HTML5: The Missing Manual Matthew MacDonald (2013)
Part 3. Building Web Apps
Chapter 11. Running Offline
If you want to view a website, you need to connect to the Internet. Everybody knows that. So why a chapter about offline applications? The very notion seems so last century. After all, didn’t web applications overthrow several generations of offline, desktop applications on their way to conquering the world? And there are plenty of tasks—from following the latest Kardashian sightings to ordering a new office chair—that just wouldn’t be possible without a live, real-time connection. But remember, even web applications aren’t meant to stay permanently online. Instead, they’re designed to keep working during occasional periods of downtime when a computer loses its network connection. In other words, a useful offline web application can tolerate intermittent network disruptions.
This fact is particularly important for people using smartphones and tablets. To see the problem, try traveling through a long tunnel while using a web application on one of these devices. Odds are you’ll get a nasty error page, and you’ll have to start all over again when you get to the other side. But do the same with an offline web application, and you’ll avoid interruption. Some of the features of the web application may become temporarily unavailable, but you won’t get booted out. (Of course, some tunnels are longer than others. An ambitious offline web application can keep working through a three-hour plane flight—or a three-week trip to the Congo, if that’s what you’re after. There’s really no limit to how long you can stay offline.)
By using HTML5’s offline application feature, you can start to shift your ordinary web page into a web-based “mini-app.” And if you combine the offline feature with plenty of JavaScript code, the data storage features described in Chapter 10, and the server communication features described in Chapter 12, your mini-app can be nearly as powerful and self-sufficient as the native applications designed for smartphones and tablets. The big advantage is that your HTML5-powered mini-app can run on any device, whereas a native app is locked into a specific platform.
In this chapter, you’ll learn how to turn any web page (or group of web pages) into an offline application. You’ll also learn how to tell when a website is available and when it’s offline, and react accordingly.
FREQUENTLY ASKED QUESTION: WHEN IT MAKES SENSE TO GO OFFLINE
Should I make my web page offline-able?
Offline web applications don’t suit every sort of web page. For example, there’s really no point in turning a stock quote page into an offline web application, since the whole point of its existence is to fetch updated stock data from a web server. However, the offline feature might suit a more detailed stock analysis tool that downloads a bunch of data at once and then lets you choose how to chart it or analyze it. Using a page like this, you could download some data while you’re online and then tweak options and fiddle with buttons until you reach the proverbial other side of the tunnel.
The offline feature also suits web pages that are interactive and stateful—ones that have piles of JavaScript code maintaining lots of information in memory. These pages do more on their own, so they make sense as offline applications. And the cost of losing your connection with one of these pages is also higher, because being kicked out in the middle of a complex task is seriously annoying. So while there’s no point in making a simple page of content offline-able, it’s immediately obvious that a word-processor-in-a-browser tool can benefit from offline support. In fact, an offline application like this might just be able to stand in for a more fully featured desktop program.
The other consideration is your audience. The offline application feature makes great sense if your visitors include people who don’t have reliable Internet connections or are likely to need mobile access (for example, if you’re creating a mapping tool for tablet devices). But if not, adding offline support might not be worth the trouble.
Caching Files with a Manifest
The basic technique that makes offline applications work is caching—the technique of downloading a file (like a web page) and keeping a copy of it on the web surfer’s computer. That way, if the computer loses its web connection, the browser can still use the cached copy of the page. Of course, caching isn’t limited to pages—it works with style sheets, JavaScript code files, pictures, fonts, and any other resource your web page needs to have on hand to do its work.
To create an offline application, you need to complete three steps. Here’s the high-level overview:
1. Create a manifest file.
A manifest is a special sort of file that tells browsers which files to store, which files not to store, and which files to substitute with something else. This package of cacheable content is called an offline application.
2. Modify your web page so it refers to the manifest.
That way, the browser knows to download the manifest file when someone requests the page.
3. Configure the web server.
Most importantly, the web server needs to serve manifest files with the proper MIME type. But as you’ll see, there are a few more subtle issues that can also trip up caching.
You’ll tackle all these tasks in the following sections.
UP TO SPEED: TRADITIONAL CACHING VS. OFFLINE APPLICATIONS
Caching is nothing new in the web world. Browsers use caching regularly to avoid repeatedly downloading the same files. After all, if you travel through several pages in a website, and each page uses the same style sheet, why download it more than once? However, the mechanism that controls this sort of caching isn’t the same as the one that makes offline applications work.
Traditional caching happens when the web server sends extra information (called cache-control headers) along with some file that a web browser has requested. The headers tell the browser if the file should be cached and how long to keep the cached copy before asking the web server if the file has changes. Typically, caching is brief for web pages and much longer for the resources that web pages use, like style sheets, pictures, and script files.
By comparison, an offline application is controlled by a separate file (called a manifest), and it doesn’t use any time limit at all. Instead, it applies the following rule: “If a web page is part of an offline application, and if the browser has a cached copy of that application, and if the definition of that application hasn’t changed, then use the cached copy.” You, the web developer, can add certain exceptions—for example, telling the browser not to cache certain files or to substitute one file for another. But there’s no need to worry about expiration dates and other potentially messy details.
