JOIN sh.customers c USING (cust_id)
ORDER BY cust_id;
-------------------------------------------
| Id | Operation | Name |
-------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | MERGE JOIN | |
| 2 | SORT JOIN | |
| 3 | PARTITION RANGE ALL| |
| 4 | TABLE ACCESS FULL | SALES |
|* 5 | SORT JOIN | |
| 6 | TABLE ACCESS FULL | CUSTOMERS |
-------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("S"."CUST_ID"="C"."CUST_ID")
filter("S"."CUST_ID"="C"."CUST_ID")
The two different values of the parameter passed to the FIRST_ROWS hint result in completely different execution plans. When we supply a value of 3000 to the hint we are asking the CBO to devise a plan that will deliver the first 3000 rows of output as quickly as possible, even if the total time for the query to return all rows may be extended. The CBO picks a NESTED LOOPS join using an INDEX FULL SCAN on the CUSTOMERS_PK index, meaning that the rows will be delivered in order without the need for a sort. The query will begin producing rows almost immediately.
When we increase the value of the hint parameter to 4000 the execution plan changes to use a MERGE JOIN. This operation requires that the rows from both tables are sorted first, meaning that there will be some delay before any rows are returned. However, once the data from the two tables have been read and sorted the rows are delivered from the query much quicker than from the NESTED LOOPS join; the CBO believes that by the time 4000 rows have been delivered the MERGE JOIN will have overtaken the NESTED LOOPS approach.
CARDINALITY and OPT_ESTIMATE hints
As I explained in Chapter 14, the CBO frequently makes errors in cardinality estimates. The CARDINALITY and OPT_ESTIMATE hints are really useful for understanding what went wrong. The CARDINALITY hint has been around for a very long time and is far better known than theOPT_ESTIMATE hint, which appeared for the first time in 10gR1 for use internally by SQL profiles. Both the CARDINALITY and OPT_ESTIMATE hints allow you to override the cardinality estimates from the CBO. Although the latter hint is far more flexible than the former, let us begin with the CARDINALITY hint, demonstrated in Listing 18-6.
Listing 18-6. Two examples of the CARDINALITY hint
SELECT /*+ cardinality(s 918) */
*
FROM sh.sales s
WHERE amount_sold > 100
AND prod_id IN (SELECT /*+ no_unnest */
prod_id
FROM sh.products p
WHERE prod_category = 'Hardware');
------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------
| 0 | SELECT STATEMENT | | 13 |
|* 1 | FILTER | | |
| 2 | PARTITION RANGE ALL | | 918 |
|* 3 | TABLE ACCESS FULL | SALES | 918 |
|* 4 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 |
|* 5 | INDEX UNIQUE SCAN | PRODUCTS_PK | 1 |
------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "SH"."PRODUCTS"
"P" WHERE "PROD_ID"=:B1 AND "PROD_CATEGORY"='Hardware'))
3 - filter("AMOUNT_SOLD">100)
4 - filter("PROD_CATEGORY"='Hardware')
5 - access("PROD_ID"=:B1)
SELECT /*+ cardinality(s 918) */
*
FROM sh.sales s
WHERE amount_sold > 100
AND prod_id IN (SELECT /*+ no_unnest push_subq */
prod_id
FROM sh.products p
WHERE prod_category = 'Hardware');
-------------------------------------------------------------
| Id | Operation | Name | Rows |
-------------------------------------------------------------
| 0 | SELECT STATEMENT | | 918 |
| 1 | PARTITION RANGE ALL | | 918 |
|* 2 | TABLE ACCESS FULL | SALES | 918 |
|* 3 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 |
|* 4 | INDEX UNIQUE SCAN | PRODUCTS_PK | 1 |
-------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("AMOUNT_SOLD">100 AND EXISTS (SELECT /*+ PUSH_SUBQ
NO_UNNEST */ 0 FROM "SH"."PRODUCTS" "P" WHERE "PROD_ID"=:B1 AND
"PROD_CATEGORY"='Hardware'))
3 - filter("PROD_CATEGORY"='Hardware')
4 - access("PROD_ID"=:B1)
Both queries in Listing 18-6 include a subquery that isn’t unnested. I could have used a complex subquery to make my point, but to avoid unnecessary complexity I have kept the subquery simple and included a NO_UNNEST hint.
The CARDINALITY hint takes the name of a row source as the first argument and the number of rows expected to be returned from the operation that accesses the row source as the second. To be clear, the cardinality estimate indicates the number of rows returned from the row sourceafter the application of predicates but before the results of any joins, aggregations, or filters. There are 918,843 rows in SH.SALES, but the CARDINALITY hint in Listing 18-6 specifies a value of just 918. Notice that in the first execution plan shown in Listing 18-6, the cardinality estimate of 918 is applied after the application of the AMOUNT_SOLD > 100 predicate but before the application of the subquery filtering that is performed as a separate step. The second statement in Listing 18-6 differs from the first only by the presence of a PUSH_SUBQ hint that causes the filtering by the subquery to be performed as part of the full table scan itself. The consequence of this is that the cardinality estimate applies after both the AMOUNT_SOLD > 100 filter and the subquery filter have been applied. You can see that the statement is expected to return 13 rows in the former case and 918 in the latter.
