JavaScript, 20 Lessons to Successful Web Development (2015)
PART II Advanced JavaScript
LESSON 14 Handling Errors and Regular Expressions

To view the accompanying video for this lesson, please visit mhprofessional.com/nixonjavascript/.
There’s no getting away from it, even the most careful programmers build unexpected errors (or bugs) into their code, and so will you—it’s perfectly normal. And even after you think you’ve fully debugged your code, the likelihood remains that there may still be obscure bugs lurking somewhere.
The last thing you want on a published website is for users to encounter errors, or sometimes even worse, just find your code doesn’t work for them—making them leave to never return. But JavaScript comes with ways you can minimize the problem by placing helper code around statements where you suspect a bug may be that will take over if one occurs.
In this lesson I show you how you can use JavaScript’s in-built error trapping for dealing with bugs, and even for managing cross-browser compatibility. I also show you how you can use regular expressions to perform powerful and complex pattern matching in single statements.
Using onerror
The simplest way to catch errors in your code is to attach a new function to the onerror event, like this:


The onerror event passes three values to a function attached to it: an error message, the URL of the page where the error was encountered, and the line number of the error. The new function in the preceding example accepts these values in the variables msg, url, and line.
The function code then calls the in-built JavaScript split() function, which splits a string (in this case url) at whatever character is supplied to it (in this case ′/′) into an array of elements containing each of the parts split out from the string, like this:
var temp = url.split(′/′)
Then the final element (indexed by temp.length - 1) is placed back into the variable url, like this:
url = temp[temp.length - 1]
The result of these two lines of code is to strip any path details from url, leaving only the name of the file in which the error occurred. If this is not done, on deeply nested pages a very large string would be displayed, making the error message very hard to read.
Having shortened url, the in-built JavaScript alert() function is called, passing it the details to display, like this:
alert(′Error in line ′ + line + ′ of ′ + url + ’\n\n′ + msg)
Therefore, for example, with this function in place, if you then introduce a mistake into your code such as the following example (in which the final e is omitted from document.write), the result will be similar to Figure 14-1:
document.writ(′Test′)
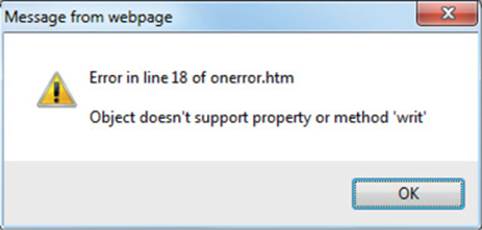
FIGURE 14-1 Attaching an alert window to the onerror event

Rather than using <br> tags to obtain the newlines in the alert dialog (which will not work because dialog boxes don’t support HTML), I have used the string \n\n, which translates into two newline characters.
Using this function, you can quickly and easily catch the bulk of bugs in your code before transferring it to a production server. I don’t recommend leaving this function in place on customer-facing websites, though.
It would probably be better to write a more obscure message along the lines of “Sorry, this web page encountered an error, please try again.” Hopefully whatever caused the error will not be in place on the second attempt, as you will have thoroughly debugged most non-obscure bugs already.
Limiting the Scope of onerror
Apart from attaching to the window object to trap all errors that may arise in a given window, you can attach to other objects too. For example, if it is so critical that a particular image should load that you need to do something if it doesn’t, you could use code such as this:
<img src=′image.jpg’ onerror=′fixError()′>
Now write whatever code you need to correct for the missing image and place it in a function called fixError() in order to deal with the error event if it occurs. Likewise, if you wish to trap errors only in a section of a document (and not the whole window), you can place that part in an element such as a <div> and attach the onerror event to it like this:

Using try … catch()
Rather than just catching errors and displaying debugging information, you can go a step further and choose to ignore errors that may be trivial.
For example, if you have some code that you know works only in some browsers but causes errors in others, it would be a shame to not allow the added functionality to at least some of your users. And you can do this by placing such code in a try … catch() structure.
The way you do this is as follows, in which the code to try and code to call upon the first code causing an error are placed in the two parts of the structure:

The argument passed to the catch() part of the structure is an error object, which can be used for obtaining the error message by displaying its message property, like this (as shown in Figure 14-2 in which an attempt to access the object MyObject has failed because it doesn’t exist):

