T-SQL Querying (2015)
Chapter 9. Programmable objects
This chapter focuses on the programmatic constructs in T-SQL. It covers dynamic SQL, user-defined functions, stored procedures, triggers, SQLCLR programming, transactions and concurrency, and exception handling. Because the book’s focus is on querying, most of the discussions involving programmatic constructs will tend to center on their use to support querying, with emphasis on the performance of the code.
Dynamic SQL
Dynamic SQL is, in essence, T-SQL code that constructs and executes T-SQL code. You usually build the batch of code as a character string that you store in a variable, and then you execute the code stored in the variable using one of two tools: the EXEC command (short for EXECUTE) or the sp_executesql stored procedure. The latter is the more flexible tool and, therefore, the recommended one to use.
The code you execute dynamically operates in a batch that is considered separate from the calling batch. That’s important to keep in mind because the batch is the unit for a number of things in Microsoft SQL Server. It’s the unit of parsing, binding, and optimization. The batch is also the scope for variables and parameters. You cannot access a variable declared in one batch within another. This means that if you have a variable in the calling batch, it is not visible to the code in the dynamic batch, and the other way around. So if you need to be able to pass variable values between the batches, and you want to avoid writing to and reading from tables for this purpose, you will need an interface in the form of input and output parameters. Between the EXEC and sp_executesql tools, only the latter supports such an interface; therefore, it is the recommended tool to use. I’ll demonstrate using both tools.
Using the EXEC command
As mentioned, the EXEC command doesn’t support an interface. You pass the character string holding the batch of code that you want to run as input, and the command executes the code within it. The lack of support for an interface introduces a challenge if in the dynamic batch you need to refer to a value in a variable or a parameter from the calling batch.
For example, suppose that the calling batch has a variable called @s that holds the last name of an employee. You need to construct a dynamic batch that, among other things, queries the HR.Employees table in the TSQLV3 database and returns the employee or employees with that last name. What some do in such a case is concatenate the content of the variable (the actual last name) as a literal in the code and then execute the constructed code with the EXEC command, like so:
SET NOCOUNT ON;
USE TSQLV3;
DECLARE @s AS NVARCHAR(200);
SET @s = N'Davis'; -- originates in user input
DECLARE @sql AS NVARCHAR(1000);
SET @sql = N'SELECT empid, firstname, lastname, hiredate
FROM HR.Employees WHERE lastname = N''' + @s + N''';';
PRINT @sql; -- for debug purposes
EXEC (@sql);
Running this code produces the following output, starting with the generated batch of code for troubleshooting purposes:
SELECT empid, firstname, lastname, hiredate
FROM HR.Employees WHERE lastname = N'Davis';
empid firstname lastname hiredate
----------- ---------- -------------------- ----------
1 Sara Davis 2012-05-01
There are two problems with this approach—one related to performance and the other to security. The performance-related problem is that for each distinct last name, the generated query string will be different. This means that unless SQL Server decides to parameterize the code—and it’s quite conservative about the cases that it automatically parameterizes—it will end up creating and caching a separate plan for each distinct string. This behavior can result in flooding the memory with all those ad hoc plans, which will rarely get reused.
As for the security-related problem, concatenating user inputs as constants directly into the code exposes your environment to SQL injection attacks. Imagine that the user providing the last name that ends up in your code is a hacker. Imagine that instead of providing just a last name, they pass the following (by running the preceding code and replacing just the variable assignment with the following one):
SET @s = N'abc''; PRINT ''SQL injection!''; --';
Observe the query string and the outputs that are generated:
SELECT empid, firstname, lastname, hiredate
FROM HR.Employees WHERE lastname = N'abc'; PRINT 'SQL injection!'; --';
empid firstname lastname hiredate
----------- ---------- -------------------- ----------
SQL injection!
Notice the last bit of output. It tells you that you ended up running code in your system that the hacker injected and you didn’t intend to run. In this example, the injected code is a harmless PRINT command, but it could have been code with much worse implications, as the following comic strip will attest: http://xkcd.com/327/.
Often hackers will not try to inject code that does direct damage, because such an attempt is likely to be discovered quickly. Instead, they will try to steal information from your environment. Using the employee-name example to demonstrate, a hacker will first pass any last name just to see the structure of the result. The hacker will see that it contains four columns: the first is an integer, the second and third are character strings, and the fourth is a date. The hacker then submits the following “last name” to collect information about the objects in the database:
SET @s = N'abc'' UNION ALL SELECT object_id, SCHEMA_NAME(schema_id), name, NULL
FROM sys.objects WHERE type IN (''U'', ''V''); --';
Instead of getting employee information, the hacker gets the following information about the object IDs, schema, and object names of all objects in the database (the object IDs in your case will be different, of course):
SELECT empid, firstname, lastname, hiredate
FROM HR.Employees WHERE lastname = N'abc' UNION ALL
SELECT object_id, SCHEMA_NAME(schema_id), name, NULL
FROM sys.objects WHERE type IN ('U', 'V'); --';
empid firstname lastname hiredate
----------- ----------- ------------------ ----------
245575913 HR Employees NULL
309576141 Production Suppliers NULL
341576255 Production Categories NULL
373576369 Production Products NULL
485576768 Sales Customers NULL
517576882 Sales Shippers NULL
549576996 Sales Orders NULL
645577338 Sales OrderDetails NULL
805577908 Stats Tests NULL
837578022 Stats Scores NULL
901578250 dbo Nums NULL
933578364 Sales OrderValues NULL
949578421 Sales OrderTotalsByYear NULL
965578478 Sales CustOrders NULL
981578535 Sales EmpOrders NULL
Because the hacker is interested in stealing customer information, his next move is to query sys.columns to ask for the metadata information about the columns in the Customers table. (Again, the hacker will need to use the object ID representing the Customers table in your database.) Here’s the query he will use:
SET @s = N'abc'' UNION ALL
SELECT NULL, name, NULL, NULL FROM sys.columns WHERE object_id = 485576768; --';
The hacker gets the following output:
SELECT empid, firstname, lastname, hiredate
FROM HR.Employees WHERE lastname = N'abc' UNION ALL
SELECT NULL, name, NULL, NULL FROM sys.columns WHERE object_id = 485576768; --';
empid firstname lastname hiredate
----------- ------------- --------- ----------
NULL custid NULL NULL
NULL companyname NULL NULL
NULL contactname NULL NULL
NULL contacttitle NULL NULL
NULL address NULL NULL
NULL city NULL NULL
NULL region NULL NULL
NULL postalcode NULL NULL
NULL country NULL NULL
NULL phone NULL NULL
NULL fax NULL NULL
Then the hacker’s next move is to collect the phone numbers of the customers by using the following code:
SET @s = N'abc'' UNION ALL SELECT NULL, companyname, phone, NULL FROM Sales.Customers; --';
He gets the following output:
SELECT empid, firstname, lastname, hiredate
FROM HR.Employees WHERE lastname = N'abc' UNION ALL
SELECT NULL, companyname, phone, NULL FROM Sales.Customers; --';
empid firstname lastname hiredate
----------- --------------- --------------- ----------
NULL Customer NRZBB 030-3456789 NULL
NULL Customer MLTDN (5) 789-0123 NULL
NULL Customer KBUDE (5) 123-4567 NULL
NULL Customer HFBZG (171) 456-7890 NULL
NULL Customer HGVLZ 0921-67 89 01 NULL
...
All of this was possible because you concatenated the user input straight into the code. If you’re thinking you can check the inputs by looking for common elements used in injection, you need to be aware that it’s hard to cover all possible injection methods. Hackers keep reinventing themselves. Like my friend and colleague Richard Waymire once said, “They’re not necessarily smarter than you, but they have more time than you.” The only real way to avoid injection is not to concatenate user inputs into your code; rather, pass them as parameters. However, to do this, you need a tool that supports an interface, and unfortunately the EXEC command doesn’t. Fortunately, the sp_executesql procedure does support such an interface, as I will demonstrate shortly.
The EXEC command has an interesting capability you can use to concatenate multiple variables within the parentheses, like so:
EXEC(@v1 + @v2 + @v2);
Even if the inputs are character strings with a limited size—for example, VARCHAR(8000)—you are allowed to exceed 8,000 characters in the combined string. With legacy versions of SQL Server prior to the support for VARCHAR(MAX) and NVARCHAR(MAX), this used to be an important capability. But with these types, you can pass an input batch that is up to 2 GB in size. EXEC supports both regular character strings and Unicode ones as inputs, unlike sp_executesql, which supports only the latter kind.
Using EXEC AT
In addition to supporting an EXEC command that executes a dynamic batch locally, SQL Server also supports a command called EXEC AT that executes a dynamic batch against a linked server. What’s interesting about this tool is that if the provider you use to connect to the linked server supports parameters, you can pass inputs to the dynamic batch through parameters.
As an example, assuming you have access to another SQL Server instance called YourServer, run the following code to create a linked server:
EXEC sp_addlinkedserver
@server = N'YourServer',
@srvproduct = N'SQL Server';
Assuming you installed the sample database TSQLV3 in that instance, run the following code to test the EXEC AT command:
DECLARE @sql AS NVARCHAR(1000), @pid AS INT;
SET @sql =
N'SELECT productid, productname, unitprice
FROM TSQLV3.Production.Products
WHERE productid = ?;';
SET @pid = 3;
EXEC(@sql, @pid) AT [YourServer];
The code constructs a batch that queries the Production.Products table, filters a product ID that is provided as a parameter, and then executes the batch against the linked server, passing the value 3 as the input. This code generates the following output:
productid productname unitprice
----------- -------------- ----------
3 Product IMEHJ 10.00
Using the sp_executesql procedure
Unlike the EXEC command, the sp_executesql procedure supports defining input and output parameters, much like a stored procedure does. This tool accepts three parts as its inputs. The first part, called @stmt, is the input batch of code you want to run (with the references to the input and output parameters). The second part, called @params, is where you provide the declaration of your parameters. The third part is where you assign values to the dynamic batch’s input parameters and collect values from the output parameters into variables.
Back to the original task of querying the Employees table based on a last name that originated in user input, here’s how you achieve it with a parameterized query using sp_executesql:
DECLARE @s AS NVARCHAR(200);
SET @s = N'Davis';
DECLARE @sql AS NVARCHAR(1000);
SET @sql = 'SELECT empid, firstname, lastname, hiredate
FROM HR.Employees WHERE lastname = @lastname;';
PRINT @sql; -- For debug purposes
EXEC sp_executesql
@stmt = @sql,
@params = N'@lastname AS NVARCHAR(200)',
@lastname = @s;
The code generates the following query string and output:
SELECT empid, firstname, lastname, hiredate
FROM HR.Employees WHERE lastname = @lastname;
empid firstname lastname hiredate
----------- ---------- -------------------- ----------
1 Sara Davis 2012-05-01
This solution doesn’t have the performance and security problems you had with EXEC. Regarding performance, the query gets optimized in the first execution of the code and the plan is cached. Subsequent executions of the code can potentially reuse the cached plan regardless of which last name is passed. This behavior is quite similar to the way plans for parameterized queries in stored procedures are cached and reused.
Regarding security, because the actual user input is not embedded in the code, there’s absolutely no exposure to SQL injection. The user input is always considered as a value in the parameter and is never made an actual part of the code.
Dynamic pivot
In Chapter 4, “Grouping, pivoting, and windowing,” I covered pivoting methods and provided the following example demonstrating how to handle pivoting dynamically:
USE TSQLV3;
DECLARE
@cols AS NVARCHAR(1000),
@sql AS NVARCHAR(4000);
SET @cols =
STUFF(
(SELECT N',' + QUOTENAME(orderyear) AS [text()]
FROM (SELECT DISTINCT YEAR(orderdate) AS orderyear
FROM Sales.Orders) AS Years
ORDER BY orderyear
FOR XML PATH(''), TYPE).value('.[1]', 'VARCHAR(MAX)'), 1, 1, '')
SET @sql = N'SELECT custid, ' + @cols + N'
FROM (SELECT custid, YEAR(orderdate) AS orderyear, val
FROM Sales.OrderValues) AS D
PIVOT(SUM(val) FOR orderyear IN(' + @cols + N')) AS P;';
EXEC sys.sp_executesql @stmt = @sql;
This example constructs a pivot query that returns a row per customer, a column per order year, and the sum of all order values for each intersection of customer and year. The code returns the following output:
custid 2013 2014 2015
------- -------- --------- ---------
1 NULL 2022.50 2250.50
2 88.80 799.75 514.40
3 403.20 5960.78 660.00
4 1379.00 6406.90 5604.75
5 4324.40 13849.02 6754.16
6 NULL 1079.80 2160.00
7 9986.20 7817.88 730.00
8 982.00 3026.85 224.00
9 4074.28 11208.36 6680.61
10 1832.80 7630.25 11338.56
...
Dynamic SQL is used here to avoid the need to hard code the years into the query. Instead, you query the distinct years from the data. Using an aggregate string concatenation method that is based on the FOR XML PATH option, you construct the comma-separated list of years for the pivot query’s IN clause. This way, when orders are recorded from a new year, the next time you execute the code that year is automatically included. If you’re reading the book’s chapters out of order and are not familiar with pivoting and aggregate string concatenation methods, you can find those in Chapter 4 in the sections “Pivoting” and “Custom aggregations,” respectively. In the next section, I’ll assume you are familiar with both.
The dynamic pivot example from Chapter 4 handled a specific pivoting task. If you need a similar solution for a different pivot task, you need to duplicate the code and change the pivoting elements to the new ones. The following sp_pivot stored procedure provides a more generalized solution for dynamic pivoting:
USE master;
GO
IF OBJECT_ID(N'dbo.sp_pivot', N'P') IS NOT NULL DROP PROC dbo.sp_pivot;
GO
CREATE PROC dbo.sp_pivot
@query AS NVARCHAR(MAX),
@on_rows AS NVARCHAR(MAX),
@on_cols AS NVARCHAR(MAX),
@agg_func AS NVARCHAR(257) = N'MAX',
@agg_col AS NVARCHAR(MAX)
AS
BEGIN TRY
-- Input validation
IF @query IS NULL OR @on_rows IS NULL OR @on_cols IS NULL
OR @agg_func IS NULL OR @agg_col IS NULL
THROW 50001, 'Invalid input parameters.', 1;
-- Additional input validation goes here (SQL injection attempts, etc.)
DECLARE
@sql AS NVARCHAR(MAX),
@cols AS NVARCHAR(MAX),
@newline AS NVARCHAR(2) = NCHAR(13) + NCHAR(10);
-- If input is a valid table or view
-- construct a SELECT statement against it
IF COALESCE(OBJECT_ID(@query, N'U'), OBJECT_ID(@query, N'V')) IS NOT NULL
SET @query = N'SELECT * FROM ' + @query;
-- Make the query a derived table
SET @query = N'(' + @query + N') AS Query';
-- Handle * input in @agg_col
IF @agg_col = N'*' SET @agg_col = N'1';
-- Construct column list
SET @sql =
N'SET @result = ' + @newline +
N' STUFF(' + @newline +
N' (SELECT N'',['' + '
+ 'CAST(pivot_col AS sysname) + '
+ 'N'']'' AS [text()]' + @newline +
N' FROM (SELECT DISTINCT('
+ @on_cols + N') AS pivot_col' + @newline +
N' FROM' + @query + N') AS DistinctCols' + @newline +
N' ORDER BY pivot_col'+ @newline +
N' FOR XML PATH('''')),'+ @newline +
N' 1, 1, N'''');'
EXEC sp_executesql
@stmt = @sql,
@params = N'@result AS NVARCHAR(MAX) OUTPUT',
@result = @cols OUTPUT;
-- Create the PIVOT query
SET @sql =
N'SELECT *' + @newline +
N'FROM (SELECT '
+ @on_rows
+ N', ' + @on_cols + N' AS pivot_col'
+ N', ' + @agg_col + N' AS agg_col' + @newline +
N' FROM ' + @query + N')' +
+ N' AS PivotInput' + @newline +
N' PIVOT(' + @agg_func + N'(agg_col)' + @newline +
N' FOR pivot_col IN(' + @cols + N')) AS PivotOutput;'
EXEC sp_executesql @sql;
END TRY
BEGIN CATCH
;THROW;
END CATCH;
GO
The stored procedure accepts the following input parameters:
![]() The @query parameter is either a table or view name or an entire query whose result you want to pivot—for example, N‘Sales.OrderValues’.
The @query parameter is either a table or view name or an entire query whose result you want to pivot—for example, N‘Sales.OrderValues’.
![]() The @on_rows parameter is the pivot grouping element—for example, N‘custid’.
The @on_rows parameter is the pivot grouping element—for example, N‘custid’.
![]() The @on_cols parameter is the pivot spreading element—for example, N‘YEAR(orderdate)’.
The @on_cols parameter is the pivot spreading element—for example, N‘YEAR(orderdate)’.
![]() The @agg_func parameter is the pivot aggregate function—for example, N‘SUM’.
The @agg_func parameter is the pivot aggregate function—for example, N‘SUM’.
![]() The @agg_col parameter is the input expression to the pivot aggregate function—for example, N‘val’.
The @agg_col parameter is the input expression to the pivot aggregate function—for example, N‘val’.
![]() Important
Important
This stored procedure supports SQL injection by definition. The input parameters are injected directly into the code to form the pivot query. For this reason, you want to be extremely careful with how and for what purpose you use it. For example, it could be a good idea to restrict the use of this procedure only to developers to aid in constructing pivot queries. Having an application invoke this procedure after collecting user inputs puts your environment at risk.
Because the stored procedure is created in the master database with the sp_ prefix, it can be executed in the context of any database. This is done either by calling it without the database prefix while connected to the desired database or by invoking it using the three-part name with the desired database as the database prefix, as in mydb.dbo.sp_pivot.
The stored procedure performs some basic input validation to ensure all inputs were provided. The procedure then checks if the input @query contains an existing table or view name in the target database. If it does, the procedure replaces the content of @query with a query against the object; if it does not, the procedure assumes that @query already contains a query. Then the procedure replaces the contents of @query with the definition of a derived table called Query based on the input query. This derived table will be considered as the input for finding both the distinct spreading values and the final pivot query.
The next step in the procedure is to check if the input @agg_col is *. It’s common for people to use * as the input to the aggregate function COUNT to count rows. However, the PIVOT operator doesn’t support * as an input to COUNT. So the code replaces * with the constant 1, and it will later define a column called agg_col based on what’s stored in @agg_col. This column will eventually be used as the input to the aggregate function stored in @agg_func.
The next two steps represent the heart of the stored procedure. These steps construct two different dynamic batches. The first creates a string with the comma-separated list of distinct spreading values that will eventually appear in the PIVOT operator’s IN clause. This batch is executed with sp_executesql and, using an output parameter called @result, the result string is stored in a local variable called @cols.
The second dynamic batch holds the final pivot query. The code constructs a derived table called PivotInput from a query against the derived table stored in @query. All pivoting elements (grouping, spreading, and aggregation) are injected into the inner query’s SELECT list. Then the PIVOT operator’s specification is constructed from the input aggregate function applied to agg_col and the IN clause with the comma-separated list of spreading values stored in @cols. The final pivot query is then executed using sp_executesql.
As an example of using the procedure, the following code computes the count of orders per employee and order year pivoted by order month:
EXEC TSQLV3.dbo.sp_pivot
@query = N'Sales.Orders',
@on_rows = N'empid, YEAR(orderdate) AS orderyear',
@on_cols = N'MONTH(orderdate)',
@agg_func = N'COUNT',
@agg_col = N'*';
This code generates the following output:
empid orderyear 1 2 3 4 5 6 7 8 9 10 11 12
------- ---------- --- --- --- --- --- --- --- --- --- --- --- ---
1 2014 3 2 5 1 5 4 7 3 8 7 3 7
5 2013 0 0 0 0 0 0 3 0 1 2 2 3
2 2015 7 3 9 18 2 0 0 0 0 0 0 0
6 2014 2 2 2 4 2 2 2 2 1 4 5 5
8 2014 5 8 6 2 4 3 6 5 3 7 2 3
9 2015 5 4 6 4 0 0 0 0 0 0 0 0
2 2013 0 0 0 0 0 0 1 2 5 2 2 4
3 2014 7 9 3 5 5 6 2 4 4 7 8 11
7 2013 0 0 0 0 0 0 0 1 2 5 3 0
4 2015 6 14 12 10 2 0 0 0 0 0 0 0
...
As another example, the following code computes the sum of order values (quantity * unit price) per employee pivoted by order year:
EXEC TSQLV3.dbo.sp_pivot
@query = N'SELECT O.orderid, empid, orderdate, qty, unitprice
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid',
@on_rows = N'empid',
@on_cols = N'YEAR(orderdate)',
@agg_func = N'SUM',
@agg_col = N'qty * unitprice';
This code generates the following output:
empid 2013 2014 2015
------ --------- ---------- ---------
9 11365.70 29577.55 42020.75
3 19231.80 111788.61 82030.89
6 17731.10 45992.00 14475.00
7 18104.80 66689.14 56502.05
1 38789.00 97533.58 65821.13
4 53114.80 139477.70 57594.95
5 21965.20 32595.05 21007.50
2 22834.70 74958.60 79955.96
8 23161.40 59776.52 50363.11
When you’re done, run the following code for cleanup:
USE master;
IF OBJECT_ID(N'dbo.sp_pivot', N'P') IS NOT NULL DROP PROC dbo.sp_pivot;
Dynamic search conditions
Dynamic search conditions, also known as dynamic filtering, are a common need in applications. The idea is that the application provides the user with an interface to filter data by various attributes, and the user chooses which attributes to filter by with each request. To demonstrate techniques to handle dynamic search conditions, I’ll use a table called Orders in my examples. Run the following code to create the Orders table in tempdb as a copy of TSQLV3.Sales.Orders, along with a few indexes to support common filters:
SET NOCOUNT ON;
USE tempdb;
IF OBJECT_ID(N'dbo.GetOrders', N'P') IS NOT NULL DROP PROC dbo.GetOrders;
IF OBJECT_ID(N'dbo.Orders', N'U') IS NOT NULL DROP TABLE dbo.Orders;
GO
SELECT orderid, custid, empid, orderdate,
CAST('A' AS CHAR(200)) AS filler
INTO dbo.Orders
FROM TSQLV3.Sales.Orders;
CREATE CLUSTERED INDEX idx_orderdate ON dbo.Orders(orderdate);
CREATE UNIQUE INDEX idx_orderid ON dbo.Orders(orderid);
CREATE INDEX idx_custid_empid ON dbo.Orders(custid, empid) INCLUDE(orderid, orderdate, filler);
Your task is to create a stored procedure called dbo.GetOrders that accepts four optional inputs, called @orderid, @custid, @empid, and @orderdate. The procedure is supposed to query the Orders table and filter the rows based only on the parameters that get non-NULL input values.
The following implementation of the stored procedure represents one of the most commonly used techniques to handle the task:
IF OBJECT_ID(N'dbo.GetOrders', N'P') IS NOT NULL DROP PROC dbo.GetOrders;
GO
CREATE PROC dbo.GetOrders
@orderid AS INT = NULL,
@custid AS INT = NULL,
@empid AS INT = NULL,
@orderdate AS DATE = NULL
AS
SELECT orderid, custid, empid, orderdate, filler
FROM dbo.Orders
WHERE (orderid = @orderid OR @orderid IS NULL)
AND (custid = @custid OR @custid IS NULL)
AND (empid = @empid OR @empid IS NULL)
AND (orderdate = @orderdate OR @orderdate IS NULL);
GO
The procedure uses a static query that, for each parameter, uses the following disjunction of predicates (OR’d predicates): column = @parameter OR @parameter IS NULL. If a value isn’t provided for the parameter, the right predicate is true. With a disjunction of predicates when one of the operands is true, the whole thing is true, so no filtering happens based on this column. If a value is specified, the right predicate is false; therefore, the left predicate is the only one that counts for determining which rows to filter.
This solution is simple and easy to maintain; however, absent an extra element, it tends to result in suboptimal query plans. The reason for this is that when you execute the procedure for the first time, the optimizer optimizes the parameterized form of the code, including all predicates from the query. This means that both the predicates that are relevant for the current execution of the query and the ones that aren’t relevant are included in the plan. This approach is used to promote plan reuse behavior to save the time and resources that would have been associated with the creation of a new plan with every execution. This topic is covered in detail later in the chapter in the “Compilations, recompilations, and reuse of execution plans” section. This approach guarantees that if the procedure is called again with a different set of relevant parameters, the cached plan would still be valid and therefore can be reused. But if the plan has to be correct while taking into consideration all predicates in the query, including the irrelevant ones for the current execution, you realize that it’s unlikely to be efficient.
As an example, run the following code to execute the procedure with an input value provided only to the @orderdate parameter:
EXEC dbo.GetOrders @orderdate = '20140101';
Observe the plan that the optimizer created for the query as shown in Figure 9-1.
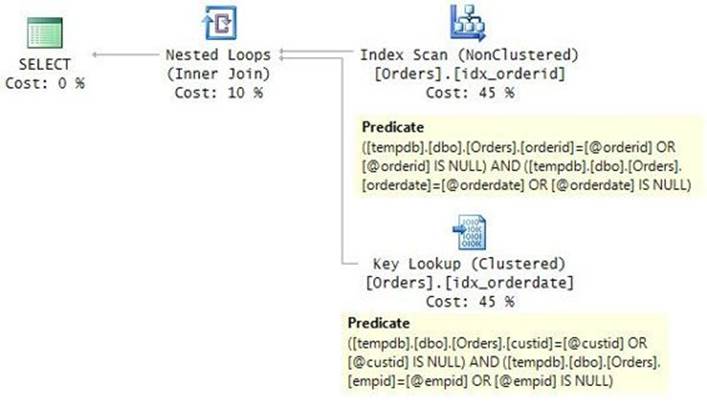
FIGURE 9-1 Plan for a solution using a static query.
There are different places in the plan where the different predicates are processed, but the point is that all predicates are processed. With a filter based only on the orderdate column, the most efficient plan would be one that performs a seek and a range scan in the clustered index. But what you see here is an entirely different plan that is very inefficient for this execution.
You can do a number of things to get efficient plans. If you are willing to forgo the benefits of plan reuse, add OPTION(RECOMPILE) at the end of the query, which forces SQL Server to create a new plan with every execution. It’s critical, though, to use the statement-level RECOMPILE option and not the procedure-level one. With the former, the parser performs parameter embedding, where it replaces the parameters with the constants and removes the redundant parts of the query before passing it to the optimizer. As a result, the query that gets optimized contains only the predicates that are relevant to the current execution, so the likelihood of getting an efficient plan is quite high.
Run the following code to re-create the GetOrders procedure, adding the RECOMPILE option to the query:
IF OBJECT_ID(N'dbo.GetOrders', N'P') IS NOT NULL DROP PROC dbo.GetOrders;
GO
CREATE PROC dbo.GetOrders
@orderid AS INT = NULL,
@custid AS INT = NULL,
@empid AS INT = NULL,
@orderdate AS DATE = NULL
AS
SELECT orderid, custid, empid, orderdate, filler
FROM dbo.Orders
WHERE (orderid = @orderid OR @orderid IS NULL)
AND (custid = @custid OR @custid IS NULL)
AND (empid = @empid OR @empid IS NULL)
AND (orderdate = @orderdate OR @orderdate IS NULL)
OPTION (RECOMPILE);
GO
Run the following code to test the procedure with a filter based on the orderdate column:
EXEC dbo.GetOrders @orderdate = '20140101';
The plan for this execution is shown in Figure 9-2.
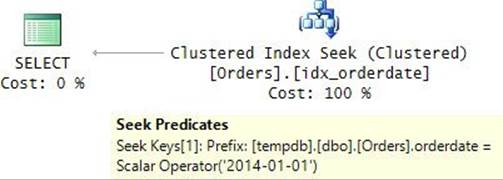
FIGURE 9-2 Plan for a query with RECOMPILE filtering by orderdate.
The plan is optimal, with a seek in the clustered index, which is defined with orderdate as the key. Observe that only the predicate involving the orderdate column appears in the plan, and that the reference to the parameter was replaced with the constant.
Execute the procedure again, this time with a filter based on the orderid column:
EXEC dbo.GetOrders @orderid = 10248;
The plan for this execution is shown in Figure 9-3.
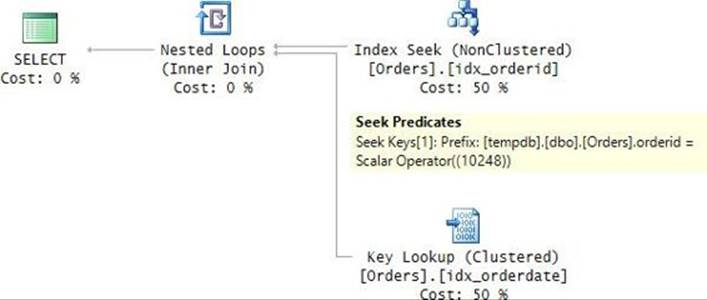
FIGURE 9-3 Plan for a query with RECOMPILE filtering by orderid.
The plan is, again, optimal, performing a seek in the index on orderid, followed by a lookup. The only predicate appearing in this plan is the one based on the orderid column—again, with the parameter replaced with the constant.
Because of the forced recompiles and parameter embedding that takes place, you get very efficient plans. The solution uses static SQL, so it’s not exposed to SQL injection attacks. It’s simple and easy to maintain. The one drawback of this solution is that, by definition, it doesn’t reuse plans. But what if the procedure is called frequently with common combinations of input parameters and you would like to get both efficient plans and efficient plan reuse? There are a couple of ways to achieve this goal.
You could create a separate procedure for each unique combination of parameters and have the GetOrders procedure use nested IF-ELSE IF statements to invoke the right procedure based on which parameters are specified. Each procedure will have a unique query with only the relevant predicates, without the RECOMPILE option. With this solution, the likelihood of getting efficient plans is high. Also, the plans can be cached and reused. Because the solution uses static SQL, it has no exposure to SQL injection. However, as you can imagine, it can be a maintenance nightmare. With P parameters, the number of procedures you will need is 2P. For example, with 8 parameters, you will have 256 procedures. Imagine that whenever you need to make a change, you will need to apply it to all procedures. Not a picnic.
Another strategy is to use dynamic SQL, but with a parameterized form of the code to promote efficient plan reuse behavior and avoid exposure to SQL injection. You construct the query string starting with the known SELECT and FROM clauses of the query. You start the WHERE clause with WHERE 1 = 1. This way, you don’t need to maintain a flag to know whether you need a WHERE clause and whether you need an AND operator before concatenating a predicate. The parser will eliminate this redundant predicate. Then, for each procedure parameter whose value was specified, you concatenate a parameterized predicate to the WHERE clause. Then you execute the parameterized query using sp_executesql, passing the query string to the @stmt input, declaring the four dynamic batch parameters in the @params input, and assigning the procedure parameters to the respective dynamic batch parameters.
Here’s the code to re-create the procedure based on the new strategy:
IF OBJECT_ID(N'dbo.GetOrders', N'P') IS NOT NULL DROP PROC dbo.GetOrders;
GO
CREATE PROC dbo.GetOrders
@orderid AS INT = NULL,
@custid AS INT = NULL,
@empid AS INT = NULL,
@orderdate AS DATE = NULL
AS
DECLARE @sql AS NVARCHAR(1000);
SET @sql =
N'SELECT orderid, custid, empid, orderdate, filler'
+ N' /* 27702431-107C-478C-8157-6DFCECC148DD */'
+ N' FROM dbo.Orders'
+ N' WHERE 1 = 1'
+ CASE WHEN @orderid IS NOT NULL THEN
N' AND orderid = @oid' ELSE N'' END
+ CASE WHEN @custid IS NOT NULL THEN
N' AND custid = @cid' ELSE N'' END
+ CASE WHEN @empid IS NOT NULL THEN
N' AND empid = @eid' ELSE N'' END
+ CASE WHEN @orderdate IS NOT NULL THEN
N' AND orderdate = @dt' ELSE N'' END;
EXEC sp_executesql
@stmt = @sql,
@params = N'@oid AS INT, @cid AS INT, @eid AS INT, @dt AS DATE',
@oid = @orderid,
@cid = @custid,
@eid = @empid,
@dt = @orderdate;
GO
Observe the GUID that I planted in a comment in the query. I created it by invoking the NEWID function. The point is to make it easy later to track down the cached plans that are executed by the procedure to demonstrate plan caching and reuse behavior. I’ll demonstrate this shortly.
Run the following code to execute the procedure twice with a filter based on the orderdate column, but with two different dates:
EXEC dbo.GetOrders @orderdate = '20140101';
EXEC dbo.GetOrders @orderdate = '20140102';
The plan for these executions is shown in Figure 9-4.
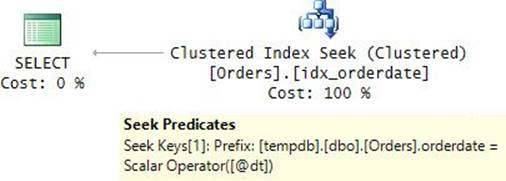
FIGURE 9-4 Plan for a dynamic query filtering by orderdate.
The plan is very efficient because the query that was optimized contains only the relevant predicates. Furthermore, unlike when using the RECOMPILE query option, there’s no parameter embedding here, which is good in this case. The parameterized form of the query gets optimized and cached, allowing plan reuse when the procedure is executed with the same combination of parameters. In the first execution of the procedure with a filter based on orderdate, SQL Server couldn’t find an existing plan in cache, so it optimized the query and cached the plan. For the second execution, it found a cached plan for the same query string and therefore reused it.
Execute the procedure again, this time with a filter based on the orderid column:
EXEC dbo.GetOrders @orderid = 10248;
This time the constructed query string contains a parameterized filter based on the orderid column. Because there was no plan in cache for this query string, SQL Server created a new plan and cached it too. Figure 9-5 shows the plan that SQL Server created for this query string.
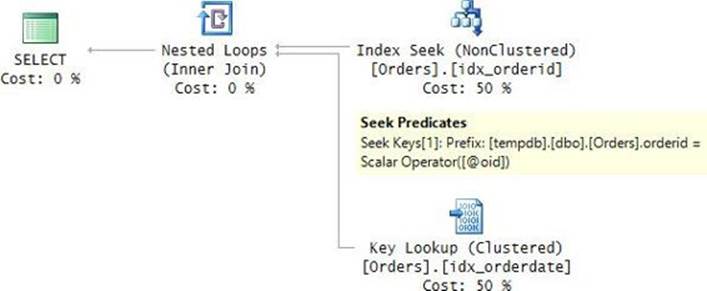
FIGURE 9-5 Plan for a dynamic query filtering by orderid.
Again, you get a highly efficient plan for this query string, with only the relevant predicates in a parameterized form. Now you have two plans in cache for the two unique query strings that were executed by the stored procedure. Use the following query to examine the cached plans and their reuse behavior, filtering only plans for queries that contain the GUID you planted in the code:
SELECT usecounts, text
FROM sys.dm_exec_cached_plans AS CP
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) AS ST
WHERE ST.text LIKE '%27702431-107C-478C-8157-6DFCECC148DD%'
AND ST.text NOT LIKE '%sys.dm_exec_cached_plans%'
AND CP.objtype = 'Prepared';
This code generates the following output:
usecounts text
----------- -----------------------------------------------------
1 (@oid AS INT, @cid AS INT, @eid AS INT, @dt AS DATE)
SELECT orderid, custid, empid, orderdate, filler
/* 27702431-107C-478C-8157-6DFCECC148DD */
FROM dbo.Orders WHERE 1 = 1 AND orderid = @oid
2 (@oid AS INT, @cid AS INT, @eid AS INT, @dt AS DATE)
SELECT orderid, custid, empid, orderdate, filler
/* 27702431-107C-478C-8157-6DFCECC148DD */
FROM dbo.Orders WHERE 1 = 1 AND orderdate = @dt
Observe that two plans were created because there were two unique query strings—one with a filter on orderid, so far used once, and another with a filter on orderdate, so far used twice.