The confusion about the meaning of the CARDINALITY hint is not limited to the application of subquery filters. Take a look at Listing 18-7, which shows CARDINALITY hints used on the probe tables of NESTED LOOPS joins.
Listing 18-7. CARDINALITY hint with NESTED LOOPS joins
SELECT /*+ cardinality(c 46000)leading(co) use_nl(c) */
*
FROM sh.countries co JOIN sh.customers c USING (country_id);
------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------
| 0 | SELECT STATEMENT | | 46000 |
| 1 | NESTED LOOPS | | 46000 |
| 2 | TABLE ACCESS FULL| COUNTRIES | 23 |
|* 3 | TABLE ACCESS FULL| CUSTOMERS | 2000 |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("CO"."COUNTRY_ID"="C"."COUNTRY_ID")
SELECT /*+ cardinality(c 46000)leading(co) use_nl(c) */
*
FROM sh.countries co JOIN sh.customers c USING (country_id)
WHERE country_region = 'Asia';
------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------
| 0 | SELECT STATEMENT | | 9281 |
| 1 | NESTED LOOPS | | 9281 |
|* 2 | TABLE ACCESS FULL| COUNTRIES | 4 |
|* 3 | TABLE ACCESS FULL| CUSTOMERS | 2421 |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("CO"."COUNTRY_REGION"='Asia')
3 - filter("CO"."COUNTRY_ID"="C"."COUNTRY_ID")
The two queries in Listing 18-7 both join SH.COUNTRIES with SH.CUSTOMERS, and we use hints to force a NESTED LOOPS join for demonstration purposes.
In the first query in Listing 18-7 there is no filter predicate on either table being joined. We have specified a CARDINALITY hint to tell the CBO to assume that SH.CUSTOMERS has 46,000 rows, and the statistics on the SH.COUNTRIES table tell the CBO to assume that said table has 23 rows, each with a different value of COUNTRY_ID. When we use a NESTED LOOPS join from SH.COUNTRIES to SH.CUSTOMERS, the CBO reports that it expects each of the 23 probes to return an average of 2,000 rows, making 46,000 rows in total.
That example may only be a little confusing, but things get more complicated when we add a filter condition to SH.COUNTRIES as we have done in the second query of Listing 18-7. Since there are six values of COUNTRY_REGION in SH.COUNTRIES, the CBO now expects that only one sixth of the 23 rows in SH.COUNTRIES will match the filter predicate on COUNTRY_REGION and that the result set will be reduced accordingly. But remember that the CARDINALITY hint specifies the number of rows returned from SH.CUSTOMERSbefore any join condition. Why has the cardinality estimate per country increased? The reason is that the column statistics on the COUNTRY_ID column of SH.CUSTOMERS suggest that there are actually only 19 countries with customers, so the cardinality estimate per iteration of the loop is determined to be 46,000/19, i.e., 2,421! The estimated cardinality after the join is 9,281 and is calculated from (46,000/19) x (23/6) because the CBO assumes that none of the four countries without customers are in Asia!
![]() Caution If you re-gather statistics on the SH schema you may find that a histogram is created for the COUNTRY_REGION column of SH.COUNTRIES. If that happens, the CBO will estimate that there are five countries in Asia.
Caution If you re-gather statistics on the SH schema you may find that a histogram is created for the COUNTRY_REGION column of SH.COUNTRIES. If that happens, the CBO will estimate that there are five countries in Asia.
By this stage you are probably realizing that the semantics of the CARDINALITY hint aren’t that straightforward. This is one reason why, despite the inestimable value of the CARDINALITY hint for research, I have never personally used a CARDINALITY hint in production code.
Although the CARDINALITY hint is very useful for research, the OPT_ESTIMATE hint is more flexible. Listing 18-8 shows the flexibility of this hint.