Creating a Manifest
The manifest is the heart of HTML5’s offline application feature. It’s a text file that lists the files you want to cache.
The manifest always starts with the words CACHE MANIFEST (in uppercase), like this:
CACHE MANIFEST
After that, you list the files you want to cache. Here’s an example that grabs two web pages (from the personality test example described on Putting It Together: Drawing a Graph):
CACHE MANIFEST
PersonalityTest.html
PersonalityTest_Score.html
Spaces (like the blank line in the manifest shown above) are optional, so you can add them wherever you want.
NOTE
Watch for typos. If you attempt to cache a file that doesn’t exist, the browser will ignore not just that file, but the entire manifest.
With an offline application, the browser must cache everything your application needs. That includes web pages and the resources these web pages use (like scripts, graphics, style sheets, and embedded fonts). Here’s a more complete manifest that takes these details into account:
CACHE MANIFEST
# pages
PersonalityTest.html
PersonalityTest_Score.html
# styles & scripts
PersonalityTest.css
PersonalityTest.js
# pictures & fonts
Images/emotional_bear.jpg
Fonts/museo_slab_500-webfont.eot
Fonts/museo_slab_500-webfont.woff
Fonts/museo_slab_500-webfont.ttf
Fonts/museo_slab_500-webfont.svg
Here, you’ll notice two new details. First, you’ll see several lines that begin with a number sign (#). These are comments, which you can add to remind yourself what goes where. Second, you’ll see some files that are in subfolders (for example, emotional_bear.jpg in the Images folder). As long as these files are on the web server and accessible to the browser, you can bundle them up as part of your offline application package.
Complex web pages will need a lot of supporting files, which can lead to long, complex manifest files. Worst of all, a single mistyped file name will prevent the offline application feature from working at all.
TIP
You might decide to leave out some resources that are unimportant or overly large, like ad banners or huge pictures. That’s quite all right, but if you think their absence might cause some trouble (like error messages, odd blank spaces, or scrambled layouts), consider using JavaScript to tweak your pages when the user is offline, by using the connection-checking trick described onChecking the Connection.
Once you’ve filled out the contents of your manifest file, you can save it in your site’s root folder, alongside your web pages. You can use whatever file name you want, although you should add the file extension .appcache (as in PersonalityTest.appcache). Other file extensions may work (for example, in the early days of HTML5 some web developers used .manifest), but the latest versions of the HTML5 specification recommend .appcache. The important thing is that the web server is configured to recognize the file extension. If you’re running your own web server, you can use the setup steps described on Putting Your Manifest on a Web Server. If not, you need to talk to your web hosting company and ask them what file extensions they use to support manifest files.
TROUBLESHOOTING MOMENT: DON’T CACHE PAGES THAT USE THE QUERY STRING
The query string is the extra bit of information that appears on the end of some URLs, separated by a question mark. Usually, you use the query string to pass information from one web page to another. For example, the original version of the personality test uses the query string to pass the personality scores from the PersonalityTest.html page to the PersonalityTest_Score.html page. If you fill out the multiple-choice questions on the first page and click Get Score, the browser redirects you using a URL like this:
http://prosetech.com/html5/Personali-
tyTest_Score.html?e=-10&a=-5&c=10&n=5&o=20
Here’s the problem. In the eyes of the HTML5 caching system, a request for the page PersonalityTest_Score.html is not the same as a request for PersonalityTest_Score.html?e=-10&a=-5&c=10&n=5&o=20. The first page is cached, according to the manifest. But the second URL may as well point to a completely different page. Unless you add the page name and the complete query string in the manifest, it won’t be cached. And because there’s no way you want to add a separate manifest entry for every possible combination of personality scores, there’s no way to properly cache the query-string-enabled version of the PersonalityTest_Score.html page.
To avoid this problem, don’t use caching and query strings at the same time. For example, if you want to add caching to the personality test, use the version that puts personality scores in local storage. (That’s the version used in the caching example on Creating a Manifest.)
Using Your Manifest
Just creating a manifest isn’t enough to get a browser to pay attention. To put your manifest into effect, you need to refer to it in your web pages. You do that by adding the manifest attribute to the root <html> element and supplying the manifest file name, like this:
<!DOCTYPE html>
<html lang="en" manifest="PersonalityTest.manifest">
...
You need to take this step for every page that’s part of your offline application. In the previous example, that means you need to change two files: PersonalityTest.html and PersonalityTest_Score.html.
NOTE
A website can have as many offline applications as you want, as long as each one has its own manifest.
Putting Your Manifest on a Web Server
Testing manifest files can be a tricky process. Minor problems can cause silent failures and throw off the entire caching process. Still, at some point you’ll need to give it a try to make sure your offline application is as self-sufficient as you expect.
It should come as no surprise that you can’t test offline applications when you’re launching files from your hard drive. Instead, you need to put your application on a web server (or use a test web server that runs on your computer, like the IIS web server that’s built into Windows).