This solution supports efficient plans and efficient plan reuse. Because the dynamic code uses parameters rather than injecting the constants into the code, it is not exposed to SQL injection attacks. Compared to the solution with the multiple procedures, this one is much easier to maintain. It certainly seems like this solution has strong advantages compared to the others.
There’s an excellent paper written on the topic of dynamic search conditions by my friend and fellow SQL Server MVP Erland Sommarskog. If this topic is important to you, be sure to check out Erland’s paper. You can find it at his website: http://www.sommarskog.se/dyn-search.html.
Dynamic sorting
Similar to dynamic search conditions, dynamic sorting is another common application need. As an example, suppose you need to develop a stored procedure called dbo.GetSortedShippers in the TSQLV3 database. The procedure accepts an input parameter called @colname, and it is supposed to return the rows from the Sales.Shippers table sorted by the input column name.
One of the most common first attempts at a solution for the task is to use a static query with an ORDER BY clause based on a CASE expression that looks like this:
ORDER BY
CASE @colname
WHEN N'shipperid' THEN shipperid
WHEN N'companyname' THEN companyname
WHEN N'phone' THEN phone
END
If you try running the procedure passing N‘companyname’ as input, you get a type-conversion error. The reason for the error is that CASE is an expression, and as such, the type of the result is determined by the data type precedence among the expression’s operands (the possible returned values in this case). Among the types of the three operands, INT is the one with the highest data type precedence; hence, it’s predetermined that the CASE expression’s type is INT. So when you pass N‘companyname’ as input, SQL Server tries to convert the companyname values to integers and, of course, fails.
One possible workaround is to add the following ELSE clause to the expression:
ORDER BY
CASE @colname
WHEN N'shipperid' THEN shipperid
WHEN N'companyname' THEN companyname
WHEN N'phone' THEN phone
ELSE CAST(NULL AS SQL_VARIANT)
END
This clause is not supposed to be activated because the procedure will be called by the application with names of columns that exist in the table; however, from SQL Server’s perspective, it theoretically could be activated. The SQL_VARIANT type is considered stronger than the other types; therefore, it’s chosen as the CASE expression’s type. The thing with the SQL_VARIANT type is that it can hold within it most other base types, including all those that participate in our expression, while preserving the information about the base type and its ordering semantics. So when the user calls the procedure with, say, N‘companyname’ as input, the CASE expression returns the companyname values as SQL_VARIANT values with NVARCHAR as the base type. So you get correct NVARCHAR-based ordering semantics.
With this trick, you get a solution that is correct. However, similar to non SARGable filters, because you’re applying manipulation to the ordering element, the optimizer will not rely on index order even if you have a supporting covering index. Curiously, as described by Paul White in the article “Parameter Sniffing, Embedding, and the RECOMPILE Options” (http://sqlperformance.com/2013/08/t-sql-queries/parameter-sniffing-embedding-and-the-recompile-options), as long as you use a separate CASE expression for each input and add the RECOMPILE query option, you get a plan that can rely on index order. That’s thanks to the parameter embedding employed by the parser that’s similar to what I explained in the discussion about dynamic search conditions. So, instead of using one CASE expression, you will use multiple expressions, like so:
ORDER BY
CASE WHEN @colname = N'shipperid' THEN shipperid END,
CASE WHEN @colname = N'companyname' THEN companyname END,
CASE WHEN @colname = N'phone' THEN phone END
OPTION(RECOMPILE)
Say the user executes the procedure passing N‘companyname’ as input; after parsing, the ORDER BY clause becomes the following (although NULL constants are normally not allowed in the ORDER BY directly): ORDER BY NULL, companyname, NULL. As long as you have a covering index in place, the optimizer can certainly rely on its order and avoid explicit sorting in the plan.
For the procedure to be more flexible, you might also want to support a second parameter called @sortdir to allow the user to specify the sort direction (‘A’ for ascending and ‘D’ for descending). Supporting this second parameter will require you to double the number of CASE expressions in the query.
Run the following code to create the GetSortedShippers procedure based on this strategy:
USE TSQLV3;
IF OBJECT_ID(N'dbo.GetSortedShippers', N'P') IS NOT NULL DROP PROC dbo.GetSortedShippers;
GO
CREATE PROC dbo.GetSortedShippers
@colname AS sysname, @sortdir AS CHAR(1) = 'A'
AS
SELECT shipperid, companyname, phone
FROM Sales.Shippers
ORDER BY
CASE WHEN @colname = N'shipperid' AND @sortdir = 'A' THEN shipperid END,
CASE WHEN @colname = N'companyname' AND @sortdir = 'A' THEN companyname END,
CASE WHEN @colname = N'phone' AND @sortdir = 'A' THEN phone END,
CASE WHEN @colname = N'shipperid' AND @sortdir = 'D' THEN shipperid END DESC,
CASE WHEN @colname = N'companyname' AND @sortdir = 'D' THEN companyname END DESC,
CASE WHEN @colname = N'phone' AND @sortdir = 'D' THEN phone END DESC
OPTION (RECOMPILE);
GO
Run the following code to test the procedure:
EXEC dbo.GetSortedShippers N'shipperid', N'D';
After parsing, the ORDER BY clause became the following:
ORDER BY NULL, NULL, NULL, shipperid DESC, NULL DESC, NULL DESC
The plan for this execution is shown in Figure 9-6.
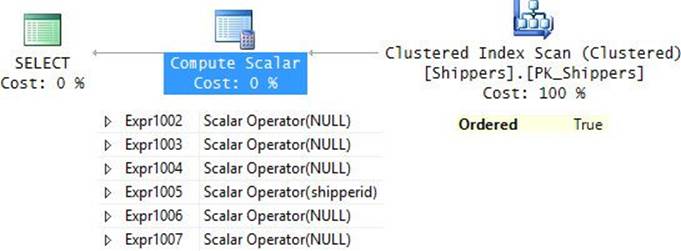
FIGURE 9-6 Plan for a query with multiple CASE expressions and RECOMPILE.
Observe that the plan performs an ordered scan of the clustered index on shipperid, avoiding the need for explicit sorting.
This solution produces efficient plans. Because it uses a static query, it’s not exposed to SQL injection attacks. However, it has two drawbacks. First, by definition, it does not reuse query plans. Second, it doesn’t lend itself to supporting multiple sort columns as inputs; you’d just end up with many CASE expressions.
A solution that doesn’t have these drawbacks is one based on dynamic SQL. You construct a query string with an ORDER BY clause with an injected sort column and direction. The obvious challenge with this solution is the exposure to SQL injection. Then, again, table structures tend to be pretty stable. So you could incorporate a test to ensure that the input column name appears in the hard-coded set of sort columns you want to support from the table. If the column doesn’t appear in the set, you abort the query, suspecting an attempted SQL injection. If the set of supported sort columns needs to change, you alter the procedure definition. Most likely, such changes will be infrequent enough to make this approach viable.
Use the following code to re-create the procedure based on this strategy:
IF OBJECT_ID(N'dbo.GetSortedShippers', N'P') IS NOT NULL DROP PROC dbo.GetSortedShippers;
GO
CREATE PROC dbo.GetSortedShippers
@colname AS sysname, @sortdir AS CHAR(1) = 'A'
AS
IF @colname NOT IN(N'shipperid', N'companyname', N'phone')
THROW 50001, 'Column name not supported. Possibly a SQL injection attempt.', 1;
DECLARE @sql AS NVARCHAR(1000);
SET @sql = N'SELECT shipperid, companyname, phone
FROM Sales.Shippers
ORDER BY '
+ QUOTENAME(@colname) + CASE @sortdir WHEN 'D' THEN N' DESC' ELSE '' END + ';';
EXEC sys.sp_executesql @stmt = @sql;
GO
The QUOTENAME function is used to delimit the sort column name with square brackets. In our specific example, delimiters aren’t required, but in case you need to support column names that are considered irregular identifiers, you will need the delimiters.
Use the following code to test the procedure:
EXEC dbo.GetSortedShippers N'shipperid', N'D';
The plan for this execution is shown in Figure 9-7.

FIGURE 9-7 Plan for a dynamic query.
It’s an efficient plan that relies on index order. Unlike the previous solution, this one can efficiently reuse previously cached plans. This solution can also be easily extended if you need to support multiple input sort columns, as the following revised definition demonstrates:
IF OBJECT_ID(N'dbo.GetSortedShippers', N'P') IS NOT NULL DROP PROC dbo.GetSortedShippers;
GO
CREATE PROC dbo.GetSortedShippers
@colname1 AS sysname, @sortdir1 AS CHAR(1) = 'A',
@colname2 AS sysname = NULL, @sortdir2 AS CHAR(1) = 'A',
@colname3 AS sysname = NULL, @sortdir3 AS CHAR(1) = 'A'
AS
IF @colname1 NOT IN(N'shipperid', N'companyname', N'phone')
OR @colname2 IS NOT NULL AND @colname2 NOT IN(N'shipperid', N'companyname', N'phone')
OR @colname3 IS NOT NULL AND @colname3 NOT IN(N'shipperid', N'companyname', N'phone')
THROW 50001, 'Column name not supported. Possibly a SQL injection attempt.', 1;
DECLARE @sql AS NVARCHAR(1000);
SET @sql = N'SELECT shipperid, companyname, phone
FROM Sales.Shippers
ORDER BY '
+ QUOTENAME(@colname1) + CASE @sortdir1 WHEN 'D' THEN N' DESC' ELSE '' END
+ ISNULL(N',' + QUOTENAME(@colname2) + CASE @sortdir2 WHEN 'D' THEN N' DESC' ELSE '' END, N'')
+ ISNULL(N',' + QUOTENAME(@colname3) + CASE @sortdir3 WHEN 'D' THEN N' DESC' ELSE '' END, N'')
+ ';';
EXEC sys.sp_executesql @stmt = @sql;
GO
Regarding security, it’s important to know that normally the user executing the stored procedure will need direct permissions to run the code that executes dynamically. If you don’t want to grant such direct permissions, you can use the EXECUTE AS clause to impersonate the security context of the user specified in that clause. You can find the details about how to do this in Books Online: http://msdn.microsoft.com/en-us/library/ms188354.aspx.
As an extra resource, you can find excellent coverage of dynamic SQL in the paper “The Curse and Blessings of Dynamic SQL” by Erland Sommarskog: http://www.sommarskog.se/dynamic_sql.html.
User-defined functions
User-defined functions (UDFs) give you powerful encapsulation and reusability capabilities. They are convenient to use because they can be embedded in queries. However, they also incur certain performance-related penalties you should be aware of. For this purpose, I’m referring to scalar UDFs and multistatement, table-valued functions (TVFs). I’m not referring to inline TVFs, which I covered in Chapter 3, “Multi-table queries.” Inline TVFs, by definition, get inlined, so they don’t incur any performance penalties.
This section covers T-SQL UDFs. Later, the chapter covers CLR UDFs in the “SQLCLR programming” section.
Scalar UDFs
Scalar UDFs accept arguments and return a scalar value. They can be incorporated where single-valued expressions are allowed—for example, in queries, constraints, and computed columns.
T-SQL UDFs (not just scalar) are limited in a number of ways. They are not allowed to have side effects on the database or the system. Therefore, you are not allowed to apply data or structural changes to database objects other than variables (including table variables) defined within the function. You’re also not allowed to invoke activities that have indirect side effects, like when invoking the RAND and NEWID functions. For example, one invocation of the RAND function will determine the seed that will be used in a subsequent seedless invocation of RAND. You’re not allowed to use dynamic SQL, and you’re not allowed to include exception handling with the TRY-CATCH construct.
Scalar T-SQL UDFs are implemented in two main ways. In one, the function invokes a single expression that returns a scalar result. In the other, the function invokes multiple statements and eventually returns a scalar result. Either way, you need to be aware that there are performance penalties associated with the use of scalar UDFs. I’ll start with an example for a scalar UDF that is based on a single expression. I’ll compare the performance of a query that contains the expression directly to one where you encapsulate the expression in a UDF.
The following query filters only orders that were placed on the last day of the year:
USE PerformanceV3;
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders
WHERE orderdate = DATEADD(year, DATEDIFF(year, '19001231', orderdate), '19001231');
If you’re not familiar with the method used here to compute the last day of the year, you can find the details in Chapter 7, “Working with date and time.”
On my system, this query got the execution plan shown in Figure 9-8.
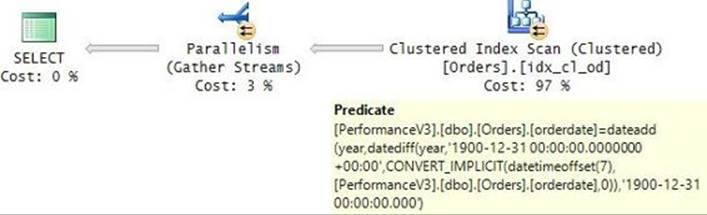
FIGURE 9-8 Plan for a query without a function.
Observe that the plan uses a parallel scan of the clustered index, mainly to process the filter using multiple threads. When running this query against hot cache in my system, the query took 281 milliseconds to complete, and it used 704 milliseconds of CPU time.
To check the impact of parallelism here, I forced a serial plan by specifying the hint MAXDOP 1, like so:
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders
WHERE orderdate = DATEADD(year, DATEDIFF(year, '19001231', orderdate), '19001231')
OPTION(MAXDOP 1);
This time, it took the query 511 milliseconds to complete. So, on my system, the execution time of the parallel plan was half the execution time of the serial plan.
Without a doubt, from a programming perspective, it’s beneficial to encapsulate the expression that computes the end-of-year date in a scalar UDF. This encapsulation helps you hide the complexity and enables reusability. Run the following code to encapsulate the expression in theEndOfYear UDF.
IF OBJECT_ID(N'dbo.EndOfYear') IS NOT NULL DROP FUNCTION dbo.EndOfYear;
GO
CREATE FUNCTION dbo.EndOfYear(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEADD(year, DATEDIFF(year, '19001231', @dt), '19001231');
END;
GO
Now run the query after you replace the direct expression with a call to the UDF, like so:
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders
WHERE orderdate = dbo.EndOfYear(orderdate);
There’s no question about the programmability benefits you get here compared to not using the UDF. The code is clearer and more concise. However, the impact of the use of the UDF on performance is quite severe. Observe the plan for this query shown in Figure 9-9.
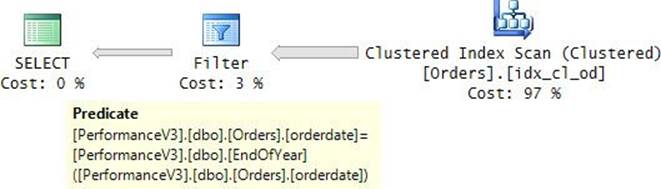
FIGURE 9-9 Plan for a query with a scalar UDF.
Unfortunately, even when the UDF is based on a single expression, SQL Server doesn’t inline it. This means that the UDF is invoked per row in the underlying table, as you can see in the Filter operator’s Predicate property in the plan. In our case, the UDF gets invoked 1,000,000 times. There’s overhead in each invocation, and with a million invocations this overhead amounts to something substantial. Also, observe that the query plan is serial. Any use of T-SQL scalar UDFs prevents parallelism.
It took this query over four seconds to complete on my system, with a total CPU cost of over four seconds. That’s about 16 times more than the query without the UDF (with the default parallel plan), and 8 times more than when I forced the serial plan. Either way, as you can see, the penalty for using the UDF is quite high.
Curiously, there’s a workaround that will allow you to encapsulate your logic in a function while not incurring the performance penalty. Instead of using a scalar UDF, use an inline TVF. The tricky part is that an inline TVF has to return a query. So specify the expression along with a column alias in a FROM-less SELECT query, and return that query from the function. Here’s the code to drop the scalar UDF and create an inline TVF instead:
IF OBJECT_ID(N'dbo.EndOfYear') IS NOT NULL DROP FUNCTION dbo.EndOfYear;
GO
CREATE FUNCTION dbo.EndOfYear(@dt AS DATE) RETURNS TABLE
AS
RETURN
SELECT DATEADD(year, DATEDIFF(year, '19001231', @dt), '19001231') AS endofyear;
GO
To invoke a table function in a query and pass a column from the outer table as input, you need to use either the explicit APPLY operator or an implicit one in a subquery. Here’s an example using the implicit form:
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders
WHERE orderdate = (SELECT endofyear FROM dbo.EndOfYear(orderdate));
This time, the expression in the function does get inlined. SQL Server creates the same plan as the one I showed earlier in Figure 9-8 for the original query without the UDF. Thus, there’s no performance penalty for using the inline TVF.
As for scalar UDFs that are based on multiple statements, those are usually used to implement iterative logic. As discussed earlier in the book in Chapter 2, “Query tuning,” T-SQL iterations are slow. So, especially when you need to apply many iterations, you’ll tend to get better performance using a CLR UDF instead of a T-SQL one. Furthermore, as long as a CLR UDF isn’t marked as applying data access, it doesn’t prevent parallelism.
As an example for a T-SQL UDF that uses iterative logic, consider the following definition of the RemoveChars UDF:
USE TSQLV3;
IF OBJECT_ID(N'dbo.RemoveChars', N'FN') IS NOT NULL DROP FUNCTION dbo.RemoveChars;
GO
CREATE FUNCTION dbo.RemoveChars(@string AS NVARCHAR(4000), @pattern AS NVARCHAR(4000))
RETURNS NVARCHAR(4000)
AS
BEGIN
DECLARE @pos AS INT;
SET @pos = PATINDEX(@pattern, @string);
WHILE @pos > 0
BEGIN
SET @string = STUFF(@string, @pos, 1, N'');
SET @pos = PATINDEX(@pattern, @string);
END;
RETURN @string;
END;
GO
This function accepts two parameters as inputs. One is @string, representing an input string. Another is @pattern, representing the pattern of a single character. The UDF’s purpose is to return a string representing the input string after the removal of all occurrences of the input character pattern.
The function’s code starts by using the PATINDEX function to compute the first position of the character pattern in @string and stores it in @pos. The code then enters a loop that keeps running while there are still occurrences of the character pattern in the string. In each iteration, the code uses the STUFF function to remove the first occurrence from the string and then looks for the position of the next occurrence. Once the loop is done, the code returns what’s left in @string.
Here’s an example for using the UDF in a query against the Sales.Customers table to return clean phone numbers (by removing all nonmeaningful characters):
SELECT custid, phone, dbo.RemoveChars(phone, N'%[^0-9]%') AS cleanphone
FROM Sales.Customers;
This function returns the following output:
custid phone cleanphone
------- --------------- -----------
1 030-3456789 0303456789
2 (5) 789-0123 57890123
3 (5) 123-4567 51234567
4 (171) 456-7890 1714567890
5 0921-67 89 01 0921678901
6 0621-67890 062167890
7 67.89.01.23 67890123
8 (91) 345 67 89 913456789
9 23.45.67.89 23456789
10 (604) 901-2345 6049012345
...
You will find coverage of CLR UDFs later in the chapter in the “SQLCLR programming” section. In that section, you will find the definition of a CLR UDF called RegExReplace. This UDF applies regex-based replacement to the input string based on the input regex pattern. With this UDF, you handle the task using the following code:
SELECT custid, phone, dbo.RegExReplace(N'[^0-9]', phone, N'') AS cleanphone
FROM Sales.Customers;
You get two main advantages by using the CLR-based solution rather than the T-SQL solution. First, regular expressions are much richer compared to the primitive patterns you can use with the PATINDEX function and the LIKE predicate. Second, you get better performance. I tested the query against a table with 1,000,000 rows. Even though there aren’t many iterations required to clean phone numbers, the query ran for 16 seconds with the T-SQL UDF and 8 seconds with the CLR one.
Multistatement TVFs
Multistatement TVFs have multiple statements in their body, and they return a table variable as their output. The returned table variable is defined in the function’s header. The purpose of the body is to fill the table variable with data. When you query such a function, SQL Server declares the table variable, runs the flow to fill it with data, and then hands it to the calling query.
To demonstrate using multistatement TVFs, I’ll use a table called Employees that you create and populate by running the following code:
SET NOCOUNT ON;
USE tempdb;
GO
IF OBJECT_ID(N'dbo.Employees', N'U') IS NOT NULL DROP TABLE dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David', $10000.00),
(2, 1, 'Eitan', $7000.00),
(3, 1, 'Ina', $7500.00),
(4, 2, 'Seraph', $5000.00),
(5, 2, 'Jiru', $5500.00),
(6, 2, 'Steve', $4500.00),
(7, 3, 'Aaron', $5000.00),
(8, 5, 'Lilach', $3500.00),
(9, 7, 'Rita', $3000.00),
(10, 5, 'Sean', $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi', $1500.00);
CREATE UNIQUE INDEX idx_unc_mgr_emp_i_name_sal ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary);
Following is the definition of a function called GetSubtree:
IF OBJECT_ID(N'dbo.GetSubtree', N'TF') IS NOT NULL DROP FUNCTION dbo.GetSubtree;
GO
CREATE FUNCTION dbo.GetSubtree (@mgrid AS INT, @maxlevels AS INT = NULL)
RETURNS @Tree TABLE
(
empid INT NOT NULL PRIMARY KEY,
mgrid INT NULL,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
lvl INT NOT NULL
)
AS
BEGIN
DECLARE @lvl AS INT = 0;
-- Insert subtree root node into @Tree
INSERT INTO @Tree
SELECT empid, mgrid, empname, salary, @lvl
FROM dbo.Employees
WHERE empid = @mgrid;
WHILE @@ROWCOUNT > 0 AND (@lvl < @maxlevels OR @maxlevels IS NULL)
BEGIN
SET @lvl += 1;
-- Insert children of nodes from prev level into @Tree
INSERT INTO @Tree
SELECT E.empid, E.mgrid, E.empname, E.salary, @lvl
FROM dbo.Employees AS E
INNER JOIN @Tree AS T
ON E.mgrid = T.empid AND T.lvl = @lvl - 1;
END;
RETURN;
END;
GO
The function returns a subtree of employees below an input manager (@mgrid), with an optional input level limit (@maxlevels). The function defines a table variable called @Tree as the returned output. The variable holds employee information as well as a column called lvl representing the distance in levels from the input subtree root manager (0 for the root, 1 for the level below, and so on).
The code in the function’s body starts by declaring a level counter called @lvl and initializes it with zero. The code then inserts the row for the input manager into the table variable along with the just-initialized level zero. The code then runs a loop that keeps iterating as long as the last insert has at least one row and, if the user provided a level limit, that limit wasn’t exceeded. In each iteration, the code increments the level counter and then inserts into @Tree the next level of subordinates. Once the loop is done, the code returns. At that point, the function hands the table variable @Tree to the calling query.
As an example of using the function, the following code requests the subtree of manager 3 without a level limit:
SELECT empid, empname, mgrid, salary, lvl
FROM GetSubtree(3, NULL);
This code generates the following output:
empid empname mgrid salary lvl
------ -------- ------ -------- ----
3 Ina 1 7500.00 0
7 Aaron 3 5000.00 1
9 Rita 7 3000.00 2
11 Gabriel 7 3000.00 2
12 Emilia 9 2000.00 3
13 Michael 9 2000.00 3
14 Didi 9 1500.00 3
One thing to remember about the use of multistatement TVFs is that they return a table variable. Remember that, unlike it does with temporary tables, SQL Server doesn’t maintain histograms for table variables. As a result, when the optimizer needs to make cardinality estimates related to the table variable, it is more limited in the tools that it can use. The lack of histograms can result in suboptimal choices. This is true both for the queries against the table variable within the function’s body and for the outer queries against the table function. If you identify performance problems that you connect to the lack of histograms, you’ll need to reevaluate your solution.
An alternative option is to use a stored procedure with temporary tables. The downside with this approach is that it’s not as convenient to interact with the result of a stored procedure as querying the result of a table function. You will need to figure out your priorities and do some testing to see if there’s a performance difference and how big it is.
Stored procedures
In this section, I cover the use of T-SQL stored procedures. As mentioned, because the focus of the book is querying, I will cover mainly how to use stored procedures to execute queries and the tuning aspects of the code. I’ll first describe the advantages stored procedures have over ad hoc code. I’ll then cover the way SQL Server handles compilations, recompilations, and the reuse of execution plans. I’ll also cover the use of table types and table-valued parameters, as well as the EXECUTE WITH RESULT SETS clause.
Stored procedures are an important programming tool that gives you a number of benefits compared to implementing your solutions with ad hoc code. Like in other programming environments, encapsulating the logic in a routine enables reusability and allows you to hide the complexity.
Compared to deploying changes in the application, deploying changes in a stored procedure is much simpler. Whether you have a bug to fix or a more efficient way to achieve the task, you issue an ALTER PROC command, and everyone immediately starts using the altered version.
With stored procedures, you tend to reduce a lot of the network traffic. All you pass through the network is the procedure name and the input parameters. The logic is executed in the database engine, and only the final outcome needs to be transmitted back to the caller. Implementing the logic in the application tends to result in more round trips between the application and the database, causing more network traffic.
The use of parameterized queries in stored procedures promotes efficient plan caching and reuse behavior. That’s the focus of the next section. I should note, though, that this capability is not exclusive to queries in stored procedures. You can get similar benefits when using sp_executesqlwith parameterized queries.
Compilations, recompilations, and reuse of execution plans
When you need to tune stored procedures that have performance problems, you should focus your efforts on two main areas. One is tuning the queries within the procedure based on what you’ve learned so far in the book. For this purpose, it doesn’t matter if the query resides in a stored procedure or not. Another is related to plan caching, reuse, parameter sniffing, variable sniffing, and recompilations.
![]() Note
Note
The examples in this section assume you have a clean copy of the sample database PerformanceV3. If you don’t, run the script PerformanceV3.sql from the book’s source code first.
Reuse of execution plans and parameter sniffing
When you create a stored procedure, SQL Server doesn’t optimize the queries within it. It does so the first time you execute the procedure. The initial compilation, which mainly involves optimization of the queries, takes place at the entire batch (procedure) level. SQL Server caches the query plans to enable reuse in subsequent executions of the procedure. When SQL Server triggers a recompilation, it does so at the statement level.
The reason for plan caching and reuse is to save the time, CPU, and memory resources that are involved in the creation of a new plan. How long it takes SQL Server to create a new plan varies. I’ve seen plans that took a few milliseconds to create and also plans that took minutes to create. SQL Server takes the sizes of the tables involved into consideration to determine time and cost thresholds for the optimization process. You can find details about the compilation in the properties of the root node (in a SELECT query, it’s the SELECT node) in a graphical or XML query plan. You will find the following properties: CompileTime (in ms), CompileCPU (in ms), CompileMemory (in KB), Optimization Level (TRIVIAL or FULL), Reason For Early Termination (Good Enough Plan Found if a plan with a cost below the cost threshold is found, or Time Out if the time threshold is reached), and others.
The assumption that SQL Server makes is that if a valid cached plan exists, normally it’s beneficial to reuse it. So, by default, it will try to. Under certain conditions, SQL Server will trigger a recompilation, causing a new plan to be created. I’ll discuss this topic in the section “Recompilations.”
I’ll use a stored procedure called GetOrders to demonstrate plan caching and reuse behavior. Run the following code to create the procedure in the PerformanceV3 database:
USE PerformanceV3;
IF OBJECT_ID(N'dbo.GetOrders', N'P') IS NOT NULL DROP PROC dbo.GetOrders;
GO
CREATE PROC dbo.GetOrders( @orderid AS INT )
AS
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @orderid;
GO
The procedure accepts an order ID as input and returns information about all orders that have an order ID that is greater than or equal to the input one. I planted a GUID as a comment in the code to easily track down the plans in cache that are associated with this query.
There is a nonclustered, noncovering index called PK_Orders defined on the orderid column as the key. Depending on the selectivity of the filter, different plans are considered optimal. For a filter with high selectivity, the optimal plan is one that uses the PK_Orders index and applies lookups. For low selectivity, a serial plan that scans the clustered index is optimal. For a filter with medium selectivity, a parallel plan that scans the clustered index is optimal. (There needs to be few enough filtered rows that when the gather streams cost is added to the scan cost it does not exceed the serial plan cost.)
Say you execute the procedure and currently there’s no reusable cached plan for the query. SQL Server sniffs the current parameter value (also known as the parameter compiled value) and optimizes the plan accordingly. SQL Server then caches the plan and will reuse it for subsequent executions of the procedure until the conditions for a recompilation are met. This strategy assumes that the sniffed value represents the typical input.
To see a demonstration of this behavior, enable the inclusion of the actual execution plan in SQL Server Management Studio (SSMS) and execute the procedure for the first time with a selective input, like so:
EXEC dbo.GetOrders @orderid = 999991;
The plan for this execution is shown in Figure 9-10.
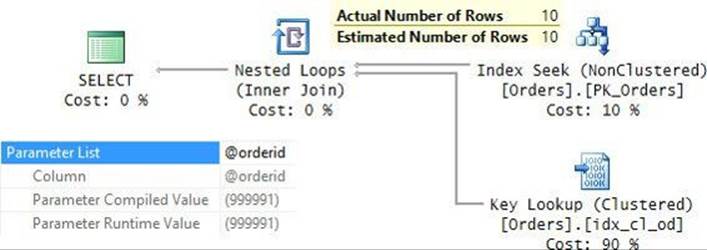
FIGURE 9-10 Plan for the first execution of the procedure.
Observe in the properties of the root node that both the compiled value and the run-time value of the @orderid parameter is 999991. Based on this sniffed value, the cardinality estimate for the filter is 10 rows. Consequently, the optimizer chose a plan that performs a seek and a range scan in the index PK_Orders and applies lookups for the qualifying rows. With 10 lookups, the execution of this plan performed only 33 logical reads in total.
If, indeed, subsequent executions of the procedure will be done with high selectivity, the default plan reuse behavior will be beneficial to you. To see an example, execute the procedure again providing another value with high selectivity:
EXEC dbo.GetOrders @orderid = 999996;
Figure 9-11 shows the graphical execution plan for this execution.
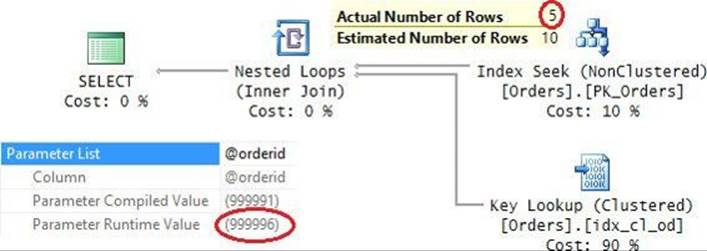
FIGURE 9-11 Plan for the second execution of the procedure.
Observe that the parameter compiled value and, hence, the estimated number of rows returned by the Index Seek operation are unchanged because they reflect the compile-time information. After all, SQL Server reused the cached plan. The parameter run-time value this time is 999996, and the actual number of rows returned is 5. With 5 matches, the execution of this plan performs only 18 reads.
You can analyze plan reuse behavior by querying the plan cache, filtering only plans for the query containing our planted GUID, like so:
SELECT CP.usecounts, CP.cacheobjtype, CP.objtype, CP.plan_handle, ST.text
FROM sys.dm_exec_cached_plans AS CP
CROSS APPLY sys.dm_exec_sql_text(CP.plan_handle) AS ST
WHERE ST.text LIKE '%703FCFF2-970F-4777-A8B7-8A87B8BE0A4D%'
AND ST.text NOT LIKE '%sys.dm_exec_cached_plans%';
At this point, the usecounts column should show a use count of 2 for our query plan.
![]() Note
Note
In an active system with lots of cached query plans, this query can be expensive because it needs to scan the text to look for the GUID. Starting with SQL Server 2012, you can label your queries using the query hint OPTION(LABEL = ‘some label’). Unfortunately, though, this label is not exposed in dynamic management views (DMVs) like sys.dm_exec_cached_plans as a separate column. I hope this capability will be added in the future to allow interesting queries to be filtered in a less expensive way. See the following Microsoft Connect item with such a feature enhancement request to Microsoft: https://connect.microsoft.com/SQLServer/feedback/details/833055.
As you can see, plan reuse is beneficial when the different executions of the procedure provide inputs of a similar nature. But what if that’s not the case? For example, execute the procedure with an input parameter that has medium selectivity:
EXEC dbo.GetOrders @orderid = 800001;
Normally, this query would benefit from a plan that performs a full scan of the clustered index. But because there’s a plan in cache, it’s reused, as you can see in Figure 9-12.
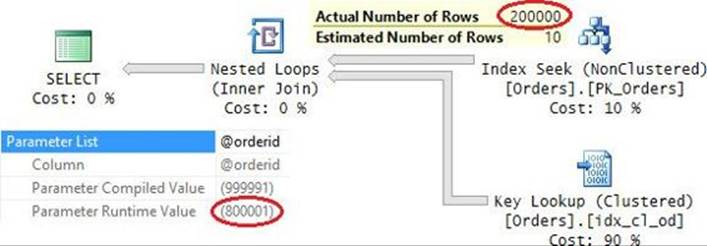
FIGURE 9-12 Plan for the third execution of the procedure.
The parameter compiled value is the one provided when the plan was created (999991), but the run-time value is 800001. The cost percentages of the operators and estimated row counts are the same as when the plan was created because they reflect the parameter compiled value. But the arrows are much thicker than before because they reflect the actual row counts in this execution. The Index Seek operator returns 200,000 rows, and therefore the plan performs that many key lookups. This plan execution performed 600,524 logical reads on my system. That’s a lot compared to how much a clustered index scan would cost you!
The query in our stored procedure is pretty simple; all it has is just a filter and a SELECT list with a few columns. Still, this simple example helps illustrate the concept of inaccurate cardinality estimates and some of its possible implications, like choosing an index seek and lookups versus an index scan, and choosing a serial plan versus a parallel one. You can feel free to experiment with more query elements to demonstrate other implications. For example, if you add grouping and aggregation, you will also be able to observe the implications of inaccurate cardinality estimates on choosing the aggregate algorithm, as well as on computing the required memory grant (for sort and hash operators). Use the following code to alter the procedure, adding grouping and aggregation to the query:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
SELECT empid, COUNT(*) AS numorders
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @orderid
GROUP BY empid;
GO
Normally, with high selectivity (for example, with the input @orderid = 999991) the optimal plan is a serial plan with an index seek and key lookups, a sort operator, and an order-based aggregate (Stream Aggregate). With medium selectivity (for example, with the input @orderid = 800001), the optimal plan is a parallel plan with an index scan, a local hash aggregate, and a global order aggregate.
Which plan you will get in practice depends on the input you provide in the first execution. For example, execute the procedure first with high selectivity. You will get a serial plan with an index seek and key lookups, a sort operator, and an order-based aggregate. Also, the query will request a small memory grant for the sort activity. (See the properties of the root SELECT node of the actual query plan.) This plan will be cached. Then execute the procedure again with medium selectivity. The cached plan will be reused. Not only that, the cached plan will be inefficient for the second execution, very likely the memory grant for the sort operation won’t be sufficient, and it will have to spill to tempdb. (The Sort operator in the actual query plan will show a warning to that effect.)
Adding grouping and aggregation to the query is just one idea of how you can experiment with different query elements to observe the implications of inaccurate cardinality estimates. Of course, there are many other things you can try, like joins, ordering, and so on.
Preventing reuse of execution plans
When facing situations like in the previous section, where plan reuse is not beneficial to you, you usually can do a number of things. If all you have is just the query with the filter (no grouping and aggregation or other elements), one option is to create a covering index, causing the plan for the query to be a trivial one. The optimizer will choose a plan that performs a seek and a range scan in the covering index regardless of the cardinality estimate. Regardless of the selectivity of the input, the same plan is always the optimal one. But you might not be able to create such an index. Also, if your query does involve additional activities like grouping and aggregating, joining, and so on, even with a covering index an accurate cardinality estimate might still be important to determine things like which algorithms to use and how much of a memory grant is required.