Listing 18-8. The OPT_ESTIMATE hint
SELECT /*+ opt_estimate(table c rows=46000)leading(co) use_nl(c) */
*
FROM sh.countries co JOIN sh.customers c USING (country_id)
WHERE country_region = 'Asia';
------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------
| 0 | SELECT STATEMENT | | 9281 |
| 1 | NESTED LOOPS | | 9281 |
|* 2 | TABLE ACCESS FULL| COUNTRIES | 4 |
|* 3 | TABLE ACCESS FULL| CUSTOMERS | 2421 |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("CO"."COUNTRY_REGION"='Asia')
3 - filter("CO"."COUNTRY_ID"="C"."COUNTRY_ID")
SELECT /*+ opt_estimate(join (co, c) rows=20000)leading(co) use_nl(c) */
*
FROM sh.countries co JOIN sh.customers c USING (country_id)
WHERE country_region = 'Asia';
------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------
| 0 | SELECT STATEMENT | | 20000 |
| 1 | NESTED LOOPS | | 20000 |
|* 2 | TABLE ACCESS FULL| COUNTRIES | 4 |
|* 3 | TABLE ACCESS FULL| CUSTOMERS | 5217 |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("CO"."COUNTRY_REGION"='Asia')
3 - filter("CO"."COUNTRY_ID"="C"."COUNTRY_ID")
SELECT /*+ index(c (cust_id))
opt_estimate(index_scan c customers_pk scale_rows=0.1)
*/
*
FROM sh.customers c;
--------------------------------------------------------------------
| Id | Operation | Name | Rows |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 55500 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| CUSTOMERS | 55500 |
| 2 | INDEX FULL SCAN | CUSTOMERS_PK | 5550 |
--------------------------------------------------------------------
The OPT_ESTIMATE hint was invented to support SQL profiles and not for SQL tuning but is, in fact, quite useful for that purpose. The first query in Listing 18-8 uses the TABLE variant of the OPT_ESTIMATE hint that behaves in exactly the same way as the cardinality hint. The second variant allows us to specify the number of rows that are returned from the JOIN of two tables. The final variant allows us to specify the number of rows returned from an INDEX SCAN. This last option is not particularly useful for us as the number of rows returned from the table itself is not affected by the hint, but I have included it in the interest of being thorough.
The INDEX SCAN example shows another feature of OPT_ESTIMATE—you don’t have to specify the exact cardinality. By using SCALE_ROWS you can multiply the cardinality the CBO would have used by a specified factor, in this case 0.1.
Object statistic hints
If you are investigating the effect of object statistics on CBO behavior, you can use object statistic hints to temporarily override the values of object statistics. For example, Listing 18-9 shows how I double-checked my hypothesis that it was the number of distinct values of COUNTRY_ID inSH.SALES that affected the cardinality estimate in the second query of Listing 18-7.
Listing 18-9. Use of COLUMN_STATS hint
SELECT /*+ cardinality(c 46000) leading(co) use_nl(c)
column_stats(sh.customers, country_id, scale, distinct=23)
index_stats(sh.customers, customers_pk, scale,
clustering_factor=1, index_rows=1 blocks=1000)
table_stats(sh.customers, scale, blocks=100 rows=46000)
*/
*
FROM sh.countries co JOIN sh.customers c USING (country_id)
WHERE country_region = 'Asia';
------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------
| 0 | SELECT STATEMENT | | 7667 |
| 1 | NESTED LOOPS | | 7667 |
|* 2 | TABLE ACCESS FULL| COUNTRIES | 4 |
|* 3 | TABLE ACCESS FULL| CUSTOMERS | 2000 |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("CO"."COUNTRY_REGION"='Asia')
3 - filter("CO"."COUNTRY_ID"="C"."COUNTRY_ID")
Listing 18-9 shows that when the CBO believes that there are 23 distinct values of COUNTRY_ID present in the SH.CUSTOMERS table and that there are 46,000 rows in the table as a whole, the number of rows per country is 2,000 as expected. The CBO doesn’t estimate that the join will return 8,000 rows, because the estimated number of countries is estimated at 23/6, not as the rounded value of 4 that is displayed.
Listing 18-9 also shows the syntax for the INDEX_STATS and TABLE_STATS hints, but these have no material effect on the execution plan details in this instance.
![]() Caution In version 12.1.0.1 specifically, the TABLE_STATS hint appears to force dynamic sampling. As a consequence of this bug the TABLE_STATS hint is unusable for SQL tuning in that version.
Caution In version 12.1.0.1 specifically, the TABLE_STATS hint appears to force dynamic sampling. As a consequence of this bug the TABLE_STATS hint is unusable for SQL tuning in that version.
Wrapping up hints that are hints
The non-prescriptive hints that simply adjust the data that the CBO uses in its calculations are extremely useful for investigating the cause of poorly performing execution plans and for devising alternative approaches. However, I wouldn’t use them in production systems without a very specific reason.
Although some would argue that it is a good idea to leave the CBO alone to come up with “fresh solutions,” as the health warning quoted at the start of this chapter put it, I beg to differ. The whole point of the CBO is that you generally don’t have to work out an execution plan yourself. By the time you have done sufficient analysis to come to the conclusion that hints are definitely required, you probably have worked out what execution plan you want. If you then decide to hint your code in production, you should use prescriptive hints, i.e., hints that are really directives. Let us focus on those hints now.
