Achieving Extreme Performance with Oracle Exadata (Oracle Press) (2011)
PART II
Best Practices
CHAPTER 6
High Availability and Backup Strategies
The continuous availability of business-critical information is a key requirement for enterprises to survive in today’s information-based economy. Enterprise database systems managing critical data such as financial and customer information, and operational data such as orders, need to be available at all times. Making important business decisions based on these systems requires the databases storing this data to provide high-service uptime with enhanced reliability.
When the loss of data or the database service occurs due to planned events such as software patching and upgrading, or due to unforeseen events such as media failures, data corruption, or disasters, the data and the database service need to be recovered quickly and accurately. If recovery cannot be performed in the optimal timeframe as dictated by the business Service Level Agreements (SLA), the business can incur loss of revenues and customers. Choosing the right high-availability architecture of the Exadata Database Machine will enable the enterprises to safeguard critical data and provide the highest level of service, availability, and reliability.
The basic premise of high-availability architectures is based on redundancies across the hardware and software components in the deployment architecture. Redundant systems provide high availability when remaining active at the same time. High availability can also be built into the software layer by incorporating features that provide continuous availability of data. A few examples are the features that help repair data corruption, perform online maintenance operations, and help you recover from user errors while the database remains available.
Oracle provides a myriad of high-availability technologies for implementing highly available database systems. This chapter highlights such technologies and the recommended practices and guidelines for implementing them. We will also discuss the best-practice methods of performing backup and recovery on the Oracle Exadata Database Machine.
Exadata Maximum Availability Architecture (MAA)
Oracle Maximum Availability Architecture (MAA) is the Oracle-recommended best-practice architecture for achieving the highest availability of service with Oracle products, using Oracle’s proven high-availability technologies.
MAA best practices are published as a series of technical whitepapers and blue prints, and assist in deploying highly available Oracle-based applications and platforms that are capable of meeting and exceeding the business service-level requirements. The MAA architecture covers all components of the technology stack, includes the hardware and the software, and addresses planned and unplanned downtime.
MAA provides a framework for high availability by incorporating redundancies into the components of the technology stack, and also by utilizing certain built-in high-availability features of the Oracle software. For example, the Database Flashback feature enables you to recover from user errors such as an involuntary DROP TABLE statement by using a simple FLASHBACK TABLE command. This cuts down the recovery time drastically, which otherwise would be needed for performing a point-in-time recovery using backups.
Figure 6-1 represents the MAA architecture using the Exadata Database Machine. The Database Machine MAA architecture has identically sized Database Machines on the primary and standby sites. The primary site contains a production database configured with Oracle Real Application Clusters (RAC). Oracle RAC provides protection from database server and instance failures. The standby site contains a physical standby database that is synchronized with the primary database by using Oracle Data Guard. The Active Data Guard option enables the physical standby database to be open in a read-only state while the database is kept in sync with the primary database. Active Data Guard enables you to offload read-only queries to the standby site and enhances the overall availability of the database by utilizing an otherwise idle standby site for reporting purposes. The figure also depicts the use of Oracle database technologies such as Flashback, RMAN, and ASM for providing high availability during planned and unplanned downtime.
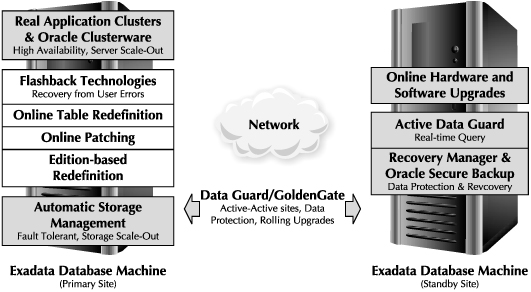
FIGURE 6-1. Exadata Database Machine MAA architecture
We’ll next cover the Oracle high-availability features that address planned and unplanned downtime. The intent is not to cover the complete set of MAA technologies, but only the topics that relate to the Exadata Database Machine and the common tasks that will be performed on the Machine. The topics discussed in this section are listed here:
![]() High availability with Oracle Data Guard
High availability with Oracle Data Guard
![]() Using Oracle GoldenGate with Database Machine
Using Oracle GoldenGate with Database Machine
![]() Database Machine patches and upgrades
Database Machine patches and upgrades
![]() Exadata Storage Server high availability
Exadata Storage Server high availability
![]() Preventing data corruption
Preventing data corruption
High Availability with Oracle Data Guard
Oracle Data Guard is an integral component of MAA and the best-practice solution for ensuring high availability and disaster recovery of the Oracle database. Data Guard provides an extensive set of features that enable you to recover from planned and unplanned downtime scenarios, such as recovering from data corruption, performing near-zero database upgrades, and conducting database migrations.
Data Guard provides the software to manage and maintain one or more standby databases that are configured as a replica of the primary database, and protects from data loss by building and maintaining redundant copies of the database. When a data loss or a complete disaster occurs on the primary database, the copy of the data stored on the standby database can be used to repair the primary database. Data Guard also provides protection from data corruptions by detecting and repairing corruptions automatically as they happen, using the uncorrupted copy on the standby database.
The Data Guard architecture consists of processes that capture and transport transactions occurring on the primary database and applying them on the standby databases. Oracle redo generated on the primary site is used to transmit changes captured from the primary to the standby site(s), using a synchronous or asynchronous mechanism. Once the redo is received by the standby site, it is applied on the standby databases using one of two possible methods: Redo Apply or SQL Apply.
The Redo Apply process uses the database media recovery process to apply the transactions to the standby databases. Redo Apply maintains a block-for-block replica of the primary database, ensuring that the standby database is physically identical to the primary one in all respects. The standby database that uses Redo Apply to sync up with the primary is called a physical standby. The physical standby database can be open and made accessible for running read-only queries while the redo is being applied; this arrangement of the physical standby is called Active Data Guard.
The SQL Apply process mines the redo logs once they are received on the standby host, re-creates the SQL transactions as they occurred on the primary database, and then executes the SQL on the standby database. The standby in this case is open for read-write activity, and contains the same logical information as the primary database. However, the database has its own identity with possibly different physical structures. The standby database that uses the SQL Apply as the synchronization method is called a logical standby.
NOTE
The SQL Apply has some restrictions on the data types, objects, and SQL operations that it supports. Refer to the Oracle Data Guard manuals for further details.
The MAA best practices dictate the use of Data Guard Redo Apply as the synchronization method for achieving the highest availability with the Database Machine. MAA also proposes the use of Active Data Guard to enhance the overall availability of the database machine by utilizing the standby database for reporting and queries.
Data Guard is tightly integrated with the Oracle database and supports high-transaction volumes that are demanded by the Exadata Database Machine deployments. When you follow the best practices for configuring Data Guard, the typical apply rates that you can achieve with Redo Apply can be over 2 TB/hr. Keep in mind that this means 2 TB/hr of database changes, which is a high transaction rate.
Although the primary purpose of Data Guard is to provide high availability and disaster recovery, it can also be utilized for a variety of other business scenarios that address planned and unplanned downtime requirements. A few such scenarios are discussed next:
![]() Database rolling upgrades The Data Guard standby database can be used to perform rolling database upgrades with near-zero downtime. The standby database is upgraded while the primary is still servicing production loads, and the primary database is switched over to the standby, with minimal interruption.
Database rolling upgrades The Data Guard standby database can be used to perform rolling database upgrades with near-zero downtime. The standby database is upgraded while the primary is still servicing production loads, and the primary database is switched over to the standby, with minimal interruption.
![]() Migrate to the Database Machine Data Guard can be used to migrate Oracle databases to the Database Machine with minimal downtime, using the physical or the logical standby database. The standby database will be instantiated on the Exadata Database Machine and then switched over to the primary role, allowing the migration to happen with the flip of a switch. Refer to Chapter 10 for further details.
Migrate to the Database Machine Data Guard can be used to migrate Oracle databases to the Database Machine with minimal downtime, using the physical or the logical standby database. The standby database will be instantiated on the Exadata Database Machine and then switched over to the primary role, allowing the migration to happen with the flip of a switch. Refer to Chapter 10 for further details.
![]() Data corruption detection and prevention The Data Guard Apply process can detect corruptions, and also provide mechanisms to automatically recover from corruptions. This topic is discussed in detail later in the chapter.
Data corruption detection and prevention The Data Guard Apply process can detect corruptions, and also provide mechanisms to automatically recover from corruptions. This topic is discussed in detail later in the chapter.
![]() User error protection You can induce a delay in the Redo Apply process to queue the transactions for a specified period (delay) before they are applied on the standby database. The delay provides you with the ability to recover from user or application errors on the primary database, since the corruption does not immediately get propagated and can be repaired by using a pristine copy from the standby.
User error protection You can induce a delay in the Redo Apply process to queue the transactions for a specified period (delay) before they are applied on the standby database. The delay provides you with the ability to recover from user or application errors on the primary database, since the corruption does not immediately get propagated and can be repaired by using a pristine copy from the standby.
![]() Offload queries and backups Active Data Guard can be used to offload read-only queries and backups to the active standby database. Offloading the queries from the primary database will improve performance and accelerate the return on investment on the standby, which otherwise would be sitting idle. Backups created on the standby can be used to recover the primary database, since the standby will be a block-for-block copy of the primary.
Offload queries and backups Active Data Guard can be used to offload read-only queries and backups to the active standby database. Offloading the queries from the primary database will improve performance and accelerate the return on investment on the standby, which otherwise would be sitting idle. Backups created on the standby can be used to recover the primary database, since the standby will be a block-for-block copy of the primary.
![]() Primary-primary configuration Instead of having a traditional Data Guard setup of a primary site and a standby site, with all primary databases configured on the primary site, you can configure both sites to be primary sites and spread the primary roles across the available machines on both sites. For example, if you have a traditional Data Guard setup of OLTP and DSS / data warehouse databases in the primary roles on site A and site Bhousing their standbys, you can configure site A with the primary OLTP database and the standby DSS database, and site B with standby OLTP and primary DSS. The primary-primary setup allows you to utilize all the systems in the configuration and spread the production load over to the standby, which leads to an overall increase in performance and at the same time, decreases the impact of individual site failures.
Primary-primary configuration Instead of having a traditional Data Guard setup of a primary site and a standby site, with all primary databases configured on the primary site, you can configure both sites to be primary sites and spread the primary roles across the available machines on both sites. For example, if you have a traditional Data Guard setup of OLTP and DSS / data warehouse databases in the primary roles on site A and site Bhousing their standbys, you can configure site A with the primary OLTP database and the standby DSS database, and site B with standby OLTP and primary DSS. The primary-primary setup allows you to utilize all the systems in the configuration and spread the production load over to the standby, which leads to an overall increase in performance and at the same time, decreases the impact of individual site failures.
When configuring Data Guard with the Exadata Database Machine, special consideration needs to be given for Exadata Hybrid Columnar Compression (EHCC) and for transporting the redo traffic over the network. These considerations are discussed next.
Data Guard and Exadata Hybrid Columnar Compression
The Exadata Hybrid Columnar Compression (EHCC) feature is the Oracle compression technology available only to the databases residing on the Exadata Storage Servers. If you plan on using EHCC compression with the Database Machine in a Data Guard configuration, the best practice is to have the primary and the standby databases both reside on the Exadata Storage Servers. Such a Data Guard configuration will provide the best performance and the highest availability of your critical data in the event of failures.
If you intend to configure a standby database on traditional storage (non-Exadata-based) for a primary database residing on Exadata Storage Servers, you need to consider the limitations mentioned next. The limitations arise mainly because EHCC compression is not supported on databases residing on non-Exadata storage.
![]() When performing a switchover operation to the standby on the traditional storage, the EHCC-compressed tables need to be uncompressed on the standby before they can be accessed by the applications. The time to uncompress EHCC tables can significantly affect the availability of the database and add to the total recovery time needed for the switchover. Since EHCC is normally used for less frequently updated or historical data, the inability to access this data momentarily may not be a serious problem for the business.