Another option is to force SQL Server to recompile the query in every execution by adding the RECOMPILE query hint, like so:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @orderid
OPTION(RECOMPILE);
GO
The tradeoff between using the RECOMPILE query option and reusing plans is that you’re likely to get efficient plans at the cost of compiling the query in every execution. You should be able to tell whether it makes sense for you to use this approach based on the benefit versus cost in your case.
![]() Tip
Tip
In case you are familiar with the procedure-level RECOMPILE option, I should point out that it’s less recommended to use. For one, it will affect all queries in the procedure, and perhaps you want to prevent reuse only for particular queries. For another, it doesn’t benefit from parameter embedding (replacing the parameters with constants) like the statement option does. I described this capability earlier in the chapter in the section “Dynamic search conditions.”
In terms of caching, an interesting difference between the two is that when using the procedure-level option, SQL Server doesn’t cache the plan. When using the statement-level option, SQL Server does cache the last plan, but it doesn’t reuse that plan. So you will find information about the last plan in DMVs like sys.dm_exec_cached_plans and sys.dm_exec_query_stats.
To test the revised procedure, execute it with both high and medium selectivity:
EXEC dbo.GetOrders @orderid = 999991;
EXEC dbo.GetOrders @orderid = 800001;
The plans for the two executions are shown in Figure 9-13.
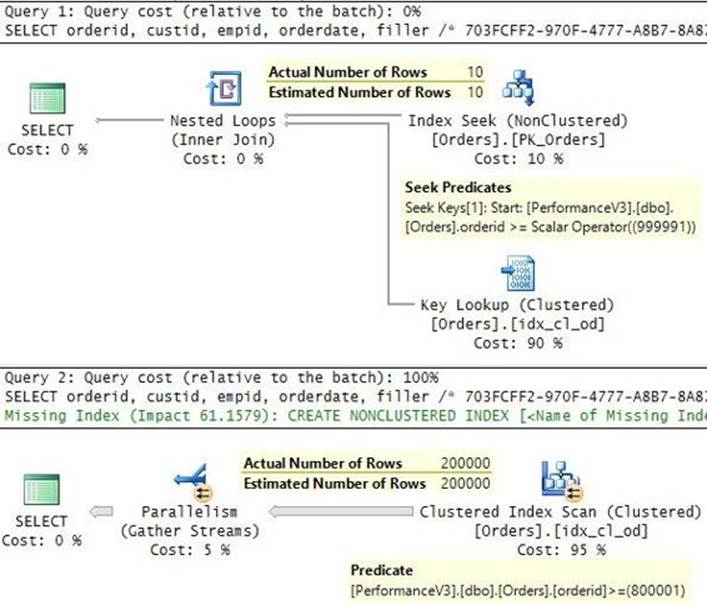
FIGURE 9-13 Plans for executions with a query using RECOMPILE.
As you can see, the plans are different. Each is optimal for its respective input, thanks to the recompiles and the accurate cardinality estimates. The first plan performs a seek in the nonclustered index PK_Orders and key lookups. The execution of this plan performed 33 logical reads on my system. The second plan is a parallel plan that performs a clustered index scan. The execution of this plan performed 25,331 logical reads on my system. There’s no Parameter List property in the root node of these plans because SQL Server applied parameter embedding due to the use of the RECOMPILE option.
Lack of variable sniffing
There’s a curious difference between how SQL Server handles parameters you pass to a procedure and variables you declare within the procedure. Remember that the initial compilation unit is the entire batch (procedure). SQL Server sniffs the parameter values before it optimizes the queries in the procedure. Therefore, the optimizer can apply cardinality estimates based on the sniffed values. You saw this behavior in previous examples. With variables, the situation is different because the optimizer isn’t supposed to run the code that assigns values to the variables as part of the optimization process. So, unlike it can with parameter values, SQL Server cannot normally sniff variable values. It has to resort to alternative cardinality-estimation methods that do not rely on known sniffed values.
As an example, consider the following revised procedure:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
DECLARE @i AS INT = @orderid - 1;
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @i;
GO
The first time you execute the procedure, the optimizer gets the batch for optimization with no information about what the value of the variable @i is. It doesn’t make sense here to use the histogram on the orderid column because there’s no value to look for. In such a case, the optimizer applies a cardinality estimation using predefined hard-coded percentages. The estimate depends on things like the operator you use, the size of the input set, whether density information is available, and whether the column is unique. Table 9-1 shows the hard-coded estimates.
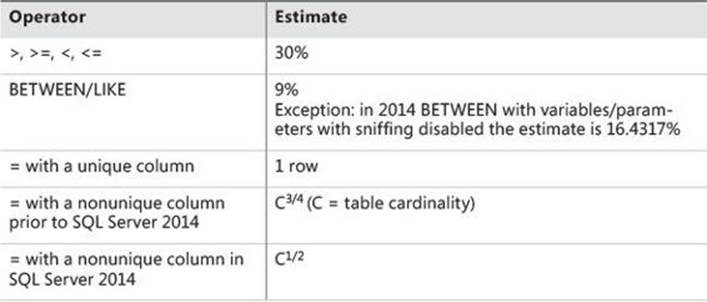
TABLE 9-1 Hardcoded estimates
Our query uses the >= operator, so the hard-coded percentage used is 30. When you apply this percentage to the cardinality of the input set, which is 1,000,000 rows, you get 300,000 rows. With such an estimate, the optimizer will choose a clustered index scan. As you might realize, this choice is suboptimal if the typical input has high selectivity. To see a demonstration of this, execute the procedure with an input value that results in only five matching rows:
EXEC dbo.GetOrders @orderid = 999997;
The plan for this execution is shown in Figure 9-14.
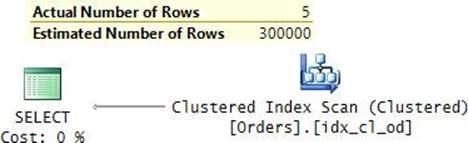
FIGURE 9-14 Plan for a query using a variable.
The execution of this plan performed 25,072 reads on my system. That’s inefficient, considering the small number of matches. Here, a plan that applies a seek in the nonclustered index PK_Orders and key lookups would have been much more efficient.
There are two main solutions to the “lack of variable sniffing” problem. Which solution you should use depends on whether plan reuse is desirable or not. Plan reuse is desirable when typically the values stored in the variable are of the same nature. In such a case, you can use the query hint OPTIMIZE FOR and provide a value for the variable for optimization purposes. In our case, the variable in question is @orderid, so you will use the following form: <query>OPTION(OPTIMIZE FOR (@i = <value>)). Because the optimizer cannot sniff the variable value, you’re telling it what value to optimize for. The optimizer will use that value to make cardinality estimates.
It’s a bit tricky to figure out which value to provide because you have to provide a constant. In our case, you want the optimizer to assume high selectivity. If you provide a value like 1000000, the estimate will be for high selectivity with the current state of the data, but after sufficiently more data is added, it won’t be anymore. It would have been handy if SQL Server supported specifying a hint with a percentage of matches from the input set, but unfortunately it doesn’t. So you need to provide a constant value that will keep getting a high-selectivity estimate even though the data keeps changing. You can achieve this by providing the maximum supported value in the type. For INT, the value is 2147483647. The cardinality estimate in such a case is 1 (the minimum amount the optimizer can estimate), and consequently the optimal plan is one that uses the nonclustered index PK_Orders and applies key lookups.
Alter the stored procedure by running the following code to implement this solution:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
DECLARE @i AS INT = @orderid - 1;
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @i
OPTION (OPTIMIZE FOR(@i = 2147483647));
GO
Run the following code to test the procedure:
EXEC dbo.GetOrders @orderid = 999997;
The plan for this execution is shown in Figure 9-15.
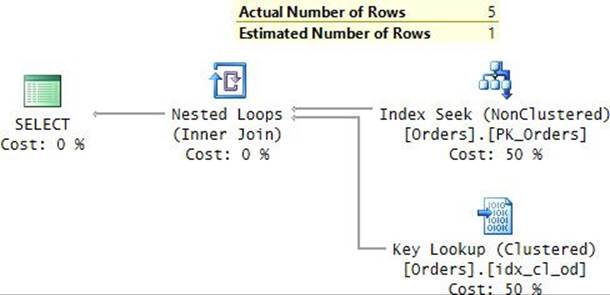
FIGURE 9-15 Plan for a query using OPTIMIZE FOR.
As you can see, the plan is the optimal one for high selectivity. Observe that the estimated number of rows returned after applying the filter is 1 and the actual number is 5. The estimate is good enough for the optimizer to choose the optimal plan. The execution of this plan performed 18 logical reads on my system.
If the typical case in your system is that the filter has low selectivity, you can specify the “optimize for” value 0. However, if the typical case is that the filter has medium selectivity, there’s no way with this hint that you can get such an estimate both with the current and future states of the data. This hint definitely has its limitations.
If you do not desire plan reuse—for example, when the different executions of the procedure store values of different natures in the variable—you’re in luck. You specify the query hint RECOMPILE to prevent reuse, and by doing so at the statement level you get an interesting side effect. The statement is optimized after the variable value is assigned. In other words, you get variable sniffing.
Alter the procedure to implement this solution:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
DECLARE @i AS INT = @orderid - 1;
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @i
OPTION (RECOMPILE);
GO
Run the following code to test the procedure with high selectivity:
EXEC dbo.GetOrders @orderid = 999997;
The plan for this execution is shown in Figure 9-16.
FIGURE 9-16 Plan for a query using RECOMPILE with high selectivity.
Notice the accuracy of the cardinality estimate in this plan, thanks to the fact that the optimizer was able to sniff the variable value. It chose the optimal plan for high selectivity with a seek in the index PK_Orders and key lookups. This plan performed 18 logical reads on my system.
Run the following code to test the procedure with medium selectivity:
EXEC dbo.GetOrders @orderid = 800002;
The plan for this execution is shown in Figure 9-17.

FIGURE 9-17 Plan for a query using RECOMPILE with medium selectivity.
SQL Server created a new plan that is suitable for the new cardinality estimate of 200,000 rows. On my system, it chose a parallel plan that scans the clustered index. The execution of this plan performed 25,322 reads on my system.
Preventing parameter sniffing
You saw cases where parameter sniffing is a beneficial feature. However, you might face cases where this feature is counterproductive. Oddly, in some of those cases, you might get a more optimal plan by disabling parameter sniffing.
As an example, consider a classic challenge with cardinality estimates that involves a column with ascending keys. The orderid column in the Orders table falls into this category because order IDs normally keep increasing. Suppose that the typical execution of the GetOrders procedure is with medium selectivity—say, five to ten percent matches. With such selectivity, the optimal plan is one that performs a clustered index scan. Furthermore, with eight logical CPUs on my system, the optimal plan is a parallel one. The question is, will the optimizer manage to figure this out?
The challenge is that histograms normally get refreshed after 500 plus 20 percent changes have occurred. In the procedure, you are querying the top range of the keys. If a large percentage of rows is added, but not a large enough number to trigger a refresh of the histogram, the new range of keys is not represented in the histogram. If, at that point, SQL Server creates a new plan and relies on the histogram alone to make a cardinality estimate, it will likely result in an underestimation.
Microsoft took measures to address this problem in SQL Server 2014. When the predicate’s interval exceeds the maximum value in the histogram, as is the case with the >= operator, the cardinality estimator takes into consideration both the existing histogram and the count of changes that took place since the last refresh. It interpolates the estimate assuming the new range has distribution that is based on the average distribution in the existing data. You can find coverage of this technique in Chapter 2 as part of the discussion about the improvements in the cardinality estimator. So, in SQL Server 2014, there’s high likelihood that in our situation you will get a decent estimate and, in turn, an optimal plan. However, prior to SQL Server 2014, by default you will likely get an underestimation. This is one case where you might be better off disabling parameter sniffing and letting SQL Server rely on the cardinality-estimation techniques it uses when the parameter value is unknown.
At the moment, the Orders table contains 1,000,000 rows with the order IDs 1 through 1000000. The statistics are up to date because the source code that creates and populates the database creates the indexes after it populates the table. Run the following code to add 100,000 rows (10 percent) to the table:
INSERT INTO dbo.Orders(orderid, custid, empid, shipperid, orderdate, filler)
SELECT 2000000 + orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders
WHERE orderid <= 100000;
Run the following code to show the histogram:
DBCC SHOW_STATISTICS (N'dbo.Orders', N'PK_Orders') WITH HISTOGRAM;
This code generates the following output:
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
------------ ------------- ------------- -------------------- --------------
1 0 1 0 1
1000000 999998 1 999998 1
Observe that the maximum value recorded in the histogram is 1000000. The histogram doesn’t have a representation of the rows you just added to the table.
Next, I’ll demonstrate an underestimation of cardinality that you get prior to SQL Server 2014. Because I’m running the code in SQL Server 2014, I’ll use the query trace flag 9481 to force SQL Server to use the legacy cardinality estimator. Execute the following query:
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= 1000001
OPTION(QUERYTRACEON 9481);
The plan for this query is shown in Figure 9-18.
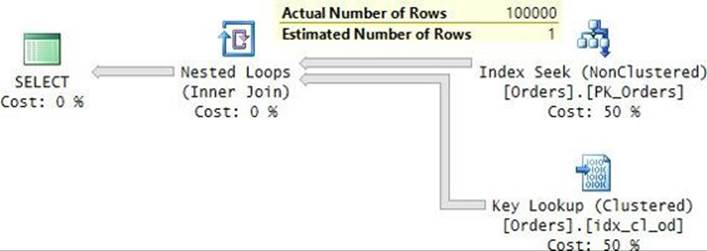
FIGURE 9-18 Plan for a query based on a cardinality estimate prior to SQL Server 2014.
The legacy cardinality estimator found that the range you are filtering is after the maximum value in the histogram. As far as it’s concerned, there are supposed to be zero matches, but the minimum it can estimate is 1. Based on the estimate of 1, the optimizer chose a plan suitable for high selectivity. In practice, the actual number of matches is 100,000. Consequently, the execution of this plan performed 300,264 logical reads on my system. That’s clearly excessive compared to what the optimal plan should cost you (about 25,000 reads for a clustered index scan).
Prior to SQL Server 2014, Microsoft provided trace flag 2389 as a possible tool to deal with the ascending-key problem. When the trace flag is enabled, if in three consecutive refreshes of a histogram SQL Server observes that the keys keep increasing, it brands the column as ascending. Then, at query compile time, SQL Server updates statistics and adds a ministep at the end of the histogram to model the recently added data.
But what if you’re using a pre-2014 version of SQL Server and you’d rather not enable this trace flag? Another option is to disable parameter sniffing. If you choose to do this, you’re forcing SQL Server to rely on cardinality-estimation methods that assume the parameter value is unknown. You can find the estimates that SQL Server uses in such a case in Table 9-1 shown earlier.
There are two main ways to disable parameter sniffing locally at the query/procedure level. The less recommended one is to store the parameter value in a variable and then refer to the variable in the query, like so:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
DECLARE @i AS INT = @orderid;
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @i;
GO
Remember, normally SQL Server cannot sniff variable values.
Test the procedure by running the following code:
EXEC dbo.GetOrders @orderid = 1000001;
The execution of this procedure generates the plan shown in Figure 9-19.
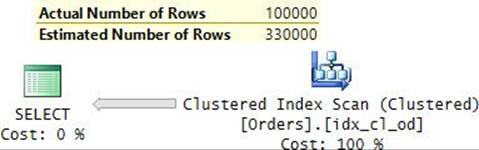
FIGURE 9-19 Plan for a query preventing sniffing with a variable.
If you examine the hard-coded estimates in Table 9-1, you will find that with the >= operator the estimate is 30 percent. Apply this percentage to the table’s cardinality (1,100,000 rows) and you get 330,000 rows. Observe in the query plan that, indeed, the estimated number of rows is 330,000 versus an actual of 100,000. Perhaps it’s not a perfect estimate, but it’s certainly better than an estimate of 1. The optimizer chose a clustered index scan, albeit a serial one, involving 27,871 logical reads on my system. With medium to low selectivity, this plan is certainly better than the one that applies a seek in the PK_Orders index and key lookups.
This method seems to do the trick, but there are a couple of problems with it. First, it’s awkward. Second, if a recompile happens, it happens at the statement level, and then SQL Server can suddenly sniff the variable value. The recommended way to disable parameter sniffing is with a designated query hint. To disable the sniffing of a particular parameter, use the hint OPTIMIZE FOR (@orderid UNKNOWN). To disable the sniffing of all parameters, use OPTIMIZE FOR UNKNOWN.
Apply this solution to our procedure:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @orderid
OPTION(OPTIMIZE FOR (@orderid UNKNOWN));
GO
Run the following code to test the procedure:
EXEC dbo.GetOrders @orderid = 1000001;
You will get the same plan shown earlier in Figure 9-19.
As mentioned, in SQL Server 2014 (thanks to the improvements in the cardinality estimator), you don’t really need to disable parameter sniffing to get a good estimate in our scenario. Run the following code to alter the procedure so that it uses the original form of the code without any hints:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @orderid;
GO
Run the following code to test the procedure:
EXEC dbo.GetOrders @orderid = 1000001;
The plan for this execution is shown in Figure 9-20.

FIGURE 9-20 Plan for a query based on a SQL Server 2014 cardinality estimate.
The new cardinality estimator took into consideration both the histogram and the count of changes since the last refresh. As you can see in the plan, the interpolated cardinality estimate is accurate. This resulted in an optimal plan for the medium selectivity of our filter—namely, a parallel clustered index scan.
The ascending-key problem is just one case where you might want to disable parameter sniffing. You might stumble onto other cases. In those cases, remember, the OPTIMIZE FOR (@parameter UNKNOWN) / OPTIMIZE FOR UNKNOWN hints are the preferred tool compared to using a variable.
When you’re done testing, run the following code for cleanup:
DELETE FROM dbo.Orders WHERE orderid > 1000000;
UPDATE STATISTICS dbo.Orders WITH FULLSCAN;
Recompilations
In some situations, SQL Server will not reuse a previously cached plan; rather, it will create a new one. The creation of a new plan instead of reusing an existing one is known as a recompilation. Generally, recompilations fall into two categories: plan correctness (also known as plan stability) and plan optimality.
SQL Server performs plan correctness recompilations when the correctness, or stability, of the cached plan is in doubt. An example for an event that triggers such recompilations is a data-definition language (DDL) change, like dropping an index or a table that the plan uses. Such an event causes the cached plans that refer to the affected object to be invalidated. The next time you run the stored procedure, the affected queries will be recompiled.
Another example of a cause of plan-correctness recompilations is when any set option that is considered plan-affecting is in a different state in the environment where you’re executing the procedure than the environment where the cached plan was created. The set options that are considered plan-affecting are these:
![]() ANSI_NULL_DFLT_OFF
ANSI_NULL_DFLT_OFF
![]() ANSI_NULL_DFLT_ON
ANSI_NULL_DFLT_ON
![]() ANSI_NULLS
ANSI_NULLS
![]() ANSI_PADDING
ANSI_PADDING
![]() ANSI_WARNINGS
ANSI_WARNINGS
![]() ARITHABORT
ARITHABORT
![]() CONCAT_NULL_YIELDS_NULL
CONCAT_NULL_YIELDS_NULL
![]() DATEFIRST
DATEFIRST
![]() DATEFORMAT
DATEFORMAT
![]() FORCEPLAN
FORCEPLAN
![]() LANGUAGE
LANGUAGE
![]() NO_BROWSETABLE
NO_BROWSETABLE
![]() NUMERIC_ROUNDABORT
NUMERIC_ROUNDABORT
![]() QUOTED_IDENTIFIER
QUOTED_IDENTIFIER
The reasoning behind such recompilations is that the same query can have different meanings when any of these set options is in a different state. SQL Server stores with the cached plans the state of the plan-affecting set options in attributes called set_options (as a bitmap), language_id,date_format, and date_first. Recall that DDL changes cause SQL Server to invalidate existing cached plans. If SQL Server doesn’t find a cached plan with a state of set options matching the state in the current environment, it handles the situation differently. SQL Server creates a new plan and caches it without invalidating the existing plans. This way, unique environments can keep reusing their respective cached plans.
Before I demonstrate recompilations related to plan-affecting set options, run the following code to force SQL Server to recompile the GetOrders procedure next time you execute it:
EXEC sp_recompile N'dbo.GetOrders';
Next, run the following code to execute the stored procedure twice—once with the default state of the option CONCAT_NULL_YIELDS_NULL (on), and again after setting it to off:
EXEC dbo.GetOrders @orderid = 1000000;
SET CONCAT_NULL_YIELDS_NULL OFF;
EXEC dbo.GetOrders @orderid = 1000000;
SET CONCAT_NULL_YIELDS_NULL ON;
This option controls what happens when you concatenate something with a NULL. When the option is on, the result is a NULL; when the option is off, a NULL is treated like an empty string. In the GetOrders procedure, there’s no string concatenation taking place. Still, because the two executions have different environments, the plan created for the first execution cannot be reused by the second.
Run the following code to request information about the plans that are associated with the query in our procedure:
SELECT CP.usecounts, PA.attribute, PA.value
FROM sys.dm_exec_cached_plans AS CP
CROSS APPLY sys.dm_exec_sql_text(CP.plan_handle) AS ST
CROSS APPLY sys.dm_exec_plan_attributes(CP.plan_handle) AS PA
WHERE ST.text LIKE '%703FCFF2-970F-4777-A8B7-8A87B8BE0A4D%'
AND ST.text NOT LIKE '%sys.dm_exec_cached_plans%'
AND attribute = 'set_options';
You get the following output:
usecounts attribute value
----------- ------------ ------
1 set_options 4339
1 set_options 4347
Observe that the set_options bitmap is different for the two plans that the query found in cache. As you probably gathered, the bit value 8 represents the CONCAT_NULL_YIELDS_NULL option in this bitmap.
The conclusion based on this behavior is that you should strive to use consistent environments to connect to SQL Server to promote efficient plan reuse behavior.
The other category of recompilations is called plan optimality. SQL Server applies such recompilations when the optimality of the cached plan is in doubt—not its correctness. As an example, a sufficient amount of data changes is considered a plan-optimality cause for a recompilation. The thinking is that, with enough data changes, the existing cached plan might not be optimal anymore.
SQL Server keeps track of changes at the column level. When SQL Server considers reusing a cached plan, for every histogram that was used during the optimization process, it checks how many changes took place in the respective column since the last statistics refresh. If a recompilation threshold is reached, SQL Server will update the statistics and trigger a recompilation. The recompilation threshold changes gradually based on the number of rows you add. The steps are a bit different for regular tables and for temporary tables. For regular tables, the steps are as follows: after 1 row is added, after 500 more are added, and then after every 500 plus 20 percent are added. With temporary tables, the steps are after 1 row is added, after 6 are added, after 500 are added, and then after every 500 plus 20 percent are added.
With large tables, 500 plus 20 percent can represent a very large number of rows. This can result in automatic statistics updates that are not frequent enough to support optimal plans. SQL Server supports trace flag 2371, which causes the percentage to be reduced as the table grows. You can find details about this trace flag here: http://blogs.msdn.com/b/saponsqlserver/archive/2011/09/07/changes-to-automatic-update-statistics-in-sql-server-traceflag-2371.aspx.
In SQL Server 2014, Microsoft introduced incremental statistics for partitioned tables. Normally, SQL Server maintains statistics at the table level. It uses up to 200 steps in the histogram for the entire table, and it applies the calculation of 500 + 20 percent to the table’s cardinality. With incremental statistics, SQL Server maintains statistics at the partition level. It uses up to 200 steps in the histogram per partition, and it applies the calculation of 500 + 20 percent to the partition’s cardinality. For details about this feature, see the INCREMENTAL option in the CREATE STATISTICS command here: http://msdn.microsoft.com/en-us/library/ms188038.aspx.
You might encounter cases where the plan SQL Server creates the first time the procedure executes keeps being the optimal one even after significant data changes. For example, suppose the typical use case for the GetOrders procedure is to query the last few orders. In such a case, the plan optimality recompilations are pointless. Every time a new plan is created, it’s going to be the same plan. To prevent such recompilations, you can add the query hint KEEPFIXED PLAN. This hint cannot prevent SQL Server from applying plan-stability recompilations, because you can’t force it to use a plan that is considered invalid. With optimality recompilations, the cached plan is known to be valid. Therefore, SQL Server has no problem accommodating a request to not recompile if you take responsibility for the performance implications of such a choice.
Use the following code to alter the GetOrders procedure with the KEEPFIXED PLAN query hint:
ALTER PROC dbo.GetOrders( @orderid AS INT )
AS
SELECT orderid, custid, empid, orderdate, filler
/* 703FCFF2-970F-4777-A8B7-8A87B8BE0A4D */
FROM dbo.Orders
WHERE orderid >= @orderid
OPTION(KEEPFIXED PLAN);
GO
When you’re done testing the code, make sure to rerun the PerformanceV3.sql script to re-create the sample database.
Table type and table-valued parameters
A table type is a table definition you store as an object in the database. You can use it as the type for table variables and for table-valued parameters in stored procedures and user-defined functions.
A table type can have the usual elements that are allowed in a table-variable definition. These elements include an identity property, computed columns, and CHECK, DEFAULT, PRIMARY KEY, and UNIQUE constraints. Starting with SQL Server 2014, a table type can even have inline index definitions. It cannot have foreign-key constraints.
As a type for table variables, it gives you reusability. If you have different places in the code where you need to declare table variables based on the same structure, with a table type you avoid repeating the definition. As an example, suppose you have multiple places in the code where you use a table variable holding order IDs and sort positions for presentation-ordering purposes. You define a table type called OrderIDs with the CREATE TYPE command, like so:
USE TSQLV3;
IF TYPE_ID('dbo.OrderIDs') IS NOT NULL DROP TYPE dbo.OrderIDs;
GO
CREATE TYPE dbo.OrderIDs AS TABLE
(
pos INT NOT NULL PRIMARY KEY,
orderid INT NOT NULL UNIQUE
);
Then, to declare a table variable of this type, use the DECLARE statement and, instead of specifying the table definition, specify AS dbo.OrderIDs. As an example, the following code declares a table variable called @T based on this type, fills it with a few rows, and queries it:
DECLARE @T AS dbo.OrderIDs;
INSERT INTO @T(pos, orderid) VALUES(1, 10248),(2, 10250),(3, 10249);
SELECT * FROM @T;
Such reusability is nice. But the real power in this feature is that you can define table-valued parameters (TVPs) in stored procedures and user-defined functions based on table types. Note, though, that as of SQL Server 2014 TVPs are read-only and have to be marked as such with the READONLY attribute. You’re not allowed to issue modifications against a TVP in a stored procedure.
To see an example of using a TVP, run the following code to create the stored procedure GetOrders:
IF OBJECT_ID(N'dbo.GetOrders', N'P') IS NOT NULL DROP PROC dbo.GetOrders;
GO
CREATE PROC dbo.GetOrders( @T AS dbo.OrderIDs READONLY )
AS
SELECT O.orderid, O.orderdate, O.custid, O.empid
FROM Sales.Orders AS O
INNER JOIN @T AS K
ON O.orderid = K.orderid
ORDER BY K.pos;
GO
The procedure accepts a TVP called @T of the OrderIDs table type. The procedure’s query joins @T with the Sales.Orders table to filter orders with order IDs that appear in @T. The query returns the filtered orders sorted by pos.
To execute the procedure from T-SQL, declare a table variable of the OrderIDs table type, fill it with rows, and then pass the variable to the TVP, like so:
DECLARE @MyOrderIDs AS dbo.orderids;
INSERT INTO @MyOrderIDs (pos, orderid) VALUES(1, 10248),(2, 10250),(3, 10249);
EXEC dbo.GetOrders @T = @MyOrderIDs;
This code generates the following output:
orderid orderdate custid empid
----------- ---------- ----------- -----------
10248 2013-07-04 85 5
10250 2013-07-08 34 4
10249 2013-07-05 79 6
Just like with table variables, SQL Server doesn’t maintain distribution statistics on columns in TVPs. However, SQL Server does maintain cardinality information. With table variables, often cardinality information isn’t visible to the optimizer due to the inability to sniff variable values, because the initial optimization unit is the entire batch. I described this limitation earlier in the section “Lack of variable sniffing.” But recall that parameter values can be sniffed. So, when you pass a TVP to a stored procedure, you do so after filling it with data. And then at least the cardinality information is visible to the optimizer. So, even though TVPs don’t have histograms, sometimes cardinality information can go a long way in helping the optimizer with cardinality estimates.
![]() Tip
Tip
Starting with SQL Server 2014, you can define a table type based on a memory-optimized table definition. You add the table option WITH (MEMORY_OPTIMIZED = ON). This way, table variables and TVPs based on this type use the In-Memory OLTP technology. You can find details about this technology in Chapter 10, “In-Memory OLTP.”
If you’re looking for extra reading material about TVPs, you can find an excellent article written by Erland Sommarskog here: http://www.sommarskog.se/arrays-in-sql-2008.html.
When you’re done testing, run the following code for cleanup.
IF OBJECT_ID(N'dbo.GetOrders', N'P') IS NOT NULL DROP PROC dbo.GetOrders;
IF TYPE_ID('dbo.OrderIDs') IS NOT NULL DROP TYPE dbo.OrderIDs;
EXECUTE WITH RESULT SETS
You can use the WITH RESULT SETS clause to define the expected shapes of the query result sets that a stored procedure or a dynamic batch returns. You can think of it as a contract between you and the procedure. If the procedure returns results that are compatible with the specified shapes, the procedure runs successfully. If it returns results that are not compatible, depending on what’s different, the execution of the procedure either fails or compensates for the difference by changing the results.
An example where this feature can be handy is when you’re the user of a procedure that you’re not responsible for maintaining. You want to make sure you execute it only when it returns the expected shapes of the query result sets. If the author changes the queries in the procedure, you don’t want your code to execute it. The exception is when the difference is what you can consider to be cosmetic.
Consider the following GetOrderInfo procedure definition:
IF OBJECT_ID(N'dbo.GetOrderInfo', N'P') IS NOT NULL DROP PROC dbo.GetOrderInfo;
GO
CREATE PROC dbo.GetOrderInfo( @orderid AS INT )
AS
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderid = @orderid;
SELECT orderid, productid, qty, unitprice
FROM Sales.OrderDetails
WHERE orderid = @orderid;
GO
The procedure accepts an order ID as input and executes two queries: one that returns the header of the input order, and another that returns the related order lines. Here’s how you execute the procedure and add the WITH RESULT SETS clause to define the expected shapes of the query result sets:
EXEC dbo.GetOrderInfo @orderid = 10248
WITH RESULT SETS
(
(
orderid INT NOT NULL,
orderdate DATE NOT NULL,
custid INT NOT NULL,
empid INT NULL
),
(
orderid INT NOT NULL,
productid INT NOT NULL,
qty SMALLINT NOT NULL,
unitprice NUMERIC(19, 3) NOT NULL
)
);
In this case, the specified shapes and the returned ones match, so the procedure runs successfully.
If you want to apply cosmetic changes like assigning your names to columns, changing types (assuming the values are convertible), or changing NULLability (assuming it’s possible), you can achieve this using the WITH RESULT SETS clause. For example, the following execution changes the name of the orderid column in both result sets to id:
EXEC dbo.GetOrderInfo @orderid = 10248
WITH RESULT SETS
(
(
id INT NOT NULL,
orderdate DATE NOT NULL,
custid INT NOT NULL,
empid INT NULL
),
(
id INT NOT NULL,
productid INT NOT NULL,
qty SMALLINT NOT NULL,
unitprice NUMERIC(19, 3) NOT NULL
)
);
This execution generates the following output:
id orderdate custid empid
------ ----------- ------- ------
10248 2013-07-04 85 5
id productid qty unitprice
------ ---------- ---- ----------
10248 11 12 14.000
10248 42 10 9.800
10248 72 5 34.800
This is similar to assigning column aliases. If you change the type of a column, SQL Server will try to convert the values. If any value doesn’t convert, execution will stop at run time with an error. Similarly, if you change a column’s NULLability from NULL to NOT NULL, SQL Server will check the values at run time, and if a NULL is found, it will stop the execution and generate an error. The ability to apply such changes as part of the execution of the code is handy when you’re not allowed to change the stored procedure’s definition.
If there’s a difference in the number of columns, the attempt to execute the procedure fails immediately. For example, run the following code indicating that you expect three columns in the first query result set:
EXEC dbo.GetOrderInfo @orderid = 10248
WITH RESULT SETS
(
(
orderid INT NOT NULL,
orderdate DATE NOT NULL,
custid INT NOT NULL
),
(
orderid INT NOT NULL,
productid INT NOT NULL,
qty SMALLINT NOT NULL,
unitprice NUMERIC(19, 3) NOT NULL
)
);
You get the following error indicating that you expected three columns in the first result set but got four:
Msg 11537, Level 16, State 1, Procedure GetOrderInfo, Line 1175
EXECUTE statement failed because its WITH RESULT SETS clause specified 3 column(s)
for result set number 1, but the statement sent 4 column(s) at run time.
When you’re done testing, run the following code for cleanup:
IF OBJECT_ID(N'dbo.GetOrderInfo', N'P') IS NOT NULL DROP PROC dbo.GetOrderInfo;
Triggers
A trigger is a special kind of stored procedure. It’s a routine you attach to an event, and when the event happens, SQL Server executes the trigger’s code. This section starts with a description of the different types of triggers SQL Server supports. It then continues with a discussion about efficient trigger programming.
Trigger types and uses
SQL Server supports different types of triggers. These include AFTER DML triggers, INSTEAD OF DML triggers and AFTER DDL triggers.
AFTER DML triggers
An AFTER DML trigger is attached to INSERT, UPDATE, and DELETE actions against a table. SQL Server doesn’t support AFTER DML triggers on views. When a user submits such an action against the target table, the trigger code executes after the action already changed the table but before the transaction commits. If you issue a ROLLBACK TRAN command within the trigger, you roll back all the work you performed within the trigger as well as all work you performed in the transaction that caused the trigger to fire.
DML triggers in SQL Server are statement-level triggers and not row-level ones. This means that one trigger instance fires per statement regardless of how many rows were affected, even zero. Within the trigger, you have access to tables called inserted and deleted, which hold the pre-modification and post-modification state of the modified rows. In INSERT triggers, only inserted has rows. In DELETE triggers, only deleted has rows. In UPDATE triggers, deleted holds the pre-modification state of the updated rows and inserted holds their post-modification state. There are no MERGE triggers. You can define INSERT, UPDATE, and DELETE triggers to handle respective actions submitted by a MERGE statement.
Typical use cases of AFTER DML triggers include auditing, maintaining denormalized data, and keeping track of the last modification date and time of a row. To see a demonstration of the last-use case, first create a table called T1 by running the following code:
SET NOCOUNT ON;
USE tempdb;
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL DROP TABLE dbo.T1;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
datacol VARCHAR(10) NOT NULL,
lastmodified DATETIME2 NOT NULL
CONSTRAINT DFT_T1_lastmodified DEFAULT(SYSDATETIME())
);
You need to create an AFTER UPDATE trigger that writes the current date and time value in the lastmodified column of the updated rows. Use the following code to create such a trigger:
CREATE TRIGGER trg_T1_u ON T1 AFTER UPDATE
AS
UPDATE T1
SET lastmodified = SYSDATETIME()
FROM dbo.T1
INNER JOIN inserted AS I
ON I.keycol = T1.keycol;
GO
Figure 9-21 illustrates the trigger you just created.
FIGURE 9-21 Trigger that updates the lastmodified value.
If you need to check whether a column was updated within an UPDATE trigger, you can use the UPDATE(<col_name>) and COLUMNS_UPDATED() functions. The former accepts a column name as input and returns true or false depending on whether the column was updated or not, respectively. This function is convenient to use when you need to check a small number of columns. The latter returns a bitmap with a different bit representing each column in the table. It requires you to use predicates with bitwise operators to figure out whether the columns of interest were updated. This function is convenient to use when you need to check a large number of columns. Note that the functions don’t tell you whether a column value changed; rather, they tell you only whether the column was the target of an assignment in the UPDATE statement.