Production-hinting case studies
Let us imagine that you have completed your analysis of an errant SQL statement, you understand why the performance was originally so bad, and you have successfully completed performance testing of your fix. However, since you can only achieve the execution plan you need with hints, you may be unsure of whether you have missed something. Here are a few case studies that might help you with the thought process.
The bushy join
I put a brief note at the bottom of Figure 11-3 that stated that the CBO never considers a bushy join. I must say I have been fascinated by the concept of a bushy join ever since I read about it in the first edition of Christian Antognini’s book Troubleshooting Oracle Performance. It is such an easy concept for a human to grasp and demonstrates the need for hinting so well. In real life, however, the need for a bushy join is extremely rare, and it isn’t even easy to come up with a plausible SQL statement using the example schemas. Instead, Listing 18-10 revisits Listing 2-3, which used the entirely artificial tables created in Listing 1-21.
Listing 18-10. The bushy join missed
SELECT *
FROM (t1 JOIN t2 ON t1.c1 = t2.c2)
JOIN (t3 JOIN t4 ON t3.c3 = t4.c4) ON t1.c1 + t2.c2 = t3.c3 + t4.c4;
-----------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)|
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 9 (0)|
|* 1 | HASH JOIN | | 1 | 9 (0)|
| 2 | MERGE JOIN CARTESIAN| | 25 | 7 (0)|
|* 3 | HASH JOIN | | 5 | 4 (0)|
| 4 | TABLE ACCESS FULL | T1 | 5 | 2 (0)|
| 5 | TABLE ACCESS FULL | T2 | 5 | 2 (0)|
| 6 | BUFFER SORT | | 5 | 5 (0)|
| 7 | TABLE ACCESS FULL | T3 | 5 | 1 (0)|
| 8 | TABLE ACCESS FULL | T4 | 5 | 2 (0)|
-----------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T3"."C3"="T4"."C4")
filter("T1"."C1"+"T2"."C2"="T3"."C3"+"T4"."C4")
3 - access("T1"."C1"="T2"."C2")
The use of ANSI join syntax in Listing 18-10 suggests a specific join tree. Using the syntax from Chapter 11, that join tree is: (T1 ![]() T2)
T2) ![]() (T3
(T3 ![]() T4). In other words, we join T1 and T2, creating an intermediate result set, we join T3 and T4, generating a second intermediate result set, and finally we join the two intermediate result sets.
T4). In other words, we join T1 and T2, creating an intermediate result set, we join T3 and T4, generating a second intermediate result set, and finally we join the two intermediate result sets.
Pictorially, we can show a bushy join as follows:
You might like to compare Figure 18-1 with Figure 11-3, which shows a right-deep join tree, and figure 11-2, which shows the left-deep join tree, (T1 ![]() T2)
T2) ![]() (T3
(T3 ![]() T4), which the CBO has produced for the query in Listing 18-10. To a human being it is quite clear how to proceed, but we need to both rewrite our code and hint it to lead the CBO to reach an execution plan that doesn’t involve a Cartesian join. Listing 18-11 shows what we must do.
T4), which the CBO has produced for the query in Listing 18-10. To a human being it is quite clear how to proceed, but we need to both rewrite our code and hint it to lead the CBO to reach an execution plan that doesn’t involve a Cartesian join. Listing 18-11 shows what we must do.
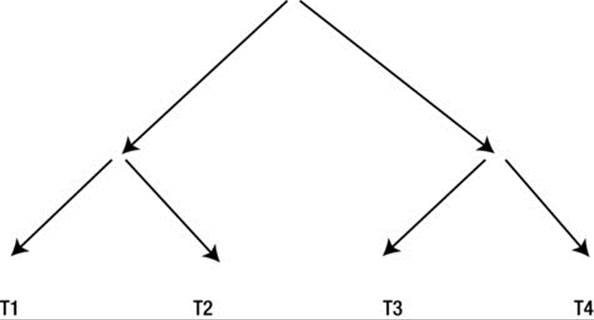
Figure 18-1. The bushy join
Listing 18-11. A bushy join with hints
WITH t1_t2
AS (SELECT /*+ no_merge */
*
FROM t1 JOIN t2 ON t1.c1 = t2.c2)
,t3_t4
AS (SELECT /*+ no_merge */
*
FROM t3 JOIN t4 ON t3.c3 = t4.c4)
SELECT /*+ use_hash(t1_t2) use_hash(t3_t4) */
*
FROM t1_t2 JOIN t3_t4 ON t1_t2.c1 + t1_t2.c2 = t3_t4.c3 + t3_t4.c4;
----------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)|
----------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 (0)|
|* 1 | HASH JOIN | | 1 | 8 (0)|
| 2 | VIEW | | 5 | 4 (0)|
|* 3 | HASH JOIN | | 5 | 4 (0)|
| 4 | TABLE ACCESS FULL| T1 | 5 | 2 (0)|
| 5 | TABLE ACCESS FULL| T2 | 5 | 2 (0)|
| 6 | VIEW | | 5 | 4 (0)|
|* 7 | HASH JOIN | | 5 | 4 (0)|
| 8 | TABLE ACCESS FULL| T3 | 5 | 2 (0)|
| 9 | TABLE ACCESS FULL| T4 | 5 | 2 (0)|
----------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1_T2"."C1"+"T1_T2"."C2"="T3_T4"."C3"+"T3_T4"."C4")
3 - access("T1"."C1"="T2"."C2")
7 - access("T3"."C3"="T4"."C4")
Without the NO_MERGE hints, the CBO would simply apply the simple view-merging transformation on the rewritten query in Listing 18-11, reproducing the original query in Listing 18-10, and then fail to come up with the optimal plan!