To test an offline application, follow these steps:
1. Make sure the web server is configured to use the MIME type text/cache-manifest when serving manifest files (typically, those are files with the extension .appcache).
If the web server indicates that the file is any other type, including a plain text file, the browser will ignore the manifest completely.
NOTE
Every type of web server works differently. Depending on your skills, you may need the help of your web hosting company or your neighborhood webmaster to set MIME types (step 1) and change caching settings (step 2). Meet the Media Formats has more information about MIME types, and shows one example of how you might add a new MIME type through a web hosting account.
2. Consider turning off traditional caching (Creating a Manifest) for manifest files.
Here’s the problem. Web servers may tell web browsers to cache manifest files for a short period of time, just as they tell them to cache other types of files. This behavior is reasonable enough, but it can cause king-sized testing headaches. That’s because when you update the manifest file, some browsers will ignore it and carry on with the old, cached manifest file, and so they’ll keep using the old, cached copies of your web pages. (Firefox has a particularly nasty habit of sticking with out-of-date manifest files.) To avoid this problem, you should configure the web server to tell browsers not to cache manifest files, ever.
Once again, every web server software has its own configuration system, but the basic idea is to tell your server to send a no-cache header whenever someone requests an .appcache file.
3. Request the page in a web browser that supports offline applications. Virtually every browser does, except old versions of Internet Explorer—you need IE 10 or better.
When a web browser discovers a web page that uses a manifest, it may ask for your permission before downloading the files. Mobile devices probably will, because they have limited space requirements. Desktop browsers may or may not—for example, Firefox does (see Figure 11-1), but Chrome, Internet Explorer, and Safari don’t.
If you give your browser permission (or if your browser doesn’t ask for it), the caching process begins. The browser downloads the manifest and then downloads each of the files it references. This downloading process takes place in the background and doesn’t freeze up the page. It’s just the same as when a browser downloads a large image or video, while displaying the rest of the page.
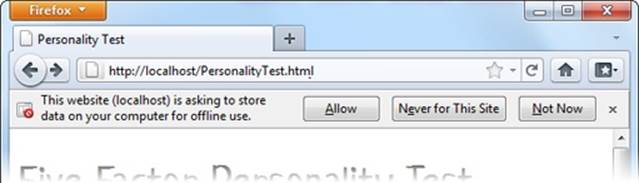
Figure 11-1. Firefox shows this message when it loads a web page that uses a manifest. Click Allow to grant permission to download and cache all the files that are listed in the manifest. On subsequent visits, when Firefox detects a changed manifest, it will download the new files without asking for permission again.
4. Go offline.
If you’re testing on a remote server, just disconnect your network connection. If you’re testing on a local web server (one that’s running on your computer), shut your website down (Figure 11-2).
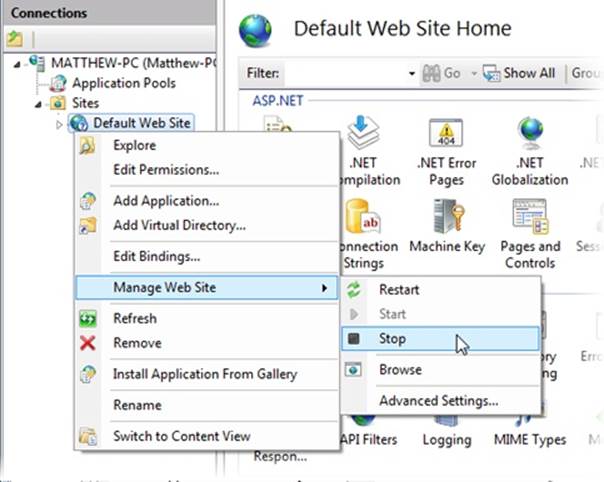
Figure 11-2. The exact way you shut down your test website depends on the type of web server software you’re using. In the Windows-based IIS software (shown here), a simple right-click gets you started.
5. Browse to one of the pages in your offline application, and refresh it.
Ordinarily, when you click the Refresh or Reload button, your browser always tries to make contact with the web server. If you’re requesting an ordinary page and you’ve lost your Internet connection, this request will fail. But if you’re requesting a page from an offline application, the browser seamlessly substitutes the cached copy, without even informing you of the switch. You can even click links to jump from one page to another, but if you navigate to a page that’s not part of the offline application, you’ll get the familiar “no response” error.
TROUBLESHOOTING MOMENT: MY OFFLINE APPLICATION DOESN’T WORK OFFLINE
The offline application feature is fragile and a bit quirky. A minor mistake can throw it all off. If you follow the steps described above, but you get a “no response” error when you attempt to access your offline pages, check for these common problems:
§ Problems downloading the manifest. If the manifest isn’t there, or isn’t accessible to the browser, you’ll have an obvious problem. But equally important is serving the manifest with the right MIME type (Meet the Media Formats).
§ Problems downloading the files that are listed in the manifest. For example, imagine that your manifest includes a picture that no longer exists. Or it asks for a web font file, and that font file uses a file type that your web server doesn’t allow. Either way, if the browser fails to download even a single file, it will give up completely (and throw away any cached information it already has). To avoid this problem, start simple, with a manifest that lists just a single web page and no resources. Or, in more complex examples, look at the web server logs to find out exactly what resources the browser has requested (which may tell you the point at which it met an error and gave up).
