Pro HTML5 Accessibility: Building an Inclusive Web (2012)
C H A P T E R 4
Understanding Accessibility APIs, Screen Readers, and the DOM
In this chapter, we’ll consider how screen readers work in more detail and take a look at the DOM and accessibility APIs that are used by assistive technology (AT) to access web content. This is important to understand. Although some of this stuff might seem a little abstract or academic and this chapter is not vital for you to build accessible HTML5 content, it will help. By design, it’s also short.
![]() Note As previously mentioned, although screen readers are not the only technology people with disabilities use to access the Web, they are arguably the most complex. Also, the technical accessibility support requirements found under the hood are probably the most extensive.
Note As previously mentioned, although screen readers are not the only technology people with disabilities use to access the Web, they are arguably the most complex. Also, the technical accessibility support requirements found under the hood are probably the most extensive.
Don’t worry too much if this chapter seems a little tricky; it’s not an easy subject. I’ve worked with people with disabilities for nearly 10 years, and I’ve had experience with a broad range of assistive technologies when I worked as an AT specialist. I was fortunate enough to gain a lot of experience in the diverse kinds of AT that exist, as well as the myriad applications for these technologies.
From this experience, I can honestly say that the screen reader is the most complex, both from a development perspective for you, the author of accessible web content and designer of groovy web sites, and from the user perspective. The range or levels of screen reader proficiency varies greatly, from the most basic “Tab around the page” or “Just hit Say All and see what happens” to complex uses of virtual cursors, various kinds of content interrogation, and so on. The advent of a screen reader like VoiceOver, with its support for gestures and the rotor, has made interactions much easier, and we’ll see a move toward more gestural interfaces. However, at the moment the keyboard interaction model is overly complex, with far too many custom keyboard combinations for the user to remember. The move to mobile devices will also result in a reduced dependence on the keyboard and a focus on more natural forms of input, such as finger swipes and other gestures.
I look forward to future iterations of these technologies, where the technology mediates the complexity and simplifies the user experience. I still get a buzz out of showing a screen reader user how to do new things with AT, and the low level of digital literacy among AT users still surprises me. AT users sometimes complain about some web site or content being inaccessible, when actually the barrier is the users’ inability to use their AT correctly. Users of AT need to be schooled in how to use their technology to the best of their ability. This is a win-win approach in that the user will get more longevity from the technology and the health service provider will have recurring lower costs. Also, paying attention to this chapter will help you to better understand how the screen reader handles the code that you write.
![]() Note Assistive technologies can be very, very expensive and, in effect, are a niche technology. This has resulted in a creative, do-it-yourself, kind of punk rock culture, which fuses imaginative use of technology within the often-limited resources available to provide solutions for people with disabilities.
Note Assistive technologies can be very, very expensive and, in effect, are a niche technology. This has resulted in a creative, do-it-yourself, kind of punk rock culture, which fuses imaginative use of technology within the often-limited resources available to provide solutions for people with disabilities.
Defining the Elements Under the Hood of Assistive Technologies
When you look at what is happening under the hood with web content and the nuts and bolts of AT interaction, it is complex. This chapter gives you a glimpse of what is happening between the various platform accessibility APIs, and a look at dynamic DOM updating and the correct application of semantics to describe custom controls.
As I mentioned, it took me at least two to three years to get a grip on how a screen reader really works, from both studying the user interaction model and getting familiar with JAWS keystrokes to understanding what’s happening under the hood. And that was just from the screen reader side—never mind how data gets Ping-Ponged between various APIs! So don’t worry if you feel a little lost at sea. This chapter is my attempt to explain things to you in a way I wish someone had done for me years ago.
What’s an API?
An API is an application programming interface. This is the framework or set of rules that provide the code, functions, or vocabulary needed to program in any given language. An API can be thought of as a library of code you use to tell software, like a browser or assistive technology, to do something.
For example, the browser converts web content written in HTML5 to a Document Object Model (DOM). This DOM of the webpage is associated with a layout engine that the browser uses. The browser then takes information from both the layout engine and the DOM to support an operating system (OS) platform accessibility API. This API allows an assistive technology to monitor and query any accessibility information that the browser exposes to it.
What’s a Layout Engine?
A layout engine is an embedded component in every browser that displays in the browser the HTML, XHTML, XML, or other such content and formatting information such as Cascading Style Sheets (CSS). Different browsers have their own rendering engine, with their own rules for how they should display web content. For example, Firefox uses the Gecko engine, Internet Explorer uses Trident, Safari and Chrome use the Webkit rendering engine, and Opera has its own rendering engine called Presto.
What Are Accessibility APIs?
Accessibility APIs are platform-specific APIs that are used either in the desktop or in the browser to communicate accessibility information in a way that assistive technologies can understand. The HTML5 code that you will write contains elements like headings, buttons, form controls, and so on. Each of these elements then has a role, state, and property set (as well as parent/child relationships to the rest of the document elements) that are defined by the accessibility API platform.