SQL Server supports nesting and recursion of AFTER DML triggers. Nesting means that an action submitted from one trigger against some table causes another trigger to fire. Recursion means that an action submitted from one trigger against some table causes the same trigger to fire, directly or indirectly. Either way, the maximum number of allowed nesting levels is 32. The nesting of triggers is enabled by default and is controlled at the instance level with a server configuration option called ‘nested triggers’. The following code will disable nesting in your instance (but don’t run it unless you’re actually interested in this behavior):
EXEC sp_configure 'nested triggers', 0;
RECONFIGURE;
Change the setting back to 1 if you want to enable nesting in an environment where it’s currently disabled.
Trigger recursion is disabled by default and is controlled at the database level using a database option called RECURSIVE_TRIGGERS. For example, say you want to enable recursive triggers in a database called MyDB. You do so by running the following code:
ALTER DATABASE MyDB SET RECURSIVE_TRIGGERS ON;
In SQL Server, you can define multiple AFTER triggers based on the same action against the same table. It will run those one at a time. You can mark which one you want to run first and last using a stored procedure called sp_settriggerorder, but you don’t have control over order beyond that.
INSTEAD OF DML triggers
INSTEAD OF DML triggers are similar to AFTER DML triggers, except that the trigger fires instead of the original statement and not after it. You still have the inserted and deleted tables available in the trigger, but they represent the before and after states of the rows that were supposed to be modified. If you need the trigger to do some work and then have the original change take place, it’s now your responsibility to generate the change against the target based on what you have in inserted and deleted. If you don’t, nothing really happens to the target.
In terms of syntax, INSTEAD OF triggers are defined similarly to AFTER triggers. In the header of the CREATE TRIGGER command specify CREATE TRIGGER ... INSTEAD OF <action> rather than specifying CREATE TRIGGER ... AFTER <action>. As mentioned, within the trigger you interact with inserted and deleted just like you do in AFTER triggers.
Unlike AFTER triggers, INSTEAD OF triggers are allowed on views. One of the interesting use cases of such triggers is to substitute an unsupported kind of modification against a view with your own logic. For example, suppose one of the columns in the view is a result of a calculation. In such a case, SQL Server will not support inserts and updates against the view. Assuming that the computation is reversible, you can intercept INSERT and UPDATE statements against the view with an INSTEAD OF trigger. In the trigger, you reverse engineer the computation based on the data in inserted and submit the change against the underlying table.
With AFTER triggers, constraints are evaluated before the trigger has a chance to execute. So, if the statement violates a constraint, the trigger doesn’t get a chance to run. With INSTEAD OF triggers, remember that the trigger substitutes the original modification. It executes before constraints are validated. This allows you to substitute actions that normally would violate constraints with your alternative actions that do not violate any constraints.
SQL Server supports nesting of INSTEAD OF triggers but doesn’t support recursion.
AFTER DDL triggers
SQL Server supports AFTER DDL triggers. Depending on the scope of the event in question, you create the trigger either as a database-level trigger or as a server-level one. As an example, a CREATE_TABLE event is obviously a database-scoped event, whereas a CREATE_DATABASE event is a server-scoped event.
You can attach DDL triggers to individual events, like CREATE_TABLE and ALTER_TABLE, or to event groups, like DDL_TABLE_EVENTS (for CREATE_TABLE, ALTER_TABLE, and DROP TABLE) and DDL_DATABASE_LEVEL_EVENTS (for all database-level events). You can find the events and event groups that DDL triggers support here: http://msdn.microsoft.com/en-us/library/bb510452.aspx.
Typical use cases for DDL triggers include auditing DDL changes, enforcing policies, and change management.
In DML triggers, you access the data that is related to the event through the inserted and deleted tables. With DDL triggers, Microsoft made an interesting choice to expose the event information through a function called EVENTDATA as XML. This information includes the login of the person who submitted the change, the post time, the affected object, and even the T-SQL statement. As you might have guessed, different events can have different associated event information. The use of XML allowed Microsoft to provide a simple and flexible solution that accommodates such differences easily. You will need to use the XML type’s value() method to extract the information from the XML instance you get from the function.
I’ll demonstrate using a DDL trigger to audit all DDL changes submitted against a database called testdb. Run the following code to create the database:
USE master;
IF DB_ID(N'testdb') IS NOT NULL DROP DATABASE testdb;
CREATE DATABASE testdb;
GO
USE testdb;
Run the following code to create the table AuditDDLEvents, where the trigger will store the audit information:
IF OBJECT_ID(N'dbo.AuditDDLEvents', N'U') IS NOT NULL
DROP TABLE dbo.AuditDDLEvents;
CREATE TABLE dbo.AuditDDLEvents
(
auditlsn INT NOT NULL IDENTITY,
posttime DATETIME NOT NULL,
eventtype sysname NOT NULL,
loginname sysname NOT NULL,
schemaname sysname NOT NULL,
objectname sysname NOT NULL,
targetobjectname sysname NULL,
eventdata XML NOT NULL,
CONSTRAINT PK_AuditDDLEvents PRIMARY KEY(auditlsn)
);
Finally, run the following code to create the audit trigger:
CREATE TRIGGER trg_audit_ddl_events ON DATABASE FOR DDL_DATABASE_LEVEL_EVENTS
AS
SET NOCOUNT ON;
DECLARE @eventdata AS XML = eventdata();
INSERT INTO dbo.AuditDDLEvents(
posttime, eventtype, loginname, schemaname, objectname, targetobjectname, eventdata)
VALUES( @eventdata.value('(/EVENT_INSTANCE/PostTime)[1]', 'VARCHAR(23)'),
@eventdata.value('(/EVENT_INSTANCE/EventType)[1]', 'sysname'),
@eventdata.value('(/EVENT_INSTANCE/LoginName)[1]', 'sysname'),
@eventdata.value('(/EVENT_INSTANCE/SchemaName)[1]', 'sysname'),
@eventdata.value('(/EVENT_INSTANCE/ObjectName)[1]', 'sysname'),
@eventdata.value('(/EVENT_INSTANCE/TargetObjectName)[1]', 'sysname'),
@eventdata );
GO
Observe that the trigger first stores the XML instance that the function returns in a variable. The trigger then inserts an audit row into the audit table. The VALUES clause has calls to the value() method to extract values you want to store in relational form in separate columns. In addition, the VALUES clause has the XML variable with the complete event information for the target XML column eventdata. That’s just in case someone needs event information you didn’t store in separate columns.
Run the following four DDL statements to test the trigger:
CREATE TABLE dbo.T1(col1 INT NOT NULL PRIMARY KEY);
ALTER TABLE dbo.T1 ADD col2 INT NULL;
ALTER TABLE dbo.T1 ALTER COLUMN col2 INT NOT NULL;
CREATE NONCLUSTERED INDEX idx1 ON dbo.T1(col2);
Run the following code to query the audit table:
SELECT * FROM dbo.AuditDDLEvents;
I got the following output when I ran this query on my system (with XML shown here in abbreviated form):
auditlsn posttime eventtype loginname
--------- ----------------------- ------------- -----------
1 2015-02-12 15:23:29.627 CREATE_TABLE K2\Gandalf
2 2015-02-12 15:23:29.713 ALTER_TABLE K2\Gandalf
3 2015-02-12 15:23:29.720 ALTER_TABLE K2\Gandalf
4 2015-02-12 15:23:29.723 CREATE_INDEX K2\Gandalf
auditlsn schemaname objectname targetobjectname eventdata
--------- ----------- ----------- ----------------- --------------------
1 dbo T1 NULL <EVENT_INSTANCE>...
2 dbo T1 NULL <EVENT_INSTANCE>...
3 dbo T1 NULL <EVENT_INSTANCE>...
4 dbo idx1 T1 <EVENT_INSTANCE>...
To create a server-level trigger, specify ON ALL SERVER instead of ON DATABASE.
You want to make sure to remember that SQL Server supports only AFTER DDL triggers. It doesn’t support INSTEAD OF or BEFORE DDL triggers. With this in mind, you don’t want to use DDL triggers to prevent expensive activities like creating and rebuilding indexes on large tables from being submitted. That’s because the trigger will fire after the event finishes, just a moment before SQL Server commits the transaction. If you issue a rollback at that point, you’ll just cause SQL Server to perform extra work to undo the operation.
When you’re done testing, run the following code for cleanup:
USE master;
IF DB_ID(N'testdb') IS NOT NULL DROP DATABASE testdb;
Efficient trigger programming
Triggers are one of those tools that, if you don’t understand them well, you can end up with performance problems. This section explains what the performance pitfalls are and provides recommendations for efficient trigger programming.
One of the most important things to understand about triggers is how to interact with the inserted and deleted tables. The rows in these tables are constructed from row versions, which are maintained in tempdb. These tables are structured just like the underlying table, but they are not indexed. You should be especially mindful of this fact when you need to access these tables repeatedly. As an example, suppose you need to define an AFTER INSERT trigger, and the task you need to implement requires you to process the rows from inserted one at a time. The first thing you need to ask yourself is whether there is a possible set-based solution you can use to achieve the task without iterations by accessing inserted only once.
Assuming the task truly mandates an iterative solution, the next thing to consider is the method to use to process the rows individually. People hear so many bad things about cursors, such as that they are evil and you should never use them, that they think any alternative is better. One of the common alternatives is to use a WHILE loop with a TOP (1) query based on key order. This solution is worse than using a cursor when you don’t have an index on the key column. Every execution of the TOP query requires a full scan of the inserted table and a Sort (Top N Sort) operation. Using a cursor involves only one pass over the data. So, despite the overhead of fetching the records from the cursor, it is a more efficient tool than the alternative.
Furthermore, within the trigger you can check how many rows were affected by the INSERT statement and determine which method to use to handle the rows accordingly. If zero rows were affected, you simply return from the trigger. If one row was affected, you don’t need a cursor. You can collect the elements from the row in the inserted table using an assignment SELECT statement. If more than one row was affected, you can use a cursor.
![]() Note
Note
Be careful not to rely on the @@rowcount function to figure out how many rows were affected by the statement that caused the trigger to fire. That’s because if the trigger fires as a result of a MERGE statement, the function will indicate how many rows were affected by the statement in total (inserted, updated, and deleted), and not just how many rows were inserted.
In our case, we just need to know if the number of affected rows is zero, one, or more. So it’s enough to use the following code for this purpose:
DECLARE @rc AS INT = (SELECT COUNT(*) FROM (SELECT TOP (2) * FROM inserted) AS D);
This way, you scan at most two rows in inserted.
Using the same T1 table you used earlier for the AFTER UPDATE trigger example, the following AFTER INSERT trigger implements this strategy:
USE tempdb;
GO
CREATE TRIGGER trg_T1_i ON T1 AFTER INSERT
AS
DECLARE @rc AS INT = (SELECT COUNT(*) FROM (SELECT TOP (2) * FROM inserted) AS D);
IF @rc = 0 RETURN;
DECLARE @keycol AS INT, @datacol AS VARCHAR(10);
IF @rc = 1 -- single row
BEGIN
SELECT @keycol = keycol, @datacol = datacol FROM inserted;
PRINT 'Handling keycol: ' + CAST(@keycol AS VARCHAR(10))
+ ', datacol: ' + @datacol;
END;
ELSE -- multi row
BEGIN
DECLARE @C AS CURSOR;
SET @C = CURSOR FAST_FORWARD FOR SELECT keycol, datacol FROM inserted;
OPEN @C;
FETCH NEXT FROM @C INTO @keycol, @datacol;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'Handling keycol: ' + CAST(@keycol AS VARCHAR(10))
+ ', datacol: ' + @datacol;
FETCH NEXT FROM @C INTO @keycol, @datacol;
END;
END;
GO
For every row in inserted, the trigger prints a message that contains the elements from the row. Normally, you would do something with those elements based on the task your trigger is supposed to fulfill.
Run the following code to test the trigger with zero affected rows:
INSERT INTO dbo.T1(datacol) SELECT 'A' WHERE 1 = 0;
The trigger returns without doing any work.
Run the following code to test the trigger with one affected row:
INSERT INTO dbo.T1(datacol) VALUES('A');
The trigger uses an assignment SELECT statement to process the row and generates the following output:
Handling keycol: 1, datacol: A
Run the following code to test the trigger with multiple affected rows:
INSERT INTO dbo.T1(datacol) VALUES('B'), ('C'), ('D');
The trigger uses a cursor to process the rows and generates the following output:
Handling keycol: 4, datacol: D
Handling keycol: 3, datacol: C
Handling keycol: 2, datacol: B
When you’re done, run the following code for cleanup:
IF OBJECT_ID(N'dbo.T1', N'U') IS NOT NULL DROP TABLE dbo.T1;
Another thing to consider in terms of efficiency is how to enforce integrity rules on data that is inserted or updated in a table. Generally, if you can enforce a rule with a constraint, you will tend to get better performance than with a trigger. That’s because the constraint rejects the change before it happens, whereas a trigger lets the change happen and then rolls it back. There are cases, though, in which a constraint cannot do what you need it to do. For example, if you need to enforce referential integrity between tables that reside in different databases, you cannot use foreign-key constraints. Triggers can be used in such a case. The point I’m trying to make is that you should consider constraints first and resort to triggers only if you can’t achieve the integrity enforcement with constraints.
You might face cases where you need to apply a modification but you don’t want a related trigger to fire. Perhaps the trigger does some further processing of new data, but you’re about to insert data that has already been processed. You don’t want to disable the trigger using the ALTER TABLE DISABLE TRIGGER command because this command will disable it globally. You just want to prevent it from firing for the specific statement you’re about to issue.
One of the tools people use for such a purpose is called session context. It’s a BINARY(128) value that is associated with your session. You can modify and query it from any point in the call stack. You overwrite the value using the SET CONTEXT_INFO command and query it using the CONTEXT_INFO function. To prevent the trigger from running the usual code, you can plant a signal in your session context before you issue the modification. You add logic to the trigger that queries the session context and returns if it finds that the signal was set. Otherwise, the trigger continues running its original code. This sounds like a good solution, but if you ever tried working with the session context you know that it can be very awkward. There’s just one such value per session. If different developers want to use it, you need to coordinate which segment of the value each developer will use. Then, to write to your segment, you need to query the current value, merge the part you want to add, and write it back. You can see that there’s great potential for problems with this solution.
The solution I like to use is simpler and has less potential for errors. It uses an empty local temporary table as the signaling mechanism. A local temporary table you create in one level in the call stack is visible throughout that level as well as in all inner levels in the call stack. This means that if you create the temporary table before you issue your statement, it’s visible inside the trigger that fired as a result of that statement. Also, if you create a temporary table but don’t insert any rows, no page allocations take place, making it a cheap tool to use for such a purpose. So, as your signaling mechanism, create a temporary table with a specific name before you issue your modification, and drop it after the modification. Have the trigger check if a temporary table with that name exists, and if so, return; otherwise, continue normally.
To see a demonstration of this strategy, first create a table called T1 by running the following code:
IF OBJECT_ID(N'dbo.T1', N'U') IS NOT NULL DROP TABLE dbo.T1;
CREATE TABLE dbo.T1(col1 INT);
Then create the following AFTER INSERT trigger on the table:
CREATE TRIGGER trg_T1_i ON dbo.T1 AFTER INSERT
AS
IF OBJECT_ID(N'tempdb..#do_not_fire_trg_T1_i', N'U') IS NOT NULL RETURN;
PRINT 'trg_T1_i in action...';
GO
The PRINT statement represents the usual code you have in your trigger. I use it to show when the usual code gets to run. The IF statement is the addition related to the signaling mechanism that returns if a temporary table named #do_not_fire_trg_T1_i exists. Notice that the table name is qualified with the tempdb database name. Without this qualifier, the OBJECT_ID function will look for it in the current database, which usually will be a user database.
To make sure the trigger keeps running as usual when you don’t create the signal, run the following code to insert a new row into T1:
INSERT INTO dbo.T1(col1) VALUES(1);
The temporary table doesn’t exist, so the trigger continues by running the usual code. The trigger generates the following output:
trg_T1_i in action...
Suppose you want to inset a new row, but this time you don’t want the trigger to run its usual code. You create a temporary table called #do_not_fire_trg_T1_i, issue the INSERT statement, and then drop the temporary table, like so:
-- Setting signal
CREATE TABLE #do_not_fire_trg_T1_i(col1 INT);
INSERT INTO T1(col1) VALUES(2);
-- Clearing signal
DROP TABLE #do_not_fire_trg_T1_i;
This time the trigger executes, finds that the temporary table does exist, and therefore returns without running its usual code.
SQLCLR programming
Although T-SQL is no doubt the premier programming language of SQL Server, it can sometimes be tricky to arrive at simple solutions when faced with certain types of problems. Complex algorithms, ordered computations, and interoperability with other systems are some of the challenges for which T-SQL isn’t always the best choice.
Starting with SQL Server 2005, developers were given a new option: an integrated .NET runtime engine known as SQLCLR. Make no mistake, SQLCLR is tied into and exposed within T-SQL, and it cannot be leveraged without T-SQL. It is not a stand-alone data language, and it certainly is not a replacement for your existing T-SQL skills. However, it can be used to enhance T-SQL and brings immense flexibility and power, allowing developers to more easily solve problems that would otherwise be extremely difficult to tackle in a database environment. Because SQLCLR is based on the Microsoft .NET Framework, it can leverage the framework’s rich library of built-in functionality, in addition to the ease of programming afforded by languages like Microsoft C# and Visual Basic .NET.
This section covers how SQLCLR works, the types of objects and routines that can be created with it (types, aggregates, functions, triggers, and procedures), as well as some guidelines for its use in practice.
![]() Note
Note
The text and examples in this section assume you have a basic understanding of C# and the .NET Framework. For more information on these topics, consult the Microsoft Developer Network at http://msdn.microsoft.com.
SQLCLR architecture
SQL Server, at its core, is intended to act as an enterprise-grade data store. The term enterprise can mean different things to different people, but at its heart are the ideas of scalability and availability. The system must be able to grow to service the demands of the largest companies and applications, and the system must provide mechanisms for ensuring it will respond when requests are made.
As a pure development platform—and not a database product itself—the .NET Framework has no particular concern with either of these qualities. Therefore, when introducing it into the SQL Server ecosystem, special care was taken to ensure both that the runtime would be able to comply with a demanding environment and that it would not reduce the ability of SQL Server to perform as an enterprise-grade system.
In-process hosting model
SQL Server leverages .NET via an in-process runtime model. This means that the runtime shares the same virtual memory and thread space as everything else running within SQL Server. This key design decision has a few pros and cons:
![]() Moving data into .NET routines, or back out into T-SQL, is computationally inexpensive because the data does not need to cross process boundaries.
Moving data into .NET routines, or back out into T-SQL, is computationally inexpensive because the data does not need to cross process boundaries.
![]() Resource utilization by hosted .NET code can potentially directly interfere with resource utilization by other SQL Server elements as a result of the shared resources.
Resource utilization by hosted .NET code can potentially directly interfere with resource utilization by other SQL Server elements as a result of the shared resources.
![]() The runtime inherits the security privileges granted to the SQL Server process, with no additional administrative work.
The runtime inherits the security privileges granted to the SQL Server process, with no additional administrative work.
![]() The core SQL Server operating system management component (SQLOS) has full access to control the runtime, without requiring special permissions or crossing process boundaries.
The core SQL Server operating system management component (SQLOS) has full access to control the runtime, without requiring special permissions or crossing process boundaries.
This final point is the most important and the key to the in-process model. SQLCLR is hosted within SQL Server, but it is also a true SQL Server component in that it is completely integrated with SQLOS. Like all other SQL Server components, SQLCLR receives both memory allocations and CPU time from SQLOS, and SQLOS is able to withhold or reallocate these resources as necessary to keep the entire SQL Server system balanced and responsive.
In addition to controlling resources, SQLOS is also responsible for top-level monitoring of the hosted runtime to ensure that overallocation or overuse of resources does not threaten the availability of the SQL Server instance. The runtime is monitored for such conditions as memory leaks and scheduler monopolization, and SQLOS is able to either dynamically unload an AppDomain (as in the case of a memory leak) or force a nonyielding thread to back off of a busy scheduler to give other queries a chance to run (which is referred to as quantum punishment).
![]() Important
Important
Before you can start running custom SQLCLR code, you must first enable the functionality at the instance level. This is done by first running “EXEC sp_configure ‘clr enabled’, 1” and then committing the change using the “RECONFIGURE” statement. This reconfiguration is not required to use built-in SQLCLR features like the HIERARCHYID and geospatial data types.
Assemblies hosted in the database
Although the runtime itself is globally (and automatically) managed at the SQL Server instance level, .NET assemblies—the modules that encapsulate our custom SQLCLR routines—are both managed and secured within individual databases. At the database level, each assembly is granted a set of permissions via one of three possible buckets. In addition, AppDomains are dynamically managed and scoped by the runtime not globally, but rather within each database that hosts assemblies.
.NET assemblies are compiled DLL or EXE files, and applications generally rely on either physical copies of these compiled files or versions loaded into a Global Assembly Cache (GAC). SQL Server, on the other hand, follows a different model. When an assembly DLL is needed within a SQL Server database, it is first loaded into the database via the CREATE ASSEMBLY statement. This statement reads and copies the DLL into the database. From this point forward, the physical file is no longer used or accessed in any way by SQL Server. This eliminates management overhead; because the assembly is literally part of the database, it moves with the database everywhere that the database goes—including replication, backups, log shipping, availability replicas, and so on.
One of the key options when bringing an assembly into SQL Server using the CREATE ASSEMBLY statement is the PERMISSION_SET. This option restricts the assembly’s operations, giving the database administrator (DBA) or database developer an element of trust that even if the assembly contains rogue (or merely buggy) code, it will not be able to go beyond certain limits. There are three available permission sets:
![]() SAFE This permission set is the most restrictive, allowing the assembly to use basic .NET Framework classes, including those necessary for math and string operations. In addition, the assembly is allowed to connect back to the hosting database, using a special type of ADO.NET connection type called the Context Connection.
SAFE This permission set is the most restrictive, allowing the assembly to use basic .NET Framework classes, including those necessary for math and string operations. In addition, the assembly is allowed to connect back to the hosting database, using a special type of ADO.NET connection type called the Context Connection.
![]() EXTERNAL_ACCESS This permission set includes everything allowed by the SAFE permission set, plus the ability for the assembly to access resources outside of the hosting database. For example, in this permission set the assembly can access another database on the same server, another database on another server, or a file somewhere else on the network.
EXTERNAL_ACCESS This permission set includes everything allowed by the SAFE permission set, plus the ability for the assembly to access resources outside of the hosting database. For example, in this permission set the assembly can access another database on the same server, another database on another server, or a file somewhere else on the network.
![]() UNSAFE This permission set includes everything allowed by the EXTERNAL_ACCESS permission set, plus the ability to take actions that can potentially destabilize the SQL Server instance. Examples include threading, synchronization, and even the ability to shut down SQL Server via code.
UNSAFE This permission set includes everything allowed by the EXTERNAL_ACCESS permission set, plus the ability to take actions that can potentially destabilize the SQL Server instance. Examples include threading, synchronization, and even the ability to shut down SQL Server via code.
These three permission sets are implemented using two different types of checks. When the assembly is just-in-time compiled (JITed), checks are made against an attribute called HostProtection. Various .NET Framework classes and methods are decorated with this attribute, and referencing them in an assembly with insufficient permissions will result in an exception during the JIT process. Security limitations, on the other hand, are enforced at run time via .NET’s Code Access Security (CAS) infrastructure. Generally speaking, granting the EXTERNAL_ACCESS set involves easing security permissions (and limiting CAS enforcement), whereas granting the UNSAFE set involves allowing potential reliability-impacting code, as enforced by HostProtection checks.
Another option specified when creating an assembly is the AUTHORIZATION, or specifying the owner of the assembly. Aside from basic database object security—the ability to ALTER or DROP the assembly—the owner has an important impact on the way the assembly is handled. Specifically, all assemblies in a given database that are owned by the same database principal will be loaded into the same AppDomain. This separation gives each set of assemblies its own memory sandbox, completely isolated from other sets of assemblies.
The main benefit of this design decision is to give SQLOS the ability to selectively spin up and tear down AppDomains on a targeted basis, without affecting other parts of the system. For example, if your database has two functional sets of assemblies, each owned by different principals, and SQL Server detects that one of your assemblies has code that is leaking memory, only the affected one of the two AppDomains will need to be recycled. Users of the other AppDomain will not be affected in any way. This design also means that if you have two or more assemblies that should closely interact with one another, they must be owned by the same principal. Developers should carefully design assembly ownership schemes bearing in mind both of these considerations.
CLR scalar functions and creating your first assembly
There are several types of SQLCLR objects and routines that can be created, but the simplest and perhaps most useful type is the scalar user-defined function (UDF). Scalar functions are useful for encapsulating complex logic or operations; mathematical algorithms, string-manipulation logic, and even data compression are all common use cases for CLR scalar functions.
Compared with T-SQL scalar functions, the CLR variety will almost always yield better performance and simpler query plans. The reason for this is that CLR functions are treated as compiled and encapsulated code, and they are referenced in Compute Scalar operators within a query plan, much the same as any built-in function. Figure 9-22 shows the query plan for a simple CLR scalar function that returns an empty string.
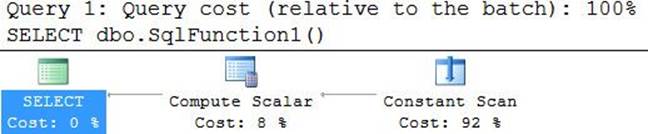
FIGURE 9-22 Query plan for a CLR scalar function.
T-SQL scalar functions, on the other hand, are treated like special stored procedures and are both logically and physically accessed and reevaluated on every iteration. Figure 9-23 shows the query plan for a T-SQL scalar UDF with the same logic as the CLR UDF (simply returning an empty string). The T-SQL version actually produces two query plans: an outer plan for the SELECT, and a second inner plan for row-by-row invocation of the UDF. This is where performance issues come into play.
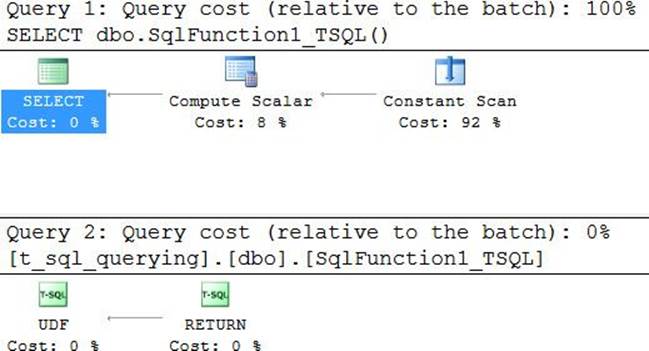
FIGURE 9-23 Query plan for a T-SQL scalar function; note the extra second plan.
One of the key aspects of CLR functions is that they look and feel—to the end user—exactly the same as T-SQL functions. So, if you have an algorithm that is not performing well in a T-SQL function, it can be migrated to a CLR function without changing any downstream code. Likewise, if you decide that a CLR function would be better as a T-SQL function, you can migrate back again. This flexibility is one of the things that makes SQLCLR a powerful tool for performance-tuning exercises.
Visual Studio and SQL Server Data Tools
Before you can create an assembly, you need to decide on an environment in which to work. Although you can easily create C# code with any text editor and compile it using csc.exe (the C# compiler), most developers prefer to use an Integrated Development Environment (IDE). The usual choice is Microsoft Visual Studio, which includes a SQL Server development add-in called SQL Server Data Tools (SSDT). This add-in is designed to help ease many of the pains of full-cycle database development, including various features that assist with refactoring, deployment, and debugging. It also includes specific templates to help with the creation of SQLCLR assemblies.
The remainder of this section assumes you are working in Visual Studio with SSDT. However, the techniques discussed herein should be easily transferrable to any .NET development environment.
SSDT projects and creating a CLR function
SSDT projects in Visual Studio are nested under the SQL Server template category. Once you have created a project in which to work, you can add a user-defined function by right-clicking on the project in Solution Explorer, selecting Add, and then clicking New Item. This will bring up a dialog box with various item types. The SQL CLR C# category contains the correct templates for creating new SQLCLR objects. Choose the SQL CLR C# User Defined Function category to bring up a generic function definition like the one shown in Listing 9-1.
LISTING 9-1 Generic template for a user-defined function
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlString SqlFunction1()
{
// Put your code here
return new SqlString (string.Empty);
}
}
The most important thing to note about this code is that it implements a complete and working scalar user-defined function. A SQLCLR scalar UDF is, in fact, nothing more than a scalar-valued static method, specially exposed to T-SQL via the CREATE FUNCTION statement. (In this case, the SqlFunction attribute that decorates the method is used to tell Visual Studio to do this work on your behalf. But that attribute is entirely optional.) That’s it; whatever type of logic, algorithm, or .NET Framework functionality you decide to put between the curly braces is fair game.
![]() Note
Note
Although the SqlFunction attribute is optional for scalar functions, it does have some important options. If you want to create an index on a function (for example, by using the function in a computed column), you must use it and you must set the IsDeterministic property to true. This is a rare use case, so it won’t be covered here. For more information, refer to the SqlFunctionAttribute documentation in the Microsoft Developer Network (http://msdn.microsoft.com).
SqlTypes namespace
One thing you might have noticed about the code in Listing 9-1 is that instead of returning a standard .NET System.String, the code returns a type called SqlString. This type, along with several others, is found in the System.Data.SqlTypes namespace. Each of the types mirrors a SQL Server built-in type and implements both proper NULL behavior (via an interface called INullable) and behavior similar to that of the base SQL Server type.
These behaviors include value ranges that follow the SQL Server data-type rules, along with actions that mimic those of SQL Server. For example, by default in .NET, adding 1 to an integer variable with a value of 2147483647 results in the variable having a value of –2147483648. In SQL Server, on the other hand, this same operation results in an arithmetic overflow exception. The SqlInt32 data type—which is designed to mirror the behavior of SQL Server’s INTEGER type—also throws an exception when this operation is attempted.
Use of the SqlTypes data types is not required for SQLCLR methods. SQL Server can internally map similar types, such as a System.String to an NVARCHAR. However, using the SqlTypes for method inputs and outputs is highly recommended, because it guarantees appropriate behaviors and capabilities and ensures that your CLR modules will respond in ways that T-SQL consumers expect—whether or not they know that they’re working with a CLR module instead of a T-SQL one.
Publishing the assembly
Once the function has been added, the assembly is just about ready for “publication” (deployment) to the target database. Prior to publishing a real assembly, you might first want to visit the project properties tab—specifically, the SQLCLR section—and configure both the Permission Level and Assembly Owner options to your liking. But given the simplicity of this example, that is probably not necessary.
To publish the assembly, right-click on the project in Solution Explorer and click Publish. You will need to first specify a target database. If this is a database that holds other objects or data you care about, you might want to visit the Advanced options dialog box and make sure to clear any options that could overwrite your prior work. Once you’ve configured things, it is recommended that you save your settings (by clicking Save Profile), because SSDT does not automatically remember them for subsequent publications.
Clicking the Publish button will deploy the function to the database. Under the hood, this is done via a series of T-SQL scripts, starting with something like the following:
CREATE ASSEMBLY [t_sql_querying_project]
AUTHORIZATION [dbo]
FROM 0x4D5A90000300000004000000FFFF0000B800000000 ... (truncated for brevity)
This code uses the CREATE ASSEMBLY statement to load the assembly into the target database. The FROM clause supports either a physical file path to a compiled dynamic-link library (DLL) or a binary string that represents the actual bytes of the DLL. In this case, Visual Studio compiles the DLL (which you can find in the build folder), reads the bytes, and represents them in string form so that they can be more easily scripted and deployed to remote locations without concern for network permissions. The AUTHORIZATION clause sets the assembly owner to dbo(the default). This statement lacks a WITH PERMISSION_SET clause, which means that the default SAFE permission set will be used.
At this point, the assembly has been loaded into the database, but the scalar function is not available to be called via T-SQL. Before that can happen, a T-SQL stub function must be created that points to the internal method. The SSDT publication does this using a script like this one:
CREATE FUNCTION [dbo].[SqlFunction1]
( )
RETURNS NVARCHAR (4000)
AS
EXTERNAL NAME [t_sql_querying_project].[UserDefinedFunctions].[SqlFunction1]
This T-SQL function has the same set of input parameters (none) and the same output parameter type as the generated C# method. Visual Studio has automatically mapped the SqlString type to NVARCHAR(4000). (Remember that .NET strings are always Unicode.) Beyond that, there is no function body, because any logic would have been implemented in C#. Instead, the EXTERNAL NAME clause is used to map this T-SQL stub to the method exposed by the assembly that has already been created. Note the class and method names are case sensitive and must exactly match the case as defined in the C# code.
Once the function has been exposed, it can be called in T-SQL just like any other scalar function:
SELECT dbo.SqlFunction1() AS result;
---
result
------
(1 row(s) affected)
Because the function does nothing more than return an empty string, the output is not especially exciting. However, again, the actual body of this method can be virtually any C# code; the important thing to notice is the ease with which .NET can be leveraged within T-SQL.
SqlTypes pitfalls and the SqlFacet attribute
Although the SqlTypes data types are key interfaces for emulating proper SQL Server data-type behaviors in .NET, and although Visual Studio automatically maps the two during its publication process, sometimes things don’t work as expected. Many SQLCLR developers have been shocked to discover that some Visual Studio behaviors are less than ideal for their given scenarios. Cases that are particularly problematic are the SQL Server NUMERIC (also known as DECIMAL) type, large strings, and some of SQL Server’s newer temporal data types.
To see the basic issue with the NUMERIC type, modify the basic function template into the following form:
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlDecimal DecimalFunction1()
{
return new SqlDecimal (123.4567);
}
}
This seems relatively straightforward: return the decimal value 123.4567. But when you publish and run it, something different happens:
SELECT dbo.DecimalFunction1() AS decimalValue;
---
decimalValue
------------
123
(1 row(s) affected)
The decimal part of the value has been truncated, effectively yielding an integer. This is probably not desired behavior if you’re explicitly using the decimal data type! The root cause becomes immediately apparent upon examining Visual Studio’s generated script:
CREATE FUNCTION [dbo].[DecimalFunction1]
( )
RETURNS NUMERIC (18)
AS
EXTERNAL NAME [t_sql_querying_project].[UserDefinedFunctions].[DecimalFunction1]
SQL Server’s NUMERIC type has fixed precision and scale. Because you haven’t told Visual Studio what precision or scale you’re looking for, a default was used: a precision of 18, with a scale of 0 (18 total digits, with zero digits after the decimal point). Neither the .NETSystem.Decimal type, nor the SqlDecimal type have fixed precision or scale, so a fix for this issue must be done purely on the SQL Server side. To change this behavior, you can either manually create your own stub function definition—specifying the correct precision and scale in the RETURNS clause—or give Visual Studio more information by using an attribute called SqlFacet:
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction]
[return: SqlFacet(Precision=24, Scale=12)]
public static SqlDecimal DecimalFunction2()
{
return new SqlDecimal (123.4567);
}
}
Here you are telling Visual Studio to generate its script using a return precision of 24 and a scale of 12. Thanks to the attribute, this version of the function behaves as expected:
SELECT dbo.DecimalFunction2() AS decimalValue;
---
decimalValue
------------
123.456700000000
(1 row(s) affected)
![]() Note
Note
The behavior described in this section depends on the version of Visual Studio and SSDT. Most versions will reproduce these issues, but as of the time of this writing the November 2014 SSDT build along with Visual Studio 2013 treats all non-overridden string types as NVARCHAR(MAX).
Another issue is related to string types. As shown with the SqlFunction1 example, Visual Studio scripts SqlString as NVARCHAR(4000). This can cause larger strings to truncate, as illustrated by the following function.
