Managing Microsoft Hybrid Clouds (2015)
Chapter 3. Understanding the Microsoft Azure Architecture
In this chapter, we will go through the various components of the architecture of Azure. This will provide a high-level understanding of the architecture. You will also learn about the features offered by Azure for computation, storage, and networking.
A look under the hood of Microsoft Azure
A good understanding of the architecture of the Microsoft Azure platform is important to understand what is going on "under the hood". This will help us in the design of our virtual infrastructure running on Azure hosts, stored on Azure Storage, and connected by Azure Virtual Networks. It will also help us to understand what kind of availability we need to create for applications running in Azure.
Data centers and regions
Microsoft Azure is available in many data centers located in many continents. Each datacenter also houses other Microsoft online services besides Microsoft Azure services, such as Office 365, Bing, Xbox Live, and so on. Actually, many Microsoft cloud services are hosted on Azure. The average Microsoft datacenter is about 7 to 10 times the size of a football field. Each datacenter is home to thousands of servers and many petabytes of storage. The maximum capacity of an Azure datacenter is around 100,000 servers.
Data centers are grouped into major geographical regions. In most cases, a single region is a continent. Azure is currently available in regions located in North America, Europe, Asia, and Brazil.
Each region has at least one datacenter. Each region is paired to another region with a minimum distance of around 500 miles. This is done so that hurricanes, floods, and other natural disasters will not destroy two regions at the same time.
Current operational regions are:
· Europe West (Amsterdam) paired to Europe North (Dublin)
· US West (California, exact location not disclosed) paired to US East (Virginia)
· Asia Pacific Southeast (Singapore) paired to Asia East (Hong Kong)
· US North Central (Chicago, IL) paired to US South Central (San Antonio, TX)
· Brazil South (Sao Paulo State) paired to US South Central (San Antonio, TX)
· Japan East (Saitama Prefecture near Tokyo) paired to Japan West (Osaka Prefecture in Kansai)
· Australia East (Sydney) paired to Australia Southeast (Melbourne)
· US Central (Iowa) paired to US East 2 (Virginia)
In China, two regions are running Microsoft Azure services. The northeast region is located in Beijing while the east region is located in Shanghai. The data centers in these regions are not operated by Microsoft itself. Microsoft licensed the technology, know-how, and rights to operate and provide Office 365 and Microsoft Azure services in China to 21Vianet. This is the biggest Internet datacenter services provider in China.
Microsoft Azure customers outside China are not able to use the China regions' data centers for consumption of services. These two Chinese regions are isolated from the Microsoft operated regions mostly for political reasons. The Chinese government wants to have control over network traffic leaving and entering China.
The following map shows all Azure data centers worldwide as of summer 2014:
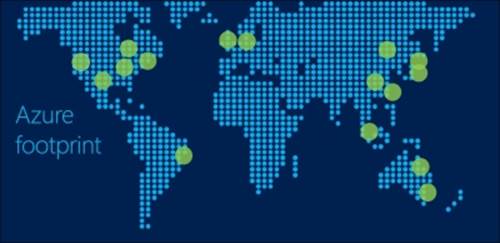
Each region is paired to another region. The pairing of regions is for redundancy reasons. By default, when data is stored in a Microsoft Azure region, it is replicated to the paired region. Data is asynchronously replicated. This means data is stored by the application. The storage layer confirms that the data has been written. Then, the Microsoft storage software will make sure the data is replicated to the paired region with a delay of about 15 minutes.
Customers can enable or disable this geo-replication feature.
Microsoft will not transfer customer data outside the major geographic region. So, data placed by customers in the European region will stay in Europe and will not be transferred to, for example, North America.
Besides large data centers, Microsoft also has 24 Content Delivery Networks (CDN) worldwide. These CDNs are small locations that cache certain content. The main purpose of a CDN is to reduce latency and enhance the user experience.
Developing Microsoft Azure is one of Microsoft's biggest priorities. In 2014, the company spent three billion US dollars on investments in infrastructure for data centers.
Microsoft also adds new services and enhances current services at a rapid pace. In a periodic interval of about three weeks, new enhancements are made available.
Zones
Regions are grouped into zones. Zones were created to charge outbound data transfers. Data that goes outside an Azure datacenter is charged by Microsoft.
The costs for outbound data transfers depend on the location of the datacenter. In the United States and Europe, costs for bandwidth are lower than in Asia and Brazil. Currently, Azure has three zones:
· Zone 1: US West, US East, US North Central, US East 2, US Central, US South Central, Europe West, and Europe North
· Zone 2: Asia Pacific East, Asia Pacific Southeast, Japan East, and Japan West, Australia East, Australia Southeast
· Zone 3: Brazil South
Servers used in Azure
Now that we know about the data centers and locations, let's have a look inside the data centers.
Microsoft operates a lot of data centers worldwide to provide various services, such as Office 365 and Microsoft Azure. Some of the data centers use containers similar to sea-containers, which are standalone units containing processing, storage, and networking.
However, in most Azure data centers, servers are not located in containers because of cost constraints. Azure servers are placed in racks. Microsoft Azure is designed such that the application running on top of Microsoft Azure provides resiliency. This type of cloud is named a best effort cloud.
This architecture makes sure the platform is relatively simple and cost-efficient. Physical servers that host the Azure virtual machines are industry-standard hardware with hardly any built-in redundancy. So, the servers of brands like Rackable Systems do not have redundant power supplies and redundant fans, for example. This keeps the costs low. Originally, Microsoft used AMD processors. Later, Intel processors were added.
The vision of Microsoft is to invest in facility redundancy instead of server redundancy. Millions of dollars spent on server hardware or network redundancy will prove to be worthless when a complete datacenter is lost because of fire or no outside world connection. Server and network redundancy adds complexity.
The network inside an Azure datacenter is a flat network. It means that each component in the network has multiple connections to other components.
Each datacenter contains many racks full of servers. Most servers are blades. Each rack is installed with a single top-of-rack switch. Each rack contains about 90 servers. These racks are grouped into clusters, or stamps, as Microsoft likes to call them.
Each stamp has about 1000 servers/nodes. The reason behind using stamps is partitioning. Partitioning is done to keep availability at a high level. By partitioning, the impact of a failure is reduced to a part of the datacenter.
Each datacenter also has multiple racks for storage with two top-of-rack switches in each. Each storage rack contains 36 storage cabinets. Microsoft uses storage stamps for grouping different racks. A storage stamp typically contains 10 to 20 racks. Each rack is a fault domain. As data is by default stored in three different copies, each copy is stored in a different storage stamp.
Top-of-rack switches are connected to multiple switches which form the cluster spine. The datacenter spine switches are located above the cluster spine level of switches.
Hypervisor used in Azure
Now that you have learned how an Azure datacenter is built using server hardware, network, and storage, it is time to learn about the software. The "secret sauce" of Microsoft Azure is the software used by Microsoft to manage a massive cloud service such as Azure. This software enables Microsoft to offer a dynamic, self-service cloud with a minimum number of administrators.
