MICROSOFT BIG DATA SOLUTIONS (2014)
Part I. What Is Big Data?
Chapter 2. Microsoft's Approach to Big Data
What You Will Learn in This Chapter
· Recognizing Microsoft's Strategic Moves to Adopt Big Data
· Competing in the Hadoop Ecosystem
· Deciding How to Deploy Hadoop
In Chapter 1 we learned a bit about the various projects that comprise the Hadoop ecosystem. In this chapter we will focus on Microsoft's approach to big data and delve a bit deeper into the more competitive elements of the Hadoop. Finally, we'll look at some of the considerations when deploying Hadoop and evaluate our deployment options. We'll consider how these deployment factors might manifest themselves in our chosen topology and what, if anything, we can do to mitigate them.
A Story of “Better Together”
Back in 2011, at the PASS Summit Keynote, then Senior Vice President Ted Kummert formally announced the partnership with Hortonworks as a central tenet of Microsoft's strategy into the world of “big data.” It was quite a surprise.
Those of us who had been following Microsoft's efforts in this space were all waiting for Microsoft to release a proprietary product for distributed scale-out compute (for example, the Microsoft Research project known as Dryad). However, it was not to be. Microsoft elected to invest in this partnership and work with the open source community to enable Hadoop to run on Windows and work with Microsoft's tooling. It was more than a bold move. It was unprecedented.
Later that week, Dave DeWitt commented in his keynote Q&A that the “market had already spoken” and had chosen Hadoop. This was a great insight into Microsoft's rationale; they were too late to launch their own product. However, this is just the beginning of the story. Competition is rife, and although Hadoop's core is open source, a number of proprietary products have emerged that are built on top of Hadoop. Will Microsoft ever build any proprietary components? No one knows. Importantly, though, the precedent has been set. As product companies look to monetize their investment, it seems inevitable that there will ultimately be more proprietary products built on top of Hadoop.
Microsoft's foray into the world of big data and open source solutions (OSS) has also overlapped with the even broader, even more strategic shift in focus to the cloud with Windows Azure. This has led to some very interesting consequences for the big data strategy that would have otherwise never materialized. Have you ever considered Linux to be part of the Microsoft data platform? Neither had I!
With these thoughts in your mind, I now urge you to read on and learn more about this fascinating ecosystem. Understand Microsoft's relationship with the open source world and get insight on your deployment choices for your Apache Hadoop cluster.
NOTE
If you want to know more about project Dryad, this site provides a great starting point: http://research.microsoft.com/en-us/projects/dryad/. You will notice some uncanny similarities.
Competition in the Ecosystem
Just because Hadoop is an open source series of projects doesn't mean for one moment that it is uncompetitive. Quite the opposite. In many ways, it is a bit like playing cards but with everyone holding an open hand; everyone can see each other's cards. That is, until they can't. Many systems use open source technology as part of a mix of components that blend in proprietary extensions. These proprietary elements are what closes the hand and fuels the competition. We will see an example of this later in this chapter when we look at Cloudera's Impala technology.
Hadoop is no exception. To differentiate themselves in the market, distributors of Hadoop have opted to move in different directions rather than collaborate on a single project or initiative. To highlight how this is all playing out, let's focus on one area: SQL on Hadoop. No area is more hotly contested or more important to the future of adoption of a distribution than the next generation of SQL on Hadoop.
SQL on Hadoop Today
To recap what you learned in Chapter 1, “Industry Needs and Solutions”: SQL on Hadoop came into being via the Hive project. Hive abstracts away the complexity of MapReduce by providing a SQL-like language known as Hive Query Language (HQL). Notice that it does not suddenly mean that Hadoop observes all the ACID (atomicity, consistency, isolation, durability) rules of a transaction. It is more that Hadoop offers through Hive a querying syntax that is familiar to end users. However, you want to note that Hive works only on data that resides in Hadoop.
The challenge for Hive has always been that dependency on MapReduce. Owing to the tight coupling between the execution engine of MapReduce and the scheduling, there was no choice but to build on top of MR. However, Hadoop 2.0 and project YARN changed all that. By separating scheduling into its own project and decoupling it from execution, new possibilities have surfaced for the evolution of Hive.