Here are some of the main accessibility APIs:
· MSAA
· UIAutomation
· Apple Accessibility API
· iAccessible2
· AT-SPI
![]() Note There are other accessibility APIs. For example, if you’re writing a JAVA application and you want to make it accessible, you need to use the JAVA access bridge to provide accessibility mapping. It’s not enabled by default in JAVA.
Note There are other accessibility APIs. For example, if you’re writing a JAVA application and you want to make it accessible, you need to use the JAVA access bridge to provide accessibility mapping. It’s not enabled by default in JAVA.
The Off-Screen Model (OSM)
Before we look at APIs themselves in any more detail, we need to backpedal a bit and discuss the first accessibility model: the off-screen model, or OSM. It was developed as a means of making the visual desktop and the first graphical user interfaces (GUIs) accessible to early screen readers and Braille output devices. An awareness of the off-screen model will help you develop a broader understanding of how these related technologies interact and behave.
Early DOS-based systems, or command-line-interface systems, can be quite accessible because they are text based. The information that the user types into the system, as well as the information that the system returns, can be captured easily in the memory buffer and synthesized into speech. This speech output is achieved by using the kind of formant synthesis I talked about in Chapter 2, “Understanding Disability and Assistive Technology.” Characters such as text strings and data are stored in a buffer (or memory store) that can be easily accessed directly by the screen reader and then output as speech to the end user.
![]() Note This basic speech output is known as TTS, or “Text-to-Speech,” synthesis. There is a wide range of both hardware and software TTS engines.
Note This basic speech output is known as TTS, or “Text-to-Speech,” synthesis. There is a wide range of both hardware and software TTS engines.
With the advent of the GUI, this all changed. Controls then moved from being input via the command line, or text based, to being grouped as related selectable controls displayed visually on the screen (such as menus and application controls) that could be understood easily by sighted people. In effect, the user interface was converted to graphical pixels on the screen rather than it being more accessible text. As a result, the original text could not be easily accessed. A method was needed, therefore, to access information from drawing calls and windowing information beforeit was converted to pixels and stored in an off-screen data model that could be accessed and read by a screen reader. Getting this to work was a very complex operation. To deal with this complexity and to provide a way for on-screen content to be rendered in an accessible way by a screen reader, the off-screen model was developed and implemented. This was a missing link that was needed to make GUIs accessible.
![]() Note For a very interesting piece of screen-reader history, I recommend the paper “Making the GUI Talk,” by Richard Schwerdtfeger, who is the CTO of the Accessibility Software Group at IBM and a renowned accessibility expert. Rich also worked with the great Dr. Jim Thatcher, who developed one of the first screen readers for DOS as well as the first screen reader for the GUI-based PC. You can get this paper at ftp://service.boulder.ibm.com/sns/sr-os2/sr2doc/guitalk.txt.
Note For a very interesting piece of screen-reader history, I recommend the paper “Making the GUI Talk,” by Richard Schwerdtfeger, who is the CTO of the Accessibility Software Group at IBM and a renowned accessibility expert. Rich also worked with the great Dr. Jim Thatcher, who developed one of the first screen readers for DOS as well as the first screen reader for the GUI-based PC. You can get this paper at ftp://service.boulder.ibm.com/sns/sr-os2/sr2doc/guitalk.txt.
For GUI-based systems, the off-screen model works by capturing information about the controls that are to be rendered visually on screen and then creating a separate version of the page (the off-screen model—hence, the name). The screen reader then interacts with this OSM and uses its contents as a basis to output speech that the end user can understand.
You can think of the off-screen model as a snapshot of the screen at any given time. What is happening is a technique known as screen scraping or hooking graphics calls. These days, for desktop systems, the OS provides vehicles to expose and retrieve this information, but it is the application and its user-interface components that expose the information through the APIs.
Modern programming languages allow for the use of descriptions of objects and elements that the screen reader can latch onto via the accessibility API. The screen reader then outputs these names and properties as speech for the user when they receive focus via the keyboard. As I mentioned, for desktop applications the need to maintain an OSM has lessened, but it's not entirely gone, and it’s still useful in cases where developers have been semantically neglectful in labeling controls. So the OSM might still come into play in a support role to provide as much information as possible to the screen reader and therefore facilitate a more complete user experience.
For an operating system, making it accessible certainly presented particular challenges, but they have more or less been conquered because an OS is usually well engineered and is a more closed type of environment. This makes design for an application like a screen reader easier, because good programmatic practices, such as correctly labelled controls and so on, can be incorporated directly into the operating system. So what about the world wild web, where anything goes?
![]() Note Confused? Well, it’s a little complicated, so don’t worry. In short, the OSM can be thought of as an internal database that the screen reader accesses before content gets rendered to the screen. As a sighted person, you look at the browser and get a picture for what the content of the page is and what the various controls are, including their function and so on. The screen reader just gets this info from the same source that the browser does, but it bypasses the visual rendering and uses the code to both navigate the page content and output it as speech.