Each Azure host runs a hypervisor. From the launch of Azure to the first half of 2012, a hypervisor very similar to Windows Server 2008 R2 Hyper-V was used. In 2013, Microsoft started upgrading hosts to Windows Server 2012 Hyper-V. It is unclear what percentage of servers are now running Windows Server 2012 Hyper-V. In summer 2014, Microsoft started to rollout Windows Server 2012 R2 Hyper-V.
When new server hardware has been installed and is ready for use, it boots from the network using PXE. PXE is a network protocol that allows a server or desktop to load an operating system over the network. It then loads Windows PE as a maintenance operating system. This cleans the local hard disk of the host and loads the host operating system from a VHD image over the network. Then, the maintenance operating system loads Hyper-V.
One of the reasons behind using network boot instead of local install is the ability to return to a good state. The VHD image is very well tested. If anything gets corrupted on the host, the clean VHD image can be used to restore the state of the server.
When security patches become available for the host, they are built into a new version of the VHD image. This image is then deployed to the hosts in a highly controlled manner.
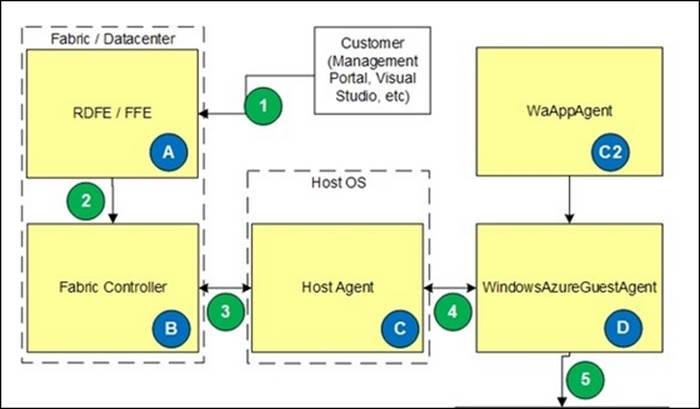
Each host, or node as we will call them from now on, runs a special piece of software called the Host Agent or Fabric Agent (FA). The FA communicates with each virtual machine running on the node. Therefore, each virtual machine has a guest agent installed.
The nodes that are running Hyper-V are not members of a Windows Failover Cluster. Azure uses its own clustering technique.
Each node runs a maximum of 12 virtual machines when the server only hosts the "extra small" virtual machines.
The following image shows the various software components of Microsoft Azure:
The Fabric Controller
The Fabric Controller (FC) is a step higher in the software stack. This is the brain of Microsoft Azure. The FC is what the kernel is for an operating system. It is responsible for blade provisioning, blade management, service deployment, monitoring and healing of services, and life cycle management.
The FC not only manages servers, it also manages storage, load balancers, switches, and routers. FCs run as software appliances and are based on a modified Windows Server 2008 instance.
The FC monitors nodes via the FA running in each node. The FC also monitors the guest operating system. If there is no heartbeat received by the FC, it will either restart the guest or the complete node in case the heartbeat of the node is lost.
If the FC detects a hardware failure of the node, it will reallocate the guest to other nodes and mark the node as "out for repair".
It is situated between the datacenter fabric (servers, network, and storage) and the services running on the fabric. The FC runs in five to eight instances that are distributed over at least five fault domains. One FC has the primary role, while the others are replicas. The state of the nodes is replicated over all FCs so each has 100 percent up-to-date status information. If all FCs go down, all Azure services will continue to be available; however, provisioning and fault tolerance will not be operational anymore.
For security reasons, the communication between FCs and the storage and compute nodes is over an isolated VLAN. This VLAN is not used for network traffic originating from Azure customers.
Red Dog Front End
Now that we know the role of the FC, we can take another step upwards.
While the FC controls nodes inside a datacenter, a process running above it controls placement in data centers and clusters. This process is called the Red Dog Front End (RDFE). The name comes from the initial project name of Azure, Red Dog.
The RDFE is responsible for publishing the publicly exposed Service Management API, which is the frontend to the Management Portal and tools such as Visual Studio, Azure Cross-Platform Command-line Interface (X-Plat CLI), and PowerShell, which communicate with the RDFE for queries and to submit tasks. An example of such a task is create virtual machine or create storage account. The RDFE instructs the FC in one of the clusters to perform a certain action.
The Azure management portal instructs the RDFE using APIs. The API-release that the RDFE is publishing is a single point of failure in Azure. There is only a single software version of the RDFE operational at the same time. This release is active in all regions. If Microsoft makes a mistake in updating the RDFE software, all regions are affected.
The reason behind having a single software version is that Microsoft wants to provide the same release of APIs to all customers. If there was a kind of rolling upgrade, there would be two different APIs operational at any given time: the previous release and the updated release.
The API is updated frequently. So, when using the API, a version request needs to be inserted in the code. For an overview of updates of the Service Management API, visit http://msdn.microsoft.com/en-us/library/azure/gg592580.aspx.
Now that we have enough information on what is located under the hood of Microsoft Azure and what it looks like, the next few sections will explain how we can manage the availability of virtual machines.
Fault domains
As you learned earlier, Microsoft Azure is designed such that the application provides resiliency. When hardware fails, the application should be clever enough to make sure it remains available.
While server hardware and top-of-rack switches are not redundant, Microsoft Azure has some resiliency built into the platform to protect it against hardware and software failures.
Azure provides so-called fault domains. Fault domains protect services for unplanned downtime.
A fault domain is a unit of failure that has single point of failures in it, such as server or storage nodes or networking and power unit rack switches. A fault domain consists of one or more racks. If, for example, a switched rack power distribution unit fails, all components in that rack will be without power. Also, a failure of a top-of-rack switch will lead to network isolation of all virtual machines running on nodes in that rack. The same rule applies to storage. As data is stored at three different places in a datacenter, this is done in three different fault domains.
You, as a customer, do not have control over the number of fault domains your virtual machines are placed in. Three virtual machines, all part of the same availability set, can be placed by the FC in two different fault domains.
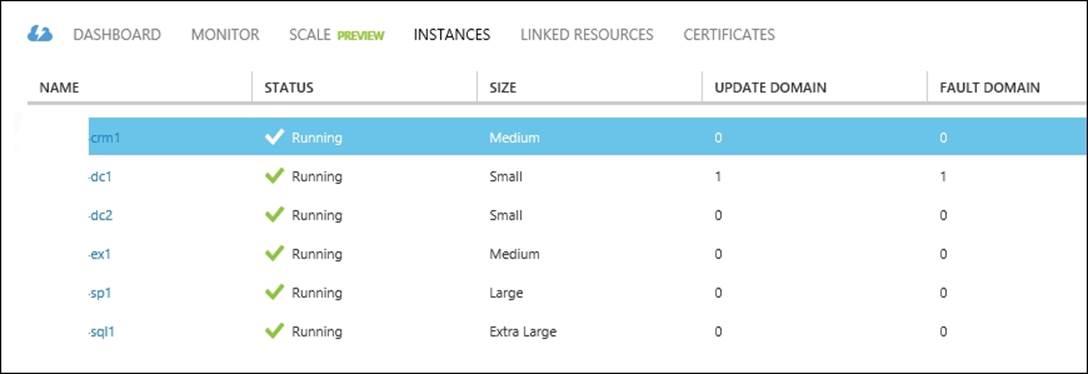
The Azure Management Portal shows in which fault domain a virtual machine is running. To check this, you can select Cloud Services, click on the name of the cloud service serving the virtual machines, and click on INSTANCES.