Hortonworks and Stinger
Hortonworks has focused all its energy on Stinger. Stinger is not a Hadoop project as such; instead, it is an initiative to dramatically improve the performance and completeness of Hive. The goal is to speed up Hive by 100x. No mean feat. What is interesting about Stinger is that all the coding effort goes directly into the Hadoop projects. That way everyone benefits from the changes made. This completely aligns with Hortonworks's commitment and charter to Hadoop.
So what is Stinger? It consists of three phases. The first two phases have already been delivered.
Stinger Phase 1
Phase 1 was primarily aimed at optimizing Hive within its current architecture. Hence it was delivered in Hive 0.11 in May 2013, forming part of Hortonworks Data Platform (HDP) 1.3 release. Phase 1 delivered three changes of notable significance:
· Optimized RC file (ORCFile): Optimizations to the ORC File format have contributed enormously to Hive's data access patterns. By adding metadata at the file and block level, queries can now be run faster. In addition, much like SQL Server's column store technology, only the bytes from the required columns are read from HDFS; reducing I/O and again adding a further performance boost.
NOTE
ORCFile stands for Optimized Record Columnar File. This file format allows for the data to be partitioned horizontally (rows) and vertically (columns). In essence, it's a column store for Hadoop.
· SQL compatibility: Decimal as a data type was introduced. Truncate was also added. Windowing functions also made the list, so Hive picked up support for RANK, LAG & LEAD, FIRST & LAST, and ROW_NUMBER in addition to the OVER clause. Some improvements were also made in the core syntax, so GROUP BY allowed aliases and ALTER VIEW was also included.
· Query and join optimizations: As with most releases of database software, query optimizations are often featured, and Hive 0.11 was no exception. Hive had two major changes in this area. The first was to remove redundant operators from the plan. It had been observed that these operators could be consuming up to 10% of the CPU in simple queries. The second improvement was to JOIN operators with the de-emphasis of the MAPJOIN hint. This was in part enabled by another change, which changed the default configuration of hive.auto.convert.join to true (that is, on).
Stinger Phase 2
Phase 2 was implemented as part of Hive 0.12, which was released in October 2013. Note that this release followed only 5 months after phase 1. The community behind Stinger are moving at a fast pace.
To continue with Stinger's three-pronged focus on speed, scale, and SQL, phase 2 also needed to cut over to Hadoop 2.0. This enabled the engineers working on Hive to leverage YARN and lay the groundwork for Tez.
NOTE
Refer back to Chapter 1 for definitions of Hadoop projects YARN and Tez.
Phase 2 included the following enhancements:
· Performance: Queries got faster with Stinger phase 2 thanks to a number of changes. A new logical optimizer was introduced called the Correlation Optimizer. Its job is to merge multiple correlated MapReduce jobs into a single job to reduce the movement of data. ORDER BY was made a parallel operation. Furthermore, predicate pushdown was implemented to allow ORCFile to skip over rows, much like segment skipping in SQL Server. Optimizations were also added for COUNT (DISTINCT), with the hive.map.groupby.sortedconfiguration property.
· SQL compatibility: Two significant data types were introduced: VARCHAR and DATE. GROUP BY support was enhanced to enable support for struct and union types. Lateral views were also extended to support an “outer” join behavior, and truncate was extended to support truncation of columns. New user-defined functions (UDFs) were added to work over the Binary data type. Finally partition switching entered the product courtesy of ALTER TABLE..EXCHANGE PARTITION.
NOTE
SQL Server does not support lateral views. That's because SQL Server doesn't support a data type for arrays and functions to interact with this type. To learn about lateral views, head over tohttps://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView.
· End of HCatalog project: With Hive 0.12, HCatalog ceased to exist as its own project and was merged into Hive.
NOTE
HCatalog is defined in Chapter 1.
Stinger Phase 3
Stinger phase 3 is underway, but will see Hadoop introduce Apache Tez, thus moving away from batch to a more interactive query/response engine. Vectorized queries (batch mode to SQL Server Query Processor aficionados) and an in-memory cache are all in the pipeline. However, it is still the early days for this phase of the Stinger initiative.