The reason that the hints are necessary in this case is that simple view merging is a heuristic transformation. As I explained in Chapter 13, heuristic transformations are applied without any regard to whether they speed up the query or not. In real life, simple view merging is almost always either beneficial or harmless, but in those extremely exceptional cases where a bushy join really is required you will have to use hints to get the right plan.
Although bushy joins are perhaps a once-in-a-lifetime experience, my next example is far more common.
Materialization of factored subqueries
Like simple view merging, factored subquery materialization is a heuristic transformation. The transformation is applied whenever the factored subquery is referenced more than once. Listing 18-12 shows an example of the INLINE hint being used to prevent the CBO from applying the transformation inappropriately.
Listing 18-12. Inappropriate factored subquery materialization
WITH q1
AS ( SELECT /*+ inline */
time_id
,cust_id
,MIN (amount_sold) min_as
,MAX (amount_sold) max_as
,SUM (amount_sold) sum_as
, 100
* ratio_to_report (SUM (amount_sold))
OVER (PARTITION BY time_id)
pct_total
FROM sh.sales
GROUP BY time_id, cust_id)
SELECT *
FROM q1
WHERE time_id = DATE '1999-12-31' AND min_as < 100
UNION ALL
SELECT *
FROM q1
WHERE time_id = DATE '2000-01-01' AND max_as > 100;
-- Execution plan without hint
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows |TempSpc| Cost (%CPU)|
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1837K| | 1233 (51)|
| 1 | TEMP TABLE TRANSFORMATION | | | | |
| 2 | LOAD AS SELECT | SYS_TEMP_0FD9D664A_64B671 | | | |
| 3 | PARTITION RANGE ALL | | 918K| | 5745 (1)|
| 4 | WINDOW BUFFER | | 918K| | 5745 (1)|
| 5 | SORT GROUP BY | | 918K| 24M| 5745 (1)|
| 6 | TABLE ACCESS FULL | SALES | 918K| | 517 (2)|
| 7 | UNION-ALL | | | | |
|* 8 | VIEW | | 918K| | 616 (1)|
| 9 | TABLE ACCESS FULL | SYS_TEMP_0FD9D664A_64B671 | 918K| | 616 (1)|
|* 10 | VIEW | | 918K| | 616 (1)|
| 11 | TABLE ACCESS FULL | SYS_TEMP_0FD9D664A_64B671 | 918K| | 616 (1)|
---------------------------------------------------------------------------------------------
PredicateInformation (identified by operation id):
---------------------------------------------------
8 - filter("TIME_ID"=TO_DATE(' 1999-12-31 00:00:00', 'syyyy-mm-dd
hh24:mi:ss') AND "MIN_AS"<100)
10 - filter("TIME_ID"=TO_DATE(' 2000-01-01 00:00:00', 'syyyy-mm-dd
hh24:mi:ss') AND "MAX_AS">100)
-- Execution plan with hint
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)|
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 312 | 43 (45)|
| 1 | UNION-ALL | | | |
|* 2 | VIEW | | 207 | 24 (0)|
| 3 | WINDOW BUFFER | | 207 | 24 (0)|
| 4 | SORT GROUP BY | | 207 | 24 (0)|
| 5 | PARTITION RANGE SINGLE | | 310 | 24 (0)|
| 6 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| SALES | 310 | 24 (0)|
| 7 | BITMAP CONVERSION TO ROWIDS | | | |
|* 8 | BITMAP INDEX SINGLE VALUE | SALES_TIME_BIX | | |
|* 9 | VIEW | | 105 | 19 (0)|
| 10 | WINDOW BUFFER | | 105 | 19 (0)|
| 11 | SORT GROUP BY | | 105 | 19 (0)|
| 12 | PARTITION RANGE SINGLE | | 153 | 19 (0)|
| 13 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| SALES | 153 | 19 (0)|
| 14 | BITMAP CONVERSION TO ROWIDS | | | |
|* 15 | BITMAP INDEX SINGLE VALUE | SALES_TIME_BIX | | |
----------------------------------------------------------------------------------------------
Predicate Information(identified by operation id):
---------------------------------------------------
2 - filter("MIN_AS"<100)
8 - access("TIME_ID"=TO_DATE(' 1999-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
9 - filter("MAX_AS">100)
15 - access("TIME_ID"=TO_DATE(' 2000-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
The factored subquery in Listing 18-12 performs several calculations on data from the SH.SALES table aggregated by TIME_ID and CUST_ID. The specifics of the calculations aren’t particularly relevant; just realize that you wouldn’t want to type them in twice.