To be able to make an application resilient on Azure, at least two instances of each role need to be running. Azure customers are able to control placement of virtual machines in different fault domains by using availability sets.
The following screenshot shows the columns named UPDATE DOMAIN and FAULT DOMAIN:
Availability set
Azure availability sets are used for two reasons:
· Availability of virtual machines
· Scaling of applications
When two or more virtual machines are members of the same availability set, the Azure FC will make sure those virtual machines are processed by different fault domains. An availability set does not span multiple cloud services. Cloud services are explained in more detail later in this chapter. A cloud service can be seen as a container that contains multiple virtual machines hosting the same application.
So, for example, when you use 10 virtual machines that are all part of the same availability set, five of those virtual machines will be part of fault domain number 1 and five virtual machines will be part of fault domain number 2. This means that if a hardware failure causes a rack to go down, in a worst case scenario, 50 percent of the capacity of your application is temporary lost. At the time of writing this book, there are no more than two fault domains.
Tip
Ensure that you create an availability set first, then create new virtual machines, and only then add those to the availability set during creation. If you create virtual machines first and later add those to the availability set, the virtual machine will immediately reboot after being added to the availability set.
The following image shows two fault domains and an availability set consisting of two virtual machines serving the same application:
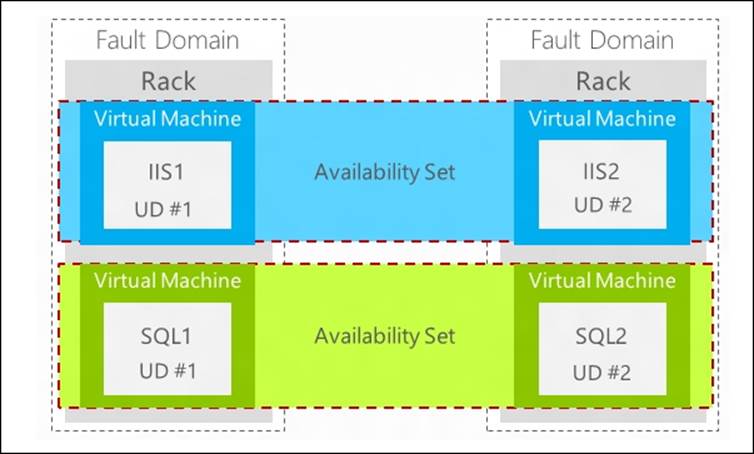
Rebooting is required to place a virtual machine (now part of an availability set) in another fault domain. Azure does not provide a live migration feature that could prevent a shutdown of virtual machines.
A second reason to use availability sets is scaling up or down of applications. Suppose the load on an application increases, for example, an e-commerce website has an increasing number of visitors in the weeks before Christmas.
This peak can automatically be covered by Azure by starting additional virtual machines or web servers. Azure will monitor the average CPU usage of virtual machines that are part of the same availability set. If the CPU usage reaches a value set by the administrator, additional virtual machines will be started. The reverse happens when the CPU usage drops below a threshold.
The advantage of this autoscale feature is that Microsoft does not charge processing costs for virtual machines that are not running. Keep in mind that storage charges still apply!
It is very important to only place virtual machines with the same role in an availability set. Therefore, place only web servers in the webservers availability set and place only database servers in the availability set named database servers. Do not mix these, since your service within the availability set, let's say a web frontend, is available through a single public IP address.
Tip
An availability set is part of a cloud service. So if you place two virtual machines in different cloud services, those virtual machines cannot be part of the same availability set.
Update domain
An update domain has a function similar to that of the fault domain. However, an update domain protects virtual machines for planned downtime.
The reason behind having update domains is that Microsoft frequently needs to update the software running on nodes. This is done once every one to three months, just as many on-premises Windows Server installations. The updates are done sequentially using groups of storage or compute nodes, one at a time. Upgrades and updates are first applied to the first group, then to the second group, and so on.
Update domains consist of multiple racks.
When an Azure node is being updated, virtual machines running on that node are not available. The node will reboot, causing the virtual customers to reboot as well. There are no plans made available by Microsoft to indicate when this happens for virtual machines that are part of an availability set.
Microsoft does plan the maintenance on hosts running single instance virtual machines. However, single instance virtual machines are those that are not part of an availability set. Microsoft communicates a date and time window to the customer. The time window is about 8 hours. Maintenance is done region-wise. Also, updates in subregions that are paired will not be done at the same time. For example, updates in the Amsterdam datacenter will be done on a Monday and for the Dublin datacenter on a Friday.
For updates on virtual machines that are part of an availability set, it is very hard for Microsoft to predict in which time window a certain server will be shut down for maintenance. Even the exact day is hard to predict. The progress of updating all the data centers strongly influences the speed of progress.
The downtime of virtual machines that run on a server that was updated can be up to 15 to 20 minutes. As explained in Chapter 2, An Introduction to Microsoft Cloud Solutions, Microsoft is working in a hot patching technique which allows virtual machines to remain operational when Azure nodes are patched.
This segmentation of updating nodes is done for two reasons. First reason is that when Microsoft applies upgrades to nodes, in many cases the nodes will require a reboot. To prevent all Azure nodes to go into reboot, the upgrades are done in groups. Microsoft starts upgrading nodes on the first group, does a reboot, and monitors if all nodes come up and behave normally. If this is the case, upgrades are applied to the next group and this process continues until all nodes are upgraded.
The second reason behind using update domains is to prevent a faulty update from bringing down major parts of the Azure infrastructure.
Azure customers cannot determine which virtual machines are part of which update domains. They can, however, instruct the FC how much percentage of their servers can be taken down when Microsoft updates nodes. This is done by configuring the Microsoft Azure Service Definition Schema file. However, this file is used when using Azure in a PaaS model.
When using virtual machines, each virtual machine placed in an availability set will not only be placed in a unique fault domain, it will also be placed in a unique update domain.
In Azure IaaS, the number of update domains used cannot be controlled by the customer. Azure will use five update domains for virtual machines that are part of the same availability set. This means that for an update, a minimum of 20 percent of the capacity will not be available during the update process.
A single upgrade domain can span multiple fault domains, and multiple upgrade domains can live in a single fault domain. This means there is no guarantee that all instances from a single upgrade domain will be placed in different fault domains.