Cloudera and Impala
Cloudera chose a different direction when defining their SQL in Hadoop strategy. Clearly, they saw the limitations of MapReduce and chose to implement their own engine: Impala.
Cloudera took a different approach to Hortonworks when they built Impala. In effect, they chose to sidestep the whole issue of Hadoop's legacy with MapReduce and started over. Cloudera created three new daemons that drive Impala:
· Impala Daemon
· Impala Statestore
· Impala Catalog Service
Impala Daemon
The Impala daemon is the core component, and it runs on every node of the Hadoop cluster. The process is called impalad, and it operates in a decentralized, multimaster pattern; that is, any node can be the controlling “brain” for a given query. As the coordinating node is decided for each query, a common single point of failure and bottleneck for a number of massively parallel-processing (MPP) systems is elegantly removed from the architecture. Note, however, that the Impala daemon you connect to when submitting your query will be the one that will take on the responsibility of acting as the coordinator. This could be load balanced by the calling application. However, it is not automatically load balanced.
Once one node has been defined as the coordinator, the other nodes act as workhorses performing delegated tasks on data subsets as defined by the coordinator. Each workhorse operates over data and provides interim results back to the coordinator, who will be responsible for the final result set.
The Impala daemons are in constant contact with the Statestore daemon to see which nodes in the cluster are healthy and are accepting tasks.
Impala Statestore
The Statestore is another daemon known as statestored. Its job is to monitor all the Impala daemons, confirming their availability to perform tasks and informing them of the health of other Impala daemons in the cluster. It therefore helps to make sure that tasks are not assigned to a node that is currently unreachable. This is important because Impala sacrifices runtime resilience for speed. Unlike MapReduce, queries that experience a node failure are canceled; so, the sooner the cluster knows about an issue, the better.
Note that only one Statestore daemon is deployed on the cluster. However, this is not an availability issue per se. This process is not critical to the operation of Impala. The cluster does become susceptible to runtime stability for query operation, but does not go offline.
Impala Catalog Service
The Catalog Service is the third daemon and is named catalogd. Its job is to distribute metadata changes to all nodes in the cluster. Again, only one Catalog Service daemon is in operation on the cluster, and it is commonly deployed on the same node as the Statestore owing to the fact that it uses the Statestore as the vehicle for transmitting its messages to the Impala daemons.
The catalog service removes the need to issue REFRESH and INVALIDATE METADATA statements, which would otherwise be required when using Data Definition Language (DDL) or Data Modification Language (DML) in Impala. By distributing metadata changes it ensures that any Impala daemon can act as a coordinator without any additional actions on the part of the calling application.
As with the Statestore, the Catalog Service is not mission critical. If the Catalog Service is down for any reason, users would need to execute REFRESH table after performing an insert or INVALIDATE METADATA after DDL operations on any Impala daemon they were connecting to.
Is Impala Open Source?
The simple answer is yes. Impala is an open source product. However, there is a catch. It's an extension to CDH (Cloudera Distribution Including Apache Hadoop). This last point is important. You cannot use Impala on any old Hadoop distribution; it is unique to Cloudera. So although it is open source, it is in many ways proprietary. Just because something is open source doesn't mean that there is no vendor lock-in.
Like Hortonworks, Cloudera monetizes their investment in Hadoop through support and training. Impala is no exception. Real Time Query (RTQ) is the technical support package for Impala and is an extension of Cloudera Enterprise (their base enterprise technical support offering). To get RTQ, you have to purchase both Cloudera Enterprise and RTQ.
Microsoft's Contribution to SQL in Hadoop
Microsoft's initial contribution was really focused on getting Hadoop (specifically Hortonworks HDP) running on Windows. This has become the basis upon which HDInsight, Microsoft's platform as a service Hadoop offering, has been built. More recently, Microsoft has been collaborating with Hortonworks on the Stinger initiative. Personally speaking, that is clear given the obvious commonality between SQL Server Column Store and batch mode processing and Hadoop's OCFile optimizations and the vectorized query processing seen in Tez. Tez also introduces a more general, expressive, cost-based optimizer for executing complex directed acyclic graphs (DAGs). Because SQL Server has one of the most sophisticated and complex cost-based optimizers on the market today, I am certain that the team will be able to make a significant and positive contribution to this new processing paradigm for Hadoop.