When performing a switchover operation to the standby on the traditional storage, the EHCC-compressed tables need to be uncompressed on the standby before they can be accessed by the applications. The time to uncompress EHCC tables can significantly affect the availability of the database and add to the total recovery time needed for the switchover. Since EHCC is normally used for less frequently updated or historical data, the inability to access this data momentarily may not be a serious problem for the business.
![]() If you need to uncompress the EHCC tables on the standby database, you should factor in the additional space needed on the standby to accommodate the uncompressed data. The additional space is dependent on the compression ratios provided by EHCC, and could range from 10 to 50 times the original compressed space.
If you need to uncompress the EHCC tables on the standby database, you should factor in the additional space needed on the standby to accommodate the uncompressed data. The additional space is dependent on the compression ratios provided by EHCC, and could range from 10 to 50 times the original compressed space.
![]() If the standby database is going to be utilized for production loads after the switchover, it needs to be able to sustain the throughput and load characteristics of the primary database. The reality is that it probably cannot match the Database Machine performance, in which case, the standby will be running in a reduced performance mode.
If the standby database is going to be utilized for production loads after the switchover, it needs to be able to sustain the throughput and load characteristics of the primary database. The reality is that it probably cannot match the Database Machine performance, in which case, the standby will be running in a reduced performance mode.
![]() Active Data Guard is not supported on the standby if you plan on using EHCC on the primary database.
Active Data Guard is not supported on the standby if you plan on using EHCC on the primary database.
NOTE
A simple way to move an EHCC-compressed table to non-EHCC is by using the ALTER TABLE MOVE command.
Data Guard Network Best Practices
The network utilized to push the Data Guard traffic (redo) from the primary database to the standby should be able to handle the redo rates generated by the primary. Otherwise, you will encounter apply lags, which can add delays to the switchover process and hamper the recoverability of data.
Before deciding on the best method of routing the redo between the primary and the standby, calculate the bandwidth required by the redo generated by the primary database. This can be easily done from the Automatic Workload Repository (AWR) report by looking at the redo size per second metric. The metric should be captured during peak loads on the primary and accumulated from all the instances generating redo in the RAC cluster. You should also add the overhead of the TCP network (~30 percent due to TCP headers) to come up with the final bandwidth requirement.
Once you calculate the bandwidth required, consider the following options for deciding the best method applicable for routing the redo:
![]() Public network Investigate the bandwidth available on the public network to push redo. If the standby is in a remote location, this might be the only option available to you, unless the primary and the standby data centers are networked using dedicated lines. Since the public network is shared with other traffic, consider using quality of service (QoS) features to guarantee the bandwidth allocation required for Data Guard.
Public network Investigate the bandwidth available on the public network to push redo. If the standby is in a remote location, this might be the only option available to you, unless the primary and the standby data centers are networked using dedicated lines. Since the public network is shared with other traffic, consider using quality of service (QoS) features to guarantee the bandwidth allocation required for Data Guard.
![]() Dedicated network If the public network is unable to handle the required bandwidth, consider isolating the traffic through a dedicated gigabit network. Each database server in the Database Machine has a set of 1 GigE and 10 GigE ports that you can use to route redo. You should be able to get an effective transfer rate of 120 MB/s through a 1 GigE port and 1 GB/s through a 10 GigE port. If you require more bandwidth than what is available from a single port, consider bonding multiple ports together or shipping the redo from multiple servers. For example, using two 1 GigE ports can give you a combined aggregated throughput of 240 MB/s, and two 10 GigE ports can give you a throughput of 2 GB/s.
Dedicated network If the public network is unable to handle the required bandwidth, consider isolating the traffic through a dedicated gigabit network. Each database server in the Database Machine has a set of 1 GigE and 10 GigE ports that you can use to route redo. You should be able to get an effective transfer rate of 120 MB/s through a 1 GigE port and 1 GB/s through a 10 GigE port. If you require more bandwidth than what is available from a single port, consider bonding multiple ports together or shipping the redo from multiple servers. For example, using two 1 GigE ports can give you a combined aggregated throughput of 240 MB/s, and two 10 GigE ports can give you a throughput of 2 GB/s.
![]() InfiniBand network Use the InfiniBand network to route redo when the redo rates cannot be accommodated using the 1 GigE or the 10 GigE ports. InfiniBand cables have a distance limitation (typically 100 m), so the distance between the primary and the standby Database Machines will be one of the deciding factors to determine if InfiniBand can be used. Using the InfiniBand network with TCP communication (IPoIB), you should be able to get a throughput of about 2 GB/s by using one port.
InfiniBand network Use the InfiniBand network to route redo when the redo rates cannot be accommodated using the 1 GigE or the 10 GigE ports. InfiniBand cables have a distance limitation (typically 100 m), so the distance between the primary and the standby Database Machines will be one of the deciding factors to determine if InfiniBand can be used. Using the InfiniBand network with TCP communication (IPoIB), you should be able to get a throughput of about 2 GB/s by using one port.
![]() Data Guard redo compression Consider transmitting the redo in a compressed format by using the Oracle Advanced Compression option. This is useful if none of the options are available to satisfy your bandwidth requirements.
Data Guard redo compression Consider transmitting the redo in a compressed format by using the Oracle Advanced Compression option. This is useful if none of the options are available to satisfy your bandwidth requirements.
Using Oracle GoldenGate with Database Machine
Oracle GoldenGate is a real-time, log-based, change data capture and replication tool that supports Oracle and non-Oracle sources and targets. Oracle GoldenGate replicates committed transactions from the source database in real time while preserving transactional integrity. GoldenGate has the intelligence to interface with the proprietary log formats of different database vendors, and using this intelligence, it can re-create the SQL statement of the transaction as it is executed on the source system and apply the re-created SQL on the destination system. GoldenGate performs these steps in real time and with minimal overhead on the source and thus, provides a solution that enables high-speed and real-time transactional data replication.
Oracle GoldenGate supports a variety of use cases, including real-time business intelligence, query offloading, zero-downtime upgrades and migrations, disaster recovery, and active-active databases with bidirectional replication, data synchronization, and high availability. A few use cases of GoldenGate focused on providing high availability for the Database Machine deployments are discussed here:
![]() GoldenGate can perform migrations of Oracle and non-Oracle databases to the Exadata Database Machine with minimal to zero downtime. The migration process starts by instantiating the source database on the Database Machine, replicating transactions from the source database to the Database Machine, keeping the two systems in sync for a time, and eventually switching the production system to the Oracle database. This method will allow you to perform comprehensive testing of your applications on the Exadata Database Machine, using production data volumes, tune them if necessary, and more importantly, allow you to attain a comfort level with the migration process before performing the actual switchover. Refer to Chapter 10 for further details on performing migrations to the Database Machine using GoldenGate.
GoldenGate can perform migrations of Oracle and non-Oracle databases to the Exadata Database Machine with minimal to zero downtime. The migration process starts by instantiating the source database on the Database Machine, replicating transactions from the source database to the Database Machine, keeping the two systems in sync for a time, and eventually switching the production system to the Oracle database. This method will allow you to perform comprehensive testing of your applications on the Exadata Database Machine, using production data volumes, tune them if necessary, and more importantly, allow you to attain a comfort level with the migration process before performing the actual switchover. Refer to Chapter 10 for further details on performing migrations to the Database Machine using GoldenGate.
![]() GoldenGate supports active-passive replication configurations with which it can replicate data from an active primary database on the Exadata Database Machine to the inactive standby database. GoldenGate can keep the two systems in sync by applying changes in real time. The standby database can be used to provide high availability during planned and unplanned outages, perform upgrades, and accelerate the recovery process on the primary.
GoldenGate supports active-passive replication configurations with which it can replicate data from an active primary database on the Exadata Database Machine to the inactive standby database. GoldenGate can keep the two systems in sync by applying changes in real time. The standby database can be used to provide high availability during planned and unplanned outages, perform upgrades, and accelerate the recovery process on the primary.
NOTE
The term standby database in this context is used to refer to a standby database replicated by GoldenGate, and should not be confused with the Data Guard standby database.
![]() GoldenGate supports active-active replication configurations, which offer bidirectional replication between primary and standby databases. The benefit of active-active is that the standby database (which is also another primary) can be used to offload processing from the primary. The standby database would otherwise be idle and will be utilized only during outages. This setup will allow you to distribute load across the primary and the standby databases based on application types and geographic location. Utilizing an idle database, which is usually considered a “dead” investment by the IT departments, will help you to justify the cost of purchasing a standby Database Machine.
GoldenGate supports active-active replication configurations, which offer bidirectional replication between primary and standby databases. The benefit of active-active is that the standby database (which is also another primary) can be used to offload processing from the primary. The standby database would otherwise be idle and will be utilized only during outages. This setup will allow you to distribute load across the primary and the standby databases based on application types and geographic location. Utilizing an idle database, which is usually considered a “dead” investment by the IT departments, will help you to justify the cost of purchasing a standby Database Machine.
![]() The Database Machine can be used as a real-time data warehouse in which other Oracle and non-Oracle databases can feed real-time transactions using GoldenGate. Real-time data warehouses are used by the enterprises in today’s competitive landscape for performing real-time analytics and business intelligence.
The Database Machine can be used as a real-time data warehouse in which other Oracle and non-Oracle databases can feed real-time transactions using GoldenGate. Real-time data warehouses are used by the enterprises in today’s competitive landscape for performing real-time analytics and business intelligence.
![]() GoldenGate can be used in situations that require the Exadata Database Machine to feed other database systems or data warehouses that require changed data to be captured from the Database Machine and propagated to the destination systems in real time. These types of deployments allow coexistence and integration of the Database Machine with other databases that you may have deployed in the data center.
GoldenGate can be used in situations that require the Exadata Database Machine to feed other database systems or data warehouses that require changed data to be captured from the Database Machine and propagated to the destination systems in real time. These types of deployments allow coexistence and integration of the Database Machine with other databases that you may have deployed in the data center.
Oracle GoldenGate Architecture
The primary components of the Oracle GoldenGate software are shown in Figure 6-2. Each component is designed so that it can perform its task independently of the other. This design ensures minimal dependencies and at the same time preserves data integrity by eliminating undue interference.
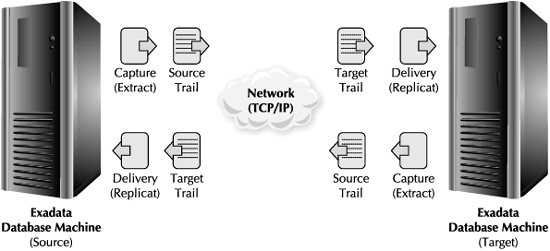
FIGURE 6-2. Oracle GoldenGate architecture
The main components comprising the GoldenGate software architecture are the following:
![]() Extract process The extract process captures new transactions as they occur on the source system. The extract process interfaces with the native transaction logs of the source database and reads the result of insert, update, and delete operations in real time. The extract can push captured changes directly to the replicat process, or generate trail files.
Extract process The extract process captures new transactions as they occur on the source system. The extract process interfaces with the native transaction logs of the source database and reads the result of insert, update, and delete operations in real time. The extract can push captured changes directly to the replicat process, or generate trail files.
![]() Trail files Trail files are generated by the extract process. They contain database transactions captured from the source system in a transportable and platform-independent format. Trail files reside outside the database to ensure platform independence, and to enhance the reliability and availability of transactions. This architecture minimizes the impact on the source system because additional tables or queries are not required on the source for supporting the data capture process.
Trail files Trail files are generated by the extract process. They contain database transactions captured from the source system in a transportable and platform-independent format. Trail files reside outside the database to ensure platform independence, and to enhance the reliability and availability of transactions. This architecture minimizes the impact on the source system because additional tables or queries are not required on the source for supporting the data capture process.
![]() Replicat process The replicat process takes the changed data from the latest trail file and applies it to the target using the native SQL for the appropriate target database system. The replicat process preserves the original sequence of the transactions as they were captured on the source system, and thereby preserves transactional and referential integrity at the target.
Replicat process The replicat process takes the changed data from the latest trail file and applies it to the target using the native SQL for the appropriate target database system. The replicat process preserves the original sequence of the transactions as they were captured on the source system, and thereby preserves transactional and referential integrity at the target.