Affinity group
Another method by which customers can control placement of processing and storage is by using affinity groups. An affinity group can be used by customers to have control over:
· Latency
· Costs
An affinity group can be used to place virtual machines and storage close to each other in the same datacenter. Since an Azure datacenter is a very large facility, latency between two virtual machines running at each end of the datacenter can be high. The affinity group will make sure both storage and processing will be placed close to each other.
First create an affinity group and then place network, storage accounts, and virtual machines in this affinity group. Once a virtual machine has been created, it cannot be added to another affinity group.
The name of an affinity group has to be unique within an Azure subscription. Each virtual network needs to be member of an affinity group.
Affinity groups can only be used to place storage and virtual machines close to each other. This is because of the way Azure services are housed. Services are housed in containers. This is not the sea container type that Microsoft uses for other data centers. An Azure container is just a collection of racks and clusters. Each of those containers have specific services, for example, compute and storage, SQL Azure, service bus, access control service, and so on. As we can see, only compute clusters and storage clusters are part of the same container.
The second function of affinity groups is control of costs. Microsoft charges for network traffic leaving the datacenter. Suppose the web tier of an application is running in the Amsterdam datacenter while the databases are running in the Dublin datacenter—this has an effect on the costs.
Microsoft Azure Storage
In this section, we will have a look at storage of Microsoft Azure. The storage service is named Microsoft Azure Storage.
Azure Storage is built using just a bunch of disks (JBOD) arrays with disk controllers running in software. You could see this as software-defined storage. Azure storage can be accessed directly using a URL. So, even when no virtual machines are used by a customer, storage can still be accessed. This kind of publishing data can be compared to, for example, CIFS shares on certain enterprise storage arrays. The storage arrays can directly present file shares to Windows servers or Windows desktops; there is no need to have a Windows server in-between the client and storage layer.
Azure Storage is very scalable. There is no limit to the amount of storage that can be used. There is a limit on performance in the storage account however.
When we look at the lowest level of storage, there are two ways to deliver raw storage capacity:
· By using local storage
· By using shared, distributed storage
Local storage
Local storage is provided by the physical servers. A set of around five hard disks located in each server contains a volume and is made available to the virtual machines running on the host.
Azure uses local storage to store nonpersistent data. That means the data is lost when the host crashes or needs to be reimaged using a fresh Windows server image.
Local storage is used for the PaaS server of Azure to store operating system virtual disks. The PaaS and IaaS services use local storage as well to store the virtual disk that holds the Windows pagefile. This is the D: volume that each virtual machine in Azure has.
Tip
Make sure you never use the D: volume to store data you want to keep!
Also, the host cache uses the local storage on the host.
Shared storage
A major component of every datacenter is the storage system. Microsoft Azure does not use the type of storage arrays we are familiar with, for example, EMC, NetApp, or HP LeftHand. This type of storage does not scale and is not able to handle the types of files used in a cloud. It is also very expensive.
Microsoft developed its own distributed storage. This is called Microsoft Azure Storage. It is a durable filesystem. Data is stored in a datacenter at three different locations. Geo-replication is enabled by default for a storage account, which means the data is replicated to the paired region and stored there as well on three different locations. So, by default, data is stored using six copies.
Azure Storage is a very complex and sophisticated way of storing data in a resilient way. This chapter will give a high-level overview of Microsoft Azure Storage.
Microsoft Azure Storage uses cabinets full of hard disks in a JBOD configuration. Racks are filled with those storage cabinets. A group of multiple racks is called a storage stamp.
Storage cabinets or nodes are similar to compute nodes controlled by the FC. There is a separate FC per storage stamp in order to prevent certain classes of errors from affecting more than one stamp.
All handling of storage is done by software-based controllers.
Azure's storage architecture separates the logical and physical partitioning of data into separate layers of the system.
The following image shows the layers used in the Azure Storage architecture:
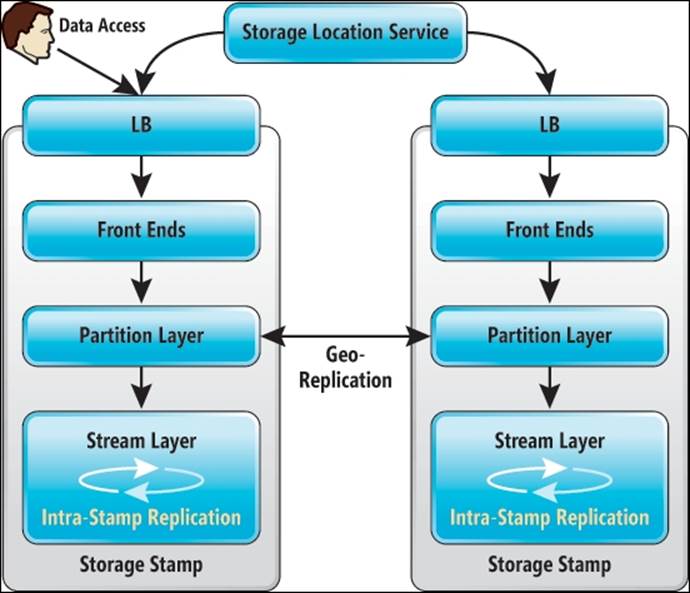
There are three layers in the preceding image:
· Front End (FE) layer: This serves as a type of router for data. The FE knows which partition server is responsible for a certain amount of data. The FE redirects transactions to the partition server responsible for controlling (serving) access to each partition in the system.
· Partition layer: The partition layer has partition servers. A partition server can be best seen as a controller for LUNs in enterprise storage. In Azure, we talk about partitions instead of LUNs. The partition server is aware of what type of data is processed. It understands blob, table, and queue storage types.
· Stream layer: This is also called the distributed and replicated file system (DFS) layer. This layer stores the data on disk and is responsible for the distribution of data over storage servers for resiliency. There are many DFS servers active in Azure. The DFS layer stores the data in "extents". This is a unit of storage on disk and a unit of replication, where each extent is replicated multiple times. The typical extent sizes range from approximately 100 MB to 1 GB in size. The stream layer is also responsible for geo-replication.
The servers used in these three layers are placed in the fault domains. At the filesystem-level, NTFS is used.
Data is stored in a single datacenter at three locations for resiliency. Each location is in another fault and update domain. If geo-replication is enabled, the data is asynchronously replicated to the secondary datacenter. The replication has a delay of 15 minutes. In the secondary datacenter, there are three copies as well.
Azure DFS is using journaling for the writes that are replicated. The data stored by Azure storage is made available over the network using REST API instructions. There is no requirement for a virtual machine to access this data. Microsoft uses hardware load balancers to distribute load over the resources.
Storing blobs, pages, and queues
Azure offers storage for three types of data:
· Unstructured files that are stored as blob storage (block or page blobs)
· Structured data that is stored as table storage
· Messages stored in queue storage
Data and messages are data types in use for the Platform as a Service model in Azure. These are very useful for applications being developed on Azure. Virtual machine data as well as backup data is stored as blob storage.