Deploying Hadoop
Now that you have a firm grip on the ecosystem that surrounds Hadoop, both from a technology and business perspective, you'll want to actually consider deploying Hadoop and trying it yourself.
As you might expect, Microsoft offers a number of choices when it comes to deploying Hadoop. However, we really need to set a benchmark to help us consider all the angles as we evaluate which is the most appropriate option for a given environment. This next section first discusses a number of the considerations. The discussion then turns to possible topologies. Ultimately, you want a scorecard to help you make some objective decisions.
Deployment Factors
Which deployment option you choose will be dictated by several factors, many of which are intertwined like the fibers of a shredded-wheat biscuit. It's therefore worth keeping them all, as follows, in mind as we work through this section:
· Elasticity
· Flexibility
· Scalability
· Security
· Proximity
· Functionality
· Usability
· Manageability
Elasticity
Think of your elasticity requirement as a rubber band:
Do you need to be able to stretch your performance requirement to enable faster processing or to cope with spikes/surges in demand?
Elastic scale is the sweet spot for cloud services such as those offered by Windows Azure. I can alter the size and compute power of my cluster at will. With an on-premise service, I am always able to grow, albeit more slowly, but shrinking the topology isn't possible. Once I've bought the kit, I am stuck with it for three years—even if I don't want it any more.
Also, ask:
· Would you like to be able to reduce your outlay/capacity when there is little or no work to do?
· Do you know your workload and could you characterize it?
· Is it predictable and constant, or is it volatile in nature?
· How quickly can you scale your target environment?
· Is this even important to you?
These are tough questions to answer, especially at the outset of a project. Each deployment option offers varying degrees of elasticity, and your understanding of your environment will be an important factor for your desired deployment option.
Flexibility
Closely tied to elasticity is the concept of flexibility:
· Are you sure of your processing requirements?
· How dynamic are your requirements?
· How complete is the vision driving your project?
· Is it possible you may need to change your mind as you enter into a voyage of discovery with big data?
Different models offer the opportunity for greater flexibility in terms of dynamic change. Buying hardware also tends to be a fixed commitment with a three-year write-down.
Scalability
You can look at the scalability factor quite simplistically and answer the following question: How many data nodes do you need?
However, this answer also drives a number of follow-up questions for you to consider:
· Where will you put these nodes?
· How will you manage and monitor them?
· Who will manage and monitor them?
Because Hadoop is a scale-out architecture, the first question of quantity is really a trigger point to think about the broader issues associated with the scale of the deployment. In actuality, the answer to the scale question provides additional context into the decision making of other factors, particularly flexibility and elasticity.
In terms of scale, there are also considerations that relate to limitations. For example, in HDInsight, Microsoft currently allows a maximum of 40 data nodes. However, this is merely an artificial cap placed on the service and can be lifted. Architecturally no limit applies.
One might say the same about an on-premise deployment. Certainly, the largest clusters in the world are on premise. However, practicalities will often get in the way. In truth, the same challenges exist for Azure. There has to be capacity in the data center to take your request. However, I have to say, I quite like the idea of making this Microsoft's problem.
Security
Hadoop doesn't have a very sophisticated method of securing the data that is resident in the Hadoop Distributed File System (HDFS). The security models range from weak to none. Therefore, your approach to meeting your security needs is an important factor in your decision-making process. You might want to consider the network layer in addition to the operating system and physical hardware when evaluating all these options. Other options include a “secure by default” configuration, which may well be worth replicating if you want to lock down your deployment.
Proximity
When addressing the question of proximity, you must know where the data is born. This is relevant for a number of reasons, but the prime reason is latency. We do not want the source and analytical systems to be far apart, because if they are, this distance will add latency to the analysis. That latency can often be directly correlated back to cost; a short local network can often be significantly cheaper and result in less impact that than a geographically dispersed network.