![]() Manager process The manager process runs on the target and the source systems, and is responsible for starting, monitoring, and restarting other GoldenGate processes, and also for allocating data storage, reporting errors, and logging events.
Manager process The manager process runs on the target and the source systems, and is responsible for starting, monitoring, and restarting other GoldenGate processes, and also for allocating data storage, reporting errors, and logging events.
![]() Checkpoint files Checkpoint files contain the current read and write positions of the extract and replicat processes. Checkpoints provide fault tolerance by preventing the data loss when the system, the network, or the GoldenGate processes need to be restarted.
Checkpoint files Checkpoint files contain the current read and write positions of the extract and replicat processes. Checkpoints provide fault tolerance by preventing the data loss when the system, the network, or the GoldenGate processes need to be restarted.
![]() Discard files Discard files are used by GoldenGate to record failed operations either by the extract or the replicat process. For example, invalid column mappings are logged into the discard file by the replicat process so that they can be further investigated.
Discard files Discard files are used by GoldenGate to record failed operations either by the extract or the replicat process. For example, invalid column mappings are logged into the discard file by the replicat process so that they can be further investigated.
Oracle GoldenGate and Database Machine Best Practices
As discussed previously, GoldenGate requires a set of key files to accomplish its tasks. The best practice for storing these files on the Database Machine is to store them in the Oracle Database File System (DBFS). DBFS is discussed in Chapter 2; in a nutshell, it provides a distributed, NFS-like file system interface that can be mounted on the database servers. DBFS and NFS are the only methods currently available in the Database Machine to allow sharing of files among the database servers. The advantage of DBFS over NFS-like file systems is that DBFS inherits the high availability, reliability, and disaster recovery capabilities of the Oracle database since the files placed in DBFS are stored inside the database as a SecureFiles object.
NOTE
NFS file systems can be mounted on the database servers using the InfiniBand network or the 1 GigE or 10 GigE ports. The underlying transport protocol supported for NFS is TCP (IPoIB for InfiniBand).
The best-practice considerations for implementing GoldenGate with the Exadata Database Machine are as follows:
![]() Use DBFS to store GoldenGate trail files and checkpoint files. If a database server in the Database Machine fails, the GoldenGate extract and replicat processes will continue to function, since the trail and checkpoint files will still be accessible from the other database servers.
Use DBFS to store GoldenGate trail files and checkpoint files. If a database server in the Database Machine fails, the GoldenGate extract and replicat processes will continue to function, since the trail and checkpoint files will still be accessible from the other database servers.
![]() Ensure that the extract and the replicat processes run only on a single database node. This requirement guarantees that multiple extract/replicat processes do not work on the same set of transactions at the same time. One way to prevent them from starting up concurrently from other database nodes is to mount the DBFS file system only on one node and use this node to run these processes. Other nodes cannot accidentally start them, since DBFS will not be mounted on them.
Ensure that the extract and the replicat processes run only on a single database node. This requirement guarantees that multiple extract/replicat processes do not work on the same set of transactions at the same time. One way to prevent them from starting up concurrently from other database nodes is to mount the DBFS file system only on one node and use this node to run these processes. Other nodes cannot accidentally start them, since DBFS will not be mounted on them.
This check is built in when using a regular file system to store the checkpoint and trail files instead of DBFS. Using file locking mechanisms, the first extract/replicat process will exclusively lock the files and ensure that the second process cannot start. DBFS currently does not support such methods and hence, the manual checks are required.
![]() The best practice for storing checkpoint files on DBFS is to create a symbolic link from the GoldenGate home directory to a directory on DBFS, as shown in the following example. Use the same mount point names on all the nodes to ensure consistency and seamless failover.
The best practice for storing checkpoint files on DBFS is to create a symbolic link from the GoldenGate home directory to a directory on DBFS, as shown in the following example. Use the same mount point names on all the nodes to ensure consistency and seamless failover.
# DBFS is mounted on /mnt/dbfs
# GoldenGate is installed on /OGG/v10_4
% mkdir /mnt/dbfs/OGG/dirchk
% cd /OGG/v10_4
% rm -rf dirchk
% ln -s /mnt/dbfs/OGG/dirchk dirchk
![]() The DBFS database should be configured as a separate RAC database on the same nodes that house the databases accessed by GoldenGate. Perform checks to ensure that the DBFS file system is mountable on all database nodes. However as a best practice stated earlier, only one node will mount the DBFS at a time.
The DBFS database should be configured as a separate RAC database on the same nodes that house the databases accessed by GoldenGate. Perform checks to ensure that the DBFS file system is mountable on all database nodes. However as a best practice stated earlier, only one node will mount the DBFS at a time.
![]() Install the GoldenGate software in the same location on all the nodes that are required to run GoldenGate upon a failure of the original node. Also ensure that the manager, extract, and replicat parameter files are up to date on all nodes.
Install the GoldenGate software in the same location on all the nodes that are required to run GoldenGate upon a failure of the original node. Also ensure that the manager, extract, and replicat parameter files are up to date on all nodes.
![]() Configure the extract and replicat processes to start up automatically upon the startup of the manager process.
Configure the extract and replicat processes to start up automatically upon the startup of the manager process.
![]() Configure Oracle Clusterware to perform startup, shutdown, and failover of GoldenGate components. This practice provides high availability of the GoldenGate processes by automating steps required to initiate a failover operation.
Configure Oracle Clusterware to perform startup, shutdown, and failover of GoldenGate components. This practice provides high availability of the GoldenGate processes by automating steps required to initiate a failover operation.
![]() The page and discard files should be set up on the local file system and within the GoldenGate installation directory structure. The page file is a special memory-mapped file and currently not supported by DBFS.
The page and discard files should be set up on the local file system and within the GoldenGate installation directory structure. The page file is a special memory-mapped file and currently not supported by DBFS.
Database Machine Patches and Upgrades
Applying patches and performing upgrades are normal events in the lifecycle of software, and the Exadata Database Machine software components are no exception. The software installed on the database servers, the Exadata Storage Servers, and the InfiniBand switches are candidates for being patched or upgraded when Oracle releases their newer versions.
Oracle Enterprise Manager (OEM) has the capability to patch the Oracle software stack. You can use OEM to simplify the patching experience on the Exadata Database Machine. OEM’s integration with My Oracle Support enables you to identify recommended patches for your system by searching Knowledge Base articles, validating them for any conflicts, finding or requesting merge patches, and lastly but not least, automating the patch deployment process by using OEM Provisioning and Patch Automation features.
We will next describe the Database Machine patching process using methods that provide zero downtimes. Database high-availability features such as RAC and Data Guard, and the built-in high-availability features of Exadata Storage Server, make zero downtime patching achievable.
We will also discuss the methods available for upgrading the database, ASM and Clusterware, with minimal downtime using Data Guard.
NOTE
The patches for the Database Machine are categorized into database software patches, database system patches (which include the OS, firmware, database, and OFED patches), and the Exadata Storage Server patches. A separate system-level patch for the Exadata Storage Server does not exist, since this is bundled into the Exadata Storage Server patch.
Exadata Storage Server Patching
The Exadata Storage Server patches encompass patches to the Exadata Storage Server Software, Oracle Linux OS, firmware updates, and patches to Open Fabrics Enterprise Distribution (OFED) packages. Under no circumstances should users apply OS, firmware, or OFED patches directly on the Exadata Storage Servers. These patches will be supplied by Oracle and will be bundled into an Exadata Storage Server patch. The patch will be applied to all the servers in a rolling fashion and one at a time, without incurring any downtime.
Exadata Storage Server patches are one of two types: overlay and staged. Overlay patches require a restart of the Exadata Storage Server Software processes (CELLSRV, RS, and MS). Upon the restart of the Exadata Storage Server Software, ASM issues an automatic reconnect and the service resumes normal operation. This process does not incur any downtime.
Staged patches require the Exadata Storage Server to be rebooted upon application. The Exadata Storage Server will be taken offline and if any interim updates to the data residing in the offline Exadata Storage Servers occur during this period, they will be tracked by ASM. The updates will be synced when the Exadata Storage Server becomes available, using the ASM fast mirror re-sync feature. Staged patches do not incur any service downtime.
Database Patching with Minimal Downtime
Oracle database patches are broadly categorized into two types—patches and patch sets. A patch is a change to the Oracle software that happens between patch sets or upgrades, whereas a patch set is a mechanism for delivering a set of patches that are combined, integrated, and tested together, and delivered on a regular basis. Patches may be applied to an Oracle database with zero or near-zero downtime, using one of two techniques: the online patching feature introduced in Oracle Database 11g and rolling patching with Oracle RAC. We will describe both features in this section. The process of applying patch sets is treated similar to an upgrade, and you should use the methods outlined in the “Database Rolling Upgrades” section of this chapter to perform minimal downtime upgrades from patch sets.
NOTE
Oracle database patches can be Interim, Merge, Bundle, or Critical Patch Update (CPU) patches.
Rolling Patching with RAC
Oracle provides the ability to apply patches to the individual nodes of a RAC cluster in a rolling fashion, to one RAC node at a time, while the other nodes are still servicing user requests. The process of applying a rolling patch starts with taking one of the RAC nodes out of service, applying the patch to the node, and putting the node back in service. These steps are repeated until all instances in the cluster are patched.
Patches need to be labeled as “rolling” before they can be applied using this method. Usually, patches that modify the database and the shared structures between the RAC instances do not qualify as rolling. Moreover, only patches, and not patch sets, can be labeled as rolling capable.
Rolling patching using RAC guarantees the availability of the database service during the patching process. However, you will be running with one less node in the cluster until the process is completed, so the impact to the business due to reduced capacity should be considered prior to proceeding with this method.
Online Patching
Online patching is the process of applying patches to the Oracle instance while the database instance is up. A patch is capable of being applied online when the scope of changes introduced by the patch is small and the patch does not modify the database or the shared structures, which are also the requirements for rolling patches.
The criteria for qualifying a patch as online is more restrictive than the criteria for the rolling patch. If the patch is not qualified as rolling, then it definitely cannot be qualified as online. Examples of patches that usually get qualified as online are the interim and debug patches.
When applying an online patch, you specify the ORACLE_HOME of the binaries that you like to patch, along with the database instance. The online patch will patch the binaries residing in the Oracle home as with a regular database patch. The online patch will also patch the database instance processes. Each database process periodically checks for patched code and copies the new code into its execution space. This means that the processes might not pick up the new patched code at the exact time the patch is applied and there might be some delay.
You will see an increase in the overall memory utilization of the patched database processes due to the extra space needed in the Program Global Area (PGA) for running patched code. The extra memory is released once the database instance is restarted. You need to consider the total free memory available on the database host before applying the patch so you can investigate the impact of the memory increase to other resources. Typically, each patched process requires about 3 to 5 percent more memory, but the actual memory will depend on the number of changes introduced in the patch. The best way to measure it would be to test the patch on a test system before applying it to the production system.
Apart from using Enterprise Manager, you can also use the opatch utility to apply online patches. Use this opatch command to query whether the patch is qualified as online. If it is, the output from the command will be “Patch is an online patch: true”.
$ opatch query <path to patch directory> -is_online_patch
Oracle Clusterware and Oracle ASM Rolling Upgrades
Oracle Database 11g Release 2 is capable of performing rolling upgrades of Oracle ASM and Oracle Clusterware when configured in a cluster environment, thereby making the cluster available to the database and the applications during the upgrade process.
Starting with Database 11g Release 2, Oracle ASM and Clusterware are both executed from one Oracle home installation called the grid infrastructure. Upgrading the grid infrastructure binaries to the next release takes care of upgrading Oracle ASM and Clusterware software.
With the rolling upgrade feature, you will take one node in the cluster down, upgrade the Oracle grid infrastructure, start up ASM and Clusterware, and put the node back in the cluster. You will repeat this process on all the nodes, one at a time, in a rolling fashion. The cluster is available during this process, and no downtime is incurred to the database.
Oracle ASM and Clusterware can run at different versions of the software until all nodes in the cluster are upgraded. It should be noted that any new features introduced by the new versions of ASM or Clusterware are not enabled until all nodes in the cluster are upgraded.