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlInt32 ReturnStringLength1(
SqlString theString)
{
return new SqlInt32 (theString.Value.Length);
}
}
This function illustrates an important point regarding the SqlTypes: each of the data types in the namespace implements a property called Value, which maps back to the base .NET type. Using this property is the recommended way to work with the type in your C# code, rather than using a static cast.
Once the function is published, it can be tested against the built-in LEN function:
DECLARE @bigString NVARCHAR(MAX) =
REPLICATE(CONVERT(NVARCHAR(MAX), 'a'), 12345);
SELECT
LEN(@bigString) AS SQL_Length,
dbo.ReturnStringLength1(@bigString) AS CLR_Length;
---
SQL_Length CLR_Length
-------------------- -----------
12345 4000
(1 row(s) affected)
Once again, the problem can be mitigated by using the SqlFacet attribute—this time applied to the input value (and, therefore, without the “return” declaration):
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlInt32 ReturnStringLength2(
[SqlFacet(MaxSize=-1)]
SqlString theString)
{
return new SqlInt32 (theString.Value.Length);
}
}
After publication, the previous script now works as expected:
DECLARE @bigString NVARCHAR(MAX) =
REPLICATE(CONVERT(NVARCHAR(MAX), 'a'), 12345);
SELECT
LEN(@bigString) AS SQL_Length,
dbo.ReturnStringLength2(@bigString) AS CLR_Length;
---
SQL_Length CLR_Length
-------------------- -----------
12345 12345
(1 row(s) affected)
The final major SqlTypes pitfall has to do with some of SQL Server’s newer temporal data types. The SqlTypes namespace was initially released in 2005, and it has not received an update in the meantime. Therefore, although it includes a SqlDateTime type that maps to DATETIME, it has no support for the DATE, TIME, DATETIME2, and DATETIMEOFFSET that first shipped in SQL Server 2008. The solution, in these cases, unfortunately requires manual intervention.
Visual Studio will automatically map System.TimeSpan to TIME and System.DateTimeOffset to DATETIMEOFFSET, but if support for NULLs is desired you will have to resort to using .NET nullable versions of the types (System.TimeSpan? and System.DateTimeOffset?). Unfortunately, these types, although fully supported for SQLCLR assemblies, cause script-generation errors in all current versions of SSDT as of the time of this writing.
The DATE and DATETIME2 classes have no corresponding .NET classes, but both are compatible with System.DateTime (and System.DateTime? for NULL support). Unfortunately, there is no way to tell Visual Studio to script these relationships via SqlFacet. So, once again, a manual step is required.
In both of these cases, the best current workaround, at least for scalar functions, is to leave the SqlFunction attribute off of the function’s C# method definition. This will cause Visual Studio to not attempt to script a T-SQL stub for the function, which will avoid the scripting errors. You can create your own stub script and include it in a post-build .SQL file, which can be added to your SSDT project from the User Scripts category.
String types and case sensitivity
When writing T-SQL, case-sensitivity concerns—or lack thereof—are dictated by the collations of the strings involved in the operation. Collations can be inherited from the database or from an individual column of a table, depending on how things are set up and what, exactly, you’re doing.
In .NET, things are a bit different. By default, all operations on strings use binary comparisons—which means that all operations are case sensitive. This behavior can be easily changed on a case-by-case basis by using flags that are available on almost all the string methods in the .NET Base Class Library (BCL). However, hardcoding a selection might not be a great option when working in SQLCLR, because an assembly might need to be used in both case-sensitive and case-insensitive contexts, and you might not want to maintain two versions of the same code with only a single modified flag.
The solution to this problem is to take advantage of the SqlCompareOptions enumeration exposed as a property of the SqlString class. This enumeration contains information about the collation of the hosting database, which can be used to infer whether or not string comparisons in SQLCLR modules should be done using case sensitivity.
Having access to this information opens the door to many useful cases. For example, the following are two regular expression functions that can be deployed to any SQL Server database and will automatically pick up the correct case-sensitivity settings.
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlBoolean RegExMatch(
SqlString pattern,
[SqlFacet(MaxSize=-1)]
SqlString input)
{
//handle NULLs
if (pattern.IsNull || input.IsNull)
return (SqlBoolean.Null);
//does the hosting database use a case-sensitive collation?
var options =
(0 != (input.SqlCompareOptions & SqlCompareOptions.IgnoreCase)) ?
System.Text.RegularExpressions.RegexOptions.IgnoreCase :
System.Text.RegularExpressions.RegexOptions.None;
//instantiate a regEx object with the options
var regEx =
new System.Text.RegularExpressions.Regex(pattern.Value, options);
//do we have a match?
return new SqlBoolean (regEx.IsMatch(input.Value));
}
[Microsoft.SqlServer.Server.SqlFunction]
[return: SqlFacet(MaxSize = -1)]
public static SqlString RegExReplace(
SqlString pattern,
[SqlFacet(MaxSize = -1)]
SqlString input,
SqlString replacement)
{
//handle NULLs
if (pattern.IsNull || input.IsNull || replacement.IsNull)
return (SqlString.Null);
//does the hosting database use a case-sensitive collation?
var options =
(0 != (input.SqlCompareOptions & SqlCompareOptions.IgnoreCase)) ?
System.Text.RegularExpressions.RegexOptions.IgnoreCase :
System.Text.RegularExpressions.RegexOptions.None;
//instantiate a regEx object with the options
var regEx =
new System.Text.RegularExpressions.Regex(pattern.Value, options);
//do we have a match?
return new SqlString(regEx.Replace(input.Value, replacement.Value));
}
These functions illustrate various techniques: SqlFacet is used for setting input and return sizes as appropriate, the IsNull property is checked to handle NULL inputs, and the SqlCompareOptions enumeration is verified. This final check is done by doing a binary and operation and checking to see whether the output is not equal to zero. If the IgnoreCase bit is set, the result will be nonzero. (It will actually be equal to the value of the IgnoreCase bit.) If, on the other hand, that bit is not set, the and operation will return zero and the code will not useRegexOptions.IgnoreCase to do its work.
SQLCLR scalar function use cases
The preceding examples are designed to show as simply as possible how to work with and develop SQLCLR functions. As such, they don’t illustrate actual cases where these functions can add value to your development tasks. These cases tend to fall into one (or more) of the following three categories:
![]() SQLCLR functions provide excellent performance compared to T-SQL functions. For complex math algorithms, it is not uncommon for a SQLCLR function to achieve performance gains of 1,000 percent or more compared with T-SQL functions. Surprisingly, SQLCLR functions can also outperform built-in SQL Server functions in some cases. A test of the built-in REPLACE function compared with a SQLCLR function that leveraged String.Replace showed a 700 percent performance improvement for very large strings (up to 50,000 characters).
SQLCLR functions provide excellent performance compared to T-SQL functions. For complex math algorithms, it is not uncommon for a SQLCLR function to achieve performance gains of 1,000 percent or more compared with T-SQL functions. Surprisingly, SQLCLR functions can also outperform built-in SQL Server functions in some cases. A test of the built-in REPLACE function compared with a SQLCLR function that leveraged String.Replace showed a 700 percent performance improvement for very large strings (up to 50,000 characters).
![]() Another case for SQLCLR scalar functions is situations where logic is simply too difficult to represent in T-SQL. As a data-access language, T-SQL is not really designed for complex iterative tasks. Imperative languages such as C# and Visual Basic .NET, on the other hand, have numerous forms of flow control, advanced collection classes, and powerful debuggers.
Another case for SQLCLR scalar functions is situations where logic is simply too difficult to represent in T-SQL. As a data-access language, T-SQL is not really designed for complex iterative tasks. Imperative languages such as C# and Visual Basic .NET, on the other hand, have numerous forms of flow control, advanced collection classes, and powerful debuggers.
![]() The final case has to do with leveraging the power of the .NET Base Class Library (BCL). This library has numerous features that are otherwise simply not available in SQL Server, such as the ability to perform disk I/O, network operations, data compression, and advanced XML manipulation.
The final case has to do with leveraging the power of the .NET Base Class Library (BCL). This library has numerous features that are otherwise simply not available in SQL Server, such as the ability to perform disk I/O, network operations, data compression, and advanced XML manipulation.
As a SQL Server developer considering SQLCLR, it is important to question whether doing a given task in SQL Server is a good idea. The same .NET code you can leverage in a SQLCLR function is also available in your application, so you should always question whether the task might be better offloaded to a different server. (Remember that SQL Server is much more expensive, from a licensing standpoint, than an application server.)
If the logic is data intensive (rather than process intensive), shared (that is, data logic that might be leveraged by numerous downstream applications), if the logic is used to filter or aggregate large amounts of data and can save network bandwidth, or any combination of these scenarios apply, doing the work in SQL Server and perhaps SQLCLR might be a good fit.
Streaming table-valued functions
Much like in T-SQL, SQLCLR functions come in two varieties: scalar and table-valued. Although the scalar-valued functions are behaviorally similar to their T-SQL counterparts, SQLCLR table-valued functions (TVFs) aren’t quite the same as either the T-SQL inline or multistatement versions. SQLCLR table-valued functions, although they’re closest in essence to T-SQL multistatement functions, do not use tempdb to store intermediate data. Rather, they are based on a streaming methodology that uses the .NET IEnumerable interface to send one row at a time back to SQL Server.
SQLCLR table-valued function life cycle
Table-valued functions are created using the same basic methods as those used for scalar functions. The core difference between the two is that a scalar function returns a single value and table-valued functions return a collection of values cast as IEnumerable. This interface is implemented by every built-in collection type in .NET, and it can easily be leveraged in your own code through either a custom implementation or via the yield statement, which tells the compiler to build an IEnumerable implementation on your behalf.
SQLCLR table-valued functions have two primary components: the IEnumerable-valued entry method, and a secondary method known as the “fill row method.” When the table-valued function is invoked from SQL Server, the query processor first calls the entry method. It is this method’s job to prepare an IEnumerable instance representing the rows to be sent back. Once the query processor gets a reference to the IEnumerable instance, it creates an instance of IEnumerator and begins calling MoveNext. Each time this method returns true, the query processor callsCurrent, passing the returned object to the “fill row” method. This second method’s job is to map the object (or its properties) to output columns, which will then be consumed by the query processor in the form of a row.
![]() Note
Note
The IEnumerable interface intentionally lacks any kind of property indicating how many elements exist to be enumerated. This means that elements can be dynamically accessed from a source, without holding references in memory. For example, if some code were reading a file line by line, only the current line would ever have to be in memory, along with a pointer to the next line in the file. This is why IEnumerable is referred to as a streaming interface, and this is what makes it especially nice within SQL Server, where memory is often at a premium.
Creating a SQLCLR table-valued function
Creating a table-valued function can start with the same template as that used for scalar functions. However, the return type must be modified, so we will revisit the SqlFunction attribute. Following is an example entry point method that implements a simple string split for comma-separated values:
[Microsoft.SqlServer.Server.SqlFunction(
TableDefinition="value NVARCHAR(MAX)",
FillRowMethodName="StringSplit_fill")]
public static System.Collections.IEnumerable StringSplit(
[SqlFacet(MaxSize=-1)]
SqlString input)
{
if (input.IsNull)
return (new string[] {});
else
return (input.Value.Split(','));
}
This method internally leverages System.String.Split, which returns a collection of strings split on whatever delimiter is provided—a comma in this case. (Of course, the delimiter can be passed to the method instead, but it is hard coded here for simplicity.) Because it doesn’t make sense to attempt to split a NULL string, a check is made against the IsNull property, which is implemented on all the SqlTypes data types for just such a purpose. If the string is NULL, you return an empty collection, which will result in no rows getting returned to the caller, which is exactly how someone might expect the function to behave if it was implemented in T-SQL.
Much like scalar functions, this method is decorated with the SqlFunction attribute, but this time it uses a couple of new options. The TableDefinition tells Visual Studio how to script the T-SQL stub. In this case, a single output column is specified, but the definition can include as many as are supported by the TDS protocol—65,535, which is probably not recommended. The other option used is FillRowMethodName, which specifies the name of the “fill row” method that will be called for each element returned by the enumerator. A common convention is to name the “fill row” method [entry method name]_fill.
The next step is to create the “fill row” method itself, which in this case would be as follows:
public static void StringSplit_fill(
object o,
out SqlString value)
{
value = (string)o;
}
The “fill row” method is always a void-valued static method. Its first parameter must be of type object, because that is what the enumerator will return. (SQLCLR does not currently use generic enumerators.) Aside from the object parameter, it must have one out parameter per column as defined in the TableDefinition option of the SqlFunction attribute on the entry method. In this case, the column is a SqlString, to match the NVARCHAR(MAX) definition. Note that the SqlFacet attribute is not required here, because the TableDefinition takes care of the mapping.
The job of the “fill row” method, again, is to map the input object to one or more output columns, and in this case that task is simple. The collection returned by the entry method consists of strings, and the enumerator returns one string at a time typed as an object. To map it back to a string, the “fill row” method must simply use a static cast.
Once both methods are written and compiled, Visual Studio produces the following T-SQL stub for publication:
CREATE FUNCTION [dbo].[StringSplit]
(@input NVARCHAR (MAX))
RETURNS
TABLE (
[value] NVARCHAR (MAX) NULL)
AS
EXTERNAL NAME [t_sql_querying_project].[UserDefinedFunctions].[StringSplit]
This function can be referenced just like any other table-valued function, and it is quite useful in a number of scenarios. It also happens to be significantly faster than any T-SQL-based method of splitting comma-separated values (CSVs). Following is an example call:
SELECT
*
FROM dbo.StringSplit('abc,def,ghi');
---
value
-----
abc
def
ghi
(3 row(s) affected)
![]() Note
Note
An optional ORDER BY clause is available for the CREATE FUNCTION statement when it’s used for SQLCLR table-valued functions. This clause tells SQL Server that the table returned by the function is guaranteed to be ordered as specified in the ORDER BY clause. This allows the query optimizer to generate better plans in some cases, and it is recommended if your function, in fact, does return its data ordered. Note that the ordering is verified at run time, and an exception will occur if the output doesn’t match the specification. More information on this feature is available in SQL Server Books Online at http://msdn.microsoft.com/en-us/library/ms186755.aspx.
Memory utilization and a faster, more scalable string splitter
It is vitally important, when leveraging SQLCLR routines in active environments, to remember that memory is always at a premium in SQL Server. Most DBAs like to see the server’s memory used for central purposes like the buffer and procedure caches, and not taken over by large allocations in the CLR space.
The string splitter created in the prior section, although functionally sound, does not do a great job of keeping its memory use to a minimum. Its behavior is, in fact, almost the opposite of what might be desirable: it uses String.Split to populate a collection of all possible substrings, and then holds onto the collection until all the elements have been returned to the caller. This means that memory will be used not only for each of the substrings, but also for references to each of those substrings. When splitting large strings, this overhead can really add up, creating a significant amount of pressure on memory resources.
Problems like this are often not simple to solve, and this case is no exception. To fix the situation, you need to stop using the simple—and built-in—String.Split method and instead roll your own string-split algorithm. The following code was developed over the course of several days, in a forum thread, in conjunction with several top SQL Server developers. (If you would like to see the thread, visit http://www.sqlservercentral.com/Forums/Topic695508-338-1.aspx.)
[Microsoft.SqlServer.Server.SqlFunction(
FillRowMethodName = "FillRow_Multi",
TableDefinition = "item nvarchar(4000)"
)
]
public static IEnumerator SplitString_Multi(
[SqlFacet(MaxSize = -1)]
SqlChars Input,
[SqlFacet(MaxSize = 255)]
SqlChars Delimiter
)
{
return (
(Input.IsNull || Delimiter.IsNull) ?
new SplitStringMulti(new char[0], new char[0]) :
new SplitStringMulti(Input.Value, Delimiter.Value));
}
public static void FillRow_Multi(object obj, out SqlString item)
{
item = new SqlString((string)obj);
}
public class SplitStringMulti : IEnumerator
{
public SplitStringMulti(char[] TheString, char[] Delimiter)
{
theString = TheString;
stringLen = TheString.Length;
delimiter = Delimiter;
delimiterLen = (byte)(Delimiter.Length);
isSingleCharDelim = (delimiterLen == 1);
lastPos = 0;
nextPos = delimiterLen * -1;
}
#region IEnumerator Members
public object Current
{
get
{
return new string(theString, lastPos, nextPos - lastPos)
}
}
public bool MoveNext()
{
if (nextPos >= stringLen)
return false;
else
{
lastPos = nextPos + delimiterLen;
for (int i = lastPos; i < stringLen; i++)
{
bool matches = true;
//Optimize for single-character delimiters
if (isSingleCharDelim)
{
if (theString[i] != delimiter[0])
matches = false;
}
else
{
for (byte j = 0; j < delimiterLen; j++)
{
if (((i + j) >= stringLen) || (theString[i + j] != delimiter[j]))
{
matches = false;
break;
}
}
}
if (matches)
{
nextPos = i;
//Deal with consecutive delimiters
if ((nextPos - lastPos) > 0)
return true;
else
{
i += (delimiterLen-1);
lastPos += delimiterLen;
}
}
}
lastPos = nextPos + delimiterLen;
nextPos = stringLen;
if ((nextPos - lastPos) > 0)
return true;
else
return false;
}
}
public void Reset()
{
lastPos = 0;
nextPos = delimiterLen * -1;
}
#endregion
private int lastPos;
private int nextPos;
private readonly char[] theString;
private readonly char[] delimiter;
private readonly int stringLen;
private readonly byte delimiterLen;
private readonly bool isSingleCharDelim;
}
This code solves the memory issue by finding and streaming back one substring at a time, rather than doing all the work up front. This means that the input string must be held in memory, but because only a single reference is needed, this generally consumes significantly less memory than holding references to each of the substrings. As a bonus, the algorithm used in this code is actually faster than that used by String.Split. So this string splitter both performs well and keeps memory utilization to a minimum.
Data access and the context connection
So far, all the examples shown have relied on the data being passed into the functions by the caller. However, both table-valued and scalar functions—as well as other SQLCLR module types—can access data from the hosting database, even if the assembly is cataloged as SAFE. This is done using standard ADO.NET access methods in conjunction with a special connection string called the context connection.
The context connection gives code running in SQLCLR the ability to access data with the same visibility and privileges as normal T-SQL code being run by the caller. This means that the CLR code will be able to see the same data that the caller can see, with no escalation of privilege. Visibility includes anything available at a nested level of scope, including local temporary tables created prior to invoking the SQLCLR routine.
The following example entry function selects and returns rows from a temporary table with a well-known shape:
[Microsoft.SqlServer.Server.SqlFunction(
DataAccess=DataAccessKind.Read,
TableDefinition="col1 INT, col2 FLOAT",
FillRowMethodName="GetTempValues_fill")]
public static System.Collections.IEnumerable GetTempValues()
{
var build = new SqlConnectionStringBuilder();
build.ContextConnection = true;
using (var conn = new SqlConnection(build.ConnectionString))
{
var comm = conn.CreateCommand();
comm.CommandText = "SELECT * FROM #values";
var adapter = new SqlDataAdapter(comm);
var dt = new DataTable();
adapter.Fill(dt);
return (dt.Rows);
}
}
This function first creates a context connection string by using the SqlConnectionStringBuilder class. The connection string is passed to a SqlConnection object, which is used to invoke a SqlCommand that selects from the temporary table. After that, a SqlDataAdapter is used to fill aDataTable with the rows from the query. The same rows are returned as a collection, which naturally implements IEnumerable. Aside from the connection string, all of this is standard ADO.NET code, making it easy to migrate code into or out of SQL Server as necessary. The only other element worth noting is the DataAccess option specified in the SqlFunction attribute, which must be set in order to access data.
![]() Note
Note
The only choices available for the DataAccess are None (the default) and ReadOnly. This is a significant point; just like with T-SQL functions, SQLCLR functions cannot cause side effects. That is, they are designed to only read data, not alter it. If you would like to alter data, a stored procedure is the recommended approach.
You also need to create a “fill row” method, which follows:
public static void GetTempValues_fill(
object o,
out SqlInt32 col1,
out SqlDouble col2)
{
var dr = (DataRow)o;
col1 = new SqlInt32((int)dr[0]);
col2 = new SqlDouble((double)dr[1]);
}
This method casts the object parameter as a DataRow, which is what the entry method returned a collection of. The DataRow is known to contain two columns: the first typed as an integer, and the second typed as a double-precision floating point. These are assigned to their respective outparameters—which map the types specified in the SqlFunction attribute on the entry method—and that is a complete implementation.
Calling the function, after creating a temporary table of the correct shape, does exactly what you might expect—the rows flow through the CLR method and back to the caller:
CREATE TABLE #values
(col1 INT, col2 FLOAT);
INSERT #values VALUES
(1, 1.123),
(2, 2.234),
(3, 3.345);
SELECT
*
FROM dbo.GetTempValues();
---
(3 row(s) affected)
col1 col2
----------- ----------------------
1 1.123
2 2.234
3 3.345
(3 row(s) affected)
Other data access—to remote servers, for example—is also possible, and that access uses the same style of ADO.NET code but requires elevated privileges. Any remote access requires that the assembly is cataloged using the EXTERNAL_ACCESS permission set. Naturally, there might also be network or database permissions issues, but those are beyond the scope of this book.
![]() Important
Important
The EXTERNAL_ACCESS and UNSAFE permission sets require either setting the database to a mode called TRUSTWORTHY or setting up a security scheme based on certificates. Both of these concepts go far beyond what can be covered here. Because these are important considerations, I highly recommended you take a look at the “Module Signing (Database Engine)” topic in SQL Server Books Online for thorough coverage. This is available at http://technet.microsoft.com/en-us/library/ms345102%28v=sql.105%29.aspx.
SQLCLR stored procedures and triggers
Compared to functions, stored procedures are much more flexible, but much less interface-driven, programmatic modules. Just like their T-SQL counterparts, SQLCLR stored procedures can have a large number of both input and output parameters, can return one or more table-valued results (or not), and can set a return value. And just like T-SQL stored procedures—but much different than T-SQL or SQLCLR functions—SQLCLR stored procedures can change their output behaviors dynamically, at run time. (Whether or not this is recommended is another topic entirely.)
Thanks to their extreme flexibility, stored procedures are the workhorses of the T-SQL world, usually by far the most common type of module in most databases. In the SQLCLR world, they are not nearly as ubiquitous thanks to the ease with which functions can be created. Nonetheless, they are handy tools and well worth understanding, especially given that unlike functions, they are designed to both read and modify data in the database.
In addition to stored procedures, this part of the chapter will also cover SQLCLR triggers. Just like in the T-SQL world, a SQLCLR trigger is nothing more than a special variant of a SQLCLR stored procedure. The coding style and patterns are almost identical.
Creating a SQLCLR stored procedure
As with the functions already discussed, SSDT includes a template for stored procedures that is available in the SQL CLR C# items list. Applying this template will create a C# program similar to that shown in Listing 9-2.
LISTING 9-2 Template for a SQLCLR stored procedure
public partial class StoredProcedures
{
[Microsoft.SqlServer.Server.SqlProcedure]
public static void SqlStoredProcedure1 ()
{
// Put your code here
}
}
Much like a function, a SQLCLR stored procedure is a static method, usually inside of a class. A big difference is that because a stored procedure does not require an explicit output type (and, in fact, most never set a return value), the template defaults to void output—which will actually set a 0 when the stored procedure is called from T-SQL. If you want to set an explicit return value, any integer type can be used rather than the void shown in the listing.
This stored procedure is also, like a function created from the template, decorated with an attribute to help SSDT with deployment. Unlike the SqlFunction attribute, the procedure attribute has no options that are required for any more advanced purposes; the attribute’s only use case is for SSDT.
Although there is no body to this stored procedure, it is still considered to be a complete implementation and can be both published and executed. Publication of a stored procedure is similar to publication of a function, in which a T-SQL stub is scripted to match the signature of the C# method. In the case of a stored procedure, only the parameter signature and return value (if any) must match; there is no output signature. Following is the script created by SSDT for SqlStoredProcedure1:
CREATE PROCEDURE [dbo].[SqlStoredProcedure1]
AS EXTERNAL NAME [t_sql_querying_project].[StoredProcedures].[SqlStoredProcedure1]
Once deployed, the procedure can be executed—although the results are not especially riveting:
EXEC SqlStoredProcedure1;
---
Command(s) completed successfully.
The procedure did nothing, but this should serve to illustrate the flexibility available to you as a programmer working with these types of modules. The body of the stored procedure can be populated with virtually any C# (or none at all), and it can do any action allowed by the permission set in which you have cataloged the assembly.
Most stored procedures will deal with data inside the host database, and for this, just like in a function, you can use standard ADO.NET via the context connection. Unlike a function, there is no DataAccess option in the attribute used to mark stored procedures; your stored procedure is free to insert, update, or delete data in any table that the calling context has access to.
For returning simple scalar values to the caller, a series of one or more output parameters can be added to a stored procedure, as in the following code block:
[Microsoft.SqlServer.Server.SqlProcedure]
public static void AddToInput(
SqlInt32 input,
out SqlInt32 inputPlusOne,
out SqlInt32 inputPlusTwo)
{
inputPlusOne = input + 1;
inputPlusTwo = input + 2;
}
After this procedure is published, it can be executed just like a T-SQL stored procedure, using the OUTPUT clause to access the values returned in the output variables:
DECLARE @out1 INT, @out2 INT;
EXEC dbo.AddToInput
@input = 123,
@inputPlusOne = @out1 OUTPUT,
@inputPlusTwo = @out2 OUTPUT;
SELECT @out1 AS out1, @out2 AS out2;
---
out1 out2
----------- -----------
124 125
(1 row(s) affected)
It is also common to return data from a stored procedure in the form of a table (or sometimes as a message). For that, you will need a slightly different set of tools.
The SQL pipe
ADO.NET, although great for reading data, has no obvious mechanism that can be exploited within a SQLCLR stored procedure to send data back to a caller. For this purpose, Microsoft introduced a class called SqlPipe, which gives developers the ability to create messages and return tabular results from within the body of a SQLCLR stored procedure.
The key method on the SqlPipe class is called Send, and it is overloaded to accept a String, SqlDataRecord, or SqlDataReader—each of which has a slightly different behavior. Sending a string, as in the following method, returns a message to the caller, similar to the following T-SQL PRINT statement.
[Microsoft.SqlServer.Server.SqlProcedure]
public static void SendMessage (SqlString message)
{
var pipe = Microsoft.SqlServer.Server.SqlContext.Pipe;
pipe.Send("The message is: " + message.Value);
}
Here a reference to a SqlPipe object was obtained via another class, SqlContext, which provides access to the SqlPipe via a static property. This class also provides access to a few other useful static properties that can help with tying your SQLCLR routines back to the calling context. These are covered later in this section.
When executed, the stored procedure sends a message but not a result set. In SQL Server Management Studio, this manifests as a message in the Messages pane, as shown in Figure 9-24.
FIGURE 9-24 Calling SqlPipe.Send with a string returns a message to the caller.
The other two overloads send back tabular results. If you would like to return a table of only a single row, a formatted SqlDataRecord can be passed to the send method. It is probably advisable, in most cases, to use output parameters instead whenever possible. If you have a reference to aSqlDataReader—for example, from reading data from a remote data source—that can also be passed directly to Send to return the data to SQL Server as a table.
The much more interesting variation of this theme is the ability to construct your own tabular result with an arbitrary number of rows, as might be derived from runtime calculations. To accomplish this, a trio of SqlPipe methods are required: SendResultsStart, SendResultsRow, andSendResultsEnd. Each of these serves a purpose, as illustrated in this method, which returns a sequence of integers:
[Microsoft.SqlServer.Server.SqlProcedure]
public static void SendRows(SqlInt32 numRows)
{
//set up the output shape
var col = new SqlMetaData("col", SqlDbType.Int);
var rec = new SqlDataRecord(col);
var pipe = Microsoft.SqlServer.Server.SqlContext.Pipe;
//start the output stream -- this doesn't actually send anything
pipe.SendResultsStart(rec);
//send the rows
for (int i = 1; i <= numRows.Value; i++)
{
//set field 0 (col) to the value
r.SetInt32(0, i);
pipe.SendResultsRow(rec);
}
pipe.SendResultsEnd();
}
Starting at the top of the method, the first task is to describe the output shape by creating one instance of SqlMetaData per output column—in this case, a single integer called “col”. This column is passed to the SqlDataRecord constructor, creating a record that will be used throughout the remainder of the method.
From there, a reference is obtained to the SqlPipe, and SendResultsStart is called for the record. This call does not actually send the record; rather, it sets up the output stream for the tabular shape that the record defines. To actually send back some rows, a local variable is initialized and looped based on how many rows were requested. For each row, its value is set on the appropriate SqlDataRecord column (0, in this case), and the row is returned using the SendResultsRow method. Finally, the stream is terminated using SendResultsEnd.
The result, once published, looks like this:
EXEC dbo.SendRows
@numRows = 3;
---
col
-----------
1
2
3
(3 row(s) affected)
Using this pattern allows for a large amount of flexibility when it comes to sending data back from a CLR stored procedure. Neither the number of rows, nor the output shape, are fixed or predetermined in any way. That said, it is generally a good idea to try to fix and document expected results from stored procedures to make it easier to write solid data-access code.
CLR exceptions and T-SQL exception handling
As mentioned previously, one of the key benefits of CLR integration is the flexibility it brings to the world of SQL Server development. Most types of CLR routines can be used, when needed, as seamless replacements for existing T-SQL routines. This allows developers to fix problems without creating any downstream consequences or even needing to tell users that something has changed.
One area in which this breaks down a bit is when dealing with exceptions. Users are accustomed to seeing T-SQL exceptions that look and feel a certain way, and CLR exceptions simply don’t meet the same standard. Consider the following stored procedure.
[Microsoft.SqlServer.Server.SqlProcedure]
public static void DivideByZero ()
{
int i = 1;
int j = 0;
int k = i / j;
}
When compared with a standard T-SQL divide-by-zero exception, the .NET counterpart is wordy and confusing to users who aren’t used to looking at stack traces:
SELECT 1/0;
GO
---
Msg 8134, Level 16, State 1, Line 1
Divide by zero error encountered.
--------
EXEC dbo.DivideByZero;
GO
---
Msg 6522, Level 16, State 1, Procedure DivideByZero, Line 2
A .NET Framework error occurred during execution of user-defined routine or aggregate
"DivideByZero":
System.DivideByZeroException: Attempted to divide by zero.
System.DivideByZeroException:
at StoredProcedures.DivideByZero()
.
If you’re dealing with SQLCLR user-defined functions or methods on SQLCLR user-defined types (covered later in this chapter), your options are quite limited. But for SQLCLR stored procedures, there are ways to emulate T-SQL-style exceptions—albeit with some consequences.
The key to producing nicer looking exceptions from SQLCLR stored procedures is to leverage yet another method of the SqlPipe class: ExecuteAndSend. This method takes as its input a T-SQL statement (in the form of a .NET SqlCommand object), which is routed to the calling context and called there, with the results sent to the client—just as though an application had directly invoked the statement. In the following stored procedure, ExecuteAndSend is used to invoke a SELECT:
[Microsoft.SqlServer.Server.SqlProcedure]
public static void ExecuteASelect()
{
var pipe = Microsoft.SqlServer.Server.SqlContext.Pipe;
var comm = new SqlCommand("SELECT 'this is the result' AS theResult");
pipe.ExecuteAndSend(comm);
}
After publication, the stored procedure is run and the results are returned directly, as though the caller executed the query directly from SSMS:
EXEC dbo.ExecuteASelect;
GO
---
theResult
------------------
this is the result
(1 row(s) affected)
This method is of limited utility except when writing dynamic SQL within a SQLCLR stored procedure, but it can be useful for creating custom errors in your stored procedures that feel a bit more like T-SQL errors than .NET errors.
An initial attempt at using ExecuteAndSend can be to simply send back a RAISERROR call, as needed:
[Microsoft.SqlServer.Server.SqlProcedure]
public static void ThrowAnException_v1()
{
var pipe = Microsoft.SqlServer.Server.SqlContext.Pipe;
var comm = new SqlCommand("RAISERROR('test exception', 16, 1)");
pipe.ExecuteAndSend(comm);
}
This code causes RAISERROR to execute, and the results (the exception) are immediately sent to the calling application. Unfortunately, a nasty side effect occurs; as soon as the exception is thrown, control returns to the .NET method and ExecuteAndSend reports that it encountered an exception. Now a second exception is thrown, this time from .NET. The result is even uglier than the normal state of affairs:
EXEC dbo.ThrowAnException_v1;
---
Msg 50000, Level 16, State 1, Line 16
test exception
Msg 6522, Level 16, State 1, Procedure ThrowAnException_v1, Line 15
A .NET Framework error occurred during execution of user-defined routine or aggregate
"ThrowAnException_v1":
System.Data.SqlClient.SqlException: test exception
System.Data.SqlClient.SqlException:
at System.Data.SqlClient.SqlConnection.OnError(SqlException exception, Boolean
breakConnection,
Action`1 wrapCloseInAction)
at System.Data.SqlClient.SqlCommand.RunExecuteNonQuerySmi(Boolean sendToPipe)
at System.Data.SqlClient.SqlCommand.InternalExecuteNonQuery(TaskCompletionSource`1
completion,
String methodName, Boolean sendToPipe, Int32 timeout, Boolean asyncWrite)
at System.Data.SqlClient.SqlCommand.ExecuteToPipe(SmiContext pipeContext)
at Microsoft.SqlServer.Server.SqlPipe.ExecuteAndSend(SqlCommand command)
at StoredProcedures.ThrowAnException_v1()
.
The solution? Notice that the nicely formatted (that is, T-SQL-style) exception is returned to the client prior to the .NET exception. So getting only the nicely formatted exception means stopping the .NET exception—and that means using try-catch:
[Microsoft.SqlServer.Server.SqlProcedure]
public static void ThrowAnException_v2()
{
var pipe = Microsoft.SqlServer.Server.SqlContext.Pipe;
var comm = new SqlCommand("RAISERROR('test exception', 16, 1)");
try
{
pipe.ExecuteAndSend(comm);
}
catch
{ }
}
Because the ExecuteAndSend call is expected to cause an exception, there is no reason to handle anything in the catch block; it can simply return control. The result of this addition is that the caller sees only the simple T-SQL-style error message:
EXEC dbo.ThrowAnException_v2;
---
Msg 50000, Level 16, State 1, Line 16
test exception
Taking this technique one step further, it can be applied to unknown and unexpected exceptions by using nested try-catch blocks:
[Microsoft.SqlServer.Server.SqlProcedure]
public static void DivideByZero_Nicer()
{
try
{
int i = 1;
int j = 0;
int k = i / j;
}
catch (Exception e)
{
var pipe = Microsoft.SqlServer.Server.SqlContext.Pipe;
var tsqlThrow = String.Format("RAISERROR('{0}', 16, 1)", e.Message);
var comm = new SqlCommand(tsqlThrow);
try
{
pipe.ExecuteAndSend(comm);
}
catch
{ }
}
}
Here the potentially exception-prone code—the math—is wrapped in an outer try block. Inside the catch block, the error message from the outer block is stripped (using the Message property of the System.Exception object), and a RAISERROR call is formatted. The result is a nicely formatted message even for a noncustom exception:
EXEC dbo.DivideByZero_Nicer;
---
Msg 50000, Level 16, State 1, Line 15
Attempted to divide by zero.
Although this technique does make for a better user experience when nondevelopers are involved, there are two important tradeoffs. First of all, the element of the standard .NET exceptions that many less-technical users find to be confusing is the stack trace. This information, for someone who does know how to read it, is invaluable for debugging purposes. So it might be a good idea to use preprocessor directives in your C# code to ensure that the well-formatted exceptions are only used in release builds, and never in debug builds.
The second tradeoff is a bit more subtle, and also somewhat shocking:
BEGIN TRY
EXEC dbo.DivideByZero_Nicer;
END TRY
BEGIN CATCH
SELECT 'you will never see this';
END CATCH;
---
Msg 50000, Level 16, State 1, Line 14
Attempted to divide by zero.