§ An old manifest is still cached. Browsers can cache the manifest file (according to the traditional caching rules of the Web) and ignore the fact that you’ve changed it. One of the signs that you’ve stumbled into this problem is when some pages are cached but other, more recently added pages are not. To solve this problem, consider manually clearing the browser cache (see the box onClearing the Browser’s Cache).
Updating the Manifest File
Getting an application to work offline is the first challenge. The next is updating it with new content.
For example, consider the previous example (Creating a Manifest), which caches two web pages. If you update PersonalityTest.html, fire up your browser, and reload the page, you’ll still see the original, cached version of the page—regardless of whether your computer is currently online. The problem is that once a browser has a cached copy of an application, it uses that. The browser ignores the online versions of the associated web pages and doesn’t bother to check whether they’ve changed. And because offline applications never expire, it doesn’t matter how long you wait: Even months later, the browser will stubbornly ignore changed pages.
However, the browser will check for a new manifest file. So you can save a new copy of that, put it on the web server, and you’ve solved the problem, right?
Not necessarily. To trigger an update for a cached web application, you need to meet three criteria:
§ The manifest file can’t be cached in the browser. If the browser has a locally cached copy of the manifest file, it won’t bother to check the web server at all. Browsers differ on how they handle manifest file caching, with some (like Chrome) always checking with the web server for new manifests. But Firefox follows the traditional rules of HTTP caching and holds onto its cached copy for some time. So if you want to save yourself development headaches, make sure your web server explicitly tells clients that they shouldn’t cache manifests (Putting Your Manifest on a Web Server).
§ The manifest file needs a new date. When a browser checks the server, the first thing it does is ask whether the last-updated timestamp has changed. If it hasn’t, the web browser doesn’t bother to download the manifest file.
§ The manifest file needs new content. If a browser downloads a newly updated manifest file but discovers that the content hasn’t changed, it stops the update process and keeps using the previously cached copy. This potentially frustrating step actually serves a valuable purpose. Re-downloading a cached application takes time and uses up network bandwidth, so browsers don’t want to do it if it’s really not necessary.
If you’ve been following along carefully, you’ll notice a potential problem here. What if there’s no reason to change the manifest file (because you haven’t added any files), but you do need to force browsers to update their application cache (because some of the existing files have changed)? In this situation, you need to make a trivial change to the manifest file, so it appears to be new when it isn’t. The best way to do so is with a comment, like this:
CACHE MANIFEST
# version 1.00.001
# pages
PersonalityTest.html
PersonalityTest_Score.html
# styles & scripts
PersonalityTest.css
PersonalityTest.js
# pictures & fonts
Images/emotional_bear.jpg
Fonts/museo_slab_500-webfont.eot
Fonts/museo_slab_500-webfont.woff
Fonts/museo_slab_500-webfont.ttf
Fonts/museo_slab_500-webfont.svg
The next time you need browsers to update their caches, simply change the version number in this example to 1.00.002, and so on. Presto—you now have a way to force updates and keep track of how many updates you’ve uploaded.
Updates aren’t instantaneous. When the browser discovers a new manifest file, it quietly downloads all the files and uses them to replace the old cache content. The next time the user visits the page (or refreshes the page), the new content will appear. If you want to switch over to the newly downloaded application right away, you can use the JavaScript technique described on Pointing Out Updates with JavaScript.
NOTE
There is no incremental way to update an offline application. When the application has changed, the browser tosses out the old and downloads every file again, even if some files haven’t changed.
GEM IN THE ROUGH: CLEARING THE BROWSER’S CACHE
When testing an offline application, it’s often helpful to manually clear the cache. That way, you can test new updates without changing the manifest.
Every browser has a way to clear the cache, but every browser tucks it away somewhere different. The most useful browsers keep track of how much space each offline application uses (see Figure 11-3). This information lets you determine when caching has failed—for example, the application’s website isn’t listed or the cached size isn’t as big as it should be. It also lets you remove the cached files for a single site without disturbing the others.
Browser Support for Offline Applications
By now, you’ve probably realized that all major browsers support offline applications, aside from the notable HTML5 laggard, Internet Explorer. Support stretches back several versions, which all but ensures that Firefox, Chrome, and Safari users will be able to run your applications offline. But Internet Explorer didn’t get around to adding support until version IE 10, which means there’s no caching in the still-popular IE 9 and IE 8.
However, the way that different browsers support offline applications isn’t completely consistent. The most important difference is the amount of space they allow offline applications to fill. This variation is significant, because it sets the difference between websites that will be cached for offline access and ones that won’t (see the box on How Much Can You Cache?).
There’s no worthwhile way to get offline application support on browsers that don’t include it as a feature (like IE 9). However, this shouldn’t stop you from using the offline application feature. After all, offline applications are really just a giant frill. Web browsers that don’t support them will still work: They just require a live web connection. And people that need offline support—for example, frequent travelers—will discover the value of having a non-IE browser on hand for their disconnected times of need.