Database Rolling Upgrades
Using Oracle Data Guard, it is possible for you to upgrade from older versions of the database and apply patch sets, in a rolling fashion and with near-zero downtime, to the end users and applications. Data Guard rolling upgrades were introduced with Oracle Database 10 g Release 1 using the SQL Apply process of the logical standby database. Oracle Database 11g enhances this capability by using a transient logical standby method that utilizes a physical standby database.
Rolling upgrades using the transient logical standby method start by using an existing physical standby database and temporarily converting it to a logical standby for the purpose of the upgrade, followed by the upgrade of the logical standby to the latest release. The logical standby database is then made the new primary by a simple Data Guard switchover process. Keep in mind that there are restrictions, based on data types and other factors, that impact the use of logical standby databases; please refer to the documentation for more details.
NOTE
During rolling upgrades, when converting the physical standby database to the logical standby, you need to keep the identity of the original physical standby database intact by using the KEEP IDENTITY clause of the ALTER DATABASE RECOVER TO LOGICAL STANDBY statement. This clause ensures that the logical standby has the same DBID and DB_NAME as the original physical standby.
During the rolling upgrade process, the synchronization of the redo is paused before the upgrade process is started on the logical standby; the redo from the primary is queued to be applied and resumes after the upgrade completes. The SQL Apply process is capable of synchronizing the redo generated by a lower release of the primary database with a higher release of the upgraded logical standby database, and this ensures that all the transactions are propagated to the standby and there is no data loss. This capability of the SQL Apply process forms the basis of performing rolling upgrades. The primary and the standby databases can remain at different versions until you perform sanity checks on the upgraded logical standby and confirm that the upgrade process has completed successfully.
At this point, you can perform a Data Guard switchover to the standby database, resulting in changing the role of the upgraded logical standby to primary. You can upgrade the old primary database by following a similar process as the one followed for the standby, and initiate a second switchover to the original production system.
There are several benefits of using the transient logical standby method for upgrades. In fact, this method is the Oracle MAA recommended best practice, because the method is simple, reliable, and robust, and requires minimal downtime. Some of the benefits of transient logical standby are highlighted here:
![]() The transient logical standby method utilizes an existing physical standby database for performing the upgrade and does not require the extra space for creating a new logical standby database solely for the purpose of performing the upgrade.
The transient logical standby method utilizes an existing physical standby database for performing the upgrade and does not require the extra space for creating a new logical standby database solely for the purpose of performing the upgrade.
![]() The rolling upgrade process provides the added benefit of testing the upgraded environment prior to performing the switchover. The tests are performed using the new version of the Oracle software, with production data and production-like workloads.
The rolling upgrade process provides the added benefit of testing the upgraded environment prior to performing the switchover. The tests are performed using the new version of the Oracle software, with production data and production-like workloads.
![]() This method greatly reduces the downtime required by running the pre-upgrade, upgrade, and post-upgrade tasks on the standby while the production system is still online and accessible to the users. The downtime incurred by this method is essentially the time it takes for the database to perform a switchover operation to the standby database.
This method greatly reduces the downtime required by running the pre-upgrade, upgrade, and post-upgrade tasks on the standby while the production system is still online and accessible to the users. The downtime incurred by this method is essentially the time it takes for the database to perform a switchover operation to the standby database.
Online Application Upgrades Using Edition-Based Redefinition
Switching gears a bit, this section focuses on providing high availability during database application upgrades, and not Oracle software upgrades as we were discussing earlier.
Upgrading user applications and database objects with zero downtime is possible by using the edition-based redefinition feature of Oracle Database 11g Release 2. Edition-based redefinition allows you to upgrade the application and its associated database objects to a newer edition (or version), while the old edition of the application and the database objects coexist and are still accessible by the users. Once the upgrade process is complete, the new connections from the upgraded application will be accessing the new edition of the objects, and the users that were still connected to the old edition will continue to be serviced until they disconnect the session.
The database concepts that enable edition-based redefinitions are
![]() Editions An edition associates the versions of the database objects that together form a semantically intact code release. The release can include all the objects, which is the case when the code is installed for the first time, or a subset of objects—if the objects are modified using a patched release. Database sessions execute in the context of an edition and a user is associated with an edition upon connect time.
Editions An edition associates the versions of the database objects that together form a semantically intact code release. The release can include all the objects, which is the case when the code is installed for the first time, or a subset of objects—if the objects are modified using a patched release. Database sessions execute in the context of an edition and a user is associated with an edition upon connect time.
![]() Editioning views An editioning view of a database object is the definition of the object as it existed in a particular edition. Editioning views expose different definitions of the database object and allow the users to see the definition that applies to its edition.
Editioning views An editioning view of a database object is the definition of the object as it existed in a particular edition. Editioning views expose different definitions of the database object and allow the users to see the definition that applies to its edition.
![]() Cross-edition triggers Cross-edition triggers are responsible for synchronizing data changes between old and new editions of tables. For example, if a table has new columns added in its latest edition, the users connected to the old edition can still perform updates using the old definition, and the cross-edition trigger will take care of populating the new columns behind the scenes.
Cross-edition triggers Cross-edition triggers are responsible for synchronizing data changes between old and new editions of tables. For example, if a table has new columns added in its latest edition, the users connected to the old edition can still perform updates using the old definition, and the cross-edition trigger will take care of populating the new columns behind the scenes.
Exadata Storage Server High Availability
Ensuring the high availability of the database storage grid is important for enhancing the overall availability of the Database Machine. Oracle ASM provides built-in high-availability features by incorporating Grid RAID, as outlined in Chapter 5. With Grid RAID, when an underlying disk on the Exadata Storage Server fails, the data is still available from the mirrored copy placed on a different Exadata Storage Server. ASM also incorporates built-in protection from data corruption, through which it will transparently access a mirrored copy when the primary copy is found to be corrupt.
Although the ASM redundancy level of NORMAL provides protection from multiple, simultaneous, failures and corruptions occurring in a single Exadata Storage Server, it may not protect you when the failures are spread across multiple Exadata Storage Servers. In such situations, your option for recovery is to perform a restore from a backup or to fail over to the Data Guard standby database (if it is configured).
The best practices outlined next guarantee higher availability and recoverability of the storage grid upon simultaneous, multiple failures that spread across multiple Exadata Storage Servers.
Storage Configuration Best Practices
The recommended ASM diskgroup best-practice configuration as discussed in Chapter 5 is to create a minimum of two diskgroups in the Database Machine. The first diskgroup will store the user and system tablespaces, and the second will store the database Fast Recovery Area (FRA). The database FRA is used for storing archived logs, flashback logs, redo logs, and control files. For the purpose of this discussion, let us assume the diskgroup that stores user data is named DATA and the diskgroup that stores the FRA is named RECOV.
NOTE
A third ASM diskgroup is created by Oracle when configuring the Database Machine. This diskgroup is typically used to store OCR and voting disks required by Oracle Clusterware, and is created on the grid disks residing on the outermost tracks.
The DATA diskgroup should be created on grid disks that reside on the hot or outer tracks of the cell disk, whereas the RECOV diskgroup should reside on the cold or inner tracks of the cell disk. This ensures higher performance for the applications by ensuring faster access to the data blocks from the hot areas of the cell disk.
Storage Configuration with Data Guard
The Data Guard setup ensures that you can tolerate all types of failures on the primary site, up to and including a total disaster of the primary. Also, for failures that are limited to a single Exadata Storage Server, the Grid RAID features will make the data available at all times without requiring the need to fail over to the standby site.
The MAA best practices for configuring DATA and RECOV diskgroups with Data Guard are
![]() Create DATA and RECOV diskgroups using ASM NORMAL redundancy.
Create DATA and RECOV diskgroups using ASM NORMAL redundancy.
![]() The DATA and RECOV diskgroups should be created across all available Exadata Storage Servers in the Database Machine.
The DATA and RECOV diskgroups should be created across all available Exadata Storage Servers in the Database Machine.
![]() This setup guarantees maximum protection due to failures, and at the same time provides the best performance by utilizing all available Exadata Storage Servers in the storage grid.
This setup guarantees maximum protection due to failures, and at the same time provides the best performance by utilizing all available Exadata Storage Servers in the storage grid.
Storage Configuration Without Data Guard
When you do not have Data Guard configured, as stated earlier, you are only protected from single failures or multiple failures confined to one Exadata Storage Server when you use ASM NORMAL redundancy. The MAA best practices for configuring DATA and RECOV diskgroups without Data Guard are
![]() Create the DATA diskgroup using ASM NORMAL redundancy.
Create the DATA diskgroup using ASM NORMAL redundancy.
![]() Create the RECOV diskgroup using HIGH redundancy. The HIGH redundancy ensures protection from double failures occurring across the Exadata Storage Servers and guarantees full recovery with zero data loss.
Create the RECOV diskgroup using HIGH redundancy. The HIGH redundancy ensures protection from double failures occurring across the Exadata Storage Servers and guarantees full recovery with zero data loss.
NOTE
If you are using ASM NORMAL redundancy without a Data Guard setup, there is a chance of data loss when multiple failures occur across a set of Exadata Storage Servers. For example, if you lose both copies of a redo log due to multiple failures, and if the redo was marked “active” by the database indicating that it was an essential component for performing a full recovery, you have essentially lost your data that was in the redo.
Preventing Data Corruption
Data corruption can occur anytime and in any layer of the hardware and the software stack that deals with storing and retrieving data. Data can get corrupted when it is in the storage, during its transmission over the network, in the memory structures, or when the storage layer performs an I/O operation. If data corruption is not prevented or repaired in a timely manner, the database will lose its integrity and can result in irreparable data loss, which can be catastrophic for the business.
In this section, we will discuss the best practices for preventing and detecting corruption, and the methods available for automatically repairing corruption when it occurs. Although the best practices can help you prevent almost all types of corruption, you might still end up with some, as corruption cannot always be completely prevented. If you have discovered corruption, you can use database recovery methods such as block-level recovery, automated backup and recovery, tablespace point-in-time recovery, remote standby databases, and transactional recovery. Keep in mind that the recovery process can be time consuming, so every effort should be taken to minimize the occurrence of corruption.
Detecting Corruption with Database Parameters
The Oracle database has internal checks which help detect corruption occurring in the database block. The checks involve calculating a checksum on the block contents, and storing it along with the block number and a few other fields in the block header. The checksum is used later to validate the integrity of the block, based on the settings of a few database parameters, that we will define shortly.
The database can also help detect lost writes. A lost write is an I/O operation that gets successfully acknowledged by the storage subsystem as being “persisted,” but for some reason the I/O was not saved to the disk. Upon a subsequent read of the block that encountered a lost write, the I/O subsystem returns the stale version of the block, which might be used by the database for performing other updates and thereby instigate the propagation of corruption to other coherent blocks.
Corruption detection is built into Oracle ASM when the ASM diskgroups are configured with NORMAL or HIGH redundancy. ASM is able to detect block corruption by validating the block checksum upon a read, and if it detects a corruption, it transparently reads the block again from the mirrored copy. If the mirrored block is intact, then ASM will return the good block to the database, and also try to write the good block over the bad block to fix the corruption. This process is transparent to the database and does not require any setup or tweaks.
When block corruption is detected by RMAN and database processes, it is recorded in the database dictionary view V$DATABASE_BLOCK_CORRUPTION. The view is continuously updated when corrupted blocks are repaired, thus allowing you to detect and report upon the status of corruption much sooner than was ever possible.
The parameters that you use to configure automatic corruption detection in the database and to prevent lost writes are
![]() DB_BLOCK_CHECKSUM This parameter determines whether the database will calculate a checksum for the block and store it in the header each time it is written to disk. DB_BLOCK_CHECKSUM can have the following values:
DB_BLOCK_CHECKSUM This parameter determines whether the database will calculate a checksum for the block and store it in the header each time it is written to disk. DB_BLOCK_CHECKSUM can have the following values:
![]() FALSE or OFF Checksums are only enabled and verified for the SYSTEM tablespace.
FALSE or OFF Checksums are only enabled and verified for the SYSTEM tablespace.