Blob storage can be best seen as a filesystem in the cloud. Blobs allow you to access individual files over the Internet. A blob is just like a text file, VHD file, or any other unstructured file on a regular filesystem. Also, each file stored in a blob has a URL associated with it. In this way, each file can be modified using HTTPS. Data can be read or modified using the REST API. There is versioning, so older versions of files can be retrieved. This can be extremely useful when you need to restore an older version of virtual disk files, for example.
Blobs are suitable for random read/write payloads and can be a maximum of 1 TB in size. A common use case of a page blob is a VHD mounted as a drive in a Microsoft Azure role.
Block blobs are useful for streaming.
Data cannot be encrypted automatically by instances in Azure storage. If customers want to encrypt data, it should be done by the appliance or application. For example, StorSimple, the Microsoft hybrid storage solution, will encrypt all outgoing data that is sent to the supported cloud platforms.
Each blob is linked to a disk object. The "disk object" kind of storage connects the blob storage to a service in Azure. The disk object is the glue that connects the virtual machine to the VHD. If the disk object is deleted, the connection is broken. However, the VHD file remains on the storage and can be reused.
Blobs are organized in containers. Containers can be seen as folders, as we know from Windows NTFS. Virtual machine disk files (VHD) are automatically created in a container named vhds.
Each container has an access control list (ACL). The default access for a container is private, which means only the owner of the storage account can access the data.
The Public blob access option allows public read access to the blob. However, the container properties cannot be read by this role.
A blob file can have multiple snapshots. A snapshot can be seen as a point-in-time copy of the file. It allows us to restore a previous version of the blob file. It works the in the same way as snapshots of virtual machines.
A blob cannot be removed as long as the blob has snapshots. In the Azure Management Portal, you are not able to manage snapshots. Snapshot management can be performed using scripts, or third-party tools can be used. Storage tools will be discussed later in this chapter.
Storage account
Storage and compute in Microsoft Azure are different services. This means a customer can use only storage without having to create virtual machines or another Azure service first. For example, a customer who uses StorSimple to back up data to the cloud only consumes disk storage.
To access the data located in Azure, customers need to have a storage account. A storage account is like an account for Active Directory—a key to authenticate.
A storage account needs to have a unique Azure name. If another Azure customer already took your favorite storage account name, you are out of luck and you will need to find another name.
The reason for the requirement of a unique storage account name is that the storage account has a URL such as <yourstorageaccount>.<type of storage>.core.windows.net.
Storage in Microsoft Azure can be accessed over the Internet using the REST API or PowerShell scripts. To reach the data, the URL is used.
When the very first virtual machine is created in an Azure subscription, a storage account is created automatically. However, Microsoft Azure randomly creates a storage account name. A storage account has an account name and two 512-bit string access keys (primary and secondary). The secondary access key is a backup for when the first one is lost or otherwise not useable.
The access keys have a function just like a password for a regular user account stored in Active Directory.
For ease of management, I advise you to create a storage account first and give the account an easy to distinguish name.
For an Azure subscription, the maximum number of storage accounts has a maximum of 100 storage accounts per Azure subscription. Customers are not charged for the total number of storage accounts they have. Each storage account is currently limited to a maximum amount of data per storage account, which is 500 TB.
When a virtual machine is provisioned for the first time, a storage account is automatically created using the wizard.
Storage accounts have limits. It is important to understand those limits. By using multiple storage accounts, storage performance can be improved.
|
Max. IOPS per storage account |
20,000 per SLA |
|
Maximum IOPS for persistent disk |
500 |
|
Maximum capacity per storage account |
500 TB |
|
Transactions |
20,000 entities/messages/blobs per second |
|
Bandwidth for geo-redundant storage account |
Ingress—up to 5 Gigabits per second Egress—up to 10 Gigabits per second |
|
Bandwidth for a Locally Redundant storage account |
Ingress—up to 10 Gigabits per second Egress—up to 15 Gigabits per second |
Tip
Do not place more than 40 highly used VHDs in an account to avoid the 20,000 IOPS limit.
When we look at the virtual disk level, each virtual disk of a virtual machine is able to deliver 500 IOPS and 60 MB/second for no caching disks for I/O of 64 KB or less.
At the time of writing this book, the 500 IOPS is not capped. However, it will be capped to give a consistent performance.
Microsoft is working on enabling Quality of Service for disk I/O. This will mean that customers can select the maximum number of IOPS and will be charged accordingly.
Disks
In the previous sections, you learned about local storage and Microsoft Azure Storage, which is a distributed storage system. You learned that Microsoft offers three types of storage: blob, page, and queue storage.
Azure virtual machines use virtual hard disks to store data. These disks are stored as VHD files. VHD is storage as a page blob.
Basically, this is the same as how Hyper-V uses VHD files. Each disk volume of a Hyper-V virtual machine uses a VHD file.
From the Azure Management console, you are not able to see VHD files. You will need an Azure storage browser to see the VHD files located in the storage account.
However, a VHD is not directly connected to an Azure virtual machine. Azure virtual machines use an object named Disks.
Microsoft Azure has three types of disks:
· Operating system disks
· Temporary disks
· Data disks
There is a one-to-one relationship between the VHD and the disk. A disk can be attached to a virtual machine or can be disconnected from a virtual machine.
The default naming convention of a virtual hard disk containing an operating system that is deployed using the image gallery is as follows:
<cloud service name>-<virtual machine instance name>-<year>-<month>-<day>.vhd
For example, a virtual machine instance with the name Fileserver01 that is part of the cloud service named production001 that is created on November 1, 2013, will have a VHD named Production001-fileserver01-2013-11-01.vhd.
You cannot adjust this default naming convention.
Windows Server operating system disks are always 127 GB in size, and similar to all Azure disks, they cannot be resized using the Azure Management Portal.
Tip
It is very important to define a naming convention for additional disks added to the virtual machines. Without a proper naming convention, it will be difficult to associate which VHD and which disk belongs to which virtual machine.
The temporary disk is always automatically assigned the letter D: when a virtual machine is deployed from the Azure Management Portal. The D: volume is a nonpersistent disk. The data stored on this disk is lost in the following situations:
· When the virtual machine is assigned to a different host. This can happen when the host has been shut down and is restarted for maintenance reasons. The FC will run the virtual machine on a new host.
· When the size of the virtual machine is adjusted by the administrator.
· When the hosts crashes.
· When the host is shut down for maintenance and a new image is installed.
Data disks are used to store anything. The maximum size of a data disk is 1 TB. In Windows Server Manager, however, you can combine several 1 TB disks to create a larger volume.
Each virtual machine can have a number of data disks. The maximum number depends on the size of the virtual machine.