Note Confused? Well, it’s a little complicated, so don’t worry. In short, the OSM can be thought of as an internal database that the screen reader accesses before content gets rendered to the screen. As a sighted person, you look at the browser and get a picture for what the content of the page is and what the various controls are, including their function and so on. The screen reader just gets this info from the same source that the browser does, but it bypasses the visual rendering and uses the code to both navigate the page content and output it as speech.
How Do Screen Readers Access Information on a WebPage or Application?
These days, not all screen readers primarily use an OSM for interacting with the Web. An OSM is seen as outdated technology. Also, maintaining an OSM is technically difficult and presents challenges for developers. For example, you might find it hard to understand what’s going on with the screen reader when you try testing webpages yourself for the first time. You will lose your place on the page or find it difficult to know where the screen reader’s focus is at certain times. (It will happen.) It helps to understand that you’re not interacting with the browser directly in the first place, but with this third place.
![]() Note When interacting with the Web, in reality that “third place” is a combination of the DOM and accessibility API output—as well as the OSM for some screen readers. It can help, when you are just getting your head around this stuff for the first time, to initially think of them as representing the same thing. They’re not the same, but in effect combine to create the “third place.” So it’s useful as an abstraction—so that your head doesn’t explode.
Note When interacting with the Web, in reality that “third place” is a combination of the DOM and accessibility API output—as well as the OSM for some screen readers. It can help, when you are just getting your head around this stuff for the first time, to initially think of them as representing the same thing. They’re not the same, but in effect combine to create the “third place.” So it’s useful as an abstraction—so that your head doesn’t explode.
Earlier we talked about the various cursors that a screen reader like JAWS uses when interacting with the Web. The PC virtual cursor is what JAWS uses mostly for browsing the Web. That virtual cursor is actually pointing at a database of content—which is really a cache of what is available from a combination of OSMs and API calls—in a virtual buffer. This buffer of what is visualized on the screen allows the AT user to browse the contents of the screen. The virtual cursor, therefore, represents the screen-reader user’s browsing point, which might not match the focus point when a sighted user visually scans a webpage.
![]() Remember What a sighted user can see in the browser is just a visual rendering of the contents of the DOM, styled by CSS. Note, this doesn’t apply to plugins like Flash content or Java Applets or, indeed, the HTML5 <canvas> API.
Remember What a sighted user can see in the browser is just a visual rendering of the contents of the DOM, styled by CSS. Note, this doesn’t apply to plugins like Flash content or Java Applets or, indeed, the HTML5 <canvas> API.
For this snapshot to work with assistive technologies or for it to be considered accessible, the off-screen model needs to be fed good semantic code, as mentioned previously. This means that the more accessibility-aware developer has marked up page headings, list items, form controls, and graphics in a way that conforms to accessibility best practice. When you do this, the contents of the OSM are structured, being supported by good semantics. So adding your <h1>s, your <li>s, and your form input <labels> isn’t just an esoteric exercise, but a vital way of creating an accessibility architecture that provides a structure for assistive technologies to use for navigation and comprehension.
You might remember earlier I talked about a Forms Mode that the screen reader uses. A screen reader like JAWS uses a virtual cursor so that the user can navigate the headings by pressing the H key, G key (for graphics), or the B key (for buttons) or bring up a dialog box of links on the page. This is possible because the virtual cursor has captured the keystrokes to use them as navigational controls. So what about when you want to enter some data on a webpage? You obviously cannot use these kinds of navigational features of the screen reader at the same time.
![]() Remember This is why there is a Forms Mode with a screen reader like JAWS. In Forms Mode, the screen reader switches from using the PC virtual cursor to interacting with the browser directly. This disables the virtual cursor and allows the screen reader user to enter data directly into a form.
Remember This is why there is a Forms Mode with a screen reader like JAWS. In Forms Mode, the screen reader switches from using the PC virtual cursor to interacting with the browser directly. This disables the virtual cursor and allows the screen reader user to enter data directly into a form.
This Forms Mode also presents certain challenges for the web developer, because when the developer is working in Forms Mode, important data that would be available via the PC virtual cursor might not be available. This missing data might be instructions on how to fill in the form and so on. Care should be taken with form validation and updating on-screen content when in Forms Mode so that the screen-reader user doesn’t miss out on instructions or feedback you need to give them, such as missing input data and so on.
In brief, you’ve seen an overview of the off-screen model, and some of the cursors that a screen reader like JAWS uses. Next, we’ll look at the DOM, and then dive into heuristics.
![]() Tip Remember that some screen readers don’t use an off-screen model at all. These include VoiceOver for the Mac and NVDA for the PC, which is an excellent free, open-source screen reader than can be used with some of the existing voice-synthesis packages on a screen-reader user’s system, such as SAPI4 or SAPI5.
Tip Remember that some screen readers don’t use an off-screen model at all. These include VoiceOver for the Mac and NVDA for the PC, which is an excellent free, open-source screen reader than can be used with some of the existing voice-synthesis packages on a screen-reader user’s system, such as SAPI4 or SAPI5.
What Is the DOM?
DOM stands for Document Object Model and represents the semantic structure of a webpage or other kinds of documents, in a kind of tree form. As shown in Figure 4-1, the various HTML elements in the webpage form the leaves on the tree that are the element nodes.