The value of the insights from the data may depreciate significantly as the data ages. In these situations, therefore, we may want to keep in close proximity to the data to reduce the mean time to value when analyzing the data.
In addition, the farther apart the systems are, the more expensive and potentially brittle the networking becomes. This is especially apparent in ultra-low latency network topologies where expensive InfiniBand cables may be used to move data at significant velocity. For example, FDR InfiniBand networks can move data at 56Gbps. However, that performance comes at a price, so the shorter the network cables are the better.
Consequently, and by way of simple example, if the data is born in the cloud, it will often make sense to provide analytics in the cloud. By doing so, your network will be local, and the performance between environments will be LAN Ethernet speed rather than Internet/VPN (virtual private network) speed. Your environment and total cost of ownership (TCO) will also benefit because you will avoid data egress charges.
Functionality
Although perhaps not immediately obvious, you need to make sure that your target platform offers the functionality you want to use. Not all Hadoop distributions are created equally. A simple example is differing support for versions of Hive or the inclusion of HBase in a Hadoop distribution. That is not to say that you cannot add/upgrade Hadoop projects to your deployment. However, when you do this, you are stepping outside of the boundaries of the hardened distribution.
Your choice of operating system also dictates the range of distributions of Hadoop available to you and therefore your deployment options.
Usability
Getting started with Hadoop can sometimes feel like a rather daunting prospect, especially if you are exclusively used to the Microsoft ecosystem. At its most extreme, you could download the source code from the Apache website, compile the code yourself, and then manually deploy the code to build the cluster. However, deployment can be as simple as configuring a wizard. Usability therefore is a sliding scale, and the spin-up cost you can accept will help to drive you toward one solution vs. another.
Whichever solution you decide on, you are probably going to want to roll your own PowerShell scripts to build your cluster so that it is a repeatable process.
Manageability
Operational considerations are often overlooked when considering deployment factors. Consider the following:
· How will the system be monitored?
· Which human resources will be needed to support the environment?
· What availability requirements exist, and what disaster recovery strategy is in place?
· How will security be addressed?
These are all common operational questions that you need to answer.
Deployment Topologies
Now that we have an understanding of the factors that might influence a deployment, we can focus on the topologies themselves before moving on to compare them with each other.
In this next section we'll compare the following options:
· On-Premise Hadoop
· Infrastructure as a Service Hadoop
· Platform as a Service Hadoop
Hadoop on Premise
You can always follow the traditional path, which is to build your Hadoop cluster on premise. Most Hadoop clusters in the world today are built using Linux as the operating system. However, as you learned in Chapter 1, Hortonworks has a distribution for Windows.
The biggest challenge when picking Hadoop on premise as your deployment option is knowing how to size it. How many data nodes will you really need?
Of course, after you have done that, you then need to procure all the hardware and rack and configure it. You will also have taken on the management and monitoring of the cluster and so will need to figure that out as well. You might choose to use the Ambari project for this purpose. Alternatively, you could stay within the Microsoft ecosystem and use System Center to drive your monitoring. An Ambari SCOM Management Pack has been created so that you can monitor Hadoop using the same infrastructure as the rest of your enterprise. Either way, you need to ensure that you have integrated the new infrastructure into your environment and make sure that all the feeds of data can access the new cluster.
So, why follow this model? Speaking personally, it often comes down to flexibility, proximity, security, and functionality. However, proximity is one factor to emphasize here. If the data is born on premise, and in significant volume, it may make greater sense to retain the data in an on-premise environment. Pushing large volumes of data to the cloud might be impractical and might introduce too much latency prior to the analysis. That said, this issue may be tempered once the initial data load has been accomplished. Subsequent loads will contain only delta changes which would hopefully reduce the burden of the latency.
Remember, though, the second part of proximity, which pertains to integration with other data environments. Business users don't actually care where or what store their data is; they just want to query (and that might be a query across environments).