Here the stored procedure call was wrapped in TRY-CATCH on the T-SQL side and an exception was thrown, yet the CATCH block was completely ignored. The reason is that this exception was already caught—in the .NET code.
There is, alas, no great solution for this particular tradeoff. Note that the @@ERROR function will return a nonzero value if checked immediately after the invocation of the stored procedure, but TRY-CATCH was added to T-SQL to eliminate the various pains and annoyances associated with checking @@ERROR. So the fact that it works here doesn’t provide much satisfaction. In the end, the best ideas are either to use this technique only when outer exception handling is not required or to educate users how to read stack traces.
![]() Note
Note
The examples in this section used RAISERROR rather than the newer T-SQL THROW statement. This was done purposefully, because THROW does not seem to interact well with the SQLCLR exception-handling mechanisms, and it causes two exceptions to be thrown either with or without the C# try-catch blocks.
Identity and impersonation
As you work with SQLCLR routines, you might hit upon cases where your method will have to reach outside of SQL Server to a remote resource. In this case—especially when dealing with file-level and other network permissions—it can be important to know under whose security credentials the request is being made.
By default, SQL Server will use the credentials of its service account when making outbound requests. However, if your users are connecting via Integrated Authentication, you might want to use their credentials instead—and, therefore, their access rights. This is accomplished by leveraging the WindowsIdentity object that is available from the SqlContext class. This object represents—when Integrated Authentication is being used—the identity of the caller (that is, the login used to authenticate to SQL Server). And the WindowsIdentity class implements anImpersonate method, which makes your SQLCLR code act on behalf of the caller’s credentials.
Setting this up in a SQLCLR stored procedure is simple:
[Microsoft.SqlServer.Server.SqlProcedure]
public static void Impersonation ()
{
var pipe = Microsoft.SqlServer.Server.SqlContext.Pipe;
var ident = Microsoft.SqlServer.Server.SqlContext.WindowsIdentity;
//if the user logged in with SQL authentication the object will be NULL
if (ident == null)
{
pipe.Send("Could not impersonate");
}
else
{
//otherwise, try to impersonate
using (var context = ident.Impersonate())
{
pipe.Send(String.Format("Successfully impersonated as: {0}", ident.Name));
}
}
}
This stored procedure attempts to impersonate only if the WindowsIdentity object is not null. This is a good check to put in place, because the property is not set on the SqlContext class when the caller has logged in using SQL authentication. If your code expects a valid security context—other than that of the SQL Server service account—such a check will make sure that everything is in order.
Once the presence of a valid object is confirmed, the code calls the Impersonate method of the WindowsIdentity class, which does the actual impersonation. This method returns an instance of a class called WindowsImpersonationContext, which is primarily used to revert the impersonation via a method called Undo. The class also implements IDisposable, so in this stored procedure Impersonate is invoked in a using block, which automatically calls the Dispose method after executing. You should take care to ensure that your impersonation code always calls either the Undo or Dispose method once the code is finished using the network resource for which you have impersonated. This keeps things as secure as possible.
SQLCLR triggers
Triggers—in either T-SQL or SQLCLR—are effectively stored procedures bound to table DML actions, with access to the special inserted and deleted virtual tables. There are also DDL triggers, which are stored procedures bound to DDL operations. Beyond what has already been discussed regarding stored procedures, there is not much to say about SQLCLR triggers; they offer the same features and functionality as stored procedures. The SSDT template for a SQLCLR trigger is shown in Listing 9-3.
LISTING 9-3 Generic template for a SQLCLR trigger
public partial class Triggers
{
// Enter existing table or view for the target and uncomment the attribute line
// [Microsoft.SqlServer.Server.SqlTrigger (Name="SqlTrigger1", Target="Table1",
Event="FOR UPDATE")]
public static void SqlTrigger1 ()
{
// Replace with your own code
SqlContext.Pipe.Send("Trigger FIRED");
}
}
Like stored procedures, the SqlContext class is available with a SqlPipe object that can be used to send messages or table-valued results back to the calling context. A SQLCLR trigger, unlike a stored procedure, is always void valued and does not support either input or output parameters; there is no syntax in T-SQL to input arguments or collect return values from a trigger.
SQLCLR triggers use an attribute called SqlTrigger, which specifies a target table as well as one or more events for which to fire. The attribute is commented out in the SSDT template so that the code will compile and pass the SSDT validation rules. To get things working, you will have to add your table to the SSDT project. For the sake of this section, the table’s DDL is
CREATE TABLE [dbo].[MyTable]
(
[i] INT NOT NULL PRIMARY KEY
);
Once the table has been added to the project, creating a functional SQLCLR trigger is a simple exercise:
[Microsoft.SqlServer.Server.SqlTrigger (
Name="SqlTrigger1", Target="MyTable", Event="FOR INSERT, UPDATE")]
public static void SqlTrigger1 ()
{
var build = new SqlConnectionStringBuilder();
build.ContextConnection = true;
using (var conn = new SqlConnection(build.ConnectionString))
{
var comm = conn.CreateCommand();
comm.CommandText = "SELECT COUNT(*) FROM inserted";
conn.Open();
int rowCount = (int)(comm.ExecuteScalar());
SqlContext.Pipe.Send(String.Format("Rows affected: {0}", rowCount));
}
}
This trigger fires after rows are either inserted or updated in MyTable. To get access to the inserted or deleted virtual tables, a query needs to be run, and just like in a stored procedure this is done by using ADO.NET in conjunction with the context connection. Here the trigger counts the rows in the inserted virtual table, returning a message with the count:
INSERT MyTable
VALUES (123), (456);
GO
---
Rows affected: 2
(2 row(s) affected)
The SqlContext class has a property called TriggerContext, which returns an instance of a class called SqlTriggerContext. This class has some useful properties and methods for various cases:
![]() The TriggerAction property identifies which action caused the trigger to fire, without having to query the inserted and deleted tables to make that determination, as you would in T-SQL.
The TriggerAction property identifies which action caused the trigger to fire, without having to query the inserted and deleted tables to make that determination, as you would in T-SQL.
![]() The IsUpdatedColumn method allows you to identify whether or not a certain column was updated in the action that caused the trigger to fire.
The IsUpdatedColumn method allows you to identify whether or not a certain column was updated in the action that caused the trigger to fire.
![]() The EventData property is quite possibly the most useful, because it returns the event data XML for a DDL action formatted as a SqlXml object. This class can expose the data via an XmlReader, which makes processing both easier and faster than in T-SQL.
The EventData property is quite possibly the most useful, because it returns the event data XML for a DDL action formatted as a SqlXml object. This class can expose the data via an XmlReader, which makes processing both easier and faster than in T-SQL.
The primary use cases for SQLCLR triggers include advanced logging and data transmission. Unfortunately, because each SQLCLR trigger must specify a specific table in the SqlTrigger attribute, a new method must be created for every targeted table. This means that it is difficult to create generic triggers (for example, for logging), and the potential for reuse is lower than it could be. It is therefore often a better idea, if you require .NET functionality in a trigger, to call either SQLCLR stored procedures or user-defined functions, as required, from a T-SQL trigger.
SQLCLR user-defined types
Of the various types of SQLCLR modules that are available, user-defined types and user-defined aggregates are the two that provide the most functionality not available within T-SQL. User-defined types allow a developer to create a complex data type that can include static or instance methods, properties, data-validation logic, or all of these things. This functionality has been successfully used by Microsoft to implement the T-SQL HIERARCHYID, GEOGRAPHY, and GEOMETRY data types, although you should be aware that these types are integrated into the query-optimization process. User types will not have quite as much flexibility, but they still have a lot of potential.
Creating a user-defined type
Much like functions and stored procedures, user-defined types can be created using SSDT. Listing 9-4 shows the template for a SQLCLR user-defined type.
LISTING 9-4 Generic template for a user-defined type
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedType(Format.Native)]
public struct SqlUserDefinedType1: INullable
{
public override string ToString()
{
// Replace with your own code
return string.Empty;
}
public bool IsNull
{
get
{
// Put your code here
return _null;
}
}
public static SqlUserDefinedType1 Null
{
get
{
SqlUserDefinedType1 h = new SqlUserDefinedType1();
h._null = true;
return h;
}
}
public static SqlUserDefinedType1 Parse(SqlString s)
{
if (s.IsNull)
return Null;
SqlUserDefinedType1 u = new SqlUserDefinedType1();
// Put your code here
return u;
}
// This is a place-holder method
public string Method1()
{
// Put your code here
return string.Empty;
}
// This is a place-holder static method
public static SqlString Method2()
{
// Put your code here
return new SqlString("");
}
// This is a place-holder member field
public int _var1;
// Private member
private bool _null;
}
SQLCLR user-defined types can be either structs or classes. They must implement the INullable interface, which includes the IsNull property. Unlike stored procedures and functions, user-defined types must be decorated with the appropriate attributes: both SqlUserDefinedType, which controls various behaviors of the type, and Serializable, which allows SQL Server to store an instance of the type in a binary format.
User-defined types have a few required methods and properties outside those defined by INullable (these methods and properties are verified during deployment):
![]() Null is a static property that must return a null instance of the type. Nullability is implemented in the template using a Boolean member, _null, and it is generally not worthwhile to modify the template’s logic of either the Null or IsNull properties.
Null is a static property that must return a null instance of the type. Nullability is implemented in the template using a Boolean member, _null, and it is generally not worthwhile to modify the template’s logic of either the Null or IsNull properties.
![]() Parse is a static method that creates an instance of the type from a string. This method is overridden via T-SQL so that the type can be initialized by using syntax like DECLARE @t dbo.YourType = ‘value’.
Parse is a static method that creates an instance of the type from a string. This method is overridden via T-SQL so that the type can be initialized by using syntax like DECLARE @t dbo.YourType = ‘value’.
![]() ToString is an instance-level method that is effectively the opposite of Parse; its job is to output a string representing the instance of the type. Ideally, ToString and Parse should be fully compatible with one another; any string output by ToString should be able to be turned into a new instance of the type via a call to Parse.
ToString is an instance-level method that is effectively the opposite of Parse; its job is to output a string representing the instance of the type. Ideally, ToString and Parse should be fully compatible with one another; any string output by ToString should be able to be turned into a new instance of the type via a call to Parse.
Deploying and using a user-defined type
Publication via SSDT is the same for user-defined types as it is for other SQLCLR routines. The assembly in which the type has been defined is pushed into the target database, after which a stub T-SQL CREATE is used to map and expose the type for use within your scripts.
Prior to publishing, a few modifications can be made to the base template to provide some basic functionality:
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedType(Format.Native)]
public struct SqlUserDefinedType1: INullable
{
public override string ToString()
{
return _var1.ToString();
}
public bool IsNull
{
get
{
// Put your code here
return _null;
}
}
public static SqlUserDefinedType1 Null
{
get
{
SqlUserDefinedType1 h = new SqlUserDefinedType1();
h._null = true;
return h;
}
}
public static SqlUserDefinedType1 Parse(SqlString s)
{
if (s.IsNull)
return Null;
SqlUserDefinedType1 u = new SqlUserDefinedType1();
u._var1 = Convert.ToInt32(s.Value);
return u;
}
private int _var1;
private bool _null;
}
The type now implements a basic container to store an integer. Parse casts the input string as an integer and stores it in _var1, and ToString reverses the operation. It is not a useful type, to be sure, but it has enough functionality to illustrate the basic behaviors of a user-defined type.
Publication from SSDT produces the following T-SQL stub:
CREATE TYPE [dbo].[SqlUserDefinedType1]
EXTERNAL NAME [t_sql_querying_project].[SqlUserDefinedType1];
Once published, the type can be instantiated much like any other type:
DECLARE @t dbo.SqlUserDefinedType1 = '123';
GO
There are two important things to note in this example. First of all, notice that the type is schema qualified; it is referenced as part of the dbo schema. Types are bound not directly to the database, but rather to schemas within a database. Unfortunately, SSDT cannot create a type in any schema except dbo. Putting a type into a different schema will require a post-deployment step. The second thing to notice is that although this type deals only with an integer, the value must be specified as a string when initializing an instance of the type.
Naturally, once the type has been defined, it can be used in virtually any way that a built-in type can be used. It can be passed to a stored procedure or function, stored in a table, or used in a query. One caveat is that because types are stored in individual databases, stored procedures and functions in other databases are not able to reference them.
The first time you use a user-defined type in a query, you might be a bit surprised by what happens:
DECLARE @t dbo.SqlUserDefinedType1 = '123';
SELECT @t AS typeValue;
GO
---
typeValue
------------
0x8000007B00
(1 row(s) affected)
Rather than returning the integer value 123 formatted as a string, as might be expected, this query returned a binary string. This string is the binary-formatted representation of the type, which is used internally by SQL Server to store and rehydrate instances of the type as needed. Each time a new instance of a given type is created, it is binary formatted and kept in that form for most of its life cycle. Only when instance methods or properties on the type are called is the binary converted back into an in-memory instance of the type.
The binary in this case was automatically generated by SQL Server, as was specified at type creation time in the SqlUserDefinedType attribute: the format for the type is Native, which means that SQL Server will automatically discover and encode the various member variables. Nativeformatting is available only if all the member variables are simple value types (for example, integers). Reference types such as strings and collections require a more involved user-defined process.
To actually get back the string representation of the type, you must explicitly call the ToString method to do the conversion work. This is done as follows:
DECLARE @t dbo.SqlUserDefinedType1 = '123';
SELECT @t.ToString() AS typeValue;
GO
---
typeValue
------------
123
(1 row(s) affected)
![]() Important
Important
Method and property names on SQLCLR user-defined types are case sensitive. Failing to use the proper casing will result in a confusing “could not find method” error.
Working with more complex types
As a developer working with user-defined types, you will not get especially far without requiring more advanced functionality in the form of either reference types or difficult parsing scenarios. Strings, collections, and classes are used throughout the .NET BCL and most other libraries, and because these types are not compatible with Native formatting, a second and more advanced option is exposed. Furthermore, the Parse method might not be the best choice for every scenario.
To illustrate the kind of type that might need different techniques, consider addresses as stored in a database. It is common to see these modeled—at least for the United States—as one column for city, one for state, one for postal code, and a column or two for address lines. An example of an address line is “546 W. Contoso St.” This address line, although usually treated as a single scalar value, actually has various constituent parts. US addresses are composed of some combination of the following:
![]() A building number, which might or might not include non-numeric characters—for example, 546 or 546B.
A building number, which might or might not include non-numeric characters—for example, 546 or 546B.
![]() A pre-directional for the street, such as the “W.” in “W. Contoso.” Not all streets use these, so they are optional when defining the parts of an address line.
A pre-directional for the street, such as the “W.” in “W. Contoso.” Not all streets use these, so they are optional when defining the parts of an address line.
![]() The name of the street.
The name of the street.
![]() The type of the street, which might be “street,” “way,” “boulevard,” and so on. These are generally abbreviated.
The type of the street, which might be “street,” “way,” “boulevard,” and so on. These are generally abbreviated.
![]() A post-directional, which like the pre-directional is not used for all streets. An example is “Contoso ST SW.”
A post-directional, which like the pre-directional is not used for all streets. An example is “Contoso ST SW.”
Imagine you want to develop a database and store address lines in the usual way—as columns in addition to city, state, and postal code—but you also want to both validate and extract the constituent parts for certain reporting requirements. In this case, a user-defined type might be an ideal choice.
This type—which will be named USAddressLine—will have to store five different strings, one for each part defined in the preceding list. This will require the following five member variables:
private SqlString _buildingNumber;
private SqlString _streetName;
private SqlString _streetType;
private SqlString _preDirectional;
private SqlString _postDirectional;
The type is intended for verification, so each of these members is defined as private, with a public getter/setter property. The building number, street name, and street type are not optional and can be verified to be both non-null and not composed entirely of white space. This can be done using the following helper method:
private SqlString validateNull(SqlString input)
{
if (input.IsNull ||
input.Value.Trim() == "")
throw new Exception("Attempted to use NULL or an empty string in a non-nullable field");
return (input);
}
Aside from being non-null, the street type can also be verified as a correct and supported type of street. For this purpose, the following method is used:
private SqlString validateType(SqlString type)
{
if (!(
type == "ST" ||
type == "LN" ||
type == "RD" ||
type == "WAY" ||
type == "BLVD" ||
type == "HWY"))
throw new ArgumentException(String.Format("Invalid type: {0}", type.Value));
return (type);
}
The final validation method required is for the pre-directional and post-directional values:
private SqlString validateDirection(SqlString direction)
{
if (!(
direction.IsNull ||
direction == "N" ||
direction == "NE" ||
direction == "NW" ||
direction == "E" ||
direction == "S" ||
direction == "SE" ||
direction == "SW" ||
direction == "W"))
throw new ArgumentException(String.Format("Invalid direction: {0}", direction.Value));
return (direction);
}
Once each of these methods is defined, public accessor properties can be created as follows:
public SqlString BuildingNumber
{
get { return (_buildingNumber); }
set { _buildingNumber = validateNull(value); }
}
public SqlString StreetName
{
get { return (_streetName); }
set { _streetName = validateNull(value); }
}
public SqlString StreetType
{
get { return (_streetType); }
set { _streetType = validateType(validateNull(value)); }
}
public SqlString PreDirectional
{
get { return (_preDirectional); }
set { _preDirectional = validateDirection(value); }
}
public SqlString PostDirectional
{
get { return (_postDirectional); }
set { _postDirectional = validateDirection(value); }
}
As long as these methods are used for both public and internal manipulation of the values, verification will be built-in and guaranteed.
Generally, the first task after defining member variables is to implement a Parse routine, but in this case it is a fairly difficult task. Figuring out which parts are and are not present—especially when dealing with street names with two, three, or four words—can be an arduous task. Rather than attempting this, you can use the simpler option of disabling the Parse method altogether by marking it as not implemented and, instead, introducing one or more static factory methods that return a fully-formed instance of the type.
Parse is disabled using the .NET convention of throwing a NotImplementedException:
public static USAddressLine Parse(SqlString s)
{
throw new NotImplementedException("Parse not supported.");
}
The method is still required by the user-defined type specifications, but once this code is in place a run-time exception will be thrown whenever someone tries to initialize the type using a string. Instead of doing that, the user can use one of the factory methods:
public static USAddressLine StandardLine(
SqlString BuildingNumber,
SqlString StreetName,
SqlString StreetType)
{
var addressLine = new USAddressLine();
addressLine.BuildingNumber = BuildingNumber;
addressLine.StreetName = StreetName;
addressLine.StreetType = StreetType;
return (addressLine);
}
public static USAddressLine PreDirectionalLine(
SqlString BuildingNumber,
SqlString PreDirectional,
SqlString StreetName,
SqlString StreetType)
{
var addressLine = StandardLine(
BuildingNumber,
StreetName,
StreetType);
addressLine.PreDirectional = PreDirectional;
return (addressLine);
}
It is common to have address lines without any kind of directional, so implementation of the StandardLine method returns an address based only on a building number, street name, and street type. The public accessors are used, so everything is verified. It is also common to see an address line that includes a pre-directional, so a second method has been implemented to handle that case. Because post-directionals are not especially common, no explicit method has been created; the user would have to call one of these two methods first, and then set the post-directional property separately. Note that two methods are required, because inheritance is not supported for public SQLCLR methods, properties, or types.
Using these factory methods requires a special referencing syntax that applies only to static methods. The following example instantiates the type using a factory method and then sets the post-directional value using the SET keyword:
DECLARE @t dbo.USAddressLine =
dbo.USAddressLine::StandardLine('123', 'Contoso', 'ST');
SET @t.PostDirectional = 'SW';
GO
Prior to the type actually being able to function on this level, it needs to be able to be binary serialized. Because it internally uses reference types, several options will have to be set on the SqlUserDefinedType attribute:
[Microsoft.SqlServer.Server.SqlUserDefinedType(
Format.UserDefined,
MaxByteSize = 82,
IsFixedLength = false,
IsByteOrdered = true)]
The format is set to UserDefined, which will require an explicit binary-formatting implementation. As part of this implementation, a developer must define the maximum size the type’s binary might reach, in bytes, from 1 to 8,000, or –1 for up to 2 GB. In this case, 82 is used, based on the following assumptions (keeping in mind that all strings in .NET are Unicode and consume two bytes):
![]() Building numbers will be at most eight characters.
Building numbers will be at most eight characters.
![]() Pre-directionals will be at most two characters.
Pre-directionals will be at most two characters.
![]() Street names will be at most 25 characters.
Street names will be at most 25 characters.
![]() Street types will be at most four characters.
Street types will be at most four characters.
![]() Post-directionals will be at most two characters.
Post-directionals will be at most two characters.
The type is not a fixed length; in other words, the binary format will have a different length depending on various instances of the types and the values of the various parts of the address line. And the type is to be considered byte ordered.
This last option is, perhaps, not especially useful on the USAddressLine type, but it is key for many others. Byte ordered means that instances of the type can be compared to one another using a greater-than or less-than operation, by comparing the types’ binary formats. If this property is set to true, a type can participate—for example, as a key in indexes or as an ORDER BY column. However, you must be careful to implement the binary format so that instances are actually properly compared, lest you introduce subtle bugs into your data.
To do the actual binary-formatting work, the type must implement an interface called IBinarySerialize:
public struct USAddressLine : INullable, IBinarySerialize
This interface specifies two methods, Read and Write. Write outputs a binary representation of the type, while Read reconstitutes the type from binary. Following is the Write method for the USAddressLine type:
public void Write(System.IO.BinaryWriter w)
{
w.Write(_null);
if (!_null)
{
w.Write(BuildingNumber.Value);
if (!PreDirectional.IsNull)
w.Write(PreDirectional.Value);
else
//represent NULL as an empty string
w.Write("");
w.Write(StreetName.Value);
w.Write(StreetType.Value);
if (!PostDirectional.IsNull)
w.Write(PostDirectional.Value);
else
w.Write("");
}
}
This method first writes the value of the _null member, which controls whether or not the instance is null. If it is not null, processing continues. The building number is written first, followed by the pre-directional. Each Write call must have a corresponding Read call. So, even if one of the values is null, something must be written—in this case, an empty string. The street name and street type are also written, followed by a similar null check against the post-directional. It is because everything is written in a specific order that this type can call itself “byte ordered,” whether or not that is useful in practice.
Read follows the same patterns as Write:
public void Read(System.IO.BinaryReader r)
{
_null = r.ReadBoolean();
if (!_null)
{
BuildingNumber = new SqlString(r.ReadString());
var preDir = r.ReadString();
if (preDir != "")
PreDirectional = new SqlString(preDir);
StreetName = r.ReadString();
StreetType = r.ReadString();
var postDir = r.ReadString();
if (postDir != "")
PostDirectional = new SqlString(postDir);
}
}
Unlike Write, which reads from the member variables, Read writes them back. The null property is checked first, and that is followed by the building number, a check against the pre-directional, and so on—in exactly the same order as the values were written.
The final implementation prior to trying out the type is the ToString method. Although, as mentioned earlier, you ideally want to have ToString and Parse methods that are compatible with one another, that is not possible here. ToString is, however, quite simple to put together:
public override string ToString()
{
return (
BuildingNumber.Value + " " +
(PreDirectional.IsNull ? "" : PreDirectional.Value + " ") +
StreetName.Value + " " +
StreetType.Value +
(PostDirectional.IsNull ? "" : " " + PostDirectional.Value));
}
This method concatenates all the strings to produce the kind of text you normally find in an AddressLine column of a database.
After putting everything together and publishing, the type can be used:
DECLARE @t dbo.USAddressLine =
dbo.USAddressLine::StandardLine('123', 'Contoso', 'ST');
SET @t.PostDirectional = 'SW';
SELECT
@t.ToString() AS AddressLine,
@t.BuildingNumber AS BuildingNumber,
@t.StreetName AS StreetName,
@t.StreetType AS StreetType;
GO
---
AddressLine BuildingNumber StreetName StreetType
------------------ --------------- ----------- -----------
123 Contoso ST SW 123 Contoso ST
(1 row(s) affected)
Once fully implemented, the type exposes the base data either as a string or as one of the constituent parts. The type implements built-in validation and can also implement other behaviors. (For example, it could internally tie into a geocoding engine.) Although more conservative practitioners might consider this to be a bad idea, this kind of design can add a lot of flexibility and functionality within the database.
SQLCLR user-defined aggregates
User-defined aggregates, like user-defined types, represent functionality available via SQLCLR that has no similarity to anything available in T-SQL. Although SQL Server ships with various aggregates—COUNT, SUM, AVG, and so on—the ability to write your own is powerful and creates an extreme amount of programmatic flexibility for complex development scenarios.
Creating a user-defined aggregate
User-defined aggregates are similar to user-defined types, with almost the same programming patterns and caveats. They are either structs or classes and must be binary formatted at various stages. The SSDT template for aggregates is shown in Listing 9-5.
LISTING 9-5 Generic template for a user-defined aggregate
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate(Format.Native)]
public struct SqlAggregate1
{
public void Init()
{
// Put your code here
}
public void Accumulate(SqlString Value)
{
// Put your code here
}
public void Merge (SqlAggregate1 Group)
{
// Put your code here
}
public SqlString Terminate ()
{
// Put your code here
return new SqlString (string.Empty);
}
// This is a place-holder member field
public int _var1;
}
User-defined aggregates must implement each of four mandatory methods, which align with the life cycle of the type:
![]() When aggregation is about to begin, one instance of the type is instantiated for each group of rows (as determined by the GROUP BY clause or other factors, depending on the query plan) and Init is called. The job of Init is to initialize any member variables to a correct starting state. This step is most important for aggregates that internally use collection classes.
When aggregation is about to begin, one instance of the type is instantiated for each group of rows (as determined by the GROUP BY clause or other factors, depending on the query plan) and Init is called. The job of Init is to initialize any member variables to a correct starting state. This step is most important for aggregates that internally use collection classes.
![]() For each row containing data to be aggregated, SQL Server calls the Accumulate method. This method consumes the data and adds it to the internal variables that are used to track the aggregation. The default input type is SqlString, but Accumulate can accept multiple parameters of any convertible SQL Server type. (As with functions and procedures, SqlTypes are usually recommended.)
For each row containing data to be aggregated, SQL Server calls the Accumulate method. This method consumes the data and adds it to the internal variables that are used to track the aggregation. The default input type is SqlString, but Accumulate can accept multiple parameters of any convertible SQL Server type. (As with functions and procedures, SqlTypes are usually recommended.)
![]() If two or more row groups are aggregated on separate threads in a parallel plan but all the aggregation belongs together in a single group, the partially aggregated data will be brought together by one or more calls to the Merge method. This method’s job is to consume the other group’s aggregated data and combine it with any locally aggregated data.
If two or more row groups are aggregated on separate threads in a parallel plan but all the aggregation belongs together in a single group, the partially aggregated data will be brought together by one or more calls to the Merge method. This method’s job is to consume the other group’s aggregated data and combine it with any locally aggregated data.
![]() Once all aggregation is finished, an aggregate must produce a scalar result. This is the job of the Terminate method.
Once all aggregation is finished, an aggregate must produce a scalar result. This is the job of the Terminate method.
Instances of a user-defined aggregate will be binary serialized at various points during processing, and the binary will be temporarily stored in tempdb. This is done primarily to reduce memory pressure in cases where many row groups, concurrent large aggregations, or both are running on a given server. Because of this, user-defined aggregates must be serializable and can implement either Native serialization—if only value types are used internally—or UserDefined serialization.
Once implemented and published, a user-defined aggregate can be used just like a built-in aggregate, in conjunction with a GROUP BY clause or partitioned (but not ordered) using the OVER clause. Note that, as with user-defined types, aggregates are bound to a schema; but unlike with types, a schema reference is required in all cases when using an aggregate.
The concatenate aggregate
A common request from SQL Server developers is a built-in aggregate that enables you to create comma-separated strings from strings stored in rows in the database. Although you can accomplish this task in a number of ways in T-SQL, most of your options for doing this are rather clunky as compared to the standard SQL aggregation and GROUP BY syntax. Implementing such an aggregate in C# is almost trivial, and a good example of the kind of thing that can be done using user-defined aggregates.
To begin with, the aggregate will need a place to store strings during accumulation. Although it could simply use an internal string and append to it each time a new row is accumulated, this approach is computationally expensive. Strings in .NET are immutable (unchangeable) once created, and modifying an existing string actually internally creates a new string. It’s better to use a collection class:
private System.Collections.Generic.List<string> stringList;
public void Init()
{
stringList = new System.Collections.Generic.List<string>();
}
Here the code is shown using the List generic collection class, typed for a collection of strings. Also shown is the implementation of the Init method, which simply instantiates the stringList local variable so that it will be ready for rows. Once this is done, Accumulate can be implemented:
public void Accumulate(SqlString Value)
{
if (!(Value.IsNull))
//prepend a comma on each string
stringList.Add("," + Value.Value);
}
This method accepts a SqlString, and first does a null check; if a null is passed in, it will simply be ignored. If the input is non-null, a comma will be prepended. Later, when producing the final output string, the comma that prepends the first string in the list will be removed so that there are no extra commas.
Next is the Merge method:
public void Merge (Concatenate Group)
{
foreach (string s in Group.stringList)
this.stringList.Add(s);
}
Merge, when called, reads the values from the other aggregate’s stringList, adding them to the local stringList. This is effectively the same as calling Accumulate one value at a time, and for more complex aggregates, an internal call to the Accumulate method itself might be a good idea. Once the values have been merged, the other aggregate will be disposed of, so there is no need to worry about removing it or its values from memory.
The final core method to implement is Terminate:
public SqlString Terminate ()
{
if (stringList.Count == 0)
return SqlString.Null;
else
{
//remove the comma on the first string
stringList[0] = stringList[0].Substring(1, stringList[0].Length - 1);
return new SqlString(string.Concat(stringList.ToArray()));
}
}
If Init was called but no non-null values were encountered, the internal collection will have zero elements and the aggregate can return a null to the caller. If, on the other hand, there is some data present, any prepending comma should be removed—this is done by taking a substring of the first element in the collection—and a concatenated string should be produced by using String.Concat and the ToArray method.
Because this aggregate uses a collection class, the defining attribute must be modified and the IBinarySerialize interface must be implemented:
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate(
Format.UserDefined,
MaxByteSize=-1,
IsInvariantToDuplicates=false,
IsInvariantToNulls=true
// This one does nothing!
// IsInvariantToOrder=false
)]
public struct Concatenate : IBinarySerialize
As with the SqlUserDefinedType attribute, SqlUserDefinedAggregate includes the Format setting, which is set to UserDefined. MaxByteSize is specified as –1 (for up to 2 GB of data) because string arrays can grow arbitrarily large.
The next two options are set to protect the aggregation process by limiting which query plans can be chosen. IsInvariantToDuplicates, if set to true, means that a query plan that might aggregate duplicate values that are not present in the source data will not cause any data problems—consider, for example, COUNT(DISTINCT). In the case of string concatenation, that’s not the case, so the option is set to false. IsInvariantToNulls, if set to true, allows the query optimizer to produce a plan that might result in additional nulls being aggregated. In the case of this aggregate, because it deals with nulls, that is not a problem, so it is set to true.
The IsInvariantToOrder option has been included on the SqlUserDefinedAggregate attribute since SQL Server 2005, and it has generated much talk and speculation. Alas, it never has been functional in any way, and Microsoft has never officially commented on it nor made a move to remove it. It is recommended that you not set it in your aggregates, in case it is one day enabled and causes unforeseen results.
The IBinarySerialize Write method follows:
public void Write(System.IO.BinaryWriter w)
{
w.Write(stringList.Count);
foreach (string s in stringList)
w.Write(s);
}
This method first writes the number of elements in the list of strings, and then writes each string. Read, as in a user-defined type, reverses the operation:
public void Read(System.IO.BinaryReader r)
{
Init();
int count = r.ReadInt32();
while (count > 0)
{
stringList.Add(r.ReadString());
count--;
}
}
Read first calls Init, because this is not automatically done prior to calling the Read method—only prior to calling Accumulate. Once the string list has been instantiated, the number of strings that was written is read in, and one call to ReadString is made per string. This number ofReadString calls should equal the number of calls that were made to Write for the same strings.
After publication, the aggregate can finally be tested:
SELECT dbo.Concatenate(theString) AS CSV
FROM
(
VALUES
('abc'),
('def'),
('ghi')
) AS x (theString);
GO
---
CSV
------------
abc,def,ghi
(1 row(s) affected)
Derived table “x” uses the VALUES clause to create three rows with string values in a column called “theString.” These values are passed to the dbo.Concatenate aggregate, and the output result is a comma-separated string, as expected.
Aggregates, in practice, are incredibly useful in a large number of T-SQL development scenarios. They can implement anything from simple tasks, such as the string manipulation shown here, to complex statistics algorithms and various exotic forms of data manipulation, such as packing data into custom interchange formats.
Transaction and concurrency
This section describes how SQL Server handles multiple sessions that interact with the database concurrently. It covers the classic ACID (atomicity, consistency, isolation, and durability) properties of transactions, locking and blocking, lock escalation, delayed durability, isolation levels, and deadlocks. This section focuses on working with disk-based tables; Chapter 10 extends the discussion to working with memory-optimized tables.
In my examples, I’ll use a database called testdb and, within it, tables called T1 and T2. Run the following code to create the database and tables and to populate the tables with sample data:
SET NOCOUNT ON;
IF DB_ID(N'testdb') IS NULL CREATE DATABASE testdb;
GO
USE testdb;
GO
IF OBJECT_ID(N'dbo.T1', 'U') IS NOT NULL DROP TABLE dbo.T1;
IF OBJECT_ID(N'dbo.T2', 'U') IS NOT NULL DROP TABLE dbo.T2;
GO
CREATE TABLE dbo.T1
(
keycol INT NOT NULL PRIMARY KEY,
col1 INT NOT NULL,
col2 VARCHAR(50) NOT NULL
);
INSERT INTO dbo.T1(keycol, col1, col2) VALUES
(1, 101, 'A'),
(2, 102, 'B'),
(3, 103, 'C');
CREATE TABLE dbo.T2
(
keycol INT NOT NULL PRIMARY KEY,
col1 INT NOT NULL,
col2 VARCHAR(50) NOT NULL
);
INSERT INTO dbo.T2(keycol, col1, col2) VALUES
(1, 201, 'X'),
(2, 202, 'Y'),
(3, 203, 'Z');
Transactions described
A transaction is a unit of work that fulfils four properties that are commonly known by their acronym ACID. The four properties abbreviated in this acronym are atomicity, consistency, isolation, and durability.
The atomicity property is what most people have in mind when they think of transactions. It means that the transaction is treated as an all-or-nothing operation. Either all of the transaction’s changes are applied or none are applied. By default, if you don’t explicitly start a user transaction with a BEGIN TRAN command, each statement is handled as an autocommit transaction. If you want to change the default from autocommit mode to implicit-transactions mode (that is, the user will have to explicitly commit the transaction), turn on the session option IMPLICIT_TRANSACTIONS.
As an example, say you start a transaction and submit some changes by running the following code:
BEGIN TRAN;
INSERT INTO dbo.T1(keycol, col1, col2) VALUES(4, 101, 'C');
Suppose a power failure occurs before you manage to submit the rest of the commit transaction for the changes. When you restart the system, SQL Server runs a recovery process that includes redo and undo phases. The redo phase involves rolling forward all changes that are recorded in the log since the last checkpoint. The undo phase rolls back all uncommitted changes, including the ones you just made, to make sure that the database isn’t left in an inconsistent state.
Suppose there was no power failure, and you managed to submit the rest of the changes and commit the transaction by running the following code:
INSERT INTO dbo.T2(keycol, col1, col2) VALUES(4, 201, 'X');
COMMIT TRAN;
As soon as you get an acknowledgment back from SQL Server for the COMMIT TRAN command, the transaction is said to be durable in its entirety. I’ll elaborate on the durability property shortly.