![]() TYPICAL Checksums are enabled on data blocks and computed only upon initial inserts into the block. This is the default setting.
TYPICAL Checksums are enabled on data blocks and computed only upon initial inserts into the block. This is the default setting.
![]() TRUE or FULL Checksums are enabled on redo and data blocks upon initial inserts and recomputed upon updates/deletes only on data blocks.
TRUE or FULL Checksums are enabled on redo and data blocks upon initial inserts and recomputed upon updates/deletes only on data blocks.
![]() DB_BLOCK_CHECKING This parameter enables the block integrity checks to be performed by Oracle using checksums computed by the DB_BLOCK_CHECKSUM parameter. DB_BLOCK_CHECKING can have the following values:
DB_BLOCK_CHECKING This parameter enables the block integrity checks to be performed by Oracle using checksums computed by the DB_BLOCK_CHECKSUM parameter. DB_BLOCK_CHECKING can have the following values:
![]() FALSE or OFF Semantic checks are performed on the objects residing in SYSTEM tablespace only. This is the default setting.
FALSE or OFF Semantic checks are performed on the objects residing in SYSTEM tablespace only. This is the default setting.
![]() LOW Basic block header checks are performed when blocks change in memory. This includes block changes due to RAC interinstance communication, reads from disk, and updates to data blocks.
LOW Basic block header checks are performed when blocks change in memory. This includes block changes due to RAC interinstance communication, reads from disk, and updates to data blocks.
![]() MEDIUM All LOW-level checks plus full semantic checks are performed on all objects except indexes.
MEDIUM All LOW-level checks plus full semantic checks are performed on all objects except indexes.
![]() TRUE or FULL All MEDIUM-level checks plus full semantic checks are performed on index blocks.
TRUE or FULL All MEDIUM-level checks plus full semantic checks are performed on index blocks.
![]() DB_LOST_WRITE_PROTECT This parameter enables (or disables) logging of buffer cache block reads in the redo log. When set to TYPICAL or FULL, the system change number (SCN) of the block being read from the buffer cache is recorded in the redo. When the redo is used by Data Guard to apply transactions from the primary to the standby database, the redo SCN can be compared to the data block SCN on the standby database and evaluated to detect lost writes.
DB_LOST_WRITE_PROTECT This parameter enables (or disables) logging of buffer cache block reads in the redo log. When set to TYPICAL or FULL, the system change number (SCN) of the block being read from the buffer cache is recorded in the redo. When the redo is used by Data Guard to apply transactions from the primary to the standby database, the redo SCN can be compared to the data block SCN on the standby database and evaluated to detect lost writes.
Lost write detection works best when used in conjunction with Data Guard (this topic is covered in the next section). When you do not use Data Guard, RMAN can detect lost writes when it performs recovery.
DB_LOST_WRITE_PROTECT can have the following values:
![]() NONE This is the default setting and disables buffer cache reads from being recorded in the redo.
NONE This is the default setting and disables buffer cache reads from being recorded in the redo.
![]() TYPICAL Buffer cache reads involving read-write tablespaces are recorded in the redo.
TYPICAL Buffer cache reads involving read-write tablespaces are recorded in the redo.
![]() FULL All buffer cache reads are recorded in the redo, including reads on read-write and read-only tablespaces.
FULL All buffer cache reads are recorded in the redo, including reads on read-write and read-only tablespaces.
As of Oracle Database 11g Release 1, you are not required to individually set each of the three parameters discussed earlier. You can set one single parameter, DB_ULTRA_SAFE, and that takes care of implementing the appropriate level of protection by setting DB_BLOCK_CHECKING, DB_BLOCK_CHECKSUM, and DB_LOST_WRITE_PROTECT. The DB_ULTRA_SAFE can have the following values:
![]() DATA_AND_INDEX This value turns on the following settings for data and index blocks:
DATA_AND_INDEX This value turns on the following settings for data and index blocks:
![]() DB_BLOCK_CHECKSUM to FULL
DB_BLOCK_CHECKSUM to FULL
![]() DB_BLOCK_CHECKING to FULL
DB_BLOCK_CHECKING to FULL
![]() DB_LOST_WRITE_PROTECT to TYPICAL
DB_LOST_WRITE_PROTECT to TYPICAL
![]() DATA_ONLY This value turns on the following settings only for data blocks:
DATA_ONLY This value turns on the following settings only for data blocks:
![]() DB_BLOCK_CHECKSUM to FULL
DB_BLOCK_CHECKSUM to FULL
![]() DB_BLOCK_CHECKING to MEDIUM
DB_BLOCK_CHECKING to MEDIUM
![]() DB_LOST_WRITE_PROTECT to TYPICAL
DB_LOST_WRITE_PROTECT to TYPICAL
![]() OFF This is the default setting. OFF will default to the individual settings of DB_BLOCK_CHECKSUM, DB_BLOCK_CHECKING, and DB_LOST_WRITE_PROTECT.
OFF This is the default setting. OFF will default to the individual settings of DB_BLOCK_CHECKSUM, DB_BLOCK_CHECKING, and DB_LOST_WRITE_PROTECT.
Turning on these parameters at various levels will incur additional overhead on the system. The overhead will typically vary between 1 and 10 percent, depending on the application and the available system resources. It is a best practice to perform sample tests to calculate the overhead as it applies to your system. The overhead should be compared to the benefits of automatically detecting and preventing corruption, especially when dealing with systems requiring high availability.
Using Data Guard to Prevent Corruptions
Oracle Data Guard provides protection from data corruption by keeping an identical copy of the primary database on the standby site. The database on the standby site can be utilized to repair the corruption encountered on the primary database, and vice versa. Moreover, the Data Guard redo apply process performs data block integrity checks while applying the redo, and ensures that the corruption on the primary database does not get propagated to the standby.
Data Guard also helps recover from logical corruption initiated by the user or the application on the primary database by delaying the application of redo to the standby site. With the delay in place, if you notice the corruption before it is propagated to the standby, you can stop the apply process and recover the data from the intact copy on the standby. You can also use the database Flashback features on the primary or the standby to recover from logical corruption.
To enable corruption protection with Data Guard, the best practice is to set the database parameter DB_ULTRA_SAFE to DATA_AND_INDEX on the primary and the standby database. As stated earlier, setting DB_ULTRA_SAFE to DATA_AND_INDEX will incur a slight performance overhead on the system, but the benefits of protecting the critical data from corruptions will surely outweigh the impact.
If performance impact on the primary database becomes an issue, at a minimum, you should enable this parameter on the standby database.
Enhanced Lost Write Protection
The lost write detection feature discussed earlier is most effective when used in conjunction with Data Guard Redo Apply. When this feature is enabled, the apply process on the standby database reads the transaction system change number (SCN) from the redo log shipped from the primary database and compares it with the SCN of the corresponding data block on the standby. If the redo SCN is lower than the data block SCN, it indicates a lost write occurred on the primary. If the redo SCN is higher than the data block SCN, it indicates a lost write occurred on the standby. In both situations, the apply process raises an error, alerting the database administrator to take steps to repair the corruption.
To repair lost writes on the primary database, you must initiate failover to the standby database and restore or recover the corrupt block on the primary. To repair a lost write on a standby database, you must re-create the standby database or restore a backup of the affected files.
Enhanced lost write protection is enabled by the setting DB_LOST_WRITE_PROTECT to TYPICAL as discussed earlier.
Automatic Block Repair Using Physical Standby
The automatic block repair feature enables automatic repairs of corrupt data blocks as soon as the database detects a block corruption, thereby improving the availability of data by fixing corruptions promptly. Without this feature, the corrupt data is unavailable until a block recovery is performed from database backups or Flashback logs. The automatic block repair feature is available when you use Oracle Data Guard physical standby operating in real-time query mode.
When the Data Guard setup is configured with automatic block repair and the primary database encounters a corrupt data block, the block automatically is replaced with an uncorrupt copy from the physical standby. Likewise, when a corrupt block is accessed by the physical standby database, the block is replaced with an uncorrupt copy from the primary database. If, for any reason, the automatic block feature is unable to fix the corruption, it raises ORA-1578 errors.
Automatic block repair is enabled by setting LOG_ARCHIVE_CONFIG or FAL_SERVER parameters. For detailed instructions on setting these parameters, refer to the Oracle Data Guard manuals.
Exadata Storage Server and HARD
The Hardware Assisted Resilient Data (HARD) is an initiative by Oracle to help prevent data corruptions occurring at the storage management layer when writing Oracle data blocks to the hard disk. With the HARD program, the storage vendors implement internal checks to validate the integrity of the Oracle block right before (or after) the block gets written to (or read from) disk. If the integrity of the block is violated, the storage management layer raises I/O errors to the database so it can retry the I/O. This feature is implemented underneath the covers in the storage layer, and is transparent to the end users and the database administrators.
Exadata Storage Server is fully compliant with HARD and provides the most comprehensive protection to prevent corruptions from being propagated to the hard disk. The HARD checks implemented by the Exadata Storage Server are more thorough and provide higher protection than the checks implemented by third-party storage vendors. For example, Exadata HARD performs extensive validation of block locations, magic numbers, head and tail checks, and alignment errors that are not typically performed by non-Exadata HARD implementations.
In order to enable HARD checks on the Exadata Storage Server, you need to set the DB_BLOCK_CHECKSUM to TYPICAL or FULL. Alternatively, you can set DB_ULTRA_SAFE to DATA_AND_INDEX as discussed earlier.
Exadata Database Machine Backup and Recovery Best Practices
A comprehensive and reliable backup and recovery strategy is the most important piece of a database high-availability strategy. Regardless of the type and size of databases, an effective strategy is focused on the methods and procedures for backing up critical data, and more importantly, for recovering the data successfully when required. While recoverability is the ultimate goal, the potential downtime incurred to recover should also be considered. The downtime includes the time to identify the problem, formulate the recovery steps, and perform recovery.
NOTE
Recovering a database using backups is generally used to recover from media failures within a single site. For recovering from a complete disaster of the site, or to recover with minimal downtime, the recommended strategy is to use Oracle Data Guard as discussed earlier in this chapter.
An effective backup and recovery strategy of the Exadata Database Machine should include all of the components that are housed within the Database Machine for which there are no built-in recovery mechanisms. The components that need to be a part of the strategy are the Oracle databases, the operating system (OS) and file systems of the database servers, the InfiniBand switch configuration, and the ILOM configuration.
The OS on the Exadata Storage Server has built-in recovery mechanisms and does not need separate backups. When OS recovery is needed on these servers, they will be restored by using the supplied CELLBOOT USB flash drive. The CELLBOOT USB drive stores the last successful OS boot image of the server. Since Oracle does not allow any deviations from the default OS install and setup of the Exadata Storage Servers, restoring using the CELLBOOT USB will be sufficient to perform OS-level recovery. Moreover, the OS resides on a file system that is configured on the first two disks of the Exadata Storage Server and uses software RAID-1 protection. If one of the first two disks fails, the server will still be available.
NOTE
You should back up the database server OS and the local file systems separately. The local storage on the database server is configured with RAID-5 protection, which can tolerate single drive failures. When two or more drives fail, the OS and the file systems need to be recovered from the backup. You should also back up the ILOM and InfiniBand switch configuration files using the native tools and methods provided for them.
This section of the chapter is focused on the backup and recovery best practices for Oracle databases residing on the Database Machine. You will see that the procedures you use for the Database Machine are no different from what you would use for Oracle Database 11g Release 2 on other hardware platforms.
We will start this section by discussing the tools available to perform backups and their best-practice considerations. Next, we will discuss the backup strategy and architecture for performing tape and disk-based backups. Last, we will touch upon the high-level best practices for performing recovery.
Backup Tools Best Practices
Oracle RMAN and Oracle Secure Backup are the two tools you will use to perform backups. This section provides an overview of the capabilities of these tools and the best practices of configuring them for performing backups on the Exadata Database Machine.
Oracle Recovery Manager (RMAN)
Backup and recovery of Oracle databases using user-managed mechanisms are not possible for the databases utilizing Exadata Storage Servers as the storage. You can only perform backups that are managed by Oracle RMAN.