The following table shows the available virtual machine sizes and the maximum number of data disks that can be attached to that virtual machine:
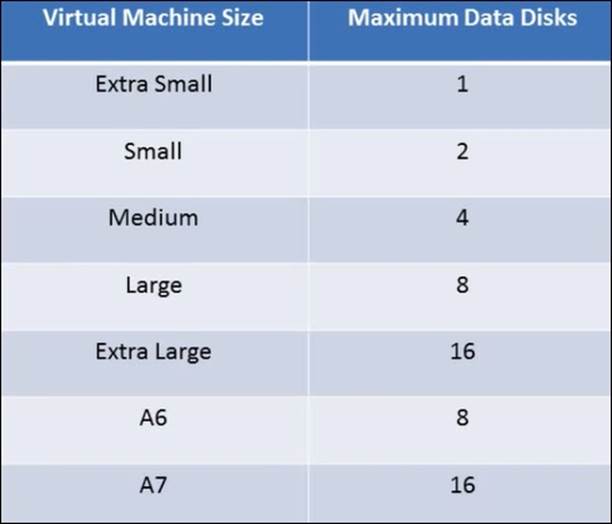
A data disk can be an empty disk. You simply use the Azure Management Portal to add an empty disk.
You can also add a disk that you uploaded yourself, for example, a disk that contains your corporate image, custom software, or data you need to share. There are several ways to upload data disks. You can use PowerShell or third-party tools. In the next chapter, we will explain how to do this in detail.
You create a disk from a VHD; think about using the uploaded VHD as a template.
Disk caching
Disk caching improves performance. When caching is set to active on a disk, the local disk of the Azure server stores reads and writes coming from Microsoft Azure Storage. So, by using local server attached storage as a buffer, data does not have to go to / come from the Microsoft Azure Storage systems that can be located somewhere else in the datacenter.
Disks can have one of the following three caching modes:
· ReadWrite: This is the default mode for the operating system disk. This can be set to data disks as well.
· ReadOnly: Set to operating system and data disks.
· None: This is the default setting for data disks.
Containers
Containers are like folders in any filesystem, such as FAT or NTFS. Containers are used to organize files. The second purpose of containers is to set access control to certain files.
Images
Images are used to deploy new virtual machines. Basically, images have the same functionality as templates used in Hyper-V or other x86-based hypervisors.
There are three types of images that can be used:
· Microsoft images
· Community images
· Your own images
Microsoft has a lot of "off the shelf" images available in the Azure Management Portal. These are either just Windows Server or Linux installations, or a complete operating system with SharePoint, SQL server, or Oracle databases.
At the time of writing this book, there are 126 different images available. Images allow you to quickly deploy server instances. In the Azure Management Portal, these images are listed as platform images.
You can simply select an image from the image gallery named Windows Server 2012 R2 or SQL Server 2012 SP1 Web on Windows Server 2008 R2.
A second image source is VM Depot. It is a community-driven catalog of preconfigured operating systems, applications, and development stacks that can easily be deployed on Microsoft Azure. These images are based on the Linux distributions Centos, openSUSE, SUSE Linux Enterprise Server, and Ubuntu.
You can either select an image from the Azure Management Portal or go to https://vmdepot.msopentech.com/List/Index, where you will find a lot of images.
Be aware that these images are supplied by the community. VM Depot is managed by Microsoft Open Technologies Inc., a subsidiary of Microsoft. They do not screen the images for security. You are responsible for making sure the image does not harm the security of your environment.
A third way of using images is to create images yourself. You can customize a virtual machine image, run sysprep, and then create an image of it. Images are based on an existing VHD (which is short for virtual hard disk) files.
Copy of blob storage
Azure storage has an interesting feature that allows us to save copies of files. Instead of a real copy where two separate files are created, Azure keeps a history of a file when a copy is done. It is the same as using snapshots to create a point in time of a virtual machine. Snapshots can be promoted in such way that the snapshot becomes active.
Blob lease
When a blob is created, an infinite lease is set on that blob. The goal of the lease is to prevent storage from being deleted while somebody is using the storage.
Protection of data
Data is protected by default in Microsoft Azure Storage. Each block of data written to a VHD file is triple-replicated to three different storage stamps located in the same datacenter. A storage stamp has the same functionality as a fault domain. If a single point of failure fails, the data is always available in two other locations.
When a storage account is created, you have an option to enable geo-replication. Geo-replication replicates the data to another region. This protects the data from a failure of a complete datacenter.
Data that is protected by geo-replication is stored at three different locations in the other regions. Geo-replication is enabled by default. However, the costs for storage are higher than when geo-replication is disabled.
Replication is performed asynchronously. The delay is about 15 minutes. This means that if the primary storage location is not available and Microsoft decides to failover, customers will lose about 15 minutes of data.
The data is stored at several locations for the purpose of disaster recovery. It is not a backup. If you delete the data, it is deleted from all the locations.
Customers are not able to actually failover to the replicated data if they want to. Only Microsoft staff is able to failover to another datacenter if the data is unavailable in the primary location.
Securing data
Data stored in Azure Storage is not encrypted by default by Microsoft. You have to take your own actions to prevent others from peeping into your data.
Data stored by SQL Server, System Center Data Protection Manager (DPM), and server backup can be encrypted if needed.
Also, BitLocker can be used to protect data of virtual hard disks. However, Microsoft only supports using BitLocker Drive Encryption on data drives and not on operating system disks in Microsoft Azure.
Storage protocol
Microsoft uses a protocol to access Microsoft Azure Storage from nodes that Microsoft developed itself. Protocols like NFS or iSCSI are not used. The protocol used by Microsoft is based on the REST API. The network traffic uses SSL certificates for encryption. These certificates are stored in the Secret Store. This is a vault internally used by Microsoft to store certificates. Both Microsoft Azure and its customers use certificates to access services running on Azure. These certificates are handled by the Secret Store such that the Microsoft staff do not have direct access to certificates for security and compliancy reasons. One of the tasks of the Secret Store is to monitor the expiration date of certificates and alert the Microsoft Azure Storage service team in advance when certificates are about to expire.
Costs of storage
Microsoft Azure Storage is a thinly provisioned filesystem. It only writes actual data.
Microsoft only charges for the actual consumption of data. So, for example, when you have a 1 TB disk assigned to your virtual machine but you are actually using 500 GB, you are charged for 500 GB.
As you might have noticed, each Windows Server operating system disk is 127 GB large when deployed form the image gallery. However, you only pay for the actual data you write to disk.
There is a small caveat in certain operating systems.
Suppose you have a 40 GB volume with 20 GB of actual data. Now, you write an additional 10 GB of data and then delete 5 GB of data.
Since September 2013, Microsoft Azure has supported TRIM. It enables the operating system to tell the storage system that the operating system deleted data. The storage system then knows it does not have to allocate data for that operating system:
· This is supported by Windows Server 2012 and 2012 R2 for both operating system and data disk
· For Windows server 2008 R2, TRIM only works on the operating system disk
· Linux currently does not have TRIM support
· TRIM is only supported on ATA disks
Azure storage tooling
The Azure Management Portal provides some basic management on storage. Basically, disks can be created or deleted.