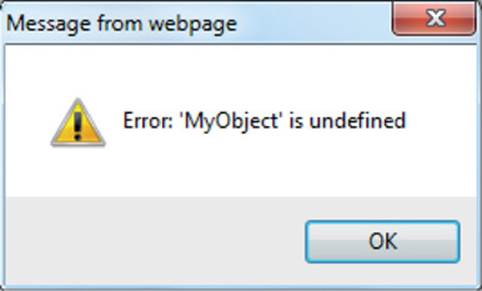
FIGURE 14-2 Using try and catch()
The code used for creating Figure 14-2 is in the try_catch.htm file in the accompanying archive.
Ignoring the Error
If you wish, you can ignore the error object and simply get on with executing alternative code. For example, you will see the following code used in Lesson 20 for creating an object with which Ajax (Asynchronous JavaScript And XML) background communication can be initiated with a web server:


For reasons that are explained in Lesson 20, it can take up to three attempts to create an Ajax object, depending on the browser used, and the preceding code handles all this gracefully to return an Ajax object in ajax, if the browser supports it.
Regular Expressions
Regular expressions were invented as a means of matching an enormous variety of different types of patterns with just a single expression. Using them, you can replace several lines of code with a simple expression and can even use regular expressions in replace as well as search operations.
To properly learn everything there is to know about regular expressions could take a whole book (and, indeed, books have been written on the subject), so I’m just going to introduce you to the basics in this lesson, but if you need to know more, I recommend you check out the following URL as a good starting point: wikipedia.org/wiki/Regular_expression.
In JavaScript you will use regular expressions mostly in two functions: test() and replace(). The test() function tells you whether its argument matches the regular expression, whereas replace() takes a second parameter: the string to replace the text that matches.
Using test()
Let’s say you want to find out whether one string occurs within another. For example, if you wish to know whether the string whether occurs in Hamlet’s famous soliloquy, you might use code such as the following:

The test() function requires passing the regular expression to it via the period operator, and the string to be searched must be passed as an argument between the parentheses.
In this example, the object RegExp is a regular expression object that is given the value /whether/, which is how you denote a regular expression. First, you place a / character, then the text to match, followed by a closing / character.
In this example, however, a match is not made because (by default) regular expressions are case sensitive, and only the word Whether (with an uppercase W) exists in the string.
If you wish to make a case-insensitive search, you can tell JavaScript this by placing the letter i after the closing / character, like this (in this case, a match will be made):
RegExp =/whether/i
You don’t have to place a regular expression in an object first if you choose not to, so the two lines can be replaced with the following single statement:
document.write(/whether/i.test(s))
Using replace()
You can also replace text that matches using the replace() function. The source string is not modified by this because replace() returns a new string with all the changes made.
Therefore, for example, to replace the string ′tis in the soliloquy with the word it’s (although Shakespeare would surely object), you could use a regular expression and the replace() function like this:
document.write(s.replace(/’tis/, ″it’s″))

The replace() function takes its arguments differently than test(). First, it requires that the string for matching against is passed to it via the period operator. Then it takes two arguments in parentheses: the regular expression and the string to replace any matches with.
Figure 14-3 shows the result of executing this statement (using the file replace.htm in the accompanying archive). In it you can see that the word after Whether is now it’s.
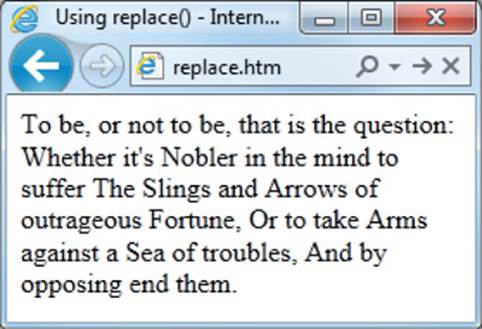
FIGURE 14-3 Applying replace() to a string
As with test() you can specify a case-insensitive replace by placing an i character at the end of the regular expression, as in the following example, which replaces the first occurrence of the word to in any combination of uppercase and lowercase, with the word TO in uppercase:
document.write(s.replace(/to/i, ″TO″))
Replacing Globally
You can also choose to conduct a global replacement and replace all occurrences of a match by placing the character g after the expression, as follows:
document.write(s.replace(/to/ig, ″TO″))
In the preceding example both the characters i and g have been placed after the expression, so this causes a global, case-insensitive search-and-replace operation, resulting in Figure 14-4 in which you can see all incidences of the word to have been changed to uppercase.
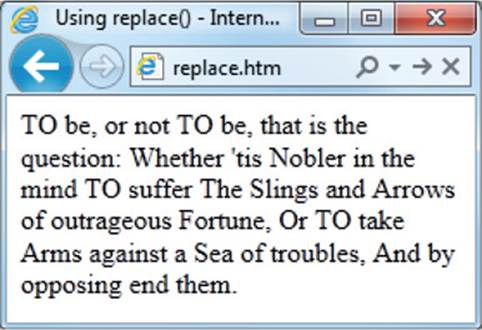
FIGURE 14-4 Performing a global, case-insensitive replace operation
Fuzzy Matching
Regular expressions are a lot more powerful than simply searching for and replacing words and phrases, because they also support complex fuzzy logic features through the use of metacharacters.
There are several types of metacharacters, but let’s look at just one for now, the * character, to see how they work. When you place a * in a regular expression, it is not treated as that asterisk character, but as a metacharacter with a special meaning, which is that when performing a match, the character immediately preceding the * may appear in the searched string any number of times (or not at all).
This type of metacharacter is particularly useful for sweeping up lots of blank space so that you can, for example, search for any of the strings ′back pack′, ′backpack′, ′back pack′ (with two spaces between the words), ′BackPack′ (with mixed case), and many other combinations, like this:

Because the i character is also used, the matching is case insensitive, and so the word BackPack is found by the regular expression, and the document.write() call displays the result of true in the browser.
If you want to use any of the characters that are metacharacters as regular characters in your regular expressions, you must escape them by preceding the characters with a \ character. For example, \* will turn the * from a metacharacter into a simple asterisk.
Matching Any Character
You can get even fuzzier than that, though, with the period (or dot) character, which can stand in for any character at all (except a newline). For example, to find all HTML tags (which start with < and end with >), you could use the following regular expression (in either a test() or replace()call):
/<.*>/
The left- and right-angle brackets on the sides serve as the start and end points for each match, respectively. Within them this expression will match any character due to the dot metacharacter, while the * after the dot says there can be zero, one, or any number of these characters. Therefore, any size of HTML tag, from the meaningless <> upward, will be matched.
Other metacharacters include the + symbol, which works like *, except that it will match one or more characters, so you could avoid matching <> by ensuring there is always at least one character between the angle brackets, like this:
/<.+>/
Unfortunately, because the * and + characters will match all the way up to the last > on a line, the previous expression will catch entire elements with start and end tags like <h1>A Heading</h1>, as well as nested HTML such as <h1><i>A Heading</i></h1>. We need a way to stop at the first > character.
Not Matching a Character
A solution to the multi-tag matching problem is to use the ^ character whose meaning is “anything but,” but which must be placed within square brackets, like this:
[^>]+
This regular expression is like .+ except that there is one character it refuses to match, the > character. Therefore, when presented with the string <h1><i>A Heading</i></h1>, the expression will now stop at the first > encountered, and so the initial <h1> tag will be properly matched. Table 14-1 summarizes the basic metacharacters and their actions.
TABLE 14-1 The Basic Metacharacters

I have already explained some of the characters in Table 14-1, whereas some should be self-explanatory. Others, however, you may find confusing, so I would recommend only using those you understand until you have learned more about regular expressions, perhaps from the Wikipedia article listed a little earlier.
There is also a selection of escape metacharacters and numeric ranges you can include, listed in Table 14-2.
TABLE 14-2 Escape and Numeric Range Metacharacters

To help you better understand how these various metacharacters can work together, in Table 14-3 I have detailed a selection of regular expression examples and the matches they will make.
TABLE 14-3 Some Example Regular Expressions and Their Matches


Remember that you can place the character i after the closing / of a regular expression to make it case insensitive, and place a g to perform a global search (or replace).
You can also place the character m after the final / which puts the expression into multiline mode, so that the ^ and $ characters will match at the start and end of any newlines in the string, respectively, rather than the default of the string’s start and end.
You may use any combination of the i, g, and m modifiers after your regular expressions.
Summary
This lesson has covered some fairly advanced things, including error handling and sophisticated pattern matching, and it tops off the last items of basic knowledge you need for the JavaScript language. Starting with the following lesson I will, therefore, concentrate on how to use JavaScript to interact with web pages, commencing with understanding how JavaScript integrates with the Document Object Model (DOM) of HTML to create dynamic functionality.
Self-Test Questions
Using these questions, test how much you have learned in this lesson. If you don’t know an answer, go back and reread the relevant section until your knowledge is complete. You can find the answers in Appendix A.
1. With which event can you trap JavaScript errors?
2. How can you trap errors (a) in a whole document and (b) only in part of a document?
3. With which statement can you mark a section of code to be tried by a browser but not issue an error if it fails?
4. How can you deal with an error that has been encountered in the manner of question 3?
5. What is a regular expression?
6. Which character is used to denote both the start and end of a regular expression?
7. With which functions can you (a) check a string using a regular expression and (b) modify a string with a regular expression?
8. In a regular expression, which metacharacter represents whitespace?
9. In a regular expression, what is a shorter way to express this set of characters: abcdefghijk?
10. Which two characters can you place after a regular expression to ensure the expression is applied both case insensitively and globally?
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.