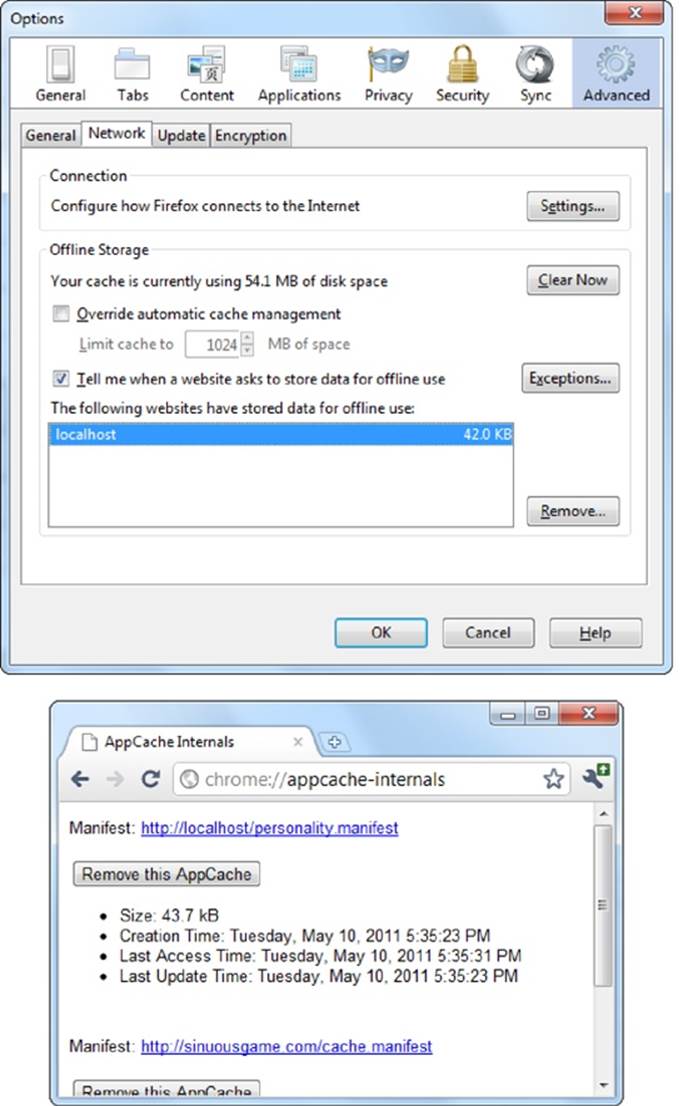
Figure 11-3. Top: In the Firefox menu, click Options, choose the Advanced icon, and then choose the Network tab to end up here. You can review the space usage of every website, or clear the cached resources of any one, by selecting it and clicking Remove. In this example, there’s just one cached website, on the domain localhost (which represents a test server on the current computer). Bottom: To get a similar display in Chrome, type chrome://appcache-internals into the address bar.
FREQUENTLY ASKED QUESTION: HOW MUCH CAN YOU CACHE?
Are there limits on how much information can be cached?
Different browsers impose wildly different size restrictions on offline applications.
Mobile browsers are the most obvious example. Because they run on space-limited devices, they tend to be stingy with their caching. Desktop browsers are more generous, but they’re equally unpredictable. Browsers may assign a fixed space limit to each website domain, or they may calculate a suitable allotment based on the current amount of free space on your computer, along with other factors. Often, space is shared between several HTML5 features—for example, if you’re using the File API or IndexedDB feature (see Chapter 10), your browser may use a single pool of space with these features and the application cache.
Unfortunately, the lack of consistency among browsers is a problem. If you create an offline application that attempts to stuff the cache beyond its limit, the browser quietly gives up and throws away all the downloaded data. Not only will you waste time and bytes, but your website users won’t get any offline benefits. They’ll be forced to use your application online.
The best rule of thumb is to assume you’ll be limited to 50 MB on Apple devices (like the iPad and iPhone) and closer to 85 MB on Android devices. All mobile browsers will ask the user for permission before allowing a website to use the cache. On desktop browsers, you’ll probably get a starting allotment of 250 or 350 MB. If your cache swells, some desktop browsers will offer to ratchet up the available space beyond the starting allotment, but there’s no guarantee.
Practical Caching Techniques
So far, you’ve seen how to package up a group of pages and resources as an offline application. Along the way, you learned to write a manifest file, update it, and make sure browsers don’t ignore your hard work. This knowledge is enough to put simple applications offline. However, more complex websites sometimes need more. For example, you may want to keep some content online, substitute different pages when offline, or determine (in code) whether the computer has a live Internet connection. In the following sections, you’ll learn how to accomplish all these tasks with smarter manifest files and a dash of JavaScript.
Accessing Uncached Files
Earlier, you learned that once a page is cached, the web browser uses that cached copy and doesn’t bother talking to any web servers. But what you may not realize is that the browser’s reluctance to go online applies to all the resources an offline web page uses, whether they’re cached or not.