The main query lists a subset of these analytics for the last day of the 20th century and the first day of the 21st century.
Without the INLINE hint the factored subquery will be materialized, and since there is no common predicate to be pushed into the view, data for all values of TIME_ID in all partitions of SH.SALES is aggregated. When we add the INLINE hint, not only does the estimated cost of the query reduce from 1,233 to 43, but also actual elapsed time reduces as well. The reason for this is that when the factored subquery is merged individually into the two branches of the UNION-ALL operation, not only can partition elimination occur but indexed access to the single partition becomes possible too.
It is possible to devise alternative ways to suppress factored subquery materialization that avoid the use of an undocumented hint. You could, for example, cut and paste the code from the factored subquery to create a duplicate factored subquery, or you could resort to inline views. Rewriting code in such a way just to avoid the use of a hint is bad practice. Not only does it make the code less readable but it also introduces the risk of having an issue with an upgrade: a future version of the CBO might recognize code duplication and “optimize” the duplicate away, recreating the original code! The most maintainable solution, perhaps counteri ntuitively, is to use the undocumented hint; Oracle couldn’t possibly stop the INLINE hint from working in a future release given its widespread legitimate use in the existing customer code base.
Suppressing order by elimination and subquery unnesting
This next example will require a little bit of imagination on your part, as it is far from ideal. Let us assume that we want to list all the rows from SH.SALES for the first month of the 21st century together with a column, COUNTRY_SALES_TOTAL, that holds the sum of AMOUNT_SOLD for the associated country for all dates. We want to order the results by COUNTRY_SALES_TOTAL. Imagine that the SH.SALES table has many more columns and many more rows than it actually has and that there are many more countries in the world than there actually are.
That being the case, you might find that after trying all the tricks in the last chapter you still can’t find a way to sum AMOUNT_SOLD for all countries at once without running into serious problems with temporary tablespace and elapsed time. You make the following plan:
· You realize that there were not sales to all countries in January 2000 and you decide to only aggregate data for those countries that are actually needed. Even so, you still have issues with temporary tablespace.
· You decide to aggregate the data for the identified subset of countries one country at a time, thus avoiding the need for any sort at this point. This might take longer in theory, but you won’t need nearly as much temporary tablespace.
· You decide to use the idea from Listing 17-12 and sort just the ROWID from SH.SALES with the associated COUNTRY_ID column from SH.CUSTOMERS.
With these thoughts in mind you devise the SQL in Listing 18-13:
Listing 18-13. Aggregating data piecemeal
SELECT /*+ leading(v2) use_nl(s3) */
s3.*, v2.country_sales_total
FROM ( SELECT /*+ no_merge */
v1.sales_rowid
, (SELECT /*+ no_unnest */
SUM (amount_sold)
FROM sh.customers c1 JOIN sh.sales s1 USING (cust_id)
WHERE c1.country_id = v1.country_id)
country_sales_total
FROM ( SELECT /*+ no_merge no_eliminate_oby */
c2.country_id, s2.ROWID sales_rowid
FROM sh.customers c2 JOIN sh.sales s2 USING (cust_id)
WHERE s2.time_id BETWEEN DATE '2000-01-01'
AND DATE '2000-12-31'
ORDER BY c2.country_id, s2.ROWID) v1
ORDER BY country_sales_total) v2
,sh.sales s3
WHERE s3.ROWID = v2.sales_rowid;
Before looking at the execution plans for the query in Listing 18-13, let us look at what the query intends to do without worrying about the embedded hints.
Let us first look at the inline view, tagged V1. This subquery obtains the ROWID from SH.SALES, the COUNTRY_ID from SH.CUSTOMERS, and then sorts them so that all the rows from SH.SALES for the same country are together. The outer subquery, V2, then takes this sorted data and uses a correlated subquery in the SELECT list to obtain the value of COUNTRY_SALES_TOTAL for the country in question. Because the data from V1 is sorted by COUNTRY_ID we can have complete confidence that scalar subquery caching will prevent the aggregation for a particular country being performed more than once.