The consistency property refers to the state of the database. The database is considered to be in a consistent state before the transaction starts and after it completes. Once the transaction makes a change, the database state becomes inconsistent until you commit the transaction or roll it back.
In SQL Server, constraints are treated as immediate constraints—namely, they are checked at the end of each statement, even if the statement is part of a user transaction. SQL Server doesn’t support deferred constraints, which are checked only when the transaction commits.
The isolation property means that SQL Server isolates inconsistent data generated by one transaction from other transactions. But what exactly consistent data means to your application is subjective to your application’s needs. For instance, suppose you have two occurrences of the same query in one transaction. Does your application require that the reads be repeatable? If the answer is yes, the second read must return the rows you read previously unchanged. If the answer is no, it’s okay if the second read returns the rows you read previously in a changed state. You can control the degree of isolation you get by setting your isolation level to the one that gives you the desired semantics.
Finally, the durability property ensures that when you commit the transaction, as soon as you get an acknowledgment back from the database, you are assured that the transaction completed and that it can be recovered if needed. The way SQL Server guarantees durability depends on the recovery model of your database. The recovery model is a database setting that determines the database’s recoverability capabilities. The supported options are SIMPLE, BULK_LOGGED, and FULL. If the recovery model is FULL, it’s enough for SQL Server to harden the changes to the log file upon commit. Hardening the changes means flushing the 60-KB log buffer to the log file on disk. If you’re using the SIMPLE or BULK_LOGGED recovery models, bulk operations perform only minimal logging to support a rollback operation if needed. Therefore, when you commit a transaction, to guarantee durability, it’s not enough for SQL Server to flush the log buffer; it also needs to flush dirty data pages from the buffer pool to the data files. As a result, commits can take longer under the SIMPLE and BULK_LOGGED recovery models.
SQL Server 2014 introduces a new feature called delayed durability. I’ll cover this feature later in this section.
SQL Server doesn’t support true nested transactions. It does allow you to nest BEGIN TRAN/COMMIT TRAN statements and to name a transaction, but there’s really only one transaction present at most. A ROLLBACK TRAN <tran_name> command (with the transaction name) is valid only when referring to the outermost transaction name. With every BEGIN TRAN command, SQL Server increases a counter, which can be queried via the @@trancount function. With every COMMIT TRAN command, SQL Server decreases the counter. The transaction actually commits only when the counter drops to 0.
Suppose you open a transaction and, within it, call a stored procedure. Within the stored procedure, you issue a BEGIN TRAN command, do some work, and then issue a COMMIT TRAN command. When the procedure finishes, you’re still in an open transaction. If there’s a failure that causes the transaction to roll back, all the transaction’s changes are undone—the ones submitted both before and after the procedure call, and the ones submitted by the procedure.
Because SQL Server doesn’t support nested transactions, there’s no way, inside the stored procedure, for you to force an actual commit. However, if you need to be able to undo only the procedure’s work in certain conditions, you can use a savepoint for this purpose. At the beginning of the stored procedure, you can check whether you’re already inside a transaction by querying @@trancount. Store this information as a flag in a variable (call it @tranexisted). If you’re not inside a transaction, issue a BEGIN TRAN to open one. If you’re already inside a transaction, issue a SAVE TRAN <savepoint_name> command to mark a savepoint. If everything goes well in the procedure, you will issue a COMMIT TRAN command only if the procedure opened the transaction. If you need to undo the procedure’s work, depending on whether the procedure opened a transaction or marked a savepoint, you’ll issue a ROLLBACK TRAN command or ROLLBACK TRAN <savepoint_name> command, respectively.
The following code demonstrates how you can implement this strategy (normally this code will reside in a stored procedure):
-- BEGIN TRAN;
DECLARE @tranexisted AS INT = 0, @allisgood AS INT = 0;
IF @@trancount = 0
BEGIN TRAN;
ELSE
BEGIN
SET @tranexisted = 1;
SAVE TRAN S1;
END;
-- ... some work ...
-- Need to rollback only inner work
IF @allisgood = 1
COMMIT TRAN;
ELSE
IF @tranexisted = 1
BEGIN
PRINT 'Rolling back to savepoint.';
ROLLBACK TRAN S1;
END;
ELSE
BEGIN
PRINT 'Rolling back transaction.';
ROLLBACK TRAN;
END;
-- COMMIT TRAN;
You can use the commented BEGIN TRAN and COMMIT TRAN commands to test the code both with and without an existing transaction. The @allisgood flag allows you to test the code both when things go well (when the flag is set to 1, you don’t want to undo the work) and when they don’t (when the flag is set to 0, you want to undo the work).
Running the code as is represents a case where there’s no transaction open when the procedure is executed, and things in the procedure don’t go well. In this case, the code opens a transaction and later rolls it back. The code produces the following output:
Rolling back transaction.
Uncomment the BEGIN TRAN and COMMIT TRAN commands, and run the code again. This execution represents a case where a transaction is open when the procedure is executed and things in the procedure don’t go well. This time, the code rolls back to the savepoint. The code generates the following output:
Rolling back to savepoint.
Locks and blocking
SQL Server supports different models to enforce the isolation semantics that you are after. The oldest one—which is still the default, in-the-box version of SQL Server for disk-based tables—is based on locking. In this model, there’s only one version of a row. Your session needs to acquire locks to interact with the data, whether for write purposes or read purposes. If your session requests a lock on a resource (a row, page, or table) that is in conflict with a lock that another session is holding on the same resource, your session gets blocked. This means that you wait until either the other session releases the lock or a timeout that you defined expires.
An alternative model for disk-based tables is a row-versioning one, which is the default model in Microsoft Azure SQL Database (or just “SQL Database” for short). In this model, when you update or delete a row, SQL Server copies the older version of the row to a version store in tempdb and creates a link from the current version of the row to the older one. SQL Server can maintain multiple versions of the same row in such a linked list. This model is a patch on top of the locking model. Writers still use locks, but readers don’t. When a session needs to read a resource, it doesn’t request a lock. If the current version of the row is not the one the session is supposed to see under its current isolation level, SQL Server follows the linked list to retrieve an earlier version of the row for the session.
Table 9-2 shows a lock-compatibility matrix with some common locks that SQL Server uses.
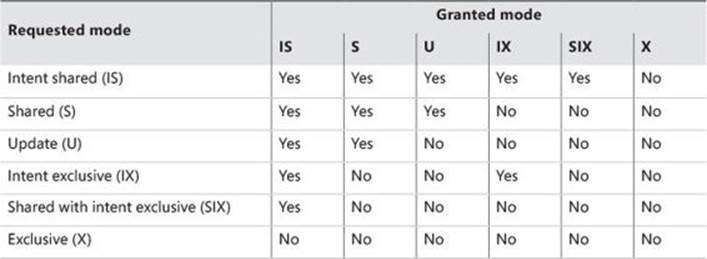
TABLE 9-2 Lock compatibility
As you can see in Table 9-2, an exclusive lock (X) is incompatible with all types of locks and vice versa. Writers are required to take an exclusive lock for all types of modifications. This is true for disk-based tables in both the locking and row-versioning models. A shared lock (S) is compatible with another shared lock. In the locking model, readers are required to take a shared lock to read a resource under most isolation levels. The exception is the Read Uncommitted isolation level, under which readers don’t take shared locks.
An update lock (U) is sort of a hybrid between shared and exclusive. Like a shared lock, an update lock is compatible with another shared lock. Like an exclusive lock, an update lock is incompatible with another update lock. This means that only one session at a time can hold an update lock on a resource. An example where SQL Server uses an update lock internally is to protect the access path in an index when searching for a row that needs to be modified. You can also request to use an update lock explicitly with a table hint in your query, like so:
SELECT ... FROM YourTable WITH (UPDLOCK) WHERE ...;
A classic use case for such an explicit hint is when you have a transaction that involves reading data, applying some calculations, and later writing to the data. If you want to ensure that only one session runs the flow at any given moment, you can achieve this by adding an UPDLOCK hint in the SELECT query that starts the process. This way, whoever issues the query first gets to run the flow. All the rest will have to wait. Later, I will explain how this method can help you prevent a phenomenon called lost updates.
The remaining locks in the lock-compatibility table are intent locks. There’s an intent shared lock (IS), intent exclusive lock (IX), and shared with intent exclusive lock (SIX). The intent shared and intent exclusive locks will block requests for conflicting locks at the same granularity level, but not at lower levels. Shared with intent exclusive is like intent exclusive, but with the additional restrictions of a shared lock, including blocking conflicting locks at lower levels of granularity.
An example where SQL Server internally uses intent locks is to protect the hierarchy of resources above the one you actually need to interact with. For example, suppose you need to update a row as part of a transaction. Your session needs an exclusive lock to update that row. Suppose your session acquires the lock and applies the update, but your transaction is still open. Suppose at this point another session tries to obtain a shared lock on the entire table. Clearly there’s a conflict. But it’s not that straightforward for SQL Server to figure out that there’s a conflict because the resources are different—one is a row, and the other is a table. To simplify the detection of such conflicts, before your session acquires a lock on a resource, it has to first acquire intent locks of the same kind on the upper levels of granularity. For example, to update a row, your session will have to first acquire an intent exclusive lock on the table and the page before it requests the exclusive lock on the row. Then, when another session tries to acquire a conflicting lock on the same table or page, it will be easy for SQL Server to detect the conflict.
The situation where your session requests a lock on a resource that is incompatible with an existing lock on the same resource is called blocking. When your session is blocked, it waits. By default, there’s no limit to how long you’ll wait. If you want to set a limit, you can do so in your session or at the client. In your session, you can set an option called LOCK_TIMEOUT to some value in milliseconds. The default is –1, meaning indefinitely. If this option is set, once the timeout expires you’ll get error 1222. At the client, you can set a command timeout that will cause the client to terminate the request as soon as the timeout expires. But then you don’t necessarily know why your request didn’t finish on time. It could be blocking, but it could be for other reasons as well, like if the system is very slow.
Short-term blocking is normal in a system that relies on the locking model. However, if blocking causes long wait times, it becomes a problem. If users experience long waits on a regular basis, you need to reevaluate the model you’re using. For more specific cases where blocking causes unusual delays, SQL Server gives you tools to troubleshoot the situation. For example, suppose you have a bug in your code that in certain conditions causes a transaction to remain open. Your session will keep holding any locks that are normally held until the end of the transaction, like exclusive ones. Until someone terminates your transaction, other sessions that try to acquire conflicting locks will be blocked. At some point, users will start complaining about the waits. Suppose you get the support call and need to troubleshoot the situation.
Before I demonstrate such a blocking situation, run the following code to initialize the row I will query in the demo:
UPDATE dbo.T1 SET col2 = 'Version 1' WHERE keycol = 2;
Open two connections; call them connection 1 and connection 2. When I did so in my system, I got session ID 53 for the first and session ID 54 for the second.
Issue the following code from connection 1 to open a transaction, and modify the row in T1 with a new value:
SET NOCOUNT ON;
USE testdb;
GO
BEGIN TRAN;
UPDATE dbo.T1 SET col2 = 'Version 2' WHERE keycol = 2;
To apply the update, the session acquires an intent exclusive lock on the table, an intent exclusive lock on the page, and an exclusive lock on the row.
Issue the following code from connection 2 to query all rows in T1:
SET NOCOUNT ON;
USE testdb;
GO
SELECT keycol, col1, col2 FROM dbo.T1;
The SELECT query is running under the default isolation level Read Committed. The session acquires an intent shared lock on the table and an intent shared lock on the page. As soon as it tries to acquire a shared lock on the row that is locked exclusively by the other session, the request is blocked. Now the user with connection 2 is waiting. After some time, the user opens a support call and you’re tasked with troubleshooting the situation.
Open a new connection (call it connection 3) to troubleshoot the problem. You can use a number of dynamic management views (DMVs) and functions (DMFs) to troubleshoot blocking. To get lock information, query the view sys.dm_tran_locks, like so:
SET NOCOUNT ON;
USE testdb;
SELECT
request_session_id AS sid,
resource_type AS restype,
resource_database_id AS dbid,
resource_description AS res,
resource_associated_entity_id AS resid,
request_mode AS mode,
request_status AS status
FROM sys.dm_tran_locks;
Here’s the output I got on my system:
sid restype dbid res resid mode status
---- --------- ----- --------------- -------------------- ----- -------
51 DATABASE 6 0 S GRANT
54 DATABASE 6 0 S GRANT
53 DATABASE 6 0 S GRANT
54 PAGE 6 1:73 72057594040549376 IS GRANT
53 PAGE 6 1:73 72057594040549376 IX GRANT
54 OBJECT 6 245575913 IS GRANT
53 OBJECT 6 245575913 IX GRANT
53 KEY 6 (61a06abd401c) 72057594040549376 X GRANT
54 KEY 6 (61a06abd401c) 72057594040549376 S WAIT
In an active system, lots of locks are acquired and released all the time. Typically, you won’t just query all rows from the view; rather, you will add some filters and perform further manipulation. For example, you likely want to focus first on the locks with the status WAIT.
Observe that session 54 is waiting for a shared lock on a key (a row in an index) in database 6 (testdb). The resource ID and description are not very useful for figuring out exactly which resource is in conflict. Their relevance is in figuring out which session is holding a conflicting lock on the same resource. Observe that session 53 is granted with an exclusive lock on the same row. Now you have the blocking chain. Also, observe that both session 54 and session 53 obtained intent locks of the respective types on the table (OBJECT) and the page. Apply the OBJECT_NAME function to the resource ID of the table (245575913, in my case), and you will get back T1 as the name of the table that is in conflict.
To get information about the connections involved, query the sys.dm_exec_connections view (replacing the session IDs with the ones in your system):
SELECT * FROM sys.dm_exec_connections
WHERE session_id IN(53, 54);
Among the columns in this view, you will find the column most_recent_sql_handle. This column holds a binary handle you provide to the table function sys.dm_exec_sql_text to get the text of the last SQL batch that the connection executed. Use the APPLY operator to apply the function to each of the connections involved, like so:
SELECT C.session_id, ST.text
FROM sys.dm_exec_connections AS C
CROSS APPLY sys.dm_exec_sql_text(most_recent_sql_handle) AS ST
WHERE session_id IN(53, 54);
I got the following output on my system:
session_id text
----------- ---------------------------------------------
53 BEGIN TRAN;
UPDATE dbo.T1 SET col2 = 'Version 2' WHERE keycol = 2;
54 SELECT keycol, col1, col2 FROM dbo.T1;
Session 53 is the blocking session. In our case, the text for this session includes the statement that caused the blocking situation. In practice, that’s not necessarily going to be the case because the session likely will continue work. Session 54 is the blocked session. Clearly, the last thing it executed was the statement that is blocked. That’s a critical piece of information during the troubleshooting process.
To get session-related information, query the view sys.dm_exec_sessions:
SELECT * FROM sys.dm_exec_sessions
WHERE session_id IN(53, 54);
Here you will find lots of useful information about the sessions involved, like the host, program, login name, NT user name, performance measures, state of set options, and isolation level.
To get information about the blocked request, you can query the sys.dm_exec_requests view, like so:
SELECT * FROM sys.dm_exec_requests
WHERE blocking_session_id > 0;
You can also find information about the blocked request in the sys.dm_os_waiting_tasks view:
SELECT * FROM sys.dm_os_waiting_tasks
WHERE blocking_session_id > 0;
Observe that in both cases you filter only the requests that are blocked.
Many people like to start the troubleshooting process by querying these views. Both views provide you the blocking session ID (53 in our case), wait type (LCK_M_S in our case, meaning a shared lock), wait time, and other information. Each of the views has some unique elements. For example, the sys.dm_exec_requests view provides the isolation level of the request, plan handle, and SQL handle. The sys.dm_os_waiting_tasks view is more informative about the resource in conflict with the resource_description column.
All the tools I described here are built-in tools in SQL Server. Adam Machanic created his own tool to troubleshoot blocking in the form of a stored procedure called sp_WhoIsActive. Many people find it useful and make it a standard tool in their system. You can find the stored procedure, with an explanation of how to use it, and licensing terms in Adam’s blog here: http://tinyurl.com/WhoIsActive.
Back to our troubleshooting process; at this point, you know that session 53 is the blocking session and that its transaction is open and will remain so until someone terminates it. To terminate the user process associated with session 53 and the open transaction in this session, use the KILL command, like so:
KILL 53;
The change applied by the transaction in session 53 is undone. Back in connection 2, session 54 managed to obtain the shared lock it was waiting for and completed the query. The query generates the following output:
keycol col1 col2
------- ----- ----------
1 101 A
2 102 Version 1
3 103 C
4 101 C
As mentioned, you can use the LOCK_TIMEOUT session option to set a lock timeout in milliseconds. To try it with our example, execute the code in connection 1 again. (You’ll first need to reconnect.) Then issue the following code in connection 2 to set a lock timeout of five seconds and run the query:
SET LOCK_TIMEOUT 5000;
SELECT keycol, col1, col2 FROM dbo.T1;
After five seconds, you get an error saying that the timeout expired:
Msg 1222, Level 16, State 51, Line 2
Lock request time out period exceeded.
Run the following code to revert back to the default indefinite timeout:
SET LOCK_TIMEOUT -1;
When you’re done testing, close both connections.
Lock escalation
Every lock your transaction acquires is represented by a memory structure that uses approximately 100 bytes. Normally, your transaction starts by acquiring granular locks like row or page locks. But at some point, SQL Server will intervene with an escalation process. If it didn’t, a transaction acquiring a very large number of locks would use large amounts of memory and take longer to complete because it takes time to allocate those memory structures. As soon as a single transaction obtains 5,000 locks against the same object, SQL Server attempts to escalate the fine-grained locks to a full-blown table lock. If SQL Server doesn’t succeed in escalating the locks—for example, when another session is locking a row in the same table—it will keep trying again every additional 1,250 locks. Once SQL Server succeeds in the escalation, your transaction will lock the entire table.
The upside in lock escalation is clear—you use less memory, and the transaction finishes more quickly. The downside is that you’re locking more than what you need, which affects the concurrency in your system. People might be blocked even when trying to access resources that are supposed to be accessible.
To demonstrate lock escalation, I’ll use a table called TestEscalation, which you create and populate by running the following code:
USE testdb;
IF OBJECT_ID(N'dbo.TestEscalation', N'U') IS NOT NULL DROP TABLE dbo.TestEscalation;
GO
SELECT n AS col1, CAST('a' AS CHAR(200)) AS filler
INTO dbo.TestEscalation
FROM TSQLV3.dbo.GetNums(1, 100000) AS Nums;
CREATE UNIQUE CLUSTERED INDEX idx1 ON dbo.TestEscalation(col1);
Run the following transaction, which deletes 20,000 rows from the table and then checks how many present locks are associated with the current session ID:
BEGIN TRAN;
DELETE FROM dbo.TestEscalation WHERE col1 <= 20000;
SELECT COUNT(*)
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID
AND resource_type <> 'DATABASE';
ROLLBACK TRAN;
The code reported that there is only one lock present, indicating that lock escalation took place.
Next, disable lock escalation and run the transaction again:
ALTER TABLE dbo.TestEscalation SET (LOCK_ESCALATION = DISABLE);
BEGIN TRAN;
DELETE FROM dbo.TestEscalation WHERE col1 <= 20000;
SELECT COUNT(*)
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID;
ROLLBACK TRAN;
This time, the code reported over 20,000 locks were present, indicating that lock escalation did not take place. You can also capture lock-escalation events using an Extended Events session with the lock_escalation event.
When you’re done testing, run the following code for cleanup:
IF OBJECT_ID(N'dbo.TestEscalation', N'U') IS NOT NULL DROP TABLE dbo.TestEscalation;
Delayed durability
Recall the earlier discussion about the durability property of transactions. SQL Server uses a concept called write-ahead logging to optimize log writes. This means that it first writes log records to a 60-KB log buffer in cache. It flushes the log buffer when it’s full, and also when a transaction commits to guarantee the transaction’s durability property. In OLTP environments with intense workloads, you have lots of small transactions, each doing a little work that causes a small amount of writing to the transaction log. Such environments tend to have frequent nonfull, log-buffer flushes that might become a bottleneck in the system.
SQL Server 2014 introduces a feature called delayed durability, which you can use to relax the classic durability requirement at the cost of possibly losing data. When you commit a transaction under the delayed durability mode, SQL Server gives control back to you once it finishes writing the transaction log records to the log buffer, without flushing it. This feature allows your transactions to finish more quickly, reducing the bottleneck related to frequent log-buffer flushes. On the flipside, if there’s a power failure, you lose all the changes that were written to the log buffer but weren’t flushed, even for committed transactions.
![]() Important
Important
It is critical to understand that with delayed durability some data loss is possible. You should use this feature only if you can regenerate the data that is lost or you really don’t care if it’s lost.
You control the durability semantics that you are after by setting the database option DELAYED_DURABILITY. You can set this option to one of three possible values:
![]() Disabled All transactions are fully durable.
Disabled All transactions are fully durable.
![]() Forced All transactions are delayed durable.
Forced All transactions are delayed durable.
![]() Allowed By default, transactions are fully durable. But with the COMMIT TRAN command, you can specify the option WITH ( DELAYED_DURABILITY = ON ) to use delayed durability with that specific transaction. You can also control this option at the atomic-block level in natively compiled stored procedures. (See Chapter 10 for details.)
Allowed By default, transactions are fully durable. But with the COMMIT TRAN command, you can specify the option WITH ( DELAYED_DURABILITY = ON ) to use delayed durability with that specific transaction. You can also control this option at the atomic-block level in natively compiled stored procedures. (See Chapter 10 for details.)
Environments with lots of small transactions are the ones that will benefit most from this feature. Environments running large transactions will see little, if any, impact. That’s because in such environments most log flushes are the result of the log buffer getting full.
To demonstrate this feature and its impact on performance, I’ll use a database called testdd and, within it, a table called T1. Run the following code to create the database and the table, and to set the DELAYED_DURABILITY option in the database to Allowed:
SET NOCOUNT ON;
USE master;
GO
IF DB_ID(N'testdd') IS NOT NULL DROP DATABASE testdd;
GO
CREATE DATABASE testdd;
ALTER DATABASE testdd SET DELAYED_DURABILITY = Allowed;
GO
USE testdd;
CREATE TABLE dbo.T1(col1 INT NOT NULL);
Before running each test, truncate the table to make sure it’s empty:
TRUNCATE TABLE dbo.T1;
Run the following code to insert 100,000 rows into T1 in 100,000 fully durable transactions executing in autocommit mode:
DECLARE @i AS INT = 1;
WHILE @i <= 100000
BEGIN
INSERT INTO dbo.T1(col1) VALUES(@i);
SET @i += 1;
END;
It took this code 33 seconds to complete on my system.
Truncate the table before running the next test:
TRUNCATE TABLE dbo.T1;
Run the following code to insert 100,000 rows into T1 in 100,000 delayed durable transactions:
DECLARE @i AS INT = 1;
WHILE @i <= 100000
BEGIN
BEGIN TRAN;
INSERT INTO dbo.T1(col1) VALUES(@i);
COMMIT TRAN WITH (DELAYED_DURABILITY = ON);
SET @i += 1;
END;
This code completed in only two seconds on my system.
Again, truncate the table before running the next test:
TRUNCATE TABLE dbo.T1;
Run the following code to insert 100,000 rows into T1 in one large fully durable transaction:
BEGIN TRAN;
DECLARE @i AS INT = 1;
WHILE @i <= 100000
BEGIN
INSERT INTO dbo.T1(col1) VALUES(@i);
SET @i += 1;
END;
COMMIT TRAN;
It took this code one second to complete on my system.
Clear the table before the final test:
TRUNCATE TABLE dbo.T1;
Run the following code to insert 100,000 rows into T1 in one large delayed durable transaction:
BEGIN TRAN;
DECLARE @i AS INT = 1;
WHILE @i <= 100000
BEGIN
INSERT INTO dbo.T1(col1) VALUES(@i);
SET @i += 1;
END;
COMMIT TRAN WITH (DELAYED_DURABILITY = ON);
This code completed in one second on my system.
These tests confirm that the type of workload that will mainly benefit from the delayed durability feature is one with many small transactions.
Isolation levels
You use isolation levels to control what “consistent data” means to you. You can experience a number of classic phenomena when interacting with data in the database; each phenomenon is either possible or not depending on the isolation level you are running under. These phenomena are
![]() Dirty reads A read of uncommitted data. One transaction changes data but does not commit the change before another transaction reads the same data. The second transaction ends up reading an inconsistent state of the data.
Dirty reads A read of uncommitted data. One transaction changes data but does not commit the change before another transaction reads the same data. The second transaction ends up reading an inconsistent state of the data.
![]() Lost updates Two transactions run the following flow in parallel: read data, make some calculations, and later update the data. With such a flow, one transaction might overwrite the other’s update.
Lost updates Two transactions run the following flow in parallel: read data, make some calculations, and later update the data. With such a flow, one transaction might overwrite the other’s update.
![]() Nonrepeatable reads (also known as inconsistent analysis) In two separate queries within the same transaction, you get different values when reading the same rows. This can happen if a second session changed the data between the queries issued by the first session.
Nonrepeatable reads (also known as inconsistent analysis) In two separate queries within the same transaction, you get different values when reading the same rows. This can happen if a second session changed the data between the queries issued by the first session.
![]() Phantoms In two separate queries within the same transaction using the same query filter, the second query returns rows that were not part of the result of the first query. This can happen if a second transaction inserts new rows that satisfy the first transaction’s query filter in between its two queries. Those new rows are known as phantom reads.
Phantoms In two separate queries within the same transaction using the same query filter, the second query returns rows that were not part of the result of the first query. This can happen if a second transaction inserts new rows that satisfy the first transaction’s query filter in between its two queries. Those new rows are known as phantom reads.
Table 9-3 summarizes the isolation levels and the phenomena that are possible under each. I’ll provide more specifics and demonstrate working under the different isolation levels shortly.
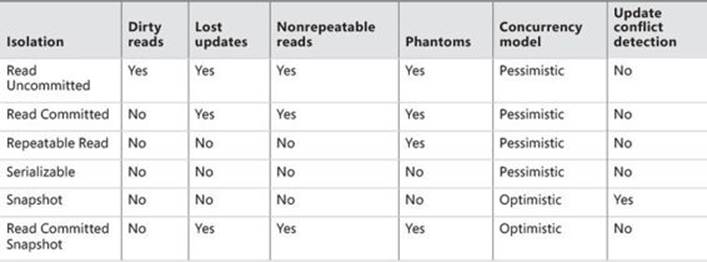
TABLE 9-3 Summary of isolation levels
With disk-based tables, there are two isolation models available to you: locking and a mix of locking and row versioning. The former supports four isolation levels: Read Uncommitted, Read Committed, Repeatable Read, and Serializable. The latter supports two isolation levels: Read Committed Snapshot and Snapshot. The default, in-the-box version of SQL Server is Read Committed, and in the cloud platform (SQL Database) it is Read Committed Snapshot.
You can set the isolation level at either the session level or the query level for each table. You set the isolation level at the session level by issuing the following statement:
SET TRANSACTION ISOLATION LEVEL <isolation level>;
In this statement, <isolation level> can be one of the following: READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE, or SNAPSHOT.
You set the isolation level at the query level for each table by using a table hint (READUNCOMMITTED, READCOMMITTED, REPEATABLEREAD, or SERIALIZABLE). The hint NOLOCK is equivalent to READUNCOMMITTED, and the hint HOLDLOCK is equivalent to SERIALIZABLE.
In the box version of SQL Server (as opposed to the cloud platform), you need to enable database flags in order to work with the Snapshot and Read Committed Snapshot isolation levels. I’ll provide the specifics when describing these isolation levels.
![]() Tip
Tip
SQL Server also provides you with a table hint called READPAST. This hint causes your query to skip locked rows rather than being blocked or getting dirty reads. Make sure, though, that it makes sense for your application to use this hint. SQL Server supports this hint both with queries that retrieve data and with ones that modify data.
The following sections discuss the details of the different isolation levels and demonstrate working under them.
Read Uncommitted isolation level
There are two sides to the Read Uncommitted isolation level—one that most people are familiar with and another that many people aren’t. The familiar side is that, unlike under the default Read Committed isolation level, under Read Uncommitted your session doesn’t acquire a shared lock to read data. This means that if one session modifies data in a transaction and keeps the transaction open, another session running under the Read Uncommitted isolation level can read the uncommitted changes made by the first session. Because the reader doesn’t acquire shared locks, there’s no conflict with the writer’s exclusive locks.
Before I demonstrate this behavior, first initialize the data by running the following code:
USE testdb;
UPDATE dbo.T1 SET col2 = 'Version 1' WHERE keycol = 2;
Open two connections. Run the following code from connection 1 to open a transaction, and modify a row with the value ‘Version 2’ instead of the current value ‘Version 1’:
BEGIN TRAN;
UPDATE dbo.T1 SET col2 = 'Version 2' WHERE keycol = 2;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
Run the following code from connection 2 to set the session’s isolation level to Read Uncommitted and read the data:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
You get the following output:
col2
----------
Version 2
You got an uncommitted read, also known as a dirty read. Remember that another way to work under the Read Uncommitted isolation level is to use the NOLOCK hint in the query.
Run the following code from connection 1 to roll back the transaction:
ROLLBACK TRAN
Close both connections.
The less familiar, or dark, side of Read Uncommitted has to do with how the storage engine carries out the requests from the relational engine when SQL Server executes a query plan. The storage engine perceives the Read Uncommitted isolation level as a blanket approval to focus on speed, even at the cost of reduced consistency. As an example, when the storage engine processes an Index Scan operator (clustered or nonclustered) with an Ordered: False property, it tends to prefer an allocation-order scan of the data (using IAM pages) over an index-order scan (using the linked list). As a result, a reader can read the same row multiple times or skip rows if another writer causes page splits during that time. Under Read Committed, the storage engine prefers to use an index-order scan exactly to prevent such things from happening. I provide more details about such problems and demonstrate such behavior in Chapter 2.
As a result, using the Read Uncommitted isolation level is rarely a good thing. Sadly, many environments use it extensively, mainly in the form of NOLOCK hints in the queries, without realizing all the implications. Environments that suffer from performance problems that are related to locking and blocking should consider either using the row-versioning technology or the In-Memory OLTP engine.
As an example where using the Read Uncommitted isolation level could be a good thing, consider a data warehouse that absorbs changes only during the night in an Extract, Transform, and Load (ETL) process. Only queries that read data are submitted during the day. You want to remove the overhead of shared locks obtained by readers and allow the storage engine to use faster access methods. You can achieve this by setting the database to read-only mode, but then you won’t allow SQL Server to automatically create statistics when needed. The Read Uncommitted isolation level gives you the performance advantages without preventing SQL Server from automatically creating statistics when needed. As long as you know with certainty the changes cannot happen while users are reading data, there’s no risk.
Read Committed isolation level
Under the Read Committed isolation level, a session is required to obtain shared locks to read data. The session releases the shared lock as soon as it is done with the resource. It doesn’t need to wait until the statement finishes, and certainly not until the transaction finishes. As a result, under this isolation level you can read only committed changes—hence the name Read Committed.
To see a demonstration of this behavior, open two connections. Run the following code from connection 1 to open a transaction and modify a row:
BEGIN TRAN;
UPDATE dbo.T1 SET col2 = 'Version 2' WHERE keycol = 2;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
Run the following code from connection 2 to set the session’s isolation level to Read Committed (also the default) and read the data:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
At this point, the reader is blocked.
Run the following code from connection 1 to commit the transaction:
COMMIT TRAN;
The session in connection 1 releases the exclusive lock from the row, allowing the session in connection 2 to obtain the shared lock it was waiting for and read the data. You get the following output in connection 2:
col2
----------
Version 2
In connection 2, you waited in order to read the committed state of the data.
Run the following code to set the value of col2 in the modified row back to ‘Version 1’.
UPDATE dbo.T1 SET col2 = 'Version 1' WHERE keycol = 2;
Close both connections.
The Read Committed isolation level does not try to prevent nonrepeatable reads. Suppose you query the same rows twice within the same transaction. Because you’re not holding any locks between reads, another session can modify the rows during that time. Therefore, two different queries can get different states of the same rows.
The Read Committed isolation level does not try to prevent lost updates. Suppose you have two transactions running in parallel, both with flow that includes reading data, making calculations, and later updating the data. Both transactions read the same initial state of the data. Each transaction, based on its calculations, tries to write its own values to the data. One transaction will apply the update first and commit. The other transaction will apply the update last, overwriting the first transaction’s update.
Repeatable Read isolation level
The Repeatable Read isolation level guarantees that once a query within a transaction reads rows, all subsequent queries in the same transaction will keep getting the same state of those rows. The way SQL Server achieves this behavior is by causing a reader to obtain shared locks on the target rows and to keep them until the end of the transaction. After you open a transaction and read some rows, any other session that tries to update those rows will be blocked until your transaction completes. Therefore, subsequent reads within your transaction are guaranteed to get the same state of those rows as in the first read.
To see a demonstration of a repeatable read, open two connections. Run the following code in connection 1 to set the session’s isolation level to Repeatable Read, open a transaction, and read a row:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN TRAN;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
You get the following output:
col2
----------
Version 1
Try to update the same row from connection 2:
UPDATE dbo.T1 SET col2 = 'Version 2' WHERE keycol = 2;
You get blocked because you need an exclusive lock on the row, and you cannot get one while the other session is holding a shared lock on that row.
Back in connection 1, run the following code to query the row again and commit the transaction:
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
COMMIT TRAN;
You get the following output, which represents a repeatable read:
col2
----------
Version 1
Meanwhile, the writer obtained the exclusive lock it was waiting for, modified the row, and committed the transaction.
When you’re done, run the following code for cleanup:
UPDATE dbo.T1 SET col2 = 'Version 1' WHERE keycol = 2;
Close both connections.
The Repeatable Read isolation level doesn’t allow update conflicts. Suppose you have two transactions running in parallel, both with flow that includes reading data, making calculations, and later updating the data. Both sessions read the same initial state of the data after obtaining shared locks, and they keep the locks until the end of the transaction. Each transaction, based on its calculations, tries to update the data with its own values. To apply the update, both sessions request exclusive locks, each getting blocked by the other’s shared locks. That’s a deadlock. SQL Server detects the deadlock, typically within a few seconds. Once it does, it chooses one of the sessions as the deadlock victim and terminates its transaction, causing it to undo the work and release all locks. That session gets error 1205. Anticipating such errors, you can have error-handling code with retry logic. If your session is chosen as the deadlock victim, when you retry the transaction you start by reading the new state of the data and use it in your calculations before updating the data. This way, no update is lost.
If you get frequent deadlocks that are related to the prevention of lost updates, you should reevaluate your solution. An alternative solution is to use the Read Committed isolation level, and in those transactions where you want to prevent lost updates you add an explicit UPDLOCK hint in the query that reads the data. The session that reads the data first gets the update lock, and the session that gets there second is blocked already in the attempt to read the data. You cause a queuing of the transactions without the need for error-handling code with retry logic.
Serializable isolation level
The Serializable isolation level guarantees that once you query data within a transaction, you will keep working with the same state of the data, seeing only your own changes, until your transaction completes. In other words, transactions work with the data in a serializable fashion. Once a session opens a transaction and accesses data, it’s as if it’s the only one working with the data.
For example, if you issue the same query multiple times in the same transaction, all occurrences of the query get the exact same result sets (assuming the same transaction doesn’t modify the data between the queries). Not only that, you’re guaranteed to get repeatable reads like under the Repeatable Read isolation level. You’re also guaranteed not to get phantom reads. Under the Repeatable Read isolation level, phantom reads are possible. Often people are surprised by this fact, but remember, the Repeatable Read isolation level guarantees only that once you read rows, subsequent reads will get the same state of the rows that you read previously. It’s not supposed to guarantee you won’t get new rows that were added between the reads.