For example, imagine you have a page that uses two pictures, using this markup:
<img src="Images/logo.png" alt="Personality quiz">
<img src="Images/emotional_bear.jpg" alt="Sad stuffed bear">
However, the manifest caches just one of the pictures:
CACHE MANIFEST
PersonalityTest.html
PersonalityTest_Score.html
PersonalityTest.css
PersonalityTest.js
Images/emotional_bear.jpg
You might assume that a browser will grab the emotional_bear.png picture from its cache, while requesting logo.png from the web server (as long as the computer is online). After all, that’s the way it works in your browser when you step from a cached web page to an uncached page. But here, the reality is different. The browser grabs emotional_bear.jpg from the cache but ignores the uncached logo.png graphic, displaying a broken-image icon or just a blank space on the page, depending on the browser.
To solve this problem, you need to add a new section to your manifest. You title this section with a NETWORK: title, followed by a list of the pages that live online:
CACHE MANIFEST
PersonalityTest.html
PersonalityTest_Score.html
PersonalityTest.css
PersonalityTest.js
Images/emotional_bear.jpg
NETWORK:
Images/logo.png
Now the browser will attempt to get the logo.png file from the web server when the computer is online, but not do anything when it’s offline.
At this point, you’re probably wondering why you would bother to explicitly list files you don’t want to cache. It could be for space considerations—for example, maybe you’re leaving out large files to make sure your application can be cached on browsers that allow only small amounts of cache space (Practical Caching Techniques).
But a more likely situation is that you have content that should be available when requested but never cached—for example, tracking scripts or dynamically generated ads. In this case, the easiest solution is to add an asterisk (*) in your network section. That’s a wildcard character that tells the browser to go online to get every resource you haven’t explicitly cached:
NETWORK:
*
You can also use the asterisk to target files of a specific type (for example, *.jpg refers to all JPEG images) or all the files on a specific server (for example, http://www.google-analytics.com/* refers to all the resources on the Google Analytics web domain).
NOTE
It may occur to you that you could simplify your manifest by using the asterisk wildcard in the list of cached files. That way, you could cache bunches of files at once, rather than list each one individually. Unfortunately, the asterisk isn’t supported for picking cached files, because the creators of HTML5 were concerned that careless web developers might try to cache entire mammoth websites.
Adding Fallbacks
Using a manifest, you tell the browser which files to cache and, using the network section, which files to always get from the Web and never cache. Manifests also support one more trick: a fallback section that lets you swap one file for another, depending on whether the computer is online oroffline.
To create a fallback section, start with the FALLBACK: title, which you can place anywhere in your manifest. Then, list files in pairs on a single line. The first file name is the file to use when online; the second file name is the offline fallback:
FALLBACK:
PersonalityScore.html PersonalityScore_offline.html
The web browser will download the fallback file (in this case, that’s PersonalityScore_offline.html) and add it to the cache. However, the browser won’t use the fallback file unless the computer is offline. While it’s online, the browser will request the other file (in this case,PersonalityScore.html) directly from the web server.
NOTE
Remember, you don’t have to be disconnected from the Web to be “offline” with respect to a web application. The important detail is whether the web domain is accessible—if it doesn’t respond, for any reason, that web application is considered to be offline.
There are plenty of reasons to use a fallback. For example, you might want to substitute a simpler page when offline, a page that doesn’t use the same scripts, or smaller resources. You can put the fallback section wherever you want, so long as it’s preceded by the section title:
CACHE MANIFEST
PersonalityTest.html
PersonalityTest_Score.html
PersonalityTest.css
FALLBACK:
PersonalityScore.html PersonalityScore_offline.html
Images/emotional_bear.jpg Images/emotional_bear_small.jpg
PersonalityTest.js PersonalityTest_offline.js
NETWORK:
*
NOTE
Incidentally, the files that you want to cache are part of the CACHE: section in the manifest. You can add the section title if you want, but you don’t need it unless you want to list files after one of the other sections.
The fallback section also supports wildcard matching. This feature lets you create a built-in error page, like this:
FALLBACK:
/ offline.html
This line tells the browser to use the fallback for any file that isn’t in the cache.
Now imagine someone attempts to request a page that’s in the same website as the offline application, but isn’t in the cache. If the computer is online, the web browser tries to contact the web server and get the real page. But if the computer is offline, or if the website is unreachable, or if the requested page quite simply doesn’t exist, the web browser shows the cached offline.html page instead (Figure 11-4).
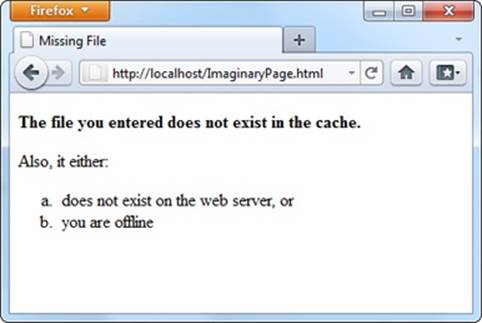
Figure 11-4. Here the page ImaginaryPage.html doesn’t exist. Interestingly, the browser doesn’t update the address bar, so the visitor has no way of knowing the exact name of the error page.