PDW Integration
Querying across environments was one of the three key design goals for project Polybase, one of the stand-out features in SQL Server Parallel Data Warehouse (PDW) 2012. Polybase provides the glue between Hadoop and the data warehouse for the parallel import and export of data. However, it also enables a unified heterogeneous querying platform for end users. In other words, I can write the following and it just works:
SELECT COUNT(*)
, SUM(s.Value) AS Total_Sales
, p.Category_name
, d.CalendarMonth_name
FROM dbo.hdfs_Sales s
JOIN dbo.pdw_Product p ON s.Product_key = p.Product_key
JOIN dbo.pdw_Date d ON s.Date_ = p.Date_key
WHERE d.CalendarYear_nmbr = 2012
GROUP BY p.Category_name
, d.CalendarMonth_name
In the preceding code, I am able to query data held in Hadoop and join it to data held in PDW with a single logical declarative statement. This is important because it enables consumers of data to work with data irrespective of the data source. They are just tables of data.
That said, project Polybase is not without its restrictions. In the release-to-manufacturing (RTM) version of PDW 2012, Polybase only currently supports a delimited file format and works with a limited number of distributions: HDP on Windows, HDP on Linux, and Cloudera. Furthermore, the RTM version does not leverage any of the compute resources of the Hadoop cluster. PDW is simply importing (at great speed) all the data held in Hadoop and holding it in temporary tables inside PDW. This model will evolve over time, and we should look forward in the future to the automatic generation of MapReduce jobs as query optimizations. One might imagine that a slightly rewritten query like the following one might trigger a MapReduce job to enable the where clause to be applied to the query as part of the Hadoop subtree of the query plan:
SELECT COUNT(*)
, SUM(s.Value) AS Total_Sales
, p.Category_name
, d.CalendarMonth_name
FROM dbo.hdfs_Sales s
JOIN dbo.pdw_Product p ON s.Product_key = p.Product_key
JOIN dbo.pdw_Date d ON s.Date_key = p.Date_key
WHERE s.Date_key >= 20120101
AND s.Date_key < 20130101
GROUP BY p.Category_name
, d.CalendarMonth_name
Exciting times lie ahead for PDW with Polybase integration into Hadoop. We will dive into PDW and Polybase in much greater detail in Chapter 10, “Data Warehouses and Hadoop Integration.”
HDInsight
When HDInsight was announced as being generally available (GA), the team also announced an HDInsight emulator. This is designed for developer scenarios in an on-premise environment. Because it is targeted for development, it can be deployed in a single node configuration only. However, you could also opt for a custom one-data-node configuration of an HDInsight cluster using the Azure benefits accompanying an MSDN subscription or Azure trial.
For some simple instructions on getting started with the emulator, head over to the following article: http://www.windowsazure.com/en-us/manage/services/hdinsight/get-started-with-windows-azure-hdinsight-emulator/.
If you don't like either of these options, Hortonworks offers either a sandbox virtual machine or you can build a one-node development environment on Windows. The advantage of this is that as HDInsight uses HDP under the hood you can be confident of developing portable code. Either way, you certainly aren't short of choices!
Hadoop in the Cloud
The single biggest transformation to occur to IT in recent times has been the advent of the cloud. By leveraging cloud computing, we can take advantage of a more dynamic, elastic service that can expand and contract as we need. However, what has also become apparent is that the drive to the cloud has forced providers to openly embrace heterogeneity. For example, in September 2013 Microsoft announced its new partnership with Oracle to run its software on Windows Azure. Who would have thought that Oracle would be offered on a service run by Microsoft? The same could also be said for Linux virtual machines.
This has all been great news for users of Hadoop. It means that customer choice is as broad as it has ever been. Do you want to run on premise using Windows or Linux? You can. Would you rather use a cloud offering and use either Linux or Microsoft? You can do that as well. Would you prefer to use a managed service? Go for it. All these options are not only available but are also actively supported and driving new meaning into what Microsoft calls its data platform.
This section delves into the two primary options for deployment with Windows Azure. At the one end, we have infrastructure as a service (IAAS), where you get to roll your own infrastructure. At the other end, there's platform as a service (PAAS) offering a managed service. Which one is most appropriate? Let your requirements decide!