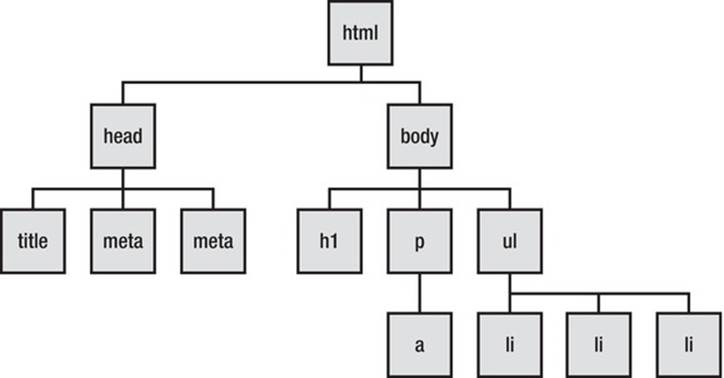
Figure 4-1. Meet the HTML that creates the DOM
The nodes shown in Figure 4-1 represent the various structural parts of the document that the browser or assistive technology will see. The DOM might also provide information about a node’s state.
As you can see in the diagram, you have a header, which contains the <title> of the document, and you have the <body>, which contains a node that is a heading (<h1>), a node that is a paragraph (<p>), which has a child that is an <a>, and a node that is an unordered list (<ul>) with three little <li> children.
![]() Note In reality, the user agent, which might be a browser or some assistive technology, has several options when building a picture or model of a web document. It might interact with the DOM directly or use an off-screen model, or it might get information about these various nodes and their states and properties via a platform accessibility API. I mentioned some of these accessibility APIs earlier, such as MSAA, iAccessible2, Apple Accessibility API, and others.
Note In reality, the user agent, which might be a browser or some assistive technology, has several options when building a picture or model of a web document. It might interact with the DOM directly or use an off-screen model, or it might get information about these various nodes and their states and properties via a platform accessibility API. I mentioned some of these accessibility APIs earlier, such as MSAA, iAccessible2, Apple Accessibility API, and others.
How Do Accessibility APIs Work?
An accessibility API acts as a gateway or bridge between the browser, DOM, and AT. For the contents of the DOM to be understood by the assistive technology, these contents need to be mapped to a corresponding role within the accessibility API. The API is like a filter to help the AT what is happening in the DOM at any given time. The actual API does more than this, because it isn’t entirely static. It can facilitate dynamic interaction between the user-interface components and the assistive technology.
![]() Remember The accessibility API is like a bridge between both the operating system and the Web for assistive technologies.
Remember The accessibility API is like a bridge between both the operating system and the Web for assistive technologies.
An API, such as MSAA or Apple Accessibility API, allows the screen-reader user to know when an item has focus and what its name is. If the item is a control, the API lets the screen reader know what type of control it is. If it is an interactive control like a check box, the API indicates what state it is in—selected or unselected, for example.
Does that sound familiar? It should—this is the kind of thing that WAI-ARIA aims to do when it gives you the ability to add these descriptive name, role, and state properties to widgets that don’t have any inherent semantics. It’s also what native HTML controls do—they expose their name, role, and so on (at this stage, you should get the picture!) to the accessibility API, and this information gets passed to the AT when the user gives an item focus via the keyboard.
Figure 4-2 gives you an overview of what exactly is going on and shows how the contents of the DOM are output visually to the screen and screen readers.
![]() Note The diagram in Figure 4-2 is a slight oversimplification, but it’s designed to outline in broad strokes the interaction between the core HTML code and what gets output as speech by the screen reader.
Note The diagram in Figure 4-2 is a slight oversimplification, but it’s designed to outline in broad strokes the interaction between the core HTML code and what gets output as speech by the screen reader.
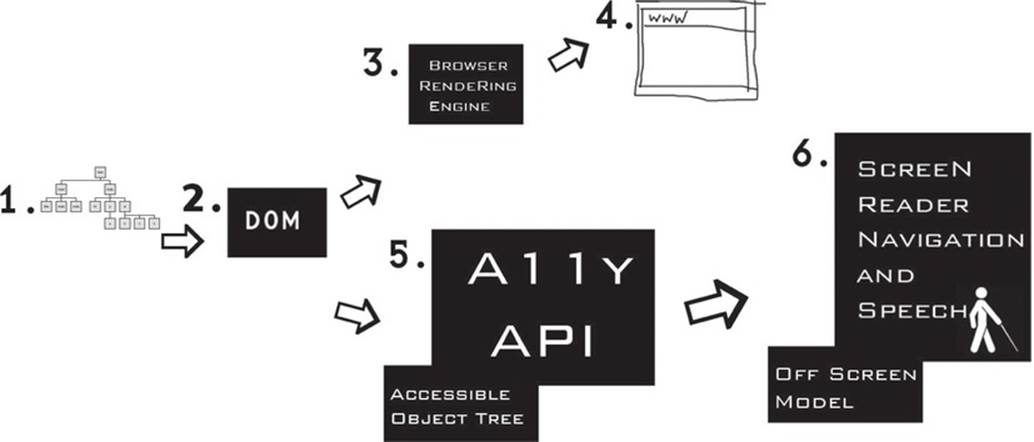
Figure 4-2. Accessible DOM output to both the screen and the Text-to-Speech engine
Here is a description of the items in the preceding illustration:
· Item 1: HTML elements—These form the DOM.