Cerebrata Azure Explorer is a free Windows tool that allows many actions on Azure Storage. It is very simple to upload files, delete files, download files, and rename files. Visit http://www.cerebrata.com/labs/azure-explorer for more information.
CloudXplorer by Clumsyleaf is another nice tool. There is a paid and a freeware edition available at http://clumsyleaf.com/products/cloudxplorer.
There are many other paid software solutions available.
Networking
Besides understanding how Azure Storage works, understanding the networking aspect is just as important.
We will discuss two parts of networking in Azure: the part under the hood that is not visible to Azure customers, as well as the part that customers have control over.
Azure networking under the hood
Initially, when Azure was released in 2008, the network was a North-South design. Traffic originating from a server went North via several layers of switches and then South to the destination server. This design did not scale very well.
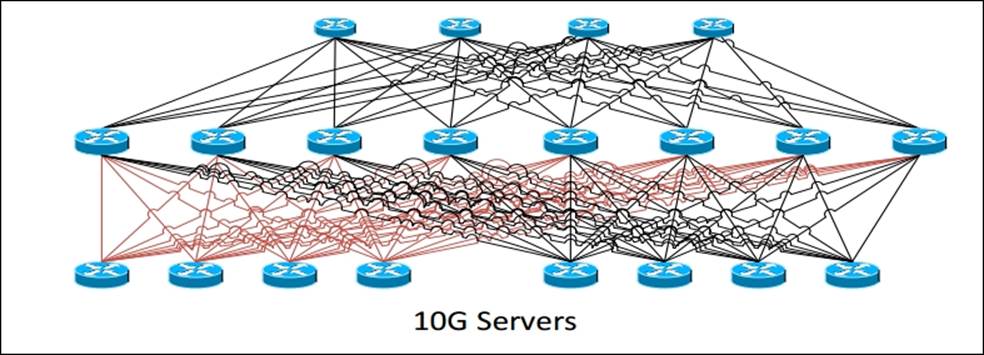
So, soon after the first release, Microsoft completely redesigned the network. All servers have at least 10 Gbps connection to multiple switches. In 2014, Microsoft even introduced new virtual machine sizes offering 40 Gbps InfiniBand network connections. Now, the network offers multiple connections from a single node to switches.
The following image shows the current Azure network diagram. On top of the Azure hosts, three layers of switches are seen.
To provide customers with network connectivity between Azure and their on-premises network, virtual networks were introduced. This allows customers to use their own customer address space, and this also means that multiple customers can use the same address space.
Microsoft is using Network Virtualization using Generic Routing Encapsulation (NVGRE) to provide customers their own customer address space.
NVGRE is a technology that allows the IP configuration of a virtual machine to be unchanged when the virtual machine is moved between data centers.
It can be compared to the mobility of your mobile phone. When you travel abroad and take your mobile phone with you, you are still reachable on the same telephone number even though you're in another county and using a different telephone network provider.
NVGRE allows service providers that the IP address spaces used in the same datacenter to overlap. So, tenants can use their own IP address space.
In network virtualization, the IP address is abstracted from the service provider network. Not only that, Azure is massive; it has hundreds of thousands of nodes and millions of virtual machines. Networks are created and modified by customers more than a hundred times per day.
All those changes in the network need to be automated. The solution is software-defined networking (SDN). Microsoft started developing a home-grown SDN in 2010 using about 100 developers. Since then, the Azure network architecture has changed completely.
SDN is a combination of software and hardware. Software is used to control components like virtual switches and routers. Most of the features offered by the network are in the software.
The SDN architecture of Azure has four main components:
· Azure frontend: The networks are created here by tenants using the API or the portal user interface
· Load balancer:
· Controller: This piece of software translates instructions and communicates with network devices to execute the instructions
· VMswitch: Each Azure node has a couple of Virtual Switches or VMswitches, and the virtual machines are connected to those switches
All four components are running as software in a virtual machine. This makes it very easy to add new features and distribute those using the same deployment tools as the virtual machines.
Load balancers
Microsoft Azure uses load balancers to be able to scale and provide performance and availability. The main purpose of a load balancer is to accept incoming network traffic sent to a virtual IP address and redirect it to a mapped internal IP address and port number.
In a massive infrastructure like Azure, it is impossible to use hardware load balancers. They cannot be provisioned automatically and do not fit in an agile infrastructure with lots of changes in configuration and performance.
Microsoft only uses software-based load balancers in Azure. All policies are software-based and are sent to the VMswitch using a protocol that is very similar to OpenFlow.
Three kinds of polices are used:
· Access control lists: This defines which virtual machine can talk to which virtual machine
· Load balancing network address translation: This defines which external IP address should be matched to which internal IP and port
· Virtual network: This is used for management of routing tables and virtual networking policies
Azure load balancers can only be reached from the public Internet. Traffic originating from an on-premises network connected over VPN cannot be load balanced using the Azure load balancers.
If network traffic increased, it is very well possible that the FC automatically adds more software load balancers.
It is, however, possible to use your own load balancing software and run it from your own virtual machine deployed in Azure.
When using Microsoft Azure IaaS, the load balancing features offered by the Azure load balancer are basic. It just redirects traffic based on the round robin technique.
When you're using the Microsoft Azure PaaS platform, more advanced rules are available.
The load balancing mechanism within the Microsoft Azure offering does not offer any Layer 7 functionality such as session affinity, content switching, compression, and any other application logic that can be applied if you are using a Layer 7 load balancer for your applications.
If you want these features, Kemp provides a free load balancer for Azure. It is installed as a virtual machine in a cloud service.
The components that have networking are as follows:
· Cloud service
· Virtual network
· Site-to-site network
· Point-to-site network
Cloud services
Cloud services are one of the main options shown in the left-hand side pane of the Azure Management Portal. It is very important to understand what the purpose of a cloud service actually is.
A cloud service can be seen as a container to group a set of virtual machines that are a part of the same application service.
Virtual machines part of the same cloud service share the same DNS domain name. These virtual machines are able to communicate with each other over the Azure internal network.
Each cloud service has a single public IP address. This is the virtual public IP address. Cloud services allow developers to use staging and are a requirement for autoscaling.
The main purpose of a cloud service is to manage applications. A cloud service is a group of one or more virtual machines. Each virtual machine can be accessed using the same public facing IP address.
A cloud service is linked to a production deployment. Virtual machines cannot be moved in or out a virtual network once they are created using a simple procedure. To perform such a movement, you will have to delete the virtual machine and recreate it using the virtual hard disk files of the original virtual machine.
If you select a cloud service for your virtual machine during provisioning, you will not be able to add the virtual machine to a virtual network.
You can secure connectivity for intra-tenant virtual machines via packet encapsulation.
Tip
A very important point is that the virtual network must be created before any cloud services are created in it. Once a cloud service has been created, it is not possible to migrate it into a virtual network.