Suppose that working under the Serializable isolation level you submit a query against the table T1 with the filter col1 = 102 twice in the same transaction. You have an index on the filtered column. To guarantee serializable behavior, SQL Server uses key-range locks. This means that once you query data for the first time in a transaction, your session locks the range of keys in the index starting with the first qualifying key and ending with the key after the last qualifying one. Your session keeps the locks until the transaction completes. If another session tries to add, update, or delete rows that satisfy your query filter after you queried the data for the first time and before you complete the transaction, it gets blocked. This way, you get no phantom reads.
To see a demonstration of serializable behavior, first create an index on col1 in T1 by running the following code:
CREATE INDEX idx_col1 ON dbo.T1(col1);
Open two connections. Run the following code in connection 1 to set the isolation level to Serializable, open a transaction, and query the rows in T1 where col1 is equal to 102:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN;
SELECT *
FROM dbo.T1 WITH (INDEX(idx_col1))
WHERE col1 = 102;
The query uses a hint to force the use of the index because the table is so small. This code generates the following output:
keycol col1 col2
------- ----- ----------
2 102 Version 1
In connection 2, run the following code to attempt to insert a new row into T1 with the value 102 in col1:
INSERT INTO dbo.T1(keycol, col1, col2) VALUES(5, 102, 'D');
If the code in connection 1 was running under the Repeatable Read isolation level, your insert would have been successful. However, the code in connection 1 is running under the Serializable isolation level, so your insert is blocked.
Back in connection 1, run the following code to execute the same query a second time and to commit the transaction:
SELECT *
FROM dbo.T1 WITH (INDEX(idx_col1))
WHERE col1 = 102;
COMMIT TRAN;
You get the same output you got in the first execution of the query:
keycol col1 col2
------- ----- ----------
2 102 Version 1
Meanwhile, the INSERT statement in connection 2 completed.
When you’re done, run the following code for cleanup:
DELETE FROM dbo.T1 WHERE keycol = 5;
DROP INDEX dbo.T1.idx_col1;
Close both connections.
Snapshot and Read Committed Snapshot isolation levels
The Snapshot and Read Committed Snapshot isolation levels are based on a model that mixes the use of locking and row versioning. Writers keep using exclusive locks as usual. In addition, when you update or delete a row, SQL Server copies the version before the change to a version store in tempdb and creates a link from the current version of the row to the older one. If you apply multiple updates to a row, SQL Server will keep adding more versions to the chain, placing the newest one in front of the others. SQL Server adds 14 bytes of versioning information to new rows that you insert. Readers don’t take shared locks; rather, if the current version of the row is not the one they are supposed to see, they request an older committed version of the row from the version store.
The Snapshot isolation level gives you a transaction-level-consistent view of the data, plus it prevents lost updates by generating an “update conflict” error. The Read Committed Snapshot isolation level gives you a statement-level-consistent view of the data and doesn’t attempt to prevent update conflicts. With this in mind, and by examining Table 9-3 that I provided earlier, identify which locking-based isolation levels are the closest parallels to the row-versioning-based ones. You will notice that Snapshot is closest to Serializable, and Read Committed Snapshot is closest to Read Committed.
A cleanup thread wakes up every minute and removes row versions that aren’t needed anymore from the tail forward until getting to the first row version that is still needed. So, if you have long-running transactions, it increases the chances for long chains.
Under the row-versioning-based isolation levels, readers don’t need to wait. The fact that they don’t use shared locks reduces the overhead related to locking and tends to result in reduced blocking and deadlocking. The tradeoff is that readers might need to traverse linked lists to get to the correct row version, and writers need to write row versions to the version store. You need to make sure that you tune tempdb to cope with the increased load and that you do thorough testing before enabling row versioning in production.
Each of the row-versioning-based isolation levels requires you to turn on a respective database option to enable it. To allow the use of the Snapshot isolation level, you turn on the database flag ALLOW_SNAPSHOT_ISOLATION. This causes SQL Server to start versioning rows. To actually use the Snapshot isolation level, you also need to set the session’s isolation level to SNAPSHOT. To work with the Read Committed Snapshot isolation level, you turn on the database option READ_COMMITTED_SNAPSHOT. Once you do, you change the semantics of the default Read Committed isolation level from locking-only-based semantics to semantics based on mixed locking and row versioning. Because enabling this database flag changes the default isolation level, you need exclusive access to the database to apply it. New connections will use the Read Committed Snapshot isolation level. Then, in cases where you want a reader to use shared locks, you add the table hint READCOMMITTEDLOCK.
To enable the use of the Snapshot isolation level in the testdb database, turn on the database option ALLOW_SNAPSHOT_ISOLATION ON, like so:
ALTER DATABASE testdb SET ALLOW_SNAPSHOT_ISOLATION ON;
Open two connections. Run the following code from connection 1 to open a transaction, update a row, and read the row:
BEGIN TRAN;
UPDATE dbo.T1 SET col2 = 'Version 2' WHERE keycol = 2;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
This code generates the following output:
col2
----------
Version 2
Query the view sys.dm_tran_version_store to see the row versions that currently reside in the version store:
SELECT * FROM sys.dm_tran_version_store;
You get one row version in the output.
Run the following code in connection 2 to set the session’s isolation level to Snapshot, open a transaction, and query the row that was modified by connection 1:
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRAN;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
Remember that under Snapshot you get a transaction-level-consistent view of the data. This means that throughout the transaction you will get the last committed state of the data at the point in time when you issued the first statement within the transaction. You get the following output:
col2
----------
Version 1
Then, in connection 1, run the following code to commit the transaction and read the row:
COMMIT TRAN;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
You get the following output:
col2
----------
Version 2
Back in connection 2, run the following code to read the row again, still in the open transaction:
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
You get the same state of the row you got in the previous query:
col2
----------
Version 1
If you were running under the Read Committed Snapshot isolation level, instead of getting ‘Version 1’, you would have got the new committed state ‘Version 2’.
Finally, run the following code in connection 2 to commit the transaction and query the row again:
COMMIT TRAN;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
You get the following output:
col2
----------
Version 2
Run the following code to update the row back to the value ‘Version 1’:
UPDATE dbo.T1 SET col2 = 'Version 1' WHERE keycol = 2;
As mentioned, the Snapshot isolation level prevents lost updates by detecting update conflicts. As an example, in connection 1 run the following code to set the isolation level to Snapshot, open a transaction, and query a row:
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRAN;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
You get the following output:
col2
----------
Version 1
In connection 2, run the following code to update the same row:
UPDATE dbo.T1 SET col2 = 'Version 2' WHERE keycol = 2;
Back in connection 1, try to update the row too:
UPDATE dbo.T1 SET col2 = 'Version 3' WHERE keycol = 2;
SQL Server detects that someone else modified the row you’re trying to update, and it generates error 3960, indicating that it detected an update conflict:
Msg 3960, Level 16, State 2, Line 7
Snapshot isolation transaction aborted due to update conflict. You cannot use snapshot isolation
to access table 'dbo.T1' directly or indirectly in database 'testdb' to update, delete, or
insert the row that has been modified or deleted by another transaction. Retry the transaction
or change the isolation level for the update/delete statement.
SQL Server terminates your transaction and undoes the work. Anticipating such conflicts, you can have error-handling code with retry logic. If you think about this, getting an “update conflict” error is better than getting a more generic deadlock error. Deadlocks can happen for all sorts of reasons, and perhaps you want to handle differently cases where an error is related to the prevention of lost updates and others.
Run the following code for cleanup:
UPDATE dbo.T1 SET col2 = 'Version 1' WHERE keycol = 2;
Close both connections.
Next, I’ll demonstrate using the Read Committed Snapshot isolation level. Assuming you have exclusive access to the database, turn on the database option READ_COMMITTED_SNAPSHOT in testdb to change the semantics of the Read Committed isolation level to Read Committed Snapshot:
ALTER DATABASE testdb SET READ_COMMITTED_SNAPSHOT ON;
Open two connections. Both are now running under the Read Committed Snapshot isolation level by default. Run the following code in connection 1 to open a transaction, update a row, and then read that row:
BEGIN TRAN;
UPDATE dbo.T1 SET col2 = 'Version 2' WHERE keycol = 2;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
You get the following output:
col2
----------
Version 2
Run the following code in connection 2 to open a transaction and read the same row:
BEGIN TRAN;
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
You get the last committed state that was available when your statement started:
col2
----------
Version 1
Go back to connection 1, and run the following code to commit the transaction:
COMMIT TRAN;
Then, in connection 2, run the following code to query the row again and commit the transaction:
SELECT col2 FROM dbo.T1 WHERE keycol = 2;
COMMIT TRAN;
You get the new state of the row that was last committed before you issued your statement:
col2
----------
Version 2
Remember that under the Snapshot isolation level in the same situation you got ‘Version 1’, because that isolation level gives you a transaction-level-consistent view of the data.
When you’re done, run the following code for cleanup:
UPDATE dbo.T1 SET col2 = 'Version 1' WHERE keycol = 2;
Close both connections.
Run the following code to restore the testdb database to its default settings:
ALTER DATABASE testdb SET ALLOW_SNAPSHOT_ISOLATION OFF;
ALTER DATABASE testdb SET READ_COMMITTED_SNAPSHOT OFF;
Deadlocks
A deadlock is a combination of blocking situations that end up in a cycle. It can involve two or more sessions. For example, suppose that session X blocks session Y, session Y blocks session Z, and session Z blocks session X. SQL Server actively searches for deadlocks normally every five seconds. When it detects a deadlock, it reduces the interval between searches to as low as 100 milliseconds, depending on the frequency of the deadlocks. After some time with no deadlocks, it increases the interval to five seconds. Once SQL Server detects a deadlock, it chooses one of the sessions involved as the deadlock victim and terminates its transaction. That session gets error 1205; all the work within the transaction is undone and all locks are released.
SQL Server chooses the deadlock victim based on two criteria. You can set an option in your session called DEADLOCK_PRIORITY to a value in the range –10 to 10. SQL Server chooses the session with the lowest deadlock priority as the deadlock victim. In the case of ties in the priority, SQL Server estimates the amount of work involved in rolling back each of the transactions based on the information recorded in the transaction log and chooses the transaction that involves the least work. In the case of ties in the priority and the estimated amount of work, SQL Server chooses the victim randomly.
SQL Server provides you with a number of tools to troubleshoot deadlocks. Trace flags 1222 and 1204 cause SQL Server to write information about the deadlock to the error log. The trace-event Deadlock graph and the Extended Events event xml_deadlock_report (part of the defaultsystem_health session) can be used to produce a deadlock graph as an XML instance. The deadlock graph can be viewed graphically in Profiler and SSMS. You can also run a trace or an Extended Events session with the following events: sql_statement_starting, sp_statement_starting, or both as needed; lock_deadlock; and lock_deadlock_chain. The deadlock-chain event reports which session IDs were involved. You analyze the statement-starting events of the sessions involved, from the moment their transactions started until the deadlock event. This way, you can identify the sequence of statements that lead to the deadlock. The problem with running such a trace or Extended Events session is that it can be expensive if you run it for long periods.
In the following sections, I demonstrate a simple deadlock example, and then I describe the measures you can take to reduce deadlock occurrences. After that, I describe a more complex deadlock example involving a single table and a single statement submitted by each session.
Simple deadlock example
To see a demonstration of a simple deadlock, open two connections. Run the following code in connection 1 to open a transaction and update a row in T1:
BEGIN TRAN;
UPDATE dbo.T1 SET col1 = col1 + 1 WHERE keycol = 2;
The session acquires an exclusive lock on the row.
Run the following code in connection 2 to open a transaction, and update a row in T2:
BEGIN TRAN;
UPDATE dbo.T2 SET col1 = col1 + 1 WHERE keycol = 2;
The session acquires an exclusive lock on the row.
Back in connection 1, run the following code to try and query the row from T2 that the other session is locking and to commit the transaction:
SELECT col1 FROM dbo.T2 WHERE keycol = 2;
COMMIT TRAN;
This session needs a shared lock to read the row but cannot obtain it while the other session is holding an exclusive lock on the same row. This session is blocked.
Run the following code in connection 2 to try and query the row from T1 that the other session is locking and to commit the transaction:
SELECT col1 FROM dbo.T1 WHERE keycol = 2;
COMMIT TRAN;
This session also gets blocked. At this point, you have a deadlock. Within a few seconds, SQL Server detects the deadlock, chooses a deadlock victim based on the logic I described earlier, and terminates the victim’s transaction. In my case, SQL Server chose the session in connection 2 as the victim. I got the following error in connection 2:
Msg 1205, Level 13, State 51, Line 5
Transaction (Process ID 54) was deadlocked on lock resources with another process and has been
chosen as the deadlock victim. Rerun the transaction.
Close both connections.
Measures to reduce deadlock occurrences
When deadlock occurrences are infrequent, you can use error-handling code with retry logic to retry the task when you get error 1205. But when deadlocks are frequent in the system, they can become a performance problem. It’s not realistic to expect that you can eliminate all deadlock occurrences in the system; after all, they have a reason to exist. But you can certainly take measures to reduce their frequency.
A common cause of deadlocks that can be avoided is a lack of important indexes. If you don’t have an index to support a query filter, SQL Server has to scan the entire table to get the qualifying rows. As it scans the table, it acquires locks even on rows you don’t really need. As a result, you can run into conflicts that lead to a deadlock even though there’s no real logical conflict between the sessions involved.
To see a demonstration of such a deadlock, open two connections. Run the following code from connection 1 to open a transaction and update the rows in T1 where col1 is equal to 101:
BEGIN TRAN;
UPDATE dbo.T1 SET col2 = col2 + 'A' WHERE col1 = 101;
Run the following code from connection 2 to open a transaction and update the rows in T2 where col1 is equal to 203:
BEGIN TRAN;
UPDATE dbo.T2 SET col2 = col2 + 'B' WHERE col1 = 203;
Run the following code from connection 1 to query the rows from T2 where col1 is equal to 201:
SELECT col2 FROM dbo.T2 WHERE col1 = 201;
COMMIT TRAN;
You get blocked even though there’s no real logical conflict.
Run the following code from connection 2 to query the rows from T1 where col1 is equal to 103:
SELECT col2 FROM dbo.T1 WHERE col1 = 103;
COMMIT TRAN;
You get blocked again, even though there’s no real logical conflict. At this point, SQL Server detects a deadlock. In my test, SQL Server terminated the transaction in connection 2, generating the following error:
Msg 1205, Level 13, State 51, Line 1
Transaction (Process ID 54) was deadlocked on lock resources with another process and has been
chosen as the deadlock victim. Rerun the transaction.
Run the following code to create the missing indexes:
CREATE INDEX idx_col1 ON dbo.T1(col1);
CREATE INDEX idx_col1 ON dbo.T2(col1);
Rerun the test, but first add the hint WITH(INDEX(idx_col1)) after the table name in both SELECT queries to force SQL Server to use the index. Normally, you do not need to do this. However, because the tables in our example are so small, the chances are that SQL Server will scan the whole table even with the index in place. This time, the test should complete with no conflicts.
In addition to using indexing, you can take other measures to reduce deadlock occurrences in your system. The order in which you access physical resources in the different transactions is important. For a deadlock to happen, you must access physical resources in different transactions in reverse order. For example, consider the simple deadlock example I presented earlier. In one transaction, you first modify T1 and then query T2, and in another transaction you first modify T2 and then query T1. If it’s not critical to your application to perform the activities in a particular order, by accessing the objects in the same order in both transactions (say, T1 first and T2 second), you prevent the deadlock from happening.
Another aspect you should consider is the length of your transactions. The longer the transaction is, the greater likelihood you have of blocking, and therefore the greater likelihood you have for deadlocks. You should try to reduce the length of your transactions by pulling out activities that aren’t really integral parts of the transaction.
Finally, another measure you should consider is changing the isolation level you’re using. For example, suppose you’re currently using the Read Committed isolation level. You have lots of concurrency problems, including deadlocks, and many of them involve writers and readers. Switching to a row-versioning-based isolation level like Read Committed Snapshot eliminates the conflicts that involve readers because readers don’t acquire shared locks. This tends to result in an overall reduction of occurrences of blocking, and consequently a reduction in occurrences of deadlocks.
To recap, the four main measures you can take are adding supporting indexes, accessing objects in the same order, reducing the length of the transactions, and using a row-versioning-based isolation level.
Deadlock with a single table
When people think of deadlocks, they usually intuitively assume more than one table is involved and at least two different statements are submitted by each of the transactions. It’s true that for a deadlock to happen at least two different sessions need to access at least two different physical resources in reverse order. But it could be that each side submits only one statement against the same table, and that the query plans for the two statements access at least two physical resources like different indexes in reverse order. Figure 9-25 illustrates such a deadlock.
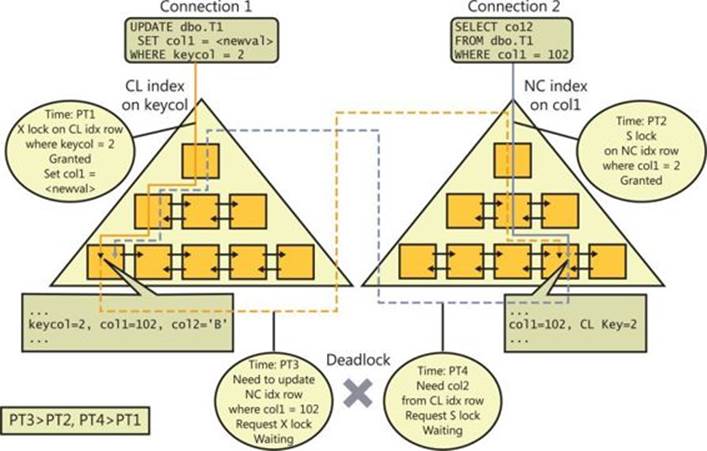
FIGURE 9-25 Deadlock with a single table.
There’s a clustered index defined with keycol as the key and a nonclustered index defined with col1 as the key. Connection 1 submits an UPDATE statement that modifies a row in T1 where keycol is equal to 2, setting col1 to some new value. At the same time, connection 2 submits a SELECT statement against T1, filtering the row where col1 is equal to 102 and returning col2 in the result. Observe that the UPDATE statement first updates the row in the clustered index (after acquiring an exclusive lock) and then tries to update the respective row in the nonclustered index (requesting an exclusive lock). The SELECT statement first finds the row in the nonclustered index (acquiring a shared lock) and, because col2 is not part of the index, it then tries to look up the respective row in the clustered index (requesting a shared lock). It’s a deadlock.
Obviously, it’s much trickier to figure out how such a deadlock happened compared to ones that involve explicit transactions with multiple activities in each transaction. But even if you manage to figure out how a deadlock happened, usually you also want to reproduce it. You need to submit the activities from both sides simultaneously. The easiest way to get the timing right is to run two infinite loops from the two connections. Usually, after a few seconds you will see it happening.
Before I demonstrate such a deadlock, first run the following code to initialize values in the row in T1 where keycol is equal to 2:
UPDATE dbo.T1 SET col1 = 102, col2 = 'B' WHERE keycol = 2;
Open two connections. Run the following code in connection 1 to execute an infinite loop that updates the row in each iteration, setting col1 to 203 minus the current value. (This will cause the current value to alternate between 101 and 102.)
SET NOCOUNT ON;
WHILE 1 = 1
UPDATE dbo.T1 SET col1 = 203 - col1 WHERE keycol = 2;
Run the following code in connection 2 to execute an infinite loop that queries the row in each iteration and returns the col2 value. (An index hint is used because the table is so small.)
SET NOCOUNT ON;
DECLARE @i AS VARCHAR(10);
WHILE 1 = 1
SET @i = (SELECT col2 FROM dbo.T1 WITH (index = idx_col1)
WHERE col1 = 102);
When I ran this test, after a few seconds SQL Server detected a deadlock and terminated the transaction in connection 2, generating the following error:
Msg 1205, Level 13, State 51, Line 5
Transaction (Process ID 54) was deadlocked on lock resources with another process and has been
chosen as the deadlock victim. Rerun the transaction.
When thinking about what measures you can take to prevent this deadlock, remember there are four things to consider. Two of them are inapplicable here because each side submits only a single statement; you cannot reverse the order of access to the objects, and you cannot shorten the transaction. However, you still have two options. One option is to extend the index on col1 to include col2. This way, you prevent the need for the lookup in the SELECT statement, and therefore prevent the deadlock. The other option is to evaluate switching to a row-versioning-based isolation level. Under such an isolation level, readers don’t acquire shared locks, which eliminates the possibility of a deadlock in our case. Obviously, you will not consider switching to a row-versioning-based isolation level just for this reason, but if you were evaluating the option anyway, that’s one more reason that you add to the list.
When you’re done testing, run the following code for cleanup:
USE testdb;
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL DROP TABLE dbo.T1;
IF OBJECT_ID('dbo.T2', 'U') IS NOT NULL DROP TABLE dbo.T2;
Close both connections.
Error handling
This section covers error handling in T-SQL using the TRY-CATCH construct. It compares error handling with and without the construct. It describes the available error functions and the THROW command. It also covers how to perform error handling in transactions and how to apply retry logic.
In my examples, I will use a table called Employees, which you create by running the following code:
USE tempdb;
IF OBJECT_ID(N'dbo.Employees', N'U') IS NOT NULL DROP TABLE dbo.Employees;
CREATE TABLE dbo.Employees
(
empid INT NOT NULL,
empname VARCHAR(25) NOT NULL,
mgrid INT NULL,
/* other columns */
CONSTRAINT PK_Employees PRIMARY KEY(empid),
CONSTRAINT CHK_Employees_empid CHECK(empid > 0),
CONSTRAINT FK_Employees_Employees
FOREIGN KEY(mgrid) REFERENCES dbo.Employees(empid)
)
The TRY-CATCH construct
The TRY-CATCH construct is a classic error-handling construct used by most modern programming languages. The implementation in SQL Server is basic, but if you’re an experienced T-SQL developer, you really will appreciate it when you compare it to the legacy error-handling tools.
In old versions of SQL Server, before the introduction of the TRY-CATCH construct, the main tool you had to handle errors was the @@error function. This function tells you how the previous statement terminated. If the statement finished successfully, the function returns 0; if there was an error, the function returns the error number. There are a number of problems with handling errors based on this function. Almost every statement you run causes the value of the function to be overwritten. Therefore, you have to capture the function’s value in a variable after every suspect statement that can generate an error in order not to lose the error number. This forces you to mix the usual code and the error-handling code, which is considered a bad practice because it hurts the maintainability and reusability of your error-handling code. In addition, when you are not using the TRY-CATCH construct, there are cases where nonsevere errors cause your batch (for example, procedure) to terminate. In such cases, if you have error-handling code within that batch, it doesn’t have a chance to run and you have to deal with the error in the caller.
The TRY-CATCH construct addresses most of the inadequacies of the legacy error-handling tools. You specify your usual code in the TRY block and the error-handling code in the CATCH block. If code in the TRY block completes successfully, the CATCH block is skipped. If there’s an error, SQL Server passes control to the first line of code in the CATCH block. As an example, run the following code to insert a new row into the Employees table:
SET NOCOUNT ON;
BEGIN TRY
INSERT INTO dbo.Employees(empid, empname, mgrid)
VALUES(1, 'Emp1', NULL);
PRINT 'After INSERT';
END TRY
BEGIN CATCH
PRINT 'INSERT failed';
/* handle error */
END CATCH;
In the first execution of the code, the INSERT statement completes successfully. The next line of code in the TRY block is executed and the CATCH block is skipped. You get the following output:
After INSERT
Execute the code again. This time, the INSERT statement fails because of a primary-key violation error. SQL Server passes control to the CATCH block. You get the following output:
INSERT failed
In case you’re curious about the proper use of the semicolon with the TRY-CATCH construct, be aware that you’re supposed to place one only after the END CATCH keywords, like so:
BEGIN TRY
...
END TRY
BEGIN CATCH
...
END CATCH;
If you specify a semicolon after the BEGIN TRY or BEGIN CATCH clause, you won’t get an error. However, in such a case, the semicolon isn’t considered to be a terminator of these clauses; rather, it is a meaningless terminator of an empty statement. If you place a semicolon after END TRY, you will get an error. In short, the proper syntax is to place a semicolon only after the END CATCH keywords.
If an error is trapped by a TRY-CATCH construct, the error is not reported to the application. If an error happens within a stored procedure (or within any other module) but not within a TRY block, the error bubbles up until a TRY block is found. SQL Server passes control to the respective CATCH block. If no TRY block is found throughout the call stack, the error is reported to the application. SQL Server supports nesting TRY-CATCH constructs, so if you anticipate errors in the CATCH block, you can place the code within a nested TRY-CATCH construct. If an error happens in a CATCH block without a nested TRY-CATCH construct, the error is treated the same as when you are not using TRY-CATCH.
Most nonsevere errors that terminate the batch when you are not using TRY-CATCH don’t terminate it and are trappable when you do use the construct. A conversion error is an example. However, there are still cases in which an error is not trappable with TRY-CATCH in the same batch. For example, compilation and binding errors—like referring to a table or column that doesn’t exist—cannot be trappable in the same batch. However, such errors are trappable in the calling batch. So, if you’re expecting such errors, make sure you encapsulate the code in a stored procedure and invoke the procedure from a TRY block. Also, some errors with severity 20 and up cause the SQL Server engine to stop processing the session and terminate the connection. Such errors obviously cannot be captured. Errors with severity 20 and up that don’t disrupt the connection are trappable.
SQL Server supports a number of functions that provide error information and that you can query in the CATCH block:
![]() ERROR_NUMBER
ERROR_NUMBER
![]() ERROR_MESSAGE
ERROR_MESSAGE
![]() ERROR_SEVERITY
ERROR_SEVERITY
![]() ERROR_STATE
ERROR_STATE
![]() ERROR_LINE
ERROR_LINE
![]() ERROR_PROCEDURE
ERROR_PROCEDURE
Mostly, the functions are self-explanatory, returning the error number, message, severity, state, line number, and procedure name where the error happened. The procedure name is interesting, especially in cases where the error bubbles up. If the error doesn’t happen in a procedure, the ERROR_PROCEDURE function returns a NULL. As for the ERROR_NUMBER function, unlike @@error it preserves its value throughout the CATCH block. That’s unless you nest TRY-CATCH constructs—in which case, the function returns the error number of the innermost one.
A common practice with error handling is that you want to deal with certain errors in the current procedure but let the upper level in the call stack deal with the rest. Prior to SQL Server 2012, there was no tool you could use to rethrow the original error. The closest tool you had was the RAISERROR command, which raises a user-defined error based on the inputs you provide to it. The typical use of this function is to construct a message containing elements you obtain from the error functions, and then raise a user-defined error with that message. But then you need to add logic to the upper level to anticipate such a user-defined error and to extract the error information from that message. This sort of handling is quite awkward.
SQL Server 2012 introduced the THROW command to address this need. This command has two modes: one with parameters and one without. The former is just an alternative to using the RAISERROR command to raise a user-defined error. The latter is the more critical addition. Without parameters, the THROW command simply rethrows the original error.
As an example of typical error handling, the following code demonstrates a TRY-CATCH construct that issues an INSERT statement, traps errors, handles some of the errors, and rethrows the rest:
BEGIN TRY
INSERT INTO dbo.Employees(empid, empname, mgrid) VALUES(2, 'Emp2', 1);
-- Also try with empid = 0, 'A', NULL, 1/0
PRINT 'After INSERT';
END TRY
BEGIN CATCH
IF ERROR_NUMBER() = 2627
BEGIN
PRINT 'Handling PK violation...';
END;
ELSE IF ERROR_NUMBER() = 547
BEGIN
PRINT 'Handling CHECK/FK constraint violation...';
END;
ELSE IF ERROR_NUMBER() = 515
BEGIN
PRINT 'Handling NULL violation...';
END;
ELSE IF ERROR_NUMBER() = 245
BEGIN
PRINT 'Handling conversion error...';
END;
ELSE
BEGIN
PRINT 'Re-throwing error...';
THROW;
END;
PRINT 'Error Number : ' + CAST(ERROR_NUMBER() AS VARCHAR(10));
PRINT 'Error Message : ' + ERROR_MESSAGE();
PRINT 'Error Severity: ' + CAST(ERROR_SEVERITY() AS VARCHAR(10));
PRINT 'Error State : ' + CAST(ERROR_STATE() AS VARCHAR(10));
PRINT 'Error Line : ' + CAST(ERROR_LINE() AS VARCHAR(10));
PRINT 'Error Proc : ' + ISNULL(ERROR_PROCEDURE(), 'Not within proc');
END CATCH;
I use this code for illustration purposes. I issue PRINT statements so that you can see which parts of the code are activated.
When you execute this code for the first time, the INSERT statement finishes successfully and the CATCH block is skipped. You get the following output:
After INSERT
When you execute the code for the second time, the INSERT statement fails because of a primary-key violation and SQL Server passes control to the CATCH block. The error-handling code identifies the error as a primary-key violation error. You get the following output:
Handling PK violation...
Error Number : 2627
Error Message : Violation of PRIMARY KEY constraint 'PK_Employees'. Cannot insert duplicate key
in object 'dbo.Employees'. The duplicate key value is (2).
Error Severity: 14
Error State : 1
Error Line : 4
Error Proc : Not within proc
Try the code a few more times after changing the employee ID value you pass to the following options: 0, ‘A’, NULL, 10/0. The last one will cause a “divide by zero” error. This error isn’t one of the errors you want to deal with in the current level; therefore, the code ends up rethrowing the error.
Errors in transactions
When an error happens in a transaction but not in a TRY block, there are two possible consequences as far as the transaction is concerned: either the error is minor enough (for example, a primary-key violation) that SQL Server leaves the transaction open and committable, or the error is severe enough (for example, a conversion error) that SQL Server aborts the transaction. In such a case, it’s enough for you to query the @@trancount function to know what the transaction state is. If the function returns zero, there’s no transaction open; if it returns a value greater than zero, the transaction is open and committable. In the latter case, you can decide what you want to do; you can either roll the transaction back or commit it. If you want all errors to cause the transaction to abort, turn on the session option XACT_ABORT.
When an error happens in a transaction within a TRY block, things are handled differently. An error that would normally cause a transaction to end outside of a TRY block causes it to enter an open but uncommittable state when it happens inside a TRY block. This state is also known as the failed, or doomed, state. When a transaction is in this state, you’re not allowed to make any changes, but you are allowed to read data. You’re not allowed to commit the transaction; rather, you eventually will have to roll it back before you can start applying changes in a new transaction. The advantage of this state compared to SQL Server ending your transaction is that you can read data that your transaction generated before you roll the transaction back.
Recall that when you turn on the session option XACT_ABORT, all errors that happen outside of a TRY block cause the transaction to abort. However, turning on this option has a different effect on errors that happen inside a TRY block; all errors cause the transaction to enter the open and uncommittable state.
When an error happens in a transaction within a TRY block, there are three possible consequences as far as the transaction is concerned. If the error is minor enough (for example, a primary-key violation), the transaction remains open and committable. If the error is more severe (for example, a conversion error) but not too severe, the transaction enters the open and uncommittable state. If the error is very severe, SQL Server might end the transaction. As mentioned, some errors with severity 20 and up cause the SQL Server engine to stop processing the session and terminate the connection, so you won’t be able to trap those with a TRY-CATCH construct. You will have to deal with such errors in the caller. However, some errors with severity 20 and up don’t disrupt the connection, and you will be able to trap them.
If you need to know the state of the transaction after trapping an error with a TRY-CATCH construct, it’s not sufficient to query the @@trancount function. This function tells you only whether the transaction is open or not, not whether it’s open and committable or open and uncommittable. To get this information, you query the XACT_STATE function. This function has three possible returned values: 0 means no open transaction, 1 means open and committable, and –1 means open and uncommittable.
The following code demonstrates how you might want to handle errors in transactions:
-- SET XACT_ABORT ON
BEGIN TRY
BEGIN TRAN;
INSERT INTO dbo.Employees(empid, empname, mgrid) VALUES(3, 'Emp3', 1);
/* other activity */
COMMIT TRAN;
PRINT 'Code completed successfully.';
END TRY
BEGIN CATCH
PRINT 'Error ' + CAST(ERROR_NUMBER() AS VARCHAR(10)) + ' found.';
IF (XACT_STATE()) = -1
BEGIN
PRINT 'Transaction is open but uncommittable.';
/* ...investigate data... */
ROLLBACK TRAN; -- can only ROLLBACK
/* ...handle the error... */
END;
ELSE IF (XACT_STATE()) = 1
BEGIN
PRINT 'Transaction is open and committable.';
/* ...handle error... */
COMMIT TRAN; -- or ROLLBACK
END;
ELSE
BEGIN
PRINT 'No open transaction.';
/* ...handle error... */
END;
END CATCH;
-- SET XACT_ABORT OFF
In the CATCH block, you query the XACT_STATE function. If the function returns –1, you can read data to investigate what you need, but then you have to roll the transaction back. If it returns 1, you can roll back or commit the transaction as you wish. If it returns 0, there’s no transaction open, so there’s no point in trying to commit or roll back the transaction. Such an attempt would result in an error. You can open a new transaction and apply changes if you like.
Run this code for the first time. The INSERT statement completes successfully, and you get the following output:
Code completed successfully.
Run this code for the second time. The INSERT statement fails because of a primary-key violation error, but it leaves the transaction open and committable. You get the following output:
Error 2627 found.
Transaction is open and committable.
Change the employee ID from 3 to ‘abc’, and run the code again. The INSERT statement fails because of a conversion error and causes the transaction to enter the open and uncommittable state. You get the following output:
Error 245 found.
Transaction is open but uncommittable.
Change the employee ID back to 3, uncomment the SET XACT_ABORT commands, and run the code again. The INSERT statement fails because of a primary-key violation error and causes the transaction to enter the open and uncommittable state. You get the following output:
Error 2627 found.
Transaction is open but uncommittable.
Retry logic
With certain kinds of errors, like deadlock and “update conflict” errors, a classic treatment involves applying retry logic. If your session is the one that got the error, once you end the transaction, the other session can continue work. There’s a likelihood that if you retry the task, you will be successful. You can create a wrapper procedure that implements the retry logic and calls the procedure that handles the original task. The following code demonstrates what such a wrapper procedure might look like (MyProc is the procedure that handles the original task):
CREATE PROC dbo.MyProcWrapper(<parameters>)
AS
BEGIN
DECLARE @retry INT = 10;
WHILE (@retry > 0)
BEGIN
BEGIN TRY
EXEC dbo.MyProc <parameters>;
SET @retry = 0; -- finished successfully
END TRY
BEGIN CATCH
SET @retry -= 1;
IF (@retry > 0 AND ERROR_NUMBER() IN (1205, 3960)) -- errors for retry
BEGIN
IF XACT_STATE() <> 0
ROLLBACK TRAN;
END;
ELSE
BEGIN
THROW; -- max # of retries reached or other error
END;
END CATCH;
END;
END;
GO
In this example, the code sets the retry counter (@retry variable) to 10. If you want, you can parameterize this counter. The code enters a loop that keeps iterating while the retry counter is greater than zero. The code executes MyProc within a TRY block. If the procedure completes successfully, the code sets the retry counter to zero to prevent the loop from executing again. Otherwise, the code reduces the retry counter by one. If, after reducing the counter, there are retries left and the error is a deadlock or “update conflict” error, the code checks whether a transaction is open. If a transaction is open, the code rolls it back. If the retry counter drops to zero or the error is not a deadlock or “update conflict” error, the code rethrows the error to let the upper level deal with it.
This example demonstrates how to handle retry logic for deadlock and “update conflict” errors involving disk-based tables. The same pattern can be used to handle errors with memory-optimized tables. However, instead of looking for errors 1205 and 3960, you will look for error numbers 41302, 41305, 41325, and 41301, which represent update conflict, repeatable read validation, serializable validation, and dependent transaction aborted errors, respectively.
Conclusion
This chapter focused on some programmability constructs SQL Server supports, mainly the ones that involve queries. It covered dynamic SQL, user-defined functions, stored procedures, triggers, SQLCLR, transactions and concurrency, and error handling. The discussions in many cases focused on robust and efficient use of the code.