RMAN is the Oracle-supplied tool that can back up, restore, and recover Oracle databases. RMAN is a client/server application that uses database server processes to perform the backup I/O operations. When performing backups of databases in the Database Machine, you can parallelize the backup task across the available database servers and the Exadata Storage Servers, and leverage the CPU, network, and disks of the entire grid to provide optimal performance.
RMAN does not back up directly to tape. However, it will integrate with media management software such as Oracle Secure Backup and utilize their capabilities to manage tape libraries.
NOTE
If you are considering third-party tools for performing backup and recovery of databases in the Database Machine, the tools should be able to interface with Oracle RMAN, and RMAN will initiate the backup and restore operations.
RMAN provides the ability to administer and manage backups by keeping a record of the backup metadata in a repository. When RMAN formulates restore procedures, it uses the repository to identify files needed for recovery. You can also generate reports of backup activity using the information available in the repository.
Oracle Enterprise Manager (OEM) provides a GUI-based interface to the RMAN client by using a comprehensive set of wizard-driven screens. The screens provide similar functionality as the RMAN client and allow you to create and schedule backup tasks, set up backup policies and procedures, formulate recovery steps based on the recovery objectives, and perform recovery.
The RMAN features that help to set the context for our discussion on backup and recovery practices on the Database Machine are discussed next.
RMAN Backup Formats
RMAN backups can be created as image copies or backup sets. An image copy is a bit-for-bit copy of a database file, whereas a backup set is an RMAN-specific format that consists of one or more database files known as backup pieces. Backup sets are the default format used by RMAN and is the only format supported when storing backups to tape. The advantage of backup sets over image copies is that they allow the use of RMAN compression features (discussed shortly).
Image copy backups, on the other hand, are only possible for disk backups. They utilize the same space as the database files since they are an exact copy. Image copies have the advantage of being restored faster than backup sets, since the database blocks do not need to be re-created during the restore process, which is the case when restoring backup sets.
Although it is not possible to use RMAN compression features with image copies, you can use compression mechanisms provided by the storage systems, such as the built-in compression features of the Sun ZFS Storage appliance. In this case, the compression performed by the storage will be totally transparent to RMAN.
RMAN Backup Types
At a high level, RMAN backups can be one of two types—full or incremental. Full backups, as the name suggests, are the backups of the complete database, whereas incremental backups only store modified blocks since the last full or incremental backup. Incremental backups can only be stored as backup sets and not image copies.
NOTE
You can apply an incremental backup to an existing image copy, which will update the image copy to reflect the changes in the incremental backup. This feature is described in more detail later in the chapter.
Incremental backups are subcategorized into two types, differential and cumulative. Differential backups contain changed data since the last full or incremental, and is the default type when no other type is specified. Cumulative backups contain changed data since the last full backup. If you have a cumulative backup, you can recover by applying just two backups, the last full and the cumulative incremental. This reduces the recovery time since fewer backups are applied during recovery. Cumulative backups are preferred when shorter recovery time is a priority over disk space.
During media recovery, RMAN prefers incremental backups over archived logs and will use one if present. This is because the incremental backups also capture changes made by NOLOGGING transactions, which by their definition are not logged into the archived logs. Such transactions are lost if recovering using archived logs.
RMAN and Compression
RMAN has several features that enable you to store backups in compressed format. Compressing the backup will provide you storage savings and also give you better performance because the backup I/O will involve fewer blocks.
NOTE
The RMAN compression features are applicable only when you create backups in the backup set format and not with image copy.
A compression feature that is inherent with RMAN and cannot be disabled is the unused block compression. With this feature, RMAN skips blocks from the database files that are not allocated to any database objects or, if allocated, have never been used to store any data (also known as null blocks). The unused block compression can also skip blocks that once had data but are now empty (blocks under the high watermark). The empty block compression feature is available when performing backups to disk, and also to tape but only when Oracle Secure Backup (OSB) is the media manager.
RMAN is also capable of performing binary compression of backup sets using industry-standard compression algorithms. Binary compression will compress the backup sets before they are written to disk. The compression can be performed using different algorithms (BZIP2, LZO, and ZLIB) and the appropriate algorithm is selected when you set the compression level (BASIC, LOW, MEDIUM, or HIGH) before initiating the backups. Based upon the compression-level settings, you get different compression ratios and backup performance.
NOTE
Compression levels of LOW, MEDIUM, and HIGH requires you to be licensed for the Advanced Compression Option for the Oracle database. The BASIC level is included with the Oracle database license.
If you are using database compression features such as OLTP compression and Exadata Hybrid Columnar Compression, you are already reducing the overall disk footprint of database files. The best practice in such a case is not to compress the data again using RMAN. Compressing the same data twice does not provide any measurable savings, and in fact in some cases, might even be an overhead.
RMAN Best Practices
Follow the RMAN best practices specified here to get higher performance and availability with the Database Machine.
![]() Use block change tracking Enhance the performance of RMAN incremental backups by using the block change tracking (BCT) feature. When BCT is enabled, the database keeps track of the blocks that get modified using a block change tracking file. The BCT file gets one entry when one or all blocks in a chunk (32K) gets modified. When RMAN starts an incremental backup, it uses the block change tracking file to identify the changed blocks since the last incremental backup, and reads only the changed blocks from the disk. Otherwise, without BCT, all blocks are read and the SCN on each block is checked to identify if the block was modified.
Use block change tracking Enhance the performance of RMAN incremental backups by using the block change tracking (BCT) feature. When BCT is enabled, the database keeps track of the blocks that get modified using a block change tracking file. The BCT file gets one entry when one or all blocks in a chunk (32K) gets modified. When RMAN starts an incremental backup, it uses the block change tracking file to identify the changed blocks since the last incremental backup, and reads only the changed blocks from the disk. Otherwise, without BCT, all blocks are read and the SCN on each block is checked to identify if the block was modified.
The incremental backup offloading feature of the Exadata Storage Server is able to filter unchanged blocks directly in the storage layer, which further improves the incremental backup performance by only sending changed blocks to RMAN for backup. The Exadata Storage Servers are capable of identifying the changed blocks at a finer granularity than the BCT feature. As you can see, the BCT and the incremental backup offload features are complementary to one another.
Best practices indicate that block change tracking provides the most benefit when 20 percent or fewer blocks get modified since the last incremental or full backup. When changes are greater than 20 percent, you might still benefit, but you need to evaluate it against the data in your environment.
![]() Configure DB_RECOVERY_FILE_DEST_SIZE The database FRA is used to store database archived logs and other recovery files including backups, and can get filled quickly if the space is not managed properly. Use DB_RECOVERY_FILE_DEST_SIZE to bind the space for each database in the FRA. If there are multiple databases on the Database Machine, the total combined FRA from all databases should be less than the free space on the ASM diskgroup allocated for FRA. In fact, you should leave enough space on the diskgroup to account for disk failures, and preferably for one complete Exadata Storage Server failure.
Configure DB_RECOVERY_FILE_DEST_SIZE The database FRA is used to store database archived logs and other recovery files including backups, and can get filled quickly if the space is not managed properly. Use DB_RECOVERY_FILE_DEST_SIZE to bind the space for each database in the FRA. If there are multiple databases on the Database Machine, the total combined FRA from all databases should be less than the free space on the ASM diskgroup allocated for FRA. In fact, you should leave enough space on the diskgroup to account for disk failures, and preferably for one complete Exadata Storage Server failure.
![]() Configure RAC Services for backup/restore The best practice is to execute the RMAN backup task across multiple database nodes in the RAC cluster by defining Oracle RAC Services. By using Services, you can allocate specific RAC nodes that you would like to take part in servicing the backup load.
Configure RAC Services for backup/restore The best practice is to execute the RMAN backup task across multiple database nodes in the RAC cluster by defining Oracle RAC Services. By using Services, you can allocate specific RAC nodes that you would like to take part in servicing the backup load.
When the RMAN clients connect to the database using Services, they get load balanced and the backup task gets distributed across the nodes defined in the service. This ensures even distribution of the CPU load across the database servers and prevents overloading of the resources on just one node.
![]() Use Recovery Catalog for RMAN repository Always use a separate database to store the RMAN catalog. The database should reside outside of the Database Machine to guarantee recoverability from local failures. You can use the servers set aside for management tools such as OEM Management Repository or the Oracle Secure Backup Administrative server.
Use Recovery Catalog for RMAN repository Always use a separate database to store the RMAN catalog. The database should reside outside of the Database Machine to guarantee recoverability from local failures. You can use the servers set aside for management tools such as OEM Management Repository or the Oracle Secure Backup Administrative server.
Oracle Secure Backup (OSB)
Oracle Secure Backup (OSB) is a centralized tape backup management software providing solutions to back up and restore file systems and Oracle databases. OSB is tightly integrated with RMAN features such as unused block compression and UNDO optimizations, and with this integration, it is able to deliver extremely efficient backup and restore operations.
OSB interfaces with the tape library for storing backups to tape. A tape library is a device that contains two or more tape drives for reading and writing backup data, along with a collection of tape cartridges. It is designed for continuous, unattended operations using robotic hardware that has mechanisms to scan, mount, and dismount the tape cartridges.
The OSB software that manages the tape library resides on a media server. The media server facilitates communication with the tape devices, and is used by RMAN to perform tape backups. The media servers connect to the Database Machine using the InfiniBand, the 1 Gigabit, or the 10 Gigabit Ethernet interfaces. Using the InfiniBand interface gives you the best performance for backups and restores; however, this option requires the media servers to support the InfiniBand connectivity through a suitable Host Channel Adapter (HCA) that is compatible with the Database Machine.
An OSB backup domain is a network of backup clients, media servers, and the tape libraries. The backup domain contains an administrative server that serves the backup clients, and also stores the OSB backup catalog. The OSB catalog is the black box of the backup domain and contains information about the backups.
An architecture diagram of Oracle Secure Backup for performing backups of the Database Machine is provided later in this chapter in Figure 6-3.
OSB Best Practices
Consider the following best practices when configuring Oracle Secure Backup with the Database Machine:
![]() Configure persistent bindings Each tape device is assigned a logical unit number (LUN) on the media server based on the order of its discovery. To ensure the LUNs are consistent when they are accessed from multiple media servers, you need to configure persistent bindings. Persistent bindings are configured at the operating system or the Host Bus Adapter (HBA) level. Consult the documentation specific to your media server operating system for further details.
Configure persistent bindings Each tape device is assigned a logical unit number (LUN) on the media server based on the order of its discovery. To ensure the LUNs are consistent when they are accessed from multiple media servers, you need to configure persistent bindings. Persistent bindings are configured at the operating system or the Host Bus Adapter (HBA) level. Consult the documentation specific to your media server operating system for further details.
![]() Back up the OSB catalog The Oracle Secure Backup catalog maintains the backup metadata that includes configuration and scheduling information for the backup domain. It is important to protect the catalog by taking regular backups using the OSB-supplied methods.
Back up the OSB catalog The Oracle Secure Backup catalog maintains the backup metadata that includes configuration and scheduling information for the backup domain. It is important to protect the catalog by taking regular backups using the OSB-supplied methods.
![]() Configure the preferred network interface (PNI) for InfiniBand When using the InfiniBand network to communicate with the media servers from the Database Machine, configure Oracle Secure Backup to favor the InfiniBand network to route backup traffic. This is done by setting the preferred network interface configuration in Oracle Secure Backup.
Configure the preferred network interface (PNI) for InfiniBand When using the InfiniBand network to communicate with the media servers from the Database Machine, configure Oracle Secure Backup to favor the InfiniBand network to route backup traffic. This is done by setting the preferred network interface configuration in Oracle Secure Backup.
Oracle Database Backup Strategy
The business continuity plan (BCP) forms the basis for architecting an effective backup and recovery strategy. The BCP is the plan to ensure the continuity of business operations when a disaster or failure strikes. The elements of BCP that will influence the backup and recovery strategy are the recovery point objective (RPO) and the recovery time objective (RTO).