IP addressing of virtual machines
In the early days of Azure, it was not possible to assign a static IP address to a virtual machine. You could do it and it worked, but after a while the networking of the virtual machine would not be operational again. Customers could have some control over IP assignment to virtual machines by using virtual networks. The first virtual machine that would boot in a newly created virtual network would get the first available IP address in the IP range. However, this was not ideal.
In 2014, Microsoft enabled the ability to assign a static IP address to a virtual machine.
You cannot use your own DHCP server in an Azure network. For security and stability reasons, Microsoft Azure has its own managed DHCP mechanism. A virtual machine always receives an internal IP address, which is also referred to as a DIP from a pool of internal IP addresses. You can't change the DIP after it has been assigned. For this reason, if you plan to create a virtual network, create the virtual network before you deploy the virtual machine. Microsoft Azure will then assign the DIP from the pool of internal IP addresses that you designated when you created your virtual network.
The private IP address spaces available for use in Azure Virtual Networks are as follows:
· 10.0.0.0 – 10.255.255.255
· 172.16.0.0. – 172.31.255.255
· 192.168.0.0 – 192.168.255.255
The public IP addresses assigned to Internet-facing devices depend on the region and datacenter.
Virtual network
A virtual network allows you to do the following tasks:
· Create a site-to-site VPN
· Use your own IP address space for virtual machines
· Set DNS servers of your choice
· Enable communications between different cloud services without having to expose services to the public Internet
The Microsoft Azure Virtual Network feature lets you provision and manage virtual private networks (VPNs) in Microsoft Azure, as well as securely link these with on-premises IT infrastructure. Companies can extend their on-premises networks into the cloud with control over network topology, including configuration of DNS and IP address ranges for virtual machines.
Virtual networks are very popular. Over 40 percent of the customers using the Azure Virtual Machines service are deploying virtual networks.
A virtual network subnet is related to the virtual network. You can divide the virtual networks into many smaller subnets.
Be aware of the fact a virtual network only lives in the data center it has been created. You cannot have a single virtual network span more than one datacenter/region.
There can be thousands of virtual machines connected to a virtual network.
A cloud service in a virtual network can directly access individual instances in a second cloud service contained in the virtual network without going through the load balancer hosting a public input endpoint for the second cloud service.
This means that once a traditional PaaS cloud service is added to a virtual network, the cloud service no longer forms a security boundary and any open port on its role instances can be accessed by any instance of any cloud service in the virtual network. This is regardless of whether the cloud service is IaaS or PaaS.
Site-to-site VPN
A VPN connection over the public Internet can be set up between an Azure virtual network and multiple on-premises sites. In the next chapter we will learn how to set up a site-to-site VPN.
Azure ExpressRoute
An alternative for a VPN connection is ExpressRoute. ExpressRoute enables a secure, reliable, high-speed direct connection from an on-premises datacenter or colocation environment into Microsoft Azure data centers. Private fiber connections can be set up by a growing number of providers. Currently supported are T&T, Equinix, Verizon, BT, Level3, TelecityGroup, SingTel, and Zadara.
ExpressRoute offers different tiers of bandwidth up to 10 Gbps and is covered by a Service Level Agreement (SLA).
Virtual machine network interface
Each virtual machine deployed in Azure is limited to a single virtual network adapter. Users cannot add network adapters to a virtual machine yet. However, Microsoft is working on support for multiple network interfaces. Also, each network adapter is limited to a single IP address. This means you cannot use a virtual machine for routing or firewall-like features.
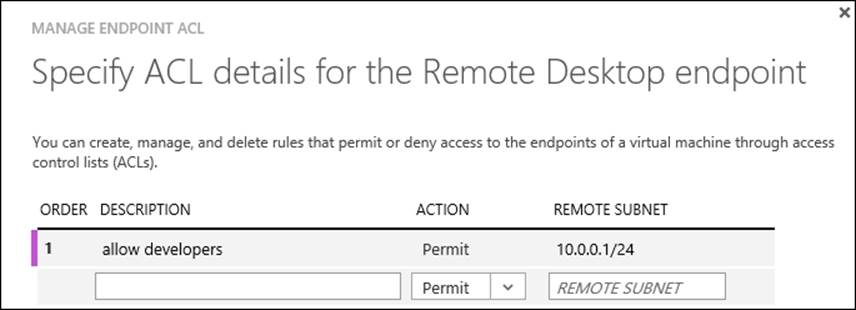
Endpoints
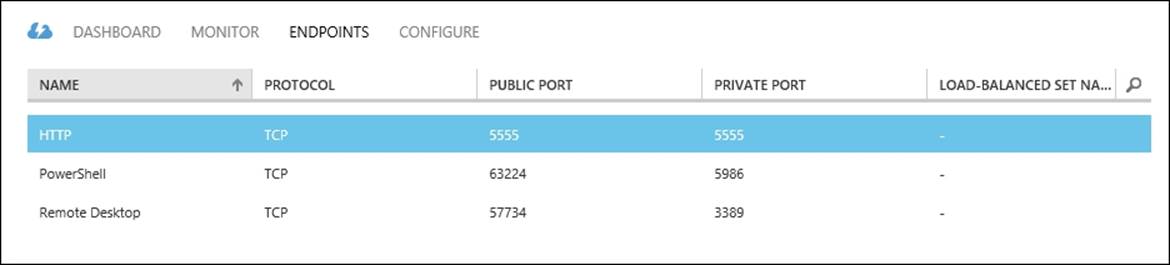
After a virtual machine has been deployed on Microsoft Azure, it is very likely services running in that virtual machine need to be accessed from the Internet. To be able to reach services, endpoints needs to be configured. An endpoint is a mapping between a public port number and a private port number over a specified protocol.
The number of endpoints per cloud service is limited. At the time of writing this book, the maximum number of incoming endpoints per cloud service was 150. Virtual machines that are a part of the same cloud service have no restriction on the number of ports.
When an endpoint is added to a virtual machine, an entry is made in one or more load balancers to allow network traffic originating from the Internet to reach the network port of the virtual machine.
Endpoints can have an ACL. By applying an ACL on an endpoint of a virtual machine, administrators can control which external IP address or range of IP addresses can access which virtual machine and its network ports.
This is another way to increase the security of the virtual machine. For example, an ACL can be set on virtual machine endpoints such that access is restricted to IP addresses used by workstations of software developers.
For each endpoint, multiple rules can be created. Each rule has an order number. The rules are evaluated in order starting with the first rule (the lowest order number) and ending with the last rule (the highest order number). This means that rules should be listed from least restrictive to most restrictive.
Summary
In this chapter, you've got a deep insight into the architecture of Microsoft Azure. You learned about the data centers and how processing, storage, and network is designed in Microsoft Azure.
You learned about the purpose of update and fault domains. In this chapter, you learned that Azure is managed as a software-defined network, which means intelligent software manages the network devices. You also learned how you can connect to Azure from on-premises using a VPN or a direct WAN connection using Azure ExpressRoute. Now, you can understand the terms used in Microsoft Azure and you are ready to deploy virtual machines.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.