· Item 2: The DOM—This is the root of what both the assistive technology and the browser use to build a picture of the document to present to the user in the way that the user requires. Note that the same core HTML document can be used by both the visual browser and the nonvisual screen reader. This is pretty amazing and shows that universal access is a technical reality.
· Item 3: The browser rendering engine—This is used to determine how the combined HTML and CSS will be presented visually within the browser.
· Item 4: The browser—This is a visual screen display that is a combination of the contents of the DOM and CSS declarations put together by the browser’s rendering engine. It’s usually the main focal point for a sighted person to use when accessing the Web. If the user isn’t sighted, however, he still needs to be able to access the same content. In a more accessible webpage, the page is rendered visually in the browser in a layered way—for example, according to the declarations defined by the CSS, the behaviors as defined by the unobtrusive and progressively enhanced JavaScript, and the HTML or WAI-ARIA code that provide the semantics that are vital for assistive technology.
· Item 5: The accessible object tree and accessibility API—The accessible object tree is mapped from the DOM. This is where the accessibility API is instantiated.
· Item 6: The screen reader and off-screen model (OSM) —The OSM is maintained by the screen reader. There is a constant interaction between the two. As the contents of the DOM are updated, the contents of the OSM also need to be updated. The screen reader drives the Text-to-Speech (TTS) engine, which is an application such as Nuance, ViaVoice, DECTalk, or Microsoft Speech.
That is the initial model for screen-reader navigation and speech output. But is it the whole picture? What about user interaction and so on?
Figure 4-3 provides a more complete picture that encompasses the interaction model and shows interaction and TTS output. (I removed the visual browser from the diagram to make things clearer.)
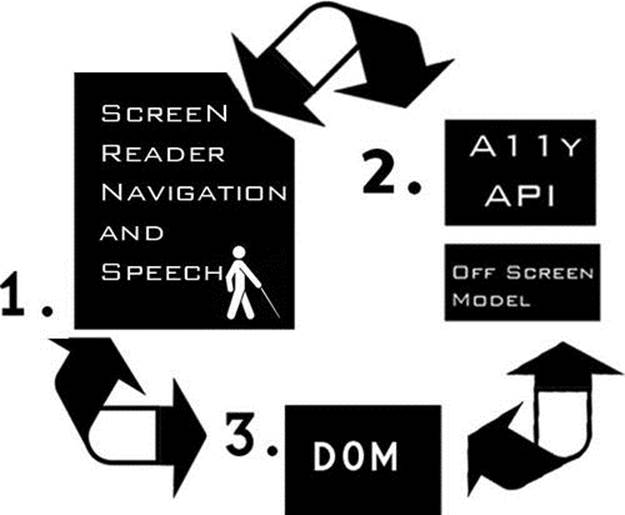
Figure 4-3. Interaction and TTS output—a dynamic, interactive loop
Here is a description of the items in Figure 4-3:
· Item 1: The user navigating or interacting with the page via the keyboard and the speech output—The user agent might be either using the DOM directly or using a combination of the OSM, the accessible object tree that is instantiated within the accessibility API, and DOM data. Hence, the bidirectional arrows depict events that can get triggered in the DOM that cause the page to update—in particular, for dynamic web content.
· Item 2: The accessibility API and OSM—These are fed via the DOM and, as stated in the previous item, the screen reader can interact either with the DOM directly or with the accessibility API/OSM that now updates every few milliseconds.
· Item 3: The DOM—The DOM responds to events that are triggered when the user interacts with web content in the browser.
“Accessibility”: The Movie, Co-starring “The Heuristics”
Often screen readers need to call on additional support to make content more accessible to the end user. To do this, screen readers use a combination of the information they get via the DOM, the accessibility API (whom you just met), and what are called heuristics. These evaluations help the user build a better picture of a webpage when there is little information (such as an inaccessible webpage) for it to go on.
For example, if a webpage has been badly authored and contains very little accessibility information (it’s poorly coded and so on), there is then little information to be passed on to the screen reader that it can make sense of. What happens then is that the software uses a method of trying to find out as much info as possible by guessing (an educated guess of course) about what certain content might be or is likely to be when found in a given context. This is called heuristic evaluation. The software activates a set of rules to try and figure out what is what. This process can involve determining what an image is likely to be by looking at content around the image or guessing what the table headers in a document are likely to be by looking at the first items contained in the top row (which are likely to be headers). This method of relying on heuristics for repair is brittle and prone to error—hence, the importance of semantically correct code.
![]() Note The term “heuristic” just means “a set of rules.”
Note The term “heuristic” just means “a set of rules.”