Platform as a Service (PAAS)
Hadoop is offered in a PAAS configuration courtesy of HDInsight on Windows Azure. HDInsight is Microsoft's branding and value-added components based on the Hortonworks distribution HDP. It is a secured, managed service that you can spin up and tear down very easily. Spin-up is measured in minutes and teardown seconds. In that sense, it is very easy to get started with HDInsight and so it scores highly in terms of usability.
To create an HDInsight Hadoop cluster, you can either use one of the two wizards available to you via the management portal or use a PowerShell script. It is also simple to tear down an HDInsight Hadoop cluster. You simply log in to the Azure Management Portal, locate the cluster, and then click the Delete button (and it's gone). This is important because Azure will be charging you for all the time your HDInsight cluster is up and running.
What Happens to the Deleted Data?
You might be wondering what happens to the data in an HDInsight cluster that has just been deleted. That is a good question. On the face of it, one could be forgiven for thinking that the data is lost. However, that is not the case. One of the most interesting parts of HDInsight is the fact that it separates data storage from the compute nodes. HDInsight uses Windows Azure Storage Blob (WASB) accounts to actually hold the data. HDFS is literally treated like a caching tier for the data. No data is actually persisted there by default. You can, of course, override this and treat HDInsight like a “normal” cluster, but then you would have to keep the cluster up and running for as long as you want the data or accept that you will lose the data if/when you decided to delete it.
HDInsight is a secure-by-default configuration. It disables access to the cluster via Remote Desktop by default and also provides (for free) a secure gateway virtual machine that performs the authorization/authentication and exposes endpoints on port 443. Similarly, you can also retrieve Ambari metrics using the REST API via the secure gateway on port 443.
HDInsight is using HDP as its base distribution, but limitations apply. For example, at the moment, HBase is not included in HDInsight. However, on the plus side, it means complete ubiquity. You can take your data set and export it from HDInsight if you want and install it in an on-premise or IAAS installation running HDP, and it will just work.
In late 2013, Microsoft released HDInsight to general availability. It currently is not installed in all Azure data centers, but I expect that to change as the space is provisioned in each data center.
Infrastructure as a Service (IAAS)
Much of what can be achieved currently with HDInsight and PAAS can also be achieved using a combination of IAAS and scripting. You can automate the process of creating your environment and also elastically adjust the resources each time you spin up a Hadoop cluster. Granted, you will have to roll your own scripts to build this environment, but you will have ultimate flexibility in your deployment during the installation process. You may find that it takes you more time to configure and build your IAAS environment as opposed to using the PAAS option with HDInsight.
Note, however, that some additional tasks do become your responsibility. For example, the secure node in HDInsight isn't automatically provisioned, and neither is the metastore. Also, if you want to save money and keep hold of your data, you will need to have your own automated process of detaching disks, deleting virtual machines and performing any additional cleanup. The same clearly is also true (in the inverse) for creating the cluster.
Interestingly enough, the IAAS option opens up the opportunity to run Linux or Windows virtual machines inside of Windows Azure. Therefore, you can actually run any flavor of Hadoop you like on Windows Azure including the latest and greatest versions of Hortonworks or even Cloudera's Impala. You simply aren't constrained to Windows as an operating system on the Microsoft data platform. If you said that to me a few years ago, I'd have looked at you somewhat quizzically. However, the world has simply moved on. Cloud platforms are more interested in managing the compute resources at massive scale than in eliminating workloads based on technology choices.
Deployment Scorecard
So what have we learned? See Figure 2.1.