The RPO is the number of hours of data loss that can be tolerated by the business. When determining the RPO, you should take into account the cost incurred due to the loss of data for the timeframe specified in the RPO and compare it with the cost of the infrastructure needed to minimize the data loss. Assessing the impact of data loss up front will help justify the appropriate hardware, storage, and software costs needed to meet the RPO set by the business. Lower RPO will require more frequent backups and additional hardware that can support the recovery within short timeframes.
The RTO defines the acceptable timeframe that is allowed to recover to the recovery point. Note that the total recovery time includes the time to identify the problem, plan the appropriate recovery steps, restore the backups, perform database media recovery, and restore the hardware, storage, operating system, and the Oracle software.
Apart from the RPO and RTO requirements, you also need to capture the backup retention requirements and devise a backup retention policy that ensures sufficient backups are available to meet the RPO and RTO requirements. The longer the retention policy, the larger the space required to retain backups.
Based on the business RPO and RTO requirements, the appropriate backup and recovery strategy can be formulated. If you have databases of size 50TB or more with short RTO requirements and zero-data-loss RPO requirements, relying only on tape backups might not suffice. Disk backups and other high-availability solutions such as Data Guard should be considered.
A backup strategy documents the method and infrastructure needed to perform backups, along with the retention policies. Essentially, you have the option to back up to disk, tape, or a combination disk/tape called a hybridapproach. Our focus in this chapter is to discuss tape and disk backups. The hybrid methods can be concocted from the two.
NOTE
The intention of this book is not to debate which backup method is the best, but rather to equip you with the options available, along with the appropriate architectures, and to enable you to select the best strategy for your environment.
Backups to Tape
Tape backups are considered to be the most cost-effective solution for backups, especially when you already have a tape-based backup infrastructure in the data center. However, the performance of backups and restores needs to be evaluated against the recovery time objective to ensure that you are able to perform the backup and recovery tasks within the allowable timeframes. Generally speaking, tapes are slower than disk with respect to read and write performance and are usually less reliable over time.
NOTE
Backups to virtual tape library (VTL) are treated similar as backups to tape. VTL emulates a standard tape interface on disk-based storage arrays, thereby exposing the arrays as tape and making the VTL invisible to the media management software.
Figure 6-3 depicts a typical architecture for performing backups to tape using the Database Machine, media servers, and the tape library. The architecture should be used as a typical building block when you are architecting a tape backup solution. The components comprising this architecture are discussed next.
![]() Tape library The tape library holds the tape drives. The speed of the tape backup is based on the number of tape drives that can be used in parallel to accomplish the backup. The backup speed can be increased almost linearly by adding more drives, provided no other bottlenecks exist.
Tape library The tape library holds the tape drives. The speed of the tape backup is based on the number of tape drives that can be used in parallel to accomplish the backup. The backup speed can be increased almost linearly by adding more drives, provided no other bottlenecks exist.
FIGURE 6-3. Architecture of the Database Machine for performing backups to tape
![]() Media servers The media servers are connected to the tape library either directly as a Network Attached Storage (NAS) device or through a Fibre Channel (FC) Storage Area Network (SAN) switch. Media servers house the Oracle Secure Backup media manager. A minimum of two media servers is preferred for high availability. Performance can scale when you add more, provided other bottlenecks do not exist.
Media servers The media servers are connected to the tape library either directly as a Network Attached Storage (NAS) device or through a Fibre Channel (FC) Storage Area Network (SAN) switch. Media servers house the Oracle Secure Backup media manager. A minimum of two media servers is preferred for high availability. Performance can scale when you add more, provided other bottlenecks do not exist.
![]() Backup network The backup network is the route of the data from where it currently resides (i.e., the Exadata Database Machine) to the backup device (i.e., the tape library). The performance of the backup and restore operations depends on the throughput of the backup network and the throughput of the processes consuming/generating the backup traffic at the network end-points. The slowest link in the network path limits the overall throughput.
Backup network The backup network is the route of the data from where it currently resides (i.e., the Exadata Database Machine) to the backup device (i.e., the tape library). The performance of the backup and restore operations depends on the throughput of the backup network and the throughput of the processes consuming/generating the backup traffic at the network end-points. The slowest link in the network path limits the overall throughput.
The Database Machine connects to the media servers using the InfiniBand ports available on the InfiniBand switch or through the 1 GigE and 10 GigE ports available on the database servers. Connecting through the InfiniBand ports will give you the best network throughput. When the 1 GigE option is used, rest assured, the bottleneck for backup performance in most cases will be the 1 GigE network.
The network protocol used is TCP/IP for both, InfiniBand as well as Gigabit Ethernet.
![]() Exadata Database Machine The Database Machine contains the databases that need to be backed up. As mentioned earlier, Oracle RMAN is the only mechanism to back up the databases that utilize Exadata Storage Servers as the storage. RMAN processes run on the database servers and interact with the Oracle Secure Backup (OSB) agent, which further interacts with the media management software and enables RMAN to communicate with the tape library. Oracle RMAN can run from one database server and up to all the available database servers in the Database Machine RAC cluster. The number of nodes that you allocate to run RMAN depends on whether adding more RMAN clients will increase the total throughput of the backup. You can also tune the throughput by increasing the number of channels allocated to each RMAN process.
Exadata Database Machine The Database Machine contains the databases that need to be backed up. As mentioned earlier, Oracle RMAN is the only mechanism to back up the databases that utilize Exadata Storage Servers as the storage. RMAN processes run on the database servers and interact with the Oracle Secure Backup (OSB) agent, which further interacts with the media management software and enables RMAN to communicate with the tape library. Oracle RMAN can run from one database server and up to all the available database servers in the Database Machine RAC cluster. The number of nodes that you allocate to run RMAN depends on whether adding more RMAN clients will increase the total throughput of the backup. You can also tune the throughput by increasing the number of channels allocated to each RMAN process.
![]() OSB administrative server The OSB administrative server stores the OSB catalog. You can designate any server as the administrative server, and the best practice is to have it separate from the servers in the backup domain for ensuring high availability. You can use the administrative server to house the RMAN catalog database and the Oracle Enterprise Manager repository, and increase the utilization rate of the server.
OSB administrative server The OSB administrative server stores the OSB catalog. You can designate any server as the administrative server, and the best practice is to have it separate from the servers in the backup domain for ensuring high availability. You can use the administrative server to house the RMAN catalog database and the Oracle Enterprise Manager repository, and increase the utilization rate of the server.
Now that you have seen how the tape backup infrastructure fits together, we will look at the process involved in sizing and tuning the individual components. The goal is to have an architecture that achieves the best throughput possible while meeting the constraints set by recovery time objective and, of course, the cost.
Tape Infrastructure Sizing Best Practices
Before you start sizing and configuring the backup infrastructure, capture the performance characteristics of each component that is involved with the transfer/processing of the backup data (tape library, network, media servers, and database servers).
The next step is to start with one component of the architecture and add more instances of it until you get the scalability benefits and an effective increase in throughput. You should repeat this process for all the components, namely, the tape library, network, media servers, and the database servers. The trick here is to make sure you do not induce bottlenecks while you perform the scaling exercise and stay focused on making the overall configuration balanced.
An example of a typical tape backup infrastructure with throughput rates of each component is depicted in Figure 6-4. For illustrating the sizing process, we assume the media servers connect to a full-rack Exadata Database Machine X2-2 using the 40 Gb/s InfiniBand network, and to the tape library using 8 Gb/s SAN links. The tape library used is the Oracle StorageTek SL500. The throughput for each of the components is measured in GB/s, which is the size of data in GB (gigabytes) processed in one second. The throughput numbers used in this exercise are specific to this environment. The numbers will vary based on your environment-specific hardware and its configuration.
FIGURE 6-4. Tape infrastructure sizing for maximum throughput
![]() As a best practice, you need to start with a minimum of two media servers and add more once you have exhausted their capacity. Each media server needs one dual-ported InfiniBand HCA card. Although each card has two ports, the ports are bonded and configured for high availability, which effectively gives you the performance of one port.
As a best practice, you need to start with a minimum of two media servers and add more once you have exhausted their capacity. Each media server needs one dual-ported InfiniBand HCA card. Although each card has two ports, the ports are bonded and configured for high availability, which effectively gives you the performance of one port.
![]() The connectivity between the media server to tape library is through 8 Gb/s SAN links, with each link providing an effective throughput of 0.8 GB/s. Having a total of four SAN links will provide you with a combined throughput of 3.2 GB/s, which is sufficient to handle the throughput needed to saturate up to 16 tape drives.
The connectivity between the media server to tape library is through 8 Gb/s SAN links, with each link providing an effective throughput of 0.8 GB/s. Having a total of four SAN links will provide you with a combined throughput of 3.2 GB/s, which is sufficient to handle the throughput needed to saturate up to 16 tape drives.
![]() The connectivity from the Database Machine to the media servers is through the dual-ported InfiniBand HCA card. Each link of InfiniBand from the media server to the Database Machine will give you an effective data transfer rate of 2 GB/s, using the TCP/IP protocol with InfiniBand (IPoIB). With two media servers, this configuration provides a combined theoretical throughput of 4 GB/s (two media servers × one InfiniBand card × 2 GB/s throughput per card).
The connectivity from the Database Machine to the media servers is through the dual-ported InfiniBand HCA card. Each link of InfiniBand from the media server to the Database Machine will give you an effective data transfer rate of 2 GB/s, using the TCP/IP protocol with InfiniBand (IPoIB). With two media servers, this configuration provides a combined theoretical throughput of 4 GB/s (two media servers × one InfiniBand card × 2 GB/s throughput per card).
![]() A single RMAN channel in the Exadata Database Machine is capable of streaming data at the rate of about 0.7 GB/sec to the media server. When you use RMAN for tape backups, the best practice is to configure the same number of channels as the number of available tape drives. Each tape performs serial writes, and it does not help to add more parallelism on the RMAN side by adding more channels than the number of tapes. Since we are using full-rack Exadata Database Machine X2-2, the effective RMAN throughput using eight RMAN channels will be about 5.6 GB/s (0.7 per RMAN channel × eight channels).
A single RMAN channel in the Exadata Database Machine is capable of streaming data at the rate of about 0.7 GB/sec to the media server. When you use RMAN for tape backups, the best practice is to configure the same number of channels as the number of available tape drives. Each tape performs serial writes, and it does not help to add more parallelism on the RMAN side by adding more channels than the number of tapes. Since we are using full-rack Exadata Database Machine X2-2, the effective RMAN throughput using eight RMAN channels will be about 5.6 GB/s (0.7 per RMAN channel × eight channels).
![]() For the tape-based backups, the slowest component is the tape library. The Oracle StorageTek SL500 tape library used in the example has 14 tape drives, and each drive within the library is capable of providing 0.17 GB/s. No matter how you scale the other components, the tape library limits you to a maximum theoretical throughput of 2.38 GB/s (14 drives × 0.17 GB/s).
For the tape-based backups, the slowest component is the tape library. The Oracle StorageTek SL500 tape library used in the example has 14 tape drives, and each drive within the library is capable of providing 0.17 GB/s. No matter how you scale the other components, the tape library limits you to a maximum theoretical throughput of 2.38 GB/s (14 drives × 0.17 GB/s).
In Figure 6-4, we used two media servers, eight database servers with eight RMAN channels, 8 Gb/s SAN links, and 14 tape drives to achieve an effective backup throughput of 2.38 GB/s, which translates to 8.6 TB/hr.
NOTE
If you are using Gigabit Ethernet (1 GigE) network between the media server and Exadata Database Machine, your bottleneck will shift to the 1 GigE network instead of the tape library. In a full-rack Exadata Database Machine X2-2, you can achieve a maximum theoretical throughput of 960 MB/s (120 MB/s × 8) with one 1 GigE port per database node. If you bond two 1 GigE ports per each database server, you should be able to achieve a combined theoretical throughput of up to 1,920 MB/s.
The recommended Oracle tape backup strategy with the Exadata Database Machine is discussed next.
Recommended Tape Backup Strategy
For performing database backups to tape, follow the Oracle MAA recommended strategy specified here:
![]() Perform database archive log backup to FRA. Use backup retention policies; otherwise, files may get deleted in FRA when it gets full and needs to make additional space.