Now that we have replaced COUNTRY_ID with COUNTRY_SALES_TOTAL in the SELECT list we can use COUNTRY_SALES_TOTAL as a key for a second sort that still has just two columns. Finally, the main query fattens out the rows in the result set with the extra columns fromSH.SALES, picking them up via the ROWID.
Listing 18-14 shows two execution plans for the query in Listing 18-13. The first execution plan is obtained without hints, and the second with hints.
Listing 18-14. Execution plans for Listing 18-13
-- Execution plan without hints
------------------------------------------------------------------------------
| Id | Operation | Name | Bytes |TempSpc| Cost (%CPU)|
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 42M| | 12922 (1)|
| 1 | SORT ORDER BY | | 42M| 51M| 12922 (1)|
|* 2 | HASH JOIN RIGHT OUTER | | 42M| | 2024 (2)|
| 3 | VIEW | VW_SSQ_1 | 342 | | 961 (4)|
| 4 | HASH GROUP BY | | 532 | | 961 (4)|
|* 5 | HASH JOIN | | 193K| | 961 (4)|
| 6 | VIEW | VW_GBC_7 | 124K| | 538 (6)|
| 7 | HASH GROUP BY | | 70590 | | 538 (6)|
| 8 | PARTITION RANGE ALL | | 8973K| | 517 (2)|
| 9 | TABLE ACCESS FULL | SALES | 8973K| | 517 (2)|
| 10 | TABLE ACCESS FULL | CUSTOMERS | 541K| | 423 (1)|
|* 11 | HASH JOIN | | 8796K| 1200K| 1061 (1)|
| 12 | TABLE ACCESS FULL | CUSTOMERS | 541K| | 423 (1)|
| 13 | PARTITION RANGE ITERATOR| | 6541K| | 131 (2)|
|* 14 | TABLE ACCESS FULL | SALES | 6541K| | 131 (2)|
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ITEM_1"(+)="C2"."COUNTRY_ID")
5 - access("C1"."CUST_ID"="ITEM_1")
11 - access("C2"."CUST_ID"="S2"."CUST_ID")
14 - filter("S2"."TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00',
'syyyy-mm-dd hh24:mi:ss'))
-- Execution plan with hints
---------------------------------------------------------------------------------
| Id | Operation | Name | Bytes |TempSpc| Cost (%CPU)|
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 11M| | 253K (1)|
| 1 | SORT AGGREGATE | | 20 | | |
|* 2 | HASH JOIN | | 7426K| | 942 (2)|
|* 3 | TABLE ACCESS FULL | CUSTOMERS | 29210 | | 423 (1)|
| 4 | PARTITION RANGE ALL | | 8973K| | 517 (2)|
| 5 | TABLE ACCESS FULL | SALES | 8973K| | 517 (2)|
| 6 | NESTED LOOPS | | 11M| | 253K (1)|
| 7 | VIEW | | 5638K| | 22723 (1)|
| 8 | SORT ORDER BY | | 5638K| 8184K| 22723 (1)|
| 9 | VIEW | | 5638K| | 3162 (1)|
| 10 | SORT ORDER BY | | 7894K| 10M| 3162 (1)|
|* 11 | HASH JOIN | | 7894K| 1200K| 1018 (1)|
| 12 | TABLE ACCESS FULL | CUSTOMERS | 541K| | 423 (1)|
| 13 | PARTITION RANGE ITERATOR| | 5638K| | 131 (2)|
|* 14 | TABLE ACCESS FULL | SALES | 5638K| | 131 (2)|
| 15 | TABLE ACCESS BY USER ROWID | SALES | 29 | | 1 (0)|
---------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("C1"."CUST_ID"="S1"."CUST_ID")
3 - filter("C1"."COUNTRY_ID"=:B1)
11 - access("C2"."CUST_ID"="S2"."CUST_ID")
14 - filter("S2"."TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00',
'syyyy-mm-dd hh24:mi:ss'))
Without hints all the hard work we have put in to get the SQL statement to run just the way we want it to has been undone. We can see evidence of subquery unnesting, group by placement, and order by elimination, among other transformations. The CBO estimate for maximum temporary tablespace consumption is 51M for the sort of the fat rows right at the end.
The execution plan obtained with hints looks more like what we want, although I had to check the column projection data to verify just when the correlated subquery was evaluated. To the casual eye it looks like the subquery is evaluated at the very end, but COUNTRY_SALES_TOTAL is the key for the SORT ORDER BY on line 8, and that is where the correlated subquery is actually evaluated.
With the addition of the hints we can see that the maximum tablespace consumption has been reduced five-fold to 10M. This 10M is needed at the point in the execution plan where we had two active workareas: one for the HASH JOIN on line 11 and one for the SORT ORDER BY on line 2.
But why did we need so many hints? Were they all really necessary? The answer is yes, they were all necessary.1 In fact, there is a strong case for adding at least one more hint. Here is the analysis:
· The two NO_MERGE hints for V1 and V2 were needed because simple view merging is a heuristic transformation that is unconditionally applied.