Changes in the DOM and Dynamic Content
The off-screen model can also be thought of as a virtual buffer. This buffer is a temporary memory store that contains a snapshot of the DOM at any given time. When this page doesn’t change, this snapshot is pretty static and the screen reader can interrogate page content happily, without the user being too worried about things changing.
![]() Note I don’t mean “interrogate” in the good cop/bad cop way, but rather in the strict sense of a user interacting with web content. You can think of this interaction as a conversation along the lines of the following:
Note I don’t mean “interrogate” in the good cop/bad cop way, but rather in the strict sense of a user interacting with web content. You can think of this interaction as a conversation along the lines of the following:
Q: What are you?
A: I’m a check box.
Q: Are you checked or unchecked?
A: I’m checked.
That’s not as exciting or dramatic as a good cop/bad cop routine, but what are ya’ gonna’ do?
This situation is markedly different when the contents of the page are changing dynamically and the buffer needs to be updated (as illustrated previously). It was a distinct problem a few years ago when AJAX came along as a development method, and asynchronous content updating became the norm, courtesy of the XHR object.
![]() Note AJAX developers will be familiar with the XMLHttpRequest or XHR object that can facilitate more client-side functionality, by reducing calls to the server, and help to create more dynamic and responsive web applications.
Note AJAX developers will be familiar with the XMLHttpRequest or XHR object that can facilitate more client-side functionality, by reducing calls to the server, and help to create more dynamic and responsive web applications.
Although client side updating is great and is a real step forward, dynamic content updating found in AJAX or Web 2.0 applications presented challenges to the more accessibility-aware developer. How can a developer let the AT know that parts of the page content have updated? How can this be done in a way that is unobtrusive? This was very tricky before the advent of WAI-ARIA, because the virtual buffer update had to be forced for the user to see any changes in the DOM. It isn’t so much of an issue now because the virtual buffer updates automatically every few milliseconds, so DOM changes can be passed on to the user far more reliably and quickly.
![]() Note For some screen-reader history about this issue, if you fancy nerding out a little, I recommend the following articles by Gez Lemon and Steve Faulkner at www.Juicystudio.com. Gez and I also wrote about the subject and presented a paper to a technical conference in Leeds, UK consisting of about five people, and we were two of them. So this subject truly does have a broad appeal, lol!
Note For some screen-reader history about this issue, if you fancy nerding out a little, I recommend the following articles by Gez Lemon and Steve Faulkner at www.Juicystudio.com. Gez and I also wrote about the subject and presented a paper to a technical conference in Leeds, UK consisting of about five people, and we were two of them. So this subject truly does have a broad appeal, lol!
For more information, go to the JuicyStudio web site and check out http://juicystudio.com/article/making-ajax-work-with-screen-readers.php and http://juicystudio.com/article/improving-ajax-applications-for-jaws-users.php.
If you do get busy with some heavily scripted webpages or applications, it’s important that you develop them to be accessible. These things are possible to do and just require some extra care and attention.
Commonly Used Accessibility APIs
The following sections describe some of the most commonly used accessibility APIs. These are found on different platforms such as Windows, Mac, and Linux. Some are also cross platform.
MSAA
MSAA is the older, big-brother API that has been used on the Windows platform since the mid to late ‘80s. There is an accessible object, which is at the heart of MSAA, as well as the ability to pass vital information about an element’s roles, names, state, and other values.
MSAA communicates information by sending small chunks of information about elements of a program to the assistive technology object. The four critical pieces of information on which the AT relies to help users interact with applications are an element’s role (what a control does), name (what it is), value (which can be a numerical value or the value of an input field), and state (whether or not a check box is selected).
![]() Note MSAA has a rather limited set of features that doesn’t allow for more sophisticated or advanced user-interface controls, and it is able to give only a relatively small amount of property information to the AT.
Note MSAA has a rather limited set of features that doesn’t allow for more sophisticated or advanced user-interface controls, and it is able to give only a relatively small amount of property information to the AT.
Welcome to the Automator!
MSAA was supposed to be partially replaced by UIAutomation with the advent of Windows Vista and newer Windows versions. UIAutomation is a more sophisticated and advanced API that has a richer object model. The idea is that it will expand the capabilities of MSAA but improve on its shortcomings.
UIAutomation shows information about a user-interface component to the assistive technology as a tree, similar to the way the DOM tree is exposed to accessibility APIs allowing AT to consume web content. Any properties associated with the component are also shown to the AT via the API, as well as system events and so on.
The API covers some common control types like drop-down menus, combo boxes, check boxes, and other controls that will prepare the AT for interaction, as well as control patterns that show the kind of functionality and interaction they support for the AT. Different functionality is represented by these control types and can be combined to create sophisticated interaction models and controls.
![]() Note I say “partially replaced” in this introduction to MSAA because it is still widely used as a platform accessibility API, as a way of exposing information to AT. The newer APIs, however, have a lot of potential in supporting new markup languages like HTML5 and WAI-ARIA. Both Web and OS information can be accessed and shared by both APIs.