The previous example used the somewhat arbitrary convention of using a single forward slash character (/) to represent any page. That might strike you as a bit odd, considering that the network section uses the asterisk wildcard character for much the same purpose. (And some browsers, like Firefox, do allow you to substitute an asterisk for the slash.) You’re simply looking at one more harmless HTML5 quirk.
Incidentally, you can write more targeted fallbacks that still use the slash to match all the files in a specific subfolder, like this:
FALLBACK:
/paint_app/ offline.html
GEM IN THE ROUGH: HOW TO BYPASS THE CACHE WHEN YOU’RE ONLINE
When you load up a cached page, the browser expects to find everything in the cache. It doesn’t matter whether you’re online or offline. The browser prefers the cache and expects to use it for everything, aside from the files you’ve explicitly identified in the NETWORK: section.
This behavior is straightforward, but it’s also frustratingly inflexible. The chief problem happens in situations where you would prefer to use the online version of a page, but you still want to have the cached copy ready if you can’t connect to the network. For example, think of the front page of a news site. If you’re online, it makes sense to grab the latest copy of the front page every time you visit it. But if you’re offline, the most recently cached page would still be helpful. The standard caching system doesn’t allow for this scenario, because it forces you to choose between caching always and caching never.
In the eleventh hour of the HTML5 standardization process, a new idea slipped in that offers the solution. The trick is to add a new section, called SETTINGS:, with the following information:
SETTINGS:
prefer-online
This tells the browser to try and get resources from the network if possible, but to use the cached version if that request fails.
Although this quick fix seems ideal, it raises several problems of its own. It’s an all-or-nothing setting that applies to every page and resource (not just the files you choose). It guarantees that the cache won’t be as fast in offline mode, because the browser will waste at least some time trying to contact the web server. But the biggest drawback is that, at the time of this writing, only Firefox respects the prefer-online setting. Other browsers simply ignore it and carry on using the cache in the normal way.
Checking the Connection
The fallback section is the secret to a handy JavaScript trick that lets you determine whether the browser is currently online. If you’re an old-hand JavaScript developer, you probably know about the navigator.onLine property, which provides a slightly unreliable way to check whether the browser is currently online. The problem is that the onLine property really reflects the state of the browser’s “work offline” setting, not the actual presence of an Internet connection. And even if the onLine property were a more reliable indicator of connectivity, it still wouldn’t tell you whether the browser failed to contact the web server or whether it failed to download the web page for some other reason.
The solution is to use a fallback that loads different versions of the same JavaScript function, depending on whether the application is online or offline. Here’s how you write the fallback section:
FALLBACK:
online.js offline.js
The original version of the web page refers to the online.js JavaScript file:
<!DOCTYPE html>
<html lang="en" manifest="personality.manifest">
<head>
<meta charset="utf-8">
<title>...</title>
<script src="online.js"></script>
...
It contains this very simple function:
function isSiteOnline() {
return true;
}
But if the online.js file can’t be accessed, the browser substitutes the offline.js file, which contains a method with the same name but a different result:
function isSiteOnline() {
return false;
}
In your original page, whenever you need to know the status of your application, check with the isSiteOnline() function:
var displayStatus = document.getElementById("displayStatus");
if (isSiteOnline()) {
// (It's safe to run tasks that require network connectivity, like
// contacting the web server through XMLHttpRequest.)
displayStatus.innerHTML = "You are connected and the web server is online.";
}
else {
// (The application is running offline. You may want to hide or
// programmatically change some content, or disable certain features.)
displayStatus.innerHTML = "You are running this application offline.";
}
Pointing Out Updates with JavaScript
You can interact with the offline application feature using a relatively limited JavaScript interface. It all revolves around an object called applicationCache.
The applicationCache object provides a status property that indicates whether the browser is checking for an updated manifest, downloading new files, or doing something else. This property changes frequently and is nearly as useful as the complementary events (listed in Table 11-2), which fire as the applicationCache switches from one status to another.
Table 11-1. Caching events
|
EVENT |
DESCRIPTION |
|
onChecking |
When the browser spots the manifest attribute in a web page, it fires this event and checks the web server for the corresponding manifest file. |
|
onNoUpdate |
If the browser has already downloaded the manifest, and the manifest hasn’t changed, it fires this event and doesn’t do anything further. |
|
onDownloading |
Before the browser begins downloading a manifest (and the pages it references), it fires this event. This occurs the first time it downloads the manifest files and during updates. |
|
onProgress |
During a download, the browser fires this event to periodically report its progress. |
|
onCached |
Signals the end of a first-time download for a new offline application. No further events occur after that happens. |
|
onUpdateReady |
Signals the end of a download that retrieved updated content. At this point, the new content is ready to use, but it won’t appear in the browser window until the page is reloaded. No further events occur after that happens. |
|
onError |
Something went wrong somewhere along the process. The web server might not be reachable (in which case the page will have switched into offline mode), the manifest might have invalid syntax, or a cached resource might not be available. If this event occurs, no more follow. |
|
onObsolete |
While checking for an update, the browser discovered that the manifest no longer exists. It then clears the cache. The next time the page is loaded, the browser will get the live, latest version from the web server. |
Figure 11-5 shows how these events unfold when you request a cached page.