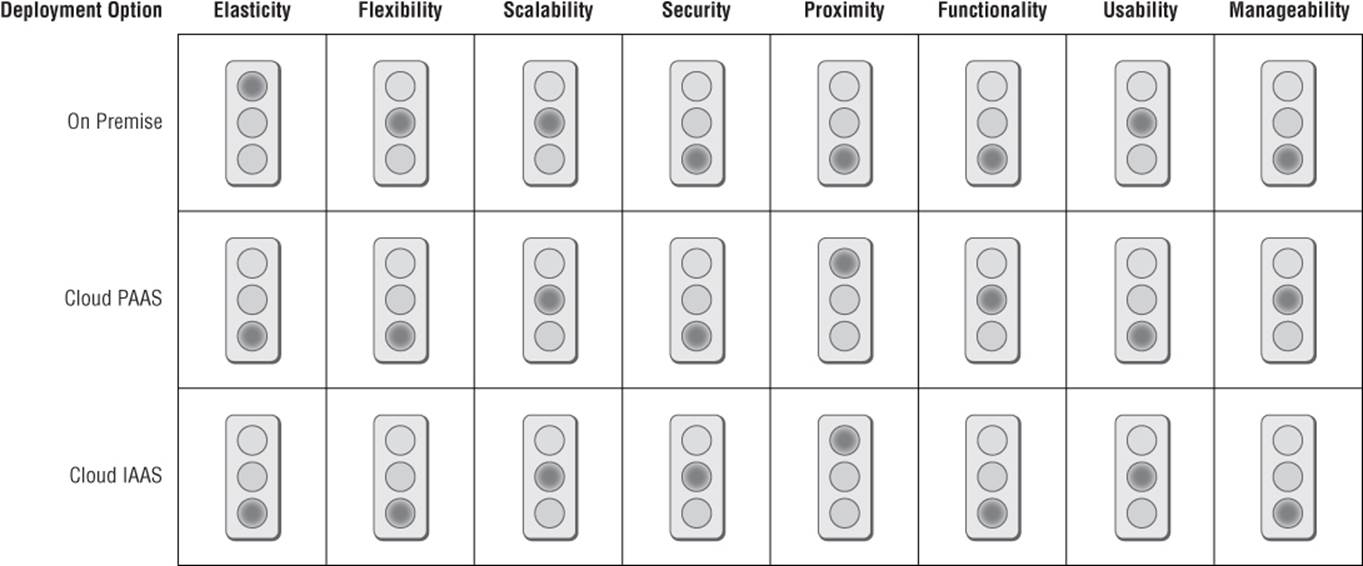
Figure 2.1 The deployment scorecard
We've learned that some of this is relative. Security, for example, is not a great situation for any option, because it is not a strength of Hadoop. Likewise, proximity depends on where the data is actually born. When data is born in the cloud, proximity of cloud offerings would be better (assuming the same service provider was used). However, for proximity I've scored this based on a more general ability to integrate with other disparate data sources throughout out an enterprise. At the time of this writing, the majority of this kind of enterprise data sits on premise, which explains the scoring.
Cloud deployments work well for the following:
· Elastic scale
· Kicking the tires
· Prototyping
On our scorecard, shown in Figure 2.1, what shines through is that the cloud offers that elusive flexibility and elastic scale that encourages experimentation and works brilliantly for “bursty” workloads. However, unless the data is consistently being born in the cloud (a mighty big if), the proximity question will probably be an issue. Remember proximity is a two-part measure:
· The distance to the system managing the data (i.e., the bandwidth question)
· The distance to other enterprise data sources (i.e., the integrated analysis dilemma)
The magnitude of this first element may be mitigated if the burden is only endured for an initial or historic load. If the subsequent deltas are of a manageable size, then the concerns may be significantly reduced. The second element is a ratio. If there is little or no integrated analysis with on-premise data sources, then the proximity issue is again less of a concern. If there is a significant amount of integrated analysis, this may prove to be a cloud deployment deal breaker.
On-premise deployments work well for the following:
· Custom deployments
· Data born on premise
· Secure data
An on-premise deployment is best suited for data that is born on premise and that perhaps also needs to be integrated with other data sources that may also reside locally. Having your own environment, although flexible, is also a commitment of both compute and human resources. It therefore suits predictable workloads, which can be more readily sized.
Summary
What have you learned? The world isn't quite what it once seemed. In the time it has taken to move from SQL Server 2008 to SQL Server 2012 the world has been turned upside down. Microsoft's data platform now includes and embraces Linux deployments of open source technology running Apache Hadoop. What's more, we have a variety of options available in terms of our deployment choices. What we choose is largely down to business need and data value (as it should be).
You should now understand the factors that could influence your deployment choice and how to evaluate the options before you. You should also have a better understanding of the Hadoop ecosystem and some of the drivers influencing its future direction.