Note I say “partially replaced” in this introduction to MSAA because it is still widely used as a platform accessibility API, as a way of exposing information to AT. The newer APIs, however, have a lot of potential in supporting new markup languages like HTML5 and WAI-ARIA. Both Web and OS information can be accessed and shared by both APIs.
IAccessible 2
The IAccessible COM method is at the heart of MSAA, and it has the ability to generate the all-important tree structure that you come across again and again.
![]() Remember Are you starting to see a pattern? It’s all about the document tree, and the various leaves or nodes on the tree being exposed to AT, as well as whatever properties, states, and so on these nodes have. That is the core of API accessibility.
Remember Are you starting to see a pattern? It’s all about the document tree, and the various leaves or nodes on the tree being exposed to AT, as well as whatever properties, states, and so on these nodes have. That is the core of API accessibility.
Although UIAutomation represents a leap forward with its potential to richly describe a user-interface component and its values and states, IAccessible2 is an alternative API that extends the capabilities of MSAA rather than intending to replace it. It was built into browsers like Mozilla Firefox from version 3 forward, as well as implemented in JAWS, NVDA, ZoomText (a popular screen-magnification program), Window-Eyes, and others.
The support for IAccessible2 for the Firefox browser was a very interesting development, as Firefox became the go-to browser for many who were testing more advanced accessibility features, such as WAI-ARIA when it first came out. Because IAccessible2 builds on MSAA, there was no conflict with the existing APIs and developers could piggyback on the support for current roles, states, and properties to expose vital accessibility information via the API to AT.
![]() Note Both UIAutomation and IAccessible2 have the ability to be cross-platform APIs. IAccessible2 is also used in the Chrome browser, for example.
Note Both UIAutomation and IAccessible2 have the ability to be cross-platform APIs. IAccessible2 is also used in the Chrome browser, for example.
Apple Accessibility API
Apple has developed accessibility APIs that are used in both OSX and IOS. This accessibility framework was introduced by Apple in Mac OS X 10.2 and was designed to accommodate the older Carbon and newer Cocoa developer framework. This was done in a rather clever way. It uses anaccessibility object that passes information about itself (again, its name, state, role properties, and so on) to both Carbon and Cocoa applications in a uniform way, regardless of the framework that was used to develop it. These accessibility objects and a uniform way of passing information about user-interface components remove much of the complexity of software development and reduce the need for code forking and so on.
The standard controls that come with the operating system are already highly accessible. It’s only when you design your own custom controls that you have to be very careful and provide the name, role, and (you guessed it) properties to the object.
The Code and Interface Builder applications make it easy to add accessibility information to your custom controls.
This really relates to applications/software. What about the Web?
Webkit Accessibility
Webkit is the rendering engine that powers the Safari browser as well as many others. Safari has support for the excellent screen reader VoiceOver. VoiceOver is a total game-changer from an accessibility perspective. It has excellent, advanced navigation and interaction features, and a blind computer user can now be equally happy using the same screen reader on a multitude of Apple iDevices.
The Webkit engine behind Safari gives it a great deal of support for many HTML5 elements and features (which I’ll get in to in the next chapter), such as HTML5 sectioning elements, CSS3 web fonts, Web sockets, HTML5 form validation, HTML5 audio and video, as well as closed captions and the infamous 2D JavaScript rendering engine, Canvas. (I’ll say more about this later.)
![]() Note Apple has the open-sourced Webkit, which is now the rendering engine behind the Chrome browser, as well as ions and Android browsers and others. Even though Webkit has been outsourced, this doesn’t mean that VoiceOver will work particularly well with other browsers. It doesn’t. It’s closely tied to Safari, but then again Safari is a great browser, so it’s a win-win situation.
Note Apple has the open-sourced Webkit, which is now the rendering engine behind the Chrome browser, as well as ions and Android browsers and others. Even though Webkit has been outsourced, this doesn’t mean that VoiceOver will work particularly well with other browsers. It doesn’t. It’s closely tied to Safari, but then again Safari is a great browser, so it’s a win-win situation.
LINUX Accessibility APIs
The main Linux accessibility API you should be aware of is the AT-SPI, or Assistive Technology Service Provider Interface. This was developed by the GNOME Project. This API is used by UBUNTU, which is an excellent flavor of Linux that has a high level of accessibility support out of the box for screen readers such as ORCA.
![]() Note The UBUNTU operating system also has screen magnification, modifier keys (rather like Sticky keys in Windows), Voice Recognition support, and an interesting app called Dasher, which requires neither a keyboard nor a mouse to work but uses dwell functionality and an eye tracker. It’s completely free, so well worth checking out. To see more and download a copy, go to www.ubuntu.com.
Note The UBUNTU operating system also has screen magnification, modifier keys (rather like Sticky keys in Windows), Voice Recognition support, and an interesting app called Dasher, which requires neither a keyboard nor a mouse to work but uses dwell functionality and an eye tracker. It’s completely free, so well worth checking out. To see more and download a copy, go to www.ubuntu.com.