Perform database archive log backup to FRA. Use backup retention policies; otherwise, files may get deleted in FRA when it gets full and needs to make additional space.
![]() Perform weekly full backups (RMAN level 0) of the database to tape.
Perform weekly full backups (RMAN level 0) of the database to tape.
![]() Perform daily, cumulative incremental backups (RMAN level 1) of the database. This will ensure that you only need to recover one full and one incremental backup during a recovery, along with the archived logs.
Perform daily, cumulative incremental backups (RMAN level 1) of the database. This will ensure that you only need to recover one full and one incremental backup during a recovery, along with the archived logs.
![]() Perform daily backups of the Oracle Secure Backup catalog.
Perform daily backups of the Oracle Secure Backup catalog.
Backups to Disk
Disk backups dramatically improve the speed and accuracy of the recovery process, and are an attractive option for the business that needs short recovery times. They are also able to meet aggressive backup windows, which is a key requirement for databases requiring high availability. Nowadays, with the declining cost of hard disks, the gap between the disk and tape is closing rapidly, and disk backups are increasingly becoming affordable and being implemented even by small to mid-sized businesses.
NOTE
Recovery time with disk backups can be reduced further by using the RMAN incremental backup merge feature. With this feature, the previous full database backup created using image copies can roll forward and be made current by applying incremental backups. When you need to recover, you will restore only the full image copy backup and not the incremental (plus any archived logs as necessary).
Disk backups can coexist with tape backups, and it is a best practice to use both when the disk backup systems reside in the same data center as the system being backed up. In such a situation, when a site failure occurs, the data and also its backup would be lost. A hybrid strategy with a combination of disk and tape backups should be pursued. With this strategy, the backup on disk can saved to tape in an offline fashion, which can be sent offsite for disaster proofing.
If you are considering implementing disk backups for the Database Machine, you have the option to either store backups on the FRA of the Database Machine or to attach additional networked storage in an external cabinet solely for the purpose of housing backups. These options are discussed next.
Backup to Fast Recovery Area (FRA)
The purpose of the database FRA is to store recovery files. You can use it to store backups, provided you have enough space allocated. This option provides the best backup/restore performance, as the I/O operations are performed in parallel against a set of Exadata Storage Servers using the high-speed InfiniBand network. Moreover, backups are protected from media failures because the FRA resides in the diskgroup that is mirrored using ASM redundancy settings.
The drawback of this method is that a chunk of your investment in the Database Machine will be allocated for backups, which considerably increases the disk cost per GB. Moreover, you still need to disaster-proof the backups by having a hybrid strategy as just discussed.
The best practices of sizing the Database Machine FRA when storing backups is to allocate 60 percent of the total capacity to FRA and the remaining 40 percent for user data. Not only are you losing 60 percent of the storage capacity of the Database Machine in this case, you may also lose 60 percent of bandwidth and I/O operations per second (IOPS) performance, especially when you configure a dedicated FRA. A dedicated FRA is the MAA best-practice configuration to guarantee availability from multiple Exadata Storage Server failures when a Data Guard standby site is not configured. This best practice is discussed in the “Exadata Storage Server High Availability” section of this chapter.
An option that might make backups to FRA a bit more attractive is when you use an Exadata Expansion Cabinet. The Exadata Expansion Cabinet is a set of Exadata Storage Servers in a rack, connected to the Database Machine rack using the InfiniBand switch. You can configure the database FRA to reside completely in the Expansion Cabinet and dedicate all the Exadata Storage Servers in the Cabinet for the sole purpose of performing backups. Even though the Storage Servers reside external to the Database Machine, they are just an extension of the Database Machine storage grid.
The Expansion Cabinet can be configured with High Capacity drives even if your Database Machine uses High Performance drives. This reduces the total disk cost per GB and makes the backup-to-disk proposition using Exadata Storage Servers even more attractive.
This setup utilizing the Expansion Cabinet guarantees the best performance for backup/restore operations and at the same time provides best performance to the application since all Exadata Storage Servers inside the Database Machine rack will be dedicated 100 percent to user traffic.
Backup to NAS
If the earlier option to back up to FRA is not feasible, consider performing backups to a Network Attached Storage (NAS) device. You can attach an NAS device to the Database Machine and use it for the purpose of backups. This option is the most cost effective, since most data centers already use some sort of NAS storage.
The best practice for attaching the NAS device is through the InfiniBand network. NAS devices such as the Sun ZFS Storage appliance depicted in Figure 6-5 have built-in support for InfiniBand, 10 Gigabit, and 1 Gigabit Ethernet networks. If your NAS appliance does not provide InfiniBand connectivity, or if the NAS InfiniBand HCA card or the protocol is not supported by the Database Machine, use the Gigabit Ethernet interfaces.
NAS devices also offer real-time compression and deduplication features. By using these features, you can significantly reduce the disk footprint of backups. Of course, there could be an overhead, and as with any feature that has an impact, a good strategy would be to test it out in your environment and with your data.
NOTE
If you have an external NAS attached to the Database Machine, you can also utilize it for a variety of other purposes. You can use NAS to stage files when performing migrations and data loads, or use it as a springboard to push data into DBFS from servers residing outside of the Database Machine.
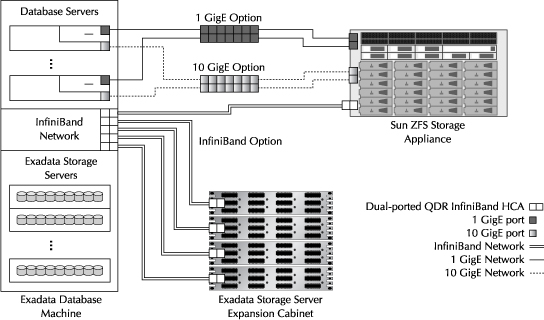
FIGURE 6-5. Disk backup options for the Database Machine using externally attached storage
Disk Backup Configuration Best Practices
Use the following guidelines as best practices for configuring the number of instances running RMAN and the number of RMAN channels per instance:
![]() Always start with one database instance running RMAN with two channels. In most cases, two RMAN channels per instance will give you the required throughput gains, although you might gain some improvements with four channels. Each RMAN channel is capable of processing about 0.7 GB/s, and two channels translate to 1.4 GB/s, which is close to the 2 GB/s throughput limitation of one database server.
Always start with one database instance running RMAN with two channels. In most cases, two RMAN channels per instance will give you the required throughput gains, although you might gain some improvements with four channels. Each RMAN channel is capable of processing about 0.7 GB/s, and two channels translate to 1.4 GB/s, which is close to the 2 GB/s throughput limitation of one database server.
![]() Add instances to run RMAN as required, each with two channels. Measure throughput gains, and if you are not getting any additional gains, you stop.
Add instances to run RMAN as required, each with two channels. Measure throughput gains, and if you are not getting any additional gains, you stop.
![]() As a RMAN best practice mentioned earlier, configure RAC services to dictate the database servers that will run RMAN.
As a RMAN best practice mentioned earlier, configure RAC services to dictate the database servers that will run RMAN.
![]() Set DB_RECOVER_FILE_DEST_SIZE to bind space in the FRA for backups. This was discussed in the section on RMAN earlier.
Set DB_RECOVER_FILE_DEST_SIZE to bind space in the FRA for backups. This was discussed in the section on RMAN earlier.
NOTE
Typical backup throughput was achieved using a full-rack Exadata Database Machine X2-2 with two instances configured to run RMAN, and each instance with four RMAN channels, with RMAN using image copies, was 7.1 TB/Hr. The backup was stored on FRA residing inside the Database Machine.
Recommended Disk Backup Strategy
The Oracle MAA strategy for performing backups to disk is the following:
![]() Use the FRA to store archived logs and database backups. If using NAS as the backup destination, use a file system on NAS instead of FRA.
Use the FRA to store archived logs and database backups. If using NAS as the backup destination, use a file system on NAS instead of FRA.
![]() Perform an initial full backup using image copies (RMAN level 0).
Perform an initial full backup using image copies (RMAN level 0).
![]() Perform daily incremental backups (RMAN level 1).
Perform daily incremental backups (RMAN level 1).
![]() With a delay of 24 hours, roll the incremental backups into the full backup using the RMAN incremental merge feature. The delay is to ensure the user-initiated data corruptions do not propagate into the backups.
With a delay of 24 hours, roll the incremental backups into the full backup using the RMAN incremental merge feature. The delay is to ensure the user-initiated data corruptions do not propagate into the backups.
![]() Consider a hybrid backup strategy to disaster-proof your backups, and copy the backups made on disk and persist them by performing another backup to tape.
Consider a hybrid backup strategy to disaster-proof your backups, and copy the backups made on disk and persist them by performing another backup to tape.
Database Recovery Best Practices
Earlier in this chapter, we discussed using Oracle Data Guard as the best practice to achieve high availability and protection from planned and unplanned failures. If media failures occur on the Database Machine and you do not have a Data Guard configuration, you have no choice but to recover the database using backups.
Oracle RMAN is the only tool that can recover databases residing on the Exadata Storage Servers. RMAN makes the recovery process simple by using just two commands, restore database and recover database. When you run these commands, RMAN will search its catalog and retrieve the list of backups needed to perform recovery, along with their respective locations. RMAN will then restore all the required backups and perform further media recovery that might be required to complete the recovery process.
The throughput of the restore operation depends on whether you are restoring in place and the original file already exists (but is now corrupt) or to a new location. In the case where the original file exists, higher restore rates are possible. This is because the initial allocation of a file incurs an overhead, especially when the files are large, and restore timings will improve if the initial allocation can be avoided. The throughput also depends on a number of other factors such as the number of RMAN channels, the backup network capacity, the number of tape drives (if restoring from tape), and the disk subsystem throughput (if restoring from disk).
The restore process is a write-intensive operation. If you use InfiniBand to connect the Database Machine to the backup infrastructure, the chances are that the restore operation will be the bottleneck and not the InfiniBand network or the tape drives.
Use these best practices to speed up recovery performance:
![]() If you are restoring into preexisting files, use all database instances for RMAN and configure two RMAN channels per each instance. If restoring from tape, the number of RMAN channels you use will be restricted by the number of tape drives.
If you are restoring into preexisting files, use all database instances for RMAN and configure two RMAN channels per each instance. If restoring from tape, the number of RMAN channels you use will be restricted by the number of tape drives.
![]() If the files are not preexisting, use two database instances for RMAN and two to four RMAN channels per each instance. Again, if restoring from tape, do not use more channels than the number of tape drives.
If the files are not preexisting, use two database instances for RMAN and two to four RMAN channels per each instance. Again, if restoring from tape, do not use more channels than the number of tape drives.
![]() When you are restoring using the 1 GigE network of the database servers, use all available 1 GigE ports for achieving the highest throughput. Each database server has four 1 GigE ports, which can be bonded in groups of two to get 240 MB/s to 480 MB/s throughput on each database server.
When you are restoring using the 1 GigE network of the database servers, use all available 1 GigE ports for achieving the highest throughput. Each database server has four 1 GigE ports, which can be bonded in groups of two to get 240 MB/s to 480 MB/s throughput on each database server.
NOTE
Typical restore rates achieved by a full-rack Exadata Database Machine X2-2 utilizing the InfiniBand network is about 23 TB/hr, and this was possible when restoring into preexisting files.
Summary
For a business to succeed, it needs to have access to highly available systems. When the service becomes unavailable due to unplanned or planned reasons, the business can lose revenue, credibility, and customers. Solutions that are designed to enhance availability help minimize the impact of hardware and software failures and enhance the availability of applications by shortening the service downtimes.
There are multiple approaches to achieving high availability with Oracle products. These approaches complement one another, and can be used alone or in combination. They range from the basic strategy of using highly reliable and redundant hardware and software to the more advanced process for detecting and repairing corruption, as well as performing zero downtime upgrades and active-active databases.
The chapter highlights the various high-availability features and technologies available on the Database Machine and guides you in choosing a solution that meets the need for stringent business continuity requirements. For more detailed information on each topic, refer to the Exadata section on the Oracle Technology Network and the Oracle database documentation.