The most useful event is onUpdateReady, which signals that a new version of the application has been downloaded. Even though the new version is ready for use, the old version of the page has already been loaded into the browser. You may want to inform the visitor of the change, in much the same way that a desktop application does when it downloads a new update:
<script>
window.onload = function() {
// Attach the function that handles the onUpdateReady event.
applicationCache.onupdateready = function() {
var displayStatus = document.getElementById("displayStatus");
displayStatus.innerHTML = "There is a new version of this application. " +
"To load it, refresh the page.";
}
}
</script>
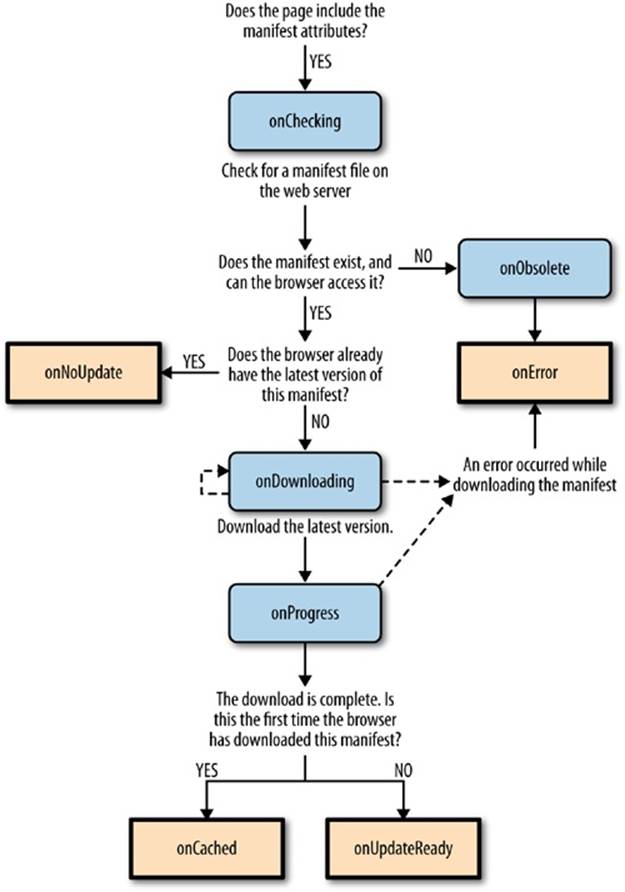
Figure 11-5. If you’re a micromanager at heart, you can take control of the caching process. But first you need to understand how the caching event unfolds, as depicted in this diagram. The process stops when the browser reaches one of the square boxes (with a bold border) shown here.
Or, you can offer to reload the page for the visitor using the window.location.reload() method:
<script>
window.onload = function() {
applicationCache.onupdateready = function() {
if (confirm(
"A new version of this application is available. Reload now?")) {
window.location.reload();
}
}
}
</script>
Figure 11-6 shows this code at work.
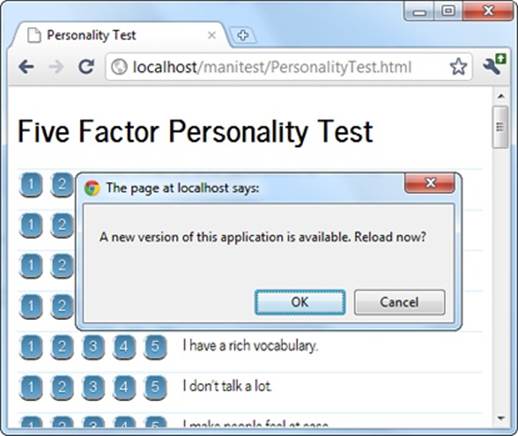
Figure 11-6. Here, the application offers to reload itself with the newly downloaded content, if the visitor clicks OK. (Otherwise, the new content will appear the next time the page is loaded or refreshed.)
The applicationCache also provides two methods for more specialized scenarios. First is the confusingly named update() method, which simply checks for a new manifest. If one exists, it starts the download process in the background. Otherwise, it does nothing more.
Although browsers check for updates automatically, you can call update() if you think the manifest has changed since the user first loaded the page. This method might be important in a very long-lived web application—for example, one that users leave open on the same page, all day.
The second method is swapCache(), which tells the browser to start using the newly cached content, if it has just downloaded an update. However, swapCache() doesn’t change the page that’s currently on display—for that, you need a reload. So what good is swapCache()? Well, by changing over to the new cache, anything that you load from that point on—say, a dynamically loaded image—comes from the new cache, not the old one. If managed carefully, swapCache() could give your page a way to get access to new content without forcing a complete page reload (and potentially resetting the current application to its initial state). But in most applications, swapCache() is more trouble than it’s worth, and it can cause subtle bugs by mixing old and new bits of the cache.