HTML5 and Accessibility APIs
For a good snapshot of how HTML5 maps to accessibility APIs, I recommend the document created by Steve Faulkner (of The Paciello Group) and Cynthia Shelly (of Microsoft). It might seem a little abstract looking at this stuff, but it can give you a good overview of how accessible the new HTML5 elements are, because they need to be mapped to an accessibility API for AT to understand what they are, what they do, and how to interact with them.
As stated in the document:
“There is not a one to one relationship between all features and platform accessibility APIs. When HTML roles, states and properties do not directly map to an accessibility API, and there is a method in the API to expose a text string, expose the undefined role, states and properties via that method.
IAccessible2 and ATK use object attributes to expose semantics that are not directly supported in the APIs. Object attributes are name-value pairs that are loosely specified, and very flexible for exposing things where there is no specific interface in an accessibility API. For example, at this time, the HTML5 header element can be exposed via an object attribute because accessibility APIs have no such role available.
For accessibility APIs that do not have object attributes per se, it is useful to find a similar mechanism or develop a new interface to expose name/value pairs. Under the Mac OS X Accessibility Protocol, all getters are already simply name-value pairs and it is possible to expose new semantics whenever necessary. Keep in mind, this also requires working with the assistive technology developers to gain support for the new semantics.”
![]() Note The full text and detailed table outlining the HTML5/API mappings is available at http://dev.w3.org/html5/html-api-map/overview.html.
Note The full text and detailed table outlining the HTML5/API mappings is available at http://dev.w3.org/html5/html-api-map/overview.html.
So these things are a work in progress. As you read this, the mappings of the various APIs to HTML5 will certainly have improved.
I am including a screen shot here (Figure 4-4) of the matrix that outlines how HTML5 elements map to accessibility APIs so that you can get an idea of what it’s like. More information can be found at the URL just shown.
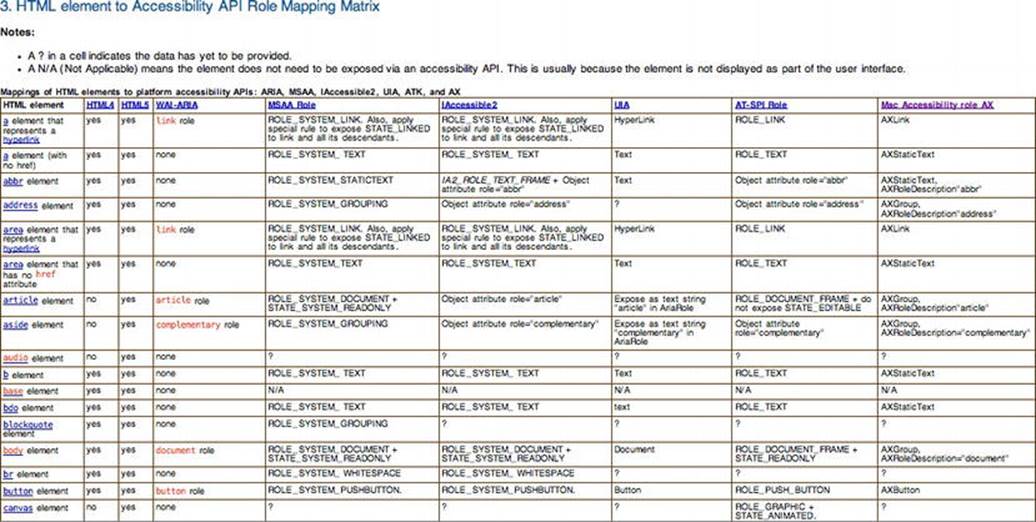
Figure 4-4. Screen shot of HTML5 and API mapping
Copyright © 2011 W3C® (MIT, ERCIM, Keio). All Rights Reserved. W3C liability, trademark, and document use rules apply.
![]() Tip If you want to find out what kind of role any HTML5 or ARIA control has, you can use several tools to do this, such as INSPECT32 (Win) or AccProbe (MSAA/IAccessible2 on Windows). When you focus on a widget in the browser, these tools will let you see how they map to the accessibility API.
Tip If you want to find out what kind of role any HTML5 or ARIA control has, you can use several tools to do this, such as INSPECT32 (Win) or AccProbe (MSAA/IAccessible2 on Windows). When you focus on a widget in the browser, these tools will let you see how they map to the accessibility API.
Conclusion
In this chapter, you learned about accessibility APIs, the DOM, and how screen readers receive information from the DOM via the accessibility API, as well as the older but still used off-screen model. In future chapters, we’ll move toward more use of accessibility APIs vs. the OSM. As mentioned earlier, a screen reader is not the only piece of AT in existence, but it is one of the most complex. In the chapters that follow, as we continue to look at HTML5 in more detail, the areas we covered in this chapter will certainly be a great help in giving you a better understanding of how the code is handled by AT. Also, I hope you can better understand why you sometimes might need to provide some extras to support older AT that, for example, doesn’t use the more advanced APIs.
The good news is that this is all doable, and with some care and attention you’ll be able to build accessible HTML5 applications that can be used easily by the newer browsers and AT that support it, while still being nice to those that don’t.