· The UNNEST hint for the correlated subquery is also needed because of the unconditional nature of the heuristic subquery unnesting transformation.
· The NO_ELIMINATE_OBY hint in V1 is needed because order by elimination is a heuristic transformation that is always applied when a subsequent sort is required. In fact, I would add a NO_ELIMINATE_OBY to V2 even though the subsequent join doesn’t currently trigger order by elimination; the order by elimination transformation might be extended to cover joins in a future release. Of course, in real life I would use factored subqueries, and I have even been known to add NO_ELIMINATE_OBY hints to those on my more paranoid of days!
· The LEADING and USE_NL hints in the main query are needed because we can’t include an ORDER BY clause in the main query for reasons that we discussed in the previous chapter.
Even if all the transformations in this last example were cost-based, the CBO probably still wouldn’t have gotten it right. For one thing, the CBO is entirely focused on reducing elapsed time and is unconcerned about temporary tablespace utilization; the CBO assumes space in a temporary tablespace never runs out. For another, the CBO currently has no way to measure the benefits of scalar subquery caching and would see no point in retaining the first sort.
Of course, this example is seriously flawed in several ways. For example, even if we wanted to perform our aggregations piecemeal we probably would want to find a way to aggregate data for more than one country at a time. The challenge here, as it is so often in this book, is to find simple examples to generate techniques used in complex situations. In this particular case, the example may be a little oversimplified. However, the principle demonstrated by the example is perfectly valid: sometimes you want to construct SQL in such a way as to force a specific way of evaluating a query, utterly abandoning the concept of the declarative programming language introduced at the start of Chapter 1. In such circumstances you need to apply hints to ensure that your carefully constructed code isn’t deconstructed by the CBO.
The v$database_block_corruption view
As you will have gathered from Chapter 9, if you didn’t already know, asking the CBO to come up with a decent execution plan when object statistics are stale or otherwise inappropriate is like asking it to fight with both hands tied behind its back. However, a couple of years ago I was unfortunate enough to encounter a situation where the CBO would always be fighting with both hands behind its back!
If you select rows from the data dictionary view V$DATABASE_BLOCK_CORRUPTION I sincerely hope, for your sake, that you get no rows back! In a healthy database this view returns no rows, but if RMAN detects corrupt blocks when performing a backup it populates underlying data structures with information about the corrupt blocks, which you can see by looking at this view.
One of the first questions that will run through your mind when you discover corrupt blocks in your database is: Which segments are corrupt? There is a well-known article, 472231.1, on the Oracle support website that includes a query that joins V$DATABASE_BLOCK_CORRUPTION,DBA_SEGMENTS, and DBA_EXTENTS to identify the corrupt blocks.
When you run the query provided in that note, the CBO will look at the statistics for the database object X$KCCBLKCOR that V$DATABASE_BLOCK_CORRUPTION references and see that it apparently has no rows, because X$KCCBLKCOR would have contained no rows the last time data dictionary statistics had been gathered. Of course there is no point in running the query in note 472231.1 unless there are corrupt blocks, so you always need to hint the query to get it to run quickly!
Incidentally, the query in note 472231.1 contains a second weakness in that it reports corruption in segments above their high-water mark, which should not be a cause for a concern. I do have an amended script (submitted to Oracle at the time) that removes the false-positive reports and includes hints to give a reasonable execution plan. The script is too long to print here but is available as corruption.sql in the downloadable materials. Do bear in mind, however, that I have not had the opportunity to verify corruption.sql on a real corrupt database, so I cannot guarantee its correctness or suitability for purpose.
Summary
There are a few hints that are used by edition-based redefinition and a few more that are mainly aimed at the runtime engine, such as the APPEND hint. The vast majority of hints, however, are optimizer hints, which fall into two categories.
On one hand, some optimizer hints really are just hints and are very useful for investigating the cause of poorly performing execution plans and for identifying possible alternatives in a SQL tuning exercise. However, the use of non-prescriptive hints on production systems is generally inadvisable because of their unpredictable behavior.
On the other hand, prescriptive hints, hints that are really directives, can legitimately be used on production systems to solve some classes of performance problems. The use of hints on production systems should only be done after due consideration, not because the hints are likely to cease to function in a future release or because the level of support from Oracle will be negatively impacted but because the supporting documentation is usually very poor or non-existent. That lack of documentation has a tendency to lead to misunderstanding and misuse.
This chapter and the preceding three have covered most of the techniques that are at your disposal in your quest to optimize SQL performance. There are, however, one or two more advanced techniques that may be of use in special situations. On to Chapter 19.
__________________
1The NO_QUERY_TRANSFORMATION hint is an alternative that may reduce the number of hints in this case.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.